

DeepMind สาธิตประสิทธิภาพของปัญญาประดิษฐ์สำหรับ StarCraft II โดยนำเสนอเกมที่บันทึกไว้ล่วงหน้า 10 เกม แบบเดียวกับครั้งแรกที่เปิดตัว AlphaGo แข่งกับ Fan Hui แชมป์ยุโรป โดยแข่งกับ TLO ที่ปกติเล่น Zerg และเอาชนะได้ 5-0 หลังจากนั้นจึงเล่นกับ LiquidMaNa ที่เล่น Protoss เป็นประจำเพื่อทดสอบอีกครั้ง และเอาชนะ 5-0 อีกครั้ง อย่างไรก็ดีในการถ่ายทอดสด AlphaStar แข่งเกมสาธิตกับ LiquidMaNa อีกครั้งโดย LiquidMaNa เอาชนะไปได้
ตัว AlphaStar ยังถูกฝึกเพื่อเล่น Protoss กับ Protoss เท่านั้น
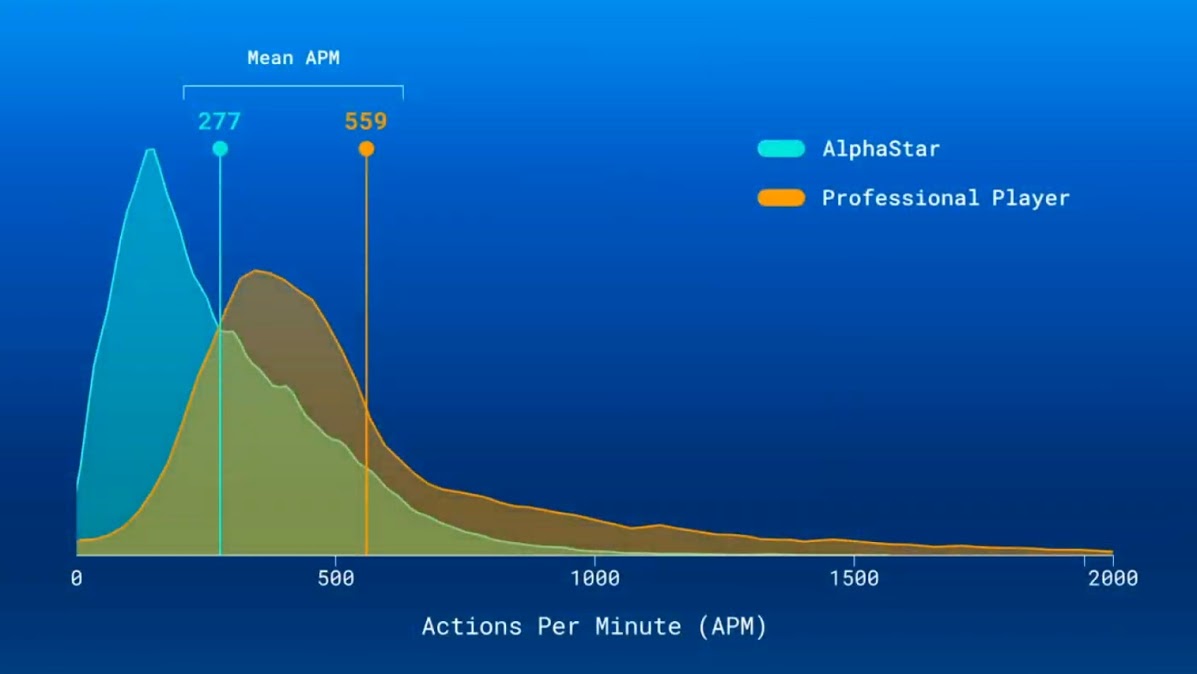
AlphaStar ตอบสนองสถานะการณ์โดยใช้เวลาประมาณ 350ms ซึ่งไม่ได้เร็วกว่ามนุษย์ และอัตราการส่งคำสั่งเฉลี่ย 277 คำสั่งต่อนาที (action per minute - APM) เท่านั้น น้อยกว่าโปรเกมเมอร์ที่ส่งคำสั่งเฉลี่ย 559 คำสั่งต่อนาที
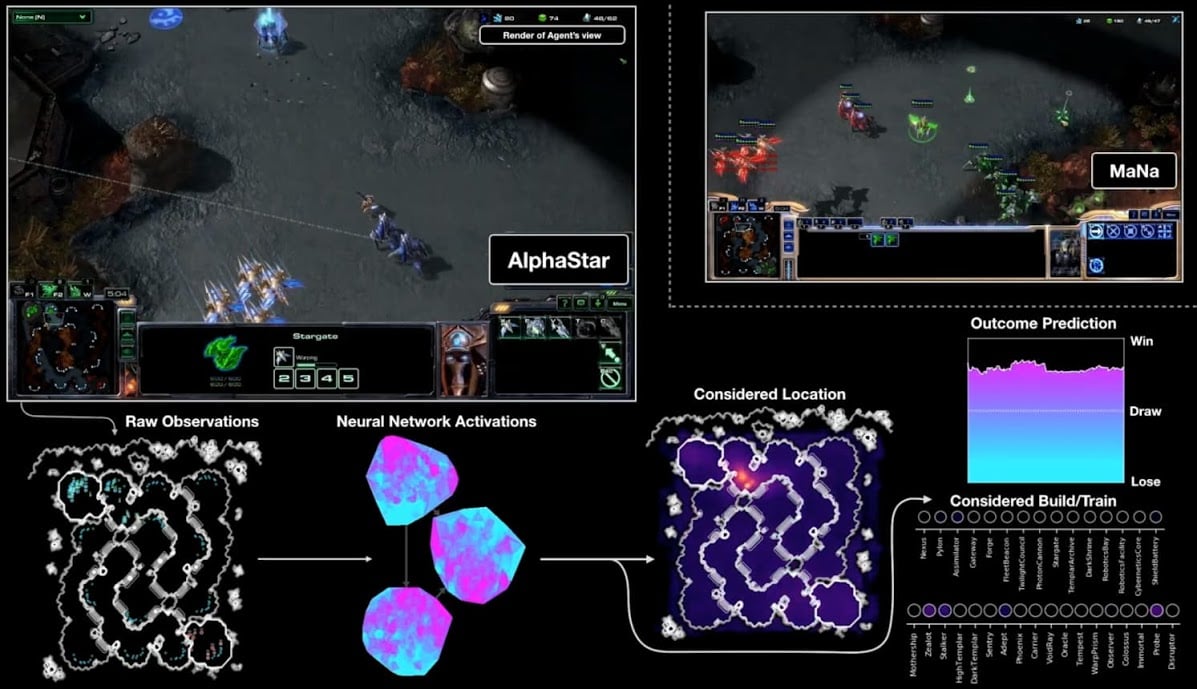
AlphaStar แสดงความสามารถของปัญญาประดิษฐ์ออกมาหลายอย่างที่มนุษย์ปกติทำไม่ได้ แม้การส่งคำสั่งจะไม่ได้สูงกว่ามนุษย์ แต่ความแม่นยำของการส่งคำสั่งแต่ละคำสั่งกลับสูงมาก และการตัดสินใจแม่นยำ การสร้าง Probe ตั้งแต่ช่วงต้นเกมมากกว่า 20 ตัว เมื่อการยอมเสียยูนิตคุ้มค่า AlphaStar ก็พร้อมจะแลกทันที และสามารถควบคุมกลุ่ม Stalker ได้พร้อมกันถึงสามกลุ่มเพื่อล้อมโจมตี
ทาง DeepMind เปิดเผยว่าการสร้าง AlphaStar นั้นเริ่มต้นจากการเรียนจากบันทึกการแข่งขันของเกมเมอร์จำนวนมากเป็นเวลา 3 วัน จากนั้นจึงสร้าง AlphaStar ตัวแรกออกมา แล้วแตกออกเป็นหลายตัวเพื่อหาตัวที่สามารถเอาชนะตัวอื่นๆ ได้ทั้งหมด ทำซ้ำไปเรื่อยๆ หลายรอบเรียกว่า AlphaStar League จากนั้นจึงเลือกตัวที่สถิติดีที่สุดมาใช้แข่งกับโปรเกมเมอร์ทั้งสองคน รวมใช้เวลาฝึกหนึ่งสัปดาห์ แต่เนื่องจาก StarCraft รุ่นที่ใช้สำหรับฝึกปัญญาประดิษฐ์เป็นรุ่นพิเศษที่ย่อเวลา กระบวนการทั้งหมดจะทำให้ AlphaStar มีประสบการณ์การเล่นเกมนานถึง 200 ปี
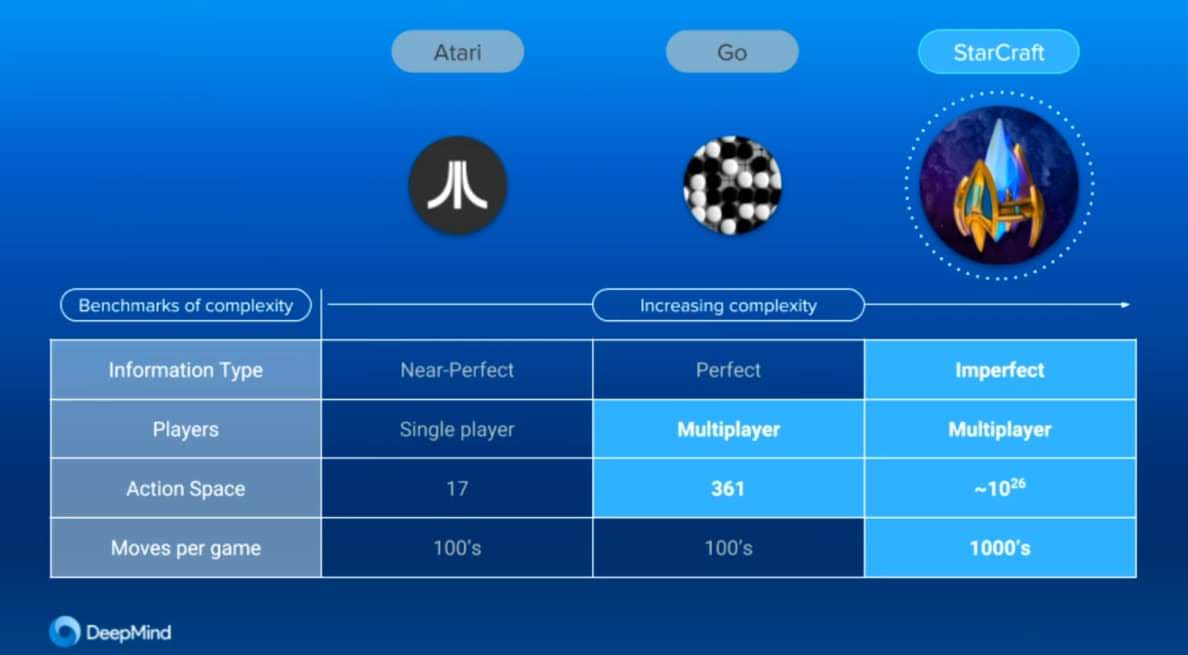
StarCraft นับเป็นหลักชัยของวงการปัญญาประดิษฐ์ที่จะสามารถตอบสนองต่อปัญหาที่ข้อมูลไม่ครบถ้วน, มีความเป็นไปได้มหาศาลแทบเป็นอนันต์, และต้องวางแผนระยะยาวเพื่อเอาชนะ ทีมวิจัยของ DeepMind หวังว่าหลักชัยนี้จะเทียบเท่ากับการแข่งขันหมากรุกของ DeepBlue กับ Garry Kasparov ในปี 1997 และการแข่งขันระหว่าง AlphaGo และ Lee Sedol ในปี 2016
ที่มา - YouTube: DeepMind , DeepMind






Comments
replay (ฝังไม่ขึ้น)
https://www.youtube.com/watch?v=cUTMhmVh1qs
samsung ใหญ่แค่ใหน ?https://youtu.be/6Afpey7Eldo
ดู live สดอยู่ อันที่จริงรายละเอียดมันเยอะมากจนอยากให้ทุกคนไปดูเอง แต่ที่เด่นๆคือ 10 เกมที่แข่งกันก่อนวันนี้ AI สามารถมองเห็นได้ทั้งแผนที่พร้อมกัน (ยกเว้นในส่วนที่เป็นหมอก ตามกฏของเกม) แต่เกมที่สาธิตสดวันนี้คือเอาข้อได้เปรียบนี้ออก คือ AI เห็นมุมมองแบบเดียวกันกับมนุษย์ ถ้าอยากเห็นพื้นที่ส่วนอื่นก็ต้องเลื่อนกล้องไปดูแล้วออกคำสั่ง
ซึ่งจากการทดสอบภายในของ DeepMind AI ตัวนี้ไม่ได้ด้อยไปกว่าตัวที่เห็นพื้นที่พร้อมกันทั้งหมด แต่ทีมงานก็บอกแล้วว่าแต่ไม่รู้ว่าจะให้ผลอย่างไรตอนแข่งกับมนุษย์ส่วนข้อจำกัดอื่นๆผมให้ความเห็นว่าก็แฟร์กับมนุษย์แล้ว ถ้าจะให้แฟร์กว่านี้คงต้องทำหุ่นยนต์มาเลื่อนเม้าส์พิมพ์คีย์บอร์ดเอง
แต่ผมว่า AI แพ้เกมนึงก็ดีนะ เพราะถ้าทุกคนจำได้ AlphaGo ก็แพ้เกมนึงให้กับ Lee Sedol (แพ้งี่เง่าๆแบบสไตล์ AI เหมือนกันด้วย) แต่หลังจากนั้น 9 เดือนก็มี AlphaGo Master เกิดขึ้นที่ชนะ 60 เกมรวด ซึ่งหลังจากนี้ 9 เดือนตรงกับ BlizzCon 2019 พอดี บังเอิ๊ญบังเอิญจังเลย 5555 (ซึ่ง DeepMind CEO ก็ทวีตบอกแล้วว่า AlphaStar กลับมาแน่นอน)
ถ้าคุณคิดว่า AlphaGo แพ้งี่เง่า ผมว่าคุณเล่นโกะไม่เป็น
Methuz'es Blog
ผมก็เล่นไม่เป็น ช่วยอธิบายคร่าวๆ ได้มั้ยครับว่า ทำไมถึงไม่งี่เง่าเหมือนที่อีกท่านบอก
ผมดูกระดานนี้อยู่ หมากที่ลี ลงเม็ดที่ 78 เป็นหมากเด็ดครับ ประมาณหัตถ์เทวะเลย แต่เป็นเม็ดที่ไม่ดีตามอัลกอริทึ่ม Monte Carlo tree search ของอัลฟ่าครับ
เม็ดที่ 79 อัลฟ่า ยังประเมินอยู่เลยว่ามีโอกาสชนะ 70%พอลงไปเรื่อยๆ อัลฟ่า ประเมินโอกาสอีกที มีโอกาสชนะ 20% เลยลงมั่วแล้วยอมแพ้ครับ
ตัวผมเองก็เล่นไม่เป็นนะครับ แต่เท่าที่ฟังจากคลิปนี้ https://www.youtube.com/watch?v=G9eA7d3ieSk&index=9&list=PLufXDtYn4vrAumvmzar_4tD-IxWstX6lHเ ค้าบอกว่าตาเดินที่ใครๆบอกว่าเป็นหัตถ์เทวะของLee เป็นหมากที่ใช้กันคนจริงๆไม่ได้ครับ แต่คาดการณ์ว่าน่าจะเป็นตาเดินที่โปรแกรมalphagoมองข้ามไป
ตอบแบบนี้มันไม่ได้มีประโยชน์อะไรต่อคนในเว็บไซด์เลยนะครับ ใครๆ ก็พิมพ์ได้
เขาต้องการสื่อว่า ไปสบประมาทAIและ Lee sedol นะครับ
เพราะหมากที่ Lee Sedol ลงไป มันเป็นหมากเด็ดจริงๆ
ไม่ใช่ว่า AI แพ้งี่เง่าไปเอง
ซึ่งคนที่ดูโกะไม่เป็น จะงงว่าทำไม AI ลงแปลกๆ
แต่สิ่งที่เกิดขึ้นจริงคือ หลังจากเจอหมากตาที่ 78 ของ Lee ไปสักพักแล้วไม่ได้รับมืออย่างถูกต้อง Win rate ที่คำนวนได้ของ Alpha Go ก็ไม่เหลือแล้วครับ
* อันนี้จาก log ของ alpha go ที่มาแจ้งทีหลัง เหมือนจะมีในบทความของ blognone ด้วย
ถูกต้องแล้วครับ เพิ่มเติม..เพราะเม็ดตาเดินที่ทำให้ AlphaGO แพ้ กรณีเป็นมนุษย์ปกติเล่นโกะ(ที่เล่นเป็นแล้ว+เก่ง) ก็สามารถพลาดได้เช่นกัน และ อาจจะเดินต่อเหมือน AlphaGO ก็ได้(ซับซ้อน) ไม่ได้พลาดแบบงี่เง่า(เดินโง่ๆให้เขากินให้ตัวเองแพ้) ถ้าอยากเข้าใจมากกว่านี้คุณ(ที่ไม่เข้าใจ) ก็ต้องมาลองเล่นโกะดูครับ ^_^
ต้องเชื่อ คคห นี้แล้วแหละ เพราะ AlphaGo มาตอบด้วยตัวเองแล้ว
แหล่งข่าวน่าจะเพิ่มลิ้งค์ข้อมูลแบบเต็มๆนะครับ
https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
ที่มนุษย์ส่งคำสั่งต่อนาทีมากกว่าคือส่งคำสั่งคลิ๊กบนแผนที่มากกว่าหรือเปล่า เห็นคลิ๊กรัวๆ
APM นี่เป็นจำนวน action ที่ผู้เล่นสั่ง ซึ่งจะสั่งได้ส่วนใหญ่ก็ต้องเลือกยูนิตก่อน หรือแม้แต่ move/attack ก็ใช้เมาส์เช่นกันครับ
ในการแข่ง SC มันมีทั้ง ภาพใหญ่ (macro) เช่น บั้มคนงาน,สะสมแร่/แก็ส,ไต่เทคทรี,สร้างกองทัพ,ฯลฯ และภาพเล็ก (micro) เช่นการควบคุมตัวยูนิตแต่ละตัวเวลาสู้รบประจัญบาน ได้แก่ สลับตัวเจ็บไว้ข้างหลัง หลบหลีก หลอกล่อ หาจังหวะปล่อยแอ็คชัน ฯลฯ ซึ่งบางคร้งการที่มียูนิตมากกว่า แต่ถ้าควบคุมไม่ดี ก็แพ้ให้กับคนที่มีการควบคุมที่ดีกว่าได้ ซึ่งใน APM จะไปมีผลกับ micro ครับ
ถ้าสังเกตในช่วงต้นเกม ผู้เล่นที่เป็นคนจะคลิ๊กแบบมากเกินความจำเป็น เชื่อว่าเป็นการวอร์มอัพมือ,นิ้ว เพื่อเตรียมตัวช่วงกลางๆต่อไปครับ
LiquidTLO เคยเล่น Terran มาก่อนเปลี่ยนเป็น Zerg นะ สมัยก่อนนี่โคตรแห่งโคตรพลิกกลยุทธ์
หลังๆ tlo เล่น Zerg ก็ไม่ได้ชนะทุกเกมส์เสมอไป คือไม่ได้ถือว่าเก่งสุด แต่ชอบตรงที่เล่นแล้วดูสนุกสุด ชอบมีอะไรไม่คาดฝันมาให้ดูตลอดๆ
tLO เล่นมาตั้งแต่เกมส์ออกเลยนะ alphastar ชนะนี่ไม่ธรรมดา
คุม stalker 3 กลุ่มพร้อมกันได้นี่ ได้เปรียบสุดๆคงต้องหาวิธีจำกัดอะไรอีกหน่อยนึง เพื่อตัดสิ่งที่มนุษย์ทำไม่ได้ออกไปให้มากที่สุด
แต่ AI ถูกสร้างมาให้ทำงานหลายอย่างพร้อมกันในแบบที่มนุษย์ทำได้ยากอ่ะครับ
เค้าก็อั้น APM ให้น้อยกว่ามีอาชีพแล้วนะครับ
ผมคุม 12 ตัวกลุ่มเดียวก็วิ่งไปให้เค้าละลายยกทัพแล้วครับ lol
กราฟ APM ของ Pro player 0 นี่คือโปรคนไหน? แล้ว 2000 นี่อะไร แฟลช?
สีส้มทั้งแถบเป็นของผู้เล่นชื่อ Mana ครับ ตีความกราฟคือ ในช่วงระยะเวลานึง (ไม่รู้ตัดทุกวิหรือห้าวิ) คนๆนั้นอาจไม่คลิกอะไรเลย ก็เป็น 0 APM แต่ต่อมาคลิกรัวๆ ช่วงพีคก็กระโดดไป 2000 APM แต่ก็เป็นแค่ระยะเวลาสั้นๆ คล้ายๆเวลาเราดาวน์โหลดไฟล์ที่จะมีช่วงเร็วช่วงช้าอ่ะครับ
ตอนแรกคิดว่าเป็นของโปรหลายๆ คน เป็นอย่างนี้นี่เองขอเสริมครับ เข้าไปดูที่มาแล้วของ pro player น่าจะเป็นของ TLO รวมกะ Mana ของ Mana นี่การกระจายดี เฉลี่ย 390 และเกาะกลุ่ม แต่ของ TLO นี่เฉลี่ยเยอะ แต่กระจายห่างมาก มีไปถึง 2000 ไปบางช่วง
อคติทำให้คนรับเหตุผลด้านเดียว
APM ของคนมันเป็น Action ที่ไม่มีผลต่อเกมซะเยอะ เทียบ action แบบนั้นก็คงไม่ถูก แต่เผื่ออัตราตอบสนองไว้ก็ถือว่าชดเชยระดับหนึ่งแล้ว
อคติทำให้คนรับเหตุผลด้านเดียว
ความรู้สึกคือ สมัยก่อน tlo เล่น Terran เก่งกว่า Zerg อีก ไม่น่าเปลี่ยนเลย
นี่มันหลักการแบบ Kage bunshin no jutsu นี่น่า
ความแม่นยำต่างกันเยอะเวลาทำอะไรผมว่าคอมฯมันคำนวนเวลาไว้หมดแล้ว ต่อให้ไปหน่วงคอมฯมันก็คงคำนวนเตรียมไว้เรียบร้อย
มันจะ เรียนรุ้เร็วไปแล้ว แค่สามวัน ได้ขนาดนี้
สถานะการณ์ => สถานการณ์
น้อยกว่า "โปรเกมเมอร์" ที่ส่งคำสั่งเฉลี่ย 559 คำสั่งต่อนาทีหมายถึง "โปรเพลเยอร์" รึเปล่าครับ
เกมเมอร์ครับ (Gamer) อาจจะอ่านเป็น โปรแกรมเมอร์ (Programmer)
แต่ในบทความต้นฉบับ ก็ใช้คำว่า professional player หนิครับ ไม่เห็นมีคำว่า gamer เลย
อันนี้ไม่รู้แฮะ เข้าใจว่าคำว่าเพลเยอร์คือมองในฐานะนักกีฬา คำว่าเกมเมอร์ก็ตามตัว
ผมไม่แน่ใจว่ามันทำให้ความหมายเปลี่ยนไปแค่ไหนครับ
มีเรื่องนึงที่คิดขึ้นมาได้ คือถ้า DeepMind เปิดเซิร์ฟเวอร์ให้ไปเล่นกับ AlphaStar ต่อให้ค่อนข้างแพง (5 เกม 500 บาทอะไรแบบนั้น)
ก็น่าจะมีคนยอมจ่ายเยอะทีเดียว
lewcpe.com , @wasonliw
เค้าอาจจะแอบคิดโมเดลนี้ไว้ ตั้งกะมาจับงานทางนี้ก็ได้นะ
มาทำ ai ให้ civ6 บ้างสิไม่ต้องเก่งมากนะ แต่ให้เล่นด้วยแล้วสนุกๆ
น่าจะเปิดให้เล่นแข่ง online ได้นะ อยากเจอ
เหมือนที่คิดไว้ ควบคุมหลาย unit ยังไงมนุษย์ก็สู้ยาก ถ้า unit น้อย ๆ แบบให้เล่น Dota2 แบบ 5-5 ผมว่า ตอน AI เปิดตัว มนุษย์น่าจะเหนือกว่านะ แต่อย่างเล่น SC2 นี่ คาดไว้แล้วว่ามนุษย์คงสู้ไม่ได้ ยิง ๆ ถอย ๆ ตอดตลอดอย่างนี้ คนต้องคุมตลอด กะระยะตลอด แถมฐานก็กลับไปดูแลยาก ในระหว่างที่ AI กลับไปกลับมาได้อย่างเร็ว
แต่ถ้าเป็น Dota2 มีมันเรื่องการ Gank การ Juke ที่ชัดเจนกว่า SC ถ้าทำ AI 5-5 น่าจะแข่งกันสนุก