
By: mk

 on 27 October 2024 - 14:51
Tags:
on 27 October 2024 - 14:51
Tags:

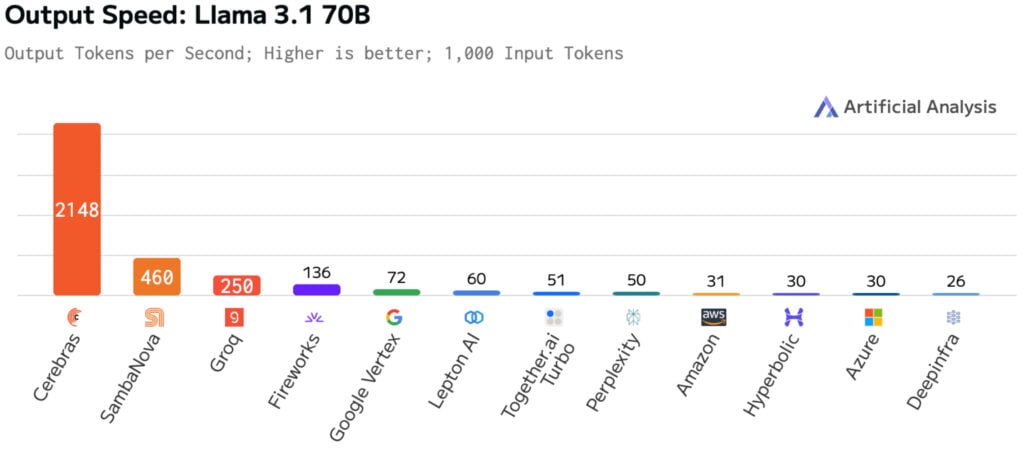
Cerebras บริษัทผู้พัฒนา ชิปเร่งความเร็ว AI ที่คุยว่าทำงานได้เร็วกว่าจีพียู โชว์ประสิทธิภาพการรันโมเดล Llama 3.2 ขนาด 70B ด้วยอัตราตอบสนอง 2,100 โทเคนต่อวินาที สูงกว่า ที่โชว์เมื่อรอบก่อนทำได้ 450 โทเคนต่อวินาที โดย Cerebras บอกว่าเป็นการรันบนชิป Wafer Scale Engine 3 (WSE-3) ตัวเดิม แต่ปรับแต่งซอฟต์แวร์ไปอีกมากเพื่อให้ได้ประสิทธิภาพเพิ่มขึ้นจากเดิมมาก
Cerebras โชว์ตัวเลขข่มว่าสถิติ 2,100 โทเคนต่อวินาที สูงกว่าที่จีพียูทำได้ 16 เท่า และถ้าเทียบกับการเช่าคลาวด์รันจะทำได้สูงกว่า 68 เท่า
ในวงการชิปเร่งความเร็ว AI ยังมีชิปของบริษัทอื่นที่เป็นคู่แข่งกันคือ Groq ที่เคยโชว์ตัวเลขการรัน Llama และ SambaNova ซึ่งก็ถูก Cerebras นำมาเปรียบเทียบด้วยเช่นกัน
ที่มา - Cerebras , The Next Platform


Get latest news from Blognone
Follow @twitterapi




Comments
อยากเห็น performance per watt ด้วยจัง...
ชิปหนึ่งตัวกินที่ทั้งเวเฟอร์