


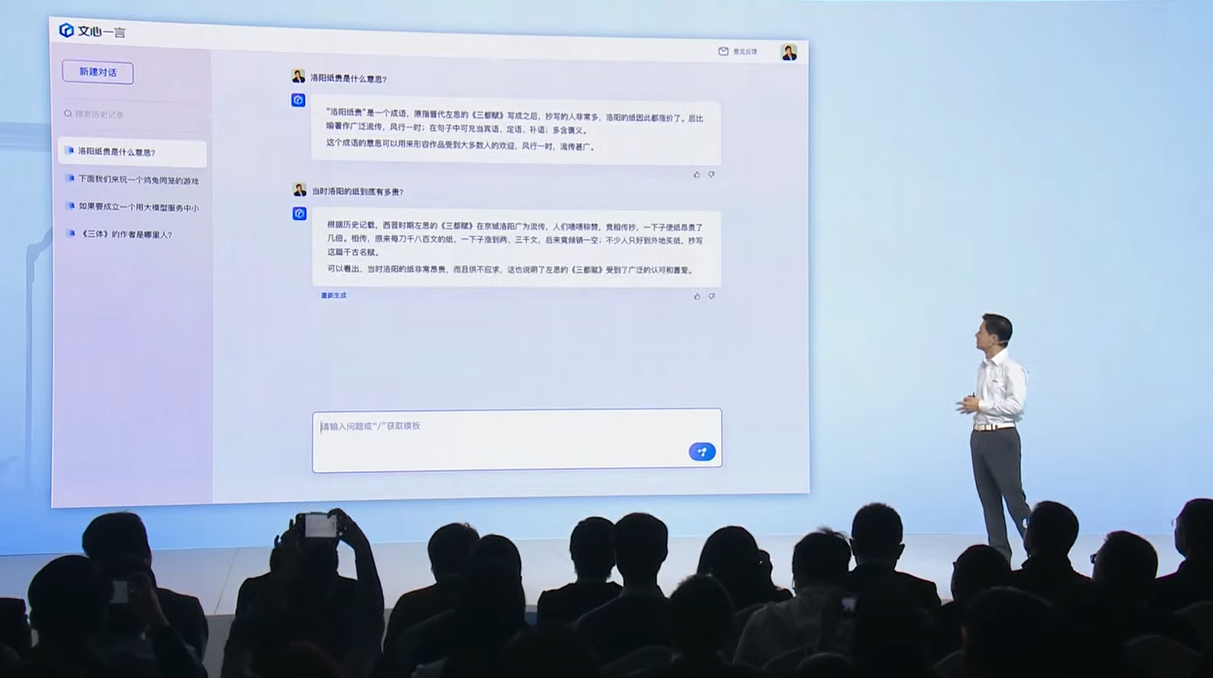
Baidu ประกาศว่าเริ่มปล่อย ERNIE 3.5 ปัญญาประดิษฐ์ภาษาขนาดใหญ่ (LLM) ให้ผู้ได้รับสิทธิ์ทดสอบได้เริ่มใช้งานแล้ว โดยผลทดสอบ AGIEval ของไมโครซอฟท์ และ C-EVAL ของนักวิจัยจีนแสดงให้เห็นว่า ERNIE 3.5 เริ่มมีประสิทธิภาพใกล้เคียง ChatGPT ที่ใช้ GPT-3.5 และเมื่อแยกเฉพาะชุดทดสอบภาษาจีนเอง ERNIE 3.5 ทำคะแนนทดสอบได้ดีกว่า GPT-4
ในแง่ฟีเจอร์ ERNIE เริ่มตาม ChatGPT มาใกล้เคียงมากขึ้น โดยรองรับระบบปลั๊กอิน เบื้องต้นมีสองตัว คือ Baidu Search สำหรับค้นข้อมูลเพิ่มเติมจากเว็บ และ ChatFile สำหรับอ่านไฟล์และถามตอบข้อมูลจากไฟล์ ในอนาคตจะเปิดให้นักพัฒนาภายนอกสร้างปลั๊กอินเข้ามามาเพิ่มเติม
ทาง Baidu ไม่ได้เปิดเผยสถาปัตยกรรมภายในของ ERNIE แต่ก็บอกว่าในรุ่นนี้ปรับปรุงการเทรนให้เร็วขึ้น การคำนวณใช้ mixed-precision ที่ผสมชนิดข้อมูลในโมเดล ตลอดจนโครงสร้างภายในของ ERNIE สามารถต้นหาข้อมูลก่อนตอบได้
ตอนนี้ ERNIE ยังจำกัด เฉพาะบริษัทที่ได้สิทธิทดสอบเท่านั้น ยังไม่เปิดให้คนทั่วไปใช้งาน
ที่มา - Baidu Research






Comments
อยากรู้อย่างเดียวเลยคือ ถ้าถามถึง "เรื่องนั้น" มันจะตอบว่าอะไร
มันก็ตอบตามข้อมูลสถิตินั่นแหล่ะ ถึงข้อมูลที่ AI เรียนรู้จะเป็น Text แต่ในทางการพิจารณาหรือตัดสินใจก็ยังใช้คณิตศาสตร์ ด้านสถิติอยู่ดี
เช่น
สิ่งของ A -> หาข้อมูลคำอธิบายหลักจากเว็บไซต์ที่น่าเชื่อถือ
นำสิ่งของ A ไปหาว่าเจอข้อมูลที่ไหนบ้าง แนวโน้มข้อมูลส่วนใหญ่มีทิศทางในทางใด ความสนใจในสิ่งของ A เป็นเช่นไร เพื่อเลือกทิศทางคำขยายความ ถ้าพบว่าสิ่งของ A เป็นของที่มีประโยชน์ มีคนชื่นชอบ มันก็จะไปหารายละเอียดในกลุ่มข้อมูลประโยชน์ของของชิ้นนั้นมาให้ เพื่อขยายข้ออธิบายหลักอีกที ลองไปหาต้นฉบับข่าว
คุณก็จะพอรู้วิธีการที่นักวิทยาศาสตร์ข้อมูลใช้สร้างข้อมูลออกมา วิทยาศาสตร์ข้อมูลไม่ใช่ไสยศาสตร์เขาคาดคะเนพฤติกรรมของมันได้ เรื่องภาษาศาสตร์ และสถิติล้วนๆ เลยล่ะ ChatGPT เนี่ย สิ่งที่นักวิทยาศาตร์ข้อมูลสนใจไม่ใช่คำอธิบาย แต่เป็นการจำแนกวัตถุทางภาษาศาสตร์ได้อย่างถูกต้องมากกว่า
ขอบคุณสำรับคำตอบสาระจริงจังครับ
เรื่องนั้นที่เขาพูดถึงน่าจะหมายถึงเรื่องจตุรัสเทียนอันเหมิน หรือเรื่องอื่นที่อาจมีการปิดกั้นโดยรัฐบาล
ถ้าเป็นเรื่องที่ต้องการ censor มันก็ทำได้อยู่ดีนี่ครับ ตั้งแต่เรื่องข้อมูลที่เอามา train หรือแม้แต่การดัก keyword ในคำถามแต่ที่เหลือก็ตามที่คุณตอบมาเลยครับ
ผมว่าไม่น่าเทียนอันเหมิน น่าจะ 112 มากกว่าถึงไม่กล้าระบุหัวข้อผมเลยต้องเลี่ยงยกตัวอย่างเป็นสิ่งของไปถ้าเขาเข้าใจหลักการเขาก็จะรู้เองว่ามันน่าจะได้ผลประมาณไหน ส่วนเรื่อง censor มันดัก input ได้ก็จริงแต่พอเข้า neural network เราคาดเดา route ที่มันวิ่งไม่ได้หรอกครับมันมหาศาล แต่เราพอคาดเดาผลลัพธ์ได้ กรณีคีย์ windows 10 ถ้าคุณเคยอ่านต้นฉบับมาก่อนจะเห็นวิธีการเลี่ยงการตรวจจับ input ของเขา
ไม่ว่าของจีน หรือของเมกา ไส้ในก็ core เดียวกันต่างแค่ภาษาที่ใช้ train ดังนั้นหลักการนี้ใช้คาดเดาผลเพื่อเปรียบเทียบได้ครับไมว่าจะเทียนอันเหมิน หรือ 112
พูดถึง chatbot จีน ก็ต้องพูดถึงเทียนอันเหมินสิครับ และอีกอย่างคือก็เพราะไม่เข้าใจหลักการไงครับ ถึงต้องโพสต์ถาม แล้วก็ขอบคุณสำหรับคำตอบครับ
ปล. อ้างอิงถึงท่านที่โควตซ้อนอยู่อีกที ทางนี้ก็ต้องการรู้จริงจังนะครับ - -"
สามารถต้นหาข้อมูลก่อนตอบได้
สามารถ ค้น หาข้อมูลก่อนตอบได้
ข้อมูลมันเยอะ เอามาฝึก ai ก็เก่งขึ้น