

Ruby 0
[Python] カテゴリの記事
全214件 (214件中 151-200件目)
-
Python のスレッドについての資料と Python の統合開発環境 (IDE)
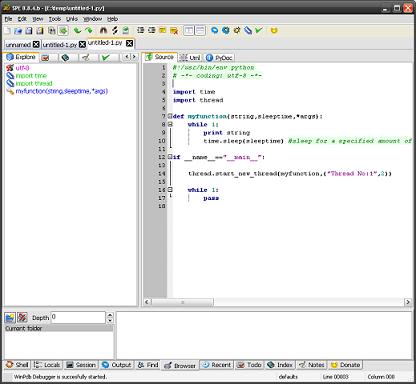
Krishna G Pai の Understanding Threading in Python を読む。2004年10月に書かれたものでちょっと古いが、たまたま検索で引っかかってきたのでメモ。構成は次の通り。中身を見てみると、ちょっと古い。2.1 Locks に この例の場合 time.sleep(sleeptime) を外すと、Thread No:1 が延々続くような表示になってしまうと書かれているが、今はちゃんと動くようになっている等。Python 2.4 で変わったのかな(記事が書かれたのは Python 2.3.4 の時代)。Why Threading in Python?The BasicsLocksThe Global Interpreter LockUsing the Threading ModuleUsing the Threading LibraryThe Thread ObjectProfiling Threaded Code.Condition, Event and Queue Objects.Python ライブラリリファレンス: 7.4 thread -- マルチスレッドのコントロール のあたりも参照。Tutorial on Threads Programming with Python (Norman Matloff and Francis Hsu) が詳しい。Wing IDE 2.x などスレッドを使ったプログラムに対応していない統合環境を使うと、赤文字の部分にブレークポイントを仕掛けても、止まってくれない。ということで、こうしたプログラムをデバグするためには、例えば Wing IDE 3.x を使う必要がある。#!/usr/bin/env pythonimport timeimport threaddef myfunction(string,sleeptime,*args): while 1: print string time.sleep(sleeptime) #sleep for a specified amount of time.if __name__=="__main__": thread.start_new_thread(myfunction,("Thread No:1",2)) while 1:passUnderstanding Threading in Python より他の IDE もちょっと使ってみるかなということで、Python の統合開発環境 (IDE: Integrated Development Environment) PyScripter を試してみる。PyScripter 自体は Delphi で書かれている。Python開発統合環境の決定版! PyScripter(for Windows)の紹介 に日本語の詳しい説明がある。マルチスレッドは非対応のようだ。とりあえず、見てみる。オフィシャルリリースは PyScripter のダウンロード から入手できる。開発版については PyScripter Development Site を見ると、PythonScripter Version 1.9.4 が最新。最新版では remote debugging に対応しているようだ。Debugging django with PyScripter のような用途にも使えるということだ。リモートデバグを行うためには、RPyC (remote python call) が必要で、Rpyc (sourceforge) からダウンロードしてインストールしておく必要がある。Remote Tk や Remote Wx を使えば、Tk や wxPython で書かれた GUI プログラムもメインループをダミー関数に置き換えてしまうことによってデバグしやすくなるようだ。(PyScripter Python Engines)。まあ、この Rpyc って、使い方を間違えなければ便利でおもしろそうな感じだが、リモートで動いている Python のインタプリタに対して透過的にアクセスできるようにするものなので セキュリティをちゃんと考えてあげない と危険なところもあるので注意かな。これはおもしろい。時間がかかる処理とか、他のマシンにやらせるとかでも簡単に書ける。ただし、やっぱり、外部からはアクセスできないようにセキュリティをちゃんとしておかないとかなりまずい。なんでもできちゃう。Rpyc のデモをちょっとやってみる。Rpyc はダウンロードしたファイルを解凍して、lib/site-package に放り込めば OK。次に、Rpyc/Servers にあるサーバをどれか動かしておく (servers に説明がある)。そして、Rpyc/Demo/testsuite.bat を動かすと、デモが次々に起動される。注意点としては、/tmp のディレクトリがないとエラーになるので、Windows で実行するときはあらかじめディレクトリを作成しておくこと。サーバのポートは、./Utils/Serving.py で DEFAULT_PORT = 18812 のように設定されているので、ファイアーウォール等でポートを塞いでいる場合は開けておくこと。デモでどういうことをやっているかはここに説明がある。その他、ドキュメントは RPyC documentation center を参照。PyScripter は Using PyScripter with Portable Python を見ると portable Python や Movable Python にも対応しているようで、次のようにすれば、PortablePython のデバグに使えるようだ。複数のバージョンの Python をインストールしているとき、こういうことができると便利。Python2.4 用、Python 2.5 用といった具合に Python の環境によって起動用のバッチファイルでも用意しておけばいいかもしれない。SET PYTHONHOME=E:\PortablePythonPyScripter --PYTHON25 --PYTHONDLLPATH "E:\PortablePython" %1 %2 %3 %4 %5でも、やっぱり PyScripter は現状、マルチスレッドプログラミングには使えない。RPyc を使ってリモートで動かすようにしてブレークポイントをしかけても止まってくれない。動き続けるようなものを動かすと、Stop で止めることもできなくなる。このあたりのできは、Wing IDE の方がいい。Wing IDE は、2.x ではマルチスレッドプログラムのデバグには対応していないが 3.x では対応している。SPE IDE - Stani's Python Editor はどうかなとみてみると、WinPdb debugger 1.0.9 が SPE の subversion にあるソースでは使われるようになったようだ ので、マルチスレッド対応になったようだ。wxGlade にも対応してる。実際に SPE で WinPdb を使ったデバグをしてみると、SPE のウィンドウとは独立して Winpdb が起動するのね。Rpyc のようにリモートでインタープリタを動かす rpdb2 の黒い窓と、Winpdb のウィンドウが起動する。WinPdb はプラットフォームに依存しない Python デバッガでマルチスレッド対応。pdb に比べて 20倍高速なようだし GUI で動くのがよい感じ。Winpdb - About にスクリーンショットがある。Ubuntu と Windows XP で動作が確認されているようだ。spe の最新版を使うには、How to download the latest SPE from subversion にあるように Subversion のソースをダウンロードして、_spe ディレクトリで SPE.py を実行すればいい。wxPython はあらかじめインストールしておく。svn checkout svn://svn.berlios.de/python/spe/trunk/_specd _spepython SPE.py画面はこんな感じ。けっこう使える。いいかもしれない。SPE の画面WinPdb の画面rpdb2 の画面考えてみたら、PyScripter でも、[Run] - [External Run] で WinPdb で動かしてデバグできるように指定すればいいじゃん。[Run] - [External Tool Properties] で C:/Python24/Scripts/winpdb.bat とかを指定すれば、F9 で WinPdb が起動するようになる。無償で使える Python の IDE もかなり進化してきた。でも、GUI にこだわらなければ、ipython とかで十分だったりして。ちなみに ipython は、Interactive Parallel Computing とかいう方向に進化しているみたい。Cookbook / InterruptingThreads みたいのもできたのね。
2007.10.29
コメント(2)
-

子供でもできる Python
RurPle and EasyGUI by Python Kids に楽しそうに子供が Python を使っているビデオがある。ここで使われているのは、子供用の簡単なロボットプログラミング RURPLE (Learning Python: Child's Play with RUR-PLE!)、簡単に GUI を作るための EasyGUI (TkInter のラッパー) と DrPython という Python の統合開発環境。EasyGUI は簡単なメッセージボックスや、オプションの選択、ファイルの選択や保存などのダイアログ、テキストの表示、などを素早くコーディングできる。コマンドラインのアプリだとなんだからちょこっと GUI を付けたいみたいな用途であれば TkInter を使って書くよりも短く素早く書ける。TkInter のラッパーだから当たり前といえば当たり前だけど。たかだか msgbox 出すのに msgbox("hogehoge") と書けないなんて Python めんどくさいと思ったら、これを使ってみるといいだろう。# -*- coding: utf-8 -*-from easygui import *msgbox("簡単なメッセージ", "タイトル表示")fname = fileopenbox(msg="開くファイルを選択してね", title="ファイル選択", argInitialFile="*.py")msgbox("%s が選択されました" % fname)とかすれば、わざわざイベントドリブンなプログラムを書かずにリニアなプログラムの中に GUI のダイアログを埋め込んでいけるので、ちょっとしたツールにも便利だったりする。ただし、表現力はほとんどないので(要するにダイアログを出す程度なので)、複雑なことはできない。まともなアプリケーションとかなら TkInter とか wxPython とか、あるいは PythonCard とか使ってねの世界ですと。なお、easygui.py を実行すると(ダブルクリックするか、 python easygui.py を実行)、デモが実行される。そこに並んでいるものがすべて。どれか選択してクリックすれば個別のデモが実行される。ウィンドウのサイズやフォントのサイズは easygui.py の中で、次のように定義されているので、この値を変えればいい。rootWindowPosition = "+300+200"import stringDEFAULT_FONT_FAMILY = ("MS", "Sans", "Serif")MONOSPACE_FONT_FAMILY = ("Courier")DEFAULT_FONT_SIZE = 10BIG_FONT_SIZE = 12SMALL_FONT_SIZE = 9CODEBOX_FONT_SIZE = 9TEXTBOX_FONT_SIZE = DEFAULT_FONT_SIZEでも、子供がビデオの中でやっているように easygui.py を直接編集するのでなく、import easyguieasygui.DEFAULT_FONT_SIZE = 26とかしてやった方がよいでしょね。RURPLE は見たまんま、ロボットに命令を与えると動かせるので、子供の興味をひくのによいかもね。Python Tutorial Videos に他にもチュートリアルのビデオがいろいろある。Python 以外にも Ruby とか Java あるいは、 を始めとしていろいろある。ついでなので、easygui をもう少し。いくつもコマンドラインで使うツールがあって、GUI からまとめて使えるようにメニューを付けたいなと。じゃあ、こうしてみよう。easygui.DEFAULT_FONT_SIZE = 12intro_message = "実行したいツールをダブルクリックしてください。"choices = [ "いかがわしいツール", "なぜかいかがわしいツール", "とってもいかがわしいツール", "もっといかがわしいツール", "さらにいかがわしいツール", "どうしようもなくいかがわしいツール",]choice = easygui.choicebox(intro_message, None , choices)reply = choice.split()if reply[0] == "いかがわしいツール": easygui.msgbox(reply[0] + "を実行します。") # なにやらいかがわしいことをする。else: easygui.msgbox(reply[0] + "はまだ実装されていません。")easygui.msgbox("終わり")ところが、ウィンドウの大きさが決めうちになっているので、実際に下のような大きさで出したいとすれば、easygui.py の中の __choicebox の中にある値を直接変更しなければならなくなる(画面の幅と長さから自動的に一定の大きさでウィンドウができるようになっている)。このあたりが簡易的に作られていることによる限界。まあ、自分で手を入れてパラメータを渡してやるようにするか、大域変数にしてしまって変更できるようにするか、何かすればよいけれど。直接、ソースをいじってしまえばこうできなくもない。もしいじらないと、横幅も長くなりすぎるし、縦も選択肢が 20行分になってしまう。まあ、細かくやりたければ、ソースをいじるか、使わないかのどちらかしかない。でも、やっぱり便利は便利。
2007.10.16
コメント(0)
-
HTTPのやりとりを見る
ちなみに、HTTP のやりとりを見るには、Python + Tk で書かれた TCPWatch がまずあげられる。2004年6月にリリースされて、それ以来、新しいバージョンは出ていないがシンプルに使えるのがいい。動作イメージ のようにやりとりが表示される。tcpwatch-1.3.tar.gz をダウンロード、解凍すればすぐに使える。使い方は、ここ や ここ も参照。TCPWatch のインストールpython setup.py install でインストールする。ただし、パスの通ったディレクトリに tcpwatch.py をコピーするだけでもいい。Windows の場合は \Python-2.4\Scripts や \Python-2.5\Scripts 等にインストールされるのでここをパスに加えておくとよい。Linux 等であればセットアップを行うと /usr/local/bin/tcpwatch.py にコピーされて実行フラグが着くので、/usr/local/bin にパスが通っていれば tcpwatch.py が実行できるようになる。C:\temp\tcpwatch>python setup.py installrunning installrunning buildrunning build_scriptscreating buildcreating build\scripts-2.4copying and adjusting tcpwatch.py -< build\scripts-2.4running install_scriptscopying build\scripts-2.4\tcpwatch.py -< C:\Python24\ScriptsLinux の場合# python setup.py installrunning installrunning buildrunning build_scriptscreating buildcreating build/scripts-2.4copying and adjusting tcpwatch.py -< build/scripts-2.4changing mode of build/scripts-2.4/tcpwatch.py from 644 to 755running install_scriptscopying build/scripts-2.4/tcpwatch.py -< /usr/local/binchanging mode of /usr/local/bin/tcpwatch.py to 755Port 3128 で Proxy Server として動作させる場合ブラウザのプロキシの設定で localhost:3128 を指定すると、ブラウザのやりとりがこのプログラムを通してやりとりされるようになる。FireFox の場合は、[ツール]メニューのオプション、[ネットワーク] タブの接続で「インターネット接続に使用するプロキシを設定します」の横の [接続設定] ボタンをクリックして [手動でプロキシを設定する] オプションを選択し、HTTP プロキシに localhost、ポートに 3128 を指定する。Internet Explorer なら、[ツール] メニューの [インターネットオプション] から、[接続] タブを選択し、[LAN の設定] ボタンをクリック、[ローカルエリアネットワーク (LAN) の設定] ウィンドウで、[プロキシサーバー] の 「LAN にプロキシサーバを使用する...」チェックボックスをオンにして、アドレスに localhost ポートに 3128 を入力して OK をクリックというような形でブラウザの設定をする。外すときはプロキシの設定を元に戻せばいい。python tcpwatch.py -p localhost:3128TCP フォワードモードで使う場合もし、社内のネットワークから外部に出るのにプロキシサーバを使っていて、それが your-proxy-server という名前で port が 3128 であれば、Proxy モードではなく、TCP Forward モードで動かすために下のようにする。そうするとすべてローカルのプロキシサーバにフォワードしてくれる。ローカルのポート 3128 へのリクエストはすべて your-proxy-server のポート 3128 に送られる。tcpwatch.py -L 3128:your-proxy-server:3128TCPWatch のメリットは、どのプラットフォームでも Python が使えれば、使えること。また、やりとりをログファイルに残したいのであれば、-r オプションを指定すれば、そのディレクトリにログが残る。たとえば、-r /path/to/logdir を付ける。-s を付ければ出力が標準出力にされるので、GUI が使えないターミナルの環境では -s で標準出力に出すという手が使える。ちなみにオプションを何も指定せずに起動すればヘルプが表示される。横取り丸他には Windows だけというのであれば、横取り丸 というのがある。InetSpy (動作イメージ) や Web Performance Analyzer (動作イメージ) を一緒に使うと TCPWatch よりもレスポンスタイムなどの状況は見やすいかもしれない。ただし、Web Performance Analyze はシェアウェア。横取り丸はソースコードは公開されていないが、横取りソフト開発キット として API は公開されている。LiveHTTPHeadersでも、ここまで書いておいてなんなのだけど FireFox を使っているのであれば、LiveHTTPHeader (動作イメージ) が楽に使えるのでよかったりする。Installation から .xpi のリンクをクリックしてインストールしたら FireFox を再起動。[ツール] メニューから LiveHTTPHeaders] を選択するとウィンドウが出てくる。[Headers] タブの下に [Capture]チェックボックスがあり、ここで ON/OFF ができる。ログの保存もできる。ただし、表示はダラダラと表示されるので、レスポンスごとにチェックするときには、TCPWatch を GUI で使っているときの方が見やすいこともあるかもしれない。最大のメリットはプロキシサーバの設定を変更する必要がないこと。その他、リクエストの一部を書き換えて再送信できること等。TCPWatch は見るだけ。ただし、TCPWatch もソースを書き換えて、途中で正規表現でマッチしたものを書き換えるなんていうことは Python が書ければできないことではないが、まあ、LiveHTTPHeaders の方が便利。その他もっとパケットレベルで見たいなら、パケット情報の解析ツール(Microsoft Network Monitor) みたいなものを使うとか、Ethereal のようなものを使うとか (Etherealを使おう) とかいうことになるんだろうが、ちょっと見るレベルであれば、上記のようなものを使った方が手軽で分かりやすくてよいと思う。tcpdump で十分とかいう人は勝手にしてくださいという感じ。View HTTP Request and Response Header でちょいと見るというのもあるのかもしれない。ちょっとこのサーバってどんなサーバ使っているのかヘッダで見てみようとかいうのであれば、もっともお手軽。見たい URL を貼り付けて [Submit] ボタンをクリックすれば確認できる。ついでなので他に何かないかと調べてみると HTTPリクエスト/レスポンスのキャプチャ にあれこれ紹介されていた。TamperData というのも FireFox 用ので見つかった。"Google Web Accelerator is not compatible with Tamper Data. Your browser will crash." とか問題もあるようだが、リクエストを出すときに書き換えたりとかいうのがやりやすいというか、そういうために作ってあるようなので開発者用としてはもってこいなのかもしれない。LiveHTTPHeaders でも送信内容を書き換えできるが、いったんリクエストを送ってから、Replay ボタンをクリックして、前に送ったものを書き換えて再送信ということになる。Odysseus のサイトを見ていたら、The Advanced Cross-site Scipting Virus というレポートがあった(December 2006)。そういえば、Gmailに個人情報漏洩につながる脆弱性--専門家が指摘[CNET Japan] なのだな。グーグル、「Gmail」の脆弱性を修正 したらしいけど。クロスサイトスクリプティングの問題はつきない。。。。。その他、WEB情報を取得できるIEのプラグイン もあるようだ。使ったことない。どこでも簡単に使えてということだと、FireFox を使っているなら気軽に使える LiveHTTPHeaders かな。機能的には TamperData。だけども、Internet Explorer を使って確認したいというのであれば他のものを使うということになる。Python がインストールされてさえいれば TCPWatch はたいていの環境で使えるだろうからつぶしがきく。環境によって使うツールを変える必要がなくなるわけだし、1500行に満たないスクリプトなので、その気になれば改造もしやすい。最近は、この手のものはどんなのが流行っているんだろう。ということで XSSは知ってても、それだけじゃ困ります? - @IT の連載には、そのうち便利なツールとかも出てくるんじゃないかと期待してみる。
2007.10.01
コメント(0)
-

Python を始めよう (codezine.jp)
Pythonを始めよう [初級] 最近普及が進みつつあるスクリプト言語Pythonに挑戦してみよう が で始まった。[初級] とついているが、他の言語の経験があるけれど Python はよく知らないよという人向けの内容。ということであれば、Python 調査報告 (サイボウズ株式会社 山本 泰宇) 2006年10月 などもよいかもしれない。だいぶ Python の露出度が上がってきた。
2007.09.12
コメント(0)
-

もっと知りたいPython
もっと知りたいPython という週1の連載が 技術評論社の gihyo.jp で始まったらしいので読むことにする。このサイト prototype.jsを読み解く とかの特集もあるな。あれこれ眺めてみるかな。タグ一覧 を眺める。FreeBSD がやけにでかい。Solaris の記事は 1 つだけ、Python は 4 つ。まだまだだな。今後に期待しておこう。
2007.09.07
コメント(0)
-
古くて新しい Python 2.5 の脆弱性
Python 2.5.x に Pythonにディレクトリトラバーサルの脆弱性 らしい。Python tarfile Module Directory Traversal and Symlink Vulnerability によると、一番使われている Python 2.4.x や Python 2.3.x はどうか未確認。問題が出るのは、extractall を使った場合で、TarFileクラスにextractallメソッドが追加されたのは、Python 2.5 から。ということで、そもそも、Python 2.3, 2.4 はこのメソッドが存在しないので安全なんじゃなかろうか。影響度は「Less critical」に位置づけられている。執筆時現在の解決策は、開発版である「Python 2.6」を利用すること。Pythonにディレクトリトラバーサルの脆弱性と書かれているが、開発版を使うぐらいならパッチあてた方がいいんじゃないのかな。こういう指示はよろしくないんじゃないかな。無茶だと思う。パッチをあてるのが嫌であれば、とりあえず、Lib/tarfile.py をどけて、空のファイルにでもしておけばいい。これを使っていないアプリケーションにはまったく問題ないわけだし、エラーが出たらそれは問題の影響があるかもしれないアプリケーションだから、とりあえず、使用を控えるとかの対処の方が現実的だろう。で、問題は tar ファイルの解凍時に危ないことができるようだからセキュリティ上特に問題になるのは /etc/password のような既存の重要なファイルの上書きを行うようなことができてしまうこと。extractall を使ったプログラムを使ってファイルを解凍しなければ問題はなさそう。でも、CVE-2001-1267 を見ると、GNU tar 1.13.19 とそれ以前のバージョンですでに指摘されていたのと同じ理由によるもののようだ。2001年とかに指摘され始めた問題が繰り返しでてきちゃうのね。出たばかりのときは、気をつけなきゃというのがプログラマの意識にあっても、いつの間にか同じような脆弱性が作り込まれてしまうことが多々あるように思える。ファイルの解凍って、この問題に限らず、やっぱり悪さをする人にはねらい所だろうな。。。。特にメジャーバージョンアップしたものは、古い問題が再び蘇る可能性がある。マイクロソフトなんかにしても、過去、いったんは直ったはずの脆弱性が後のバージョンでまた再現なんていうことがあったと思う。[Python-Dev] tarfile and directory traversal vulnerability の Python 言語の開発者のこれに対する対処のスレッドがある。http://mail.python.org/pipermail/python-dev/attachments/20070824/5605f4ef/attachment.bin のちょっとしたパッチで対処できるようなので、そのうち Python 2.5.2 がリリースされることになるんだろう。クリティカルなものじゃないととらえられるようなので、別の修正と一緒にリリースされるのかもしれない。そういえば、[Python-Dev] Python 3.0a1 released! がリリースされたようだ。これは開発者向けで、正式な 3.0 のリリースは2008年の8月が現状のリリース計画のようだ。Python 3000 は、Python 2.x 系統とは互換性がなくなるのね。これまで Python は後方互換性を重視してきたけど、この系統ではそれが途切れる。The language is mostly the same, but many details, especially how built-in objects like dictionaries and strings work, have changed considerably, and a lot of deprecated features have finally been removed.ということで、この系統が広まるのは何年も先って感じかな。2008年からは何年もに渡って、3.x 系統と 2.x 系統が並列して用いられるだろう。ちょうど、Apache 1.x と 2.x が並列して用いられるように。Python 界もすでに Zope の 2.x と 3.x を並列して継続させるのに成功している。3.x から 2.x に一部をバックポートしながら、両方のよいところを享受するといったことが行われている(古いものを継続して使いながら、新しいもののメリットもある程度得られる)。世の中が複雑でしがらみいっぱいになってくると、新しいものと古い物とが混在して使われる。このときに、今のものを漸次よくしていくというやり方ではなく、まったく新しいものをしがらみにとらわれず、きれいな思想と設計で作り直してしまい、それはそれで進ませる。しがらみにとらわれているところへは、橋渡しをしてやる。時間をかけて古いものは廃れていくもの、新しいものへ移行するものをサポートする。ただし、無制限にサポートされるのではなく、古すぎるものはいつかは寿命を終えるけれど、新しくてよいものに乗り換える時間は与える。ドラスティックな革命ですべてを変えるのではなく、ゆったりとした革命というのが 21世紀の潮流なのだろう。ある程度のところまで来ているから、何も急ぐことはないってかんじで。新しいものへの乗り換えが、徹底的な優位性を簡単に持つことができた時代は終わっているということ。ゆるやかな革命としてのオープンソース。バイナリしかないと緩やかな革命は難しい。どこかで跳躍が必要になる。まあ、オープンソースでも実際のところ跳躍は必要になるところもあるが、バイナリだけの世界よりは、跳躍のときのリスクは低いと思う。
2007.09.01
コメント(0)
-
ADOBAPI が win32
DBAPI-2.0 に 100% 互換性を持つ、Microsoft ADO 用のデータベース接続モジュール ADODBAPI が Mark Hamond 氏の pywin32 に統合される流れらしい。ADOAPI のオリジナルの作者は、Henrik Ekelund 氏。現在のプロジェクトリーダーは Vernon Coles 氏。ADODBAPI で SQLServer にアクセス SQL Server + adodbapi でバイナリファイルを取り扱いたい ちなみに、データベース接続のときの文字列は ConnectionStrings.com を見るとまとまっている。全然関係ない話だが、スペースシャトルの OS について On Self-Modifying Code and the Space Shuttle OS を見て、やっぱり米国のやつは、壊れるの前提に変態していると思った。フォルトトレラントはある意味、偏執狂の人がやるのがいい。とどうでもいいことを考えた。
2007.08.22
コメント(0)
-
Python の統合開発環境 WingIDE 3.0 まだ使ってないが
Python プログラミングの統合開発環境 WingWare WingIDE 3.0.0-b がリリースされたようだ。トライアル版 が出ているか見てみたら、まだ 2.1.4-2 しかないので、表に出てくるのは b がとれてからなのかなぁ。ということで、まだ 3.0 は試していない。マルチスレッドのデバグに対応したらしいのと、ユニットテストツールが入ったのと、あれこれアップグレードに値する点はあるようだ。Feature listちなみに WingWare のページがこぎれいになったな。Python Success Stories みたいなページもできている。ShowMeDo に WING IDE 2.1 を使ったデモビデオがある。その他 ShowMeDo には、Python のビデオあれこれがある(Django とか IPython とかあれこれ)。Python 101 - easygui and csv みたいのもある。ShowMeDo みたいのって日本にはないのかな。こうやってジャンルごとにまとまっているといいな。Python の開発統合環境は、DevelopmentEnvironments にまとまっている。フリーのものでもあれこれいいのがあるから、探してみるとよいだろう。vi とか Emacs でよいという人は見る必要もないだろう。Eclipse を使っている人は、必然的に pydev とかになるのかな。 関係ないが、『Python クックブック』は評判がとてもよいらしいがまだ買ってない。積読状態のものがたくさんあるし。。。。。
2007.08.01
コメント(0)
-
pyblosxom 1.4.1 がリリースされた
pyblosxom 1.4.1 がリリース された。1.4.0 の問題がいくつか解決されているようだ。Download pyblosxomWSGI にまつわる問題Paste にまつわる問題Python 2.5 でインストールするときの問題そのあたりで問題があればアップグレードしたら解決するかもしれないので、アップグレードが強く推奨されている。あるディレクトリ配下のディレクトリやファイルを処理する Walk から os.listdir を取り除いて最適化するなども行われているようだ。いいかげん Pybloxsom を使ったサイト作るかなぁとか思いつつ、また、月日は流れていくのであった。過去の pyblosxom 関連のエントリ。自分で書いたものは、Infoseek の叔母かな検索や Google の検索使うより、自分の swick のサイトで検索した方が見つけやすいなと思う今日この頃。あらかじめ登録しておいたサイトだけを検索してくれるようなもの、かつ、もっと速いものがあればいいのだけどな。あるキーワードについては、登録してあるものから1段先のリンク先まで検索可能にするとか、2段先まで可能にするとか。とりあえず pyblosxom とは関係ないけど、blog 内検索で自分の文書内のリンクから検索するとか、その手のものとかも欲しかったりするし。なわけで、自分でいじれるものが欲しかったりするわけで pyblosxom もいじりやすかろうということで注目しているわけなのであった。
2007.07.29
コメント(0)
-
SQLite の全文検索を Python から使ってみる (3)
とりあえず、SQLite で FTS2 を使うことはできるようになった。次は Python から FTS2 を使えるようにしたいということでやってみる。#179 Implement virtual table support や #180 Implement loadable extensions を見ると pysqlite では、まだ FTS2 が使えないようだ。enable_load_extension-r296.patch があるのだな。しかし、考えてみたらモジュールを組み込んでコンパイルしてしまったので、もしかして行けるかな?と試してみる。VIRTUAL TABLE で引っかかるかなと思ったら使えてしまった。もう、VIRTUAL TABLE には対応できているのか。というか、SQLite に渡して実行してもらっているから、この手の使い方の場合は、通常のテーブルと同じで問題にならないようだ。import MeCabimport pysqlite2.dbapi2 as sqlite# とりあえず、日本語をまず分かち書きにしておく# 挿入したいデータdata = [('日本語を使う', '日本語使ってやってみるよ。'),('分かち書きはMeCab', '日本語の分かち書きはMeCabを使ってみる。'),('メモメモ', '元のデータは分かち書きしてなくても大丈夫。'),('こんな具合', 'こんな具合で日本語書いてる。') ]# 分かち書きしておくt = MeCab.Tagger ("-Owakati")data = [(t.parse(x[0]), t.parse(x[1])) for x in data]# 全文検索用のテーブルを作るcon = sqlite.Connection(":memory:")con.execute("CREATE VIRTUAL TABLE memo using FTS2(title, body);")cur = con.cursor()# テーブルにデータを挿入するsql_str = "insert into memo (title, body) values (?,?);"cur.executemany(sql_str, data)# 試してみるprint "テスト 1"sql_str = "select rowid, title, body from memo where title match '日本語';"res = list(con.execute(sql_str))for l in res: title = l[1].split() body = l[2].split() print l[0], "".join(title), "".join(body) print "-" * 20print "テスト 2"sql_str = "select rowid, title, body from memo where body match '日本語';"res = list(con.execute(sql_str))for l in res: title = l[1].split() body = l[2].split() print l[0], "".join(title), "".join(body) print "-" * 20そうすると、次のような出力が得られる。テスト 11 日本語を使う 日本語使ってやってみるよ。--------------------テスト 21 日本語を使う 日本語使ってやってみるよ。--------------------2 分かち書きはMeCab 日本語の分かち書きはMeCabを使ってみる。--------------------4 こんな具合 こんな具合で日本語書いてる。--------------------ということで、とりあえず使えるようになった。が、こうやって、分かち書きをした文字列をテーブルに登録するやり方だと原文を取り出せないので、オリジナルと分かち書きをした FTS2 用のそれぞれの文字列をテーブルに保存しておかなければならなくなる。これはちょっと記憶領域の点でも手間の点でも好ましくない。けど、これは誰かがそのうちやるだろうから、とりあえずここまでにしておく( 日本語用の tokenizer を作る人が出てくるだろうから )。とりあえず、インチキで分かち書きをしたものを登録して、取り出してからスペースを削除している。このやり方だと、本当のスペースが消えてしまうのでダメだけど。とりあえず、ということで。
2007.07.28
コメント(1)
-
SQLite の全文検索を Python から使ってみる (2)
SQLite の全文検索を Python から使ってみる (1) では、とりあえず使ったところを書いたが、設定の仕方は次のようにした。Windows で FTS2 を使うSQLite Download Page の "Precompiled Binaries For Windows から sqlite-3_4_1.zip、sqlitedll-3_4_1.zip、fts2dll-3_4_1.zip をダウンロード、解凍して、同じディレクトリに配置。sqlite3.exe を実行。MinGW用のSQLite3 (3.4.0) を作っている方がいらっしゃるようなので MinGW を使ってコンパイルしたいときには、参考になるだろう。.load fts2これで FTS2 が読み込まれて使える状態になる。あとは、昨日のようにすれば動作が確認できる。Linux で FTS2 を使うソースから作る場合、SQLite Download Page の Source Code から sqlite-3.4.1.tar.gz をダウンロードして解凍する。ちなみに、ここでは、FTS2 を SQLite3 に組み込んでコンパイルしてしまうことにする。そうすると、わざわざ load しなくても使えるから。パッチは、こんなもので Makefile.in をちょっと書き換えてみた。「patch > fts2embed.patch」でパッチを当てて、make して、テストしてみる。テストは、同じく前の日の通り。問題なければ「sudo make install」でインストール。$ patch < fts2embed.patch$ ./configure LIBS=-ldl$ make $ export LD_LIBRARY_PATH="`pwd`:$LD_LIBRARY_PATH"$ ./sqlite3さて、問題は Python からこれが使えるようになるかというところになる。#179 Implement virtual table support や #180 Implement loadable extensions のように、まだ pysqlite では VIRTUAL TABLE にも対応していないし、loadable extensions にも対応していないということなのだ。ということで、SQLite の全文検索を Python から使ってみる (3) へ続く。
2007.07.28
コメント(0)
-
SQLite の全文検索を Python から使ってみる (1)
SQLite の全文検索 FTS2 をちょっと試してみた。だが、結論から言えば、Python から FTS2 を使うのはまだちょっと辛い。というか、FTS2 で日本語を使うのはまだ辛いところがある。けれど、まったく使えないということはないのでやってみる。Full-text Search for SQLite は FTS1 と FTS2 の 2つのバージョンがある。どちらも SQLite の外部モジュールとして開発されている。FTS1 のパフォーマンスを改善しているのが FTS2。FTS1 と FTS2 は互換性がないので、後々のことを考えると今から FTS2 を使っておいた方がよいようだ。表面上の使い方は FTS1 を FTS2 と書き換えるだけで、現状同じようだが、内部的なデータの保存方法に関してはまったく違うようだ。ソースは、CVS からダウンロードするか、SQLite のソースの中の ext/fts1、ext/fts2 にある。SQLite Download から、とりあえず Windows 上で動かすためのバイナリ fts2dll-3_4_1.zip を使って試すと動いた。Linux 版も試す。これは自分でコンパイルした。下のは、簡単に試したもの。分かち書きしていないとダメなので、手で分かち書きしたものを使ってやってみる。-- VIRTUAL TABLE を使い-- USING FTS2 で全文検索用のインデックスが作られるようだ。CREATE VIRTUAL TABLE memo USING FTS2(title TEXT, body TEXT);-- INSERT は普通に INSERT する。INSERT INTO memo (title, body) VALUES ('日本語 を 使う', '日本語 を 使っ て メモ を 作っ て み ます 。');INSERT INTO memo (title, body) VALUES ('分かち書き', '日本語 は 分かち書き を あらかじめ やっ て から 文字 列 を 書き込み ます 。');INSERT INTO memo (title, body) VALUES ('SQLite の 拡張','FTS2 は 拡張モジュールだがあとで');INSERT INTO memo (title, body) VALUES ('メモ を 使う', '日本語 を 使っ て メモ を 作っ て み ます 。');-- とりあえず、INSERT したものを見てみる。SELECT rowid, title, body FROM memo;1|分かち書き|日本語 は 分かち書き を あらかじめ やっ て から 文字 列 を 書き込み ます 。2|メモ を 使う|日本語 を 使っ て メモ を 作っ て み ます 。3|日本語 を 使う|日本語 を 使っ て メモ を 作っ て み ます 。-- MATCH を使って検索する文字を指定する。SELECT title FROM memo WHERE title MATCH '使う';メモ を 使う日本語 を 使うSELECT title, body FROM memo WHERE body MATCH 'メモ';メモ を 使う|日本語 を 使っ て メモ を 作っ て み ます 。日本語 を 使う|日本語 を 使っ て メモ を 作っ て み ます 。とりあえず、分かち書きしてあれば検索ができることは確認できた。SQLite の全文検索を Python から使ってみる (2) へ続く
2007.07.27
コメント(0)
-
Python から Excel データを操作できる pyExcelerator なるもの
Python から Excel データを操作できるpyExcelerator なるものがあると知る。 Creating Charts in Excel with pyExcelerator.ExcelMagic にあるのは、win32com.client 使った例だけだな。pyExcelerator を使わないとこの手のやり方になるので Windows でないと使えない。pyExcelerator なら Windows 以外でも OKと。pyExcelerator/0.6.0aGenerating Excel Spreadsheets from Python (2006/02/02)PythonでExcelファイル作成(2006/05/09)PythonでExcelファイルを生成:pyExceleratorCommentsAdd Star (2006/09/03)pyExceleratorメモ その1 (2006/09/25)Python2.5でExcelを使わずにExcelファイルを読み書きする。(2006-12-06)Converting MS-EXCEL file into CSV file. (2006/12/23)pythonでExcelを利用するための資料リンク (2007/05/13)pyExcelerator (2007-07-25)Technorati pyExceleratorとりあえずまだ使っていないのでメモのみ。
2007.07.26
コメント(0)
-

SQLite と Python: pysql vs. APSW
Python から pysqlite を使うときには、pysqlite と APSW がある。pysqlite は、Python 2.5 から標準ライブラリに組み込まれるなど標準的に位置にあるが、APSW (Another Python SQLite Wrapper) はどうだろうか。こちらの方が SQLite の API を忠実に使う形になっている。だから、よけいなことをやっていないから速いんじゃなかろうか。と調べてみる。実際にテストしてみると、予想に反して pysqlite の方が insert でパフォーマンスがよい。pysqlite 2.3.5 でこのあたりパフォーマンスが改善されたのが効いているのかな。average insert time: 1.719000 seconds # pysqliteaverage insert time: 2.000000 seconds # APSW問題なのは、select のとき。fetchall がないので、まとめて結果を取得することができない。なので [row for row in cursor.execute("....")] のように取り出してやらなければならない分、かなり遅くなる。ということで、pysqlite が速くなってしまった今、速度の上でのメリットはまったくない。メリットを探すと、SQLite の API に直接対応しているから、その点では分かりやすいこと、Virtual Tables が使えるとかなのだろうか。ちなみにドキュメントを読んでいて、Compile-Time Authorization Callbacks を使うとセキュリティ確保に役立つなと思った。SQLite はそういうものがないと思ってた。うまく使えば authorizer callback (pysqlite) や authorizer functions (APSW) を使えば、SQL injection とかの対策にもなると思う。
2007.07.24
コメント(0)
-
pysqlite 2.3.5 使うべし
現在の最新リリースは、pysqlite 2.3.5 released (Wed Jul 18 01:32:38 CEST 2007)。これを見ると、パフォーマンスについて PysqliteTwoBenchmarks のリンクがあり、大量のデータに対する DML (insert, update, delete) の最適化が施され、高速化されたとある。これまで 7.0377440 秒かかっていたようなものが 2.788332 秒と書かれている。ただし、fetch については、3.066811 秒から 3.095180 秒と微妙に遅くなっている(ほぼ、同じと考えていいレベルかな)。Gerhard Haring さんの pysqlite installation guide - source distribution を一応確認しておく。この文書の先頭に、Windows ユーザについてはバイナリ配布されているものを使用することが推奨されている。ちなみに initd.org Trac root/pysqlite/trunk/benchmarks にも fetch.py と insert.py のベンチマークプログラムがある。こっちにあるものは、use_pysqlite2 = yesno("Use pysqlite 2.0?")use_autocommit = yesno("Use autocommit?")use_executemany= yesno("Use executemany?")と、インタラクティブに pysqlite のバージョンや autocommit, executemany を使うかどうかを設定してから実行するようになっている。何はともあれ、大量にまとめてインサートしたいときには executemany を使った方が速くなるので、ちまちまひとつずつインサートしない。1レコードずつ autocommit でインサートしていたら当然遅くなる。コマンド実行時に自動的にコミットさせる(autocommit を使う)場合は、pysqlite2 の場合、con.isolation_level = None とする。SQL As Understood By SQLite BEGIN TRANSACTION によると、The default behavior for SQLite version 3.0.8 is a deferred transaction. For SQLite version 3.0.0 through 3.0.7, deferred is the only kind of transaction available. For SQLite version 2.8 and earlier, all transactions are exclusive.なので、2.8 より後のバージョンでは DEFERRED がデフォルトなのであった。SQLite 3.0.8 以降のバージョンを使うときに、トランザクシヨンで指定できるのは DEFERRED、IMMEDIATE 及び EXCLUSIVE。SQLite のトランザクシヨンに附いて。 に日本語の説明があった。詳細については File Locking And Concurrency In SQLite Version 3 も参照。TurboGears の人は TurboGearsでSQLiteのトランザクションの隔離レベルを設定する方法CommentsAdd Star とかも参照。インストール後のチェック方法インストール後には、一応下のようにしてチェックする。>>> from pysqlite2 import test>>> test.test()....................................................................................................................................................................................----------------------------------------------------------------------Ran 180 tests in 3.750sOK
2007.07.22
コメント(0)
-
SQLite 3.4.1 で VACUUM バグに対処
オープンソースの軽量快適 RDBMS SQLite 3.4.1 が2007年7月20日にリリースされた。 SQLite Version 3.4.1 は VACUUM のバグ対応が入っている。VACUUM は PostgreSQL と同じようなものでデータベースファイルの使わなくなった領域を解放するのでデータベースサイズが小さくすることができる。3.3.14 以降のバージョンを使っている場合には、VACUUM がエンバグしているのでデータベースが壊れる可能性があるらしく、3.4.1 でこの対処が入ったのでアップデート推奨。2つのコネクションが同時にデータベースにアクセスしているとき、片方が VACUUME を実行し、もう片方が更新すると壊れるらしい。本来、こういうことがおきないようにトランザクションが開始されている場合は VACUUM が実行されない実装になっていると思ったが、これがちゃんと機能していなかったということか。sqlite - Database Corruption を見ると、バックアップは欠かせないなと改めて思う。ちなみに、Python から pysqlite を使うときには、pysqlite と APSW がある。どちらも SQLite のラッパーなのだが、実装のちがいがある。pysqlite が Python DB-API 2.0 インターフェースを実装しているのに対して、APSW は、SQLite の API に対する直接のラッパーになっている点。比較すると速度的にどうなんだろうか。探してみると Fastest Python Database Interface が見つかったが APSW はここでは試されていない。一度、各 RDBMS を Python から使ったときのパフォーマンスについて自分で調べてみるかなとか思う。
2007.07.22
コメント(0)
-
Python Magazine
最初の Python 専門の月刊誌が 10月1日に創刊されるようだ。Python Magazine がそれ。以前に PyZine というのがあったなとみてみると、Issue 8 (October 20, 2005) を最後に休刊中のようだ。それは不幸ではあるが、現状、無償で参照できるようになっている。ZopeMag も March 25, 2005 を最後に休刊中。これは残念なことだが、有償だった古い記事もパスワードなしで閲覧できるようになっているので、時間ができたらまとめて読んでみるかな。Python Magazine 続いてほしいな。創刊号が出てから購読するか考える。
2007.07.08
コメント(0)
-
pyblosxom 1.4 がリリースされた
[pyblosxom-users] pyblosxom 1.4 released! ということで、今度こそ Python で書かれたブログ pyblosxom を使ったサイトを作ってみるかなと思うのであった。ブログだけでなくて静的なページも作りやすくなっているはず。コマンドラインで出力を確認できるようなテスト用のコマンドとかも加わったようだ。機能的なものだけでなく、ドキュメントも更新されて(形式も Docbook から reST になっている)、現状に合うようになっているはずなので、本格的に使ってみようかと思う。けど、そんなときに限って、2週間ばかり忙しいので、手をつけるとすると 7月中旬以降かな。
2007.07.03
コメント(0)
-
Python Workshop the Edge 2007 カンファレンスのライブ中継
Python Workshop the Edge 2007(2007年6月30日開催) 明日なのね。カンファレンスのライブ中継 があるらしい。行けないので、見てみるかな。しかし、アクセスする人が多かったら見ることができないかもしれないなぁ。
2007.06.29
コメント(0)
-
Python クックブック
書評 - Pythonクックブック第二版: 404 Blog Not Found を見る。「力作にして傑作。」らしい。久しぶりに、原著よりもお薦めの訳本に出会った。値段も4,200円。この品質でこの値段は超お買い得。Pythonユーザーのみならず、技術翻訳の何たるかを知りたい人も、本書は必携の書である。べた褒め。書評 - Rubyクックブック はボロボロ評価だったのと対照的。なるほどと思ったのは、Foo Cookbookというのは、Fooの中級者だけが読む本じゃない。むしろ他の言語の中級者以上の人が、「ではFooではどうか」というのを確認する需要の方がずっとある。中華料理の達人にして和食の初心者が読んで納得するのが、Cookbookのはずだ。よい Cookbook があれば、他の言語の習得者が Python を使ってみようという気にもなるだろうから、Python 界隈の人にとっては、この本の高評価の影響は大きいかもしれない。とか思うと同時に、他の言語のものもついでに買って見比べてみるかなとか思ったりする。ちなみに、Python のメーリングリスト見たら、例として載っているプログラムはすべてコピペで動くようにバグとりもしてあるらしい。ということでこの本は買うことにする。で、よさそうな本なので積読リストの上に載せることにする。
2007.06.22
コメント(0)
-

Python Workshop the Edge 2007
Python Workshop the Edge 2007 なるものが、2007年6月30日(土) 1に開かれるらしい。場所は、東京大学駒場キャンパスで 140名の定員のイベント。その他、株式会社セガ VE研究開発部での事例、荷電粒子加速器制御システムでのPythonの活用をはじめとして、聞いてみたいものがたくさんある。セミナーとハンズオンがあって、ハンズオンでは、IronPython, Twisted, Pygames, Django, TurboGears が予定されているようだ。その他、マイクロソフトからは、Mahesh Prakriya さんと、荒井 省三さんが参加予定のようだ。Mahesh Prakriya さんについて調べてみると、Mahesh Prakriya - Tip for optimizing .NET code や Mahesh Prakriya - What do you do on the SQL Server team and are you going to TechED India? あるいは、http://blogs.msdn.com/ironpython/ では Our talks at Teched 2007 (June 4-8th) in Orlando のようなものが見つかった。荒井 省三さんは、IronPythonの世界 の著者。.NET 畑のエバンジェリストのようだ。ちなみに『IronPython の世界』は買ったがまだ読んでない。Python も最近、日本人が書いた本がだいぶ増えてきたようだ。ちなみに、このイベントに参加したいと思ったのだが、日程的に無理そうなので諦めた。残念。
2007.06.06
コメント(0)
-
ppkf で日本語の文字コード判別
ppkfなんてのを作ってみました を見つける。Pure Python で書かれた日本語の文字コード判別か。Python の一つあれなのは標準でそういうものがないところなのだな。手はいろいろあるけれど。低速(nkf_pythonと比べて100倍ほど遅い...とはいえ、 51万個の単語を71秒で処理する程度 は可能です)51万語 / 71秒 = 7183語か。ppkf対python_nkfガチンコ対決 を見ると、 [ppkf] Recognize 512084 strings within 71 seconds. [nkf] Recognize 512084 strings within 1 seconds.ということで、遅いことは遅いが、POST された文字列のコードをチェックして程度なら、それほど問題にならない速度かな。短い文字列に対しても高い判別精度(であってほしい)これがうまく動いているようなら使ってみる価値はありそう。Universal Encoding Detector は、文字コード判定ライブラリ Universal Encoding Detector の投稿にあるようにファイル単位とか長めの文字列で判定するにはよいけど、短い文字列の判定は苦手っぽい。ppkf の方はコメントを見たらeucjpでエンコードされた文字列で、半角英数と全角がほぼ同数ほど入っていた場合に間違うことがあるりました。なようだ。これを読んで、思いつく。ちょっと意地悪してみる。>>> import ppkf>>> p = ppkf.ppkf()>>> jstr = u"蛇のとぐろを見る".encode("euc-jp")>>> print p.guess(jstr) (0.7142857142857143, 'euc_jp')>>> print p.guess(jstr[:-1])IndexError: array index out of rangeのエラーで落ちる。中途半端にぶった切られた文字列が渡されたときにはエラーになるかもしれないので、それなりの対処が必要ね。標準的な日本語の判別モジュールがないところが Python のあれなところ。いろいろ選択肢があるのはよいのだけど。
2007.05.21
コメント(1)
-
グニャラくんのグニャグニャPython備忘録を見る
グニャラくんのグニャグニャ備忘録@はてな を久々に見たら、Python 関連の話題が グニャラくんのグニャグニャPython備忘録 が分離されたので見に行く。Google vs 2ちゃんねる?-- 純国産検索エンジンに本気のベンチャー も見る。Wikipedia 検索 も使ってみる。Django 使っているのね。なんていうのはどうでもよいのだが、例えば、「簿記」で検索すると、Wikipedia には「簿記」というそのもののエントリがあるのだが、これがトップにこないのはなぜなんだろう。「タイトルで検索」のところにも出てないのね。不思議。「コンテンツで検索」で「2月10日」がトップに来ているのもまた不思議に思ったが、簿記の日だったのね。Google で 簿記 site:ja.wikipedia.org を検索したときと並び順が違うので、おもしろいものが見つかったりする。ふと、Wikipedia を KWIC で見るとおもしろいかなとか思った。
2007.05.15
コメント(0)
-
Pure-Python の PDF 読み込みのためのライブラリ
Pure-Python の PDF 読み込みのためのライブラリ pyPdf を使ってみる。Pure Python PDF to text converter のようにして日本語のファイルを読み込ませてみると、ちゃんとテキストを抽出できたと思ったら、ファイルによって扱えたり、だめだったりする。画像が入った 2M ほどのファイルを読み込ませたらかなり時間がかかった上にとんでもないことになった(ビープ音が鳴り続いて、文字化け状態の出力が延々続く)。試すときは、いったんファイルにリダイレクトしてテキストエディタで開いて確認しないと悲惨。お勉強用か、がんばってハックして日本語でも大丈夫なように書き換えるかしないと使えない。ソースはまだは見ていない。
2007.05.08
コメント(0)
-
SQLite での DECIMAL の扱い
日経平均の予測プログラムを少しずつ考え始める。取得した株価文字列のデータを float にすると、例えば、1.1 が 1.1000000000000001 とかなったりして困る。あくまで 1.1 になって欲しい。だから、5.5 decimal -- 10進浮動小数点数の算術演算 を使う。でも、SQLite を使うとすれば、Datatypes In SQLite Version 3 を見ると、REAL. The value is a floating point value, stored as an 8-byte IEEE floating point number.で保存しておいて、Python 側では Decimal で扱うしかないか。PostgreSQL や MySQL は DECIMAL があるが SQLite には DECIMAL がないのが困る。[pysqlite] Converter for decimal.Decimal (again)If you really need to store Decimals values, and do some operations with them in the database, just do *not* use SQLite.ごもっともな話。SUM とか集約関数を使うと REAL で保存されている値を使うことになって、誤差が出てしまうから。もっとも、簡単な予想だけなら、そこまで厳密に考えなくても問題ないだろうけど。いっそのこと FireBird 試してみるかな。Python から FireBird を使うには KInterbasDB がある。更新もされているようだし、FireBibird Data Types を見ると、Deciaml はあるし。日本医師会のオープンソース医療ソフトでFirebirdのユーザーが1万4000に とかで、安定して使えそうな感じだし。実際のところ、あれこれインストールし直すのが面倒だから SQLite なら Python 2.5 を使えば標準で SQLite に対応したモジュールがあって楽だしというのもあったんだけど。。。。。演算誤差の正体 ―― IEEE 754 浮動小数点数の仕組み
2007.05.07
コメント(0)
-
日経平均を表示する
日経平均 や 東証株価指数 (TOPIX: TO-kyo- stock Price IndeX) の予測を行うのに、ベースとなる日経平均等、株価情報をどこからとるか考える。最低限、欲しいデータは次のもの。始値高値安値終値(前日比)(出来高)前日比のプラスマイナスは計算から求めることができるので必須ではない。出来高はあった方がよいが、出来高まで取れるところは限られているので(たとえば QUICK Money Life や ケンレミ株式会社の株式指標のページなら各種指標の出来高をまとめてとってくることができる)、第一段階では省略。最初はなるべく単純なところから始める。よって、始値、高値、安値、終値のみでやってみる。実際のところ、それだけで予測ができれば誰も苦労しないわけだが、すべての情報がこの4つの値に織り込まれているというスタンスで、まずはやってみる。あの日の日経平均は を使えば、正確な値を確認することができる。その他の情報源としては、Infoseek なら 日経平均株価 (指数コード:100000018) 2003年1月1日~ 2007年5月3日まで 等日付を指定してやれば、まとめてとってくることができるので、これで試してみる。その後、「あの日の日経平均は」を使ってデータが正しく登録されているかチェックをすればよいかな。何年分のデータを使うかというのは難しいところだが、実際のところ Infoseek が 2003年以降のデータしかとれないのでそれに合わせる。古いところが必要なら改めて あの日の日経平均は から取り出すことにする。Infoseek からは BeautifulSoup を使ってスクレイピングと、「あの日の日経平均は」に日付を指定してデータが取れるようになった。あの日は、下のような感じで簡単に取れる。Infoseek からとってくるのも、少し長くなるだけでできた。やっぱり BeautifulSoup は便利。# -*- encode: utf-8 -*-import urllibimport urllib2from BeautifulSoup import BeautifulSoupurl = 'http://www3.nikkei.co.jp/nkave/data/index.cfm'def print_nikkei225(yyyy, mm, dd): """ get Nikkei 225 index """ values = {'yyyy':yyyy, 'mm':mm , 'dd':dd} data = urllib.urlencode(values) req = urllib2.Request(url, data) b = BeautifulSoup(urllib2.urlopen(req)) data = b.findAll('tr', bgcolor="#FFF5DE", align="right")[0].findAll('td') data = [x.contents[0].contents[0].string for x in data] print "始値=%s, 高値=%s, 安値=%s, 終値=%s" % tuple(data)print_nikkei225(2007, 5, 2)実行すると、2007年5月2日の値が、次のように表示される。始値=17,310.75, 高値=17,441.10, 安値=17,227.09, 終値=17,394.92Infoseek の方もラフに書いたのであれだが、次のような感じでまとめてとってくることができる。# -*- encode: utf-8 -*-import urllib2from BeautifulSoup import BeautifulSoupimport sockettimeout = 10socket.setdefaulttimeout(timeout)URL='http://money.www.infoseek.co.jp/MnStock/slast.html?qt=100000018.i'def print_nikkei225(sy,sm, sd, ey, em, ed): global URL op = '&sy=%s&sm=%s&sd=%s&ey=%s&em=%s&ed=%s&k=d' % (sy,sm, sd, ey, em, ed) req = URL + op while req != None: b = BeautifulSoup(urllib2.urlopen(req)) data = b.find('table', 'ruled').tbody.findAll('tr') for tr in data: td = tr.findAll('td') print tr.th.string, td[1].string, td[2].string, td[3].string, td[0].string next_url = None next_urls = b.findAll('a', href=re.compile('/MnStock/100000018.i/slast/\?sy')) for n in next_urls: if n.contents[0] == u'\u6b21\u306e50\u4ef6 ': next_url = n.get('href', None) if next_url == None: req = None else: req = "http://money.www.infoseek.co.jp" + next_url req = req.replace("&", "&")print_nikkei225(2007, 1, 1, 2007, 5, 2)これで 2007年1月1日~2007年5月2日のデータが表示される。とりあえず動くかどうか適当に書いてみたので、後で汎用性があるように書き換えることにしよう。しかし、スクレイピングの弱点は、やっぱり、ちょっとでもHTML を変えられるとこけちゃうところだな。。。。追記追記req = req.replace("&amp;", "&") のところが、そのまま &amp; とそのまま書いてあったので、HTML になったときに消えてしまって req = req.replace("&", "&") に見えていたので修正。
2007.05.04
コメント(0)
-
スペル修正プログラムはどう書くか
Zope / Pythonのリンク配信 - 日本の Zope 情報 を見ていたら、スペル修正プログラムはどう書くか が目についた。へぇ、日本人でもこういうプログラム書いてみる人がいるんだ。と思ってよく見たら、Peter Norvig / 青木靖 訳、と翻訳であった。読み始めたとき、「訳」というのが目に入っていなくて、海外留学している日本人が書いているものかと思ってしまった。オリジナルは How to Write a Spelling Corrector。青木靖さんは Fine Software Writings をみたら、いろいろ翻訳して公開されている方なのでした。失敗した結婚みたいな企業が多すぎる なんていう記事ももおもしろい。そのほかにもあれこれおもしろい記事があった。
2007.05.02
コメント(0)
-

クールからホットへ,2007年のPythonコミュニティ
クールからホットへ,2007年のPythonコミュニティ を読む。『みんなのPython』や『TurboGears×Python』の著者、柴田淳さんの記事。PyCon に出て、私は祖国を売ってしまったのかもしれませんが,とにかく会場は大爆笑でした。自虐ネタで笑いをとってきたらしい。笑いをとるのは重要だな。言語として大変魅力のあるPythonですが,私がそれ以上に魅力を感じるのがPythonに引き寄せられてくる「人」についてです。クール過ぎて一見つきあいにくそうだけど,クレバーで物事についてよく知っていて,美しいものについて造詣が深く,リテラシーが高い。海外でも国内でも, Pythonistaにはそんな有能な人が多いような気がしています。日本人に対しては、ちゃんと日本人の Python 使いをほめあげて記事を終えている。Google でも使われています戦略から、Python 使いほめあげ戦略へ転換かな。クールからホットへという話の流れも良い感じで終わっている記事。オンラインメディアの影響力は大きくなる一方だけど、良書を出し、流行に加担する出版社の役割というのは大きい。技術評論社にとりあえず次の一手を期待しておく。『Xen × Twisted × Python』とか『MailMan × Python』だとか、Python で書かれたものを 扱ったチューニングだとか、改造だとかを掘り下げたものとかもおもしろいかもしれない。『TurboGears × Python』は、昨日、本をまとめ買いしたときにいっしょに注文した。株価のデータを扱うのに、TurboGears でも使ってみようかなと。
2007.05.02
コメント(0)
-
Tiny HTTP Proxy in Python
沖電気がオープンソース専門組織を設立しサービスを開始,ドキュメントやソフトを公開 ということで見てみる。OSS ソリューション のサイトには、Python のカテゴリもあった。Python & IronPython 入門Cygwin 上の PythonPython で作る Prolog 処理系Tiny HTTP Proxy in Python なんてものもあった。よく見たら、SUZUKI Hisao さんで Python のメーリングリストとかにときおり投稿している人か。見たことあると思ったら、これ以前に ML に投稿されていたものの新しいバージョンか。体力ある会社がこうやって OSS資料室 のような日本語資料を公開するのはよいことだと思う。でも、沖ソフトウェアさん、第1回 Hibernate で作る HelloWorld アプリケーション のページで、トップページのリンククリックするとリンク切れでっせ。http://www.okisoft.co.jp/esc/hibernate3/index.htm にリンク貼られてる。ニュースリリース出す前には、サイト全体リンクチェックぐらい入れようねとか思ったりする。
2007.04.14
コメント(0)
-
Python Win32 Automation
Python Win32 Automation を見てみる。GUI アプリケーションを Python からコントロールできるようなもの。例えば、Notepad を開いて閉じる、なんていうのも、import pywinauto.applicationapp = pywinauto.application.Application().start_("notepad")app.notepad.TypeKeys("%FX") のようにすればできる。昔、Scriplayer というソフトがあって、GUI ベース操作を記録して、同じ操作を何回でもできるようなものがあったなぁ。あれはあれで便利であった。win32com を使えば、PythonでExcelの初歩的な操作 みたいなことができるのは分かっているのだが、COM の知識がなくても、キーボードの操作が分かっていれば使えちゃうと便利だなと思って試してみた。が、日本語だとちと問題がある。例えば、app.Notepad.MenuSelect("File->SaveAs")app.SaveAs.ComboBox5.Select("UTF-8")app.SaveAs.edit1.SetText("Example-utf8.txt")app.SaveAs.Save.Click()のようなコードは動かない。app.Notepad.MenuSelect(u"ファイル->名前を付けて保存")のようにしなければいけない。まあ、この方がメニューそのままで都合が良いわけだが。その後が問題。app.SaveAs.ComboBox5.Select("UTF-8") を実行したところで次のようにエラーになってしまう。pywinauto.findbestmatch.MatchError: Could not find 'SaveAs' in '[u'\u540d\u524d\u3092\u4ed8\u3051\u3066\u4fdd\u5b58', u'\u540d\u524d\u3092\u4ed8\u3051\u3066\u4fdd\u5b58Dialog', 'Dialog']'まじめにハックすれば使えるようにできそうな気もするが、今、特に使う用途もないので、止めておく。どういうオチなんだ。いや、こうやって書いておけば誰か、解決方法を見つけてくれるかなとか。他力本願か!
2007.04.10
コメント(0)
-
Pylons を使う人が出始めたみたいね
Python のアプリケーションフレームワークとしては、Zope がとりあえず先頭を切って日本で普及しはじめ、次いで、TurboGears や Django あたりが使う人が増え始めているというところか。個人的には、Pylons を使う人が何で出てこないのかなと思っていたのだが、Pylonsのトレースバックは凄い! とか、Blogを作る(1)プロジェクトを作る とか書き始めている方がいらっしゃった。この方の perezvonの日記 を駆け足で眺めてみる。けっこう興味あることが書かれているようなので、今度、まとめて読んでみることにしよう。IronPython の本も出たのね。だいぶ、Python の本も増えてきたな。
2007.03.27
コメント(0)
-

Gmailへの一括インポートツールと Pythonmegawidgets
Gmail Loaderを用いた既存電子メールのGmailへの一括インポート は、Python で書かれたツール。GUI は Pmw (Python megawidgets) を使って書かれている。Pmw は、最終リリースが 2003-08-05 の Pmw 1.2 で開発が終わっているみたいだが、逆に言えば長年使われているだけに安定して使えるということか。Python による Tk の実装 TkInter の上に作られたウィジェットなので、表示は wxPython などで作られたものに比べると、独特な見栄え。wxPython だと Windows であれば、通常の Windows のアプリケーションと同じような感じに見えるが、TkInter で作ったものだとちょっと浮いた感じになる。でも、比較的簡単に扱える上のがメリット。ちなみに Windows でも Mac でも Linux でも同じような見栄えになる。
2007.03.23
コメント(0)
-

Pythonプログラミング入門
『Pythonプログラミング入門』がまた新たに出版されるようだ。地道に日本人が書いた Python 本が増えてきたかな。『Python for 702 NK/702 NK2プログラミングブック』を書いた人か。
2007.03.17
コメント(0)
-

『最新Pythonエクスプローラ』と 『TurbGears×Python』
Python の2大フレームワーク、Django と TurboGears の対決特集の本が出ていた。TurboGears の本も出ていた。今買っても積ん読になりそうなので、ストックがクリアされてから買うことにしようかな。徐々に日本人が書く Python の本も増えてきた感じ。よい傾向。IronPython 本もそのうち出るんだろうか。もう一年ぐらいしたら、少し流行っぽくなってくるか。そういえば、2007年5月にサービス開始4周年を迎える「EVE online」,日本語版は8月にスタート予定 のゲームは Python が使われているようだ。開発会社の CCP の人たちは、2007年のPyConにも参加していたようだ。
2007.03.11
コメント(0)
-
英国の RFIDパスポートのクラッキング
セキュリティ専門家が英国のRFIDパスポートのクラッキングに成功 本物のパスポートを使ったデータ抜き取り実験で実証 らしい。RFIDとBluetooth技術に携わってきたセキュリティ・コンサルタントのアダム・ローリー氏は、一般的なRFIDリーダーとカスタム・コードを使って、封筒に入っているパスポートからRFIDチップのデータだけを抜き取ることに成功したことを公表した。被害者にはデータが抜き取られたことがまったくわからないという。英国民は、いつの間にか自分の情報を誰かに抜き取られてしまうということが起きる可能性があるということか。偽造は当局によると難しいということだが、もし、偽造ができてしまうなら、知らない間に自分に成り代わった自分物が世界のあちこちで悪さをするなんていうこともあり得る。まあ、映画の世界みたいだな。そうならないように関係者は努力しているんだろうけど、比較的新しい分野だけに、技術と運用を含めてまだまだ発展の余地ありという感じか。Security expert cracks RFID chip in U.K. passport を見ると RFIDIOt のリンクが見つかった。RFIDIOt (RFID IO tool) は Python で書かれたツール。クラック用途とかいうことではなくて普通のツール。RFID について知らなかったから Idiot の視点で試行錯誤しながら作ったから RFID IO のツールだから RFIDOt みたい。ACG serial readers に対応したツールなので、他のメーカーのものだと手を入れないとだめだろうけど、Pure Python で書かれているから詳しい人なら書き換えられるかな?そもそも、詳しい人しか使いようがないだろうけど。これを使うためには、pySerial、pycrypt、Imaging の各モジュールが必要なようだ。RFIDIOt (Adam Laurie)pySerialpycryptImaging
2007.03.08
コメント(0)
-
SIG for Python support for the Web
Web-SIG -- SIG for Python support for the Web というメーリングリストがあるのね。そのうち流し読みしてみようかな。そのうち、それっきりばかりだ。。。。。
2007.03.04
コメント(0)
-
SQLObject と SQLAlchemy
Python から RDBMS にアクセスするときに便利なのが SQLObject。いわゆる Object-relational mapping。プログラム中のオブジェクトと RDBMS のデータを関係づけて、プログラム中でオブジェクトを操作すれば、データベースも更新されるので SQL 文を書く必要がなく、Python っぽくプログラムできる。SQLObjectのページの例のように書けるのでとても便利。Python で書かれた Ruby on Rails 的な開発プラットフォームの TurboGears なども、SQLObject を使っている。ということで SQLObject いいなと思うのだが、0から作る場合はよいけど、すでにある RDBMS のデータを扱おうとすると困る。SQLOjbect は勝手にテーブルを作ってくれるのはいいのだが、既存の DB を Python から自由にアクセスする用途には使えない。自由度が高いのは、SQLAlchemy。これも Python で使える ORM の一種。SQLObject vs SQLAlchemy。SQLObject よりも手間は増えるが、その分、自由度が高いようだ。簡単に使うなら SQLObject でいいけど手に余るようなゴリゴリしたものは SQLAlchemy か。SQLObject 0.7 マニュアル日本語訳SQLObject and Database Programming in Python by Ian Bicking
2007.03.01
コメント(0)
-

Pyblosxom contributed pack 1.3.2 リリース
Pyblosxom contributed pack 1.3.2 がリリースされた。ディレクトリ構成が変更されている。pycalendar, weblogsping, comments, trackback, xmlrpc_pingback, moinmoin, editfile などが改良されているようだ。comments プラグインは特に UTF-8 のテキストが正しく扱えるようになったりだとか、anti-spam 関連だとか AJAX 対応だとか、いろいろ改良されているとか、うれしいことがありそうなので試してみることにする。そういえば Pyblosxom 途中までいじって放置してた。なんだかんだで、このブログがあるから、急いでやる必要ないやと思うと、いつまでたっても進まない (^^;;『実践Python』も買ったけど、まだ放置してある。。。。
2007.02.23
コメント(0)
-
mod_python 3.3.1
"mod_python 3.3.1"公開 - プロダクションレベルの安定版と位置づけ らしい。mod_python マニュアルMod_Python-SIG -- mod_python Special Interest Groupmod_python による Trac と Apache の連携メモ/Mod_pythonでTrac
2007.02.17
コメント(0)
-
Python 2.4 の拡張モジュールのコンパイル
Python では、C 言語や C++ 言語で書かれた拡張モジュールを使う場合がある。これをコンパイルするとき、Linux なら gcc 等がインストールされていれば何も悩むことはないのだが、Windows の場合はどうするか。Python 2.4 Extensions w/ the MS Toolkit Compiler を見ると、Microsoft の無償のコンパイラを使うときに参考になることが書かれている、と思う。こういうの日本語でまとめておけば誰かの役に立つかなと思いつつ、とりあえずリンクのみ。その他、参考。- E02 - Support for MinGW Open Source CompilerPython Tutorials
2007.02.17
コメント(0)
-

Wing IDE 2.1.4
Python の統合開発環境 Wing IDE 2.1.4 が 2月9日にリリースされた。Personal と Professional の違いは ここを参照。Wing IDE ダウンロードいろを変えるとこんな風にもなる(デフォルトの画面は、スクリーンショット参照)
2007.02.10
コメント(0)
-
Bio なんとかと、グローバルトレンド、ローカルトレンド
すべてのDBにウェブの窓を! 日本発のプログラム言語BioRubyの Googleヒット数が1年で倍増 を読む。片山助手が1年ほど前に調べたGoogle検索のヒット数がBioRubyは5.8万だったのに比べ、ほぼ2倍に増えた。ライバル言語の1年ほど前のヒット数はBioPythonが18.5万、BioJavaが24.3万、BioPerlが96.2万だった。ここ1年ほどでBioPythonは減少し、 BioJavaは微増だったことになる。へぇ。BioRuby っていうのが伸びているのね。バイオの世界は直接触れることはないので関係ないけど、とりあえず、現時点で Google で検索しておく。bioRuby だいぶ増えてきたのね。bioRuby 約 107,000 件bioPython 約 167,000 件BioJava 約 265,000 件BioPerl 約 991,000 件Ruby って、後発なだけに、他の言語ですでに実装されているよいところを取り入れていく勢いがあるみたいね。とはいえ、来年も、また倍増するかといえば、その分野の人が増えないと、一定以上に増えてからは、そうそう簡単には増えないだろうが。ま、それにしても Perl が圧倒的に多い。日本語のページに限定して調べてみると、日本人のバイオ研究者は BioRuby が強いということなのかな。日本語情報が得やすいのと、誰かが使っていればそれを使うという傾向もあるだろうから、来年はもっと数の差がつくかな。BioRuby 約 36,700 件BioPython 約 768 件BioJava 約 557 件BioPerl 約 26,600 件bioRuby の全体/日本語ページを計算してみると、36,700 / 107,000 = 0.3429.. と実に 35パーセント近くが日本語のページだったりする。日本人が英語で書いているであろうものも含めると、もっと割合が上がるだろう。グローバルトレンドとローカルトレンドという2つの視点が必要かもしれない。たとえば、地図上である言葉のホットな地域/国を表示してくれるようなサービスがあるとおもしろい。Ruby は言語そのものの魅力に加えて、国産!という強い推しがあるのだな。いわゆる「外人」が認めてくれた国産ブランドは、日本ではとても強くなる。何かを広めようとしたら、日本人より、むしろ外人に対してアピールするのが有効だったりするところがあるだろう。ジャストシステムの xfy なんかも、日本語で情報を出すより、むしろ外人に対してまずアピールしたものね。グローバルな時代は、ローカルをとるのにグローバルからアプローチするというのもありと。保守的な日本人より、先進的なものを認めてくれるようなところにアプローチするのが得策だったりして。Ruby にしても Ruby on Rails が出てから一気に勢いを強めたような気がする。もともと日本人が作ったもの + 外国人も認めて革新的なものを作って公開してくれる + 日本語の情報が豊富 = やたら強くなる土壌となる。Ruby は最初からそういう意図を持って普及活動を行ったところにも、強さの源があるんだろうな。
2007.02.06
コメント(0)
-

Eclipse+PyDEV とデモ画面のキャプチャ
Eclipse+PyDEV=Python統合開発環境 の記事が Open Tech Press のサイトに公開されている。 PyDev Eclipse IDE Videos のビデオを見ると、どんなものか分かりやすい。それにしても無償で Eclipse のように高度な統合環境が使える時代というのは、すごいものがあると改めて感じるし、デモ画面なども動画であれこれ公開されるというのも時代だなぁと感じる。この ShowMeDo というビデオがアップロードされているサイト知らなかったが、A Collection of Python Programming Videos にいろいろ Python 関連のビデオがアップロードされている。他の言語のビデオもいろいろあるのでお好みの言語のビデオをどうぞという感じ。Python がそのまま使える shell 環境の IPython なども使ってみると便利なのだが、Python Development with IPython みたいなものを見ると、あぁなるほどねと分かりやすいでしょ。操作画面のビデオを撮るのは、camstudio とか使えばよいのね (Windows 版のダウンロード)。もともと、CamStudio は RenderSoft がリリースしたけど eHelp に買われて、RoboDemo にその機能が吸収されて、さらには MacroMedia が RoboDemo を買って Captivate になって、その MacroMedia は Adobe に買われて... という経緯があるようだ。どこかに使い方を日本語でまとめてあるところはないかと探してみると、次のあたりかな。画面動画キャプチャーソフト CamStudio 日本語版のCamstudio ヘルプのページを見るとよいのかな。商用版の画面キャプチャツールもあれこれある。
2007.02.06
コメント(0)
-

Eclipse のメモ
Eclipse 使ってみようかなと思っているので、メモ。EclipseでのWeb開発を支援するWeb Tools PlatformPythonプログラミングを楽にするEclipseプラグイン (ITPro)スクリプト言語をサポートするEclipseプラグイン (PyDEV が載っている)Eclipse (amateras)Eclipse+Pydevを使って見る (Days of Liris)http://pydev.sourceforge.net/TruStudio - PHP IDE and Python IDE built on EclipsePython使いに開発環境をきいてみる (ueBLOG)Python使いに開発環境をきいてみる vol.2 (ueBLOG)eclipseでpython (ueBLOG)Eclipseの環境を一気に整え。「EasyEclipse」EasyEclipseEasyEclipse for LAMP関連記事JUnitフレームワークによるJava ME単体テスト
2006.12.26
コメント(0)
-
Perl, Python, Ruby 比較
「Perl, Python, Ruby の比較」があまりにもいい加減な件 なるページがあった。Perl, Python, Ruby の比較のページには、あくまで、初心者の私見ですので気軽に聞き流してください。と書かれているが、「Perl, Python, Ruby の比較」があまりにもいい加減な件 を書いた人は、「Perl, Python, Ruby の比較」はどうも調査が足りないのか、結果的にかなり嘘のまじった文章になっている。あくまで、初心者の私見ですので気軽に聞き流してください。Perl, Python, Ruby の比較とはあるものの、はてブのコメント等で「参考になる」とか言っている人もいるので一応指摘しておこうと思う。ということで記事を書いたようだ。それに関連して、Google で「スルー力」を検索したら、スルー力 約 812,000 件。すごいあえて言及しない勇気本当に「どうでもいい」ことなら言及しないほうがいいのかブログ観測者問題・スルー論ブログ観測者問題・追加。スルー力カンファレンス (スルカン) 開催決定!スルカン開催中止スルー力なんて無くていいITエンジニアにはスルー力が足りません「スルー力」を被害者に要求することの残酷さ「スルー力」をスルーできないはてなブックマーク > キーワード > スルー力
2006.12.14
コメント(0)
-
Pyblosxom のトラックバックとコメントのプラグイン
sh1.2 で MagicWord/comments/trackback plugin 改良パッチが公開されているので、見に行く。Pyblosxom のトラックバックとフィード で、最初にMagicWord/commentsプラグインでトラックバックを受け取る トラックバックをいただいて、パッチを見て試していたら、んんっというところがあった。そこで疑問をメールを送ったところ答えていただいて、そのうえ改良していただいて感謝。これならよさそうですねということで、使わせていただくことにします。cb_comment_reject()関数を持つpluginとして実装したらいいんだね。そっちのが美しい気がする。なるほど、確かにそうですね。勉強になります。Pyblosxom は Google Trends で検索すると、トレンドが表示されなないので、流行っているにはほど遠いものだとはいえ、シンプルなので Zope のように迷路をさまよわずにいじることができておもしろいと思う。Python のウェブプログラミング入門としてもよさそうかなと。でも、やっぱり Pyblosxom は無愛想といえば無愛想で、最初の一歩を踏み出すのに気合いがいる。なので、スタータキットみたいなのがあればいいんでしょうね。というのは、かなり同意できますね。まだ先のことになると思うけど、Pybloxsom を XREA で動かすときに、この通りにやればとりあえず動かせるというような文書でも書いてみようかな。そもそも、Python の CGI が動かせる無料のサービスは?とかいう話もあるかもしれない。Infoseek の isweb は、Perl だと CGI が無料で使えるけれども、月額525円の isweb ベーシック でないと Python の CGI が使えないとかあるし。ちょっと、どこなら無料で使えるかも調べてみようかな。Blosxomで行こう!(1)Blosxomとは何ぞや みたいなものもあった方がよいかもしれない。blosxom starter kit のようなものも参考になるかな。Blosxom とは、同根なだけに、いろいろ共有できる(というか、パクれる)ような気がする。今、いじりたいところは、Pyblosxom も Blosxom と同様、記事のカテゴリ(ファイルシステム上のディレクトリがカテゴリになる)で日本語が使えるのだけれど、日本語を使うと URL が UTF-8 をエンコードされたものになって長ったらしくなってしまうところ。Perl で書かれた Blosxom の方は日本語の場合、ディレクトリはアルファベットで表示のところだけ日本語のようなので 上記のページのように できないかなというところ。どこでやるのがきれいなのか、Blosxom の方もちょっと見てみようかな。
2006.12.12
コメント(0)
-

Pyblosxom の lucene プラグイン
Pyblosxom の lucene プラグインを使って投稿したブログのエントリを全文検索できるようにしたいと思ったが、エラーが出てインデックスを作成するための index.sh を動かすことができない。Exception in thread "main" java.lang.NoClassDefFoundError: org.apache.lucene.util.Arrays at BlosxomIndexer.indexDocs(BlosxomIndexer.java:163) at BlosxomIndexer.indexDocs(BlosxomIndexer.java:157) at BlosxomIndexer.main(BlosxomIndexer.java:111)このプラグインが作られたのは 2004年で lucene 1.2 の時代なので、そのままだと使えないのか、それとも環境がちゃんとしていないからなのか。そもそも、Lucene も分かっていなし(汗)。全文検索エンジン「Lucene」関口宏司のLuceneブログ Java全文検索APIのLuceneについてLucene (TECHSCORE)Lucene (Yuna Wiki)Sen Projectとりあえず、面倒なので挫折しておく。しかし、テキスト検索エンジンライブラリ - Apache Lucene 2.0 登場 を見ると、* 1MBのヒープを要求する程度の少量なメモリサイズ* テキストインデックスのだいたい20%から30%で済むインデックスサイズ* バッチインデックス機能と同等に高速に動作するインクリメンタルインデックス機能* フレーズクエリ、ワイルドカードクエリ、プロクシミテクエリ、レンジクエリなど多種多投なクエリ* フィールドに特化した検索、データレンジでおこなう検索* 複数のフィールで整理できるソート機能* 検索結果をマージする複数インデックス検索機能* 同時検索や更新のサポートと魅力的なので、なんとかがんばって使えるようになっておこうかなぁ。PyLucene project とかもあるようだし。でも、やっぱりいったん放置。
2006.11.27
コメント(0)
-
Pyblosxom の reStructuredText プラグイン
Wiki にしても、YAML にしても、stikkit にしても、プレーンテキストを使って簡易なマークアップを使う方式なのだな。プレーンテキストの復権ってやつか。最終的にそれがどんな形式に変換されるかは別として。というわけで、Pyblosxom の記事を書くときには、reStructuredText(reST) を使うことにした。はやわかり reStructuredTextReStructuredText 入門reStructuredTextXMLの論考: reStructuredText: 軽量で強力な文書マークアップ改造版reStructuredTextQuick reStructuredTextdocutilsPyblosxom Plugin: rst を使うと reStructuredText が使えるようになる。これは contrib に含まれているので、プラグインディレクトリにコピーして、load_plugins を使っていればそこに追加するだけ。記事は、拡張子 .rst を付けたファイル名にする。もし、すべて reST を使って書くし、拡張子は .txt がいいというのであれば、config.py に次の行を追加する。py['parser'] = 'reST'もうひとつの方法としては、.txt ファイルのタイトル行(1行目) に続いて「#parser reST」という行を入れておけばよい。reStructuredText で記事を書く#parser reST記事の本文が続く。<H1>からレベルを付けていきたい場合は、次の行を config.py に追加する。「1」となっているところを変更すれば、好きなレベルから開始できる。py['reST_initial_header_level'] = 1ドキュメントのタイトルは標準でレベル 1 に変換されるが、これも config.py に追加すれば変更できる。py['reST_transform_doctitle'] = 1とソースには書いてあるようなのだが、ヘッダレベルはここを変更しても変わらない。このあたりは、またの機会に時間を作ってみることにする。とりあえず、py['parser'] = 'reST' にするか、#parser reST のどちらにするかについては、全部、reST にしてしまうので config.py で parser を指定することにした。これで .txt のファイルはすべて reST として解釈される。正しく reST が扱えているかどうかはまた別途チェックする( reStructuredText の問題になるし)。
2006.11.26
コメント(0)
-
Pyblosxom のトラックバックとフィード
PyBlosxom Manual: 8.6. Installing trackback を見る。インストールは次の手順。contrib/plugins/comments/plugins/trackback.py をプラグインディレクトリにコピー(必要なら config.py の load_plugins に追加)trackback ping link リンクを config-story.html に記述する($base_url/trackback.cgi/$file_path)。RDFの記述を HTML 内に埋め込むなら上記ページを参考に story.html や comment-story.html に記述を追加する。pingback のインストールはrssfinder と rssparser、xmlrpc をインストール。contrib/plugins/comments/plugins/xmlrpc_pingback.py をプラグインディレクトリにコピー(必要なら config.py の load_plugins に追加) は、Mark Pilgrim さんがオリジナルの作者で、現在は Aaron Swartz さんがメンテナンスしているようだ。rssparser はどこにあるんだろう。。。このあたりのマニュアル、FIXME - this text probably needs fixing. と書いてあるだけあって。。。xmlrpc_pingback.py を見ると、rssfinder と rssparser が必要だが、trackback.py では使われていない。ゆえに trackback.py を使うだけであれば、rssfinder と rssparser は必要ない。from rssfinder import getFeedsfrom rssparser import parsepingback.py を見ると、 次のようになっている。trackback.cgi ではなく trackback。これを変更したければ、config.py に py['trackback_urltrigger'] = '/path_for_trackback' を入れればよいのだろう。urltrigger = config.get('trackback_urltrigger','/trackback')trackback.cgi ではなく trackback に変えてみると doesn't exist だったのが、次のようにエラーがでなくなったが、依然として書き込みができていない。<?xml version="1.0" encoding="utf-8"?><response><error>0</error></response>おかしいなぁと思って調べてみると、トラックバックされたものは comments.writeComment を使ってコメントと同様に書き込まれている。コメントのスパム対策に入れている magicword.py、nospam.py、 wbgcomment_blacklist.py のどれかが悪さをしているかと思って、すべていったん外してみるとめでたくトラックバックが打てた。ちなみに、次のようにスクリプトから試した。#!/usr/bin/env pythonimport urllibcdict={'title':"TB Test",'blog_name':"Kugutsushi Labs", 'author':"Kugutsushi", 'url':'http://localhost/cgi-bin/pyblosxom.cgi', 'excerpt':'Trackback Test Send'}blogpage='http://localhost/cgi-bin/pyblosxom.cgi/trackback/python/Memo'data = urllib.urlencode(cdict)ret = urllib.urlopen(blogpage,data)print ret.read()ちなみに、マニュアルのとおりにトラックバックの URL をリンクで入れると紛らわしいのでこれは、トラックバック用の URL を表示するだけにしてリンクはつけないことにする。で、問題は MagicWord を入れると、そのままだとトラックバックが使えないので、MagicWord をトラックバックのときはスキップするように改造するか、あるいはインストールしないかということになる。これはとりあえず後回しにしてはずしたままにしておく。教訓: 予期した通りに動かないときはよけいなプラグインをすべてはずすこと。その他、pyblosxomへのTBテスト やtrackbackプラグイン導入あたりを参考。次に PyBlosxom Manual: Chapter 9. Syndication を読む。9.1. Feed formats that come with PyBlosxom を見ると、Pyblosxom のフィードが対応しているのは、RSS 0.91、RSS 2.0、Atom 1.0 となっている。RSS (Wikipedia)。http://localhost/cgi-bin/pyblosxom.cgi/?flav=rss20 あるいは /index.rss20 とかすると、rss20.flav が使われるので、これで RSS 2.0 形式で出力してくれる。修正する必要があればテンプレート(flavor)をいじるだけなので特に問題はないだろう。rss2renderer プラグインがインストールされていれば、フレーバーがなくても http://localhost/cgi-bin/pyblosxom.cgi/index.rss2 で RSS 2.0 形式でフィードが出力できる。フレーバーで出力されたものとこのプラグインで出力されたものを比べてみると微妙に違ったりする。。。プラグインの方は dc:creator や、admin:generatorAgent、admin:errorReportTo が入っているが、フレーバーの方は入っていない。flavor の方は copyright が入っているがプラグインの方は入っていない、等々。ここはちゃんと見直して規格を確認してなるべく一般的に正しいところに合わせることにしようかな。FeedValidatorで最終的にチェックして。さしあたっては、そのままにしておく。プラグインには atom1renderer、pyrss2 plugin、rss2renderer がある。レンダラのプラグインをインストールしておけば、フレーバーが必要ないが、どちらがいいんだろう。判断保留。とりあえず大枠は見終ったので、Chapter 10. PyBlosxom Architecture をざっと眺めてから有用なプラグインがないか眺めていくことにする。
2006.11.26
コメント(4)
-
サイボウズの Python 調査報告
Python 調査報告 サイボウズ株式会社 を読む。単に調べただけなのか、それとも Python を使おうとしているのか、Web API とかの関係で Python も対象に含めるためなのか、Python が流行る可能性を感じてレポートを出したのか、どこからかの依頼が発端となっているのか、背景はよく分からないが、とりあえず、こういうまとまった文書が公開されるのはよいことだと思う。公開後、若干、アップデートが入ったようだ。もっとも、この報告書、一定のレベルのプログラミング経験がある人でないと読んでもピンとこないかもしれないが。この報告を書いた山本泰宇さんをはじめとして、サイボウズ・ラボって奥 一穂さん、須之内 元洋さんと、3/8 が未踏ソフトウェア創造事業で採択された人なのね。それにしてもサイボウズって、昔、最初にグルーウェアを出した頃、ここまでお金持ちの会社になるとは思わなかった。とはいえ価格帯の置き方がうまかったし、最初からけっこう宣伝費を使って、雑誌の CD-ROM に同梱させる等、マーケティングセンスのある会社だなとは思っていたが、うまく資本を入れて荒波乗り切ってきた会社だなぁと思う。伸びるソフト会社っていうのは、やっぱり広義のマーケティングにそれなりの費用をかけるもんだよなぁと思う。プログラミング言語にしても、普及という点では、やっぱりマーケティング的な視点が必要で、Python があまり日本で普及してこなかったのは、Python を使っている人たちが自分が便利に使えればいいやというタイプの人が多かったからとかあるだろうか。もちろん、それ以外の要因もあるが、やっぱり、隅っこでお上品に生きてきたのねという感じもある。最近、徐々に Python の市民権が確保されつつあるようなので、もう少し利用が広がってくれると、そこから受けられるメリットも大きくなるんだがなぁと思うのであった。そのうち pygame とかの本が出ると、普及に弾みがつくんじゃないかと予想。しかし、誰かが書いているという話は聞かない。新しい Python の本が出版されるとか聞いたが、まだ楽天のアフィリエイトには登録されていない。
2006.11.25
コメント(0)
全214件 (214件中 151-200件目)
-
-

- 新生活にむけてほしい家電は?
- 【2000円OFFクーポンで5980円♪11/11 …
- (2024-11-10 20:25:40)
-
-
-

- 楽天アフィリエイト♪
- 葬送のフリーレン ミミックぬいぐるみ
- (2024-11-11 01:57:06)
-




