

Ruby 0
[検索] カテゴリの記事
全116件 (116件中 1-50件目)
-
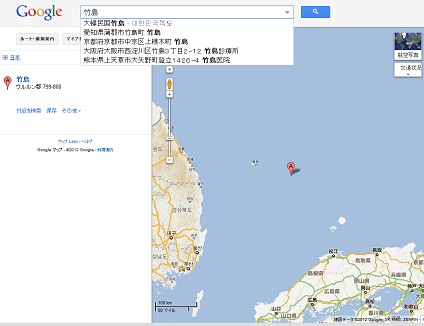
Google はアンフェアな企業
Google がこんなにアンフェアな反日行為を続けるならば、一つ一つ、Google のサービスを使うのをやめていくことにする。Google の反日行為というのは、これ。大韓民国竹島ってなにそれ。どうしてそういうサジェスチョンが出てくるわけ???島根県の竹島が出てないのはどういうわけ??? Google は完全に、竹島を韓国領として扱うようになっているわけね。まずは、Chrome を使うのをやめて、Firefox に戻した。みんなで Chrome 使うのやめよう。やめた上で Google で検索しようw そうすると、Chrome のシェアが下がって、Firefox のシェアが上がるのを Google が簡単に確認できるから。それでだめなら、Google の検索エンジンも使うのをやめる。次は、YouTube。音楽を聴くのに YouTube を使うのも止めよう。と、毎月、使うサービスを減らしていく。少しずつ、真綿で首を絞めるように、減らして減らして減らしていく。そうすれば、スイッチングのための痛みは少ないから。何はともあれ、Chrome の使用は中止したよ。そもそも、Google に個人情報を任せてしまうのも不安だし、今まで使わなかった他者のサービスも試してみよう。直す気がないなら、脱 Google だな。
2012.03.18
コメント(1)
-
グーグル八分発見システムはおもしろそうだが、IPA は無署名のコンポーネントをいかに考えるのか
未踏ソフトで開発したグーグル八分発見システム,「パソコンの空き時間を提供してくれる協力者募集」、IPAが採択した「グーグル八分発見システム」の深意等から、∞Eyes - グーグル八分発見システム 公式サイト を見る。そして、本システムで見つけたグーグル八分一覧(仮) を見る。Google 八分にされたページからタグクラウド作るとおもしろいだろうなぁ。グーグル八分発見システム (IE版)をインストールして協力しようかと思ったが、インストール中に「発行元を確認できません」のメッセージが出るので、あえてインストールを止めた。IPA も未踏で援助しているんだから、ちゃんと発行元を確認できるようにデジタル署名を入れさせるように指導すべきじゃなかろうか。IPA は署名なしのコンポーネントのインストールを推奨するのかなぁ。Firefox のアドオンなんかもそうなのだけど、ちゃんと仕組みがありながらも使われない。原因はなんなのだろうか。面倒だからか。デジタル署名が簡単に、普通に行われるようになるにはどのようなインフラと啓蒙が必要なのだろうか。IPA には、そういうところも考えて、対応してほしいな。まともなものは普通にデジタル署名が行われるようになれば、マルウェアの被害とかも少しは減るだろうに。「発行元を確認できません」と表示されたら、それでもインストールを続けますか?
2008.06.01
コメント(0)
-
Yahoo!検索の検索語データの開放
国立情報学研究所の 「情報爆発時代のサーチ技術研究を加速する産学連携の開始 ~Yahoo!検索の検索語データの開放による研究の推進~」プレスリリース資料 を読む。国立情報学研究所(NII)とヤフー株式会社は、このほど「Yahoo!検索」検索語データの利用について合意し、NIIが事務局を担当している、文部科学省科研費による特定領域研究「情報爆発時代に向けた新しいIT基盤技術の研究」(情報爆発プロジェクト)に、「Yahoo!検索」検索語データが無償で提供されることになりました。ということで、Yahoo! 検索の上位 1万件のデータが 4月1日から無償提供されるらしい。平成20年3月3(月)、4日(火)に 文部科学省情報爆発プロジェクト成果報告会(H19年度) が秋葉原で開かれて、このあたりの研究の発表もよう(会費 6,000円で誰でも参加可能)。インサイダー取引で今話題の NHK からは、爆笑問題のニッポンの教養3月4日の放送で「検索エンジンは脳の夢を見る」では、高野明彦(たかの・あきひこ)国立情報学研究所 連想情報学研究開発センター長 兼 東京大学大学院情報理工学系研究科教授が出演するようだ。秋葉原には行けないが、この番組は見ることにしようかな。「連想検索」という新しい情報技術を提唱しているのが高野だ。2002年に高野が開発した『連想検索エンジン』は、ユーザーの関心を類推し、人間の“連想”と同じように関連情報と関連キーワードを提示することを目指す。この「人の想いを汲み取る検索エンジン」は今、情報の海を泳ぐ新たなツールとしての可能性を秘めている。ちなみに、以前に Google が N-gram のデータを学術用に提供しているが、学術目的限定で商用利用は不可だったが、これも同じような感じの提供方法になるんだろうか。All Our N-gram are Belong to You、GSK2007-C Web日本語Nグラム第1版。大規模日本語 n-gram データの公開。でさぁ、文部科学省主導の 情報爆発時代に向けた新しいIT基礎技術の研究 のプロジェクトがありながら、経済産業省主導の 情報大航海プロジェクトがまたあるわけだが、こっちはどうなったんだと見てみる。経済産業省のページは更新する気なし状態で 外部の情報大航海プロジェクト ページに投げているのでそちらを見ると、平成20年3月4日(火)~5日(水)に「日EU・ICT研究協力フォーラム」が開催されます。5日のセッション「Next Generation Information Retrieval and Analysis Technologies」の中で情報大航海プロジェクトを紹介します。ぜひご聴講下さい。 とかあった。また、平成20年3月17日(月)に「情報価値の共創による国際競争力強化にむけて」シンポジウムを開催します。情報大航海プロジェクトの取り組みや成果についてご紹介いたしますので、ぜひご参加下さい。参加お申し込みはリンク先をご参照下さい。(お申し込み締切日:3月10日(月)) とかあった。一応、現状、一般人が見ることができる成果としては、下のあたりがトッピックにあったのでメモ。2008-02-25 『サグールテレビ(sagool.tv)』が複数のニュースサイトで紹介されました2008-02-25 日本経済新聞「チームラボ お薦め動画次々表示 キーワード検索手間省く」2008-02-19 東京IT新聞「Viewサーチ北海道」 人の情報処理能を活用してアシスト タグに依存しない逍遥型次世代検索」
2008.03.02
コメント(0)
-
東工大奥村研のblogWatcherサービス終了
東工大奥村研のブログ検索「blogWatcher」が2月末でサービスを終了 らしい。なんでもRSS と versus search は今後も運用されるということらしい。blogWatcher の技術は Yahoo!ブログ検索 や SHOOTI とかでも使われているから、そっち見れということで、余計なサービスの保守管理するより、新しい研究に精出しますと。株式会社ブログウォッチャー もできたことだしと。まあ、よろしいんじゃないでしょかというところかな。とりあえず、なくなる前にバースト検索で "北畑隆生次官"のバースト度の推移 を見ると、ぜんぜんデータがない。がっかり。餃子"のバースト度の推移 で見てみると、ん、ぜんぜん最近のバースト度が上がっていない。071024 検索機能回復のお知らせなお,ブログ記事のクローリングは現在行っていないため,最近のブログ記事は検索することが出来ません.だから、もうクローリングは止まっちゃってるのね。そういう意味ではすでに終わっているか。バースト検索は生きている内に使っておくんだったな。古い話題は忘れちゃってるから、おもしろいキーワードが思いつかない。調べるのも面倒だし。ということで Yahoo! で 評判検索結果 餃子を見ると、ポジティブ 60%。餃子事件は、餃子食べたい熱に火を付けてしまったのかもしれない。実際、私はオークションで大量に餃子を落札して、毎日、餃子食べてるし。北畑次官の評判は出ない。ストップがかかったんだろうかw まとめ検索結果「北畑次官」のキーワードで絞り込むを見ると、 * デイトレーダー * パソコン * 証券市場 * 競馬場 * 競輪場 * 経済産業省 * 無責任 * 本当 * ホームページ上 * ここ * 株主 * 経産省 * 浮気 * 人 * 次官の真意 * バカ * 講演会 * 発言 * 堕落 * 講演録 * 経産省次官 * 掲載 * 経済産業省の北畑隆 ... * 罵倒 * 波紋 * 8日 * 手数料 * 経済オンチ * 批判例の話題がちゃんととらえられているようだ。ノーパンしゃぶしゃぶがないのは、単純に反応した人が多いせいだろうか、キーワード化されてないからだろうか。ノーパンしゃぶしゃぶから検索してみると、あぁ、ちゃんと出てくるわ。でも、評判検索の結果はやっぱり出ない。残念。SHOOTI のクチコミ検索 で北畑次官をクチコミ検索してみると、クローリングの速度は低いみたい。やっぱり処理が多くて計算機の資源食うから感度は低くなっちゃうのかな。人気のワードを見ても、ちと古い。数学ガールiPod Touch初音ミクふんわり名人新月ロードレース704i一太郎シネマコンプレックスまあ、実際、かなりリアルタイムに膨大なブログをクローリングするのって、無茶苦茶大変だと思うのだけど。Yahoo! なんかと手を組んだのはそのあたりなんだろうな。カバー率が低かったり、鮮度がよろしくなかったりすると、ちとあれなんだが。研究を超えて実用になるときにはそこら辺がネックなのかなぁ。以前に オートバイテルと blogWatcher、クチコミ分析 を書いたときには、「ネガポジの抽出精度は、これまで見た中で一番よいかな。」とか書いているな。そのうち、ネガポジやっているところ、まとめて見直してみようかな。
2008.02.10
コメント(0)
-

大人のサイトにとっても詳しい東京大学大学院講師たち
タ"アタ"ルト・サイトは相互リンクが多い,トレンドと東大が研究成果を発表 を読む。「アタ"ルト・サイトは相互リンクが多い」なんていうのは誰でも分かることで、それ自体は単に数値として証明したところであまり意味はない。それが題名にされているのは、まあ、目立ちやすいようにということなんだろう。で、中身。この記事には明記されていないがクローリングはたぶんトレンドマイクロ にやってもらったのだろう。トレンドマイクロはこれ以前に膨大な量のクローリングを常時行っているから。それに東大から膨大なアタ"ルトサイトへのアクセスが下手にばれると体裁が悪いからw まあ、各種リソースはトレンドマイクロ側が提供したと推測。いわゆる産学連携ってやつね。そこを協調すると トレンドマイクロ、東大の知力でセキュリティ機能向上を狙う みたいな記事なるか。到達ホストのカテゴリ比率を見ると見にくいけど、おもしろいかもしれない。「芸術/エンターテインメント」分野のあるウェブサイトを選び、ページ内リンクに飛ぶとする。1ページ先のリンクが有害サイトの確率は0.27%。以降、2ページ先のリンクで0.68%、3ページ先のリンクで2.69%と、有害なサイトにたどり着く可能性が上昇していく。と記事にある。芸術・エンターテイメントを安全なカテゴリとしてとらえて、そこからの確率なのだな。ゆえに、実際のところスタートするカテゴリによっては、安全なサイトからでも、1クリックごとの危険性が高い分野もあるということか。今回の「Webリンクの構造解析」について、「グローバルで共有できる優れた研究成果が上がってきたので、半年で区切らずにこれからも続けていく」と大三川氏は述べている。地道に継続的にやっていくとおもしろい分野だろうな。比較的安全なリンクしか表れない検索エンジンとかだってありえるわけだし。アタ"ルトサイトどうしのつながりは強い「周りを見ればそのサイトが分かる」、東大とトレンドマイクロが共同研究 も、とりあえず釣りとして東大とアタ"ルトサイトをキーワードに使っている。こうやって、東大とアタ"ルトサイトとの共起度が高まっていくのが笑える。東大がアタ"ルトサイト研究の権威となる。アタ"ルトサイトで検索すると、東大の記事がトップに来る日wこういう視覚化は無条件に好き。黒系統の背景に蛍光色っぽい感じのがきれい。同じ図でも、白地に単一色だと地味になる。色に意味があれば情報量も多くなるなんていうのは二の次で美的な問題としてきれいなのは好き(次の絵は上記記事より)例えば、ジャンプ先のURLを解析したところ、「どこから出発するかによって、到達するところはかなり異なる」(東京大学大学院情報理工学系研究科講師の増田直紀氏)という。アタ"ルトサイトはアタ"ルトサイトにリンクすることが多い。一方、不動産サイトはリンク先がきれいに階層化し、分散して枝分かれしていたり、ストリーミングサイトは逆にいくつかのサイトに集中し、相互にリンクしていたりといった具合だ。とかあるから、アタ"ルトサイトだけ研究対象にしたんじゃなかろうな。まあ、アタ"ルトサイトがというときには、他のものとも比較しなきゃ何ともいえないところがあるから健全。どの程度、広範囲な分野でやっているかが興味あるところ。リンク関連からカテゴライズというのは、古くて新しいところがあるのかもしれない。言語やテキスト情報に頼らず類推したり、分類の精度を高めていくことができるのではないかというところがトレンドマイクロの製品開発に直結するところだな。「安全サイトから3クリックでアタ"ルトサイト」の確率は2.69% 東大が解析 は、 安全なカテゴリのサイトでも、リンクをたどるにつれて有害サイトに到達する可能性が高くなることも判明した。安全なサイトの3リンク先がアタ"ルトサイトである確率は2.69%になった。と、おもしろいところを拾ってきた。It's a mall world after all.安全なカテゴリからアタ"ルトサイトに到達する可能性は1ジャンプで10倍【東京大学とトレンドマイクロ共同研究】 も、その点について説明している記事。すべてのカテゴリについて、コンピュータ/インターネット関連や検索エンジン/ポータルサイトへの結びつきが強いことが認められたという。だが、18以上ならサイトを見る、18未満なら見ない Exit という類のリンクで見ない方を選択するとポータルサイトに飛ぶことが多いことや、ポータルサイトのブログを使ったアタ"ルト系ブログものとかも沢山あるから、そういうことになるのだろう。安全なサイトもリンクたどれば危険なサイトへ - トレンドマイクロと東大が共同研究 も、同系統。セキュリティ系ほど危険性を煽るところが使われる。トレンドマイクロにより38カテゴリに分類された1200万件のURLデータベースを解析。危険サイトや有害サイトのリンクに関する実態の把握や、ウェブ閲覧時の危険度予測技術への応用可能性を検討した。この記事を見て、やっと 38カテゴリの分類が使われていることが分かった。東大とトレンドマイクロ、情報セキュリティ分野の共同研究で連携 東京大学とトレンドマイクロが情報セキュリティ分野の共同研究で連携 1200万以上38カテゴリに渡る大規模Webページデータの「Webリンク構造の解析」成果を発表~ は、プレスリリースなので、網羅性が高い。というか発信源からの情報だものね。トレンドマイクロのサイト 東京大学とトレンドマイクロが情報セキュリティ分野の共同研究で連携 ~1200万以上38カテゴリに渡る大規模Webページデータの「Webリンク構造の解析」成果を発表~ が大元。3.巨大クリークの存在 性的カテゴリ内で930ドメインが全て相互リンクする集合が確認された。ネットワーク上のアタ"ルト業界地図。コンテンツ製作系、配布・販売系、情報配信・掲示板系、出会い・チャット系、風俗系、リンクアフィリエイト系でコアなところがあって、それらの相互リンクと、どわーっと広がるゴミ系のような感じになっているかな。イメージ的には。コアの資本を調べるとおもしろかもしれない。資本的には暴力団系がフロント・舎弟系も含めてかなり入っているのだろう。有害サイトのネットワークを可視化する研究--東大とトレンドマイクロを見ると、4人の人間が4人とも友人同士という親しい関係が存在することはあるが、10や20を超える関係はほとんど存在しないと前置きした上で、542個のクリークを検出し、中でも最大のものは930のホストノードを有するものだったと語る。930のノードそれぞれが、他の929ノード全てとリンクを結び合っているという巨大なクリークだ。やっぱり派閥はあるわけだな。山口組系とか、稲川会系とか、蛇頭系とか、マフィア系とか、そういう分類から考えても、コアの部分では距離が出るものがあるのかもしれない。クリークの中にそうしたフロント系のものを見つけると、色分けがある程度できたりして。まあ、このあたりは警察や公安の情報がないとなかなかできないだろう。何にせよ、競合があるからこそ、アフィリエイト系やリンク系が生じるわけだしな。そういえば、日本の株式市場が冷えている一つの原因に、マネーロンタ"リング対策があると思う。これは仕方ないと思うのだけど、意外に影響が大きいんじゃないかと。顧客の本人確認、3月義務化=犯罪収益移転防止法を全面施行 でさらに厳しくなるから、全体的にそうしたアングラマネーの動きが慎重になる傾向にあり、これが仕手筋の動きにも繋がっている可能性を感じる。つまりアングラマネーの金の巡りが悪くなっている。新興市場なんかも、実はアングラマネーがけっこう動かしていた銘柄も多いから打撃が大きいのだろう。なんていうのはさておき、mixiに「関連が強いコミュニティ」表示機能 とかも、関係性のお話だけど、村社会の日本では関係性の話題っていうのは、向いている方向なのかもしれない。評判系とかもだけど。この話題とはちょっと違うけど 悪質なアフィリエイト参加者がつくる「ワードサラタ"」に注意 - ワークスタイル - nikkei BPnetとか、それ系って本当に多い。そういえば 経済産業省: 情報大航海プロジェクト ってどうなっているんだろう。金使っている割に情報開示度低い。最近、どこの官庁も調達関連でこまめに開示してんのに、情報古代航海プロジェクトって、どういう風に金が使われているか、まったく分からない。国民はステークホルタ"ーだ。ステークホルタ"ーに予算とプロジェクト進行の報告を怠るプロジェクトは、タ"メじゃ。ましては期待を煽ったプロジェクトなんだから。景気が悪いんだから楽しいネタを振りまいて干し芋のだ。
2008.01.29
コメント(0)
-
したたかなマイクロソフトの戦略ともっとしたたかな FAST
これぞGoogleキラー?Wikipedia創始者らの手による検索エンジン公開 なんていうのが話題になっているときに、Microsoft,企業向け検索技術ベンダーのFASTに総額12億ドルで買収を提案、 マイクロソフトが検索事業を強化、ノルウェーのファストを買収 なんていうニュースが流れてくる。やっぱり、マイクロソフトはマーケティング戦略がしたたか。でも、もっとしたたかなのは FAST だったのかもしれない。2004年に ヤフー、米ヤフーのウェブ検索エンジン“Yahoo! Search Technology”を導入 を見ると、Yahoo に FAST は ウェブ検索部門(AlltheWeb)を売却している。そして、今度は高値でマイクロソフトに会社そのものを売却。最高のエグジットって感じ。FAST の経営陣は、優秀でしたたか。もちろん、技術自体も 「FASTはGoogleの検索技術より2年先行」 とか書かれているぐらいで優秀なんだろうけど、技術だけでなく、経営といったいになって成功させているところが偉い。マイクロソフトは買収した FAST の技術を SharePoint Server の増強に使ってくるのかな。 驚異的な伸びを示すSharePoint Server 2007-その理想と現実を見る【前編】、 驚異的な伸びを示すSharePoint Server 2007-その理想と現実を見る【後編】 。マイクロソフト SharePoint Server。やっぱりマイクロソフトは企業としてみたときに強い原因はマーケティング戦略のうまさだと思う。別にクソミソに言われることなど気にせずに、どうやったら儲け続け、存続していけるかを考えた行動をとっている。当分の間は後進国の新規ユーザーも増えていくことだし、先進国で多少のユーザーが減ったとしても、業績を伸ばしていけるだろう。もうダメだダメだとか終わったとか言われながらも、ここまでやってきているのは、やっぱり偉い。たとえ、倫理的な問題があったとしても、人から恨まれようと、貶められようとも。まあ、したたかな企業だなと。なんだかんだで、この 5年間の株価を見ても こんなんだからね。ただし、パフォーマンスとしてみると、S&P, Nasdaq, Dow & MSFT、すでにイケイケの会社ではなくなっているのは事実だけど。MSFT vs. GOOG で見てみると、やっぱり Google のパフォーマンスに比べると劣りまくっている。じゃあ、現在ダメダメの NIKKEI225 と比較してみる。株価的には、もうマイクロソフトはパフォーマンスがダメだから夢を買うような企業ではなくなっているのは確かだけど、常に一定の評価は受けている感じ。ちなみに こうやって NIKKEI 225 を見てみる と、14000円以下に落ちないと安心して買いに入れるような感じに見えない。今の日経平均って、サブプライムローン問題もさることながら、官僚と政治家と企業とみんなで作った株価だからねぇ。さらに追い打ちで 成田など空港管理会社に外資規制…公共性確保、安全保障 みたいに外資規制がこの時期出てくる。昨年から官民で外資を追い出したから株価が下げたというのも、かなり真実味がある話。スティール「濫用的買収者」のインパクト もかなりあるだろう。昨年一年の世界の海外への直接投資は日本よりブラジルへの直接投資が大きい。もちろん、中国への方がさらに大きい。もう一度、今度は MSFT vs NIKKEI 225 の 6ヶ月のパフォーマンス を見てみよう。マイクロソフトが終わっているならば日本株はもっと終わっていることになる。かなり危機的な状況。
2008.01.09
コメント(0)
-
Google の knol って Wikipedia + AllAbout ?
グーグル版ウィキペディア「knol」がテスト運用を開始 を読む。この記事からだけ思ったのは、Google 版 Wikipedia というか、All About の要素を取り入れたって感じで、Wikipedia + All About が knol なのかなと。人が全面に出てるから。印象でそう思った。Wikipedia って、ページ上には表れない編集者たちがいるわけで、Deletion of article web.py みたいに、これはページとして作るべきではないみたいな編集も行われている。Aaron Swartz のページはあるけれど、web.py は不要という判断がされている。これだけでなく編集を巡って紛争も起きるわけで、ページの執筆者が明確で議論はその執筆者とすればよく、最終的な判断は明確にそのページの執筆者が権限を持ち、同じ単語のページに対して、複数のページが成り立ち得て、その人気によってランクが変わるという方向は、十分にあり得るし、ある意味分かりやすい。集団体制を取るところの場所が違うわけだな。作り手は、一人(フィードバックを反映させるというのはあるにしても)なのか、複数なのか。そして、評価のランキング手法に検索のランキング手法を応用するということで、既存の Google の路線から出ないで妥当な線なのだろう。Google はコンテンツの作り手ではなく、あくまでコンテンツの収容するだけであり、使いやすく検索機能を提供するという路線からのブレがない。それとともに、言葉の検索から、人という単位での検索にも力を入れ始めているということなのかもしれない。Google Finance にしても、企業名を軸とした検索として考えると、やっぱり同じ路線。属性(株価等)を持った主体の検索。ちなみに Google で MSFT とかティッカーシンボルを使ったイメージ検索をするとおもしろい。Googleイメージ: MSFT みたいに。Google イメージ: graph とかしても、いろんなグラフが出てくるので眺めてみると楽しい。加えて適当な単語を付けるともっと楽しい。グラフ でも同様。グラフにすると分かった気になれる。が、判断を誤らせるグラフもたくさんある。
2007.12.22
コメント(0)
-

メーリングリスト・アーカイバ Lurker
Lurker なるメーリングリストのアーカイバがあるのをたまたま知った (Lurker っていう名前は、投稿はしないけれど潜んで見ている人たち)。なかなか高速で使いやすそうな感じ。大量のメールでも速度が落ちないそうだ。MailMan のアーカイブより見やすい感じがする。Luker 自体にはメーリングリスト自体の機能はなく、あくまでアーカイバのみなので、MailMan + Lurker とかもありだろう。見た目は W4PY Archives な感じ。大量でも大丈夫っていうのは、Mailing List Archives by the Free Network Group あたり見ると感じられる。ここを見ると 以前、池田さんという方が日本語化をされていたようだが、そのページにアクセスしてみると動いていなかった。残念。
2007.12.11
コメント(0)
-
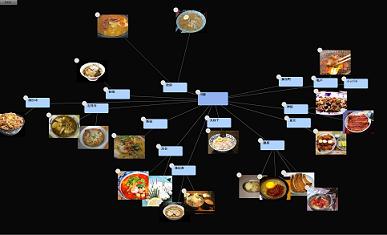
Marici の「ブログ関心マップ」など
ちょっと TurboGears を使ってみようとふらついていた。Marici - TurboGarsで作られたMind Map風サービス から マインドマップ風Webサービス Marici を見て、Marici (マインドマップを作ってみよう!) を見てみる。TurboGears を使って作っているらしい。マップの表示は Flash で、こんな感じ。ちょうど pydot - Graphviz でグラフ書いていたところで、こういうものが出てくると目についちゃうのね。通常のページを見てみると、「マップを開く」というというリンクの文字が小さい。たとえば、外部の検索エンジンから こういうページに飛んできたとして、マップを開くというリンクをクリックできるだろうか。押したくなるようなものにしないと分かっている人しかマップを見ない。もったいない。マップを 縮小したような画像を入れるなり、もっと目立つボタンにでもした方がいいんじゃなかろうか。技術的にはおもしろいことろがあるけど、サービスとして見たときには改善の余地有りって感じ。やりようによっては、まだ、この分野おもしろいものが出てきそうな気はするのだが。と思っていたら、ブログの内容をマインドマップ風に表示する「ブログ関心マップ」 で ブログ関心マップ ができたことを知る。これおもしろいかもしれない。傀儡師の館のブログ関心マップ を見てみると、こんな感じ。こっちの方がさしあたっておもしろみがある。本文の切り出しもうまくやっているみたいだし、なかなか良くできているかもしれない。定期的に画面を保存して、ペラペラで眺めてみると、同じ人のブログがどういう興味の変化かって分かるかもしれない。そうすると、固定的な話題をけいぞくしているブログと、あちこち動くブログとの分類が出てきておもしろいかもしれない。スナップショットが時系列でどう変化していくか。似たような複数のブログをまとめた状態(合成して)、一つのブログとして扱って、その変化をみていくとコミュニティの興味変化とかも見れたりするのでおもしろいかもしれない。Planet を対象にすればいいのね。たとえば、「unofficial planet python」の関心マップ とか、「Planet Plone」の関心マップ とか見てみるわけですな。そうすると流行が追える。でも、英語が対象だと今いちな感じがする。にゃんとなくアルゴリズムがふふふっ。せっかくなら英語圏の人が使ってもいい感じが出せるとよいのにね。でも、なかなかおもしろいかもしれない。ちょこちょこ使ってみるかな。つながりといえば、関心空間 を思い出した。テーマに沿ってキーワード(記事)を集めたのがコレクション コレクション β とかあるな。といえば、「といえばサーバ」 なんていうのもあったな。分類といえば、i-FILTER の URL カテゴリって、API 化されて一般公開されると嬉しいのにね。トラックバックスパムをはじくために、トラックバックが来たら、その URL を渡して、どの分類に当てはまるかを返してもらって、大丈夫そうなカテゴリからだったらばトラックバックを OK にするとかいった使い方で。1日 50までは無料にして、それ以上であれば有料。サイト単位だったら幾らとか、トラックバックチェック用のサービスでも作ってくれればいいのにね。そういえば、i-FILTER SSL Adapter はおもしろい。「i-FILTER SSL Adapter」オプションを使用すると、従来は管理者の手が及ばなかったSSL通信を「丸裸」にします。i-FILTER SSL Adapterなるほどね。それはさておき、結局、こういう会社って、機械的にやる部分はあっても、結局、人手の介在があるから強いのね。発展しつづけるWebサイトにキャッチアップして、進化する独自検索エンジンと人の判断をマシンラーニングするデータ分類が実現しました。i-FILTERの次世代フィルタリングテクノロジー「ZBRAIN」人がつけるつながりや分類と、機械的な分類をミックスさせる。いわゆる CGM 的なものの場合、人手を使っているところはユーザなわけだけど、こういうサービスはそこを会社がやっている。検索では オープンディレクトリプロジェクト のように人手でがんばっているのがあるが、フィルタリングではその手のものはないんだろうか。メールのスパムとかもベイジアンでやっても、今いちなところがあるから、ブラックリスト も積極的に使いたくもなる。メールのスパムとトラックバックのスパムと、発信元にはどの程度の相関関係があるんだろうか。スパムメールをたくさん送るようなところは、トラックバックでもはじいちゃっていいんじゃなかろうかとか。MediaWiki‐ノート:Spam-blacklist とか見てみると、こういうところも大変ねと思う。
2007.11.19
コメント(0)
-
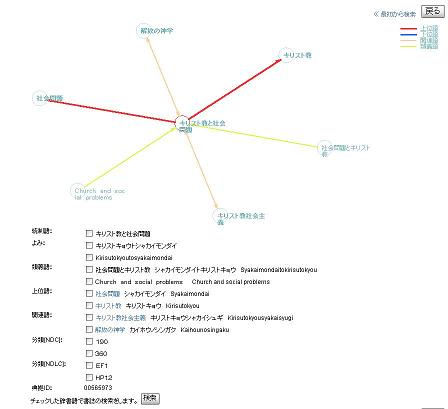
国会図書館の検索ポータル 「PORTA」 を見てみる
国会図書館、約800万件のデジタルデータを検索できるポータル「PORTA」 ということで、PORTA (国立国会図書館デジタルアーカイブ) を見に行く。何ページか見ていたら、エラーが出てまともに使えなくなった。Request Entity Too LargeA request entity is longer than the server can handle.なんとなく、Internet Explorer だと問題ないが、FireFox だと問題が出てしまうようなつくりになっているような気がする。善処を希望するってここに書いて意味あるかって話もあるが、以外に直リンク張っておくと見に来るものなので書いておくのであった。ユーザ登録すると何がいいことあるのかなと思って見てみると、次のカスタマイズができるようになるということらしい。とりあえずまだユーザ登録はしていない。ユーザグループの選択デザインの選択ポートレットの表示位置の変更、表示/非表示の切替検索オプションの初期設定ダイレクトメニューの編集ブックマーク機能キーワードランキング を見てみると夏目漱石がトップだった。とりあえず試してみようって感じで使われている感じ。ちなみに夏目漱石は私は好きではないが、それはどうでもいい。アクセスランキング なども見てみる。第1位 (51ヒット) なのでまだ、あまり使われていない感じ。第4位(12ヒット) の 「日本之下層社会 横山源之助著 土屋喬雄解説」 をクリックして見てみる。確認した後、元に戻ろうと思ってもアクセスランキングの画面に戻れない。貧困といえば、このサイトとの話とはまったく関係ないけど 日本経済 ~低所得層を苦しめる物価の二極化~ なんていうレポートが第一生命経済研レポート 2007.11に出ている。辞書検索で、「貧困」とか検索してみる。関連後がたくさん出てくる。そこから、「社会問題」の「キリスト教と社会問題」をクリックすると、こんな画面が出てきた。このインターフェイスはおもしろい。貧困から解放の神学にたどりつけるのね。視点を広げるときには、やはりこの手のものは使える。辞書検索の結果は、テキストで表示するほか、統制語、よみ等、類義語、上位語、下位語、関連語の関係を視覚的に見ることができるようグラフィカル表示を行っています。グラフィカル表示では次々にクリックした他の語を起点とした表示に移動していくことができます。相関関係をもつ語が多い統制語を表示する場合、表示に数分程度の時間を要することがあります。機能概要 辞書検索連想検索は、次のを参照と書いてあるので、そのあたりと同じ仕組みか。汎用連想計算エンジン(GETA) 公開HP Webcat Plus 連想検索についてでも、残念なことに全般的にとっても使いにくい。サイト自体には意味があるにしても、こんなに使いにくいってのはいかんなぁ。機能的にはおもしろいものもあるけど、何しろ使いにくい。もったいないなぁ。開発したところってあまり一般人向けのサイトを作ってないところじゃないかな。ふつー、一般人向けのサイトでこんなにユーザビリティの悪いもの作ったら、お客さんからダメだし食らうと思うけど。。。。。そういえば 近代デジタルライブラリー の資料が 7月に増えていたのね。国立国会図書館入門
2007.11.05
コメント(0)
-

goo と BIGLOBE の評判検索サイト
「goo 評判検索」がリニューアル、評判情報をグラフでわかりやすく表示 の goo 評判検索 と、 BIGLOBE、評判分析サービス「みんなの評判」に紅葉スポットの評判情報を追加 の BIGLOBE みんなの評判 を見る。パッと見た目のわかりやすさは goo のが分かりやすい。けれども実際の評判のチェックには BIGLOBE の方が分かりやすい。BIGLOBE は表面のデザインを再検討した方がいいかも。直感的に goo の方は商品の評判でも対象を限ってしまうことによって、特定分野でまず鍛えて強くなるという戦略で、BIGLOBE の方が幅広くやっていこうという感じか。微妙に戦略に差があるような気がする。BIGLOBE 評判検索 【紅葉版】 の方向はおもしろかもしれない。月別とか、対前年比が出るようになると、今年の流行の場所とか、いついつに流行だった場所とか、そういうのを見ることができるようになるとさらにおもしろいかもしれない。だんだんと評判検索も充実し始めたようで、だんだんとおもしろくなってきた。けど、まあ、細かく見ていくと、うーんとかあるけど、基本的に好ましい方向に徐々に行っているかなという感じ。この調子で 2,3年もすればこなれてくるかな。自己組織化マップ的な発想と表示で製品を図式化表示するなんて方向もあってもいいだろうし。一つのマップの上に製品が並べられているなんていうのもおもしろい。観光地なんかにしても、自己組織化マップを使ったらおもしろい観光地評価ができるかもしれない。地理的に遠いところがイメージ的には近くにあるようなもの。しばらくは、見え方と企画の勝負って感じ。言語処理的には少し知識処理ってところに入り込みこみつつあるか。NTT と NEC には、試しにいろいろやってみて欲しいな。蓄積がいろいろあるわけだし。言葉といえば、広辞苑。第6版が出版されたようだ。まだ、楽天で第6版の置いてあるショップはない。
2007.10.24
コメント(0)
-
Keywalker検索
あなたの好みに合った検索結果を表示します - "Keywalker検索"α版が公開 ということで、Keywalker検索 を使ってみた。今いち、ピンとことない。以上。
2007.10.19
コメント(0)
-

捜し物は何ですか? 探す行為の類型
“さがす”行為の4類型~さがしものは何ですか?~ を読む。だからどうしたという気がしないでもないが、まあ、とりあえず、これ系のはきれいにまとめんの好きねと。みずほ総研は、環境エネルギー のページのものがおもしろいかな。探す行為の類型については、もう一つ上の段階もあると思う。「原油価格と金価格は、あともう少し上げたあと、ふたたび調整局面に入るはずである」という仮説をたて、「調整はいつか」を検討するとき、この仮説を裏付けてくれるような事象を探す、という探索は、次のどれにあたるのだろうか。既知情報検索・再入手探求探索巡回/探索散策全部使うでしょ。単純な検索だけでなくて、もう一つ上のレベルの探索推論行為類型化すると、帰納型の探索演繹型の探索アブダクション型の探索検索を単発のものと考えないで一連の行為の中に位置づけると、検索の鎖がどうやってできあがっていくかを考えるに至り、一発型の検索から文脈型の検索につながるんじゃなかろうか。最近の複数キーワードの提示なんていうのもその流れと言えるだろう。ちなみに、Wikipedia の「アブダクション」を見ると、チャールズ・サンダース・パース の名前が挙がっているが、エドガー・アラン・ポーの方が時代的にこの言葉を使い始めたのは先だな。ポーはたぶん、チャールズ・サンダー・パースの父親の ベンジャミン・パース の論文読むなりして、影響受けているような気がする。ポーの『ユリイカ』なんかはそういう文脈でできたような気がする。ベンジャミン・パースとエドガー・アラン・ポーもともに 1809年生まれ。ベンジャミン・パースは数学で世界を語り、ポーは詩で世界を語った。数学と詩と音楽が彼らを結びつけている。語られた対象はとっても近かった。チャールズはその両方を受け継いだ。ベンジャミン・パースとポーがある日出会って語り合い、ベンジャミンはそれを日記に残した。チャールズが後にそれを見つけて読みながら、幻想の世界に浸る。なんて小説にしたいものだ。マニア過ぎる。ちなみにパースとポーが出会ったかどうかは記録にない。時代と場所からすると会っていたとしてもおかしくはない。ちなみに、チャールズ・サンダース・パースがポーの小説を読んでいたであろうことはかなり確率が高いと思われる。根拠はない。abuduction という言葉を使い始めたのはポーの影響なのか、父親の影響なのか。どちらだろう。ベンジャミン・パースの全著作を探して、最初に abuduction という言葉を使った時期を探るとおもしろいかもしれない。もしなければ、チャールズパースとポーを比べたら、ポーの方が時代的に先なので、その言葉自体はポーの影響となる。が、コンセプト自体は、ベンジャミン・パース発のような気がする。さらに大元は、アリストテレスだろうけど。
2007.10.16
コメント(0)
-
kizasiサーチエンジンなど
きざしカンパニー「kizasiサーチエンジン」狙いはポストGoogle“話題の変化”をとらえる を読む。kizasi をよく使っているユーザからすると、特に目新しいことは書いていない。そういえば、kizasi.jp をいつから自分は使っているんだろうと調べてみる。Google で調べてみる。58件しかない。もっと使っているかなと思ったら意外に少ない。初出を見ると、マグロのトレンドを見る 2006年12月04日のようだが、何気に使っているので、もう少し前にありそうなものだが、調べるのが面倒なのでやめる。前から、ブログでのあるキーワードの初出を調べるサービスがあってほしいと思っているのだが。。。。。OED (Oxford English Dictionary) のイメージ。初出が xxxx年、出典はどのブログ、そのキーワードを含む文。これが年代ごとに並ぶようなイメージ。使用方法(意味)によって分けられていればなお良いが、そこまでは望まない。さらに、オプションとしてブログごとに検索できるようなもの。自分用のを作るかなと思いつつ、そのうちどこかがそういうサービスを始めてくれるんじゃないかと思って、ときどき、そんなことをブログに書いたりもするのだが、いまだに出てこない。ニュースとかもそうなのだけど。早くどこかやってくれないかなぁ。まあ、ブログ自体にそういう機能があればいいのだけど。楽天ブログつけてくれないかなぁ。どこかの会社がやってくれるなら協力するのだけど。連絡先は kugutsushi2 @ infoseek.jp と書いておいても連絡してくる人はいないだろうが、誰か作ってくれぇ。というのはさておき、ついでなのでいくつか kizasi.jp を使ったエントリを上げておく。スプログが生み出すキーワードが Yahoo! トレンドワードに現れる問題銀行株安値更新経済参謀不在の日本の株価、底堅い指数雑然とあれこれ通貨当局kizasi.jp のグラデーションエンジンkizasi.jp の単語分割おかしいなぁ きざし (kizasi.jp) が会社化マグロのトレンドを見るこの手の検索サービスって、まだ Google なんかと違ったところを追求できるから、やりようはいくらでもあると思う。なんで自分でやらないのかといえば、そんなものクローラー作ってなんてところから個人でやってられねぇやだから、すでにクローラーを動かしていて、ブログのエントリ本文の抽出がきれいにできていてとかいうところがやるのがよいと思うのだな。「福田総理」について語っているブログ を見てみる。このやり方も、いいところついていると思う。ちなみに、福田総理のぶっきらぼうさはおもしろかったのだが、最近、人当たりが少し良くなってきてしまったようでおもしろくない。基本的に優等生発言をして株価にとってはプラス。何気に株価をとっても意識した発言が多いように思える。つまり、外国人買いがなくならないように発言を考慮している感じ。株価危機対策内閣とでもいえるような感じ。
2007.09.27
コメント(0)
-

社会インフラとしての統計データ
統計データらくらく検索 (2007/6/16) を以前に書いた京都府の統計システムの新しい記事が京都新聞電子版 データで見る、地域の姿人気 京都府統計システム にまた扱われている。アクセス件数が、2カ月半(8月末)で約8000件に上っている。この 8000件を 75日で割ると 1日 100件程度。ウェブサイトのアクセスとしては多くないが、意味はある数だとは思う。ところで、Visualizing Economics: United States Household Income Map で Social Explorer: Population Density の存在を知る。米国の国勢調査の結果をグラフィカルに見ることができる。右端の Choose a Map の下の 2つめのリストで Income を選択すれば、収入マップになるし、Unemployment を選択すれば失業状態マップになるし、さらには3つめのリストで Black 16+ を選択すれば、16歳以上の黒人の失業状態マップになる。Poverty を選択すれば、貧困状態マップになる。すばらしい。。ニューヨークの1910年から2000年にかけての白人の居住状態をスライドで見ることができたり、黒人の居住状態 を見たりすることができる。ロサンジェルスも % White 1940-2000、 % Black 1940-2000、 % Hispanic 1940-2000 のように見ることができる。日本の国勢調査もこうした形でデータが公開されればよいのに。統計データ・ポータルサイト にいくと、国勢調査報告のデータが Excel で取得できたりするが、米国から見ると、相当に遅れている。
2007.09.24
コメント(0)
-
あるブログから特定の話題に関して一文だけ抽出するとしたらどうする
kizasi.jp、みんなのきざしスペシャル「安倍総理辞任」を公開 を読む。みんなのきざしスペシャル 「安倍首相辞任」 を見てみる。あるブログのエントリの中から一文だけ抽出するとしたら、どの文を抽出するか。これってよく見てみるとおもしろいことしているかもしれない。よく見てみると、それなりに何かのルールを作ってやっているようだ。単純に最初の一文を取ってくるとか、先頭の文から見ていき、キーワードが含まれている文を抽出するとかいう感じでもない(そう見えるものもあるが)。そうではないことを証明するのは、安倍会見を聞いた印象 から抽出されている一文が、「辞めて局面が変るという保証がないなら、辞めてなんになるの?」の一文であること。これはブログのエントリの下の方にある。安倍首相辞任 から抽出されているのは、「株式市場にはたいしたサプライズでもなかったようだ。なんか寂しいね…。」の一文。絶句 から抽出されているのは、「有閑倶楽部のキャスト…絶句」。なかなか工夫してるなあと思った。実際にどうやってるんだから知らないが、たとえば、よけいな改行とスペースを取り除いて文字列をつなぎ、一定の長さ以下であれば、すべてを抽出。一定以上の長さであれば、パラグラフの中にキーワードを含むかどうか調べて、ポイントを付け、どのパラグラフから抽出するかを決定する。キーワードと+αの単語だけしかない文は捨てる。その話題のキーワードとは別に、感情や推定を表すような一般的なキーワードを含む文を抽出する。一文が長い場合は後ろを残す。等々、それなりにルールを作って見ないと、こういう結果は出てこないと思う。なんにせよ、なかなかおもしろいところがある。
2007.09.18
コメント(0)
-
統計情報のグラフ化とデータコミュニティ
Webビジネス - アメリカの経済をわかりやすくグラフ化した情報を紹介する Blog「Visualizing Economics」(Japan.internet.com) で紹介されているサイト Visualizing Economics を見る。こういうの好きだ。統計データらくらく検索 で以前に 京都府の統計データ検索システム を見た。都道府県の統計資料の視覚化 とか、Swivel は期待が持てるサービス では、Swivel を見た。Google と公的記録の検索 とかも書いたか。可能性を感じると、我ながらけっこうくどく登場するなぁ。Tasty Data Goodies (The Official Weblog of Swivel) の How to blog a graph を見たら、TypePad の Swivel 対応の話が出ている。ジャストシステムのジャストブログも TypePad だから将来対応するとよいな。xfy Blog Editor をどのようにそこに絡ませていくかなんて方向もあり得るだろうか。Swivel は、やっぱり自分の注目するサイトの一つだな。こういうの日本にも出てきてくれると嬉しいんだけど。官公庁が出している様々なデータが、こうやって定期的にグラフ化されて出てくると嬉しいんだが。たとえば、日本の人口の推移を見てみるととかブログに書いたときにペタっと、こういうところにあるデータのグラフを貼り付けたりとかしながら使えると嬉しいわけ。たとえば、Google hiring faster than it can afford? のようなグラフを Swivel - Draw Conclusions from Data のようにブログで使えたらいいでしょと。Google Full-time Employees みたいなのが見えると嬉しいでしょと。ランキングも、Most Viewed Graphs (Today)、 Most Discussed Graphs、 Highest Rated Graphs (Today) のようにあって、データのコンテンツ化、ランキングのコンテンツ化が行える。これにタグクラウド化が付け加わるともっとおもしろい。お金持ちの日本の会社が Swivel と提携してくれるとおもしろいのだが。決算情報の XBRL 化と合わせて考えると、そうした情報をいち早くグラフ化して、さらには他の指標と重ね合わせて表示できるなんていう方向性もあるだろう。何にしても Google がこういう会社を買っちゃったら、おもしろくないな。とっても可能性があって、おもしろい分野だと思うのだが。例えば、Infoseek でも Yahoo でもいいのだが、検索結果の中にグラフも出てきたらおもしろいし。データで語るコミュニティというのもあり得る。データを使って語る人が増えると、官公庁もデータの出し方が変わる。「大衆向けのBI」の概念を変えたSwivel (ITPro)【Web 2.0 Expo】OECDも注目する「データ版YouTube」,その名は「Swivel」Swivel Aims To Become The Internet Archive For Data (TechCrunch)Swivel,データのためのインターネットのアーカイブを目指す (TechCrunch日本語版)Swivel初体験記 (404 Blog Not Found)Swivel Google Finance Data?Plotting Swivel Data In Google MapsSwivel - Draw Conclusions from DataSwivel (Google Code)Swivel It for Google Spreadsheets (YouTube)
2007.09.13
コメント(0)
-
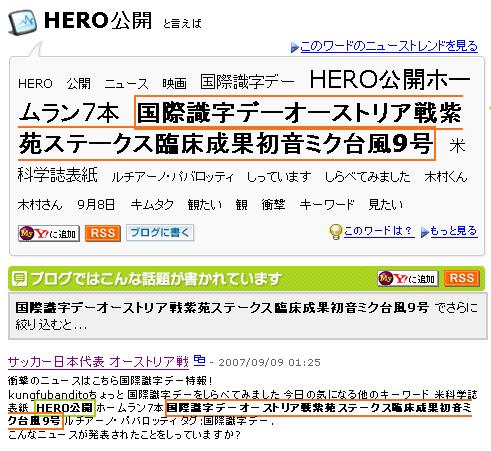
スプログが生み出すキーワードが Yahoo! トレンドワードに現れる問題
Yahoo! JAPAN トレンドワード バグってないかい。「国際識字デーオーストリア戦紫苑ステークス臨床成果初音ミク台風9号」というキーワードが切り出されている。「HERO公開ホームラン7本」もなんだけど。不信に思って元のサイトを調べてみたらスプログだった。この手のサイトって、もうちょっと工夫しないと、スプログを助けることになってしまうなとかも思う。加えて有りもしないキーワードを増産してしまうことがあり得る。形態素解析エンジン「マリモ」の記事から で扱ったマリモのように自動的に単語を学習していくタイプの形態素解析エンジンにしても、そうしたものに対する弱さがあるのかもしれない。発生件数が少なければ無視するということによって、ある程度少ないものに関しては排除されるとは思うが、ある程度、意図的に増産されるものに対しては効力を発揮しないかもしれない。つまり、スプログがスプログをリンクして本来意味のない単語が増産されることや、RSS による伝播によって、本来ない単語がウェブ上で大量に生産されてしまう。これを元にして単語が学習されていくならば、辞書の質が落ちる。ゆえに、辞書を作成するときに使う対象は、クリーンである必要がある。スプログによって生産されたキーワードが大きく出ているって何事なの?って思ってしまう。Google とかで検索したときよりも、この手のサイトの方がスプログを開いてしまう可能性が高いような感じがする。単なるアフィリエイト目当てのスプログであったらまだよいが、有害なサイトも現れやすくなる可能性がある。その手の悪事を考えている人の場合は、検索エンジンよりも、こうしたブログ検索サイトをターゲットにした方が効率がよいとか考えているかもしれない。Yahoo! がスプログ判定 API とか公開したら、Yahoo! の API を使う人がさらに増えると思う。スプログとはスパムのブログ版「スプログ」、ブログ界の脅威にブログスパムの悪夢--「スプログ」でグーグルのBloggerが大混乱まあ、このキーワードの切り出しは powered by kizasi.jp だから、直接の責任はそっちにあるんだろうけど。
2007.09.09
コメント(0)
-

フレッシュアイと、桝添ウォッチ
このところ フレッシュアイ のクリップを使い始めた。で、桝添洋一のクリップをチェックすることにした。気になるものはこれまで Google ニュース アラートのメールでチェックしていたのだが、フレッシュアイのクリップもちょっと使ってみるかな。デイリーニュース検索キーワードランキング なんかも、時系列で見ることができるようになるとおもしろいんだが。基礎年金の財源、消費税率上げで…舛添厚労相。そういえば、この人は明確に消費税上げの人だったな。まあ、実際のところ、避けられないでしょうというのは皆分かっているから、こういう人が言う分には悪印象はない。実際に上がったら嫌は嫌だけど。親戚から…!? 厚労省前九州局長が高級車受領 舛添厚労相は30日朝、民放番組の中で、「そういう問題は恥ずかしい限りで、親類からもらったからいいんじゃないかと言っているようですけど、今は正しい情報を大至急出せということで、省を挙げて調べさせている」と調査に乗り出したことを明らかにした。ビシビシやって欲しい。親戚関係だからこそ、利害関係のある団体の人から贈与を受けるということ自体がいかがわしい行為に見えることを分からずにやるとしたら、それこそおかしな話。やっぱり、こういう人たちって、常識がないんだな。乗用車無償で受け取る 前九州厚生局長例外的に相手が親族などの私的関係者で「公正な職務の執行に対する国民の疑惑や不信を招く恐れがないと認められる場合」は、金品などの受け取りを認めている。普通、障害者療護施設などを運営している社会福祉法人の前理事と、障害保健福祉部の障害福祉課長、企画課長をやっていた人の関係というのは、疑惑や不信を招く恐れがあると判断するのが、常識ある人だと思う。私には、そんなに気前がよい親戚はいないのが悲しい。世の中って、そんなに親戚づきあいが良好なものなんだろうか。いいなぁ。格差社会っていうのはこういうところにもあらわれているのだな。普通の人たちは、車を親戚にあげたりするわけだ。日本に出稼ぎに来ている外国人とかで、せっせと本国の親戚たちのために送金するような人がいるのは分かるんだけど。気になるのは障害福祉に関わる人たちだってこと。これを食い物にした人たちが過去にたくさんいるので、この分野に関わる人は普通以上に身の回りをきれいにしておかないとまずい。白か黒かに関わりなく、厚生労働省は、これを気に、障害者や低所得者等の弱者に対する行政を見直した方がいいんじゃなかろうか。「生活保護」が機能しない背景にあるのは? なんて話もあるし、その一方で、暴力団組員に生活保護の給付金が渡されているなんてこともあるだろうし (行政対象暴力 断固たる組織的対応貫け)、ウメさん 緊急生活保護支給決定の顛末 のようなものを見ても、かなり複雑な思いはある。たぶん、この手のことに関わっている現場の人は、けっこういろんな意味で辛いところがあると思う。障害者福祉 (障害者自立支援法)に関わる人も実際のところいろいろ大変だと思う。だからこそ一定の利益を得ないとというのが上部だけで吸収されて現場にちゃんとまわっていないのではないか。だからこそ、ちゃんと洗い直しをして一般の人も含めた議論とコンセンサスが得られる方向に持って行くべきなんじゃなかろうか。現場はこんな事で困っているというのを公にするのだって一つの方法だろう。ということで、舛添要一氏にはがんばってもらいたいので期待しておく。厚生労働省の役人を何人も引っ張り出して、テレビで公開討論やってほしいものだ。コムスンとかの不正にしても、厚生労働省の方針転換とかも背景にあるんじゃないのかな。悪いものは悪いけど、それを作り出している背景もなんとかしてもらわんと。
2007.08.30
コメント(2)
-
クチコミクリック
クチコミクリップ=個人ブログの情報を企業サイトに表示する販促秘策 を読む。カレン が クチコミクリップ というサービスを始めたという記事。この記事、カレンのリンクが http でなくて、ttp とかなっていてリンク切れになっている。リンクチェックってはいってないのね、とよけいなところにこだわる。アスクドットジェーピーと日経リサーチ、検索データのデータフィード を書いたときに、だんだんと事業者間のこうした提携が増えるだろうな。全部自前よりも、得意なところに専念して、他社が得意なところはサービスを使うと。と書いたが、このクチコミクリックでも、kizasi.jp のデータを使っているのね。マッシュアップの時代だからコラボはそれを効率化するためにも必然なのかもしれない。加えて、人の目視が入る。フィルタリングソフトも、悪質なサイト、エロサイトのチェックを人が目視して確認するというフェーズが入っているのと同じ。一種の目視ビジネスという点からとらえてみたりする。プールの監視員、サーバーの監視員、電車の車掌、等々。まあ、考えてみると経営者にしても、積極的に何かするのでないときは、経営指標の監視員だったりするのかもしれない。監視の後にどんな行動をするかによって、単なる監視員か、それ以上のものかが変わると。ところでいつも気になるのが、ブロガーに「クチコミの元」になる体験を提供というのは、販促は反則を常に伴うんだろうかという気がする。金を払ってブログを書いてもらうとか、物を渡してブログを書いてもらうとか、そういう仕組み。これをやってしまうと、真の声(ってなに)を聞くことができなくなってしまう。もちろん、こういうサービスでは作り出したブロガーと、ほんとうのブロガーを切り分けて顧客が見ることができるようになってるんだよねぇ、とか思ったりする。まあ、そんなことはどうでもよいが暑い。何でこんなに暑いんだろう。kizasi.jp でダメを検索してみる と、なぜかダメの数が減ってきている。どういうことなんだろう。年末年始は我を振り返りダメ発言が増え、夏場になるとダメな状態であっても、それを言語化して意識しなくなるからとかいうことなんだろうか。言葉にも季節変動があるのかもしれない。その季節変動を見落とすと、季節要因によって発言が増えるのを何かがうまくいったと誤解してしまうこともあるかもしれない。今年の アイスクリーム のピークは5月だったんだ。くそ暑いのに何でなんだ。いや、くそ暑いときは かき氷 か。実際の売上げもそんな感じなのかな。かき氷にかけるシロップは何が流行っているんだろう。ブログ見るより売上げチェックした方が正確なわけだけど、なんていうのはどうでもいいが、消費者欺しをせずに、まじめにやれば消費者にとっても有効だろうねと。ただし、企業サイトにあると、どうしても検閲してるんでしょとなるから、見る方としては微妙かなとか思うけど。もっとも自分が何か買ったときに、その購買行動を正当化したいという意識が働くときに、そうしたクチコミ情報が案外役だったりすることもあるのかもしれない。そういうときは、悪い話はききたくなくて、よいことを中心として見たい。ま、掲示板を置いて炎上するよりもリスクは少ないから、ものによってはよい効果が得られることもあるのかもしれない。どうでもいいけど暑い。
2007.08.22
コメント(0)
-
情報大航海プロジェクトのその後
ブログウォッチャー、法人向け体験談ブログ抽出サービス「PETTATO SHOOTI」 を読む。エイビーロードがこれを導入ということだが、分かりにくい。ブログウォッチャー の 【リリース】エイビーロードへの提供開始07/07/31 を見て、イースター島のページの下の方を見て、これかなというのが分かった。powered by SHOOTI というところがある。もうちっと分かりやすい形でリリース出した方がいいんじゃないのと思った。だいたい、プレスリリース垂れ流しの記事が多いわけだし。あとエイビーロードのページって Goole Maps とかも使っているのね。いわゆる流行ものの技術もあれこれ使って仕上げたサイトになっている。テッキーとマーケッターの組み合わせというのはよい組み合わせだろう。だけど、【リリース】「情報大航海プロジェクト」のサービス検証の開始2007/7/25 って、意外にリリースが広まっていない感じ。経済産業省の「情報大航海プロジェクト モデルサービスの開発と検証」を受託したことを受けて、利用者の様々な発信情報を蓄積し、情報提供サービスに活用していくモデルサービス、「プロファイルパスポート事業」の実証サービスの開発をスタートいたします。 ってことらしい。これはおもしろい方向だと思うのだけど、いつもプライバシーの問題を最終的にどうするかというのが関わってくる領域だなと思う。 株式会社リクルートが東京工業大学の奥村准教授と共同で設立した株式会社ブログウォッチャーが本プロジェクトの実施主体となり、全体サービス設計・技術設計・技術開発を行います。技術開発には、KDDI研究所、PlaceEngine(ソニーCSL提供)、大日本印刷、メタキャスト、東京工業大学、奈良先端科学技術大学院大学など、大学・民間の研究機関や技術ベンチャー企業の協力を得てシステムを構築し、リクルートの持つサービス開発のノウハウを活かし、魅力ある新サービスの立ち上げを目指します。大連合だな。これでまた一つ情報大航海プロジェクトの方向が具体的な形で見えてきた。 「情報大航海プロジェクト」の委託先、第1弾 で見たのは NTTドコモ系のお話なので、それに対して、KDDI がここで絡んできた。やっぱりバランス取るのねぇ。やっぱり、公募の前にある程度、ネゴができているのだよね、たぶん。次世代検索サービス、モデル事業に10件採択・経産省 なのね。どこに公開されているのか不明なので、経済産業省、「情報大航海プロジェクト」モデルサービス実施企業を決定 を見ると、第2回目の公募は、4月18日から6月6日まで実施され、37件の応募の中から、NTTデータ、沖電気工業、財団法人国際医学情報センター、チームラボ、データクラフト、東京急行電鉄、ブログウォッチャー、モバイルジャッジの8件が採択された。とある。なんか、どの記事もリソースが明確じゃなくていやねぇ。経済産業省 「情報大航海プロジェクト」モデルサービス実施企業の決定について に一次リソースがあるのか。ざっとめぼしいところを検索。経済産業省 「情報大航海プロジェクト」モデルサービス実施企業の決定について情報大航海プロジェクト。コラボ企業とそのプロジェクト内容とは?OKIとリクルート、会話で掘り下げる「ラダリング型検索サービス」を共同開発 (2007/07/27)沖電気とリクルート、次世代型「ラダリング型検索サービス」の共同開発を開始[リリース] OKIとリクルート、次世代型「ラダリング型検索サービス」の共同開発を開始 - 経済産業省の「情報大航海プロジェクト」に採択、ユーザの真のニーズを引き出す検索サービスを目指すNTTドコモ、次世代ネット検索で角川と提携「Viewサーチ北海道」事業、経済産業省の情報大航海プロジェクトに採択 ~道内企業・大学のコンソーシアムとして初、「モデルサービス開発と実証」に採用~[リリース] ソフトフロント: 「Viewサーチ北海道」事業、経済産業省の情報大航海プロジェクトに採択~道内企業・大学のコンソーシアムとして初、「モデルサービス開発と実証」に採用~ チームラボ: 経済産業省・情報大航海プロジェクトに採択「情報大航海プロジェクト」に北海道案件が採択モバイルジャッジの対話型自動アンケートシステム、情報大航海プロジェクトに採択日本航空 事故を未然に防ぐための安全運航支援システムを導入へ情報大航海プロジェクトへの批判と経産省の回答沖電気のラダリング型の検索サービスについて、「ラダリング」とは、相手との対話の中で徐々に掘り下げた質問を繰り返すことにより、相手のニーズや価値観を引き出す手法のこと。OKIとリクルート、会話で掘り下げる「ラダリング型検索サービス」を共同開発 (2007/07/27)沖電気のページを見ると例が分かる。こういう自然言語処理型の対話って、技術もさることながら、ユーザーがどれだけそうした対話ができるようになるかというのもキーなんだと思う。単語中心の入力に慣れちゃっているから。だいたい、日本人男子は、「風呂」とか「飯」とかワード対話型が多かったりするところもあるから、実際作るときにはユーザー側の発話はワード単位の発言が多くなっていることも前提として作られるんだろうな。デモでは文章の入力であっても。そういえば 「第2日本テレビ」で配信中の「東京六大学野球」に動画検索機能が追加! 好きな選手や、見たい場面を検索して楽しむことが可能になりました! なんていうのもついでに見つかった。これはどこの技術なんだろう。それにしても、そろそろ、まとまった情報大公開プロジェクトの記事を読みたいもんだと思う。関係者へのインタビューも含めたようなやつ。
2007.08.03
コメント(0)
-
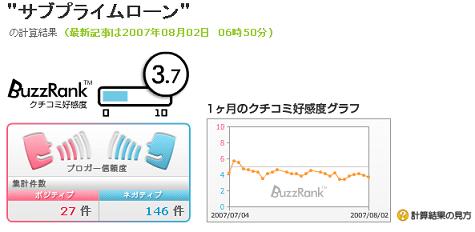
サブプライムローンをブログ検索のグラフで見る
ブログ検索でグラフを表示するものを使って、感度にどれだけ差があるのか気になったので見てみることにした。見てみたのは BuzzTunes, goo, kizasi, Technorati の4つ。それぞれ画面を記録しておく。それぞれサブプライムローンを検索したところ。ネガティブ、ポジティブがあるものについては、ネガティブが多くなるだろうと予測したがその通りになっている。が、BuzzTunes でポジティブに分類されているものを見ると、んー。まあいいや。goo の方は個々のブログについてのネガポジは見ることができないが、評価ポイントを見ると、可能性-(小さい,劣化する)、担保-(適正でなくなった)、市場-(非常に大きい) ,etc. のようなものが挙げられてているので評価ポイントが分かりやすい。goo は反応が鈍いが、主語述語のような関係を捉えた上でやっているようなのでおもしろみがある。「暗い陰」を「陰が暗い」と抜き出していたりするところからして、ちゃんと構文解析しているんじゃないかなという印象。が、「不透明感の拡大」を「拡大-不透明感」としているところを見ると A の B をある程度何とかしようとしているようだが、これは本来、不透明感-拡大にならなければならないところだろう。サ変名詞(A) の 名詞(B) のパターンであれば、もしかすると確率的には B を主語として、A を述語とした方がいいんじゃないのかな。ブログ数の反応についてはどうか。BuzzTunes は過去の件数の推移が自分で数えないと分からないので、好感度グラフにマウスを持って行ったときにネガポジの件数とか表示するともっといいなと思う。7/27,28 の評価が一番ネガティブになっているところがおもしろい。加えて、全体を眺めてみると、ネガティブの度合いが強くなっているところもおもしろい。goo は、たぶん反応が鈍目。kizasi と Technorati の方が反応がよいようだ。でも、やはり表示の仕方がユニークなので許す。1週間ぐらいしたらどうなっているかまた見てみようかな。テクノラティは「オーロリティ☆☆☆」と「全体」を比べてみるとおもしろい。実はこれはかなりおもしろい機能だと思う。kizasi はタグクラウドがあり、また、期間ごとの件数が見やすい。この話題の主成分がページとして(画面には映っていないが)「経済、怒った、驚いた、おもしろかった」が挙げられているがこれは良い感じかな。成分が似ている話題については、ニュースものの場合、1つのブログ内に複数のニュースが表示されることが多いということを考慮すると「サムティ、参院選惨敗、サブプライムローン問題、赤城農水大臣、路線価格、大相撲夏巡業」が挙げられるのは分からないでもない。けど、成分が似ている話題というのを純粋に考えると、ちと違うかもとか思う。けど、本当に似た話題を抽出するとなると難しいだろうけど。それぞれ特徴があっておもしろいかもしれない。BuzzTunes での検索goo ブログ検索での検索kizasiでの検索テクノラティでの検索テクノラティでの検索(オーソリティ)
2007.08.02
コメント(0)
-

グーグル八分発見システム
「グーグル八分発見システム」を悪徳商法?マニアックス管理人が開発へ, IPAの未踏ソフト採択プロジェクトが決定 を読む。これはおもしろいかもしれないな。IPA も思い切ったプロジェクトを採択したもんだ。
2007.08.01
コメント(0)
-
カカクコム 表記のゆれも吸収した検索
カカクコム、“表記ゆれ”に対応した商品検索サービス開始--日本語解析技術生かし を読む。例えば、「幅」と「W」など異なるサイズ表記の商品同士であっても、任意の表記によるサイズ入力でこれらを一括検索できる。 また、新語抽出技術を応用した辞書ファイルにより、新商品や新たな属性情報にもすばやく対応できるとしている。何気に、「幅」と「W」を一括検索できたりするのは便利かもしれない。「横」も対応しているのかな。「ショッピングサーチ」でまず インテリア小物 時計 「横」で検索して、その結果に最初に出てきた 縦置き横置き兼用の斬新な掛時計!!激安販売に店長大激怒!!でも売っちゃいます。北欧デザインの壁掛け時計 LEON CM102 置き時計 新品 のページを見る。「横200mm」が見つかる(サイズ 縦500mm×横200mm×奥行き97mm)。次に、「インテリア小物 時計 「幅 200mm」で検索する。 が、その検索結果の中には、最初の時計が含まれていない。ダメじゃん、というのは意地悪だろうか。熱は下がったが、まだ風邪で調子悪いので性格も悪い。とりあえず、これから対応ってことかな。ちなみに応用編として、暖色系とか寒色系とか、ある程度の大枠の色で検索したいとか対応するのがそのうち出てこないのかな。洋服とか。赤っぽいやつとか、青っぽいやつとか。大きいやつとか、小さいやつとか。「大きいの」は、そのジャンルの標準偏差調べて、1σ~2σのものを「特大」は2σ~のものをとか、そんなものもありかなぁ。本を探すときにも、ある分野の薄目の解説書が欲しいとか、分厚いのは読みたくないので検索対象からはずすとか。スキャンした書籍が増えてくると、画像や表の類の比率とかも検索対象になるとかなってくると、絵が多い本がいいとか選べるんだけど。もっといえば、スキャンした内容の単語の分析から同じような書籍を分類するなんていうことも理屈上はできないことじゃないだろうな。2つの書籍を並べて、かぶっている箇所が多ければ買わなくていいやという判断ができるとか。迷ったときに同じ題名でも重複が少なければ買ってもいいやとか。重複がやけに高いページは、並べて表示しちゃったり。盗作ばれちゃったり。画像なんかも、写真を撮るときに一定の基準で撮るようにしておけば、ほんとはあれこれできるんだろうな。もっともそんなものを作って、どの程度売上げ向上に役立つのかは知らないが。
2007.07.24
コメント(0)
-
Eコマース向け検索エンジンの WiSE EC が日本語類語辞書など機能強化したらしい
純国産のEコマース向け検索エンジン「WiSE EC」、日本語類語辞書など機能強化 を読む。日本語類語システム辞書が追加された。この辞書では、同じ意味の語や揺れ語、言い換え語などが、見出し語として約6万7000語が含まれている。こういう辞書って、個人で作るのはやっぱり面倒で辛い。こういうところは商用で資金投じてできる強みになるだろうな。でも、どんどん新しくしないといけないと思ってWiSE ECを見てみるが、辞書のアップデートサービスはないみたいね。ジャストシステムは ジャストシステムとはてな 「ATOK 2007」の「はてなダイアリーキーワード」を活用したサービスの提供で連携 ~第一弾として「はてなダイアリーキーワード辞書 for ATOK」を本日より提供開始~ (2007.06.19) みたいなこともやっている。辞書が更新されるのって、やっぱり製品の魅力のひとつだと思う。とか書いておきながら、まだ ATOK 2007 は持っていない。興味本位で WiSE V1.3C (Linux & Windows) 評価版ダウンロード を使ってみようかと思ったが登録が面倒なのでやめた。なんか見覚えがあると思ったら 自治体ドットコム、WiSE、その他 で WiSE についてちょっと書いてた。
2007.07.20
コメント(0)
-
クチコミプロモーション効果の測定 CA-Buzz Optimizer
クチコミプロモーション効果を可視化する「CA-Buzz Optimizer」 を読む。次のことができるらしい。従来の広告効果指標意見や評判の量/質/推移商材ごとのクチコミシェア比率商材に対して消費者の印象/反応度合/行動行動パターンのレベルごとに、商材に対するユーザーの印象/反応度合を数値化そして、各段階の数をクチコミした全体数で割ることによって、Blog 出現回数に対しての「共有」につながったコンバージョン率など、転換率を測定することも可能。ということで、サイバーエージェントとニフティが得意なところを持ち寄ってできたもののようだ。この手の得意なものを持ち寄って一つの製品とするパターンはまだ増えてきそうな感じ。特に本格的な技術を持っている会社と、ノリのよい技術を持っている会社の組み合わせ。クチコミプロモーション効果を可視化するマーケティングソリューション「CA-Buzz Optimizer」提供開始 (サイバーエージェントのリリース)、 ニフティ、サイバーエージェントとCGM上のクチコミプロモーションにおける共同商品「CA-Buzz Optimizer」の提供を開始 (ニフティのリリース)。元になっている ニフティ、ネット上の「口コミ」評価分析からコンサルティングまでをサポートする企業向けマーケティングサービス「BuzzPulse」(バズパルス)を開始 (2006年3月30日) の 「BuzzPulse」 を見てみる。ご利用例 を見ると、アフラック、富士重工、ネスレ日本、NHK、JALブランドコミュニケーション、WOWOW などが使っているようだ。ニフティ、東京都知事選挙の候補者に関するブログ分析結果を発表 ~ブロガーはどう捉えたか!東京都知事選挙の評判分析速報~ なんてのもやっていたのね。都知事選は、どう思われていた? BuzzPulse によるブログ評判分析 を見てみると、ポジティブワードの出現率の方がネガティブ出現率より高い傾向が共通していて、絶対出現数が多い者が勝つということになりそうだが、繰り返し、発表してくんないとわからんね。選挙ではよほどのことがない限り、ある程度、ネガティブポジティブが拮抗しながら、基本的にはポジティブが多くなるはず。だって、支持者のブログとかもあるだろうし、ニュースのコピペ的なものも多いわけだし。平成19年 東京都知事選挙 開票結果 の結果を合わせてみる。1位、2位に関しては、ある程度、ブログへの出現数から予測できそうな感じ。今回のは、圧勝パターンだが接戦のときはまた違った感じになるかな。繰り返していけば、選挙の結果が出る前に、ある程度結果が推測できるようになるだろうな。候補者名得票数ブログ出現数石原 慎太郎 2,811,4861196浅野 史郎1,693,323698黒川 紀章159,126332吉田 万三629,549141でも、出現数ってあまり多くないのね。都知事選でこの程度の数しかないってことは、参院選だと各候補者のレベルでの判断は難しいから、党別ってことになるか。参院選といえば、C2cubeが参院選の口コミ好感度ランキングを公開 はどんな具合かなと見てみる。7月11日で掲載終了 なのね。まあ、正しい姿勢かもしれない。候補者別では こんな順位だったようだ。バズロボ1号と話そう とかいうのができている。機能素解析とか、バズランク計算とかあらかじめ答えが用意されているものが来ると説明が出てくる。チャットとか入れると、バズロボがニューロンストリング方式と名づけられた独自の方法で対話するように構成されていることがわかる。これは知識の連関とその繋がりの強さ、そして、知識と知識をつなぐファンクションという複数の要素を同時にデータベース化したものです。これにより、ボクは自分の持っている複数のシナリオを質問に応じて最適なパターンに組み合わせて答えることができます。らしい。ぱっと見た目、賢いタイプのものというより、ヘルプ表示的なチャット向きという感じかな。また関係ないけど Blog Keyword Visualizer Flash version β はランキングを視覚化していて、おもしろいとは思うが目が疲れる。
2007.07.19
コメント(0)
-
テクノラティのグラフ
テクノラティって、記事数のグラフに対するリンクがあったりするのね。へぇ、これはいいかもしれない。過去90日間に書かれた、参院選を含む日本語のブログ記事このグラフをブログに貼ろう!けれども日付で始まり終わりを指定するようなものもほしいな。最近90日とかいうのだと、特定の時点でのグラフを指して何か書くことができない。ダメじゃん。関係ないけど 柏崎市刈羽村、原子力発電所敷地の航空写真をアップしました。断層の走る方向をほぼ特定。政府は情報を隠さず正直に公開せよ。 なんてページがあった。「発電所もサイバー攻撃の対象になる」,米SANSのアラン・パーラー氏が警告 なんて話もあるが、米エネルギー省,セキュリティ侵害でカリフォルニア大学に300万ドルの罰金 ってのもすごい。政府はこういう罰金刑という稼ぎ方というのもあるな。社保庁なんかも NTTデータの落ち度をついて金返せっていうので少しでも失点回復なんていうのをやればおもしろいんだが。しばらく前原発ブームだったけど(株価とか原発関連上がっていた)、この先どうなるかな。アルカイダ、対米攻撃要員をイラクで起用の可能性 報告書、米国、アルカイダに関する報告書を17日に公表へ とかいう話もあるし、原油は先高かな。生活用品次々値上がり…物価指数はマイナス 庶民感覚と統計にズレ にあるようにバイオ燃料のせいで値上がりしているものもあるし、「庶民感覚では“インフレ不安”が着実に高まっている。 」っていえてるな。NY原油、一時75ドル台 高値続く見通し のようだし。原発への依存度は高くなる可能性が高い。長~い目で見ると東芝とか三菱重工とか原発リスクを大きくしているのだな。三菱重工業、原子力発電所情報がWinnyで流出 とか米国でやったらどうなるんだろうな。東芝が米原発受注、総事業費6000億円 とかが将来いくらのコストを払うことにつながるんだろうか。米国は恐ろしい国だからなぁ。まあ、作ってもいないものの事なので、かなり先のことになるけど。何でもありの返品制度が築くゴミの山 の国で小売市場の返品率 20% で4600億ドル相当らしいから、原発作ったあとで問題あるから返品とかやったらすごいわな。罠。そういえば 原油決済を円建てに変更へ 新日石、イランの要請で核開発問題で米国と対立するイランは、米政府主導の経済制裁などを警戒し、ドル以外の通貨による貿易決済を増やそうとしている。とかいう理由らしいが、そろそろ円安傾向打ち止めで円高に向かう材料が増えてきたかな。参議院選挙が終わってからどうなるか明確になるかな。8月利上げはするのかな。雰囲気からすると今度は利上げするだろうということなんだけど。銀行株がまた下がっている。どこで買ったらよいかなの様子見って感じ。トヨタも安くなってそろそろ底打ちなのかな。でも、参議院選挙の結果出るまで強気の買いはなさそうな感じか。歳をとったせいか風邪がなかなか治らない。
2007.07.18
コメント(0)
-
検索あれこれ
検索エンジン関連のニュースあれこれ読む。未来検索ブラジル、2ちゃんねるトップページに検索フォームを設置ブログウォッチャー 「また聞き」「うわさ」はなし、精度重視の体験談検索サイトhttp://shooti.jp/「検索」でビジネスを支援するBIGLOBEのサーチプラットフォームサービス検索からおすすめへ - goo「おすすめRSS」に見るリコメンデーションの力国内初の商品評判検索「goo評判検索」提供開始 - NTTレゾナントgoo評判検索「2011年の市場規模は7520億円」---経産省が“Web 2.0”の調査報告書を公開検索市場は2011年に5500億円--経産省がIT市場の現状と展望を発表新たなIT市場の現状と展望(経済産業省)goo評判検索を見てみると、まだまだだねって感じだけど、たくさんの人に使われながら、だんだんよくなっていくんじゃないかな。こういう実験的な公開に関しては寛容であるべきだろう。逆に精度がよくなってきたときに、評価の悪い製品を持つ企業がどのような対処をすべきか、あるいは、クレームをつけてきた企業にどのように対処すべきか、なんていうのを今から考えておくべきなのだろう。購買に結び付く評判検索については、ある高い評価の製品が、ある日、欠陥商品と分かった場合を極端な例として考え、欠陥商品を高い評価で掲示することについての道義的な責任をどうとるのかなど、購買行動に結びつくものに関しては、もう一度、それが社会的に大きな力を持つようになったときのことまで考えてポリシーを考え直すのがよいようがする今日この頃。
2007.07.03
コメント(0)
-

違いを吸収した検索
株式会社アドイン研究所 の 全文検索エンジン FlexSearch をなんとなく見てみる。デモ はリンク切れで使えない。。。。FlexSearch の特徴 を見てみると、「FlexSearch」は、文字間をラバーバンドで連結して伸縮させるように類似文字列を検出する、Rubber Band Matching(RBM -ラバーバンドマッチング)アルゴリズムを採用しています。 RBMアルゴリズムを採用することで、表現の差違を吸収して検索対象を抽出できます。 とある。部分文字列、文字の挿入、文字の欠落、文字の置換に対応して、表現の違いを吸収した検索ができるという特徴を持っているようだ。アドイン研究所、ゲノムマッチング技術を応用したAI検索エンジンを発売 (2001年7月12日) から基本が変わっていないとすると、ゲノムマッチング技術の応用ということで、連想検索エンジン「reflexa」のWeb API の 高速なゲノム解析処理を1台のPCで実現する全文検索エンジン『Sedue Flex』 (2007/03/05) とかとも似た技術なんだろうか。今回開発したエンジンは、どのような長さの文字列に対しても曖昧検索を可能にしているため、従来手法では実現できなかった高度なゲノム解析処理やノイズを含んだデータに対する検索を実現可能にしています。特に、ゲノム解析においては従来手法では困難であった、50塩基程度の短い長さの塩基配列に対するミスマッチあり(一部の文字が異なる)・ギャップあり(一部の文字が欠落・追加している)の検索も可能です。こういう手法はちっとも分からない。けれども一つの方向性としておもしろいものがあるんだろうな。テキストマイニング・ツール VextMinerで テキストマイニング技術の音楽情報への適用 では、音符をカタカナにマッピングして半小節を単語に対応させて、似た曲を分類するということに VextMiner を使っている。ジャンルの分類もできるようだ。と書いたが、同じようなことが上記の2つの検索エンジンでもできるのかな。論文の引用調査とか、盗作とかの調査にも応用が利くんだろうな。いったん意味を持っても持たなくてもどうでもいい単なる文字の連鎖として扱う手法は人手によるメンテナンスコストが低く、比較的高速に処理が行えるんだろうなぁとか直感的に思える。けれど、それはそれであれこれ細かくみていけば問題があるんだろうな。本題に戻って、違いを吸収した検索と、完全マッチングの検索が欲しい場合と両方あるなとか思う。
2007.06.30
コメント(0)
-
検索エンジン 2本
テクノラティ、シンプルなブログ検索サービスをリリース を見る。シンプルブログサーチ(β版) は、オーソリティの強さ(☆から☆☆☆)で検索対象を絞り込むことができるようなので、そのうち試してみよう。今試してみたら、レスポンス悪すぎなので、軽い時間帯に試してみる。世界が認める頭脳が集結したガレージ--検索エンジンのPFI を読む。「Anthy」の開発者もいるのか。ふーん。reflexa は WebAPI も公開されている のでそのうち使ってみようかと思っている。連想検索って、まだ、とりあえず関連性の高いものを出しているだけだと思うのだが、発展性があっておもしろい分野だと最近思う。ジャストシステムなんか、こういうところに出資させてもらって、2,3人、人も送り込んで、いっしょになにかやればいいのに。sedue もちょっと試してみたいのだが今時間がないのでそのうちためす。全文検索エンジン性能評価 (2006/08/19) とか見ると、まとめて試してみたい気がする。Sedueのサイトに、各種全文検索システムの速度比較が載ってるよ!(グニャラくんのグニャグニャ備忘録@はてな) に、[追記]再現率をあわせるためだそうです。なるなる。なるなる。オープンソースの全文検索のベンチマークなんてあるといいと思う今日この頃。コーパスのプロジェクトが進んできているのだから、これを有効活用すればよいかなと。コーパスのプロジェクトなんかは、そういう形で自己存在をアピールすることもできると思う。検索エンジンの性能を高めていくためにも、ベンチマークが取りやすいようにコーパスプロジェクトって大事だと思うのだな。検索漏れのチェックなんかはコーパスベースでやるのがいいと思う。
2007.06.22
コメント(0)
-
キーワードに頼らない検索
Xerox,キーワードに頼らない検索が可能なテキスト・マイニング・ソフト「FactSpotter」 を読む。「(FactSpotterは)文脈を“理解する”ことで,検索している人にとって適切な情報を返すとともに,文書内で回答のある場所を正確に示す」(同氏)。 検索用のインデックスを作成するときに、文脈処理で代名詞が何を指しているかを解析して、その単語をインデックス化するということなのかな。文書を検索したときに、どの文書かを探すだけでなく、その文書のどの文がヒットしたかをハイライト表示するときに文脈上の判断が加わって表示される。例えば Angelina Jolie" で検索したとき、"she" と表記されていても意味上 "Angelina Jolie" であれば、"she" もハイライト表示されるといったもののようだ。たしかに、うまく動いていれば役に立つだろう。また、"Angelina Jolie" がある文書の中に1回しか登場しなくても、"she" で 100回参照されていれば、それは、"Angelina Jolie" で検索したときにヒットすると嬉しい文書なのかもしれない。Surpassing Search: New Xerox Text Mining Software Goes Beyond "Keywords" To Deliver More Relevant Informationを見ると、FactSpotter recognizes abstract concepts, like "people" or "building," and will retrieve all the words that fit within that category. とある。人や建物の類には対応しているようだ。拾いやすいところから手をつけたのかな。これをやるためには、機械翻訳レベルの構文解析を行う必要があるだろうから、インデックス作成の時間は長くかかるようになるんだろう。日本語の場合、主語を省略する場合も多々あるから、英語に比べたら難易度が一段上がるだろうし、処理時間もさらに増えるだろう。いわゆるゼロ代名詞 の対応が必要と。決定木を用いた日本語ゼロ代名詞補完、日英対訳コーパス中のゼロ代名詞とその指示対象の自動認定、教師なし学習で推定した確率分布によるゼロ代名詞の解析 とか出てきた。とはいえ、並大抵のことで、Xerox が日本語対応した FactSpotter を英語版と比較的近い品質で作ることはないように思える。万が一できたとしても同じ値段で作るのは無理だと思われる。何にせよ、文書(ファイル)を探し出す次元から、より厳密に、その文書の中の特定の箇所を引き出すという方向へ高度な検索は移りつつあるということか。文書に対する知識処理を行おうとすれば、文脈処理が必要になる。さて、日本で一番最初に実用的なそうしたシステムを出してくるのはどこになるんだろうな。評判検索なんかも、そういうレベルでやらないとなかなか正確なものはできないだろうし。客体的表現とゼロ代名詞に関する考察 。
2007.06.21
コメント(2)
-
Yahoo! Pipes をちょっとだけ試す
Plaggerとの違いは? 簡単マッシュアップ、「Yahoo! Pipes」を試してみた を読む。Yahoo の形態素解析 API をちょっと試したついでにこっちも見てみる。公開されてから、ずいぶん経っているが。。。。Yahoo! Pipes をちょっとだけ使ってみた。これ意外と便利かもしれない。いったん作ったものや他人が作ったものの clone を作ってちょっと書き換えるとかして使うと敷居が下がる。あれこれ探してみる。「Yahoo!Pipes」で自分のマスターフィードを作るかんたんすぎ かっこよすぎ Yahoo pipesYahoo!Pipesの使い方(全モジュール解説)「YahooPipes」モジュール日本語リファレンスモジュールを繋げてマッシュアップ!「Yahoo! Pipes」の使い方Yahoo!Pipesが気になるYahoo! Pipes でブログのフィードを拡張してみましたYahoo の pipes で日本語 RSS を使う場合の注意点指定したURLに関するソーシャルブックマークのコメントをまとめて取得するAPIをYahoo! Pipesで作ったYahoo! Pipesでfeedを翻訳英語←→日本語の翻訳APIとして使えるYahoo Pipesを作ったYahoo Pipes (英語圏のブログ検索をして、スニペットを日本語で表示するようなのを作ってみました)Feedから自動投稿系アイテムをカットするPipesを作ってみたDojo、Yahoo! PipesをサポートYahoo! Pipes ちょっぴり追加情報Yahoo! Pipesを使ってブログのヘッドラインを表示す『Badger』Yahoo! Pipesで『百式マスターフィード』を作ってみたさ思ったよりおもしろい使い方ができるサービスなのかもしれない、と今頃になって思った。
2007.06.19
コメント(0)
-
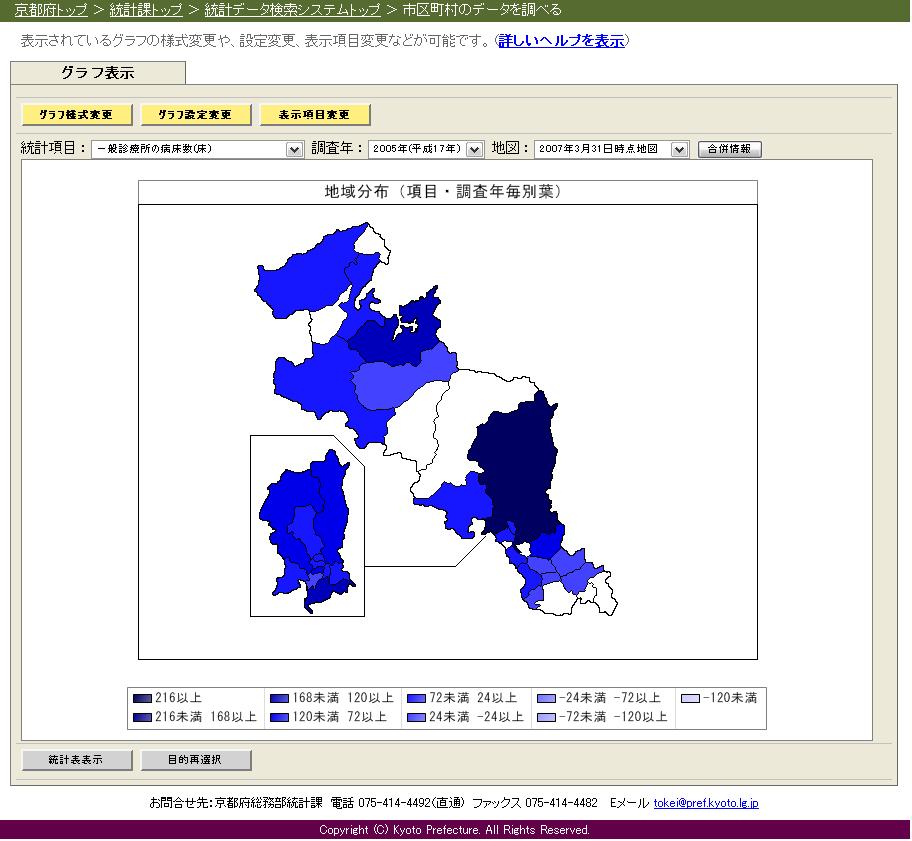
統計データらくらく検索
統計データをらくらく検索、京都府、ネットで新システム を読む。統計調査の正式名称を知らなくても「地域」「項目」「調査年」の3つのキーワードで検索できて、簡単に6種類のグラフに加工できる。すばらしい。ということで、京都府のウェブサイト から、京都府の統計 のページへ行き、統計データ検索システムトップ を見る。直感的に使いやすいかというと、ちょっと戸惑うところがあるが、何度か使えばなんとかなりそうな感じ。これは自治体のお仕事としては、すばらしいことなんじゃなかろうか。こうした形で情報開示というのもありだと思う。惜しいのは、全国のデータと付き合わせてみようとしても、他の都道府県のデータが得られなかったりすること。この仕組み、統計局で使って全国規模のデータを簡単に参照できるようになるといいと思う。ヘルプを見ると、Q1.このシステムで検索できるデータの範囲は?A1.「1.都道府県のデータを調べる」では、全都道府県のデータを検索できますが、一部の統計項目では京都府のみのデータとなっています。調査年は最大1975(昭和50)年まで遡って検索することができます。最初は取っつきにくいが、あれこれ試していると、なかなかおもしろい。これはすばらしい。 こういう統計データを簡単に参照できるような仕組みがいろいろあって簡単に比較ができ、さらには、特定のパラメータで検索した結果を他者に簡単に参照させられるようになると嬉しい。今のシステムだと、画像をとっておくか、CSV データを保存するなどしないとならない。このデータやグラフを参照してみて、とできるようになればさらにすばらしいものになるだろう。統計データで市町村をアピールすることだってやりやすくなるだろう。その逆もあるだろうけど。
2007.06.16
コメント(0)
-
半日完成サービス
「サービスは半日で完成させる」――SETAKE・たつをさん を読む。気軽にぽんぽんと作って試して、使ってもらって見えてくるというものもあるんだろうな。アフィリエイトのサイトにもなっているものであれば若干の収入にも結びつくだろうし、あるいは、他者の Web API を使っていたら表示された結果に対して責任感はあまり持たなくても罪悪感がないとかもあるかもしれない。別に表示されたページにブラウザの脆弱性をつくようなページがあったとしても関係ない。XX の API でとってきたやつだからしょうがないというスタンスが取れる。一番おもしろいというか発展性があるのは 買ったら検索 かもしれない。「買ったよ」検索ではなくて、「買ったら」なところがおもしろみがある。この発想はおもしろいかもしれない。ちなみに「ったら、っても」のように語尾に注目して検索してみると別のものが見えてくる。なんにしても、名詞中心主義からいったん脱却するとおもしろいかもと思わせるものがある。英語例文検索 EReK は実用的で便利。
2007.06.14
コメント(0)
-

顔ちぇき、ひと月でのべ 1500万人
口コミの威力 ひと月で1500万人 を読む。プレスリリース 『顔ちぇき! ~ 誰に似てる? ~』サービス開始1ヶ月で利用者1500万人突破 も読む。顔ちぇき が流行っているようだ。1日平均80万人か。すごい。口コミがどうのという話はおいておき、ジェイマジックCEO宮田拓弥のBlog 顔ちぇき リリース を見てみると、今回、「顔ちぇき」の開発に関しては、顔画像認識技術のリーディングカンパニーである沖電気工業様にご協力いただきました。沖電気さんの顔画像処理ミドルウェアは、すでに本人認証技術として国内外の携帯電話などに搭載されているものですが、今回エンターテインメント利用という新しい分野での活用ということでご協力いただきました。なるほど、こういうことなのか。ベンチャー系のノリと固い企業の技術が結びついてできたものだったのね。どこかで顔ちぇきをやったら云々の記述は見ていたが、お遊びレベルの認識だと思っていた。裏側で実はすごくまともな技術も使われていたわけか。こういうパターンでいろいろ出てくるとおもしろいなと思った。大企業だと怖くてできないようなものも、ベンチャーだったらできる。ただ、「顔」という非常に重要な情報を取り扱うということに関しての認識が足りなかったと深く反省をしております。利用規約に一部紛らわしい表現があったため、顧問弁護士と協議の下、至急見直しを実施いたします。顔ちぇき 予想外の反響+障害そりゃ、そうだろうという話なのだけれど、これぐらいの思慮の足りなさがないと、なかなかできない企画だな思う。大企業で法務部門がしっかりしているところだと、スタート前に社内ですったもんだあって時間がかかってしまうんじゃなかろうかと。沖電気は裏方の技術提供だけだから、そのリスクを冒すことなく、技術を売ることができた。画像の認識技術って、その気になれば、いろいろ凄いことができる時代になってきたと思うが、安心感をいかに作っていくかというのも同時に重要になってくるなとも思う。ジェイマジック、携帯で商品撮影すると通販サイトに誘導 のもおもしろいと思う(eyenowa)。画像を送ってあれこれというサイトを調べてみようと思ったが、面倒なのでやめた。
2007.06.01
コメント(1)
-
Senna を組み込んだ MySQL Enterprise認定バイナリ
住商情報、MySQL Enterpriseに日本語全文検索エンジン"Senna"をマージ を読む。Senna も徐々に表舞台に上がってきたようだ。作者の直接の手を離れたところでいろいろ動くというのは成功といえるだろう。リリースの中に Senna が 未来検索ブラジル の開発によるものというのを入れてあげたほうがいいと思うのだけど。しかし、2ちゃんねる系であることがあれなのか、会社名があれなのか。住商情報システム、日本語全文検索に対応した「MySQL」の技術サポートを開始Senna 組み込み型全文検索エンジングニャラくんのグニャグニャ備忘録@はてな [Senna]TritonnTritonnとは21世紀の最新エンジンたち傀儡師の館の Senna 関連のエントリを見てみる。まともに使っていな割には何度も言及しているので、関心はあるようだ(人ごとのように)。でも、今、ちょっと興味が別方面に行っているが。NTTデータの全文検索エンジン Ludia を調べてみる組み込み型全文検索エンジン Senna を使ってみるSennna をもう少し使ってみるSenna のメモ全文検索エンジン Senna 1.0Tritonnプロジェクト
2007.05.31
コメント(0)
-
IT統計メタ情報検索サービス
JIPDEC: 日本情報処理開発協会をなんとなく見てみる。IT統計メタ情報検索サービス経済産業省における「我が国のIT利活用に関する調査研究(IT統計ポータルサイトの構築に関する調査研究)」において構築されたサイト Web上で公表されたIT関連の調査や統計の所在情報を一元的に収集し、カテ ゴリ別に 分類整理して検索を容易にしてあります。(登録件数:約900調査 2006/6/26現在)Google で検索できないことはないけど、まともなリンクしかないので、これはこれで便利かもしれない。情報化白書2006 (平成18年11月15日発表) のページの画像がリンク切れしている。
2007.05.25
コメント(0)
-

特許流通DB検索
独立行政法人 工業所有権情報・研修館 の 特許流通DB検索 なるものを見つける。活用可能な膨大な開放特許を、産業界、特に中小・ベンチャー企業に円滑に流通させ実用化を推進していくため、企業や研究機関・大学等が保有する提供意思のある特許をデータベース化(ライセンスの条件、利用想定技術分野、技術指導の有無等を蓄積)し、「ライセンス情報」としてインターネットを介して無料で提供しています。というもののようだ。それにしても、この手のもの重複投資が甚だしいんじゃなかろうか。あちこちに作られているような。NICT公開特許情報 みたいなものもあるし。これはあくまで 独立行政法人 情報通信機構 (NICT) のもので、こちらはそれ以外の一般企業のものも含んでいるという違いはあるのかもしれないが。その他、政府系の TLO として (財)日本産業技術振興協会 産総研イノベーションズ(経済産業省)、(財)ヒューマンサイエンス振興財団(厚生労働省)、(社)農林水産技術情報協会(農林水産省)、(財)テレコム先端技術研究支援センター (総務省)といった具合で縦割りでいろいろあるのね。データベースなんて、共同で一つ作って入り口を統一しておかないと使い勝手悪いし、利用度高めるの難しいんじゃないかな。これに加えて、各自治体でもいろいろあるだろうし。こういうのを全部集めると予算幾ら使っているのかなぁの世界。J-STORE 科学技術振興機構 研究成果展開総合データベース とかもあるし。ちなみに、特許流通DB検索は企業に対しては入力のインセンティブとして、ライセンスの情報登録を見ると、 画面から直接入力、または登録アプリケーションにて作成し提出された電子データから、新規のライセンス情報が登録された場合には、1件の登録につきデータ作成料(3,000円)をお支払いします。なのね。1000件で300万円、5000件なら 1500万円か。さて、予算はいくらとってあるのだろう。今年度の予算オーバーしたら、いったん新規登録を休止とかそういうことするんだろうか。あらかじめ、企業に打診して何件程度とかいう話になっているんだろうか。1億かけても、ほんとうにそこから億単位のビジネスがいくつも生まれるのであれば企業が支払う税金として戻ってくるからいいんだろうけど。特許流通DB検索については、対価条件とか、ある程度明示されていないと中小企業は使いにくいんじゃなかろうか。目安として 例:売上金額の○%、生産・販売数量×○円、一時金等 のようにもう少し情報開示が必要なのではないかな。特に中小企業にとって一時金の有無とその金額は利用するかを判断する上での大きな要員の一つになると思うのだが。結局、話し合いしないと話は進まないんだからということなのかもしれないし、ライセンスする気があるものかないものか、特許権の譲渡があり得るものかそうでないかが分かるだけでも意味はあるといえばあるだろうけど。あえて、こういう形で公開する特許というのは、単に後生大事に抱えているだけでは仕方ないから、何とかお金にしようという方向なのだろうから、なるべく高く特許料をせしめたい場合と、売れればいいの世界を明確に分けて、売れればラッキーというものについては、買い手がつきやすい形の提示方法ってあるんじゃなかろうか。すぐに売れるものならオークションの方が必要なのかもしれないし。あるいは、NS(ニーズシーズ)ハイウェイ みたいな方向とまた比べてみたりする。最後のオチとして、グーグル、特許検索サイト「Google Patent Search」を公開 のようなものにデータ取り込まれて検索は必要なくなりましたとか。あれこれ分散して作っていると、利用者の視点からしたら、まとめて検索できるところに行きたくなるだろうし。
2007.05.22
コメント(0)
-

HyperEstraier を使ったサイト
MonotaRO、全文検索システムを使用した「新商品検索エンジン」を導入 を読む。この「新商品検索エンジン」は、N-gram方式(※-3)による漏れのない全文検索システム「HyperEstraier」を使用しており、メーカー名、商品名といったキーワードだけではなく、特長や用途といった商品説明などからもテキスト検索できると同時に、インデックスを使った検索を行うため、同社が取り扱う80万点のアイテムからの高速検索も可能となります。HyperEstraier を使っているのね。MonotaRO で「テーパドリル 25.5」とか検索してみる。ちゃんと検索できた。「コレット 内径 12」とか「S-TPT」のような型番も大丈夫。この手の商品検索は N-Gram がやはり正解だと思う。まあ、当然といえば当然。ここで「着脱簡単」を考えてみる。N-Gram だと完全マッチで検索結果が出てくる。故に「簡単着脱」「簡単な着脱」「着脱が簡単」はヒットしない。形態素解析を使った検索であれば、どれも「簡単」「着脱」で検索することになり、どれもヒットするだろう。一般論としては、N-Gram の方が検索結果にノイズが多いと言われるが、こういうパターンでは逆の結果になるんじゃないだろうかとか、ふと思う。ということで、複合語で微妙にバリエーションが生じる言葉を検索するようなことになるときには形態素解析の方が意図としては漏れがない結果になることだってある。漏れがないとはいったいどういうことかを冷静に考える。
2007.05.20
コメント(0)
-

連想検索エンジン「reflexa」のWeb API
プリファード、連想検索エンジン「reflexa」のWeb APIを公開 を読む。reflexaは、キーワードとキーワードの関連を計算し入力したキーワードに対して関連の深いキーワードを抽出する「連想検索」を行う検索エンジン。大量の文章を「確率モデル」を利用して分析することでキーワード間の関連度の計算を高精度で計算するほか、連想検索に用いるインデックスを圧縮技術を用いることにより効率的に格納。連想キーワードの抽出が高速に行える仕組みだ。ということで、reflexa Web APIの概要 あたり眺めてみる。Yahoo! JAPAN の関連検索ワードWebサービス あたりと比べると、返ってくる関連語がどのように違うか調べてみたらおもしろいかもしれない。プリファード は、Sedue 次世代検索エンジン を作っている会社なのね。高速なゲノム解析処理を1台のPCで実現する全文検索エンジン とか、まねっこさんじゃない独自路線を持っているのか。Sedue Flex - あいまい検索が可能な全文検索エンジン の GENOME SEDUCE を検索してみる。でも分からん(笑)。 で、連想検索エンジン reflexa を使ってみる。抹茶で検索してみる。なんだ、バスター事件 てと思って見てみたら、抹茶に含まれるカフェインは競馬施行規則によって禁止薬物に指定されていたため、抹茶を摂取した可能性のあるバスターは出走取消を余儀なくされた(なおその後の検査により、バスターは抹茶を摂取していなかったことが判明した)。が引っかかってきた。意外だったのは、「茶筅」が関連語として抽出されていないこと。抹茶を茶筅で点てて飲む人が少ないからなんだろうか。でも、データとしては拾ってきてほしいところ。Python で検索してみる。モンティ・パイソン、蛇のパイソン、言語の Python のそれぞれの関連のものが出てきているところはよいとして、関連語がざっくり3分野に分けられた上で出てくるともっとおもしろい。連想検索の類は、今の性能でも、見せ方をもう一工夫するとおもしろい何か出てきそうな気もする。だからこそ、それを期待して API を公開するってことかな。連想検索といえば、汎用連想計算エンジン(GETA) を使ってみようと思いつつ、まだ使っていない。
2007.05.16
コメント(0)
-
農業概念検索
独立行政法人 農業・食品産業技術総合研究機構 中央農業総合研究センター を、農業経営シミュレーション を下記ながら眺めていたら、データマイニング研究チーム があるのを見つける。考えてみるまでもなく、この手のものってデータマイニングの対象の宝庫なわけなのね。そこで、農業概念検索を見つける。例によって、この手のものを調べるときには「抹茶」で検索する。今、サーバーが停止しています!暫くしてから、また、アクセスしてください!御迷惑をお掛けしまして、誠に申し訳ありません。がっかりさせやがる。「SDD」は Semi-Discrete Decompostion の略で潜在的意味インデキシングLatent semantic indexing(LSI)で実現した概念検索システムです。らしい。SDD ヘルプを見ると、SDDPACK Software for the Semidiscrete Decomposition へのリンクもある。農林水産省委託研究プロジェクト「データベース・モデル協調システムの開発」 当たりを見ると、質問応答システム(農林漁業情報) なんていうのも動かしているようだ。パラメータ指定して設定ボタンをクリックすると質問受付画面になる。質問応答システム(World Wide Web) は対象が各種検索エンジンを使ったものになるので何でも質問有り版のようだ。Copyright c 1998-2005 Mori LaboratoryGraduate School of Environment and Information SciencesYokohama National Universityと画面に書かれている。なんか、どこかで見たことがあるようなと思ってみたら、横浜国立大学 森研究室 各種サービス(デモ&ダウンロード) のところにあるやつか。受託研究費 のページを見ると、「独立行政法人農業技術研究機構. 森 辰則(代表). 「農業・水産情報テキスト知識ベース構築技術の開発」 H16-H17.」等々の受託研究があるので、そういうところからお金が出ていたのね。
2007.05.16
コメント(0)
-
goo、Blog 検索、口コミ・評判の分析機能
goo、Blog 検索機能を強化~口コミ・評判の分析機能を実装 を読む。この仕組みは、NTT のサイバーソリューション研究所が開発した「Eigen Rumor」という分析アルゴリズムを活用しており、「注目度」と「鮮度」の観点で、効率的かつ手軽に目的の Blog 記事を探し出せる。「goo」の Blog 検索サービス をちょっと使ってみる。こんな比較はおもしろい。こんな分析もおもしろい。いい線行っているかもしれない。このレベルまで来ると、ちょっと使ってみてもいいかなという気がしてくる。が、なんだかんだで情報を探すのには Google 使っている。要するに、みんながどう思っているかはどうでもよくってという世界になると、評判なんてどうでもいいから。であれば、次の話題は何かという、話題の萌芽と情報源を抽出してくれるようなものがあるとよいのだな。「次のネタ」というような情報検索サイトが欲しかったりして。別のところで ビー、商品から社会問題まで、ユーザー評価をグラフ表示する「マイ評価ドットコム」 も見てみる。ユーザーの指定したさまざまなジャンルのテーマについて、ほかのユーザーが評価とコメントを投稿できる。評価結果は、レーダーや円、棒グラフでリアルタイムに提供するとともに、評価順と話題性順でランキング表示する。ユーザーは、無料で利用できる。評価系のものが日々増えているな。まあ、マーケティングと結びつきやすいところだし、広告とも結びつきやすいところだからなんだろうか。myhyouka.com(マイ評価ドットコム) に行ってみる。製品に関してはコレを見るなら、価格.com に行くなぁ。評価投稿系か。これはあまり興味を感じない。投稿系よりブログから抽出されたものの方がおもしろい。
2007.05.15
コメント(0)
-

ヒヤリハットデータベース
総務省消防庁 の 「消防ヒヤリハットデータベースの運用開始」~ 消防職団員の事故事例の情報収集・提供システム~(pdf) で公開された 消防ヒヤリハットデータベース を眺めてみるとおもしろい。IT のシステム運用でも、こうしたヒヤリハットデータベースが作られて公開されるとおもしろいというか有意義。
2007.05.07
コメント(0)
-
swicki を少しだけ鍛える
昨年の12月に swicki を使い始めてはみたものの 、やっぱり反応が遅いのがちょっとネック。今日、少しだけ kugutsushi swickiを鍛えてみたものの、やっぱり、レスポンスが悪いのでたくさんやる気にならない。やっぱり、検索エンジンとしても毎日使いながら、地道に使ってやらないとだめだな。でも、やっぱりレスポンスが悪すぎ。このあたりがネック。利用者を増やすにはレスポンスの改良が必要。でも、利用者が増えないと新規投資(マシン等)についてはなかなかできないだろう。ということで、ニワトリが先か卵が先かというところがこの手のものにはあると思う。世の中にはサービスのアイデア自体はおもしろくても、リクエスト処理のパフォーマンスの悪さから利用度を上げることを自ら放棄しまっているかのようなサービスがたくさんあるかもしれない。意外とメジャーになりきれないけれどおもしろいものというのはたくさんある。日本でおもしろいサービスが伸びない原因の一つに、ユーザの保守性とかもあるかもしれない。利用者にとっても、将来性がわからないサービスを使うのは労力の先行投資でもあるわけだし、そのリスクを嫌えば定評のあるサービスのみを使うといった行動に出る。ソフトウェアについてもそう。育てゲームの一つとしてのソフトウェアやサービスの利用。かわいがってもらいやすいサービスやソフトウェアはどのようなものか。
2007.05.02
コメント(0)
-

ソーシャルブックマーク利用と情報漏れ
ソーシャルブックマーク利用と導入のポイント を読む。特定企業内でソーシャルブックマークが多用されるようになると何が起きるか。ブックマークが付けられ、その企業にとって価値があるとされた情報源にはたくさんのアクセスが生じる可能性がある。特定企業からたくさんのアクセスがあるページ、あるいは検索語については、その企業にとって重要性が高いものであると推測されることになる。機密性が高い課題については、それを研究していることさえ秘匿したくなるはず。よって、安全に企業を特定されずに外部の情報にアクセスできる手段が必要とされる。有料の匿名プロキシーサービスはやはりニーズがあるんじゃなかろうか。もちろん、そのプロキシーサービスへの特定企業のアクセス状況は秘匿されなければならないのは当然だが。そうなると、利用者からどれだけ信頼度を得られるかがキーになる。加えて不要なキャッシュが再利用されないように保証する仕組みも必要になる。その一方で逆に考えればアクセス元をさらすことをウェブサイトの作成者にプレッシャーとして使うということもできる。特定企業の悪口を書いたときに、比較的公開から短期間でその企業がやってきたのがログに残れば、なんとなく監視されているというイメージを与えることができる。無言のプレッシャーを与えるわけだ。これによって確信犯以外は躊躇を生じさせることができる。アクセス元を匿名化するか、しないか、それぞれメリットを考える。プレゼンスを示すという特殊な場合以外はやはり匿名化の方がメリットが大きい。あるいは大規模キャッシュ。社内でソーシャルブックマークが付けられたページについはキャッシュ期間を長くとってキャッシュされるようにする。ただし、動的なページについてはキャッシュされない方がよいのだが。あるいは特定のネットワークからのアクセスのときのみ、個別のふるまいをするオンライン広告。たとえば、A社からのアクセスに対してB社の広告が絶対に表示されないようにする。そうすると、A社はB社のオンラインプレゼンスを過って判断する。インプレッション型の課金方式をとる広告では、ライバル会社による消費を抑える意味もある。アクセス元によって悪意のあるサイトはピンポイントで攻撃を仕掛ける可能性もある。匿名化されていれば、これを排除することもできる。
2007.05.02
コメント(0)
-
Google と公的記録の検索
Swivel は期待が持てるサービス で Swivel が OECD の公的な統計情報を取り込んだ形でサービスしていると書いたが、米グーグル、公的記録のウェブ上での公開を支援 は、これに対する Google の一つの答えだろう。さしあたりアリゾナ州、カリフォルニア州、ユタ州、バージニア州と提携と契約を結び、教育、不動産、医療、環境など、これまで検索エンジンの対象になっていなかった情報を検索対象になるように支援するということだ。日本の公的な情報もできる限り、検索エンジンから検索しやすい状態になってほしい。国立情報学研究所が管理する学術論文300万件が Google の対象に(これは英断だと思う)といったよい方向もあるが、日本でも各種機関の情報ができるだけ検索エンジンから検索可能になってほしい。例えば東京都など、比較的お金のあるところが先行してデータ供給についてのポリシー等を定めて、他の自治体はそれをひな形になどというのもありだろう。情報公開の一つのあり方としても、いろいろ検討すべきことがあるだろう。ちょっと違う話だが、図書館退屈男 を見ていたら、電子図書館のその先は、電子図書館のその先は(2) というエントリがあった。本質的におもしろいところが語られていると思う。
2007.04.30
コメント(0)
-
自治体ドットコム、WiSE、その他
自治体ドットコム ってあったのね。自治体ドットコムとは、地方自治体のまちづくりを支援するために設立され、株式会社クロス・カルチャーが設備を貸与し、その管理運営の公平性を保持する為に設置された「企画編集委員会」により運営方針やコンテンツのサイト掲載の判断等を実施している「地域総合ポータルサイト」を目指したサイトです。ここの検索エンジンは、ビジネスサーチテクノロジ の WiSE か。というか、WiSE からここにたどり着いたのだが。導入事例 を見るとおもしろいところで使われている。官報情報ナビゲーション とかもある。政府系の情報に目を付けている視点がいいかも。この手のもっとたくさんあってもいい。あっても知られていなかったりするんだろうけど。WiSE を使っている インテック・アンド・ゲノム・インフォマティクス 見ていたら、「修辞構造解析システム」の特許取得について(特許第3908261号) なんてあった。「特許明細書読解支援システム」や「特許明細書解析エンジン」の根幹をなす技術です。また、現在盛んに利用されている特許検索サービスや各種の特許検索システムなどのへの応用も期待されます。やっぱり WiSE が使われている 日本郵政公社 日本切手デザインポータル を見る。日本切手のデータベース をクリックするとエラーになる。ダメじゃん。これは検索エンジンとは関係ないけど。運用がなってません。Not FoundThe requested URL /db/index.html was not found on this server.何はともあれ、検索エンジン系を調べなおすと、おもしろいものが見つかりそうな気がしてきた今日この頃。
2007.04.26
コメント(0)
-
「情報大航海プロジェクト」の委託先の部分予測
「情報大航海プロジェクト」の委託先、第1弾 には、NTTドコモと日本航空の案を採択された。残りは、7つのサブワーキンググループ から、それぞれ選択されていく、できレースなんじゃなかろうかとか思っているのだが、大規模格フレームの自動構築 の 黒橋研究室 の 検索エンジン基盤 TSUBAKI に絡んだプロジェクトにはお金が落ちるのだろうか。コラボレーションSWGに京都大学は入っている。医療用例対訳の競争的な収集(京都大学)なんてものがコラボレーションの例にある。このあたりでつながるか。会話エージェントとかの方向もあるか。こういうところにもっとお金を流してあげるとおもしろい。まあ、400CPU とかで計算しているわけだから、それなりのお金はもっているんだろうけど。ちなみに民間企業ではどの会社がつながりが強いんだろう? 卒業生とかの進路を見ると分かるかな。タミフル騒動で中外製薬がどういう大学にお金を出しているか、その一端が分かったけれど、この手の分野では産学協同がどういう形で進んでいるかお金の動きとか、企業が提供講座のあるなしとか、調べてみると見えてきておもしろいかも。どの企業がどの研究室に金をつぎ込むかが見えると、その企業の方向性の一端も分かる。興味本位としておもしろい。
2007.04.20
コメント(1)
-
新聞記事検索利用者に「気付き」を与える
「新聞記事検索に新しい気付きを与える」新サービスGNavi3の提供開始~業界初、新聞雑誌記事を言語解析し、関連性の高いコンテンツを自動的にピックアップ・表示~ (ジー・サーチ のプレスリリース) を見る。富士通の技術か。有料サービスの場合、たくさん読んでもらえばもらうほど料金もとれるから、よいかもね。そういえば、汎用連想計算エンジン(GETA) のページが 3/27 に更新されている。汎用連想計算エンジンGETA 3.2 RELEASE (64bitアーキテクチャ対応, 2007/03/30) なのね。GETA って試してみようと思いつつ、試してないのね。インストールしてみようかな。
2007.04.20
コメント(0)
-
Swivel は期待が持てるサービス
OECDも注目する「データ版YouTube」,その名は「Swivel」 を読む。ユーザーが自由にデータをアップロードして,グラフを作ったり統計分析を行ったりできる「Swivel」だ。じゃあ、Google SpreadSheet と何が違うのか? Google Docs & Spreadsheetsが日本語対応、アップロード時の文字化けも解消 があるじゃないと一瞬思う。が、「現在われわれは,OECD(経済協力開発機構)からもデータの提供を受けている」と強調した。なのだね。日本の官公庁が出している様々なデータは、おもしろいのだけど、あちこち分散して探すの面倒だし、そのまま分析に使える形になっているとは限らないし。こういう形でデータが共有されると便利でよいなぁと思っていたが、まさにそういうことをやっている会社がアメリカにはすでにあったのね。これは好みのタイプのサービス。Death Rates of Japan by Ages 日本人もアップロードしているな。"Data contributed by the OECD." となっているのが OECD のデータ。当然、変なデータがアップロードされることもあるだろうから、そのあたり、フィルタリングを考えるのか、それとも信頼できる筋を明確にするのかという方向がある。Swivel はまず信頼できるデータの提供元を確保した。これがすばらしい。いいなぁ。
2007.04.20
コメント(0)
全116件 (116件中 1-50件目)






