
全1415件 (1415件中 1-50件目)
-
MSX0 温度表示成功
前回、温度表示に失敗(MSX0 温度表示 | Kazu Home Page - 楽天ブログ (rakuten.co.jp))していましたが、ついに温度表示に成功しました。流れとしては1. Arduinoで空スケッチをGrove Beginner Kitに書き込み2. キーボードをつけていないMSX0とGrove Beginner Kitの右上(I2C)と接続3.MSX0を起動し、DHT_KNJ.BASをロード4,Runです。Xユーザーのkazux68kさん: 「@NinuneWa @nishikazuhiko プランBなので、MSX0が2台あることを思い出して、もう1台で再度実験。普通に温度も湿度もOKでした。 #MSX0 #MSX https://t.co/tPvM68GKU7」 / Xただ、キーボードとDHT20のI2Cのアドレスは競合しないということだったので真の原因は違うかもしれないです。また、研究で。ただ、とりあえず動くようになってほっとしています。
Sep 22, 2024
コメント(0)
-
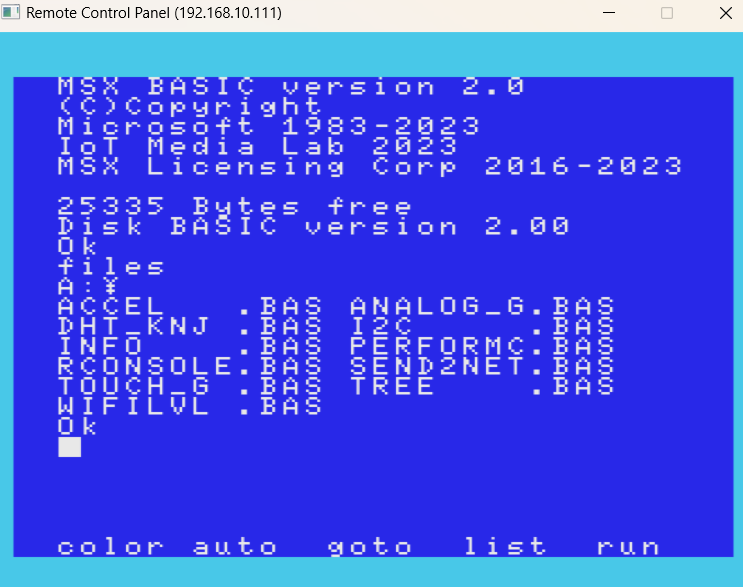
MSX0 温度表示
MSX0 Grove Beginner Kit | Kazu Home Page - 楽天ブログ (rakuten.co.jp)MSX0の温度表示プログラムで前回はDHT_KNJ.BASで-1℃と動かすことは出来なかったため、今回はI2C.BASを実験してみることにしました。そうすると、I2C.BASは普通に動き、温度も表示されます。Xユーザーのkazux68kさん: 「@nicorinB @NinuneWa I2C.BASの方は動きました。 29.88℃。蒸し暑い。 DHI_KNJ.BASと何が違うのかデバッグしてみます。 #MSX0 https://t.co/u1Ei3kt0bP」 / Xプログラムをみると使っているコマンドが違います。I2C.BASN$="device/i2c_a/38"_IOTGET(N$,S$)DHT_KNJ.BASN$="device/dht/temperature"_IOTGET(N$,A)です。dhtが認識しないのかもしれないです。#MSX#MSX0
Jul 15, 2024
コメント(0)
-
MSX0 Grove Beginner Kit
MSX0 Grove Beginner Kitを動かしたく情報収集。Twitterだと流れてわからなくなるのでメモMSX0 Grove Beginner Kitを試す際の注意点はここに切り離しが大事。サンプルコード集空のスケッチ書き込み時のBoard選択で悩んだので調べるとGrove Beginner Kit for Arduino | Seeed Studio Wiki1.Open the Arduino IDE on your PC. 2.Click on Tools -> Board-> Arduino AVR Boards-> Arduino Uno to select the correct Development Board Model. Select Arduino Uno as Board.と書いてあった。書き込みは成功ただし、温度は読めない。なぜ?
Jun 8, 2024
コメント(0)
-

MSX0 Stack対応 保護フィルム
MSX0 Stack対応 PerfectShield 保護 フィルム 3枚入 を購入 PDA工房 MSX0 Stack対応 PerfectShield 保護 フィルム 3枚入 反射低減 防指紋 日本製 自社製造直販
Mar 23, 2024
コメント(0)
-

レノアハピネス アロマジュエル
レノアハピネス アロマジュエル アンティークローズ&フローラルの香り 詰替 特大(1080mL) TinyTAN あす楽対応1,100円でした。4袋買えば送料無料でお得です。レノアハピネス アロマジュエル アンティークローズ&フローラルの香り 詰替 特大(1080mL) TinyTAN あす楽対応
Feb 20, 2024
コメント(0)
-

ドウシシャ スリムフィットチェア バランスチェア おしゃれ コンパクト スリム オフィスチェア…
ドウシシャ スリムフィットチェア バランスチェア おしゃれ コンパクト スリム オフィスチェア 腰痛 姿勢 デスクチェア ダイニングチェア 学習チェア 椅子 イス こども SFC-BK ブラック
May 11, 2023
コメント(0)
-

Redmi watch 2 Lite 日本語版購入
Redmi watch 2 Lite 日本語版を購入しました。mi band4より文字盤が大きくて見やすいです。GPS機能があるのが楽しみです。kazux68kさんはTwitterを使っています 「Redmi watch 2 Lite 日本語版を購入しました。bandより文字が大きいので見やすいです。 https://t.co/ggj1CcYLJa」 / Twitter
Mar 12, 2022
コメント(0)
-
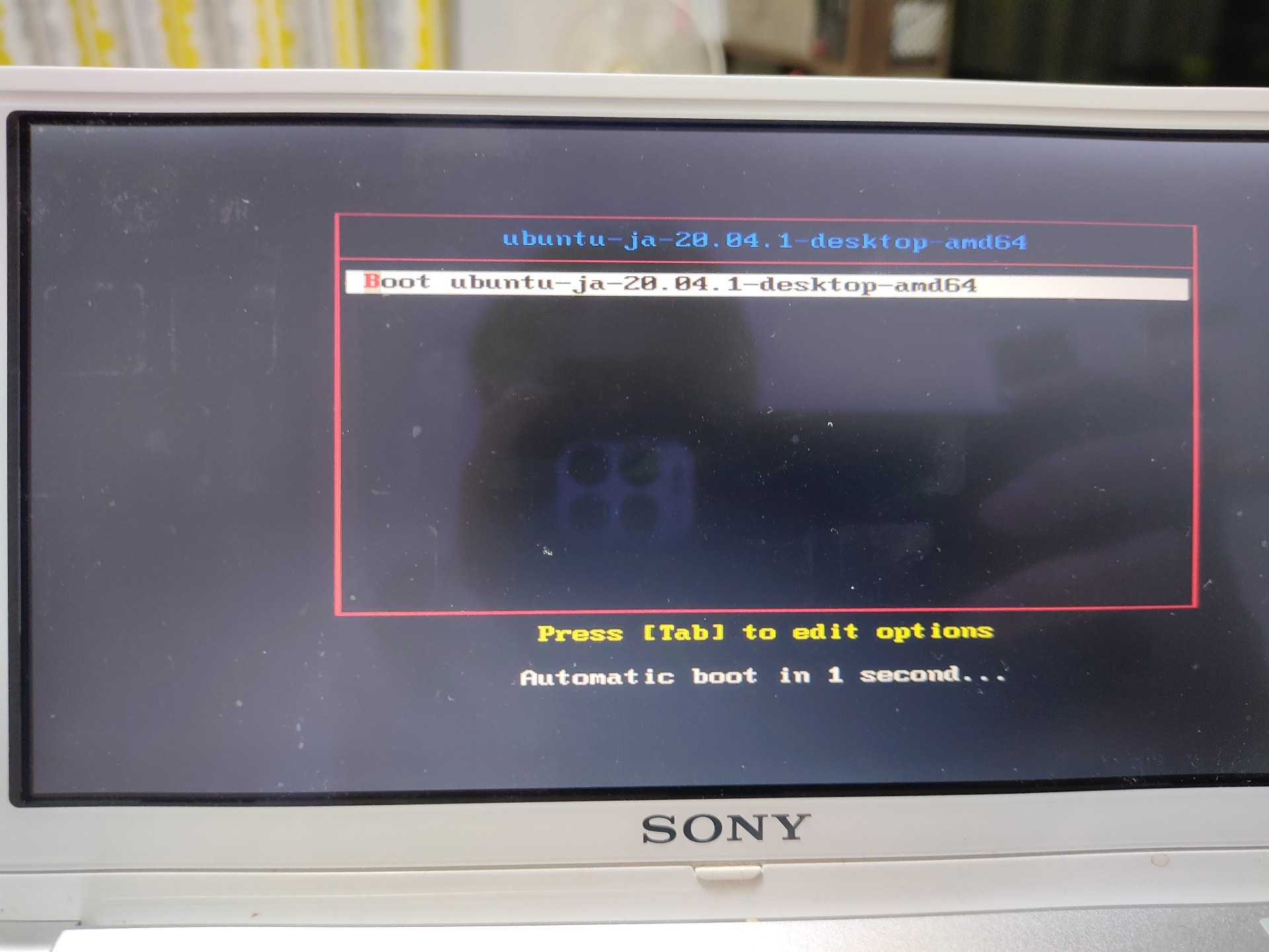
UbuntuをUSBから起動し、Scratchで遊ぶ
以前、LinuxをUSBから起動するシリーズをやっていましたが、久々にやってみたいと思い最新情報を調べました。今はそのままのタイトルのこちらを参考にして試しています。今回やりたいと思ったのは、子供がプログラミングをしたいというので自分のパソコンを使われると自分が全くできなくなるので、久々にVAIO-TYPE-Pを登場させようとおもっているところです。言語はScratchでお手軽にと思っているので、こちらを参考にしようと思っています。起動が無事できたらスクショを上げたいと思います。参考にしたページ通りに行ったところ(VAIOはF2キーでbootを選べる)、残念ながらエラーがでました。下記、boot画面起動後のエラー画面 i686CPUエラーです。CPUが32bitで対応していない模様です。もう少し古いLinuxを入れなければならないようです。と言う事でubuntu 16.04.6 i386を導入しました。起動画面です。じゃじゃ~ん、しっかり起動しました。ただなぜかWiFiを認識しません。スクラッチドリルブック 作って学ぶ実践プログラミング練習帳/石原正雄【3000円以上送料無料】
Sep 22, 2021
コメント(0)
-
2021年ブログ初め 文字化け解消
明けましておめでとうございます。2021年もよろしくお願いします。さて、早速ですが今年の初めは文字化けを快勝しました。下記が2020年の機会学習、RandomForestの予測結果です。2020年競馬予想結果買い方が良くないのか回収率は良くありません。今年はもっと研究が必要です。で、今回のタイトルは文字化け解消ということで、UTF-8でセーブしたり、charset="utf-8"を書いたりしていたのですが、昨年はどうしても解消できませんでした。年始に検索してこちらのサイトを参照にして行ったらすぐに解消できました。<head><meta charset="utf-8"> HTMLの中身</head>で解消できました。ようやくこれで皆様に文字化けなく予測および予測結果を紹介できます。今年はもっと的中率を上げるアルゴリズムおよび、予測ソフト(UI)の充実を検討していきたいです。今年もよろしくお願いします。
Jan 4, 2021
コメント(2)
-
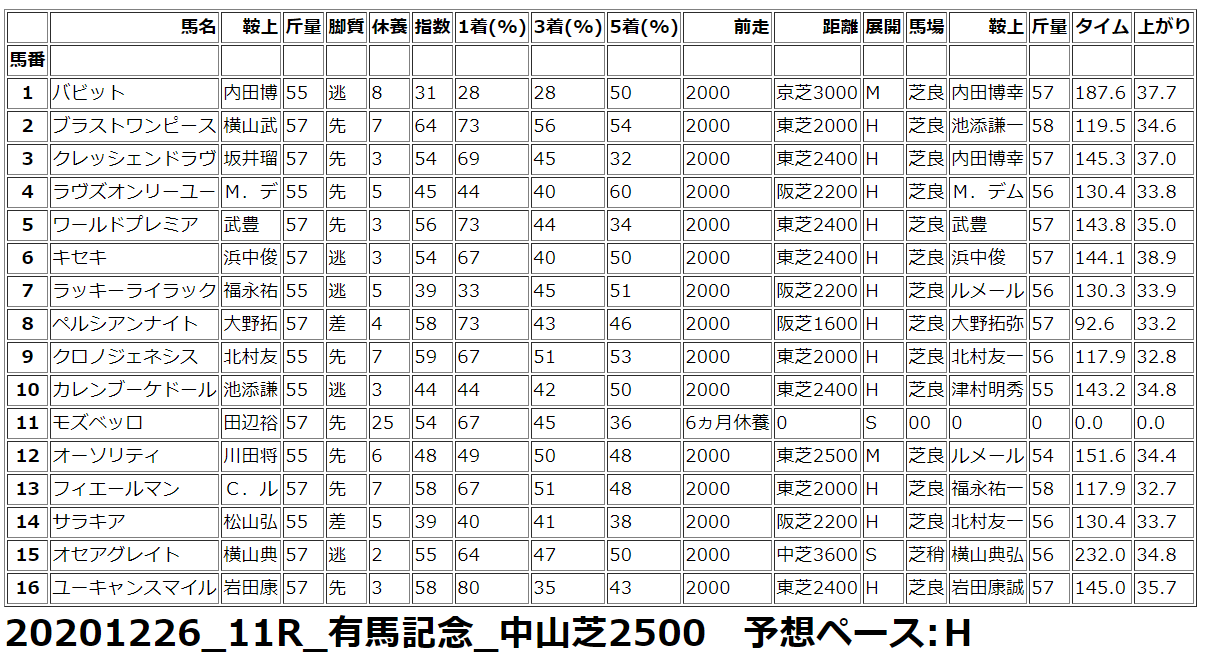
Python で 競馬予想 実践第12回 2020年有馬記念他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)2020年12月26日の予想◆有馬記念◆その他 阪神、中山、中京 2020年度の総決算 有馬記念。AIはハイペースを予想。バビットが逃げる展開を想定しています。ブラストワンピースが本命と出ましたが結果はいかに。SONY 【テレワーク応援】VAIO S11 SSD256GB メモリ8GB 11.6インチ Core i5 Windows 10 Pro 有線LAN, 無線LAN中古パソコン【3年保証】【お気楽返品OK】【送料無料】中古ノートパソコンB5・モバイルノート
Dec 26, 2020
コメント(0)
-
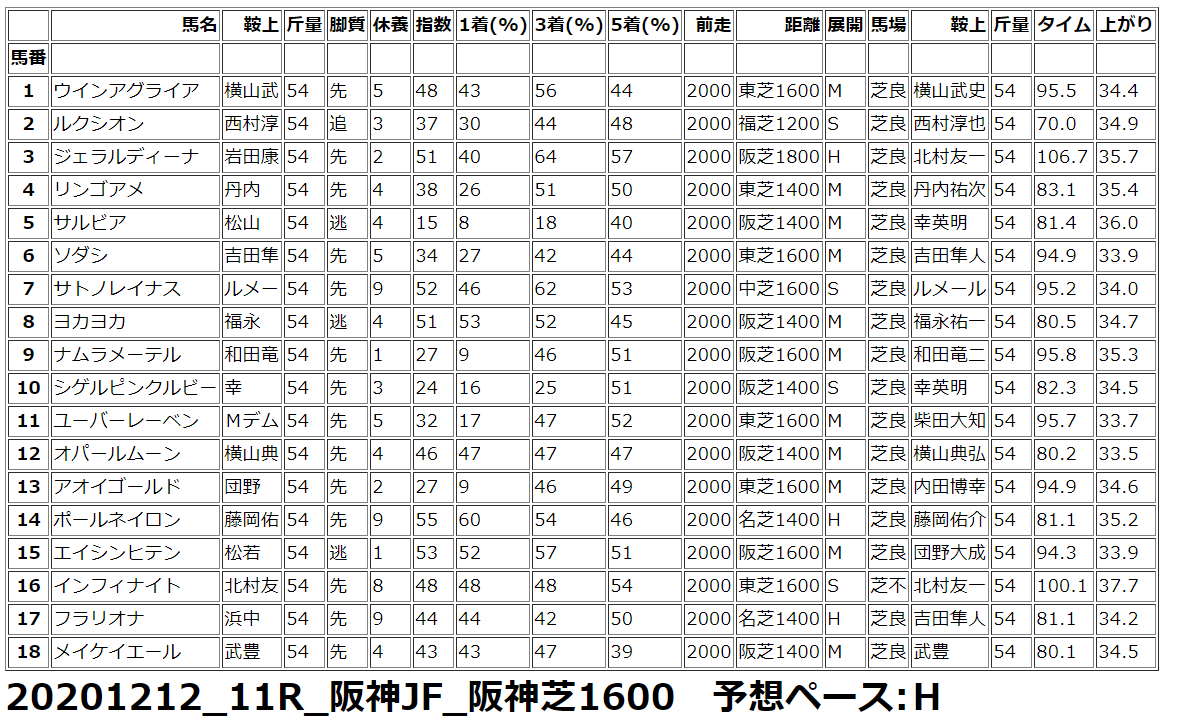
Python で 競馬予想 実践第11回 阪神JF他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)2020年12月13日の予想◆阪神JF◆その他 阪神、中山、中京 阪神JFは難しすぎます。ランダムフォレストの結果では信頼度63と鉄板のようにみえますが、どうでしょうか?SONY 【テレワーク応援】VAIO S11 SSD256GB メモリ8GB 11.6インチ Core i5 Windows 10 Pro 有線LAN, 無線LAN中古パソコン【3年保証】【お気楽返品OK】【送料無料】中古ノートパソコンB5・モバイルノート
Dec 13, 2020
コメント(0)
-
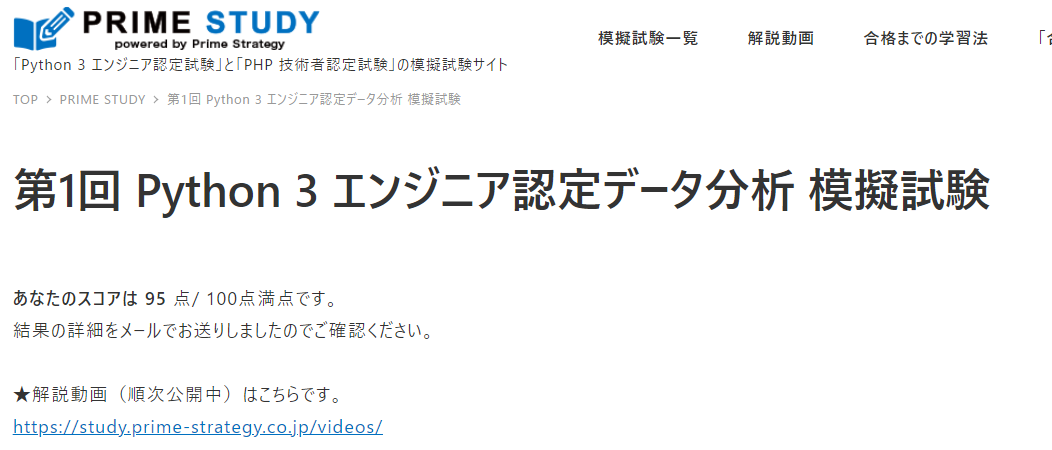
Python 3 エンジニア認定データ分析 模擬試験 第1回を再試験
競馬予想でも使っている言語、Python 3のデータ分析模擬試験を再試験しました。結果は95点。前回から約20点アップです。(再試験なので当然ですが。。。)でも100点ではなかったです。間違った問題は下記でした。確かになぜ間違ったのか理解できないです。機械学習に関する次の記述のうち、正しいものはどれか。あなたの回答: 教師あり学習は、説明変数の種類により回帰と分類の2種類に分けられる。回帰は目的変数が連続値となる。正答: 教師あり学習は、正解となるラベルデータが存在する場合に用いられる方式であり、そのラベルを目的変数という。ここで受験できます。第1回はほぼ出来るようになったので次は第2回です。試験要綱はこちら今なら教科書無料配布キャンペーンもあります。始めるなら今です。#Python 3のデータ分析 #Python #データ分析 #python試験
Dec 8, 2020
コメント(0)
-

Python 3 エンジニア認定データ分析 模擬試験 第1回を受験
競馬予想でも使っている言語、Python 3のデータ分析模擬試験を受験しました。結果は72.5点とギリギリです。オンラインで模擬試験を受けれて、テスト時間も測定されているので緊張感もあります。もう一度行って100点取れるようになったら第2回を受験したいです。ここで受験できます。間違った問題もメールで回答が送られてくるのでしっかり復習も出来そうです。テストの受験料が高額なのが気になりますが、100点を余裕で取れるようになったら受験します。年末までにはしっかりと100点取れるように頑張りたいです。試験要綱はこちら今なら教科書無料配布キャンペーンもあります。始めるなら今です。#Python 3のデータ分析 #Python #データ分析 #python試験
Dec 7, 2020
コメント(0)
-
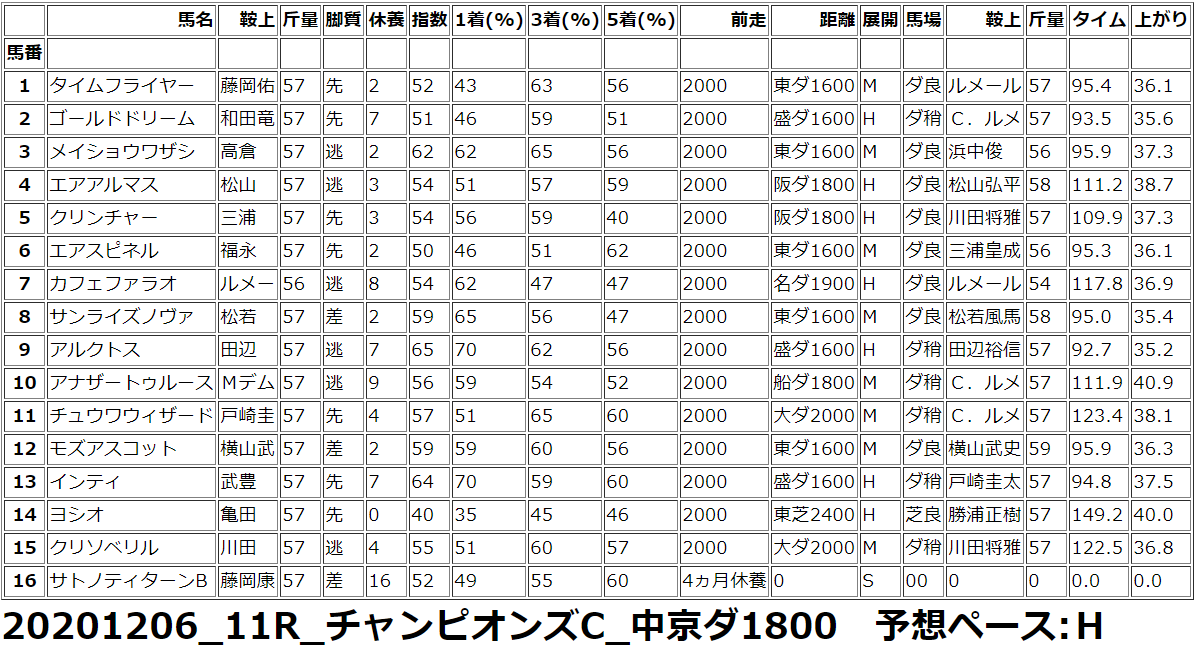
Python で 競馬予想 実践第10回 チャンピオンズカップ他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)2020年12月06日の予想◆チャンピオンズカップ◆その他 阪神、中山 10R~12Rチャンピオンズカップは難しいですね。相手探しだとは思うのですが、その相手が自分には見えなかったので、機械学習を参考に購入しました。SONY 【テレワーク応援】VAIO S11 SSD256GB メモリ8GB 11.6インチ Core i5 Windows 10 Pro 有線LAN, 無線LAN中古パソコン【3年保証】【お気楽返品OK】【送料無料】中古ノートパソコンB5・モバイルノート
Dec 6, 2020
コメント(2)
-

Python で 競馬予想 実践第9回 ステイヤーズS他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)2020年12月05日の予想今日は阪神11レース、12レースが信頼度が高くなっています。期待したいですね。SONY 【テレワーク応援】VAIO S11 SSD256GB メモリ8GB 11.6インチ Core i5 Windows 10 Pro 有線LAN, 無線LAN中古パソコン【3年保証】【お気楽返品OK】【送料無料】中古ノートパソコンB5・モバイルノート
Dec 5, 2020
コメント(0)
-

Python で 競馬予想 実践第8回 ジャパンカップ他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)2020年11月28日の予想ジャパンカップ、京阪杯他 全8レースを予想しています。ジャパンカップは3強が1頭もいないという結論に。。。。さすがに違う気がしますね(爆)SONY 【テレワーク応援】VAIO S11 SSD256GB メモリ8GB 11.6インチ Core i5 Windows 10 Pro 有線LAN, 無線LAN中古パソコン【3年保証】【お気楽返品OK】【送料無料】中古ノートパソコンB5・モバイルノート
Nov 28, 2020
コメント(2)
-

Python で 競馬予想 実践第7回 東京スポーツ杯2歳S他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)今日は東京スポーツ杯2歳S 他5レースを予想します。リンク先にまとめているのですが、なぜか文字化けが直らないです。うーん、UTF-8でメタを書いて、テキストでUTF-8でセーブしているのに。。。謎です。2020年11月23日の予想マイルCSも的中しました。アドマイヤマーズも抑えていたので従ったらよかったのですが、自分は敬遠して外したのでグランとの馬連だけでした。SONY 【テレワーク応援】VAIO S11 SSD256GB メモリ8GB 11.6インチ Core i5 Windows 10 Pro 有線LAN, 無線LAN中古パソコン【3年保証】【お気楽返品OK】【送料無料】中古ノートパソコンB5・モバイルノート
Nov 23, 2020
コメント(0)
-

Python で 競馬予想 実践第6回 マイルCS
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)今日はマイルCS 他5レースを予想します。マイルCSも掲載してます。2020年11月22日の予想昨日は1レース的中しています。レインボーロマンスの激走でワイド的中です。私はこの機会学習を元に自分の予想も組み入れることで回収率、的中率ともアップしています。良いですね、機械学習。SONY 【テレワーク応援】VAIO S11 SSD256GB メモリ8GB 11.6インチ Core i5 Windows 10 Pro 有線LAN, 無線LAN中古パソコン【3年保証】【お気楽返品OK】【送料無料】中古ノートパソコンB5・モバイルノート
Nov 22, 2020
コメント(0)
-

Python で 競馬予想 実践第5回 アンドロメダS他 マイルCSも
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)今日はアンドロメダS 他4レースを予想します。マイルCSも掲載してます。2020年11月21日の予想ちょっと最近不調ですね。予想レースを増やしたのでさらに精度があがると思っていたのですが、Random Forestがイマイチなのか、Deep learningもチャレンジしようかなあと思っているところです。SONY 【テレワーク応援】VAIO S11 SSD256GB メモリ8GB 11.6インチ Core i5 Windows 10 Pro 有線LAN, 無線LAN中古パソコン【3年保証】【お気楽返品OK】【送料無料】中古ノートパソコンB5・モバイルノート
Nov 21, 2020
コメント(2)
-

Python で 競馬予想 実践第4回 エリザベス女王杯 他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)今日はエリザベス女王杯 他6レースを予想します。そのままHTMLをここに書きたかったのですが、楽天ブログの仕様でテーブル処理は駄目なようなので、リンクを張ります。2020年11月15日の予想的中したら予測時間改善のために新しいPCを購入したいです。【中古】 中古パソコン ノートパソコン 富士通 LIFEBOOK U747/P FMVU06011 Corei5 7300U 2.6GHz メモリ8GB SSD256GB 14インチ Win10Home【1年保証】【E】【TG】【ヤマダ ホールディングスグループ】【中古】あす楽 WEBカメラ搭載 テレワークに最適 送料無料 ノートパソコン Office付き Windows10 SONY VAIO Cシリーズ VPCCB4AJT Core i5 2450M 2.5GHz メモリ 8GB 新品SSD256GB ブルーレイ Bランク K15
Nov 15, 2020
コメント(0)
-

Python で 競馬予想 実践第3回 武蔵野S、デイリー杯 他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)今日は武蔵野S、デイリー杯 他5レースを予想します。そのままHTMLをここに書きたかったのですが、楽天ブログの仕様でテーブル処理は駄目なようなので、リンクを張ります。2020年11月14日の予想実は上記の第7回からかなり進化しています。(1) 予測するための説明変数に使うレースをnetkeibaの詳細レース条件からスクレイピング これで、距離、コース、馬場が同じレースをいくらでも取り込めます。(2) 予測結果をまとめるプログラムを作成。 これで、予測結果が的中していたかどうかを自動で判断できます。(3) 予想結果が的中するか否かの数値を信頼度で数値化 的中したかしなかったかを再度学習し信頼度を再度学習させることに成功しました。 これで信頼度が高いレースのみを買えばウハウハ(爆)(3)は予測に使ったパラメータを説明変数として、的中したかしないかを目的変数にし、再度予測させてます。これで、レースを重ねれば重ねるほど強い機械学習プログラムが出来てくるという算段です。上記のように信頼度を再学習しています。結果と配当も右側に、的中の〇、×(的中したかどうかは指数上位4頭の馬連、ワイド、3連複BOXで判断)にはネット競馬のリンクを貼りました。で、今日の予想結果はこうなってます。赤枠で囲っているところが信頼度が50を超えています。武蔵野S,デイリー杯も好スコアなので期待したいです。回収率は低めですが、これを見ながら自分の予想を入れると回収率、的中率ともにあがっているのでこれからも続けたいです。アーモンドアイのJC参戦で競馬も盛り上がりそう。私のA.I.予想も炸裂させたいです。的中したら予測時間改善のために新しいPCを購入したいです。【中古】 中古パソコン ノートパソコン 富士通 LIFEBOOK U747/P FMVU06011 Corei5 7300U 2.6GHz メモリ8GB SSD256GB 14インチ Win10Home【1年保証】【E】【TG】【ヤマダ ホールディングスグループ】【中古】あす楽 WEBカメラ搭載 テレワークに最適 送料無料 ノートパソコン Office付き Windows10 SONY VAIO Cシリーズ VPCCB4AJT Core i5 2450M 2.5GHz メモリ 8GB 新品SSD256GB ブルーレイ Bランク K15
Nov 14, 2020
コメント(2)
-
Python で 競馬予想 実践第2回 菊花賞 他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)今週は菊花賞 他2レースを予想します。そのままHTMLをここに書きたかったのですが、楽天ブログの仕様でテーブル処理は駄目なようなので、リンクを張ります。(1)20201024_11R_室町S_京都ダ1200(2)20201024_11R_富士S_東京芝1600(3)20201025_11R_菊花賞_京都芝3000菊花賞はコントレイル1強は揺るがない感じです。期待したいですね。
Oct 24, 2020
コメント(0)
-
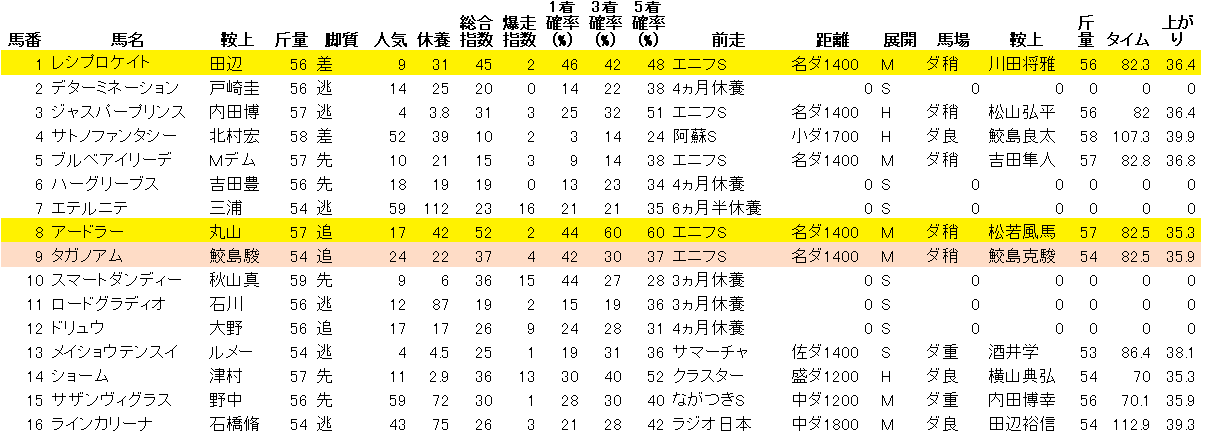
Python で 競馬予想 実践第1回 毎日王冠、京都大賞典 他
pythonで競馬予想。競馬予想までに行きつくまでの経過は下記です。今回から実践となります。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)今週は東京 10R グリーンチャネルC(東ダ1400m),11R 毎日王冠(東芝1800m),京都大賞典(京芝2400m)の3レースを予想します。総合指数が高いのが機械学習的には有力です。私は色がついている馬を買う予定です。東京 10R グリーンチャネルC(東ダ1400m)要因分析(レース予想モデルに起因した目的変数)1位.2走前戦法2位.4走前レースポイント3位.5走前上がり4位.1走前レースポイント5位.1走前着差<短評>要因分析から総合的に力がある馬が有力。東京 11R 毎日王冠(東芝1800m)要因分析(レース予想モデルに起因した目的変数)1位.5走前斤量2位.3走前頭数3位.3走前上がり4位.4走前斤量5位.レース間隔<短評>機会学習の予想では5走前、4走前の斤量に勝利の法則があるとのことだが。。。自信なし京都 11R 京都大賞典(京芝2400m)要因分析(レース予想モデルに起因した目的変数)1位.4走前斤量2位.脚質3位.4走前脚質4位.1走前出走頭数5位.5走前レースポイント<短評>機会学習の予想では脚質(戦法)が大きな要因とのこと。逃げ、先行が有利と考える。レース結果、要因、予想結果まで自動で出力するようなソフトを作りたいです。エクセルを開いたり、コピペしたりするのが手間です。ソフト作成をこれから行おうと思います。
Oct 11, 2020
コメント(1)
-
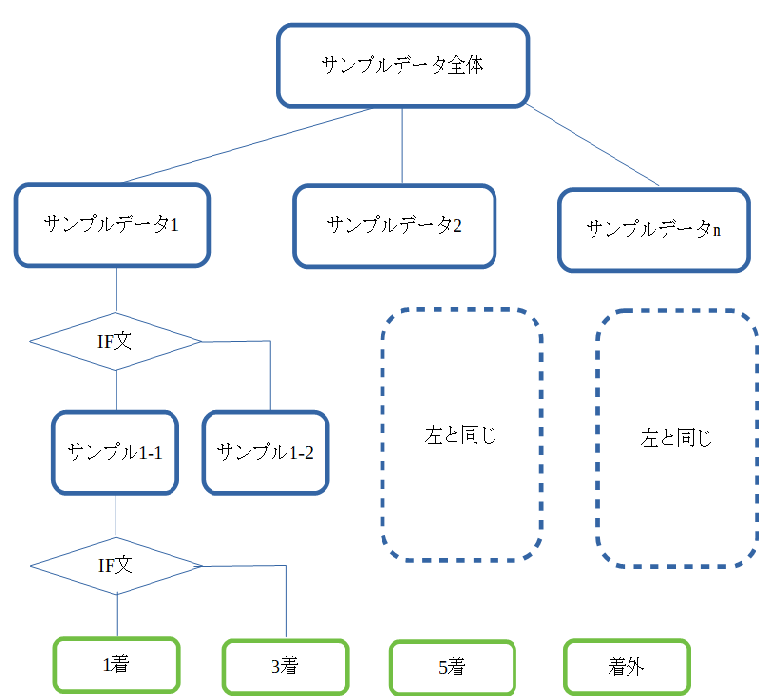
Python で 競馬予想 第7回(機械学習実践)
pythonで競馬予想。これまでのバッグナンバーは下記です。今回はいよいよ機械学習実践です。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2) Python で 競馬予想 第7回(機械学習実践)前回までで機械学習を行う前準備(下記)が完了しました。1.不要データの削除、数値への置き換え2.データに文字列がはいっていないかのチェック3.正規化の実施今回がようやく機械学習を実践できます。機械学習と言ってもいろいろあるのですが、今回私が採用した方法はRandom Forest Regressionによる機械学習です。Random Forestとは何ぞや?という事ですが、Random Forestを理解するためには決定木を理解する必要があります。決定木とは学習用のデータをいくつかのサンプル群にわけて、そのサンプル群に条件に合うかどうかで更に細かいサンプル群に分けていって、最終的に目的の答えに導くというものです。自分なりな図を作ってみました。図をみると木のように見えるので決定木といわれるのかもしれません。決定木はIF分がひとつの条件で行うので、各データに対して影響度を揃える必要がない(正規化不要)。また、IF分のかたまりで判定した内容が明らかという長所を持つ反面、弱点は枝を何本も作っていくと過学習になって、間違った答えを出しやすい。(ずれが大きい)ということもあります。Random Forestは文字通り、この決定木を何本も作ってそれを組み合わせることで、そのずれの影響を減らすという利点を持っています。まあ、説明はこのくらいで。詳しいことはWEBをぐぐれば出てきますし、そっちの方が説明も上手だと思います。では、やることを順番に説明します。1.学習データと評価データにわける。2.Random Forest Regression実行(1着、3着、5着の回帰モデル作成)3.回帰モデルから1着、3着、5着になる確率を予想。4.競馬新聞風に加工し出力5.回帰モデル影響度の確認という流れです。◆1.学習データと評価データにわける。テストデータの分割です。学習用と評価用にわけます。説明データは過去の5年分の馬データと着順データなので、それほど多くありません。16頭×5=90データぐらい。ここで、評価データにたくさん取られると肝心の学習が出来なくなるので可能な限り学習データを増やしました。X_train,X_test,Y_train,Y_test = sklearn.model_selection.train_test_split(X_multi3,X_multi2['1着'],test_size=0.01, random_state=0)◆2.Random Forest Regression実行(1着、3着、5着の回帰モデル作成)ここまでの説明が長かったですが、ランダムフォレスト実行はたったの2行です。1行目がランダムフォレスト回帰のパラメータ設定。n_estimationというのはランダムフォレストに使う決定木の数です。2行目がランダムフォレスト回帰モデル作成です。rfr1で1着になる回帰モデルが作られます。#Random Forestを実行します。rfr1 = RandomForestRegressor(n_estimators=min_loss*2+1, random_state=500) #fitでモデルを作りますが、使うのは学習用のデータだけです。rfr1.fit(X_train, Y_train) # 学習実行◆3.回帰モデルから1着、3着、5着になる確率を予想。同じく、3着以内、5着以内も回帰モデルを作って(rfr1,rfr3,rfr5)、予測したい馬情報から1,3,5着になる確率を算出します。#作成した回帰モデルを元に予想Y_pred_test1 = rfr1.predict(Y_multi3)Y_pred_test3 = rfr3.predict(Y_multi3)Y_pred_test5 = rfr5.predict(Y_multi3)Y_pred_test_all = Y_pred_test1 * 0.5 + Y_pred_test3 * 0.35 + Y_pred_test5 * 0.15#Y_pred_test_all4.競馬新聞風に加工し出力5.回帰モデル影響度の確認Random Forestはその予測モデルに影響したパラメータを簡単に確認することが出来ます。今回の予測モデルに影響したのは上のような順番です。何週明けか?というパラメータである休養が一番手というのは微妙な気がします。coeff_df = check_important_element(X_train , rfr1) #df.sort_values(指定列",ascending=False)で降順に並び替え#df.head(数値)で数値分のデータを抽出 sort_coeff_df = coeff_df.sort_values("coefficient_estimate",ascending=False)#sort_coeff_df['Features']# indexを振りなおします(上から順に1とする)sort_coeff_df.reset_index(drop=True , inplace=True)これで予測までできました。次はいよいよモデルを使って競馬予想にGoとその結果についてレポートしたいと思います。
Oct 10, 2020
コメント(0)
-
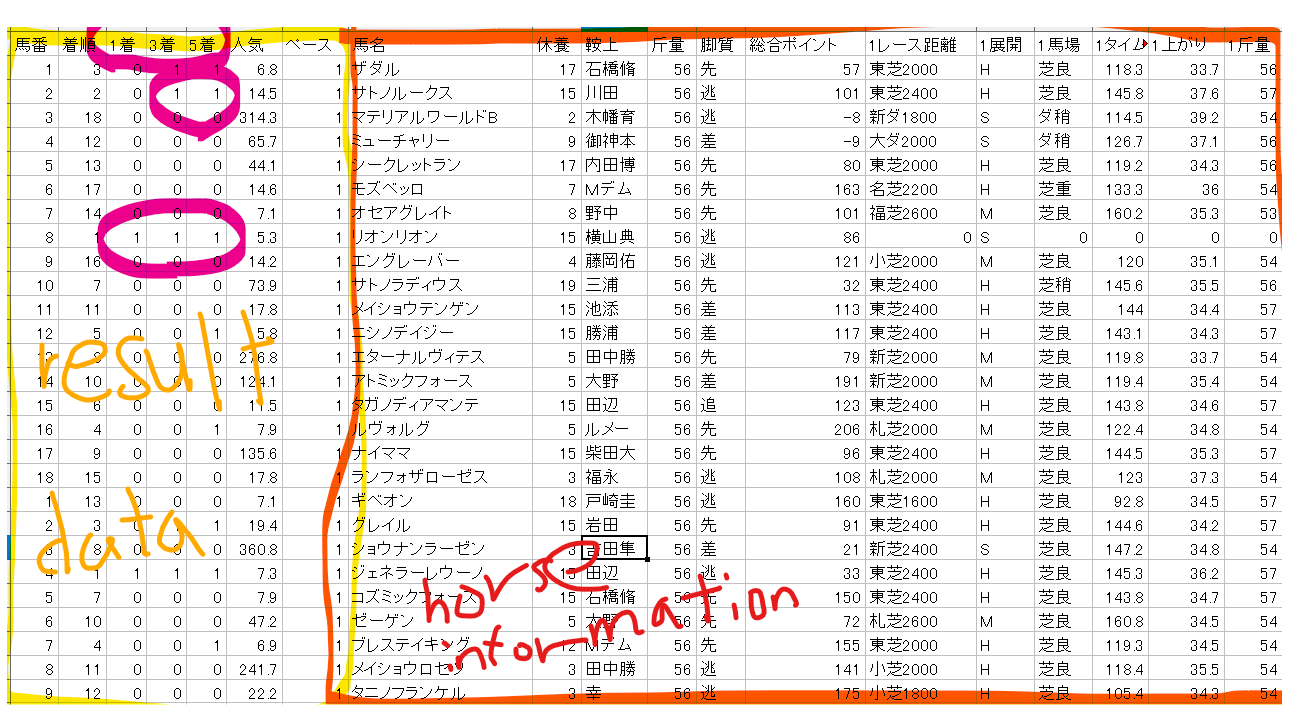
Python で 競馬予想 第6回(機械学習用の前処理 2)
pythonで競馬予想。これまでのバッグナンバーは下記です。今回は機械学習用の前処理 2にチャレンジです。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1) Python で 競馬予想 第6回(機械学習用の前処理 2)前回まででひとつの配列に出走馬情報をまとめて、数値化できる部分は数値化しました。結果ファイルも数値化して以下のようなファイルになりました。ひとつは学習データ、もうひとうは予想データです。と、その前に機会学習の基礎を自分の理解なりに説明しておきます。(間違っていても責任はとりません。悪しからず)機械学習には大きくわけて教師あり学習と教師なし学習というのがあり、教師なし学習といのは今はやりのDeep Learningもそうだと思っていますが、正解がわからない状態でもデータの差(特徴とか)を見出してクラスタリング(グルーピング)するようなもので、教師あり学習というのは正解をあらかじめ教えておいて、それに基づいて違うデータを予測するというものと思っています。私が使おうと思っているのは、過去のレースから正解を学習させておいて、今回のレースを予測することなので教師あり学習です。という事でデータの説明に入りたいと思います。まずは学習データから紹介します。下記の黄色枠で囲ったところが結果データ。すなわち教師データになります。右の馬情報(horse information)から、左の黄色枠(答え)が導かれています。黄色内の紫で囲った部分が答え、1着になったら1、3着以内だったら1、5着以内だったら1を示しています。この答えになるように学習させることになります。こちらが予想データです。同じように結果ファイルと馬情報ファイルがありますが、結果ファイルをみてわかるように1着、3着、5着が全て0.まだ予測されていないことになります。機会学習上では、horse informationを説明変数、result dataを目的変数と呼びます。私がやりたいことをもう一度、説明すると。学習データの説明変数(赤枠 horse information)と目的変数(黄枠 result data)で学習を行って回帰モデルを作って、予想データの説明変数(赤枠 horse information)から目的変数(黄枠 result data)を導き出すというものです。 で本題の前処理 2についてですが、機械学習と言えどすべて数値化していなければコンピュータなので予測は難しいので数値化を目的としています。数値化の処理としては以下の3つのステップで進めます。1.不要データの削除、数値への置き換え2.データに文字列がはいっていないかのチェック3.正規化の実施まずは1.不要データの削除、数値への置き換えです。下記を見てもらえればわかりますが、1着以内、3着以内、5着以内を的中させたいので、正確な着順は不要なので削除、あと馬名、レース名も不要。あとはすでに指数として反映されている鞍上、距離、タイム、上がりや馬場情報も不要なので削除します。戦法は数値に、そのレースのぺースも数値に置き換えます。次に2.データに文字列がはいっていないかのチェックです。下記はサブルーチンで組んでいますので呼び出し側が必要です。見つけた場合はごみデータとして削除することにしています。頭を使ったのは小数点等も数値ではないと判断されてしまうので、それらの数値を置き換えたあとにジャッジをしているところです。最後に3.正規化です。正規化って何だ?と思われると思いますが、いろいろな変数があってひとつの回帰モデルをつくるのでどのパラメータも同じように影響するように値を0~1の数値に置き換えるという作業を行っています。機械学習の手法として下記ではランダムフォレストを使うと書いていますが、ランダムフォレストは正規化の必要はないですが、ほかの機会学習用にも今回正規化しておくことにしました。出力データが下記になります。見事0~1になったと思います。呼び出し側のプログラムも載せておきます。変数の確認と正規化の呼び出し側です。<文字列チェックの呼び出し側プログラムです><正規化の呼び出し側プログラムです>次回はいよいよ、機械学習です。今日のプログラムです。<不要データの削除、数値への置き換え># 学習データの加工# 学習に使わない不要な列の削除X_multi1 = Study_dframe.copy() #deep copyX_multi1.drop(columns=['着順','馬名','鞍上','5鞍上','4鞍上','3鞍上','2鞍上','1鞍上','人気'], axis=1, inplace=True)X_multi1.drop(columns=['5レース名','4レース名','3レース名','2レース名','1レース名'], axis=1, inplace=True)X_multi1.drop(columns=['5タイム','4タイム','3タイム','2タイム','1タイム'], axis=1, inplace=True)X_multi1.drop(columns=['5上がり','4上がり','3上がり','2上がり','1上がり'], axis=1, inplace=True)X_multi1.drop(columns=['5馬場','4馬場','3馬場','2馬場','1馬場'], axis=1, inplace=True)X_multi1.drop(columns=['5レース距離','4レース距離','3レース距離','2レース距離','1レース距離'], axis=1, inplace=True)X_multi1.replace('逃', '0', inplace=True)X_multi1.replace('先', '1', inplace=True)X_multi1.replace('差', '2', inplace=True)X_multi1.replace('追', '3', inplace=True)X_multi1.replace('S', '0', inplace=True)X_multi1.replace('M', '1', inplace=True)X_multi1.replace('H', '2', inplace=True)#X_multi1.head()<データフレーム数値化サブルーチン># Dataの列中に数字でないものが含まれていたら行ごと削除する。def check_string_dframe(check_dframe) : del_index=[] for i in range((len(X_multi1))-1) : y_posi = i # 1行取り出してリストにする data_check = X_multi1.iloc[y_posi] # 数字以外のものがあるかのフラグ isnumeric_check=0 for j in range(len(data_check)) : # 1要素毎抜き出す str_a = str(data_check[j]) # isnumeric関数は小数点、マイナスを文字列として扱うので置換する。 str_b = str_a.replace(',', '').replace('.', '').replace('-', '').replace('e', '') #print (i,j,str_b) if str_b.isnumeric() == False : #文字列を発見したら、フラグを1にする isnumeric_check = 1 #発見した行と文字列の表示 print ('alarm',y_posi,str_a) if isnumeric_check == 1 : #行を削除するindexの記録 print ('文字列が含まれているので削除します',y_posi,str_a) del_index.append(y_posi) return del_index<データフレーム数値化チェック呼び出し側>del_index_ret = check_string_dframe(X_multi1)if len(del_index_ret) != 0 : X_multi1=X_multi1.drop(X_multi1.index[del_index_ret]) X_multi1 print ('学習データ一部文字列を含む行がありました')else : print ('学習データは文字列を含んでいません。正常です')<正規化サブルーチン># 正規化を実施(ランダムフォレストでは不要だが、いろいろなもので予測したいためdef preprocess_dataframe(prepro_dframe) : #値を0~1に正規化します。 mscaler = preprocessing.MinMaxScaler() mscaler.fit(prepro_dframe) xms = mscaler.transform(prepro_dframe) #正規化すると#データフレームからリストに戻るので再度DataFrameへ戻します。 prepro_after_dframe = pd.DataFrame(xms) #縦軸、横軸も消えているので戻します。 prepro_after_dframe.columns = prepro_dframe.columns prepro_after_dframe.index = prepro_dframe.index return prepro_after_dframe<正規化呼び出し側>X_multi2 = preprocess_dataframe(X_multi1)X_multi2.head(3)
Sep 29, 2020
コメント(0)
-
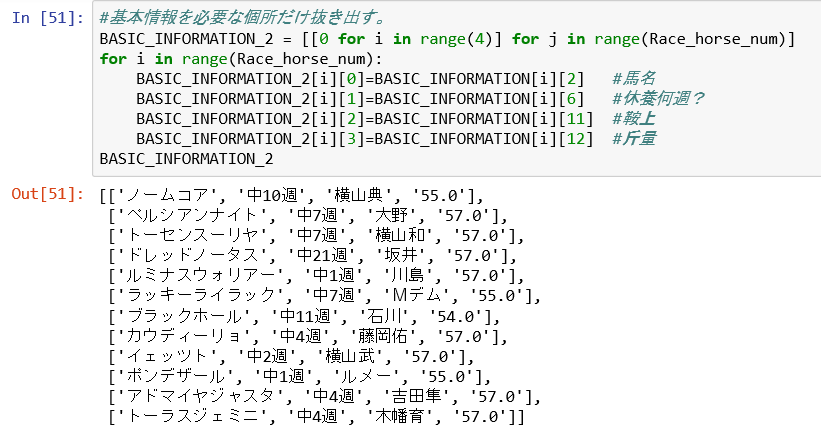
Python で 競馬予想 第5回(機械学習用の前処理 1)
pythonで競馬予想。これまでのバッグナンバーは下記です。今回は機械学習用の前処理にチャレンジです。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) Python で 競馬予想 第5回(機械学習用の前処理 1)前回までで、配列まで到達できたので、あとは自由自在に配列をいじって、数値化すれば機械学習の前準備、いわゆる前処理が完成することになります。今回は数値化の前に競馬新聞のような表を作りたいと思います。前回までで馬柱を配列情報に変更するまで到達しました。(下記のような感じです。)これを数値情報にしていきます。私の場合は拾ってきた情報を、独自の評価基準をまとめたエクセル(と言っても大したものではないですが)を使って、競馬場情報、騎手情報を数値化します。<競馬場情報の読み込み><騎手情報の読み込み>簡単に言うと競馬場情報は自分の評価基準の走破タイム、末脚評価(3F)。騎手情報は、前走で乗った場合のポイント乗数、今回乗った場合のポイント乗数です。他にもペースや馬場状態の別表を用いました。まとめると下記のようになります。まずは基本情報です。左から、馬名、休養が何週、鞍上、斤量、予想される戦法となります。次にレース情報です。(前5走のレースデータです。下記はその中から1レースのみを記載)左から開催場所、レース名、芝ダの種別、距離、走破タイム、馬場状態、人気、騎手、斤量、レース時のポジション、3F上がりタイム、着差です。ここまでで、競馬新聞のようにはなったのですが、もう少し機械学習にかけられるようにデータを数値します。左から馬名、休養週、騎手、斤量、戦法、総合指数、1走前のレースの(距離等、ペース、馬場状態、走破タイム(秒表示)、上がり3Fタイム、鞍上、走破タイム指数、3F末脚指数、着差、1走前総合指数、レース名、頭数、位置取り)としました。これが5走前まで1行で表示されます。全プログラムは長くなってきたので割愛ですが、よく使った関数はFind(文字を検索し、見つけた場所を返すコマンドとmath.ceil(切り上げ)コマンドです。<findコマンド 下記だと芝のある場所返す><math.ceilコマンド 切り上げ>下記がプログラムの一部です。下のメイン関数からmake_race_info_4_2ndを呼んで(def定義)、コールバックをする処理をしています。サブルーチンも使えるようになったので冗長なプログラムがなくなって見やすくなりました。 次回は結果ファイルを読み込みしようかと思いましたが、そろそろ機械学習に入りたいのでスキップして、そちらを掲載します。<呼び出され側 サブルーチン>def make_race_info_4_2nd(BASIC_INFORMATION_2,RACE_INFORMATION_4,Race_horse_num,RACE_POSITION_INFORMATION_CALL) : #5走の情報データから馬の戦法(逃げ、先行、差し、追い込み)を決める。 for i in range(Race_horse_num): running_plan = [0,0,0,0] for j in range(5) : if RACE_INFORMATION_4[i][j][13] !=0 : for k in range(4) : if RACE_INFORMATION_4[i][j][13] == RACE_POSITION_INFORMATION_CALL[k][0] : running_plan[k] += 1 #print ('展開',i,j,k,running_plan[0],running_plan[1],running_plan[2],running_plan[3]) else : running_plan[1] += 1 # もし入っていなかったら先行として扱う #一番大きい先方が入っているindexをひろう BASIC_INFORMATION_2[i][4] = RACE_POSITION_INFORMATION_CALL[running_plan.index(max(running_plan))][0] #print (i,max(running_plan)) print ('make_race_info_4_2nd end') return BASIC_INFORMATION_2<メインプログラム ここでエクセルへの書き出し(csv)まで行います。>for iraceloop in range(len(url_info)) : url_text=url_info[iraceloop] str_race= url_text[len(url_text)-2:]+'R' print (str_race) lines_s1_ret,Race_name_ret,Race_place_ret,Race_horse_num_ret,Race_sort_ret,Race_distance_ret = web_scribe(url_text,str_race) BASIC_INFORMATION_ret,Race_INFORMATION_ret = make_race_info(lines_s1_ret,Race_horse_num_ret) BASIC_INFORMATION_2_ret,RACE_INFORMATION_2_ret = make_race_info_2_1st(BASIC_INFORMATION_ret,Race_INFORMATION_ret,Race_horse_num_ret) RACE_INFORMATION_2_2nd_ret = make_race_info_2_2nd(RACE_INFORMATION_2_ret,Race_horse_num_ret) RACE_INFORMATION_3_ret = make_race_info_3(RACE_INFORMATION_2_2nd_ret,Race_horse_num_ret) RACE_INFORMATION_4_1st_ret = make_race_info_4_1st(RACE_INFORMATION_3_ret,Race_horse_num_ret) BASIC_INFORMATION_2_2nd_ret = make_race_info_4_2nd(BASIC_INFORMATION_2_ret,RACE_INFORMATION_4_1st_ret,Race_horse_num_ret,RACE_POSITION_INFORMATION) RACE_INFORMATION_4_2nd_ret = make_race_info_4_3rd(RACE_INFORMATION_4_1st_ret,RACE_INFORMATION_3_ret,Race_horse_num_ret,Race_Place_list,RACE_CONDITION_INFORMATION,Race_Person_list) file_name=str_race+'_'+Race_name_ret+'_'+Race_place_ret+Race_sort_ret+str(Race_distance_ret)+".csv" if iraceloop == 0 : RACE_WRITE_1st_ret = make_write_1st() f = open(file_name, 'w', newline='' , encoding='utf_8_sig') writer = csv.writer(f) writer.writerows(RACE_WRITE_1st_ret) RACE_WRITE_2nd_ret = make_write_2nd(BASIC_INFORMATION_2_2nd_ret,RACE_INFORMATION_4_2nd_ret,Race_horse_num_ret,Race_Person_list) f = open(file_name, 'a', newline='' , encoding='utf_8_sig') writer = csv.writer(f) writer.writerows(RACE_WRITE_2nd_ret) f.close() print (iraceloop+1,'/',len(url_info),'出馬情報スクレイピング完了') print ('抽出完了',file_name)
Sep 27, 2020
コメント(0)
-
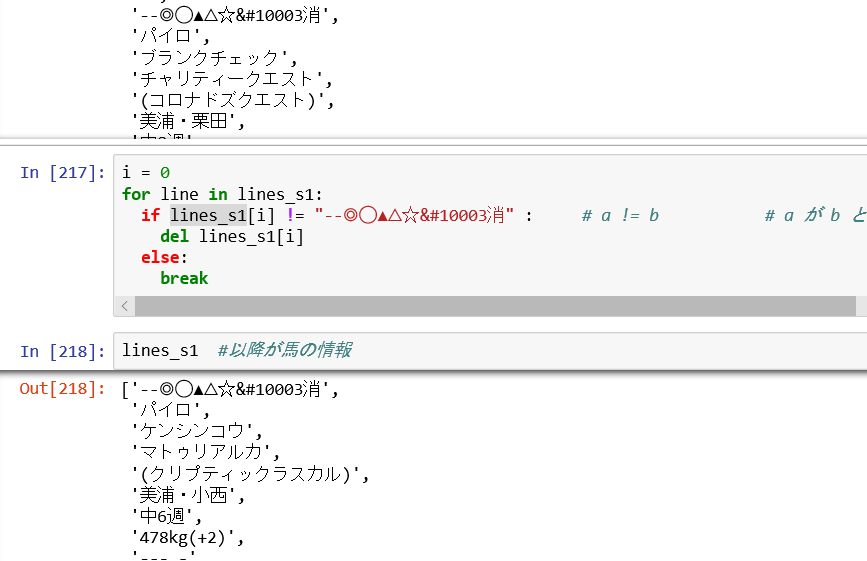
Python で 競馬予想 第4回(Pyhton上での配列定義)
pythonで競馬予想。これまでのバッグナンバーは下記です。今回は配列にチャレンジです。Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) Python で 競馬予想 第4回(Python上での配列定義) --- 今回はここ。前回までで馬柱を抜き出す前段階まで到達しました。(下記のような感じです。)ただ、まだこのままですと、メモ帳に書いてあるのと変わらないので、これを必要な配列に入れていく作業を今回はしたいと思います。まずは配列の定義です。DataFrameでも出来るのかもしれないですが、いろいろと調べるとリストの方が扱いやすそうだったので、リストで配列を定義しました。定義の仕方もいろいろありますが、箱を作るという事だけに専念するのであれば、今回の方法が一番良いと思います。コマンドは結構特殊です。次にWEBデータを箱に詰めていきます。休養している馬もいるのでその場合は飛ばす処理を追加しています。出来上がった基本出走馬情報です。この中で私が使う情報は馬名、休養何週、鞍上、斤量のみなので、それだけ抜き出しました。きれいに並んだと思います。次に前5走情報を処理します。詳しいことは割愛しますが、Find関数は便利に使えます。これを使えば文字サーチできて、その場所を返すので非常に有用です。最初の馬の前走と最後の馬の5走前の情報が見事表示できました。レース場所、レース名、芝orダート、距離、走破タイム、馬場状態、頭数、鞍上、斤量、位置、上がり3Fデータを予想に使います。次は機械学習するために数値化するための前処理をしたいと考えています。今日のリスト#馬柱情報を入力するリストを作成する。# BASIC_INFORMATON[Race_horse_num,i] ... 基本情報# 予想印,父、馬名、母、母の父、所属・厩舎、休養何週、馬体重、オッズ、人気順、馬齢、鞍上、斤量# 0 1 2 3 4 5 6 7 8 9 10 11 12 13# Race_INFORMATON[Race_horse_num,i,j] j --- x走前のレース情報# 1走前 日付場所、着順、レース名、グレード、芝ダ距離・タイム・馬場状態、頭数・枠・人気・鞍上・斤量、位置・上がり・馬体重、1着馬・着差# 0 1 2 3 4 5 6 7 # :# 5走前 日付場所、着順、レース名、グレード、芝ダ距離・タイム・馬場状態、頭数・枠・人気・鞍上・斤量、位置・上がり・馬体重、1着馬・着差# 0 1 2 3 4 5 6 7 #2次元、3次元配列宣言BASIC_INFORMATION = [[0 for i in range(13)] for j in range(Race_horse_num)]Race_INFORMATION = [[[0 for i in range(7)] for j in range(5)] for k in range(Race_horse_num)]#すべて情報には”0”を代入している。リストの最大の個所が使えるかを閣員print(BASIC_INFORMATION[Race_horse_num-1][12],Race_INFORMATION[Race_horse_num-1][4][6])#WEBデータをリストに詰める作業を開始。休養だった場合は次のレースへ移動する。line_count = 0lines_s2=lines_s1for i in range(Race_horse_num): for j in range(13) : str =lines_s2[line_count] BASIC_INFORMATION[i][j]=str line_count +=1 for j in range(5) : for k in range(7) : break_flag = lines_s2[line_count].find('休養') if break_flag != -1 : #休養だった場合、次のレースへ移動 Race_INFORMATION[i][j][k]=lines_s2[line_count] line_count +=1 k = 8 break else : skip_flag_1 = lines_s2[line_count].find('芝') skip_flag_2 = lines_s2[line_count].find('ダ') skip_flag_3 = (k == 2) if (skip_flag_1 != -1 or skip_flag_2 !=-1) and (skip_flag_3 != 0) : k=k+1 line_count -=1 Race_INFORMATION[i][j][k]=lines_s2[line_count] line_count +=1 for l in range(3): if lines_s2[line_count].isdigit() : #半角整数はTrue line_count +=1 else: l = 300 break line_count#基本情報を必要な個所だけ抜き出す。BASIC_INFORMATION_2 = [[0 for i in range(4)] for j in range(Race_horse_num)]for i in range(Race_horse_num): BASIC_INFORMATION_2[i][0]=BASIC_INFORMATION[i][2] #馬名 BASIC_INFORMATION_2[i][1]=BASIC_INFORMATION[i][6] #休養何週? BASIC_INFORMATION_2[i][2]=BASIC_INFORMATION[i][11] #鞍上 BASIC_INFORMATION_2[i][3]=BASIC_INFORMATION[i][12] #斤量BASIC_INFORMATION_2#近5走の情報の表示で必要な情報をコピー# Race_INFORMATON[Race_horse_num,i,j] j --- x走前# 1走前 日付場所、レース名、グレード、芝ダ距離・タイム・馬場状態、頭数・枠・人気・鞍上・斤量、位置・上がり・馬体重、1着馬・着差# 0 1 2 3 4 5 6 7 8 9 10 # [0] [1] [2] [3] [4] [5] [6] [7]RACE_INFORMATION_2 = [[[0 for i in range(11)] for j in range(5)] for k in range(Race_horse_num)]for i in range(Race_horse_num): for j in range(5) : RACE_INFORMATION_2[i][j][0]=Race_INFORMATION[i][j][0] #場所 RACE_INFORMATION_2[i][j][1]=Race_INFORMATION[i][j][1] #Race名 RACE_INFORMATION_2[i][j][2]=Race_INFORMATION[i][j][3] #芝 or ダ RACE_INFORMATION_2[i][j][3]=Race_INFORMATION[i][j][3] #距離 RACE_INFORMATION_2[i][j][4]=Race_INFORMATION[i][j][3] #タイム RACE_INFORMATION_2[i][j][5]=Race_INFORMATION[i][j][3] #馬場状態 RACE_INFORMATION_2[i][j][6]=Race_INFORMATION[i][j][4] #頭数 RACE_INFORMATION_2[i][j][7]=Race_INFORMATION[i][j][4] #鞍上 RACE_INFORMATION_2[i][j][8]=Race_INFORMATION[i][j][4] #斤量 RACE_INFORMATION_2[i][j][9]=Race_INFORMATION[i][j][5] #位置取り RACE_INFORMATION_2[i][j][10]=Race_INFORMATION[i][j][5] #上がり RACE_INFORMATION_2#文字の場所指定をすれば、MID$のような使い方が出来る。# RACE_INFORMATION_2[i][j][0][11]#find関数は文字がある場所を返す。ない場合は"-1"となる。fd = RACE_INFORMATION_2[i][j][0].find('\xa0')print (RACE_INFORMATION_2[i][j][0][11],':',fd,':',RACE_INFORMATION_2[i][j][0][fd+1])for i in range(Race_horse_num): for j in range(5) : fd = RACE_INFORMATION_2[i][j][0].find('\xa0') if fd != -1 : RACE_INFORMATION_2[i][j][0]=RACE_INFORMATION_2[i][j][0][fd+1] #場所 RACE_INFORMATION_2[i][j][1]=RACE_INFORMATION_2[i][j][1] #Race名 if RACE_INFORMATION_2[i][j][2] != 0 : fd = RACE_INFORMATION_2[i][j][2].find('芝') if fd != -1 : RACE_INFORMATION_2[i][j][2]="芝" #芝 or ダ RACE_INFORMATION_2[i][j][3]=RACE_INFORMATION_2[i][j][3][fd+1:fd+5] #距離 fd = RACE_INFORMATION_2[i][j][4].find(':') if fd != -1 : RACE_INFORMATION_2[i][j][4]=RACE_INFORMATION_2[i][j][4][fd-1:fd+5] #タイム length =len(RACE_INFORMATION_2[i][j][5]) RACE_INFORMATION_2[i][j][5]=RACE_INFORMATION_2[i][j][5][length-1] fd = RACE_INFORMATION_2[i][j][2].find('ダ') if fd != -1 : RACE_INFORMATION_2[i][j][2]="ダ" #芝 or ダ RACE_INFORMATION_2[i][j][3]=RACE_INFORMATION_2[i][j][3][fd+1:fd+5] #距離 fd = RACE_INFORMATION_2[i][j][4].find(':') if fd != -1 : RACE_INFORMATION_2[i][j][4]=RACE_INFORMATION_2[i][j][4][fd-1:fd+5] #タイム length =len(RACE_INFORMATION_2[i][j][5]) RACE_INFORMATION_2[i][j][5]=RACE_INFORMATION_2[i][j][5][length-1] if RACE_INFORMATION_2[i][j][6] != 0 : fd = RACE_INFORMATION_2[i][j][6].find('頭') if fd != -1 : RACE_INFORMATION_2[i][j][6]=RACE_INFORMATION_2[i][j][6][:fd] #頭数 fd1 = RACE_INFORMATION_2[i][j][7].find('人') fd2 = RACE_INFORMATION_2[i][j][7].find('.') RACE_INFORMATION_2[i][j][7]=RACE_INFORMATION_2[i][j][7][fd1+1:fd2-2] #鞍上 length =len(RACE_INFORMATION_2[i][j][8]) RACE_INFORMATION_2[i][j][8]=RACE_INFORMATION_2[i][j][8][length-4:] #斤量 if RACE_INFORMATION_2[i][j][9] != 0 : fd = RACE_INFORMATION_2[i][j][9].find('\xa0(') if fd != -1 : RACE_INFORMATION_2[i][j][9]=RACE_INFORMATION_2[i][j][9][:fd] #位置取り RACE_INFORMATION_2[i][j][10]=RACE_INFORMATION_2[i][j][10][fd+2:fd+6] #上がり #欲しいところを取り出した情報 最初の馬の、もっとも最近のレースと、最後の馬の最古のレース情報を表示#ずれていないか確認print(RACE_INFORMATION_2[0][0],":",RACE_INFORMATION_2[Race_horse_num-1][4])
Aug 29, 2020
コメント(0)
-

Python で 競馬予想 第3回(Pyhton上でのデータ加工)
これまでの2回でスクレイピングし、HTMLを解析までして、ファイルに出力しようと思いましたが、データが全て1行に書き込まれており頓挫してしまいました。今回はもう少しpython上で所望のデータに変換をしたいと思いトライしています。これまでのバッグナンバーは下記Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)Python で 競馬予想 第2回(HTML解析編)Python で 競馬予想 第3回(Python上でのデータ加工) --- 今回はここ。今回はテキストにしたところから、余計なscriptを省くところからスタートします。参考にしたURLはこちらになります。for script in soup(["script", "style"]): script.decompose()#print(soup).decompose()は、削除のメソッドだそうです。次に前回も行いましたが、テキストを取得します。text=soup.get_text()#print(text)前回と同じように改行がいっぱいできてしまいます。今回違うのはこれからです。テキストを改行ごとにリストに入れて、リスト内の要素前後の空白を除去します。lines= [line.strip() for line in text.splitlines()]# textを改行ごとにリストに入れて、リスト内の要素の前後の空白を削除これを行うことで1次配列の中にすべて入って作業がやりやすくなりました。次に余計な空白行の除去に取り組みます。関数を使うのはお手の物なので、行が何も入っていなかったら削除して、関数を詰めます。i = 0for line in lines: if lines[i]=="" : del lines[i] # print (i) else: print(lines[i]) i += 1そうすると、何も書いていない行が省かれます。次にリストをコピーしてデータを眺めるとレース名は"11R"が2回出てきたところにあるので、そこまではデータを削除します。lines_s0 = linesi = 0j = 0for line in lines_s0: if lines_s0[i] != "11R" : # a != b # a が b と異なる del lines_s0[i] else: j += 1 i += 1 if j == 2: # 2回目の11Rで抜ける 2回目の11Rの次がレース名 print("11R 2times out loop") break else : print(lines_s0[i],j)lines_s0[2] # レース名が表示されればOK見事レース名が表示されました。次に馬柱の前には必ず'--◎◯▲△☆✓消'が入りそうなので、そこまでのデータは消します。i = 0for line in lines_s1: if lines_s1[i] != "--◎◯▲△☆✓消" : # a != b # a が b と異なる del lines_s1[i] else: breaklines_s1 #以降が馬の情報見事、馬柱から必要なデータを確保できそうです。次に馬ごとに分けなければなりませんが、疲れたので今日はこの辺りで。今日の一覧soup =BeautifulSoup(res.text , 'html.parser')for script in soup(["script", "style"]): script.decompose()#print(soup)text=soup.get_text()#print(text)lines= [line.strip() for line in text.splitlines()]# textを改行ごとにリストに入れて、リスト内の要素の前後の空白を削除i = 0for line in lines: if lines[i]=="" : del lines[i] # print (i) else: print(lines[i]) i += 1i = 0j = 0for line in lines_s0: if lines_s0[i] != "11R" : # a != b # a が b と異なる del lines_s0[i] else: j += 1 i += 1 if j == 2: # 2回目の11Rで抜ける 2回目の11Rの次がレース名 print("11R 2times out loop") break else : print(lines_s0[i],j)i = 0for line in lines_s1: if lines_s1[i] != "--◎◯▲△☆✓消" : # a != b # a が b と異なる del lines_s1[i] else: break
Aug 9, 2020
コメント(2)
-

Python で 競馬予想 第2回(HTML解析編)
前回WEBデータをスクレイピングするところまでは出来ました。ただ、下記のようにHTMLになっていて、編集するのが大変です。<div class="Data05">芝1200 1:08.5 <strong>稍</strong></div><div class="Data03">16頭 15番 12人 柴田大知 57.0</div><div class="Data06">1-1 (34.5) 498(-2)</div><div class="Data07"><a href="https://db.netkeiba.com/horse/2016104500" target="_blank">ブレイブメジャー</a>(-0.8)</div><a class="movie_202003020311" href="../race/movie.html?race_id=202003020311" style="display: none">HTMLを解析して、テキストを抽出するにはどうしたらよいかと再度ぐぐっていたら、Pythonで取得したWebページのHTMLを解析するはじめの一歩という良いページを見つけました。読んでみると前回最後に紹介した#BeautifulSoupを使うようでした。紹介したWEBページではインストールにはpipを使っていましたが、私はanacondaなのでconda install beautifulsoup4となります。インポートはrequestsをインストールした場所で行います。#requests をインポートします。(Web scrapingには必須)import requests#BeautifulSoup は文字化け対策from bs4 import BeautifulSoup解析を行うにはHTMLからBeautiful Soupオブジェクトを生成します。soup =BeautifulSoup(res.text , 'html.parser')書式は上記のようで、BeautifulSoup(HTML文字列, パーサー)となります。パーサーが良くわからないですが、Pythonに標準で付属している「html.parser」を指定しておくのがベターだと思います。あとは解析したいHTMLを取り出すことが出来ます。soup =BeautifulSoup(res.text , 'html.parser')print(soup.title)見事、アイビスサマーダッシュのタイトルをゲット出来ました。枠情報や前5走の情報を仕入れたいですが、まずはテキストで情報をだすとどのようになるのか調べてみました。for elem in elems: print(soup.getText())空白がかなり多いですが、ボチボチデータになっていそうです。CSVファイルで書き出せば何か編集できる形になりそうなので、出力してみようとすると。f = open('out.csv', 'w')data =soup.getText()writer = csv.writer(f)writer.writerow(data)f.close()書き出そうとしたところでエラーが出ました。CP932は変換できないと。またまた、ぐぐらなければなりません。早速CP932でぐぐると簡単にみつかりました。(リンクはここ)日本語OSや特殊OSの文字コードがPyhtonでは変換できないと書いてあります。中身を読むと、表現できない字は無視する便利なコマンドがあるようです。# CP932 で表現できない文字は無視するf = open('all_names.csv', 'w', encoding='CP932', errors='ignore') 早速適応してみましょう変換は出来た模様です。ちょっと出力された文字にまた、HTMLが入ってきているのが不安なのですが、とりあえずファイルに出力してみることにしました。writer = csv.writer(f)writer.writerow(data)f.close()出来上がったフィルは、、、インポートしようとすると文字化けおよび、1行にすべて書かれているようでダメなようです。別な手法を探さなければなりません。
Aug 9, 2020
コメント(0)
-
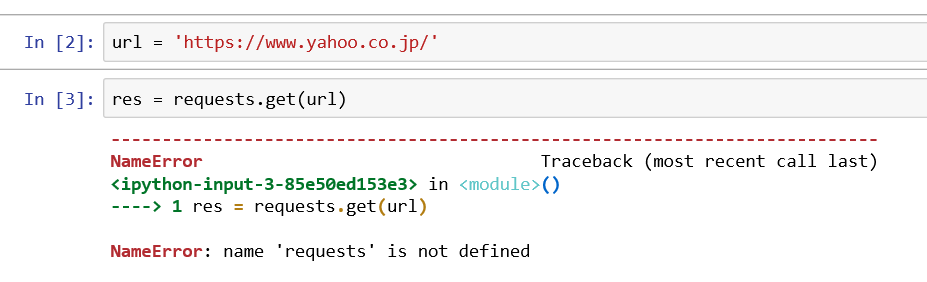
Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)
2年前に機械学習を使ってAI競馬予想を行っていましたが、ある時から私のLibreofficeからデータが取得できなくなり、頓挫してしまいました。純粋エクセルが欲しくなりましたが、何か良い方法を考えていました。私の行いたい手順としては下記の通りです。1.netkeibaからレース情報の取得(<-- ここが出来なくなった)2.自分で作った関数で重みづけ(<-- Libreoffice で可能)3.機械学習による競馬予想(<-- Anacondaで可能)という事で情報取得をPythonで動かしたいというのが今回の目的です。調べると、スクレイピングという言葉が出てきました。このページがヤフーをスクレイピングしていたのでとっつきやすいと思い手を付けました。たった2行で取得できるのか?と思い早速入力してみました。url = 'https://www.yahoo.co.jp/'res = requests.get(url)res.text[:500]上記のようにさっそくエラーがでました。もう少し読むと、requestsを入れるにはインストールやインポートが必要になります。詳しい説明は、「図解!Beautiful SoupでWEBスクレイピング徹底解説!」を参照ください。と書いてあります。やり方は、自分はAnaconda3を使っているので、promptを選択してから。conda install requestsを入力するようです。良し出来たと思い、先ほどのコマンド実行前に下記のコマンドを入力して#requests をインポートします。(Web scrapingには必須)import requests再度実行すると。resまではゲットできたようですが、表示させようとしたresponseで再度エラー、躓きました。どうやら、responsesもインストールかと思いましたが、resにinputしたので、resを出力しないと行けなかったです。yahooは表示できましたが、netkeibaは文字化けしているようです。再度ぐぐっていると。encodeが出来るとのこと。下記コマンドを実行です。res.encoding = res.apparent_encodingそうすると、表示してくれました。HTMLがそのまま出ているようです。とりあえずスクレイピングは出来た模様です。次回はこれをテキストに出力、取り込みたいフォーマットに変換するところをまで行いたいです。今日のプログラムです。簡単に取得できるものですね。#requests をインポートします。(Web scrapingには必須)import requests#urlを取得 url = 'https://race.netkeiba.com/race/shutuba_past.html?race_id=202004020211&rf=shutuba_submenu'#resに内容を代入res = requests.get(url)#resをencodeして文字化け回避res.encoding = res.apparent_encoding#画面出力print(res.text)文字化け対策には別のコマンドもあるようです。上記でダメな場合は使ってみても良いと思います。#BeautifulSoup は文字化け対策from bs4 import BeautifulSoupres.encoding = 'shift_jis'soup =BeautifulSoup(res.text , 'html.parser')
Jul 22, 2020
コメント(2)
-
FEH 比翼2種同時ゲット
アルフォンスとマルスの比翼キャラを同時にゲットしました。嬉しさのあまりひさびさ投稿です。 英検1級に向けて頑張らないと行けない時期ですが、たまには😄 でる順パス単書き覚えノート英検1級 (旺文社英検書) [ 旺文社 ]
Jun 17, 2020
コメント(0)
-

2019/11/14 英検準1級 合格
今まではTOEIC1本を受講していたのですが、高校生以下の子供たちにはTOEICはあまり馴染みがなく、815点やったーと言ってもピンと来ないようだったので、昨年から英検を受け始めました。そして、今週の火曜の合格発表で準1級を見事合格しました。(パチパチパチ)まずは合格証書です。次にCSEスコアです。CSEスコアの説明はここに英検のリンクを張りますが、理解はしていません。次に1次試験の詳細スコアです。TOEICでは440点と好スコアだったリスニングが6割弱の出来で非常に危なかったですが、リーディングに救われたようで何とか1次試験をパスです。<TOEICと英検が違う点 +-ポイントは私の所感です>・英検は文法よりも単語力が重要。(-ポイント)・リスニングは文章が長い。TOEICのような瞬発力勝負ではなく持続できる聞く能力が試される (+ポイント)・作文があるので文章作成能力が養われる(+ポイント)2次試験。面接の結果です。Q&Aが4問あるのですが、1問が難問でした。韓国の学生に対して大学は十分か?というような問題だったと思います。Korean??とマークがついてもう一度聞きなおしたのですが、やはりヒアリングは間違えていないようでした。何と回答すれば良かったのか今でもわかりません。アティテュードに救われ何とか合格です。そして最後に受験履歴です。1回1次試験は夏に落ちてしまっていたので今回こその意気込みで勉強しました。滑り込みでしたが、合格出来て良かったです。今後についてですが、英検1級はさらに単語がパワーアップするのが非常に辛いところです。ただ、英作文を作る過程は論理的に説明できる力もパワーアップできると思うので引き続き勉強はしたいです。来年1月はさすがに間に合わないでしょうが、その次ぐらいを目指して頑張りたいです。あと、結果から言うと私はTOEIC815点を持っていたので、初めから準1級を受けるべきでした。(換算表はこちら)参加者は3級は小中学生、準2級は中高校生、2級は高校生が多いです。準1級くらいになると1次試験は高校生もいましたが、2次には大人しか見ませんでした。まだまだ努力しなければならないと思うので頑張ります。
Nov 14, 2019
コメント(2)
-

TOEIC 800点 達成
先週の金曜、ポストを見ると、自分宛の手書きのオレンジ色の封書を発見しました。こ、これは先日受験したTOEICの結果が返ってきていました。ということで神に祈りをささげて封を切りました。結果はLISTENING 440点、READING 375点、合計815点と過去最高得点をゲットしました。受けたときは600点から800点の間のどこか?と思っていたぐらいだったのでびっくりです。これまでの点数と比較すると圧巻のリスニング能力です。440点はずば抜けています。でも、まだ映画を字幕なしで見れないので自分的にはまだまだだと思っています。◆良かったポイント ・長めの会話、アナウンス、ナレーションなどの中で明確に述べられている情報をもとに要点、目的、基本的な文脈を理解できる 達成度 89% ・短めの会話、アナウンス、ナレーションなどにおいて詳細が理解できる 達成度 88% ・短めの会話、アナウンス、ナレーションなどの中で明確に述べられている情報をもとに要点、目的、基本的な文脈を推測できる 達成度 88% ・文章の中の具体的な情報を見つけて理解できる 達成度83%◆努力すべきポイント ・ひとつの文章の中でまたは複数の文書間でちりばめられた情報を関連付けることが出来る 達成度 71% ・文法が理解できる 達成度 75%まとめると、リスニングはすべて80%以上で問題なく、リーディングがまだ文が読めていないということのようです。発音に力を入れてEnglish Centralを勉強しているので聞く力が養われていると思いたいです。思えば、350点からスタートした(履歴はこちら)TOEIC受験ですが、やり続ければ伸びるを信条に続けてきた甲斐がありました。最近は発音にも力を入れています。これからも頑張ります。
Jun 16, 2019
コメント(2)
-
2018/08/28 SG116j 内臓マイクが認識されない
以前もあったのですが、旭エレクトロニクス製のノートパソコン ヨドバシカメラで購入したSG116Jのマイクが認識されなくなりました。今日も英語レッスンの1時間前くらいに気づき、スマートフォンで受講しました。直すには下記のブログに書いてあるように、旭エレクトロニクスさんに問い合わせが必要かもしれません。https://www.google.co.jp/amp/s/gamp.ameblo.jp/aki-mickey-minnie/entry-12349573269.html 以前は、結局再インストールしたんですよね。今回もクリーンインストールが早いかもしれません。入れているソフトも少ないので問題ないでしょう。こちらを参考にやっていきましょう。https://plaza.rakuten.co.jp/kazux68k/diary/201802120002/comment/write/#comment
Aug 28, 2018
コメント(1)
-
2018/07/15 機械学習,Deep learningによる競馬予想 函館記念
今週は函館記念をA.I.を使って予想です。本命はデムーロ鞍上のトリコロールブルー、対抗はクラウンディバイダ、穴にスズカデヴィアスを指名です。函館の直線は短いのでクラウンディバイダはいい狙いかな?と思います。Deep learning(過去レース説明変数に使った)の収束グラフです。
Jul 15, 2018
コメント(0)
-
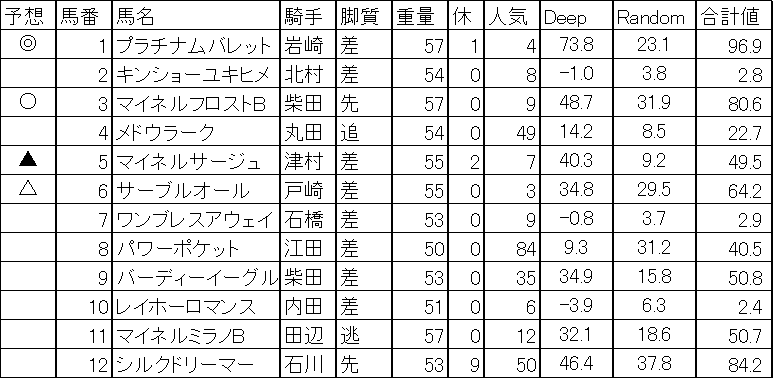
2018/07/07 機械学習,Deep learningによる競馬予想 七夕賞
今週は七夕賞をA.I.を使って予想です。本命は4歳馬プラチナムバレット、対抗は7歳馬マイネルフロスト、穴はマイネルサージュとサーブルオールです。Deep learning(過去の七夕賞を説明変数に使った)の収束グラフです。
Jul 8, 2018
コメント(0)
-
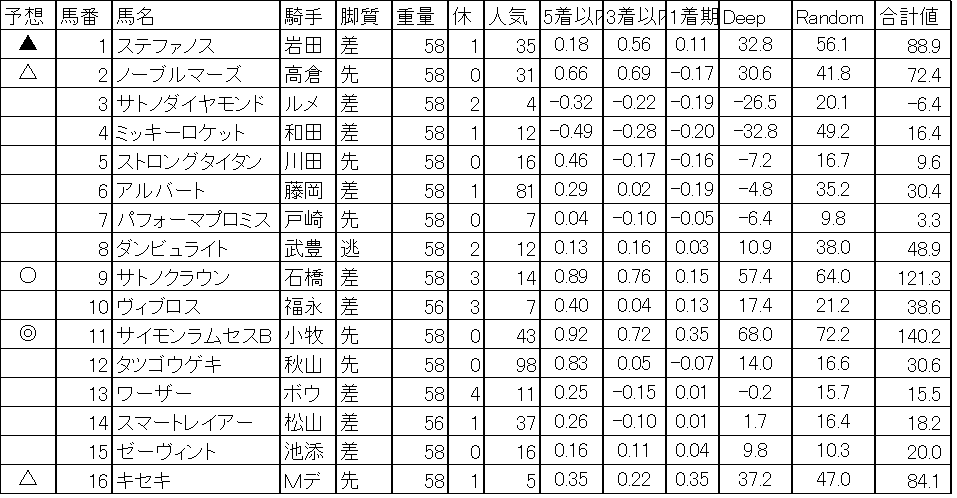
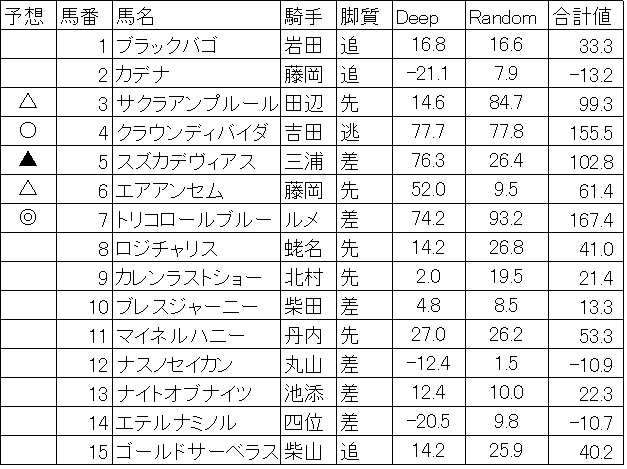
2018/06/23 機械学習,Deep learningによる競馬予想 宝塚記念
今週は宝塚記念をA.I.を使って予想です。本命は8歳馬サイモンラムセス、対抗は6歳馬サトノクラウン、穴は7歳馬ステファノス、大穴4歳馬キセキ、5歳馬ノーブルマーズになりました。Deep learning(過去の宝塚記念を説明変数に使った)の収束グラフです。8歳馬の逃げ切りはさすがに。。。と思いますが、どうでしょうか?もうちょっと考えます。
Jun 23, 2018
コメント(0)
-

2018/06/10 TOEIC結果 730点クリア
先週の金曜、ポストを見ると、自分宛の手書きのオレンジ色の封書を発見しました。こ、これは先日受験したTOEIC結果がもう返ってきました。ということで神に祈りをささげて封を切りました。結果はLISTENING 380点、READING 380点、合計760点と受験した時の印象ではREADNINGはもっとできて、LISTENINGはイマイチと思っていたのですが、結果は全く同じ点数でした。これまでの点数と比較すると文法が最高得点です。日頃の勉強の成果が出てきていると考えてよいでしょう。◆良かったポイント ・長めの会話、アナウンス、ナレーションなどの中で明確に述べられている情報をもとに要点、目的、基本的な文脈を理解できる 達成度 86% ・短めの会話、アナウンス、ナレーションなどにおいて詳細が理解できる 達成度 88% ・文章の中の具体的な情報を見つけて理解できる 達成度81% ・文法が理解できる 達成度 81%◆努力すべきポイント ・短い会話、アナウンス、ナレーションなどにおいて詳細が理解できる。 達成度 67% ・文章の中の情報をもとに推測できる。 達成度 68%まとめると、PART4,5はOK。PART2,3がイマイチと言うことですが、だいぶアベレージがあがっているので、全体的に努力が必要です。まあ、730点は3年連続クリアできましたが、800点には到達できなかったのは残念です。思えば、350点からスタートした(履歴はこちら)TOEIC受験ですが、やり続ければ伸びるを信条に続けてきた甲斐がありました。最近は発音にも力を入れています。これからも頑張ります。
Jun 10, 2018
コメント(0)
-
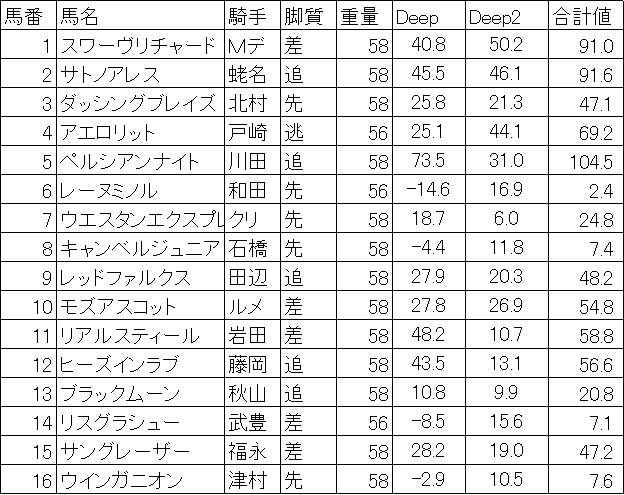
2018/06/03 機械学習,Deep learningによる競馬予想 安田記念
今週は安田記念をA.I.を使って予想です。本命はペルシアンナイト、対抗はサトノアレス、穴はスワーヴリチャードになりました。今回はDeep Learningを2つ行っています。重量の右のDeepが過去4年分のデータを利用して予想。その右が東京のレースをいろいろ使ってJCや毎日王冠、天皇賞(秋)も使ってデータを増しました。Deep learning(安田記念のみを説明変数に使った)の収束グラフです。Deep learning2(安田記念,毎日王冠、JC,天皇賞(秋)を説明変数に追加した)の収束グラフです。データが増えると迷い始めますが、最後はある程度収束しています。さあ、安田記念。楽しみですね。
Jun 3, 2018
コメント(0)
-
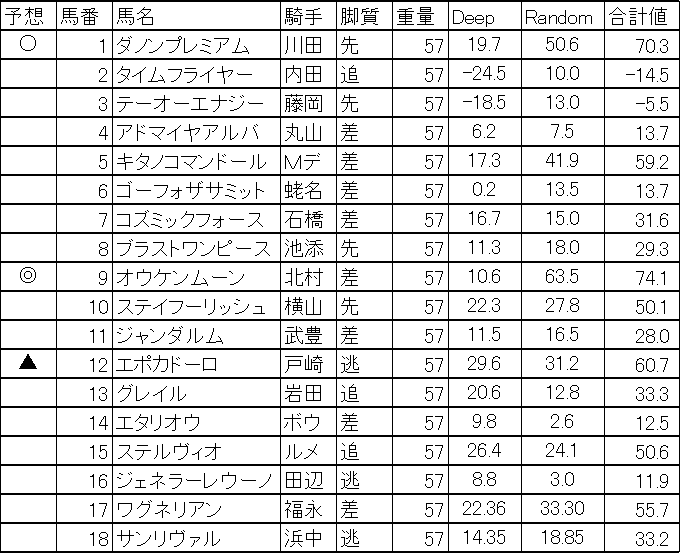
2018/05/27 機械学習,Deep learningによる競馬予想 日本ダービー
今週は日本ダービーを予想しました。本命はオウケンムーン、対抗はダノンプレミアム、穴はエポカドーロになりました。オウケンムーンはランダムフォレストでポイントが高いのが影響しています。Deep Learningだけみるとかなりの混戦模様です。下記がDeep learningの収束グラフです。A.I.もかなり悩んでいそうですね。さあ、日本ダービー、楽しみですね。
May 27, 2018
コメント(0)
-
5/20 TOEIC受験感想 と オークス予想
昨年は735点だったTOEIC。今年も受験しました。ということで受験しました。と言うことで、本日の受験印象です。◆Listening (65/100)PART1 ・・・ 『最後の1問は微妙』 自信度 ◎(5/6)PART2 ・・・ 『わからなかった』 自信度 ×(10/25)PART3 ・・・ 『まずまず』 自信度 ▲(30/39)PART4 ・・・ 『まずまず』 自信度 ▲(20/30)◆Reading (70/100)PART5 ・・・ 『わかったはず』 自信度 ◎(20/30)PART6 ・・・ 『同上』 自信度 ◎(12/16)PART7 ・・・ 『まずまずできた』自信度 ○(40/54)◆合計 137/200(あとは読み飛ばした問題が鍵か?)2年前の受験感想はこちら。3年前の受験感想はこちら。2年前の760点を超えられるかは全て運ですね。これまでの受験履歴はこちらに。ちなみに今日のオークスは◎アーモンドアイ〇リリーノーブル▲マウレアで堅く狙います。
May 20, 2018
コメント(0)
-

2018/05/12 TOEIC模試 Reading 450点
来週はTOEIC試験を受講します。ヤフオクで購入して温存していた模試をやってみました。今日はReadingを実施です。結果は下記に。Part5 34/40Part6 9/12Part7 45/48Total 88/100試験時間 55分/75分Part5を始めた瞬間に思ったのですが、この問題は簡単すぎた気がします。発行年月日を見ると平成21年でしたので9年前。模試が悪いのか?昔は簡単だったのかはわかりませんが。。。本番がこんな問題だったら良いのにと思います。Part5で間違った問題は下記です。1.Mr.Akiyama ( ) be mentally and physically tried after the long negociation(A) is able to(B) have to(C) can(D) must2.In order to reimburse travel and hosipitality ( ) , requests must be submitted to the accounting section in a timely manner.(A) incentives(B) benefits(C) incomes(D) expenses3.We are ( ) to annnounce that we have just signed a contract with Hong Kong Lee Crop.(A)delight(B)delightedly(C)delighting(D)delighted-------------------------------------------------------------答え (1) D (2) D (3) D1. ~に違いない2. hospital expenses 接待費の意味3. 空所の前にare 後に toがあるので、名詞のAや副詞のBは不適切。感情を表すdelightは喜ぶ際には受動態になる。3番はわかりたかったですね~
May 12, 2018
コメント(0)
-

2018/05/09 English central で Go Live を受講(52回目)
通算52回目のEnglish Centralの会話練習です。47~51回目はどうしたんだ?と言われそうですが、週1,2のペースで実施中です。今回の先生もlouiseさん。14回目の指名です。最近はこの方のスピードには慣れてきたのですが、やっぱり自分の意思をスムーズに伝えられていないなあというのが、感想です。今日はマクドナルドの話でしたが、フィリピンではjollibeeというレストランが有名でマクドナルドよりも安く提供できるそうです。2018年には東京店もできるかもという噂もあるようですので、出来たら行ってみたいですね。今日の単語です。RACK UP (Verb) 7[rack up] My company rack up sales 20% to sell new innovative item.LURE (Verb) 5Innovative electronic item lures me.IN A ROW (Adverb) 4We won badminton games 3times in a row.質問事項は下記に。1.Apart from raising wages, in what other ways can companies keep their workers happy?For example , giving 2weeks holiday per year and giving chance to study something by free.2.If you had two million dollars, what company would you invest in? Why?If I had 2 million dollars, I don't want to invest. I want to have a trip all over the world.By the way, I have to invest some company, I invest bank. Because Bank stocks value is stable compared with other field maker and give me good dividend income.3.Where would you rather eat: McDonald's, Taco Bell or Starbucks? Why?I choice McDonald's. Because My children like that very much. If I am free , I choice Taco Bell. I have never been to this restaurant. That's why I want to go.今までの履歴はこちらにTOEIC760点の軌跡も忘れずにTOEIC760点を獲得して、次のステップは発音と会話と言うことでEnglish Centralの体験レッスンを受講し入会しました。講師と会話出来るのはGo Liveと言うものですが、10本のビデオを見て、単語、発音練習をすれば1回受講できます。第2回の受講の所感はこちらしました。第3回目受講の所感はこちらに。第4回目受講の所感はこちらに。(一言メモ ”NOT"と”TOP”です。発音的には”ア”とする)第5回目受講の所感はこちらに。第10回目受講の所感はこちらに。第24回目受講の所感はこちらに。(一言メモ ”V”は下唇を噛むような形で発音する)第25回目受講の所感はこちら(一言メモ ”th”は下を噛むようにして発音する。think)第26回目の受講の所感はこちら第27-29回目の受講の所感はこちら第30回目の受講の所感はこちら第31,32回目の受講の所感はこちら第33,34,35回目の受講の所感はこちらRational(合理的な)の単語の発音。Raの発音が巻き舌になる。benefitはfitが舌を噛むような。第36,37,38,39回目の受講の所感はこちら第40,41回目の受講の所感はこちら”Production”は”Pro"ではなく、”Pra”と発音(発音記号は/prə)”world”はrとlが聞こえにくい。rlで巻き舌(発音記号は”wˈɚːld”)”awe”は 発音記号がˈɔːです。カタカナだと”ァオー”。巻き舌ですね。第42,43,44回目の受講の所感はこちら第45,6回目の受講の所感はこちら
May 9, 2018
コメント(0)
-
149$ Mini PC
約15,000円の5インチ MINI PCがクラウドファンディングに出ています。こちらhttps://www.indiegogo.com/projects/the-world-s-most-powerful-pocket-sized-pc#/形はちょっと不細工ですが、欲しいですねでも、私は英語勉強のためのカメラとマイクが欲しいですね。このPCには残念ながらついていません。
May 7, 2018
コメント(0)
-
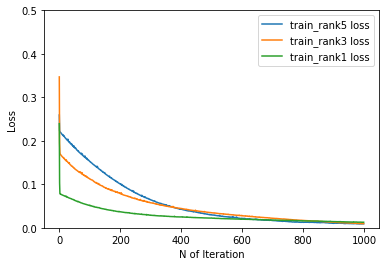
2018/04/29 機械学習,Deep learningによる競馬予想 天皇賞(春)
昨年の武蔵野Sでは万馬券を的中させた機械学習による競馬予想。今週は皐月賞を予想しました。 1ミッキーロケット 和田 差 58 -61 2 チェスナットコート 蛯名 差 58 79 3シホウB 浜中 差 58 38 4 カレンミロティック 池添 先 58 20△ 5 ヤマカツライデン 松山 逃 58 153△ 6 ガンコ 藤岡 先 58 95 7 ピンポン 宮崎 追 58 4 8 クリンチャー 三浦 先 58 8 9 ソールインパクト 福永 差 58 -4 10サトノクロニクル 川田 先 58 13○ 11 シュヴァルグラン ボウ 差 58 97 12 レインボーライン 岩田 追 58 69 13 トウシンモンステラ 国分 差 58 -5▲ 14 アルバート ルメ 差 58 40◎15 トーセンバジル Mデ 先 58 48△ 16 スマートレイアー 四位 差 56 100 17 トミケンスラーヴァ 秋山 先 58 4機械学習では逃げるヤマカツライデンを本命視ですが、さすがに厳しいと思っています。ガンコ、スマートレイアーも好スコアですが、自分には買うことができません。本命はトーセンバジル。こういう混戦の時に終わってみれば外人ということがよくあるし、天皇賞(春)は基本的に後ろにいては届かないので先行できるこの馬が人気の盲点かも。終わってみれば、またデムーロ。ということもあるでしょう。対抗はシュヴァルグラン。大阪杯は2度負けている宝塚記念もあるし、阪神は苦手と思い度外視。京都は得意なので、このメンバーなら負けるわけにはいかない。穴はアルバート。ルメールならこの馬の力を引き出す先行策をもっているかもしれない。◆予測結果の見方◆数字は左から”Deep Learning”による予測結果(5着以内、3着以内、1着以内を足したもの)、”Random forest"による予測結果(5着以内、3着以内、1着以内を足したもの)、Deep LearningとRandom forestの予測結果を足したものとなっています。収束グラフは下記の通り deep learningの結果です
Apr 29, 2018
コメント(0)
-
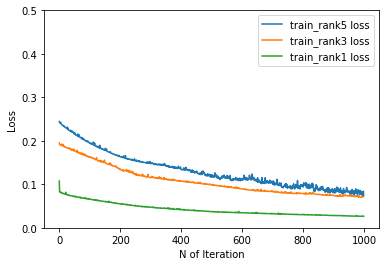
2018/04/14 機械学習,Deep learningによる競馬予想 皐月賞
昨年の武蔵野Sでは万馬券を的中させた機械学習による競馬予想。今週は皐月賞を予想しました。◆皐月賞◆▲ 1 タイムフライヤー 内田 追 18◎ 2 ワグネリアン 福永 差 113△ 3 ジャンダルム 武豊 差 30 4 スリーヘリオス 柴田 先 20 5 キタノコマンドール Mデ 追 82 6 アイトーン 国分 先 12○ 7 エポカドーロ 戸崎 逃 50 8 ケイティクレバー 浜中 逃 128 9 オウケンムーン 北村 差 57 10 ジェネラーレウーノ 田辺 先 68 11 マイネルファンロン 柴田 先 40☆2 12 グレイル 岩田 差 59 13 ダブルシャープ 和田 差 44 14 サンリヴァル 藤岡 先 22☆1 15 ステルヴィオ ルメ 追 86 16 ジュンヴァルロ 大野 先 -9私はワグネリアンは連を外さないとみました。下のグラフは繰り返し学習を繰り返して、予想と結果のずれを表しています。下に行けば行くほど、学習の効果が出ていることになります。青が5着以内、オレンジが3着以内、緑が1着になる予想と学習のずれです。これでモデリングを行って、今回の馬たちをいれると上の期待値が産出される仕組みです。2枚グラフがありますが、機械学習の種類の違いです。上がRandom forest、下がdeep learningです。◆予測結果の見方◆数字は左から”Deep Learning”による予測結果(5着以内、3着以内、1着以内を足したもの)、”Random forest"による予測結果(5着以内、3着以内、1着以内を足したもの)、Deep LearningとRandom forestの予測結果を足したものとなっています。
Apr 14, 2018
コメント(0)
-
2018/04/12 SG116j 内臓マイクが認識されない
先程、English Centralで英語レッスンを受けようとおもっていたら、5分くらい前にskypeの音声テストを行ったらマイクを認識していないという驚愕の事実が発覚しました。マイクが悪いのかと思って、ヘッドフォンを外しましたが解決せず、先生にメッセージを送るも、届かずで、先生から電話がかかってきても取れない状態に陥りました(汗)急いで、スマートフォンにSkypeを入れて、レッスン自体もこれで乗り切りましたが、このままではまずいです。解決方法はないかと調べていると見つかりました。こちら要約すると、Windowsの再インストールです。以下、コピペ。-------------------------------------------------------------------------------別な機種(SG116j)ですが、サウンドデバイスのマイク(録音デバイス)だけ認識されなくなりデバイスマネージャから消えたことがありました。他のUSBのサウンドデバイスを接続すると組み込まれましたので、ハード的な故障? とも考えましたが、設定-更新とセキュリティ-回復から個人用ファイルを保持する方で再インストールを試みたところ再度認識され回復することができました。この作業前に、デバイスマネージャでハードウェアのスキャンも実施していますが、検出できませんでした。----------------------------------------------------------------------------せっかく、使いやすくなってきたのに、ここで再インストールはつらすぎです。とりあえず、週末じっくり考えます。困った困った
Apr 13, 2018
コメント(1)
-
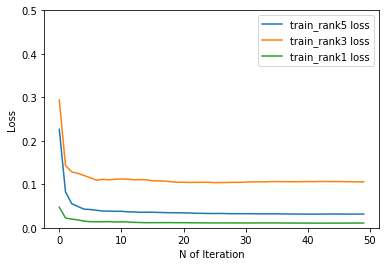
2018/04/07 機械学習,Deep learningによる競馬予想 桜花賞、阪神牝馬S
昨年の武蔵野Sでは万馬券を的中させた機械学習による競馬予想。今週は桜花賞を予想しました。◆桜花賞◆◎ 1 ラッキーライラック 石橋 先 55 128 2 アマルフィコースト 浜中 先 55 83 3 リバティハイツ 北村 差 55 53▲ 4 アンコールプリュ 藤岡 差 55 62 5 レッドサクヤ 松山 差 55 20 6 スカーレットカラー 岩田 差 55 22 7 トーセンブレス 柴田 追 55 -2 8 ハーレムライン 大野 先 55 57○ 9 リリーノーブル 川田 先 55 79 10 アンヴァル 藤岡 先 55 33 11 コーディエライト 和田 先 55 20 12 デルニエオール 池添 差 55 27 13 アーモンドアイ ルメ 追 55 9 14 レッドレグナント Mデ 先 55 61 15 プリモシーン 戸崎 差 55 8 16 フィニフティ 福永 先 55 27 17 マウレア 武豊 先 55 14 18 ツヅミモン 秋山 逃 55 -9やっぱりラッキーライラックには逆らえないですね。下のグラフは繰り返し学習を繰り返して、予想と結果のずれを表しています。下に行けば行くほど、学習の効果が出ていることになります。青が5着以内、オレンジが3着以内、緑が1着になる予想と学習のずれです。これでモデリングを行って、今回の馬たちをいれると上の期待値が産出される仕組みです。2枚グラフがありますが、機械学習の種類の違いです。上がRandom forest、下がdeep learningです。◆予測結果の見方◆数字は左から”Deep Learning”による予測結果(5着以内、3着以内、1着以内を足したもの)、”Random forest"による予測結果(5着以内、3着以内、1着以内を足したもの)、Deep LearningとRandom forestの予測結果を足したものとなっています。◆阪神牝馬S◆◎ 1 ジュールポレール 幸 先 54 118 2 アドマイヤリード Mデ 追 56 46○ 3 リスグラシュー 武豊 差 54 84 4 ミエノサクシード 福永 追 54 27▲ 5 デンコウアンジュ 蛯名 差 54 57 6 ソウルスターリング ルメ 先 56 30 7 エテルナミノル 四位 先 54 25 8 ミリッサ 岩田 追 54 44 9 クインズミラーグロ 藤岡 先 54 41 10 レッドアヴァンセ 北村 差 54 24 11 ミスパンテール 横山 差 54 33 12 ワントゥワン 藤岡 追 54 9 13 ラビットラン 川田 差 55 -1
Apr 7, 2018
コメント(2)
-
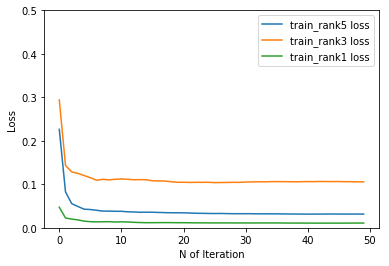
2018/03/31 機械学習,Deep learningによる競馬予想 大阪杯
昨年の武蔵野Sでは万馬券を的中させた機械学習による競馬予想。今週は大阪杯を予想しました。◆大阪杯◆ 1 ミッキースワロー 横山 差 46◎ 2 サトノダイヤモンド 戸崎 差 120 3 ヤマカツエース 池添 差 58▲ 4 シュヴァルグラン 三浦 差 58 5 ペルシアンナイト 福永 追 43 6 スマートレイアー 四位 追 53 7 ゴールドアクター 吉田 先 52 8 アルアイン 川田 先 45○ 9 トリオンフ 田辺 先 71 10 サトノノブレス 幸 先 37 11 ウインブライト 松岡 先 40 12 ヤマカツライデン 酒井 逃 31 13 マサハヤドリーム 北村 追 34 14 ダンビュライト 浜中 逃 45△ 15 スワーヴリチャード Mデ 差 57 16 メートルダール 松山 差 53一番右の数字が期待値です。今回は大激戦になりそうですね。下のグラフは繰り返し学習を繰り返して、予想と結果のずれを表しています。下に行けば行くほど、学習の効果が出ていることになります。青が5着以内、オレンジが3着以内、緑が1着になる予想と学習のずれです。これでモデリングを行って、今回の馬たちをいれると上の期待値が産出される仕組みです。2枚グラフがありますが、機械学習の種類の違いです。上がRandom forest、下がdeep learningです。deep learningは今回収束しなかったです。◆予測結果の見方◆数字は左から”Deep Learning”による予測結果(5着以内、3着以内、1着以内を足したもの)、”Random forest"による予測結果(5着以内、3着以内、1着以内を足したもの)、Deep LearningとRandom forestの予測結果を足したものとなっています。
Mar 31, 2018
コメント(2)
-
2018/03/25 English central で Go Live を受講(45,46回目)
通算45,46回目のEnglish Centralの会話練習です。45,6回目の先生もlouiseさん。9,10回目の指名です。来週は出張で英語を使うチャンスがあるという会話から入りました。先生に英語は上達したかな?と聞いたのですが、良くなってますよ。という回答です。この2か月間で結構頑張って、確かに発音は上達してきた気がします。ただ、文章を作る、話すというのはまだまだ出来ていないので繰り返しの練習が必要です。今日がキャビンアテンダントになる彼女のお姉さんが誕生日という事で喜ばれていました。では、今日の指摘事項です。見れば簡単なんですけどね。話すと間違っています。People can go back to home earlier. (X)People can go back home earlier. (O)It's same. (X)It's the same. (O)◆今日の単語ですFUND(Verb)6 意味:使用法:Japanese goverment funds this institution to study A.I. field.OUTSOURCE(Verb)6 意味:使用法:We outsource our producttion to keep wide range of capacity.OVERSEAS(Adj)5 意味:使用法:We outsource our producttion to the overseas company to keep wide range of capacity. IMMERSE(Verb)5 意味:使用法:I Immersed playing game in my childhood.APPLY(Verb)2 意味:使用法:I apply for another job.(1)Which of the following travel options in the video did you like the most? WhyIf it possible, I want apply for a transfer for six months to a year to your country.If I could be, I become a good speaker in English. And In my fields(Semiconductor) , there are big factory in your country. And they have a innovative skill and equipment. So I want to check this. And I have a family. so it is difficult for me to stay long time. so it is the best term for six month to a year.(2)Describe the job market and cost of living in your country.just now. our country job market is high demand. so any people find a job.may be until 2020 which is olynpic year. But in Japan , cost of living is so high. so part time job worker is hard to live. it needs full time job.(3)Would you consider working for an office in another country? Explain your answer.Of course , I would like to. that's why this is my dream to stay outside country and feel other cultures and to eat other meals. And I can study and master to English and other langues. 今までの履歴はこちらにTOEIC760点の軌跡も忘れずにTOEIC760点を獲得して、次のステップは発音と会話と言うことでEnglish Centralの体験レッスンを受講し入会しました。講師と会話出来るのはGo Liveと言うものですが、10本のビデオを見て、単語、発音練習をすれば1回受講できます。第2回の受講の所感はこちらしました。第3回目受講の所感はこちらに。第4回目受講の所感はこちらに。(一言メモ ”NOT"と”TOP”です。発音的には”ア”とする)第5回目受講の所感はこちらに。第10回目受講の所感はこちらに。第24回目受講の所感はこちらに。(一言メモ ”V”は下唇を噛むような形で発音する)第25回目受講の所感はこちら(一言メモ ”th”は下を噛むようにして発音する。think)第26回目の受講の所感はこちら第27-29回目の受講の所感はこちら第30回目の受講の所感はこちら第31,32回目の受講の所感はこちら第33,34,35回目の受講の所感はこちらRational(合理的な)の単語の発音。Raの発音が巻き舌になる。benefitはfitが舌を噛むような。第36,37,38,39回目の受講の所感はこちら第40,41回目の受講の所感はこちら”Production”は”Pro"ではなく、”Pra”と発音(発音記号は/prə)”world”はrとlが聞こえにくい。rlで巻き舌(発音記号は”wˈɚːld”)”awe”は 発音記号がˈɔːです。カタカナだと”ァオー”。巻き舌ですね。第42,43,44回目の受講の所感はこちら
Mar 31, 2018
コメント(0)
全1415件 (1415件中 1-50件目)
-
-

- がんばれ!地方競馬♪
- 12/1金沢・高知・佐賀の1点勝負
- (2024-11-30 23:13:32)
-
-
-

- 機動戦士ガンダム
- HG 1/144 デスティニーガンダムSpecI…
- (2024-11-23 16:12:08)
-
-
-

- フォトライフ
- 源氏物語〔12帖 須磨 10〕
- (2024-11-30 10:20:09)
-



