
Seabornを使ってデータ相関を見てみる
Seabornとは
matplotlibではできないようなグラフを簡単に作ることができる。
なので、データ解析の際にあたりを見る際に使うのに便利なライブラリだ。
今回はsklearnのデータセットを使って自分でもグラフ作成をやってみた。
ちなみにsklearnとはscikit-learnのことで、機械学習のライブラリである。
このライブラリにはサンプルのデータが含まれている。
今回使うのは、その中の1つのサンプルデータだ。
早速、講座の復習がてら、いろいろを試してみた。
bostonのデータをつかって、住宅価格のとの相関するデータを見つけてグラフを見てみた。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston
#データの読み込み
bs = load_boston()
このbsのデータ型を調べるとsklearn.utils.Bunchというものらしい。
下記によると、dictionaryを拡張して、obj["member"], obj.member の両方でアクセスできるようにしたものらしい。
https://scikit-learn.org/stable/modules/generated/sklearn.utils.Bunch.html
データの中身を見てみよう。
bs.keys()
=> dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
data :データ
target :予測対象(住宅価格)
feature_names:予測に用いられる変数(下記参照)
DESCR:データの説明
filename:ファイルパス
●feature_namesのそれぞれの要素の意味
CRIM: 町別の一人当たりの犯罪率
ZN: 25,000平方フィートを超える区画にゾーニングされた住宅用地の割合。
INDUS: 町ごとの非小売業のエーカーの割合
CHAS: チャールズ川のダミー変数(路が川に接している場合は1、それ以外の場合は0)
NOX: 一酸化窒素濃度(1000万分の1)
RM: 住居あたりの平均部屋数
AGE: 1940年より前に建てられた持ち家の割合
DIS: 5つのボストン雇用センターまでの加重距離
RAD: 放射状高速道路へのアクセスの指標
TAX: 全額固定資産税-10,000ドルあたりの税率
PTRATIO: 町別の生徒と教師の比率
B: 1000(Bk-0.63)^ 2ここで、Bkは町ごとの黒人の割合
LSTAT: 人口の%低いステータス
MEDV: 1000ドルの持ち家の中央値
住宅の価格に相関しそうな要素はどれだろうか?
少なくとも、部屋の数(RM)は住宅の価格に相関していそうだ。
data, target:予測対象(住宅価格)を入れたデータフレームを作成する。
#pandas dataframe生成
bsdf = pd.DataFrame(np.c_[bs['target'],bs['data']] ,columns= np.append('target',bs['feature_names']))
データ:

Heatmap
まず、heatmapで相関があるものを見つける。
plt.figure(figsize=(10,10))
sns.heatmap(bsdf.corr(),annot=True)
結果:
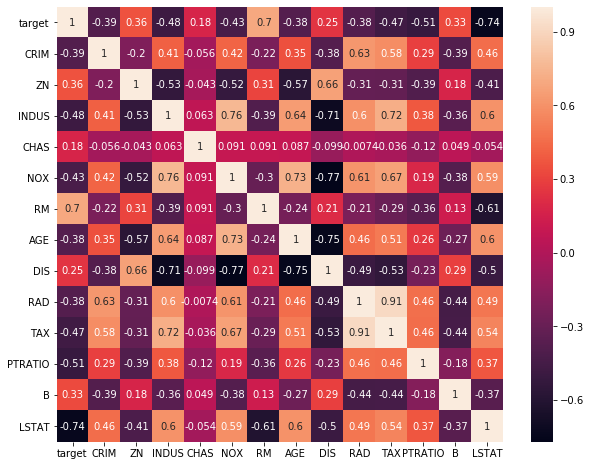
予想通りの左端列のtargetと"RM(0.7)", "LSTAT(-0.74)"が相関(逆相関)が強いのがわかる。
散布図
散布図のグラフも確認しておこう。scatterplotで表示させてみる。
sns.scatterplot(x='RM',y='target',data=bsdf)
結果:

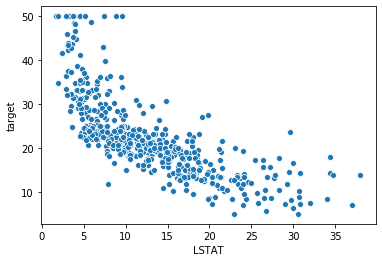
sns.scatterplot(x='LSTAT',y='target',data=bsdf)
結果:
なるほど、相関があるのが確認できた。
次はようやくファイナンシャルデータの分析に入る。
このコースへのリンク
Python & Machine Learning for Financial Analysis

全般ランキング
【このカテゴリーの最新記事】
-
- no image
- no image
- no image
- no image
