
By: tontan



 on 6 September 2021 - 14:07
Tags:
on 6 September 2021 - 14:07
Tags:

วันนี้ทางสถาบันวิจัยปัญญาประดิษฐ์ประเทศไทย (AIResearch) และทีม PyThaiNLP ปล่อยโมเดลถอดความจากเสียงพูดภาษาไทย (Automatic Speech Recognition) ที่มีความแม่นยำทัดเทียมกับกูเกิล และบริษัทชั้นนำอื่น ๆ
โมเดลดังกล่าวฝึกฝนบนชุดข้อมูล Mozilla Common Voice 7.0 ที่ได้รับการบริจาคเสียงภาษาไทย จำนวน 133 ชั่วโมง ผู้พูด 7,212 คน (อ่านเพิ่มเติม ร่วมบริจาคเสียงพูดภาษาไทยด้วย Mozilla Common Voice ) โดยฝึกกับโมเดล XLSR-Wav2Vec2 ของ Facebook
ทางสถาบันวิจัยได้ปล่อยโมเดลมาในรูปแบบลิขสิทธิ์ CC-BY-SA 4.0 และได้อัปโหลดขึ้น Hugging Face โดยสามารถใช้งานได้ผ่านไลบรารี transformers ในภาษาไพธอนได้
ท่านที่สนใจสามารถอ่านวิธีการใช้งานได้ที่ Hugging Face
ที่มา: สถาบันวิจัยปัญญาประดิษฐ์ประเทศไทย - Medium

Get latest news from Blognone
Follow @twitterapi





Comments
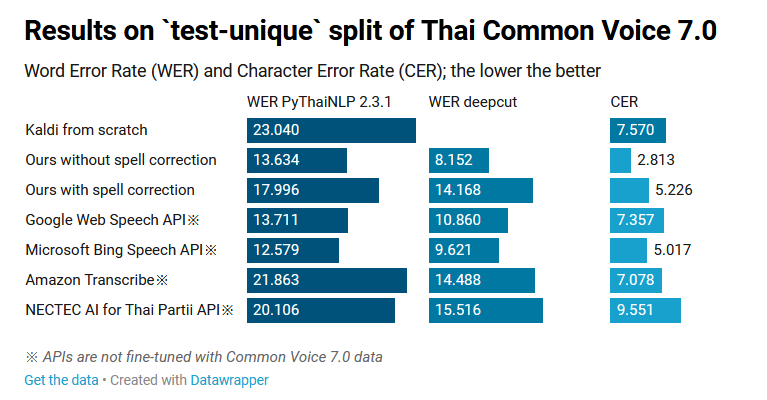
จากตารางบอกว่า WEP และ CER น้อยจะดีนะแต่ของ NECTEC ยังสูงที่สุดอยู่นะ
ตัวในข่าวน่าจะเป็น ours ทั้ง 2 ข้อนะครับไม่ใช่ NECTEC
งานนี้ทำโดย "AIResearch และทีม PyThaiNLP" ครับ ไม่ได้ทำโดย NECTEC
ดี ๆ แจ่ม ๆ