
TPU v5e
This document describes the architecture and supported configurations of Cloud TPU v5e.
TPU v5e supports single and multi-host training and single-host inference. Multi-host inference is supported using Sax . For more information, see Cloud TPU inference .
System architecture
Each v5e chip contains one TensorCore. Each TensorCore has four matrix-multiply units (MXUs), a vector unit, and a scalar unit.
The following diagram illustrates a TPU v5e chip.

The following table shows the key specifications and their values for v5e.
| Specification | Values |
|---|---|
| Performance/total cost of ownership (TCO) (expected) | 0.65x |
| Peak compute per chip (bf16) | 197 TFLOPs |
| Peak compute per chip (Int8) | 393 TOPs |
| HBM capacity per chip | 16 GB |
| HBM bandwidth per chip | 800 GiBps |
| Bidirectional inter-chip interconnect (ICI) bandwidth (per chip) | 400 GBps |
| ICI ports per chip | 4 |
| DRAM per host | 512 GiB |
| Chips per host | 8 |
| TPU Pod size | 256 chips |
| Interconnect topology | 2D torus |
| BF16 peak compute per Pod | 50.63 PFLOPs |
| All-reduce bandwidth per Pod | 51.2 TB/s |
| Bisection bandwidth per Pod | 1.6 TB/s |
| Per-host NIC configuration | 2 x 100 Gbps NIC |
| Data center network bandwidth per Pod | 6.4 Tbps |
| Peak compute per Pod | 100 PetaOps (Int8) |
Configurations
Cloud TPU v5e is a combined training and inference (serving) product. Training jobs are optimized for throughput and availability, while serving jobs are optimized for latency. A training job on TPUs provisioned for serving could have lower availability and similarly, a serving job executed on TPUs provisioned for training could have higher latency.
The following 2D slice shapes are supported for v5e:
| Topology | Number of TPU chips | Number of hosts |
|---|---|---|
|
1x1
|
1 | 1/8 |
|
2x2
|
4 | 1/2 |
|
2x4
|
8 | 1 |
|
4x4
|
16 | 2 |
|
4x8
|
32 | 4 |
|
8x8
|
64 | 8 |
|
8x16
|
128 | 16 |
|
16x16
|
256 | 32 |
VM types
Each TPU VM in a v5e TPU slice contains 1, 4 or 8 chips. In 4-chip and smaller slices, all TPU chips share the same non-uniform memory access (NUMA) node.
For 8-chip v5e TPU VMs, CPU-TPU communication will be more efficient within NUMA
partitions. For example, in the following figure, CPU0-Chip0
communication
will be faster than CPU0-Chip4
communication.
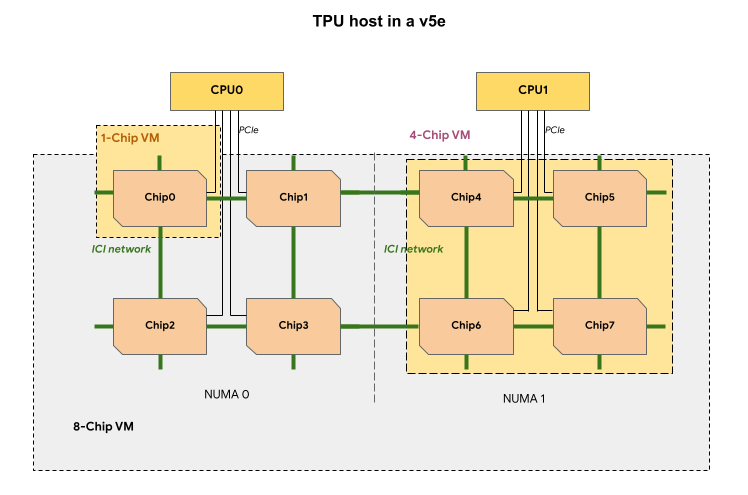
The following table shows a comparison of TPU v5e VM types:
| VM type | Machine type (GKE API) | Number of vCPUs per VM | RAM (GB) per VM | Number of NUMA nodes per VM |
|---|---|---|---|---|
|
1-chip VM
|
ct5lp-hightpu-1t
|
24 | 48 | 1 |
|
4-chip VM
|
ct5lp-hightpu-4t
|
112 | 192 | 1 |
|
8-chip VM
|
ct5lp-hightpu-8t
|
224 | 384 | 2 |
Cloud TPU v5e types for serving
Single-host serving is supported for up to 8 v5e chips. The following configurations are supported: 1x1, 2x2 and 2x4 slices. Each slice has 1, 4 and 8 chips respectively.

To provision TPUs for a serving job, use one of the following TPU slice sizes in your CLI or API TPU creation request:
| Number of TPU chips | Machine type (GKE API) |
|---|---|
1
|
ct5lp-hightpu-1t
|
4
|
ct5lp-hightpu-4t
|
8
|
ct5lp-hightpu-8t
|
For more information about managing TPUs, see Manage TPUs . For more information about the system architecture of Cloud TPU, see System architecture .
Serving on more than 8 v5e chips, also called multi-host serving, is supported using Sax . For more information, see Cloud TPU inference .
Cloud TPU v5e types for training
Training is supported for up to 256 chips.
To provision TPUs for a v5e training job, use one of the following TPU slice sizes in your CLI or API TPU creation request:
| Number of TPU chips | Machine type (GKE API) | Topology |
|---|---|---|
16
|
ct5lp-hightpu-4t
|
4x4 |
32
|
ct5lp-hightpu-4t
|
4x8 |
64
|
ct5lp-hightpu-4t
|
8x8 |
128
|
ct5lp-hightpu-4t
|
8x16 |
256
|
ct5lp-hightpu-4t
|
16x16 |
For more information about managing TPUs, see Manage TPUs . For more information about the system architecture of Cloud TPU, see System architecture .