



私はしつこく Xbench の無料版 (V2.9) を使っていますが、無料版で一番残念なのが QA チェックの CamelCase Mismatch と ALLUPPER CASE Mismatch を有効にできない ことです。有料版の V3 以降では有効にできるらしいですが、V2.9 では DISABLED と表示されるだけで、これを有効にするオプションがありません。このチェックは、大文字の単語 (WAF や HTTP など) とキャメルケースの単語 (GetStatus や SetTranslationMemory など) が原文と訳文で一致しているかを確認してくれるものだと思います。英単語は「必ず原文からコピーする」というルールを徹底していれば間違うはずはないのですが、それでも抜けてしまったりすることがあるので、こうしたチェックはどうしても必要になります。
そこで、今回はこのチェックを Trados の QA Checker を使って再現することに挑戦します。日英翻訳と英日翻訳の両方向について再現する方法を考えてみました。で、考えてみたので今回はその方法を紹介しますが、実はあまりうまく機能しないケースがあります。どうしても誤検出が増えてしまいます。もし、改善案などありましたら、教えて頂けると嬉しいです。
QA Checker の正規表現
QA Checker の詳細については、以前の記事「 正規表現なしで、検証機能を使う 」を参照してください。この記事でも書いているとおり、QA Checker の設定はファイルにエクスポートして保存しておくことができます。同じように、正規表現にも [アクション]の中に [アイテムのエクスポート]と [アイテムのインポート]が用意されています。この画面のエクスポートは正規表現のみをエクスポートします。また便利な点として、この画面のインポートは削除をせず、追加と更新だけをしてくれます。つまり、既存のアイテムはそのまま残り、新しいアイテムは追加され、そして更新されたアイテムは更新されます。QA Checker 全体のプロファイルからインポートをすると、総入れ替えになるので古いアイテムは削除されます。

日本語 -> 英語の場合
日英翻訳の場合は、大文字やキャメルケースなど関係なく単純に「英単語を抜き出す」と考えればよいので簡単です。
英単語
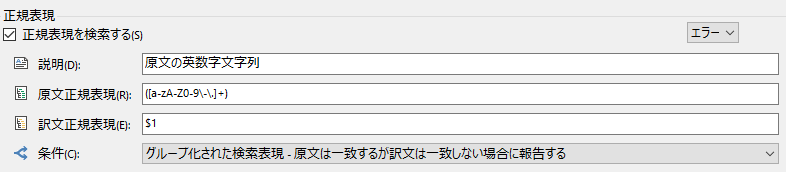
原文:
([a-zA-Z0-9\-\.]+)
訳文:
$1
私は、数字、ハイフン、ピリオドも含めて上記のように設定しています。これで、英語の小文字、大文字、数字、ハイフン、ピリオドで構成される単語を原文から抽出できます。訳文の
$1
は「原文の (
)
内とまったく同じ内容」ということを意味します。原文から CATが抽出されたら、訳文でも CATを探します。全角の英単語
ここまでは簡単ですが、日英翻訳で問題になるのは全角です。原文が日本語の場合、英数字が全角で書かれていることがあります。上記の式は全角にはマッチしません。そこで、私は以下の式も追加しています。
原文:
([a-zA-Z0-9]+)
訳文:
$1
これで全角の英数字も抽出できます。抽出はできますが、訳文の
$1
はうまく機能しません。訳文の英語では英数字は半角にするので、原文の全角 CATを訳文で正しく半角 CATに変換していてもすべてエラーとして検出されます。安全のためにこの式を使ってはいますが、誤検出が多くなります。英語 -> 日本語の場合
原文が英語の場合は、当然ながらすべてが英単語なので上記のように単純にはいきません。大文字とキャメルケースを指定する必要があります。
大文字で構成される単語
大文字は比較的簡単です。私は、ハイフンも含めて以下のように指定しています。「大文字かハイフンが 2 回以上連続する」という意味です。
原文:
([A-Z\-]{2,})
1 文字の英数字
上記の条件は「2 回以上」という指定なので server Aなどにはマッチしません。そこで、英数字 1 文字だけを抽出する式も追加します。
原文:
(\b[\w\d]\b)
\b
は単語の始まりまたは終わりを示します。 \w
は英文字、 \d
は数字です。この式は「単語の始まりがあって、英数字が 1 つあって、単語の終わりになる」という条件になります。私は数字も含めていますが、数字は数字チェックの機能が別にあるのでここに含めなくても OK です。キャメルケース
いよいよキャメルケースです。少し複雑になります。私は、考えていたら複雑すぎてよくわからなくなったので「小文字始まり」と「大文字始まり」の 2 つに分けることにしました。
・小文字始まりキャメルケース ( getTableStatusなど)
原文:
(\b[a-z]+\-*[A-Z]+[a-z\-]*)
\b
は単語の始まりなので「小文字で始まって、大文字が 1 回以上登場して、また小文字がある」という条件です。念のため、ハイフンもありということにしています。・大文字始まりキャメルケース ( GetTableStatusなど)
原文:
(\b[A-Z]+\-*[a-z]+\-*[A-Z]+[\w\d\-]*)
こちらは「大文字で始まって、小文字が登場して、また大文字が登場する」という条件です。「大文字で始まって、小文字が登場する」だけでは、先頭を大文字にする通常の文すべてに一致してしまうので、2 度目の大文字が必要です。
文頭以外の大文字始まり( This is a Windows serverなど)
大文字の連続やキャメルケースではなく、単に文の中で大文字で始まる単語もチェックしたい場合があります。ただ、英語の文は通常大文字で始まるのでこれがなかなか大変です。文頭の大文字は抽出しないようにする必要があります。
原文:
^.+([A-Z]+\-*[a-z0-9]+\-*\b)
先頭の
^
は正規表現で「文頭」を意味します。この式は「文頭から何か文字があった後に大文字が登場する」という条件になります。すみません、これも考えてはみたものの、かなり誤検出が多くなります。文頭以外に大文字が登場する文は実はかなりあります。たとえば、見出しでヘッドライン スタイルが使われている、文全体が丸括弧で囲まれている、 Note:のようなコロンの後に文が書かれている、などです。こうしたケースを除外しようとするとなかなか面倒です。原文と訳文を入れ替えてチェックする
さて、いろいろなチェックをしても、コマンドやプロパティ名などが満載の IT 系文書のときは英単語の記述にどうしても不安が残ります。そんなときは、原文と訳文を入れ替えてチェックをしてみます。これはかなり有効です。
Trados の正規表現の一部は「原文から訳文」方向のチェックしか行いません。正規表現の条件をよく見てみると「グループ化された検索表現」は以下の 2 つしか条件がありません。

訳文に
$1
などと記述するケースが「グループ化された検索表現」にあたりますが、この場合は必ず原文を先に検索する必要があります。それ以外の場合は「訳文は一致するが〜」や「訳文チェックのみ」が可能ですが、 $1
などを使う場合はそれができません (この画面上ではどの条件も選択できますが、期待どおりの動作になりません)。このため、通常は「訳文に余計な英単語が入っている」というケースは検出できませんが、原文と訳文を入れ替えてチェックをすれば検出できます。また、上記のとおり、英語 -> 日本語のチェックはかなり複雑で False positive も False negative も多くなります。これを、日本語 -> 英語に変えるとチェックが単純になり、エラーも見つかりやすくなります。英語 -> 日本語の場合、 setや getなどの小文字始まりのプログラム コマンドは普通の英語と区別がつかないので検出できませんが、訳出後に日本語 -> 英語に変えて英単語のチェックをすれば検出できます。このチェックは、私の経験上、けっこう有効に機能します。
今回は以上です。Trados で原文と訳文を入れ替える方法については、次回とりあげたいと思います。正規表現をいろいろ考えていると、素直に新しい Xbench を購入した方がいいんじゃないかという考えが頭をよぎらないこともないですが、とりあえず、もう少し頑張ってみます。正規表現はよくわからないことが多いので、アドバイス頂けるととても嬉しいです。
Tweet