
Oct 10, 2020

カテゴリ: 競馬
pythonで競馬予想。これまでのバッグナンバーは下記です。今回はいよいよ機械学習実践です。
Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)
Python で 競馬予想 第2回(HTML解析編)
Python で 競馬予想 第3回(Python上でのデータ加工)
Python で 競馬予想 第4回(Python上での配列定義)
Python で 競馬予想 第5回(機械学習用の前処理 1)
Python で 競馬予想 第6回(機械学習用の前処理 2)
Python で 競馬予想 第7回(機械学習実践)
前回までで機械学習を行う前準備(下記)が完了しました。
1.不要データの削除、数値への置き換え
2.データに文字列がはいっていないかのチェック
3.正規化の実施
今回がようやく機械学習を実践できます。機械学習と言ってもいろいろあるのですが、今回私が採用した方法はRandom Forest Regressionによる機械学習です。Random Forestとは何ぞや?という事ですが、Random Forestを理解するためには決定木を理解する必要があります。決定木とは学習用のデータをいくつかのサンプル群にわけて、そのサンプル群に条件に合うかどうかで更に細かいサンプル群に分けていって、最終的に目的の答えに導くというものです。自分なりな図を作ってみました。
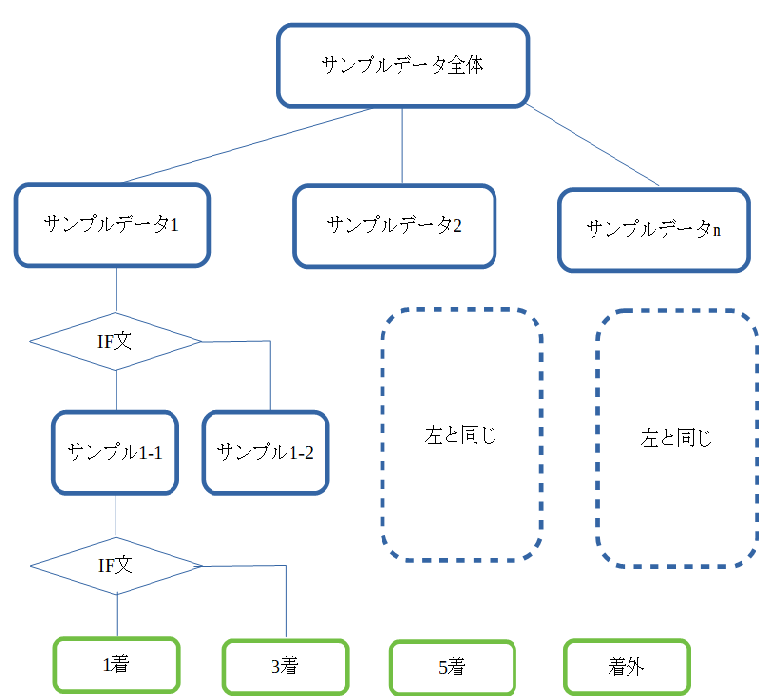
図をみると木のように見えるので決定木といわれるのかもしれません。決定木はIF分がひとつの条件で行うので、各データに対して影響度を揃える必要がない(正規化不要)。また、IF分のかたまりで判定した内容が明らかという長所を持つ反面、弱点は枝を何本も作っていくと過学習になって、間違った答えを出しやすい。(ずれが大きい)ということもあります。Random Forestは文字通り、この決定木を何本も作ってそれを組み合わせることで、そのずれの影響を減らすという利点を持っています。
まあ、説明はこのくらいで。詳しいことはWEBをぐぐれば出てきますし、そっちの方が説明も上手だと思います。では、やることを順番に説明します。
1.学習データと評価データにわける。
2.Random Forest Regression実行(1着、3着、5着の回帰モデル作成)
3.回帰モデルから1着、3着、5着になる確率を予想。
4.競馬新聞風に加工し出力
5.回帰モデル影響度の確認
という流れです。
◆1.学習データと評価データにわける。

テストデータの分割です。学習用と評価用にわけます。説明データは過去の5年分の馬データと着順データなので、それほど多くありません。16頭×5=90データぐらい。ここで、評価データにたくさん取られると肝心の学習が出来なくなるので可能な限り学習データを増やしました。
Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)
Python で 競馬予想 第2回(HTML解析編)
Python で 競馬予想 第3回(Python上でのデータ加工)
Python で 競馬予想 第4回(Python上での配列定義)
Python で 競馬予想 第5回(機械学習用の前処理 1)
Python で 競馬予想 第6回(機械学習用の前処理 2)
Python で 競馬予想 第7回(機械学習実践)
前回までで機械学習を行う前準備(下記)が完了しました。
1.不要データの削除、数値への置き換え
2.データに文字列がはいっていないかのチェック
3.正規化の実施
今回がようやく機械学習を実践できます。機械学習と言ってもいろいろあるのですが、今回私が採用した方法はRandom Forest Regressionによる機械学習です。Random Forestとは何ぞや?という事ですが、Random Forestを理解するためには決定木を理解する必要があります。決定木とは学習用のデータをいくつかのサンプル群にわけて、そのサンプル群に条件に合うかどうかで更に細かいサンプル群に分けていって、最終的に目的の答えに導くというものです。自分なりな図を作ってみました。
図をみると木のように見えるので決定木といわれるのかもしれません。決定木はIF分がひとつの条件で行うので、各データに対して影響度を揃える必要がない(正規化不要)。また、IF分のかたまりで判定した内容が明らかという長所を持つ反面、弱点は枝を何本も作っていくと過学習になって、間違った答えを出しやすい。(ずれが大きい)ということもあります。Random Forestは文字通り、この決定木を何本も作ってそれを組み合わせることで、そのずれの影響を減らすという利点を持っています。
まあ、説明はこのくらいで。詳しいことはWEBをぐぐれば出てきますし、そっちの方が説明も上手だと思います。では、やることを順番に説明します。
1.学習データと評価データにわける。
2.Random Forest Regression実行(1着、3着、5着の回帰モデル作成)
3.回帰モデルから1着、3着、5着になる確率を予想。
4.競馬新聞風に加工し出力
5.回帰モデル影響度の確認
という流れです。
◆1.学習データと評価データにわける。
テストデータの分割です。学習用と評価用にわけます。説明データは過去の5年分の馬データと着順データなので、それほど多くありません。16頭×5=90データぐらい。ここで、評価データにたくさん取られると肝心の学習が出来なくなるので可能な限り学習データを増やしました。
X_train,X_test,Y_train,Y_test = sklearn.model_selection.train_test_split(X_multi3,X_multi2['1着'],test_size=0.01, random_state=0)
◆ 2.Random Forest Regression実行(1着、3着、5着の回帰モデル作成)

ここまでの説明が長かったですが、ランダムフォレスト実行はたったの2行です。1行目がランダムフォレスト回帰のパラメータ設定。n_estimationというのはランダムフォレストに使う決定木の数です。
2行目がランダムフォレスト回帰モデル作成です。rfr1で1着になる回帰モデルが作られます。
◆ 2.Random Forest Regression実行(1着、3着、5着の回帰モデル作成)
ここまでの説明が長かったですが、ランダムフォレスト実行はたったの2行です。1行目がランダムフォレスト回帰のパラメータ設定。n_estimationというのはランダムフォレストに使う決定木の数です。
2行目がランダムフォレスト回帰モデル作成です。rfr1で1着になる回帰モデルが作られます。
#Random Forestを実行します。
rfr1 = RandomForestRegressor(n_estimators=min_loss*2+1, random_state=500)
#fitでモデルを作りますが、使うのは学習用のデータだけです。
rfr1.fit(X_train, Y_train) # 学習実行

同じく、3着以内、5着以内も回帰モデルを作って(rfr1,rfr3,rfr5)、予測したい馬情報から1,3,5着になる確率を算出します。
#作成した回帰モデルを元に予想
Y_pred_test1 = rfr1.predict(Y_multi3)
Y_pred_test3 = rfr3.predict(Y_multi3)
Y_pred_test5 = rfr5.predict(Y_multi3)
Y_pred_test_all = Y_pred_test1 * 0.5 + Y_pred_test3 * 0.35 + Y_pred_test5 * 0.15
#Y_pred_test_all
4.競馬新聞風に加工し出力


5.回帰モデル影響度の確認

Random Forestはその予測モデルに影響したパラメータを簡単に確認することが出来ます。
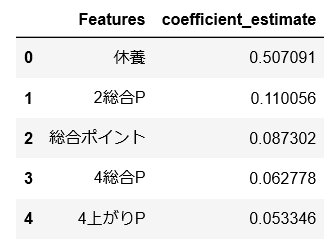
今回の予測モデルに影響したのは上のような順番です。何週明けか?というパラメータである休養が一番手というのは微妙な気がします。
4.競馬新聞風に加工し出力
5.回帰モデル影響度の確認
Random Forestはその予測モデルに影響したパラメータを簡単に確認することが出来ます。
今回の予測モデルに影響したのは上のような順番です。何週明けか?というパラメータである休養が一番手というのは微妙な気がします。
coeff_df = check_important_element(X_train , rfr1)
#df.sort_values(指定列",ascending=False)で降順に並び替え
#df.head(数値)で数値分のデータを抽出
sort_coeff_df = coeff_df.sort_values("coefficient_estimate",ascending=False)
#sort_coeff_df['Features']
# indexを振りなおします(上から順に1とする)
sort_coeff_df.reset_index(drop=True , inplace=True)
これで予測までできました。次はいよいよモデルを使って競馬予想にGoとその結果についてレポートしたいと思います。
お気に入りの記事を「いいね!」で応援しよう
[競馬] カテゴリの最新記事
-
Pyxelで競馬予想 日本ダービー May 31, 2026
-
2025 チャンピオンズカップ調教タイム一覧… Dec 7, 2025
-
Python で 競馬予想 実践第12回 2020年… Dec 26, 2020




【毎日開催】
15記事にいいね!で1ポイント
PR
Free Space
設定されていません。
Calendar
Comments
Mar , 2026
Feb , 2026
Feb , 2026
Freepage List
© Rakuten Group, Inc.