
PR

FlipHTML5
FlipHTML5のブログへようこそ、デジタルブック作成サビース──FlipHTML5についての最新情報を持続的に発信いたします。
カレンダー
カテゴリ
コメント新着
コメントに書き込みはありません。
キーワードサーチ
▼キーワード検索
2026.05.28

テーマ: PDF(4)
カテゴリ: PDF
PDFを扱う仕事や学習の場面で、ふと「この文字を検索できない…」「コピーもできない…」と戸惑った経験はありませんか?大量の資料やレポートをめくりながら必要な情報を探すのは、思った以上に時間と手間がかかります。特に急ぎの作業や重要な確認事項があるときには、ストレスも倍増です。
PDFは便利な形式である一方で、文字認識がうまく機能しないと、効率的に活用することが難しくなります。せっかく作った資料も、検索やコピーができなければ情報の取り出しに手間がかかり、作業全体のスピードが落ちてしまいます。
そこで本記事では、PDFで文字検索ができない原因を丁寧に解説し、すぐに実践できる対応策や便利なツールも紹介します。これを読めば、もう「ページを一枚ずつめくって探す」という無駄な作業から解放され、PDFをもっと効率的に活用できるようになります。
PDF内の文字が検索できないケースには、いくつかの代表的な理由があります。原因を理解しておくことで、適切な対策を選びやすくなります。
最も多く見られる原因のひとつが、紙の書類をスキャンしてPDF化した場合です。この場合、文書の文字は「画像」として取り込まれるため、テキストとして認識されず、検索やコピーができなくなります。外見上は通常の文書と変わらないため、多くの人は文字が見えるのに検索できないことに戸惑います。
PDFの作成者が資料の内容保護や編集制限のために、ファイルに「テキストの抽出禁止」や編集制限を設定している場合があります。この場合、PDF自体は開けるものの、内部の文字情報は存在しても検索やコピーができなくなります。意図的に制限されているため、通常の操作では文字を取り出すことができません。
前述の原因を除外しても検索ができない場合は、PDFに使用されているフォントに問題があることがあります。作成時にフォント情報が正しく埋め込まれていなかったり、特殊なフォントを使用していたりすると、見た目は正常でも検索やコピーを行うと文字化けしたり、検索結果に反映されないことがあります。
Illustratorなどで文字をアウトライン化してPDF化した場合、文字は線や図形として保存されるため、テキストとして認識されません。そのため、検索やコピーはできません。また、多言語を含むPDFでは、文字コードが正しく埋め込まれていないと、日本語やその他の言語でも検索が正しく機能しないことがあります。
前章で紹介した原因を理解したうえで、自分のPDFがどの問題に該当するか確認できたら、次は具体的な解決策を見ていきましょう。ここでは、原因ごとに効果的な対応方法をわかりやすく解説します。
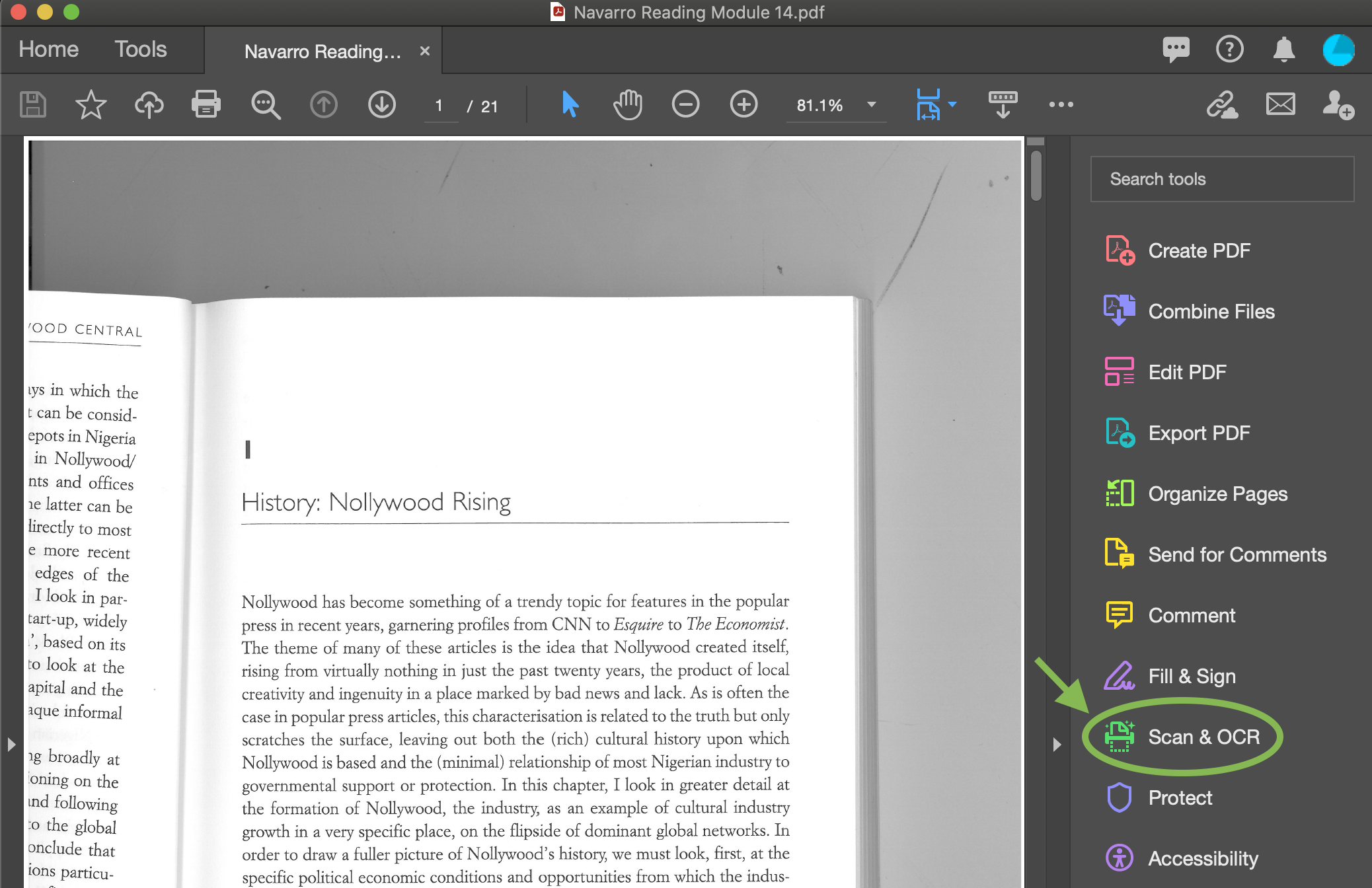
OCRを利用すれば、編集や検索が可能なテキストとしてPDFに追加できます。多くのPDF編集ソフトにはOCR機能が搭載されており、目的や使いやすさに応じて選択可能です。例えばAdobe Acrobatでは以下の手順でOCR処理ができます:
1.Acrobatを起動し、対象のPDFを開きます。
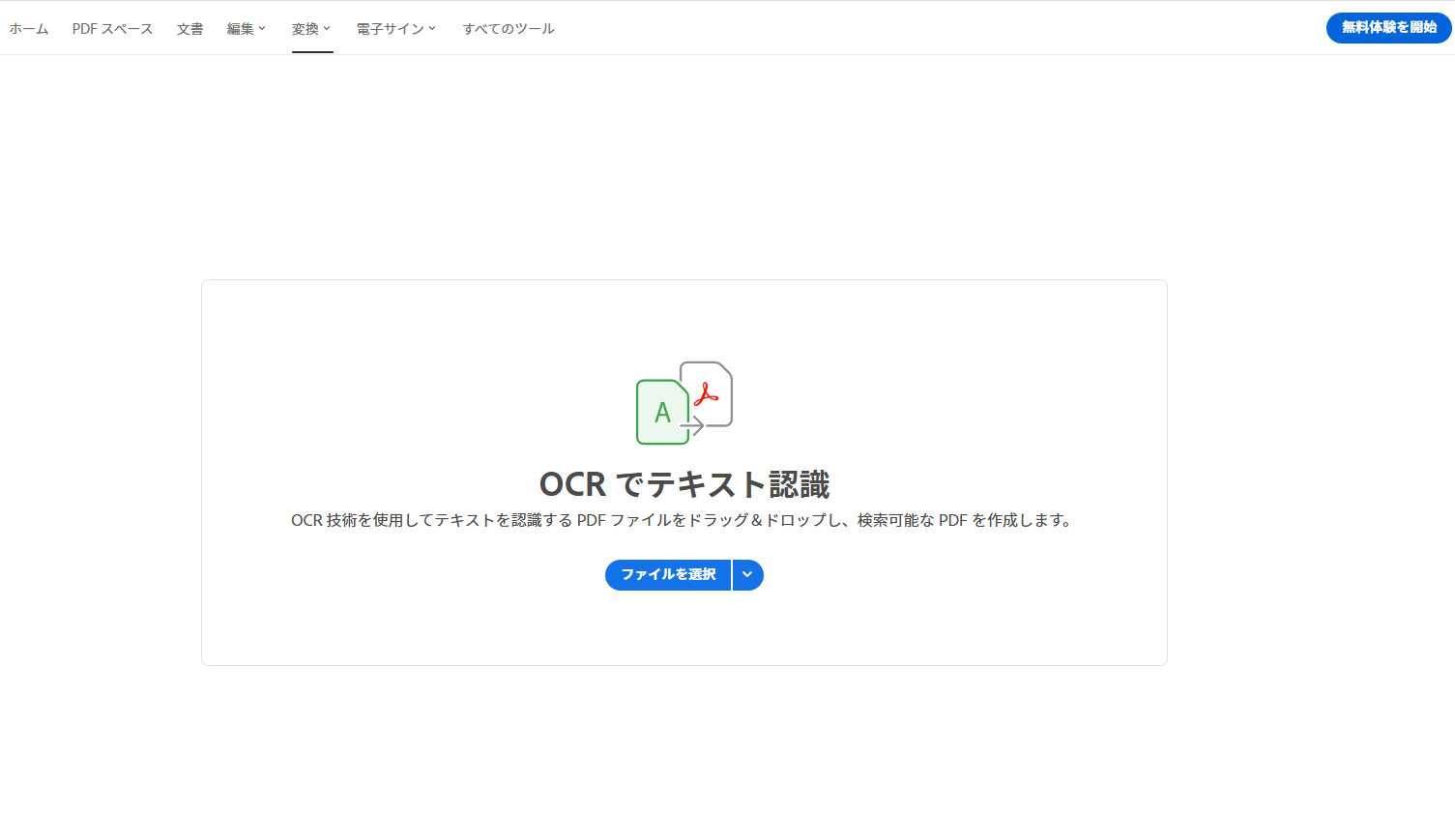
2.右側パネルの「ツール」から「PDFを編集」を選択すると、自動で文字認識が実行されます。
3.または、Adobeのオンライン OCRサービス を利用する方法もあります。オンライン上で認識する言語を指定し、処理後にテキスト化されたPDFをダウンロードすることが可能です。
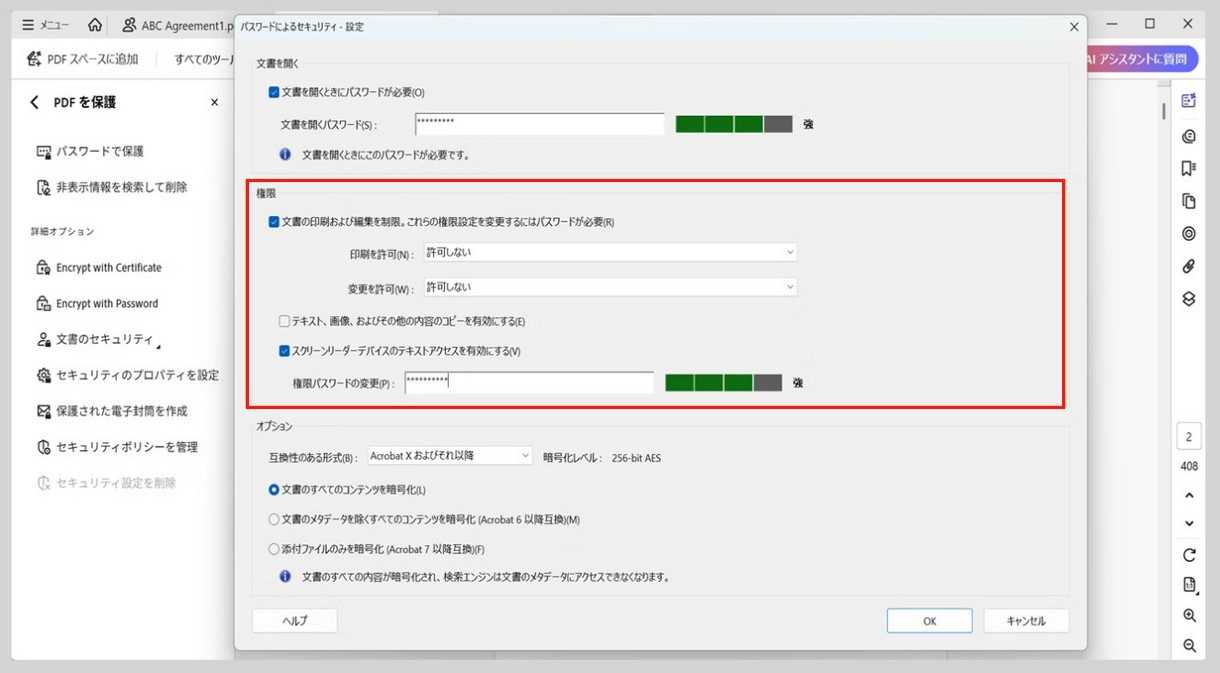
PDFに編集やコピーの制限が設定されている場合は、まず正しい権限を取得して制限を解除する必要があります。作成者や管理者に連絡してパスワードや利用権限を入手すれば、検索やコピーが可能になります。Adobe Acrobatを使った具体的な解除手順は次の通りです:
1.Acrobatを起動し、対象のPDFを開きます。取得したパスワードを入力してアクセスを許可します。
2.画面上部の「ツール」から「保護」を選び、「暗号化」→「セキュリティを削除」の順に操作します。
3.変更を保存してPDFを再度開くと、文字の検索やコピーが自由にできる状態になります。
PDF内の文字が検索できない原因として、フォントが正しく埋め込まれていないことがあります。この場合、状況に応じて2つの方法で対処できます。
元の文書が手元にある場合
元の文書がない場合
Adobe Acrobatを起動し、対象のPDFを開きます。 「プリフライト」機能を利用してフォント情報の埋め込み状況を確認します。 不足しているフォントを埋め込む設定を適用し、PDFを保存します。
なお、文字コードが取得できないPDFは、実質的に画像PDFと同じ扱いになります。その場合はOCR処理を行うことで、文字検索を可能にすることができます。
文字がアウトライン化されたPDFの場合の基本的な対策は、元のデータをアウトライン化する前の状態に戻してPDFを再作成することです。具体的な操作手順は、フォント埋め込みの対処法とほぼ同じなので、重複した解説は省略します。
多言語を扱うPDFでは、使用するフォントに注意することも重要です。日本語なら「MS ゴシック」や「メイリオ」、英語なら「Arial」や「Times New Roman」などの標準的なフォントを使用すると安全です。特殊なフォントや未埋め込みフォントは、検索可能な標準フォントに置き換えることで、文字情報として認識され、検索やコピーが可能なPDFを作ることができます。
本記事では、それぞれの原因に対して、具体的な解決方法や操作手順をわかりやすく解説しました。PDFの文字検索がうまくいかないときの参考として役立てていただければ幸いです。
PDFは便利な形式である一方で、文字認識がうまく機能しないと、効率的に活用することが難しくなります。せっかく作った資料も、検索やコピーができなければ情報の取り出しに手間がかかり、作業全体のスピードが落ちてしまいます。
そこで本記事では、PDFで文字検索ができない原因を丁寧に解説し、すぐに実践できる対応策や便利なツールも紹介します。これを読めば、もう「ページを一枚ずつめくって探す」という無駄な作業から解放され、PDFをもっと効率的に活用できるようになります。
PDFで文字を検索できない原因は?
PDF内の文字が検索できないケースには、いくつかの代表的な理由があります。原因を理解しておくことで、適切な対策を選びやすくなります。
1:PDFが画像として保存されている
最も多く見られる原因のひとつが、紙の書類をスキャンしてPDF化した場合です。この場合、文書の文字は「画像」として取り込まれるため、テキストとして認識されず、検索やコピーができなくなります。外見上は通常の文書と変わらないため、多くの人は文字が見えるのに検索できないことに戸惑います。
2:暗号化やセキュリティ設定による制限
PDFの作成者が資料の内容保護や編集制限のために、ファイルに「テキストの抽出禁止」や編集制限を設定している場合があります。この場合、PDF自体は開けるものの、内部の文字情報は存在しても検索やコピーができなくなります。意図的に制限されているため、通常の操作では文字を取り出すことができません。
3:フォント情報が埋め込まれていない
前述の原因を除外しても検索ができない場合は、PDFに使用されているフォントに問題があることがあります。作成時にフォント情報が正しく埋め込まれていなかったり、特殊なフォントを使用していたりすると、見た目は正常でも検索やコピーを行うと文字化けしたり、検索結果に反映されないことがあります。
4:文字がアウトライン化されている
Illustratorなどで文字をアウトライン化してPDF化した場合、文字は線や図形として保存されるため、テキストとして認識されません。そのため、検索やコピーはできません。また、多言語を含むPDFでは、文字コードが正しく埋め込まれていないと、日本語やその他の言語でも検索が正しく機能しないことがあります。
PDFの文字検索ができない場合の対処法
前章で紹介した原因を理解したうえで、自分のPDFがどの問題に該当するか確認できたら、次は具体的な解決策を見ていきましょう。ここでは、原因ごとに効果的な対応方法をわかりやすく解説します。
1:PDFが画像化されている場合
OCRを利用すれば、編集や検索が可能なテキストとしてPDFに追加できます。多くのPDF編集ソフトにはOCR機能が搭載されており、目的や使いやすさに応じて選択可能です。例えばAdobe Acrobatでは以下の手順でOCR処理ができます:
1.Acrobatを起動し、対象のPDFを開きます。
2.右側パネルの「ツール」から「PDFを編集」を選択すると、自動で文字認識が実行されます。
3.または、Adobeのオンライン OCRサービス を利用する方法もあります。オンライン上で認識する言語を指定し、処理後にテキスト化されたPDFをダウンロードすることが可能です。
2:暗号化制限の対処法
PDFに編集やコピーの制限が設定されている場合は、まず正しい権限を取得して制限を解除する必要があります。作成者や管理者に連絡してパスワードや利用権限を入手すれば、検索やコピーが可能になります。Adobe Acrobatを使った具体的な解除手順は次の通りです:
1.Acrobatを起動し、対象のPDFを開きます。取得したパスワードを入力してアクセスを許可します。
2.画面上部の「ツール」から「保護」を選び、「暗号化」→「セキュリティを削除」の順に操作します。
3.変更を保存してPDFを再度開くと、文字の検索やコピーが自由にできる状態になります。
3:フォント情報が正しく埋め込まれていない場合の対処法
PDF内の文字が検索できない原因として、フォントが正しく埋め込まれていないことがあります。この場合、状況に応じて2つの方法で対処できます。
元の文書が手元にある場合
元の文書がない場合
Adobe Acrobatを起動し、対象のPDFを開きます。 「プリフライト」機能を利用してフォント情報の埋め込み状況を確認します。 不足しているフォントを埋め込む設定を適用し、PDFを保存します。
なお、文字コードが取得できないPDFは、実質的に画像PDFと同じ扱いになります。その場合はOCR処理を行うことで、文字検索を可能にすることができます。
4:文字がアウトライン化されている場合の対策
文字がアウトライン化されたPDFの場合の基本的な対策は、元のデータをアウトライン化する前の状態に戻してPDFを再作成することです。具体的な操作手順は、フォント埋め込みの対処法とほぼ同じなので、重複した解説は省略します。
多言語を扱うPDFでは、使用するフォントに注意することも重要です。日本語なら「MS ゴシック」や「メイリオ」、英語なら「Arial」や「Times New Roman」などの標準的なフォントを使用すると安全です。特殊なフォントや未埋め込みフォントは、検索可能な標準フォントに置き換えることで、文字情報として認識され、検索やコピーが可能なPDFを作ることができます。
まとめに
本記事では、それぞれの原因に対して、具体的な解決方法や操作手順をわかりやすく解説しました。PDFの文字検索がうまくいかないときの参考として役立てていただければ幸いです。
お気に入りの記事を「いいね!」で応援しよう
[PDF] カテゴリの最新記事
-
魅力的なインタラクティブPDF作成法!Flip… 2026.05.29




【毎日開催】
15記事にいいね!で1ポイント
© Rakuten Group, Inc.