
Sep 29, 2020

カテゴリ: 機会学習(A.I.)
pythonで競馬予想。これまでのバッグナンバーは下記です。今回は機械学習用の前処理 2にチャレンジです。
Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)
Python で 競馬予想 第2回(HTML解析編)
Python で 競馬予想 第3回(Python上でのデータ加工)
Python で 競馬予想 第4回(Python上での配列定義)
Python で 競馬予想 第5回(機械学習用の前処理 1)
Python で 競馬予想 第6回(機械学習用の前処理 2)
前回まででひとつの配列に出走馬情報をまとめて、数値化できる部分は数値化しました。結果ファイルも数値化して以下のようなファイルになりました。ひとつは学習データ、もうひとうは予想データです。と、その前に機会学習の基礎を自分の理解なりに説明しておきます。(間違っていても責任はとりません。悪しからず)機械学習には大きくわけて教師あり学習と教師なし学習というのがあり、教師なし学習といのは今はやりのDeep Learningもそうだと思っていますが、正解がわからない状態でもデータの差(特徴とか)を見出してクラスタリング(グルーピング)するようなもので、教師あり学習というのは正解をあらかじめ教えておいて、それに基づいて違うデータを予測するというものと思っています。
私が使おうと思っているのは、過去のレースから正解を学習させておいて、今回のレースを予測することなので教師あり学習です。という事でデータの説明に入りたいと思います。
まずは学習データから紹介します。下記の黄色枠で囲ったところが結果データ。すなわち教師データになります。右の馬情報(horse information)から、左の黄色枠(答え)が導かれています。黄色内の紫で囲った部分が答え、1着になったら1、3着以内だったら1、5着以内だったら1を示しています。この答えになるように学習させることになります。
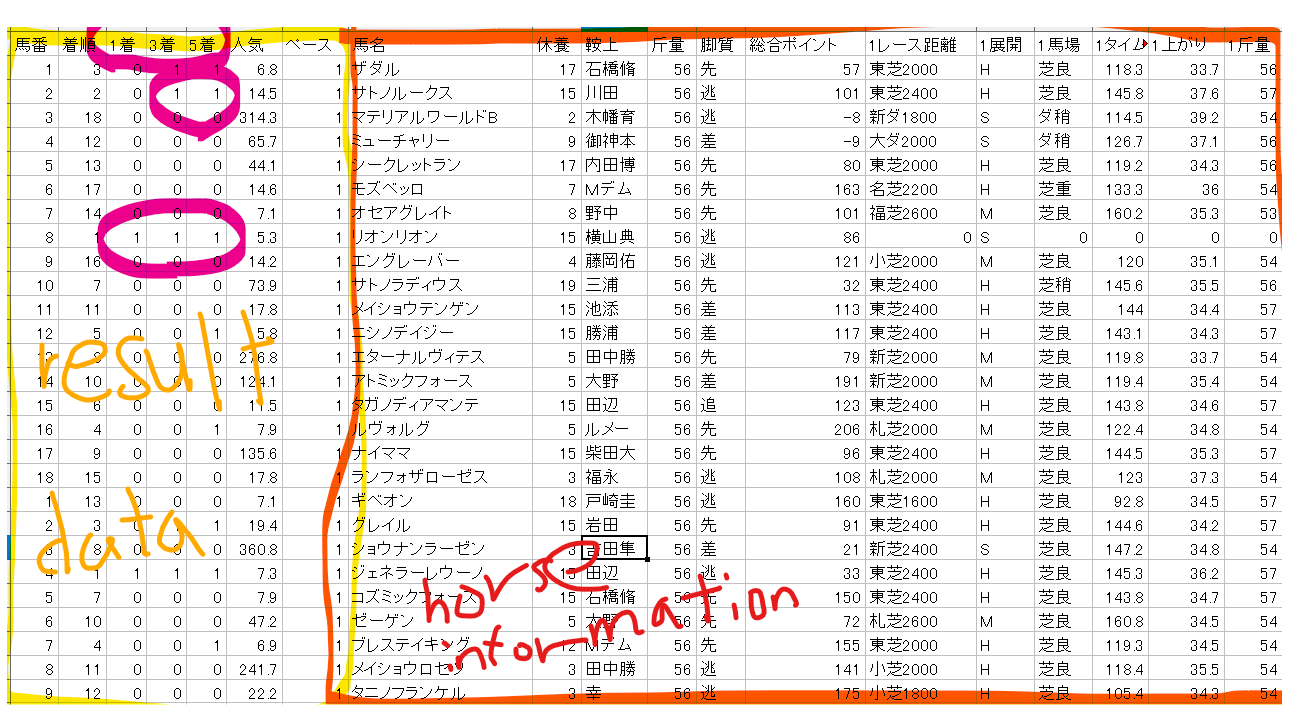
こちらが予想データです。同じように結果ファイルと馬情報ファイルがありますが、結果ファイルをみてわかるように1着、3着、5着が全て0.まだ予測されていないことになります。

機会学習上では、horse informationを説明変数、result dataを目的変数と呼びます。私がやりたいことをもう一度、説明すると。学習データの説明変数(赤枠 horse information)と目的変数(黄枠 result data)で学習を行って回帰モデルを作って、予想データの説明変数(赤枠 horse information)から目的変数(黄枠 result data)を導き出すというものです。
で本題の前処理 2についてですが、機械学習と言えどすべて数値化していなければコンピュータなので予測は難しいので数値化を目的としています。
数値化の処理としては以下の3つのステップで進めます。
1.不要データの削除、数値への置き換え
2.データに文字列がはいっていないかのチェック
3.正規化の実施
まずは1. 不要データの削除、数値への置き換えです。下記を見てもらえればわかりますが、1着以内、3着以内、5着以内を的中させたいので、正確な着順は不要なので削除、あと馬名、レース名も不要。あとはすでに指数として反映されている鞍上、距離、タイム、上がりや馬場情報も不要なので削除します。戦法は数値に、そのレースのぺースも数値に置き換えます。

次に 2.データに文字列がはいっていないかのチェックです。下記はサブルーチンで組んでいますので呼び出し側が必要です。見つけた場合はごみデータとして削除することにしています。頭を使ったのは小数点等も数値ではないと判断されてしまうので、それらの数値を置き換えたあとにジャッジをしているところです。

最後に3.正規化です。正規化って何だ?と思われると思いますが、いろいろな変数があってひとつの回帰モデルをつくるのでどのパラメータも同じように影響するように値を0~1の数値に置き換えるという作業を行っています。機械学習の手法として下記ではランダムフォレストを使うと書いていますが、ランダムフォレストは正規化の必要はないですが、ほかの機会学習用にも今回正規化しておくことにしました。
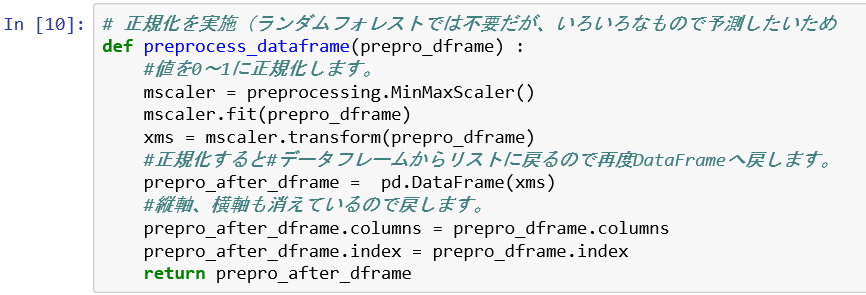
出力データが下記になります。見事0~1になったと思います。
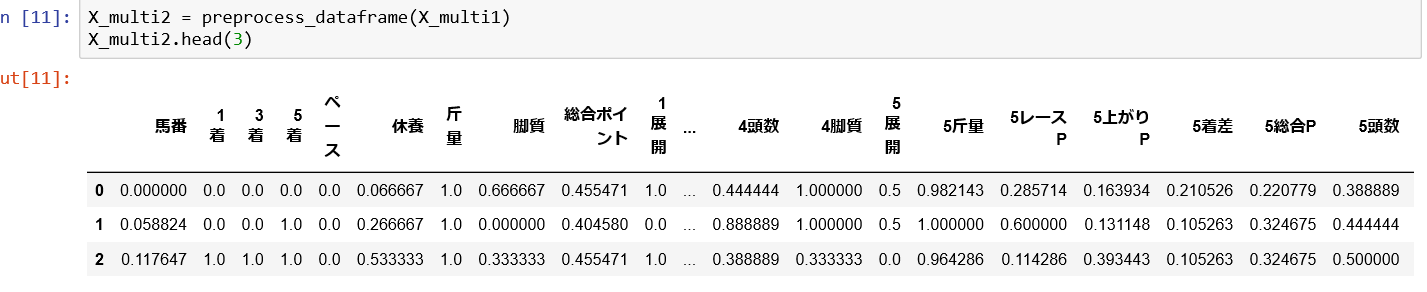
呼び出し側のプログラムも載せておきます。変数の確認と正規化の呼び出し側です。
<文字列チェックの呼び出し側プログラムです>

<正規化の呼び出し側プログラムです>

次回はいよいよ、機械学習です。
今日のプログラムです。
< 不要データの削除、数値への置き換え>
Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)
Python で 競馬予想 第2回(HTML解析編)
Python で 競馬予想 第3回(Python上でのデータ加工)
Python で 競馬予想 第4回(Python上での配列定義)
Python で 競馬予想 第5回(機械学習用の前処理 1)
Python で 競馬予想 第6回(機械学習用の前処理 2)
前回まででひとつの配列に出走馬情報をまとめて、数値化できる部分は数値化しました。結果ファイルも数値化して以下のようなファイルになりました。ひとつは学習データ、もうひとうは予想データです。と、その前に機会学習の基礎を自分の理解なりに説明しておきます。(間違っていても責任はとりません。悪しからず)機械学習には大きくわけて教師あり学習と教師なし学習というのがあり、教師なし学習といのは今はやりのDeep Learningもそうだと思っていますが、正解がわからない状態でもデータの差(特徴とか)を見出してクラスタリング(グルーピング)するようなもので、教師あり学習というのは正解をあらかじめ教えておいて、それに基づいて違うデータを予測するというものと思っています。
私が使おうと思っているのは、過去のレースから正解を学習させておいて、今回のレースを予測することなので教師あり学習です。という事でデータの説明に入りたいと思います。
まずは学習データから紹介します。下記の黄色枠で囲ったところが結果データ。すなわち教師データになります。右の馬情報(horse information)から、左の黄色枠(答え)が導かれています。黄色内の紫で囲った部分が答え、1着になったら1、3着以内だったら1、5着以内だったら1を示しています。この答えになるように学習させることになります。
こちらが予想データです。同じように結果ファイルと馬情報ファイルがありますが、結果ファイルをみてわかるように1着、3着、5着が全て0.まだ予測されていないことになります。
機会学習上では、horse informationを説明変数、result dataを目的変数と呼びます。私がやりたいことをもう一度、説明すると。学習データの説明変数(赤枠 horse information)と目的変数(黄枠 result data)で学習を行って回帰モデルを作って、予想データの説明変数(赤枠 horse information)から目的変数(黄枠 result data)を導き出すというものです。
で本題の前処理 2についてですが、機械学習と言えどすべて数値化していなければコンピュータなので予測は難しいので数値化を目的としています。
数値化の処理としては以下の3つのステップで進めます。
1.不要データの削除、数値への置き換え
2.データに文字列がはいっていないかのチェック
3.正規化の実施
まずは1. 不要データの削除、数値への置き換えです。下記を見てもらえればわかりますが、1着以内、3着以内、5着以内を的中させたいので、正確な着順は不要なので削除、あと馬名、レース名も不要。あとはすでに指数として反映されている鞍上、距離、タイム、上がりや馬場情報も不要なので削除します。戦法は数値に、そのレースのぺースも数値に置き換えます。
次に 2.データに文字列がはいっていないかのチェックです。下記はサブルーチンで組んでいますので呼び出し側が必要です。見つけた場合はごみデータとして削除することにしています。頭を使ったのは小数点等も数値ではないと判断されてしまうので、それらの数値を置き換えたあとにジャッジをしているところです。
最後に3.正規化です。正規化って何だ?と思われると思いますが、いろいろな変数があってひとつの回帰モデルをつくるのでどのパラメータも同じように影響するように値を0~1の数値に置き換えるという作業を行っています。機械学習の手法として下記ではランダムフォレストを使うと書いていますが、ランダムフォレストは正規化の必要はないですが、ほかの機会学習用にも今回正規化しておくことにしました。
出力データが下記になります。見事0~1になったと思います。
呼び出し側のプログラムも載せておきます。変数の確認と正規化の呼び出し側です。
<文字列チェックの呼び出し側プログラムです>
<正規化の呼び出し側プログラムです>
次回はいよいよ、機械学習です。
今日のプログラムです。
# 学習データの加工
# 学習に使わない不要な列の削除
X_multi1 = Study_dframe.copy() #deep copy
X_multi1.drop(columns=['着順','馬名','鞍上','5鞍上','4鞍上','3鞍上','2鞍上','1鞍上','人気'], axis=1, inplace=True)
X_multi1.drop(columns=['5レース名','4レース名','3レース名','2レース名','1レース名'], axis=1, inplace=True)
X_multi1.drop(columns=['5タイム','4タイム','3タイム','2タイム','1タイム'], axis=1, inplace=True)
X_multi1.drop(columns=['5上がり','4上がり','3上がり','2上がり','1上がり'], axis=1, inplace=True)
X_multi1.drop(columns=['5馬場','4馬場','3馬場','2馬場','1馬場'], axis=1, inplace=True)
X_multi1.drop(columns=['5レース距離','4レース距離','3レース距離','2レース距離','1レース距離'], axis=1, inplace=True)
X_multi1.replace('逃', '0', inplace=True)
X_multi1.replace('先', '1', inplace=True)
X_multi1.replace('差', '2', inplace=True)
X_multi1.replace('追', '3', inplace=True)
X_multi1.replace('S', '0', inplace=True)
X_multi1.replace('M', '1', inplace=True)
X_multi1.replace('H', '2', inplace=True)
#X_multi1.head()
<データフレーム数値化サブルーチン>
# Dataの列中に数字でないものが含まれていたら行ごと削除する。
def check_string_dframe(check_dframe) :
del_index=[]
for i in range((len(X_multi1))-1) :
y_posi = i
# 1行取り出してリストにする
data_check = X_multi1.iloc[y_posi]
# 数字以外のものがあるかのフラグ
isnumeric_check=0
for j in range(len(data_check)) :
# 1要素毎抜き出す
str_a = str(data_check[j])
# isnumeric関数は小数点、マイナスを文字列として扱うので置換する。
str_b = str_a.replace(',', '').replace('.', '').replace('-', '').replace('e', '')
#print (i,j,str_b)
if str_b.isnumeric() == False :
#文字列を発見したら、フラグを1にする
isnumeric_check = 1
#発見した行と文字列の表示
print ('alarm',y_posi,str_a)
if isnumeric_check == 1 :
#行を削除するindexの記録
print ('文字列が含まれているので削除します',y_posi,str_a)
del_index.append(y_posi)
return del_index
<データフレーム数値化チェック呼び出し側>
<正規化サブルーチン> del_index_ret = check_string_dframe(X_multi1)
if len(del_index_ret) != 0 :
X_multi1=X_multi1.drop(X_multi1.index[del_index_ret])
X_multi1
print ('学習データ一部文字列を含む行がありました')
else :
print ('学習データは文字列を含んでいません。正常です')
# 正規化を実施(ランダムフォレストでは不要だが、いろいろなもので予測したいため<正規化呼び出し側>
def preprocess_dataframe(prepro_dframe) :
#値を0~1に正規化します。
mscaler = preprocessing.MinMaxScaler()
mscaler.fit(prepro_dframe)
xms = mscaler.transform(prepro_dframe)
#正規化すると#データフレームからリストに戻るので再度DataFrameへ戻します。
prepro_after_dframe = pd.DataFrame(xms)
#縦軸、横軸も消えているので戻します。
prepro_after_dframe.columns = prepro_dframe.columns
prepro_after_dframe.index = prepro_dframe.index
return prepro_after_dframe
X_multi2 = preprocess_dataframe(X_multi1)
X_multi2.head(3)
お気に入りの記事を「いいね!」で応援しよう
[機会学習(A.I.)] カテゴリの最新記事
-
Python 3 エンジニア認定データ分析 模擬… Dec 7, 2020
-
人工知能と競馬 (機会学習ランダムフォ… Aug 10, 2017




【毎日開催】
15記事にいいね!で1ポイント
PR
Free Space
設定されていません。
Calendar
Comments
Dec , 2025
Nov , 2025
Oct , 2025
Nov , 2025
Oct , 2025
Sep , 2025
Aug , 2025
Aug , 2025
Freepage List
© Rakuten Group, Inc.