PR
Free Space
警察はスタンドプレーばかりで、地味な事件については何もしていない!!!
【中東の混乱】いつ終息するのか?本当に大迷惑!!
【デジタル公共事業の闇】マイナンバーカードの更新申請の制度欠陥
〖政治の貧困〗緊急銃猟って、政府、国会の無為無策の結晶か?
〖政治の貧困〗公共事業の誘致が地域政党の生きる道?万博の次は副首都?
〖政治の貧困〗物価高対策はどうなるの?理屈が破綻している?
〖OCNモバイルONE〗そろそろ終了が近いのか?格安SIMサービスの弱点を利用して解約させるのか??非論理的で驚愕の対応!
〖超便利なTailscale VPN〗ロケフリ、アニメロッカーだけでなく、RDPも便利に
【消費税減税】消費税減税に反対の構図とは?
【ソニーロケフリのDDNS終了】ソニーのロケフリのDDNS(ダイナミックDNS)サービス停止後にロケフリを利用する方法
【中東の混乱】いつ終息するのか?本当に大迷惑!!
【デジタル公共事業の闇】マイナンバーカードの更新申請の制度欠陥
〖政治の貧困〗緊急銃猟って、政府、国会の無為無策の結晶か?
〖政治の貧困〗公共事業の誘致が地域政党の生きる道?万博の次は副首都?
〖政治の貧困〗物価高対策はどうなるの?理屈が破綻している?
〖OCNモバイルONE〗そろそろ終了が近いのか?格安SIMサービスの弱点を利用して解約させるのか??非論理的で驚愕の対応!
〖超便利なTailscale VPN〗ロケフリ、アニメロッカーだけでなく、RDPも便利に
【消費税減税】消費税減税に反対の構図とは?
【ソニーロケフリのDDNS終了】ソニーのロケフリのDDNS(ダイナミックDNS)サービス停止後にロケフリを利用する方法
2020.07.17

テーマ: パソコンを楽しむ♪(3747)
カテゴリ: データ分析
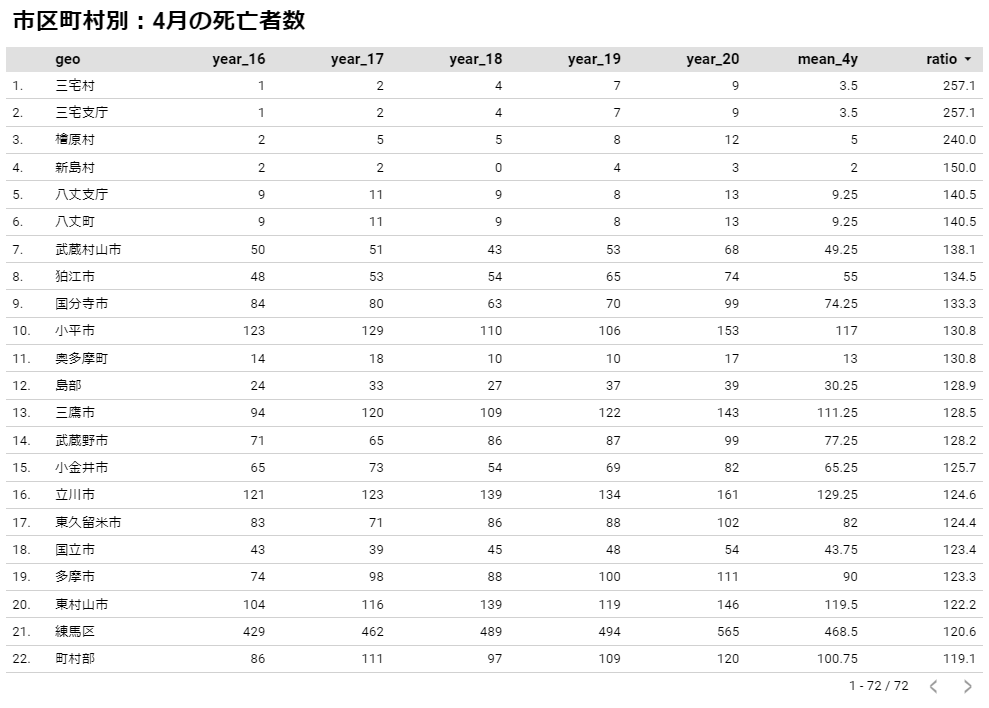
新型コロナウイルスによる超過死亡を推し量るために、20年の東京都の月別死亡者数と過去の年の平均値とを比べました。
その際、一つの例外を除き、Excelの表のコピペをすることなく、データの前処理をしました。コピペをしていないので、データの誤削除、誤上書などといったコピペミスとは無縁です。
↓R言語で作成した集計表をデータポータルのダッシュボードに読み込んでいます。
まず、東京都の人口統計のページから簡単に入手できる16年以降の月別のExcelファイルからデータを抽出して、分析のための前処理をします。
分析といっても、とりあえず4年間の平均値と20年の値を比較するくらいです。そのための前処理がかなり面倒です。
この場合のデータの前処理とは、
「東京都の人口統計のページから毎月のExcelファイルのダウンロード」
「ダウンロードしたファイルから必要なデータの抽出」
「抽出したデータの整形」
などになります。
このような前処理では、データ分析といっても、かなりアナログな作業が含まれます。
ただでさえ、アナログな作業になりがちなのですが、今回のデータにはR言語などの処理になじまない部分が多くありました。
まず、Excelのファイル名に、1月から9月までは数字が使われていて、10月から12月はa、b、cが使われているなど、繰り返し処理で扱いにくい形になっています。
また、R言語などで処理する場合は、csvファイルの方が扱いやすいです。Excelファイルでは、見出しがセル結合になっていたりするので、面倒な場合があります。
今回のデータでは、抽出すべき死亡者数のデータの含まれる表の位置が一定ではありませんでした。
各月のExcelファイルには複数の表が並んでいて、当該データを含む表の位置が一定していませんでした。
16年1月から20年6月までの54個のファイルの中で、当該データの表の最初の行番号は、「148、147、158、160、159」の5通りもありました。
繰り返し処理で、データを読み込む場合は、読み込む範囲が変動することを吸収するような処理を追加する必要があります。
当該データの1行目が「148、147、158、160、159」の5通りということですが、これに対しては、読み込む行数の設定を2通りにして、読み込んだ後で空白を削除することで、対応できました。
データ表ごとにcsvファイルになっていれば、処理は簡単なのですが・・・。
今回のアナログな前処理作業
ダウンロードしたファイルの名前の文字列中のa、b、cを手作業で10、11、12に変更しました。
データの読み込み範囲がファイルによって変動しているので、すべてのファイルのデータ位置を目視で確認した後で、Rのコードで何通りのパターンがあるのかを確認しました。
R言語によるデータ前処理の内容(抜粋)
以下のコードですが、国立感染症研究所のサイトからインフルエンザの定点当たり報告数のデータをダウンロードして、分析する際に作成したコードが基になっています。
◆ファイル中の当該データ表の位置の確認(何行目から当該データ表が始まっているのかを確認)
20年のファイルは6月までなので、ループ処理で、20年7月のところでエラーが出ますが、20年6月までの処理はできています。表の位置が毎月同じであれば、このような処理は一切不要なのですが。
◆ファイルのダウンロード(抜粋です)
繰り返しの入れ子処理で、16年から19年までの一括処理も可能ですが、下記の例は年単位での処理にしています。
◆ダウンロードしたデータの読み込み
各月のファイルには、前月の人口の動き(つまり、死亡者数)のデータが含まれているので、ファイル名の中の数字から1を引いた値を死亡者数のデータのインデックスに用います。つまり、読み込んだ死亡者数のデータの列に、いつのデータなのかの情報の列を加えます。しかし、1月のファイルでは12月の死亡者数のデータになるので、ファイル名の中の数字から1を引く形では対応できません。「if else」で処理を分岐させるか、1月と2月以降で処理を分けるなどの対応が必要です。今回は、 1月と2月以降で処理を分けました。
◆16年から19年の2月から12月までのファイルの読み込み
あらかじめ、Excel上で、手作業で市区町村名のファイルgeo.csv(列名をgeoにしておきます)を作成しておきます。今回、Excelでの手作業はこの作業のみです。市区町村名の列にセル結合があって、抽出が面倒なので手作業で対応しました。
市区町村別に、20年4月の死亡者数を16年から19年の4月の平均値と比較する
############################
############################

楽天市場で「イソジン うがい薬」を探す
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/1aa553d2.fbb22853.1aa553d3.bb389f51/?me_id=1310982&item_id=10000871&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Frakutenmobile%2Fcabinet%2Fitem%2Faquos-sense3-lite%2Fmain_01sim.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Frakutenmobile%2Fcabinet%2Fitem%2Faquos-sense3-lite%2Fmain_01sim.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/1aa553d2.fbb22853.1aa553d3.bb389f51/?me_id=1310982&item_id=10000869&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Frakutenmobile%2Fcabinet%2Fitem%2Fgalaxy-a7%2Fmain_03.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Frakutenmobile%2Fcabinet%2Fitem%2Fgalaxy-a7%2Fmain_03.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
その際、一つの例外を除き、Excelの表のコピペをすることなく、データの前処理をしました。コピペをしていないので、データの誤削除、誤上書などといったコピペミスとは無縁です。
↓R言語で作成した集計表をデータポータルのダッシュボードに読み込んでいます。
まず、東京都の人口統計のページから簡単に入手できる16年以降の月別のExcelファイルからデータを抽出して、分析のための前処理をします。
分析といっても、とりあえず4年間の平均値と20年の値を比較するくらいです。そのための前処理がかなり面倒です。
この場合のデータの前処理とは、
「東京都の人口統計のページから毎月のExcelファイルのダウンロード」
「ダウンロードしたファイルから必要なデータの抽出」
「抽出したデータの整形」
などになります。
このような前処理では、データ分析といっても、かなりアナログな作業が含まれます。
ただでさえ、アナログな作業になりがちなのですが、今回のデータにはR言語などの処理になじまない部分が多くありました。
まず、Excelのファイル名に、1月から9月までは数字が使われていて、10月から12月はa、b、cが使われているなど、繰り返し処理で扱いにくい形になっています。
また、R言語などで処理する場合は、csvファイルの方が扱いやすいです。Excelファイルでは、見出しがセル結合になっていたりするので、面倒な場合があります。
今回のデータでは、抽出すべき死亡者数のデータの含まれる表の位置が一定ではありませんでした。
各月のExcelファイルには複数の表が並んでいて、当該データを含む表の位置が一定していませんでした。
16年1月から20年6月までの54個のファイルの中で、当該データの表の最初の行番号は、「148、147、158、160、159」の5通りもありました。
繰り返し処理で、データを読み込む場合は、読み込む範囲が変動することを吸収するような処理を追加する必要があります。
当該データの1行目が「148、147、158、160、159」の5通りということですが、これに対しては、読み込む行数の設定を2通りにして、読み込んだ後で空白を削除することで、対応できました。
データ表ごとにcsvファイルになっていれば、処理は簡単なのですが・・・。
今回のアナログな前処理作業
ダウンロードしたファイルの名前の文字列中のa、b、cを手作業で10、11、12に変更しました。
データの読み込み範囲がファイルによって変動しているので、すべてのファイルのデータ位置を目視で確認した後で、Rのコードで何通りのパターンがあるのかを確認しました。
R言語によるデータ前処理の内容(抜粋)
以下のコードですが、国立感染症研究所のサイトからインフルエンザの定点当たり報告数のデータをダウンロードして、分析する際に作成したコードが基になっています。
◆ファイル中の当該データ表の位置の確認(何行目から当該データ表が始まっているのかを確認)
20年のファイルは6月までなので、ループ処理で、20年7月のところでエラーが出ますが、20年6月までの処理はできています。表の位置が毎月同じであれば、このような処理は一切不要なのですが。
##############################
y <- 16
y_num <- 20
i <- 1
data_num <- 12
rownum <- NULL
get_rownum <- NULL
df_rownum <- NULL
df_indx <- NULL
for(y in seq(y,y_num,by = 1)) {
for(i in seq(1,data_num,by = 1)) {
indx <-read_excel(paste0('C:/Users/user/tokyo/','js',y,i,'a0000.xls'),sheet=1,range = 'A1:A200',col_names = F)
indx <- t(indx)
rownum <- min(which(grepl("*月中の人口の動き",indx)))
get_rownum <- as.data.frame(rownum)
df_rownum <- get_rownum %>% mutate(year_n = y) %>% mutate(month = paste0("M0",i))%>% mutate(month_n =i)
df_indx <- rbind(df_indx,df_rownum)}}
view(df_indx)
indx_list <- unique(df_indx$rownum)
indx_list
indx_list
##############################
◆ファイルのダウンロード(抜粋です)
繰り返しの入れ子処理で、16年から19年までの一括処理も可能ですが、下記の例は年単位での処理にしています。
#####2016年の各月のファイルをダウンロード
url_txt <- "https://www.toukei.metro.tokyo.lg.jp/jsuikei/2016/"
data_num <- 9
for(i in seq(1, data_num, by = 1)) {
url <- paste0(url_txt,'js16',i,'a0000.xls')
destfile <- paste0('C:/Users/user/tokyo/','js16',i,'a0000.xls')
download.file(url,destfile,mode = "wb")
print(i)
print(i)
Sys.sleep(3)
}
urla <- paste0(url_txt,'js16aa0000.xls')
destfilea <- paste0('C:/Users/user/tokyo/','js16','a','a0000.xls')
download.file(urla,destfilea,mode = "wb")
urlb <- paste0(url_txt,'js16ba0000.xls')
destfileb <- paste0('C:/Users/user/tokyo/','js16','b','a0000.xls')
download.file(urlb,destfileb,mode = "wb")
urlc <- paste0(url_txt,'js16ca0000.xls')
destfilec <- paste0('C:/Users/user/tokyo/','js16','c','a0000.xls')
download.file(urlc,destfilec,mode = "wb")
◆ダウンロードしたデータの読み込み
各月のファイルには、前月の人口の動き(つまり、死亡者数)のデータが含まれているので、ファイル名の中の数字から1を引いた値を死亡者数のデータのインデックスに用います。つまり、読み込んだ死亡者数のデータの列に、いつのデータなのかの情報の列を加えます。しかし、1月のファイルでは12月の死亡者数のデータになるので、ファイル名の中の数字から1を引く形では対応できません。「if else」で処理を分岐させるか、1月と2月以降で処理を分けるなどの対応が必要です。今回は、 1月と2月以降で処理を分けました。
◆16年から19年の2月から12月までのファイルの読み込み
あらかじめ、Excel上で、手作業で市区町村名のファイルgeo.csv(列名をgeoにしておきます)を作成しておきます。今回、Excelでの手作業はこの作業のみです。市区町村名の列にセル結合があって、抽出が面倒なので手作業で対応しました。
############################
df_geo <- read.csv("geo.csv",stringsAsFactors = FALSE)
df_geo <- read.csv("geo.csv",stringsAsFactors = FALSE)
y <- 16
y_num <- 19
i <- 2
data_num <- 12
data_num <- 12
df_data19 <- NULL
for(y in seq(y,y_num,by = 1)) {
for(i in seq(2,data_num,by = 1)) {
indx <- read_excel(paste0('C:/Users/user/tokyo/','js',y,i,'a0000.xls'),sheet=1,range = 'A1:A200',col_names = F)
indx <- read_excel(paste0('C:/Users/user/tokyo/','js',y,i,'a0000.xls'),sheet=1,range = 'A1:A200',col_names = F)
indx <- t(indx)
rownum <- min(which(grepl("*月中の人口の動き",indx)))
if (rownum <= 150)
{page <- NULL
get_data <- NULL
page <- read_excel(paste0('C:/Users/user/tokyo/','js',y,i,'a0000.xls'),sheet=1,range = 'L148:L224',col_names = F)
colnames(page) <- "deaths"
page <- na.omit(page)
print(nrow(page))
j <- i-1
get_data <- page %>% mutate(year_n = y) %>% mutate(month = paste0("M0",j))%>% mutate(month_n =j)
get_data <-get_data[!(get_data$deaths=="死亡"),]
get_data <- cbind(df_geo, get_data)
df_data19 <- rbind(df_data19, get_data)}
else
{page <- NULL
get_data <- NULL
page <- read_excel(paste0('C:/Users/user/tokyo/','js',y,i,'a0000.xls'),sheet=1,range = 'L159:L235',col_names = F)
colnames(page) <- "deaths"
page <- na.omit(page)
j <- i-1
get_data <- page %>% mutate(year_n = y) %>% mutate(month = paste0("M0",j))%>% mutate(month_n =j)
get_data <-get_data[!(get_data$deaths=="死亡"),]
get_data <- cbind(df_geo, get_data)
df_data19 <- rbind(df_data19, get_data)}
}
}
view(df_data19)
############################
16年から19年までの1月のデータ(前年12月の死亡者数)の読み込み
20年の1月のファイルと2月から6月のファイルを読み込む
16年から19年までの1月のデータ(前年12月の死亡者数)の読み込み
############################
y <- 16
y_num <- 19
page12 <- NULL
get_data12 <- NULL
df_data12 <- NULL
for(y in seq(y,y_num,by = 1)) {
page12 <- NULL
get_data12 <- NULL
page12 <- read_excel(paste0('C:/Users/user/tokyo/','js',y,'1','a0000.xls'),sheet=1, range = 'L148:L224',col_names = F)
colnames(page12) <- "deaths"
page12 <- na.omit(page12)
print(nrow(page12))
get_data12 <- page12 %>% mutate(year_n = y-1) %>% mutate(month = paste0("M",12))%>% mutate(month_n =12)
get_data12 <-get_data12[!(get_data12$deaths=="死亡"),]
get_data12 <- cbind(df_geo, get_data12)
df_data12 <- rbind(df_data12, get_data12)
}
view(df_data12)
df_data19a <- rbind(df_data19, df_data12)
view(df_data19a)
############################
############################
page1912 <- NULL
get_data1912 <- NULL
y <- 20
page1912 <- read_excel(paste0('C:/Users/user/tokyo/','js',y,'1','a0000.xls'),sheet=1, range = 'L159:L235',col_names = F)
colnames(page1912) <- "deaths"
page1912 <- na.omit(page1912)
print(nrow(page1912))
get_data1912 <- page1912 %>% mutate(year_n = y-1) %>% mutate(month = paste0("M",12))%>% mutate(month_n =12)
get_data1912 <-get_data1912[!(get_data1912$deaths=="死亡"),]
get_data1912 <- cbind(df_geo, get_data1912)
df_data1912 <- get_data1912
data_num <- 6
y <- 20
i <- 2
j <- NULL
df_data20 <- NULL
page <- NULL
get_data <- NULL
for(i in seq(2,data_num,by = 1)) {
page <- read_excel(paste0('C:/Users/user/tokyo/','js20',i,'a0000.xls'),sheet=1,range = 'L159:L235',col_names = F)
colnames(page) <- "deaths"
page <- na.omit(page)
print(nrow(page))
j <- i-1
get_data <- page %>% mutate(year_n = y) %>% mutate(month = paste0("M0",j))%>% mutate(month_n =j)
get_data <-get_data[!(get_data$deaths=="死亡"),]
get_data <- cbind(df_geo, get_data)
df_data20 <- rbind(df_data20, get_data)
}
view(df_data20)
df_data20a <- rbind(df_data1912, df_data20)
view(df_data20a)
df_data1620a <- rbind(df_data19a, df_data20a)
view(df_data1620a)
細かな部分を調整
############################
df_data1620a$month <- str_replace_all(df_data1620a$month, "M010","M10")
df_data1620a$month <- str_replace_all(df_data1620a$month, "M011","M11")
df_data1620a$month <- str_replace_all(df_data1620a$month, "M012","M12")
df_data1620a$month <- factor(df_data1620a$month, levels=c("M01","M02","M03","M04","M05","M06","M07","M08","M09","M10","M11","M12"))
df_data1620a <- mutate(df_data1620a,year = paste0(df_data1620a$year_n,"年"))
df_data1620a <- df_data1620a [!(df_data1620a$year_n==15),]
df_data1620a$deaths <- as.numeric(df_data1620a$deaths)
df_data1620a[order(df_data1620a$year_n, df_data1620a$month_n),]
write.csv(df_data1620a,"TokyoPop.csv",fileEncoding = "UTF8")
市区町村別に、20年4月の死亡者数を16年から19年の4月の平均値と比較する
############################
geotky_list <- unique(df_data1620a$geo)
df_tky <- NULL
i <- 1
for (i in seq_along(geotky_list))
{
df_tkytemp1 <- subset(df_data1620a,df_data1620a$geo==geotky_list[i])
df_tkytemp2 <- df_tkytemp1[df_tkytemp1$month=="M04",]
df_tkytemp3 <- df_tkytemp2[,c(1,2,4,6)]
df_tkytemp4 <- spread(df_tkytemp3, key = year, value = deaths)
colnames(df_tkytemp4) <- c("geo","month","year_16","year_17","year_18","year_19","year_20")
df_tkytemp5 <- df_tkytemp4 %>% mutate(mean_4y = rowMeans(df_tkytemp4[,3:6]))
df_tkytemp6 <- df_tkytemp5 %>% mutate(ratio = year_20/mean_4y * 100)
df_tky <- rbind(df_tky,df_tkytemp6)
}
write.csv(df_tky,"TokyoRate04.csv",fileEncoding = "UTF8")
df_tky_d <- df_tky[order(df_tky$ratio, decreasing=T), ]
############################
楽天市場で「イソジン うがい薬」を探す
AQUOS sense3 lite+Rakuten UN-LIMITプランセット(事務手数料3300円込)【22000円相当のポイント還元】
価格:31280円(税別、送料別) (2020/7/15時点)
楽天で購入
Galaxy A7+Rakuten UN-LIMITプランセット(事務手数料3300円込)【15000円相当のポイント還元】
価格:22000円(税込、送料無料) (2020/5/31時点)
楽天で購入
↑楽天市場店で購入すればよかったと思います:アマゾン・プライム・ビデオはHD 1080Pで視聴できます:有機ELなので、黒がきれいです:ヘッドホンでのドルビーアトモスに対応しています。
↓楽天市場以外の有名ストアの利用でも楽天ポイントが貯まります。

-------------------------------------------------------------
-------------------------------------------------------------


--------------------------------------------------------------------------

↓ECDCデータ版ダッシュボードはこちらからアクセスできます。

-------------------------------------------------------------------------
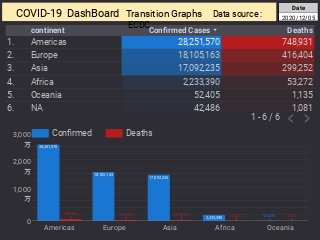
【ダッシュボード 「COVID-19 Transition Graphs」 を試作】
こちらは、ジョンズ・ホプキンス大学のデータを利用したダッシュボードです。
中国本土以外の地域への感染が拡大しているため、国別、地域別の感染者数の推移を簡単に確認できるダッシュボードを試作しています。
随時、ページを追加しています。グラフのデータは、右上部分の操作でダウンロードすることができます。
アメリカの「地域別の変数」を前処理して、「州別」での推移をグラフ化できるようにしました。
また、州コードのフィールドを作成してコロプレス地図も作成しています。
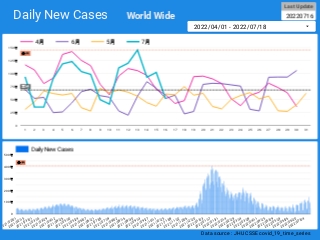
楽天ブログでは「iframe」タグが使えないので、Bloggerのページから利用できるようにしています。
無料で利用できる、グーグルの「データポータル」のダッシュボードです。データさえあれば、簡単に作成できます。「国」別、「地域」別に日ごとの感染者数の推移を見ることができます。
↓ダッシュボードの試作です。下記リンクのページから利用できます。

ジョンズ・ホプキンス大学の「JHU CSSE」の「Covid19 Daily Reports」のデータを利用しています。
★おすすめの記事


◆How Windows Sonic looks like.:Windows Sonic for Headphonesの音声と2chステレオ音声の比較:7.1.2chテストトーンの比較で明らかになった違い:一目で違いがわかりました


--------------------------------------------------------------------------
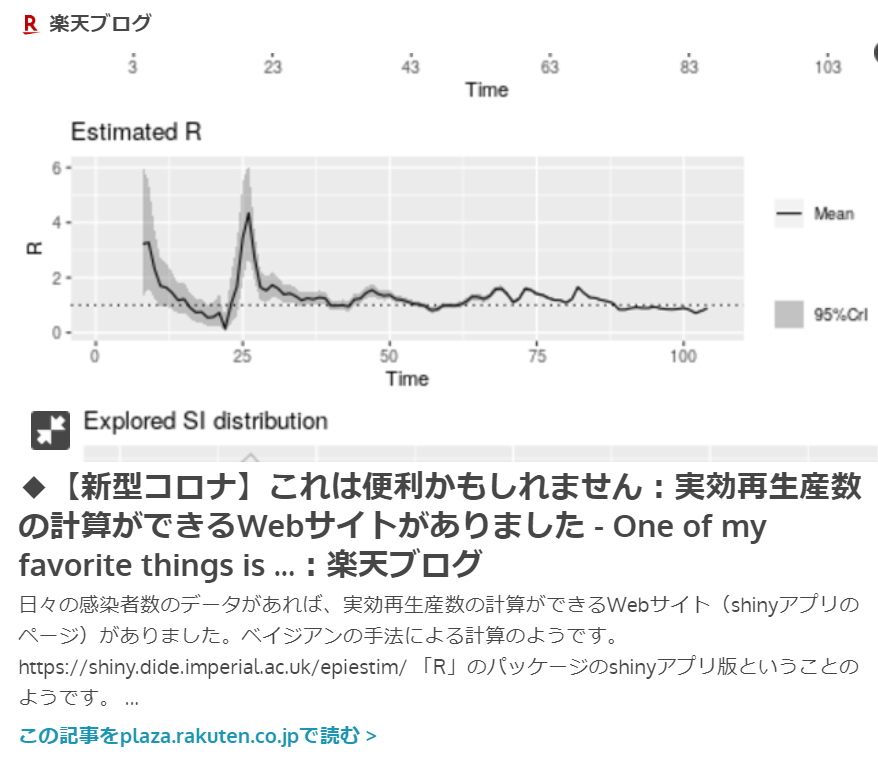
↓実効再生産数を計算できる
Webアプリがあります。
↓倍加時間についてです。

--------------------------------------------------------------------------
↓倍加時間についてです。
--------------------------------------------------------------------------
↓ECDCデータ版ダッシュボードはこちらからアクセスできます。
-------------------------------------------------------------------------
【ダッシュボード 「COVID-19 Transition Graphs」 を試作】
こちらは、ジョンズ・ホプキンス大学のデータを利用したダッシュボードです。
中国本土以外の地域への感染が拡大しているため、国別、地域別の感染者数の推移を簡単に確認できるダッシュボードを試作しています。
随時、ページを追加しています。グラフのデータは、右上部分の操作でダウンロードすることができます。
アメリカの「地域別の変数」を前処理して、「州別」での推移をグラフ化できるようにしました。
また、州コードのフィールドを作成してコロプレス地図も作成しています。
楽天ブログでは「iframe」タグが使えないので、Bloggerのページから利用できるようにしています。
無料で利用できる、グーグルの「データポータル」のダッシュボードです。データさえあれば、簡単に作成できます。「国」別、「地域」別に日ごとの感染者数の推移を見ることができます。
↓ダッシュボードの試作です。下記リンクのページから利用できます。
ジョンズ・ホプキンス大学の「JHU CSSE」の「Covid19 Daily Reports」のデータを利用しています。
EdgeブラウザやIEブラウザなど、Chromeブラウザ以外での利用の場合はうまく表示されないことがあるようです。
↓ 上記のダッシュボードのデータの出所のサイトです。マップがメインのダッシュボードです

↓WHOのサイトでも、感染者数、地域などの「Situation Report」が日々更新されています。関心がある場合は、一日に一度見るといいのではないかと思います。


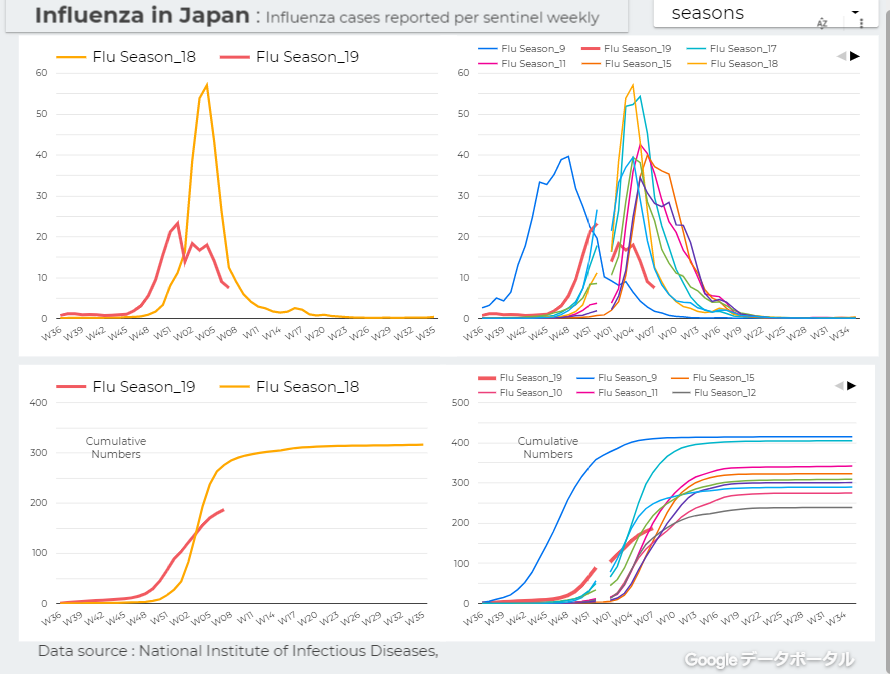
↓日本のインフルエンザの「定点当たり報告数」をグラフ化できるダッシュボードを試作。都道府県別にグラフ化可能です。
--------------------------------------------------------------------------
↓ 上記のダッシュボードのデータの出所のサイトです。マップがメインのダッシュボードです
↓WHOのサイトでも、感染者数、地域などの「Situation Report」が日々更新されています。関心がある場合は、一日に一度見るといいのではないかと思います。
↓日本のインフルエンザの「定点当たり報告数」をグラフ化できるダッシュボードを試作。都道府県別にグラフ化可能です。
--------------------------------------------------------------------------
★おすすめの記事
◆How Windows Sonic looks like.:Windows Sonic for Headphonesの音声と2chステレオ音声の比較:7.1.2chテストトーンの比較で明らかになった違い:一目で違いがわかりました
お気に入りの記事を「いいね!」で応援しよう
[データ分析] カテゴリの最新記事
-
CHATGPTって何しているの? 2023.11.22
-
コスタリカの話題はあまり見られない:ツ… 2022.12.03
-
【新型コロナ】Qatarでは感染確認者数が減… 2022.11.29




【毎日開催】
15記事にいいね!で1ポイント
© Rakuten Group, Inc.