

This page explains how to migrate your GKE Inference Gateway setup from the
preview v1alpha2
API to the generally available v1
API.
This document is intended for platform administrators and networking specialists
who are using the v1alpha2
version of the GKE Inference Gateway and want
to upgrade to the v1 version to use the latest features.
Before you start the migration, ensure you are familiar with the concepts and deployment of the GKE Inference Gateway. We recommend you review Deploy GKE Inference Gateway .
Before you begin
Before you start the migration, determine if you need to follow this guide.
Check for existing v1alpha2 APIs
To check if you're using the v1alpha2
GKE Inference Gateway API, run the
following commands:
kubectl
get
inferencepools.inference.networking.x-k8s.io
--all-namespaces
kubectl
get
inferencemodels.inference.networking.x-k8s.io
--all-namespaces
The output of these commands determines if you need to migrate:
- If either command returns one or more
InferencePoolorInferenceModelresources, you are using thev1alpha2API and must follow this guide. - If both commands return
No resources found, you are not using thev1alpha2API. You can proceed with a fresh installation of thev1GKE Inference Gateway.
Migration paths
There are two paths for migrating from v1alpha2
to v1
:
- Simple migration (with downtime):this path is faster and simpler but results in a brief period of downtime. It is the recommended path if you don't require a zero-downtime migration.
- Zero-downtime migration:this path is for users who cannot afford any
service interruption. It involves running both
v1alpha2andv1stacks side-by-side and gradually shifting traffic.
Simple migration (with downtime)
This section describes how to perform a simple migration with downtime.
-
Delete existing
v1alpha2resources: to delete thev1alpha2resources, choose one of the following options:Option 1: Uninstall using Helm
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAMEOption 2: Manually delete resources
If you are not using Helm, manually delete all resources associated with your
v1alpha2deployment:- Update or delete the
HTTPRouteto remove thebackendRefthat points to thev1alpha2InferencePool. - Delete the
v1alpha2InferencePool, anyInferenceModelresources that point to it, and the corresponding Endpoint Picker (EPP) Deployment and Service.
After all
v1alpha2custom resources are deleted, remove the Custom Resource Definitions (CRD) from your cluster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml - Update or delete the
-
Install v1 resources: after you clean up the old resources, install the
v1GKE Inference Gateway. This process involves the following:- Install the new
v1Custom Resource Definitions (CRDs). - Create a new
v1InferencePooland correspondingInferenceObjectiveresources. TheInferenceObjectiveresource is still defined in thev1alpha2API. - Create a new
HTTPRoutethat directs traffic to your newv1InferencePool.
- Install the new
-
Verify the deployment: after a few minutes, verify that your new
v1stack is correctly serving traffic.-
Confirm that the Gateway status is
PROGRAMMED:kubectl get gateway -o wideThe output should look similar to this:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10m -
Verify the endpoint by sending a request:
IP = $( kubectl get gateway/inference-gateway -o jsonpath = '{.status.addresses[0].value}' ) PORT = 80 curl -i ${ IP } : ${ PORT } /v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}' -
Ensure you receive a successful response with a
200response code.
-
Zero-downtime migration
This migration path is designed for users who cannot afford any service interruption. The following diagram illustrates how GKE Inference Gateway facilitates serving multiple generative AI models, a key aspect of a zero-downtime migration strategy.
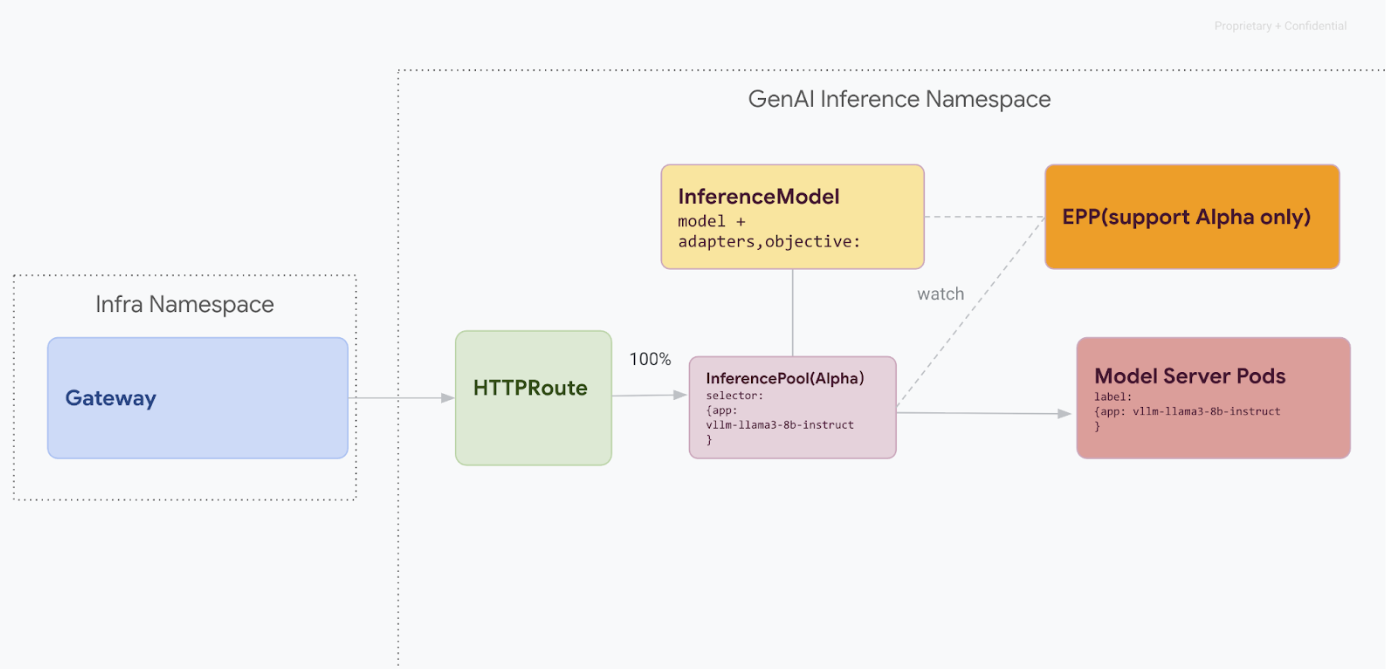
Distinguishing API versions with kubectl
During the zero-downtime migration, both v1alpha2
and v1
CRDs are installed
on your cluster. This can create ambiguity when using kubectl
to query for InferencePool
resources. To ensure you are interacting with the correct
version, you must use the full resource name:
-
For
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.io -
For
v1:kubectl get inferencepools.inference.networking.k8s.io
The v1
API also provides a convenient short name, infpool
, which you can use
to query v1
resources specifically:
kubectl
get
infpool
Stage 1: Side-by-side v1 deployment
In this stage, you deploy the new v1 InferencePool stack alongside the existing v1alpha2 stack, which allows for a safe, gradual migration.
After you finish all the steps in this stage, you have the following infrastructure in the following diagram:
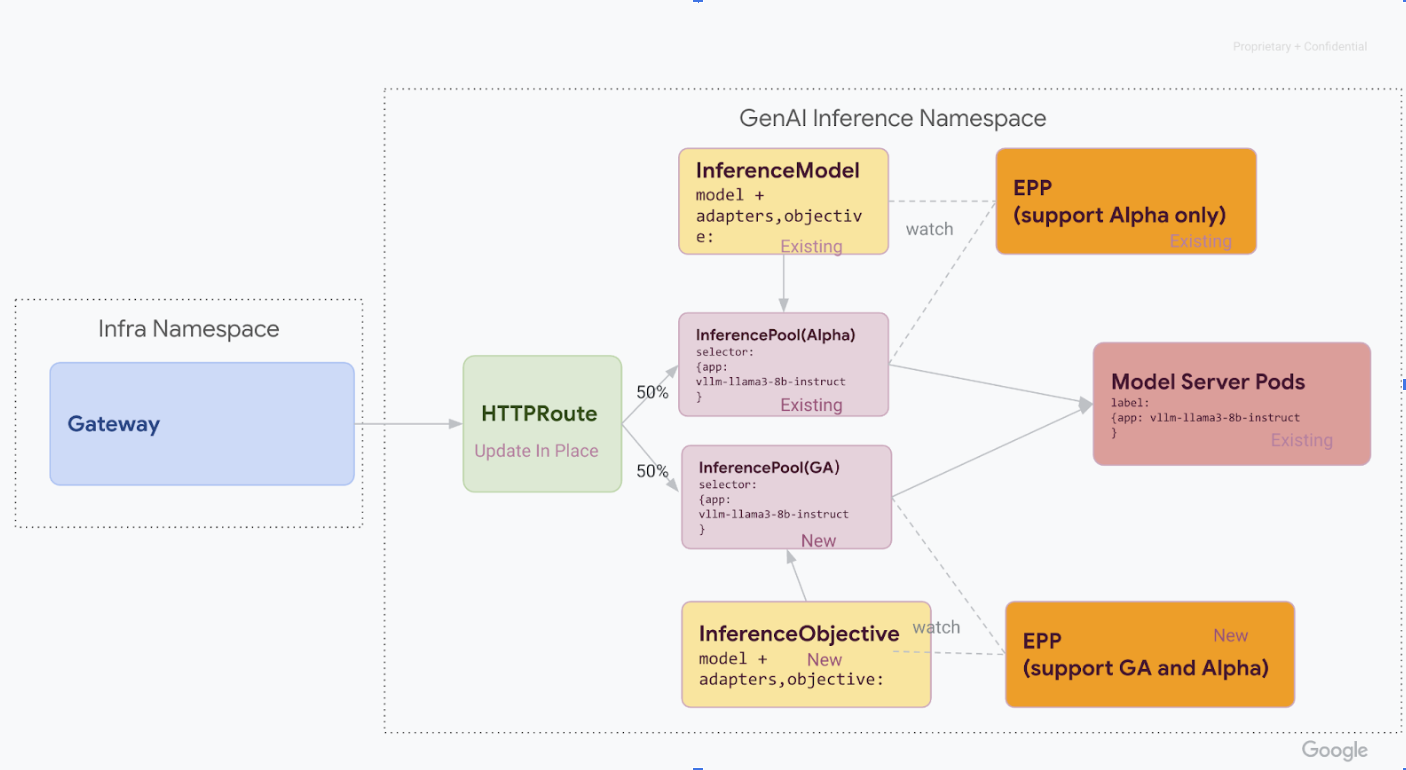
-
Install needed Custom Resource Definition (CRDs) in your GKE cluster:
- For GKE versions earlier than
1.34.0-gke.1626000, run the following command to install both the v1InferencePooland alphaInferenceObjectiveCRDs:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- For GKE versions
1.34.0-gke.1626000or later, install only the alphaInferenceObjectiveCRD by running the following command:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml - For GKE versions earlier than
-
Install the
v1 InferencePool.Use Helm to install a new
v1 InferencePoolwith a distinct release name, such asvllm-llama3-8b-instruct-ga. TheInferencePoolmust target the same Model Server pods as the alphaInferencePoolusinginferencePool.modelServers.matchLabels.app.To install the
InferencePool, use the following command:helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app = MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name = gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool -
Create
v1alpha2 InferenceObjectiveresources.As part of migrating to the v1.0 release of Gateway API Inference Extension, we also need to migrate from the alpha
InferenceModelAPI to the newInferenceObjectiveAPI.-
Apply the following YAML to create the
InferenceObjectiveresources:kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
-
Stage 2: Traffic shifting
With both stacks running, you can start shifting traffic from v1alpha2
to v1
by updating the HTTPRoute
to split traffic. This example shows a 50-50 split.
-
Update HTTPRoute for traffic splitting.
To update the
HTTPRoutefor traffic splitting, run the following command:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOF -
Verify and monitor.
After applying the changes, monitor the performance and stability of the new
v1stack. Verify that theinference-gatewaygateway has aPROGRAMMEDstatus ofTRUE.
Stage 3: Finalization and cleanup
Once you have verified that the v1 InferencePool
is stable, you can direct all
traffic to it and decommission the old v1alpha2
resources.
-
Shift 100% of traffic to the
v1 InferencePool.To shift 100 percent of traffic to the
v1 InferencePool, run the following command:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOF -
Perform final verification.
After directing all traffic to the
v1stack, verify that it is handling all traffic as expected.-
Confirm that the Gateway status is
PROGRAMMED:kubectl get gateway -o wideThe output should look similar to this:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10m -
Verify the endpoint by sending a request:
IP = $( kubectl get gateway/inference-gateway -o jsonpath = '{.status.addresses[0].value}' ) PORT = 80 curl -i ${ IP } : ${ PORT } /v1/completions -H 'Content-Type: application/json' -d '{ "model": " YOUR_MODEL , "prompt": YOUR_PROMPT , "max_tokens": 100, "temperature": 0 }' -
Ensure you receive a successful response with a
200response code.
-
-
Clean up v1alpha2 resources.
After confirming the
v1stack is fully operational, safely remove the oldv1alpha2resources. -
Check for remaining
v1alpha2resources.Now that you've migrated to the
v1InferencePoolAPI, it's safe to delete the old CRDs. Check for existing v1alpha2 APIs to ensure you no longer have anyv1alpha2resources in use. If you still have some remaining, you can continue the migration process for those. -
Delete
v1alpha2CRDs.After all
v1alpha2custom resources are deleted, remove the Custom Resource Definitions (CRD) from your cluster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlAfter completing all steps, your infrastructure should resemble the following diagram:
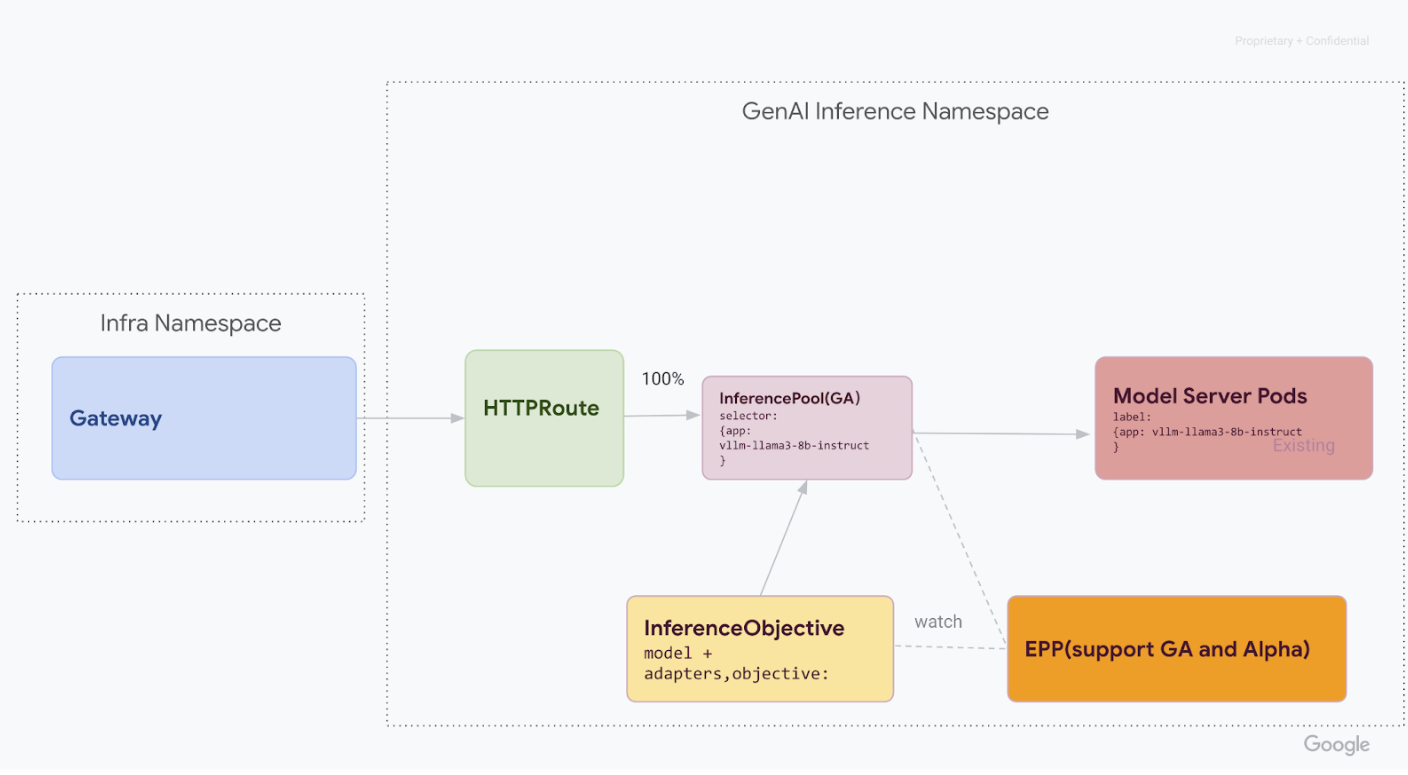
Figure:GKE Inference Gateway routing requests to different generative AI models based on model name and priority
What's next
- Learn more about Deploy
GKE Inference Gateway
.
- Explore other GKE networking features .