
-
1
Python で 競馬予想 第1回(データ取得編 scraping スクレイピング)
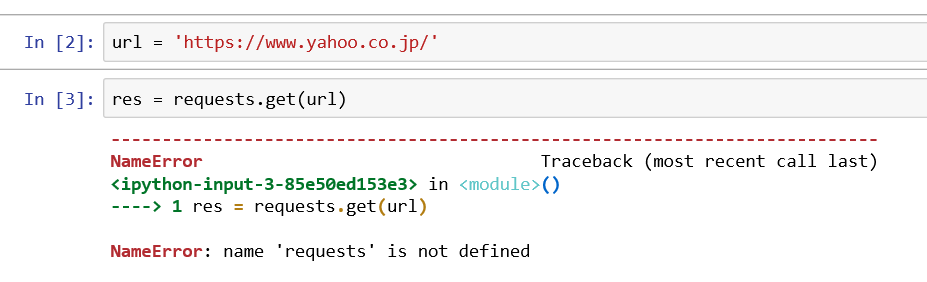
2年前に機械学習を使ってAI競馬予想を行っていましたが、ある時から私のLibreofficeからデータが取得できなくなり、頓挫してしまいました。純粋エクセルが欲しくなりましたが、何か良い方法を考えていました。私の行いたい手順としては下記の通りです。1.netkeibaからレース情報の取得(<-- ここが出来なくなった)2.自分で作った関数で重みづけ(<-- Libreoffice で可能)3.機械学習による競馬予想(<-- Anacondaで可能)という事で情報取得をPythonで動かしたいというのが今回の目的です。調べると、スクレイピングという言葉が出てきました。このページがヤフーをスクレイピングしていたのでとっつきやすいと思い手を付けました。たった2行で取得できるのか?と思い早速入力してみました。url = 'https://www.yahoo.co.jp/'res = requests.get(url)res.text[:500]上記のようにさっそくエラーがでました。もう少し読むと、requestsを入れるにはインストールやインポートが必要になります。詳しい説明は、「図解!Beautiful SoupでWEBスクレイピング徹底解説!」を参照ください。と書いてあります。やり方は、自分はAnaconda3を使っているので、promptを選択してから。conda install requestsを入力するようです。良し出来たと思い、先ほどのコマンド実行前に下記のコマンドを入力して#requests をインポートします。(Web scrapingには必須)import requests再度実行すると。resまではゲットできたようですが、表示させようとしたresponseで再度エラー、躓きました。どうやら、responsesもインストールかと思いましたが、resにinputしたので、resを出力しないと行けなかったです。yahooは表示できましたが、netkeibaは文字化けしているようです。再度ぐぐっていると。encodeが出来るとのこと。下記コマンドを実行です。res.encoding = res.apparent_encodingそうすると、表示してくれました。HTMLがそのまま出ているようです。とりあえずスクレイピングは出来た模様です。次回はこれをテキストに出力、取り込みたいフォーマットに変換するところをまで行いたいです。今日のプログラムです。簡単に取得できるものですね。#requests をインポートします。(Web scrapingには必須)import requests#urlを取得 url = 'https://race.netkeiba.com/race/shutuba_past.html?race_id=202004020211&rf=shutuba_submenu'#resに内容を代入res = requests.get(url)#resをencodeして文字化け回避res.encoding = res.apparent_encoding#画面出力print(res.text)文字化け対策には別のコマンドもあるようです。上記でダメな場合は使ってみても良いと思います。#BeautifulSoup は文字化け対策from bs4 import BeautifulSoupres.encoding = 'shift_jis'soup =BeautifulSoup(res.text , 'html.parser')
Jul 22, 2020
閲覧総数 2933
-
2

キッチン LED照明取り付け panasonic HH-LC122N
キッチンの照明が暗いとクレームをもらっていたので、PanasonicのLED照明 HH-LC122Nを購入しました😃光量が4500ルーメンで普通の蛍光灯より3倍💡ですこれは前の照明です。外したところです。付属品一式です。 アダプタを取り付けました 外枠をはめたところです。 取り付け完了~点灯式です😃横に長いのもありますが、明るさは段違いです🎵3倍は明るそうです🎵付けて良かったです。私が購入したLED照明。普通の蛍光灯を外して工事不要で取り付けられて、3倍明るいのでおすすめです😃【送料無料】 パナソニック HH-LC122N LEDキッチンベースライト HH-LC122N[HHLC122N]
Feb 20, 2016
閲覧総数 1368
-
-

- 何か手作りしてますか?
- カードケースを作る その4
- (2025-12-04 20:19:12)
-
-
-

- 妖怪ウォッチのグッズいろいろ
- 今日もよろしくお願いします。
- (2023-08-09 06:50:06)
-
-
-

- 寺社仏閣巡りましょ♪
- 萬年山 法輪寺 透かし御朱印 11月
- (2025-12-04 23:40:04)
-



