
Specify nested and repeated columns in table schemas
This page describes how to define a table schema with nested and repeated columns in BigQuery. For an overview of table schemas, see Specifying a schema .
Define nested and repeated columns
To create a column with nested data, set the data type of the column to RECORD
in the schema. A RECORD
can be accessed as a STRUCT
type
in GoogleSQL. A STRUCT
is a container of ordered fields.
To create a column with repeated data, set the mode
of the column to REPEATED
in the schema.
A repeated field can be accessed as an ARRAY
type in
GoogleSQL.
A RECORD
column can have REPEATED
mode, which is represented as an array of STRUCT
types. Also, a field within a record can be repeated, which is
represented as a STRUCT
that contains an ARRAY
. An array cannot contain
another array directly. For more information, see Declaring an ARRAY
type
.
Limitations
Nested and repeated schemas are subject to the following limitations:
- A schema cannot contain more than 15 levels of nested
RECORDtypes. - Columns of type
RECORDcan contain nestedRECORDtypes, also called child records. The maximum nested depth limit is 15 levels. This limit is independent of whether theRECORDs are scalar or array-based (repeated).
RECORD
type is incompatible with UNION
, INTERSECT
, EXCEPT DISTINCT
, and SELECT DISTINCT
.
Example schema
The following example shows sample nested and repeated data. This table contains information about people. It consists of the following fields:
-
id -
first_name -
last_name -
dob(date of birth) -
addresses(a nested and repeated field)-
addresses.status(current or previous) -
addresses.address -
addresses.city -
addresses.state -
addresses.zip -
addresses.numberOfYears(years at the address)
-
The JSON data file would look like the following. Notice that the addresses
column contains an array of values (indicated by [ ]
). The multiple addresses
in the array are the repeated data. The multiple fields within each address are
the nested data.
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
The schema for this table looks like the following:
[ { "name" : "id" , "type" : "STRING" , "mode" : "NULLABLE" }, { "name" : "first_name" , "type" : "STRING" , "mode" : "NULLABLE" }, { "name" : "last_name" , "type" : "STRING" , "mode" : "NULLABLE" }, { "name" : "dob" , "type" : "DATE" , "mode" : "NULLABLE" }, { "name" : "addresses" , "type" : "RECORD" , "mode" : "REPEATED" , "fields" : [ { "name" : "status" , "type" : "STRING" , "mode" : "NULLABLE" }, { "name" : "address" , "type" : "STRING" , "mode" : "NULLABLE" }, { "name" : "city" , "type" : "STRING" , "mode" : "NULLABLE" }, { "name" : "state" , "type" : "STRING" , "mode" : "NULLABLE" }, { "name" : "zip" , "type" : "STRING" , "mode" : "NULLABLE" }, { "name" : "numberOfYears" , "type" : "STRING" , "mode" : "NULLABLE" } ] } ]
Specifying the nested and repeated columns in the example
To create a new table with the previous nested and repeated columns, select one of the following options:
Console
Specify the nested and repeated addresses
column:
-
In the Google Cloud console, open the BigQuery page.
-
In the left pane, click Explorer:

If you don't see the left pane, click Expand left paneto open the pane.
-
In the Explorerpane, expand your project, click Datasets, and then select a dataset.
-
In the details pane, click Create table.
-
On the Create tablepage, specify the following details:
- For Source, in the Create table fromfield, select Empty table.
-
In the Destinationsection, specify the following fields:
- For Dataset, select the dataset in which you want to create the table.
- For Table, enter the name of the table that you want to create.
-
For Schema, click Add fieldand enter the following table schema:
- For Field name, enter
addresses. - For Type, select RECORD.
- For Mode, choose REPEATED.
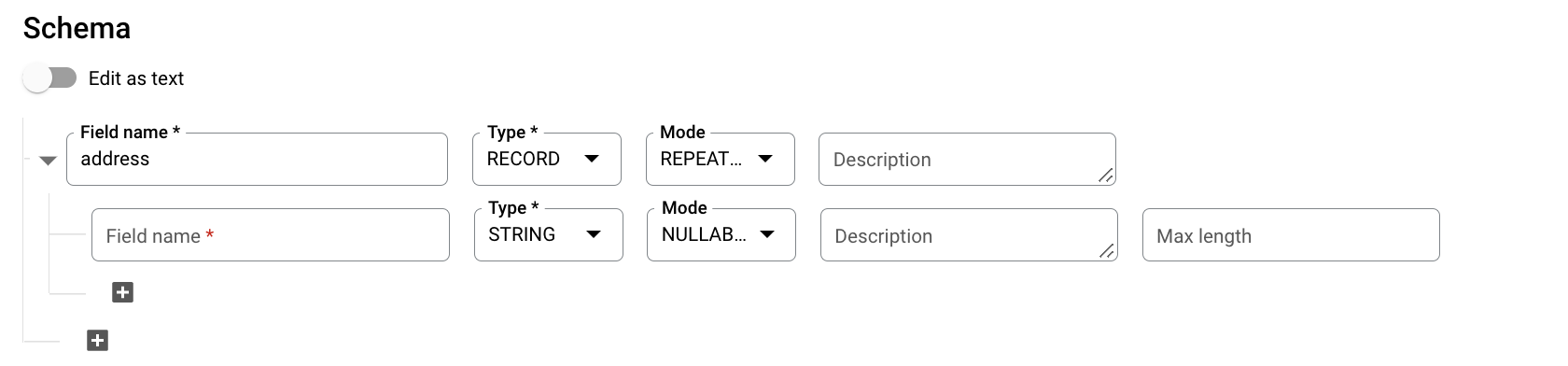
-
Specify the following fields for a nested field:
- In the Field namefield, enter
status. - For Type, choose STRING.
- For Mode, leave the value set to NULLABLE.
-
Click Add fieldto add the following fields:
Field name Type Mode addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
Alternatively, click Edit as textand specify the schema as a JSON array.
- In the Field namefield, enter
- For Field name, enter
SQL
Use the CREATE TABLE
statement
.
Specify the schema using the column
option:
-
In the Google Cloud console, go to the BigQuerypage.
-
In the query editor, enter the following statement:
CREATE TABLE IF NOT EXISTS mydataset . mytable ( id STRING , first_name STRING , last_name STRING , dob DATE , addresses ARRAY < STRUCT < status STRING , address STRING , city STRING , state STRING , zip STRING , numberOfYears STRING >> ) OPTIONS ( description = 'Example name and addresses table' );
-
Click Run.
For more information about how to run queries, see Run an interactive query .
bq
To specify the nested and repeated addresses
column in a JSON schema file,
use a text editor to create a new file. Paste in the example schema
definition shown above.
After you create your JSON schema file, you can provide it through the bq command-line tool. For more information, see Using a JSON schema file .
Go
Before trying this sample, follow the Go setup instructions in the BigQuery quickstart using client libraries . For more information, see the BigQuery Go API reference documentation .
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries .
Java
Before trying this sample, follow the Java setup instructions in the BigQuery quickstart using client libraries . For more information, see the BigQuery Java API reference documentation .
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries .
Node.js
Before trying this sample, follow the Node.js setup instructions in the BigQuery quickstart using client libraries . For more information, see the BigQuery Node.js API reference documentation .
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries .
Python
Before trying this sample, follow the Python setup instructions in the BigQuery quickstart using client libraries . For more information, see the BigQuery Python API reference documentation .
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries .
Insert data in nested columns in the example
Use the following queries to insert nested data records into tables that have RECORD
data type columns.
Example 1
INSERT INTO mydataset . mytable ( id , first_name , last_name , dob , addresses ) values ( "1" , "Johnny" , "Dawn" , "1969-01-22" , ARRAY < STRUCT < status STRING , address STRING , city STRING , state STRING , zip STRING , numberOfYears STRING >> [ ( "current" , "123 First Avenue" , "Seattle" , "WA" , "11111" , "1" ) ] )
Example 2
INSERT INTO mydataset . mytable ( id , first_name , last_name , dob , addresses ) values ( "1" , "Johnny" , "Dawn" , "1969-01-22" , [ ( "current" , "123 First Avenue" , "Seattle" , "WA" , "11111" , "1" ) ] )
Query nested and repeated columns
To select the value of an ARRAY
at a specific position, use an array subscript
operator
.
To access elements in a STRUCT
, use the dot operator
.
The following example selects the first name, last name, and first address
listed in the addresses
field:
SELECT first_name , last_name , addresses [ offset ( 0 ) ] . address FROM mydataset . mytable ;
The result is the following:
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
To extract all elements of an ARRAY
, use the UNNEST
operator
with a CROSS JOIN
.
The following example selects the first name, last name, address, and state for
all addresses not located in New York:
SELECT first_name , last_name , a . address , a . state FROM mydataset . mytable CROSS JOIN UNNEST ( addresses ) AS a WHERE a . state != 'NY' ;
The result is the following:
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
Modify nested and repeated columns
After you add a nested column or a nested and repeated column to a table's schema definition, you can modify the column as you would any other type of column. BigQuery natively supports several schema changes such as adding a new nested field to a record or relaxing a nested field's mode. For more information, see Modifying table schemas .
When to use nested and repeated columns
BigQuery performs best when your data is denormalized. Rather than preserving a relational schema such as a star or snowflake schema, denormalize your data and take advantage of nested and repeated columns. Nested and repeated columns can maintain relationships without the performance impact of preserving a relational (normalized) schema.
For example, a relational database used to track library books would likely keep
all author information in a separate table. A key such as author_id
would be
used to link the book to the authors.
In BigQuery, you can preserve the relationship between book and author without creating a separate author table. Instead, you create an author column, and you nest fields within it such as the author's first name, last name, date of birth, and so on. If a book has multiple authors, you can make the nested author column repeated.
Suppose you have the following table mydataset.books
:
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
You also have the following table, mydataset.authors
, with complete
information for each author ID:
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
If the tables are large, it might be resource intensive to join them regularly. Depending on your situation, it might be beneficial to create a single table that contains all the information:
CREATE TABLE mydataset . denormalized_books ( title STRING , authors ARRAY<STRUCT<id INT64 , name STRING , date_of_birth STRING >> , num_pages INT64 ) AS ( SELECT title , ARRAY_AGG ( STRUCT ( author_id , author_name , date_of_birth )) AS authors , ANY_VALUE ( num_pages ) FROM mydataset . books , UNNEST ( author_ids ) id JOIN mydataset . authors ON id = author_id GROUP BY title );
The resulting table looks like the following:
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery supports loading nested and repeated data from source formats that support object-based schemas, such as JSON files, Avro files, Firestore export files, and Datastore export files.
Deduplicate duplicate records in a table
The following query uses the row_number()
function to identify duplicate records that have the same values for last_name
and first_name
in the examples used and sorts them by dob
:
CREATE OR REPLACE TABLE mydataset . mytable AS ( SELECT * except ( row_num ) FROM ( SELECT * , row_number () over ( partition by last_name , first_name order by dob ) row_num FROM mydataset . mytable ) temp_table WHERE row_num = 1 )
Table security
To control access to tables in BigQuery, see Control access to resources with IAM .
What's next
- To insert and update rows with nested and repeated columns, see Data manipulation language syntax .