



自動処理はできるのですが、この「自動」というのがやっかいです。実際に作業をしていると、自分が想定している「自動」と違って戸惑うことがよくあります。今回は、この自動動作に影響を与えている設定をいくつか紹介します。
まず、繰り返し処理の基本的な設定は [ファイル] > [オプション] > [エディタ] > [自動反映]で行います。これについては、以前の記事「 CAT ツール比較:繰り返しの自動入力 」を参照してください。今回は、これ以外の設定で自動反映の動作に影響を与えるものを主に取り上げます。
メモリは使わないが、メモリの設定は使う
最初に書いたように、繰り返しの自動反映にメモリは不要です。プロジェクトにメモリを 1 つも設定していなくても、以下のように自動反映は行われます。

しかし、メモリがなくても、メモリの設定は使われます。この辺りが Trados のよくわからないところですが、 メモリにはいろいろと重要な設定が存在 し、それが使われます。
使われる設定は、メモリの [設定]から設定する「言語リソース」と、プロジェクト設定の [翻訳メモリと自動翻訳]から設定する「ペナルティ」です。どちらも、本来はメモリのための設定であり、繰り返しの自動反映のための設定ではありませんが、これらの設定が自動反映の動作に影響を与えます。
言語リソース
では、言語リソースの設定から見ていきます。この設定はメモリに付属するものですが、下図のように、メモリを 1 つも指定していないプロジェクトでは「既定の言語リソース」が使用されます。

プロジェクトにメモリを設定した場合は、そのメモリの [設定]画面から以下のような設定が可能になります。

今回は、言語リソースの設定のためにダミーのメモリを 1 つ設定しました。おそらく、言語リソースを直接編集することも可能でしょうが、言語リソースをどう編集するのかとか、プロジェクトを作った後に編集してもその変更は反映されるのかとか、パッケージを受け取った場合はどうなるのかとか、いろいろ考えることが多くなりそうなのでダミーのメモリを使うことにしました。ただし、メモリとの 100% 一致が発生すると検証が面倒になるので、今回は [更新]チェックボックスをオフにしてメモリが登録されないようにしています。

さて、言語リソースの設定で注意するのは [次を認識する]です。ここでチェックボックスがオンになっていないと繰り返しの自動反映でも認識がされません。ここに表示されている「日付」「頭字語」「変数」「英数字文字列」の詳細については、Trados のヘルプ「 自動置換の例 」を参照してください。ただ、その他の項目も含め、自動置換の動作はなかなか複雑でよくわからないことがたくさんあります。本当によくわからないので、すみません、今回は数字と頭字語だけに着目したいと思います。頭字語は、簡単にいうと「大文字の英字のみ」で構成される単語です。

たとえば、 [数字]と [頭字語]のチェックボックスをオフにすると、自動反映の結果は以下のようになります。
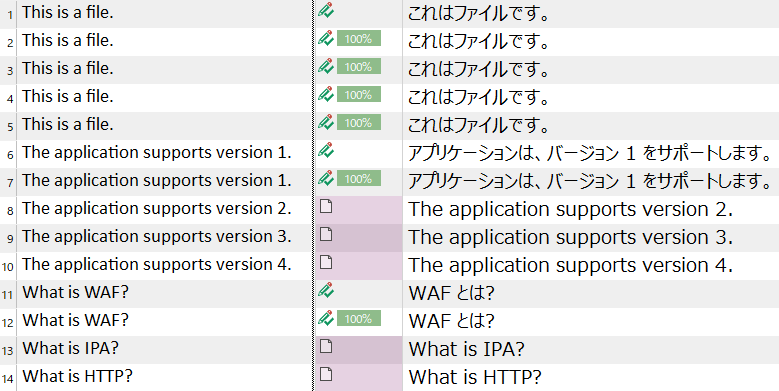
分節 6 〜 10 は数字の例です。数字を認識しない設定の場合、分節 6 と 7 はまったく同一なのでそれでも繰り返しと見なされますが、分節 8 〜 10 は繰り返しになりません。分節 11 〜 14 は頭字語の例です。これらも頭字語を認識しない設定にしていると、まったく同一でない限り繰り返しになりません。
認識しない設定にすると、むやみに自動反映されることがないので安全にはなりますが、正直にいって不便です。この設定は、繰り返しの自動反映だけでなく、メモリとのマッチや QuickPlace 機能 (ショートカット キーは Ctrl+Alt+下矢印または Ctrl+カンマ) にも影響します。ワード数やマッチ率への影響は要検討ですが、入力時の負荷だけを考えれば、たくさん認識してくれた方が助かります。
というわけで、私はいつもすべてのチェックボックスをオンにして作業しています。しかし、そうしていると繰り返しが無条件に自動反映されてしまうので、それを防ぐための手段は必要です。
少し余談ですが、プロジェクトの [翻訳メモリと自動翻訳]の設定や、メモリの [設定]から行う設定は、反映されるタイミングが実はよくわかりません。 [次を認識する]のチェックボックスをオンにしても認識されなかったり、逆に、オフにしているのに認識されたりします。私が何回か試してみた結果としては、設定をした後、エディタでいったんファイルを閉じ、改めて開き直すと設定が反映されるような気がしています。今回の記事を書くためにいろいろ試したのですが、かなり混乱しました。
※※※※※※ 追記 2022/12/14 ※※※※※※※※※※※※※※※※※※※※※※※※※※※※
上記では、[次を認識する] のチェックボックスについてしか記述していませんでしたが、実は [自動置換] のチェックボックスも併せてオンにする必要がありました。すみません、[自動置換] の存在にまったく気づいていませんでした。詳細については、こちらの記事「 タイピングを減らそう 」を参照してください。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
ペナルティ
むやみな自動反映を防ぐ手段の 1 つとして使えるのが ペナルティ です。設定する場所は、 [プロジェクトの設定] > [言語ペア] > [すべての言語ペア] > [翻訳メモリと自動翻訳] > [ペナルティ]です。ペナルティを設定しておくと、マッチ率をペナルティ分だけ引き下げられます。「1」を設定しておけば、100% マッチでも 99% と見なされるのでさまざまな自動処理の予防になります。
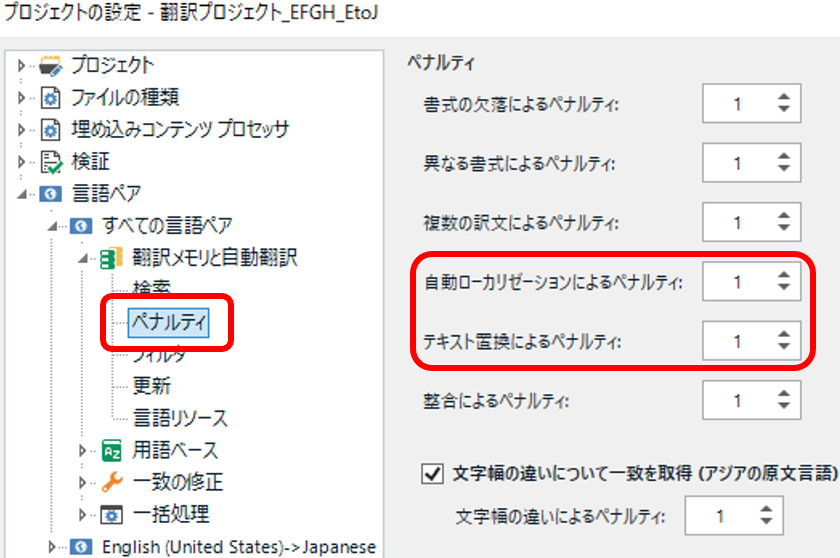
今回注目するのは、既定でゼロになっている [自動ローカリゼーションによるペナルティ]と [テキスト置換によるペナルティ]の 2 つです。簡単に説明すると、「自動ローカリゼーション」は日付や数値の置換、「テキスト置換」は頭字語や英数字文字列の置換です。詳細については、Trados のヘルプ「 TM ペナルティ 」を参照してください。
先に説明した言語リソースで数字と頭字語を認識する設定にしていても、この 2 つのペナルティを「1」に設定すれば、繰り返しの自動反映は下図のように制限されます。まったく同一でない限り、ペナルティが効くので 100% マッチにならず自動反映はされません。
でも、やっぱり自動反映したい
上記のペナルティは、当然ながら、繰り返しの自動反映だけでなく、メモリから訳文を入力するときの動作に影響します。このため、私は必ず全項目に「1」を設定して作業しています。数字が複数あったりすると自動置換の動作は信用できないので、必ず確認する必要があります。
必ず確認する必要はあるのですが、数字だけが違う分節がずらずらと並ぶ場合など、やっぱり自動反映してほしいときはあります。その場合は、最初に挙げたエディタの設定を変えます。

[一致率の最小値]を「99」に設定し、 [ユーザーへの確認メッセージ]が「常に」表示されるようにします。これで、ペナルティが効いて 99% マッチになっても自動反映が行われ、確認メッセージが毎回表示されるようになります。
注意点として、一致率の最小値を引き下げるとかなり危険な動作になることを心しておいてください。ペナルティではなく、通常の文字の違いで 99% マッチになっているものも自動反映されるので、これはあくまで一時的な設定という扱いにし、必要でなくなったらすぐに元に戻します。
確認メッセージは下図のように表示されます。「99%」の下に表示されている青色のマークは自動ローカリゼーションで置換が行われたことを示しています。(ただし、どこが置換されたのかはわかりません。そこは自分で確認するしかありません。)
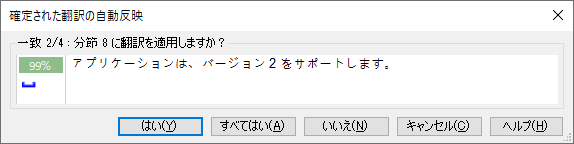
このメッセージはすべての繰り返しについて毎回表示されますが、本当に確認が不要な場合は、 [すべてはい]をクリックすることで一気に自動反映を適用できます。
で、結局どう設定すればいいの?
繰り返しの自動反映に関する設定の説明は以上です。繰り返しの処理にメモリは不要ですが、メモリの設定は使われるのでいろいろな注意が必要です。
私は、たいてい以下のように設定して作業しています。
言語リソース
・ すべての項目を認識する (すべてのチェックボックスをオン)
ペナルティ
・ すべての項目に「1」を設定する
エディタ
・ 一致率の最小値は「100」
・ 確認メッセージは「常に」表示する
上記のように設定した場合、まったく同一でない限り繰り返しの自動反映は行われません。ただ、今回は検証のためにメモリの更新をオフにしていましたが、通常はメモリに訳文を登録しているので、繰り返しとして自動反映がされなくても、メモリから訳文を入力できます。どうしても不便な場合は「一致率の最小値」を引き下げますが、これは危険なのでむやみには行いません。
今回は以上です。繰り返し処理の設定はかなり複雑で、私は今も試行錯誤することがあります。繰り返しがほとんど発生しない文書も多いので、設定しては忘れ、またいろいろ試す、ということを繰り返しています。
| |
|