

PR
くぴん74
くぴんのブログへようこそ! 計算力学1級を持っているCAEエンジニアです。読んだ本の紹介を中心に日々の出来事などを綴っています。
フリーページ
おすすめCD
DREAM THEATER
EXTREME
DEF LEPPARD
MR.BIG
METALLICA
MEGADETH
LOSTPROPHETS
HOOBASTANK
TRAPT
FOO FIGHTERS
EAGLES

System Of A Down
ローンの計算方法
橘玲
クレジットカードのしくみ
大切な言葉集
この世界を混乱に導く悪魔のルール
ETF140銘柄チャート画像取得マクロ
エクセルVBAで高速フーリエ変換
株・資産運用
1.株式会社の始まり
2.資産形成の方程式
3.利回りに対する理解
4.単利と複利
5.債券価格
6.キャピタルゲインとインカムゲイン
7.株式投資の投資戦略
8.BS(貸借対照表)とPL(損益計算書)の関係
9.リスクと不確実性について
10.72の法則
11.家賃から物件価格を推定する方法
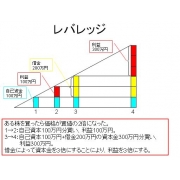
12.レバレッジ
13.ファンダメンタル指標
14.サラリーマンの生涯賃金
15.BPS+EPS×10の有効性
16. 裁定取引 (arbitrage)
fortran90で高速フーリエ変換
カレンダー
楽天ラッキーくじ更…
 New!
じゃっかすさん
New!
じゃっかすさん
2025年11月のまとめ。 New! みきまるファンドさん
DOW 47427.12 +314.6… どらりん0206さん
まさかの Maryu21さん
自分を愛することは… まりあのじいじさん
New!
じゃっかすさん2025年11月のまとめ。 New! みきまるファンドさん
DOW 47427.12 +314.6… どらりん0206さん
まさかの Maryu21さん
自分を愛することは… まりあのじいじさん
キーワードサーチ
▼キーワード検索
2016年02月21日

カテゴリ: 本の紹介
第1部 しくみと概要を学ぼう!
特集1 機械学習を使いたい人のための入門講座
特集2 機械学習の基礎知識
特集3 ビジネスに導入する機械学習
特集4 深層学習最前線
第2部 手を動かして学ぼう!
特集1 機械学習ソフトウェアの外観
特集2 Pythonによる機械学習
特集3 推薦システム入門
特集5 Jubatusによる異常検知
↓ぼくにとってのポイント
Pythonによる機械学習のscikit-learn入門から
線形回帰(linear regression)、ロジスティック回帰、サポートベクターマシン(SVM)、KMeansによるクラスタリングがコードとともに紹介されている。
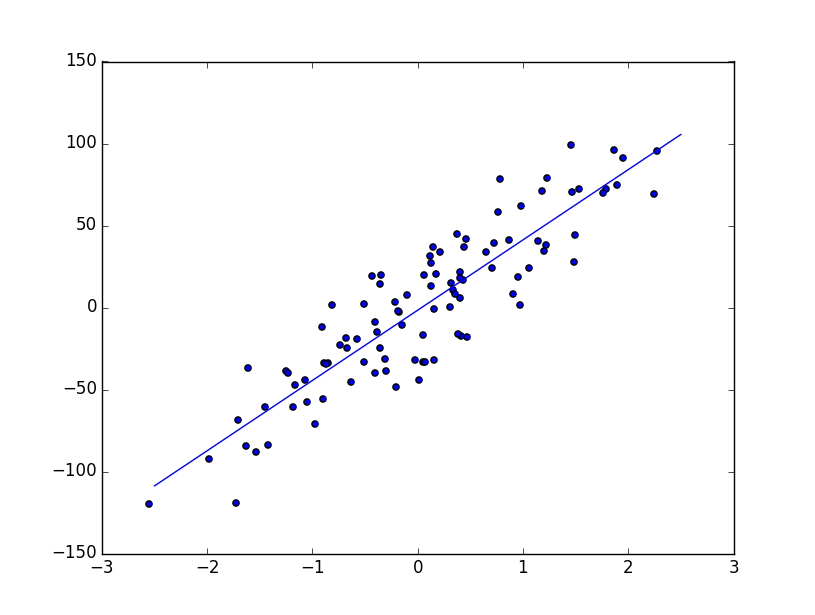
〇線形回帰(linear regression)
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model, datasets
np.random.seed(0)
regdata=datasets.make_regression(100,1,noise=20.0)
lin.fit(regdata[0],regdata[1])
print("coef and intercept :",lin.coef_,lin.intercept_)
print("score :", lin.score(regdata[0],regdata[1]))
xr=[-2.5,2.5]
plt.plot(xr,lin.coef_*xr+lin.intercept_)
plt.show()
↓結果
('coef and intercept :', array([ 42.85335573]), -1.6283636540614514)
('score :', 0.80333572865564484)
〇ロジスティック回帰
ロジスティック回帰は2値(0, 1など)をとる値に説明変数であてはめようとする手法。
以下は、あやめの測定値と種類(0または1)からあやめの傾向を学習し、測定値が与えられたときにあやめの種類が0か1を当てる。
# coding: utf-8
import sklearn.datasets as datasets
from sklearn.linear_model import LogisticRegression
from sklearn import cross_validation
iris=datasets.load_iris()
data=iris.data[iris.target !=2]
target=iris.target[iris.target !=2]
logi=LogisticRegression()
scores=cross_validation.cross_val_score(logi,data,target,cv=5)
print(scores)
↓結果
[ 1. 1. 1. 1. 1.]
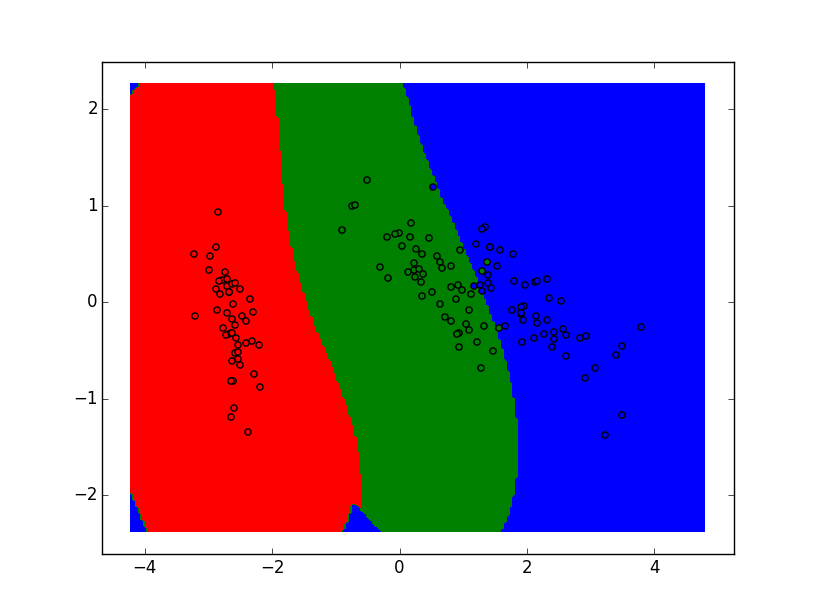
〇サポートベクターマシン(SVM)
あやめのデータの分類を可視化。
svc.fit(data,iris.target)で学習し、
z=svc.predict(np.c_[x.ravel(),y.ravel()])で予測している。
# coding: utf-8
from sklearn import datasets
from sklearn import svm
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
iris=datasets.load_iris()
pca=PCA(n_components=2)
data=pca.fit(iris.data).transform(iris.data)
datamax=data.max(axis=0)+1
datamin=data.min(axis=0)-1
n=200
x,y=np.meshgrid(np.linspace(datamin[0],datamax[0],n),
np.linspace(datamin[1],datamax[1],n))
svc=svm.SVC()
svc.fit(data,iris.target)
z=svc.predict(np.c_[x.ravel(),y.ravel()])
plt.contourf(
x,y,z.reshape(x.shape),levels=[-0.5,0.5,1.5,2.5],
colors=["r","g","b"])
for i,c in zip([0,1,2],["r","g","b"]):
d=data[iris.target==i]
plt.scatter(d[:,0],d[:,1],c=c)
plt.show()
↓結果
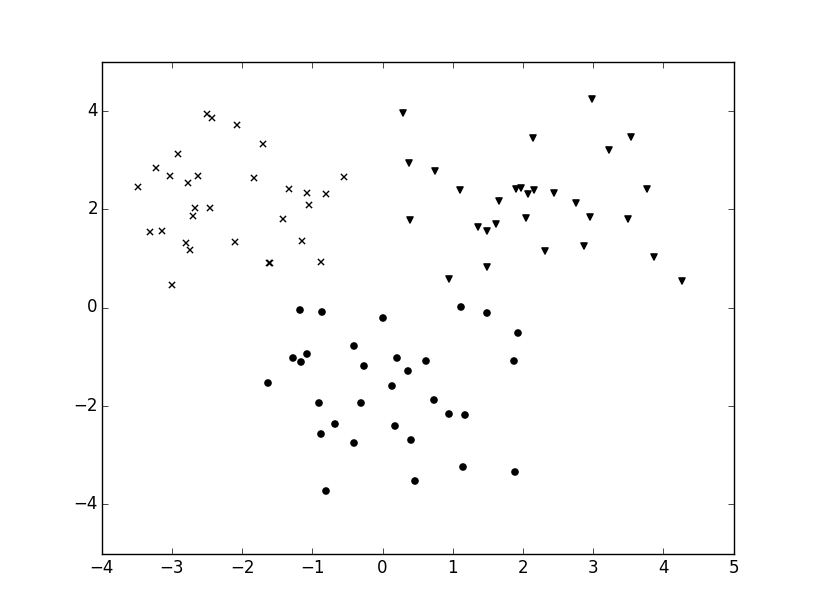
〇KMeansによるクラスタリング
教師なし学習の例。
n_clusters=3で3つに分類。
kmeans.fit(x)で学習させる。
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
np.random.seed(0)
x=np.r_[np.random.randn(30,2)+[2,2],
np.random.randn(30,2)+[0,-2],
np.random.randn(30,2)+[-2,2]]
kmeans=KMeans(n_clusters=3)
kmeans.fit(x)
markers=["o","v","x"]
for i in range(3):
xx=x[kmeans.labels_==i]
plt.scatter(xx[:,0],xx[:,1],c="k",marker=markers[i])
plt.show()
↓結果


にほんブログ村
特集1 機械学習を使いたい人のための入門講座
特集2 機械学習の基礎知識
特集3 ビジネスに導入する機械学習
特集4 深層学習最前線
第2部 手を動かして学ぼう!
特集1 機械学習ソフトウェアの外観
特集2 Pythonによる機械学習
特集3 推薦システム入門
特集5 Jubatusによる異常検知
↓ぼくにとってのポイント
Pythonによる機械学習のscikit-learn入門から
線形回帰(linear regression)、ロジスティック回帰、サポートベクターマシン(SVM)、KMeansによるクラスタリングがコードとともに紹介されている。
〇線形回帰(linear regression)
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model, datasets
np.random.seed(0)
regdata=datasets.make_regression(100,1,noise=20.0)
lin.fit(regdata[0],regdata[1])
print("coef and intercept :",lin.coef_,lin.intercept_)
print("score :", lin.score(regdata[0],regdata[1]))
xr=[-2.5,2.5]
plt.plot(xr,lin.coef_*xr+lin.intercept_)
plt.show()
↓結果
('coef and intercept :', array([ 42.85335573]), -1.6283636540614514)
('score :', 0.80333572865564484)
〇ロジスティック回帰
ロジスティック回帰は2値(0, 1など)をとる値に説明変数であてはめようとする手法。
以下は、あやめの測定値と種類(0または1)からあやめの傾向を学習し、測定値が与えられたときにあやめの種類が0か1を当てる。
# coding: utf-8
import sklearn.datasets as datasets
from sklearn.linear_model import LogisticRegression
from sklearn import cross_validation
iris=datasets.load_iris()
data=iris.data[iris.target !=2]
target=iris.target[iris.target !=2]
logi=LogisticRegression()
scores=cross_validation.cross_val_score(logi,data,target,cv=5)
print(scores)
↓結果
[ 1. 1. 1. 1. 1.]
〇サポートベクターマシン(SVM)
あやめのデータの分類を可視化。
svc.fit(data,iris.target)で学習し、
z=svc.predict(np.c_[x.ravel(),y.ravel()])で予測している。
# coding: utf-8
from sklearn import datasets
from sklearn import svm
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
iris=datasets.load_iris()
pca=PCA(n_components=2)
data=pca.fit(iris.data).transform(iris.data)
datamax=data.max(axis=0)+1
datamin=data.min(axis=0)-1
n=200
x,y=np.meshgrid(np.linspace(datamin[0],datamax[0],n),
np.linspace(datamin[1],datamax[1],n))
svc=svm.SVC()
svc.fit(data,iris.target)
z=svc.predict(np.c_[x.ravel(),y.ravel()])
plt.contourf(
x,y,z.reshape(x.shape),levels=[-0.5,0.5,1.5,2.5],
colors=["r","g","b"])
for i,c in zip([0,1,2],["r","g","b"]):
d=data[iris.target==i]
plt.scatter(d[:,0],d[:,1],c=c)
plt.show()
↓結果
〇KMeansによるクラスタリング
教師なし学習の例。
n_clusters=3で3つに分類。
kmeans.fit(x)で学習させる。
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
np.random.seed(0)
x=np.r_[np.random.randn(30,2)+[2,2],
np.random.randn(30,2)+[0,-2],
np.random.randn(30,2)+[-2,2]]
kmeans=KMeans(n_clusters=3)
kmeans.fit(x)
markers=["o","v","x"]
for i in range(3):
xx=x[kmeans.labels_==i]
plt.scatter(xx[:,0],xx[:,1],c="k",marker=markers[i])
plt.show()
↓結果
にほんブログ村
お気に入りの記事を「いいね!」で応援しよう
[本の紹介] カテゴリの最新記事
-
サトシ・ナカモトはだれだ? 世界を変え… 2025年10月26日
-
日本人拉致 2025年08月13日
-
最高の老後 「死ぬまで元気」を実現する5… 2025年07月12日




【毎日開催】
15記事にいいね!で1ポイント
© Rakuten Group, Inc.