
カテゴリ未分類 0
[プログラミング] カテゴリの記事
全42件 (42件中 1-42件目)
1
-
女子高生とクイックソート
今日の帰りの電車で隣に座っていた女子高生2人組が、クイックソートについて談義していました。いまどきの高校では、授業でコンピュータのアルゴリズムなんて教えるのかな?時期的には期末試験の勉強でしょうね。ちょっと聞耳をたててみると、必死に説明している娘とそれをふんふん聞いて理解しようとしている娘という構図です。必死に説明しているのですが、何やら怪しい。聞いている方もうなづいてはいるけど理解していないっぽい。私は一応はソフトウェアの世界の人なので、うおー、教えてあげたいー、おにいさんにまかせなさいー、と思いつつ降りる駅に到着してしまいました。クイックソートは再帰の概念が理解できれば8割かた理解できたも同然なのですが、私が在籍していた大学の情報工学科の学生でも再帰をなかなか理解できない人がいました。何はともあれ、彼女たちが試験で良い点を取れるよう祈っております。
2006年12月08日
コメント(2)
-
NFSマウント内のファイルに対するstat(2)が失敗。なぜ?
こちらに移動しました。NFSマウント内のファイルに対するstat(2)が失敗。なぜ?
2006年12月06日
コメント(0)
-
仕事のプログラミングで完徹
久しぶりに徹夜で仕事をしてしまった。WindowsのNTFS ACL関連のテスト用プログラムをC++で実装するのと、別件のPowerPoint+Excelの資料2枚を作成した。業務で使うプログラムなので、あまり工数をかけて凝った作りにするのは適切でないのだが、つい自分で満足のいくものにしようとしてえらい時間がかかってしまう。若い頃は一日くらい徹夜しても頑張れたのだが、もう眠くて眠くて仕方がない。資料の直しを明日の午前11時までにしなければならないのだが…。ここは割りきって寝てしまい、明日の朝に猛烈なプレッシャーの元で資料修正に集中しよう。寝ます。
2006年12月05日
コメント(2)
-
トラックバックの仕組み
トラックバックについて規定したドキュメントを読んでます。Six Apart : Developer Documentation : TrackBack Technical Specificationトラックバックは、Six Apart社がプロトコルを規定し、自社ブログツールに実装したものです。仕様は公開されており、だれでもトラックバックシステムを構築できるようになっています。トラックバックの仕組みは非常に単純明快ですが、それ以上に"トラックバック"という発明がすばらしい。他人の記事に関連する(あるいは参照する)記事を書いたことを相手に伝えるという意味の他に、私は「未来へのリンク機能」としても捉えることができると考えています。自分の書いた昔の記事に対して訂正記事や補足記事を書いた場合、昔の記事から未来への記事にトラックバックすることは、「昔の記事から未来の記事へのリンクを張る」という行為を意味するからです。仕様書を見てたら、なんか実装してみたくなりました。なんかおもしろいことできないかな。
2006年10月31日
コメント(0)
-
Eclipseの最新版(3.2.1)への乗り換えをした
趣味のプログラミングではWindowsベッタリなプログラムを書く場合を除いてJavaを使っています。最近はJ2SE5.0の新言語仕様にも慣れてきて、ますますプログラムが書きやすくなりました。そんなプログラミングで手放せないのがEclipseです。これまでEclipse3.1.1を使っていましたが、久しぶりに公式サイトをチェックしたら3.2.1が出ていたので、最新版への乗り換えをしました。といっても最新版を適当なディレクトリに解凍して、初回実行時にこれまで使っていたワークスペースのディレクトリを指定するだけです。Eclipseは変にWindowsのレジストリをいじったりしないので、インストール・アンインストールが楽でいいですね。ついでにGUIプログラミングで使っているVisual Editorプラグインも1.0から1.2.1にアップグレードしました。今日現在のVisual Editor関連プラグインの最新版は以下でした。ご参考まで。 GEF-SDK-3.2.1.zip emf-sdo-xsd-SDK-2.2.1.zip VE-SDK-1.2.1.zip
2006年10月28日
コメント(0)
-

C++の奥深さに立ち向かう
仕事でVisual C++で純粋なC++プログラム書いてます。本当はJavaで書きたいところですが、NTFSのACLをガリガリ扱う必要があるので、どうしてもWindowsとの親和性が高いVC++になってしまいます。CではなくC++を使うのは、Javaに比べて貧弱ながらSTLというライブラリが用意されていることと、メモリ管理のめんどくささから解放されたいからです(C++でも十分面倒だけどCよりは楽)。しかし…C++は言語仕様が深い。以前仕事でC++コンパイラの研究をしていたことがあるので言語仕様の細かいところまで一応把握してるつもりですが、なかなかコンパイル一発通し!というわけにはいかず。明日もがんばってコード書きだ。 (画像が無いのが残念)「プログラミング言語C++第3版」やっぱりこの本がC++のバイブルでしょうね。これ無しにはC++プログラミングはできません。
2006年10月23日
コメント(4)
-
プログラムを検索するGoogle Code Search
自分でプログラムを書く人にとって、これまで使ったことのないライブラリ関数のサンプルコードはのどから手が出るほど欲しいものです。そんなあなたにGoogle Code Searchはいかがでしょうか。まだGoogle Lab内での実験段階ですが、なかなかこれがおもしろいです。通常のGoogle検索と異なるのは、検索式に正規表現が使えることです。また、検索対象は生のソースプログラムだけでなく、.zipや.tar.gzの中にあるものまで探してくれます。さらにプログラミング言語の種類やコードのライセンスをオプションとして指定できるという、プログラマにとってはうれしい機能付き。試しにJavaのBufferStragegyクラスの使い方を調べてみました。検索式は以下のように指定しました。lang:"Java" license:"GPL" BufferStrategy.*=Java言語のプログラムでライセンスがGPLであって、BufferStrategyクラスの変数宣言と初期値の代入をしているもの、という意味での検索となります。検索結果は17件でした。とりあえず検索結果とJava APIのオンラインマニュアルを使って、一応動くプログラムをつくることができました。Google Code Searchの今後の発展に期待してます。
2006年10月13日
コメント(2)
-
.NET Framework 3.0RC1がリリースされました。
マイクロソフトの仮想マシン実行環境.NET Framework 3.0のRC1がリリースされました。ベータ版ダウンロード基本的に来年の1月に出るWindows Vistaに対応したものだと私は考えています。.NET 3.0の新しい機能は、従来の.NET 2.0に次の新しい技術を追加したものです。Windows Presentation Foundation (コード名Avalon)Windows Vistaのユーザインターフェースを定義するAPI群(と言ってもいいと思う)であり、新しいグラフィックサブシステム。Windows Communication Foundation (コード名 Indigo)ネットワークに分散するサービス(Webサービス)を統合管理できる新しいプログラミングインターフェース。Windows Workflow Foundation 企業などで導入されることが多いワークフロー型アプリケーションを構築するためのインターフェース。Windows CardSpace 複数のサイトでユーザ認証をするために発行する「名刺」のようなユーザ識別コードを管理するインターフェース私は仕事以外ではだいたいJavaを使っていますが、Windowsにベッタリのアプリケーションを作るためには.NET Frameworkを使った方が遥かに楽なことがあるので、C#もたまに使います。とりあえず今のところは技術のウォッチをしておいて、正式リリースが出たらいろいろ試してみようと思ってます。
2006年09月24日
コメント(0)
-
楽天テーマ検索機能 データ更新
個人的に作っている楽天テーマ検索機能のデータを最新版にしました。→ 楽天テーマ検索昨日の夜から今日の昼くらいにかけてデータを取得しているので、それ以降に登録されたテーマには対応していません。この機能を実装するに当たっての技術的な顛末は2006年3月25日の日記を参考にしてください。なおデータ取得時点での全テーマ数は262778個でした。すでに楽天ブログでのテーマというシステムは破綻しているような気がします。せめて楽天側で公式にテーマ検索機能を作ってくれれば、もっとテーマが有効活用されると思うのですが…。
2006年09月06日
コメント(0)
-
検索機能高速化版完成 【楽天テーマ検索機能の機能拡張(その7)】
楽天テーマ検索サービスの機能拡張を検討しています。これまでの経緯は以下です。 楽天テーマ検索機能の機能拡張 (2006/3/19) chasenのインストール 【楽天テーマ検索機能の機能拡張(その2)】(2006/3/20) 単語数予備調査 【楽天テーマ検索機能の機能拡張(その3)】(2006/3/21) インデックスファイルのデータ構造 【楽天テーマ検索機能の機能拡張(その4)】(2006/3/22) インデックスファイル作成プログラム 【楽天テーマ検索機能の機能拡張(その5)】(2006/3/23) 検索実行プログラム 【楽天テーマ検索機能の機能拡張(その6)】(2006/3/24)一応完成したので早速サーバにアップロードして新機能版に置き換えました。→ 楽天テーマ検索サービス実際に使ってみると非常に高速化したと感じるものとそうでもないかなと感じるものの2種類あります。 名詞の組み合わせでの検索はとても速い。(「楽天 広場 機能」など) 日本語文での検索はあまり速くない。(「子育について教えて」など) 未知語に弱くなった。日本語文で今一つ遅いのは、おそらく検索キーとして「てにおは」などの「助詞」が検索対象に入っていることが一因であると考えています。実際、「は」という助詞だけで数万件のテーマがマッチするので、ここから絞り込む処理に時間がかかるのでしょう。助詞は検索対象から外した方が良いかもしれません。また形態素解析に用いた茶筌は辞書を利用して単語の判別を行うのですが、この辞書に載っていない単語は思ったように単語分解してくれません。例えば、「コストコホールセール」という卸売りの店があるのですが、これは本来「コストコ + ホールセール」というように分けて欲しいところです。ところが「コストコ」なんていう単語は辞書に載っていないため、「コストコホールセール」をひとかたまりの単語として認識します。そうすると「コストコホールセール」というテーマがあったとして、「コストコ」で検索しても「単語が違う」ので検索にひっかかりません。これに対処するには辞書を充実かするしかありません。* * *今回の機能拡張で、簡単な検索エンジンを作ったことになるのですが、いざ自分で作ってみると改めてgoogleやYahooなどの「プロが作成した」検索エンジンの凄さを実感します。辞書の規模もすごいだろうし、日本語処理にも様々なテクニックを用いてカスタマイズしてるんだろうな。技術的におもしろそうな分野です。もっと調べてみたい。
2006年03月25日
コメント(1)
-
検索実行プログラム 【楽天テーマ検索機能の機能拡張(その6)】
楽天テーマ検索サービスの機能拡張を検討しています。これまでの経緯は以下です。 楽天テーマ検索機能の機能拡張 (2006/3/19) chasenのインストール 【楽天テーマ検索機能の機能拡張(その2)】(2006/3/20) 単語数予備調査 【楽天テーマ検索機能の機能拡張(その3)】(2006/3/21) インデックスファイルのデータ構造 【楽天テーマ検索機能の機能拡張(その4)】(2006/3/22) インデックスファイル作成プログラム 【楽天テーマ検索機能の機能拡張(その5)】(2006/3/23)今回は前回作成したインデックスファイルを使って検索を実行する部分を作成します。検索する本体の部分はCで作成し、ユーザインターフェースの部分はPHPで作成しました。それぞれのプログラムはフリーページ(高速化版楽天テーマ検索プログラム)の方に載せているのでご参考まで。PHPから外部プログラムを呼び出すために、proc_open関数を使ってます。これにより外部プログラムの標準入出力をPHP側から制御できます。便利ですね。Cで作った検索本体部分は、アルゴリズム上まだ改善の余地があるかもしれません。特に位置情報集合の共通部分を求める部分は、集合の要素が多いとちょっと時間がかかるので、暇なときにカスタマイズしてみようと思います。さて次は実際に検索して評価してみます。
2006年03月24日
コメント(0)
-
インデックスファイル作成プログラム 【楽天テーマ検索機能の機能拡張(その5)】
楽天テーマ検索サービスの機能拡張を検討しています。これまでの経緯は以下です。 楽天テーマ検索機能の機能拡張 (2006/3/19) chasenのインストール 【楽天テーマ検索機能の機能拡張(その2)】(2006/3/20) 単語数予備調査 【楽天テーマ検索機能の機能拡張(その3)】(2006/3/21) インデックスファイルのデータ構造 【楽天テーマ検索機能の機能拡張(その4)】(2006/3/22)今回はインデックスファイルを作成するためのプログラムを作成します。テーマファイルからCRC32値を求める部分をPerlで作成し、求めたCRC32値とテーマファイル名、テーマのファイル内位置情報をまとめて二つのファイル(目次ファイルと位置情報ファイル)を作成する部分をCで作りました。プログラムのすべてはフリーページ(高速化版楽天テーマ検索プログラム)の方に載せておきます。このプログラムは必要ならご自由に使っていただいて構いませんが、実行の結果何らかの不具合が発生しても私は責任をとれませんのでご了承ください。でもここが間違っているなどのご指摘はいつでも歓迎します。プログラムの実行の結果、約530KBの目次ファイルと約7MBの位置情報ファイルが生成されました。さて次は検索を実行する部分の実装です。
2006年03月23日
コメント(0)
-
インデックスファイルのデータ構造 【楽天テーマ検索機能の機能拡張(その4)】
楽天テーマ検索サービスの機能拡張を検討しています。これまでの経緯は以下です。 楽天テーマ検索機能の機能拡張 (2006/3/19) chasenのインストール 【楽天テーマ検索機能の機能拡張(その2)】(2006/3/20) 単語数予備調査 【楽天テーマ検索機能の機能拡張(その3)】(2006/3/21)今回は検索を高速に行うためのインデックスファイルのデータ構造を考えます。まず検索のおおまかなアルゴリズムはこんな感じにしようと考えています。(説明を分かりやすくするため「形態素」をあえて「単語」と表現します) 入力文を単語に分割 単語の一つを取り出す。 単語にマッチするテーマファイルとファイル内位置の集合(S1)を求める。 次の単語を取り出す。 単語にマッチするテーマファイルとファイル内位置の集合(S2)を求める。 S1とS2の共通部分を求め、これを新たにS1とする。 以下、未処理の単語がなくなるまで4から繰り返す。 S1の要素を一つずつ取り出し、検索結果として表示する。つまり単語をキーにして、その単語を含むファイルと場所を求められればよいことになります。ここで、日本語の単語をそのまま扱うのはいくつかいやらしいところがあります。 マルチバイト文字を考慮したプログラミングが必要 単語の長さが一定でないのでインデックスファイルの構造が複雑になる。そこで一度すべての単語を固定長の数値に変換して、結果を表示する直前までその内部表現のまま扱うことにします。固定長への変換にはCRC32を使うことにしました。これによりすべての単語が32ビット値(4バイト)になります。以上を踏まえて、次の二つのファイルを作ることにします。 目次ファイルstruct toc { unsigned long hash; /* 単語のCRC32値 */ long location; /* 位置情報ファイル内の位置(ftellの値) */};この構造体の配列を格納するバイナリファイル。配列要素はhashフィールドの値でソートされているものとする。 位置情報ファイルstruct location { char filename[8]; /* テーマファイル名 */ long location; /* テーマファイル内位置 (ftellの値) */};この構造体の配列を格納するバイナリファイル。これらのファイルとテーマファイルの関係を以下に示します。目次ファイル 位置情報ファイル テーマファイル("Gaa.csv")+=========+ +==========+ +---------------------------+| hash1 | +-->|"Gaa.csv" | |ID1, テーマ名, テーマ説明文|+---------+ | +----------+ +---------------------------+| 0 |--+ | 1356 |-------->|ID2, テーマ名, テーマ説明文|+=========+ +==========+ +---------------------------+| hash2 | |"Gab.csv" | | ..... |+---------+ +----------+| 144 |--+ | 2488 |+=========+ | +==========+| ... | | | NULL |
2006年03月22日
コメント(0)
-
単語数予備調査 【楽天テーマ検索機能の機能拡張(その3)】
楽天テーマ検索サービスの機能拡張を検討しています。これまでの経緯は以下です。 楽天テーマ検索機能の機能拡張 (2006/3/19) chasenのインストール 【楽天テーマ検索機能の機能拡張(その2)】(2006/3/20)今回は、検索速度のキモと言えるインデックスファイルについて、データ構造を決定する前の予備調査を行います。前回インストールした茶筌を利用して、形態素の数を求めてみます。まず入力となるテーマとテーマ説明文を、処理しやすいように文字の正規化を行います。 半角カナを全角カナに変換 半角英数字を全角英数字に変換 英字をすべて小文字から大文字に変換茶筌は連続する半角英字をアルファベットの列に分解してしまうため、全角英字に統一しておく必要があります。例えば、半角の「Windows」という文字を茶筌に与えると、W ダブリュー W 記号-アルファベットi アイ i 記号-アルファベットn エヌ n 記号-アルファベットd ディー d 記号-アルファベットo オー o 記号-アルファベットw ダブリュー w 記号-アルファベットs エス s 記号-アルファベットEOSというように単語がバラバラにされてしまうのですが、全角の「Windows」なら、Windows 未知語EOSとなって一応ひとつのかたまりと認識してくれます。ただし辞書に載っていないせいか「未知語」と判定されています。この処理のために次のようなPerlスクリプトを作りました。、#!/usr/bin/perluse Jcode;while () { print Jcode->new($_)->h2z->tr('A-Za-z0-9a-z', 'A-ZA-Z0-9A-Z');}これをcharconv.plと名付けて、次のようなシェルスクリプトでテーマファイルの内容を形態素に分解します。% awk 'BEGIN{FS=","}{printf("%s\n%s\n", $4,$5);}' G*.csv | ./charconv.pl | chasen -c -F '%m\n' | sort | uniq -c > keitaiso.datテーマは"G*.csv"という名前の45個のCSV形式ファイルに格納されており、その第4フィールドがテーマ名、第5フィールドがテーマ説明文です。chasenコマンドでは品詞情報は出力せず形態素のみ出力するようにして、その結果をsortコマンドでソートしたのちuniqコマンドで同一内容の行を圧縮します。結果、keitaiso.datファイルには約67000個の形態素が作成されました。思っていたより少ない感じで、この程度ならあまりがんばってインデックスファイルを設計しなくても良さそうです。なお参考のため重複するキーワードトップ20を以下に示します。(名詞に限定しています)キーワード出現回数人32104あなた12538自分10776情報10085子供9465日記9101今8708今日8587皆さん8100最近7830みんな7466話6384年6504みなさん6014映画5773生活5750紹介5676ゲーム4981ママ4599曲4557
2006年03月21日
コメント(0)
-
chasenのインストール 【楽天テーマ検索機能の機能拡張(その2)】
楽天テーマ検索サービスの機能拡張をしています。3/19の日記の続きです。まずは形態素解析ソフトウェア「茶筌」(chasen)のインストールについて。形態素とは簡単に言えば文を構成する文法上の最小単位のことで、茶筌は与えられた日本語の文を形態素に分解してくれるソフトウェアです。検索エンジンで正しく日本語のキーワード検索をするためには形態素解析は必須の技術です。以下に茶筌の実行の一例を示します。入力出力形態素読み品詞楽天からのお知らせ楽天ラクテン名詞-一般からカラ助詞-格助詞-一般のノ助詞-連体化お知らせオシラセ名詞-サ変接続楽天市場でこれはおすすめという情報楽天ラクテン名詞-一般市場シジョウ名詞-一般でデ助詞-格助詞-一般これコレ名詞-代名詞-一般はハ助詞-係助詞おすすめオススメ名詞-サ変接続というトイウ助詞-格助詞-連語情報ジョウホウ名詞-一般日本語文法に従って正しく形態素に分解されていますね。「市場」を「イチバ」ではなく「シジョウ」という読みにしてしまっていますが、検索エンジンのためのキーワード抽出という今回の目的に対しては特に問題なないでしょう。文を分かち書きするというソフトウェアとしては茶筌の他にもKAKASIが有名ですが、KAKASIの構文解析能力は茶筌よりも弱く、上記の例はうまく分かち書きできません(そういう例をわざと選んでます)。入力出力楽天からのお知らせ楽天からのお知らせ楽天市場でこれはおすすめという情報楽天市場でこれはおすすめという情報どうもひらがなの連続に弱いようです。これだと「お知らせ」や「おすすめ」というキーワードで検索しても検索結果に現れてくれません。そんなわけで今回は茶筌を選択しました。以下に私が利用しているレンタルサーバ(さくらインターネット)でのインストール手順を示しておきます。 以下の各ソースをダウンロードする。 茶筌 (配布元)今日現在の最新版はchasen-2.3.3.tar.gzです。 IPA辞書 (配布元)今日現在の最新版はipadic-2.7.0.tar.gzです。 Darts(Double-ARray Trie System) (配布元)今日現在の最新版はdarts-0.3.tar.gzですが、最新版だとchasen-2.3.3がコンパイルできないので、darts-0.2.tar.gzを使う必要があります。こちらからダウンロードできます。 GNU libiconv (文字コード変換ライブラリ) (配布元)今日現在の最新版はlibiconv-1.9.1.tar.gzです。GNU本家のダウンロードサーバは非常に重いので、適当なミラーサイトを利用した方が良いです。なお他のレンタルサーバなどで、システムにlibiconvがインストールされていれば改めてダウンロードする必要はありません。 各ソースを以下の順でコンパイル・インストールする。prefixに指定するパスはインストールする環境に応じて適当に変えてください。またインストールの詳細については各配布元やソースに付属のドキュメントを参照してください。 libiconvソースを展開・ディレクトリ移動% ./configure --prefix=/home/asamomiji% make% make install Dartsソースを展開・ディレクトリ移動% ./configure --prefix=/home/asamomiji% make check% make install 茶筌ソースを展開・ディレクトリ移動% ./configure --with-darts=/home/asamomiji/include --prefix /home/asamomiji --with-libiconv=/home/asamomiji% make check% make install IPA辞書ソースを展開・ディレクトリ移動% ./configure% make% make installここまで実行してchasen -hでUsageが表示されればインストール完了です。標準入力から日本語文を与えて遊んでみましょう。さて次はインデックスファイルのデータ構造を考えます。
2006年03月20日
コメント(0)
-
楽天テーマ検索機能の機能拡張
楽天広場にテーマ検索機能が無いのが不満で、しょうがないので自分で作って公開しています。これまでの経緯は以下も参考にしてください。 楽天ブログに存在するテーマはいくつ? (2006/2/23) たくさんある重複するテーマ (2006/2/24) 記事ゼロのテーマが多すぎる (2006/2/26) 重複テーマベスト30(その1) (2006/2/27) 重複テーマベスト30(その2) (2006/2/27) グループとテーマと記事数の関係 (2006/2/28) 楽天ブログのテーマ検索機能を作りました (2006/3/2) 楽天テーマ検索機能のプログラムについて (2006/3/3) 楽天広場のテーマが1時間当たりに増える数 (2006/3/4)公開から1ヶ月近く経ってアクセスカウンタが112になっているので、1日に4回程度使われているようです。自分で作っておいて何ですが、検索にかかる時間が非常に長いのと、複数キーワードによるAND検索ができないのが私としては不満で、ここらでちょっと機能拡張することにしました。現在は1行1テーマとして約22万件のテーマ一覧を保存しているファイルの全行に対してキーワードマッチングを行っているため、検索の度に22万行のテキストデータをすべて読み込みます。これが遅さの原因です。これを改善するために以下の方法を考えました。 Namazuなどの検索エンジンを使う。 テーマ格納用にMySQLなどのデータベースを利用する。 独自のキーワード検索エンジンを作成する。1.の方法は一見簡単なのですが、Namazuなどの検索エンジンは「キーワードを含むファイルを検索する」ことが目的であって、「ファイル中からキーワードを含む行を検索する」のには向いていません。テーマごとにファイルを1つ作るという手もありますが、22万ファイルを作成するとディスク資源を圧迫してしまいます(i-nodeを大量に消費するため)。2.の方法は良い選択肢で、大量にアクセスがあるような正式運用を目指すならこれがベストだと思います。しかし「システムを設計して実装する」という、エンジニアとして一番おもしろい部分を他人任せにしているような感じでつまらない。そこで今回は3.の方法をとることにしました。道具として形態素解析用のツールである「茶筌」(chasen)を使ってインデックスファイル(テキストファイル)を作成し、そのファイルをPHPでアクセスしてバイナリサーチすることを考えています。今後進展があるたびに報告していきます。……続く。
2006年03月19日
コメント(1)
-
JavaでRSSを読み込むプログラム
オリジナルのRSSリーダを作ってみたいという個人的興味に駆られて、RSSデータをJavaから読み込むプログラムを作ってみました。RSSデータはXMLデータなのでJavaのXML関連のパッケージを使うことになります。以下にJ2SE5向けのプログラムを示します。import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.NodeList;public class XMLtest { private static enum Namespace { DC ("http://purl.org/dc/elements/1.1/"), RDF ("http://www.w3.org/1999/02/22-rdf-syntax-ns#"), XHTML ("http://www.w3.org/1999/xhtml"); private final String uri; Namespace(String uri) { this.uri = uri; } public String uri() { return uri; } }; public static void main(String[] args) { String rss = "http://api.plaza.rakuten.ne.jp/kemusiro/rss/"; try { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); // 名前空間をサポートするように設定する。 dbf.setNamespaceAware(true); DocumentBuilder db = dbf.newDocumentBuilder(); Document d = db.parse(rss); // ドキュメントのルートを取得 Element root = d.getDocumentElement(); // ルート直下の"channel"タグに含まれるノードリストを取得 NodeList channel = root.getElementsByTagName("channel"); // "channel"タグ直下の"title"タグに含まれるノードリストを取得する。 NodeList title = ((Element)channel.item(0)).getElementsByTagName("title"); // "title"タグの値を取得する。 System.out.println( "タイトル: " + title.item(0).getFirstChild().getNodeValue()); // 各"item"とその中の"title"、"dc:date"を取得する。 NodeList item_list = root.getElementsByTagName("item"); for (int i = 0; i < item_list.getLength(); i++) { Element elem = (Element)item_list.item(i); NodeList item_title = elem.getElementsByTagName("title"); NodeList item_date = elem.getElementsByTagNameNS(Namespace.DC.uri(), "date"); System.out.print( item_date.item(0).getFirstChild().getNodeValue()); System.out.print(" "); System.out.println( item_title.item(0).getFirstChild().getNodeValue()); } } catch (Exception e) { e.printStackTrace(); } }}列挙型を使っているのでJ2SE5でしか動きませんが、J2SE1.4で動かす場合は適当に定数フィールドで置き換えてください。main()の1行目で、RSSデータを取得したいURLを定義します。上記の例では私の楽天広場のRSSを指定しています。後は、RSSのXMLデータ形式に従ってXMLをパースしてノードを取り出していくだけです。このプログラムの実行結果を以下に示します。タイトル: けむしろうの部屋別館2006-03-07T05:27:33+09:00 XOOPS Cubeでポータルサイト作り(その2)2006-03-06T05:14:27+09:00 オーロラのライブ中継2006-03-06T02:23:35+09:00 オライリーの動物本の表紙を作ろう2006-03-05T17:10:14+09:00 楽天広場のテーマが1時間当たりに増える数2006-03-03T02:48:16+09:00 楽天テーマ検索機能のプログラムについて2006-03-02T05:02:49+09:00 楽天ブログのテーマ検索機能を作りました2006-03-01T04:14:03+09:00 技術系彼女へのホワイトデー向けアイテムにこんな下着はいかが2006-02-28T04:28:30+09:00 ナムコミュージアム Vol.2 (PSP) ジョイスティックが欲しい2006-02-28T02:35:26+09:00 グループとテーマと記事数の関係2006-02-27T04:45:13+09:00 重複テーマベスト30(その2)2006-02-27T04:55:22+09:00 重複テーマベスト30(その1)2006-02-26T05:00:27+09:00 記事ゼロのテーマが多すぎる2006-02-25T18:40:10+09:00 高3次男への虐待弁当!2006-02-24T02:25:47+09:00 たくさんある重複するテーマ2006-02-23T02:36:49+09:00 楽天ブログに存在するテーマはいくつ?2006-02-22T04:57:53+09:00 3歳児+0歳児+33歳夫婦のリアルな生態がフラッシュアニメで!日付がW3Cフォーマットなのでちょっと見にくいですが、データさえ取得できれば後は文字列の操作だけの問題ですね。Javaのライブラリが揃っているおかげで意外とプログラムは簡単でした。あとはSwingを使ってJFrameを作れば、ちょっとしたRSSリーダを作れそうです。
2006年03月08日
コメント(0)
-
楽天テーマ検索機能のプログラムについて
現在、楽天ブログで選択できるテーマの集計を独自に行っています。これまでの経緯は以下の日記もご参照ください。 楽天ブログに存在するテーマはいくつ? (2006/2/23) たくさんある重複するテーマ (2006/2/24) 記事ゼロのテーマが多すぎる (2006/2/26) 重複テーマベスト30(その1) (2006/2/27) 重複テーマベスト30(その2) (2006/2/27) グループとテーマと記事数の関係 (2006/2/28) 楽天ブログのテーマ検索機能を作りました (2006/3/2)今回は自作の検索機能のプログラムについて紹介します。実装はPHPで行っています。以下に検索プログラムのコア部分を示します。if (mb_strlen($k) < 3) { echo "キーワードの長さが短すぎます。3文字以上のキーワードを指定してください。"; return ;}$dir = './data';$dh = opendir($dir);$result = array();while (false !== ($file = readdir($dh))) { if (preg_match("/^G.*\.csv$/", $file)) { $handle = fopen($dir . "/" . $file, "r"); while (($data = fgetcsv($handle, 512)) !== FALSE) { foreach ($data as $str) { if (mb_eregi(mb_convert_kana($k, "KVa"), mb_convert_kana($str, "KVa"))) { array_push($result, $data); continue 2; } } } fclose($handle); }}closedir($dh);PHPはマルチバイトのライブラリが揃っていてプログラミングがしやすいです。スクリプトのあるディレクトリの下に./data/というディレクトリがあって、その下にGaa.csv~Gbs.csvというファイル名のCSVファイルを置いています。PHP5であれば、ディレクトリ内のファイル名を一気に配列に読み込むscandir()という関数があるのですが、私が使っているレンタルサーバはPHP4.4なのでopendir()でディレクトリハンドルを開いてreaddir()で一つずつファイルを選択して処理しています。マッチング処理は英数字の大文字・小文字・全角・半角を区別しないですむように、mb_convert_kana()に"KVa"オプションを指定して、 半角カナを全角カナに 半角カナの濁点つき2文字を全角カナの1文字に 全角英数字を半角英数字に全文字を正規化した上で、mb_eregi()を使って英字の大文字・小文字を無視したマッチング処理を行います。各関数のマニュアルはPHPの公式サイトもご参照ください。ここまでくると今度はand検索やor検索をしたくなってきますが…。楽天に無料奉仕しているように見えて実は私自身のPHPプログラミングの勉強になっているので、楽しんでやってます。でも他にも趣味のプログラミングをしているものがたくさんあるので、また時間ができたときに拡張していきたいと思います。(本当は楽天広場にテーマ検索機能ができてくれるのが一番ありがたい)
2006年03月03日
コメント(0)
-
楽天ブログのテーマ検索機能を作りました
現在、楽天ブログで選択できるテーマの集計を独自に行っています。これまでの経緯は以下の日記もご参照ください。 楽天ブログに存在するテーマはいくつ? (2006/2/23) たくさんある重複するテーマ (2006/2/24) 記事ゼロのテーマが多すぎる (2006/2/26) 重複テーマベスト30(その1) (2006/2/27) 重複テーマベスト30(その2) (2006/2/27) グループとテーマと記事数の関係 (2006/2/28)このたび楽天スタッフ様から、楽天広場の運営の妨げになるようなことがなければ、楽天外部にテーマ検索機能のようなサービスを設置することは可能、とのご回答をいただけましたので、早速作ってみました。楽天広場用ツール上のページに検索用のテキストボックスがあるので、そこから任意のキーワードを入力してください。検索結果から、テーマを選んで任意の日付の日記を書くこともできます。なお楽天広場に迷惑をかけないように配慮したプログラミングをしていますが、以下の場合はサービスを停止します。 不正な使い方がされていることを発見した場合 楽天広場に悪い影響を与えるような使い方を発見した場合 利用者が多すぎてサービス設置サーバの負荷が高くなり過ぎた場合 楽天広場に正式にテーマ検索サービスが設置された場合 その他、私がサービスを停止する必要があると判断した場合使ってみた感想などあれば、掲示板にてご連絡ください。Enjoy!
2006年03月02日
コメント(0)
-
たくさんある重複するテーマ
先日集計した楽天ブログのテーマですが、まずは私がよく書くプログラミングについてのテーマがどれくらいあるのか簡単に検索してみました。検索キーワードは「プログラミング」です。テーマ番号記事件数テーマ名テーマ説明文217862プログラミングの悩み・・・立場は違えど、悩みます。行き詰った時の愚痴や解決策など、教えてください。298011XPって?XPエクストリーム・プログラミングって何??<br>322691プログラミング・・・普通プログラミングって何を使うんですか?<br>ちなみに、俺はHSPを使ってます<br>無料だからお勧めです421091プログラミングソフトについてプログラミングのソフトは何を使ってますか?503951プログラミングに話そうよ!日曜プログラマさんから職業プログラマさんまで、プログラミング言語に関する事だったらなんでも642761プログラムについてWeblog、PHP、CGI、JAVA<br>などなどのプログラミングについて68707プログラミングについてC言語をはじめとする、様々なプログラミング言語の情報交換ができたらと考えています。HSP主体になると思います。739419プログラミングの学習パソコンのプログラムを学習することや、関連する情報などを取り扱います。743161プログラミングの始め方これからプログラマー、SEとしてプログラミングを始める人のためのTIPS&テクニック80615289NLP(神経言語プログラミング)の魅力NLPを使って楽しく楽に生きたり、コミュニケーションをとったりについて考えます82247プログラミングプログラミングについて9518125プログラミング全般言語を問わず、プログラミングに関することを書くためのテーマです。1078331NLPを生活に取り入れてみる密かにプロコーチも取り入れつつあるという「神経言語プログラミング」に注目してみました。114558Let's,プログラミング1405782プログラミングプログラミングって楽しいですよね?164009NLP(神経言語プログラミング)NLP(神経言語プログラミング)についてのテーマです。NLPを日々の生活でどのように活用されていますか?1640115NLP(神経言語プログラミング)NLPを日々の生活の中でどのように活用されていますか?1700681プログラミングをしる!!HTMLからC++、Java、.NETなどのプログラムを教えて下さい・・・自作の紹介も併せてどうぞ。17724212プログラミングの苦悩プログラマー集まれ1785912ゲームプログラミングについて特にプラットフォームにこだわらず、ゲームに関係するプログラミングの話題について話しましょう。17996611日常に活かそう♪NLP/神経言語プログラミングコミュニケーションのコツ♪188142投資とビジネスとニューロ・リングイスティック・プログラミング米国で日本人が億万長者めざして不動産投資やビジネスでがんばります。それから、NLPの話も少し!皆さん応援してくださいネ。205353プログラミングでの自慢・失敗ソフトウェアのプログラミングをするにあたって、失敗した経験や自慢したい技などを話しましょう。こんなにあるんですねぇ。ちなみにテーマ番号205353は私が投稿したものですが、ある方がすでに別のテーマがあるということを教えてくださったのでそちらを使っています。ということでテーマ番号205353は記事数ゼロです。テーマを削除できればいいのですが…。
2006年02月24日
コメント(2)
-
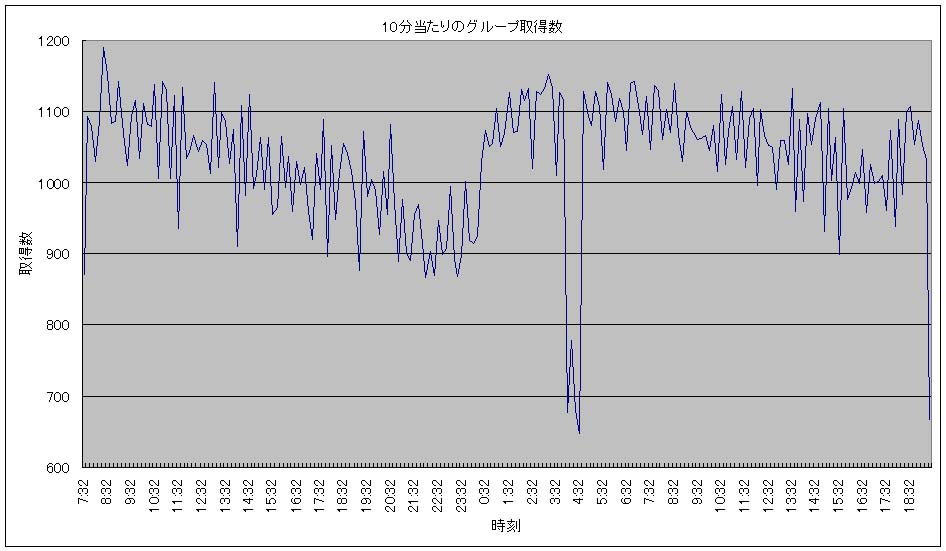
楽天ブログに存在するテーマはいくつ?
毎日のブログを書くときにいつも悩まされるのがテーマ選択です。楽天ブログではテーマの検索ができないので、ぴったりくるテーマを見つけ出すのが困難です。そうなると適当なテーマで妥協するか、新しくテーマを投稿するか考えることになりますが…。以前楽天スタッフにテーマ検索できないのか問い合わせしたところ、「テーマ一覧から選んでくれ」という回答を得たので、いまのところテーマ検索機能を作る予定は無いようです。ところでテーマはどれくらいあると思いますか。2006/2/23の19:30頃現在、222890個あります。こんなにあるということは、きっと重複テーマが大量にあるに違いないと踏んで、ここで一挙にグループ一覧を取得してみることにしました。以下のようなシェルスクリプトを、自宅にある24時間通電のファイルサーバ(Linux)で動かしました。#!/bin/bashfor (( i=0; $i<=223000; i=$i+1 ))do w=`/usr/bin/time -f '%e' ./wget http://plaza.rakuten.co.jp/thm/$i -a get.log 2>&1 | gawk '{print $1*2000000}'` g=`sed -n 's#^.*<a href="/thm/\(g[0-9]*\)/">テーマ一覧.*$#\1#p' $i` r=(`gawk "BEGIN{FS=\": \"}/^theme_id/{id=\\$2}/^theme_title/{title=\\$2}/^theme_text/{text=\\$2}END{printf(\"%s %s\",title,text)}" $i`) n=`sed -n "s/^.*${r[0]}(\(.*\)).*\$/\1/p" $i` echo $i >> groups.txt echo $g >> groups.txt echo ${r[0]} >> groups.txt echo ${r[1]} >> groups.txt echo $n >> groups.txt rm $i usleep $wdone楽天サーバに負荷をかけすぎないように、テーマ画面を1画面取得するたびに、取得にかかった時間の2倍の待ち時間をあけてから次の画面取得をするようにしています。10分ごとのテーマ取得数のグラフを以下に示します(クリックすると大きな画像が見られます)。最大で10分当たり1200テーマ、サーバが混雑していると思われる22時から23時で900テーマ程度となりました。また全部取得するまでに35時間ほどかかっています。10分あたり900テーマということは1秒当たり1.5テーマとなります。1日当たり5000万ページビュー(1秒当たり約580ページビュー)を誇る楽天ですから、1秒当たり1.5画面というのはそれほど大きな負荷ではないと考えます。これからは取得したテーマ一覧を集計して、ブログで結果を報告します。楽天の規約に違反していないことが確認できれば、テーマ検索用のページを私のWebページで公開したいです。
2006年02月23日
コメント(0)
-
J2SE 5.0でナノ秒単位の時間を計測する
J2SEの最新バージョンJ2SE 5.0では、ナノ秒単位の時間を計測するためのメソッドjava.lang.System.nanoTime()が導入されました。私が現在趣味で開発しているプログラムではなるべく正確な時間を知る必要があるため、このメソッドが使い物になるなら非常にありがたいです。そこでどれくらいの精度があるのかざっくり調べてみました。次のようなプログラムを実行して、1ループごとに計測時間を表示します。public class Test { public static void main(String[] args) { while (true) { long start = System.nanoTime(); long end = System.nanoTime(); System.out.println("elapsed time: " + (end - start)); } }}このプログラムで表示される時間の意味は、System.nanoTime()を1回実行する時間と、実行結果をローカル変数に代入する時間の合計値になります。私のところの実行環境は以下の通り。Pentium4 (Northwood) 3.4GHz メモリ 1GB Windows XP Professional SP1 JDK 1.5.0_06この環境でおおむね500ナノ秒程度の実行時間となりました。毎ループで違う値が表示され1の位も毎回異なるので、有効数字は1の位までありそうです。ところで、500ナノ秒をCPUのクロック数で表わすと1700クロック(500[ns]*3.4[1/ns])となります。Pentium4(Northwood)のパイプライン段数は20段ですから、最悪の場合で85命令(1700/20)、平均IPCが5くらい(根拠無し)なら340命令くらい実行してることになります。java.lang.SystemはfinalクラスでnanoTime()メソッドはstatic nativeなメソッドなので、nanoTime()メソッドがオーバーライドされることはなく直接nanoTime()メソッドをJNIで実装した関数を呼び出しているはずです。一方JNIを介した呼び出しは、Javaの世界とOSネイティブな世界との往復のために複雑なインターフェースを通過しますから、上記の85命令~340命令という数値はそれほど掛け離れてはいない感じです。というわけでnanoTime()メソッド非常におおざっぱな見積もりをする限りでは、まともに使えそうな感触が得られました。これから実アプリケーションに適用してみて、もう少し正確な評価をしてみたいと思います。
2006年02月10日
コメント(0)
-
IOCCC(国際邪悪なCコードコンテスト)
プログラミングの世界にいる人なら知っている方も多いと思います。IOCCC(International Obfuscated C Code Contest)。日本語に訳すなら「国際邪悪なCコードコンテスト」。毎年1回開催され、2005年で18回目となる歴史あるコンテストです。公式サイトはこちらです。→ http://www.ioccc.org/このコンテストの目的を公式サイトから引用します(日本語訳は私の手による超意訳です)。To write the most Obscure/Obfuscated C program under the rules below.以下のルールに従って最大限に"邪悪な"Cプログラムを書くこと。To show the importance of programming style, in an ironic way.プログラミングスタイルの重要性について示すこと。皮肉的な方法で。To stress C compilers with unusual code.普通でないコードによってCコンパイラの限界を試すこと。To illustrate some of the subtleties of the C language.C言語がもつプログラミングの機微を表現すること。To provide a safe forum for poor C code. :-)お粗末なCコードに対して(プロの厳しい批判の無い)"安全な"フォーラムを提供すること:-)毎年3月~5月の間にその年の作品を募集し、秋に受賞作品が決まります。2006年度(第19回)の募集開始がそろそろのはずなので、C言語を知り尽くしているという自信のある方はチャレンジしてみてはいかがでしょうか。なお栄えある第1回(1984年)の最優秀作品はこんなプログラムです。short main[] = { 277, 04735, -4129, 25, 0, 477, 1019, 0xbef, 0, 12800, -113, 21119, 0x52d7, -1006, -7151, 0, 0x4bc, 020004, 14880, 10541, 2056, 04010, 4548, 3044, -6716, 0x9, 4407, 6, 5568, 1, -30460, 0, 0x9, 5570, 512, -30419, 0x7e82, 0760, 6, 0, 4, 02400, 15, 0, 4, 1280, 4, 0, 4, 0, 0, 0, 0x8, 0, 4, 0, ',', 0, 12, 0, 4, 0, '#', 0, 020, 0, 4, 0, 30, 0, 026, 0, 0x6176, 120, 25712, 'p', 072163, 'r', 29303, 29801, 'e'};配列の初期値を設定してるだけです。"たまたま"mainという名前の配列を。邪悪すぎて、次の年からのコンテストルールを変えさせたほどの影響力あるプログラムです(特定の実行環境に依存するようなプログラムはNGになった)。なおこのプログラムはVAX-11またはPDP-11でしか動きませんが、同様のアイデアで他の機種やOS版も作れるはずです。C言語のオブジェクトのスタートアップルーチン(crt0.o)の挙動を理解していれば、これが立派なプログラムであることは理解できると思いますが、それにしてもよくこんなの思いついたなぁというのが初めて見たときの率直な感想でした。こんなのに勝てるプログラムを私も書いてみたい。
2006年02月09日
コメント(0)
-
青空文庫をPSPで読む(その1)
著作権の切れた書籍をWebで公開している青空文庫というサービスがあります。これを無線LANとWebブラウザを内蔵しているPSPで見られたら、外出先でも電子ブックとして使えてどんなに便利だろうと思ってアクセスしてみました。ところがPSP内蔵のWebブラウザはXHTMLで導入されたルビタグ(<ruby>~</ruby>)をサポートしていないため、「蠍(さそり)」のように漢字の横に括弧でルビが表示され、これが非常に見にくいです。そこで青空文庫所蔵の文書からルビをすべて削除するフィルタリングサービスを作ってみました。→青空文庫ゲートウェイ (使い方)例えば宮沢賢治の銀河鉄道の夜を読みたい場合は、上記の青空文庫ゲートウェイにアクセスして、作者ID=81、文書ID=43737を入力すればフィルタリングした文書を読むことができます。実装はPHPで行いました。コードの核の部分だけ以下に示します。$fp = fopen($filename, "r");if ($fp == FALSE) { echo "文書が存在しません。"; exit();}mb_internal_encoding("Shift_JIS");while (!feof($fp)) { $pos1 = 0; $s = fgets($fp); $s = str_replace("../../default.css", "http://www.aozora.gr.jp/cards/default.css", $s); while (($pos1 = strpos($s, "<ruby>", $pos1))) { $pos1 += 6; // 6 for strlen("<ruby>") while (!($pos2 = strpos($s, "</ruby>", $pos1))) { $pos1 += strlen($s); $s .= fgets($fp); } print(preg_replace("/<ruby><rb>(.*)<\/rb>.*<\/ruby>/s", "\\1", substr($s, 0, $pos2 + 7))); $pos1 = 0; $s = substr($s, $pos2 + 7); } print($s);}fclose($fp);$filenameには、文書のURLを代入しています。ただこのスクリプトではすべてのルビタグが削除されず、残ってしまうものがあります。正規表現にマッチしない場合があるようですが原因は調査中です。今後もデバッグを続けていきます。
2006年01月31日
コメント(0)
-
Javaアプリケーションでのヘルプ表示(その4) Eclipse+Ant
1月21日の日記の続きです。Eclipseを開発環境に使っていると、Eclipse本体の機能では複数のjarファイルの統合ができないため、ユーザが作成したアプリケーションにJavaHelpのjarファイルをマージすることができません。そこでEclipseからAntを呼び出してJavaHelpのマージを行うことにしました。次のようなAntのビルドファイル(build.xml)をプロジェクトのルートディレクトリに作って、EclipseからAntを実行すれば良いです。手順の詳細はこちらのページを参照ください。<project name="JavaHelpDemo" default="packaging" basedir="."> <property name="target_name" value="JavaHelpDemo.jar" /> <property name="main_class" value="jp.asamomiji.test.JavaHelpDemo" /> <property name="javahelp_jar" value="c:/jh2.0/javahelp/lib/jh.jar" /> <target name="packaging"> <delete file="${target_name}" /> <jar jarfile="${target_name}"> <fileset dir="bin"/> <zipfileset src="${javahelp_jar}" excludes="META-INF/*"/> <manifest> <attribute name="Main-Class" value="${main_class}" /> </manifest> </jar> </target></project>これでだいぶ楽になりました。ヘルプ作成が加速しそうです。
2006年01月27日
コメント(0)
-
8bitパソコン時代のBASIC
JR-100という1981年に発売されたナショナルのパソコン(時代的にはマイコンと言った方が相応しいが)のエミュレータを作ってます。ROMデータを吸い上げなくてもだれでも使えるように、ユーザーズガイドに載っている外部仕様を満たすように一から作っているのですが、実機では少々の文法違反でも許容してしまうのが悩みの種です。使う側にとっては融通が効いていいのかもしれませんが…。文法違反許容の例: 予約語が空白を含んでいても良い。例えば"PRINT"も"P R I N T"もエラーとならない。→入力文字列をトークンに分割する処理が複雑になって困る。 FOR文が入れ子になってなくても良い。一般的にはFOR文は入れ子になっていないとスタックオーバーフローになって実行が停止するが、JR-100のBASICでは次のようなプログラムが正常動作する。10 FOR I=1 TO 10020 FOR J=1 TO 10030 GOTO 5040 NEXT J50 NEXT IこのままだとJループの状態がスタックに積まれ続けるためいずれオーバーフローするはずだがしない。→NEXT文の処理で特別な処理をする必要がある。 IF文が文法違反の形式を受け付ける。JR-100のBASICでのIF文の文法は以下です。IF 条件式 [THEN] 文の並びTHENは省略可能。ところがTHENの後ろの文の並びの部分で数値定数を書くことができ、その場合はGOTO文が省略されていると見なされる。例えば"IF A=0 10"は"IF A=0 THEN GOTO 10"と等価となる。→IF文を文法解析するときに特別な処理が必要となる。コンパイラを作ったことがある人は分かると思いますが、IF 式 [THEN] 式という文法を作れば追加したくなりますがそれは間違い。"IF A=0 THEN B=C"という文を解析しようとすると、Bというトークンを読み込んだ時点で、これがGOTO文を省略したものか代入文の左辺なのかが区別できない。したがってTHENの後ろは数値定数でなければならない。他にもまだ知らない落とし穴があるかもしれません。現代的なプログラミング言語の理論から見るとちょっとルーズですが、当時はユーザ視点に立った(立ちすぎた)プログラムが作れたわけで、ある意味では幸せだったのかもしれません。プログラミング可能なメモリ領域も16KBと非常に限られてましたし、1行も72文字以内という制限もあり、仕方なかったという面もあります。もっとも、エミュ作者としては淡々と機能を実装していくのみです。
2006年01月25日
コメント(0)
-
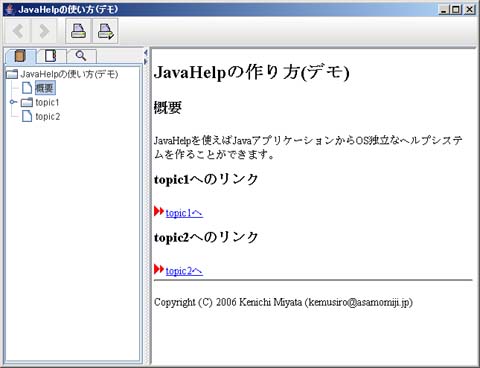
Javaアプリケーションでのヘルプ表示(その3) JavaHelp
1月20日の日記に引き続いて、JavaHelpについてです。JavaHelpにはヘルプ内のテキストの全文検索用のツールが付属していて、JavaHelpで作成したヘルプからテキスト検索を行うことが可能です。実際に実験してみた結果、日本語テキストでも(今のところ)問題なく検索できているので、ぜひ導入しておきたいところです。JavaHelpで作ったヘルプのスクリーンショット導入手順についてはこちらに追記しました。参考になれば幸いです。それにしてもJavaでも色々なツールが揃ってきて、マルチプラットフォームでの開発が面白くなってきましたね。
2006年01月21日
コメント(0)
-
Javaアプリケーションでのヘルプ表示(その2) JavaHelp
1月18日の日記で、Javaアプリケーションからヘルプを表示するのに、ユーザに新たなライブラリをダウンロードさせるのが好ましくないためJavaHelpを使いたくないと書きました。しかしJavaHelpのドキュメントを読むと、JavaHelpライブラリは再配布可能であることが分かったので、最初から自分のアプリケーションにJavaHelpを同梱してしまえば問題ないことが分かりました。そこでJavaHelpを使ったアプリケーションの作り方をまとめてみました。ちょっと長くなるので、詳細は専用のページを私個人のホームページにまとめたのでそちらを参照してください。とりあえず作り方の流れの概略を以下に示します。 ヘルプを記述したHTMLファイルを作る。 ヘルプセットファイルを作る。 マップファイルを作る。 目次ファイルを作る。 インデックスファイルをつくる。 できあがったヘルプファイル群をjarファイルにまとめる。これでだいぶすっきりしました。これからはJavaHelpを使ってヘルプを書くようにしたいです。
2006年01月20日
コメント(0)
-
Javaアプリケーションでのヘルプ表示
個人的に作っているJR-100エミュレータですが、こいつはすべてJavaで書いています。Javaアプリケーションでヘルプをつくる場合、次の2通りがあると思います。 JavaHelpを使用する。 エディタペインやテキストペインを使って通常のダイアログウィンドウを使用する。(他に方法があったら教えて欲しいです)もっとも正当なのはJavaHelpを使う方法だと思いますが、JavaHelpパッケージ(javax.help)は標準のJavaパッケージ群には含まれていないため、ヘルプを参照するためにはユーザがJavaHelpをダウンロードしてインストールする必要があります。Java Plug-inがクライアントにインストールされていることを前提とすれば、必要なパッケージ(この場合はJavaHelp)を自動的にインストールしてくれるようにmanifestファイルを記述すれば良いのですが、標準以外のパッケージを使うことは個人的にはあまり好きになれません。そこで後者のテキスト表示用のペインを使うことにしました。HTMLデータであればJEditorPaneを使うのが一番楽なので以下のようなコードを書いてみました。private JScrollPane getJScrollPane() { if (jScrollPane == null) { jScrollPane = new JScrollPane(); jScrollPane.setViewportView(getJEditorPane()); } return jScrollPane;}private JEditorPane getJEditorPane() { if (jEditorPane == null) { jEditorPane = new JEditorPane(); jEditorPane.setEditable(false); try { URL url = new URL("http://www.asamomiji.jp/antique/"); jEditorPane.setPage(url); } catch (MalformedURLException e) { // エラー処理 } catch (IOException e) { // エラー処理 } } return jEditorPane;}url変数に、表示したいHTMLファイルのありかを記述します。今回はインターネット上のファイルを参照するようにしてます(上の例では適当なURLをしてしていますが、実際は正しいHTMLファイルへのリンクを記述している)。これをヘルプメニューが選択されたときのイベント発生時に表示するダイアログに載せればOKです。ところがJEditorPaneが表示するHTMLページはあまり質が良くなく、ちょっと表示が乱れます。画面上部にあるテーブルがうまく表示されていないJEditorPane用にHTMLファイルをカスタマイズする必要がありそうなので、もうちょっと研究を継続してみます。
2006年01月18日
コメント(0)
-
PHPでRSS取得(補足)
1月15日の日記で、PHPを使ってRSSデータを取得し、自分のホームページに最新日記を表示する件を書きました。これに関して何点か自分用に雑件的に補足しておきます。 トップページがindex.htmlからindex.phpに変わったことへの対処私のホームページのURLは末尾が'/'で終わる形式で外部には公開していて、かつ現在のレンタルサーバではデフォルトでindex.phpをインデックスファイルとして検索してくれるので、トップページのファイル拡張子が変わっても問題ありません。しかしたまにindex.htmlを指定してアクセスされる場合があるためその対処が必要です。そこで.htaccessファイルに以下の記述をしました。DirectoryIndex index.phpRedirect permanent /kemusiro/index.html \ http://www.asamomiji.jp/kemusiro/index.php最初の行(DirectoryIndex)は、index.htmlという名前のファイルがゴミとして残っていてもアクセスされないようにするための指定です。2行目と3行目(この2行を合わせて1行で書いても構いません)が本質的なところで、index.htmlへのアクセスがあった場合に、自動的にindex.phpへリダイレクトするようにしています。リダイレクト元はドキュメントルートからの絶対パス名、リダイレクト先はhttpから始まるURLで記述する必要があります。 取得したRSSデータのキャッシュについてindex.phpにアクセスがある度に毎回RSSデータを取得しているとサーバへの付加がかかりますし、ページを表示するまでの応答時間も長くなってしまいます。そこでMagpieRSSのキャッシュ機能が有効です。デフォルトではキャッシュ機能はオンになっていて、キャッシュの有効時間は1時間となっています。この設定を変えたい場合は以下のように定数を設定してください。定数名設定値意味デフォルト値MAGPIE_CACHE_ONtrueまたはfalseキャッシュを使用するか否かtrueMAGPIE_CACHE_DIRディレクトリ名キャッシュを保存するディレクトリ名./cacheMAGPIE_CACHE_AGE数値キャッシュの有効時間(秒単位)3600MAGPIE_CACHE_FRESH_ONLYtrueまたはfalseRSSのフェッチに失敗したときにエラーを返すか否かfalse
2006年01月16日
コメント(0)
-
PHPでブログの最新記事をRSSで取得しホームページに貼り付ける。
私はこの楽天ブログ(けむしろうの部屋別館)の他に、個人のホームページ(けむしろうの部屋本館)を持っています。以前は近況を本館の方に書いていたのですが、ブログを始めてからはその便利さに負けて近況についてはすべてブログを利用しています。かといって自分のホームページにもせめて最新の近況のいくつか載せておきたいと思い、いまや多くのブログで採用されているRSSを利用して最新記事を自動取得し、本館の方に表示することにしました。幸い現在利用しているレンタルサーバ(さくらインターネット)ではPHPが使えるため、PHPによるRSSデータ処理ライブラリを導入してRSS記事を取得することにします。今回導入したRSSデータ処理ライブラリはフリーソフトの「MagpieRSS」です。作成者は日本人ではありませんが、マルチバイト文字も扱えるので日本語も問題なく通ります。私の行った作業を備忘録として書いておきます。何かの参考になる方もいらっしゃるかもしれません。できあがったものは「けむしろうの部屋」のトップページ(index.php)で、このページの近況のところに最新の記事5件分を表示されていることで確認できます。 MagpieRSSをダウンロードする。 公式サイトのページ上部にある「DOWNLOAD」のところをクリックし、適当なミラーサイトから最新版をダウンロードします。 私はmagpierss-0.72.tar.gzをダウンロードしました。 magpierss-0.72.tar.gzを展開してインストールする。 これから作りたいindex.phpのあるディレクトリ直下にmagpierssという名前のディレクトリを作成して、以下のファイルとディレクトリをその下にコピーする。 rss_utils.inc rss_cache.inc rss_fetch.inc rss_parse.inc extlib/Snoopy.class.inc index.phpの先頭に以下のPHPプログラムを記述する。<?php require_once('magpierss/rss_fetch.inc'); define('MAGPIE_OUTPUT_ENCODING', 'UTF-8'); $count = 5; $length = 60;?>なお最初の2行だけが必須です。$count変数は表示する最新日記の件数、$lengthは表示する日記記事の最大文字数です。 RSS記事をフェッチして必要なデータを表示する。私の場合は記事の日付、タイトル、記事内容の一部だけが必要でしたので、以下のようなコードを書きました。$url = 'http://api.plaza.rakuten.ne.jp/kemusiro/rss/';$rss = fetch_rss($url);echo "<ul>";array_splice($rss->items, $count);foreach ($rss->items as $item) { $href = $item['link']; $title = mb_convert_encoding($item['title'], "SJIS", "auto"); $date = date('Y/m/d H:i:s', parse_w3cdtf($item['dc']['date'])); $description = mb_convert_encoding($item['description'], "SJIS", "auto"); if (mb_strlen($description) > $length) { $description = mb_strcut($description, 0, $length) . "..."; } echo "<li>"; echo "<FONT color=\"#ff8040\">(" . $date . ")</FONT> "; echo "<a href=$href>" . $title . "</a><BR>"; echo $description . "</li>";}echo "</ul>";取得したいRSSデータのURLを1行目で指定し、2行目でRSSデータを取り込みます。後は必要なデータに応じて$rss変数のフィールドを参照してください。RSSデータとして保存されている日付のフォーマットはW3Cフォーマットですが、このフォーマットは少し少し見辛いので、見慣れたフォーマットに変換するために私のプログラムではparse_w3cdtfメソッドを利用してフォーマット変換しています。また文字コードをUTF-8からSJISに変換するためにmb_convert_encodingメソッドを利用しました。その他、文字色や箇条書きなどにするために適当にHTMLタグを記述しています。こんな感じで意外と簡単にできました。MagieRSSの作者に大感謝です。なおRSS1.0の仕様はこちらから参照できます。
2006年01月15日
コメント(4)
-
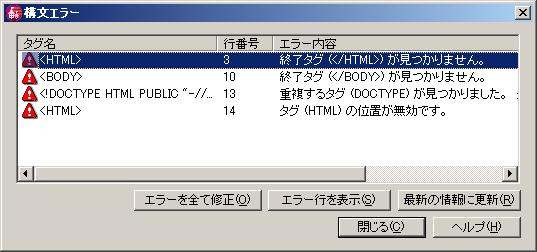
PHPEclipseとホームページビルダーの連携(その3)
1月10日の日記にも書いたPHPEclipseとホームページビルダーの連携についての続報です。ホームページビルダーの設定で、「ツール→オプション→一般」で「HTML構文エラーを自動修正する」のチェックは外しておくべきです。プログラミングスタイルにもよると思いますが、ホームページビルダーの行うHTMLファイルの構文チェックルーチンが<?php ... ?>をPHPタグだと認識してくれない(というかPHPに対応してない)ので、場合によってはHTMLファイルを破壊してしまうことがあります。以下に一例を示します。POSTメソッドで"command"引数に値"show"が与えられたときとそれ以外のときで文書のタイトルと本文の見出しを変えるプログラムで、PHP的には正当です。しかしホームページビルダーは構文エラーを出してファイルの意味を変えてしまいます。 元HTMLファイル<?php if ($_POST["command"] == "show") {?><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"><HTML><HEAD><META name="GENERATOR" content="IBM WebSphere Studio Homepage Builder Version 10.0.1.0 for Windows"><META http-equiv="Content-Type" content="text/html; charset=EUC-JP"><META http-equiv="Content-Style-Type" content="text/css"><TITLE>情報のリスト</TITLE></HEAD><BODY><H1>情報のリスト</H1><?php } else {?><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"><HTML><HEAD><META name="GENERATOR" content="IBM WebSphere Studio Homepage Builder Version 10.0.1.0 for Windows"><META http-equiv="Content-Type" content="text/html; charset=EUC-JP"><META http-equiv="Content-Style-Type" content="text/css"><TITLE>それ以外のコマンド</TITLE></HEAD><BODY><H1>それ以外のコマンド</H1><?php }?><HR><P>(c) けむしろう</P></BODY></HTML> ホームページビルダーの出すエラーメッセージ 修正後のHTMLファイル<?php if ($_POST["command"] == "show") {?><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"><HTML><HEAD><META name="GENERATOR" content="IBM WebSphere Studio Homepage Builder Version 10.0.1.0 for Windows"><META http-equiv="Content-Type" content="text/html; charset=EUC-JP"><META http-equiv="Content-Style-Type" content="text/css"><TITLE>情報のリストそれ以外のコマンド</TITLE><META name="GENERATOR" content="IBM WebSphere Studio Homepage Builder Version 10.0.1.0 for Windows"><META http-equiv="Content-Type" content="text/html; charset=EUC-JP"><META http-equiv="Content-Style-Type" content="text/css"></HEAD><BODY><H1>情報のリスト</H1><?php } else {?><H1>それ以外のコマンド</H1><?php }?><HR><P>(c) けむしろう</P></BODY></HTML>二つあるHTMLのヘッダ部分の一部が見事に消されてしまいました。したがってホームページビルダーと連携することのできるPHPプログラムにはある程度の制限があるということになります。少なくとも構文エラーの自動修正をされると何が起こるか分からないので、このオプションをオフにしておくことは必須でしょう。他にもまだあるかもしれません。また何かあったら報告します。
2006年01月11日
コメント(0)
-
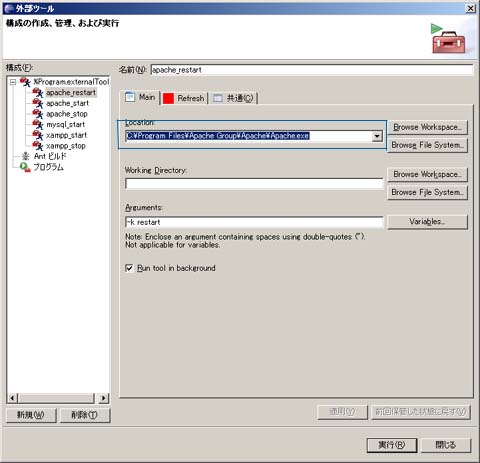
PHPEclipseとホームページビルダーの連携(その2)
ホームページビルダーとPHPEclipseとを連携させて、PHPファイルを開発する手法を探っていると12月31日の日記で書きましたが、今のところうまくいっている各種設定方法について紹介します。私が試したソフトウェアのバージョンは以下です。ホームページビルダー v10 Eclipse 3.1.1 PHPEclipse 1.1.7 Apache 1.3.34 PHP 4.3.10以下に手順を示します。 Apacheのプログラムパスの設定 (PHPEclipse) PHPEclipseはxamppの使用を前提としていますが、私のところではApacheのバージョンの関係でxamppを使えないため、Apacheのパスの変更が必要です。 PHPEclipseの「実行→外部ツール→外部ツール」でApacheのプログラムパスを入力しててください。下記の細い青枠で囲った部分に、Apache.exeの絶対パスを入力します。これをapache_restart, apache_start, apache_stopの3個所で設定します。 Apacheの手動起動化 (Windows)PHPEclipseのメニューボタンからApacheの開始・停止を制御するために、Apacheが自動起動しないように設定します。WindowsXPの場合は、「スタート→設定→コントロールパネル→管理ツール→サービス」でサービス一覧画面を出し、Apacheのスタートアップの種類を「自動」から「手動」に変える。 ファイル格納場所の設定 作成するPHPファイルの置き場を確保する。以下では「C:\home\kemusiro\asamomiji\www\hpb-php」というディレクトリに、PHPファイルや関連するHTMLファイルなどを置くことを前提として説明します。 ホームページビルダーでサイトの新規作成これから作りたいサイトの情報を設定してください。今回は以下のようにしました。 サイト名: "PHP連携" トップページの作成先: C:\home\kemusiro\asamomiji\www\hpb-php トップページのファイル名: index.php Eclipseで新規PHPプロジェクトの作成これから作りたいプロジェクトの情報を設定してください。今回は以下のようにしました。 プロジェクト名: "PHP連携" プロジェクトコンテンツ: 「デフォルトの使用」のチェックを外してホームページビルダーのサイトディレクトリと同じものを設定する。 文字コードの設定PHPEclipseはシフトJISを受け付けないようなので、ホームページビルダー側とPHPEclipse側でEUC-JPに統一する。 ホームページビルダーでHTMLソースを修正する。HTMLソースのMETAタグでcharsetを指定している部分を、"Shift-JIS"から"EUC-JP"に修正する。<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"><HTML><HEAD><META name="GENERATOR" content="IBM WebSphere StudioHomepage Builder Version 10.0.1.0 for Windows"><META http-equiv="Content-Type" content="text/html; charset=EUC-JP"><META http-equiv="Content-Style-Type" content="text/css"><TITLE></TITLE></HEAD><BODY></BODY></HTML></code> PHPEclipseの文字コードを変更する。プロジェクトのプロパティでの「情報」ページ内の「テキスト・ファイル・エンコード」として、「その他: EUC_JP」を指定する(リストボックスに"EUC-JP"が無い場合は、直接"EUC-JP"と入力してください。 Apacheの設定ファイルの修正Apacheでサイトのディレクトリにアクセスできるように、http.confの<IfModule mod_alias.c>セクションでエイリアスを設定してください。Alias /hpb-php/ "C:/home/kemusiro/www/asamomiji/hpb-php/"<Directory "C:/home/kemusiro/www/asamomiji/hpb-php"> Options Indexes FollowSymlinks MultiViews AllowOverride None Order allow,deny Allow from all</Directory>これでHPBとPHPEclipseでHTMLファイル(.phpファイル)を共有する準備ができました。HPB側でファイルを編集した後、PHPEclipse側で同ファイルを編集しようとすると、ファイルの再ロードを促すメッセージが出るので、「はい」を選んで最新の状態にしてください。いかがでしょうか。今後、ホームページビルダーとPHPEclipseを使ってプログラム開発をしてみて、何か問題が発生したらまた報告したいと思います。
2006年01月10日
コメント(0)
-
自分自身のインスタンスを参照する変数名いろいろ
1月8日の日記で、VBAでは自分自身のインスタンスを参照するのにキーワード「Me」を使うと書きましたが、その他の言語ではどうなのか気になったのでちょっと調べてみました。 thisを使うもの Java, C++, C#, JavaScript, PHP selfを使うもの Ruby, Smalltalk, Objective-C, COBOL2000 (正確にはSELF), Delphi Meを使うもの VBA, VB.NET サブルーチン・メソッドの第1引数で明示的に変数名を指定するもの Perl, Pythonけっこう色々ありますね。thisが普通かと思っていましたが、selfもよく使われています。MeはVB以外では見かけませんでした。こういうのは言語設計者の趣味や思想が色濃く反映してそうです。もちろんプログラミング言語の系譜から考えて必然的に決まってしまうものもあるでしょうけど。他の言語ではこうだとか間違いなどがあればコメントください。(2006/1/11追記) Delphi言語を"self"に追加しました。Prophetさんありがとうございます。
2006年01月09日
コメント(2)
-
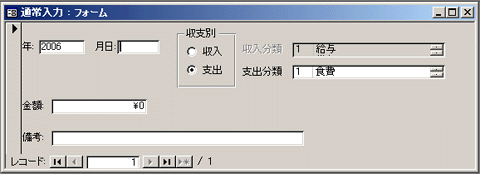
Accessで家計簿(その3)
12月30日の日記に引き続いて家計簿をMS-Accessで作ってます。マクロ内からテーブルのレコードを操作する方法が分からず、結局VBAを使ってイベントプロシージャを書いてしまいました。このフォームの「年」と「月日」に入力されたテキスト(「月日」は"0107"のような4桁の文字列)を日付に変換してテーブル内のフィールド「日付」に保存する処理でてこずっていたのですが、以下のようにしてみました。レコードの更新前というイベントに対する処理を記述しています。Private Sub Form_BeforeInsert(Cancel As Integer) Me!日付 = DateSerial([Forms]![通常入力]![年], _ [Forms]![通常入力]![月日] / 100, _ [Forms]![通常入力]![月日] Mod 100) If Forms!通常入力!フレーム6 = 1 Then Me!入出金分類 = True Else Me!入出金分類 = False End If Me!登録日 = Date Me!登録時刻 = TimeEnd SubVBAでは自分自身のオブジェクトを参照するのに「Me」という識別子を使うんですね。普通は「this」だと思うんですが何か理由があるのでしょうか。ちょっと調べてみたいところです。とりあえず家計簿の方は通常運用に入ってデータが入り始めました。次は集計機能を作り込んでいこうと思います。
2006年01月08日
コメント(0)
-
PHPEclipseとホームページビルダーの連携(その1)
12月25日の日記で書いたように、最近PHPの勉強を始めました。今までは動的に生成するページはPerlによるCGIで作っていましたが、PHPを使う場合とCGIを使う場合では考え方が逆になっていて興味深いです。 PerlによるCGI Perlソースの中にHTMLを生成するプログラムが組み込まれている。 PHPによるHTMLファイル HTMLソースの中にプログラムが組み込まれている。つまりPHPプログラムは基本的にHTMLファイルなので、ホームページビルダーなどのHTML編集ソフトによってページのデザインをする方が楽です。一方でPHPプログラムの開発には専用の開発環境で行った方がデバッグ等も含めてはるかに楽で効率的です。そこでホームページビルダーとPHPEclipseとを連携させて、PHPファイルを開発する手法を探っています。文字コード等でハマるところもありますが、基本的な部分はできるようになりました。面白くなってきた。詳しいことはもう少しまとまってからまた報告します。
2005年12月31日
コメント(0)
-
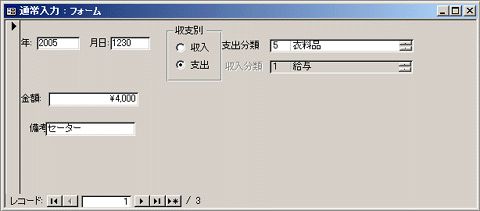
Accessで家計簿(その2)
12/10の日記に書いたように、Accessを使って家計簿を作成中です。初めて本格的に触ってみて、これは本格的に使いこなすのは難しいなと感じました。お仕着せのテンプレートで満足できるならともかく、ちょっとカスタマイズしようとすると悩みまくりです。フォーム画面でいくつかのテキストボックスに入力した値を組み合わせてテーブルに登録する、という一見簡単そうなマクロの作り方が分からず(できない?)、しょうがないので不可視のテキストボックスにいったん組み合わせた値を代入して、そのテキストボックスとレコード内のフィールドを関連づけることで解決しました。これであっているのか不安ですが…。とりあえずここまでできた。今年中に完成させるという目標が達成できるか不安になってきた。この本を参考にしてます。
2005年12月30日
コメント(0)
-
EclipseでのPHP開発環境を構築しました。
現在契約しているレンタルサーバ(さくらインターネット)では、PHPやMySQLが使えるということなので、新しもの好きの私としてはPHPでのプログラミングを始めてみました。そこで開発環境の整備をします。JavaプログラムはEclipseで開発しているので、どうせならPHPもEclipseでということでEclipse3.1 + PHPEclipseプラグインを使うことにしました。それに伴って、WindowsXP上にApache+PHP+Perl+MySQLの環境をインストールが必要です。この辺の周辺サーバのインストール情報は関連書籍やWeb上の情報がたくさん出ているので、詳細はそちらをご参考ください。なお私はこちらのサイトを参考にさせていただきました。一応簡単に私の環境構築手順を簡単に列挙しておきます。各サーバ類のバージョンはレンタルサーバの仕様に合わせているので、必ずしも最新版をインストールしていません。まだ始めたばかりで無駄なインストールをしているかもしれません。ご指摘などありましたらコメントいただけると幸いです。 PHPEclipseプラグインのインストール こちらのサイトが参考になると思います。なお私が使用しているレンタルサーバの仕様とxamppに含まれている各サーバのバージョンが異なっているため、xamppは使用せずにApache/Perl/PHP/MySQLを個別にインストールしています。PHPEclipseはxamppを使うことを前提としているようですが、とりあえずPHPスクリプトを書いてテストできればそれで良いと割りきりました。 Apache 1.3.34のインストール このページのミラーサイト一覧の中から適当なダウンロードサイトを選んで、/pub/net/apache/dist/httpd/binaries/win32/apache_1.3.34-win32-x86-no_src.msiをダウンロードして実行・設定 Active Perl 5.8.7.815のインストール こちらのサイトからFree Distribution版のActive Perlをダウンロード(ActivePerl-5.8.7.815-MSWin32-x86-211909.msi)して実行・設定 PHP 4.3.10のインストール こちらのサイトからphp-4.3.10-Win32.zipをダウンロードして実行・設定 MySQL 4.0.2のインストール こちらのサイトからphp-4.3.10-Win32.zipをダウンロードして実行・設定ここまででうまく設定できていればPHPファイルをローカルマシン上で実行できるはずです。あとはEclipse+PHPEclipseの開発環境とApacheとの連携の設定をすればOKです。やることはApacheのディレクトリエイリアスとしてEclipseのPHPプロジェクトのワークスペースディレクトリを割り付けるだけです。私は以下のように設定しました。 ● Apacheのhttpd.conf <IfModule mod_alias.c>ブロックに新規にエイリアスを追加する。Alias /PHPtest/ "ワークスペースのルートディレクトリ/PHPプロジェクト名/"<Directory "ワークスペースのルートディレクトリ/PHPプロジェクト名"> Options Indexes FollowSymlinks MultiViews AllowOverride None Order allow,deny Allow from all</Directory>これだけです。とりあえずこれでPHPスクリプトの実行結果のプレビューを見ながらPHPスクリプトの編集ができるようになり、今のところ満足です。さてこれから言語仕様書を見ながら遊んでみることにします。
2005年12月25日
コメント(0)
-
Eclipse3.0から3.1への乗り換え
個人的に作っているプログラム(JR-100エミュレータ宣伝^^:)の作業が一段落したので、開発環境として使っているEclipseをこれまで使っていた3.0から3.1にアップデートしました。3.1での大きな変更はJ2SE 5.0への対応でしょう。ただ、私としてはまだJ2SE 1.4でプログラミングを続けるつもりですので、個人的には3.1になっても使用感は変わってません。見た目がきれいになったなー程度です。[余談]とはいいつつJ2SE 5.0での総称型にはとても興味があります。C++では良く使っていたので、Javaに無いのが不満でした。総称型の最大のメリットは、静的型検査が適用できることだと思っています。今までは例えばVectorクラスに格納できるオブジェクトの型はObjectクラスだったので、Vectorに本来望んでいないクラスのオブジェクトを代入したとしても、実行時に例外が発生するまで気付かないという問題がありました。しかしVector<MyClass>のように型を定義すれば、MyClassクラス(およびその子クラス)以外のクラスのオブジェクトを代入しようとしても、コンパイル時に不正な代入であることを検知できます。プログラマとしてはありがたい機能です。[余談終わり]なお3.1に移行してハマったのが、CVSのデフォルトオプションが'-kkv'から'-kk'に変更されていたことです。例えば$Revision$というCVSのキーワードが、'-kkv'だと$Revision: 1.3$のように置換されますが、'-kk'だと$Revision$のままです。早速CVSの設定(チーム→CVS→ファイルおよびフォルダ─)のデフォルトのテキスト・モードを「キーワード拡張のある ASCII (-kkv)」に変更しました。
2005年12月22日
コメント(0)
-

Accessで家計簿。そして家庭内リボ払い。
当家ではPCで家計簿をつけてます。Lotus1-2-3(1995年頃)→Excel95→Excel97→Exel2002とソフトウェアのバージョンアップとともに、家計簿用マクロもわが家の家計管理用にカスタマイズし続けてきました。それとともにデータ管理も複雑化してきたため、ここらで自分の勉強も兼ねて、来年分は初めてAccessで作成することにしました。Word/Excel/PowerPointは仕事がら酷使していてそれなりに使いこなしていますが、Accessはこれまで使う機会がありませんでした。そこでインプレス社の「できる」シリーズのAccessの本を買いました。これはとても重宝してます。ページ数も926ページと分厚い分、データベース構築の各フェーズ(テーブル定義、クエリ作成、フォーム作成、レポート作成、関数・マクロの説明、データベースの連携・運用など)ごとに実画面を参照しつつ分かりやすく解説してます。これでなんとか年内に完成させないと…。ところで、わが家の家計管理を少し複雑にしているものとして「家庭内リボルビング払い」制度というものがあります。お小遣いではすぐに買えないような高い品物を家計に借金をして購入し、毎月の小遣いから一定額を天引きして家計に返済していくという仕組みです。ただし本当の金融機関ではないので延滞しても利息はつきません(^^;私の場合は、PC関連ハード(本体・周辺装置)や高額なソフトウェア(MSDNを個人で契約してます)、情報処理学会やACMなどの学会会費、携帯電話の通信費、個人で持っている独自ドメインとレンタルサーバの管理費などを小遣いから出していて、一時は40万円くらいまで借金が膨らんでました。しかしたまにボーナスによる「恩赦」があるので、何とかいまではほぼゼロ円まで返し切りました。ふー。いつまで借金ゼロの状態が続くか…。できる大事典 Access 2003&2002(インプレス) 私はお勧めします。
2005年12月10日
コメント(2)
-

Eclipse+Visual Editorは優れているが、しかし…。
仕事ではC言語やシェルスクリプトを使うことがほとんどですが、趣味のプログラミングではJavaがほとんどです。開発環境はEclipseを使い、GUIプログラミングにはVisual Editorプラグインを活用しています。以前はEmacsなどのエディタでバリバリ書いていましたが、ファイル数が200を越えてきたり、GUIプログラミングをしようとすると、もはや開発環境無しではプログラムできない体になってしまいました。それは良いのですが、Visual Editorを使っていると変数の名前に非常に無頓着になってしまいました。以前ならGUI部品ごとに意味を考えて適切な名前をつけていましたが、Visual Editorが自動的につけた名前(jButton1/jButton2)などを一々変えていくのが面倒で、美しいプログラムからは掛け離れていってしまっています。いかんなーとは思いつつ便利さに負けてしまう軟弱モノです。Eclipse.org Eclipseプロジェクトの本家Visual Editor Project Visual Editorプロジェクトの本家 私が参考にしている本
2005年11月25日
コメント(0)
-
ドキュメントの作成
プログラミングはコードを書いたりデバッグしたりするのは楽しいですが、他人に公開するためにドキュメントを書くのが面倒だ。書き始めたら始めたで、あれもこれも書きたくなって収拾がつかなくなるのですが…。
2005年11月17日
コメント(0)
全42件 (42件中 1-42件目)
1
-
-

- 【楽天市場】新製品の激安 価格比較…
- Có nên mua máy lọc nước ion kiềm
- (2022-12-29 13:40:56)
-
-
-

- 新製品発売情報・予約情報
- 私たちは売りたくない!【無知は罪】
- (2024-09-30 14:42:03)
-
-
-

- 楽天市場のおすすめ商品
- おすすめのヨガポール
- (2024-10-02 09:00:13)
-



