

この広告は30日以上更新がないブログに表示されております。
新規記事の投稿を行うことで、非表示にすることが可能です。
広告
posted by fanblog
2018年12月27日
最近悩むこと
リポジトリのxmlでは、作成者に言語属性を付けます。そこでこの言語は何語だろう、と引っかかることがしばしばあります。
ロシア語とか(キリル文字の場合、たまにモンゴル語ということもありますが)ハングルとか中国語の簡体字とかだとわかりやすくていいのですが、ヨーロッパ語系は時々判断に困ります。そしてさらに困るのが漢字です。
李白、杜甫、王安石、李清照(女流詩人)、陸游、屈原、この辺って何語なんでしょうね^^
現代でも日本で活躍する中国や韓国の研究者たちは、どっちで扱うべきなのだろう。
気にしだすととまらないくろすけでした^^
ロシア語とか(キリル文字の場合、たまにモンゴル語ということもありますが)ハングルとか中国語の簡体字とかだとわかりやすくていいのですが、ヨーロッパ語系は時々判断に困ります。そしてさらに困るのが漢字です。
李白、杜甫、王安石、李清照(女流詩人)、陸游、屈原、この辺って何語なんでしょうね^^
現代でも日本で活躍する中国や韓国の研究者たちは、どっちで扱うべきなのだろう。
気にしだすととまらないくろすけでした^^
【このカテゴリーの最新記事】
- no image
- no image
2018年12月22日
JPCOARの作成者について
ふと思ったのですが、JPCOARの作成者の表記って、別に本文言語に合わせなくてもいいんですね。
junii2だと本文言語に表記を合わせることを推奨していましたが、JPCOARのcreatorにはそのような注意書きがない。ということは、英語論文であっても日本語表記を優先してもいいのかな。そもそもcreatorNameが0-N(各言語は1回まで)だし、別に困らない、ということか。
むしろ作成者を書誌の著者標目のように統一したほうが検索性も上がるでしょうし、場合によってはメンテナンス性や新規作成も楽になることがあるかもしれませんし、そういう運用を考えていったほうがいいのかな?
junii2だと本文言語に表記を合わせることを推奨していましたが、JPCOARのcreatorにはそのような注意書きがない。ということは、英語論文であっても日本語表記を優先してもいいのかな。そもそもcreatorNameが0-N(各言語は1回まで)だし、別に困らない、ということか。
むしろ作成者を書誌の著者標目のように統一したほうが検索性も上がるでしょうし、場合によってはメンテナンス性や新規作成も楽になることがあるかもしれませんし、そういう運用を考えていったほうがいいのかな?
2018年09月03日
ハゲタカジャーナルにご用心
かなり長い間放置してしまいましたが、今日のネットニュースを見ていたらなかなか由々しき事態になっているようで。
粗悪学術誌:論文投稿、日本5000本超 業績水増しか - 毎日新聞
正直、日本がここまでとは思わなかったですね。まともなアカデミズムがなかなか育たないのもうなずける話です。
OA2020を受けてオープンアクセスが注目される図書館界。これからは論文をどうやって入手するか、だけでなく、どこから入手するか、というのも大事な学生指導になりそうです。
粗悪学術誌:論文投稿、日本5000本超 業績水増しか - 毎日新聞
正直、日本がここまでとは思わなかったですね。まともなアカデミズムがなかなか育たないのもうなずける話です。
OA2020を受けてオープンアクセスが注目される図書館界。これからは論文をどうやって入手するか、だけでなく、どこから入手するか、というのも大事な学生指導になりそうです。
2018年05月12日
関数解説 SUBTOTAL関数
「=Subtotal(集計方法,対象1,対象2......)」
「リストまたはデータベースの集計値を返します。」
しばらく間隔があいてしまいましたが、今回取り上げるのは、統計作業に便利なSUBTOTAL関数です。
一見難しそうに見えるこの関数ですが、全然そんなことはなく、使いやすく強力な統計のお友達です。
今回は、下のような学部ごとの図書費の合計と、その総計を出すような表を作ってみようと思います。図書館業務で必ず訪れる統計の季節には、こんな感じの表は珍しくないかと思います。
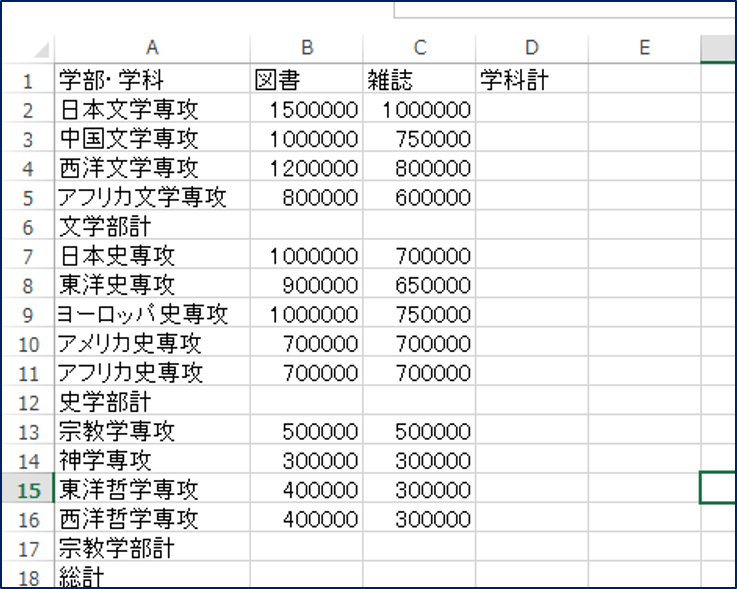
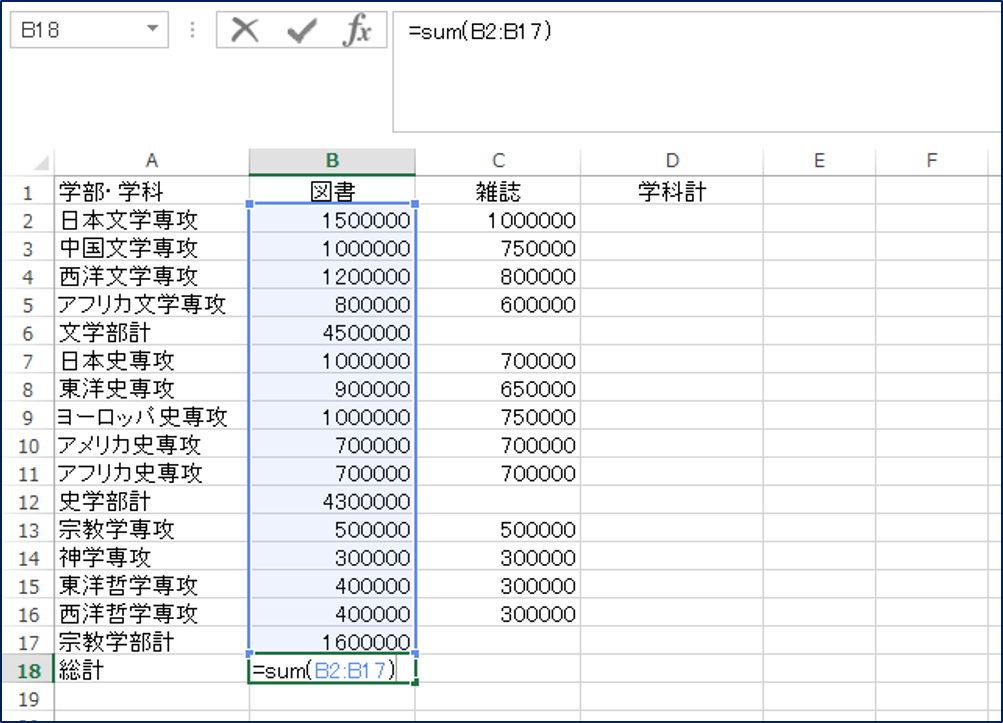
単純に考えたら、下のようにSUM関数で処理をするのが多いかなと思います。
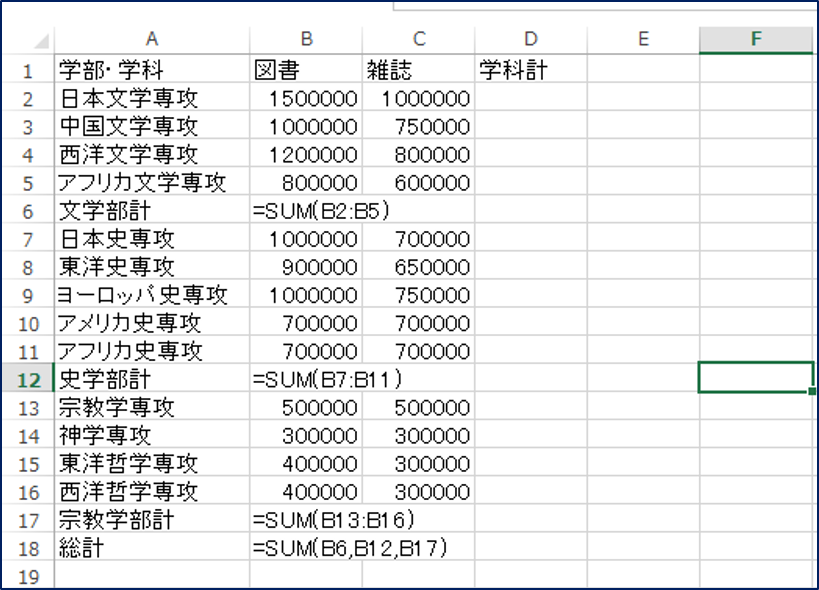
SUM関数の場合、特に、一番下の総計の部分が面倒ですよね。学部の合計が計算されているセルを指定してあげないといけないのですが、指定を間違えることもしばしばありますし、そもそも大きくなったり、入り組んだりすると、どこに学部の合計があるかわかりづらいものもあります。そもそもそんな表を作るな、というのが答えの一つなのですが、それでも作らなければいけない時に力を発揮するのが、このSUBTOTAL関数です。
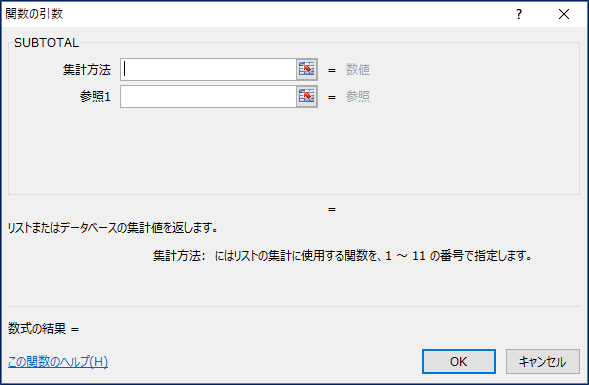
SUBTOTAL関数の入力画面を呼び出すと、まず「集計方法」に「?」となってしまう方も多いかもしれません。説明も「リストまたはデータベースの集計値を返します。」とそっけないものです。
実はSUBTOTALは合計だけでなく、平均やカウント、最大、最小などを算出することもできるのです。なので、まずは何をしたいのか、を宣言する必要があります。
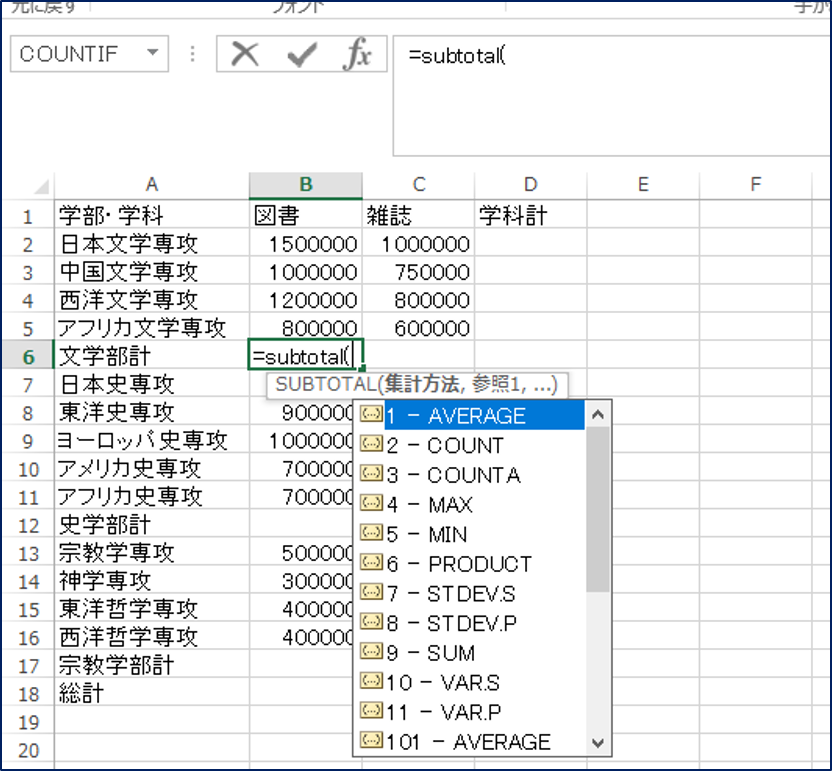
計算方法は、以下の1〜11の11通りです。101〜111もありますが、ひとまずは1〜11で十分でしょう。その差異は今回は割愛させていただきます。これを数字で指定します。見慣れない関数も混ざっていますが、ひとまず、今回は合計ですので、「9」を使います。さっそく先程の表に使ってみましょう。
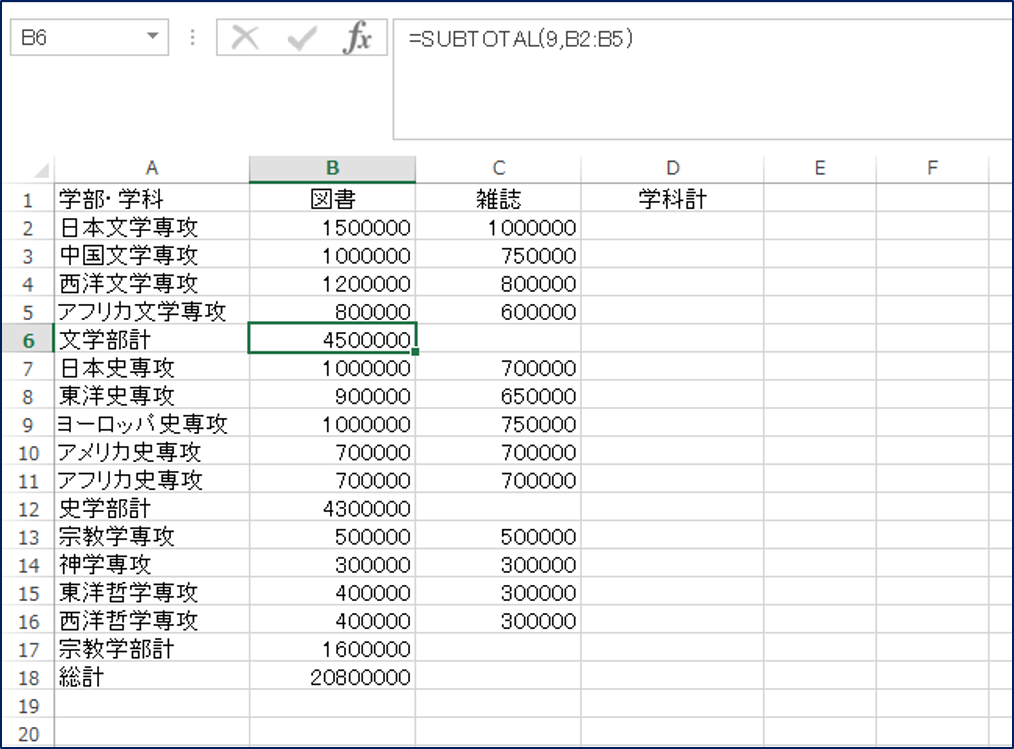
これだけだと、ただのSUM関数と変わりませんね。ひと手間増えたSUM関数といった感じになってしまいますが、SUBTOTAL関数が威力を発揮するのはここからで、説明にない特徴として、「SUBTOTAL関数はSUBTOTAL関数を無視する」という特徴があります。さっそく下の図を見てみましょう。
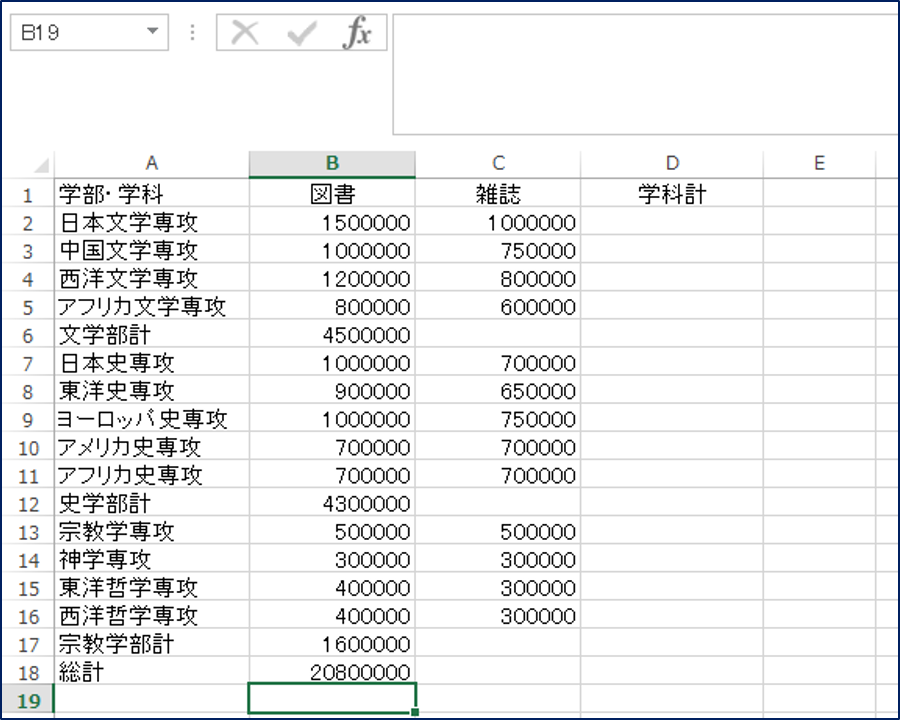
このような形でSUM関数を使った場合、学部計欄のSUM関数を再度計算してしまい、結果が本来の2倍になってしまいます。ですが、SUBTOTAL関数の場合は、
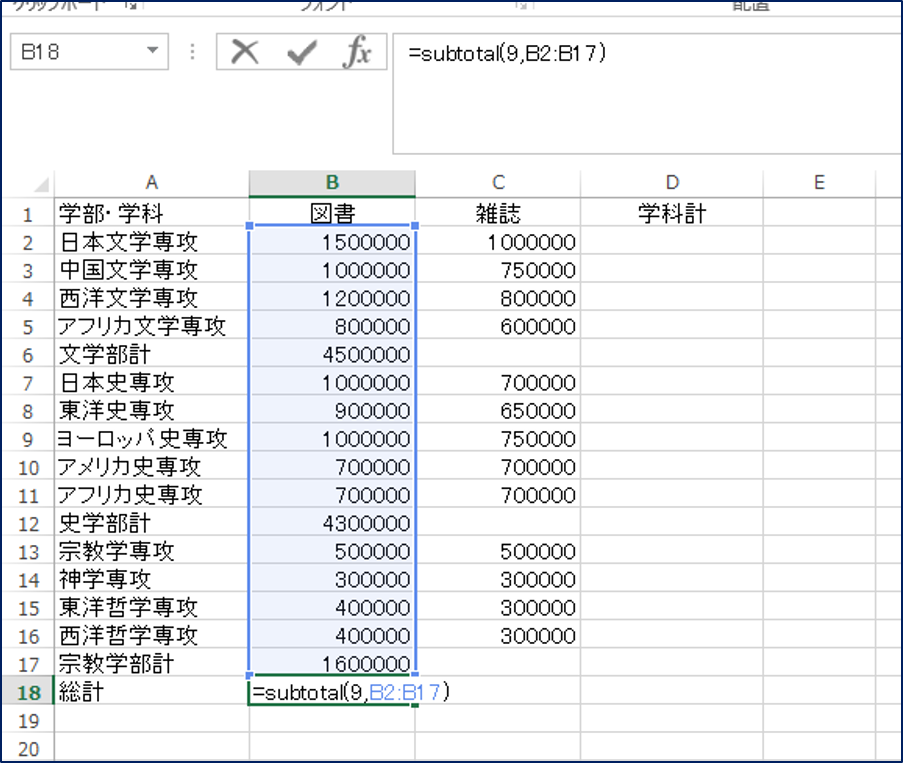
すべての学部計をSUBTOTAL関数で計算したうえで、総計にSUBTOTAL関数を使用した場合、
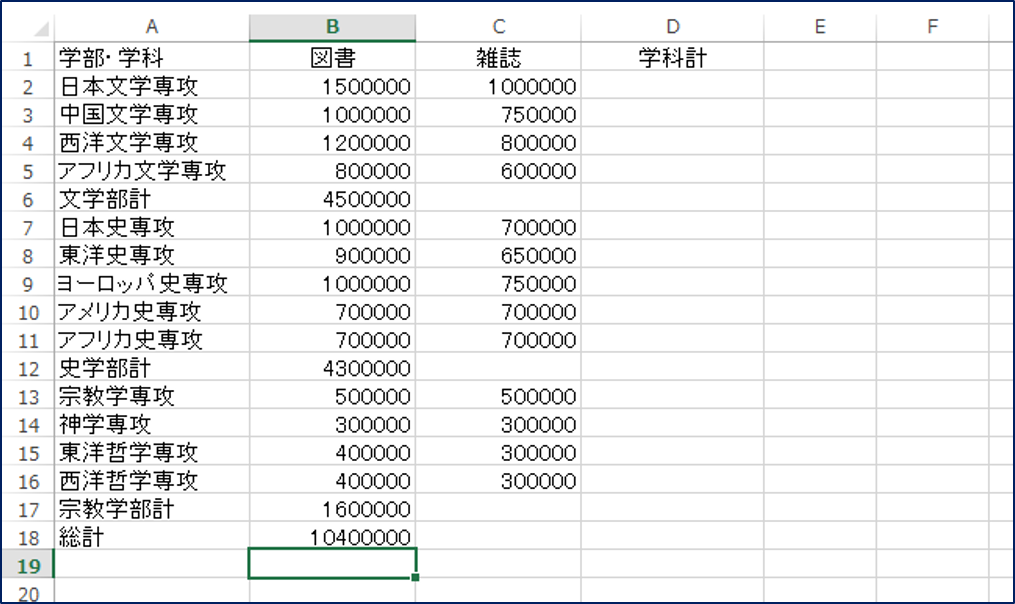
このように、学部計欄のSUBTOTAL関数を無視して、計算結果を返してくれます。つまり、小計が入り組んでいるような構造の表であっても、簡単に総計を算出することができるのです。また、このような使い方ができるということは、メンテナンス性も上がります。是非SUBTOTAL関数を使いこなして、厄介な業務を短縮させてください。
「リストまたはデータベースの集計値を返します。」
しばらく間隔があいてしまいましたが、今回取り上げるのは、統計作業に便利なSUBTOTAL関数です。
一見難しそうに見えるこの関数ですが、全然そんなことはなく、使いやすく強力な統計のお友達です。
今回は、下のような学部ごとの図書費の合計と、その総計を出すような表を作ってみようと思います。図書館業務で必ず訪れる統計の季節には、こんな感じの表は珍しくないかと思います。
単純に考えたら、下のようにSUM関数で処理をするのが多いかなと思います。
SUM関数の場合、特に、一番下の総計の部分が面倒ですよね。学部の合計が計算されているセルを指定してあげないといけないのですが、指定を間違えることもしばしばありますし、そもそも大きくなったり、入り組んだりすると、どこに学部の合計があるかわかりづらいものもあります。そもそもそんな表を作るな、というのが答えの一つなのですが、それでも作らなければいけない時に力を発揮するのが、このSUBTOTAL関数です。
SUBTOTAL関数の入力画面を呼び出すと、まず「集計方法」に「?」となってしまう方も多いかもしれません。説明も「リストまたはデータベースの集計値を返します。」とそっけないものです。
実はSUBTOTALは合計だけでなく、平均やカウント、最大、最小などを算出することもできるのです。なので、まずは何をしたいのか、を宣言する必要があります。
計算方法は、以下の1〜11の11通りです。101〜111もありますが、ひとまずは1〜11で十分でしょう。その差異は今回は割愛させていただきます。これを数字で指定します。見慣れない関数も混ざっていますが、ひとまず、今回は合計ですので、「9」を使います。さっそく先程の表に使ってみましょう。
これだけだと、ただのSUM関数と変わりませんね。ひと手間増えたSUM関数といった感じになってしまいますが、SUBTOTAL関数が威力を発揮するのはここからで、説明にない特徴として、「SUBTOTAL関数はSUBTOTAL関数を無視する」という特徴があります。さっそく下の図を見てみましょう。
このような形でSUM関数を使った場合、学部計欄のSUM関数を再度計算してしまい、結果が本来の2倍になってしまいます。ですが、SUBTOTAL関数の場合は、
すべての学部計をSUBTOTAL関数で計算したうえで、総計にSUBTOTAL関数を使用した場合、
このように、学部計欄のSUBTOTAL関数を無視して、計算結果を返してくれます。つまり、小計が入り組んでいるような構造の表であっても、簡単に総計を算出することができるのです。また、このような使い方ができるということは、メンテナンス性も上がります。是非SUBTOTAL関数を使いこなして、厄介な業務を短縮させてください。
2018年03月04日
EXCELでISBNの変換
これまで何気なくやっていたISBNによる所蔵の重複チェックですが、少し古い資料の場合、ISBN10で書誌を作られている場合があります。そういう資料を最近購入した場合、ISBN13が付与されなおしています。これは出版、及び図書館業界では共通認識で、図書館システムなんかにも、自動で変換してチェックをしてくれたりします。
ISBNが何?って人はとりあえず こちら(TRC) や こちら(Wikipedia) をご覧いただければと思いますが、簡単に言うと、本固有の記号ですね。車とか家電とかパソコンとかの型式番号に近いものです。ただ、国際的に振出のルールが決まっていて、それが2007年を境に10桁から13桁に変更されたのですね。なので、2007年以前に出版されたものが、2007年以降に重版やらなんやらで販売される場合、10桁から13桁に書き換えられています。
で、問題なのは、そういう資料は割と高い確率で書誌データにISBN10が採用されているんですね。なので、あとから購入したものと同じ本なのにISBNが違う、という事態が発生します。図書館システムならまず同じものとして扱ってくれますが、それは業界ルールだからであって、世間一般のルールではありません(笑)EXCELにとってはISBN10とISBN13は、完全に別の値なのです。なので、EXCEL上で比較する場合、どちらかの形式に変換して統一しないといけないのですが、それがまあ、ちょっと面倒くさいなあ、という場面に最近出会ってしまったのでした。
10桁から13桁の変換は基本的には頭に「978」をつければ完成なので問題ないのですが、面倒なのはチェックデジットの計算が変わってしまうことです。計算方法自体は単純で特に問題ありませんが、それをEXCEL上でどうやって関数で表現するか、となるとなかなかめんどくさいですね^^
VBAなら割と簡単で、
Private Sub ISBN
dim x as long,z as long
dim cd as long 'チェックデジットを格納する変数
dim y(12) as long ’ISBNの1桁目から12桁目までの数字を格納する変数
dim isbn10 as string,isbn13 as string 'ISBN
isbn10 = cells(1,1) 'セルA1にISBN10が入力されているとして
isbn13 = "978" & isbn10 'ISBN10の頭に「978」を付けてISBN13の形にする
for x = 1 to 12 ’For NextでISBNの各桁の数字を獲得。13桁目はチェックデジットなので不要。
y(x) = mid(isbn13,x,1)
next x
'奇数桁の和*1と偶数桁の和*3の総和を計算する。
z = (y(1)+y(3)+y(5)+y(7)+y(9)+y(11))+(y(2)+y(4)+y(6)+y(8)+y(10)+y(12))*3
z = z mod 10 '総和を10で割った余りを計算する。
cd = 10-z '10から余りを引くとチェックデジットになる。
isbn13 = mid(isbn13,1,12) & cd '初めに作ったISBN13の12桁目までと、チェックデジットを合わせる。
End Sub
書き方はいくつかありますが、おおざっぱにはこんなところです。
これを関数で表現するのは、意外にめんどくさくて、mid関数を12個使うのか、まあ、978は固定なのでそこを除いても9個使うのか、となるとあんまりスマートじゃないなあ、メンテも面倒そうだなあ、使いまわしが面倒そうだなあ、となるわけです。いくつか案はあるけど、どれも「スマートだぜ」とは言えない状況です。
大したことではないけど、ちょっとした悩みでした。
ISBNが何?って人はとりあえず こちら(TRC) や こちら(Wikipedia) をご覧いただければと思いますが、簡単に言うと、本固有の記号ですね。車とか家電とかパソコンとかの型式番号に近いものです。ただ、国際的に振出のルールが決まっていて、それが2007年を境に10桁から13桁に変更されたのですね。なので、2007年以前に出版されたものが、2007年以降に重版やらなんやらで販売される場合、10桁から13桁に書き換えられています。
で、問題なのは、そういう資料は割と高い確率で書誌データにISBN10が採用されているんですね。なので、あとから購入したものと同じ本なのにISBNが違う、という事態が発生します。図書館システムならまず同じものとして扱ってくれますが、それは業界ルールだからであって、世間一般のルールではありません(笑)EXCELにとってはISBN10とISBN13は、完全に別の値なのです。なので、EXCEL上で比較する場合、どちらかの形式に変換して統一しないといけないのですが、それがまあ、ちょっと面倒くさいなあ、という場面に最近出会ってしまったのでした。
10桁から13桁の変換は基本的には頭に「978」をつければ完成なので問題ないのですが、面倒なのはチェックデジットの計算が変わってしまうことです。計算方法自体は単純で特に問題ありませんが、それをEXCEL上でどうやって関数で表現するか、となるとなかなかめんどくさいですね^^
VBAなら割と簡単で、
Private Sub ISBN
dim x as long,z as long
dim cd as long 'チェックデジットを格納する変数
dim y(12) as long ’ISBNの1桁目から12桁目までの数字を格納する変数
dim isbn10 as string,isbn13 as string 'ISBN
isbn10 = cells(1,1) 'セルA1にISBN10が入力されているとして
isbn13 = "978" & isbn10 'ISBN10の頭に「978」を付けてISBN13の形にする
for x = 1 to 12 ’For NextでISBNの各桁の数字を獲得。13桁目はチェックデジットなので不要。
y(x) = mid(isbn13,x,1)
next x
'奇数桁の和*1と偶数桁の和*3の総和を計算する。
z = (y(1)+y(3)+y(5)+y(7)+y(9)+y(11))+(y(2)+y(4)+y(6)+y(8)+y(10)+y(12))*3
z = z mod 10 '総和を10で割った余りを計算する。
cd = 10-z '10から余りを引くとチェックデジットになる。
isbn13 = mid(isbn13,1,12) & cd '初めに作ったISBN13の12桁目までと、チェックデジットを合わせる。
End Sub
書き方はいくつかありますが、おおざっぱにはこんなところです。
これを関数で表現するのは、意外にめんどくさくて、mid関数を12個使うのか、まあ、978は固定なのでそこを除いても9個使うのか、となるとあんまりスマートじゃないなあ、メンテも面倒そうだなあ、使いまわしが面倒そうだなあ、となるわけです。いくつか案はあるけど、どれも「スマートだぜ」とは言えない状況です。
大したことではないけど、ちょっとした悩みでした。
2018年01月21日
関数解説 Search関数
「=Search(検索文字列,検索対象,開始文字位置)」
「文字列が最初に現れる位置の文字番号を返します。大文字、小文字は区別されません。」
先日紹介したFind関数とよく似ていますが、いろいろ違う動きをする関数です。
普通に使う分にはあまり影響しないかもしれませんが、使い分けられるときっと幅が広がるでしょう。
基本的な部分は Find関数 と同じなので、ここでは違いについてをメインにしましょう。
まず違うのは「大文字、小文字は区別されません」です。下の図を見てみましょう。

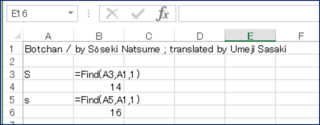
Search関数では大文字小文字どちらも同じ結果になっているのがわかると思います。なので、特にアルファベットの検索をするときには、目的に応じて使い分ける必要があります。
ちなみに、日本語のカタカナ、ひらがな、半角、全角はすべて別物として扱われます。
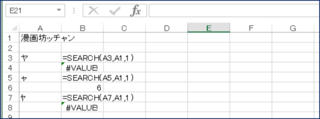
ヤ(全角カタカナ)とヤ(半角カタカナ)はエラーが返ってきていますね。Findもですが、見つからなかった場合はエラーが返ってきますので、それを利用してIf関数などに組み込むことも可能です。
もう一つの特徴は、ワイルドカードを使うことができる、ということです。下の図を見ていただけると早いですが、H列は「坊」で終わる単語を、K列は「坊」で始まる単語を、N列は「坊」が真ん中にある単語をSearch関数で探した結果です。一行目だけ、何を見つけてきたのかをそれぞれ横に表示しています。

H列の場合、3,4行目はセルが「坊」で始まっているので、対象外となりエラーになります。逆に7行目は「坊」で終わっているため、「坊?」ではエラーになりますが、「スペース+坊」として扱っているので、「?坊」では「坊」の前の半角スペースの位置を返します。
また、1行目でも、H列は「学坊」のため、「坊」の一文字前を返し、N列は「坊っ」のため、「坊」の位置を返します。
こういう特徴があるため、一部の記号の検索がFindとSearchで違います。それを理解して使い分ければ、かなり複雑な文字列制御も可能になるでしょう。
「文字列が最初に現れる位置の文字番号を返します。大文字、小文字は区別されません。」
先日紹介したFind関数とよく似ていますが、いろいろ違う動きをする関数です。
普通に使う分にはあまり影響しないかもしれませんが、使い分けられるときっと幅が広がるでしょう。
基本的な部分は Find関数 と同じなので、ここでは違いについてをメインにしましょう。
まず違うのは「大文字、小文字は区別されません」です。下の図を見てみましょう。


Search関数では大文字小文字どちらも同じ結果になっているのがわかると思います。なので、特にアルファベットの検索をするときには、目的に応じて使い分ける必要があります。
ちなみに、日本語のカタカナ、ひらがな、半角、全角はすべて別物として扱われます。

ヤ(全角カタカナ)とヤ(半角カタカナ)はエラーが返ってきていますね。Findもですが、見つからなかった場合はエラーが返ってきますので、それを利用してIf関数などに組み込むことも可能です。
もう一つの特徴は、ワイルドカードを使うことができる、ということです。下の図を見ていただけると早いですが、H列は「坊」で終わる単語を、K列は「坊」で始まる単語を、N列は「坊」が真ん中にある単語をSearch関数で探した結果です。一行目だけ、何を見つけてきたのかをそれぞれ横に表示しています。
H列の場合、3,4行目はセルが「坊」で始まっているので、対象外となりエラーになります。逆に7行目は「坊」で終わっているため、「坊?」ではエラーになりますが、「スペース+坊」として扱っているので、「?坊」では「坊」の前の半角スペースの位置を返します。
また、1行目でも、H列は「学坊」のため、「坊」の一文字前を返し、N列は「坊っ」のため、「坊」の位置を返します。
こういう特徴があるため、一部の記号の検索がFindとSearchで違います。それを理解して使い分ければ、かなり複雑な文字列制御も可能になるでしょう。
2018年01月14日
これから委員会の意見交換会の報告を聞いて
業務都合で行くことができなかった、これから委員会の報告をやっと聞くことができました。
簡単な所感としては、
1.現場レベルのことはまだ何も決定していない
問題を想定していないわけではなく、検討自体は進められている様子。でもこの一年が勝負な気がします。
2.様々なIDを利用したリンク機能が強化される
一部手動で設定していたリンクが、自動化されるかもしれません。他にも、NIIを通じてのILLなどは、効率化が進む可能性もあります。
3.TRC-MARCやJP-MARCにもNCIDがつく?
ILLには大きな要素。ただし、既存のものにもつくのか?すでにローカルで登録しているものにはどうするのか?どこかで一括でメタデータをCSVやTSVやらでダウンロードできるのか?
4.名寄せ率は94%
あと少し。関係ない書誌が混ざるのも怖いですが、名寄せされていなければいけないものが除外されるのも怖いですね。がんばってほしいけど、メタデータは人が作るものである以上、100%は無理な気もします。書誌の並列を許容するとは言いつつ、並列させるには何らかの制限もかかるみたいなので、無駄な書誌が増えなければ、自ずと精度が上がると思います。
5.書誌が物理単位になることでOPACはどうなる?
利用者に一番影響するのはここですよね。これまではVolについては、一つのデータにまとまっていましたが、それがばらばらに表示されると、利用者にとってはとても見づらくなります。ここへの懸念が一番多いみたいです。親書誌リンクがほとんど必須の扱いになる、という話ですが、親書誌リンクだと叢書とかも拾ってしまうのでなかなか大変。
書誌データから、何巻から何巻まで持っている、というデータを読み取ることができなくなるのもなかなか曲者。特殊な巻号を持つ者の場合、ソートにも影響します。(実は、単純な上巻中巻下巻でも、何も考えずにソートすれば下巻、上巻、中巻になってしまいます)「Volリンク」や「Vol表示順」みたいなフィールドがあれば、アルゴリズム的には楽なのですが、現場がひと手間増えてしまいます。システム開発者の腕の見せどころかもしれませんね^^
6.図書館サービスプラットフォーム(LSP)の検討
Ex Libris社の「Alma」のようなものの導入を検討するようです。実際電子ジャーナルの管理はなかなか面倒なので、あればいいなあ、とは思います。現在はAlmaがデファクトスタンダードとなっていますが、海外ではオープンソースの開発も進められています。日本だとやっぱりNIIが中心になるのでしょうか?
楽になるポイントもあれば、デメリットも当然出てきますが、様々なデータの連動性を高めていくことは、一大学図書館にとどまらないデータの広がりの可能性があります。最終的には絶対にメリットのほうが大きくなるので、今後の動きに注目です。
簡単な所感としては、
1.現場レベルのことはまだ何も決定していない
問題を想定していないわけではなく、検討自体は進められている様子。でもこの一年が勝負な気がします。
2.様々なIDを利用したリンク機能が強化される
一部手動で設定していたリンクが、自動化されるかもしれません。他にも、NIIを通じてのILLなどは、効率化が進む可能性もあります。
3.TRC-MARCやJP-MARCにもNCIDがつく?
ILLには大きな要素。ただし、既存のものにもつくのか?すでにローカルで登録しているものにはどうするのか?どこかで一括でメタデータをCSVやTSVやらでダウンロードできるのか?
4.名寄せ率は94%
あと少し。関係ない書誌が混ざるのも怖いですが、名寄せされていなければいけないものが除外されるのも怖いですね。がんばってほしいけど、メタデータは人が作るものである以上、100%は無理な気もします。書誌の並列を許容するとは言いつつ、並列させるには何らかの制限もかかるみたいなので、無駄な書誌が増えなければ、自ずと精度が上がると思います。
5.書誌が物理単位になることでOPACはどうなる?
利用者に一番影響するのはここですよね。これまではVolについては、一つのデータにまとまっていましたが、それがばらばらに表示されると、利用者にとってはとても見づらくなります。ここへの懸念が一番多いみたいです。親書誌リンクがほとんど必須の扱いになる、という話ですが、親書誌リンクだと叢書とかも拾ってしまうのでなかなか大変。
書誌データから、何巻から何巻まで持っている、というデータを読み取ることができなくなるのもなかなか曲者。特殊な巻号を持つ者の場合、ソートにも影響します。(実は、単純な上巻中巻下巻でも、何も考えずにソートすれば下巻、上巻、中巻になってしまいます)「Volリンク」や「Vol表示順」みたいなフィールドがあれば、アルゴリズム的には楽なのですが、現場がひと手間増えてしまいます。システム開発者の腕の見せどころかもしれませんね^^
6.図書館サービスプラットフォーム(LSP)の検討
Ex Libris社の「Alma」のようなものの導入を検討するようです。実際電子ジャーナルの管理はなかなか面倒なので、あればいいなあ、とは思います。現在はAlmaがデファクトスタンダードとなっていますが、海外ではオープンソースの開発も進められています。日本だとやっぱりNIIが中心になるのでしょうか?
楽になるポイントもあれば、デメリットも当然出てきますが、様々なデータの連動性を高めていくことは、一大学図書館にとどまらないデータの広がりの可能性があります。最終的には絶対にメリットのほうが大きくなるので、今後の動きに注目です。
2018年01月08日
関数解説 Find関数
「=Find(検索文字列,検索対象,開始文字位置)」
「文字列が他の文字列内で最初に現れる位置を返します。大文字と小文字は区別されます」
というExcelのヘルプを聞いてピンと来づらいかもしれませんが、とある文字(列)が、頭から何文字目に出てくるか、ということを調べる関数です。ちなみに、見つからなかった場合はエラーが返ります。
基本的な使い方は以下の通りです。OPACからコピーしてきたデータのうち「/」が何文字目にあるかを調べてみます。
「=find("/",A5,1)」と入れてみましょう。


「6」と返ってきます。このとき、空白を1文字として数えています。全角でも半角でも1文字です。FindBにすると、全角は2文字として扱われます。普通の業務で必要になる場面は少ないですが、頭に入れておいて損はないと思います。
大文字と小文字を区別するので、次のような場合、返ってくる値が変わります。

大文字の場合は、「by」のすぐ後の「S」の文字位置を返します。小文字の場合は「So」の次の「s」を返します。思っていた結果と違う場合、大文字小文字の違いが影響している場合があります。
この特徴を利用して、大文字でなければならないのに小文字が混ざっていないかを調べる、といったことも可能です。エラーが返ってきたものは小文字、ということになりますね。まあ、その場合はそもそも「UPPER」関数(小文字を大文字にする)や「LOWER」関数(大文字を小文字にする)を使ったほうが多分早いです。
もちろん、一文字だけでなく、単語や文章の有無をチェックすることもできます。

ここで返ってくる値は、「Natsume」の「N」の位置です。書誌データでは「/」「;」などを区切り記号に使いますが、普通にタイトルやその他の情報で使われることも多いため、「 / 」「 ; 」など、書誌規則と同じように、前後に半角スペースを入れて使うと、区切り位置を調べる時には便利でしょう。
また、これを利用して、一覧データから、特定の文字列を含むものだけを抜き出すのには使えます。Find関数を使ってエラーが返ってきたものを除外すればいいわけです。
他にも、開始位置を指定することもできます。「 ; 」以降の「s」の位置を知りたい、というときには、「 ; 」の文字位置を指定すれば、それ以後の「s」の位置を調べることができます。今回は30文字目なので、開始位置に「30」を指定します。

この時でも、返ってくる値は「先頭から何文字目」となります。以下のようにFind関数の開始位置にもう一度Find関数を組み合わせてあげれば、もっと柔軟に対応できますね^^

また、Mid関数やLeft関数といった関数と組み合わせるのもとても有効です。Mid関数の開始位置や、Mid関数、Left関数の文字数の指定に使うことで、大きなリストに対しても、柔軟に対応してくれます。


書誌のようにある程度の規則があるものに対しては有効です。明確な規則がなくても、一番多く使われているパターンに対してまずこれで抽出し、他を手動でコピペする、とするだけでも、だいぶ負担が軽くなると思います。
ただ、Find関数では位置を調べられない特殊記号があったり、ワイルドカードが使えないといった部分もあります。普段はあまりお目にすることがないと思いますが、それが影響することもあります。思うような結果が出ない場合は、特殊記号がないかどうかをチェックしてみましょう。
なお、Find関数によく似たものに、Search関数があります。普段使う分にはあまり変わらない関数ですが、実は奥が深い差があるのです。これはまた別でアップします。
「文字列が他の文字列内で最初に現れる位置を返します。大文字と小文字は区別されます」
というExcelのヘルプを聞いてピンと来づらいかもしれませんが、とある文字(列)が、頭から何文字目に出てくるか、ということを調べる関数です。ちなみに、見つからなかった場合はエラーが返ります。
基本的な使い方は以下の通りです。OPACからコピーしてきたデータのうち「/」が何文字目にあるかを調べてみます。
「=find("/",A5,1)」と入れてみましょう。
「6」と返ってきます。このとき、空白を1文字として数えています。全角でも半角でも1文字です。FindBにすると、全角は2文字として扱われます。普通の業務で必要になる場面は少ないですが、頭に入れておいて損はないと思います。
大文字と小文字を区別するので、次のような場合、返ってくる値が変わります。
大文字の場合は、「by」のすぐ後の「S」の文字位置を返します。小文字の場合は「So」の次の「s」を返します。思っていた結果と違う場合、大文字小文字の違いが影響している場合があります。
この特徴を利用して、大文字でなければならないのに小文字が混ざっていないかを調べる、といったことも可能です。エラーが返ってきたものは小文字、ということになりますね。まあ、その場合はそもそも「UPPER」関数(小文字を大文字にする)や「LOWER」関数(大文字を小文字にする)を使ったほうが多分早いです。
もちろん、一文字だけでなく、単語や文章の有無をチェックすることもできます。
ここで返ってくる値は、「Natsume」の「N」の位置です。書誌データでは「/」「;」などを区切り記号に使いますが、普通にタイトルやその他の情報で使われることも多いため、「 / 」「 ; 」など、書誌規則と同じように、前後に半角スペースを入れて使うと、区切り位置を調べる時には便利でしょう。
また、これを利用して、一覧データから、特定の文字列を含むものだけを抜き出すのには使えます。Find関数を使ってエラーが返ってきたものを除外すればいいわけです。
他にも、開始位置を指定することもできます。「 ; 」以降の「s」の位置を知りたい、というときには、「 ; 」の文字位置を指定すれば、それ以後の「s」の位置を調べることができます。今回は30文字目なので、開始位置に「30」を指定します。
この時でも、返ってくる値は「先頭から何文字目」となります。以下のようにFind関数の開始位置にもう一度Find関数を組み合わせてあげれば、もっと柔軟に対応できますね^^
また、Mid関数やLeft関数といった関数と組み合わせるのもとても有効です。Mid関数の開始位置や、Mid関数、Left関数の文字数の指定に使うことで、大きなリストに対しても、柔軟に対応してくれます。
書誌のようにある程度の規則があるものに対しては有効です。明確な規則がなくても、一番多く使われているパターンに対してまずこれで抽出し、他を手動でコピペする、とするだけでも、だいぶ負担が軽くなると思います。
ただ、Find関数では位置を調べられない特殊記号があったり、ワイルドカードが使えないといった部分もあります。普段はあまりお目にすることがないと思いますが、それが影響することもあります。思うような結果が出ない場合は、特殊記号がないかどうかをチェックしてみましょう。
なお、Find関数によく似たものに、Search関数があります。普段使う分にはあまり変わらない関数ですが、実は奥が深い差があるのです。これはまた別でアップします。
2017年11月18日
そもそも、スキーマって何?
2017/10/10にJPCOARスキーマが正式に公開されました。
こちらを参考
junii2スキーマと互換性を持たせる、としつつ、ダブリンコアなどを意識し、かなり詳細な記述の書き込みが可能な形式になったのですが、その分、リポジトリ担当者の負担もしばらくは大きくなりそうな気配です。まあ、落ち着いたらそうでもなくなると思います。現在の、「リポジトリって何?」な環境から、今後リポジトリの価値を高めるためにも、国際環境を意識したスキーマは必要になると思います。
で、そもそもなのですが、「スキーマ」って何?という疑問をお持ちの方もおられると思います。
用語的には こちら(IT用語辞典 e-Words) などを参考にしていただければと思いますが、いろいろ端折って平たく言うと、今回の場合は「リポジトリ版書誌規則」です。もうちょっと正確に言うとXML版書誌規則です。
基本的に、リポジトリはXMLという形式でデータを持っています。これは、インターネット間で情報をやりとりするのに便利な形式で、XML自体はさまざまなところで使われています。
XMLの記述ですが、例えば、
<タイトル>源氏物語</タイトル>
<著者>紫式部</著者>
というように<>と</>で囲まれた形式で構成され、開始の<>は「ここからが〜ですよ」と開始を
宣言する部分。終わりの</>は「ここで終了ですよ」と明確な区切りを意味します。そして<>と</>で囲まれた中身がデータとなります。この<>と</>を「タグ」と呼びます。ブログとかでHTMLに触れている方にはお馴染みですね。
この場合、「タイトル」は「源氏物語」で、「著者」は「紫式部」です。という意味を持たせていますが、このタグ、実はXMLでは自由に設定することができます。
タイトルのところでも、<本の名前>にしてもいいですし、平仮名にしてもいいです。言語にも制限がなく、<Title>と英語にしても、ドイツ語にしても、韓国語にしても、中国語にしても、ロシア語にしても、アラビア語にしてもいいわけです。つまり、なんでも自由に使えるため、データをやり取りしたり、保管したりするのにも便利なコンピュータ言語なのです。
そのXMLを読み取って、どう処理するかはシステム側の問題です。データベースとしてどのように格納するか、またはOPACやリポジトリなどのWeb上にどのように表示するか、それらはすべてシステム側の役目になります。そこで問題になるのが、この自由さです。
例えば、リポジトリの論文名の欄に論文のタイトルを表示するのに、システムではXMLの「タイトル」というタグを探し出し、読み取って表示するとします。でも、必ずしもタイトルが「タイトル」というタグで設定されているとは限りません。「論文名」「Title」「論文の名前」「論文タイトル」など、XMLではまちまちに設定することが可能です。で、これらをシステムで処理することはできるでしょうか?不可能です。ある程度はいけても、限界があります。きっと、100件200件と処理していたら、人間だって「表記を統一してくれ」と思うに違いありません。システムは、もっと応用が利きません。そこで、統一したルールを作りましょう、というのが、スキーマです。目録の書誌規則も同じような背景ですよね。なので、初めに「リポジトリの書誌規則」と表現しました。
別に自分の館一つで完結しているなら、リポジトリのスキーマも不要なのですが、相互利用を推し進めるためにはやはり統一された形式が必要です。A館のリポジトリのデータがB館では使えない、というのでは、相互利用はなかなか進みません。そしてそのためには、データ提供側も協力する必要があります。その結果、世界から日本のリポジトリに注目が集まり、個々のリポジトリが世界から利用されるようになる。そういういい循環が作れるようになったらいいなと思います。大変な部分はありますが、前向きにとらえていただければと思います。
こちらを参考
junii2スキーマと互換性を持たせる、としつつ、ダブリンコアなどを意識し、かなり詳細な記述の書き込みが可能な形式になったのですが、その分、リポジトリ担当者の負担もしばらくは大きくなりそうな気配です。まあ、落ち着いたらそうでもなくなると思います。現在の、「リポジトリって何?」な環境から、今後リポジトリの価値を高めるためにも、国際環境を意識したスキーマは必要になると思います。
で、そもそもなのですが、「スキーマ」って何?という疑問をお持ちの方もおられると思います。
用語的には こちら(IT用語辞典 e-Words) などを参考にしていただければと思いますが、いろいろ端折って平たく言うと、今回の場合は「リポジトリ版書誌規則」です。もうちょっと正確に言うとXML版書誌規則です。
基本的に、リポジトリはXMLという形式でデータを持っています。これは、インターネット間で情報をやりとりするのに便利な形式で、XML自体はさまざまなところで使われています。
XMLの記述ですが、例えば、
<タイトル>源氏物語</タイトル>
<著者>紫式部</著者>
というように<>と</>で囲まれた形式で構成され、開始の<>は「ここからが〜ですよ」と開始を
宣言する部分。終わりの</>は「ここで終了ですよ」と明確な区切りを意味します。そして<>と</>で囲まれた中身がデータとなります。この<>と</>を「タグ」と呼びます。ブログとかでHTMLに触れている方にはお馴染みですね。
この場合、「タイトル」は「源氏物語」で、「著者」は「紫式部」です。という意味を持たせていますが、このタグ、実はXMLでは自由に設定することができます。
タイトルのところでも、<本の名前>にしてもいいですし、平仮名にしてもいいです。言語にも制限がなく、<Title>と英語にしても、ドイツ語にしても、韓国語にしても、中国語にしても、ロシア語にしても、アラビア語にしてもいいわけです。つまり、なんでも自由に使えるため、データをやり取りしたり、保管したりするのにも便利なコンピュータ言語なのです。
そのXMLを読み取って、どう処理するかはシステム側の問題です。データベースとしてどのように格納するか、またはOPACやリポジトリなどのWeb上にどのように表示するか、それらはすべてシステム側の役目になります。そこで問題になるのが、この自由さです。
例えば、リポジトリの論文名の欄に論文のタイトルを表示するのに、システムではXMLの「タイトル」というタグを探し出し、読み取って表示するとします。でも、必ずしもタイトルが「タイトル」というタグで設定されているとは限りません。「論文名」「Title」「論文の名前」「論文タイトル」など、XMLではまちまちに設定することが可能です。で、これらをシステムで処理することはできるでしょうか?不可能です。ある程度はいけても、限界があります。きっと、100件200件と処理していたら、人間だって「表記を統一してくれ」と思うに違いありません。システムは、もっと応用が利きません。そこで、統一したルールを作りましょう、というのが、スキーマです。目録の書誌規則も同じような背景ですよね。なので、初めに「リポジトリの書誌規則」と表現しました。
別に自分の館一つで完結しているなら、リポジトリのスキーマも不要なのですが、相互利用を推し進めるためにはやはり統一された形式が必要です。A館のリポジトリのデータがB館では使えない、というのでは、相互利用はなかなか進みません。そしてそのためには、データ提供側も協力する必要があります。その結果、世界から日本のリポジトリに注目が集まり、個々のリポジトリが世界から利用されるようになる。そういういい循環が作れるようになったらいいなと思います。大変な部分はありますが、前向きにとらえていただければと思います。
2017年10月15日
関数解説 COUNTIF関数
「=COUNTIF(範囲,検索条件)」
「指定された範囲に含まれるセルのうち、検索条件に一致するセルの個数を返します」
COUNT系関数の中でも特によく使われるものの一つではないでしょうか?ちょっと複雑に感じられるかもしれませんが、とても簡単な割に、使える局面の多い関数です。
今回は中国の詩人の特集を組もうという中で、時代別に詩人を分けて展示しようと思いますが、その中で下準備をしようと思います。
主だった詩人を上げて、時代別の人数を出してみようと思います。
(選定は独断と偏見で行っています。また、スペースの関係で一部の時代に限定しています)
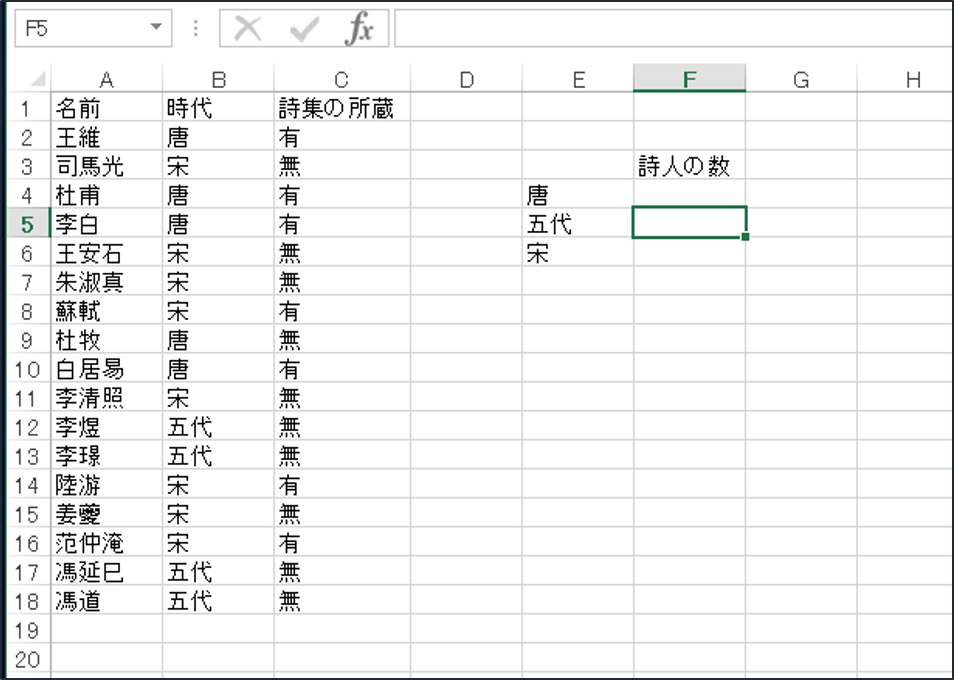
E列に設けた時代の表に、時代別の人数を入力するのですが、これぐらいならともかく、大量のデータから該当するものを数えるのも大変です。そこで力を発揮するのが今回の関数です。
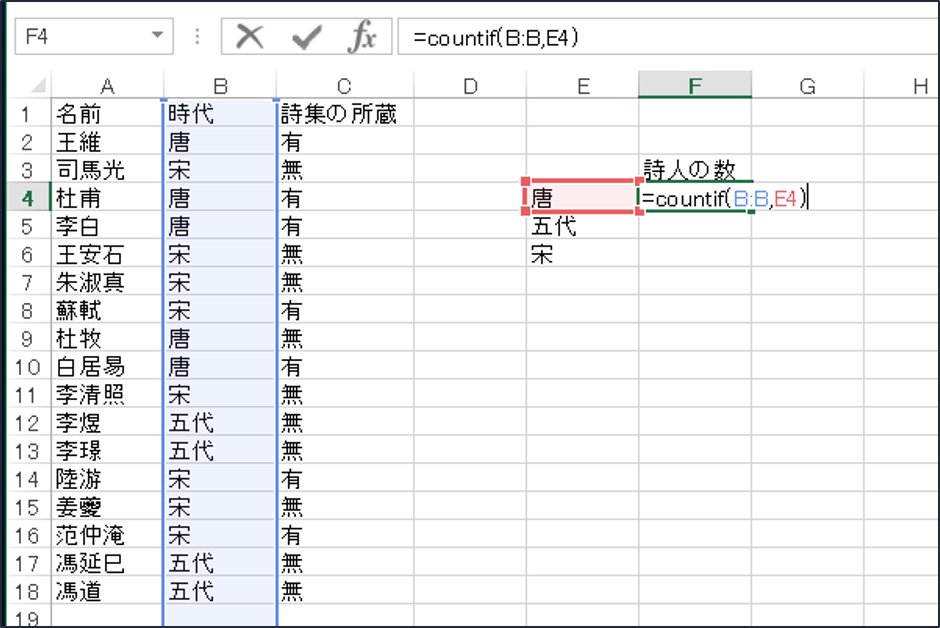
B列に時代が入力されていますが、その中に、E列と一致するものはいくつあるのか、という関数です。
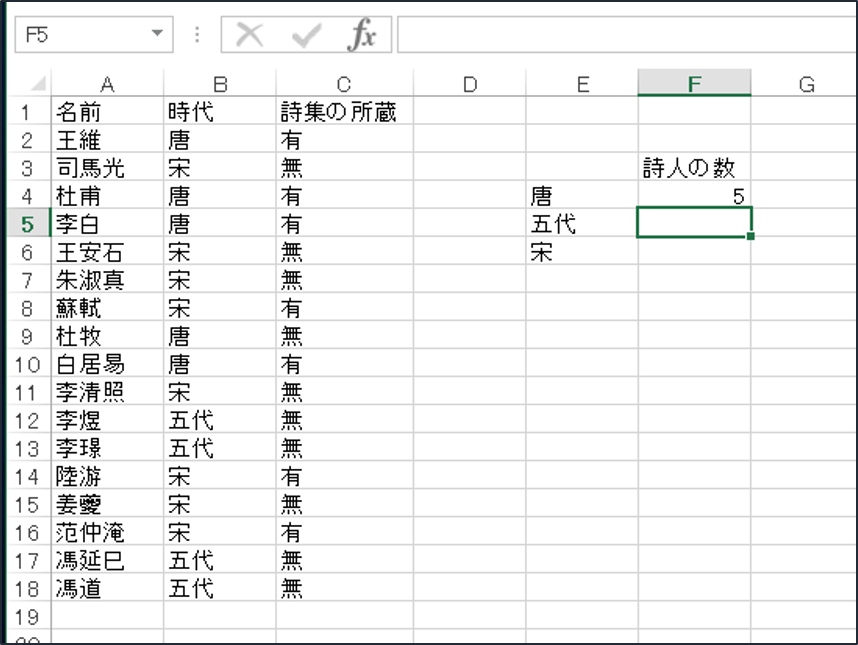
で、これであっさり結果が出ました。あとはドラッグして五代と宋にも適応させましょう。
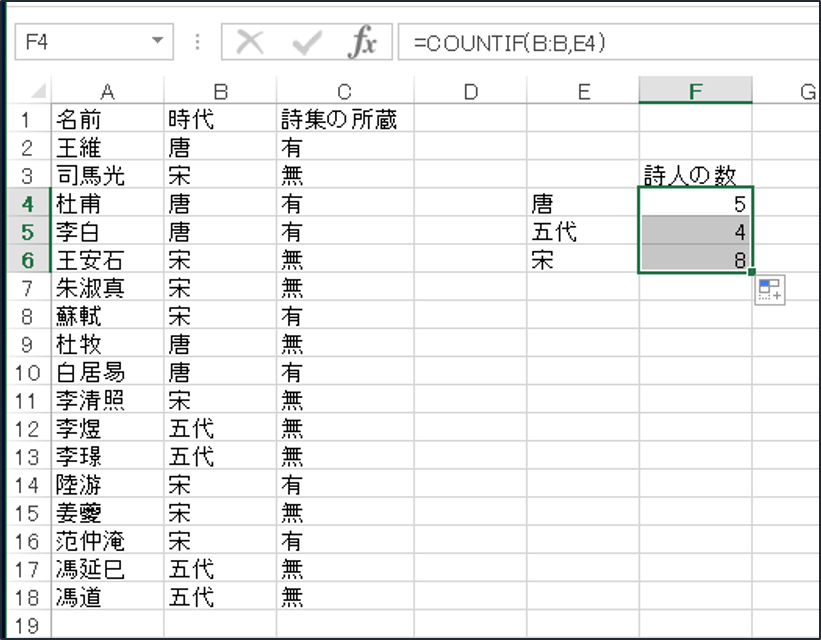
簡単に完成です。
使い方は簡単な割に強力で、また先に応用編を紹介したぐらい、使い方に応用の効く関数です。是非マスターしてほしい関数です。
「指定された範囲に含まれるセルのうち、検索条件に一致するセルの個数を返します」
COUNT系関数の中でも特によく使われるものの一つではないでしょうか?ちょっと複雑に感じられるかもしれませんが、とても簡単な割に、使える局面の多い関数です。
今回は中国の詩人の特集を組もうという中で、時代別に詩人を分けて展示しようと思いますが、その中で下準備をしようと思います。
主だった詩人を上げて、時代別の人数を出してみようと思います。
(選定は独断と偏見で行っています。また、スペースの関係で一部の時代に限定しています)
E列に設けた時代の表に、時代別の人数を入力するのですが、これぐらいならともかく、大量のデータから該当するものを数えるのも大変です。そこで力を発揮するのが今回の関数です。
B列に時代が入力されていますが、その中に、E列と一致するものはいくつあるのか、という関数です。
で、これであっさり結果が出ました。あとはドラッグして五代と宋にも適応させましょう。
簡単に完成です。
使い方は簡単な割に強力で、また先に応用編を紹介したぐらい、使い方に応用の効く関数です。是非マスターしてほしい関数です。