「文字列が他の文字列内で最初に現れる位置を返します。大文字と小文字は区別されます」
というExcelのヘルプを聞いてピンと来づらいかもしれませんが、とある文字(列)が、頭から何文字目に出てくるか、ということを調べる関数です。ちなみに、見つからなかった場合はエラーが返ります。
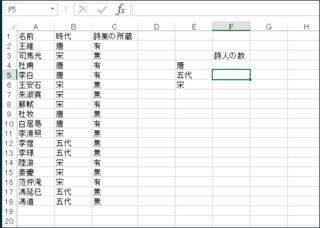
基本的な使い方は以下の通りです。OPACからコピーしてきたデータのうち「/」が何文字目にあるかを調べてみます。
「=find("/",A5,1)」と入れてみましょう。


「6」と返ってきます。このとき、空白を1文字として数えています。全角でも半角でも1文字です。FindBにすると、全角は2文字として扱われます。普通の業務で必要になる場面は少ないですが、頭に入れておいて損はないと思います。
大文字と小文字を区別するので、次のような場合、返ってくる値が変わります。

大文字の場合は、「by」のすぐ後の「S」の文字位置を返します。小文字の場合は「So」の次の「s」を返します。思っていた結果と違う場合、大文字小文字の違いが影響している場合があります。
この特徴を利用して、大文字でなければならないのに小文字が混ざっていないかを調べる、といったことも可能です。エラーが返ってきたものは小文字、ということになりますね。まあ、その場合はそもそも「UPPER」関数(小文字を大文字にする)や「LOWER」関数(大文字を小文字にする)を使ったほうが多分早いです。
もちろん、一文字だけでなく、単語や文章の有無をチェックすることもできます。

ここで返ってくる値は、「Natsume」の「N」の位置です。書誌データでは「/」「;」などを区切り記号に使いますが、普通にタイトルやその他の情報で使われることも多いため、「 / 」「 ; 」など、書誌規則と同じように、前後に半角スペースを入れて使うと、区切り位置を調べる時には便利でしょう。
また、これを利用して、一覧データから、特定の文字列を含むものだけを抜き出すのには使えます。Find関数を使ってエラーが返ってきたものを除外すればいいわけです。
他にも、開始位置を指定することもできます。「 ; 」以降の「s」の位置を知りたい、というときには、「 ; 」の文字位置を指定すれば、それ以後の「s」の位置を調べることができます。今回は30文字目なので、開始位置に「30」を指定します。

この時でも、返ってくる値は「先頭から何文字目」となります。以下のようにFind関数の開始位置にもう一度Find関数を組み合わせてあげれば、もっと柔軟に対応できますね^^

また、Mid関数やLeft関数といった関数と組み合わせるのもとても有効です。Mid関数の開始位置や、Mid関数、Left関数の文字数の指定に使うことで、大きなリストに対しても、柔軟に対応してくれます。


書誌のようにある程度の規則があるものに対しては有効です。明確な規則がなくても、一番多く使われているパターンに対してまずこれで抽出し、他を手動でコピペする、とするだけでも、だいぶ負担が軽くなると思います。
ただ、Find関数では位置を調べられない特殊記号があったり、ワイルドカードが使えないといった部分もあります。普段はあまりお目にすることがないと思いますが、それが影響することもあります。思うような結果が出ない場合は、特殊記号がないかどうかをチェックしてみましょう。
なお、Find関数によく似たものに、Search関数があります。普段使う分にはあまり変わらない関数ですが、実は奥が深い差があるのです。これはまた別でアップします。