

投資 0
[AIの勉強] カテゴリの記事
全38件 (38件中 1-38件目)
1
-
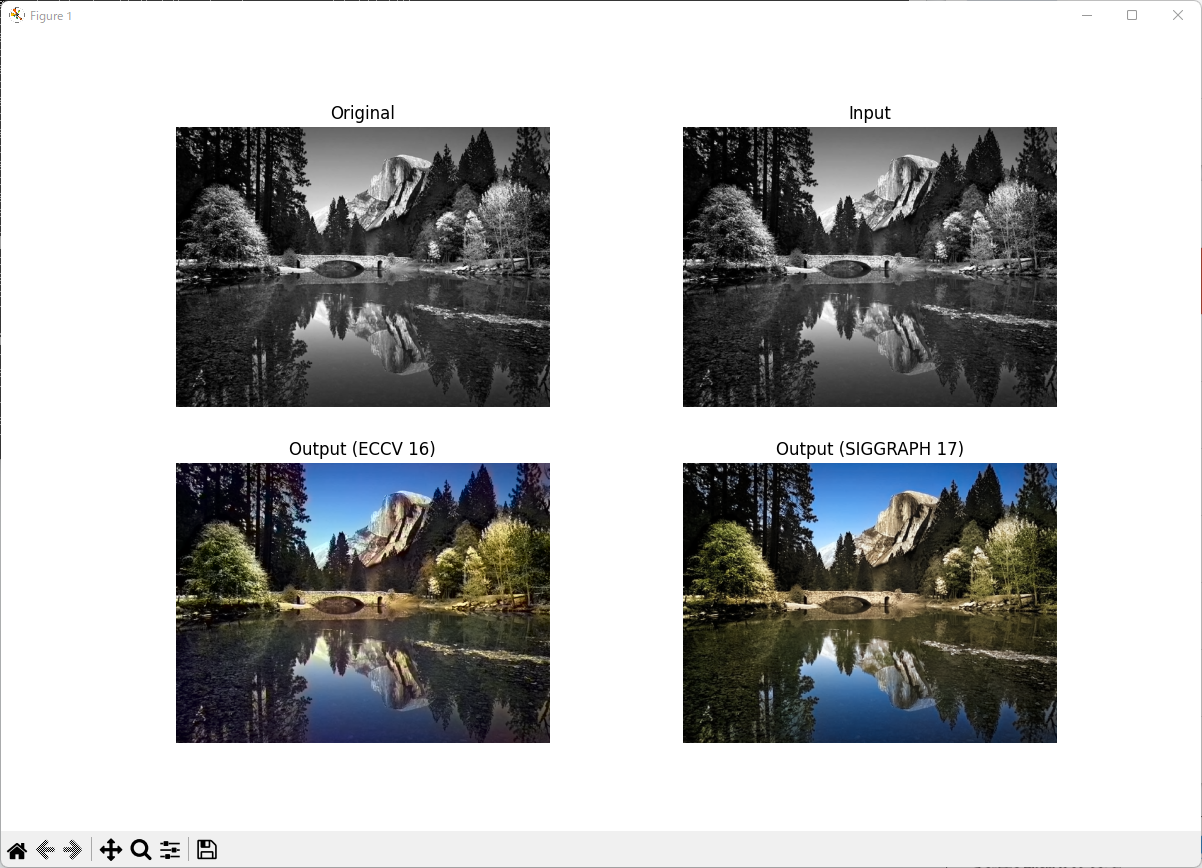
AIを使って白黒写真をカラー写真にしてみる。(colorization)
前回、解像度をあげてみたわけですが、あれは異常にGPUメモリーが必要でした。。。12GBのメモリ容量を誇るTeslaK40cでも900x600ぐらいが精いっぱいです。仕方ないので、分割して解像度をあげるも、合体したときに境目がどうしても見えてしまう問題があります。20GB以上のGPUが欲しいですねぇ。。。というわけで、今回は白黒写真をカラー写真化してみます。結論を言うと、それっぽい色が乗りますが、おそらく再現まではいかないだろうと思います。でもそれなりに面白いし、この処理はそれほど重くないので、ノートパソコンでも気軽にチャレンジできそうです。今回はAnacondaの環境構築からやっていきます。1.Anacondaをインストールする。https://www.anaconda.com/products/distribution上記サイトよりAnacondaのインストール用ファイルをダウンロードします。ダウンロードしたファイルを実行し適当にインストールします。2.Windowsの場合、gitをインストールします。AIをやる場合、プロジェクトよりPythonで動作する環境をgithubより取得することが多くなります。gitはインストールしておいたほうが楽なのでインストールします。https://gitforwindows.org/上記サイトよりGit for Windowsをダウンロードしこちらも適当にインストールします。3.AnacondaでPython3.9の環境を作成します。まず、スタートメニューからAnaconda Promptを起動します。黒いウインドウが表示され、コマンドを受けつける状態になっています。(base) C:\Users\User名>そこに以下のコマンドを入力することでAnacondaにPython3.9の環境を作成できます。今回は「colorization」という名前で環境を作成します。(base) C:\Users\User名>conda create -n colorization python=3.9上記コマンドを入力後Enterキーを押下すると、y/nの質問で止まりますのでyを押します。あとは待っていれば環境が作成されます。3.Anacondaで新しく作成した環境を利用します。以下のコマンドを実行し、新しく作成した「colorization」という環境にします。(base) C:\Users\User名>conda activate colorization4.gitよりスクリプトをダウンロードします。以下のコマンドを実行し、gitよりスクリプトを取得します。(colorization) C:\Users\User名>git clone https://github.com/richzhang/colorization5.必要なライブラリをインストールします。まず、ダウンロードしたスクリプトのフォルダに移動します。(colorization) C:\Users\User名>cd colorization次にライブラリをインストールします。(colorization) C:\Users\User名\colorization>pip install -r requirements.txtするとskimageでこけました。scikit-imageをインストールしなさいっていうメッセージなので、skimageの代わりにsckit-imageにします。requirements.txtをメモ帳などでひらくと、以下のように記載があります。torchskimagenumpymatplotlibargparsePILskimageをscikit-imageに変更し、PILも多分だめなのでPillowに変更します。結果、requirements.txtは以下のようになりました。torchscikit-imagenumpymatplotlibargparsePillow上記コマンドを再度実行し、しばらく待つとインストールが完了します。6.テスト実行します。とりあえず、パッケージに含まれる画像をカラー化してみます。カラー化するコマンドは以下の通りです。-i以降がカラー化する画像ファイル名になります。(colorization) D:\AI\APs\colorization>python demo_release.py -i imgs\ansel_adams3.jpg動きません。ライブラリが足りないようデス。以下のコマンドを実行して足りないライブラリをインストールします。(colorization) D:\AI\APs\colorization>pip install IPython再度、カラー化のコマンドを動かします。今度は成功です。成功すると、以下のようなウィンドウが表示されます。このウィンドウは×で閉じて構いません。上記画像のした二つの画像については、colorizationのフォルダに「saved_eccv16.png」「saved_siggraph17.png」というファイルで保存されています。7.本当にカラー化されているのか?カラー画像をグレースケールにしてAIでカラーにして比べてみます。左からオリジナル、グレースケール、AIカラー1、AIカラー2の順番です。カラー化はされていますが、なんだか色あせた写真って感じになっていますね。緑とか赤とか現職が再現しにくそうですね。とはいっても、白黒写真しかない場合はなんかそれらしいカラーがつくので、面白いといえば面白いですね。
2023年02月14日
コメント(0)
-

AIを使って写真の解像度を上げてみる(SwinIRを使ってみる)
久しぶりにAI関連についてです。AIって最近ではニュースでよく聞きますよね。ChatGPTが巷ではだいぶ大きく報道されているみたいですね。私もちょっとみてみましたが、本当に人間を相手にチャットしている感じで驚きました。プログラムの例とかも勝手に作ってくれますし、そのうち仕様書渡したらプログラムは組んでくれそうですね。さて、そういったチャットAIの話ではなく、今回は写真の解像度を上げて見る話です。左の写真が右のようになります。昔撮影した古いデジカメデータや容量を少なくするために解像度を落としたデータなどの画像データの解像度をあげあげにしてくれるAIの話です。今回は環境さえあれば、特に難しくはないのですが、この解像度を上げる処理はメモリーをバカ喰いしますので、あまり解像度の高い画像をさらに上げるってことには向いてないです(できなくはないでしょうが、どうなんでしょうね)。今回はWeb用に保存された1000x600程度の画像を4倍にしてみます。以下の流れでやっていきます。1.gitより環境を作成する。git clone https://github.com/JingyunLiang/SwinIRhttps://github.com/JingyunLiang/SwinIR2.pythonの環境を整える。このSwinIRはPytorchを利用していますんで、その環境が必要になります。カレントディレクトリ(上記gitコマンドで作成されたSwinIRというフォルダ)にある、「main_test_swinir.py」のimport文を参照して、必要そうなモジュールをpipで入れていきます。Detectron2やMMdetectなどの環境があれば、ほぼその環境で動作します。私が追加したのは、以下のライブラリです。pip install timm3.学習済みモデルをダウンロードする。次に学習済みモデルをgitよりダウンロードします。https://github.com/JingyunLiang/SwinIR/releases/tag/v0.0上記サイトより、「003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth」をダウンロードしカレントディレクトリに配置します。4.テストデータで動かしてみる。以下のコマンドを利用して、用意されているテストデータを使い高解像度化を行ってみます。python main_test_swinir.py --task real_sr --model_path 003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth --folder_lq testsets/RealSRSet+5images --scale 4 --large_model結果が「SwinIR\result\swinir_real_sr_x4_large」に配置されます。4倍に解像度が増えています。色々やってみて一つ問題となるのは、文字についてです。文字はいい感じで修復というか読めるようにはなりません。この高解像化は見た目いい感じに高解像度化してくれるって感じのものになります。5.独自データで試してみる。さて、独自のデータ(うちのワンちゃん)でやった結果は冒頭にある通りなのですが、色々と写真を並べてみます。まずはオリジナル。4800X3200のサイズです。縮小したAIに放り込むサイズです(4分の1にしています)1200x800です。そして、AIで4倍に拡大して元のサイズにした画像が次の通りです。GPUのメモリーが足りないので、4分割して合体させているのでよく見ると、結合あとが見えますね。。。GPUメモリー12GBでは足りないってことなのでしょう。。。わかりやすいように。目の部分を拡大してみます。左がオリジナル、真ん中が縮小された画像、右がAIによる高解像度化さらに拡大してみます。ちょっとまって。AIの高解像度化のほうがオリジナルより改造間があるように見えますが。。。。なんか、すごい技術ですよねーAIって。
2023年02月13日
コメント(0)
-
DeeplabV3+の環境を構築
iPhoneでCoreMLを試してみるために、CoreMLのモデルを作りたいところなのですが、今まで、作成してきたPytorchを利用したModelではなかなか変換の難易度が高すぎてとりあえず断念しました。というわけで、別のモデルを検討していたのですが、どうやらTensorflowを利用したDeeplabV3+がよさげな感じだったので、そちらのほうで構築をすることにしました。まずは、DeeplabV3の実施環境を整えることから始めます。TensorflowにはObjectDetectionAPIというものがあり、そちらのほうに学習や推測のサンプルが用意されています。ですので、そちらをとりあえずGitより取得します。※Windows版のGitがインストールされていることが前提です。(https://gitforwindows.org/) c:\>git clone https://github.com/tensorflow/modelsこの取得した環境には色々なモデルのサンプルなどがありますが、その中にDeeplabV3+があります。では学習に行きたいってところですが、その前にPythonの環境を整える必要があります。今回環境はAnacondaで構築したいと思います。Anacondaがすでにインストールされているものとします。(https://www.anaconda.com/products/distribution)まず、AnacondaPromptを立ち上げます。そこに以下のコマンドを利用して新しい環境を構築します。 (base) C:\Users\hoge> conda create -n deeplab python=3.6 (base) C:\Users\hoge> conda activate deeplab (deeplab) C:\Users\hoge>必要となる各種パッケージを導入するわけですが、TensorflowのバージョンとNumpyのバージョンで引っかかったんで、とりあえず、Numpyをバージョン指定で導入します。 (deeplab) C:\Users\hoge> conda install numpy=1.16.4次にTensorflowをバージョン指定でインストールします。Tensorflowはバージョン1系と2系でソースコードの書き方が大きく変更されていますので、必ずバージョン1系とします。バージョン1系であれば1.13、1.14、1.15のいずれでも大丈夫だと思いますが、私はバージョン1.14を選択しました。 (deeplab) C:\Users\hoge> conda install tensorflow-gpu=1.14あとはバージョンを気にせずに必要なパッケージを導入していきます。ちなみに私の環境のconda listはこんな感じです。# Name Version Build Channel_tflow_select 2.1.0 gpuabsl-py 0.15.0 pyhd3eb1b0_0astor 0.8.1 py36haa95532_0attr 0.3.2 pypi_0 pypiattrs 22.1.0 pypi_0 pypiblas 1.0 mklca-certificates 2022.6.15.1 h5b45459_0 conda-forgecertifi 2021.5.30 py36haa95532_0colorama 0.4.5 pypi_0 pypicoremltools 4.1 pypi_0 pypicudatoolkit 10.0.130 0cudnn 7.6.5 cuda10.0_0cycler 0.11.0 pyhd3eb1b0_0dataclasses 0.8 pyh4f3eec9_6freetype 2.10.4 hd328e21_0gast 0.5.3 pyhd3eb1b0_0grpcio 1.35.0 py36hc60d5dd_0h5py 2.10.0 py36h5e291fa_0hdf5 1.10.4 h7ebc959_0icc_rt 2019.0.0 h0cc432a_1icu 58.2 ha925a31_3importlib-metadata 4.8.1 py36haa95532_0importlib-resources 5.4.0 pypi_0 pypiintel-openmp 2022.1.0 h59b6b97_3788jpeg 9e h2bbff1b_0keras-applications 1.0.8 py_1keras-preprocessing 1.1.2 pyhd3eb1b0_0kiwisolver 1.3.1 py36hd77b12b_0lerc 3.0 hd77b12b_0libdeflate 1.8 h2bbff1b_5libpng 1.6.37 h2a8f88b_0libprotobuf 3.17.2 h23ce68f_1libtiff 4.4.0 h8a3f274_0lz4-c 1.9.3 h2bbff1b_1markdown 3.3.4 py36haa95532_0matplotlib 3.3.2 haa95532_0matplotlib-base 3.3.2 py36hba9282a_0mkl 2020.2 256mkl-service 2.3.0 py36h196d8e1_0mkl_fft 1.2.0 py36h45dec08_0mkl_random 1.1.1 py36h47e9c7a_0mpmath 1.2.1 pypi_0 pypinumpy 1.16.4 py36h19fb1c0_0numpy-base 1.16.4 py36hc3f5095_0olefile 0.46 py36_0opencv 3.3.1 py36h20b85fd_1openssl 1.1.1q h8ffe710_0 conda-forgepackaging 21.3 pypi_0 pypipillow 8.3.1 py36h4fa10fc_0pip 21.2.2 py36haa95532_0protobuf 3.17.2 py36hd77b12b_0pyparsing 3.0.4 pyhd3eb1b0_0pyqt 5.9.2 py36h6538335_2pyreadline 2.1 py36_1python 3.6.13 h3758d61_0python-dateutil 2.8.2 pyhd3eb1b0_0qt 5.9.7 vc14h73c81de_0scipy 1.5.2 py36h9439919_0setuptools 58.0.4 py36haa95532_0sip 4.19.8 py36h6538335_0six 1.16.0 pyhd3eb1b0_1sqlite 3.39.2 h2bbff1b_0sympy 1.9 pypi_0 pypitensorboard 1.14.0 py36he3c9ec2_0tensorflow 1.14.0 gpu_py36h305fd99_0tensorflow-base 1.14.0 gpu_py36h55fc52a_0tensorflow-estimator 1.14.0 py_0tensorflow-gpu 1.14.0 h0d30ee6_0termcolor 1.1.0 py36haa95532_1tf_slim 1.1.0 pyhd3deb0d_1 conda-forgetk 8.6.12 h2bbff1b_0tornado 6.1 py36h2bbff1b_0tqdm 4.64.1 pypi_0 pypityping_extensions 4.1.1 pyh06a4308_0vc 14.2 h21ff451_1vs2015_runtime 14.27.29016 h5e58377_2werkzeug 2.0.3 pyhd3eb1b0_0wheel 0.37.1 pyhd3eb1b0_0wincertstore 0.2 py36h7fe50ca_0wrapt 1.12.1 py36he774522_1xz 5.2.5 h8cc25b3_1zipp 3.6.0 pyhd3eb1b0_0zlib 1.2.12 h8cc25b3_3zstd 1.5.2 h19a0ad4_0基本的にcondaを利用してインストールしていますが、condaでインストールできない場合はpipでインストールしています。上記で環境が整いましたんで、次回はデータを揃えます。
2022年09月26日
コメント(0)
-
XcodeでDeeplabV3+のセグメンテーションをやってみた。
前回までにiOSにて使えるCoreMLモデルをDeeplabV3より変換させてみましたが、Xcodeでのアプリ作成がまだまだ実力不足でなかなかプログラム化するのが難しく、いまさらながらXcodeとSwiftの勉強をやっています(笑)さて、とは言ったものの、折角作ったModelファイルですので、どうにか簡単にちゃんと動作するのか見てみたいということで、いろんな人が作成しているプログラムを探してみました。んで見つけたプログラムが以下のリンクhttps://github.com/tucan9389/SemanticSegmentation-CoreMLここで利用しているCoreMLモデルを自分で作ったCoreMLモデルに変えるだけの簡単な変更でちょっと試してみました。今度はこのプログラムを参考にして、自分でプログラミングしてみたいところです。あと、Deeplabのモデルが反応してほしい物体とは別の物体にも反応するので、それを再度どうにかならないかと思案中です。転移学習の場合だと仕方ないのでしょうかねぇ・・・・
2022年09月21日
コメント(0)
-
Xcodeでswift 1日目
エッジ抽出をAIでできるようになって、APIも作成したけど、iOSのアプリで実装してみたくなり、今更ながらswiftを勉強することにしました。とりあえず、「Hello Swift!」って表示されるプログラムから始めます。書き方のお作法はまだまだよく分からないですが、本を見ながらカメラの起動とカメラで撮影した後、画面い表示させるところまで出来ました。次は写真で撮影させた画像をAIに通しマスク画像を表示させるところまでやりたいです。
2022年09月18日
コメント(0)
-
AIでSegmentationをやってみた
1ヶ月半程度AIでSegmentationを勉強して色々と教育してモデルデータを作成してきました。YolactやDetectron2、MMdetectionなどなど、色々と試してみました。最初は何もわからない状態だったんでWebページのサンプルややってみた情報を元に試してはうまく行かず、というのを繰り返していましたが、ようやく、スタート地点に立てたかなーって思います。きっかけは名刺のエッジ抽出でした。最初はOpenCVを利用して画像の調整をしエッジの抽出を行うことを考えたのですが、コントラストの状況によって、画像の調整ができたりできなかったり。。。。やはり限界がある感じで、そこまで劇的に良い結果は得られませんでした。そこで、ディープラーニングを利用したオブジェクトディテクションを試してみることにしました。最初はオブジェクトディテクションという物体を検知するというところからはじめ、Yolo3やFasterRNNなどのボックスタイプのオブジェクトディテクションをやってみて、なかなか精度が高いって言うことがわかったので、エッジの抽出方法について色々と調べました。すると、Segmentationという物体を検知した上で、そのエリアをあわせて検知するという物があることを知り、そちらを試してみることに。そこからが大変でした。名刺を学習させるにはそれなりの画像数とアノテーションデータそれから学習させる環境が必要になります。その時持っていたパソコンはMacbookPro2016 13インチ、自作デスクトップ(PhenomII1055T、RadeonR9)ということで、GPUがある自作デスクトップを利用しようと思ったのですが、なんと、Radeon系では高いハードルが更に激高くなりそうだったので、ハードウェアの調達からはじめました。ヤフオクでHPのワークステーションZ440を購入しGPUを購入して環境を整えたのですが、やはり、中古やジャンク系で揃えるのはおすすめしません。(結果、とりあえず、環境は整いましたが、大変な苦労をしました。)まず、GPUにはQuadroK2200がZ440に付属していたのでそれではじめましたが、GPUメモリが4GBしかなく、また、CUDAの性能もそこまで高くなく、それなりに時間がかかるのと、そもそもメモリ不足で学習できないという問題にぶち当たりました。そこで、ヤフオクでTeslaK40を購入しました。14000円程度の出費でしたが、どうせなら、3万円程度を捻出しRTX2060を購入したほうが良いかもしれません。AI学習性能的にはRTX2060のほうがもちろん高性能ですが、価格が2倍となっていて、2倍の性能差があるかというとそういうわけでもなく。さて、TeslaK40を購入したことに今は満足していますが、当初は後悔しました。その理由は、Cuda Computing Capabillityのバージョンの問題でした。ディープラーニングをPythonでやろうとしたときに、大きく2つの方法があります。一つはTensorflowを利用する方法。もう一つはPytorchを利用する方法です。他にも方法はありますが、Segmentationを利用しようとして日本語のWebページに情報がそれなりにあるのはこの二つです。そして、既にやっていたYolactやDetectron2はPytorchを利用します。Quadro K2200で問題なく実施できていたので、あまり考えなかったんですが、Quadro K2200のCuda Computing Capabillityは3.7。Tesla K40は3.5なのです。たった0.2なのですが、Pytorchの公式で配信されているpipやcondaでインストールできるビルドずみのものは3.5以下はサポートしないってなっています。なので、3.5のTeslaで実行させようとした場合、ソースからビルドする必要があり、環境構築その他がかなり面倒でした。2週間ぐらいあーでもない、こーでもないって悩みながらようやくできた感じでした。ただ、他のアプリケーションを利用する場合にそのバージョンで動かないとなると、再度バージョンを変えてリビルドする必要があり、かなり面倒なことになります。これから環境を整えるのであれば、Pytorchが動作するCuda Computing Capabillityバージョンを選択することをお勧めします。そして、色々とエッジ抽出のAIを試しましたたが、結果、速度と精度のバランスはYolactが良さげでした。MMdetectionでModelをYolactで学習させた結果であれば、CPUでも3秒程度で認識ができます。精度ではMask2Formerが良かったです。これは認識にCPUで実行すると10秒〜11秒程度かかって遅い感じです。あと、Deeplav v3ですね。これは、TensorflowのObjectDetectionでやってみました。これも精度はだいぶ良いです。速度はGPUを使わないと10秒程度かかってしまいますので、ちょっと遅いですね。ただ、これを選択した理由としては、CoreMLに変換が容易だったからです。結局、Pythonで作成した認識ツールをWeb APIで構築してみてはいるのですが、やはり、早いと言っても1枚につき4秒かかると、大量のアクセスには耐えれそうにありません。というわけで、スマホアプリで認識させることを念頭においたわけですが、その場合、iOSであればCore MLを利用する形になりそうなので、変換するのが容易なこのModelを選択してみました。結果、CoreMLへの変換及びXcodeでの読み込みと簡単なプレビューができました。一旦、名刺画像を写真から認識するAIについてはここまでとし、次はiOSアプリでそのAIを利用して名刺を認識させるアプリを作成してみたいと思います。
2022年09月17日
コメント(0)
-
マウスを使いすぎると手首にダメージが来るわけで。。。
最近、AIの勉強を始めてからマウスの利用頻度が多くなりました。理由はアノテーション用のデータを作成しなければならないから。。。vottやlabelmeなど、GUIにてアノテーション用のデータを作成できるツールがあり、とっても便利ではあるのですが、画像を見ながら意味づけするタグの部分を囲う作業はマウスを駆使します。そして、かなり手首に負荷をかけているようです。最近、右手首にふとした時、激痛が走ります。。。orzということで、マウス運用を改めようかと検討中です。今まではキーボードをたたいている時間が長く、マウスを可能な限り触らないような操作ばかりしていましたが、アノテーションを行う作業はそうはいきません。なので、マウスを長時間利用しても手首が痛くならない何かを探さないといけないと感じています。マウスを持つ右手の手首のところに置くリストレストが一つの案としてあります。こんなやつですね。よく、書斎系ユーチューバーの方が利用されている感じです。ちょっとおしゃれ。あとは、マウスではなくトラックボールを使うといったもの。トラックボールは慣れが必要ですが、慣れると楽だという話をよく聞きます。私が知っている人も何人か利用していますが、利用し始めるとそれが楽で離れることができなくなる模様ですwデメリットとしては種類が少ないのと、マウスに比べて価格が高いですかねー。あとは掃除をしなければならないってことでしょうかwオフホワイトのボディがいいですね。しばらく様子をみて、やはり手首の痛みが引かないようだったら、どっちか買ってみたいと思います。
2022年08月27日
コメント(0)
-
detectron2-->mmdetection
現在、detectron2を利用して画像認識を色々と試行錯誤しているのですが、調べていると、MMDetectionというものがあり、こちらの方が活発に活動されている様です。こちらを次は試してみたいと思います。環境はPytorchが動けば他はおおむね問題なさそうですが、Configの書き方などは独自っぽいので、そこは今から色々調べてみる必要がありそうです。MMDetectionは利用できるモデルも豊富で選択肢がさらに増えそうです。
2022年08月27日
コメント(0)
-
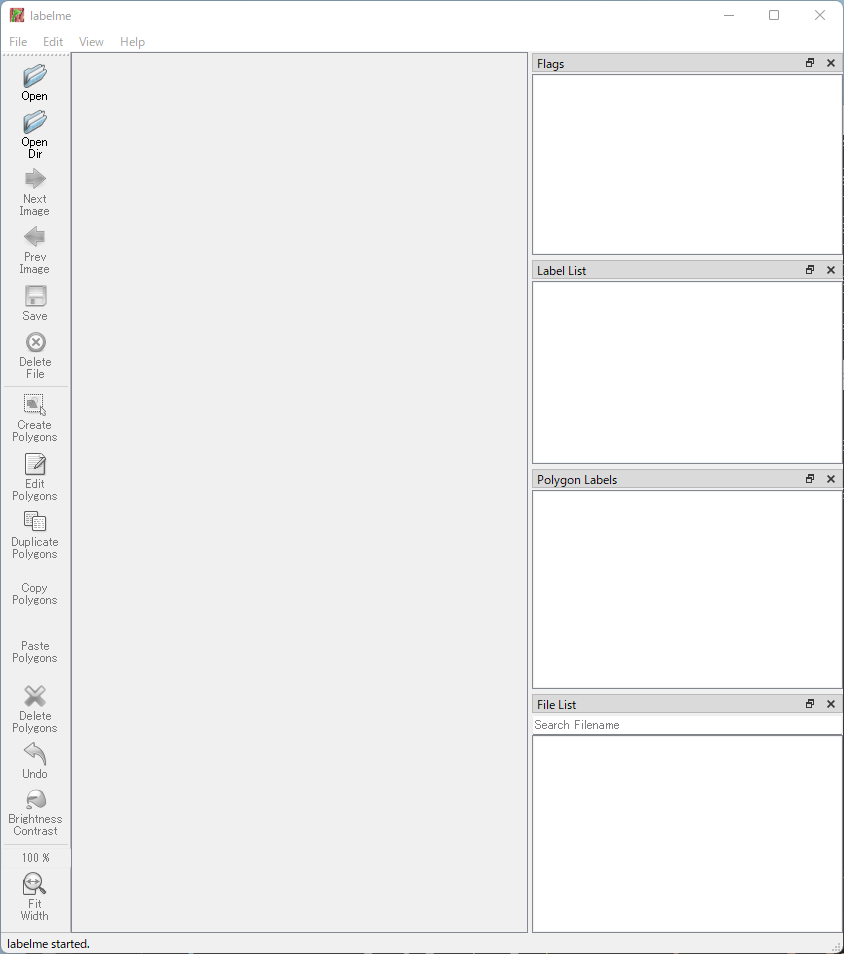
detectron2で独自データを学習させてみる
detectron2の環境が整いましたんで、独自データを学習させてみたいと思います。1.学習データの準備まず、学習用データを準備します。用意するデータは学習させたい画像データとその物体を囲ったデータとなります。detectron2では様々な形式の学習データを利用することができそうですが、ここではCOCOという形式のデータにしたいと思います。1)学習用の画像データ(Jpgなど)をそれなりの数集める。 ※今回私は1000程度の画像データを用意しました。2)教育データを作成するためのアプリを実行させる環境を作成する。 ・Anacondaで環境を作成しているのであれば、Python3.6の環境を用意します。 Anacondaのコマンドプロンプトで以下のコマンドを発行します。 (base) C:\> conda create -n wk_py36 python=3.6 (base) C:\> conda activate wk_py36 (wk_py36) C:\> python -m pip install pip setuptools --upgrade (wk_py36) C:\> pip install labelme Python3.6の環境を作成 →その環境を利用する →アプリのインストールコマンドの最新化 →アプリのインストール という流れのコマンドになっています。3)labelmeを利用して学習データを用意する。 この作業が最も面倒ですが、1枚1枚の画像に対し、物体の位置を囲う作業(手作業)となります。 Anacondaのコマンドプロンプトで以下のコマンドを実行することでLabelmeを起動できます。 (wk_py36) C:\> labelme Labelmeが起動すると以下の画面になります。左上にある、「OpenDir」をクリックして画像を保存しているフォルダを選択します。フォルダを選択すると、FileListにそのフォルダに保存されている画像が一覧で表示され、選択された画像がメインのエリアに表示されます。こんな感じですね。次に、教育させたい物体を囲います。左にある「CreatePolygons」をクリックし、学習させたい物体を囲います。囲うと以下のような画面が出ますんで、物探の名前を付けてOKをクリックします。物体に名前を付けると、LabelListにその名前が表示され、Polygon Labelsにもその名前が表示されます。また、Label Listの名前の右にある●の色と同色に囲った線が変わります。これでこの画像の設定は終わりですので、左のメニューにある「Next Image」をクリックし次の画像へ移動します。すると、保存しますか?的なWindowsが表示されるので「Save」をクリックして保存します。これをすべての教育用画像に行っていきます。4)Labelme教育用データをCOCO形式へ変換する。 ・変換用のライブラリをインストールする。 環境はPython3.6の環境でも問題ないので、その環境を利用して変換ライブラリーをインストールします。 (wk_py36) C:\> pip install -U labelme2coco ・インストールしたら変換用のプログラムを作成します。# import packageimport labelme2coco# set directory that contains labelme annotations and image fileslabelme_folder = "C:/Temp/Pen/"# set export direxport_dir = "C:/Temp/Teach/"# set train split ratetrain_split_rate = 0.85# convert labelme annotations to coco# labelme2coco.convert(labelme_folder, export_dir, train_split_rate)labelme2coco.convert(labelme_folder, export_dir) Gitにあるサンプルプログラムをまるコピーしても動作しそうなのですが、Python3.6の環境が古いのかそのままでは動作しなかったため、train_spilit_rateを引数から外したら動作しました。この引数は教育用データと確認用データの比率を設定できそうな気配がするのですが、動かなかったんでよくわかりません。※後からPython3.10の環境で実行したところ、train_split_rateの引数があっても動作しました。やはり、教育データと確認データの比率っぽいです。変換されたJSONファイルとイメージファイルのパスを学習用プログラムで利用します。2.学習プログラムの作成それでは、学習用のプログラムを作成していきます。以下のプログラムを作成します。import detectron2from detectron2.utils.logger import setup_loggersetup_logger()# import some common librariesimport numpy as npimport os, json, cv2, random# import some common detectron2 utilitiesfrom detectron2 import model_zoofrom detectron2.engine import DefaultPredictorfrom detectron2.config import get_cfgfrom detectron2.utils.visualizer import Visualizerfrom detectron2.data import MetadataCatalog, DatasetCatalogfrom detectron2.data.datasets import register_coco_instancesfrom detectron2.engine import DefaultTrainerdef main(): register_coco_instances("pen_Train", {}, "C:/Temp/train.json", "C:/Temp/Image/") register_coco_instances("pen_Valid", {}, "C:/Temp/val.json", "C:/Temp/Image/") cfg = get_cfg() cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")) cfg.DATASETS.TRAIN = ("pen_Train",) cfg.DATASETS.TEST = ("pen_Valid",) cfg.DATALOADER.NUM_WORKERS = 16 cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml") # Let training initialize from model zoo cfg.SOLVER.IMS_PER_BATCH = 8 cfg.SOLVER.BASE_LR = 0.1 # pick a good LR cfg.SOLVER.MAX_ITER = 1000 # 300 iterations seems good enough for this toy dataset; you will need to train longer for a practical dataset cfg.SOLVER.STEPS = [] # do not decay learning rate cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 512 # faster, and good enough for this toy dataset (default: 512) cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # 1クラスのみ cfg.TEST.EVAL_PERIOD = 500 #cfg.MODEL.DEVICE = "cpu" os.makedirs(cfg.OUTPUT_DIR, exist_ok=True) #trainer = DefaultTrainer(cfg) trainer = DefaultTrainer(cfg) trainer.resume_or_load(resume=False) trainer.train()if __name__ == '__main__': main()代替コピペで大丈夫ですが、1で用意したデータの保存場所の変更をします。 register_coco_instances("pen_Train", {}, "train.jsonのパス", "イメージを保存しているフォルダのパス") register_coco_instances("pen_Valid", {}, "val.jsonのパス", "イメージを保存しているフォルダのパス")また、検証データを用意していない場合は、以下の箇所をコメントアウトもしくは修正すればOKだと思います。#コメントアウト#register_coco_instances("pen_Valid", {}, "C:¥Temp/val.json", "C:/Temp/Image/")#修正cfg.DATASETS.TEST = ()#コメントアウト#cfg.TEST.EVAL_PERIOD = 500 学習状況をみて修正する場所は大体以下の箇所になるかと思います。 '処理が重いようだったら数字を少なくする。2~4程度がよいと思われる。 cfg.DATALOADER.NUM_WORKERS = 16 'メモリが足りないようだったら数字を少なくする。 cfg.SOLVER.IMS_PER_BATCH = 8 'Learning Rateと呼ばれるもので、学習率のこと。大きいほど学習が早いが、最適解にたどり着けない可能性もある。数字を変えて色々試すべし。 cfg.SOLVER.BASE_LR = 0.1 # pick a good LR ’学習回数。よくepochsなどと言われるもの。 cfg.SOLVER.MAX_ITER = 1000 'イメージのサイズ(と思う。)大きくするとメモリ消費が大きくなるのでメモリ足りない場合は小さく。 cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 512 # faster, and good enough for this toy dataset (default: 512) '学習させたい物体の種類。今回はペンだけなので1。 cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # 1クラスのみ ’nVIDIAのGPUが載っていない場合やRadeon系でPytorchをビルドしていない場合などはGPUが利用できないため、このコメントアウトを外してCPUで実行する。(めちゃめちゃ時間がかかるので、上記パラメータで処理を軽くして実行することをお勧めします。) #cfg.MODEL.DEVICE = "cpu"私は500枚ぐらいの学習データを用意して上記設定でTESLA K40cをフルに利用して約1時間30分~2時間程度の実行時間がかかります。なので、Quadro K2200であれば4時間程度、Xeon E5-2698v3のCPU実行であれば、12時間~20時間程度かかるのではないかと思います。
2022年08月23日
コメント(0)
-
detectron2を利用してみる。
detectron2とは、Facebook AI Researchが開発したPytorchベースの物体検出ライブラリです。detectronとMask R-CNN Benchmarkの後継となるライブラリです。さまざまな物体検出のライブラリを試していますが、なかなか、容易に環境の構築ができず自分の技術力のなさを感じてしまいます。さて、このdetectron2ですが、セットアップを行いインポートモジュールとして動作するようです。ソースコードをダウンロードし、Pythonでsetup.pyを叩く感じです。ただ、このセットアップが正常終了しなかったりするので面倒なところです。基本的にPytorchをビルドする環境があれば、問題なさそうです。さて、私の環境ではPytorchをビルドする必要があるため、その環境が整っています。なので、detectron2をビルドします。問題なく正常終了しました。ただ、簡単な確認用プログラムを作成し動作確認すると、エラーが発生します。。。そのエラーはnumpyのエラーでした。numpyのインポートでエラーが発生するわけですが、もちろんnumpyはインストールされています。色々と調べてみると、numpyを再インストールすると治るよ?という事でしたので、numpyを再インストールしてみました。numpyのエラーは無くなったものの、以下のエラーが発生します。これにはどうにもわかりませんでした。RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase. This probably means that you are not using fork to start your child processes and you have forgotten to use the proper idiom in the main module: if __name__ == '__main__': freeze_support() ... The "freeze_support()" line can be omitted if the program is not going to be frozen to produce an executable.かなり、いろいろと調べて、このエラーの前にエラーメッセージとして表示されている各種モジュールを見てみたりしましたが、Pythonの知識が不足しているので、どうにもわかりませんでした。と、ふとした時に、プログラムをこのメッセージの形式で書けばいいんじゃね?って思って作り替えたところ正しく動作しました!今まではimport ~~~処理A処理B処理Cみたいな感じで、普通のBASICやPHPみたいなプログラムの最初から流れるような形で単準備記載していたのですが、それをimport ~~~def main(): 処理A 処理B 処理Cif __name__ == '__main__': main()と書き換えただけで動きました。対応方法としては、エラーメッセージに表示されているのですが、どこをこの書き方に変えてよいのかっていうのでかなり悩みましたが、結果、動作させるメインのプログラムに書けばよかっただけという単純なものでした。やはり、Pythonの知識不足でしょうかね。。。んで、ようやく、detectron2での教育プログラムが動作することが分かったので、いよいよ教育していきたいと思っています。数は少ないのですが、20程度の教育データをテスト的に用意して教育したところ、なかなかよさそうな結果が出てきているので、教育データを用意して教育してみたいと思います。※先日環境をいろいろといじっていたら誤って教育データ(coco形式)を全削除してしまったので、作成しなおしなのです。。。orz
2022年08月17日
コメント(0)
-
AIのプロジェクトで試したもの
色々とAIのプロジェクトってありますよねー。試したものと感想をそれぞれーYolov5これは比較的簡単でした。用意されたModelで検出のテストをするのもそんなに難しくなかったですし、自前データでの学習も容易でした。問題はPytorchを利用していることでしょうか。問題というのはおかしいかもしれませんね。私の環境ではnViidiaのTESLA K40というのを使っており、最新のPytorchではビルドの条件から外れてしまったため、ソースよりビルドしなければなりませんでした。その環境構築にかなり時間を要しました(私が無知なだけですが。。。)。Anacondaでバージョンを考慮した構築をすればすんなりいけるかもです。別記事に記載しています!YolactYoloだと検出結果が長方形で表示されます。何が画像に映っているのかを検知したいだけなら問題ないのですが、どのエリア(正確な形)まで認識させようとすると、Yolactなどセグメンテーションでのディープラーニングを利用しなければなりません。その中で、最初に学習まで成功したのが、Yolactでした。ほか(下記)もいろいろとかじりながら、あっちやったりこっちやったりしていましたが、ようやく学習に成功しました。結果は良好でいいんじゃね?って感じの結果が表示されましたが、なにせ、環境構築とかが結構面倒でした。あと、その結果の利用方法の解析に時間がかかってしまって、いま後回しにされています。MASK R-CNNこれも有名なセグメンテーションでのディープラーニングです。これも環境構築や学習方法などについてある程度、理解構築できましたが、環境が古く、Python3.6、Tensolflow1.5という環境でした。まだ、TensorflowとKerasが合体する前のソースであるため、古い環境でないと手直しなしでは動きません。で、CUDAを利用して学習させようとすると、CUDAToolKit9が必要になります。現在11をインストールしていますんで、アンインストールしてインストールしなおしは色々とハードルが高いです。というわけで、現在放置中。学習データを自動的にダウンロードして学習させたりできます。maskrcnn_benchmarkこれは上記、MASK R-CNNと同じように思いましたが、Pytorchが必要です。現状動かせてないです。検知は動かせましたが、学習が動かせていない状態です。SOLOv2本日発見したものです。まだ、環境構築なども行っていないので、明日以降環境構築と検証をしてみたいです。今のところ、物体検知はYolov5が簡単で検知結果もよいと思いました。利用も楽です。(Yolov5のソースを全部動作環境に置く必要がありますが。)ただ、セグメンテーションでの検知が必要な場合は、Yoloではダメなため、別の方法を検討しなければなりません。現状では別の方法でよいものが見つかってない感じです。上記のほかにセマンティックセグメンテーションの学習で利用されるEncoder-Decoder方式で作ったプログラム(私が作ったわけではないですが。。。)での学習もやってみていますが、教育データが悪いのかあまり芳しくありません。
2022年08月06日
コメント(0)
-

名刺の枠の認識に「YOLACT」を使ってみる!
Yolov5で名刺を教育しました。結果はすごく良好です。名刺としてしっかりと認識します。しかしながら、名刺として認識はするものの、Yoloでは発見したオブジェクトを囲う四角で表現されるため、正確なエッジを取得することができません。長方形でしっかりと撮影できていればきちんと切り抜けると思いますが、台形など長方形以外の四角形で撮影されてしまった場合は、そのエリアを明確に取得できません。それでは非常に困っちゃいます。名刺のみを切り抜くことが困難です。というわけで、他の方法を色々検索してみました。MASK R-CNNやFast CNNなど色々と調べてみましたが今の知識では少し難しいのと参考にできるWebページがないのが厄介です。他にないかなーって探していたら、Yolo系で良さそうなのを発見しました。https://github.com/dbolya/yolactそして、使い方が書いてあるWebページも発見!https://farml1.com/yolact/参考にさせていただきました。ありがとうございます!というわけで、vottで作成していたデータを変換させてやってみました!エラーです。。。よくわかりませんが、エラーが出ます!エラーはなんてかいてあるか分からないから困ります。・・・・・・どうやら、教育データが悪いようです。仕方ないので、参考ページに書いてあるlabelmeを使ってちょっとデータを作成してみます。10件ぐらい。そして、上記ページにある様にデータを作成し教育してみると、うまくいきます!。。。そうですか、作り直しですか。。。。ぽちぽちと前回vottでやった作業を再度labelmeでやりましたとも!350件ぐらいですが。。。で、教育しました!ところが、モデルデータが吐き出せません。この教育プログラム。いいと思ったらCTRL+Cで止めてね!って感じのものなのです。今まではepochの数字を入れると、その回数学習してくれたのですが、CTRL+Cでとめろって。。。で、いいところでCTRL+Cを押下します!とまりません!どうにもとまりません!こまりました。というわけで、タスクマネージャーからKILLします!とまりました!しかし、学習結果が作成されません。そりゃそうですよね。タスクKillしてますもん。。。どうしようか、しばらく悩みました。まぁ、私もプログラマーの端くれ。プログラムを修正してやりました!ループしているところでカウントとって、カウントがある数値以上になったら内部的にexceptionを発生させ、CTRL+Cが押下されたことにしました。これで、ようやく学習結果のModelファイルができました!んで、この結果はどうかというと、なかなかですよ!なかなかいいんじゃないでしょうか!ちょっとみた感じはよいと思います。こんな感じで認識されました!さて、このモデルを使って名刺の切り取り処理を作ろうと思います!
2022年08月05日
コメント(0)
-
名刺の枠の認識をAIでやる方法を考える
OpenCVとかを使ってある程度名刺の枠の検出についてはできたのですが、名刺と背景がある程度はっきりと区別がつかないと正しく認識ができないです。また、影が映り込むとこれはこれで難しく、また、名刺が変なデザインをしているとこれも正しく認識できないという状態になります。名刺に凝ったデザインすんな!って思いたくなります。ロゴと文字だけにしてほしい。そして色は白色にしてほしい。できることなら法律で決めてほしいwwwと無茶な考えは頭の隅に追いやって、実際のところを考えると、やはり、一筋縄ではいかないのです。スキャナーとかであれば、真っ黒背景とかも可能でしょうが、スマホの写真で名刺を認識させるのは至難の技です。コントラストが低い場合と高い場合。明るさが明るい場合と暗い場合、背景の写り込みなどなど同じパラメータでできるとは到底思えません。そこで、考えるのを諦めて、AIで認識してくれない?って安易な考えでAIでできないか検討します。名刺の写真とそれに写る名刺の位置をエッジで表示した白黒画像を使って勉強させるといったことをやってみました。そして、そのエッジ画像を再現させるといった形です。しかし、これはなかなかうまくいきませんでした。ある程度、それっぽい画像は得られるのですが、やはりズレます。しっかりと、名刺の枠をとらえることができません。若干のズレがどうしても発生します。難しいですね。名刺を白で塗りつぶすといったこともやってみましたが、やはり、同じ様になんとなく認識はできるものの、はっきりと認識はできません。難しいですね。とりあえず、ググって出てきたTensorflowでエッジを再現する的なページでやってみたんですが、そんな感じです。ここの記事を参考にさせていただきました。ありがとうございます。もう少し精度を上げるためにはどうしたら良いか色々と検討していますが、これといった決定的な方法g見当たりません。また、教育用データも不足している感じです。もう少し色々と調べてみたいと思います。
2022年08月04日
コメント(0)
-
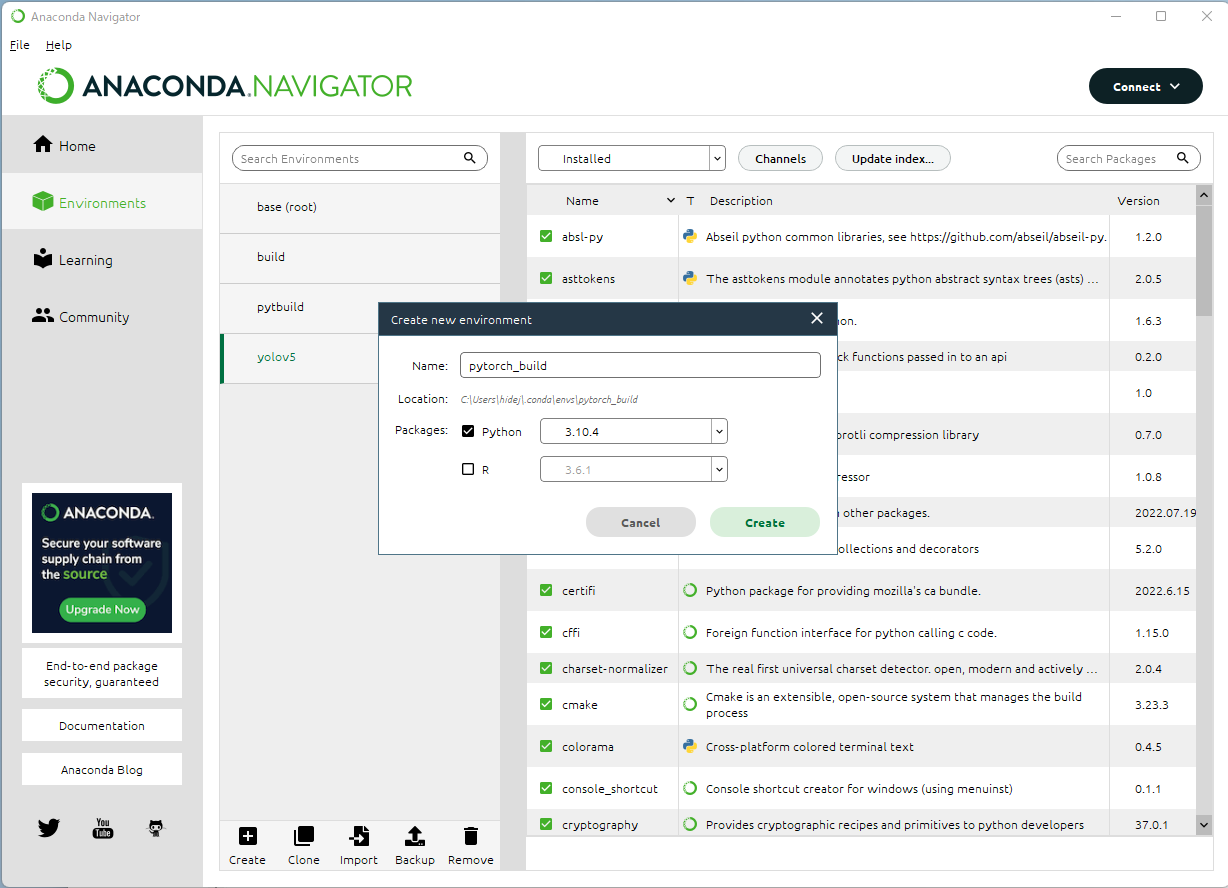
TESLA K40で動作するPytorchをWindowsでビルドする(Anaconda環境のみ)
1週間ほど格闘して、ようやくTESLA K40で動作するPytorch環境が作成できましたので手順を記載します。まず、各ドライバーなどの環境は以下の通り。nVIDIA関連・ドライバー:463.15-data-center-tesla-desktop-win10-64bit-dch-international・CUDATool:cuda_11.2.460.89_win10・cuDNN:cudnn-11.2-windows-x64-v8.1.1.33Anaconda関連・Anaconda3・Python3.10.4VisualSutudio関連・Visual Studio 2019 16.11.17 選択した個別のコンポーネント v14.27のx86およびx64と書いてあるコンポーネントすべて。 例:MSVC v142 - VS2019C++x64/x86ビルドツール(v14.27)など VS2019はここからダウンロードできます。Intel MKL・OneMKL20221.0.192 ここからダウンロードできます。まず、AnacondaNavigatorでビルド用の環境を作ります。Pythonでバージョンは3.10.4を利用しました。AnacondaNavigatorのホームで作成した環境に対しCMDをインストールします。インストールが終わったら「Launch」をクリックしコマンドプロンプトを起動します。(pytorch_build) C:\> このように先頭にAnacondaの作成した環境名がかっこ書きで表記されます。Condaコマンドを利用し各種モジュールをインストールします。conda install astunparse numpy ninja pyyaml setuptools cmake cffi typing_extensions future six requests dataclassesconda install mkl mkl-includeconda install -c conda-forge libuv=1.39githubよりソースを取得します。git clone --recursive https://github.com/pytorch/pytorchcd pytorch# if you are updating an existing checkoutgit submodule syncgit submodule update --init --recursive --jobs 0環境変数を整えます。set CMAKE_INCLUDE_PATH=C:\Program Files (x86)\Intel\oneAPI\mkl\2022.1.0\includeset LIB=C:\Program Files (x86)\Intel\oneAPI\mkl\2022.1.0\lib\intel64;%LIB%set CMAKE_GENERATOR_TOOLSET_VERSION=14.27set DISTUTILS_USE_SDK=1for /f "usebackq tokens=*" %i in (`"%ProgramFiles(x86)%\Microsoft Visual Studio\Installer\vswhere.exe" -version [15^,17^) -products * -latest -property installationPath`) do call "%i\VC\Auxiliary\Build\vcvarsall.bat" x64 -vcvars_ver=%CMAKE_GENERATOR_TOOLSET_VERSION%set CUDAHOSTCXX=C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.27.29110\bin\HostX64\x64\cl.exe※forのところでこけた場合、VisualStudioの14.27ビルドツール関係がインストールされていない可能性が高いです。再度VisualStudioインストーラーを起動し、個別コンポーネントから14.27関係をインストールしてください。以上で環境は整いました。あとは以下のコマンドでビルドするだけです。python setup.py installちなみにWHLファイルを作成するにはpython setup.py bdist_wheelコマンドで行けます。(ただ、ここで作成したWhLファイルでWindows標準のPython環境にインストールしたんですが、正常に動かなかったです。。。)ようやく、pytorchのWindowsでのビルドのついて、まとめ記事が書けました。ただ、いろいろと試行錯誤しているので、もしかしたら、ここに記載のない何かしらを入れないと動かないかもしれません。もし、エラーでビルドできないなど質問がありましたらコメントまでどうぞ。私のわかる範囲でお手伝いいたします。
2022年08月02日
コメント(0)
-

日付印のモザイク化に目途が付きました!
先日、14時間弱かけて、Yolov5で日付印のAI教育をしました。教育のコマンドは以下の通りpython train.py --data data.yaml --cfg yolov5m.yaml --weights '' --batch-size 25 --epochs 500んで、いい感じで教育完了しました。以前は誤認識していた某ハウスメーカーのロゴも誤検知しなくなりました。一旦検知については、この学習モデルで行くとして、容易にモザイク化ができるプログラムを組みたいと思います。ただ、知識があまりないので、Yoloをベースに作成します。作成する際のディレクトリ構造は以下の通り。DateStamp|-model-DateStamp.pt|-yolov5(gitで取得したソース)|-MosicDtStmp.py(今回作成したプログラム)教育したモデルファイルの読み込ませ方がいまいちわからず、結果、Yolov5のソースを借りて動かすこととしました。ちなみに、pythonの環境はYolov5の動作する環境となります。教育ではなく、検知なのでGPUがなくても、そこそこの速度で動作します。今回作成するプログラムはコマンドライン引数でモザイクをかけたい画像ファイルを取得し、その画像に日付印があれば、日付印部分をモザイク化し、結果ファイルを保存するといったものです。それでは、環境構築からやっていきます。Dドライブのルートに作成していきます。>mkdir DateStamp>cd DateStamp>mkdir model>git clone https://github.com/ultralytics/yolov5次に、modelフォルダに前回学習させたbest.ptというファイルをコピーします。yolov5にて学習された情報は以下のフォルダに作成されます。学習環境の[yolov5\runs\train\weight\best.pt]がそのファイルになります。学習環境のyolov5のフォルダがD:\train\yolov5だとした場合は以下のコマンドでコピーします。名前は一応わかりやすいようにDateStampModel.ptにします。>copy d:\train\yolov5\yolov5\runs\train\exp\\weights\best.pt d:\DateStamp\model\DateStampModel.ptそして、DateStampの直下にMosicDtStmp.pyを作成します。ソースは以下の感じ(素人なので、誤っている箇所もあるかもしれません。)import osos.environ['CUDA_VISIBLE_DEVICES'] = '1' #GPU1で実行する。import torchfrom pathlib import Pathfrom PIL import Imageimport argparseimport sys#ルートパスを取得FILE = Path(__file__).resolve()ROOT = FILE.parents[0]FULLPATH = str(ROOT)if str(ROOT) not in sys.path: sys.path.append(str(ROOT))ROOT = Path(os.path.relpath(ROOT, Path.cwd()))#引数より値を取得する。parser = argparse.ArgumentParser()parser.add_argument('image', type=str,help='ImageFile Path')#元画像parser.add_argument('--outpath', type=str, default=ROOT / 'result.jpg',help='Add Mosic ImageFile output FilePath')#保存画像parser.add_argument('--weights', type=str, default=FULLPATH + '/model/DateStampModel.pt', help='model path')#学習済みモデルファイルparser.add_argument('--yolo5path', type=str, default=FULLPATH + '/yolov5', help='yolov5 Folder Path(git clone path)')#yolov5のパスparser.add_argument('--conf', type=float, default=0.85, help='confidence threshold')#マッチ度args = parser.parse_args()#print('ルート :',ROOT)#print('引数 image : ', args.image)#print('引数 OutPath : ', args.outpath)#print('引数 weights : ', args.weights)#print('引数 yolo5path : ', args.yolo5path)#print('引数 conf : ', args.conf)model = torch.hub.load(args.yolo5path ,'custom', args.weights,source='local')#モデルを読み込みprint(model.names) # 検出できる物体の種類#画像データ読込with Image.open(args.image) as src: data = src.getdata() mode = src.mode size = src.size#画像よりexif除法削除した画像を作成with Image.new(mode, size) as img: img.putdata(data)results = model(img) # 画像パスを設定し、物体検出を行うobjects = results.pandas().xyxy[0] # 検出結果を取得 for i in range(len(objects)): if objects.confidence[i] > args.conf: #マッチ度を比較 name = objects.name[i] xmin = objects.xmin[i] ymin = objects.ymin[i] width = objects.xmax[i] - objects.xmin[i] height = objects.ymax[i] - objects.ymin[i] #print(f"{i}, 種類:{name}, 座標x:{xmin}, 座標y:{ymin}, 幅:{width}, 高さ:{height}") dtStmp=img.crop((xmin,ymin,xmin+width,ymin+height)) #デート印部分を切り抜く dtStmp=dtStmp.resize((int(width/(width*0.0635)),int(height/(width*0.0635))),resample=Image.BOX)#デート印部分を縮小 dtStmp=dtStmp.resize((int(width),int(height)),resample=Image.BOX)#デート印部分を拡大 img.paste(dtStmp,(int(xmin),int(ymin)))#モザイク化したデート印部分を貼り付けimg.save(args.outpath)#画像出力なかなかいい感じにできました。コールする際は以下のように使います。>python MosicDtStmp.py test.jpg入力画像が左で、出力画像が右です。 なかなかいい感じでしょう? 印の場所が変わっても多少文字と被ってもいい感じでモザイク化してくれています。一旦、日付印のモザイク化はここまでにして、次は名刺の切り抜きに戻りたいと思います。
2022年08月01日
コメント(0)
-
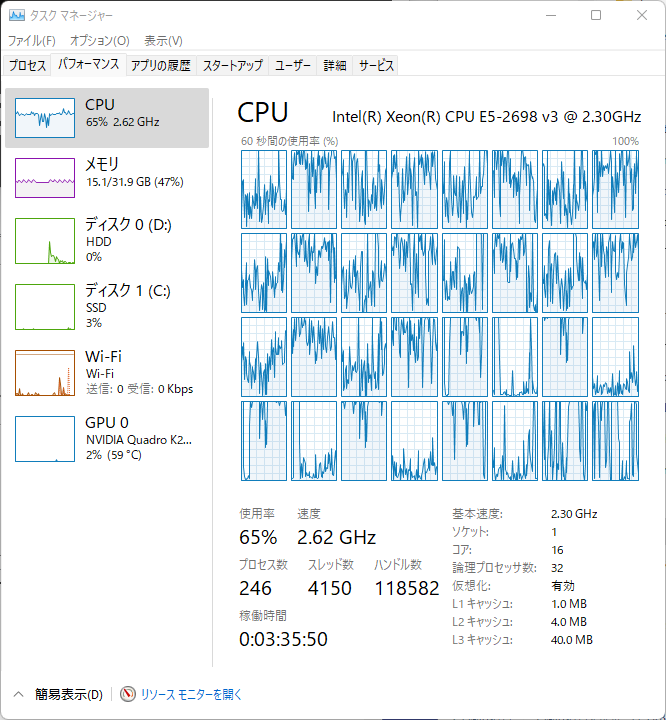
TESLA K40でYolov5を動かすと、Quadoro K2200より早いのか?
結局、別の環境にインストールするのはいったん諦めました。ビルドした環境であれば、問題なく動作します。しかし、その環境でWHLファイルを作成して、そのWHLファイルを別環境でインストールすると、なんかエラーが出てまともに動作しませんでした。とりあえず、環境構築はいったん完了にします。環境構築については後程まとめて記事にします。さて、TESLA K40の実力はどうなんでしょうか?Yolov5で検証します!環境はPython3.10.4とPytorch1.12.0、torchvisionは0.13.0です。CUDAToolKitは11.2を利用しています。QuadroもTESLAも同一環境で動作させます。切り替えはソース(train.py)に以下を追加して切り替えます。import osos.environ['CUDA_VISIBLE_DEVICES'] = '0'0がTeslaで1がQuadroになります。教育用データは合計264枚の写真データとなり、サイズは424x256です。教育用に230枚、残りを検証用に使います。タグは1種類でバッチサイズは両方とも5で実行し、epoch10でかかった時間を比較します。python train.py --data data.yaml --cfg yolov5m.yaml --weights '' --batch-size 5 --epochs 5まずはQuadro K2200で実行します。結果は586秒かかりました。次にTESLA K40で実行すると、266秒です!約半分の時間で終わることができました。さらに、K2200+K40で実行したら、363秒かかりました。これは2つのGPUで手分けして実行はしているのでしょうが、その間のやり取りがボトルネックになっている可能性がありますね。ついでにCPU(Xeon E5-2698v3)で実行してみました。結果は1141秒。。。いかにGPUで実行すると早いかってことですね。K40266sK40+K2200363sK2200586sCPU1141sこんな感じですね。やはり、TESLAは早いですね!ついでにメモリもたくさん積んでいますんで、バッチサイズを上げてやってみます。以前。K2200(メモリ4GB)の時にバッチサイズを7にしたのですが、ギリギリだったようで、動作中画面がちらついていました。TESLAはGPGPU専用なので、画面に影響を及ぼさないのがいいですね。バッチサイズ5で2.13GBだったので、思い切って25ぐらいにあげてみます。K40は12GBのメモリを積んでいますのでいけるんじゃないでしょうか?!バッチサイズを上げたんで、メモリ使用量が9.38GBにまでなりました。しかし、実行にかかった時間は241秒。。。そんなに早くならなかったです。でも、大きなデータを教育データとして利用できるのでメモリ量が多いほうが良いです。というわけで、yolov5を利用して、手持ちのGPUとCPUで速度を図ってみました。ようやく、環境構築できたので、今後、様々なデータで教育させて賢いAIを目指してみます!ちなみに,CPUで実行したときの使用率は60~65%程度でした。
2022年07月31日
コメント(0)
-
TESLA K40で動作するpytorchをWindowsでビルドした!(できた!)
ようやく、ようやくできました。色々と試行錯誤しましたが、結果、できました!やり方のメインは公式の方法ですね(英語だし、ちょっとわかりづらいので敬遠していたのが誤りでした)私と同じように古いグラボでCUDAの効いたPytorchをビルドしたい場合は以下のサイトを参照してやってみてください。https://github.com/pytorch/pytorch/tree/7496937e3fb3545b6ab63736b4a70d59ed3156bf#from-sourceさて、私が大きく躓いた部分を何点かご紹介します。まず、1点目。コンパイルがエラーとなる問題。これはVCのバージョンの問題でした。もともと、VCは何種類かバージョンがありますが、問題を起こさないようにビルドするのであれば、最新の2022ではなく2019をお勧めします。また、インストールする際に個別のコンポーネントを選択し、v142ビルドツール関連で14.27を選んでください。公式のやり方はV14.27で行います。また、2019の最新のビルドツールではコンパイルがこけます。それと実際使用されるVCのバージョンですが、この辺も本来はキチンと切り替わるように公式のやり方ではされているのですが、念のため、以下のフォルダにあるファイルに書いてあるバージョンを書き換えることをお勧めします。C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Auxiliary\BuildMicrosoft.VCRedistVersion.default.txtMicrosoft.VCToolsVersion.default.propsMicrosoft.VCToolsVersion.default.txtMicrosoft.VCToolsVersion.v142.default.propsMicrosoft.VCToolsVersion.v142.default.txtあと、公式のやり方でビルド前に設定する内容についてですが、以下のように私は行いました。cmd:: Set the environment variables after you have downloaded and upzipped the mkl package,:: else CMake would throw an error as `Could NOT find OpenMP`.set CMAKE_INCLUDE_PATH={Your directory}\mkl\includeset LIB={Your directory}\mkl\lib;%LIB%:: Read the content in the previous section carefully before you proceed.:: [Optional] If you want to override the underlying toolset used by Ninja and Visual Studio with CUDA, please run the following script block.:: "Visual Studio 2019 Developer Command Prompt" will be run automatically.:: Make sure you have CMake >= 3.12 before you do this when you use the Visual Studio generator.set CMAKE_GENERATOR_TOOLSET_VERSION=14.27set DISTUTILS_USE_SDK=1for /f "usebackq tokens=*" %i in (`"%ProgramFiles(x86)%\Microsoft Visual Studio\Installer\vswhere.exe" -version [15^,17^) -products * -latest -property installationPath`) do call "%i\VC\Auxiliary\Build\vcvarsall.bat" x64 -vcvars_ver=%CMAKE_GENERATOR_TOOLSET_VERSION%:: [Optional] If you want to override the CUDA host compilerset CUDAHOSTCXX=C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.27.29110\bin\HostX64\x64\cl.exeCMAKE_INCLUDE_PATHについては以下のようになりました。C:\Program Files (x86)\Intel\oneAPI\mkl\2022.1.0\includeそしてLIBに追加するところですが、ここをミスってるのにずっと気づかずに時間がかかりました。ここはC:\Program Files (x86)\Intel\oneAPI\mkl\2022.1.0\lib\intel64例が「mkl/lib」って書いてあったため、「lib」で止めていました。実際は、その下のフォルダまで指定する必要がありました。上記の設定でビルドしたところ問題なく実行でき、最後までとおりました。ようやくです。1週間かかりました。結果、アウトプットされた情報はよく見るべしですね。さて、whlファイルも作り、Windows標準環境にpipでインストールしたのですが、これが正しく動作しません。import torchでライブラリの参照エラーが発生します。参照できないと言っているライブラリは存在するのですが。。。色々と調べた結果、buildの中のlibフォルダをpipでインストールされたtorchフォルダのlibフォルダに上書きコピーすれば動作しました。しかし、visionがダメです。visionはどうしてもエラーがなくなりません。調べると、バージョン落としたよ!とか再インストールで治ったとか、直接的な回答はなく、困りました。また、Audioのビルドには成功していません。というわけで、まだまだ、環境構築には時間がかかりそうですが、一応、torchだけは動きました!
2022年07月30日
コメント(0)
-
Pytorchのビルドに悩む(途中経過)
あれから、永遠にビルド地獄でした。まだ解決していませんが、やったことを一通り記載します。前日投稿したやり方での結果は、途中でコンパイルエラーが多発しており、まともにビルドできていませんでした。原因不明です。色々と原因を探りましたが、やはり不明。(このやり方はこちらのサイトを参考にしました。)で、一旦あきらめて、WSLのUbuntu20.04にビルド環境を作ってビルドしました。結果ダメ。。。やはり、ビルド中にコンパイルエラーが多発してしまいます。(このやり方はこちらやこちらのサイトを参考にしました。)次に試したのは、Anaconda環境でのやり方。これはPytorchの公式のやり方を参考にしました。こちらが公式のやり方です。(これについてはUbuntuとWindows両方試しました)あとは、野良ビルドされているものを探していろいろとインストールしてみました。古いビルドからいろいろ試しましたがやはりダメでした。あと、Dockerを使ったやり方も試しました。(こちらの記事を参考にしました)結果、すべてダメでした。んで、現在、Dockerを使ったやり方のコンパイルを鋭意継続中です。ふと、思ったのが今コンパイルしているPCはXeonで16コア32スレッドなのですが、すべてのスレッドを利用して高速にコンパイルしています。なんか、その辺で問題が発生しているのではないか?と思い、最大のジョブ数を2に制限して動かしています。その状態だと、エラーが今のところ出ていないのですが、異常に時間がかかっています(;^_^Aとりあえず、その結果待ちです。あと、Windowsでのビルドを同様にジョブ数制限してやってみようと思っているところです。おそらく今日中には終わらないと思いますので、一旦、現状報告です。
2022年07月29日
コメント(0)
-
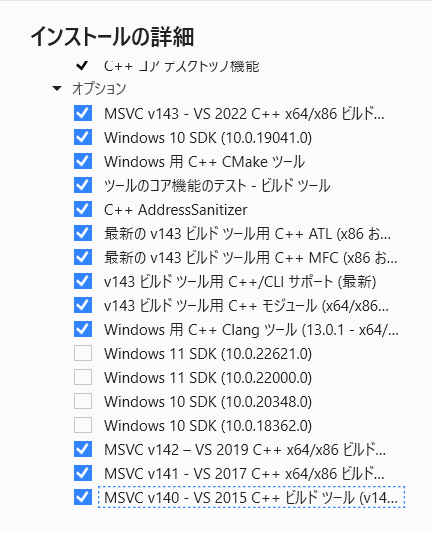
TESLA K40で動作するpytorchをWindowsでビルドする(失敗)
取り合えず、ビデオドライバーはCUDAのバージョンは11.2のものを使い、CUDA TOOLKitも合わせて11.2にしています。(そして一回目いろんなところで躓いて結局、原因がわからなかったため、Windowsをクリーンインストールしてから再挑戦の記録です。。。)Pythonのバージョンは3.10.5。pipとsetuptoolsの最新化コマンドプロンプトを管理者で起動します。pipとsetuptoolsを最新にするため以下のコマンドを実行します。>python -m pip install -U pip setuptools※上記コマンドを実行した後、pipは22.2.1となり、setuptoolsは63.2.0となっております。2022年7月末時点で最新としています。VisualStudioのインストール次にVisual Studio Build Toolsをインストールします。以下のリンクからVisualStudioのビルドツールをダウンロードしセットアップします。https://visualstudio.microsoft.com/ja/downloads/セットアップするのは「C++によるデスクトップ開発」にチェックをつけ、以下のオプションを選択しインストールを実施。cmakeのインストール以下のURLよりインストーラーをダウンロードしインストールする。https://cmake.org/download/ダウンロードするのはWindows x64のInstaller(拡張子msiのもの)です。インストールする際に、パスを追加するかどうか聞かれるところがありますので、そこではパスを追加するを選択します。PyTorchのビルド作業VisualStudio2020の「x64 Native Tools Command Prompt for VS 2022」を管理者として実行する。作業する場所へ移動する(私はDドライブ直下で作業を行う)。>cd d:/Pytorchのソースコードを取得する。>git clone --recursive https://github.com/pytorch/pytorchその他Pythonの環境を整える。numpy、pyyaml、ninja、pillow、sixのインストールを行う。>python -m pip install numpy pyyaml ninja pillow sixONNXのインストールvcpkgのインストールを行う。>git clone https://github.com/microsoft/vcpkg >.\vcpkg\bootstrap-vcpkg.bat >.\vcpkg\vcpkg integrate install vcpkgにパスを通す。インストールしたフォルダ(c:\で上記作業をした場合、c:\vcpkgとなる)にパスを通す。ONNXをインストールする。>c:\vcpkg\vcpkg search onnx>c:\vcpkg\vcpkg install onnx[pybind11]:x64-windows>c:\vcpkg\vcpkg install onnxruntime-gpu:x64-windows>python -m pip install -U onnxruntimecmake を用いて,ソースコードからビルドし、インストールする>cd c:\>cd pytorch>cmake -G "Visual Studio 16 2019" -A x64 -T host=x64 -DUSE_BREAKPAD=OFF -DOpenMP_CXX_FLAGS='/openmp' .>cmake --build . --config RELEASE >cmake --build . --config RELEASE --target INSTALL※最初のcmakeの箇所で以下のエラーが発生した。 Generator Visual Studio 16 2019 could not find specified instance of Visual Studio: なんでこんなエラーが出てくるのかもよくわからないし、調べても解決策がなかなか出てこない。なので、面倒だけど、VS2022をアンインストールしてVS2019を入れることにした。VS2019はここからダウンロードできます。https://docs.microsoft.com/ja-jp/visualstudio/releases/2019/release-notes#16.11.17そのほかCUDA TOOLが見つからないといわれ、CUDA TOOLkitを再インストールし、typing-extensionsが見つからないといわれ、pipで該当モジュールをインストールし、といろいろ紆余曲折ありましたが、何とか、ビルドに成功しました。Pythonへのインストール以下のコマンドでPythonへビルドしたpytorchをインストールする。>cd pytorch>del CMakeCache.txt>python setup.py build>python setup.py installここでもやはりコケました。。。すんなりなかなかいかないもんです。原因はよくわからないのですが、調べるとIncludeするファイルが見つからないみたいです。そのファイルはビルド時にできるようでしたので、再度、ソースをダウンロードするところからやり直しです。(ソースビルドは地味に時間がかかるので面倒です。。。)※結局原因はわかりませんでした。ー--続く
2022年07月28日
コメント(0)
-

Tesla K40が届いたんので取り付けます!
先日ヤフオクで仕入れたグラフィック拡張カードNvidia Tesla K40が届きました!性能のおさらいをするとこんな感じ。CUDAコア:2880(4.5倍)クロック:745MHz(0.71倍)メモリ:12GB(3倍)単精度:4.29TFLPS(2.98倍)倍精度:1.43TFLPS(31.8倍)※カッコの倍率は今使っているQuadroK2200との比較。クロック以外はすべて向上しています。現在、Z440には二つのグラボが乗っています。Quadro K2200とRadeon R9 380です。性能はRadeonのほうが良いのですが、Tesla K40を搭載するにあたり電源の問題が発生します。Z440には標準で6ピンのグラボ用電源が2系統出ています。Radeon R9 380は6ピンを2本差す必要があり、現状電源が余っていません。SATA電源などは余裕で余っていますので、SATAからグラフィック用6ピン変換とかでもよいのですが、さすがに電源ユニットに負荷をかけすぎかと思い、今回Radeonを外してTeslaを取り付けようと思います。届いたカードはこちら!nVIDIA TESLAの文字が神々しい!側面にはK40の型番が!それでは取り外して取り付けていきます!まず、ケースを開けて、PCIE2番目に取り付けてあるRadeonを外します。続いて、TESLAを取り付けます。Quadroと並んでイメージが同じですね。こいのぼりみたいwwwTeslaは6ピンと8ピンが必要なのでAmazonで6ピン8ピン変換ケーブルを仕入れました。あとは、ケースのふたを閉めて完了!最初起動時に画面が写らない問題が発生しました!Radeonがプライマリになっていたかもしれません。取り外す前にBIOSをチェックしとかなければならないですね。幸い、再起動したら表示されるようになりました。続けて、ドライバを更新していきます。今回、TESLAのドライバーを入れたいと思いますので、現在のRadeonとQuadroのドライバはキレイに削除したいです。そこで、グラフィックドライバーをキレイに削除するツールをダウンロードします。DDUというツールなのですが、以下からダウンロードできます。https://www.wagnardsoft.com/このツールを利用して現在のグラフィックドライバーを削除します。削除するにはセーフモードで起動したほうが良いらしいです。Windows11はShiftを押しながら再起動したら、起動メニューが表示されるので、そこから選択してセーフモードにできます。再起動して青い画面が表示されたら「トラブルシューティング」⇒「詳細オプション」⇒「スタートアップ設定」⇒「再起動」でセーフモードで起動できます。無事、グラフィックドライバーの削除が終えたらTESLAのドライバーをインストールします。以下の場所よりTeslaのドライバーを探してダウンロードします。https://www.nvidia.co.jp/Download/index.aspx?lang=jp製品のタイプは「Data Center / Tesla」。製品シリーズは「K-Series」。この製品は「K40C」なのでそれを選択。OSはWindows11なのですが、それだと見つからないので、Windows10 64itを選択します。CUDA Toolkitはこのドライバーで最新の11.2を選択しました。※ただ、実際インストールしているCUDA ToolKitは11.7です。再インストールしていないので。。。そして、ダウンロードしたファイルを実行しドライバーをインストールします。以上で準備完了です!さて、どの程度早くなるのかなー?Yolov5のデート印の学習時間で比較しようと思います。まず、Quadro K2200の場合、230の学習データ+34の確認データを利用し、Epochs=5、batch-size=7(メモリ容量からギリギリ7でした。)で実行し約10分かかりました。それではK40で実行してみます。・・・・エラー!!!!!実行すらできませんorzちょっと原因究明します。なんとなくですが、CUDAのバージョンあたりに問題がありそうです。現在、CUDA ToolKitのバージョンは11.7を入れていますが、K40のドライバーは11.2まで対応のドライバーしか落とせません。ちなみに、Pytorchは11.3の下は10.2となります。そして、CUDA10.2となると、Pytorch1.12.0が入れれず、1.8.2となります(1.11とかもありますが。。。)。しかしながら、そこまでPytorchのバージョンを落とすと、どうやらPython3.10.5ではインストールできないようです。えっと、詰んできました。とりあえず、Anacondaで、Pythonのバージョンを3.9.Xあたりの環境を作ってやってみます。色々と調べました。まず、nVIDIAのドライバーは463.15でCUDAは11.2までのサポートのものが最新となりますんで、そこに合わせていきたいと思います。ですので、CUDA TOOLkitも11.2のものをダウンロードしてインストールします。11.7はアンインストールしときます。あと、cuDNNについてはCUDAの10系と11系の2種類しかないので、11系を選択します。PytorchにはCUDA11.2のバージョンにあったものがないので、CUDA11.1のものを利用したいと思います。インストールコマンドは以下の通りです。pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.htmlというわけで、環境構築をまたやってきます。うまく動作したらいいのですが。。。AnacondaでYolov5用の環境を構築します。Pythonのバージョンは3.9.12としました。CMD.exeとPowerShellをAnacondaNavigatorからインストールします。そして、Yolov5の環境構築を再度行います。AnacondaNavigatorから先ほどインストールしたPowerShellを起動します。そこで、Yolov5のフォルダにCDし、以下のコマンドを実行。>pip install -U -r requirements.txtそして、問題のPytorchのインストール。pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.htmlダメでした。。。torchvisionのそのバージョンはないよ?っていう感じで、ダメでした。なんか、Pytorchのインストールコマンドって動かないやつがあるんですね・・・さらに古めのバージョンで試してみます。pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.htmlこれもダメ。なんなんだ?毎回3GB程度のダウンロードがあって、エラーがでるからちょっとイラっとする。。。pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.htmlこれでようやく通りました。さて、テストしてみます!>python detect.py --source ./data/images/ --weights yolov5s.pt --conf 0.4ダメでした。。。さらに調べてみると、K40ではPytorch1.8までという情報がありました。。。。ということで、今度は1.8.0を狙います。Anacondaなのでcondaコマンドでやってみます。conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forgeインストールはうまくいきました。それでは確認してみます。やはり、CUDAのバージョンの問題が解決しません。CUDAにはCompute Capabilityなるものがあり、K40は3.5になるみたいです。そして、Pytorchは3.7以上じゃないと最近のバージョンは動かないようです。困りました。ビルドするといった方法もあるようですが、Windowsではなかなか難しいみたいです。Linuxだとそこそこいける気がしますが・・・というわけで、Pytorchのバージョンを1.7系まで落としてみます。1.7.1に落としましたがダメですね。やはり、自分でソースからビルドするしかないように思います。長くなりそうなので、今日の記事はこの辺で。
2022年07月27日
コメント(0)
-
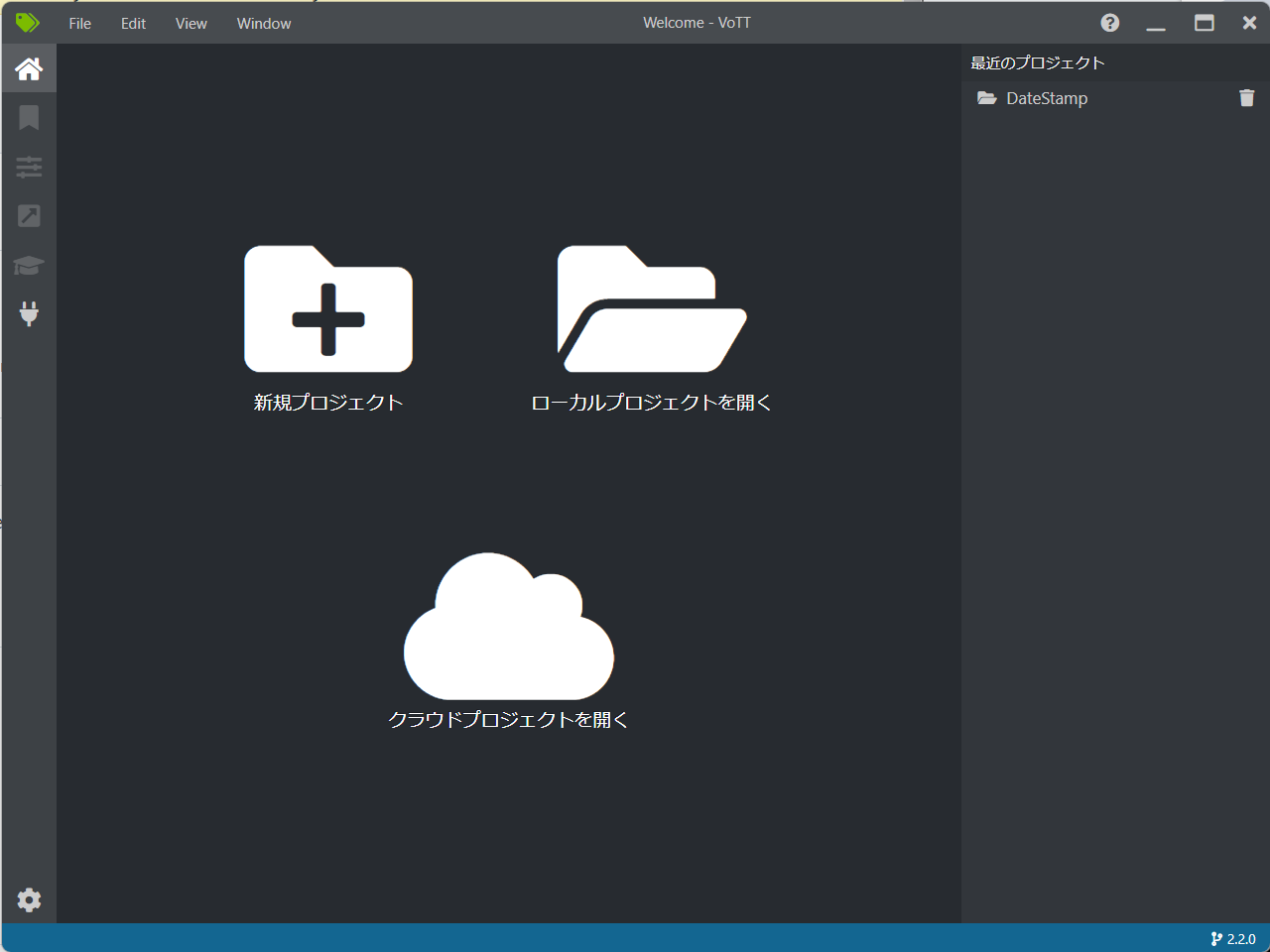
Yolov5の環境構築と学習、物体検知(名刺のデート印)をやってみる!
Yoloとはリアルタイムオブジェクト検出アルゴリズムです。YOLO(You Look Only Onse)の略ということで、今回はPythonで構築してみます。あと、Anacondaとかの仮想環境ではなく、Windows標準でインストールされている3.10.4の環境でやってみます。まず、Yoloの環境をgithubから取得します。>git clone https://github.com/ultralytics/yolov5次に必要なライブラリをインストールします。・上記で取得した環境のディレクトリに入ります。>cd yolov5・ライブラリをインストールします。>pip install -U -r requirements.txt私の環境はGPU(NvidiaCUDA)が利用できるため、その環境を構築します。GPUに対応したPytorchをインストールします。以下のサイトよりインストール用のコマンドを仕入れます。https://pytorch.org/PyTorch BuildはStable(1.12.0)を選択し、YourOSはWindows、PackageはPip、LanguageはPython、Compute PlatformはCUDA11.6としました。(実際は11.7をインストールしているのですが、選択肢がなかった)すると、Run This Commandのところにインストール用のコマンドが表示されます。今回の選択で表示されたコマンドを実行します。>pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116上記はpip3コマンドが表示されましたが、pipコマンドに変更して実行しました。以上で環境構築は完了です。動作確認をしてみます。>python detect.py --source ./data/images/ --weights yolov5s.pt --conf 0.4結果がruns\detect\exp##のフォルダに作成されますので、内容を確認すると、なんかいい感じで検知できているのがわかります。さて、次は独自の教育データで学習させたいと思います。まず、教育用データを集めます。教育させたい物体が写っている写真をできるだけ集めます。私は、300枚程度しか集めることができませんでした。タグ付けを行うアプリはMicrosoftのvottを利用しました。まず、vottをインストールします。以下のサイトよりインストーラをダウンロードします。https://github.com/microsoft/VoTT/releases/tag/v2.2.0私はWindows環境でしたのでwin32っていうものをダウンロードしました。インストールして起動すると、以下の画面が表示されます。最初起動した場合は、新規プロジェクトを選択します。続きを行う場合はローカルプロジェクトを選択して、保存されている拡張子「vott」ファイルを開きます。新規プロジェクトを選択すると以下の画面が表示されます。表示名は適当な名前、セキュリティトークンは入力しなくてOKです。あと、ソース選択ですが、AddConnectionをクリックして新しい接続を作ります。AddConnectionをクリックすると以下の画面が表示されます。表示名は適当な名前、説明は記入しなくてOKです。プロバイダーをローカルファイルシステムを選択します。フォルダーパスは今回「C:¥Temp」を選択しました。入力用と出力用の二つのローカルファイルシステムの接続を作成します。接続を作成したら、ソースに作成したローカルファイルシステムの入力用を選択し、ターゲットに出力用を選択します。ビデオ設定は特に変更せずにプロジェクト保存をクリックします。すると、ソースフォルダに保存されている画像が読み込まれて以下のような画面が表示されます。タグ付けするエリア。今回はデート印の箇所にタグ付けしますんで、そこを四角で囲います。続けて、右上にあるTAGSの箇所にある+ボタンからタグを追加します。タグを追加したら、選択した四角エリアに右上の追加したタグ名部分をクリックし、タグを付与する。タグが付与されると、四角部分が右上のタグと同色になります。このような感じで、すべての画像に対してタグ付けを行う形となります。タグ付けが全部完了しましたら、情報を出力します。出力方式はyolo形式でvottからは出力できませんので、一旦、Pascal VOC形式で出力します。左のメニューにあるエクスポートアイコンをクリックし、エクスポート設定を開きます。プロバイダーはPascalVOCを選択し、アセットの状態は「タグ付きアセットのみ」を選択します。そして、「エクスポート設定を保存」をクリックし、エクスポートの設定を保存します。タグ付けをする画面の上部にあるアイコンの中からプロジェクトをエクスポートをクリックし、ファイルを出力します。出力した結果は、プロジェクトを作成した際に出力先として設定したフォルダに「Test-PascalVOC-export」といったフォルダが作成され、その中に出力されます。PascalVOCからYoloの形式への変換に関しては、以下のサイトを参考して実施しました。https://qiita.com/taront/items/cc405a7b4103d50a0bfe上記サイトで実施した結果、labelsというフォルダにtxtファイルが作成されます。エクスポートされたフォルダに「JPEGImages」というフォルダができており、その中にイメージファイルが保存されています。上記、テキストファイルと画像ファイルを以下のように配置します。yolov5\data\train\images---教育用イメージファイルを配置yolov5\data\train\labels---教育用ラベルテキストファイルを配置yolov5\data\valid\images---確認用イメージファイルを配置yolov5\data\valid\labels---確認用ラベルテキストファイルを配置yorov5フォルダに、変換されたlabesフォルダの上のフォルダに作成された「data.yaml」ファイルを保存します。以上で教育準備は完了です。以下のコマンドで教育を行うことができます。python train.py --data data.yaml --cfg yolov5m.yaml --batch-size 8 --epochs 1000エラーが発生する場合や時間がかかる場合はbatchサイズやepochsを調整して下さい。実施状況はTensorboardで参照できますが、vscodeで簡単に確認できますので、そちらで確認します。vscodeを起動した後、CTRL+SHIFT+Pでコマンドパレットを開き、Tensorboardと入力すると、TensorBoardを起動することができます。あとは、参照するフォルダを設定するとグラフで学習状況を確認できます。参照するフォルダはyolov5\runs\trainとなります。学習が完了すると、上記フォルダの中にexp##というフォルダに学習結果が保存されます。exp##フォルダの中にある、weightsというフォルダにbest.ptというファイルがありますので、こちらが学習結果のmodelファイルとなります。教育結果を利用した検出は以下のコマンドで実行できます。>python detect.py --source ./data/train/images/ --weights ./runs/train/exp##/weights/best.pt --conf 0.4検出結果は、./runs/detect/ep##フォルダに画像として保存されます。今回は230ほどの教育データと30ほどの確認データを用意しました。結果はなかなか良好でした。一部発見できない場合や某ハウスメーカーの会社ロゴを誤認しますが、おおむね良好です。お疲れさまでした。
2022年07月26日
コメント(0)
-

Object Detection APIのためのAnacondaの環境構築
Object Detection APIを利用する環境を整えようと色々と試行錯誤しましたが、既存のyolov5を動作させている環境と同一環境ではバージョン違いからか動作しなかったため、Anacondaを利用して専用環境を整えてみたいと思います。まず、Anacondaのインストールをします。以下の公式サイトよりセットアップ用ファイルをダウンロードします。https://www.anaconda.com/products/distribution私がダウンロードしたときは、Python3.9の環境が最新のようでした。最新のバージョンをダウンロードしてインストールします。インストールはダウンロードしたファイルをダブルクリックで実行すればOKです。インストール後、AnacondaNavigatorを起動します。最初にアップデートの確認とあればアップデートが動きますので、最新にアップデートします。AnacondaNavigatorが起動したら、左のメニューからEnvironmentsを選択し、下にある+Createを選択します。 Create New environmentってウインドウがでますんで、Nameを適当につけて、PakegesはPythonの3.7.13を選択しCreateをクリックします。作成が完了したら、左のメニューからHomeを選択します。すると、Applications onのところが先ほど作成したNameに代わっていると思います。これで一応の環境ができました。とりあえずPowerShell Promptをインストールしておきましょう。上の画像のInstallをクリックしてインストールします。インストールが終わるとLaunchに代わりますのでクリックするとPowerShellが起動します。試しに起動してPythonとコマンドをたたくと、Python 3.7.13 (default, Mar 28 2022, 08:03:21) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32Type "help", "copyright", "credits" or "license" for more information.>>>このように表示され、Pythonが3.7.13であることがわかります。普通にPowerShellを起動してPythonとたたくと、Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (AMD64)] on win32Type "help", "copyright", "credits" or "license" for more information.>>>と表示されますんで、環境が異なっていることがわかります。さて、それではObject Detection APIの環境を作っていきたいと思います。必要なライブラリをインストールしていきます。Anacondaはpipではなくcondaを利用します。>conda install flask >conda install pillowProtocolBufferを実行できるようにします。ProtocolBufferは以下のサイトよりダウンロードして解凍するとExeがありますので、それで利用できます。https://github.com/protocolbuffers/protobuf/releases/tag/v21.3必要な情報をgitより取得します。>git clone --depth 1 https://github.com/tensorflow/modelsその他必要な処理を実行します。>cd .\models\research\> ..\..\protoc\bin\protoc.exe object_detection/protos/*.proto --python_out=.※modelsと同じ階層にprotocというフォルダで上記ProtocolBufferを解凍済み次に必要なライブラリのセットアップを行います。> copy .\object_detection\packages\tf2\setup.py .> python -m pip install .※ここはpipでしか通らないのでpipでインストールしているが、良いのかどうかわからない。。。一応正常終了しました。さて、それでは正常動作するか確認してみます。>python object_detection/builders/model_builder_tf2_test.pyやはりエラーが発生しました。。。エラーの内容は「ImportError: cannot import name 'builder' from 'google.protobuf.internal'」です。とりあえず、protobufをインストールしてみます。>conda install protobufそして、再度、確認してみます。キター!すごい長いログがどんどん表示され、そして最後に、OK (skipped=1)の表示。環境はうまくできたようです。長かったです。やはり、pythonの環境はバージョン関連がキモになりそうですね。Anacondaで任意のバージョンや環境が作れそうなので、こちらの環境でHPなどに記載されている内容をそのまま実行したり、マネしたりする場合は使いたいです。自分でプログラム作って実行する場合は、Windows標準環境でできるだけやりたいですね。どうにかこうにか環境の作成が完了しました!
2022年07月23日
コメント(0)
-
TensorflowのObject Detection APIの環境を作ってみる(失敗)
まず、環境を整えようと思います。※この記事は結果失敗して諦めましたorzとりあえず、各種スクリプトなどを以下のコマンドで取り寄せる。>git clone https://github.com/tensorflow/modelsそして、そのスクリプトの中に、テスト用のスクリプトがあるので実行してみる。>cd models\research>python object_detection/builders/model_builder_tf2_test.pyするとエラーが発生した。ModuleNotFoundError: No module named 'object_detection'どうやら、モジュールが足りないらしい。ということでインストールしてみる。> pip install object_detection大量のログが流れ、最後に「Successfully~~~」と表示されたので、おそらく問題なくインストールできたらしい。(途中のログにはWARNINGが山のように出てるのだが。。。)再度、テスト用スクリプトを動かしてみる。またまたエラーが発生する。ImportError: cannot import name 'anchor_generator_pb2' from 'object_detection.protos'何かしらが足りないらしい。ググってみると、以下のコマンドを事前に実行する必要があるということです。>protoc object_detection/protos/*.proto --python_out=.実行してみたら、「protoc」というコマンドが見つかりませんって感じです。さらにググってみると、protocは別にインストールできるようでした。以下のURLからWindows版をダウンロードして解凍する。https://github.com/protocolbuffers/protobuf/releases/tag/v21.3binフォルダにexeファイルが置いてあるだけなので、パスを通すなり、絶対パスでコマンドたたくなりして動かしてみる。解凍したフォルダを「protoc」というフォルダ名にして、modelsと同じ階層に配置して以下のコマンドを実行してみる。>..\..\protoc\bin\protoc.exe object_detection/protos/*.proto --python_out=.特にエラーもなく正常終了。ググったところを見てみると、このコマンドを実行した後、pip installしろって感じなのでやってみる。>pip install . エラーが発生しました。ERROR: Directory '.' is not installable. Neither 'setup.py' nor 'pyproject.toml' found.見た感じ「setup.py」ができている感じもないですし、さらにググってみた。Linuxの説明サイトではあるが、以下のコマンドをpipの前に実行していた。「cp object_detection/packages/tf2/setup.py .」なので、同様に以下のコマンドを実行してみる。copy .\object_detection\packages\tf2\setup.py ./さらに、pipインストールしてみる。>pip install . すごい勢いでログが流れて、以下のエラー。。。ERROR: Could not build wheels for pycocotools, which is required to install pyproject.toml-based projects調べた結果、どうやら「python-dev」がいるらしい。というわけで、それをインストールする方法を調べて以下のコマンドを実行する。>pip install python-dev-toolsしかし、上記エラーは解決せず。。。よくよくエラーを見てみると、「error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/」ってありました。どうやら、Microsoft C++のBuildツールがいるようです。というわけで、Microsoftのサイトからセットアップツールをダウンロードします。https://visualstudio.microsoft.com/ja/downloads/セットアップツールをダウンロードして起動したら、「C++ によるデスクトップ開発」をチェックし、インストールの詳細で「v143 ビルドツール用 C++/CLI サポート(最新)」にチェックを入れインストールします。再度、pipでインストールします。>pip install .なんか、OSErr的なものが見えたんですが、再度同じコマンドを実行したら正しく終了しました。再度、テストを行います。>python object_detection/builders/model_builder_tf2_test.pyエラーです。。。沼にはまってきました。ImportError: cannot import name 'builder' from 'google.protobuf.internal'とりあえず、protobufを再度インストールしてみます。>pip install --upgrade protobuf先ほど見えたOSErrが再度発覚!ERROR: Could not install packages due to an OSError: [WinError 5] アクセスが拒否されました。この後も色々やってみたものの、ダメでした。同時にやっていたyoloの環境まで壊れてきたので、ちょっと、あきらめて、Anacondaの環境に逃げたいと思います。その記事は別途記載しますね。
2022年07月23日
コメント(0)
-
グラフィックボードが欲しくなってきた。。。
yolov5を使って物体検知のディープラーニングをやってみてるんですが、とっても時間がかかるのです。1回のEpochで42秒かかります。これを1000Epoch回すので42000秒かかっちゃいます。11時間半ぐらいかかりますね。。。。今、使っているGPUはQuadro K2200というものです。Maxwell第1アーキテクチャのGPUで2014年ごろのものになります。性能は以下の通り。コアはGM107というものでGeforceでいうとGTX750Tiをベースにしています。コアクロックは1046 MHz [ブースト時1124 MHz]コア数はSM:5,CUDA:640,TMU:40,ROP:16メモリはL2キャッシュが2MB,グラフィックメモリが4GBとなっており、GDDR5 5Gbps計算性能は単精度が1.439TFLOPS、倍精度が0.04496TFLOPSQuadroのさらに性能が良いものかGeForceの性能が良いものに今後はしたいなーって漠然に思っていたのですが、最近、Teslaというものがあるということを知りました。電気自動車ではないですよ(笑)TeslaってGPGPU専用の拡張ボードでなんと、モニター出力がついていません!すごい思い切った設計ですよね。グラボなのにモニター出力できないなんてwで、やはり、そういう用途なため、高性能であるが非常に高額でもあります。しかしそこは、ヤフオクで世代落ちを探してみるってことで、色々とありました。手の届きそうなやつ。大体1万円前後で探したいので、その辺の価格帯を見てみると、以下のグラボが候補に挙がってきます。Tesla K20、K20X、K40、K10この辺あたりですね。ただこの辺は今使っているQuadroの1世代前のGPUになります。なので、ここは世代を合わせたいところ。そうなると、M6とかM4,M60、M40あたりになりますが、ヤフオクではM60しかなく、7万円前後と高額すぎて手が出ません。仕方ないので、上記、1世代前のKeplerマイクロアーキテクチャを狙ってみたいと思います。K2200より前の2012年前後の発売みたいで、ちょっとドライバーの互換性などが気になるところですが、安ければ頑張ってみたいです。性能は以下の通り。K10CUDAコア:3072(4.8倍)クロック:745MHz(0.71倍)メモリ:8GB(2倍)単精度:4.577TFLPS(3.18倍)倍精度:0.191TFLPS(4.25倍)K20CUDAコア:2496(3.9倍)クロック:706MHz(0.67倍)メモリ:5GB(1.25倍)単精度:3.52TFLPS(2.45倍)倍精度:1.17TFLPS(26倍)K20XCUDAコア:2688(4.2倍)クロック:732MHz(0.7倍)メモリ:6GB(1.5倍)単精度:3.95TFLPS(2.74倍)倍精度:1.31TFLPS(29倍)K40CUDAコア:2880(4.5倍)クロック:745MHz(0.71倍)メモリ:12GB(3倍)単精度:4.29TFLPS(2.98倍)倍精度:1.43TFLPS(31.8倍)いやー、1世代前といっても、さすが専用GPUですね。どのカードも単精度性能が2.5倍以上ありますね。2.5倍の性能が出るんだったら、10時間かかる作業が5時間で終わるじゃないですか!それは素晴らしいです。ただねー。。。実は、補助電源がもうないんですよ。今、Radeon R9に使い切っていまして、Quadro外してTeslaつけても補助電源がない。そうすると、Radeon外して、Tesleつけるってことになるんですが、世代が違うことでの問題がなければよいのですが。。。。ちょっと悩みますね。安かったらダメ元で狙ってみたいと思います!
2022年07月22日
コメント(0)
-

OpenCV+Pythonを利用した名刺画像の認識 その3
前回エッジの抽出と二値化により上と右の線が消えてしまうという問題が残っています。元画像がこんな感じエッジ抽出した画像がこれそして二値化するとこれというわけで二値化を色々と変更していきたいと思います。Python+OpenCVで二値化する方法は「threshold」といメソッドを利用する形となります。以下のサイトに詳しく書いてあります。http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_imgproc/py_thresholding/py_thresholding.html見たところ、「threshold」と「adaptiveThreshold」があるようです。それぞれ試してみます。# 二値画像の生成#ret,thresh1 = cv2.threshold(wkimg,127,255,cv2.THRESH_BINARY)wkimg = np.uint8(wkimg)ret,th1 = cv2.threshold(wkimg,127,255,cv2.THRESH_BINARY)th2 = cv2.adaptiveThreshold(wkimg,255,cv2.ADAPTIVE_THRESH_MEAN_C,\ cv2.THRESH_BINARY,11,2)th3 = cv2.adaptiveThreshold(wkimg,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,\ cv2.THRESH_BINARY,11,2)# 結果書き込みcv2.imwrite('meishi3_Result2_th1.jpeg',th1)cv2.imwrite('meishi3_Result2_th2.jpeg',th2)cv2.imwrite('meishi3_Result2_th3.jpeg',th3)上記のようにテスト的に3つの結果を出力するように変更しました。そして結果がこんな感じノイズが多いですね。。。そして、やはり、右と上が切れています。結局、上と右の線はノイズと同じ感じでノイズを除去すると線も除去されてしまう状態です。そして、あまりにもノイズが多いと、想定外の箇所が線として認識されてしまうため、ちょっと利用は難しい感じです。色々と行き詰った感じです。とりあえず、パラメータを手動で調整して、以下の状態まで持っていけました。# 二値画像の生成ret,thresh1 = cv2.threshold(wkimg,30,255,cv2.THRESH_BINARY)いやー難しいですね。あとはどのようにすればいけるのでしょうか?ちょっと色々考えてみます。
2022年07月21日
コメント(0)
-
OpenCV+Pythonを利用した名刺画像の認識 その2
前回、作成したプログラムは背景が濃い色で名刺が白であれば境界線を認識し、四角形を描画することができました。それでは、白い背景に白い名刺だとどうなるでしょうか?このような画像を用意してみました。そして、前回と同じプログラムを実行してみると、以下のようになります。はい!上と右の線が認識されていません。これは、ライトが写真の上のほうにあり、上部の影が見えないため、閾値から外れエッジとして認識されなかったものと思われます。前回のプログラムでエッジを認識している箇所は以下でした。# エッジの抽出wkimg = cv2.Canny(image=wkimg, threshold1=100, threshold2=130)このCannyという関数の、threshold1とthreshold2というのがパラメータで閾値となります。細かい話については公式サイトを見て頂くものとして、私は安易に以下のように考えています。threshold2は値が小さくなればエッジを取得しやすくなる。threshold1は値が小さくなれば取得したエッジが長くなる。公式サイト(Canny)ということで、パラメータをいじってみます。エッジが取得できなかったのでthreshold2の値を小さくしてみます。# エッジの抽出wkimg = cv2.Canny(image=wkimg, threshold1=30, threshold2=50)色々と試しましたが、上記のような組み合わせでようやく以下のようになりました。右の下のほうと左の上のほうを若干認識できるようになりました。ただ、これはパラメータを手動であーでもないこーでもないと調整しながら手動で見つけたパラメータとなりますので、自動化ができません。ここの閾値の最適な値を自動で見つける方法はないのでしょうか?次にエッジ検出の方法を変更してみます。エッジ検出された結果の画像はこんな感じです。人間であれば途切れた線を脳内補正できますが、コンピュータだと難しいところ。あとノイズが多いのも気になります。ということで、Canny関数からsobel関数に変えてエッジを拾ってみます。# エッジの抽出#wkimg = cv2.Canny(image=wkimg, threshold1=30, threshold2=50)gray_x = cv2.Sobel(wkimg, cv2.CV_32F, 1, 0, ksize=3)gray_y = cv2.Sobel(wkimg, cv2.CV_32F, 0, 1, ksize=3)wkimg = np.sqrt(gray_x ** 2 + gray_y ** 2)# 結果書き込みcv2.imwrite('meishi3_Result1.jpeg',wkimg)Cannyの部分をコメントアウトし、Sobelのコードを入れてみます。xの変化量によるエッジ抽出とyの変化量によるエッジ抽出をそれぞれ取得し、その双方を合体させる形としています。この結果がこんな感じノイズもある程度ありますが、薄いながら線が切れていないように見えます。これでそのまま動かすと、二値画像取得で線が薄すぎて取得できませんでした。というわけで、エッジの取得については一旦ここで終了したいと思います。次は二値画像取得のところの方法やパラメータを検討し、薄い線でも取得できるか?ってところを検討していきたいです。
2022年07月19日
コメント(0)
-
Xeon E5-2698v3でCineBenchを回してみた。それとAI勉強用WSの価格
16コア32スレッドでCineBenchが回っているだけの動画を撮ってみました。まずはCINEBENCH R20です。なかなかのマルチスレッドな動きです。スコアは4415とかそのくらいですね。そして、R23も回してみました。こちらのスコアは、11156です。今回、AIの勉強をするにあたり、デスクトップPCを新調したわけですが、いかんせん、先立つものがあまりないという状況で、それなりの性能がないとディープラーニングに時間がかかるし、画像処理も相当時間がかかってしまうってことで、用意したワークステーションですが、今のところ、まぁ、満足しています。最新のチップでもないし、最高のスペックでもないのですが、十分なスペックだと思います。スペックについては、Z440の紹介の時に記載していますんで、とりあえず、そちらを見て頂くとして、かかった費用について記載します。まず、本体。「HP Z440 WorkStation」こちらはヤフオクで仕入れました。落札価格22,000円、送料1,800円の合計23,800円です。次にCPU「Xeon E5-2698v3」。もともと搭載されていたCPUがXeon E5-1603v3だったため、載せ替えようとして購入。こちらもヤフオクで仕入れました。落札価格13,980円、送料210円の合計、14,110円です。最後にSSD「Samsung 980 1TB」とPCIe NVMe拡張カード。SSDはPayPayフリマで購入しました。10,500円。PCIeカードはAmazonで990円で購入しました。メモリは最初から32GB搭載されており、グラボはQuadroK2200が搭載されていましたのでそのまま利用しています。グラボについては、追加で以前のPCに搭載されていたRadeon R9 380も併せて搭載しています。ということで、23,800+14,110+10,500+990=49,400円。約5万円となりました。うーん。。。最新のRyzen5が搭載された小型PCがあと1万円出せば購入できるって感じですが、どうなんでしょうねーシングルスレッドでは最新のCPUには勝てないですし、32GBのメモリ、1TBのSSDにしようとすると、それなりに価格が上がってくるので、安くできたのではないかなーって個人的には思います。どこの性能が欲しいか?ってことですしね。あとは、やはりディープラーニングするのであれば、グラボの性能を上げていきたいってところと、メモリーをやはり増やさないと厳しい感じではあります。次はメモリーかなー。+64GBで96GBのメモリ搭載を目指します。そしてグラボへって感じで行きたいですね!
2022年07月19日
コメント(0)
-

OpenCV+Pythonを利用した名刺画像の認識 その1
写真から画像の一部を認識し切り抜くという処理を作りたくて、とりあえず、その一部を認識させる方法を考えてみたいと思います。今回プログラムの作成及び実行に利用した環境はWindows標準環境(Microsoft StoreよりダウンロードインストールされるPython)を利用しています。(執筆時のバージョンは3.10.5)OpenCVは上記バージョンのpipにてインストールされるバージョンを利用しています。今回、挑戦するのは名刺。スマホのカメラで撮影された名刺画像から背景などの余分な箇所を除き、名刺だけにしたい。とまぁ、言葉でするのも、人の判断でするのも特に難しくない作業です。最近の名刺管理アプリケーション(Eightなど)はAIを利用して、名刺を認識しているようですが、いかんせん、まだまだ勉強不足。とりあえず、画像をごにょごにょすることでどうにか精度を上げていきたい。名刺の写真ってことで大きな問題になってくるのが、背景と名刺の境界線のところです。背景が黒で名刺が白であれば、それなりに判別できそうですが、背景が白で名刺も白だと難しそうです。あと、背景なのか名刺のデザインなのか?っていう判断も難しそうです。ただ、全部を最初からできるわけでもないので、最も簡単な画像を試してみたいと思います。背景が濃い色で名刺が白のパターンですね。緑の背景に白色の名刺を置いています。この画像をもとに以下のプログラムで加工してみます。import cv2# イメージファイル読込img = cv2.imread('meishi.jpeg',)#グレースケールwkimg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# エッジの抽出wkimg = cv2.Canny(image=wkimg, threshold1=100, threshold2=130)# 結果書き込みwkimg = cv2.imwrite('meishi_Result.jpeg',img)このように、名刺の縁のみを抽出してくれます。次に、この画像から四角形の箇所を認識させる処理を追加してみます。まず、結果の画像をよく見ると、二重線になっている箇所がありますので、それらを結合します。その後、輪郭線の抽出のために「findContours」を利用するのですが、そのためには二値画像が必要となります。二値画像とは単純にいうと白黒の画像です。その画像を得るために、「threshold」を利用します。thresholdは閾値を設定して、二値画像を得るわけですが、実際本当にシステムとして認識させるためには、その閾値の設定が難しくなります。写真の明るさや名刺の色、背景の色によって最適な閾値が変わるため、非常に厄介です。この二値画像の作成に関しては再度検証して別途記事にしたいと思います。というわけで、二値画像を得るまでのプログラムがこんな感じです。import numpy as np# エッジの結合wkimg = cv2.morphologyEx(wkimg, cv2.MORPH_CLOSE, np.ones((5, 5), dtype=wkimg.dtype))# 二値画像の生成ret,thresh1 = cv2.threshold(wkimg,127,255,cv2.THRESH_BINARY)# 結果書き込みcv2.imwrite('meishi_Result2.jpeg',thresh1)それでは、いよいよ輪郭線の抽出と輪郭線に基づいた描画を行っていきます。輪郭線の抽出は「findContours」を使ってやっていきます。この関数で、輪郭線の位置情報が配列として取得できます。取得した位置情報をもとに線を描画するわけですが、描画する際にあまりにも小さなオブジェクトはノイズである可能性が高いため、そちらを除いていたりします。この辺の閾値も実際のプログラムになると値の設定が悩ましいものになります。この辺の詳しい内容については私もまだ理解できていないので、参考にしたサイト様をいかに貼り付けております。参考にしたサイト# 輪郭線の抽出contours, hierarchy = cv2.findContours(thresh1, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)for i in range(0, len(contours)): if len(contours[i]) > 0: # remove small objects if cv2.contourArea(contours[i]) < 500: continue rect = contours[i] x, y, w, h = cv2.boundingRect(rect) cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 10)# 結果書き込みcv2.imwrite('meishi_Result3.jpeg',img)結果、このように検出した画像の周りに赤線で枠を描画することができました。ただ、このやりかただと、名刺の配置が若干斜めになったりすると以下のようになってしまいます。なので、描画する箇所のプログラムをちょっといじってみます。この辺の情報もネットを調べれば何個か出てきますので、そちらを参考にします。参考サイト# 輪郭線の抽出contours, hierarchy = cv2.findContours(thresh1, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)for i in range(0, len(contours)): if len(contours[i]) > 0: # remove small objects if cv2.contourArea(contours[i]) < 500: continue cv2.polylines(img, contours[i], True, (0, 0, 255), 10)# 結果書き込みcv2.imwrite('meishi_Result3.jpeg',img)rectangleからpolylinesに変更しています。rectangleは長方形を描画する関数ですので、前述のとおり、検知された画像が丸々入る長方形を描画しています。しかし、polylinesは頂点をつなぐ線を描画するため、各頂点から頂点への描画となり、以下のような画像になります。一旦は、必要な情報(名刺の枠を認識し座標情報を取得する)はできました。しかし、記事の中にあるように、各種閾値については現状固定で指定しており、今回のサンプル写真であればうまくいきますが、背景が緑ではなく黄色だったら?とか、模様がついていたら?とかなっていくと、閾値の最適化を動的に行う必要が出てくると思います。また、白の背景に白の名刺の場合などは特に閾値が難しくなるかと思います。次回以降、その辺の各種閾値なや光、影の影響なども併せて検討して改良していきたいと思います。※当プログラムは各種サイト様の情報を参考にしております。勝手ながらリンクを張らさせて頂いておりますので、問題があるようでしたらコメントに記載いただければリンクを削除いたします。
2022年07月18日
コメント(0)
-
Windows標準?のPython環境を整える。
Microsoft StoreにPythonが置いてあるんで比較的容易にPythonの環境は整えれますね。Microsoft Storeで「Python」って検索して、インストールしてもいいですし、PowerShellでPythonって入力してEnter押すと、Microsoft StoreのPythonページが表示されるので、そこからインストールしてもいいです。2022年7月14日現在、StoreにあるPythonのバージョンは3.10.5が最新っぽいです。さて、Pythonを入れたら、pipを最新化します。python -m pip install --upgrade pipってPowerShellで入力すると、pipが最新化されます。んで、とりあえずTensorFlowを使いたいのでインストールします。pip install tensorflowしかし、ここでエラーが発生しました。ファイルが見つかりません的なエラーですね。しかし、なんか、よく見てみるとPathが長すぎるんじゃね?みたいな感じのことが書いてあります。ググってみると、同様のエラーが発生している方もいらっしゃいました。レジストリをいじることで対処可能みたいです。regeditでレジストリエディタを起動し、以下の項目を探します。HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystemその中にある「LongPathsEnabled」の値を0から1にすればOK。再度、pip install tensorflow無事インストールできました。さて、前回の設定でCUDAやcuDNNなどのインストールも終わって環境も構築できています。エラーとかでないか確認してみます。エラーが出ますねー。。。W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not foundDLLが見つかんないってさー。でも、あるんですよねー。pathも通ってるみたいだし、原因がわかりません。色々と調べてみましたが、すっきりした解決策はなく、結局、以下の方法で解決することにしました。import tensorflow as tfって書く前にimport osos.add_dll_directory("C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.7/bin")というおまじないを入れてあげるってことでした。ディレクトリの場所については、CUDAのインストールディレクトリになりますんで、インストールしたバージョンによって変わります。(上記は11.7の場合)なんだかなーって感じですが、まぁ、良しとします。
2022年07月15日
コメント(0)
-
Anacondaの環境
Pythonの環境って色々と作り方がありますよね?私が今回作成している環境は以下の通り。Windows標準のPython環境Microsoft StoreよりインストールできるPythonでVersionは3.10系簡単な動作確認なんかはこちらの環境で実施している。コードの作成はVSCodeを利用して作成し、そのままVSCodeで実行すると楽。WSLなUbuntu20.04での環境サンプルプログラムにシェルがあったりした場合、Linuxで実行したほうが簡単なので、こちらの環境を利用している。あまり使わないけど、とりあえず環境として構築した。Anacondaの環境様々な環境を切り替えたり、JupyterNotebookなども簡単に構築できるので非常に便利。標準Pythonでも仮想環境の切り替えできるけど、Windows使いのGUIに慣れていればAnacondaのGUIで設定の切り替えなどができる環境は使いやすい。プログラムの作成はVSCodeを利用している。https://azure.microsoft.com/ja-jp/products/visual-studio-code/インストールも簡単だし、情報もたくさんWebに出ているしデバッグも実行も環境づくりも簡単。多機能でPythonだけじゃなくて他の言語にも利用できる。非常に便利です。とりあえず、コマンドパレットのところで日本語化した後、拡張機能でPython(Microsoft製)を入れてやれば、Python使えます。Pythonの環境がたくさんあれば、Pythonのプログラムを作る際にどの環境で実行するの?みたいな感じで聞かれるので、実行したい環境を選択すればOKAnacondaで複数の環境を作っていれば、それらがすべて選択肢に出てくるのでいいですよ。しかし、新しいパソコンの新しいCPUなのですが、マルチスレッド性能はよいのですが、シングルスレッド性能はそこまでよくないわけで、Pythonの実行については、マルチコアを十分に使用できていないようで、かなり時間がかかってしまいます。プログラムをマルチスレッドで実行できるように作り変えないといけないんでしょうね。もうちょっと、プログラムのマルチスレッド化を勉強してみます。あと、やはりGPGPUでQuadra K2200はそこまで速くないのか、結構時間がかかってしまいますね。まぁ、これでもCPUよりは早いんだろうけど。。。。ちょっと、マルチスレッド化の勉強をしてきます( ̄▽ ̄)ゞ追記ちょこっと変更したらいけそうな感じだったーまず、プログラムの構成がfile_list=pathlib.Path(読込フォルダ).glob('**/*.jpg'))for i in range(len(file_list)): image= cv2.imread(str(file_list[i]),) #画像関連の処理を以下に記載って感じになっていますんで、処理部分を関数にサブルーチンにしてしまって、以下のようにすればOKdef img_proc(inFile): image= cv2.imread(str(inFile),) #画像関連の処理を以下に記載if __name__ == '__main__': max_workers = os.cpu_count()#CPUコア数取得 #元データの読み込み # フォルダ内に保存されているファイル一覧 file_list = list(pathlib.Path(読込フォルダ).glob('**/*.jpg')) # ファイル数分繰り返す Parallel(n_jobs=max_workers )(delayed(img_proc)(file_list[i]) for i in range(len(file_list )))こんな感じでイケルっぽい。tensorflowの学習で今手一杯なので、それが終わったら、マルチスレッドのテストやってみる!テストの結果、820枚の画像を色々OpenCVで加工したりする処理がもともと39分かかっていたのが、4分になりました!すっげー!1スレッドで39分、32スレッド利用すれば、単純計算で32倍ですが、そう単純な計算にはならなくって、10分の1ぐらいの速度になりました。それでも十分早いっす!
2022年07月13日
コメント(0)
-

Z440にM.2 SSDを搭載する!
順調に改造を続けているZ440ワークステーションですが、今回はストレージの変更をしていきたいと思います。現状搭載されているストレージはHDDが1TB、SATAのSSDが256GBとなっています。SATAのSSDはSAMSUNG製の旧PCから載せ替えたもので、シーケンシャルリード500MB程度の速度のものです。基本的にあまり不満もないのですが、折角ですのでM.2のSSDにしたいなーっと思い色々調べてみました。まぁ、第4世代Coreシリーズと同世代のZ440のマザーボードにはM.2 SSDのスロットはついていません。しかし、オプション品でHPよりZ TURBO Drive G2というSSDを乗っけたPCIe拡張カードがあります。ということは、基本的に載せることは考慮されているってことですね。さらに色々調べてみると、起動ドライブにはできないとかできるとか様々な情報があり、確実にできるって感じではありませんでした。純正品を購入すればできるのでしょうが、新品は高く、また、中古品も256GBで7000円前後とお高い。M.2にOptionROMがついていればいける!とか、UEFIにドライバーがあればいけるとかそういう記事が色々とありましたが、やはり、この組み合わせではできる!って情報がありませんでした。とりあえず、Windows10まで入れれば、Windows10のドライバーはあるので、ドライブとして使えることは確実っぽい。起動ドライブとして使えるかどうかが不確定な感じです。というわけで、ダメもとでやってみました。最悪、CLOVER EFIを使ったUSB起動からの対応でもいいかーっていう感じで各種パーツを購入しました。私の環境ではうまくいきましたが、以下の組み合わせで必ずうまくいくという保証をしているわけではありません。実施される場合は自己責任でお願いいたします。購入パーツは以下の通り・M.2 SSD:SAMSUNG SSD 980MZ-V8V1T0B/IT サムスン Samsung SSD 980 1TB PCIe Gen 3.0(最大転送速度 3500MB/秒) NVMe M.2 国内正規保証品価格:12980円(税込、送料別) (2022/7/11時点)楽天で購入https://amzn.to/3RoSeyt・PCIe拡張カード:GLOTRENDS M.2 PCIe NVMe4.0/3.0変換アダプターGLOTRENDS M.2 PCIe NVMe 4.0/3.0 変換アダプター、M.2ヒートシンク(3mm厚み)付き、M.2用 PCI-express 4.0/3.0 x4変換ボード、M.2 スロット、M.2 PCIE SSD(NVMeとAHCI)、PCI-E GEN4フルスピード、デスクトップPC価格:1750円(税込、送料無料) (2022/7/11時点)楽天で購入https://amzn.to/3c3G1zf注文してしばらくしてパーツが届きました。作業はとても簡単です。拡張カードにM.2 SSDを装着し、Z440のPCIeのスロット(空いている下から3番目のx4スロットを使いました。)に装着するだけ。そして、電源ポチっ!Esc連打でBIOS画面へ。ブート関連の項目にNVMeの文字が見えます。これは期待が持てます!とりあえず、Windowsインストール用のUSBメモリより起動させて、Windowsをインストールします。インストールの途中で再起動されます。無事、M.2 SSDから起動されました!特にその後も問題なく、WindowsUpdateやSSDのファームウェア更新なども問題なくクリアし、無事起動ドライブをPCIe拡張カードに搭載されたNVMe M.2 SSDにすることができました。できるかできないか不安でしたが、問題なくできちゃいました。特に作業中引っかかるところもなく、すんなりできちゃったので、拍子抜けではありましたが、問題は起こらないことがいいですからね!BIOSの設定やUEFIの設定、Windowsインストーラーでの追加ドライバなど特に何もなかったです。ちなみにWindowsは11を使っています。スピードもシーケンシャルリードはとてもサクサクです!
2022年07月12日
コメント(0)
-
旧kerasのimport文をtensorflowで書く
tensorflowを色々なサイトで情報拾うと、kerasっていうモジュールをimportしていることが少なくないんだけど、これが最新の環境だとエラーになるんですよねー。ついつい、コピペで楽しようとしてるのが問題なんだろうと思うんですが、どうやら、kerasはtensorflowに合体したみたいで、それ以前のimportの書き方とそれ以後のimportの書き方が変わっています。ソースコピペしたあと、頭にtensorflowってつけるといい感じです。例えば、from keras.preprocessing.image import load_img, img_to_arrayこれは、from tensorflow.keras.preprocessing.image import load_img, img_to_arrayこんな感じになります。ちなみにPIL関連でハマりました。PIL関連のリードエラーが出る場合は以下の以下のモジュールをインストールするとエラーがなくなります。pip install pillowあと、keras関連だと、以下のところもわかりづらかったです。from keras.layers.convolutional import Conv2D, Conv2DTransposeこれは、頭にtensorflowをつけるだけでなくて、layersより後もいらない感じになります。なので、以下のように書けばエラーがなくなります。from tensorflow.keras.layers import Conv2D, Conv2DTransposekeras関連の情報はtensorflowと合体する前の情報と後の情報が混在しているので、そのままコピペでは動かないことが多いです。ちょこっと修正すれば動く様になりますので、エラーメッセージと戦いましょうw
2022年07月11日
コメント(0)
-
Windows11のWSLにUbuntu環境をいれてTensorflowを使えるようにしてみる。
WSLはWindowsの基本機能としてあります。(Pro版だけだっけ?Proしか使ってないからわからないです。)WSLとはWindows Subsystem for Linuxの略らしいです。その昔、同じPCでLinuxとWindowsを利用するためには、デュアルブートするか、VirtualBoxやVMWareなどで仮想環境を作ってインストールするしかなかったのですが、今はこんな便利な機能がWindowsについているんですね!準備まずは、BIOSでパソコンの仮想化機能を有効にしてあげる必要があります。このHPのWSの場合はBIOSのメニューから「セキュリティ」タブの「システムのセキュリティ」。その中に、仮想化技術やIntel VT-dなどの設定項目があるのでEnable(有効)にします。これをしないとWSLインストール後のUbuntuのインストールでこけます。(こけてるかどうかわからないこけ方をしたりします。)WSLのインストールPowerShellを管理者モードで起動します。wsl --installとコマンドを叩きEnterを押下すると、WSLのインストールが走ります。再起動を求められるので再起動します。UbuntuのインストールWindowsストアでUbuntuと検索すると、何種類かのバージョンが出てきますので20.04をインストールします(後ほどインストールするlibcudnn8が20.04までしか出てないです。)インストール後、スタートメニューよりUbuntuを起動できます(CUIですよー)Ubuntuの最新化sudo apt updatesudo apt upgrade上記コマンドでUbuntuを最新化しておきます。pipのインストールsudo apt install python3-pip上記コマンドでpipをインストールします。pipはPythonのモジュールインストール用のコマンドです。CUDAToolKitなどをインストール$wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin$sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600$wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb$sudo dpkg -i cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb$sudo cp /var/cuda-repo-wsl-ubuntu-11-7-local/cuda-*-keyring.gpg /usr/share/keyrings/$sudo apt-get update$sudo apt-get -y install cuda上記コマンドでCUDA Tool Kitをインストールします。cuDNNのインストールこれにはNvidiaのアカウントが必要になります。cuDNN Download | NVIDIA Developer上記サイトよりcuDNNをダウンロードしてください。Ubuntu20.04用をダウンロードします。「Local Installer for Ubuntu20.04 x86_64 (Deb)」こんな表記がされています。ダウンロードしたファイルのディレクトリに移動して以下のコマンドを実行します。$sudo dpkg -i cudnn-local-repo-ubuntu2004-8.4.1.50_1.0-1_amd64.deb$sudo cp /var/cudnn-local-repo-ubuntu2004-8.4.1.50/cudnn-local-E3EC4A60-keyring.gpg /usr/share/keyrings/sudo apt install libcudnn8tensorflowのインストールsudo pip install tensorflow上記コマンドでtensorflowのインストールができます。確認python3>>>import tensorflow as tfここの間にCUDA使えねぇよって出なければとりあえずOK>>>tf.print('TEST')ここで初回にいろいろメッセージが出ますが、最後のほうにGPUに関するメッセージが出ていれば大丈夫だと思います。とりあえず以上でWSLにTensorflowのGPU(CUDA)サポートで設定ができた感じです。最後に出てきたメッセージは以下のメッセージです。tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 2795 MB memory: -> device: 0, name: Quadro K2200, pci bus id: 0000:03:00.0, compute capability: 5.0大丈夫ですよね?(笑)
2022年07月11日
コメント(0)
-

HPワークステーションZ440のCPU換装16コア32スレッドへ!
先日購入したZ440ですが、順調です。色々と試しながら環境を整えていく予定ですが、CPUがちょっと弱いのです。今まで利用していたPhenomIIx6 1055Tとあまり変わらない感じ。シングルは良くなっていますが、マルチではあまり変わらないのです。しかし、それはこのワークステーションを選んだ時からわかっていたことです。そもそも換装前提でした。このWSに乗っているCPUはXeon E5-1603V3という、Haswell世代(Coreでいうと第4世代)のCPUです。Wikipediaにラインアップとして乗っていないのが謎ですが、一応、Intelの製品ページには掲載されています。以下Intelの製品情報です。製品コレクション インテル® Xeon® プロセッサー E5 v3 ファミリー開発コード名 製品の開発コード名 Haswell発売日 Q3'14リソグラフィー 22 nmCPU の仕様 コアの数 4 スレッド数 4 プロセッサー ベース動作周波数 2.80 GHz キャッシュ 10 MB Intel® Smart Cache TDP 140 Wメモリの仕様 メモリーの種類 DDR4 1333/1600/1866 最大メモリーチャネル数 4 最大メモリー帯域幅 59 GB/sPCI Express リビジョン 3.0PCI Express 構成‡ x4, x8, x16うーん。4コア4スレッド2.8Ghz。お世辞にも強いCPUとは言えないですね。まぁ、前回の日記に書いている様に、各種ベンチマークはお察しの通りでした。そこで!このHaswellのE5-1603v3の代わりを色々と悩みました。コア数が増えればクロック数が下がり、コア数が減ればクロックが上がる。また、性能が良いCPUやバランスが良いCPUはヤフオクの価格も高くなる傾向にあります。HaswellコアのCPU一覧はここから見れます。https://ark.intel.com/content/www/jp/ja/ark/products/codename/42174/products-formerly-haswell.htmlこの一覧から狙ったのは、E5の2687W、2697、2698、2699です。2687Wと2699は高くて手が出なかったので、2697と2698で探しました。両方ともにヤフオクにありましたが、1000円違いでしたので、2698にすることにしました。やはり、コア数スレッド数が多いタスクマネージャーを見たいじゃないですかwwというわけで、Xeon E5-2698v3を14000円ぐらいで購入しました。しかし、このZ440のメーカー構成ではE5-1680v3が最高のCPUとして設定されています。ちゃんと動くのか?取り付けてみるまでドキドキです。下手をすれば、14000円をドブに捨てる様なものです。(一応、ネットで換装できているという情報は見つけています)基本仕様インテル® Xeon® プロセッサー E5 v3 ファミリー製品の開発コード名 Haswell発売日 Q3'14リソグラフィー22 nmCPU の仕様 コアの数16 スレッド数32 ターボ・ブースト利用時の最大周波数3.60 GHz プロセッサー ベース動作周波数2.30 GHz キャッシュ40 MB Intel® Smart Cache バススピード9.6 GT/s TDP135 Wメモリーの仕様 最大メモリーサイズ (メモリーの種類に依存)768 GB メモリーの種類DDR4 1600/1866/2133 最大メモリーチャネル数4 最大メモリー帯域幅68 GB/sPCI Express リビジョン3.0PCI Express 構成x4 x8 x16何気にTDP下がっていますwというわけで届きました。E5-2698V3です!作業は比較的簡単。今ついているCPUを取り外し、新しいCPUを取り付けるだけ。さて、それでは既存のCPUを取り外していきます。HPのWSはケースが秀逸です。工具なしでカパっと開きます。開けたら、CPUファンにかぶさっているパーツを取り外します。これも工具なしで余裕です。CPUファンを取り外します。四角のネジを外すのですが、ここで一つ注意点。ドライバーはマイナスになり。CPUファンが干渉するので長さのあるドライバーがあると便利です。FANが外れました。そして、レバーを上げてCPUの固定を外します。CPUの固定が外れたら簡単にCPUが取れます。あとは、新しいCPUを取り付けて逆の手順で組み上げるだけ。CPUには一箇所の角に▲の印が付いており、ソケット側にも同じ印がついているのでそこを合わせて配置すればいいだけなので簡単です。新しいCPUが乗りました。さて、組み上げてスイッチOnです!まずはBIOSでCPUが認識されているか確認します。Xeon E5-2698V3きたー!というわけで、認識されました!一安心ですね。このままWindowsを起動させて、各種ベンチマークをとってみました。1603v3の時が以下の値CPUZ_Single:309.5CPUZ_Multi:1228.6CINEBENCH R23_Single:677CINEBENCH R23_Multi:25942698v3になるとCPUZ_Single:366.6(118%)CPUZ_Multi:6254.0(509%)CINEBENCH R23_Single:738(109%)CINEBENCH R23_Multi:11349(437%)非常に満足な結果になりました。問題なく動作していますんで、このまま様子見たいと思います。ちなみに、マルチスレッド性能は3年前ぐらいのハイパフォーマンスデスクトップ用CPUと同等な感じです。
2022年07月10日
コメント(0)
-
AI勉強の環境を整える。Tensorflowまでの道のり
とりあえず、環境を構築するために、各種ドライバーを入れていく必要がある。今回、Tensorflowを使いたいので、IntelCPUとNvidiaGPUの組み合わせにしてみた。そこで、まずは、Nvidiaのドライバーをインストールする。1.ディスプレイドライバーのインストールうちのQuadro K2200は以下のドライバーが最新であったので、そちらをインストールする。516.59-quadro-rtx-desktop-notebook-win10-win11-64bit-international-dch-whql 2.CUDA Toolのインストールこちらも最新のバージョンをインストールする。cuda_11.7.0_516.01_windows3.Cudnnをインストールする。これは、上記CUDA Toolのバージョンと合わせてインストールする。まぁ、最新のCUDA Toolなので最新をインストールする。cudnn-windows-x86_64-8.4.1.50_cuda11.6-archive.zipインストールといっても、上のCuda Toolのインストールフォルダにコピーしてパス通すだけ。C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7の直下に上記ファイルを解凍してできたフォルダやファイルを配置する。4.その他ごにょごにょZLIB DLL のダウンロードとインストール管理者として実行した コマンドプロンプトで,次のコマンドを実行.cd "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin"curl -O http://www.winimage.com/zLibDll/zlib123dllx64.zipcall powershell -command "Expand-Archive zlib123dllx64.zip"copy zlib123dllx64\dll_x64\zlibwapi.dll .あとはパスを通して終わり。call powershell -command "[System.Environment]::SetEnvironmentVariable(\"CUDNN_PATH\", \"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\", \"Machine\")"以下のサイトより情報をいただきました。ありがとうございます。https://www.kkaneko.jp/tools/win/cuda.html#cudnn84それじゃ、アナコンダ入れてみる!
2022年07月09日
コメント(0)
-
HPのワークステーションZ440をTPM2.0化してWindows11を入れてみた。
先日購入したHPのワークステーションZ440ですが、公式にはWindows11に対応していません。Windows11というと、TPMやらCPUの制限やらで色々とハードルが高いことで有名ですよねー。一応、インストール時にレジストリをごにょごにょすればそのチェックを飛ばすことはできるのですが、面倒ですし、いつか使えなくなるんじゃないかとドキドキします。んで、このワークステーション(以下WS)ですが、TPMは2.0に上げることができました。HPSBHF03568 レビジョン 11 - Infineon TPM セキュリティ アップデート | HP®カスタマーサポートここからZ440を探してsp87753.exeを実行すると、ファイルが解凍されますので、その中にある、TPMConfig64.exeを起動するだけですね。64ビット版OSは上記ですが、32ビット版OSの場合はTPMConfig.exeでよいと思われます。同じフォルダに英語の説明書があるのでなんとなくそれでできると思います。ただ、画面上にあと何回とか、エラー~~とかなんか不穏な文言があるのが気になります。私の場合は、1回目更新したのですが、結果変わっておらず、2回目を実行したらTPM2.0になりました。ドライバー類はWindows10のドライバーで11も動きそうなので、Windows11を入れてみました。インストール時にレジストリでごにょごにょする必要もなく、すんなりいきましたが、Windows10の時に実施した互換性チェックではCPUがNGでした。このWSのCPUはHaswell世代のCPUで対象外となっており、互換性チェックではじかれたものだと思います。なので、Windows11のインストールUSBを作成して、USB起動からのアップグレードを試みます。毎度おなじみWindows 11 をダウンロードする (microsoft.com)ここからWindows11はダウンロードできます。インストール媒体を光ディスクで作るひとは最近いないと思いますが、ISOのダウンロードもできます。「Windows 11 のインストール メディアを作成する」のところにあるリンクより作成ツールをダウンロードして空のUSBメモリを挿して実行したら出来上がりです。あとは、再起動して起動中にESCを押下し、BootメニューからUSBで起動したらWindows11のインストーラーが起動します。注意点は、このやり方だとWindows10からのアップグレードインストールはできません。クリーン?インストールになります。一応、各種ファイルは保存されていますが、Windows10の環境は保持されません。まぁ、インストールは画面に従って進めるだけなのでラクチンですね。面倒なのは各種ドライバをHPのサイトから落としてきてインストールしなければならないところでしょうか。なんか、Windowsのデフォルトドライバーで動いてほしいところですが、ないんですよねー。WSだからなのか、とてもびっくりしました。とりあえずデバイスマネージャーでは不明なデバイスが山のように検出されます。HPのワークステーション用ドライバダウンロードサイトよりドライバーをダウンロードしてインスコすれば不明なデバイスはすべて認識されます。HP Z440 Workstation ソフトウェア及びドライバーのダウンロード | HP®カスタマーサポートちなみに、チップセットのドライバーだけでも入れたら不明なデバイスはなくなる感じですが、できれば、すべて公式のドライバーにしたほうがよいでしょうね。というわけで、Windows11にしてみました。特に性能に差はないですね。若干起動が早くなった気がします。簡単ですがZ440のWindows11化でした。
2022年07月08日
コメント(0)
-
AI勉強用の新しいパソコンHP Z440が届きました!
先日AIの勉強をしようと思って、所有しているパソコンを使おうとしたらAMDの罠にハマり勢い余ってヤフオクで落札したPCが届きました。HPのZ440というワークステーションです。これから色々と改造をしていくつもりですが、とりあえず購入時のスペックは以下の通り。CPU:Intel(ここ重要!)Xeon E-1603 V3MEM:Registard DDR-4 8GBx4HDD:WD Blue 1TBHDDグラボ:Nvidia(ここ重要!)QuadroK2200OS:Windows10Proとなっております。前回ハマったAMD CPUとRadeonの罠にかからない様にIntelとNvidiaで攻めてみました。ただ、CPUの性能はシングルスレッドこそ前所有していたPCを上回りますが、マルチスレッドはどっこいどっこいの処理性能。。。というわけで、えいや!とヤフオクでCPUも落札しました。これについては、届いたらBlogに書きますね。HDDも所有PCよりSATA SSD(Samsung製)を載せ替えましたが、M.2SSDをPCIeで接続して起動ドライブにしたいと色々と調査中。Option ROMがどうだこうだ。。。ってよくわからんし・・・グラボについてはNvidiaのQuadro K2200が乗っておりCUDA処理ができるはず!ただ、Game性能は前のPCよりも劣ります。前のがRadeon R9 380だったので、とりあえず、両方載せとくことにしました。Tensorflowでグラボ2枚あったときちゃんと動くのか?っていうのも気になりますが、徐々に色々と調べながらやっていく予定です。というわけで、先日到着したおニューのPCは以下の様になっています。CPU:Intel Xeon E-1603 V3MEM:Registard DDR-4 8GBx4HDD:Samsung SATA256GBSSD、HITACHI 1TBHDDグラボ:Nvidia QuadroK2200 & Radeon R9 380OS:Windows10Pro改造が進めばまた情報載せますねーCPUZ_Single:309.5CPUZ_Multi:1228.6CINEBENCH R23_Single:677CINEBENCH R23_Multi:2594FF14:7995FF15:3993
2022年07月07日
コメント(0)
-
最近仕事でAI関連の話題が尽きないのでAIを勉強してみる。
最近さまざまなところでAIが普及しているみたいで、どんどん私たちの生活にAIが食い込んできていますね。ログイン時に人間かロボットかを判断する絵合わせとかあの辺もAIみたいですよ。以前、会社でAIの講習に行ってPythonをかじったぐらいだったんですが、その後、しばらくAIについてはあまり真剣にしてこなかったんです。私の仕事はもっぱらオフィスオートメイーションで基本的にAIって何?それの美味しいの?って感じで、それに携わることも殆どなかったんです。しかし、最近、ある仕事でAIを使って画像認識(画像検出)をするときにAIを使うと非常に精度が高いってことを知りました。今までAIなんて勉強したこともないし、どうやるのかも全くわからないんですが、色々とWebサイトを見ながらAIについて勉強していきたいと思っているところです。というわけで、まずはモノマネからしようと自宅PCにAIの勉強をするための環境を作ろうと今週末頑張りました。AIでDeepLearningさせるにはGPUがあるといいということなので、私が大昔に作成した自作PCで環境構築しようと思いました。これが悲劇の始まりでした。。。。まず、スペックCPU:PhenomII 1055(6Core)Mem:12GBGPU:Radeon R9 380SSD:250GBHDD:1TBって感じです。まぁ、古い構成ですね。10年以上前の構成ですし。。。でも、Windows 10も問題なく動きますし、最新の3Dゲームでなければそれなりに動作します。マイクラぐらいであれば十分なのですよ。スペックは問題ないと判断し、色々と調べているとWindows 10の仮想状態だとGPUがうまく認識できないって感じで、Windows10とLinux(Ubuntu)のデュアルブートにすべく、Windows 10を再セットアップ。そして、Ubuntu20.04をインストール。。。画面が表示されない。ubuntuのインストールが始まらない!ここでハマりました。4時間ぐらい。何度もインストーラーを作り直したり、USBメモリを変えてみたりと色々試しました。Ubuntuも22.04や18.04を試したりもしましたが、結局、グラボのDVI-Pからの出力がバグってるのか、ubuntuのGUIに切り替わった際にDVI-Iからの出力は見えるけど、DVI-Pの出力は死んでる状態になっていた。ただね、認識はされているのよねー。。。謎というわけで、古いモニターを引っ張り出してきて、つなげてようやくUbuntuのインストールが始まりました。そしてインストール完了!ただ、ネットが繋がらない。。。どうしても繋がらない。USBのWifiどんぐる(TPーLinkのAcher T2U Nano)が認識されない。ググって調べて、色々やってみたけど、ダメで。困った。ローカルだと拉致が開かないので、Wifi中継機を接続し、中継機経由の有線LANで接続することでオンライン状態を作り色々と作業をするが、どうしても繋がらない。RTL8812auのドライバーを拾ってきてインスコしたらいけるよ!っていう記事はいっぱいあるんだけど、認識はしてるっぽいものの、Wifiのアクセスポイントを拾ってこない。諦めて、ディスプレイドライバを入れてみたら、DVI-P側に表示された!やったー!って思って、再起動すると、また表示されなくなった。。。とりあえず、無線もつながらない、モニターも思ったところに表示されないので、Ubuntuを22.04でインストールし直すことにした。すると、すんなりWifiがRTL8812auのドライバーで認識し、接続できた。でも、22.04はRadeonのドライバーがない。。。ここで、ようやくubuntuとのデュアルブートを諦めて、CPUだけでとりあえずいいやってことで、Windows 10を再セットアップし、シングルブートに。。。次に、WSLでUbuntuをインストールし、ROCmというAMDのAI関連のやつから、Dockerを使って環境構築しようとDockerをインストールし、ROCmを入れてみる。動かすと普通にエラーがもりもり。。。もちろん意味不明なので、ROCmも一旦諦めて、CPUのみの環境構築するために、WSLにUbuntu22.04いれて、pipいれてTensorflowを入れてみる。流石に動くだろうと思って、tensorflowをインポートしたら・・・「The TensorFlow library was complied to use SSE4.1 instructions, but these aren't available on your machine.」まぁ私は英語読めませんが、SSE4.1でコンパイルしてるからあんたのマシンじゃ動かねーぜ!って感じでしょうか?まぁ、うちのCPUはPhenomIIでどうやらSSE4.1はサポートしていないようです。ここにきて、この環境はハードルが高いことを悟りました。勉強始める環境を揃えるのにハードル高すぎ!ってことで、諦めて、別のPCを物色しましたが、自由に再セットアップを繰り返すことができるマシンもなく、結局、ヤフオクで古めのワークステーションを落札してみました。HPのZ440ですが、CORE4世代のCPUが乗るやつですね。若干古いものの、まぁ、AIの勉強用としてはいいんじゃないでしょうか。CPUだけは載せ替えようと思っています。届いたらまたご報告しますねー!というわけで、今週末はAIの勉強のための環境構築をやるつもりで轟沈したのでした。。。。w
2022年07月04日
コメント(0)

全38件 (38件中 1-38件目)
1
-
-

- 楽天ブログいろいろ
- ブログの編集|日付変更|記事にいく…
- (2024-11-06 14:53:45)
-
-
-

- Amazonマケプレ
- 100円 【ダウンロード版】契約事務…
- (2024-11-08 22:56:41)
-
-
-

- iPhone
- iPhoneの画面をなんとかしたい。iPho…
- (2024-11-15 11:09:25)
-



