



upLIFT テクノロジーについては以前に何回かとりあげました ( 前編 、 後編 ) が、そのときはまだよくわかっていないことがあったので、アップデートされた機能なども含めて改めてまとめてみたいと思います。ただし、バージョンは 2017 を前提とします (すみません、私がまだ 2017 を使っているので)。
upLIFT テクノロジーについての SDL さんからの情報としては、以下のブログに最近の状況がまとめられています。参考にしてください。
SDL Trados Blog: ハウツーガイド
Trados Studio 2019 – 進歩した日本語原文の解析
日本語原文の場合は SDL Trados Studio 2017 SR1 CU15が必要
まずは、バージョンです。英語 (などのヨーロッパ言語) が原文の場合は 2017 の初期バージョンから upLIFT が使えたようですが、日本語 (などのアジア言語) が原文の場合は SR1が必要です。さらに、当初の SR1 には文字数のカウントに不具合 (?) があり、あいまい一致のカウントが大きく違った結果になるようなので、 CU15が必要です。
日本語原文の場合は、料金の単位が「単語」ではなく「文字」であることが多いので、文字数のカウント方法はかなり重要です。CU15 より前のときは、あいまい一致のカウントが翻訳者にとってかなり不利な感じになっていました。上記のブログによると、CU15 でこの不一致は解消されたようです。(が、すみません、本当に解消されたのかを私は検証していません。一応、信じるけど、どうなのかなぁ。)
しかし、最新の CU を適用してはいけない
※※※※※ 追記 2019/12/26 ※※※※※※※※※※※※※※※※※
以下の問題は、2017 でも解決されました。
SDL Trados Studio 2017 SR1 CU18 (Build 14.1.10018.54792) に更新すれば、問題が発生しなくなると思います。私は、問題が発生していたパッケージを 2 つ試してみましたが、2 つとも無事に開くことができました。
かなり困っていたので、解決してホントに良かったです。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
CU15 は必要なのですが、最新の CU を適用すると、前回の記事に書いた パッケージが開けない という問題が発生します。この問題はファイル名などに全角文字が含まれている場合に発生しますが、日本語原文のときはファイル名も日本語であることが多いので要注意です。
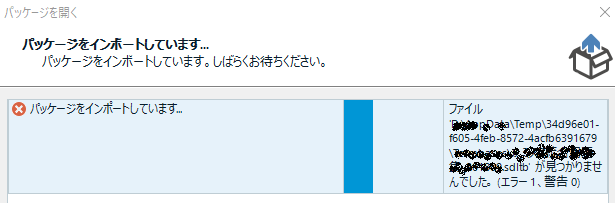
上記のブログで必要とされているビルド: 14.1.10015.44945
コミュニティ で問題が発生するとされているビルド: 14.1.10016.54660
微妙に違います。SDL のサイトからダウンロードできる最新のファイルは、SDL Trados Studio 2017 SR1 CU15 (SDLTradosStudio2017_SR1_44945.exe) です。なので、これをインストールして、後は更新しない、というのがベストかと思います。(すみません、これも実際にやってみたわけではありません。)
[ アジア言語の原文テキストの場合に単語単位のトークン化を使用する] は作業時の動作に影響しない
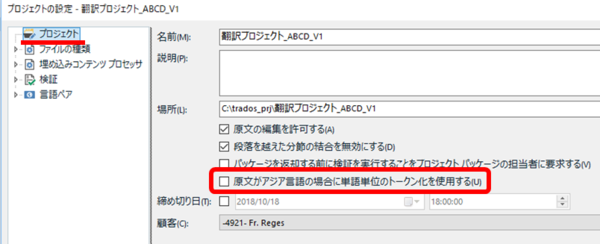
プロジェクトの設定にあるオプションです。これは、上にも書いたように、文字数のカウントを単語ベースではなく文字ベースで行うために「単語単位のトークン化を使用しない」にしておく必要があります。この設定について私が不安に思っていたのは、「使用しない」にすると翻訳作業時の upLIFT の動作に影響するのではないか?という点でした。これは影響しないそうです。この設定は、文字数のカウントに影響するだけで、実際に翻訳作業をしているときの動作には影響しません。つまり、この設定で「単語単位のトークン化を使用しない」ことにしていても、作業時は upLIFT をちゃんと使えます。
デフォルトで「使用しない」設定になっていると思いますが、文字カウントをする方は、どうぞ安心してそのまま「使用しない」にしておいてください。お願いします。
※※※※※ 追記 2020/03/31 ※※※※※※※※※※※※※※※※※
いろいろ混乱しておりましたが、こちらの新しい記事 「単語単位のトークン化」は単語数を数えるだけ をご覧ください。
だいたい、上記の記述のとおりですが、
・文字数ではなく、単語数のカウントのための設定であり
・翻訳作業時に使う必要はないので、デフォルトのままオフにしておけばよい
ということになります。この設定のオン・オフにより翻訳作業時の動作や解析結果が変わりますが、この設定はあくまで単語数を数えるためのものなので、普段はオンにする必要はありません。オフにしたままでも upLIFT は有効ですし、単語やフレーズ単位でのマッチもちゃんと見つかってきます。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
メモリのアップグレードは 1 回だけではない
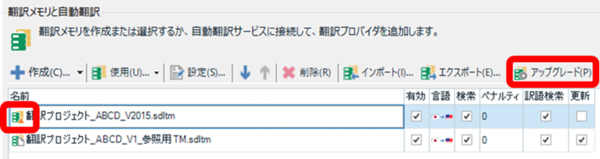
upLIFT テクノロジーが導入されてから、下位のバージョンで作ったメモリはアップグレードして使うことになっています。最初にプロジェクトを開いたときに、設定画面やエディタなど、いろいろなところに警告が出てきます。このアップグレードですが、1 回実行したらそれで終わりではありません。ある程度メモリが増えたら、再度アップグレードをする必要があります。また、2017 SR1 CU15 以降で新規作成したメモリでも、ある程度まで量が増えるとアップグレードが必要になります。
私は、何回も警告が表示されてきてかなり焦りましたが、それが正常な動作のようです。警告が表示されたら素直にアップグレードしましょう (かなり面倒ですが)。
[ TU のフラグメント] を有効にする
プロジェクトの設定にある [ TU のフラグメント] チェックボックスをオンにします。これはデフォルトではオフですが、オンにした方が一致が多く見つかるので、私は、毎回、オンに変更しています。
プロジェクトの設定: [言語ペア] > [翻訳メモリと自動翻訳] > [検索] > [upLIFT 用のフラグメント一致のオプション]
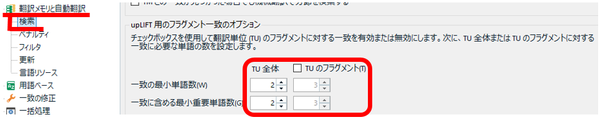
単語数は、以前のセミナーで SDL さんが「2」を推奨していたので、そのように設定しています。ただ、メモリの内容によっては一致が多くなりすぎることもあります。その場合は「3」にすると一致が少なくなります。
詳しくは、 以前の記事 も参照してください。
動作が遅いときは [ 一致の修正] を無効にする
upLIFT が導入されてから、メモリの検索などの動作がかなり遅くなって耐えられないということがたびたびあります。そんなときは、エディタ上での [ Match Repair の使用] を無効にすると改善することが多いと思います。エディタと一括タスクそれぞれについて設定できますが、デフォルトでエディタのみ有効になっています。
プロジェクトの設定: [言語ペア] > [一致の修正] > [Match Repair の使用]
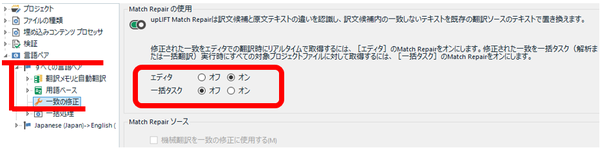
この機能は SDL さんの説明では必ず紹介されますが、私個人の感想としては、それほど役立ちません。無効にして動作が速くなるなら、その方がいいと思っています。
これについても、詳しくは、 以前の記事 を参照してください。
今回は、以上です。特に新しい情報はないのですが、前回の パッケージが開けない という問題が 2017 で対応されない件がどうしても諦めきれず、、、 しつこく書いてみました。
| |
|
タグ: 文字数
カウント
2017 SR1
CU15
フラグメント一致
Match Repair の使用
upLIFT テクノロジー
TU のフラグメント
一致の修正
原文がアジア言語の場合に単語単位のトークン化を使用する
あいまい一致の自動修正
メモリ
アップグレード
パッケージが開かない
単語単位のトークン化
Tweet