

この広告は30日以上更新がないブログに表示されております。
新規記事の投稿を行うことで、非表示にすることが可能です。
広告
posted by fanblog
2021年12月12日
Udemy安くなっています!(12/14まで)
Udemyの講座が安くなっています。1,730円から対象コースがあるので、何か勉強を始めてみたらいかがでしょうか。


全般ランキング
全般ランキング
【このカテゴリーの最新記事】
- no image
- no image
- no image
- no image
- no image
2021年05月19日
Pythonでファイナンス分析の勉強(その6)
Seabornを使ってデータ相関を見てみる
Seabornとは
Seabornは、matplotlibを使ったデータをビジュアル化するライブラリだ。
matplotlibではできないようなグラフを簡単に作ることができる。
なので、データ解析の際にあたりを見る際に使うのに便利なライブラリだ。
今回はsklearnのデータセットを使って自分でもグラフ作成をやってみた。
ちなみにsklearnとはscikit-learnのことで、機械学習のライブラリである。
このライブラリにはサンプルのデータが含まれている。
今回使うのは、その中の1つのサンプルデータだ。
早速、講座の復習がてら、いろいろを試してみた。
bostonのデータをつかって、住宅価格のとの相関するデータを見つけてグラフを見てみた。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston
#データの読み込み
bs = load_boston()
このbsのデータ型を調べるとsklearn.utils.Bunchというものらしい。
下記によると、dictionaryを拡張して、obj["member"], obj.member の両方でアクセスできるようにしたものらしい。
https://scikit-learn.org/stable/modules/generated/sklearn.utils.Bunch.html
データの中身を見てみよう。
bs.keys()
=> dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
data :データ
target :予測対象(住宅価格)
feature_names:予測に用いられる変数(下記参照)
DESCR:データの説明
filename:ファイルパス
●feature_namesのそれぞれの要素の意味
CRIM: 町別の一人当たりの犯罪率
ZN: 25,000平方フィートを超える区画にゾーニングされた住宅用地の割合。
INDUS: 町ごとの非小売業のエーカーの割合
CHAS: チャールズ川のダミー変数(路が川に接している場合は1、それ以外の場合は0)
NOX: 一酸化窒素濃度(1000万分の1)
RM: 住居あたりの平均部屋数
AGE: 1940年より前に建てられた持ち家の割合
DIS: 5つのボストン雇用センターまでの加重距離
RAD: 放射状高速道路へのアクセスの指標
TAX: 全額固定資産税-10,000ドルあたりの税率
PTRATIO: 町別の生徒と教師の比率
B: 1000(Bk-0.63)^ 2ここで、Bkは町ごとの黒人の割合
LSTAT: 人口の%低いステータス
MEDV: 1000ドルの持ち家の中央値
住宅の価格に相関しそうな要素はどれだろうか?
少なくとも、部屋の数(RM)は住宅の価格に相関していそうだ。
data, target:予測対象(住宅価格)を入れたデータフレームを作成する。
#pandas dataframe生成
bsdf = pd.DataFrame(np.c_[bs['target'],bs['data']] ,columns= np.append('target',bs['feature_names']))
データ:

Heatmap
まず、heatmapで相関があるものを見つける。
plt.figure(figsize=(10,10))
sns.heatmap(bsdf.corr(),annot=True)
結果:
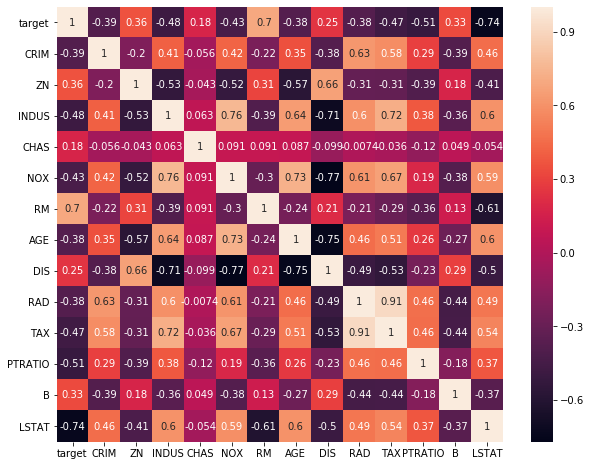
予想通りの左端列のtargetと"RM(0.7)", "LSTAT(-0.74)"が相関(逆相関)が強いのがわかる。
散布図
散布図のグラフも確認しておこう。scatterplotで表示させてみる。
sns.scatterplot(x='RM',y='target',data=bsdf)
結果:

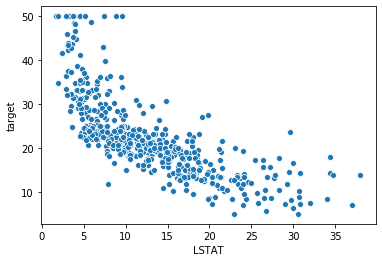
sns.scatterplot(x='LSTAT',y='target',data=bsdf)
結果:
なるほど、相関があるのが確認できた。
次はようやくファイナンシャルデータの分析に入る。
このコースへのリンク
Python & Machine Learning for Financial Analysis
全般ランキング
2021年05月18日
2021年05月16日
Pythonでファイナンス分析の勉強(その5)
Matplotlib
Matplotlibの復習に入った。
Matplotlibとはグラフを描画するライブラリだ。
折れ線グラフ、棒グラフや、散布図、ヒストグラムなど様々なグラフを描画することができる。
ところで、Google colabはすごいのだが、今、復習している範囲であれば、jupyter notebookで十分であるので、最近はjupyter notebookで演習を行っている。
基本的にはchromeブラウザ、udemyプレーヤー、jupter notebook, vscode(), 手元のノートを行き来しながら進めている。
効率化のためにショートカットを手元のノートのメモして覚えながら進めている。
さて、グラフの描画だが、本講座では、折れ線グラフ、棒グラフ、円グラフ、散布図、ヒストグラム、複数のグラフの組み合わせ、3Dグラフ、箱ひげ図を学習した。
この講座では、pandasに含まれる、matplotlibの機能を使った勉強もしたが、自分なりにmatplotlibのみを使って、シンプルなグラフを作ってみた。
宣言
・はじめに宣言しておく
import matplotlib.pyplot as plt
折れ線グラフ
#data
y = [int(n) for n in list("13256")] # [1,3,2,5,6]
x = range(1,6)
#line plot
plt.bar(x,y)
円グラフ
#data
y = [int(n) for n in list("13256")] # [1,3,2,5,6]
labels=list("abcde") #["a", "b", "c", "d", "e"]
colors = "rgbym"
plt.figure(figsize=(5,5))
plt.pie(y,colors=colors,labels=labels)
次はSeabornを勉強する。
このコースへのリンク
Python & Machine Learning for Financial Analysis
全般ランキング
2021年05月15日
Pythonでファイナンス分析の勉強(その4)
Pandas
次はPandasの勉強に入る。
Pandasとは、データ操作に用いられるライブラリで、CSVの表やhtmlから表の抽出して加工計算できるライブラリだ。機械学習の際に対象のデータを整理する際に便利に使えるものだ。
本講座では、PandasのSeries, DataFrameの作り方から、csvの読み込み, htmlからの表の抽出、独自関数の適用に関して学習する。
Pandasの読み込み関数であるread_*は多くのフォーマットに対応しており、いろいろなデータ形式からテーブル情報を抽出して読み込みができる。
いったん、よく使いそうなAPIを列挙しておこう。
・read_clipboard
クリップボードデータの読込み
・read_csv
csvデータの読込み
・read_excel
・excelデータの読込み
・read_html
htmlの読込み
・read_json
jsonデータの読込み
・read_sql
sqlデータの読込み
使い方の例:
csv = pd.read_csv("temp.csv")
csv.to_csv("temp_bk.csv", index = False)
独自の関数を適用する際は、関数を定義して、dataframeのapplyのメソッドでその独自関数を指定することでできる。
次は、ソートとデータのマージ結合に関して勉強だ。
ソートはsort_valuesのAPIにbyでソートする列を指定して行う。
DataFrame自体の内容に結果を反映させるためには、inplace=Trueの指定を行う必要がある。
最後は、DataFrameのマージと合体を行った。
この章では頻繁にSeriesやDataFrameの作成を行ったが、これが私にとってはとても面倒くさかった。
例えば、Seriesを作る際に、
i = "A", "B", "C", "D"
d = [1,2,3,4]
s = pd.Series(d, index = i)
ダブルコーテーションが多くて面倒だし、1,2,3,4と数字をいちいち入力するのも面倒くさい。
そこで改善策を考えた。
i = list("ABCD")
d = range(1,5)
s = pd.Series(d, index = i)
ましになった。
よかった、よかった。
次はmatplotlibを復習する。
このコースへのリンク
Python & Machine Learning for Financial Analysis
全般ランキング
2021年05月10日
Pythonでファイナンス分析の勉強(その3)
ファイルの読み込みのパートに進む。これが終われば、とりあえずpythonの基礎文法の確認は終了で、次にデータサイエンス系のほうに移る。
ファイルの読み込みの際は、google driveをマウントしておく必要がある。
ファイルの読み込みは問題なくできるが普通にループで書いてしまっていて、リスト内法表記ができてない。
とりあえず、CSVファイルの読み方、データの扱いを確認して、pythonの基礎は完了した。
次は、データサイエンスの定番のライブラリのnumpyの学習に移る。
numpyは結構覚えていた。
忘れていたのは、np.randomの下のrandファミリーとargmax, argminだ。
np.random.rand(d1,d2...dn): N次元配列のランダム配列作成
np.random.randn(d1,d2...dn): 標準正規分布からN次元配列のランダム配列作成
np.random.randint(low, [high], size, dtype):値の範囲指定のランダム整数作成
argmax: 指定した軸における最大値のインデックスを返却
argmin: 指定した軸における最小値のインデックスを返却
次はPandasの勉強に入る。
このコースへのリンク
Python & Machine Learning for Financial Analysis
全般ランキング

入門Python3 第2版 [ Bill Lubanovic ]
価格: 4,180円
(2021/12/12 07:50時点)
感想(1件)
2021年05月09日
Pythonでファイナンス分析の勉強(その2)
pythonの基礎的な文法の復習。print、inputなど基本的な関数の勉強だ。
この講座は、さすが、ファイナンスの知識を得る講座だけあって、ちょっとした変数や例題もAppleの株の名前や銀行の申し込みのフォーマットなどになっていて、全てをファイナンスに紐づけていて好感が持てる。
この講座を受講する際に、私のようにpythonをすでに触って少し知っている人はどうすればよいのだろうか?
とりあえず、先生は、スキップして言いというが、自信がないのでタイトルを見て、自信がないところだけをつまみ食いして視聴することにした。
ただ視聴するだけでは退屈なので、教材の問題を実際に解いてみて、わからないところだけを視聴することにする。
built-in functionsからはじめてみる。
早速、lambda、map, filterで詰まる。すっかり忘れていたなぁ。
基本的なところでいきなり躓いて恥ずかしいところだが、これらの機能は、関数の宣言とループがあればすぐに書けるものだ。
最低限を覚えているという観点で言うと問題ない。はず。
list(map(lambda x: x**2, [1,2,3,4]))
<==>
l = []
for i in [1,2,3,4]:
l.append(i**2)
ちなみにpythonの本家のページではこのあたりのこと。 https://docs.python.org/3/library/functions.html
このページを見ると約70個くらいBuilt-in functionがあるというのがわかる。
すぐにわかるのは1/3くらいだろうか。
そのうち勉強することにして、先に進もう。
このコースへのリンク
Python & Machine Learning for Financial Analysis
全般ランキング
2021年05月08日
Pythonでファイナンス分析の勉強(その1)
この講座は3つのことを勉強するとのこと。
1,python
2,ファイナンスの知識
3,pythonとファイナンスの知識を使った株価の予測趣味レーションなどのプロジェクト実習
どの項目もそこそこかじっているので楽しめそうな感じだ。
講座の資料は、完成版と空のものがあり、自分で勉強して、完成版と比較することができる。
学習はGoogle Colab上で行うのだそうだ。
早速、Google Driveに資料をUploadしてみる。
jupyter notebookのクラウド版ということだな。GPU、TPUも使うことができる。すごい!
以前、mac book airで機械学習をしていつまでも計算が終わらなけったときにこれを知っていればなぁ...
さて、早速第一部のPythonの基本の勉強のセクションをスタートする。
このセクションでは、python基本から、numpy, pandas, matplotlib, seabornの勉強を行う。
ところで、このセクションのタイトルの101は英語のスラングで”基本”という意味らしい。
一応、冒頭で、pythonを知っていたらスキップしてね、の説明あり。
101と言うだけあり、変数に数字を代入するところから始まる。さすがにこれくらいは思い出せるので、2倍速で飛ばしながら進める。
演算、計算順序、も同様に速習する。
このコースへのリンク
Python & Machine Learning for Financial Analysis
全般ランキング
2021年05月06日
Pythonでファイナンス分析の勉強
はじめに
講座名:Master Python Programming Fundamentals and Harness the Power of ML to Solve Real-World Practical Applications in Finance(23時間)
このコースの受講動機
pythonを使ってファイナンスに関して勉強をしてみよう。pythonやデータサイエンスを今まで学んできたが、さらにその応用に関して見聞を広めていくことは非常に有意義であると考えられる。
そこで、今回、この講座でPythonを復習しながら、財務分析をpythonで行うことを学び、最終的には、AI/MLアプリケーションを作成し、株価予測や自然言語処理を活用した株式予測に関して学んでいこうと思う。
このコース完了の際のゴールイメージ
・財務分析の用語を学び、pythonを駆使してそれが計算できるようになる
・株価予測に応用可能なディープニューラルネットワークの手法や、機械学習をマスターし使えるようになる。
・自然言語処理の基本を理解して、使えるようになっている。
コース詳細の紹介
・レクチャー数と時間
・132のレクチャー、23時間の動画
・言語
・英語
・内容要約
Pythonプログラミングの基礎を学び、それらを直接適用して、金融や銀行業務で使用される実際のアプリケーションの開発に関しての全てを学びます。
・受講に際しての前提条件
・データサイエンスとAIの力を利用して、ビジネスプロセスを最適化し、収益を最大化し、コストを削減したい金融アナリスト。
・金融/銀行セクターにおけるPythonおよびデータサイエンスアプリケーションの基本的な理解を得たいと考えているPythonプログラマーの初心者およびデータサイエンティスト。
・キャリアを伸ばし、データサイエンスのポートフォリオを構築し、実際の実務経験を積みたいと考えている投資銀行家や金融アナリスト。
・事前の経験は必要ありません。Pythonやプログラミング言語を使用したことがない場合でも、心配する必要はありません。取り上げるトピックごとに、明確なビデオ説明があります。基本から始めて、徐々に知識を積み上げていきます。
計画
・2か月くらいで終わるとよい。
このコースへのリンク
Python & Machine Learning for Financial Analysis
全般ランキング
2021年05月03日
Udemyゴールデンウィークセール中(5/3-5/6)
Udemyでゴールデンウイークセールが開始されました。ゴールデンウイークは、家でステーホームされている方、1500円からコースがあるので、この際、何か勉強を始めてみたらいかがでしょうか。
全般ランキング