

[プログラミング] カテゴリの記事
全78件 (78件中 1-50件目)
-

Pyxel Python向けレトロゲームエンジン
pythonでゲームエンジンを検索すると、Pyxelなるものが見つかった。https://github.com/kitao/pyxel/blob/main/docs/README.ja.mdTakashi Kitaoという方が開発している。https://tkitao.hatenablog.com/サンプルが18(py15, app3)あり、動作を確認できる。子どもの頃にやったアクションゲームやシューティングゲーム、サウンドのサンプルもあり、興味深い。以下のシューティングゲームは09_shooter.py を実行したときの画面で、サウンドもあって、なかなかおもしろかった。338行で書かれていた。Pyxel ではプラットフォームによらず動作する、Pyxel アプリケーションファイルを生成し、python実行環境がなくてもゲームを起動できるようだ。また、Pyxel アプリケーションファイルは、pyxel app2exeコマンドやpyxel app2htmlコマンドで、実行可能ファイルや HTML ファイルに変換できるということだ。にほんブログ村
2024年01月08日
コメント(0)
-

pythonでテトリス
pythonでテトリスを作ろうとするとどうなるのか、検索すると以下のサイトが見つかった。https://kusakarism.info/?p=11314python標準モジュールのtkinterを使用し、わずか140行ほどで書かれていて感動した。リンク先の動画でも丁寧に説明されていて勉強になった。コーディングのキーポイントは、横12、縦21のマス目の状態を空間とブロックに識別し、横の両端1列ずつと下端1列をブロックとして白で表示、その内側を空間として黒で表示することにある。7種類のテトロミノ(T字やL字のブロック)が積み上がるとその場所はブロックとなり、テトロミノがブロックと当たると移動や回転ができないようになっている。1列がすべてブロックとなると、その段を消去して、順次上のブロックが落ちるようになっている。操作性もよくて、快適に遊べる。コードをみると操作方法がわかるが、カーソルキーで左右と下への移動、スペースキーで回転になっている。せっかくなので、Timerと次のブロックが表示されるように改変してみた。-----以下コード、コピー&ペーストで動作したので、よかったらお試しください。#################### Rough TETRIS ##################### https://kusakarism.info/?p=11314# import tkinter as tkimport randomfrom tkinter import messageboxSIZE = 30 #ブロックのサイズmoveX = 4 #テトロミノ表示位置(横)moveY = 0 #テトロミノ表示位置(縦)type1 = random.randint(0, 6) #テトロミノのタイプnext1 = random.randint(0, 6) #次のテトロミノtimer = 800 #ゲームスピードコントロールscore = 0 #スコアcolor = ["magenta", "blue", "cyan", "yellow", "orange", "red", "green", "black", "white"]#テトロミノデータtetroT = [-1, 0, 0, 0, 1, 0, 0, 1]tetroJ = [-1, 0, 0, 0, 1, 0, 1, 1]tetroI = [-1, 0, 0, 0, 1, 0, 2, 0]tetroO = [ 0, 0, 1, 0, 0, 1, 1, 1]tetroL = [-1, 0, 0, 0, 1, 0,-1, 1]tetroZ = [-1,-1, 0,-1, 0, 0, 1, 0]tetroS = [ 0, 0, 1, 0, 0, 1,-1, 1]tetro = [tetroT, tetroJ, tetroI, tetroO, tetroL, tetroZ, tetroS]#フィールドデータfield=[]for y in range(22): sub=[] for x in range(12): if x==0 or x==11 or y==21: sub.append(8) else: sub.append(7) field.append(sub) #落ちるテトロミノを表示する関数def drawTetris(): for i in range(4): x=(tetro[type1][i*2]+moveX)*SIZE y=(tetro[type1][i*2+1]+moveY)*SIZE can.create_rectangle(x, y, x+SIZE, y+SIZE, fill=color[type1])#次のテトロミノを表示する関数def nextTetro(): can_next.delete("all") for i in range(4): x=(tetro[next1][i*2]+1)*SIZE y=(tetro[next1][i*2+1]+1)*SIZE can_next.create_rectangle(x, y, x+SIZE, y+SIZE, fill=color[next1])#フィールドを表示する関数 1が壁、0が空間def drawField(): for i in range(21): for j in range(12): outLine=0 if color[field[i+1][j]]=="white" else 1 can.create_rectangle(j*SIZE, i*SIZE, (j+1)*SIZE, (i+1)*SIZE, fill=color[field[i+1][j]], width=outLine)#テトロミノを動かす関数def keyPress(event): global moveX, moveY afterX=moveX afterY=moveY afterTetro=[] afterTetro.extend(tetro[type1]) if event.keysym=="Right": afterX+=1 elif event.keysym=="Left": afterX-=1 elif event.keysym=="Down": afterY+=1 elif event.keysym=="space": afterTetro.clear() for i in range(4): afterTetro.append(tetro[type1][i*2+1]*(-1)) afterTetro.append(tetro[type1][i*2]) judge(afterX, afterY, afterTetro) #アタリ判定関数呼び出しdef judge(afterX, afterY, afterTetro): #アタリ判定をする関数 global moveX, moveY result=True for i in range(4): x=afterTetro[i*2]+afterX y=afterTetro[i*2+1]+afterY if field[y+1][x]!=7: result=False if result==True: moveX=afterX moveY=afterY tetro[type1].clear() tetro[type1].extend(afterTetro) return resultdef dropTetris(): global moveX, moveY, type1, next1, timer afterTetro=[] afterTetro.extend(tetro[type1]) result=judge(moveX, moveY+1, afterTetro) if result==False: for i in range(4): x=tetro[type1][i*2]+moveX y=tetro[type1][i*2+1]+moveY field[y+1][x]=type1 deleteLine() type1=next1 #次のテトロミノを落とす next1=random.randint(0,6) #can_next.delete("all") moveX=4 moveY=0 can.after(timer, dropTetris) timer-=2 if timer<140: timer=180def deleteLine(): global score for i in range(1, 21): if 7 not in field[i]: for j in range(i): for k in range(12): field[i-j][k]=field[i-j-1][k] score+=800-timer for i in range(1, 11): if 7!=field[1][i]: messagebox.showinfo("information", "GAME OVER!") exit()#################### ゲームループ #################### win=tk.Tk()win.geometry("340x760")win.title("TETRIS")can=tk.Canvas(win, width=12*SIZE, height=21*SIZE)can.place(x=-10, y=130)can_next=tk.Canvas(win, width=4*SIZE, height=4*SIZE, bg="black") #次のテトロミノ表示位置can_next.place(x=110, y=0)var=tk.StringVar()lab_score = tk.Label(win, textvariable=var, fg="blue", bg="white", font=("", "12")) #得点表示lab_score.place(x=0, y=730)var1=tk.StringVar()lab_timer = tk.Label(win, textvariable=var1, fg="blue", bg="white", font=("", "12")) #タイマー表示lab_timer.place(x=200, y=730)lab_next = tk.Label(win, text="Next", fg="black", bg="white", font=("", "15")) #Nextlab_next.place(x=50, y=50)win.bind("<Any KeyPress>", keyPress)def gameLoop(): can.delete("all") var.set(f"score: {score}") var1.set(f"timer: {timer}") drawField() drawTetris() nextTetro() can.after(10, gameLoop)gameLoop()dropTetris()win.mainloop()-----ここまでにほんブログ村
2024年01月07日
コメント(0)
-
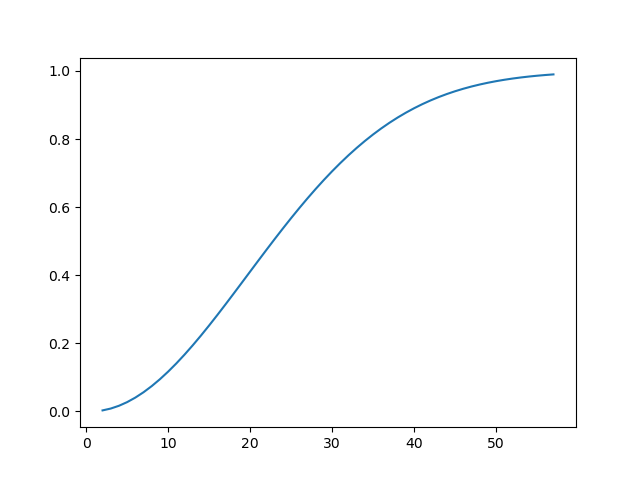
誕生日のパラドクス
・23人以上の人が集まれば、同じ誕生日の人が一組以上いる確率は1/2を超える。57人以上いれば、確率は99%になる。ちょっと直感的には理解できない。計算してみる。誕生日の数はうるう年の2/29も入れると366。2人の誕生日が異なる確率は順列をPとすると366P2/366^2。23人がすべて異なる誕生日である確率は、366P23/366^23。同じ誕生日の人が一組以上いる確率はこの確率を1から引く。pythonで計算すると以下のようになる。In [30]: import mathIn [31]: math.perm(366,23)/366**23Out[31]: 0.49367698818054007In [32]: 1-math.perm(366,23)/366**23Out[32]: 0.506323011819459957人の場合は以下。In [33]: 1-math.perm(366,57)/366**57Out[33]: 0.98998979806519872人から57人のときの確率を描画してみる。In [34]: x=range(2,58)In [39]: y=[1-math.perm(366,i)/366**i for i in range(2,58)]In [36]: import matplotlib.pyplot as pltIn [40]: plt.plot(x,y)In [41]: plt.show()こんなカーブを描かれると確かに間違える。にほんブログ村
2023年07月29日
コメント(0)
-
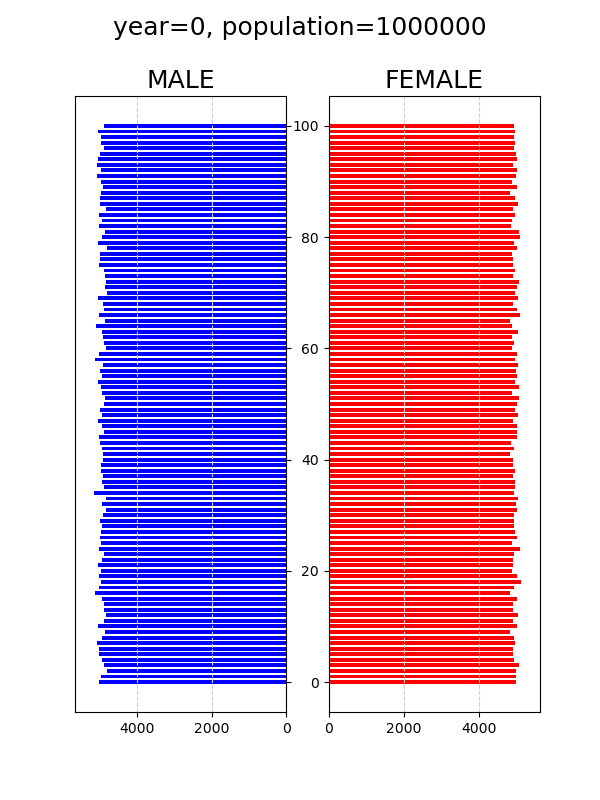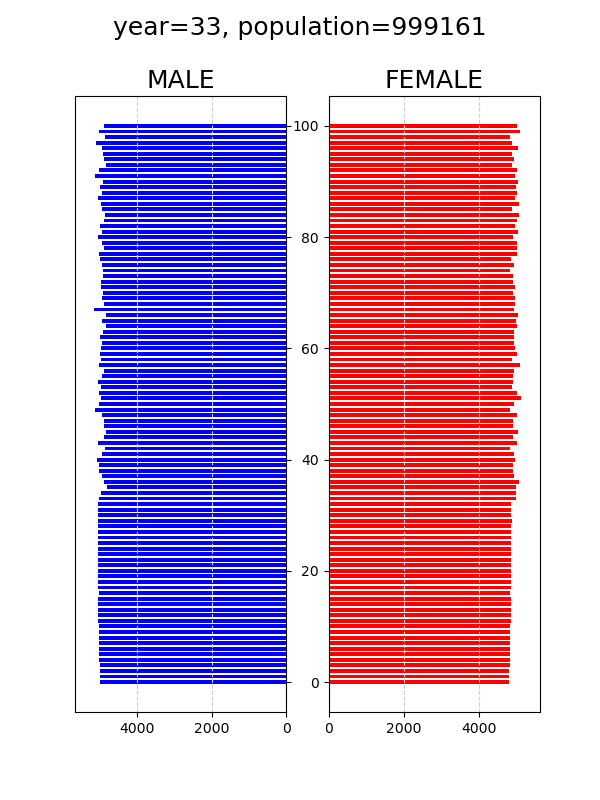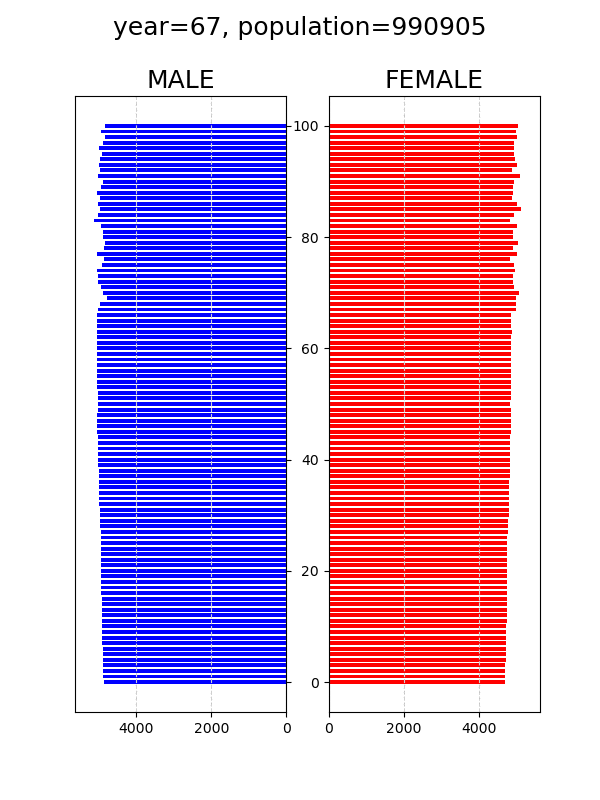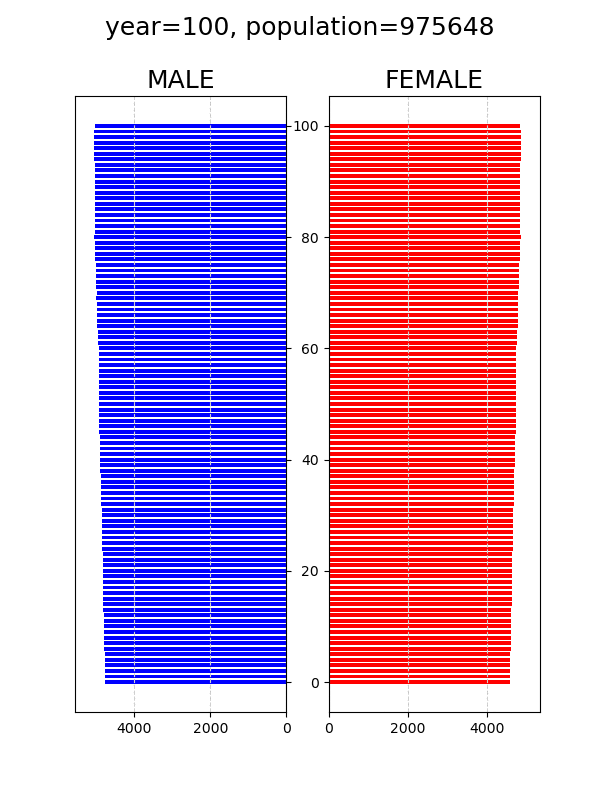
人口動態シミュレーション python
pythonの勉強としてやってみた。↓条件1. 初期条件→総人口100万人(男50万人、女50万人)、0~100歳までrandint(0,101)で一様分布。2. 期間は100年間3. 途中で死亡することはなく、すべて100歳まで生き、101歳になったら消える4. 適齢期(18~40)の男か女、少ない方の数に割合(0.1など)をかけた数が毎年出生する5. 男児の出生率を0.51↓定常シナリオ (4の割合を0.1)↓減少シナリオ (4の割合を0.02)↓早婚 (15~35)、晩婚 (25~45)の影響を増加シナリオ (4の割合を0.2)で確認↓早婚 (15~35)↓晩婚 (25~45)このモデルでは適齢期を約20年であり一様分布なため適齢期人口は20万人。カップル数は10万。ここから0.1の割合で出生すると1万人となって、ほぼ定常状態となる。当たり前だけれど、増加シナリオでは、早婚であれば、再生産のサイクルが早く回るため、晩婚に比べて人口が早く増える。このモデルでは、個体識別せずに、ざっくりと適齢期の半分をカップルとし、そこからある割合で再生産されるとしている。人口を増やすという観点からは、やはり結婚という形態にとらわれずに、適齢期の人たちが、毎年、前の年よりも多く生んでくれると効果がありそうだ。可視化は以下のサイトを参考にした。https://note.com/michell72/n/nf4183efdc5dapngからgifを作成するには、以下のコマンドをsubprocessで実行した。環境はUbuntu 22.04.2 LTS。cmd="convert -delay 30 -loop 0 graph0*png graph_.gif"subprocess.call(cmd.split())↓ソースコード-----"""population simulation"""import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport timeimport subprocesssta=time.time()timespan=100ratio=0.1male_ratio=0.51# children are born from couple between lower and upper years old.lower=18upper=40lifespan=100ini_pop=500000print("timespan=",timespan,"ratio=",ratio,"male_ratio=",male_ratio, "lower=",lower,"upper=",upper,"lifespan=",lifespan,"ini_pop=",ini_pop)def plot(male, female): fig, ax = plt.subplots(ncols=2, figsize=(6,8)) male1=pd.Series([len(male[male==i]) for i in range(lifespan+1)]) female1=pd.Series([len(female[female==i]) for i in range(lifespan+1)]) # male ax[0].barh(male1.index, male1, color='b', height=0.7, label='male', alpha = 1) ax[0].yaxis.tick_right() # x reverse ax[0].set_yticklabels([]) #hide ticks ax[0].set_xlim([male1.max()*1.1, 0])# x reverse ax[0].set_title('MALE',fontsize=18) ax[0].xaxis.grid(True, which = 'major', linestyle = '--', color = '#CFCFCF') #plt.setp(ax[0].get_xticklabels(), fontsize=14) # female ax[1].barh(female1.index, female1, color='r', height=0.7, label='female', alpha = 1) ax[1].set_xlim([0,female1.max()*1.1]) ax[1].set_title('FEMALE',fontsize=18) ax[1].xaxis.grid(True, which = 'major', linestyle = '--', color = '#CFCFCF') fig.suptitle("year="+str(year)+", population="+str(len(male)+len(female)), size=18) plt.savefig('graph'+str(year).rjust(4,"0")+'.png') #plt.show() plt.close(fig)#initial male and female for 500,000male=pd.Series(np.random.randint(0,lifespan+1,ini_pop))female=pd.Series(np.random.randint(0,lifespan+1,ini_pop))new_b=0for year in range(timespan+1): plot(male, female) print("year=", year, "new_b=", new_b, "male= ",len(male), "female= ", len(female), "population= ", len(male)+len(female)) # children are born from couple between lower and upper years old. young_m=len(male[lower<male][male<upper]) young_f=len(female[lower<female][female<upper]) new_b=int(ratio*min(young_m, young_f)) n_male=int(male_ratio*new_b) # aging male=male+1 female=female+1 # children are added male=pd.concat([male, pd.Series(np.zeros(n_male))]) female=pd.concat([female, pd.Series(np.zeros(new_b-n_male))]) male=male.reset_index(drop=True) female=female.reset_index(drop=True) male=male[male<lifespan] female=female[female<lifespan]plot(male, female)cmd="convert -delay 30 -loop 0 graph0*png graph_.gif"subprocess.call(cmd.split())fin=time.time()print("elapsed time [sec]=", fin-sta)-----何かの参考になれば幸いです。にほんブログ村
2023年07月17日
コメント(0)
-

python翻訳ライブラリ
これまで見つけたものをメモ。・googletrans 4.0.0rc1google翻訳のライブラリ・deepl-translate高精度なDeepLの翻訳ライブラリ 本来は有料サービス・translateMicrosoft Translation API, Translated MyMemory API, LibreTranslate, and DeepL’s free and pro APIsを使用した翻訳ライブラリにほんブログ村
2022年01月20日
コメント(0)
-
pythonでpptxのテキストをgoogle翻訳して置換する
大量の英語のパワーポイントを日本語訳する必要があり、このpythonスクリプトを書いてみた。googletransというgoogle翻訳のpythonモジュールがあった。バージョンは4.0.0-rc1指定でないとうまく動作しないようだ。サンプルのpptxは以下https://scholar.harvard.edu/files/torman_personal/files/samplepptx.pptxコードは以下、実質23行。-----"""Apply Google translation to pptxtqdm, googletrans and pptx are necessary in advance.pip install tqdmpip install googletrans==4.0.0-rc1pip install python-pptx"""import timeimport tqdmfrom googletrans import Translatorfrom pptx import Presentationsta=time.time()#driver launchtranslator = Translator()prsname="samplepptx"prs = Presentation(prsname+".pptx")for slide in tqdm.tqdm(prs.slides): for shape in slide.shapes: if shape.has_text_frame: try: changed=translator.translate(shape.text, dest='ja', src='en').text shape.text = shape.text.replace(shape.text,changed) except: passprs.save(prsname+"_JP1.pptx")fin=time.time()print (f"elapsed time:{fin-sta} sec")-----お役に立てれば幸いです。にほんブログ村
2022年01月13日
コメント(0)
-
python enumerateでリストにインデックスをつける
以下のリンクが参考になった。https://note.nkmk.me/python-enumerate-start/In [7]: l = ['Alice', 'Bob', 'Charlie'] In [10]: for i, name in enumerate(l,1): ...: print(i,name) ...: ...: 1 Alice2 Bob3 Charlieにほんブログ村
2020年04月19日
コメント(0)
-
vimで検索ヒット件数を表示
便利だったのでメモ。以下のリンクを参考にvimrcに必要な記述を追加した。https://qiita.com/akira-hamada/items/eb46ef02fabfdd418449-----ここからnnoremap <expr> / _(":%s/<Cursor>/&/gn")function! s:move_cursor_pos_mapping(str, ...) let left = get(a:, 1, "<Left>") let lefts = join(map(split(matchstr(a:str, '.*<Cursor>\zs.*\ze'), '.\zs'), 'left'), "") return substitute(a:str, '<Cursor>', '', '') . leftsendfunctionfunction! _(str) return s:move_cursor_pos_mapping(a:str, "\<Left>")endfunction-----ここまでにほんブログ村
2019年05月30日
コメント(0)
-

python selenium headless chrome
python seleniumでchromeを自動操作できることは知っていたが、ブラウザを表示することなく操作できることを以下のサイトで知った。https://qiita.com/orangain/items/6a166a65f5546df72a9dheadlessモードを使うとブラウザを表示することなくchromeを自動操作できるため、速くなる。サンプルコードを転載----ここからfrom selenium.webdriver import Chrome, ChromeOptionsfrom selenium.webdriver.common.keys import Keysoptions = ChromeOptions()# ヘッドレスモードを有効にする(次の行をコメントアウトすると画面が表示される)。options.add_argument('--headless')# ChromeのWebDriverオブジェクトを作成する。driver = Chrome(options=options)# Googleのトップ画面を開く。driver.get('https://www.google.co.jp/')# タイトルに'Google'が含まれていることを確認する。assert 'Google' in driver.title# 検索語を入力して送信する。input_element = driver.find_element_by_name('q')input_element.send_keys('Python')input_element.send_keys(Keys.RETURN)# タイトルに'Python'が含まれていることを確認する。assert 'Python' in driver.title# スクリーンショットを撮る。driver.save_screenshot('chrome_search_results.png')# 検索結果を表示する。for a in driver.find_elements_by_css_selector('h3'): print(a.text)driver.quit() # ブラウザーを終了する。----ここまでにほんブログ村
2018年11月10日
コメント(0)
-
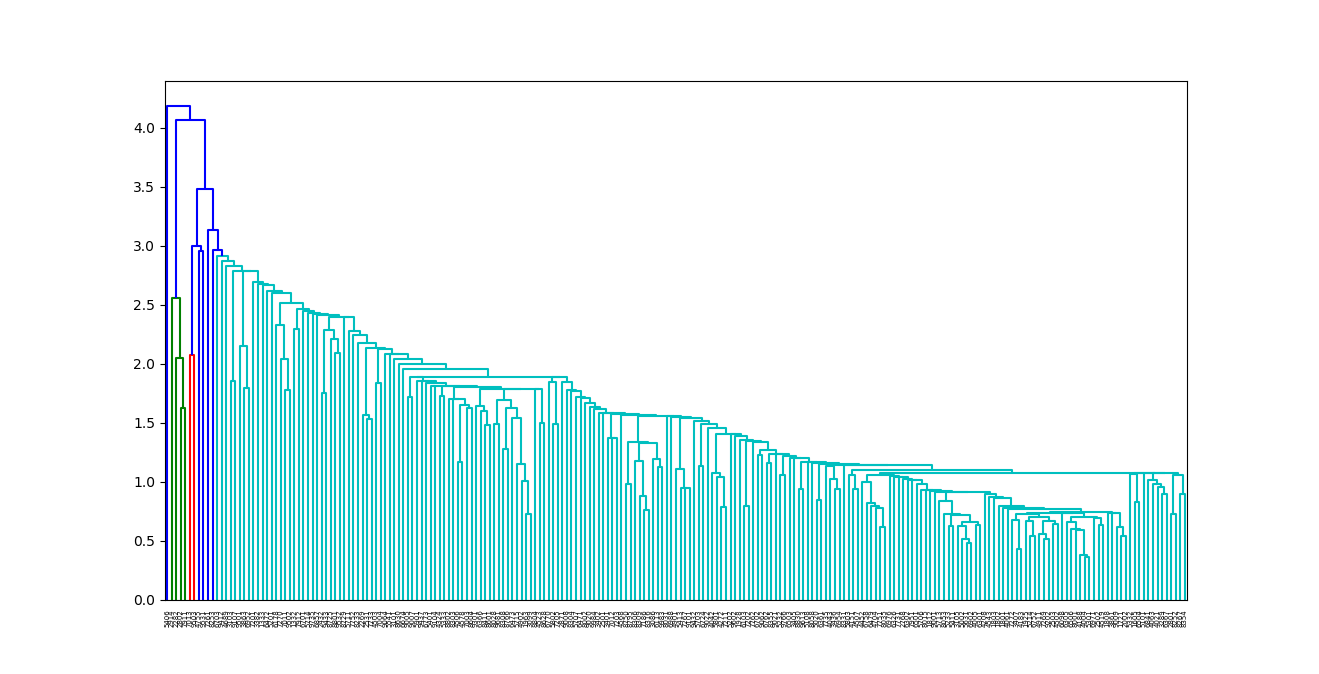
日経225の時刻歴データをクラスター分析
日経225の2017年1月〜12月の週足時刻歴データで相関係数をとってクラスター分析してみた。In [1]: import pandas as pdIn [2]: import matplotlib.pyplot as pltIn [3]: df=pd.read_csv("2017nikkei225.csv",index_col=0)In [5]: from scipy.cluster.hierarchy import linkage,dendrogramIn [6]: li=linkage(df.corr())In [7]: r=dendrogram(li,labels=df.columns)In [8]: plt.show()seabornのclustermapも描いてみた。In [9]: import seaborn as snsIn [10]: sns.clustermap(df.corr())In [11]: plt.show()In [13]: r["ivl"]Out[13]: ['5406', '2914', '2282', '2802', '7911',さすがにデータ数225になると見づらくなる。にほんブログ村
2018年04月14日
コメント(0)
-
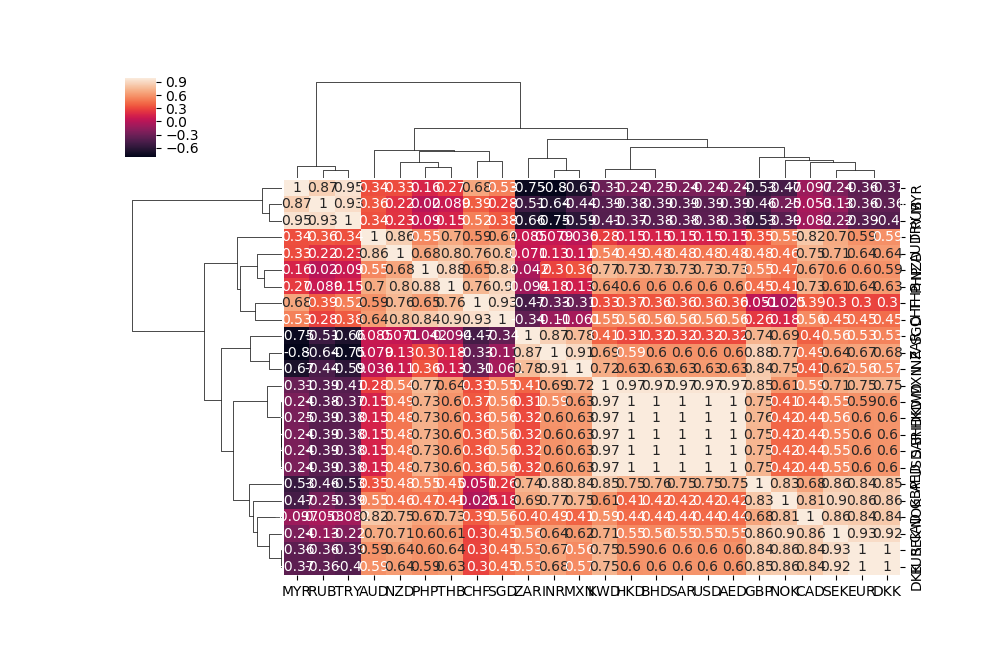
python dendrogram clustermap クラスター分析
多くのデータがあるとき、特徴が似た物どうしでグループを作ることにより、扱いやすくなる。→クラスター分析seabornのclustermapやscipyのdendrogramを使うとクラスター分析を簡単にできる。以下、為替の時系列データを例にしてみた。みずほ銀行為替データから2002/4/1〜2018/4/13のデータを取得https://www.mizuhobank.co.jp/rate/market/historical.htmlseabornのclustermapとscipyのdendrogramでクラスター分析。以下、ipythonで実行。In [1]: import pandas as pdIn [2]: import matplotlib.pyplot as pltIn [3]: import seaborn as snsIn [4]: df=pd.read_csv("quote_01.csv",index_col=0)#最初の日付(2002/4/1)の値で規格化し、df1In [6]: df1=df/df.iloc[0]In [7]: df1.head()Out[7]: USD GBP EUR CAD CHF SEK \2002/4/1 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 2002/4/2 1.000376 1.010485 1.009128 0.998802 1.010974 1.010101 2002/4/3 1.000376 1.007745 1.007234 1.002036 1.009334 1.006216 2002/4/4 0.999624 1.007060 1.008870 1.002875 1.011352 1.004662 2002/4/5 0.993616 0.999737 1.001722 0.993771 1.002397 1.000000 DKK NOK AUD NZD ... PHP \2002/4/1 1.000000 1.000000 1.000000 1.000000 ... 1.000000 2002/4/2 1.008957 1.010610 0.998313 1.001020 ... 1.003831 2002/4/3 1.007678 1.009947 1.000000 1.000170 ... 1.003831 2002/4/4 1.008957 1.016578 0.995361 0.995238 ... 1.000000 2002/4/5 1.001280 1.009284 0.988614 0.992517 ... 0.996169 SGD THB KWD SAR AED MXN \2002/4/1 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 2002/4/2 0.999585 0.996743 1.002004 1.000282 1.000276 0.999325 2002/4/3 0.998754 0.990228 1.005620 1.000282 1.000276 0.997299 2002/4/4 1.000692 0.993485 1.002234 0.999437 0.999448 0.995949 2002/4/5 0.995015 0.990228 0.995554 0.993525 0.993657 0.989872 RUB TRY MYR 2002/4/1 1.000000 1.000000 1.000000 2002/4/2 1.007299 1.000000 1.000000 2002/4/3 1.000000 1.000000 1.000000 2002/4/4 1.000000 0.999378 1.000000 2002/4/5 1.000000 0.993163 0.994764 [5 rows x 24 columns]In [10]: sns.clustermap(df1.corr(),annot=True)In [11]: plt.show()In [12]: from scipy.cluster.hierarchy import linkage,dendrogramIn [13]: li=linkage(df1.corr())In [18]: r=dendrogram(li,labels=df1.columns)In [19]: plt.show()dendrogramは縦棒の長さがクラスター間の距離に対応している。縦棒が短ければ、よく似ており、長ければ似ていないことを表す。dendrogramの並び順を確認In [20]: r["ivl"]Out[20]: ['MYR', 'RUB', 'TRY', 'AUD', 'CHF', 'SGD', 'NZD', 'PHP', 'THB', 'KWD', 'HKD', 'BHD', 'SAR', 'USD', 'AED', 'GBP', 'NOK', 'CAD', 'SEK', 'EUR', 'DKK', 'ZAR', 'INR', 'MXN']HKD,BHD,SAR,AEDはドルペッグ制でUSDと相関係数が1になる。以前も似たようなことをやった。https://plaza.rakuten.co.jp/takupin/diary/201705230000/にほんブログ村
2018年04月14日
コメント(0)
-
Google Colaboratory
Pythonって環境構築が結構面倒なんだけれど、Google Colaboratoryにはnumpyやpandasなどの基本的なライブラリがすでにインストール済みで、ブラウザで以下にアクセスすれば、いきなりJupyter notebookを使える。https://colab.research.google.com/結構びっくり。TensorflowでGPUを使う方法にも対応しているようだ。ノートブックの共有やコメントも簡単にできるようだ。↓参考URLhttp://tadaken3.hatenablog.jp/entry/first-step-colabratoryhttp://karaage.hatenadiary.jp/entry/2018/03/21/073000にほんブログ村
2018年03月21日
コメント(0)
-
python list 内包表記 メモ
以下のテキストデータからitem2のcを抽出したいときIn [1]: cat sample.txtitem1 aitem2 a b citem3 cIn [3]: fi=open("sample.txt","r")In [4]: lines=fi.readlines()In [5]: [l for l in lines if "item2" in l][0].split()[3]Out[5]: 'c'列の数が揃わないテキストデータから、任意の文字列を1行で抽出できる。↓参考URLhttps://ja.stackoverflow.com/questions/33700/python-%E3%83%AA%E3%82%B9%E3%83%88%E5%86%85%E3%82%92%E9%83%A8%E5%88%86%E4%B8%80%E8%87%B4%E3%81%A7%E6%A4%9C%E7%B4%A2%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6にほんブログ村
2018年03月03日
コメント(0)
-
【3日でできる】はじめての Django 入門
udemyの講座。anacondaをインストールしconda create -n py36でpy36という仮想環境を作ってconda install djangoでdjangoをインストールする。pythonの仮想環境を作る理由→python2系でないと動かなかったり、特定のパッケージが必要なことがあるから。勉強になる。にほんブログ村
2018年01月27日
コメント(1)
-
パワーポイント 画像挿入 マクロ VBA
大量の画像をパワーポイントに貼付ける必要があり、"ppt 画像挿入 マクロ"でググると以下のサイトが見つかった。https://www.ka-net.org/blog/?p=8228これを少し編集し、タイトルにファイルパス、テキストとして"サンプル"を挿入するようにしてみた。画像はpngのみを対象としている。1つのスライドに1枚の画像が挿入される。-----ここからSub InsertImages()'指定したフォルダ内の画像ファイルを一括挿入 Dim prs As PowerPoint.Presentation Dim sld As PowerPoint.Slide Dim shp As PowerPoint.Shape Dim txt As PowerPoint.Shape Dim tmp As PowerPoint.PpViewType Dim fol As Object, f As Object Dim fol_path As String '開いているプレゼンテーションをprsに格納 Set prs = ActivePresentation 'スライドショー表示になっていたら解除 If SlideShowWindows.Count > 0 Then prs.SlideShowWindow.View.Exit With ActiveWindow tmp = .ViewType 'ウィンドウの表示モード記憶 .ViewType = ppViewSlide End With '画像フォルダ取得 Set fol = CreateObject("Shell.Application") _ .BrowseForFolder(0, "画像フォルダ選択", &H10, 0) If fol Is Nothing Then GoTo Fin fol_path = fol.Self.Path 'フォルダ内のファイル処理 With CreateObject("Scripting.FileSystemObject") If Not .FolderExists(fol_path) Then GoTo Fin For Each f In .GetFolder(fol_path).Files 'PNGファイルのみ処理 Select Case LCase(.GetExtensionName(f.Path)) Case "png" 'スライド追加 Set sld = prs.Slides.Add(prs.Slides.Count + 1, ppLayoutChartAndText) sld.Select '画像挿入 Set shp = sld.Shapes.AddPicture(FileName:=f.Path, _ LinkToFile:=False, _ SaveWithDocument:=True, _ Left:=0, _ Top:=0) With shp .LockAspectRatio = True '縦横比を固定 .Select '画像サイズ変更 .Width = .Width * 0.85 .Height = .Height * 0.85 End With '画像をスライド中央に配置 With ActiveWindow.Selection.ShapeRange .Align msoAlignCenters, True .Align msoAlignMiddles, True End With End Select'スライドタイトルをファイルパスに変更 sld.Shapes(1).TextFrame.TextRange.Text = f.Path 'テキスト挿入 Set txt = sld.Shapes.AddTextbox( _ Orientation:=msoTextOrientationHorizontal, _ Left:=600, _ Top:=50, _ Width:=250, _ Height:=10) With txt .Name = "AddedTextBox" .TextFrame.TextRange = "サンプル" .TextEffect.FontSize = 20 End With Next End WithFin: ActiveWindow.ViewType = tmp 'ウィンドウの表示モードを元に戻すEnd Sub-----ここまでお役に立てば幸いです。にほんブログ村
2018年01月26日
コメント(3)
-
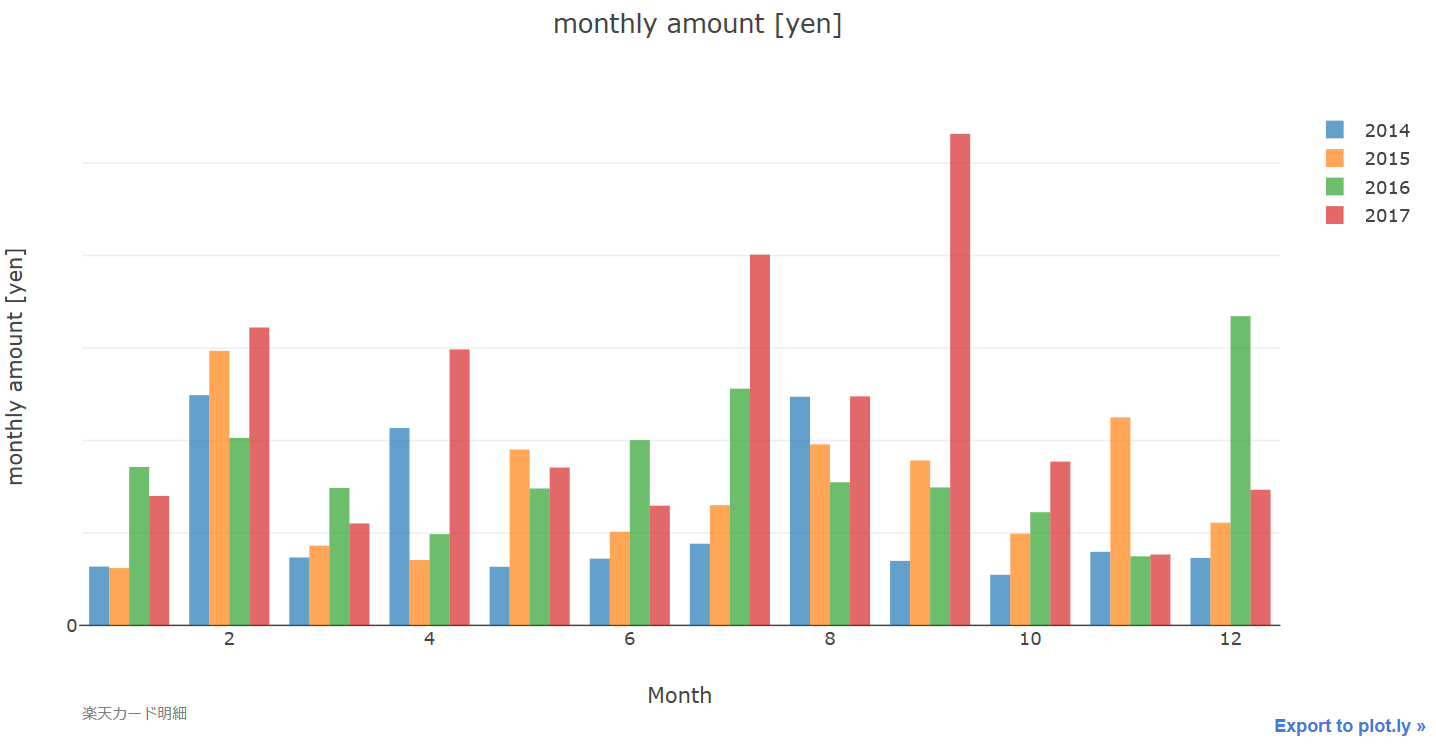
python plotly
plotlyを使って楽天カードのここ4年間の使用状況を可視化してみた。とはいっても金額と項目は伏せることにする。↓月ごとの合計金額を年ごとに比較する棒グラフ↓2017年で使用額が大きい項目順にソートした棒グラフpandasで元のcsvをうまく編集して作成した。matplotlibとseabornでもできるけれど、plotlyはhover機能があり、マウスポインタをグラフに乗せると数値などを確認できる。さらに凡例をクリックしてグラフの表示、非表示を切り替えられる。plotlyでの基本的な棒グラフ作成法は以下のリンクにある。https://plot.ly/python/bar-charts/udemyでもData Visualisation with Plotly and Pythonというplotlyのコースがある。-----I visualized a usage of rakuten card for this four years. But I did not show the amount.I made bar charts by editing the original csvs with pandas.Though I can make bar cahrts with matplotlib and seaborn, plotly has hover feature and mouse cursor on the graph shows the values of the graph and so on. I can switch display and hide by clicking the legend.The following link shows how to make basic bar charts.https://plot.ly/python/bar-charts/udemy also provides the Plotly course, "Data Visualisation with Plotly and Python".にほんブログ村
2018年01月02日
コメント(0)
-
vimでサブフォルダ以下の複数のテキストファイルを一括置換
便利だったのでメモ。FEMの入力ファイルなどで、サブフォルダ以下の複数のテキストファイルの一部分を一括置換したい場合がある。:args **/*.txt:args:argdo %s/hoge/fuga/g | update↓参考URLhttp://blog.ruedap.com/2010/11/30/vim-grep-replace-----The way to replace a certain string in multiple text files in subfolders simultaneously.にほんブログ村
2017年08月28日
コメント(0)
-
robobrowserをmechanizeのかわりに使う python3対応
これまで、ログインした先の情報を取得するのにmechanizeを使っていた。しかし、mechanizeはpython2のみ対応で3には対応していない。python3対応でmechanizeのかわりを探したところ、robobrowserが見つかった。(検索するとmechanicalsoupもあったがうまくいかなかった。)以前、mechanize使って、楽天カード明細を取得するスクリプトを書いた。https://plaza.rakuten.co.jp/takupin/diary/201501170001/これのrobobrowser版を書いてみた。-----ここから#coding: utf-8from robobrowser import RoboBrowser# ブラウザオブジェクトを作るbr = RoboBrowser()# ログイン名とパスワードを指定username = "hogehoge"password = "fuga"# URLを開くurl = "https://www.rakuten-card.co.jp/e-navi/?l-id=corp_de_enavi_login_top_003"br.open(url)# フォームを指定して、ユーザ名とパスワードを設定して送信する。form = br.get_forms()[0]form['u'] = usernameform['p'] = passwordbr.submit_form(form)# 明細のページへ移動link=br.get_link("ご利用明細")br.follow_link(link)# 明細のページを出力print(br.find())-----ここまでrobobrowserはpipでインストールできる。pip install robobrowser参考URLhttps://robobrowser.readthedocs.io/en/latest/にほんブログ村
2017年05月30日
コメント(0)
-
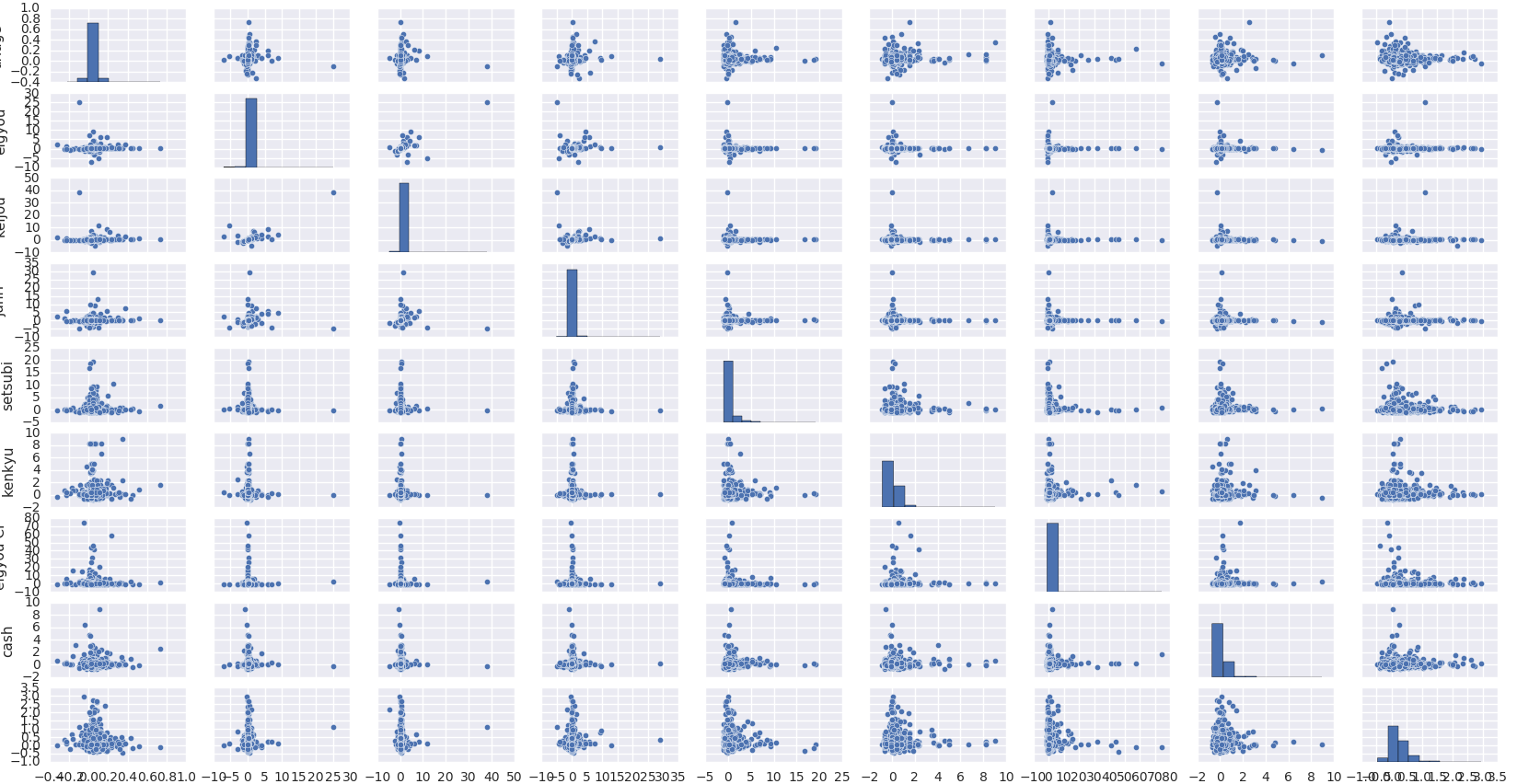
seabornで株のデータをplot
四季報2016年3月発売号のデータと、2016年3月14日から2017年3月14日の株価伸び率のデータでpairplotとjointplotを試してみた。日本語フォントの表示を試みたがうまくいかなかった。売上高の増減予想→uriage営業利益の増減予想→eigyou経常利益の増減予想→keijou純利益の増減予想→junnri株価伸び率→kabuka nobi↓pairplot↓jointplotにほんブログ村
2017年05月28日
コメント(0)
-
matplotlibで周波数応答関数の描画
振動・騒音解析業務では、数多くの周波数応答関数(Frequency Response Function)を描く。入力点x方向(x,y,z)x応答点x方向x,y,z)で、何百という数になる。そこで、matplotlibで9枚のグラフを描画するコードを描いてみた。ここではグラフの枠だけ。中身は好きに埋めてください。ax[i].plot(x,y)で。In [19]: import matplotlib.pyplot as pltIn [20]: fig=plt.figure(figsize=(8,6))In [21]: ax=range(18)In [22]: ax[0]=fig.add_axes((0.1,0.9,0.25,0.05)) ...: ax[1]=fig.add_axes((0.1,0.7,0.25,0.18)) ...: ax[2]=fig.add_axes((0.4,0.9,0.25,0.05)) ...: ax[3]=fig.add_axes((0.4,0.7,0.25,0.18)) ...: ax[4]=fig.add_axes((0.7,0.9,0.25,0.05)) ...: ax[5]=fig.add_axes((0.7,0.7,0.25,0.18)) ...: ax[6]=fig.add_axes((0.1,0.6,0.25,0.05)) ...: ax[7]=fig.add_axes((0.1,0.4,0.25,0.18)) ...: ax[8]=fig.add_axes((0.4,0.6,0.25,0.05)) ...: ax[9]=fig.add_axes((0.4,0.4,0.25,0.18)) ...: ax[10]=fig.add_axes((0.7,0.6,0.25,0.05)) ...: ax[11]=fig.add_axes((0.7,0.4,0.25,0.18)) ...: ax[12]=fig.add_axes((0.1,0.3,0.25,0.05)) ...: ax[13]=fig.add_axes((0.1,0.1,0.25,0.18)) ...: ax[14]=fig.add_axes((0.4,0.3,0.25,0.05)) ...: ax[15]=fig.add_axes((0.4,0.1,0.25,0.18)) ...: ax[16]=fig.add_axes((0.7,0.3,0.25,0.05)) ...: ax[17]=fig.add_axes((0.7,0.1,0.25,0.18)) ...: In [23]: for i in range(18): ...: ax[i].set_xlim(10,200) ...: ax[i].set_xlabel("Frequency [Hz]") ...: ax[i].grid() ...: if i%2==0: ...: ax[i].set_ylabel("Phase [deg]") ...: ax[i].set_ylim(0,360) ...: if i%2==1: ...: ax[i].set_ylabel("Magunitude [db]") ...: ax[i].set_ylim(0,100) ...: In [24]: plt.show()大量のグラフを描かなきゃならないとき、ほんと、matplotlibは助かる。-----I draw numerous graphs in NVH analysis.The number is input points by the direction (x,y,z) by respons points by the direction (x,y,z).I coded the drawing 9 graphs script with matplotlib.I show only the graph frame. Please fill your graph with ax[i].plot(x,y).Matplotlib helps me a lot when drawing numerous graphs.にほんブログ村
2017年05月27日
コメント(0)
-

通貨の時刻歴データで相関係数を確認
昨日の補足pandasのDataFrameはそのままplotできるんだった。df2のindexをdfのDATEとする。In [14]: df2.index=df["DATE"]In [15]: df2Out[15]: USD GBP EUR CAD CHF SEK \DATE 2002/4/1 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 2002/4/2 1.000376 1.010485 1.009128 0.998802 1.010974 1.010101 2002/4/3 1.000376 1.007745 1.007234 1.002036 1.009334 1.006216 2002/4/4 0.999624 1.007060 1.008870 1.002875 1.011352 1.004662 In [16]: df2.plot()In [17]: plt.show()ヒストグラムも簡単に描ける。In [12]: df2.hist()df2.corr()でdf2の各項目の相関係数を数値で確認できる。In [18]: df2.corr()Out[18]: USD GBP EUR CAD CHF SEK \USD 1.000000 0.788880 0.601459 0.445916 0.349983 0.569909 GBP 0.788880 1.000000 0.857143 0.685949 0.114371 0.856715 EUR 0.601459 0.857143 1.000000 0.840930 0.316401 0.930616 CAD 0.445916 0.685949 0.840930 1.000000 0.428916 0.856816 CHF 0.349983 0.114371 0.316401 0.428916 1.000000 0.345189 SEK 0.569909 0.856715 0.930616 0.856816 0.345189 1.000000 DKK 0.604500 0.859385 0.999925 0.837822 0.311634 0.929918 NOK 0.459964 0.827909 0.885467 0.818451 0.056670 0.909866 AUD 0.148808 0.364647 0.593474 0.829004 0.614794 0.706079 NZD 0.476935 0.522166 0.652619 0.768790 0.760281 0.741156 ZAR 0.363446 0.733953 0.548567 0.402185 -0.423005 0.555165 BHD 0.999955 0.791010 0.603569 0.448606 0.347694 0.571623 HKD 0.999796 0.783444 0.598896 0.446592 0.359251 0.566177 INR 0.635536 0.874704 0.688723 0.490010 -0.289883 0.640677 PHP 0.733401 0.559403 0.598052 0.673539 0.690698 0.607045 SGD 0.555170 0.323379 0.468884 0.602471 0.924799 0.500770 THB 0.599988 0.524815 0.658452 0.775611 0.740537 0.661132 KWD 0.968904 0.875076 0.747369 0.594935 0.341325 0.716675 SAR 0.999984 0.789996 0.602408 0.446916 0.348938 0.570900 AED 0.999996 0.789377 0.602038 0.446478 0.349488 0.570306 MXN 0.692245 0.837368 0.588042 0.413683 -0.247618 0.616862 IDR(100) 0.595615 0.764383 0.487969 0.302434 -0.387710 0.525052 TWD 0.934051 0.732648 0.627012 0.576726 0.580208 0.650713 相関係数でクラスター分析In [11]: sns.clustermap(df2.corr(),annot=True)4つのクラスターに分かれる。1. [TWD, KWD, HKD, BHD, SAR, USD, AED]2. [GPB, CAD, NOK, SEK, EUR, DKK]3. [CHF, AUD, SGD, NZD, PHP, THB]4. [ZAR, DR(100), INR, MXN]USDとの相関係数が1に近い通貨は、ドルペッグ制の通貨。にほんブログ村
2017年05月23日
コメント(0)
-
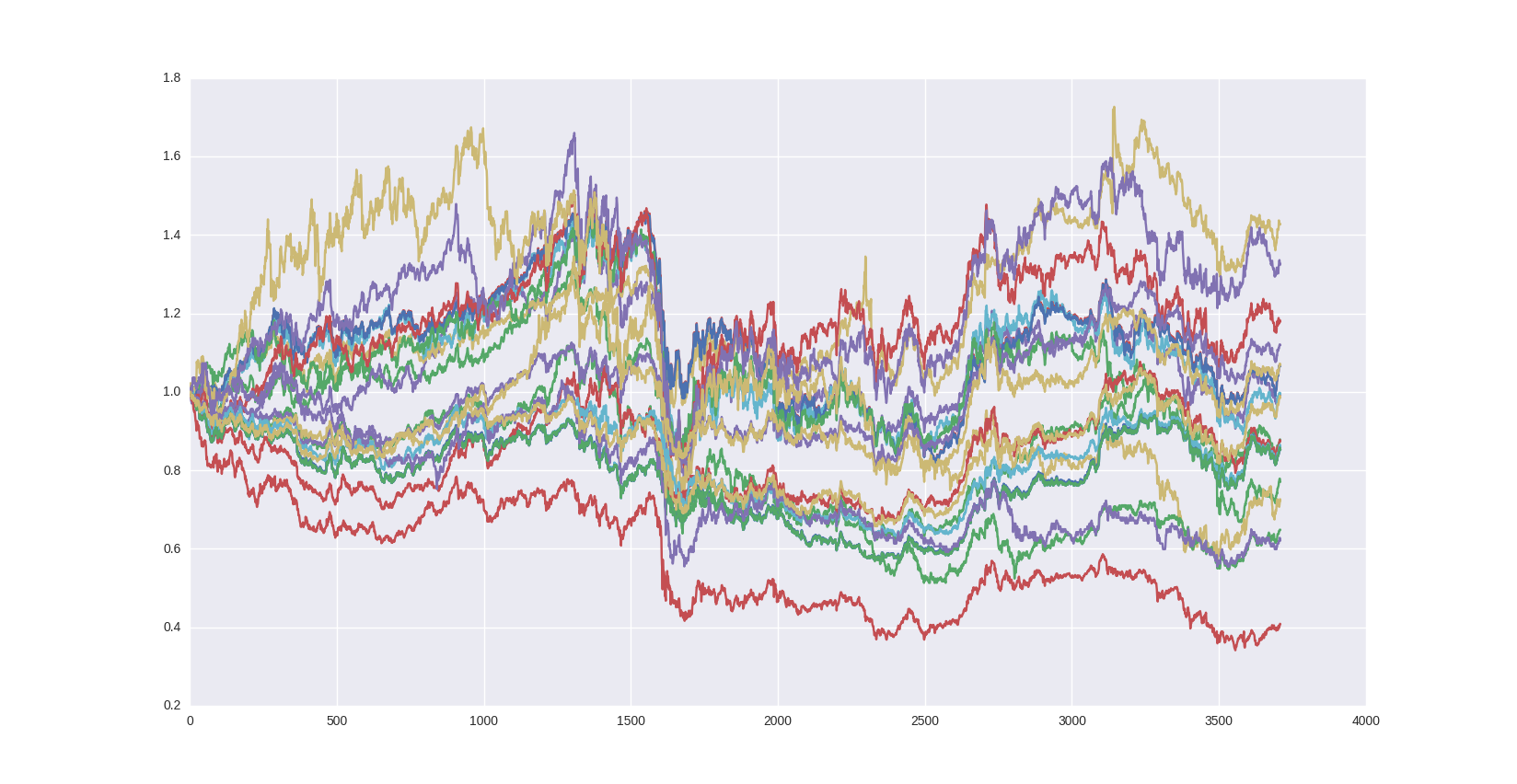
通貨の時刻歴データで相関係数を確認
みずほ銀行為替データから2002/4/1〜2016/5/15のデータを取得https://www.mizuhobank.co.jp/rate/market/historical.html以下、ipythonで実行。In [2]: import pandas as pdIn [3]: import matplotlib.pyplot as pltIn [4]: import seaborn as snsIn [5]: df=pd.read_csv("quote_170516.csv")#日付以外をdf1In [6]: df1=df.ix[:,1:]#最初の日付(2002/4/1)の値で規格化し、df2In [7]: df2=df1/df1.ix[0]In [8]: #比較チャートを描画In [9]: for curr in df2.columns: ...: plt.plot(df2.index,df2[curr]) ...: In [10]: plt.show()In [11]: sns.pairplot(df2)In [12]: plt.show()In [13]: sns.heatmap(df2.corr(),annot=True)In [14]: plt.show()USD, BHD, HKD, KWD, SAR, AED, TWDは相関係数がほぼ1であり、ほぼ同じ値動きをすることがわかった。にほんブログ村
2017年05月22日
コメント(0)
-

pythonでランダムウォーク
ググるといろいろ出てきますが、とても簡単だったのでメモ。In [1]: import numpy as npIn [2]: import matplotlib.pyplot as pltIn [3]: a=np.random.randn(10000) #mu=0, sigma=1の標準正規分布に従う乱数10000個In [4]: b=a.cumsum() #aの乱数を累積In [5]: x=np.arange(10000) #x軸の用意In [6]: plt.plot(x,b)In [7]: plt.show()10回繰り返しIn [3]: for i in range(10): ...: a=np.random.randn(10000) ...: b=a.cumsum() ...: x=np.arange(10000) ...: plt.plot(x,b)In [4]: plt.show()にほんブログ村
2017年02月14日
コメント(0)
-

idle3のTurtle Demo
AnacondaのIdle3のHelpからTutle Demoを起動すると、いろいろと面白いexampleがあった。↓AnacondaのIdle3↓tdemo_tree.py↓tdemo_fractalCurves.pyにほんブログ村
2017年01月05日
コメント(0)
-
python selenium geckodriver
最新のselenium (3.0.2)とfirefox50.1.0で以下のエラーが出た。selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH. 以下のサイトでgeckodriverを入れることができた。http://d.hatena.ne.jp/rougeref/20161014#1476427143geckodriverを以下からダウンロードhttps://github.com/mozilla/geckodriver/releases解凍してbinの下に置く。$ tar -zxvf ./geckodriver-v0.11.1-linux32.tar.gz$ sudo cp ./geckodriver /usr/local/binおかげで解決できた。にほんブログ村
2016年12月26日
コメント(0)
-
windows10にubuntuインストール
オープンCAE勉強会で発表されたので、試しにインストールしてみた。以下のサイトの手順に従ってできた。http://qiita.com/Aruneko/items/c79810b0b015bebf30bbバージョンは以下。pyontaku14@DESKTOP-UP0L4M0:~$ cat /proc/versionLinux version 3.4.0-Microsoft (Microsoft@Microsoft.com) (gcc version 4.7 (GCC) ) #1 SMP PREEMPT Wed Dec 31 14:42:53 PST 2014pyontaku14@DESKTOP-UP0L4M0:~$pythonは2.7.6だった。(古い)pyontaku14@DESKTOP-UP0L4M0:~$ pythonPython 2.7.6 (default, Jun 22 2015, 17:58:13)[GCC 4.8.2] on linux2Type "help", "copyright", "credits" or "license" for more information.>>>にほんブログ村
2016年10月03日
コメント(0)
-
Pyconjp2016 2日目
↓講演のメモ○Keynote・Python3.6の紹介・Python2と3の話・Pycharmの紹介○Pythonではじめるfinance hack入門↓概要https://pycon.jp/2016/ja/schedule/presentation/24/・エクセルで消耗からpythonへ移行・xlwingsでエクセルからpython実行できる・pandasのdatetime index→date_range→土日スキップした連続データ作れる・highcharts使うと簡単にローソク足作れ↓資料https://github.com/drillan/pyconjp2016○Deep Learning with Python & TensorFlow↓概要https://pycon.jp/2016/ja/schedule/presentation/20/・与えたデータ量が増えると劇的にパフォーマンスが上がる。○Building Distributed System with Celery on Docker Swarm↓概要https://pycon.jp/2016/ja/schedule/presentation/5/・celeryの紹介ジョブ管理システムのようだ。○pandasによる時系列データ処理↓概要https://pycon.jp/2016/ja/schedule/presentation/23/・リサンプリング.resample・補間.interpolate・ウィンドウ関数.rolling・シフト.shift・差分.diff・プロパティアクセス.dt・クロス集計.pivot_table・pandas.tseries.offsets.CustomBusinessDay・japandas・JapaneseHolidayCalendar○Building a data preparation pipeline with Pandas and AWS Lambda↓概要https://pycon.jp/2016/ja/schedule/presentation/39/○LT・自走ルータ、走るのを見たかった。-----Pandas活用の話を詳しく聴くことができた。講演は厳選されただけあり、どの話も充実していた。来年も参加したいと思う。スタッフの方々に感謝。にほんブログ村
2016年09月22日
コメント(0)
-
Pyconjp2016 1日目
今年初めて、以下のイベントに参加した。http://pyconjp.connpass.com/event/30692/↓講演のメモ○Keynote・プログラミングは思考を変える。・重要なのはシステム・テクノロジーで素晴らしい政府をつくる。○Blockchain for Pythonists・働き方、組織、イノベーション、サステイナブル・Fintechを可能とさせた技術や開発の進化→CSS, クラウド、API化、アジャイル開発・日本のFintechへの投資規模は米国の1/200、中国よりもずっと少ない・Bitcoinの特長→手数料がかからない、改ざんが困難、システムがダウンしていない・ビットコインのステークホルダー→ユーザー、マイナー・ビットコインの構成技術ハッシュ関数、ちがう値から同じ入力ができない、公開鍵暗号、電子署名、P2Pネットワークプルーフオブワーク、コンセンサス、アルゴリズム・課題→法律、金融規制、税制・ブロックチェーンのテクノロジー→スマートコントラクト、スマートプロパティ○Pythonで作るWebクローラ入門http://sssslide.com/speakerdeck.com/amacbee/pythondezuo-ruwebkuroraru-men○数学的基礎から学ぶDeep Learning・Forward Propagagtion→NNに入力を与え、問題を解いてもらう例:画像のクラス分類・Back Propagation→エラーに関する情報を返す・学習すべきパラメータ・ユニットのモデル詳細l:レイヤー番号k:ユニット番号kが出す側、jが受ける側のユニット番号y2=f(Wy1+b2)○基礎から学ぶWEBアプリケーションフレームワークの作り方http://c-bata.link/webframework-in-python/slide.html#1○LT・カラオケ採点システム→面白い。リアルタイムで、自分の歌とお手本の差が表示され、採点される。・仮想通貨の取引http://qiita.com/Akira-Taniguchi/items/e52930c881adc6ecfe07・自分の成長・Pythonと天文学-----パーティーでドイツ人とオーストリア人と話をした。ドイツ人は、世界中で広告関連の仕事をしていて、wEBアプリなどでPythonを使っているということだった。オーストリア人は、日本在住で、顧客データ分析などにPythonを使っているということだった。Fintech、WEBスクレイピングの具体的な手順、Deep Learningの基礎的な話と最先端の話が聞けたりして、刺激を受けた充実の1日だった。にほんブログ村
2016年09月21日
コメント(0)
-
chromeのアドオン vimium
最近、地味にvimにはまっていて、chromeブラウザをvimと同じように操作できるアドオンをいれてしまった。chromeウェブストアで"vimium"と検索すると出てくる。https://chrome.google.com/webstore/search/vimium?hl=jahjklで画面を移動し、iをタイプするとリンクに記号がつき、その記号をタイプするとリンクに飛べる。shift+jで左のタブに移動し、shift+kで右のタブに移動できる。?でキーボード・ショートカットを表示できる。以下の本家のサイトに短い動画があり、参考になる。http://vimium.github.io/ブラウジングにほとんどマウスが必要なくなる。結構感動。快適にほんブログ村
2016年08月30日
コメント(0)
-
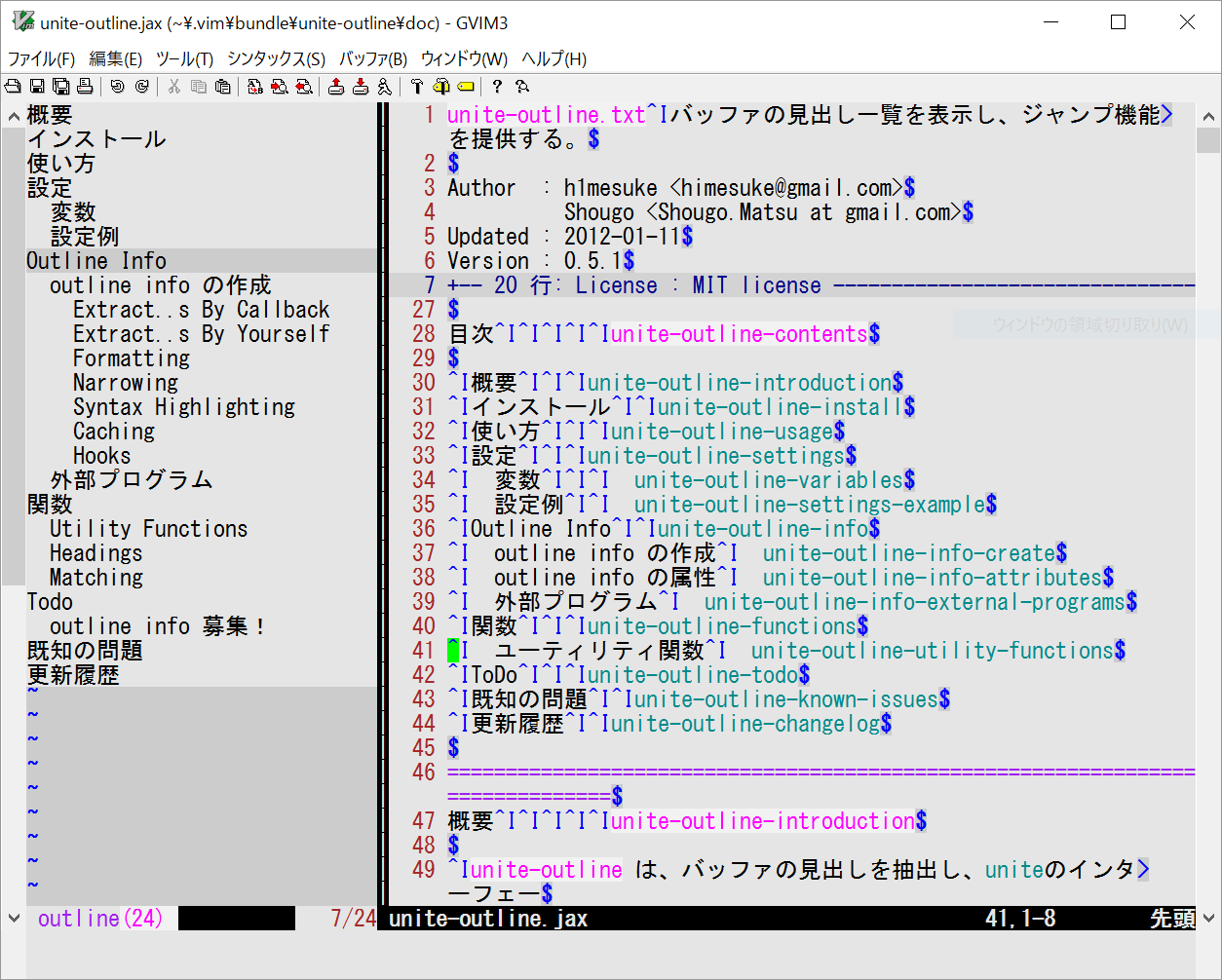
vim unite-outline
いろいろとテキストエディタを遍歴したが、ただで、WindowsでもLinuxでも使えて、軽くて、高機能ということで、最近はvim(とgvim)を使っている。前からアウトライン表示をして、見出しをダブルクリックすると飛べる機能を探していた。検索するとunite-outlineでできるようだ。これを使うためには、NeoBundleというプラグインが必要になる。NeoBundleを導入するには、gitが必要になる。以下、Windowsでunite-outlineを導入するまでのメモ書き。0. vimの取得以下から、ダウンロードし、解凍して任意のフォルダにコピーhttps://www.kaoriya.net/software/vim/1. gitのインストール以下から、ダウンロード&インストール。https://git-scm.com/downloads↓インストール手順参考URLhttps://opcdiary.net/?page_id=270652. NeoBundle導入git bash起動し、以下を入力&実行% mkdir ~/.vim/bundle% git clone https://github.com/Shougo/neobundle.vim \~/.vim/bundle/neobundle.vim3. _vimrc作成vim設定ファイルがあるフォルダ(vimrcがあるフォルダ)に_vimrcを作成し、以下のサイトを参考に_vimrcに書き込む。http://qiita.com/hikachan/items/a189f3051dd94f551cc9以下2つのプラグインを_vimrcに追加NeoBundle 'Shougo/unite.vim'NeoBundle 'Shougo/unite-outline'3. git bashからgvim起動環境変数pathにvimrcがあるフォルダまでのパスを通しておく必要がある。gvimで:NeoBundleInstallとコマンド入力するとプラグインがインストールされる。4. unite-outlineの使い方:Unite outlineとコマンド入力するとアウトラインが表示される。:Unite -vertical -winwidth=30 -no-quit outlineとコマンド入力すると左側にアウトライン表示される。↓unite-outline.jaxに適用見出しをダブルクリックすると飛べる。ここまで来るのに結構苦労した。見出し語の登録方法を調査中。↓参考URLhttp://kaworu.jpn.org/vim/NeoBundlehttp://hinagishi.hateblo.jp/entry/2011/11/18/135701にほんブログ村
2016年08月27日
コメント(0)
-
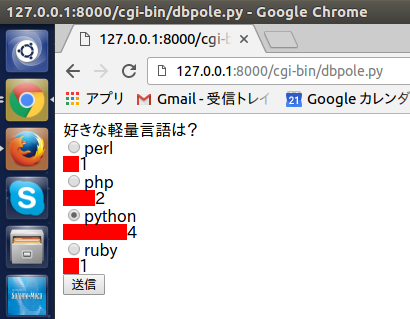
みんなのPython(Webアプリ編)
1 PythonとWebアプリケーション(Webアプリケーション概論/復習!!Python/PythonでWebサーバを作る/Webアプリケーションに値を渡す ほか)2 効率的なWebアプリケーション開発(効率的なWebアプリケーション開発とは/Pythonとテンプレートエンジン/O/Rマッパーを使ったデータベースの操作/RSSリーダーを作る ほか)webプログラミングをちょっとやってみたいと思い、だいぶ前に買ったきりになっていたこの本を開いてみた。ほかの言語では、WEBサーバーをたてるのにApacheが必要だったり、SQLを使うためにxamppが必要だったりするが、pythonでは、モジュールとしてimportすれば使える。CHAPTER 07のdbpole.pyを再現してみた。ラジオボタンを選択して送信ボタンを押すと、投票数が集計されていく。集計結果はcon=sqlite3.connect('./dbbfile.dat')により、dbfile.datに保存される。この例題は、pythonプログラム、webサーバー、データベースとの連携を確認できる。これまでwebアプリの仕組みがわかっていなかったが、少しわかったように思う。にほんブログ村
2016年08月20日
コメント(0)
-
みんなのPython勉強会#12
以下の勉強会に参加した。http://startpython.connpass.com/event/28360/◯Talk 1:「私のPython学習奮闘記#5 〜学習のTIPs編〜」守破離ハマった時は、ググる→人に聞く聞ける人と知りあうために勉強会を活用◯Talk 2:「Pythonのプロファイリング」プロファイリング→プログラムのボトルネックになっているところを探す。cProfileusage: python -m cProfile ファイル名出力結果の見方tottime→cumtimeプロファイラを使えば、ボトルネックになっている箇所が可視化できるので、パフォーマンスがいいアプリケーションへ改善するための大きな手助けとなる。◯Talk 3:「Pythonで見る関数型言語の考え方」関数型言語は破壊的代入を許さない。pandas0.16.2にpipeが導入された。他の部分に影響を与えず、仕様変更が容易になる。関数は、引数をとって戻り値を返す。外部に影響を与えない関数のほうがいい。-----cProfileというものをはじめて知った。関数型言語、ぱっと見、使いにくそう。正直、言語のパラダイムが何であろうが、やりたいことができればそれでいいと思ってしまう。それでも、言語のパラダイムを知ったほうが、よりよりコードが書けるのかもしれない。にほんブログ村
2016年05月10日
コメント(0)
-
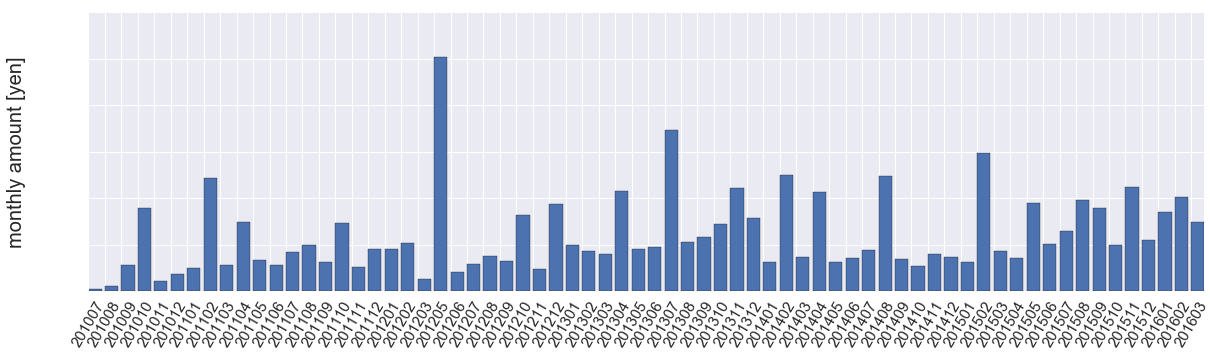
pythonで楽天カードの明細を分析
2010年7月から2016年3月までの月ごとの利用額合計をグラフにしてみた。(金額は非表示)必要なモジュールをインポートimport pandas as pdfrom pandas import Series, DataFrameimport matplotlib.pyplot as pltimport seaborn as snsあらかじめ、csv名のテキストファイル"csv_list.txt"を用意して読み込み、リストに格納する。csv_list=pd.read_csv("csv_list.txt",header=None)csv_list=list(csv_list.ix[:,0])以下の関数で、csvのファイル名を渡して、月ごとの総額を出している。def month_sum(csv_name): df1=pd.read_csv(csv_name, encoding="SHIFT-JIS") sum1=df1[u"利用金額"].sum() return sum1月ごとのcsvの総額をmonth_sum_listに格納。month_sum_list=[]month=[]for csv_name in csv_list: month_sum_list.append(month_sum(csv_name)) month.append(csv_name[5:11])x, yを以下のように定義。x=range(len(csv_list))y=month_sum_list描画で上の画像が出る。plt.figure(figsize=(20,5))plt.xticks(x,month,fontsize=15,rotation=60)plt.yticks(fontsize=15)plt.ylabel("monthly amount [yen]",fontsize=20)plt.bar(x,y)年ごとは以下。期間の利用額合計トップ20の店舗小田急は、定期を買うので、利用額が大きい。店舗名は、結局、手作業で重複などを修正しなければならず、手間がかかった。何にいくらつかったかを把握することができた。にほんブログ村
2016年04月28日
コメント(2)
-
みんなのPython勉強会#11
4月、初心に帰れる内容だった。http://startpython.connpass.com/event/28359/Talk 2:「春からはじめるPython環境の作り方」・Windows、Mac、LinuxともAnacondaを使うのがいい。・pyenvなどで環境変数設定すれば、使いたいpythonが使えるはず。Talk 3:「Pythonとデータサイエンスの歴史」・weatherpyという気象情報を提供するパッケージがある。scipyconは2004・numpyは1995ごろから使われている。・Numpy arrayとlistのちがいlistは値の参照、実体ではないarrayにはValueがある。・Pyhton+Numpy(Scipy)+matplotlibでMATLABと同等になる。・IPython notebookがPython普及のためのキラーコンテンツになりそう。質疑応答にて・Pythonの正しいやり方は標準ライブラリを見るといい。-----通常、目的を達成するには、いろいろな言語のツールをかき集なければならないが、Pythonなら、モジュールインポートで、たいていの目的は達成できる。にほんブログ村
2016年04月12日
コメント(0)
-
みんなのPython勉強会#10
前回は出張で参加できなかったが、今回は参加できた。http://startpython.connpass.com/event/25269/祝!10回記念!ペッパーのデモを見ながら、ペッパーの感情生成の開発者から話を聞くことができた。〇「データサイエンスにおけるPythonの存在感」東京大学 ゲノムサイエンス分野 特任助教 辻真吾氏データサイエンティストのスキル→Python, Matlab, SAS, RMatlab, SASはオープンではない。重力波を観測(Ligo)→使われていたのはipython notebook。データはnotebookとともに公開されている。オープンだと門戸が開かれている。Rはオープンだが、pythonは汎用言語。結論:データサイエンスにはpythonがいい。↓「実践Pythonデータサイエンス」先着100名様に45ドルキャンペーンhttps://www.udemy.com/python-jp/?couponCode=201603D45〇「心の鍵を開く感情技術」第1部東京大学大学院医学系研究科 音声病態分析学講座 特任講師 光吉俊二氏↓メモそのままPepperの感情をつくった。感情→工業規格?工業規格化した。感情はいくつあるか?怒りとは何か?→調べていった。感情を表す単語→日本語4500語→英語223語223語を4色にあてこんだ。→黄色joy、緑calm、青sadness、赤anger感情の色彩化→単純化情動反応、身体反応と物質の関係調査脳の伝達物質が多い少ないを可視化した。喜んだり悲しんだりして波打ちながら定常状態に収束する。感情のホメオスタシス→性のフィードバック、負のフィードバック人の感情発話の評価2800名に実施ミモシス(アンドロイドアプリ)→情動を見えるようにした。人の主観→自分でわからない興奮→喜怒哀楽より原始的ネガティブな声とポジティブな声の脳のちがいうつ病と健常者をきれいに分離できた。精神疾患、神経疾患、認知症、循環器疾患、呼吸器疾患、代謝性疾患、耳鼻科疾患に適用音声の病態分析を用いたフォローアップ〇「心の鍵を開く感情技術」第2部cocoro SB株式会社 取締役 大浦清氏↓メモそのままペッパーの感情を実装感情地図上で感情を創発7/1よりペッパーをアルバイト派遣ペッパーが人々の生活の中で、実際にやれることをやってみよう。→ティッシュ配り、握力は70gくらいしかない。実際にティッシュをもらった。言葉がなくても心があればコミュニケーションができる。感情生成エンジン→センサー群からあがってきた情報をポジティブとネガティブに分ける感情創発→当初は感情生成エンジンはpythonで書いた→今はC++Pepperの心を揺らす入力ペッパーが痛いというと人がかまってくれる。ペッパーの将来→家族の喜びにつながる行動にする。パーソナルロボット→感情エンジン+クラウドAI空気を読んで人を笑顔にする感情の大きな振れ→重点的に記録いつもの感情→簡略的に記録空気を読んで成長愛によって自律行動人とロボットが共に働く時代へ人、モノ、場所、言葉、記憶に対し印象や感情を持つ独自に固有の人格を持つAImugen神電(バイク)の感情さまざまな電子デバイスが心を持つ。-----10回記念ということで、ビッグなゲストスピーカーが来てくれた。リーディングエッジ社、クリークリバー社の社長が冒頭であいさつをしていた。報道関係者が入ってきた。参加者が100人を超えていた。ペッパーからティッシュをもらった。3回目から参加してきたけれど、本当に大きな勉強会に育ってきて感慨深かった。主催者たちのがんばりが、これだけの人たちを集めている。人の感情を明確に定義し、感情地図を作成。それをプログラミングによってロボットに実装する。感情って、科学で扱いにくい最たるものの一つだと思うが、ここまで研究が進み、形になっていることを見せられて斬新だった。参加できて得した気がした。にほんブログ村
2016年03月08日
コメント(2)
-
Python勉強会飲み会
Start Python Clubの主催者メンバーと常連メンバーで飲み会。場所は、渋谷の琉球チャイニーズTAMA。家で騒音を出しても近所迷惑にならないかをオープンCAEで可視化したいという人がいた。調べてみると以下のものがあった。http://sfepy.org/doc-devel/examples/acoustics/acoustics3d.htmlhttp://jikosoft.com/software/xfem/download.htmlただ、これでできるかは難しそうだ。参加者には、データベースを扱っている人、3Dデータを扱っている人などがいて話が面白かった。前回の勉強会では長野会場との中継をやっていたが、うまくいかない部分があり、改善方法を話し合っていた。次回勉強会が楽しみだ。にほんブログ村
2016年01月27日
コメント(0)
-
python, tclからLinuxのコマンド実行
〇pythonimport oscmd="cp aaa.txt bbb.txt"os.system(cmd)〇tclset cmd "cp aaa.txt bbb.txt"eval excec $cmd-----仕事でパラスタするのに必要だったのでメモ。にほんブログ村
2016年01月26日
コメント(0)
-
Pythonのライブラリをpipで管理する
以下の記事から。http://joppot.info/2014/01/29/522pip freeze または pip listでインストールされているPythonライブラリとそのバージョンを確認できる。pyontaku14@pyontaku14-Inspiron-5437:~/anaconda$ pip freezeCython==0.20.1post0Jinja2==2.8MarkupSafe==0.23PAM==0.4.2Pillow==2.3.0Pygments==2.0.2Twisted-Core==13.2.0Twisted-Web==13.2.0VTK==5.8.0adium-theme-ubuntu==0.3.4apptools==4.1.0apt-xapian-index==0.45argparse==1.2.1arronax==0.06backports.ssl-match-hostname==3.4.0.2certifi==2015.9.6.2chardet==2.0.1colorama==0.2.5command-not-found==0.3configobj==4.7.2debtagshw==0.1decorator==3.4.0defer==1.0.6dirspec==13.10duplicity==0.6.23envisage==4.1.0functools32==3.2.3-2gdata==2.0.18googlecl==0.9.13html5lib==0.999httplib2==0.8igakit==0.1ipykernel==4.1.0ipython==4.0.0ipython-genutils==0.1.0jsonschema==2.5.1jupyter-client==4.1.1jupyter-core==4.0.6lockfile==0.8lxml==3.3.3matplotlib==1.3.1mayavi==4.1.0mercurial==2.8.2mistune==0.7.1nbconvert==4.0.0nbformat==4.0.1notebook==4.0.6numexpr==2.2.2numpy==1.8.2oauthlib==0.6.1oneconf==0.3.7path.py==8.1.2pexpect==3.1pickleshare==0.5piston-mini-client==0.7.5ptyprocess==0.5pyOpenSSL==0.13pycrypto==2.6.1pycups==1.9.66pycurl==7.19.3pyface==4.1.0pygobject==3.12.0pyparsing==2.0.1pyserial==2.6pysmbc==1.0.14.1pysparse==1.1python-apt==0.9.3.5ubuntu2python-dateutil==1.5python-debian==0.1.21-nmu2ubuntu2pytz==2012cpyxdg==0.25pyzmq==14.7.0reportlab==3.0requests==2.2.1scipy==0.13.3sessioninstaller==0.0.0simplegeneric==0.8.1six==1.5.2software-center-aptd-plugins==0.0.0sympy==0.7.4.1system-service==0.1.6tables==3.1.1terminado==0.5tornado==4.2.1traitlets==4.0.0traits==4.1.0traitsui==4.1.0unity-lens-photos==1.0urllib3==1.7.1wheel==0.24.0wsgiref==0.1.2wxGlade==0.6.8wxPython==2.8.12.1wxPython-common==2.8.12.1xdiagnose==3.6.3build2zope.interface==4.0.5にほんブログ村
2016年01月10日
コメント(0)
-
みんなのPython勉強会#8
今年最初の勉強会。http://startpython.connpass.com/event/24092/Talk 1:「Pythonによる機械学習はじめの一歩」Talk 2:「pandasとmatplotlibで株価分析」Talk 3:「moxを使ってユニットテストを書く」Talk 4:「tornadoとArduinoをつなげてみる!」Talk 5:「MQTTで亀を操る」資料はipynbで提供されているので、じっくりと検証&確認ができる。今回は、以下の新しい試みがあった。1. 長野とのライブ接続2. ipython notebook(*.ipynb)とGitHubでのリアルタイム資料提供3. 学生優待制度の開始アンケートでは、「もっとコードの解説がほしい」という声があったようで、それに応えた内容だった。本当に主催者の「勉強会をみんなにとってもっと価値あるものに」という姿勢が伝わる。3月までは続けるということだったが、4月も実施することになった。いろんな方がいろんな目的でPythonを使用している。今回も新しい友達ができた。にほんブログ村
2016年01月08日
コメント(2)
-
fortran90 構造型
ベクトルを返り値にする関数って、どうすればいいのかわからず、調べていると構造型というものが見つかった。type 構造型名 型 :: 成分名 …end type 構造型名例えば、ベクトル2つを入力して、ベクトルの外積を返す関数は以下になる。構造型の成分は%をつけて定義する。-----ここからprogram outer_product type vector double precision :: x, y, z end type vector type(vector) :: a, b, c a%x=1.0d0 a%y=0.0d0 a%z=0.0d0 b%x=1.0d0 b%y=1.0d0 b%z=0.0d0 c = vector_product(a,b) write(*,*) ccontains function vector_product( u, v) result(w) type(vector) :: u, v, w w%x = u%y * v%z - u%z * v%y w%y = u%z * v%x - u%x * v%z w%z = u%x * v%y - u%y * v%x end functionend program outer_product-----ここまで↓参考URLhttp://www7b.biglobe.ne.jp/~fortran/education/fortran90/sec9.htmlにほんブログ村
2016年01月08日
コメント(0)
-

sololearn
以下のサイトとAndroidアプリでpythonとhtmlを勉強した。http://www.sololearn.com/適切な章分けがされていて、テキスト直後にクイズが3問程度ある。テキストの内容が定着しやすい。進捗が目に見えて、どんどん進めたくなる。Certificateをとることができた。プログラミング、エクセル、WEBなどを独学したい人にはおすすめ。↓python↓htmlにほんブログ村
2015年12月20日
コメント(0)
-
みんなのPython勉強会#7
今年最後。もう7回目だ。http://startpython.connpass.com/event/22661/〇Talk 1:「いま再びのPython入門」・Pyhtonには勢いがある・Pythonのインストール→Anaconda・2 or 3 →3→printと文字列の扱い方が大きな違い・Jupyter notebook→Webブラウザ内にコードと結果(画像を含む)などを一括管理できる。・便利なモジュール→glob, pandas, seaborn→データ可視化、双方向の階層的クラスタリングもできる、・WSGI(Web Server Gateway)便利なモジュールがPython人気を支えている気がする。〇Talk 2:「ゼロから始めた私のPython勉強録?Webアプリ編?」)・Pyramid→Webフレームワーク・js,jQuery・IDE: PyCharm・Jinja・Bootstrap→簡単にモダンなデザインができる、簡単に覚えられる、公式ドキュメント充実・Git-GitHub→気軽に機能追加ができる、commit,checkout,pushだけでも便利・twilio・テストはこまめにした方がいい。・ajax通信を使って今風なアプリを作りたい・周辺知識に手を広げすぎない・マルチタスクは集中力が落ちる・一つのことを一気に覚えたほうが効率がいい。・バージョン管理をする・OpnStackなどを学びたいゼロから4ヶ月でWEBアプリ作成ができるところまでになった実例。本人の資質と努力が大きいと思うが、勉強法は参考になる。〇Talk 3:「PythonによるWebアプリケーション入門 ?Django編?」・pythonでのWebアプリケーション開発・Djangoでの開発イメージ→モデル、ビュー、テンプレート・Admin機能・Pythonでの選択肢 CGI WSGI→Webサーバーとアプリケーションの共通のインターフェース Webアプリケーションフレームワーク・Webアプリケーションは複雑・Webアプリケーションフレームワーク→枠組みに乗る、クラス、テンプレート作る・代表的なフレームワーク Pyramid→小さく早く堅実なフレームワーク Tornado,→FriendFeed(現Facebook)が開発、非同期のネットワークI/Oライブラリ、シンプルで高速なのが特徴、大規模な実例 Flask→軽量なフレームワーク、Werkzeug,Jinja2 Bottle→軽量なフレームワーク、一つのPythonファイルで提供、フレームワークの学習にも最適 Django→フルスタックのフレームワーク、最新1.9、ドキュメント、テストが充実、コミュニティが活発、大規模な事例・Djangoが提供する機能→モデル、ビュー、テンプレート、フォーム、管理サイト、セキュリティ、国際化、ユーザー認証・Djangoでの開発の流れプロジェクトの作成→アプリケーションの作成→初期設定(setting.py)→モデルの作成→ビューの作成→テンプレートの作成→ルーティングの定義・djangoのインストール→pip install django・ブログ管理アプリケーション開発のデモ・管理サイト開発の流れモデル→フォーム→ビュー→テンプレート→ルーティングWEBアプリは使うばかりで作ることは考えたこともなかったが、ブログ管理のデモで開発の流れを見ることができた。次回1/8にほんブログ村
2015年12月09日
コメント(0)
-
機械学習について思ったこと
先日、python勉強会で機械学習の話を聞いて以来、機械学習の情報を前より目にするようになった。これまでは判断が簡単な繰り返し作業をコンピュータにやらせることはできているが、より高度な判断が必要な作業についてもコンピュータを使うことが目的なようだ。例えば、機械学習の典型的な例題に、アヤメの分類や手書き文字画像の認識などがある。単に1つの数値の大小で場合分けするのは簡単だが、こういった例題は、いくつもの評価項目を総合して、適切な判断をしなければならない。そのためのアルゴリズムが機械学習アルゴリズムのようだ。CAE分野では、複雑な実現象をいかにしてコンピュータで解ける問題に置き換えるか(モデル化)が重要だ。そのために、実験データと解析データを比較し、モデル化を改善することをPDCAとして回していく。実験計画法、最適化、統計処理ということもCAEで盛んにおこなわれるようになってきているが、これらは道具であり、適切に使用するには高度な知識を有する有識者でないと難しい。機械学習アルゴリズムで、これらの判断も可能になれば、ぼくらの仕事の多くは簡略化される。(っていうかなくなる。)人間の価値基準、判断基準を修得させることが機械学習(AI=人工知能)の究極の目標なのだろう。にほんブログ村
2015年11月12日
コメント(0)
-
みんなのPython勉強会#6
以下の勉強会に参加した。http://startpython.connpass.com/event/21490/〇Talk 1:「私のPython学習奮闘記#4 ?機械学習編?」・トーマス・H・ダベンポート、データ・アナリティクス3.0→ビッグデータのインパクト、ビジネス事例(GE, UPS)・データサイエンスの3要素→ハッキング、数学、実務能力・機械学習の本→「パターン認識と機械学習」、「機械学習プロフェッショナルシリーズ」、「実践機械学習システム」、オライリー・以下のブログから機械学習を習得する3つの方針http://qiita.com/puriketu99/items/c519a95c0b16ea63c1ac1.機械学習に明るい友人をもつこと2.学習用データの縦と横のサイズダウンをすること3.理論を勉強するよりコードをかいた方がはやい・方針-理論の基礎レベルはつかもう-コード実習を重視・Scikit-learnホームページhttp://scikit-learn.org/stable/・どういうデータセットを用意するかが重要→参考になる本やサイト、勉強する方針が紹介された。〇Talk 2:「30分で理解する!機械学習アルゴリズムの全体像」・機械学習ツール→R, Weka, Orange, scikit-learn・機械学習のおおまかな分類→サンプル、説明変数、目的変数(クラス)・データの特徴を見る→クラスタリング、次元縮約・PCA→高次元データの次元を減らす。サンプルが最もばらついている方向に軸を設定・K-meansクラスタリング→ランダムな開始点から初めて、近くのサンプルをクラスター化。その後クラスの重心に新たな中心を設定。・SVM,決定木、Random Forests、Deep Learning・Kernel trick→簡単な境界で分類するテクニック・Leave One Out Cross Validataion (LOOCV)→主な機械学習アルゴリズムについての解説。どのアルゴリズムを使うかはscikit-learnのcheat-sheetが参考になる。機械学習について少し理解が進んだ気がする。〇Talk 3:「俺のアソシエーション分析がこんなに効果が出ないわけがない 最終回」・Pythonライブラリ厳選レシピ 、Pythonエンジニア養成読本の執筆者の講演・アソシエーション分析とは→パンとバター、パンとジュースを一緒に買う人が多い。→セット割引、近くに置く→共起性・MovieLensを題材とした事例紹介→アソシエーション分析の考え方と事例が紹介された。なかなか一筋縄ではいかないようだ。-----てっきり申し込んでいたと思いこんでいたら、申込みされていなかった。当日の朝あわてて申し込んだら、補欠で11人待ちだった。今回はぜひとも参加したいと思っていたので、日中やきもきしていたが、キャンセルが出て18:00過ぎに定員に入れた。ラッキーだ。pythonによる機械学習は人気のコンテンツで、大盛況だった。にほんブログ村
2015年11月09日
コメント(0)
-
業務のためのPython勉強会#5
65人が参加し、これまでで最多だった。Talk1→初心者がつまづきやすいところ、Talk2→専門家からのpythonの講義、talk3→実務での最先端の適用事例という構成になっており、初心者からプロまで参考になる内容になっている。http://startpython.connpass.com/event/20092/〇Talk 1: 「ゼロから始めた私のPython勉強録」・紹介された書籍、サイト新しいLinuxの教科書CodeKataRaspberry pi×電子工作・こんな勉強会があったらいいPythonの開発環境を作るための勉強会Pycharmを使い倒すwebアプリケーションフレームワークを基礎から解説してくれる本Raspberry Piの電子工作教室エンジニアのための速読英単語みたいのたしかに、pythonの開発環境を整えるのは一苦労だ。〇Talk 2: 「pandasを使いたおす」都道府県の人口のcsvを題材に、pandasのいろいろな機能を紹介してくれた。エクセルで定番のソート、行や列の追加、削除などはもちろん、matplotlibと組み合わせて簡単にヒストグラムや散布図が作れる。資料がアップされたら確認してみたい。〇Talk 3: 「ソーシャルリスニングシステム新潮流とPythonによる実行例」ソーシャルリスニング→流れている情報をモニタリングエコノミックインデックス社のミッション→すべての経済活動に等価性を・物事の因果関係を明らかにする・既存のリスニングシステム→流通する情報を集計し、整理しただけ→費用対効果を正確に知りたい・情報に接する→行動する→行動の結果(現象)がどうなったか・エコノミックインデックス社は因果関係をほぼリアルタイムに提供する。→そのために情報を見逃さない。・ソーシャルリスニングのフロー情報源→ストレージ→ノイズ除去→word count→p/n判定(たいていここまで)→sentiment→出力(エコノミックインデックス社はsentimentまでやる)・キーワード機械学習、自然言語処理、サポートベクターマシン(SVM)、カーネル法、カーネルトリック、コストパラメータ:C、Bag of Words:単語の出現回数、形態素解析:Mecab-----ビアバッシュでは、LT(ライトニングトーク)2件聴けた。データベースの活用例とPyConjp 2015の様子だった。どの話も非常に興味深かった。特にTalk3では、機械学習の最先端適用事例が聴けた。ツイッターなどの断片的な情報を集めて、分類し、新しい知見を得るというのは、マーケッターのみならず興味があるところだと思う。にほんブログ村
2015年10月14日
コメント(0)
-
incr tclの社内トレーニング
昨日、今日10:00~12:00、tclにオブジェクト指向の機能を持たせたincr tclの社内トレーニングだった。主にクラスについての講義とハンズオントレーニングを受けた。↓ぼくにとってのポイントオブジェクト指向プログラミング(Object Oriented Programming)では、世界をモノ(Object)の集まりととらえる。モノはプロパティ(属性)とメソッド(動作)を持つ。クラスはよくたい焼きの型にたとえられる。たい焼きの型がクラスで、たい焼きがインスタンス。たい焼きの型のプロパティ→形、大きさなどたい焼きの型のメソッド→開く、閉じる、焼くなど上位概念がクラスでその具体例がインスタンス。哺乳類クラスの犬クラスのポチ。哺乳類クラスのプロパティ→頭、足、しっぽ、毛などなど哺乳類クラスのメソッド→走る、食べる、寝るなどなど犬クラスは哺乳類クラスのプロパティとメソッドを継承する。is-a関係Dog is a mammal. (犬は哺乳類です。)Pochi is a dog. (ポチは犬です。)クラスにより、モジュール化、パッケージ化が可能になり、大規模開発がやりやすくなる。クラスはプログラムの特徴を決めるため、クラス設計が非常に重要になる。オブジェクト指向の世界観は、この世界をかなりうまく記述できるように思えた。クラスとは、モノを記述するための上位概念なので、うまく汎用性の高いクラスを設計すれば、少ないクラスで多くのモノを記述できる。ぼくは、このような、汎用性の高い、少数で用の足りるクラスのような枠組み、モノの見方が好きだ。大は小を兼ねる。しかし、しゃもじは耳かきにならない。鶏を割くに焉んぞ牛刀を用いん。適材適所。この世界は複雑系なので、そう簡単に記述しきることはできない。どうしても、局所的なケースバイケースでの対応が必要になる。トレーニングのおかげで、前よりはクラスについて理解ができるようになった。にほんブログ村
2015年10月02日
コメント(0)
-
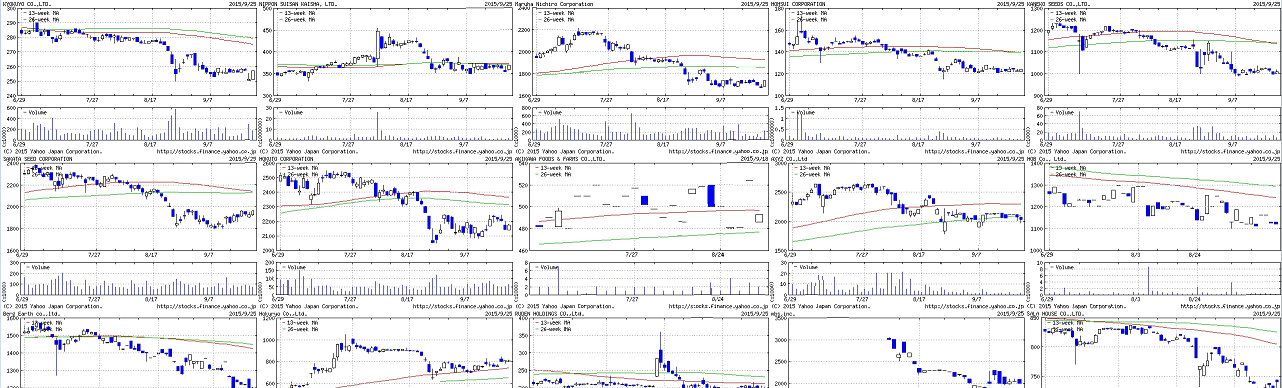
python 画像のダウンロードと複数画像を並べる
株価3ヶ月チャート画像をダウンロードして5x10=50個ずつ並べるスクリプトを書いてみた。-----ここから # -*- coding: utf-8 -*-import urllib2from PIL import Image#yahooファイナンスから3ヶ月チャート画像をダウンロードして50個ずつ並べるdef download(url, path): fp = urllib2.urlopen(url) local = open(path + code+'.jpg', 'wb') local.write(fp.read()) local.close() fp.close()def paste(code, h, v, k): img = Image.open(str(code)+'.jpg', 'r') canvas.paste(img, (((k-1)%5)*h, ((k-1)//5)*v))f=open('codes_150926.csv', 'r') #銘柄コードi=0j=1k=0h=512 #水平ピクセルv=310 #垂直ピクセル# マージに利用する下地画像を作成するcanvas = Image.new('RGB', (5*h, 10*v), (255, 255, 255))for code in f: code=code.rstrip() i+=1 k=i-50*(j-1) print code, k url='http://chart.yahoo.co.jp/?code='+str(code)+'.T&tm=3m&type=c&log=off&size=m&over=m65,m130,s&add=v&comp=' download(url, './') paste(code, h, v, k) if i==50*j: # 保存 canvas.save('c'+str(j)+'.jpg', 'JPEG', quality=100, optimize=True) canvas.close() canvas = Image.new('RGB', (5*h, 10*v), (255, 255, 255)) j+=1canvas.save('c'+str(j)+'.jpg', 'JPEG', quality=100, optimize=True)canvas.close()f.close()-----ここまで ↓結果はこんな感じ codes_150926.csvは以下のような銘柄コードのリスト。 1301 1332 1333 … 9995 9996 9997 画像ダウンロードは、以下の関数で実施。def download(url, path): fp = urllib2.urlopen(url) local = open(path + code+'.jpg', 'wb') local.write(fp.read()) local.close() fp.close() pillowというモジュールで画像の編集がいろいろとできる。画像を並べるのは以下の関数で実施。def paste(code, h, v, k): img = Image.open(str(code)+'.jpg', 'r') canvas.paste(img, (((k-1)%5)*h, ((k-1)//5)*v)) ↓参考URLhttp://blog.takkinoue.com/entry/2015/04/04/171000https://librabuch.jp/2013/05/python_pillow_pil/ にほんブログ村
2015年09月26日
コメント(0)
-
アプリを作ろう! Android入門
第1章 Androidというアプリについて知ろう第2章 アプリを作る準備をしよう第3章 Android Studioでアプリ作成を始めよう第4章 アプリでJavaの基本を学ぼう第5章 アプリに画像を組み込もう第6章 アプリを完成させよう第7章 アプリから画面を呼び出そう第8章 アプリをAndroid端末で動かそう第9章 アプリを公開しようタブレット、スマートフォンのアプリ開発というものを、どうやるのか知りたくて読んでみた。本の通りにやれば、開発環境の準備から、おみくじアプリを作成し、アンドロイド端末で動作させることができた。開発言語はJavaで、書く量は結構多いんだけど、Android Studioの補完機能でずいぶん楽に書ける。説明が丁寧で、図を見ながら進めれば、どこをクリックして、どこに書けばいいのかがわかる。作業の意味についても解説があり、何のためにこの作業をやっているのかがわかる。Javaの基礎についても学ぶことができる。ぼくも仕事でトレーニング資料を作ることがあるので、参考になる。Androidは各バージョンにコードネームがついていて、お菓子の名前になっている。現バージョンの5.0, 5.1はLollipopだ。親しみやすいようにということだろうか。↓Android Studio↓おみくじアプリ【楽天ブックスならいつでも送料無料】【高額商品】【3倍】プリを作ろう! Android入門 Andro...
2015年09月21日
コメント(0)
-
業務のためのpython勉強会#4
ハンズオンでipython notebookの使い方を学んだ。ipython notebookはその名のとおり、pythonコマンドの勉強記録として使えることがわかった。補完機能もあり、pythonコマンドをためすのに適している。matplotlibのグラフも即座に確認できる。懇親会で様々な業種の人と知り合うことができた。インフラサーバー管理、大学の先生、クラウド、マーケティング、ゲノム解析、画像処理など。マーケティングに機会学習を使いたい人が多いようだった。http://startpython.connpass.com/event/18053/?utm_campaign=event_reminder&utm_source=notifications&utm_medium=email&utm_content=detail_btnにほんブログ村
2015年09月10日
コメント(0)
-
テキスト処理の流れ
基本的な流れ1.テキストファイルを開く。2.1行ずつ読み込む。3.必要なデータを変数に入れる。4.出力フォーマットに合わせて書き出す。〇エクセルVBAの例点の座標とIDをdata.txtから読み込んで、距離計算してout.txtに書き出す。Open "C:\data.txt" For Input As #1 '入力ファイルOpen "C:\out.txt" For Output As #2 '出力ファイルDo Until EOF(1) Line Input #1, buf If InStr(buf, "aaaaa") > 0 Then Do Line Input #1, buf inod = inod + 1 nid(inod) = Left(buf, 8) xnod(inod) = Mid(buf, 9, 16) ynod(inod) = Mid(buf, 25, 16) znod(inod) = Mid(buf, 41, 16) Loop End IfLoopFor i = 1 To inod-1 for j=i+1 to inod dist=sqr((xnod(j)-xnod(i))^2+(ynod(j)-ynod(i))^2+(znod(j)-znod(i))^2) print #2, nid(i) & "," & nid(j) & "," & dist nextnextClose #1Close #2にほんブログ村
2015年09月01日
コメント(0)
全78件 (78件中 1-50件目)
-
-

- 最近買った 本・雑誌
- 雑誌『映画秘宝 2024年 11月号』 「…
- (2024-11-23 00:00:20)
-
-
-

- ジャンプの感想
- 週刊少年ジャンプ2024年51号感想
- (2024-11-18 17:45:00)
-
-
-

- 私の好きな声優さん
- 声優の篠原恵美さん、病気療養中に死…
- (2024-09-12 00:00:14)
-



