
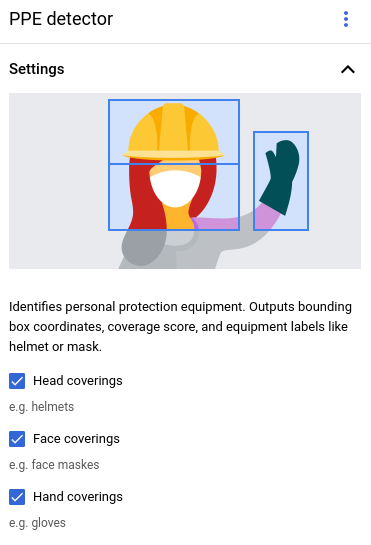
The Personal Protective Equipment (PPE) Detectormodel helps you verify the presence of equipment that limits exposure to hazards in a workplace or community environment.
The model detects people and the PPE items (gloves, masks, and helmets) on a specific person. The model detects the PPE items, and if the items cover the corresponding human body parts. The model reports this coverage information as a coverage score ranging from [0, 1]. The model accepts a video stream as input. The model outputs detection results as a protocol buffer that you can view in BigQuery. The model runs at one FPS.
The PPE detection operator has three control parameters you can set:
-
Head coverings: The
operator outputs head coverage-related PPE item information. Set this value
in the Google Cloud console, or set
enableHeadCoverageDetectionto true in thePersonalProtectiveEquipmentDetectionConfig. -
Face coverings: The operator outputs face
coverage-related PPE item information. Set this value
in the Google Cloud console, or set
enableFaceCoverageDetectionto true in thePersonalProtectiveEquipmentDetectionConfig. -
Hand coverings: The operator outputs hand
coverage-related PPE item information. Set this value
in the Google Cloud console, or set
enableHandsCoverageDetectiontrue in thePersonalProtectiveEquipmentDetectionConfig.
PPE detector model app specifications
Use the following instructions to create a PPE detector model in the Google Cloud console.
Console
Create an app in the Google Cloud console
-
To create a PPE detector app, follow instructions in Build an application .
Add a PPE detector model
-
When you add model nodes, select the PPE detectorfrom the list of pre-trained models.
-
Set the types of PPE you want to detect in the options menu.
Add a BigQuery connector
-
To use the output, connect the app to a BigQueryconnector.
For information about using the BigQueryconnector, see Connect and store data to BigQuery . For BigQuery pricing information, see the BigQuery pricing page.
View output results in BigQuery
After the model outputs data to BigQuery, view output annotations in the BigQuery dashboard.
If you didn't specify a BigQuery path, you can view the system-created path in the Vertex AI Vision Studiopage.
-
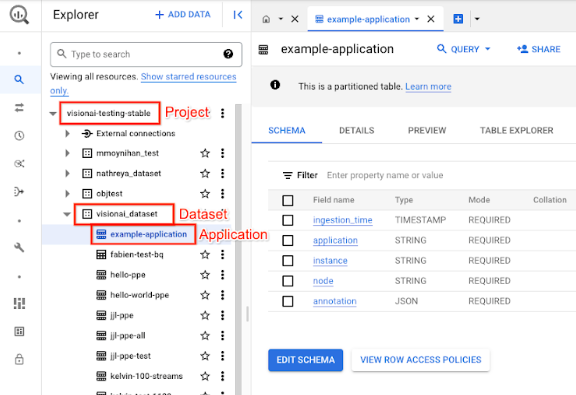
In the Google Cloud console, open the BigQuery page.
-
Select Expandnext to the target project, dataset name, and application name.
-
In the table detail view, click Preview. View results in the annotationcolumn. For a description of the output format, see model output .
The application stores results in chronological order. The oldest results are the beginning of the table, while the most recent results are added to the end of the table. To check the latest results, click the page number to go to the last table page.
Model output
The model output includes a timestamp, the detection boxes, object labels that correspond to the boxes, and confidence scores from that object. The rate of the output stream is one frame per second.
The model output is a protocol buffer format that includes information on the video frame and PPE detection prediction result. The goal of the model is to check whether people are properly wearing protective equipment. As a result, the model focuses on detecting people and the PPE the person wears. The model output focuses on person detection. For each person that is detected, the model lists the PPE around the person and the coverage score of each piece of equipment.
In the protocol buffer example that follows, note the following.
- Current time - The timestamp notes the time the inference result is made.
- Detected persons - The main detection result that includes one person-identified box, multiple PPE-identified boxes, and a coverage score for each body part.
- Person identified box - The bounding box, confidence score, and person entity.
- PPE identified box - The bounding box, confidence score, and PPE entity.
Sample annotation output JSON object
{ " currentTime": " 2022-11-10T21:02:13.499255040Z ", " detectedPersons": [ { "personId": "0", " detectedPersonIdentifiedBox": { "boxId": "0", "normalizedBoundingBox": { "xmin": 0.486749 , "ymin": 0.35927793 , "width": 0.048630536 , "height": 0.21746585 }, "confidenceScore": 0.31775203 , "personEntity":{ "personEntityId":"0" } }, " detected_ppe_identified_boxes": { "normalized_bounding_box": { "xmin": 0.07268746 , "ymin": 0.80575824 , "width": 0.22973709 , "height": 0.18754286 }, "confidence_score": 0.45171335 , "ppe_entity": { "ppe_label_string": " Glove ", "ppe_supercategory_label_string": " Hand Coverage " } }, " detected_ppe_identified_boxes":{ "normalized_bounding_box":{ "xmin": 0.35457548 , "ymin": 0.016402662 , "width": 0.31828704 , "height": 0.18849815 }, "confidence_score": 0.44129524 , "ppe_entity":{ "ppe_label_string": " Helmet ", "ppe_supercategory_label_string": " Head Coverage " } } } ] }
Protocol buffer definition
// Output format for Personal Protective Equipment Detection Operator
message
PersonalProtectiveEquipmentDetectionOutput
{
// Current timestamp
protobuf
.
Timestamp
current_time
=
1
;
// The entity info for annotations from person detection prediction result
message
PersonEntity
{
// Entity id
int64
person_entity_id
=
1
;
}
// The entity info for annotations from PPE detection prediction result
message
PPEEntity
{
// Label id
int64
ppe_label_id
=
1
;
// Human readable string of the label (Examples: helmet, glove, mask)
string
ppe_label_string
=
2
;
// Human readable string of the super category label (Examples: head_cover,
// hands_cover, face_cover)
string
ppe_supercategory_label_string
=
3
;
// Entity id
int64
ppe_entity_id
=
4
;
}
// Bounding Box in the normalized coordinates
message
NormalizedBoundingBox
{
// Min in x coordinate
float
xmin
=
1
;
// Min in y coordinate
float
ymin
=
2
;
// Width of the bounding box
float
width
=
3
;
// Height of the bounding box
float
height
=
4
;
}
// PersonIdentified box contains the location and the entity info of the
// person
message
PersonIdentifiedBox
{
// An unique id for this box
int64
box_id
=
1
;
// Bounding Box in the normalized coordinates
NormalizedBoundingBox
normalized_bounding_box
=
2
;
// Confidence score associated with this box
float
confidence_score
=
3
;
// Person entity info
PersonEntity
person_entity
=
4
;
}
// PPEIdentified box contains the location and the entity info of the PPE
message
PPEIdentifiedBox
{
// An unique id for this box
int64
box_id
=
1
;
// Bounding Box in the normalized coordinates
NormalizedBoundingBox
normalized_bounding_box
=
2
;
// Confidence score associated with this box
float
confidence_score
=
3
;
// PPE entity info
PPEEntity
ppe_entity
=
4
;
}
// Detected Person contains the detected person and their associated
// PPE and their protecting information
message
DetectedPerson
{
// The id of detected person
int64
person_id
=
1
;
// The info of detected person identified box
PersonIdentifiedBox
detected_person_identified_box
=
2
;
// The info of detected person associated ppe identified boxes
repeated
PPEIdentifiedBox
detected_ppe_identified_boxes
=
3
;
// Coverage score for each body part
// Coverage score for face
optional
float
face_coverage_score
=
4
;
// Coverage score for eyes
optional
float
eyes_coverage_score
=
5
;
// Coverage score for head
optional
float
head_coverage_score
=
6
;
// Coverage score for hands
optional
float
hands_coverage_score
=
7
;
// Coverage score for body
optional
float
body_coverage_score
=
8
;
// Coverage score for feet
optional
float
feet_coverage_score
=
9
;
}
// A list of DetectedPersons
repeated
DetectedPerson
detected_persons
=
2
;
}
Best practices and limitations
To get the best results when you use the PPE detector, consider the following when you source data and use the model.
Source data recommendations
Recommended: When possible, have detection subjects stand still and face the camera.
Sample image data the PPE detector is able to process correctly:
 |
 |
 |
Not recommended: Avoid image data where the key PPE items are too small in the frame.
Sample image data the PPE detector isn't able to process correctly:

Not recommended: Avoid image data that show the key PPE items from an uncommon point-of-view or irregular angles.
Sample image data the PPE detector isn't able to process correctly:

Limitations
- Resolution: The recommended maximum input video resolution is 1920 x 1080, and the recommended minimum resolution is 160 x 120.
- Minimum detectable object size: The model ignores any object in the scene that occupy less than 5% of the frame size.
- Lighting: Video lighting should be normal. Extreme brightness or darkness in video data can cause lower detector performance.
- PPE item placement: The PPE model focuses on analyzing if people are properly using PPE items. As a result, if someone is not wearing a PPE item, the model ignores the item.
- PPE item type: The model focuses on construction protective equipment and not medical PPE items. Therefore, the detector might not work well in medical centers or hospitals.
- Custom PPE types: The PPE model doesn't support customer-defined PPE items. The model supports detection of helmets, masks, and gloves.
This list is not meant to be exhaustive, and these limitations and functionality are subject to future product modifications.