

全1110件 (1110件中 1-50件目)
-
クオータニオンの勉強
ずっと、続けている、MPU関係ですが、ちょっと問題があって・・・。あまり気にせずセンサをマウントしたのですが、MPUの出力(センサ)のXYZ軸が、機体に搭載したときのXYZ軸と違うというか・・・。で、MPUの出力に座標変換をかまして、センサのマウントの問題を処理しようとしたのですが、MPUの直接の出力は、クオータニオンなんです。で、ここ、とか、ここで勉強したのですが、やりたいことには繋がらず、ここを見て、やっと理解できました・・・。つまり、姿勢=回転をあらわすクオータニオンに更に座標変換=回転をおこなうためには、クオータニオンの掛け算を使う。ある点=ベクトル(長さは単一でもない)を回転させるためには、さらに共役クオータニオンを掛けるけど、これは必要ない。さらに、落とし穴だったのが、最初に回転したとき、実は座標軸も一緒に回転しているので、もう一度回転させる(掛け算する)ときには、一緒に回転した座標軸を元に回転させる必要があるという・・・。分かりにくい表現ですが、ここのアニメーションを見てもらうとわかると思います。オイラー角とかの回転処理が頭にあると、座標軸まで動いているって考えがないので、結構、試行錯誤して、意味不明で、混乱していました・・・。よって、今回の機体のセンサマウントの方向からすると、MPUの出力結果(クオータニオン)に、その結果回転した座標軸基準に、X軸回りに90度回す(クオータニオンを掛ける)だけでOKでした。クオータニオンの作り方はここがわかりやすかった。もともとのスケッチの、printIMUData()の変更箇所はこんな感じです。#define S 0.707106781 qx =int(( S*q1 +0*q2 +0*q3 +S*q0 ) * 16384.0f); qy =int(( 0*q1 +S*q2 +S*q3 +0*q0 ) * 16384.0f); qz =int(( 0*q1 -S*q2 +S*q3 +0*q0 ) * 16384.0f); qw =int((-S*q1 +0*q2 +0*q3 +S*q0 ) * 16384.0f);0部分は書く必要はないのですが、理解しやすいために残してあります。また、今回は、右から掛ける方を行列にする計算を使っています。それ以外にも、配列上で、qwが[0]に入る場合や、[4]に入る場合など、作法がいろいろあってこのあたりもややこしいのがクオータニオンです。作法の違いは、ここ参考。で、その結果を、もう一度、プロセッシングで飛行機を飛ばして確認したのですが、ヨー軸に初期値があるとわかりにくいので、下記のとおりオイラー角でアニメーション処理して、ヨー軸を殺して、serialEvent()のオイラー角計算部分を復活させると、ヨー軸に無関係に、X-Y軸回りにのみ傾く飛行機が表示されました。結果は、OK。これでまた先に進めます。// rotateY(-ypr[0]); rotateZ(-ypr[1]); rotateX(-ypr[2]);// float[] axis = quat.toAxisAngle();// rotate(axis[0], -axis[1], axis[3], axis[2]);
2021年02月23日
-
delayについて
年明けからずっと納期に悩まされて、残業、休日作業が続いていた仕事がやっと片付いた・・・。緊急事態宣言で、テニススクールでの息抜きもできず、体力も落ちて、体重も落ちて(ラッキー!)、こんなに天気が良いなら散歩でも行けばいいのに・・・。PS2コントローラーの接続部分の時間的なスリムアップを考えています。PS2Xライブラリはポートを直接ON-OFFさせて信号を作るソフトウェアSPIなのだけど、そのクロックを作っているdelayMicroseconds()は精度が悪いらしい・・・。#define CTRL_CLK 5// the setup function runs once when you press reset or power the boardvoid setup() { // initialize digital pin 13 as an output. pinMode(13, OUTPUT);}// the loop function runs over and over again forevervoid loop() { digitalWrite(13, HIGH); // turn the LED on (HIGH is the voltage level)// delay(1000); // wait for a second delayMicroseconds(CTRL_CLK); digitalWrite(13, LOW); // turn the LED off by making the voltage LOW delay(20); // wait for a second}こんなスケッチで、その精度を昔懐かしいサーボプログラマーで計測したところ、6μsだった。悪くないじゃん!まあ、Adafruit Itsy Bitsy M0 Expressは、48MHz(UNOの3倍)で動くからね・・・。ライブラリとしては、ON、5μs、OFF、5μsで、100kHzでSPIを動かしている風だけど、確かPS2コントローラーは、250kHzまで対応するハズだから、まずはここを攻めてみる。ON、2μs、OFF、2μsで、250kHzで先のスケッチを動かすと・・・。やばいっ!サーボプログラマーで4μs以下は測れない・・・。かろうじて2μs程度で動いているような・・・。avr系なら、until/delay.hってライブラリもあるようだけど・・・。そもそも、digitalWrite();自体、1.6μs使っているじゃん!!うーん。残り0.4μsをasm("nop\n");×20個で埋めてみる!?ちなみに、デフォルトの5/5/18μsで動かすと、SPIの通信部分は1.4msくらい。2/2/9μsで動かすと、0.9msくらい。nop/nop/5μsで、0.7msで処理できた。また、ビストンのVS-C1のIDは、0x73で、SCPH-1150(アナログコントローラ)の(アナログモード:赤LED点灯)相当とのこと。データは、9バイト。さてと、あとはこれにモーションセンサも加えて、5ms周期でLinuxボードに伝えないと・・・。
2021年02月07日
-

基板の完成
ユニバーサル基板で作ってみた。 それぞれ、KONDOサーボのシリアル、9軸センサ、PS2コントローラーの単独スケッチは動作確認済み。 これを統合させていく。
2021年01月15日
-

Linuxボードとの通信確認
年末から上手くいってなかった、KONDOサーボの通信規格でのLinuxボードとArduinoの接続確認ですが、年が明けて、やっと繋がりました。今回、レベル変換などは、KONDOのICS変換基盤を使用しました。3.3Vに直結できるし、一つのUARTしか使わないから自作よりも部品点数(面積)が少なくなるのですよね。上手くいかなかった理由は、いろいろあるのですが、スケッチの参考になったサイトはここです。それと、Adafruit ItsyBitsy M0 Expressですが、USBシリアルと、0番1番ピンのシリアルが同時に使えます。USBシリアルが、Serial(無印)、0番1番シリアルが、Serial1です。動作確認したときのスケッチを以下に示します。unsigned char a[3];int i = 0;void setup() { // put your setup code here, to run once: Serial1.begin(115200,SERIAL_8E1); // 偶数パリティ pinMode(7,OUTPUT); // 送受信切り替えピン digitalWrite(7,LOW);}void loop() { // put your main code here, to run repeatedly: if ( Serial1.available() > 0 ) { // 受信確認 switch ( i ) { case 0: a[i] = Serial1.read( ); if ( a[i] == (0x80 + 31) ) i++; break; case 1: a[i] = Serial1.read( ); i++; break; case 2: a[i] = Serial1.read( ); digitalWrite(7,HIGH); a[0] = 0x7f & a[0]; a[1] = 0x3a; a[2] = 0x4c; Serial1.write(a,3); Serial1.flush(); // 送信完了確認 digitalWrite(7,LOW); i = 0; break; } } }
2021年01月01日
-
IMUとPS2コントローラーの統合のその前に・・・
単体での動作確認をした、IMUとPS2コントローラーですが、統合させた上で、KONDOサーボの通信規格(1線式UART)に乗せてLinuxボードに伝えることが今の目標です。5ms周期で渡せると良いのですが・・・。って、ことで、まずは、ArduinoのUARTのテストをしました。ちょー簡単!ちなみに、Arduino 日本語リファレンスを参考にしています。#define SerialPort Serialint a;void setup() { // put your setup code here, to run once: SerialPort.begin(115200);}void loop() { // put your main code here, to run repeatedly: if ( Serial.available() > 0 ) { a = Serial.read( ); Serial.write( a ); }}
2020年12月28日
-

Arduino(アルドゥイーノ)の霧(キリ)・・・
前回、Processingで飛行機を飛ばしてから、2週間も経ってしまった・・・。そのあと、すぐに今度は、PS2コントローラーをArduinoに繋げようとして・・・深いキリを彷徨っていました・・・。今回、私が使っているのが、Adafruit Itsy Bitsy M0 Expressなのですが、Arm Cortex M0+なので、基本のUNOとかと違い、ちょっと高度化しようとハードウェアよりの関数を使っているとライブラリがそのまま使えないらしいです・・・。案の定、2つほど試したライブラリの両方が、エラーでコンパイル不可(ハードウェアが理由の)に。でも、エラーメッセージを見ると、そんな大したエラーじゃないのですよ。こう、ハードウェアとC++を知っていれば、簡単に修正できるような・・・。う~ん。冬休みの宿題かなー、とか諦めかけていたのですが、いやいや、世界にはきっと、おなじことで悩んでいるアマチュアがいっぱいいるハズだ~!って思い直して、ネットをぐりぐり。Arduino Forumにあった~!!!ってことで、無事、簡単な修正で動作確認終了!(ソフトウェアSPIだけど・・・)今回のボードは、13番にLED(+抵抗)がついているので、そこはSELに。代わりに10番をDATにしてプルアップ抵抗もつけて、ばっちりでした~!
2020年12月13日
-
Processingで飛行機を飛ばす
引き続き例のサイトで、MPU-9250のDMPの動作確認をおこなう。次はセンサーの値をPCに取り込んで、飛行機のグラフィックスを動かすのだけど、先のサイトでは、Processingについて、詳しく書いてないので、ちょっと調べてみた。こことか良いかなー。書いてあるとおりダウンロードして、展開するだけ。「processing.exe」が本体なので、実行してみる。ちょっと、起動が遅いけど、立ち上がると、「Arduino IDE」とまったく同じデザイン。GitHubから丸ごとダウンロードしたファイルの中の「MPUTeapot.pde」を開いて、試しに実行してみると、「toxi」ライブラリがないとのこと。ライブラリは、「スケッチ」「ライブラリをインポート」「ライブラリを追加」より、「toxi」で検索すると「ToxicLibs」がみつかるので、インストールすればOK。MPU-9250と接続したArduinoに「クォータニオンをProcessing用に配列にして送信」するプログラムを転送。リセットしてから、processing用の「MPUTeapot.pde」を実行すると・・・センサーの動きに合わせて、PCの中で飛行機のグラフィックスの姿勢が変わります。ひととおり、ぐるぐる動かして遊んでも、センサーを落として衝撃を与えてみても、かなり安定してセンサーの出力が続きます。これなら、歩行用ロボットに使っても全然問題なし!ただし、1点だけ、ずっと動かしていると、どうしてもヨー軸(Z軸回り)の誤差が大きくなってきます。まあ、それはそうかなー、高性能ジャイロを加速度センサーだけで補正しているのだから、加速度センサーでヨー軸はわからないもんねー。ただし、短時間であれば、ヨー軸もまったく狂わない。そこは、ジャイロの分解能とDMPの素晴らしいところかなー。いずれは、磁気センサーで、ヨー軸も補正してあげたいけど、まずは、ロボットで必要な値は、オイラー角のロールとピッチだもんねー。さて、クオータニオンをどうやってオイラー角にしようかなー。
2020年11月27日
-

DMPの動作確認
ここのサイトを参考に、MPU-9250のDMPの動作確認をおこないました。まずは、DMPライブラリのサンプルプログラム「MPU9250_DMP_Quaternion」を動かしてみる。結果は、成功!
2020年11月25日
-

Arduino(アルドゥイーノ)
ずっとなんだろう?これ~?って思っていたArduinoですが、ついに手にしました!だって、MPU-9250で、DMP使いたいのだもの~!!参考ページのまま、スイッチサイエンスから、Adafruit Itsy Bitsy M0 Expressを購入。今日、ネコポスで入ってた(箱の内側になにやらコメントが・・・)。とりあえず参考書を2冊買って、読みながら進めていきます~。
2020年11月20日
-
MPU-9250の使い方
やばーいっ!!MPU-9250の使い方ですが、ここを参考にsparkfunのDMPライブラリを読み解いていたら・・・。なにこれ! ライブラリがファームウェアを書き換えている!? そりゃ、標準マニュアルに記述がないわけだ・・・。こまったな、この雰囲気だと、このファームウェア、I2Cにしか対応してなさそうだな。中継器用のマイコンの選定からやりなおしだ~!!
2020年11月16日
-
win10で署名なしドライバをインストールする
MPU-9250の中継器にSTK-7125をつかおうと思って、8年ぶりにSH/Tiny開発キット「STK-7125EVB-KIT」を取り出す。ネットから、開発ツール、コンパイラなどをダウンロード&インストールして、USBデバイスドライバを入れたところで、・・・嫌な記憶がよみがえる・・・。そういえば、FTDIのドライバって、マウスのドライバと干渉して、面倒だったよな・・・。で、今回もトラブル発生。まず、安定して使えていた、XBeeのUSBドングルと干渉。こちらは、デバイスマネジャーから、「UBS Serial Converter」のドライバを更新するときにDigiのものを選んだら復旧したー。で、残りは「STK-7125EVB USB Serial Converter」だけど、こちらが解決に丸一日かかった・・・。どうも「署名がアウト」らしい。で、更に調べて、「署名なしドライバのインストール」に行き着く。するとやっと、ドライバが使えるようになった・・・。ふぅ。
2020年11月15日
-
MPU-9250
まずは、ジャイロセンサーを繋げる必要があるので、ちょっとだけ調べて、IMUでもあるMPU-9250をストロベリーリナックスから購入! DMPって、姿勢を計算してくれる機能がついているので、これが使えたらいいな。 でも、ドキュメントを読んでもDMPの詳細がない。しかし、英文読むのも楽になったなー。グーグル翻訳で普通に読めちゃう。 DMPについては、ネットで使えたーって記事があったから、そこを参考にチャレンジしよう。 で、今日は時間ができたので、秋葉原まで行って、レベルシフタとか、細かい物を購入。 MPU-9250をLinuxボードに繋げるには一工夫が必要なんです… なにせSCIF全部、サーボ駆動に使っているので、間にマイコン入れて、サーボ駆動と同じプロトコルで通信する必要があるという… で、過去の財産から、5Vマイコンのsh7125を使うことに…、再びクリスタルとか、汎用ICとか、いろいろごちゃごちゃに付ける必要があるのかー
2020年11月14日
-
上手く動かない理由(その2)
youtubeの動画サーボのバックラッシュじゃなかったー!!(>_<)なにも考えずにバックラッシュ対策を組み込んだら、足がビクビクして使い物にならなかった。そして昔も同じようなことを考えていたことを思い出した・・・。結論、サーボのバックラッシュの対策は難しい。で、仕方ないので、バックラッシュの多いサーボを特定して、バックラッシュがあっても問題ないひざのサーボと交換してみた(ひざは常にトルクがかかるから、バックラッシュが起きにくい)。すると・・・。バックラッシュが起きない・・・。そっかー。これバックラッシュじゃないのかー。そうだよね。出力軸に直接ポテンションメーターがついているハズだから、バックラッシュも計測できるハズ、デッドバンドの設定とも関係するけど。つまり・・・。ポテンションメーターの抵抗が削れて、鈍感帯(?)ができているんだー。ずっと基準姿勢の時間が多かったからなー。で、サーボを組み替えた際に、使う角度帯が大きくずれて、削れている部分を使わないことになったからガタツキ(バックラッシュのように見えるもの)が収まったと・・・。まだ、ちょっとトリム調整が甘いけど、とりあえず足踏み完成ー!!
2020年11月08日
-
上手く動かない理由
関節負荷補正をしているのに上手く動かない理由を、一つずつ潰していきます。1)トリム調整&ポテンションメーター特性 まず、トリム調整が甘かった部分があります。少し大きめの差し金を使って、中立位置を丁寧に調整します。足裏については、機体を逆さまにして、足裏にiphoneを乗せて、水平器機能を使って調整しました。 また、これは盲点だったのですが、サーボのポテンションメーターの線形性が悪く、トリム調整時のホームポジションは、足をまっすぐ伸ばした状態なのですが、実際に歩く時は、ひざや腰のピッチ軸を大きく曲げた状態なので、ホームポジションから60度以上動いています。駆動角がホームポジションから近いと問題ないのですが、大きく動いた場合は、センサ特性から、リニアに想定した角度から大きく外れることになります。よって、ホームポジションでトリム調整をおこなったあとに、実際の歩行に近い姿勢で再度調整をおこなう手順としました。2)ねじの緩み お恥ずかしい話ですが、見てみると、機体のあちこちのねじが大きく緩んで、部分的には抜け落ちている箇所もありました。一番ひどかったのが、腰のヨー軸のサーボホーンを止めるねじが緩んで、片足がぐらついていました・・・。反省。3)フレームのたわみ 腰のロール軸とヨー軸をつなぐ部品(ここは購入品)なのですが、ロール軸方向の剛性が弱く、大きな荷重がかかると歪んで弾性変形していました。関節負荷に対してサーボ自体の負荷補正はしていたのですが、それとは別に負荷によって生じるフレームのたわみもサーボと同様に上乗せして補正してあげると良さそうです。4)サーボのバックラッシュ サーボの負荷補正と似たようなものですが、負荷補正やフレームのたわみが、負荷に比例して補正するのに対して、サーボのバックラッシュやリンク機構の遊びは、わずかでも荷重がかかると即一定量の変位が生じます。これは負荷補正とは別に組み込む必要があります。5)足裏のグリップ シミュレーションは、足裏がフルでグリップしている前提ですので、床面との摩擦が必要になります。とりあえず、コルクボードの上で足踏みさせています。1)~3)までを調整し、歩行周期を倍の1.2秒にして足踏みさせたところ、どうにか見れる動作にはなったのですが、更に4)を組み込んで、ビシッと足踏みさせたいところではあります。
2020年11月07日
-

XBee3
もともとマイコンのコンソールの無線化には、XBeeのシリーズ1のU.FLアンテナ型を使っていたのだけど、前回、Linuxボードを使う際に、SC2タイプで115.2kbpsに通信速度を上げたのだけど、基板アンテナタイプしか売っていなくて・・・。今日、久しぶりに都内で仕事の打合せがあって、ふらっと神田から秋葉原へ。千石電商を覗いたら、なんと更に新しいXBee3があるじゃないですか!しかも、U.FLアンテナ型が!!さっそく2個ペアで買って帰って、XCTUを最新版に更新して、いつもの参考ページで、ピアツーピアに設定して・・・。接続確認も良好で、アルミケースにアンテナが生えました~!!
2020年11月06日
-

上手く動かない?
プログラムの統合は終わったのだけど、関節トルクの負荷補正もちゃんと機能しているハズなのだけど、上手く動かない…。
2020年11月03日
-
プログラムの統合
一週間まるっとお休みがあったのですが、映画見たり、病院行ったり、落語を見に寄席に行ったり、ハイキングに行ったりと、思ったより開発は進まず・・・。リフレッシュは十分できたけど、開発でモヤッとするなー。シミュレーションと、サーボに指示を出す、2つのプログラムの統合に、ちょっと手間取っています。できるだけ統合しやすいようにシミュレーション部分を作ったつもりでも、やっぱりツメが甘かったり。やっと、サーボの指示周期と同じ、5ms毎に計算する関節トルク部分をまとめたのだけど、その1周期ごとの計算時間を見てみると・・・。純粋にシミュレーション計算のみをしていたときは、キャッシュが効くと150μsで安定してたけど、サーボ指示部分とシミュレーション部分を2つのスレッドに分けて処理すると、200μsとか、最大450μsとか、揺らぎがあるんだなー。今はまだ、処理時間に余裕があるけど、この辺りの計算の遅れも考慮したプログラムが必要になるんだろうなー。
2020年11月01日
-
逆動力学まで完成!!\(^o^)/やったー!
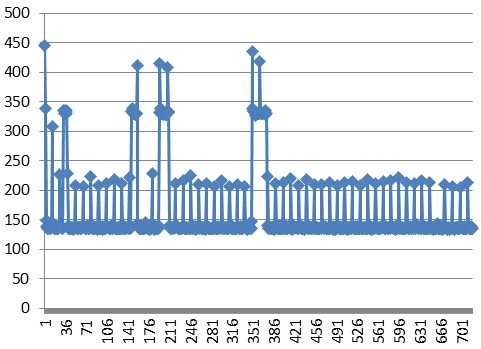
実は、週末から次の週末まで、勤続20年のリフレッシュ休暇なんです!娘の学校があるから、週末に一泊で大阪USJまで旅行には行きましたが、後は自宅警備員(予定)です。と言う理由で、先々週から取り組んでいる逆動力学部分を仕上げちゃいました!!ちなみに、もちろんNEON化してあるので、91ステップ、23自由度の計算で13ms程度でした。関節サーボのフィードフォワード用に使うので、1制御周期に1ステップ分計算すれば良いので本当は計算速度とか、あまり関係ないのだけどね。1ステップ150μsくらいですか。逆動力学のNEON化は、やはりできるだけ使うレジスタを減らすために、積和演算を多用しています。計算順序も工夫して、だから、デバックも大変!!コードを印刷してマーカーでチェックして、レジスタの運用もフロー書いて、シミュレーションの途中の値をとって、エクセル上で一部再現計算して、1ステップ分の関節トルクも、エクセルで静止時トルク+慣性モーメントも考慮してオーダーチェックして。ふぅ、疲れた・・・。まあ、大丈夫かな?(^^;;;「ヒューマノイドロボット改定2版」にオープンソースのロボットシミュレータ「コレオノイド」のことが書かれていた。C++でコーディングされているらしいから、今度時間があるときに、自分の関節トルクシミュレータと計算結果のチェックをしてみたいな。時間があったら・・・。関節トルクまで計算できたから、やっぱり、次は、実機を動かしたいよね。大量のシミュレーション計算と、サーボ角度指定を同時に「pthread」で処理する。大丈夫かなー(汗)。まあ、頑張ってみよー!!あっ、下のグラフは、今回計算した関節トルクを脚部だけ抜粋してグラフ化したものです。値が大きなものは、ほぼ静止時トルクと同じ値なんですね。これって、頑張って関節トルクを計算する理由が・・・(涙)。抜粋したコードを以下に示します(逆動力学NEON版)。足裏反力の計算部分も空間速度で計算しなおしたので、参考にしてください。/********** 逆動力学 **********/void ID(LINK lin[],unsigned char j,int s){ unsigned char i; float32x4_t c0,c1,c2,r0,r1,r2,r3; c0 = vdupq_n_f32(0.0); c1 = vdupq_n_f32(0.0); c2 = vdupq_n_f32(0.0); r0 = vld1q_f32( &lin[j].C[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,vgetq_lane_f32(c0,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(c1,0)); r0 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(c2,0)); r1 = vmulq_n_f32(c0,vgetq_lane_f32(c0,1)); r1 = vmlaq_n_f32(r1,c1,vgetq_lane_f32(c1,1)); r1 = vmlaq_n_f32(r1,c2,vgetq_lane_f32(c2,1)); r2 = vmulq_n_f32(c0,vgetq_lane_f32(c0,2)); r2 = vmlaq_n_f32(r2,c1,vgetq_lane_f32(c1,2)); r2 = vmlaq_n_f32(r2,c2,vgetq_lane_f32(c2,2)); c0 = vmulq_n_f32(r0,lin[j].m); c1 = vmulq_n_f32(r1,lin[j].m); c2 = vmulq_n_f32(r2,lin[j].m); r2 = vmulq_n_f32(c0,lin[j].w[0]); // I*w r2 = vmlaq_n_f32(r2,c1,lin[j].w[1]); r2 = vmlaq_n_f32(r2,c2,lin[j].w[2]); r3 = vmulq_n_f32(c0,lin[j].dw[0]); // I*dw r3 = vmlaq_n_f32(r3,c1,lin[j].dw[1]); r3 = vmlaq_n_f32(r3,c2,lin[j].dw[2]); c0 = vdupq_n_f32(0.0); c1 = vdupq_n_f32(0.0); c2 = vdupq_n_f32(0.0); r0 = vld1q_f32( &lin[j].C[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,lin[j].v0[0]); r0 = vmlaq_n_f32(r0,c1,lin[j].v0[1]); r0 = vmlaq_n_f32(r0,c2,lin[j].v0[2]); r0 = vmulq_n_f32(r0,lin[j].m); r2 = vaddq_f32(r0,r2); // L r0 = vmulq_n_f32(c0,lin[j].dv0[0]); r0 = vmlaq_n_f32(r0,c1,lin[j].dv0[1]); r0 = vmlaq_n_f32(r0,c2,lin[j].dv0[2]); r0 = vmulq_n_f32(r0,lin[j].m); r3 = vaddq_f32(r0,r3); // r0 = vld1q_f32( &lin[j].w[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vld1q_f32( &lin[j].v0[0] ); r0 = vmlaq_n_f32(r0,c0,lin[j].C[0]); r0 = vmlaq_n_f32(r0,c1,lin[j].C[1]); r0 = vmlaq_n_f32(r0,c2,lin[j].C[2]); r1 = vmulq_n_f32(r0,lin[j].m); // P r0 = vmlaq_n_f32(r3,c0,vgetq_lane_f32(r2,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(r2,1)); r3 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(r2,2)); // r2 = vmulq_n_f32(c0,vgetq_lane_f32(r1,0)); r2 = vmlaq_n_f32(r2,c1,vgetq_lane_f32(r1,1)); r2 = vmlaq_n_f32(r2,c2,vgetq_lane_f32(r1,2)); // r0 = vld1q_f32( &lin[j].dw[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vld1q_f32( &lin[j].dv0[0] ); r0 = vmlaq_n_f32(r0,c0,lin[j].C[0]); r0 = vmlaq_n_f32(r0,c1,lin[j].C[1]); r0 = vmlaq_n_f32(r0,c2,lin[j].C[2]); r0 = vmulq_n_f32(r0,lin[j].m); r2 = vaddq_f32(r0,r2); // f0 r0 = vld1q_f32( &lin[j].v0[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmlaq_n_f32(r3,c0,vgetq_lane_f32(r1,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(r1,1)); r3 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(r1,2)); // t0// if ( (s == 25) && (j == 5) ){// printf("t0 %12.6e %12.6e %12.6e\n",vgetq_lane_f32(r3,0),vgetq_lane_f32(r3,1),vgetq_lane_f32(r3,2));// } r1 = vdupq_n_f32(0.0); r1 = vsetq_lane_f32(-lin[j].m*g,r1,2); r2 = vsubq_f32( r2, r1 ); r0 = vld1q_f32( &lin[j].C[0] ); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c2,vgetq_lane_f32(r1,2)); r3 = vsubq_f32( r3, r0 ); i = lin[j].child; if ( i == 0 ) { if ( j == 7 ) { r0 = vld1q_f32( &lin[j].fEp[0] ); r1 = vld1q_f32( &lin[j].fE[0] ); r2 = vsubq_f32( r2, r1 ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,vgetq_lane_f32(r1,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(r1,1)); r0 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(r1,2)); r3 = vsubq_f32( r3, r0 ); } else if ( j == 13 ) { r0 = vld1q_f32( &lin[j].fEp[0] ); r1 = vld1q_f32( &lin[j].fE[0] ); r2 = vsubq_f32( r2, r1 ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,vgetq_lane_f32(r1,0)); r0 = vmlaq_n_f32(r0,c1,vgetq_lane_f32(r1,1)); r0 = vmlaq_n_f32(r0,c2,vgetq_lane_f32(r1,2)); r3 = vsubq_f32( r3, r0 ); } } else { ID(lin,i,s); r0 = vld1q_f32( &lin[i].f[0] ); r1 = vld1q_f32( &lin[i].t[0] ); r2 = vaddq_f32(r0,r2); r3 = vaddq_f32(r1,r3); } if ( j == 1 ) { } else { r0 = vld1q_f32( &lin[j].sv[0] ); r1 = vld1q_f32( &lin[j].sw[0] ); r0 = vmulq_f32(r0,r2); r1 = vmulq_f32(r1,r3); r0 = vaddq_f32(r0,r1); lin[j].u = vgetq_lane_f32(r0,0) + vgetq_lane_f32(r0,1) + vgetq_lane_f32(r0,2); } i = lin[j].sister; if ( i == 0 ) { } else { ID(lin,i,s); r0 = vld1q_f32( &lin[i].f[0] ); r1 = vld1q_f32( &lin[i].t[0] ); r2 = vaddq_f32(r0,r2); r3 = vaddq_f32(r1,r3); } vst1q_f32( &lin[j].f[0], r2 ); // f vst1q_f32( &lin[j].t[0], r3 ); // t}/********** 足裏反力の算定 **********/ LR = 0.0; sR = 0.0; Lzmp = 0.0; szmp = 0.0; ezmp = 0.0; LRzmp = 0.0; if ( step[s].lfoot_s == 1 ) { if ( step[s].rfoot_s == 1 ) { // 両足支持 LR = sqrtf((step[s].rfoot_x - step[s].lfoot_x)*(step[s].rfoot_x - step[s].lfoot_x) + (step[s].rfoot_y - step[s].lfoot_y)*(step[s].rfoot_y - step[s].lfoot_y)); sR = atan2f(step[s].rfoot_y - step[s].lfoot_y, step[s].rfoot_x - step[s].lfoot_x); Lzmp = sqrtf((zmp[s].x - step[s].lfoot_x)*(zmp[s].x - step[s].lfoot_x) + (zmp[s].y - step[s].lfoot_y)*(zmp[s].y - step[s].lfoot_y)); szmp = atan2f(zmp[s].y - step[s].lfoot_y, zmp[s].x - step[s].lfoot_x); ezmp = Lzmp * sinf( szmp - sR ); LRzmp = Lzmp * cosf( szmp - sR ); if ( LRzmp < 0.0 ) { // 左足支持 lF[0] = Fx; lF[1] = Fy; lF[2] = Fz; lF[3] = 0.0; rF[0] = 0.0; rF[1] = 0.0; rF[2] = 0.0; rF[3] = 0.0; lFp[0] = zmp[s].x; lFp[1] = zmp[s].y; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = 0.0; rFp[1] = 0.0; rFp[2] = 0.0; rFp[3] = 0.0; } else if ( LRzmp > LR ) { // 右足支持 lF[0] = 0.0; lF[1] = 0.0; lF[2] = 0.0; lF[3] = 0.0; rF[0] = Fx; rF[1] = Fy; rF[2] = Fz; rF[3] = 0.0; lFp[0] = 0.0; lFp[1] = 0.0; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = zmp[s].x; rFp[1] = zmp[s].y; rFp[2] = 0.0; rFp[3] = 0.0; } else { // 両足支持 lF[0] = Fx / LR * (LR - LRzmp); lF[1] = Fy / LR * (LR - LRzmp); lF[2] = Fz / LR * (LR - LRzmp); rF[0] = Fx / LR * LRzmp; rF[1] = Fy / LR * LRzmp; rF[2] = Fz / LR * LRzmp; ex = ezmp * cosf( sR + PI/2 ); ey = ezmp * sinf( sR + PI/2 ); lFp[0] = step[s].lfoot_x + ex; lFp[1] = step[s].lfoot_y + ey; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = step[s].rfoot_x + ex; rFp[1] = step[s].rfoot_y + ey; rFp[2] = 0.0; rFp[3] = 0.0; } } else { // 左足支持 lF[0] = Fx; lF[1] = Fy; lF[2] = Fz; lF[3] = 0.0; rF[0] = 0.0; rF[1] = 0.0; rF[2] = 0.0; rF[3] = 0.0; lFp[0] = zmp[s].x; lFp[1] = zmp[s].y; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = 0.0; rFp[1] = 0.0; rFp[2] = 0.0; rFp[3] = 0.0; } } else { // 右足支持 lF[0] = 0.0; lF[1] = 0.0; lF[2] = 0.0; lF[3] = 0.0; rF[0] = Fx; rF[1] = Fy; rF[2] = Fz; rF[3] = 0.0; lFp[0] = 0.0; lFp[1] = 0.0; lFp[2] = 0.0; lFp[3] = 0.0; rFp[0] = zmp[s].x; rFp[1] = zmp[s].y; rFp[2] = 0.0; rFp[3] = 0.0; } link[7].fE[0] = rF[0]; link[7].fE[1] = rF[1]; link[7].fE[2] = rF[2]; link[7].fE[3] = 0.0; link[7].fEp[0] = rFp[0]; link[7].fEp[1] = rFp[1]; link[7].fEp[2] = rFp[2]; link[7].fEp[3] = 0.0; link[13].fE[0] = lF[0]; link[13].fE[1] = lF[1]; link[13].fE[2] = lF[2]; link[13].fE[3] = 0.0; link[13].fEp[0] = lFp[0]; link[13].fEp[1] = lFp[1]; link[13].fEp[2] = lFp[2]; link[13].fEp[3] = 0.0; ID(link,1,s);
2020年10月27日
-
ヒューマノイドロボット改定2版
大阪旅行の帰り道に津田沼の丸善で、ヒューマノイドロボット改定2版を購入!! 一冊しか置いてなかったけど、マイナーなんだなー。 持った瞬間、分厚い!60ページくらい加筆されて、300ページになってる… 値段も高くなったような…、税込みで4000円近い… パラパラって見た感じは、ほぼ内容に変更は無くて、ただ、間違いはしっかり修正されている感じ。 足裏反力の記述が追加されているから、ここはしっかり読まねば!!
2020年10月25日
-
空間加速度まで終わったー
前回作った、ロボットの胴体の位置・姿勢、空間速度、空間加速度から、再帰計算を使って全身の値を計算するサブルーチンを作った。空間加速度、やっぱり実感わかないので、プログラムは印刷してマーカーでチェック、計算結果も一部抜粋して、エクセル上で確認計算。・・・とりあえず、大丈夫だと思う・・・。あと、外積のneon化ですが、うまく計算がハマれば、そこまで苦にならない感じがしました。これはこれで収穫かな。neonは、スタック退避を考えたら、できるだけ少ないレジスタ群で計算したいところなので、ちょっと読みにくいコードになってしまいます。コードを下に示します。/********** 順運動学 **********/void FAK(LINK lin[],unsigned char j){ unsigned char i; float32x4_t c0,c1,c2,r0,r1,r2,r3; if ( j == 0 ) return; if ( j == 1 ) { } else { i = lin[j].mother; c0 = vld1q_f32( &lin[i].Rp[0] ); c1 = vld1q_f32( &lin[i].Rp[4] ); c2 = vld1q_f32( &lin[i].Rp[8] ); r0 = vmulq_n_f32( c0, lin[j].a[0] ); r1 = vmulq_n_f32( c1, lin[j].a[1] ); r2 = vmulq_n_f32( c2, lin[j].a[2] ); r0 = vaddq_f32( r0, r1 ); r3 = vaddq_f32( r0, r2 ); vst1q_f32( &lin[j].sw[0], r3 );// lin[j].sv[0] = lin[j].Rp[13] * lin[j].sw[2] - lin[j].Rp[14] * lin[j].sw[1];// lin[j].sv[1] = lin[j].Rp[14] * lin[j].sw[0] - lin[j].Rp[12] * lin[j].sw[2];// lin[j].sv[2] = lin[j].Rp[12] * lin[j].sw[1] - lin[j].Rp[13] * lin[j].sw[0];// lin[j].sv[3] = 0.0; c0 = vdupq_n_f32(0.0); c1 = vdupq_n_f32(0.0); c2 = vdupq_n_f32(0.0); r0 = vld1q_f32( &lin[j].Rp[12] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,vgetq_lane_f32(r3,0)); r1 = vmulq_n_f32(c1,vgetq_lane_f32(r3,1)); r2 = vmulq_n_f32(c2,vgetq_lane_f32(r3,2)); r0 = vaddq_f32(r0,r1); r0 = vaddq_f32(r0,r2); vst1q_f32( &lin[j].sv[0], r0 ); c0 = vld1q_f32( &lin[i].w[0] ); c0 = vmlaq_n_f32( c0,r3,lin[j].dq ); vst1q_f32( &lin[j].w[0], c0 ); c0 = vld1q_f32( &lin[i].v0[0] ); c0 = vmlaq_n_f32( c0,r0,lin[j].dq ); vst1q_f32( &lin[j].v0[0], c0 ); c0 = vdupq_n_f32(0.0); c1 = vdupq_n_f32(0.0); c2 = vdupq_n_f32(0.0); r0 = vld1q_f32( &lin[i].v0[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,vgetq_lane_f32(r3,0)); r1 = vmulq_n_f32(c1,vgetq_lane_f32(r3,1)); r2 = vmulq_n_f32(c2,vgetq_lane_f32(r3,2)); r0 = vaddq_f32(r0,r1); r3 = vaddq_f32(r0,r2); r0 = vld1q_f32( &lin[i].w[0] ); r2 = vld1q_f32( &lin[j].sv[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,vgetq_lane_f32(r2,0)); r1 = vmulq_n_f32(c1,vgetq_lane_f32(r2,1)); r2 = vmulq_n_f32(c2,vgetq_lane_f32(r2,2)); r0 = vaddq_f32(r0,r1); r2 = vaddq_f32(r2,r3); r3 = vaddq_f32(r0,r2); // dsv r2 = vld1q_f32( &lin[j].sw[0] ); r0 = vmulq_n_f32(c0,vgetq_lane_f32(r2,0)); r1 = vmulq_n_f32(c1,vgetq_lane_f32(r2,1)); r2 = vmulq_n_f32(c2,vgetq_lane_f32(r2,2)); r0 = vaddq_f32(r0,r1); r2 = vaddq_f32(r0,r2); // dsw r0 = vld1q_f32( &lin[i].dw[0] ); r1 = vld1q_f32( &lin[j].sw[0] ); r0 = vmlaq_n_f32( r0,r1,lin[j].ddq ); r0 = vmlaq_n_f32( r0,r2,lin[j].dq ); vst1q_f32( &lin[j].dw[0], r0 ); r0 = vld1q_f32( &lin[i].dv0[0] ); r1 = vld1q_f32( &lin[j].sv[0] ); r0 = vmlaq_n_f32( r0,r1,lin[j].ddq ); r0 = vmlaq_n_f32( r0,r3,lin[j].dq ); vst1q_f32( &lin[j].dv0[0], r0 ); } FAK(lin,lin[j].sister); FAK(lin,lin[j].child);}
2020年10月18日
-
neonは外積が苦手?
仕事が忙しく、思うように進まない・・・前回エクセルで確認した胴体の角速度ベクトルの計算から、空間速度の計算まで、neon化してみたのだけど、どうも、外積の計算は、neonには向いていない気がする・・・。一応、エクセルで確認計算までしてokだったけど、今一、間違っていない自信がない。空間速度って値が、こう、実感わかないのだよね~。コードは、以下のようです。 r0 = vld1q_f32( &link[1].Rp[0] ); // 古い r1 = vld1q_f32( &link[1].Rp[4] ); r2 = vld1q_f32( &link[1].Rp[8] ); c0 = vld1q_f32( &body.Rp[0] ); // 新しい c1 = vld1q_f32( &body.Rp[4] ); c2 = vld1q_f32( &body.Rp[8] ); vst1q_f32( &link[1].Rp[0], c0 ); // 更新 vst1q_f32( &link[1].Rp[4], c1 ); vst1q_f32( &link[1].Rp[8], c2 ); c0 = vsubq_f32( c0, r0 ); c1 = vsubq_f32( c1, r1 ); c2 = vsubq_f32( c2, r2 ); c0 = vmulq_n_f32(c0,Tra.inv_dt); // dR c1 = vmulq_n_f32(c1,Tra.inv_dt); c2 = vmulq_n_f32(c2,Tra.inv_dt); r3 = vld1q_f32( &link[1].w[0] ); // 古い r0 = vmulq_n_f32( c0, link[1].Rp[0] ); r1 = vmulq_n_f32( c1, link[1].Rp[4] ); r2 = vmulq_n_f32( c2, link[1].Rp[8] ); r0 = vaddq_f32( r0, r1 ); r0 = vaddq_f32( r0, r2 ); link[1].w[2] = vgetq_lane_f32(r0,1); r0 = vmulq_n_f32( c0, link[1].Rp[1] ); r1 = vmulq_n_f32( c1, link[1].Rp[5] ); r2 = vmulq_n_f32( c2, link[1].Rp[9] ); r0 = vaddq_f32( r0, r1 ); r0 = vaddq_f32( r0, r2 ); link[1].w[0] = vgetq_lane_f32(r0,2); r0 = vmulq_n_f32( c0, link[1].Rp[2] ); r1 = vmulq_n_f32( c1, link[1].Rp[6] ); r2 = vmulq_n_f32( c2, link[1].Rp[10] ); r0 = vaddq_f32( r0, r1 ); r0 = vaddq_f32( r0, r2 ); link[1].w[1] = vgetq_lane_f32(r0,0); link[1].w[3] = 0.0; r0 = vld1q_f32( &link[1].w[0] ); // 新しい r0 = vsubq_f32( r0, r3 ); r0 = vmulq_n_f32(r0,Tra.inv_dt); vst1q_f32( &link[1].dw[0], r0 ); // 更新 c0 = vld1q_f32( &link[1].Rp[12] ); // 古い r0 = vld1q_f32( &body.Rp[12] ); // 新しい vst1q_f32( &link[1].Rp[12], r0 ); // 更新 r3 = vsubq_f32( r0, c0 ); r3 = vmulq_n_f32(r3,Tra.inv_dt); // dp // 外積 c0 = vdupq_n_f32(0.0); c1 = vdupq_n_f32(0.0); c2 = vdupq_n_f32(0.0); r0 = vld1q_f32( &link[1].w[0] ); c0 = vsetq_lane_f32( vgetq_lane_f32(r0,2),c0,1); c0 = vsetq_lane_f32(-vgetq_lane_f32(r0,1),c0,2); c1 = vsetq_lane_f32(-vgetq_lane_f32(r0,2),c1,0); c1 = vsetq_lane_f32( vgetq_lane_f32(r0,0),c1,2); c2 = vsetq_lane_f32( vgetq_lane_f32(r0,1),c2,0); c2 = vsetq_lane_f32(-vgetq_lane_f32(r0,0),c2,1); r0 = vmulq_n_f32(c0,-link[1].Rp[12]); // r1 = vmulq_n_f32(c1,-link[1].Rp[13]); // r2 = vmulq_n_f32(c2,-link[1].Rp[14]); // r0 = vaddq_f32(r0,r1); r2 = vaddq_f32(r2,r3); // r0 = vaddq_f32(r0,r2); c0 = vld1q_f32( &link[1].v0[0] ); // 古い vst1q_f32( &link[1].v0[0], r0 ); // 更新 r0 = vsubq_f32( r0, c0 ); r0 = vmulq_n_f32(r0,Tra.inv_dt); vst1q_f32( &link[1].dv0[0], r0 ); // 更新
2020年10月11日
-
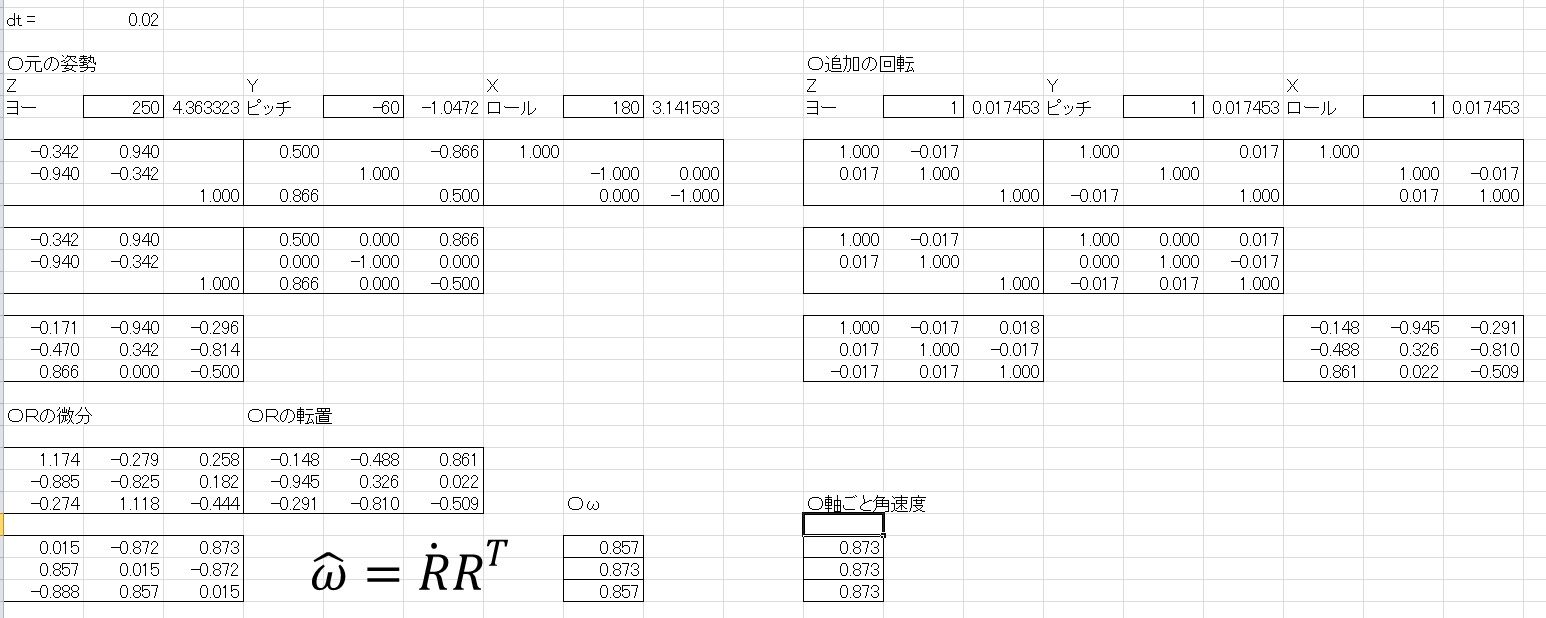
回転行列と角速度ベクトルの関係
関節トルクを計算する次の一歩として、ロボット胴体の位置・姿勢、空間速度、空間加速度を計算する必要がある。位置は、重心軌道計算結果より、姿勢はどちらかと言うと、最初から指定している感じで、空間速度を計算する上で、まずは角速度ベクトルを計算するのがちょっとひと手間掛かる。シミュレーション中は、姿勢を表す回転行列を使っているから、ここから角速度ベクトルを計算することに。想定した方法でとりあえず問題なく計算できそうなことを、エクセルで確認した。空間加速度は、単純に空間速度の変化量を微小時間で割れば良い。さて、後は、全身分の空間速度と空間加速度を計算して、それを元に逆動力学を使って関節トルクを計算するだけ。教科書で言うと4ページ分のコードをNEONを使って書くだけです!あと、もう2歩ってところかな?
2020年10月04日
-
ZMPから足裏に作用する床反力の推定
関節トルクの計算部分に先立ち、ZMPから足裏に作用する床反力の推定部分を作成しました。今回は、念のため、計算結果の一覧や、コードを印刷して、マーカーでチェックしながら、間違いがないか丁寧に作業しています。そうそう、先日書いたコードもついでにマーカーでチェックしていたら、教科書と違うっ!!って部分を見つけたのだけど、修正したコードを実行したら、とんでもない結果に・・・。10年前に自分で書いたコードを確認しても、やっぱり、そっちが正解みたいで、教科書の間違いって、困るよね・・・って思っていたら!!!!ヒューマノイドロボット(改訂2版)発売されます!! さっそく買わねば(笑)。話は戻るけど、今回の足裏の作用する床反力の推定だけど、自分で考えた部分だから、正解ではないです。だから、「推定」って言葉を使っている。より正確には、Z軸回りのモーメントとかも考える必要があるけど、10年前同様、今回もそっちは無視。サーボモーターのフィードバックに使える、ある程度の精度があれば良し!この部分だけのコードの抜粋を下に示します。/********** 足裏反力の算定 **********/ LR = 0.0; sR = 0.0; Lzmp = 0.0; szmp = 0.0; ezmp = 0.0; LRzmp = 0.0; if ( step[s].lfoot_s == 1 ) { if ( step[s].rfoot_s == 1 ) { // 両足支持 LR = sqrtf((step[s].rfoot_x - step[s].lfoot_x)*(step[s].rfoot_x - step[s].lfoot_x) + (step[s].rfoot_y - step[s].lfoot_y)*(step[s].rfoot_y - step[s].lfoot_y)); sR = atan2f(step[s].rfoot_y - step[s].lfoot_y, step[s].rfoot_x - step[s].lfoot_x); Lzmp = sqrtf((zmp[s].x - step[s].lfoot_x)*(zmp[s].x - step[s].lfoot_x) + (zmp[s].y - step[s].lfoot_y)*(zmp[s].y - step[s].lfoot_y)); szmp = atan2f(zmp[s].y - step[s].lfoot_y, zmp[s].x - step[s].lfoot_x); ezmp = Lzmp * sinf( szmp - sR ); LRzmp = Lzmp * cosf( szmp - sR ); if ( LRzmp < 0.0 ) { // 左足支持 lF[0] = Fx; lF[1] = Fy; lF[2] = Fz; rF[0] = 0.0; rF[1] = 0.0; rF[2] = 0.0; lT[0] = - Fy *(-link[13].c[2]) + Fz * (zmp[s].y - step[s].lfoot_y); lT[1] = Fx *(-link[13].c[2]) - Fz * (zmp[s].x - step[s].lfoot_x); lT[2] = 0.0; rT[0] = 0.0; rT[1] = 0.0; rT[2] = 0.0; } else if ( LRzmp > LR ) { // 右足支持 lF[0] = 0.0; lF[1] = 0.0; lF[2] = 0.0; rF[0] = Fx; rF[1] = Fy; rF[2] = Fz; lT[0] = 0.0; lT[1] = 0.0; lT[2] = 0.0; rT[0] = - Fy *(-link[ 7].c[2]) + Fz * (zmp[s].y - step[s].rfoot_y); rT[1] = Fx *(-link[ 7].c[2]) - Fz * (zmp[s].x - step[s].rfoot_x); rT[2] = 0.0; } else { // 両足支持 lF[0] = Fx / LR * (LR - LRzmp); lF[1] = Fy / LR * (LR - LRzmp); lF[2] = Fz / LR * (LR - LRzmp); rF[0] = Fx / LR * LRzmp; rF[1] = Fy / LR * LRzmp; rF[2] = Fz / LR * LRzmp; ex = ezmp * cosf( sR + PI/2 ); ey = ezmp * sinf( sR + PI/2 ); lT[0] = - lF[1] *(-link[13].c[2]) + lF[2] * ey; lT[1] = lF[0] *(-link[13].c[2]) - lF[2] * ex; lT[2] = 0.0; rT[0] = - rF[1] *(-link[ 7].c[2]) + rF[2] * ey; rT[1] = rF[0] *(-link[ 7].c[2]) - rF[2] * ex; rT[2] = 0.0; } } else { // 左足支持 lF[0] = Fx; lF[1] = Fy; lF[2] = Fz; rF[0] = 0.0; rF[1] = 0.0; rF[2] = 0.0; lT[0] = - Fy *(-link[13].c[2]) + Fz * (zmp[s].y - step[s].lfoot_y); lT[1] = Fx *(-link[13].c[2]) - Fz * (zmp[s].x - step[s].lfoot_x); lT[2] = 0.0; rT[0] = 0.0; rT[1] = 0.0; rT[2] = 0.0; } } else { // 右足支持 lF[0] = 0.0; lF[1] = 0.0; lF[2] = 0.0; rF[0] = Fx; rF[1] = Fy; rF[2] = Fz; lT[0] = 0.0; lT[1] = 0.0; lT[2] = 0.0; rT[0] = - Fy *(-link[ 7].c[2]) + Fz * (zmp[s].y - step[s].rfoot_y); rT[1] = Fx *(-link[ 7].c[2]) - Fz * (zmp[s].x - step[s].rfoot_x); rT[2] = 0.0; }
2020年10月04日
-
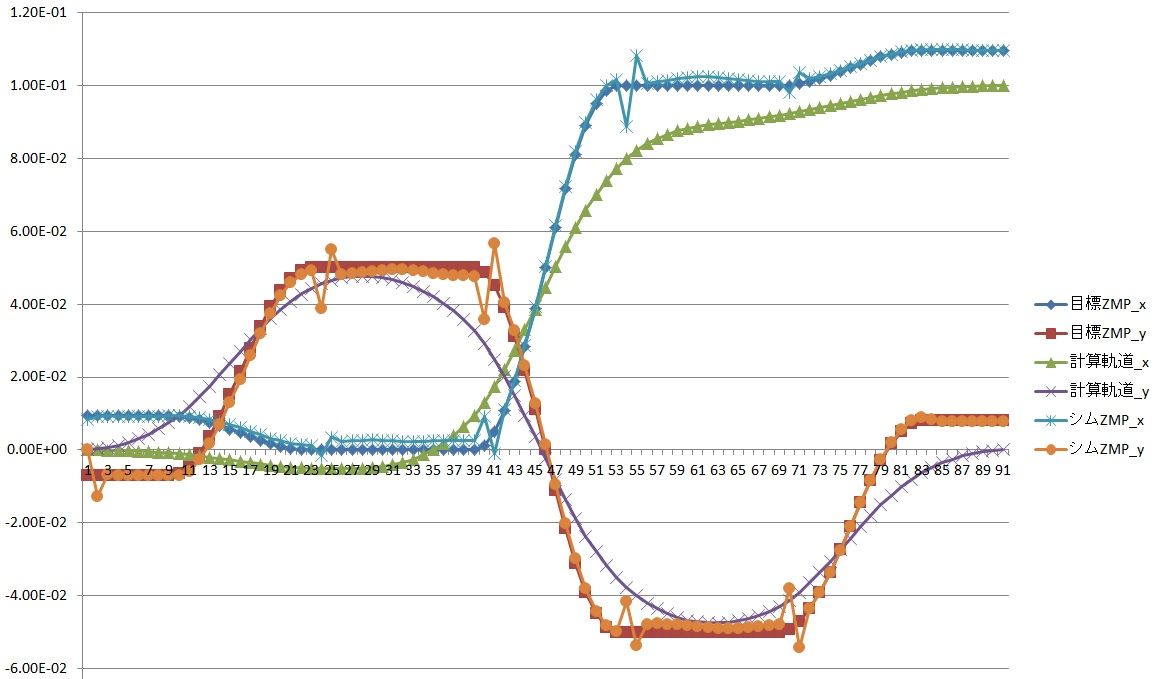
オフライン歩行パターン生成の完成\(^o^)/
連休に頑張ったおかげで、オフライン歩行パターン生成が完成しました。着地位置をZMPとして、重心軌道を計算し、そこから歩行モーションを作成して、更に全身運動でZMPのシミュレーションをおこない、出てきた結果との誤差から再び重心軌道を修正するところまでが、オフライン歩行パターン生成なのですが、なんと、N=91の計算が、自由度23のZMPシムまで入れて、2ms以下!!!NEON様様って感じです。これだと、リアルタイムで姿勢制御による軌道計算ができちゃいます!ちなみに、下のグラフで、x方向のZMPが重心軌道と8mmほどずれているのは軌道上の機体の基準点と、足を少し前に曲げて腰を落とした機体の重心が8mmほどずれているためです。それと、途中でところどころにスパイクがあるのでは、遊脚の上げ下げをsinカーブで指定して、グイっと上げて、ドンと下す動きになっているためです。こうやって見えちゃうと、もうちょっとだけ、マイルドにしたいような・・・。こんな感じで、計算結果をログに大量に残せることもLinuxボードの利点ですね。さて、ここまで来て、やっと自分が10年前の自分に追いつきつつある実感が湧きました。次は、要注意ポイント!! 関節トルクの計算部分です! サーボモータのフィードフォワードに使用して、モーションの再現性を上げるために使います。さーて、頑張るぞ~!!
2020年09月26日
-
3Dビュワーの続き
折角の4連休ですが、開発を進めています。逆運動学、順運動学、オフライン歩行パターン生成(アレンジ版)を1本のプログラムにまとめて、パターン生成の方は、NEON化(X軸、Y軸と修正計算用のX軸+dx、Y軸+dyをベクタ化)もして、とりあえず、3Dビュワー用に連続データを取り出してみた。で、3Dビュワーで連続再生させてみた。動画いい感じかも。使ったエクセルマクロはこんな感じ。Sub データコピー() s = Sheets("Sheet1").Cells(1, 5) For i = 1 To 144 Sheets("Sheet1").Cells(5, i) = Sheets("Sheet2").Cells(s, i) Next iEnd SubSub 連続再生() For i = 1 To 91 Sheets("Sheet1").Cells(1, 5) = i Call データコピー Sheets("Sheet1").ChartObjects("グラフ 2").Chart.Refresh DoEvents DoEvents Next iEnd Sub
2020年09月21日
-
重心位置の計算
平日も少しずつ開発を進めようと、今日は、重心位置の計算をNEONを使ってやってみた。/********** 重心の計算 **********/ c0 = vld1q_f32( &link[1].C[0] ); r0 = vmulq_n_f32( c0,link[1].m ); M = link[1].m; for (i = 2; i < JointMax + 1; i++ ) { M += link[i].m; c0 = vld1q_f32( &link[i].C[0] ); r0 = vmlaq_n_f32( r0,c0,link[i].m ); } r0 = vmulq_n_f32( r0,1.0/M ); printf("com %12.6e %12.6e %12.6e\n",vgetq_lane_f32(r0,0),vgetq_lane_f32(r0,1),vgetq_lane_f32(r0,2));
2020年09月14日
-
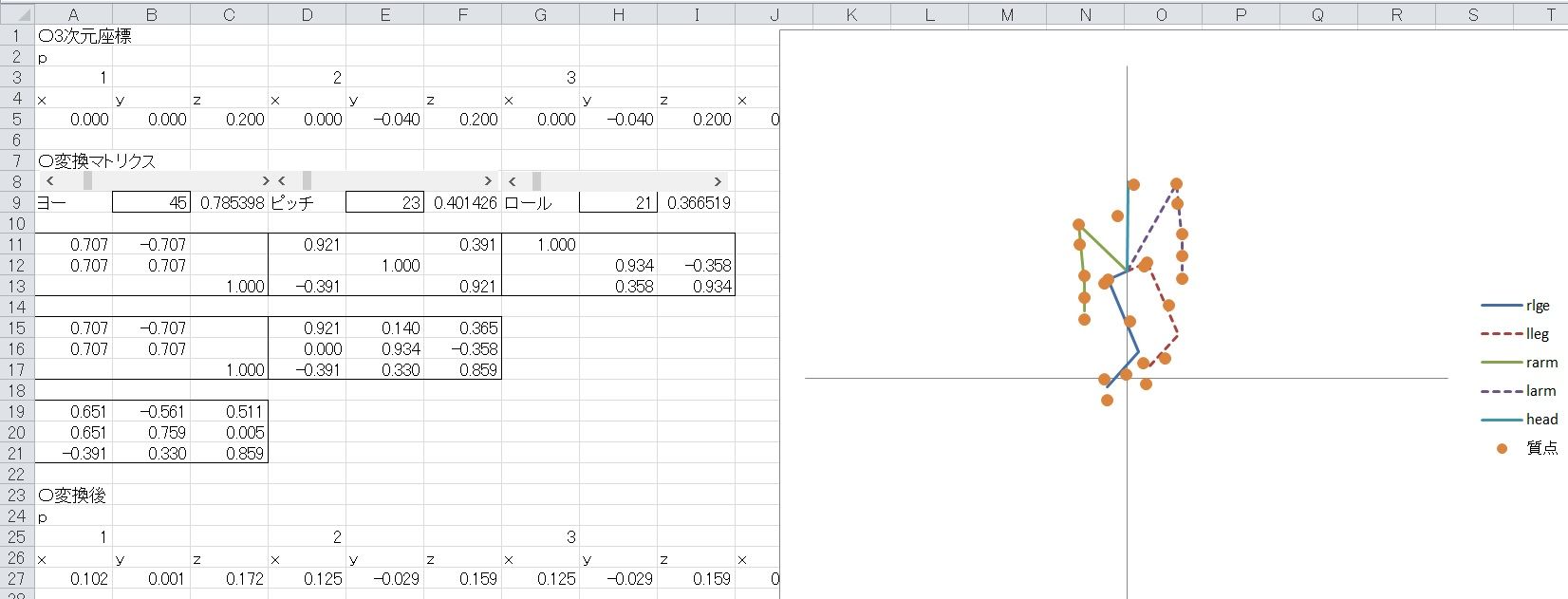
3Dビュワー
机上検討(ノートの上)では、いろいろ進んでいるのだが、どうもコーディングが進まない・・・。現在の目標は、重心軌道を変えることで姿勢制御をおこなうシステムだけど、個々の要素プログラムを組み合わせたときに、将来的に組み合わせやすいよう要素プログラムを修正しておきたくて、それとNEONによる高速化もしたくて、って思うとどうすればよいか悩んでしまう・・・。やっと、重い腰を上げてプログラムを組み合わせ始めたけど、ちゃんと計算できているか確認できるツールが欲しくて、エクセルで3Dビュワーを作ってみた。なんのことはない、座標変換で斜め上からみた風に回しているだけだけど、あとは、ロボットのモーションもログを取って、アニメーション風に見せる予定。
2020年09月13日
-
逆運動学(NEON版)
「ヒューマノイドロボット」(オーム社)の逆運動学のコードをNEON化してみた。結果は、両足1回あたりキャッシュありで、9μs → 8μsの改善で、1割程度だった。まあ、三角関数が多くて、そっちは変わらないからなー、仕方ないです。とは言え、NEONを使うことには慣れたので、結果オーライ!当然、行列を1次元配列で表すときは、a[i+j*N]のルールもバッチリ!!さ、ノドの小骨も取れたし、どんどん開発進めるぞー!次は、軌道計算から歩行モーションを生成して、簡易ZMPシミュレータに入れるところまで。もちろん、使えるところはNEON化するぞ~。/********** 逆運動学 **********/float sign(float s){ if (s < 0) { return -1.0; } else { return 1.0; }}void IK2(LINK lin[],IKF bod,IKF lfo,IKF rfo){ float c,cc,c5,q6a,cz,sz,q2,q3,q4,q5,q6,q7; float Sphi,Sthe,Cphi,Cthe; float32x4_t c0,c1,c2,c3,r0,r1,r2,r3; float32x4x2_t c01,c23;// 右足 c0 = vld1q_f32( &bod.Rp[0] ); c1 = vld1q_f32( &bod.Rp[4] ); c2 = vld1q_f32( &bod.Rp[8] ); r3 = vld1q_f32( &bod.Rp[12] ); r0 = vmulq_n_f32(c0,lin[2].b[0]); r1 = vmulq_n_f32(c1,lin[2].b[1]); r2 = vmulq_n_f32(c2,lin[2].b[2]); r0 = vaddq_f32( r0, r1 ); r3 = vaddq_f32( r3, r2 ); r3 = vaddq_f32( r3, r0 ); c0 = vld1q_f32( &rfo.Rp[0] ); c1 = vld1q_f32( &rfo.Rp[4] ); c2 = vld1q_f32( &rfo.Rp[8] ); r1 = vld1q_f32( &rfo.Rp[12] ); r3 = vsubq_f32( r3, r1 ); c3 = vdupq_n_f32(0.0); c01 = vtrnq_f32(c0,c1); c23 = vtrnq_f32(c2,c3); r0 = vcombine_f32(vget_low_f32(c01.val[0]),vget_low_f32(c23.val[0])); r1 = vcombine_f32(vget_low_f32(c01.val[1]),vget_low_f32(c23.val[1])); r2 = vcombine_f32(vget_high_f32(c01.val[0]),vget_high_f32(c23.val[0])); c0 = vmulq_n_f32(r0,vgetq_lane_f32(r3,0)); c1 = vmulq_n_f32(r1,vgetq_lane_f32(r3,1)); c2 = vmulq_n_f32(r2,vgetq_lane_f32(r3,2)); c0 = vaddq_f32( c0, c1 ); c0 = vaddq_f32( c0, c2 ); r0 = vmulq_f32( c0, c0 ); cc = vgetq_lane_f32(r0,0)+vgetq_lane_f32(r0,1)+vgetq_lane_f32(r0,2); c = sqrtf(cc); // ベクトルの長さ c5 = (cc-leg_length1*leg_length1-leg_length2*leg_length2)/(2.0*leg_length1*leg_length2); if (c5 >= 1) { q5 = 0.0; } else if (c5 <= -1) { q5 = PI; } else { q5 = acosf(c5); } q6a = asinf((leg_length1/c)*sinf(PI-q5)); q7 = atan2f(vgetq_lane_f32(c0,1),vgetq_lane_f32(c0,2)); if (q7 > PI/2) { q7 = q7 - PI; } else if (q7 < -PI/2) { q7 = q7 + PI; } q6 = -atan2f(vgetq_lane_f32(c0,0),sign(vgetq_lane_f32(c0,2))*sqrtf(vgetq_lane_f32(r0,1)+vgetq_lane_f32(r0,2))) - q6a; c0 = vld1q_f32( &bod.Rp[0] ); c1 = vld1q_f32( &bod.Rp[4] ); c2 = vld1q_f32( &bod.Rp[8] ); c3 = vdupq_n_f32(0.0); c01 = vtrnq_f32(c0,c1); c23 = vtrnq_f32(c2,c3); r0 = vcombine_f32(vget_low_f32(c01.val[0]),vget_low_f32(c23.val[0])); r1 = vcombine_f32(vget_low_f32(c01.val[1]),vget_low_f32(c23.val[1])); r2 = vcombine_f32(vget_high_f32(c01.val[0]),vget_high_f32(c23.val[0])); c0 = vmulq_n_f32(r0,rfo.Rp[0]); c1 = vmulq_n_f32(r1,rfo.Rp[1]); c2 = vmulq_n_f32(r2,rfo.Rp[2]); c0 = vaddq_f32( c0, c1 ); c0 = vaddq_f32( c0, c2 ); c3 = vmulq_n_f32(r0,rfo.Rp[4]); c1 = vmulq_n_f32(r1,rfo.Rp[5]); c2 = vmulq_n_f32(r2,rfo.Rp[6]); c1 = vaddq_f32( c1, c3 ); c1 = vaddq_f32( c1, c2 ); c3 = vmulq_n_f32(r0,rfo.Rp[8]); r3 = vmulq_n_f32(r1,rfo.Rp[9]); c2 = vmulq_n_f32(r2,rfo.Rp[10]); c3 = vaddq_f32( c3, r3 ); c2 = vaddq_f32( c2, c3 ); Sphi = sinf(-q7); Sthe = sinf(-q6-q5); Cphi = cosf(-q7); Cthe = cosf(-q6-q5); r1 = vmulq_n_f32(c1,Cphi); r0 = vmulq_n_f32(c1,-Sphi); r2 = vmulq_n_f32(c2,Sphi); c1 = vaddq_f32(r1,r2); r2 = vmulq_n_f32(c2,Cphi); c2 = vaddq_f32(r0,r2); r0 = vmulq_n_f32(c0,Cthe); r1 = vmulq_n_f32(c0,Sthe); r2 = vmulq_n_f32(c2,-Sthe); c0 = vaddq_f32(r0,r2); r2 = vmulq_n_f32(c2,Cthe); c2 = vaddq_f32(r1,r2); q2 = atan2f(-vgetq_lane_f32(c1,0),vgetq_lane_f32(c1,1)); cz = cosf(q2); sz = sinf(q2); q3 = atan2f(vgetq_lane_f32(c1,2),-vgetq_lane_f32(c1,0)*sz + vgetq_lane_f32(c1,1)*cz); q4 = atan2f(-vgetq_lane_f32(c0,2),vgetq_lane_f32(c2,2)); lin[2].q = q2; lin[3].q = q3; lin[4].q = q4; lin[5].q = q5; lin[6].q = q6; lin[7].q = q7; // 左足 c0 = vld1q_f32( &bod.Rp[0] ); c1 = vld1q_f32( &bod.Rp[4] ); c2 = vld1q_f32( &bod.Rp[8] ); r3 = vld1q_f32( &bod.Rp[12] ); r0 = vmulq_n_f32(c0,lin[8].b[0]); r1 = vmulq_n_f32(c1,lin[8].b[1]); r2 = vmulq_n_f32(c2,lin[8].b[2]); r0 = vaddq_f32( r0, r1 ); r3 = vaddq_f32( r3, r2 ); r3 = vaddq_f32( r3, r0 ); c0 = vld1q_f32( &lfo.Rp[0] ); c1 = vld1q_f32( &lfo.Rp[4] ); c2 = vld1q_f32( &lfo.Rp[8] ); r1 = vld1q_f32( &lfo.Rp[12] ); r3 = vsubq_f32( r3, r1 ); c3 = vdupq_n_f32(0.0); c01 = vtrnq_f32(c0,c1); c23 = vtrnq_f32(c2,c3); r0 = vcombine_f32(vget_low_f32(c01.val[0]),vget_low_f32(c23.val[0])); r1 = vcombine_f32(vget_low_f32(c01.val[1]),vget_low_f32(c23.val[1])); r2 = vcombine_f32(vget_high_f32(c01.val[0]),vget_high_f32(c23.val[0])); c0 = vmulq_n_f32(r0,vgetq_lane_f32(r3,0)); c1 = vmulq_n_f32(r1,vgetq_lane_f32(r3,1)); c2 = vmulq_n_f32(r2,vgetq_lane_f32(r3,2)); c0 = vaddq_f32( c0, c1 ); c0 = vaddq_f32( c0, c2 ); r0 = vmulq_f32( c0, c0 ); cc = vgetq_lane_f32(r0,0)+vgetq_lane_f32(r0,1)+vgetq_lane_f32(r0,2); c = sqrtf(cc); // ベクトルの長さ c5 = (cc-leg_length1*leg_length1-leg_length2*leg_length2)/(2.0*leg_length1*leg_length2); if (c5 >= 1) { q5 = 0.0; } else if (c5 <= -1) { q5 = PI; } else { q5 = acosf(c5); } q6a = asinf((leg_length1/c)*sinf(PI-q5)); q7 = atan2f(vgetq_lane_f32(c0,1),vgetq_lane_f32(c0,2)); if (q7 > PI/2) { q7 = q7 - PI; } else if (q7 < -PI/2) { q7 = q7 + PI; } q6 = -atan2f(vgetq_lane_f32(c0,0),sign(vgetq_lane_f32(c0,2))*sqrtf(vgetq_lane_f32(r0,1)+vgetq_lane_f32(r0,2))) - q6a; c0 = vld1q_f32( &bod.Rp[0] ); c1 = vld1q_f32( &bod.Rp[4] ); c2 = vld1q_f32( &bod.Rp[8] ); c3 = vdupq_n_f32(0.0); c01 = vtrnq_f32(c0,c1); c23 = vtrnq_f32(c2,c3); r0 = vcombine_f32(vget_low_f32(c01.val[0]),vget_low_f32(c23.val[0])); r1 = vcombine_f32(vget_low_f32(c01.val[1]),vget_low_f32(c23.val[1])); r2 = vcombine_f32(vget_high_f32(c01.val[0]),vget_high_f32(c23.val[0])); c0 = vmulq_n_f32(r0,lfo.Rp[0]); c1 = vmulq_n_f32(r1,lfo.Rp[1]); c2 = vmulq_n_f32(r2,lfo.Rp[2]); c0 = vaddq_f32( c0, c1 ); c0 = vaddq_f32( c0, c2 ); c3 = vmulq_n_f32(r0,lfo.Rp[4]); c1 = vmulq_n_f32(r1,lfo.Rp[5]); c2 = vmulq_n_f32(r2,lfo.Rp[6]); c1 = vaddq_f32( c1, c3 ); c1 = vaddq_f32( c1, c2 ); c3 = vmulq_n_f32(r0,lfo.Rp[8]); r3 = vmulq_n_f32(r1,lfo.Rp[9]); c2 = vmulq_n_f32(r2,lfo.Rp[10]); c3 = vaddq_f32( c3, r3 ); c2 = vaddq_f32( c2, c3 ); Sphi = sinf(-q7); Sthe = sinf(-q6-q5); Cphi = cosf(-q7); Cthe = cosf(-q6-q5); r1 = vmulq_n_f32(c1,Cphi); r0 = vmulq_n_f32(c1,-Sphi); r2 = vmulq_n_f32(c2,Sphi); c1 = vaddq_f32(r1,r2); r2 = vmulq_n_f32(c2,Cphi); c2 = vaddq_f32(r0,r2); r0 = vmulq_n_f32(c0,Cthe); r1 = vmulq_n_f32(c0,Sthe); r2 = vmulq_n_f32(c2,-Sthe); c0 = vaddq_f32(r0,r2); r2 = vmulq_n_f32(c2,Cthe); c2 = vaddq_f32(r1,r2); q2 = atan2f(-vgetq_lane_f32(c1,0),vgetq_lane_f32(c1,1)); cz = cosf(q2); sz = sinf(q2); q3 = atan2f(vgetq_lane_f32(c1,2),-vgetq_lane_f32(c1,0)*sz + vgetq_lane_f32(c1,1)*cz); q4 = atan2f(-vgetq_lane_f32(c0,2),vgetq_lane_f32(c2,2)); lin[8].q = q2; lin[9].q = q3; lin[10].q = q4; lin[11].q = q5; lin[12].q = q6; lin[13].q = q7;}
2020年08月29日
-
NEONの心の敷居を低くする
ありゃりゃ(^^;;; いつの間にか前回更新から10日もたっている。その間もちゃんと少しずつ開発してましたよ~。前回、開発環境が再構築できてから、すぐに逆運動学のプログラムを書いていました。といっても、SEMB1200A用のコードを移植しただけだけど・・・。で、それはあっさりOKになったのだけど、なんだか実行速度でモヤモヤが。NEON使って、早くならないかなー、でも、あんまり出番なさそうだなーとか、NEONって、ベクタのロードとかストアに時間が掛かって、ちょっとした処理だと逆に遅くなりそーとか、思ってたりして、ちょっと敷居が高かったんですよねー。で、いろいろと実験してみた。いくつかの行列計算を試してみて、速度がトントンから2倍速いくらいまで。よって、なーんだ、気軽にNEON使っても、少なくとも遅くはならないことがわかって、ずいぶん、NEONを使うことに対する心の敷居が低くなりました。あと、NEONを常用する上で重要なことが、行列を1次元配列で表すときのルールなのだけど、通常は、行(i)、列(j)としたときに、a[i*N+j」とするのが普通だと思ってたけど、こと、NEONを使うときは、a[i+j*N]とするのが断然有利になるってこと。ちなみに、今日のサンプルコードは、「ある物体を与えられた角度だけ、ロール、ピッチ、ヨー回転させたときの回転行列」の通常の行列計算版と、NEON版です。// ロールピッチヨーを回転行列に変換void rpy2rot(float e[9],float ph,float th,float ps){ float Sphi,Sthe,Spsi,Cphi,Cthe,Cpsi; Sphi = sinf(ph); Sthe = sinf(th); Spsi = sinf(ps); Cphi = cosf(ph); Cthe = cosf(th); Cpsi = cosf(ps); e[0] = Cpsi*Cthe; e[1] = -Spsi*Cphi+Cpsi*Sthe*Sphi; e[2] = Spsi*Sphi+Cpsi*Sthe*Cphi; e[3] = Spsi*Cthe; e[4] = Cpsi*Cphi+Spsi*Sthe*Sphi; e[5] = -Cpsi*Sphi+Spsi*Sthe*Cphi; e[6] = -Sthe; e[7] = Cthe*Sphi; e[8] = Cthe*Cphi;}void rpy2rot2(float e[12],float ph,float th,float ps){ float Sphi,Sthe,Spsi,Cphi,Cthe,Cpsi; float32x4_t c0,c1,c2,r0,r1,r2; Sphi = sinf(ph); Sthe = sinf(th); Spsi = sinf(ps); Cphi = cosf(ph); Cthe = cosf(th); Cpsi = cosf(ps); c0 = vdupq_n_f32(0.0); c1 = vdupq_n_f32(0.0); c2 = vdupq_n_f32(0.0); c0 = vsetq_lane_f32(Cpsi,c0,0); c0 = vsetq_lane_f32(Spsi,c0,1); c1 = vsetq_lane_f32(-Spsi,c1,0); c1 = vsetq_lane_f32(Cpsi,c1,1); c2 = vsetq_lane_f32(1.0,c2,2); r0 = vmulq_n_f32(c0,Cthe); r1 = vmulq_n_f32(c0,Sthe); r2 = vmulq_n_f32(c2,-Sthe); c0 = vaddq_f32(r0,r2); r2 = vmulq_n_f32(c2,Cthe); c2 = vaddq_f32(r1,r2); r1 = vmulq_n_f32(c1,Cphi); r0 = vmulq_n_f32(c1,-Sphi); r2 = vmulq_n_f32(c2,Sphi); c1 = vaddq_f32(r1,r2); r2 = vmulq_n_f32(c2,Cphi); c2 = vaddq_f32(r0,r2); vst1q_f32(&e[0],c0); vst1q_f32(&e[4],c1); vst1q_f32(&e[8],c2);}
2020年08月24日
-
開発環境の再構築(追記あり)
バックアップに60時間とか言われたので、前回展開した全てのファイルのバックアップはやめて、必要最低限のものをwindows との共有フォルダにコピーして、開発環境の再構築を始める。まずは、VirtualBoxを最新バージョンにアップデート。壊れた仮想マシンはそのままに、隣に新規の仮想マシンを作って、ubuntu14.04LTS日本語Remixをインストール。ところが、Guest Additionsがうまく動かない。仕方ない、Remixはやめて、以前のUbuntuを入れ直す・・・が、しかし、実は、最新のVirtualBoxが、古いubuntuに対応していなかった・・・再び、古いVirtualBoxをインストールして、Remixを入れなおす。今度はOK。しかし・・・、このブログにこまめに情報書いといてよかったー。一年前の自分に助けられながら、環境を構築中。再びネットワークの設定から、NFSなどの設定、クロス開発環境用パッケージを入れて、最後にYoctoをビルド(再びbitbakeに1日半コース(^^;;;)して、やっとプログラムをmakeできるように!!NFSつかってプログラムを転送して、ターミナル越しにLinuxボードで実行、再び計算結果を転送して、エクセルでグラフ化して内容確認して、OK。ううっ、開発環境の再構築に貴重な2日半を費やす・・・
2020年08月11日
-
約1年ぶりのロボット開発・・・
約1年ぶりのブログ更新・・・プライベートではいろいろあったけど・・・約1年ぶりのロボット開発。お盆休みで、帰省もできず、ってわけでもないのだけど、立ち寄った書店で、ラズベリーパイ4のことを知る。なんと標準のピンで複数のUART(シリアル通信)が使えるらしい。計算歩行の垣根がぐっと低くなるような気がする・・・。たぶん。とは言え、また、CPUボードから、開発環境から整備している時間もないため、いつものLinuxボードで、開発を再開しようと、1年前にどこまで進んでいたか2日間掛けて内容確認し、さあ、再開ってところで・・・仮想Linuxマシンのシステムにトラブルが・・・どうにか、まだ動くのでただいまファイルのバックアップ中ー。さて、どうなることやら・・・
2020年08月11日
-
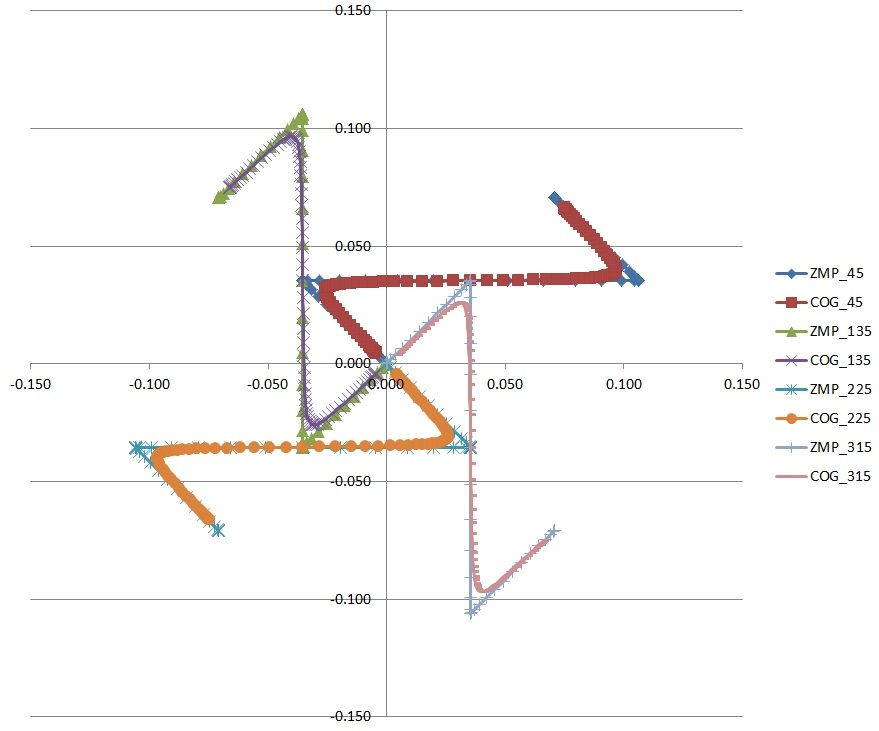
オフライン歩行パターン生成の基本プログラム完成
高速化を追求した(?)オフライン歩行パターン生成の基本プログラムが完成した。今回は、ソースを見てもらうために気を使って書いてみた。(^^;;;高速化のポイントは、1)グローバル変数を使用しない(十分CPUが速いので、複数コアで共有の必要がない)2)割り算しない(シンプルだが重要)3)おなじループで複数処理をおこなう(条件分岐を減らす)4)構造体配列を使って、同じタイミングで使う変数を近くのアドレスに配置(オフセットアドレス命令)5)コンパイラの邪魔をしない(良かれと思ったひと手間が逆効果)6)アセンブラを吐き出させて確認(-save-tempsオプション)結構、ベタベタに無駄っぽく書く方が速いという・・・。今回は、全体座標のX成分とY成分を同時に計算(高速化のため)しているのだけど、グラフ化しないとちゃんと目的の軌道になっているかわからない・・・。上記グラフは、機体の向きを45度から90度ずつ向きを変えて計算した結果。両足がそろっている状態から、左足に体重移動、右足を一歩前へ、右足に体重移動、左足を右足と揃えて、重心を体の真ん中で停止。機体の向きをX方向に向けるとおなじみのグラフになる。今回は、両足支持期の床反力(ZMP)の移動をスムーズにできるように、変移区間の幅をある程度変えることができるようにしてある。歩行周期や、この辺りのパラメータを変えて、より安定した歩行を探れるようにする。ちなみに、目標ZMPを入力して、計算結果で出てきた重心軌道を使い、エクセル上で、速度、加速度を求め、ZMP方程式(p=x-Zc/g*x'')に代入すると、目標ZMPとかなり近い結果がでてくる。これで一安心。あっ、ソースコードは、以下のとおりです。#include <stdio.h> // printf,fopen#include <math.h> // sinf,cosf#include <sys/time.h> // gettimeofday#define g 9.8 // 重力加速度#define PI 3.141592654#define torad PI/180.0#define TRACK_N0 15 // 始動、停止#define TRACK_N1 30 // 一歩#define TRACK_N 90 // 歩行開始struct timeval tvs,tve;typedef struct{ float P; float L; float Q0; float Q1; float D0; float D1; float X0; float X1;} TDMA;typedef struct{ int DSP_N; // double stance phase:両足支持期 float DSP_T[14]; // DSP_N max=7*2 float P0[4]; float P1[4];} TRACK;typedef struct{ float p[3]; float theta;} IKF;void TDMA_init(TDMA tdm[],float a,float b,int N);void TDMA_set (TDMA tdm[],TRACK tra);void TDMA_calc(TDMA tdm[],float a,float b,int N);/********** メインルーチン **********/int main(int argc, char **argv){ int i; float step_length,step_width,step_angle; IKF Sbody,Srfoot,Slfoot; IKF Ebody,Erfoot,Elfoot; float track_dt,track_Zc; float track_Vs[2],track_Ve[2]; float tdma_a,tdma_b; TRACK track; TDMA tdma[TRACK_N + 1];/********** ファイルオープン **********/ FILE *file; file = fopen("output.txt","w"); if (file == NULL) { printf("Can't open file:%s\n","output.txt"); }/********** 初 期 化 **********/ step_length = 0.1; step_width = 0.1; step_angle = 0.0 * torad; Sbody.p[0] = 0.0; // BODYの位置 Sbody.p[1] = 0.0; Sbody.p[2] = 0.2; Sbody.theta = 0.0 * torad; Slfoot.p[0] = Sbody.p[0] + step_width/2.0*sinf(-Sbody.theta); // 左足の位置 Slfoot.p[1] = Sbody.p[1] + step_width/2.0*cosf(-Sbody.theta); Slfoot.p[2] = 0.0; Slfoot.theta = Sbody.theta; Srfoot.p[0] = Sbody.p[0] - step_width/2.0*sinf(-Sbody.theta); // 右足の位置 Srfoot.p[1] = Sbody.p[1] - step_width/2.0*cosf(-Sbody.theta); Srfoot.p[2] = 0.0; Srfoot.theta = Sbody.theta; Ebody.theta = Slfoot.theta + step_angle; // BODYの目標値 Ebody.p[0] = Slfoot.p[0] - step_width/2.0*sinf(-Slfoot.theta) + step_length*cosf(Ebody.theta); // 右足から踏み出し Ebody.p[1] = Slfoot.p[1] - step_width/2.0*cosf(-Slfoot.theta) + step_length*sinf(Ebody.theta); Ebody.p[2] = 0.2; Elfoot.p[0] = Ebody.p[0] + step_width/2.0*sinf(-Ebody.theta); // 左足の目標値 Elfoot.p[1] = Ebody.p[1] + step_width/2.0*cosf(-Ebody.theta); Elfoot.p[2] = 0.0; Elfoot.theta = Ebody.theta; Erfoot.p[0] = Ebody.p[0] - step_width/2.0*sinf(-Ebody.theta); // 右足の目標値 Erfoot.p[1] = Ebody.p[1] - step_width/2.0*cosf(-Ebody.theta); Erfoot.p[2] = 0.0; Erfoot.theta = Ebody.theta; track_dt = 0.02; // 0.02 * TRACK_N1 = 0.6sec(一歩の周期) track_Zc = Sbody.p[2]; // 重心高 track_Vs[0] = 0.0; // 初速度 track_Vs[1] = 0.0; track_Ve[0] = 0.0; // 終端速度 track_Ve[1] = 0.0; /********** TDMA初期化 **********/gettimeofday(&tvs,NULL); tdma_a = - track_Zc/(g*track_dt*track_dt); tdma_b = 2.0*track_Zc/(g*track_dt*track_dt) + 1.0; TDMA_init(tdma,tdma_a,tdma_b,TRACK_N);gettimeofday(&tve,NULL); printf("TDMA初期化 %ld usec\n",(long)((tve.tv_sec-tvs.tv_sec)*1000000+tve.tv_usec-tvs.tv_usec));/********** ZMP設定 **********/ track.DSP_N = 7*2; for ( i = 1; i < track.DSP_N ; i++ ) { track.DSP_T[i] = (cosf(PI/track.DSP_N*(i-1)) - cosf(PI/track.DSP_N*i))/2.0; }gettimeofday(&tvs,NULL); track.P0[0] = Sbody.p[0]; track.P0[1] = Slfoot.p[0]; track.P0[2] = Erfoot.p[0]; track.P0[3] = Ebody.p[0]; track.P1[0] = Sbody.p[1]; track.P1[1] = Slfoot.p[1]; track.P1[2] = Erfoot.p[1]; track.P1[3] = Ebody.p[1]; TDMA_set (tdma,track); tdma[0].D0 += tdma_a * track_Vs[0] * track_dt; // 初速度 tdma[0].D1 += tdma_a * track_Vs[1] * track_dt; tdma[TRACK_N].D0 -= tdma_a * track_Ve[0] * track_dt; // 終端速度 tdma[TRACK_N].D1 -= tdma_a * track_Ve[1] * track_dt;gettimeofday(&tve,NULL); printf("ZMP設定 %ld usec\n",(long)((tve.tv_sec-tvs.tv_sec)*1000000+tve.tv_usec-tvs.tv_usec));/********** 重心軌道計算 **********/gettimeofday(&tvs,NULL); TDMA_calc(tdma,tdma_a,tdma_b,TRACK_N);gettimeofday(&tve,NULL); printf("軌道計算 %ld usec\n",(long)((tve.tv_sec-tvs.tv_sec)*1000000+tve.tv_usec-tvs.tv_usec));/********** 結果出力 **********/ for ( i = 0; i < TRACK_N + 1; i++ ) { fprintf(file,"%12.6e,%12.6e,%12.6e,%12.6e\n",tdma[i].D0,tdma[i].X0,tdma[i].D1,tdma[i].X1); }/********** ファイルクローズ **********/ fclose(file); return 0;}/********** サブルーチン **********/void TDMA_init(TDMA tdm[],float a,float b,int N){ int i; tdm[0].P = - a / ( a + b ); for ( i = 1; i < N; i++ ) { tdm[i].L = 1.0 / ( b + a * tdm[i - 1].P ); tdm[i].P = - a * tdm[i].L; } tdm[i].L = 1.0 / ( b + a + a * tdm[i - 1].P );}void TDMA_set (TDMA tdm[],TRACK tra){ int i; float track_00,track_01; float track_10,track_11; float track_20,track_21; for (i = 0; i < TRACK_N0 - tra.DSP_N/2 + 1; i++ ) { tdm[i].D0 = tra.P0[0]; tdm[i].D1 = tra.P1[0]; tdm[TRACK_N0 + tra.DSP_N/2 + TRACK_N1*2 + i].D0 = tra.P0[3]; tdm[TRACK_N0 + tra.DSP_N/2 + TRACK_N1*2 + i].D1 = tra.P1[3]; } for (i = 0; i < TRACK_N1 - tra.DSP_N + 1; i++ ) { tdm[TRACK_N0 + tra.DSP_N/2 + i].D0 = tra.P0[1]; tdm[TRACK_N0 + tra.DSP_N/2 + i].D1 = tra.P1[1]; tdm[TRACK_N0 + tra.DSP_N/2 + TRACK_N1 + i].D0 = tra.P0[2]; tdm[TRACK_N0 + tra.DSP_N/2 + TRACK_N1 + i].D1 = tra.P1[2]; } track_00 = tra.P0[0]; track_01 = tra.P1[0]; track_10 = tra.P0[1]; track_11 = tra.P1[1]; track_20 = tra.P0[2]; track_21 = tra.P1[2]; for (i = 1; i < tra.DSP_N; i++ ) { track_00 += (tra.P0[1] - tra.P0[0]) * tra.DSP_T[i]; track_01 += (tra.P1[1] - tra.P1[0]) * tra.DSP_T[i]; track_10 += (tra.P0[2] - tra.P0[1]) * tra.DSP_T[i]; track_11 += (tra.P1[2] - tra.P1[1]) * tra.DSP_T[i]; track_20 += (tra.P0[3] - tra.P0[2]) * tra.DSP_T[i]; track_21 += (tra.P1[3] - tra.P1[2]) * tra.DSP_T[i]; tdm[TRACK_N0 - tra.DSP_N/2 + i].D0 = track_00; tdm[TRACK_N0 - tra.DSP_N/2 + i].D1 = track_01; tdm[TRACK_N0 - tra.DSP_N/2 + TRACK_N1 + i].D0 = track_10; tdm[TRACK_N0 - tra.DSP_N/2 + TRACK_N1 + i].D1 = track_11; tdm[TRACK_N0 - tra.DSP_N/2 + TRACK_N1*2 + i].D0 = track_20; tdm[TRACK_N0 - tra.DSP_N/2 + TRACK_N1*2 + i].D1 = track_21; }}void TDMA_calc(TDMA tdm[],float a,float b,int N){ int i; tdm[0].Q0 = tdm[0].D0 / ( a + b ); tdm[0].Q1 = tdm[0].D1 / ( a + b ); for ( i = 1; i < N + 1; i++ ) { tdm[i].Q0 = ( tdm[i].D0 - a * tdm[i - 1].Q0 ) * tdm[i].L; tdm[i].Q1 = ( tdm[i].D1 - a * tdm[i - 1].Q1 ) * tdm[i].L; } tdm[N].X0 = tdm[N].Q0; tdm[N].X1 = tdm[N].Q1; for (i = N - 1; i > -1; i-- ) { tdm[i].X0 = tdm[i].P * tdm[i + 1].X0 + tdm[i].Q0; tdm[i].X1 = tdm[i].P * tdm[i + 1].X1 + tdm[i].Q1; }}
2019年09月15日
-
オフライン歩行パターン生成の再プログラミング
ロボット開発をする時間を作っています。なにせ10年前のコード、ただ移植するだけじゃないので時間がかかる・・・。理由は簡単。計算が間違っている可能性がゼロじゃないから。心配性なんです。少なくとも数式はチェックしないと。それと高速化。とっかかり。まずは、オフラインパターン生成だけど、作り直しています。いや、計算結果は変わらないのだけどね。そして、あまり高速化も必要ない部分なのだけど。三重対角行列の解法にTDMAという計算方法を今回は採用。計算量はちょっと少なくなるくらいだけど、その他の高速化テクも使って、50%の高速化に成功。特に構造体配列を使った行列の計算は、途中でアセンブラを覗いてみても、想像とおりのコードでシンプルで速い。満足満足。
2019年09月08日
-
10年前に追い付いていない・・・。
10年前のソースコードを読み解く。あっ、GMailのアカウントでグーグルドライブが使えることに気づいたので、再度、公開します。読み解きながら、10年前の動画も見ちゃう・・・。なんだか、最近たまに思うのだが、「昔の俺って優秀だったんだな」って。10年。まぁ、いろいろあったけどね。やむを得ず、新しいことに挑戦している部分もあるけど、基本、まだ、10年前に追い付いていない・・・。
2019年09月01日
-

バックパック!
仕事はまだまだ忙しいけど、今週末は仕事をしない!!って決めて、今日はロボットを触る。Linuxボードを、アルミ板金のバックパックに入れて、ロボットに背負わせてみた。バックパックは、かなり前に設計してたけど、ロボスポットで切断加工してもらって、曲げ曲げして完成。配線もある程度まとめてみた。機体がデカイぶん、思ったよりバックパックの収まりが良い。が、アルミケースの中だと、XBeeも多少通信に手間取るみたい。ここら辺は考えないとね。
2019年08月31日
-

XBeeによるターミナルの無線化
Linuxボードをロボットに積込むにあたって、ターミナル(コンソール)の無線化は必須なのだけど、以前から、XBeeを使っていました。ただし、前のXBeeは通信速度に不満があったのだけどね。今回、XBeeのS2Cに切り替えたので、通信速度も115.2kbpsで安定しています。2枚のXBeeを用意して、PC側は、UBS変換アダプタ、Linuxボード側は、3.3V直結です。ここを参考に、専用ソフトで設定するだけで、あっという間に無線化完了♪
2019年07月13日
-
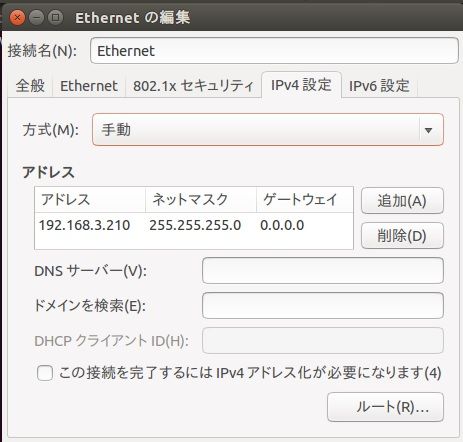
LANクロスケーブル
5か月振りの更新。もともと住んでいたマンションへの引っ越し。私立中学へ進んだ娘。GWは、親戚行脚。仕事も残業するようになって・・・。引っ越し荷物が片付かない。(>_<)マンションのインターネット契約が変わって、部屋の中にルーターがない。もろもろ重なって、ほったらかしだったけど、そろそろ再開しよう!!まずは、LinuxボードとのLAN接続。アパートでは、ADSLのルーターを介して接続していたけど、クロスケーブルを買ってきて、直接接続!う~ん。安定しない。ネット検索するとSISOさんのページに行き着いた。内容を読むと、設定するのはIPアドレスとネットマスクのみとのこと。試しにPC側のみ、イーサーネットの設定のゲートウェイ、DNSサーバーを空欄にしてみる。ビンゴ!! きっと、ありもしないゲートウェイとかDNSサーバーをずっと探していたのかも・・・。ちなみに、Linuxボード側は、ゲートウェイもDNSサーバーもウソ設定されたままだけど、ちゃんと安定して繋がっている・・・。まぁ、いいか。
2019年07月05日
-

BOXER JOE 再び立つ!!(^^;;;
ここ最近の検討したものを全部突っ込んで、ロボットのトリム調整プログラムを作成しました。ちゃんと、23個のサーボモーターに5msで指示が出せています。(^-^)Vコンパイルしたプログラムは、LAN経由でLinuxボード(のSDカード内のフォルダ)に保存してあるので、ターミナル接続するだけで実行できます。ただし、環境設定してないので、実行するためにはフルパスが必要です。/home/root/robo って感じです。しかし、アルミ板金でバックパックを早く作らねば・・・。プログラムはこんな感じ。#include <stdio.h> // printf#include <stdlib.h> // exit,strtol#include <time.h> // clock#include <pthread.h> // pthread#include <termios.h> // termios#include <unistd.h> // read & write#include <sys/types.h> // open#include <sys/stat.h> // open#include <sys/ioctl.h> // ioctl#include <fcntl.h> // open#include <string.h> // memcpy#define hz 200 // 5msec#define N_servo 25#define console_view_time 20 // 0.1*hz#define approach_time 600 // 3*hz#define POS_MIN 3500#define POS_MAX 11500/********************************//* サーボスレッド用マクロ記述部 *//********************************/ /* 機能SW */#define CH1_1_S 1#define CH1_2_S 1#define CH1_3_S 1#define CH1_4_S 0#define CH2_1_S 1#define CH2_2_S 1#define CH2_3_S 1#define CH2_4_S 0#define CH3_1_S 1#define CH3_2_S 1#define CH3_3_S 1#define CH3_4_S 0#define CH4_1_S 1#define CH4_2_S 1#define CH4_3_S 1#define CH4_4_S 0#define CH5_1_S 1#define CH5_2_S 1#define CH5_3_S 1#define CH5_4_S 1#define CH6_1_S 1#define CH6_2_S 1#define CH6_3_S 1#define CH6_4_S 0#define CH7_1_S 1#define CH7_2_S 1#define CH7_3_S 1#define CH7_4_S 1 /* リンクID */#define CH1_1_L 4#define CH1_2_L 3#define CH1_3_L 2#define CH2_1_L 10#define CH2_2_L 9#define CH2_3_L 8#define CH3_1_L 11#define CH3_2_L 12#define CH3_3_L 13#define CH4_1_L 14#define CH4_2_L 19#define CH4_3_L 24#define CH5_1_L 20#define CH5_2_L 21#define CH5_3_L 22#define CH5_4_L 23#define CH6_1_L 5#define CH6_2_L 6#define CH6_3_L 7#define CH7_1_L 15#define CH7_2_L 16#define CH7_3_L 17#define CH7_4_L 18 /* サーボID */#define CH1_1_ID 28#define CH1_2_ID 27#define CH1_3_ID 26#define CH2_1_ID 22#define CH2_2_ID 21#define CH2_3_ID 20#define CH3_1_ID 23#define CH3_2_ID 24#define CH3_3_ID 25#define CH4_1_ID 1#define CH4_2_ID 9#define CH4_3_ID 0#define CH5_1_ID 10#define CH5_2_ID 11#define CH5_3_ID 12#define CH5_4_ID 13#define CH6_1_ID 29#define CH6_2_ID 30#define CH6_3_ID 31#define CH7_1_ID 2#define CH7_2_ID 3#define CH7_3_ID 4#define CH7_4_ID 5#define PP_W_0(c,i) \ do { \ } \ while (0);#define PP_W_1(c,i) \ do { \ a[0] = 0x80 + CH ## c ## _ ## i ## _ID; \ a[1] = 0x7f & (sPOS[CH ## c ## _ ## i ## _L] >> 7); \ a[2] = 0x7f & sPOS[CH ## c ## _ ## i ## _L]; \ write(fd ## c ,a,3); \ } \ while (0);#define PP_W_SS(c,i,s) PP_W_ ## s (c,i)#define PP_W_S(c,i,s) PP_W_SS(c,i,s)#define PP_W(c,i) PP_W_S(c,i,CH ## c ## _ ## i ## _S)#define PP_R_0(c,i) \ do { \ } \ while (0);#define PP_R_1(c,i) \ do { \ if (read(fd ## c ,a,64) == 6) { \ if ((int)(0x7f & a[3]) == CH ## c ## _ ## i ## _ID) { \ sTCH[CH ## c ## _ ## i ## _L] = (((int)(a[4])) << 7) + (int)(a[5]); \ } else { \ sTCH[CH ## c ## _ ## i ## _L] = 0; \ } \ } else { \ sTCH[CH ## c ## _ ## i ## _L] = 0; \ } \ } \ while (0);#define PP_R_SS(c,i,s) PP_R_ ## s (c,i)#define PP_R_S(c,i,s) PP_R_SS(c,i,s)#define PP_R(c,i) PP_R_S(c,i,CH ## c ## _ ## i ## _S)#define PP_O(c) \ do { \ fd ## c = open("/dev/ttySC1" # c ,O_RDWR); \ if (fd ## c < 0) { \ printf("open error\n"); \ exit(1); \ } \ tcsetattr(fd ## c ,TCSANOW,&tio); \ ioctl(fd ##c ,TCSETS,&tio); \ } \ while (0);/************************//* グローバル変数記述部 *//************************/pthread_mutex_t mutex_servo;pthread_cond_t cond_servo;struct timespec tsb;int POS[N_servo];int TCH[N_servo];int timer_servo;int stop_request;/**********************//* サーボスレッド *//**********************/void *servo_thread(void *arg){ struct timespec tsrq; int fd1,fd2,fd3,fd4,fd5,fd6,fd7; struct termios tio; int baudRate = B115200; int sPOS[N_servo]; int sTCH[N_servo]; unsigned char a[64]; /* シリアル通信起動 */ bzero(&tio,sizeof(tio)); cfsetispeed(&tio,baudRate); cfsetospeed(&tio,baudRate); cfmakeraw(&tio); tio.c_cc[VMIN] = 0; tio.c_cc[VTIME] = 0; tio.c_cflag += CREAD; tio.c_cflag += CLOCAL; tio.c_cflag += PARENB; PP_O(1) PP_O(2) PP_O(3) PP_O(4) PP_O(5) PP_O(6) PP_O(7) /* タイマ初期化 */ clock_gettime(CLOCK_REALTIME,&tsb); tsb.tv_sec++; tsb.tv_sec++; tsb.tv_nsec = 0; clock_nanosleep(CLOCK_REALTIME,TIMER_ABSTIME,&tsb,NULL); timer_servo = 0;pthread_mutex_lock(&mutex_servo); /* 繰り返し処理 */while(!stop_request){ /* POS読み込み */ memcpy(sPOS,POS,sizeof(int)*N_servo); pthread_mutex_unlock(&mutex_servo); /* 1回目送信 */ PP_W(1,1) PP_W(2,1) PP_W(3,1) PP_W(4,1) PP_W(5,1) PP_W(6,1) PP_W(7,1) /* 1msスリープ */ tsrq.tv_sec = 0; tsrq.tv_nsec = 1000000; nanosleep(&tsrq,NULL); /* 1回目受信 */ PP_R(1,1) PP_R(2,1) PP_R(3,1) PP_R(4,1) PP_R(5,1) PP_R(6,1) PP_R(7,1) /* 2回目送信 */ PP_W(1,2) PP_W(2,2) PP_W(3,2) PP_W(4,2) PP_W(5,2) PP_W(6,2) PP_W(7,2) /* 1msスリープ */ tsrq.tv_sec = 0; tsrq.tv_nsec = 1000000; nanosleep(&tsrq,NULL); /* 2回目受信 */ PP_R(1,2) PP_R(2,2) PP_R(3,2) PP_R(4,2) PP_R(5,2) PP_R(6,2) PP_R(7,2) /* 3回目送信 */ PP_W(1,3) PP_W(2,3) PP_W(3,3) PP_W(4,3) PP_W(5,3) PP_W(6,3) PP_W(7,3) /* 1msスリープ */ tsrq.tv_sec = 0; tsrq.tv_nsec = 1000000; nanosleep(&tsrq,NULL); /* 3回目受信 */ PP_R(1,3) PP_R(2,3) PP_R(3,3) PP_R(4,3) PP_R(5,3) PP_R(6,3) PP_R(7,3) /* 4回目送信 */ PP_W(1,4) PP_W(2,4) PP_W(3,4) PP_W(4,4) PP_W(5,4) PP_W(6,4) PP_W(7,4) /* 1msスリープ */ tsrq.tv_sec = 0; tsrq.tv_nsec = 1000000; nanosleep(&tsrq,NULL); /* 4回目受信 */ PP_R(1,4) PP_R(2,4) PP_R(3,4) PP_R(4,4) PP_R(5,4) PP_R(6,4) PP_R(7,4) /* 時刻指定スリープ */ tsrq.tv_sec = tsb.tv_sec + (timer_servo + 1) / hz; tsrq.tv_nsec = ((timer_servo + 1) % hz) * (1000000000 / hz); if(clock_nanosleep(CLOCK_REALTIME,TIMER_ABSTIME,&tsrq,NULL) != 0) { printf("Error: on clock_nanosleep.\n"); exit(1); }pthread_mutex_lock(&mutex_servo); /* タイマ処理 */ timer_servo++; /* TCH書き込み */ memcpy(TCH,sTCH,sizeof(int)*N_servo); /* メインスレッドに通知 */ pthread_cond_signal(&cond_servo);}pthread_mutex_unlock(&mutex_servo); /* ストップ処理 */ close(fd1); close(fd2); close(fd3); close(fd4); close(fd5); close(fd6); close(fd7); return NULL;}/**********************//* メインスレッド *//**********************/int main(int argc, char **argv){ pthread_t thread_servo; FILE *file; int mPOS[N_servo]; int iPOS[N_servo]; int aPOS[N_servo]; int mTCH[N_servo]; int timer_main; int step_console; int timer_console; int console_select_no; int i; char c; struct termios term_attr,term_backup; struct timespec tsm; /* 標準入力設定(入力待ちなし) */ tcgetattr(0,&term_attr); term_backup = term_attr; term_attr.c_lflag &= ~(ICANON|ECHO); term_attr.c_cc[VMIN] = 0; term_attr.c_cc[VTIME] = 0; tcsetattr(0,TCSANOW,&term_attr); fcntl(0,F_SETFL,O_NONBLOCK); /* 初期化 */ stop_request = 0; step_console = 0; timer_console = 0; console_select_no = 2; /* 起動画面 */ printf("\n**********************************\n"); printf( "* RoBo System Powered by Linux *\n"); printf( "**********************************\n"); /* iPOS読み込み */ file = fopen("iPOS.txt","r"); if(file == NULL) { printf("Can't open file:%s\n","iPOS.txt"); exit(1); } for(i = 2; i < N_servo; i++ ) { fscanf(file,"%d\n",&iPOS[i]); } fclose(file); /* iPOS表示 */ printf("\n*** Load iPOS ***\n\n"); for ( i = 2; i < (N_servo+1)/2+1; i++ ) { printf("No.%2d ",i); } printf("\n"); for ( i = 2; i < (N_servo+1)/2+1; i++ ) { printf("%5d ",iPOS[i]); } printf("\n"); for ( i = (N_servo+1)/2+1; i < N_servo; i++ ) { printf("No.%2d ",i); } printf("\n"); for ( i = (N_servo+1)/2+1; i < N_servo; i++ ) { printf("%5d ",iPOS[i]); } printf("\n"); printf("\nCapture Start\n\n\n\n\n\n\n"); /* POS初期化 */ for(i = 2; i < N_servo; i++) { POS[i] = 0; } /* サーボスレッド作成 */ pthread_mutex_init(&mutex_servo,NULL); pthread_cond_init(&cond_servo,NULL); if(pthread_create(&thread_servo,NULL,servo_thread,NULL) != 0) { printf("Error: Failed to create servo thread.\n"); exit(1); }pthread_mutex_lock(&mutex_servo); /* 繰り返し処理 */while(!stop_request){ /* サーボスレッドの通知待ち */ if(pthread_cond_wait(&cond_servo,&mutex_servo) != 0) { printf("Error: on pthread_cond_wait.\n"); exit(1); } /* タイマ処理 */ timer_main = timer_servo; /* TCH読み込み */ memcpy(mTCH,TCH,sizeof(int)*N_servo); pthread_mutex_unlock(&mutex_servo); /* コンソール処理 */ switch( step_console ) { case 0: timer_console++; if(timer_console > console_view_time-1) { timer_console = 0; /* mTCH表示 */ printf("\033[5A"); // カーソルを上に for ( i = 2; i < (N_servo+1)/2+1; i++ ) { printf("No.%2d ",i); } printf("\n"); for ( i = 2; i < (N_servo+1)/2+1; i++ ) { printf("%5d ",mTCH[i]); } printf("\n"); for ( i = (N_servo+1)/2+1; i < N_servo; i++ ) { printf("No.%2d ",i); } printf("\n"); for ( i = (N_servo+1)/2+1; i < N_servo; i++ ) { printf("%5d ",mTCH[i]); } printf("\n"); printf("[q:Quit a:Approaching iPOS h:Hold(iPOS < TCH)]\n"); if ( read(0, &c, 1) == 1 ) { if ( c == 'q' ) stop_request = 1; if ( c == 'a' ) { step_console = 1; for(i = 2; i < N_servo; i++) { aPOS[i] = mTCH[i]; } timer_console = 0; } if ( c == 'h' ) { step_console = 2; for(i = 2; i < N_servo; i++) { iPOS[i] = mTCH[i]; } timer_console = 0; printf("\n*** Hold(iPOS < TCH) ***\n\n\n\n\n\n\n"); } } } for(i = 2; i < N_servo; i++) { mPOS[i] = 0; } break; case 1: timer_console++; for(i = 2; i < N_servo; i++) { mPOS[i] = aPOS[i] + ((iPOS[i]-aPOS[i])*timer_console)/approach_time; } if(timer_console > approach_time - 1) { step_console = 2; printf("\nIn Operation\n\n\n\n\n\n\n"); } if ( read(0, &c, 1) == 1 ) step_console = 0; break; case 2: timer_console++; if(timer_console > console_view_time-1) { timer_console = 0; /* iPOS表示 */ printf("\033[5A"); // カーソルを上に for ( i = 2; i < (N_servo+1)/2+1; i++ ) { printf("No.%2d ",i); } printf("\n"); for ( i = 2; i < (N_servo+1)/2+1; i++ ) { printf("%5d ",iPOS[i]); } printf("\n"); for ( i = (N_servo+1)/2+1; i < N_servo; i++ ) { printf("No.%2d ",i); } printf("\n"); for ( i = (N_servo+1)/2+1; i < N_servo; i++ ) { printf("%5d ",iPOS[i]); } printf("\n"); printf("[Trim No.%2d 1-8:Trim f:Free s:Save iPOS]\n",console_select_no); if ( read(0, &c, 1) == 1 ) { if ( c == 'f' ) { step_console = 0; printf("\n*** Servo Free ***\n"); printf("\nCapture Start\n\n\n\n\n\n\n"); } if ( c == 's' ) { file = fopen("iPOS.txt","w"); if (file == NULL) { printf("Can't open file:%s\n","iPOS.txt"); } for ( i = 2; i < N_servo; i++ ) { fprintf(file,"%d\n",iPOS[i]); } fclose(file); printf("\n*** Save iPOS ***\n\n\n\n\n\n\n"); } if ( c == '1' ) { iPOS[console_select_no] = iPOS[console_select_no] - 1; if (iPOS[console_select_no] < POS_MIN) { iPOS[console_select_no] = POS_MIN; } } if ( c == '2' ) { iPOS[console_select_no] = iPOS[console_select_no] - 10; if (iPOS[console_select_no] < POS_MIN) { iPOS[console_select_no] = POS_MIN; } } if ( c == '3' ) { iPOS[console_select_no] = iPOS[console_select_no] - 100; if (iPOS[console_select_no] < POS_MIN) { iPOS[console_select_no] = POS_MIN; } } if ( c == '4' ) { iPOS[console_select_no] = iPOS[console_select_no] + 1; if (iPOS[console_select_no] > POS_MAX) { iPOS[console_select_no] = POS_MAX; } } if ( c == '5' ) { iPOS[console_select_no] = iPOS[console_select_no] + 10; if (iPOS[console_select_no] > POS_MAX) { iPOS[console_select_no] = POS_MAX; } } if ( c == '6' ) { iPOS[console_select_no] = iPOS[console_select_no] + 100; if (iPOS[console_select_no] > POS_MAX) { iPOS[console_select_no] = POS_MAX; } } if ( c == '7' ) { console_select_no = console_select_no - 1; if (console_select_no < 2) { console_select_no = N_servo - 1; } } if ( c == '8' ) { console_select_no = console_select_no + 1; if (console_select_no > N_servo - 1) { console_select_no = 2; } } } } for(i = 2; i < N_servo; i++) { mPOS[i] = iPOS[i]; } break; }pthread_mutex_lock(&mutex_servo); /* POS書き込み */ memcpy(POS,mPOS,sizeof(int)*N_servo);}pthread_mutex_unlock(&mutex_servo); /* ストップ処理 */ clock_gettime(CLOCK_REALTIME,&tsm); printf("\nservo %dsec %dmsec\n",timer_main / hz,(timer_main % hz)*1000/hz); printf( "main %dsec %ldmsec\n\n",(int)(tsm.tv_sec - tsb.tv_sec),(tsm.tv_nsec - tsb.tv_nsec)/1000000); if(pthread_join(thread_servo,NULL) != 0) { printf("Error: Failed to wait for servo thread termination.\n"); exit(1); } pthread_mutex_destroy(&mutex_servo); pthread_cond_destroy(&cond_servo); /* 標準入力復帰 */ tcsetattr(0,TCSANOW,&term_backup); return 0;}
2019年02月21日
-
エスケープシーケンス♪(画面制御文字列)
サーボのトリム調整をおこなう場合、ターミナルにパラメータをいろいろ表示できると便利だな~って、生まれて初めて、エスケープシーケンスを使ってみた。(^^;;;ターミナルっていうと、いつもダラダラ、情報を垂れ流すイメージだけど、画面制御文字列を使ってカーソルを操作すると、それらしいウィンドウ画面になります。調整したトリム情報は、ファイルに保存して、起動時に読み込むことができます。エスケープシーケンスの参考にしたのはここ。コードはこんな感じ。#include <stdio.h>#include <stdlib.h>int main(int argc, char **argv){ char buf[40],*cp; int a,b; int iPOS[25]; int i; FILE *file; file = fopen("iPOS.txt","r"); if (file == NULL) { printf("Can't open file:%s\n","test.txt"); } for ( i = 2; i < 25; i++ ) { fscanf(file,"%d\n",&iPOS[i]); } fclose(file); printf("\n*** Servo Trimer ***\n\n\n\n\n\n\n"); while(1) { printf("\033[5A"); // カーソルを上に for ( i = 2; i < 14; i++ ) { printf("No.%2d ",i); } printf("\n"); for ( i = 2; i < 14; i++ ) { printf("%5d ",iPOS[i]); } printf("\n"); for ( i = 14; i < 25; i++ ) { printf("No.%2d ",i); } printf("\n"); for ( i = 14; i < 25; i++ ) { printf("%5d ",iPOS[i]); } printf("\n"); printf("\033[K"); // カーソルから行末までクリア fgets(buf, sizeof(buf), stdin); if ( buf[0] == 'q' ) break; a = (int)(strtol(buf, &cp,0)); b = (int)(strtol(cp, &cp,0)); iPOS[a] = b; } file = fopen("iPOS.txt","w"); if (file == NULL) { printf("Can't open file:%s\n","test.txt"); } for ( i = 2; i < 25; i++ ) { fprintf(file,"%d\n",iPOS[i]); } fclose(file); return 0;}
2019年02月13日
-
入力待ちしないキーボード入力
通常、アプリの中でターミナルを使ってキーボードから入力するには、標準入力として、fgets()なんかを使うのだけど、エコーもあって使いやすいのだけど、enterを押すまでスレッドが止まってしまう・・・。もちろん、止まっててもよいように、キー入力用スレッドを別に作ってもいいのだけど、あまりスレッドをポイポイ作らない方が、実時間実効性を確保できそうで、ちょろっと調べて、入力待ちしない設定にできることが判明。参考にしたのはここ。コードはこんな感じ。#include <stdio.h> // printf#include <stdlib.h> // exit,strtol//#include <sys/time.h> // gettimeofday#include <time.h> // clock#include <pthread.h> // pthread#include <termios.h> // termios#include <unistd.h> // read & write#include <sys/types.h> // open#include <sys/stat.h> // open#include <sys/ioctl.h> // ioctl#include <fcntl.h> // open#include <string.h> // memcpy#define hz 200 // 5msec#define N_servo 23pthread_mutex_t mutex_servo;pthread_cond_t cond_servo;int POS[N_servo];int TCH[N_servo];int timer_servo;int stop_request;/**********************//* サーボスレッド *//**********************/void *servo_thread(void *arg){ struct timespec tsb,tsrq; int sPOS[N_servo]; int sTCH[N_servo]; int i; /* タイマ初期化 */ clock_gettime(CLOCK_REALTIME,&tsb); tsb.tv_sec++; tsb.tv_sec++; tsb.tv_nsec = 0; clock_nanosleep(CLOCK_REALTIME,TIMER_ABSTIME,&tsb,NULL); timer_servo = 0;pthread_mutex_lock(&mutex_servo); /* 繰り返し処理 */while(!stop_request){ /* POS読み込み */ memcpy(sPOS,POS,sizeof(int)*N_servo); pthread_mutex_unlock(&mutex_servo); /* 処 理 */ for(i = 0; i < N_servo; i++) { sTCH[i] = 0; } /* 時刻指定スリープ */ tsrq.tv_sec = tsb.tv_sec + (timer_servo + 1) / hz; tsrq.tv_nsec = ((timer_servo + 1) % hz) * (1000000000 / hz); if(clock_nanosleep(CLOCK_REALTIME,TIMER_ABSTIME,&tsrq,NULL) != 0) { printf("Error: on clock_nanosleep.\n"); exit(1); }pthread_mutex_lock(&mutex_servo); /* タイマ処理 */ timer_servo++; /* TCH書き込み */ memcpy(TCH,sTCH,sizeof(int)*N_servo); /* メインスレッドに通知 */ pthread_cond_signal(&cond_servo);}pthread_mutex_unlock(&mutex_servo); return NULL;}/**********************//* メインスレッド *//**********************/int main(int argc, char **argv){ pthread_t thread_servo; int mPOS[N_servo]; int mTCH[N_servo]; int timer_main; int old_sec; int i; char c; struct termios term_attr,term_backup; struct timespec tsm; /* 標準入力設定(入力待ちなし) */ tcgetattr(0,&term_attr); term_backup = term_attr; term_attr.c_lflag &= ~(ICANON|ECHO); term_attr.c_cc[VMIN] = 0; term_attr.c_cc[VTIME] = 0; tcsetattr(0,TCSANOW,&term_attr); fcntl(0,F_SETFL,O_NONBLOCK); /* 初期化 */ stop_request = 0; old_sec = 0; /* POS初期化 */ for(i = 0; i < N_servo; i++) { POS[i] = 0; } /* サーボスレッド作成 */ pthread_mutex_init(&mutex_servo,NULL); pthread_cond_init(&cond_servo,NULL); if(pthread_create(&thread_servo,NULL,servo_thread,NULL) != 0) { printf("Error: Failed to create servo thread.\n"); exit(1); }pthread_mutex_lock(&mutex_servo); /* 繰り返し処理 */while(1){ /* サーボスレッドの通知待ち */ if(pthread_cond_wait(&cond_servo,&mutex_servo) != 0) { printf("Error: on pthread_cond_wait.\n"); exit(1); } /* タイマ処理 */ timer_main = timer_servo; /* TCH読み込み */ memcpy(mTCH,TCH,sizeof(int)*N_servo); pthread_mutex_unlock(&mutex_servo); /* 入力処理 */ if ( read(0, &c, 1) == 1 ) { if ( c == 's' ) break; } /* 処 理 */ clock_gettime(CLOCK_REALTIME,&tsm); printf("%d %ld\n",timer_main,tsm.tv_nsec); if ( timer_main / hz > old_sec ) { old_sec++; printf("%d sec\n",old_sec); } for(i = 0; i < N_servo; i++) { mPOS[i] = 0; }pthread_mutex_lock(&mutex_servo); /* POS書き込み */ memcpy(POS,mPOS,sizeof(int)*N_servo);} /* ストップ処理 */ stop_request = 1; if(pthread_join(thread_servo,NULL) != 0) { printf("Error: Failed to wait for servo thread termination.\n"); exit(1); } pthread_mutex_destroy(&mutex_servo); pthread_cond_destroy(&cond_servo); /* 標準入力復帰 */ tcsetattr(0,TCSANOW,&term_backup); return 0;}
2019年02月09日
-
テキストファイルにログを残す準備
今回は、ここを参考にLinuxのアプリ内からテキストファイルにログを残すサンプルプログラムを作ってみた。ちなみに、バイナリに残すときは、ここが参考になりそうです。結果すんなりOK。アプリの実行ファイルと同様、PCのNFSにLAN経由で転送できるから、どんなに大量のログでも一瞬で取り出せる。サンプルプログラムは以下のとおり。#include <stdio.h>int main(int argc, char **argv){ FILE *file; file = fopen("test.txt","w"); if (file == NULL) { printf("Can't open file:%s\n","test.txt"); } fprintf(file,"Hello world\n"); fclose(file); return 0;}
2019年02月08日
-

4ヶ月振りのサーボ駆動音♪
10月にLinuxボードを焼損させてから、はや4ヶ月… やっと、再びLinuxボードで、シリアルサーボが動きましたー!! 今回の拡張ボード、試行錯誤でパターンがハゲたり見た目はかなり悪いですが、とりあえず動きます(^_^;) まず、ラッチアップ対策の基本として、電源を11Vに一本化しました。 Linuxボード用に5V1Aのスイッチングレギュレータを2個載せて、サーボ側のみ切れる外部スイッチも入れました。 それと、Linuxボードのシリアル端子に1kΩの保護抵抗をRXとTX側にも挿入、あと3.3Vのツェナーダイオードも入れた。 双方向ロジックレベルコンバータの直後にも保護抵抗入れたかったけど、コンバータに10kΩのプルアップ抵抗が入っているので、適当な抵抗が入らない。 分圧を考慮して100kΩなんて入れたらシリアル端子の内部キャパシタで波形が鈍化して、115200bpsでは通信できなかった。 なにはともあれ、これでソフトの方を進めていきます。
2019年01月31日
-
なかなか作業出来ず…
本日、娘の試合会場(白子:千葉の太平洋側)まで連れてきた後、 車の中で、すでに5時間待機… この一週間は、仕事と家事と、頭痛で作業出来ず。 やっと、出来た時間が車内待機中。 開発用PCで、シリアル通信部分のLinuxのカーネルの改変部分を再確認。 この間、neon絡みで、マクロの勉強したので、読み解き易かった。 結果、とりあえずOK。 とりあえずってのは、メーカーが用意したコードに?な箇所があって、 でも、とりあえず動くならいいか〜って (^_^;)
2019年01月14日
-
冬休み最終日!
娘は朝から友達と映画に出かけた。 仕方がないので、アートワークの最終チェックから 版下の印刷、露光、現像、エッチング、穴あけまで、 ここでお昼休憩。コンビニパスタ。 チップ抵抗や、レギュレータ、汎用ロジックをハンダで付けたところで、 なんと、0.8mm孔ではピンヘッダのピンが刺さらないことが発覚。 千枚通しで孔拡大。無理矢理押し込んだら人差し指から玉のような血が…(>_
2019年01月06日
-
冬休みが終わる〜!
冬休み7日目(4日) 大掃除&秋葉原に感光基板買出し 冬休み8日目(5日) レンジフードとガスコンロを磨く&娘のお迎え 思うように進まなかった… 拡張基板は、アートワークに手を入れて、 ピンヘッダの周りのGNDベタを外したり、 手配線を出来るだけ減らしてみた。 まだ印刷はしていない…
2019年01月05日
-
順運動学のneon化♪
冬休み5日目(2日) 拡張基板はあきらめて、順運動学のneon化をおこなう冬休み6日目(3日) 大掃除&娘をテニスキャンプへ送る順運動学のneon化は、完了です!!前回、四肢の先端からベタベタの展開で計算したときが、1回7μsだったけど、今回、汎用性を残しつつ、マクロを使ってneon化したら、1回7.7μs!!!1割ほど悪化したけど、汎用性が残るなら、まぁ、いいかな。これで行きます。コードはこんな感じ。前半の#defineが・・・#include <arm_neon.h>#include <math.h>#define PP_S_0(i,j) \ do { \ c0 = vld1q_f32( &uLINK[i].RpT[0] ); \ c1 = vld1q_f32( &uLINK[i].RpT[4] ); \ c2 = vld1q_f32( &uLINK[i].RpT[8] ); \ r3 = vld1q_f32( &uLINK[i].RpT[12] ); \ } \ while (0);#define PP_S_1(i,j) \ do { \ } \ while (0);#define PP_AX_0(i,j) \ do { \ vst1q_f32( &uLINK[j].RpT[0], c0 ); \ r1 = vmulq_n_f32( c1, cosv ); \ r2 = vmulq_n_f32( c2, sinv ); \ r1 = vaddq_f32( r1, r2 ); \ vst1q_f32( &uLINK[j].RpT[4], r1 ); \ r1 = vmulq_n_f32( c1, -sinv ); \ r2 = vmulq_n_f32( c2, cosv ); \ r1 = vaddq_f32( r1, r2 ); \ vst1q_f32( &uLINK[j].RpT[8], r1 ); \ } \ while (0);#define PP_AX_1(i,j) \ do { \ r0 = vmulq_n_f32( c0, cosv ); \ r2 = vmulq_n_f32( c2, -sinv ); \ r0 = vaddq_f32( r0, r2 ); \ vst1q_f32( &uLINK[j].RpT[0], r0 ); \ vst1q_f32( &uLINK[j].RpT[4], c1 ); \ r0 = vmulq_n_f32( c0, sinv ); \ r2 = vmulq_n_f32( c2, cosv ); \ r0= vaddq_f32( r0, r2 ); \ vst1q_f32( &uLINK[j].RpT[8], r0 ); \ } \ while (0);#define PP_AX_2(i,j) \ do { \ r0 = vmulq_n_f32( c0, cosv ); \ r1 = vmulq_n_f32( c1, sinv ); \ r0 = vaddq_f32( r0, r1 ); \ vst1q_f32( &uLINK[j].RpT[0], r0 ); \ r0 = vmulq_n_f32( c0, -sinv ); \ r1 = vmulq_n_f32( c1, cosv ); \ r0 = vaddq_f32( r0, r1 ); \ vst1q_f32( &uLINK[j].RpT[4], r0 ); \ vst1q_f32( &uLINK[j].RpT[8], c2 ); \ } \ while (0);#define PP_AX_3(i,j) \ do { \ cosv = 1.0 - cosv; \ cv0 = uLINK[j].a[0] * cosv; \ cv1 = uLINK[j].a[1] * cosv; \ cv2 = uLINK[j].a[2] * cosv; \ cv00 = uLINK[j].a[0] * cv0; \ cv11 = uLINK[j].a[1] * cv1; \ cv22 = uLINK[j].a[2] * cv2; \ cv01 = uLINK[j].a[0] * cv1; \ cv02 = uLINK[j].a[0] * cv2; \ cv12 = uLINK[j].a[1] * cv2; \ sv0 = uLINK[j].a[0] * sinv; \ sv1 = uLINK[j].a[1] * sinv; \ sv2 = uLINK[j].a[2] * sinv; \ r0 = vmulq_n_f32( c0, 1.0 - cv22 - cv11 ); \ r1 = vmulq_n_f32( c1, cv01 + sv2 ); \ r2 = vmulq_n_f32( c2, cv02 - sv1 ); \ r0 = vaddq_f32( r0, r1 ); \ r0 = vaddq_f32( r0, r2 ); \ vst1q_f32( &uLINK[j].RpT[0], r0 ); \ r0 = vmulq_n_f32( c0, cv01 - sv2 ); \ r1 = vmulq_n_f32( c1, 1.0 - cv22 - cv00 ); \ r2 = vmulq_n_f32( c2, cv12 + sv0 ); \ r0 = vaddq_f32( r0, r1 ); \ r0 = vaddq_f32( r0, r2 ); \ vst1q_f32( &uLINK[j].RpT[4], r0 ); \ r0 = vmulq_n_f32( c0, cv02 + sv1 ); \ r1 = vmulq_n_f32( c1, cv12 - sv0 ); \ r2 = vmulq_n_f32( c2, 1.0 - cv11 - cv00 ); \ r0 = vaddq_f32( r0, r1 ); \ r0 = vaddq_f32( r0, r2 ); \ vst1q_f32( &uLINK[j].RpT[8], r0 ); \ } \ while (0);#define PP_S(i,j,s) PP_S_ ## s (i,j)#define PP_AX(i,j,ax) PP_AX_ ## ax (i,j)#define PP_FK(i,j,ax,s) \ do { \ sinv = sinf(uLINK[j].q); \ cosv = cosf(uLINK[j].q); \ PP_S(i,j,s) \ PP_AX(i,j,ax) \ r0 = vmulq_n_f32( c0, uLINK[j].b[0] ); \ r1 = vmulq_n_f32( c1, uLINK[j].b[1] ); \ r2 = vmulq_n_f32( c2, uLINK[j].b[2] ); \ r0 = vaddq_f32( r0, r1 ); \ r2 = vaddq_f32( r2, r3 ); \ r3 = vaddq_f32( r0, r2 ); \ vst1q_f32( &uLINK[j].RpT[12], r3 ); \ c0 = vld1q_f32( &uLINK[j].RpT[0] ); \ c1 = vld1q_f32( &uLINK[j].RpT[4] ); \ c2 = vld1q_f32( &uLINK[j].RpT[8] ); \ r0 = vmulq_n_f32( c0, uLINK[j].c[0] ); \ r1 = vmulq_n_f32( c1, uLINK[j].c[1] ); \ r2 = vmulq_n_f32( c2, uLINK[j].c[2] ); \ r0 = vaddq_f32( r0, r1 ); \ r2 = vaddq_f32( r2, r3 ); \ r0 = vaddq_f32( r0, r2 ); \ vst1q_f32( &uLINK[j].C[0], r0 ); \ } \ while (0);メインからまず関数を呼び出して・・・ uLINK[1].RpT[0] = body.R[0]; // 転置 uLINK[1].RpT[1] = body.R[3]; uLINK[1].RpT[2] = body.R[6]; uLINK[1].RpT[3] = 0.0; uLINK[1].RpT[4] = body.R[1]; uLINK[1].RpT[5] = body.R[4]; uLINK[1].RpT[6] = body.R[7]; uLINK[1].RpT[7] = 0.0; uLINK[1].RpT[8] = body.R[2]; uLINK[1].RpT[9] = body.R[5]; uLINK[1].RpT[10] = body.R[8]; uLINK[1].RpT[11] = 0.0; uLINK[1].RpT[12] = body.p[0]; uLINK[1].RpT[13] = body.p[1]; uLINK[1].RpT[14] = body.p[2]; uLINK[1].RpT[15] = 0.0; FK2();マクロはこう使う・・・void FK2(){ float sinv,cosv; //float cv0,cv1,cv2,cv00,cv11,cv22,cv01,cv02,cv12,sv0,sv1,sv2; float32x4_t c0,c1,c2; float32x4_t r0,r1,r2,r3; c0 = vld1q_f32( &uLINK[1].RpT[0] ); c1 = vld1q_f32( &uLINK[1].RpT[4] ); c2 = vld1q_f32( &uLINK[1].RpT[8] ); r3 = vld1q_f32( &uLINK[1].RpT[12] ); r0 = vmulq_n_f32( c0, uLINK[1].c[0] ); r1 = vmulq_n_f32( c1, uLINK[1].c[1] ); r2 = vmulq_n_f32( c2, uLINK[1].c[2] ); r0 = vaddq_f32( r0, r1 ); r2 = vaddq_f32( r2, r3 ); r0 = vaddq_f32( r0, r2 ); vst1q_f32( &uLINK[1].C[0], r0 ); PP_FK( 1, 2,2,1) // ( i, j, ax, s ) PP_FK( 2, 3,0,1) PP_FK( 3, 4,1,1) PP_FK( 4, 5,1,1) PP_FK( 5, 6,1,1) PP_FK( 6, 7,0,1) PP_FK( 1, 8,2,0) PP_FK( 8, 9,0,1) PP_FK( 9,10,1,1) PP_FK(10,11,1,1) PP_FK(11,12,1,1) PP_FK(12,13,0,1) PP_FK( 1,14,1,0) PP_FK(14,15,0,1) PP_FK(15,16,2,1) PP_FK(16,17,1,1) PP_FK(17,18,1,1) PP_FK( 1,19,1,0) PP_FK(19,20,0,1) PP_FK(20,21,2,1) PP_FK(21,22,1,1) PP_FK(22,23,1,1) PP_FK( 1,24,2,0)}
2019年01月03日
-
ショボン(´・ω・`)
冬休み4日目(1日)昨日、回路図チェックとグラウンドベタも終わって、1回目のエッチング・・・。露光ミスで線が溶ける。(>_<)夜が明けて、2回目のエッチング・・・成功♪多数の穴あけ後、面実装部品のハンダ付け、それからピンヘッダーを付けようとして・・・。2列25ピンがささらない。(>_<)うわぁ・・・。超久しぶりにインクジェットプリンタ使ったから、設定が「フチなし」になってる。これで版下が5%程拡大されてた。ショボン・・・。感光基板、2枚しか買ってなった・・・。ここまでか・・・。
2019年01月01日
-
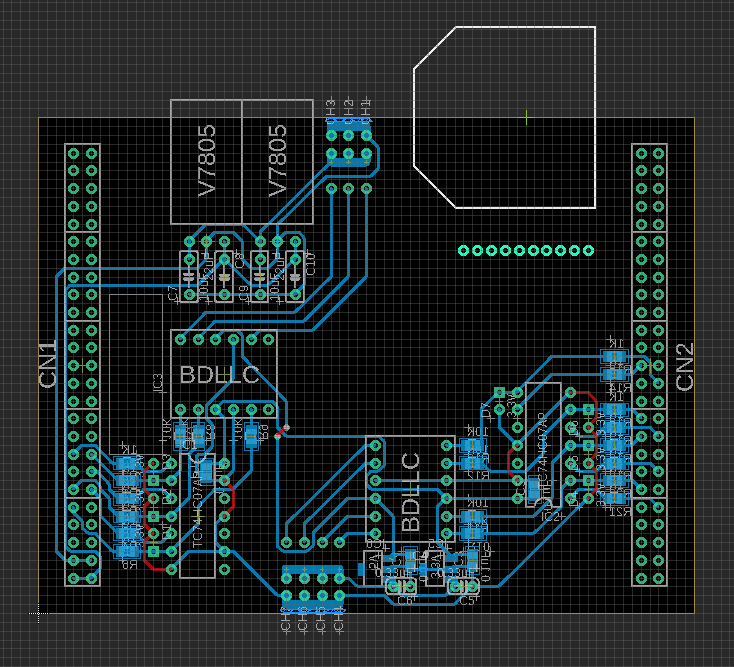
とりあえず、拡張基板が形になってきた
冬休み1日目(29日) 秋葉原に不足部品・消耗品の買い出し冬休み2日目(30日) ひたすらEAGLE。ちょっと使い方忘れてた・・・冬休み3日目(31日) これから回路図とアートワークのチェック!チェックが終わったらGNDベタして、感光基板か~。今回は片面にしました(一部手配線)。
2018年12月31日
-
明日から冬休み!(9日間♪)
せっかくの冬休み、まとまった作業がしたくて、 先日からEAGLE(基板設計ソフト)触っています。 いつのまにかautodeskからの提供になってた… 両面感光基板の自作しかしないから、FREEが健在で助かりました。 さて、Linuxボードを焼損させてしまった原因ですが、 どうも、ラッチアップっぽい(>人<;) サーボ動作テストの際、何も考えずに、 Linuxボード用の5V電源とサーボ用の11V電源の 2電源で(そもそもコレが間違い)作業し、 Linuxボードのリセットが効かなくなった時に ボード側の電源のみ抜き差ししてた気がする… サーボ動作中に、サーボのコネクタ抜き差ししてた気がする… (活線抜き差し) まずは1電源化、そして最悪を想定して、 入力保護抵抗と、ツェナーダイオードも仕込む。 手配線ミスと作業効率を考えて感光基板とする。 可能ならコネクタピンは、GNDを長くしたいな。
2018年12月28日
-
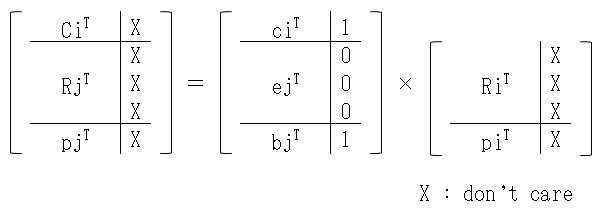
プリプロセッサ!!
前回、比較的簡単にneon(ベクトル計算機能)が使えることがわかってから、ずっと、コンパイラのプリプロセッサについて調べていました。というのも、neonで順運動学の計算をおこなう方法として、以前、SH4の行列計算機能を使うために考えた行列計算式がそのまま使えるんですね。これです。で、neonでは、右側のRとかpは、ベクトルとして扱うのですが(4列目がもったいないけど・・・)、それに乗算する、c、e、bは、スカラとして一つ一つベクトルと掛け算します。ロドリゲスの計算結果eは、ロボットの関節が直行座標軸を向いていると要素の内4つが0となって、そもそも計算不要なんですね。以前は、この辺りは、プログラム中で分岐させたり、または、計算速度を優先して最初からベタに展開してたりしていたのですが、そろそろ、もう少しスマートに、書きたいな~って。つまり、プリプロセス段階で、ロボットの構造は決まっているのですから、コンパイル時点では、構造に合わせた最適化がされつつ、ソースコードでは機体汎用性が高いと・・・。ただ・・・、なかなかマクロ(プリプロセス)についての情報って探しづらい。津田沼丸善でいろいろ本を探したのですが、どうも、こうピンポイントなものがなくて・・・。なぜか、私がやりたいことって、マニアックでイレギュラーなことが多いみたい。(--;そしたら、ここに、超マニアック!!なマクロの使い方の解説があったので、頑張って読み解いて、これを参考に書いてみたものを以下に示します。#include <stdio.h>#define PP_AX_0(i,j) \ do { \ printf("AX_0"); \ printf(" %d",(i)); } \ while (0);#define PP_AX_1(i,j) \ do { \ printf("AX_1"); \ printf(" %d",(j)); } \ while (0);#define PP_AX_2(i,j) \ do { \ printf("AX_2"); \ printf(" %d",(i)+(j)); } \ while (0);#define PP_AX_3(i,j) \ do { \ printf("AX_3"); \ printf(" %d",(i)-(j)); } \ while (0);#define PP_AX(c,i,j) PP_AX_ ## c (i,j)#define PP_FK(c,i,j) \ do { \ printf("FK_"); \ PP_AX(c,i,j) \ printf("\n"); } \ while (0);int main(int argc, char **argv){ PP_FK(0,3+1,2+1) PP_FK(1,3+1,2+1) PP_FK(2,3+1,2+1) PP_FK(3,3+1,2+1) return 0;}これを、make -Eオプションでプリプロセスで止めると、こんな感じ・・・。(^-^)vint main(int argc, char **argv){ do { printf("FK_"); do { printf("AX_0"); printf(" %d",(3+1)); } while (0); printf("\n"); } while (0); do { printf("FK_"); do { printf("AX_1"); printf(" %d",(2+1)); } while (0); printf("\n"); } while (0); do { printf("FK_"); do { printf("AX_2"); printf(" %d",(3+1)+(2+1)); } while (0); printf("\n"); } while (0); do { printf("FK_"); do { printf("AX_3"); printf(" %d",(3+1)-(2+1)); } while (0); printf("\n"); } while (0); return 0;}
2018年12月23日
全1110件 (1110件中 1-50件目)


