

[ソフト開発日誌] カテゴリの記事
全882件 (882件中 1-50件目)
-

Futaba M202MD10B アプリ と コマンドシート - 古めかしく C 言語で実装
今時になって、共立エレショップで特価品蔵出し販売されていたFutaba M202MD10B を操作するコマンドラインアプリ(リンク先は github)を作る。M202MD10B は既に販売終了している。M202MD10B はシリアルポートで制御出来る。shell script で redirect を使えばある程度制御可能だ。自分が作った接続回路だと Break 信号を送ることと、細やかな待ちが必要になってしまった。C 言語でポートアクセス処理を実装した。Linux と Windows Cygwin で動く様にしてある。Bash on Ubuntu on Windows で動かすと動作が不完全だ。break 信号が出せない。ioctl による端末設定に失敗する。使い方は test ディレクトリ以下にデモアプリとして用意した。2400bps に設定されていることを前提にしている。平凡な実装と機能だ。シリアルポートを開いて設定する。Break 信号を送る(これは Reset として使う)。command line に送る文字列を与える、stdin から読んで port に送り込む、オプションで Control Code を指定する。M202MD10B の Control Code を忘れないように githubに置いておく。1 枚のシートに回路図と Control Code 一覧をまとめた。回路に使っている TC4001BP は大量にある手持ち部品だ。強い指定は無い。C-MOS 5V level を扱えればどのシリーズを使っても良い。PNG 画像の回路図ダンボール箱加工ももう少し上手くなれば...
2023.09.05
コメント(0)
-

Intel Core i5-10600K 偽物説 - 近所の HARD OFF で買ったら動かない
近所の HARD OFF で Intel Core i5-10600K が 2 個出ていた どちらとも 22,000 円だった。妥当な値段だったので、うち 1 個を買う。動かない。10 日間の中古保証が付いていたので翌日返品する。買う時に「動作確認していますか?」と聞いたら、「中古保証で返品できますよ」と。こういうことか...2 個のうち 1 個を選んだのは「どちらとも同じ」だったから。買ったときの画像とネットで出回っている画像を見ると一致するものが無い。手元に残してある画像をあらためて見て行く。キャプション無しの元画像バッチ番号と V024D683 と シリアル番号 02744 からIntel 「保証に関する情報」を調べてみる。結果トレイ版だと分った。この時点で怪しむべきだった。ブリスターパックに入っていたのだ。店先で気がかりだったのが、2 個のブリスターパックが一致していなかった。ネットにある i5-10600K の画像から、ヒートスプレッダー面の怪しいところを挙げる。切り欠き部分にパターンが被っている。本物はパターンと切り欠き部分にクリアランスが 0.5mm くらいある。クリアランスがあるのが妥当な設計だろう。K の字形が違う。右上・右下に延びる線のセリフ部分が、アセンダーライン、ベースラインに並行して切れていない。刻印は見分けが付きにくい。かなり精巧に似せたのだろう。端子面を見てみる。キャプション無しの元画像こちらは分かりやすい。抵抗器が黒く水色の(恐らく)金属皮膜精密抵抗器が使われていない。コンデンサが斜めになってはんだ付けされている。正規品であれば外観検査で不合格になると思われる。コンデンサの斜め具合は偽物の出来上がり次第では皆無な場合も有るだろう。パットからのズレも多い感がある。綺麗に並ぶはずのコンデンサが、上下左右にズレてガタガタに並んでいる。ここからは、よく行く近所の HARD OFF の状況と推測を書く。少し奇妙な傾向がある。バイヤーが寄っている? AliExpress のような中国系通販サイトで買わないと手に入らないような PC 周辺機器がたまに出ている。国内外メーカーのブランドが箱に全く書かれていない物だ。薄茶色の紙そのままの箱であったり、内容物の構成にチェックマークを入れる印刷があり、チェックが無いか、内容と一致しない。試し買いしてみて、ダメだった感がある。PC ショップか組み立て業者が出入りしている? ショップブランド PC 余剰品なのか「リテール CPU クーラーだけ」、「付属マウスだけ」が大量に置いてある。「未開封 HDD が大量に出ている」「3 世代前ほどの DIMM memory がトレイカートンごと」売られている。外国人の出入りが多い。東南アジア系の言語を喋る外国人が、5 ~ 6 人の集団で物色しているのを見掛ける。買い付けているのを見た。売却もしているのだろうか?小さな HARD OFF の割には出入りの人たちが一般人とは思えない。Core i5-10600K も奇妙な売り出し状況だった。突然 2 個ショーケースに並ぶ。同一値段 22,000 円で、シリアル番号違いだった。ブリスターパックは前述の通り違っていた。薄青みが掛かっているのと、透明なもの 2 種だった。バックヤードに PC パーツチェックコーナーは無し。恐らく緩い鑑定で売買していると思われる。店員に「動作確認していますか?」と聞いたときに「はい」ではなかった。2 個とも店の人に頼んで見せて貰っている。頭に残る記憶を辿ると、2 個ともヒートスプレッダ面、端子面はこの blog に上げた画像の通りだった。同一人物が売ったのか、別々の人物が売ったのかは不明だ。もし、同一人物であれば、偽物と気づかれないように、鑑定が緩い店を狙い、2 個同時に売って比較結果が一致するので、怪しまれないようにした可能性がある。同一品・類似ランク品の売り出しが無い状態も条件としている可能性がある。推測の通りなら、なかなか知能的な企みだ。一つ抜けているとすれば、ブリスターパックが一致しなかったこと。ハッキリと偽物と鑑定できない店なので、即刻売った人の会員情報に要注意取引履歴は付かないだろう。自分は「返品履歴」が付くかもしれない。i5-10600K はそんなに入手性は良くなかったはず。それなのに 2 個も同時に中古出品。検索してみると偽物情報が多い。i7, i9 じゃないのでつい警戒が緩んてしまった。
2023.09.04
コメント(0)
-

ASRock J5040-ITX を RAM 32Gibyte で動かす - 一番初めの起動時は 1 ~ 2 分くらい待つ
KBN-I-5200 が動かなくなってしまったため、代わりの ITX フォームファクタマザーボードを探す。ファンレスの方が都合が良いので ASRock J5040-ITX を選ぶ。基板を見ると eMMC が乗りそうなランドがヒートシンクの脇に見える。M.2 スロットが WiFi になっているのは、ここに eMMC を乗せるから、SSD は被る機能だと考えたのかもしれない。Pentium Silver J5040の仕様を読むと RAM は最大 8GiByte だ。J5040-ITX 対応メモリに 16Gibyte の SO-DIMM が入っている。しかも 2 枚差し対応だ。どういうこと?何か変だなと思いつつ。Crucial CT2K16G48FD8266 を買ってしまった。16Gibyte x 2 で、基板両面にチップが乗る。バスの負荷は最大で重い構成だ。2 枚組にパッケージされていたメモリは CT16G4SFD8266.C16FN だった。メモリのサポートリストに載っていないな...組み立てて動かしてみると、直ぐに画面が出ない。ああ、組み合わせ悪かったかな?と思い何度か電源を入れ直す。うーん。ボダン電池付け直し、C-MOS クリアジャンパ掛けを試した後、何回目かの電源投入をして「どうしよう」と放置していたら、BIOS (とは最近言わないのか UEFI だっけ)の初期化進行メッセージが出始めた。1 ~ 2 分くらい待たないと、DRAM 信号キャリブレーション(あるいはトレーニング)が終わらないのか。まぁ、そうだろうな。Intel の仕様を越える様なことをしているのだから、Firmware で色々と処理を補っているのかも。1 回起動に成功すると、その後は 5 秒くらいで起動する。パラメータを覚えているようだ。MemTest86 (+ は付かない方) でメモリテストを実施する。PASS した。alias している心配も無い。UEFI 対応の MemTest86 の方が起動は簡単だ。Memtest86+ だと UEFI 対応していないのか、そもそも起動候補にも出てこない。PXE boot も UEFI 対応が必要みたいだ。MemTest86 実行中はヒートシンクに弱くても良いので、風を当てた方が良い。無風で 22 ℃ほどの室内で MemTest86 を実行していたら 94 ℃まで CPU 温度が上昇した。Junction 温度 105 ℃なので、余裕は 10 ℃くらいだ。温度の読みはそれ程正確ではない。ほどよい風量の USB 扇風機で風を当てて、Memtest86 実行中は 60 ~ 62 ℃に CPU 温度を押さえた。TDP 10W って本当かなぁ。
2021.04.04
コメント(0)
-

Super Speed USB to Gigabit Ethernet Adapter - LUA4-U3-AGTE-WH:AX88179, UE300:r8152
在宅勤務で家庭内 LAN 環境を変更する必要が出てきた。具体的には LAN - Router - WAN だった単純なネットワーク環境に、WAN には繋がらない閉じた LAN 環境を追加した。いくつかのマシンに LAN Adapter を追加して、閉じた LAN 側に接続する。USB - Ethernet Adapter を買う。せっかくなので Super Speed USB to Gigabit Ethernet Adaper を選ぶ。あー、Linux (Ubuntu 18.04 x64) で繋がるのかなぁ... 心配なので 2 品種買うことにした。どちらも繋がることが分かった。Linux 認識の列にあるリンクは dmesg, ethtool で認識結果を確認したコンソールログだ。メーカー型名Linux 認識BUFFALOLUA4-U3-AGTE-WHax88179_178aTP-LinkUE300r8152LED の点き方は LUA4-U3-AGTE-WH は状態確認重視だ。UE300 はデザイン重視、どこがどう光るかは点いてみないと分からない。パケットが通ると点滅する。もともと自分でも WAN 側から LAN 側への入り方、忘れるくらい面倒な家庭内 LAN なんだよなぁ...
2020.10.12
コメント(0)
-
筆算方式で uint32_t の平方根を求める処理 - MO メディアから発掘したコード
MO メディアをサルベージしていたら、懐かしいコードが見つかる。筆算方式で uint32_t (32 bit で表した正の整数) の平方根を求めるコードだ。8086 Assembler のコードで記述してある。アルゴリズムの概要をコメントに書いてあるので他の言語やアセンブラでも容易に書き直せると思う。idealmodel small,ccodeseg;in A;; X=0; w=0; Count=16; @@l1:; w<<=1; X<<2bit<<A; save X; X-=(w+1); if cond CY; {recover X; }; else; {w|=2;; }; LOOP @@l1;; w>>1 -> ans;in dx:ax;proc NOLANGUAGE sqrrootxor si,si ;bl:si Xxor di,di ;bh:di wmov cx,10hmov bh,0c0hjmp @@l0ineven@@l0:dec cxjz @@exitshl ax,1rcl dx,1shl ax,1rcl dx,1@@l0in:test dh,bhjz @@l0xor bx,bxeven@@l1:shl di,1rcl bh,1shl ax,1rcl dx,1rcl si,1rcl bl,1shl ax,1rcl dx,1rcl si,1rcl bl,1push sipush bxstcsbb si,disbb bl,bhjnb @@j1pop bxpop siloop @@l1shr bh,1rcr di,1mov ax,diret@@j1:add sp,4inc diinc diloop @@l1shr bh,1rcr di,1mov ax,di@@exit:retendpevenpublic ulsqrrootproc ulsqrrootarg @@a:dworduses si,dimov dx,[word high @@a]mov ax,[word low @@a]call sqrrootretendpevenendコメントのアルゴリズムに対し、実装は上位桁に 0 が続く場合、計算を少し速くする工夫がある。それ以上の変わった処理やアセンブラ独特の高速化は導入していない素朴な処理だ。今時は浮動小数点計算がお手軽に使えるし、8 ~ 16 bit の組み込みマイクロプロセッサもメーカーが実装例を示しているので、開平処理を態々書くことも無いか。これをテストするコードは C 言語で書いてあった。分かりやすく書き直してテストしてみる。ビルドできて、実行すると期待通りの動作をした。Borland C++ 3.1 (TASM, BCC, MAKE, TLINK) でビルドできるソースコード一式を作る。ビット化け、重複、欠落を起こさずに MO から読み出せていた。今でも懐かしく思えで、動かそうかなと思うコードってそんなに多くないのかな。
2020.08.20
コメント(0)
-

Google 先生これは何ですか? - 調理温度計(クッキング温度計)は何に似ている
暫く日記をサボっているのでネタ発掘。いつ買ったのか調べたくて、食品温度計(あるいは調理用温度計、クッキング温度計)を検索してみる。始めに次の画像で検索してみた。タイルの壁をバックに何がトイレットペーパーホルダーや手すり、ちょっとした壁掛け小物入れが写った画像が類似画像として見つかった。もしかしたら、google 画像検索エンジンが賢くなって、結果が変わっているかもしれない。なるほど、背景に写る工作用紙の方眼がタイルに見えたのか。背景・食品温度計のどちらも画像の文脈だと捉えて、背景はタイル、食品温度計はタイルに接近して存在する器物に近い何かだと判断して検索したのか。両方の文脈を満たす画像の組み合わせがトイレットペーパーホルダーの画像だったのか。面積的に広い背景の方眼用紙が邪魔なのかな。殆どの人間は、背景の方眼用紙は画像の主要部分では無いと判断するはずだ。わかった。無地で撮ってみよう。次の画像で検索してみる。なにやら水道配管やシャワーヘッドのような画像が良く一致する。こんどは白壁背景を選んできた様だ。水道配管にシャワーヘッドねえ... 似た形なのかな。google 先生画像の各部分を文脈(もうちょっと言うとベクトルや相互の配置接続関係を要素として纏めた情報)に分解することまではできている様だ。複数の文脈をそれぞれをある程度満たす画像を見つけてくるのかな。分解した文脈のうち、一つだけ非常に良く一致する画像を見つけるような仕掛けではなさそうだ。余白あるいは背景の大きさも検索結果に影響するようだ。次の画像で検索するとやはり水道配管の画像が多く見つかる。画像の殆どは部品の状態になっている。もう少し余白を広くすると鍵が見つかる。google 先生に色々なことを聞くとたまに「captcha 認証をして」と言われる。あれはどうやって作っているのだろう?
2020.08.19
コメント(0)
-
サルベージした MO の文字化け - 単純なビット誤りではなさそう
MO ドライブを HARD OFF で見つけて、手持ちの MO メディアをサルベージしてみた。ディレクトリが不思議な文字化けをする。次は化け方の例だ。DOS で扱いが難しいのでファイル名に入った空白は '_' で置き換え、コントロール・コード、使えない文字は置き換えている。size mon day year file-name 7714 3 14 1993 G3FIL.ASM 7735 3 14 1993 G3FIL.BAK 7263 3 14 1993 G3FIL.JNK 1247 3 14 1993 G3FIL.OBJ 8688 3 15 1993 G3FIL2.ASM 8688 3 15 1993 G3FIL2.BAK 4749 3 15 1993 G3FIL2.OBJ 1701 2 19 1993 GTII___O.OBJ duplicated extension 4323 3 15 1993 GTII2__O.OBJ Under line = space 131 11 14 1992 GTII2__T.TFA 0 3 14 1993 GTR22.AAK bit error? B turns into A 0 4 8 1993 GTR22.RRJ 5140 11 10 1992 GTRFFIL.AAK 2804 11 15 1992 GTRI.BAK 2817 2 19 1993 GTRI.C 223 1 27 1993 GTRI.EEE bit error? 4918 1 27 1993 GTRI.EXE 28 8 26 1992 GTRI__.EEE 3682 4 7 1993 GTRI3.BAK 3899 4 7 1993 GTRI3.C 194 3 15 1993 NONAME.OBJ 3084 12 13 1995 ROO.NNK missing T, J turns into N? 919 12 12 2010 ROOT.ASM 27 11 26 1992 ROOT0.PZJ R turns into Z 9954 11 18 1992 ROOTT.EXE 519 11 18 1992 ROOTT.OBJ 1932 12 13 1995 ROOTT.TXT 332 11 18 1992 'ROOTT__(dq).C' (dq) = '"' 8 6 10 1992 TAMM___C.CFG 2013 2 11 1993 TRIGON.BAK 2017 2 11 1993 TRIGON.DOC 13204 2 11 1993 TRIGON.LZH 36 1 1 1970 TTRI.PR 1427 3 15 2101 TTRI2.PF 5272 3 12 1981 TTRIFLL.AS 702 11 29 1992 WAYING.BAK 702 11 29 1992 WAYING.C 21112 2 19 1993 WAYING.EXE 1452 2 19 1993 WAYING.OBJ 28 11 29 1992 WAYING.PRJ 4623 12 13 1995 ZOOTT.BAK化け方かディレクトリ構造を壊した場合は除いてある。. .. が化けてディレクトリの親子関係が壊れたファイルサイズ部分が壊れて異様に大きくなったファイル(主に 10Mibyte 以上)は除いてあるディレクトリエントリーのクラスタ番号部分が壊れて子ディレクトリにたどり着けなくなった気づいた化け方の傾向は次の様になった。1 ~ 3 bit 程化けているファイル名の文字が重複する訂正しきれず、数ビットの 0/1 が反転するのは理解できる。重複(厳密に言えば隣接するバイトで上書きされてしまう)が起きるのはなぜなんだろう。誤り訂正符号の理論をよく勉強すればもう少し背景が分かってくるのかも。それとも Linux の FAT file system driver が壊れたディレクトリに弱く、意図しない memcpy, memmove などをしてしまうのだろうか?ディレクトリ化けで永久にソースは失われた? 化ける前のファイル名を推測して、現役のハードディスクを探してみる。別の系譜で子孫が生き残っていた。
2020.08.13
コメント(0)
-

ハードオフでジャンク 640MByte MO drive を買う - 家の中では一番良く動くドライブかな
ハードオフでジャンク 640MByte MO drive OLYMPUS MO643U5 を買う、110 円でジャンク box に入っていた。そう言えば、手持ちの MO メディアは読めるのだろうか?一応、SCSI 接続のドライブは持っている。「予備になるかもしれない」機材が 110 円なら良いかな。足が取れているなぁ。後で代わりの足を貼り付けるか。ん?もしかして一度開けた?足が貼ってあった部分がシールになっている。綺麗に貼り戻したのかな?あっ、そうだ。MO メディアを見たことが無い人がいるかもなぁ。手持ちの 640Mbyte メディアを出しておこう。虹色に輝いている円盤を格納した四角いケースが MO メディアだ。この大きさで 640Mbyte を格納する。比較のため右上に 32Gbyte の Micro SD card を置いておいた。簡単に諸元を比較してみる。いずれも実測値、Micro SD の容量はメーカー品種によって違う。大きさは見ての通り、重さは比較していない。項目640M MO32G Micro SDSD / MO容量(bytes)635,600,89631,914,983,424約 50.21sequential read転送速度(Mbytes/sec)2.0192.1約 45.8テクノロジーの進化は驚異的だな。640Mbyte MO メディア 1 枚で 2,000 ~ 3,000 円くらいだったか。ドライブが 20,000 ~ 40,000 円くらいした。MO が普及していた頃に USB は無く、さらに SCSI Interface, cable, terminator も必要だった。SCSI 部分で 10,000 ~ 20,000 円くらいかな。今時 Micro SD card reader はメーカー製パソコンなら普通に付いているし、スマホに標準装備されている。無くても 100 円ショップで探せば 100 円で売っている。外観的な不具合は EJECT ボタンが引っ込んでいること、カラカラ音がすること(ネジが取れていた)、汚れがついていること。あー、AC アダプタで給電が必要か。調べてみると EIAJ 極性統一プラグ(RC5320A) 区分 2 で 5V 1.6A だ。適当な変換ケーブルを付けて供給しよう。ネジは 2 個の後ろ足の下にあるシールを剥がすと出てくる(自分が手にしたドライブは 1 個足が無い)。シール下からカラカラと音がしていた。ネジが外れた状態になったのは何でだろう。ポストが割れていた。これでネジが締まらなかったのか。反対側はポストの形が残っていた。良く見るとヒビが入っていて、手で軽く強度を確かめたら、崩れてしまった。丁寧にポスト再建?いずれパテとか使うのも慣れないとなぁ。ダサく養生テープで「仮止め」という恒久処置をして使うか。そのうちベタつくかカラカラに乾いて剥がれるかもしれない。ドライブに皮脂が付いているなぁ。やっぱり開けたのか。ハードオフ・ジャンクなのだ。普通にあること。ドライブは OLYMPUS MOS3393E で 2002 年 8 月製だと読める。製造から 17 年 11 ヶ月経過している。皮脂をパーツクリーナーで拭き取る。レーザー・ダイオードが劣化していることも考えられる。今後、書き込みで使う事は無いからレーザー強度は弱くなっていても平気かな。透明スモークパーツのポストの一部が割れて動く様になっていた。ボタンの支えも折れていた。スモーク・パーツとボタンの支えは接着剤で補強することにした。瞬間接着剤を使って見たけれど、ダメなんだよなぁ。盛れる接着剤の方が上手くいく。内部を補修して、養生テープでケースを留める。緑のアクセントがダサダサ・デザインだな。ダイソーで買った汎用の足も取り付けた。結局付けた足も余り役に立たない状況だったのが後で判る。手持ちにあった EIAJ 極性統一 DC プラグ区分 2 で電源供給ケーブルを作る。EIAJ 極性統一 DC プラグって RC5320A と言う規格名が付いているのか...電源 ON、Windows10 PC に接続する。アクセスランプが点いてディレクトリを読み込んだ。おお、Windows10 はまだ MO に対応しているのか。あれ?なんか変だな。MO メディアによって読める・読めないがある。読んだ内容も部分的に壊れている。なんか変な壊れ方だなぁ。MO メディアによってはドライブの挿入側を下にして読めるようになった。ハードオフ・ジャンク、この程度は中難度だ。データの壊れ方が... ECC による訂正限界を超えたのか。手持ちのドライブも動かしてみる。さらに問題が悪化した。機会が有れば別の日記に書くか。ディスク表面はホコリで汚れているし、拭き取ると砂埃でキズが付いてしまった。俗な環境と使い方だと 25 年持たないのか。
2020.07.26
コメント(0)
-
SMR HDD WD60EZAZ 買った直後に近い状態に戻す - trim(blkdiscard) を使う
SMR HDD WD60EZAZ を買った直後に近い状態にするには、trim (Linux の command line で blkdiscard) を使う。あるいは mount option に discard を付ける。具体的には blkdiscard command を次の様にして使うと、HDD の全領域が trim される。# blkdiscard -v -p 16MiB /dev/sdXblkdiscard は ubuntu 16.04 以降で使える。util-linux package に入っているので、標準的なインストール構成なら使える状態になっているはず。-v は進捗表示をする指定、-p オプションで指定している値は trim (SCSI なら unmap) command 1 回につき、何 byte 分を実施するかと言う値だ。16MiB は 16Mibyte 刻みで trim を発行する指定になる。理想は SMR HDD の allocation unit の整数倍にするのが良いと考えられる。外部からは分からないので、1Mibyte ~ 32Mibyte 程度の間で良いと思う。小さくしても、許容できる実行時間で済むと思われる。blkdiscard 実行例: 対象 /dev/sdc WD60EZAZ, -p 16MiB, 実行時間約 214 秒(経過出力 1 行で 1 秒)/dev/sdX は trim しようとする HDD のノードだ。よく調べて指定して欲しい。WD60EZAZ の場合、trim すると block から読み出したデータは 0x00 の連続となる。実質的に消去になる。firm ware に直接 command を送って(送る手段があったとして) trim を取り消すなどの操作をしないと、データは復活しない。普段使いならば、mount option に次の様に discard を指定するのが良いだろう。/etc/fstab にも同様に記述できる。# mount -o discard /dev/sdXI /mount/pointlinux kernel 5.4.47 で file system が discard に対応しているか簡単に検索してみると btrfs, ext4, f2fs, fat(exfat), gfs2, jfs, nilfs2, xfs が対応している。主要な file system は入っている。種類が少ないので惜しいと思う人もいるかも。SMR HDD WD60EZAZ の trim command (discard あるいは unmap) の挙動は興味深い。色々と試した結果を書いていく。HDD の状態は前の日記でテストをした後の状態だ。ramdom read/write - sequential read x 1 - sequential {write and read} x 2 をした後だ。各操作の途中ディスク容量に対して 2 ~ 3% 程度のお試し read/write をしている。この状態で trim (blkdiscard) を全領域に対して、分割無しに実行してみた。blkdiscard command に device の node を指定するだけだ。# blkdiscard -v /dev/sdc/dev/sdc: Discarded 6001175126016 bytes from the offset 05 秒も経たないうちに blkdicard は終了する。ちゃんと trim しているの?多分 HDD の firm ware が back ground で処理しているのだろう。ほぼ 3 時間待って、sequential read の転送速度を測ってみた。グラフの縦軸は転送速度、横軸は進捗 0%: LBA=0, 100%: LBA=Last LBA だ。あれ?外周部分、分割構造境界だけ trim されている。trim された場所は平均で 400Mbytes/sec 出ている。3 時間放置ている。frim ware が動作時間の 100% を使って trim 処理を実行していたら、平均転送速度 150Mbytes/sec として、 150Mbytes/sec x (3600 x 3sec) = 1,620,000 Mbytes の範囲、割合に換算して 27% は trim された状態になっていると期待していた。綺麗に 0x00 で wipe するまでもなく、allocation unit に trim された範囲を追記するなら、もっと早いはず。当面の書き込み需要に応じるなら、trim する範囲は 10% 未満で十分というのも分かる。何だかなぁ。転送速度プロットの様にモヤモヤする。(2回目) 同じ blkdiscard command を実行して、6 時間ほど放置する。sequential read の転送速度を測る。16 ~ 17% くらいが trim された様だ。重ねて blkdiscard を実行すると、前の trim が取り消しになるのか、それとも 3 時間で 8% が back ground で trim されるのか。(3 回目) 同じ blkdiscard command を実行して、12.5 時間ほど放置する。sequential read の転送速度を測る。24 ~ 25% くらいが trim された様だ。一括の trim (blkdiscard) では直ぐに trim されないことは確かだ。転送速度が 400Mbytes/sec 出ていないところを狙って dd で読んでみると書き込んだデータが読める。そこを狙って trim するとデータは 0x00 になり dd の転送速度は上がった。blkdiscard 範囲を分割する指定 -p を付けて実行してみる。次に示す command line の太字部分のような指定だ。指定する値をいくつか試してみた。実行終了までに時間が掛かる。手応えがある。次の例のように 512Kibytes 分割だと見込みで約 4500 秒かかる。途中 ctrl-c で停止した。# blkdiscard -v -o $(( 0 )) \ -l $(( 6001175126016 )) -p $(( 512 * 1024 )) /dev/sdc-p に 512Mibyte を指定すると、23 秒で終了する。HDD の中で何か変化していると期待できる。全領域で sequential read の転送速度は 400Mbytes/sec 前後出る様になった。転送速度のブレが大きく、買ったばかりと違っている。trim command の動作は allocation unit に trim 範囲を追記するだけのようだ。read/write command に対して allocation unit を通しで読んでみて trim された記録が見つかったら、範囲を記憶し、trim 済みか判断する。次の read/write command に対して、trim された領域なのか、いくつか記憶した trim 範囲と照合してみて最適な動作を決める様だ。trim された後の sequential write の転送速度を測ってみる。CMR HDD に近い転送速度の傾向を示した。最外周で 200Mbytes/sec、最内周で 80Mbytes/sec 出ている。分割構造の特徴は見えにくくなっている。相変わらず中央の分割の後半で転送速度 130Mbytes/sec で底打ちする。謎なままだ。WD60EZAZ は都度細かく trim する使い方で性能が出る見込みがある。OS の file system に trim 指定を(Linux ならば discard 指定を)するか、自動で trim を積極的に使う環境ならば、CMR HDD に少し劣る程度の性能で使えるかもしれない。(注: ここで行った random read/write のテストは trim を使っていない)より具体的には大規模ソースの build 作業で生成される object file の様に create - write - read - remove の繰り返しならば、障害を引き起こしそうなアクセス速度の低下や応答時間の長期化は経験せずに済むと思われる。それでも CMR HDD とほぼ同等は無理そう。trim をせずに defrag したり、record file / data base の様にファイルの一部を read/write する使い方を続けたり、trim に対応しない RAID 構成で使うと、障害になるほどのアクセス速度の低下や応答時間の長期化が発生する可能性も分かった。SMR HDD WD60EZAZ の性質が分かってきた。この HDD を買った目的は何だっけ? えーっと、バックアップ作業用に買ったはず。うん、バックアップを数分で消す blkdiscard の魔法を覚えた!SMR 記録の HDD WD60EZAZ ランダムアクセステスト結果SMR HDD random read/write アクセス後の sequential read/write 速度
2020.07.18
コメント(0)
-
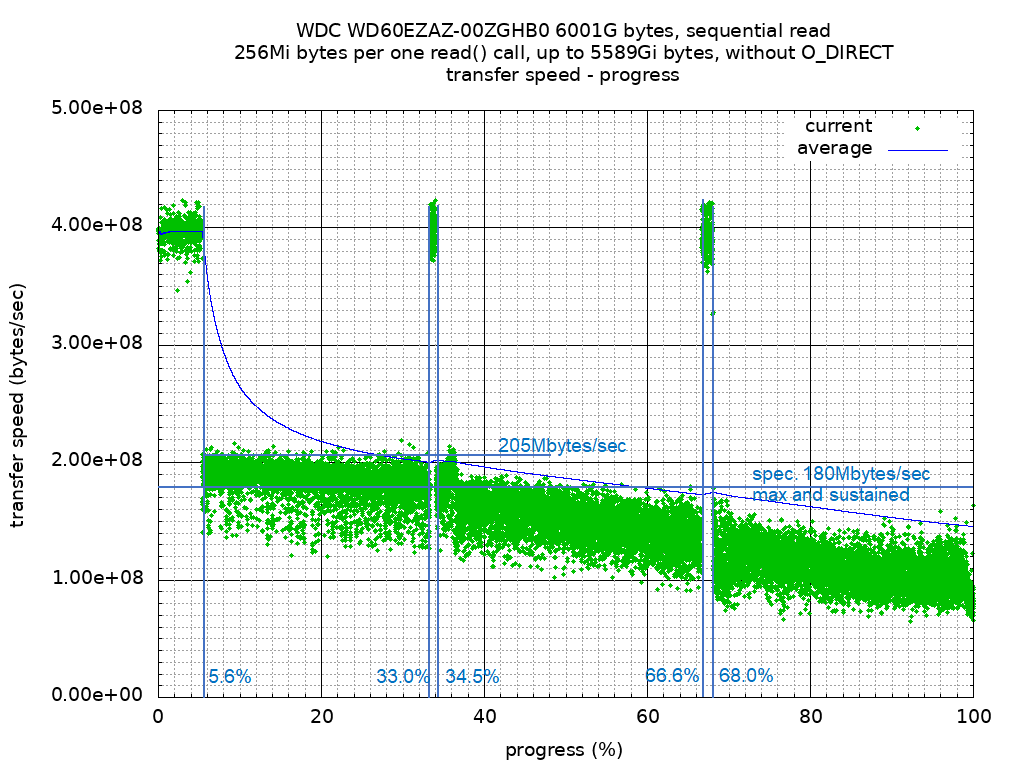
SMR HDD random read/write アクセス後の sequential read/write 速度 - 遅くなるなぁ
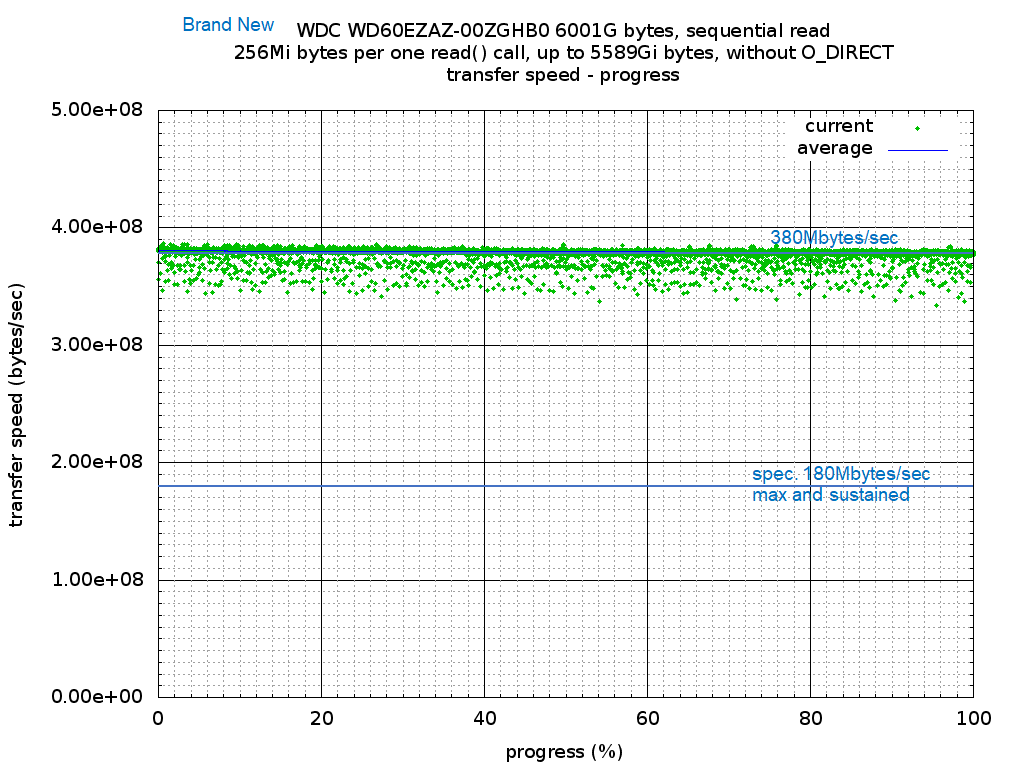
まず買ったばかりの SMR HDD WD60EZAZ の sequential read 速度を見てみる。縦軸は転送速度 bytes/sec, 横軸は 進捗で 0% が LBA=0, 100% が LBA=Last LBA だ。380Mbytes/sec 出ている。データシート上の最大転送速度は 180Mbytes/sec だ。実用上この速度は出ない。Trim された領域を read して出ている速度だ。File System を構成するならば、書き込んだことが無い領域を読むことは無い。読んだとしてクラスタ単位で操作する都合上で行われるはずだ。380Mbytes/sec は記憶媒体に律速されない AHCI SATA I/F - WD60EZAZ 間の最大転送速度を示していると考えられる。Trim されているので何回 sequential read を繰り返してもほぼ同じ結果になると考えていた。繰り返してみると、転送速度に僅かな変動が見られたり、瞬間的に(全容量に対して 2 ~ 3% 程度の範囲で)突如として転送速度が低下する現象がみられた。なぜ起きるのか良く分かっていない。買ったばかりなのに媒体上に不安定な領域でもあるのだろうか?あるいは、HDD の firm ware に使われているアルゴリズムが動作履歴に左右されやすい時間オーダーになっているのだろうか?先に行った random read/writeに続けて、sequential read/write をする。1 回目の sequential read は転送速度が進捗に対して 3 段階で変化した。各段階で最大転送速度と最小転送速度の差が大きい。比較的早い外周領域(0% ~ 33.3%)の範囲でも 90Mbytes/sec 差が有り、ほぼ 2 倍の振れ幅がある。振れ幅も密度に差が有り、allocation unit に沿うように転送速度が低下している様に見える。段階の位置を見るとほぼ進捗の 33.3%, 66.6% の所で段ができている。いかにも意図的な位置だ。大規模な分割構造がある様に見える。LBA で綺麗に 3 分割されているということは、媒体上では外周では細い環、内周では太い環に分割されているのだろうか? さらに細かく分割して最適化を追求するよりは動作検証をしやすくした様に見える。1 回目のsequential write の転送速度(リンク先は続く sequential read を含む)を見てみる。「これは HDD なのか?」転送速度が波打つ様に変化した。分割構造の境界付近では最高転送速度は 200Mbytes/sec を越える。それ以外では IDE I/F 時代の HDD 程度の速度になった。外周部分で 30M ~ 70M bytes/sec だ。ULTRA ATA 33 ~ 100 が全盛で容量 20Gbyte ~ 100Gbyte の HDD がよく使われた時代に戻った感じだ。転送速度の変化も分割構造の前後で非対称だ。ヘッドを静定する時間がシーク方向に依存しているか、HDD 媒体上の allocation unit に未使用追記領域が無かった場合の空き検索アルゴリズムに方向性があるのか?特定条件を満たしたときにデーターシートスペック 180Mbyte/sec を出しているようにも見える。何が何でもスペックを出すような構造を設計した?分割構造の境界付近を「SMR 追記を早く行うための余剰領域」かつ「不良ブロックが発生した場合に代替利用する領域」にしているのだろうか?転送速度が速くなる進捗の幅が 3%, 5%, 5%, 3% となるので、何か意図的な割り振りを感じる。おおよそ HDD に書き込んだデータのうち、15 ~ 20% 位が書き換えられると想定して、追記未使用領域を用意しているのだろうか?あるいは運用中に不良ブロックが発生したとして、最大 20% 程の代替領域があれば、運用継続可能と想定している?そうだとすると SMR 方式は物理的な記録密度向上に対して、性能と耐不良ブロックのために払う代償も大きい。コスト競争が激しい製品で、差し引き 3 割り増しにもなれば大きいのも確かだ。全領域を Sequential write すればスッキリするのだろうか? sequential read 転送速度が向上し、CMR 方式 HDD と同等と見なせる程度に転送速度のブレは減るのだろうか?2 回目の sequential read をしてみる。転送速度は全般的に向上した。分割構造の外周部で、205Mbytes/sec が出る様になった。転送速度のブレは依然として大きい。最外周の分割部分で転送速度の振れ幅は 70Mbytes/sec 程度、速度低下の機会はある程度減ったように見える。中央、内周分割部分でも転送速度は 10M ~ 20Mbytes/sec 向上している。気持ち速度低下頻度が下がったように見える。HDD 内の allocation unit をほぼカバーするような sequential write を行った積もりだった。write() システムコールに対して転送長 256Mibyte、Linux Kernel の BIO から AHCI driver 間の最大転送長は 30720kiByte (30Mibyte) にしている。HDD 上の allocation unit を綺麗に上書きで書き直せると期待していた。sequential read 転送速度の結果を見ると、依然として allocation unit に対して追記、溢れた場合は隣接 allocation unit に対する追記に振り替えている様に見える。2 回目の sequential write をしてみる。転送速度が波打つ様なことは無くなった。最外周の分割構造で、upper 205M ~ 200Mbytes/sec, lower 160M ~ 155Mbytes/sec の転送速度が出ている。ある程度 block 配置状態が整理された様に見える。依然として、転送速度に振れ幅がある。 奇妙なことに真ん中の分割構造で、転送速度の下限が 130Mbytes/sec 程に安定して底打ちする現象が見られた。原因は分からず。勘ぐった見方をすると転送速度調整をしている様に見える。外周側の分割構造でも、転送速度の変化が進捗に対して 5Mbytes/sec になっている。HDD に乗ったチップ内の DMA controller 速度を媒体記録密度とは別の調整パターンで設定している?マーケティング / ブランディングと言った大人の事情?3 回目の sequential read をしてみる。2 回目と比べて大きな変化は無い。分割構造の境界付近で転送速度が妙に遅くなったり、早くなるようなパターンは依然として残る。媒体上の場所毎に使い方が違うことを示唆している。WD60EZAZ は Trim command を受け付ける。何か変化があるから command として受け付けるのだろう。試してみるか。2020.7.15 22:50 追記: 手順の流れを明確化した。2020.7.18 追記: SMR 記録の HDD WD60EZAZ ランダムアクセステスト結果SMR HDD WD60EZAZ 買った直後に近い状態に戻す - trim(blkdiscard) を使う
2020.07.15
コメント(0)
-
x86/x86-64 arch で cache flush 関数を試しに実装してみる - kernel の実装を持ってくる
Linux の Userland で cache flush をしたくなったので、x86/x86-64 アーキテクチャ上で cache flush 関数を実装してみる。Linux kernel 内に有った実装をほぼそのまま持ってくる。#include <stdint.h>static void clflush(volatile void *p){ asm volatile("clflush %0" : "+m"(*(volatile uint8_t *)p));}clflush ソースkernel から持ってきた理由は、検索をしていたらcacheflush() system call が見つかったからだ。kernel source を調べてみると x86/x86-64 アーキテクチャではこの system call は無い様に見える。特権を持っていなくても、CLFLUSH 命令は使えるからだろう。試しに使ってみるコードを実装する。#include <stdint.h>#include <stdio.h>#include <string.h>static void clflush(volatile void *p){ asm volatile("clflush %0" : "+m"(*(volatile uint8_t *)p));}const char hello[] = "Hello world.\n";void MainB(char *buf){ memcpy(buf, hello, sizeof(hello)); clflush(buf); fputs(buf, stdout);}int main(int argc, char **argv, char **env){ char buf[128]; MainB(buf); return 0;}clflush テストコード全体逆アセンブルしてみる。まぁ、まぁ、綺麗に inline でオブジェクトコードが生成されていた。0000000000400620 <MainB>: 400620: 48 b8 48 65 6c 6c 6f movabs $0x6f77206f6c6c6548,%rax 400627: 20 77 6f 40062a: c7 47 08 72 6c 64 2e movl $0x2e646c72,0x8(%rdi) 400631: 48 89 07 mov %rax,(%rdi) 400634: b8 0a 00 00 00 mov $0xa,%eax 400639: 66 89 47 0c mov %ax,0xc(%rdi) 40063d: 0f ae 3f clflush (%rdi) 400640: 48 8b 35 09 0a 20 00 mov 0x200a09(%rip),%rsi # 601050 <stdout@@GLIBC_2.2.5> 400647: e9 74 fe ff ff jmpq 4004c0 <fputs@plt> 40064c: 0f 1f 40 00 nopl 0x0(%rax)より良い使い方は、前後にmemory barrierを使う。cache line size も /proc/cpuinfo から拾わないと。clflush size : 64cache_alignment : 64
2020.07.02
コメント(0)
-
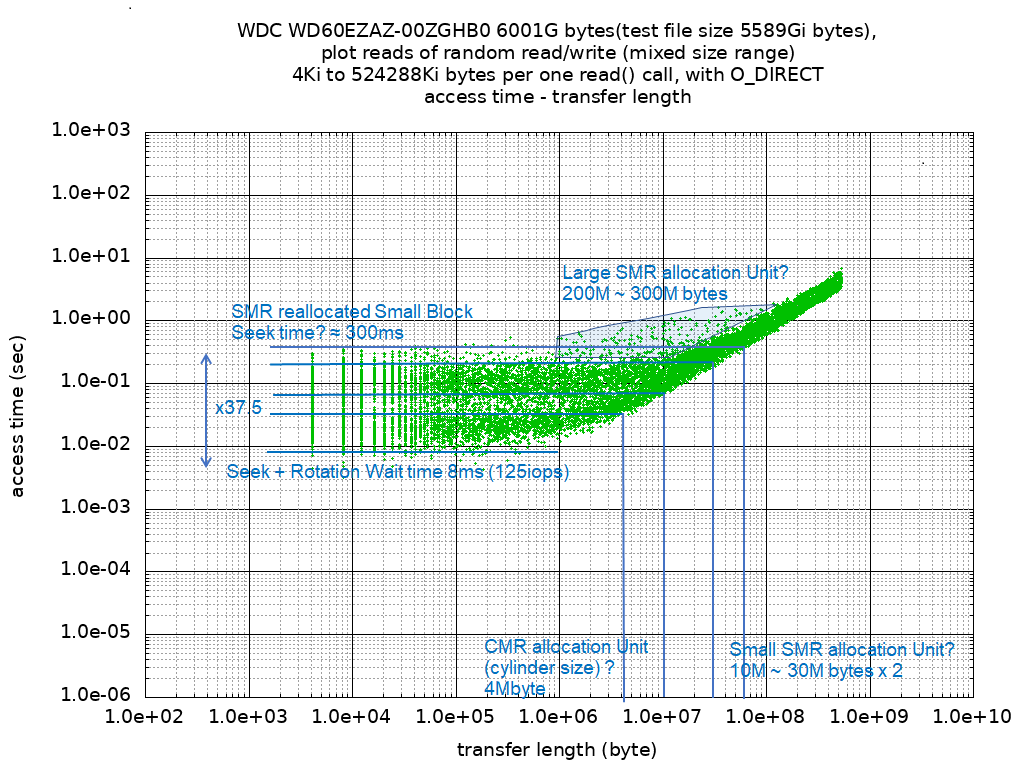
SMR 記録の HDD WD60EZAZ ランダムアクセステスト結果 - Android, Linux Kernel, yocto ソースコードを格納して build するのは向かないかも
SMR 記録の HDD WD60EZAZ を Linux で使うには BIO (Block IO request) のタイムアウト設定 /sys/block/block_device_name/queue/io_timeout に 240000 (240秒) を設定すれば sync() でハングせずに使えそうなことが分かってきた。設定値は kernel が管理する cache 量、稼働中に想定される単位時間当たりの書き込み量、頻度に依存すると思われる。主記憶サイズ 24Gibyte での値だ。ランダムアクセステストの結果に気になる傾向があったので、記録に残しておく。ランダムアクセスの分布は LBA: [0..MaxLBA] = a*random(), Length: [4096..512Mibytes] = exp(l * random()) bytes となる様に a, l を定めている。read, write はほぼ半々になる様に混在させている。ランダムアクセステストをする前に行った HDD アクセス履歴の概要を書く。最後の全 block 連続書き込みから、次の表の様にランダムアクセスをした状態だ。6Tbyte に対して、221266 回 write のランダムアクセスをしている。テスト前のランダムアクセス数Read / Write回数Read220113Write221266テスト後のランダムアクセス数Read / Write回数Read269244Write270439均等に分散しているアクセスだと仮定すると 6Tbyte / 221266 ≒ 27,121,994 (27Mbyte) 程度の範囲に 1 箇所はランダムアクセスをして乱れがあるはずだ。厳密にはアクセス長分布は 512Mibyte まで有るので、27Mbyte 丸々上書きされている場合もある。意外と疎な感もある。OS の Cache を使わずに Read/Write Random Access をした結果から、Read のアクセス時間と転送長の関係をプロットしたグラフを見てみる。最小 Read Turn Around Time は約 8ms だった。Seek time + Rotation 待ち時間として考えられる。気になるのは、アクセス時間の分布がいくつかの帯に分かれることだ。構造を示すような資料は見つからなかったので推測で書く。HDD の記録面は4Mbyte 程の CMR Allocation Unit10M ~ 30M byte 程度の単位で管理された Small SMR Allocation Unit200M ~ 300Mbyte 程度の単位で管理された Large SMR Allocation Unit (Small SMR Allocation Unit をまとめたか、あるいはさらに高密度記録を行っている)といった階層的な構造になっている様に見える。シーケンシャルアクセステストの結果から、ドライブ全体を 3 分割する構造も見えている。SMR HDD らしい所は転送長が 1Mbyte 未満の所で、Access Time が 8ms ~ 300ms 程度の幅があることだ。最小アクセス時間と最大アクセス時間の比は 37.5 倍になる。細かいアクセスが多発する場合、総アクセス時間の予測をしにくい。Small SMR Allocation Unit も Large SMR Allocation Unit も追記を行っていく構造になっていると思われる。2020.06.29 加筆 書き込みをした場合、LBA, (新しい書き込みだと印を付ける)SerialNumber, block data を組みで追記し、プラッタ上の LBA の並びは追記順になっている様に見える。SMR 記録された track を読んでいって、読みたい LBA の最新が見つかるまで、シーケンシャルにアクセスしていると推測する。Write のアクセス時間と転送長の関係をプロットしたグラフを見てみる。条件は先ほどの Read 同様 OS の Cache は使わない。最小 Write Turn Around Time は 140us 程になっている。10Mbyte 程の書き込みまで多くの場合 転送速度は 400Mbyte/sec だ。SATA-III I/F の転送速度 6Gbps の上限に近い。プラッタに書き込まず、HDD 基板上の半導体メモリに格納したら、転送完了している様に見える。もし、電源断になったらどうするのだろう?プラッタとスピンドルモーターでフライホイールを構成して、Flash Memory か特別な磁気媒体領域に書き込み終わるまで、電源供給無しに動作し続けるのだろうか?実効的な HDD の cache size は 10Mbyte 程に見える。WD Blue Data Sheetには 256Mbyte と表記されているので 10Mbyte x n tansaction の様に使っているか、Small/Large SMR Allocation Unit の再構築に使っている可能性がある。転送長に対して顕著にアクセス時間が長い場合が見られる。アクセス時間からして Small/Large SMR Allocation Unit を再構築しているのでは?と考えられる。追記ができなくなった場合、近隣の Allocation Unit に追記するか、それも出来なくなった場合は、再構築をするのだろう。このグラフからは読み取りにくい。HDD を休ませることなく連続してランダムアクセステストを実施していると、次の様なグラフに変化する。分布がより鮮明に現れ、転送長が 512Mibyte の場合のアクセス時間は 7 ~ 10 秒だったのが、45 秒程に変化する。連続してランダムアクセステストを実施していると、read もアクセス時間が変化する。転送長が 1Mbyte 以下で 8ms でアクセス完了する場合が減る。Small SMR allocation Unit から読んでいると思われる 300ms 程のアクセス時間になる。転送長が 1Mbyte 以上の場合も、Large SMR Allocation Unit を 2 つ跨ぐ様なアクセス時間に変化している。対数グラフで一マス上なので体感的に速度は 1/5 ~ 1/10 程度に下がってしまった様に感じるかも。OS の cache を使った場合のアクセス時間と転送長の関係を見ていく、Read の方は、Queue に溜まった transaction が完了するまで待つ場合が出てくる。待つ場合は 100Mbyte/sec 出ている転送速度が 3Mbyte/sec 程度まで低下した様に見える。最大で 30 ~ 40 秒待つ場合が出てきている。アプリケーションによってはフリーズしたような体感になる。連続アクセスを続けていると、待ち時間はさらに長くなる。200 秒ほどの待ちになる。先行する write transaction が完了するまでの待ちだと考えられる。これが、冒頭で触れた「タイムアウト設定 /sys/block/block_device_name/queue/io_timeout を 240000」にしようと考えた背景だ。OS の cache を使った場合の write は、順調に OS の cache に格納して完了している。転送速度が 2Gbytes/sec と 3Gbytes/sec に別れる原因は探っていない。OS の cache 管理構造が原因なのか、主記憶が 24Gibyte なので Memory Bus の channel 構成が非対称なのが原因なのか。ランダムアクセスですっかり遅くなってしまった SMR HDD WD60EZAZ のアクセス速度を回復する方法は有るのだろうか?2020.7.16 追記: SMR HDD random read/write アクセス後の sequential read/write 速度2020.7.18 追記: SMR HDD WD60EZAZ 買った直後に近い状態に戻す - trim(blkdiscard) を使う2020.7.18 追記: Android, Linux Kernel の様な大規模ソースを格納して build 作業に使う場合、mount option discard (trim) を付ければ hang up に近いような応答時間にならずに済むかもしれないことが分かった。それでも、ランダムアクセスは性能的に不利だ。積極的には build 作業に使わない方が良さそう。
2020.06.28
コメント(2)
-
SMR の HDD を Linux で使うと sync() で hang するかも - Waiting in uninterruptible disk sleep
SMR 記録方式の HDD WD WD60EZAZ を linux (Lubuntu 20.04)でベンチマークテストしている。ベンチマークプログラムが kill -9 (SIGKILL) も効かない状態でハングする。ランダムアクセステストで kernel の cache は有効な状態、ベンチマークプログラムは root 権限で動作している。raw block device をアクセスするためだ。ps uaxwwでハングアップしている状態を見てみる。STAT が DL+ となった。"Waiting in uninterruptible disk sleep" (割り込み不可の状態でディスク I/O 完了待ち)だ。$ ps uaxww | grep ssdstress &34176 0.0 6.4 1576728 1574484 pts/1 DL+ 613 1:30 ./ssdstress -f 6001175126016 -pn -xb -rn -my -b 4096 -i 1 -a 131072 -i exp -n 24576 -u 65536 -dn -dY -s 20200614 /dev/sdcroot 権限でプログラムを動かしたとしても、uninterruptible 状態が長時間続く様な動作を kernel がすることはまずあり得ない。Linux Kernel で uninterruptible あるいはその逆の interruptible というのは誤解を招きやすい表現の一つだ。この場面において、純粋に「割り込み (interrupt) を受け付けない」という意味ではなく、Userland process が呼び出した「system call 処理中に signal を受け付けない」状態ということだ。どんな signal も受け付けない。signal 9 (SIGKILL) も含まれる。/proc/pid directory 内にあるいくつかの process status を見てみる。stat と status も D stateで止まっていることを示していた。/proc/34176 # cat stat34176 (ssdstress) D 34175 31200 31057 34817 31200 4194560 393297 0 1 0 6180 2875 0 0 20 0 1 0 23546681 1614569472 393621 18446744073709551615 94412556185600 94412556207685 140733693111200 0 0 0 0 0 0 1 0 0 17 3 0 0 3976146 0 0 94412556225760 94412556226828 94412566093824 140733693114159 140733693114281 140733693114281 140733693116396 0/proc/34176 # cat statusName:ssdstressUmask:0022State:D (disk sleep)Tgid:34176Ngid:0Pid:34176PPid:34175TracerPid:0Uid:0000Gid:0000FDSize:64Groups:0 -- snip --ps コマンドで得た情報は確かだ。ベンチマークプログラムはどこまで進んでいたのだろうか。ログ出力が途切れていたので、活動状況を類推できる fd/* file descriptor 使用状態(open している状態)を見てみる。/proc/34176/fd # ls -latotal 0dr-x------ 2 root root 0 6 13 15:46 .dr-xr-xr-x 9 root root 0 6 13 15:46 ..lrwx------ 1 root root 64 6 13 15:46 0 -> /dev/pts/1l-wx------ 1 root root 64 6 13 15:46 1 -> 'pipe:[233565]'l-wx------ 1 root root 64 6 13 15:46 2 -> 'pipe:[233565]'stdin, stdout, stderr だけだった。ほぼプログラムは終了している状態と考えられる。ん? stack ってなんだ。system call を発行してから kenel 内でどこまで進んでいるか見ることができる call stackだった。/proc/34176 # cat stactk[<0>] submit_bio_wait+0x60/0x90[<0>] blkdev_issue_flush+0x94/0xd0[<0>] ext4_sync_fs+0x15d/0x200[<0>] sync_fs_one_sb+0x23/0x30[<0>] iterate_supers+0xa3/0x100[<0>] ksys_sync+0x62/0xb0[<0>] __ia32_sys_sync+0xe/0x20[<0>] do_syscall_64+0x57/0x190[<0>] entry_SYSCALL_64_after_hwframe+0x44/0xa9各 kernel 関数のリンク先は Lubuntu 20.04 で使っている 5.4.0-37 に近い5.4.47 のソースにリンクしている。sync() を起点として submit_bio_wait で止まっている。「まぁ、そうだろう」と思う状況だ。真に止まっている場所は submit_bio_wait 内から呼び出した wait_for_completion_io か少し進んだ先のはず。ここで、TASK_UNINTERRUPTIBLE 状態で止まるように wait_for_common_io を呼び出している。signal を受け付けない訳だ。厄介だ。call stack の流れは、ext4_sync_fs を経由している。ハングアップの真の原因を作ったと推測している raw block device access と違う。raw block device access と ext4 file system を格納しているドライブに対する access が何処かで queue なり fifo を共用している? 同じ SATA controller に繋がっているのだ。システム全体が停止してしまう可能性を示唆している。この現象が出た後、reboot できない。途中で途切れてしまったベンチマークテストの結果を見てみると、kenel cache を経由したアクセスで、完了まで 100 秒以上経過している場合がある。63 回だ。出始めの SSD に良く見られたプチフリーズとよく似ている。より悪い挙動かもしれない。Linux kernel 5.x から/sys/block/block_device_name/queue/io_timeout と言う ms (ミリ秒) 単位でタイムアウトを設定できるノード(リンク先は kernel 内の store 実装)が増えたようだ。各 Controller 毎にバラバラに実装されていた timeout を統一的に扱うノードなのだろうか? SSD や SMR HDD といった癖があるデバイスが増え、実装する機運が高まったのかも。一方で各 Controller 毎にあった複雑な事情を吸収しきれず、complete しないゾンビののような BIO request (Block IO request) が生じやすい?io_timeout ノードの設定を変えて SMR HDD を使えるようにできるだろうか? なんだな、筋が悪い予感がする。以前プチフリ SSD を Linux で使うのを断念している。よく似た状況だ。
2020.06.23
コメント(0)
-
しばらく日記をサボっていたわけ - プログラミングスキルチェックサイトに没頭していた
ここしばらく、日記がサボりがちになっている。プログラミングスキルチェックサイト(Paiza)に没頭していた。100 点は目指さない。「好きにプログラムを作ってみよう」。という姿勢だ。もう少し「好き」を具体的に書くと、問題文ある入力範囲の制限はできるだけ取り除くあまり面倒でなければ Secure coding をしてみる入力エラー、内部ロジックエラー、メモリ不足など不意な状況もなるべく検出する時には over kill のアルゴリズムを投入してみる。そして、逆もあり素朴でのんびりと動くアルゴリズムで臨むこともするちゃんと動くことを目標にする。時間が掛かってもよいから、テスト入力は 100% 期待値と一致させる「たまには bash で...」と思ったら、まだちゃんと動いていないみたいいくつかの問題で統計された正解率が極端に低い問題が有った。なんでだろう。試しに解いてみることにした。おおよそ次の傾向があることが分かってきた。そもそも問題文に誤りがある入力に可変要素がある(特にテキスト入力の列方向)ステートマシンの様に内部記憶をもち、それを順次変化させる必要があるマシンイプシロンなど環境に依存性があり、作ったコードが題意を満たすかどうか証明するのに時間がかかる(マシンイプシロンは DBL_EPSILON などで取得可能だ。厳密にいえば環境依存なので、調査する必要があるし、値をなるべく真値に近く扱える実装が必要だ)全部言及すると長くなる。何かネタが無い時の機会に回そう。「そもそも問題文に誤り」は出題側は気付かないのだろうか?正解率は低く回答時間が長い。他の問題の傾向と比べて突出してる。しばらくして、「何かおかしい」と気付くはずだ。表に出す前(本番環境稼働させる前)に、レビュー、テストを十分にするのが教科書に書かれていることだ。誤りもそれほど難しい論理証明をせずとも発見できるものだった。どうやって問題作ったのかな。何も考えずにどこかのサイトのコピペ? コピペ技術者で十分というのはちょっと悲しいな。
2020.06.20
コメント(0)
-
dmesg (kernel long) に予兆が出ていたのか - スイッチングハブが壊れた
スイッチングハブが壊れた時に「あれ?ネットワーク」とふと思っていた。他に仮定できるいくつかの原因が有ったはず。故障した HUB に接続しているlinux PC の dmesgを見直してみたら、故障の兆候が記録されていた。[511464.633473] r8169 0000:05:00.0 enp5s0: Link is Up - 1Gbps/Full - flow control rx/tx[511465.026759] r8169 0000:05:00.0 enp5s0: Link is Down[511467.505506] r8169 0000:05:00.0 enp5s0: Link is Up - 1Gbps/Full - flow control rx/tx[511467.891947] r8169 0000:05:00.0 enp5s0: Link is Down[511484.046647] r8169 0000:05:00.0 enp5s0: Link is Up - 100Mbps/Full - flow control rx/tx[511484.614987] r8169 0000:05:00.0 enp5s0: Link is Down[511744.850145] r8169 0000:05:00.0 enp5s0: Link is Up - 1Gbps/Full - flow control rx/tx故障する前に見ていた。「高頻度で接続・切断の繰り返し、Ethernet link の調子が悪いけどなんだろう?」程度にしか思っていなかった。「繋がっているしな...」とログに記録された兆候を見逃していた。Ethernet HUB を「動いている」時に積極的に外すことはしない。経験として、ネットワークから HUB を(あるいは HUB から PC を) 10 秒程度切り離しても、つなぎ直せば平然と TCP/IP のコネクションは維持されつづけるし、UDP だって何事もなかったように続行する。上流 HUB から常用/予備のケーブルが伸びていれば、HUB の予防交換をしたかもしれない。予備 HUB を予備ケーブルでネットワーク基幹に繋ぎ、故障 HUB に繋がった機器類を 予備 HUB へ移していけば、何事も発生しない 10 秒の空白時間で保守ができる。ケーブルを抜いて挿す時間だ。引っ越す前は常用/予備のケーブルを張ってあったんだよなぁ。兆候の表れ方も解ったし、こんど似たような現象に遭遇したら、保守計画を考えることにしよう。あっ、考えると壊れる謎ジンクスがあったな。考えないことが一番の予防?
2020.06.19
コメント(0)
-
もう 1 枚壊れたメモリが増えた - CFD Elixir D2U800CQ-1GLZJ
保管していたマザーボードを出してきて動作試験をしていた。可能で有れば稼働しているマシンの性能が少しでも上がればと思い、入れ替え予定だった。Ubuntu 20.04 amd64 を起動すると、なぜか kernel log に stack dump が出る。しばしば GUI ログインまで辿り着かずにハングアップする。memtest86+ でメモリをテストしたら、エラーが見つかった。1 ビットのエラーで症状が複数出る? memtest86+ でテストを暫く続けていたら、さらにエラーが出てきた。64byte 毎で、bit30 か。行線切れ?立て続けに不良メモリが見つかる。また CFD Elixier だ。基板の色は紺色、ロットが違っても品質はイマイチなのか。CFD のページを見ると、Elixir ブランドの扱いは DDR3 で終了していた。何か有ったのかなぁ。過電圧も、高クロックも掛けずに普通に使っていたのにな。
2020.06.09
コメント(0)
-

DDR2 PC6400 1Gbyte メモリ 4 枚のうちどれが故障している? - memtest86+ では見つからない memory fault
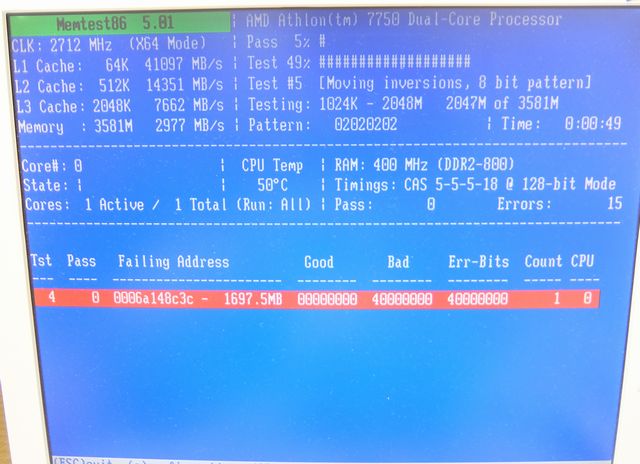
SMR HDD のベンチマークを 自分で作った SSD/HDD テストツールで行っていた。比較のため CMR HDD のベンチマークを行っていたら、読み出したデータのチェックサムが合わないエラーに遭遇した。CheckStrictlyFileImage: Error: Checksum not match. blocknumber=563962486, a=-2048(0xfffffffffffff800).単純に 8byte 毎を 64bit 値で加算していくだけの素朴なアルゴリズムだ。2048 足りないので何処かの bit 11 が 1 から 0 に変わっていると考えるのが最もらしい状況だ。変えられそうな所を変えてみて様子を見る。項目変化ケーブル変更エラーは出るポート変更エラーは出るSATA I/F 変更エラーは出るPC 変更(OS も変わる)エラーは出なくなるメモリ入れ替えエラーは出なくなる発生 LBA不定ベンチマークを行っていた PC で使っているメモリにエラー(Fault)があると考えるのが最も可能性が高い。DDR2 PC6400 1Gbyte x 4 を総取っ替えして、エラーは解消している。どの DIMM が問題なのか memtest86+ でテストしてみた。エラーが出ない。下の画像で横に並んだメモリ 4 枚のうち、エラーがある DIMM だけ取り替える積もりだった。こうなると「4 枚ともエラーが有るかも」と言う扱いになる。一気に 4 枚全損か。ベンチマークソフトのアルゴリズムから推測できることは、12 ~ 24 時間 程度メモリに記憶させていると化ける可能性がある。なんだろう、リフレッシュが掛かるまでに揮発するのか、隣接ビットに対する write/read で乱れるのか。memtest86+ は記憶させたデータが生きているべき時間は精々 2 ~ 3 時間の短期間だ。エラーは再現できないかも。CFD ELIXIR は時間が経つと、エラーが出てくる印象だ。上の画像で縦に置いたメモリは、明らかにエラーが出たメモリだ。使用開始 1 年程経過してエラーが発生した。DDR2 memory なんだよなぁ。手持ちで使えるマザーボードもこれから故障などで目減りするだろう。ハードオフで漁るのも難度が高いし。
2020.06.05
コメント(0)
-

Blu-ray ドライブ BDR-207M BD-R/RE DL 読み書き難 - 殆ど BD-R DL / BD-RE DL を使っていないのに
メイン PC で使っていた Blu-ray ドライブ BDR-207M が不調なので、状況を調査することにした。調査した結果 BD-R DL, BD-RE DL の読み書き(焼き)でエラーが発生し、難があることが分かった。BDR-207M は買った当初から難があった。トレイ開ボタンを押してもトレイが出てこない。ケースの化粧蓋を押し開ける構造だったので、それに引っかかっているのかと思っていた。ネットで調べると、普通に使っていてもトレイ開に難が有ったようだ。使っていて BD-R DL が上手く書き込めないことが気になっていた。いつの頃からだっけ? 1Tbyte 規模のバックアップをする必要が出てきたので、BD-R DL を焼いてみる。3 枚ほど途中で書き込みが中断してしまった。おおよそ、2 層目書き込みに入って 2, 3 割程度の所だろうか。何かおかしい。 BD-R DL が本当に上手く書き込めるのか調べてみることにした。Linux(ubuntu 18.04) で動く GUI burning tool k3b と k3b が呼び出している command line tool の動作状況を観測してみる。結果は上の画像のように Dual Layer (DL) 系のメディアが辛うじて読める程度で、消去、書き込み(焼き)は全滅だった。1 層 R メディアは読めていて、焼けている実績がある。実質的に BD-ROM 機能付きの CD/DVD R/W ドライブになっていた。1 層の BD メディアは 100 枚も焼いていないはず。BD に焼くくらいなら、ハードディスクに保存した方が安上がりになってしまった。この成果は BD-207M を対象にテープラベル作り・張り練習の練習かな。なかなか真っ直ぐ貼れない。
2020.06.02
コメント(0)
-
ソースが公開された GW-BASIC を build してみる - missing low level I/O functions
ソースが公開された GW-BASIC (リンク先は記事)(GW-BASIC github repository) を build しようとしてみた。build tool は MASM ではなく、Turbo Assembler だ。一応 MASM 互換の範囲で修正を試みた。GW-BASIC を clone したリポジトリに色々と追加した修正を置いておく。全ソースをアセンブルして .OBJ ができるところまで進めた。リンケージする段階で low level I/O function 群が不足していることが分かった。.MAP ファイルに不足している procedure(MASM アセンブラで言うと PROC) が並んだ。ソース全体を grep しても symbol が見つからない。次に .MAP ファイルの一部を示す。Error: Undefined symbol PNTINI in module ADVGRP.ASMError: Undefined symbol MAPXYC in module ADVGRP.ASMError: Undefined symbol STOREC in module ADVGRP.ASMError: Undefined symbol TUPC in module ADVGRP.ASM-- snip --Error: Undefined symbol SCROLL in module SCNDRV.ASMError: Undefined symbol EDTMAP in module SCNDRV.ASMError: Undefined symbol PRTMAP in module SCNDRV.ASMTurbo linker 向けツールをアセンブラで書いたりもした。久しぶりに 8086 アセンブラで書く、おお、意外とまだ書けるなぁ。エディタに補完機能があると長いシンボルが苦にならない。足りない部分は GW-BASIC 移植先のパソコンメーカーが持っているのだろう。full build は遠い。
2020.05.30
コメント(0)
-
Ubuntu 20.04 を SMP の Virtual Machine で動かす - apt-get remove intel-microcode か kernel parameter に dis_ucode_ldr を加える
Ubuntu 20.04 を SMP の Virtual Machine (具体的には VirtualBox) で動かそうとすると、カーソルが点滅するだけの真っ黒な画面で止まってしまう。手っ取り早く解消するには、仮想マシンの CPU を 1 個にする UP (Uni Processor) 構成にすることだ。この状態で起動して、intel-microcode パッケージを削除する。dpkg -l コマンドで intel-microcode パッケージがインストールされていることを確かめて、apt-get remove intel-microcode でパッケージを削除する。$ dpkg -l | grep intelii intel-media-va-driver:amd64 20.1.1+dfsg1-1 amd64 VAAPI driver for the Intel GEN8+ Graphics familyii intel-microcode 3.20191115.1ubuntu3 amd64 Processor microcode firmware for Intel CPUsii libdrm-intel1:amd64 2.4.101-2 amd64 Userspace interface to intel-specific kernel DRM services -- runtimeii xserver-xorg-video-intel 2:2.99.917+git20200226-1 amd64 X.Org X server -- Intel i8xx, i9xx display driver$ sudo apt-get remove intel-microcode検索で見つけた Q and Aを参考にした。次の起動からは SMP 構成でも起動できるはずだ。micro code の update は host OS で済んでいるので仮想マシン内から micro code update をする必要はない。問題を解消する前後に状況を色々調べていた。その記録を書く。どうも、SMP 構成だと仮想マシン内で CPU micro code update をしようとしたところ(あるいはその後で)でハングしてしまうらしい。kernel log が出る様に kernel parameter から quiet splash を消して起動すると、次の様に "x86: Booting SMP configuration:" で止まっていることが分かる。SMP 構成の仮想マシン上で止まってしまうコンソールログの例(Serial Port に kernel log を出すようにした)[ 0.673941] Spectre V1 : Mitigation: usercopy/swapgs barriers and __user pointer sanitization[ 0.678855] Spectre V2 : Mitigation: Full generic retpoline[ 0.679467] Spectre V2 : Spectre v2 / SpectreRSB mitigation: Filling RSB on context switch[ 0.681919] Speculative Store Bypass: Vulnerable[ 0.682437] MDS: Vulnerable: Clear CPU buffers attempted, no microcode[ 0.683316] Freeing SMP alternatives memory: 40K[ 0.795826] smpboot: CPU0: Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz (family: 0x6, model: 0x3a, stepping: 0x9)[ 0.797545] Performance Events: unsupported p6 CPU model 58 no PMU driver, software events only.[ 0.797909] rcu: Hierarchical SRCU implementation.[ 0.797909] NMI watchdog: Perf NMI watchdog permanently disabled[ 0.798395] smp: Bringing up secondary CPUs ...[ 0.799204] x86: Booting SMP configuration:検索で見つけた Q and A はでできた kernel log をキーワードに探した。intel-microcode を削除せず、意地でも SMP で起動する方法も探してみた。特にインストールメディアから起動できるようにしたかった。kernel parameter に dis_ucode_ldr を加えれば良いことが分かった。kernel-parameters に説明がある。次は Ubuntu 20.04 インストールメディアを SMP 上で起動するために dis_ucode_ldr を使った kernel parameter の例だ。起動の様子を観察するため quiet splash は消してある。file=/cdrom/preseed/ubuntu.seed initrd=/casper/initrd dis_ucode_ldr ---kernel paramter に dis_ucode_ldr を加えて起動したときに得られた kernel log。Ubuntu 20.04 インストールメディアから起動したときに kernel parameter を修正する手順が書かれたページを参考に dis_code_ldr を kernel parameter に加えることができるだろう。Ubuntu 20.04 インストールメディアから起動して kernel parameter を変更するスクリーンショットを並べておこう。キーボードとアクセシビリティアイコンが表示されたところで、何かキーを押す([Shift] の様に具体的な入力が無いキーが良い)。言語選択をする。キーボードに合わせた選択をするか、デフォルトの英語に合わせて [Enter] を押す。実キーボードが VM 内に反映されると「英語」キーボードになっているかも。"Try Ubuntu" を選んで、[F6] を押す。[Esc] を押して、kernel paramter popup を閉じる。dis_ucode_ldr を追加する。編集が終わったら [Enter] を押して起動。guest machine から micro code を弄ろうとすると口封じでもされる?
2020.05.27
コメント(0)
-

USB3.0(Super Speed) 4 port HUB が 330 円 - 中難度のハード・オフジャンク
ハード・オフに寄ったら、USB3.0(Super Speed) 4 port HUB が 330 円で出ていた。ジャンクボックスに転がっていたのを手に取って買う。ELECOM U3H-S410SWHだ。新品で 3,000 ~ 5,000 円 はする PC 周辺機器だ。330 円なのは何かあるのだろうな。お店で手に取るときに考えていたことは、AC アダプタか HUB 内のコンデンサがダメになっていて、何を繋いでも認識しない(一番あり得るかな)発煙歴がある(臭いはしない)水没したとか?(不可解な錆は付いていないし)色々と良くない報告があるのかなぁ(自分自身が ORICO A3H7 で痛い目に合っているのだ)まさか、お店の人が青い挿し口が Super Speed port であることを理解せずに、ただの USB HUB としてジャンクボックス行きにしたとか?あり得ないよなぁ。そういえば Up Stream 用のケーブルが欠品になっている。手持ちが有るので問題なし。1 port だけ使ってみて、特に異常が無かった。AC アダプタが壊れているとか、HUB 内のコンデンサが痛んでしまったなどの、深刻な故障はなさそうだ。4 port 全てに USB3.0 Super Speed 規格 device を繋げてみる。おお、接続認識ランプが 4 port 全て点灯した。ん?普通に動く Hub なの?いやいや、ハード・オフの難度を甘く見てはいけない。Linux で接続状況を確認してみる。# lsusb -t で device tree を見てみる。# lsusb -t/: Bus 06.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/2p, 5000M |__ Port 1: Dev 2, If 0, Class=Mass Storage, Driver=usb-storage, 5000M |__ Port 2: Dev 3, If 0, Class=Mass Storage, Driver=usb-storage, 5000M/: Bus 05.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/2p, 480M/: Bus 04.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/2p, 5000M |__ Port 1: Dev 2, If 0, Class=Hub, Driver=hub/4p, 5000M |__ Port 1: Dev 3, If 0, Class=Mass Storage, Driver=usb-storage, 5000M |__ Port 2: Dev 4, If 0, Class=Mass Storage, Driver=usb-storage, 5000M |__ Port 4: Dev 5, If 0, Class=Mass Storage, Driver=usb-storage, 5000M/: Bus 03.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/2p, 480M |__ Port 1: Dev 2, If 0, Class=Hub, Driver=hub/4p, 480M |__ Port 3: Dev 6, If 0, Class=Mass Storage, Driver=usb-storage, 480M/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=ehci-pci/2p, 480M |__ Port 1: Dev 2, If 0, Class=Hub, Driver=hub/8p, 480M |__ Port 3: Dev 3, If 0, Class=Vendor Specific Class, Driver=pl2303, 12M/: Bus 01.Port 1: Dev 1, Class=root_hub, Driver=ehci-pci/2p, 480M |__ Port 1: Dev 2, If 0, Class=Hub, Driver=hub/6p, 480Mあれ、おかしい。Super Speed device が 3 port しかぶら下がっていない。一つだけ、High Speed port にぶら下がっている。dmesg で kernel log を見てみる。Transcend TS-RDF5が High Speed で認識されたのか。[41609.386256] usb 3-1.3: new high-speed USB device number 6 using xhci_hcd[41609.408016] usb 3-1.3: New USB device found, idVendor=8564, idProduct=4000[41609.408022] usb 3-1.3: New USB device strings: Mfr=3, Product=4, SerialNumber=5[41609.408026] usb 3-1.3: Product: Transcend[41609.408029] usb 3-1.3: Manufacturer: TS-RDF5 [41609.408032] usb 3-1.3: SerialNumber: 000000000039[41609.408940] usb-storage 3-1.3:1.0: USB Mass Storage device detected[41609.409068] scsi19 : usb-storage 3-1.3:1.0[41610.407412] scsi 19:0:0:0: Direct-Access TS-RDF5 SD Transcend TS37 PQ: 0 ANSI: 6[41610.407767] sd 19:0:0:0: Attached scsi generic sg8 type 0[41610.767806] sd 19:0:0:0: [sdh] 31291392 512-byte logical blocks: (16.0 GB/14.9 GiB)[41610.768820] sd 19:0:0:0: [sdh] Write Protect is off[41610.768825] sd 19:0:0:0: [sdh] Mode Sense: 23 00 00 00[41610.769756] sd 19:0:0:0: [sdh] Write cache: disabled, read cache: enabled, doesn't support DPO or FUA[41610.774874] sdh: sdh1[41610.777853] sd 19:0:0:0: [sdh] Attached SCSI removable disk他の Super Speed USB device も色々と試して、dmesg を読んでみる。port 3 の Super Speed lane が不調だ。不調になっている port 3 は二股で A plug が付いている cable の補助電源ポートとして使うとか、積極的に使う用途はある。3/4 の機能で、新品価格比 1/10 以下ならば良しかな。ラベルシールに文字を入れる技も一つ覚えた。▼ 文字を引き延ばして、場所を示せる。
2020.05.26
コメント(0)
-
GRUB に root partition を volume label で指定する - 普通は UUID 指定で困らないはず
GRUB で Linux を起動できない問題が発生した。原因は kernel parameter に指定する root volume の指定 root=uuid と file system volume に付いている uuid が一致しなくなったためだ。clonezilla で backup & restore の予行練習をしていたら発生した。ネットで現象を調べてみると、同様の現象が 発生する/発生しない の両方が見つかる。最新の clonezilla を使用することで解消した。未使用かつなぜか boot flag が付与されたパーティションが有り、 grub.cfg の残骸が残っていたのが主原因だと思う。これも、解消した。ubuntu の upgrade の時に /boot partition を / partition に統合してしまった時にこの状態になったのだろう。作業途中で root volume (root partition) の指定を uuid ではなく、volume label (あるいは file system lablel とか partition label と呼ばれているもの)にすれば、そもそもこういう問題に遭遇しないのでは?と思い GRUB に volume label 指定で root partition の指定をするように設定してみた。kernel parameter が root=LABEL=root-part の様になる指定だ。前提として partition に volume label の設定ができているものとする。次のようなコマンドで設定する。ext{2,3,4} file system に volume label を設定する(斜字体部分は環境に合わせて変える部分)# tune2fs -L root-part block-device-partition-nodeswap partition に volume label を設定する(参考、これは必須ではない)# swaplabel -L swap-part block-device-partition-nodefstab (リンク先は例)を volume label 指定にするfile system の volume label を確認する(リンク先は例)ここまで設定をしたところで、/etc/default/grub の設定に次を加える。既に存在する場合は修正する。修正が終わった/etc/default/grub の例GRUB_DISABLE_LINUX_UUID=trueGRUB_DEVICE="LABEL=root-part"/etc/grub.d/ に配置されたスクリプトを読むと、GRUB_DISABLE_LINUX_UUID と GRUB_DEVICE の設定は RAID partition など、特殊なパーティションから起動するために便宜をはかるために有るらしい。使わせて頂く。update-grub で /etc/default/grub を /boot/grub/grub.cfg (リンク先は反映結果の例)に反映する。# update-grubこれて root partition が volume label 指定になった。起動後に kernel parameter を確認してみる。$ cat /proc/cmdlineBOOT_IMAGE=/boot/vmlinuz-4.4.0-174-generic root=LABEL=root-part ro vga=791なんだな、こんな指定をしなくても普通に最新の clonezilla で clone したら起動できるし、update-grub で uuid 指定で root volume が設定される。今後は使わない設定になるはず。upgrade をしても何故か kernel version が古いままな現象を見た時に、未使用パーティションに潜んでしまった grub.cfg が有ることに気付くべきだった。
2020.05.23
コメント(0)
-
tar の書き出し先が /dev/null だと file を読み書きしない - gnu tar のソースに dev_null_output 変数がある
Linux の上で tar cvf コマンドを使ってファイルを読み取るテストをしようとしていた。読み取るはずの容量に比べて素早く終わってしまった。なんか変だ。色々と試して、調べて分かったことを先に書く、次の様に tar cvf の出力先が /dev/null だと、ファイルを読み取らず、出力先に書き込まない。今まで知らなかっただけ?$ time tar cvf /dev/null directory_or_fileリダイレクトを使っても、同様に読み取り、書き出ししない。$ time tar cvf - directory_or_file > /dev/nullmd5dum に pipe で繋ぐと読み取りと書き出しをする。$ time tar cvf - directory_or_file | md5sum何だな、 /dev/blackhole とか blackhole command とか有るんだっけ?GNU tar のソースを読んでみる。src/common.h に bool dev_null_output (修正が加わって行が多少前後するかもしれない)が見つかった。分かりやすく怪しい変数だ。src/buffer.c:_flush_write() 関数に dev_null_output が纏わり付いている。書き出しをしない仕掛けかな。src/bcreate.c:file_dumpable_p() 関数に纏わり付く dev_null_output が file_dumpable_p() の return value に影響して、読み取りをしないような仕掛けになっている様に見える。static 関数なので create.c の中でソースは追える。GNU tar は出力先が /dev/null だと特別な扱いをしていることが分かった。ここからは、tar command 動作を確かめた流れを追う。整理した一連のログはこのリンク先に置いた。おおよそ 50Gibyte 保持しているディレクトリ(RaspberryPi3 向けに色々とストレージイメージを置いたディレクトリ)だと確かめる。$ du RaspberryPi3/52725612 RaspberryPi3/tar でファイル読み取ってみる。読み取りできることを確かめるので tar cvf を使用する。$ time tar cvf /dev/null RaspberryPi3RaspberryPi3/RaspberryPi3/root-configured.tar.gzRaspberryPi3/root-broken-20180101.tar.gzRaspberryPi3/root-orgin.tar.gzRaspberryPi3/2016-09-23-raspbian-jessie.imgRaspberryPi3/root-fpc3.0-withO3.tar.gzRaspberryPi3/zerofill-result.txtRaspberryPi3/2017-11-29-raspbian-stretch.zipRaspberryPi3/root-cofigured-base-2017-11-29.tar.gzreal0m0.087suser0m0.087ssys0m0.000s50Gibyte の読み取りを 87ms で終わるとか、あり得ない。/dev/null にリダイレクトする方法にコマンドを変更する。$ time tar cvf - RaspberryPi3 > /dev/nullRaspberryPi3/RaspberryPi3/root-configured.tar.gz-- snip --RaspberryPi3/root-cofigured-base-2017-11-29.tar.gzreal0m0.089suser0m0.084ssys0m0.004s早っ。んー、tar に気づかれず、ある程度気が利いた特殊なリダイレクトなり、pipe 連結先を考えてみる。md5sum かな。$ time tar cvf - RaspberryPi3 | md5sumRaspberryPi3/RaspberryPi3/root-configured.tar.gz-- snip --RaspberryPi3/root-cofigured-base-2017-11-29.tar.gzf963f8661034b53341c496587d5ab5c4 -real5m11.738suser1m29.177ssys0m46.174sこんどは 5 分 11 秒掛かった。ファイルを読み出し書き込みしている。
2020.05.17
コメント(0)
-
Ubuntu 20.04 grub boot の timeout が 30 秒になる - /etc/default/grub に GRUB_RECORDFAIL_TIMEOUT=5 を設定して取りあえず回避
Ubuntu 20.04 を試しにインストールして使っている。実 PC 環境で起動時に grub の timeout が 30 秒になってしまう現象が出た。/etc/default/grub に次の様に設定して、# update-grub をしてもやはり 30 秒のままだ。GRUB_TIMEOUT=2多分 boot 時か shutdown 時に systemd がお気に召さない状況が発生しているのだと思う。grub-editenv で怪しい grub 環境変数 recordfail を見つけた。# grub-editenv /boot/grub/grubenv listrecordfail=1grub recordfail で検索してみると、この環境変数を消せば良いとあった。消してもやはり 30 秒 timeout のままだった。# grub-editenv /boot/grub/grubenv unset recordfail仕方がない。dirty-hack をする。根本的な問題を解消するのが正しい道筋なのは分かっている。"30 秒" を短くすることにした。/etc/default/grub に次の行を追加し、# update-grub を実行する。これで何かの fail 時は 5 秒で timeout する様になる。GRUB_RECORDFAIL_TIMEOUT=5参考までに /etc/default/grub に今使っている grub の設定ファイルを置いておく。本当の問題を気にした方が良いかな?先に進まなくなるなぁ。
2020.05.13
コメント(1)
-

Ubuntu 20.04 を PXE (network) boot してみる - APPEND 行に ip=dhcp が必要になった
dhcpd, tftpd, nfs server が稼働しているネットワーク環境で、Ubuntu 20.04 amd64 を network boot (PXE boot) しようとした。今までと同じ設定では PXE boot に失敗した。Netbooting the live server installerを読んでみると、pxelinux.cfg/default の APPEND 行に ip=dhcp を追記する必要があることが分かった。LABEL Ubuntu 20.04 x64 Desktop KERNEL ../ubuntu-20.04-desktop-amd64/vmlinuz APPEND ip=dhcp boot=casper netboot=nfs nfsroot=192.168.0.160:/export/ubuntu-20.04-desktop-amd64 initrd=../ubuntu-20.04-desktop-amd64/initrd vga=791 nomodeset --これで PXE boot するようになった。以下問題発生状況を書いていく。注: ここでは dhcpd, tftpd, nfs server の設定方法は省略する。既にこれらの server が稼働していて、ファイル配置が済んでいる(リンク先はファイル配置状況のメモ書き)。ここまで設定して、pxelinux.cfg/default の記述に次の様に ip=dhcp が含まれていないと、PXE boot しなかった。LABEL Ubuntu 20.04 x64 Desktop KERNEL ../ubuntu-20.04-desktop-amd64/vmlinuz APPEND boot=casper netboot=nfs nfsroot=192.168.0.160:/export/ubuntu-20.04-desktop-amd64 initrd=../ubuntu-20.04-desktop-amd64/initrd vga=791 nomodeset --PXE boot 失敗の様子を見ていると、NFS mount をしようとするところで、"connect: Network is unreachable", "NFS over TCP not available from" と出てきて、mount に失敗している。暫くこの状態で待っていると、busybox に fallback する。/bin/ifconfig -a で確かめてみる(実体は busybox build-in command)。network の IP address, subnet mask が構成されていない。どうやら、DHCP で一度構成された IP address, subnet mask を引き継がなくなった様だ。DHCP server から IP address を再振り出しすることになる。厳密には PXE boot した時の IP address と同一である保証は無い。vmlinuz, initrd を tftp で down load するおおよそ数分以内であれば、同一の IP address が振り出されるであろうという最もらしい期待だ。色々と調べて、先に出した様に APPEND 行 (kernel の boot parameter) に ip=dhcp を加えれば良いことが分かった。Ubuntu 20.04 の installer は Network boot の時に down load したファイルをチェックするらしく、local server を立てていた場合でもこの工程に 2, 3 分は費やすかもしれない。kernel parameter から quiet splash を外して、vga=791 nomodeset を加えた。やっぱり linux はワシャワシャと boot log を出して、動いている感を全開にしないと。
2020.05.11
コメント(0)
-
(1_Tri_-3r0_-3r0).png)
LabTool 波形発生機能に Offset 加算を実装してみる - Firmware の互換性は無くなったなぁ...
LabTool(秋月にリンク)の波形発生機能に offset を加算する機能を実装する。振幅の方も汎用性を持たせるために signed に拡張した。これて、Firmware の互換性は無くなった。GitHub に置いた Source Code は Host Application, Firmware とも再構築が必要だ。UI の設定ウインドウ DC Offset を加える。Amplitude に符号を指定できるように拡張した。Offset V0, Amplitude A, 時間 t, 出力 Vout(t), DAC 入力範囲外をクリップする関数を Clip(), 波形関数を f(t) とすると次の様な式で出力する(はず)。Vout(t)= Clip(V0 + A * f(t))出力電圧が AOUT_0: High: -0.28V, Low: -0.21V くらいズレている。ノイズ込みでオシロの MEAS 機能で測っているからなぁ... 周波数も 1kHz を示さない。合わせ込みが必要かもしれない。Sine 波も試してみる。AOUT_1 側は振幅、オフセットの設定でクリップするか見ている。クリップ処理は Firmware の計算で行っている。出力電圧のずれ方が、三角波で見たときと違う。AOUT_0 の方はズレの方向が上に凸ピークと下に凸ピークで符号が違う、-60mV と + 28mV 位か。DAC の分解能より大きい。AOUT_1 のクリップの様子も要注意かも、クリップは DAC の code 範囲で行っている。出力 opamp TLV272 の仕様で制限されているのか、見極めかな。Rail to Rail なんだけどな。DC 出力(Application, Firmware とも Level と表現)機能も使えるようにしたので、精度の良さげなテスタで測定かな。ベンチトップのマルチメーターは持ってない。オシロの MEAS 機能で測った電圧値はノイズ込みだ。オシロの ADC は 8bit 分解能なのも要注意だ。サンプル数は 20Msample、十分に分解能は補っているかなぁ。LabTool の波形測定機能の Calibration は DAC 出力機能を使っている。DAC 側の出力が単純な線形補間と離散化で表現しきれないかも。ん? LabTool の出力を測定しているオシロで十分ではないか? LabTool が気軽に使えるオシロになればなぁ。出力を測定したオシロには波形発生機能無いし...
2020.03.09
コメント(0)
-
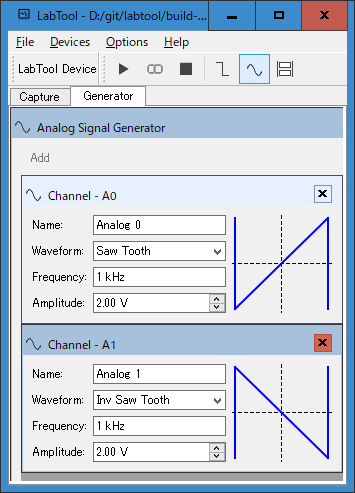
LabTool にノコギリ波発生機能を実装してみる - 未完成部分だったところ
LabTool の firmware を読んでいたらノコギリ波発生機能が実装されているのでは?と思える部分があった。USB Host 側(つまり PC)の実装を追加すれば使えそうに見えた。実装を追加してみる(リンク先は GitHub)。UI で設定して、出力してみる。振幅は DAC 出力フィルタの帯域制限による鈍りなのか、少し小さくなっている。出力できた方が少し便利なはず。ノコギリ波を出せる様にしたのは中間的な段階、DAC 出力を詳しく見たく、Level (DC) 出力を使いたいのが目標だ。LabTool device の Firmware には DC Offset を設定する機能も実装されている。こうやって波形を観測してみると、位相も設定したくなる。
2020.03.06
コメント(0)
-

Ployer MOMO7(or MOMO8) SileadTouch.fw を失いタッチパネル使用不可 - Windows10 1909 をクリーンインストールして失敗
タブレット PC WDP-081-32G-81BT(Ployer MOMO7 か MOMO8)を Windows Update で Windows10 1903 から 1909 にアップデートできなかった。ストレージのバックアップに失敗して、Windows10 1909 をクリーンインストールした時にタッチパネルドライバを失う。バックアップファイルを仮想環境か仮想ドライブにリストアする予行練習をしていれば防げたかもしれない。特にパネルセンサーのファームウエア(あるいは調整パラメータ) C:\Windows\System32\drivers\SileadTouch.fw を失ったのが致命的だった。タッチパネルがまともに使えなくなる。blog を暫くサボってしまったのもこの Tablet PC に手こずってしまったからだ。 Microsoft Update Catalog にも Silead touch panel driver がいくつかある。2, 3 試して、どれもタッチ座標がまともに取れない。多分テスト用のドライバで、実用は考えていない可能性がある。Control Panel → タブレット PC 設定で行う調整も全く効かない。1 本指で触れているのに 2 本指で触れているかのような応答をする時点で、調整以前の問題が起きている。Android 端末のドライバ開発をしていたときに、タッチパネル向けにパネルセンサーのファームウエア blob がリポジトリに投入される度にバイナリをレビューしていた。訳が分からないし、何かの機械語とも違うようだし、ドライバのソースを見るとセンサーのメモリにダウンロードするアドレスも、バージョン毎に変わっていたし。他の機種どころか、少しでもドライバ・バージョンが違うと全く互換性がない。現状のユースケースを考えてタッチパネル操作は諦めることにした。Bluetooh マウスとキーボードを使い操作することにした。タブレット PCは先に出した画像のようにアームに取り付け、作業台で使っている。タッチができ方が便利そう?アームを買う前はそう思っていた。アームはバネの張力で角度を維持している。一応、角度固定用のノブもある。パネルに触る度に何度もお辞儀をするようにアームは前後する。剛性がないというか、そもそも、タッチすることは力学的にバネや細いフレームに伸び縮みや曲げの変位を与え、開放することだ。振動を始めるのだ。タブレット PC のタッチパネルも SileadTouch.fw を失わなかったとして、操作性に不満が有った。作業台で使うので型番を検索するのにスクリーンキーボードを使う。画面の半分が覆われ、情報が隠れてしまう。タッチパネル系の UI は前の画面は「覚えておく」あるいは「覚えなくても済むレベルの情報しか扱えない」。Android にしても Windows にしても今のところ、1 画面前の事なんてすっかり忘れて下さい的な UI だ。本当に必要だったのは、PC 用ガジェット箱に眠っている Bluetooh マウスとキーボードのホルダーだった。段ボールで作ってアームにぶら下げることにした。2, 3 日ドライバインストールに格闘するのではなく、1 時間掛けて段ボール工作をするのが最も良い解決策だった。
2020.01.16
コメント(0)
-

LabTool 弄りを続けていて日記はサボり気味 - ぱっと見た目はあまり変わらない
ぱっと見た目は変化が少ないかもしれない。LabTool を弄り続けている。アナログ波形レンダリングを変えている。sin(x)/x 補完とかもっと本質的にやることはある。これはやっていない。処理が重くならない範囲で少しはマシな表示になる様な修正を試している。元のアルゴリズムはオシロ使ったことあるのかな?と思うようなところが有る。
2019.11.14
コメント(0)
-

LabTool 弄り - 買ってからずーと気になっていたこと
LabTool をビルド出来るようになったのでデザイン的に「まぁまぁ」になるかどうか、色々と弄っている。「おわかり頂けただろうか?」という感じの些細な変化だ。Qt と久しぶりに書く C++ の触りだけ勉強してみて、ちょっと修正する。見た目が変わるの楽しいな。
2019.11.05
コメント(0)
-

データドライブが壊れた (3) - 壊れたファイルはダウンロード、コピー元が存在すると判明
バックアップ先のハードディスクを別のケースに入れることにした。予備で買っておいた UNITCOM の UNI-HAL35 を化粧箱から出す。買ったときにブリッジチップを確かめていれば、USB 接続は早々にあきらめて、SATA 接続でクローニングを始めていたと思う。基板を確かめてみる。12V から 5V に降圧するスイッチングレギュレーターの IN, OUT 両方のコンデンサが高リプルに耐えられるかどうか怪しい。105 ℃規格品なのは確かだ。インダクタも開磁路型なのでノイズ放射が大きい。ブリッジチップの刻印を読む、JMS567 だ。ファームは何だろうか?使ってみたところ、ランプの点き方は Version 138.01.00.01 かその派生の様に見える。コンデンサとインダクタを交換する。場合によっては長く使うかもしれない。コンデンサは東信 UTWRZ 25V 220uF に交換、並列に MLCC 25V 10uF Z class、インダクタは準閉磁路型(狭いギャップがある)で同一定数 33uH に交換する。ブリッジ線を入れたのは、部品を外す時にパターンを痛めたので補強した。半田ごてを二刀流で使えばよかったかも。導通・非導通チェック、基板単体動作で電圧チェックをする。主要な電源ライン 12V, 5V, 3.3V を確認できた。問題なし。ここまで手を入れた UNI-HAL35 は結局使わないことにした。先の Asmedia ASM1053 を使った 玄人志向 GW3.5TV-SU3/SV と同じ挙動になる。同じようなファイルを読みだしたところで、USB 接続が切れてしまう。ハードディスクに問題が有ると考えた。先にバックアップ先のハードディスクの不良ブロックマップを出す。これも、実際の作業流れではクローニング完了後に分かる情報だ。画像をクリックすると PDF を開きます。LBA の大きい方(後方)に不良ブロックが集中していた。全部で 102Kibyte だ。バックアップ元もバックアップ先も不良ブロックが発生している。クローニングしたドライブはどちらも不完全だ。比較してみて、一致しなければどちらかが壊れている。先に言及した通り、このドライブは 2016/10 に不良ブロックが発生している。次が 2016/10 時点の不良ブロックマップだ。Zero Fill をして不良ブロックを代替して使い始める(代替すると不良ブロックが消えたように見える)。画像をクリックすると PDF を開きます。不良ブロックは近隣にじわじわと広がらず、飛び火する様に広がっていた。この壊れ方ではパーティションを切って使わないようにしたり、fsck.ext4 の -l または -L オプションで拡大的な不良ブロックリストを指定して避けても、効果はない。USB 接続では安定したクローニングができない。SATA 接続にして、クローニングを行う。データドライブと同様に sg_dd を使用してクローニングをした。不良ブロックの近辺でいわゆる「低速病」になった。16block を読み出すのに 1 ~ 2 秒ほど掛かる状態が 1 日程度続く。途方もなく長い作業を覚悟した。終わってみれば全ブロックをコピーする速度は 23.09 Mbyte/sec だった。「低速病」の原因の一つは、不良になりかかったブロックのエラー訂正、あるいは何かの条件を変更した読み出しを行ってデータ修復を行う動作なのか。遅いクローニングに並行して照合作業を迅速に行う方法を調査・検討していた。cmp コマンドで双方のファイルを一つ一つ読み出し byte to byte で比較すると数日では終わらないことが分かってきた。多少冗長なスクリプト(リンク先はスクリプトのソース)で、一つ一つの md5sum を計算し、パス名を正規化(パスからマウントポイントを削除する), sort, diff を行い差分から、破損、喪失(ないはず) ファイルを見つけることにした。#!/bin/bashCDir1=/mnt/sdd3/furuta/backup2nd/whitenine-2nd # path to mount backup rootif [ -n "$1" ]then CDir1="$1"fiCDir1T="${CDir1}"if ( ! echo "${CDir1}" | grep -q '/$' )then CDir1T="${CDir1}/"fi(cd "$CDir1"; find . -name '*') |while readdo File1="${CDir1T}${REPLY}" if [ -d "${File1}" ] then continue fi sum=`md5sum "${File1}" | cut -f 1 -d ' '` echo "\"${File1}\" ${sum}"done厳密にいえば md5sum は全く別のバイナリ列が同一値を示す場合もある。ファイルにブロック単位で 0x00 の穴を空けて、偶然に md5sum が一致することはほぼ無いと考えている。もし、一致することが有るならば md5sum に対してハッシュ衝突をするバイナリ列の生成方法に多くの手法が考案され、指摘が出るはずだ。67 万行の diff を上手くできないツールも有るので、いくつかのツールを試し、出力を比較して妥当だと考えられる出力を選ぶ。diff で得られた差分から、ファイル内容を読んでみる。幸い目視で可能な量だった。7 個の破損ファイルを確認し、ダウンロード、あるいは他にコピー元があるファイルだと分った。ここ 4, 5 年は使った実績も皆無だった。色々と長かった。不良ブロック番号をファイルのパスに変換するツールを探した方が早々に作業は完了したのかも。2019.10.25 追記データドライブが壊れた (1) - バックアップドライブも壊れていたデータドライブが壊れた (2) - クローニングが上手くいかない
2019.10.24
コメント(0)
-

データドライブが壊れた (2) - クローニングが上手くいかない
データドライブが壊れた (1)の続き、データドライブのクローニング作業を始める。作業は Linux マシンで行う。sg3_utils の sg_dd を修正したものを使う。sg_dd は SCSI command で直接ドライブをアクセスする dd コマンドだ。dd コマンドを使わない理由は、リトライを頻発させて、DID_BAD_TARGET, DID_NO_CONNECT, あるいは "rejecting I/O to offline device" になってしまう可能性を下げるためだ。次のコマンドでコピーを開始する。/dev/sdd は障害があるドライブ、/dev/sde はクローン先のドライブ、abortrep, abortnum は拡張したパラメータだ。素の sg_dd には存在しない。いずれもっと使いやすいコマンドに仕立て直したい。 # sg_dd if=/dev/sdd of=/dev/sde bpt=16 bs=512 iflag=coe,sgio abortrep=0 abortnum=10240 coe=1 time=1 skip=0 seek=0初め bpt=512 としていた。1 回の SCSI command 当たり 512 block を転送する指定だ。bpt=512 は良くないことが分かった。512 block のうち複数箇所に障害があると、ドライブ内部のエラー回復リトライが増えて、timeout 至り、デバイスドライバがドライブを切断 (offline) してしまう機会が増えてしまった。クローニング作業が中断してしまう。認識すらできない可能性があるドライブだ。作業をやり直す機会は僅かしかない。bpt が小さい値だと、転送効率が下がりクローニング時間は延びる。クローニング出来ない致命的な事態は第一優先で避ける。bpt=16 とした。これでも失敗するなら bpt=8 (AFT block size の 4Kibyte) なのかな...これでメイン PC のドライブはクローニングができた。sg_dd の出力から、688.5Kibyte 分の不良ブロックがある。約 67 万個あるファイルのうちどれが壊れたのだ?作業過程で知り得たことを正確に書くと、クローニングが終わった時点でドライブに格納されたファイル数は把握できていなかった。「全部で 1.5T byte になるファイルのうちいくつかが壊れた。」というぼんやりとした認識だ。クローニングをしたドライブを Linux マシンから windows マシンに付け替えて chkdsk /f を掛ける。エラー出力、修復動作は行われなかった。ファイル管理構造は壊れていない。全てのファイルは中身は壊れたかもしれないけれど、存在はしている。バックアップ先と照合することにした。バックアップは 2 つある。(1) 「バックアップと復元」によるバックアップと (2)「ファイル単位の差分コピー」による Linux バックアップサーバーへのコピー」だ。クローンとなったドライブを (2) のコピー先とファイル単位で照合することにした。照合していると、サーバー上にファイルが無いエラーが発生し、以降継続的にエラーが発生する。最初から試しても、ほぼ同じようなファイルを照合する辺りでエラーが継続してしまう。サーバーのログを見てみる。Synchronize Cache(10)、場合によっては Read(16) を含めて、bus reset を繰り返している最中に、"rejecting I/O to offline device" になり、バックアップ先のドライブを見失っている。[ 6927.678052] sd 6:0:0:0: [sdg] tag#0 uas_eh_abort_handler 0 uas-tag 1 inflight: CMD IN[ 6927.678063] sd 6:0:0:0: [sdg] tag#0 CDB: Read(16) 88 00 00 00 00 01 bc 2c 8f 80 00 00 02 00 00 00[ 6957.749432] sd 6:0:0:0: [sdg] tag#1 uas_eh_abort_handler 0 uas-tag 2 inflight: CMD[ 6957.749443] sd 6:0:0:0: [sdg] tag#1 CDB: Synchronize Cache(10) 35 00 00 00 00 00 00 00 00 00[ 6957.749452] scsi host6: uas_eh_bus_reset_handler start[ 6957.821569] usb 2-1.1: reset SuperSpeed USB device number 3 using xhci_hcd[ 6957.840875] scsi host6: uas_eh_bus_reset_handler success[ 6988.668563] sd 6:0:0:0: [sdg] tag#0 uas_eh_abort_handler 0 uas-tag 1 inflight: CMD IN[ 6988.668575] sd 6:0:0:0: [sdg] tag#0 CDB: Read(16) 88 00 00 00 00 01 bc 2c 8f 80 00 00 02 00 00 00[ 7018.676035] sd 6:0:0:0: [sdg] tag#1 uas_eh_abort_handler 0 uas-tag 2 inflight: CMD[ 7018.676046] sd 6:0:0:0: [sdg] tag#1 CDB: Synchronize Cache(10) 35 00 00 00 00 00 00 00 00 00[ 7018.676055] scsi host6: uas_eh_bus_reset_handler start[ 7018.752588] usb 2-1.1: reset SuperSpeed USB device number 3 using xhci_hcd[ 7018.772325] scsi host6: uas_eh_bus_reset_handler success[ 7018.772680] sd 6:0:0:0: [sdg] tag#1 Medium access timeout failure. Offlining disk![ 7018.772688] sd 6:0:0:0: Device offlined - not ready after error recovery[ 7018.772703] sd 6:0:0:0: [sdg] tag#0 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_TIMEOUT[ 7018.772709] sd 6:0:0:0: [sdg] tag#0 CDB: Read(16) 88 00 00 00 00 01 bc 2c 8f 80 00 00 02 00 00 00[ 7018.772713] blk_update_request: I/O error, dev sdg, sector 7452004224[ 7018.772764] sd 6:0:0:0: rejecting I/O to offline device[ 7018.772789] sd 6:0:0:0: rejecting I/O to offline device[ 7018.772794] sd 6:0:0:0: [sdg] killing request[ 7018.772817] sd 6:0:0:0: [sdg] FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK[ 7018.772823] sd 6:0:0:0: [sdg] CDB: Synchronize Cache(10) 35 00 00 00 00 00 00 00 00 00[ 7018.772828] blk_update_request: I/O error, dev sdg, sector 3917744192[ 7018.772852] Aborting journal on device sdg3-8.[ 7018.772887] sd 6:0:0:0: rejecting I/O to offline device[ 7018.772904] JBD2: Error -5 detected when updating journal superblock for sdg3-8.[ 7019.777687] sd 6:0:0:0: rejecting I/O to offline device[ 7019.777742] sd 6:0:0:0: rejecting I/O to offline deviceバックアップ先にも障害がある。何が原因だろうか?ディスクドライブに障害がある→ 障害があってもハングしないハードディスクケースに変える。または、ドライブをクローニングするUSB/SATA ブリッジチップ ASM1053 またはファームウエアにバグがあり、状況により UASP 処理がおかしくなる→ ハードディスクケースを変える。または、Linux の UAS ドライバを使わないようにする。Linux の UAS ドライバが未熟(stack dump とか見るしなぁ)→ ハードディスクケースを変える。または、Linux の UAS ドライバを使わないようにする。考えられる原因に対する対応方法からすると、ハードディスクケースを外して開ける必要がある。ケースは玄人志向 GW3.5TV-SU3/SV だ。ブリッジチップは Asmedia ASM1053 を使用している。ハードディスクケースの動作状況を見ているとアクセスランプが全く点かない。リブート時、"offline device" になる前の正常アクセスできる状態でもランプが点かない。気づいたときには複数の障害が溜まっている典型的な状態になっていた。バックアップ先に使っているハードディスクは一度不良ブロックを出したものだったのも致命的な運用だった。パーティションを切り直して避ければ良いと考えていた(経験的に避けても不良ブロックは広がりやすい)。この時点で当初の見込みと比べ作業量は 2 ~ 3 倍になる。続くなぁ...2019.10.25 追記データドライブが壊れた (1) - バックアップドライブも壊れていたデータドライブが壊れた (3) - 壊れたファイルはダウンロード、コピー元が存在すると判明
2019.10.21
コメント(0)
-

データドライブが壊れた (1) - バックアップドライブも壊れていた
10/14(月) 23 時頃、メイン PC で作業中にエクスプローラーでファイルを一覧すると操作に応答せず画面が更新されなくなった。何か重いな... と感じる。そう言えばサムネイルが壊れる現象が出ている。イベントビューアーで Windows ログ/システム イベントログを見てみる。ログの名前: Systemソース: disk日付: 2019/10/14 23:32:02イベント ID: 153タスクのカテゴリ: なしレベル: 警告キーワード: クラシックユーザー: N/Aコンピューター: whitenine説明:ディスク 3 (PDO 名: \Device\00000029) の論理ブロック アドレス 0x24d7018 で IO 操作が再試行されました。...むむ。ディスク 3(別の表示では harddisk3 と表示)ってどのドライブ?イベントログにディスクの障害が残るのだから、システムドライブ以外に何かが起きている可能性を考える。システムドライブに障害が発生すると、イベントログを開くのも困難になりがちだ。コンピューター管理/記憶域/ディスクの管理 でディスクドライブの番号を確認する。「ディスク 3」→2ND4T(データドライブのボリュームラベル) だと分かった。4Tbyte のドライブに格納したデータが壊れ掛かっている。この時点ではいつもの様にドライブを取り出し、クローンを作成、バックアップと照合、ファイル損傷状況を確認すれば良いと考えていた。バックアップコピーを作っていないファイルをバックアップドライブへコピーして、クローニング作業を始める段取りで進める。バックアップドライブへコピー中にバックアップが進まなくなっていた。深夜の作業だったので、バックアップ中に就寝する。朝起きてみたら、アクセス障害が原因なのか、再起動していた。想定より深刻かもしれない。データドライブに発生した不良ブロックマップを先に出しておく、初めから分かっているマップではない。クローニング完了後に分かる情報だ。不良ブロック全体で 688.5Kibyte ある。画像をクリックすると PDF を開きます。この状態の S.M.A.R.T. 情報を見ると「何か起き始めているかも」程度の状況だ。実際はデータを失う寸前の状態だ。不良ブロックマップは悪い状況を示している。LBA 0 付近に不良ブロックが多数あり、クローニングの作業を始める前、あるいは始めたとして何かの原因で失敗し、再挑戦しようとしたところで、ドライブを認識できなくなる可能性を示唆している。LBA 0 付近はパーティションテーブルが存在し、これを読み込もうとした時点で、ドライブが応答しなくなる。幸いなことに、同一容量のハードディスクが 2 台有る。1 台買ったのを失念して、2 台買ったんだっけ... ようやく 1 台が就役か... この時点で 2 台とも使う状況になることは分かっていなかった。クローニングを行うマシンにデータドライブを繋ぎ直す。あれ?クローニング作業マシンが起動しない。この時点で、俯瞰的な不良ブロックマップを知らないのだ。状況が悪いことは分かった。なぜだかは判らずに作業を進めるしかない。マシンを起動した後に、データドライブを繋ぎ、認識させることに成功する。ドライブとお話しできる口はできた。長くなりそうなので、とりあえずここまで。2019.10.25 追記データドライブが壊れた (2) - クローニングが上手くいかないデータドライブが壊れた (3) - 壊れたファイルはダウンロード、コピー元が存在すると判明
2019.10.20
コメント(0)
-

kernel と userland で違う使われ方をする linux の dev_t 型 - major, minor 値のビット位置
Linux で device (driver) と Userland を結ぶ node に付く major, minor 番号の成り立ちについて調べていた。おそらく今時の Linux user は major, minor 番号を意識することは殆ど無いと思う。多くの場合、udev が煩雑な処理を自動的に行っているはずだ。簡単に major, minor 番号について見ていく、コマンド ls -la /dev で表示される中で、次の様に "8, 0", "8, 1", ... と表示される値が "major, minor" だ。device に付けられた番号で、この番号を持つ node を mknodコマンドで major, minor 番号 と {block | character} device の区別を加えてファイルシステム上に作ると、open(), read(), write(), ioctl(), close(), ... などの system call で操作できるようになる。$ ls -la /dev-- snip --brw-rw---- 1 root disk 8, 0 Sep 25 02:21 sdabrw-rw---- 1 root disk 8, 1 Sep 9 05:23 sda1brw-rw---- 1 root disk 8, 2 Sep 9 05:23 sda2brw-rw---- 1 root disk 8, 3 Sep 9 05:23 sda3brw-rw---- 1 root disk 8, 5 Sep 9 05:23 sda5-- snip --major, minor 番号とも 0..255 の範囲だと思っていた。これは違うことに気づいたのか調べる切っ掛けだ。古くから unix 系 OS を使っていた思い込みだ。major, minor 番号はビット単位の論理演算により dev_t 型に格納され扱われている。Userland では stat() 系の関数に使われる struct stat の st_dev がその代表だ。Kernel では device driver と file system を中心として、dev_t 型に major, minor 番号を(userland と同様ではない)ビット単位の論理演算で格納している。Linux Kernel と Userland の dev_t に格納された major, minor のビット位置を調査してお絵描きしてみたのが次の図だ。上半分が kernel の中の dev_t、下半分が Userland の dev_t だ。流れは Kernel to Userland の方向で書いてある。Kernel の中の dev_t の値が、Userland の dev_t (例えば struct stat 構造体のメンバ st_dev) にどのように格納されるかを示している。初めに押さえておくべきことは、kernel の中では、MAJOR(), MINOR(), MKDEV()、Userland の中では major(), minor(), makedev() を使っていれば dev_t の bit 配置がどうなっているのか気にしなくて良いということだ。kernel の中で dev_t は unsigned の 32bit 型として定義されている。dev_t の型定義、__kernel_dev_t の型定義、と追っていけば比較的容易に確認できる。CPU 語長に依存しない実装だ。単純に上位 12bit が major 番号、下位 20bit が minor 番号になっている。SystemV 系 OS の Userland で dev_t は unsigned 64bit 型として定義されている。GLIBC の実装を分かりやすそうな経路で追うと、posix/bits/types.h (dev_t を __dev_t で型定義), posix/bits/types.h (__dev_t を __DEV_T_TYPE で型定義), sysdeps/unix/sysv/linux/generic/bits/typesizes.h (__DEV_T_TYPPE を __UQUAD_TYPE で定義、あるいは CPU arch. 毎の実装), posix/bits/types.h(__UQUAD_TYPE を __uint64_t で定義あるいは 64bit 語長 CPU では unsigned long int で定義), と追っていけば確認できる。Userland の dev_t は bit 19 .. 8 (0x13 .. 0x08) の 12bit が major 番号、bit 31 .. 20 (0x1f .. 0x14), bit 7 .. 0 (0x07 .. 0x00) の部分が Minor 番号になっている。Userland で dev_t は 64bit ある。kernel 内 dev_t から userland の dev_t に変換する new_encode_dev() は 32bit 型の整数を返すので常に上位 32bit は 0 になっている。GLIBC の bits/sysmacros.h に Userland の major(), minor(), makedev() の実装が有るので、userland の dev_t に対するビットシフトとマスク処理を確認できる。注: 古い GLIBC は別の場所に実装がある。Userland の dev_t が複雑なビット配置になってしまった事情は古い Unix 系 OS の慣習であった major, minor とも 8bit だったのが原因なのだろうか。
2019.10.09
コメント(0)
-

サムネイル表示が壊れた - 縮小表示をクリーンアップして解消
デジカメで撮ったサムネイルが青または緑で 5 本の横帯状に表示されるようになった。帯は何となくグラデーションが掛かっている。初めのうちは撮った画像の何枚かがこのような表示になる。何だろう?と思っているうちに半分、9 割、全部と言った具合に症状が悪化した。デジカメのファームが壊れた?と思った。サムネイルを作り直すと正常表示になるのも状況の判断をおかしくしてしまった。何となく思いつき、同じファイルを別の PC にコピーしたらどうなるのだろう?と思ってコピーして表示したら正常表示された。表示が壊れた PC の状態が異常だと気づく。エクスプローラでドライブ C (厳密にはシステムドライブ)を右クリックして、プロパティの中に表示される「ディスクのクリーンアップ」→「システムファイルのクリーンアップ」を実行して解消する。クリーンアップするときの縮小表示に使っていた容量は 2.01Gbyte だった。2Gbyte 位になるとおかしくなるのか?もう一回画像を表示し直してみる。縮小表示の容量が 2.29Gbyte になっても表示は正常だ。画像を追加しても正常。何で壊れたのだろう?まさか 交換した SSHD がもう寿命?
2019.09.29
コメント(0)
-
scp が stalled する - 転送速度制限 -l オプションが効かない場合、~/.ssh/known_hosts を直す
384Gbyte のファイルを scp でネットワーク越しにコピーしていた。64Gbyte 程を転送した辺りで stalled で止まる。ネットで検索すると scp に -l オプションで転送速度制限を掛けると解消するとあった。試してみて効果無し。scp がダメなので、仕方が無く ssh を直接使い、pipe を使った転送をする。同様に 64Gbyte 程転送したところで次の様なメッセージが出てきた。鍵交換でもするときに、known_hosts に矛盾があると止まるのか?Warning: the ECDSA host key for '2ndwatt' differs from the key for the IP address '192.168.0.160'Offending key for IP in /home/furuta/.ssh/known_hosts:5Matching host key in /home/furuta/.ssh/known_hosts:25Are you sure you want to continue connecting (yes/no)? yesfuruta@2ndwatt's password: パスワード入力おおよそ 64Gbyte を転送する度に表示され、2 度ほど同じように手入力で、yes と パスワードを入力した。known_hosts を修正することにした。最近の known_hosts はエンコードされていて、エディタで編集しにくい。状況確認、IP アドレスとホスト名が known_hosts に登録されているか確認する。192.168.0.160 と 2ndwatt は接続先の IP address と netbios ホスト名だ。$ ssh-keygen -F 192.168.0.160encoded string line$ ssh-keygen -F 2ndwattencoded string lineどちらもエンコードされた文字列で構成された行が表示された。IP アドレスの方を削除する。場合によってはどちらとも削除し、ssh でログインし直した方が良いだろう。$ ssh-keygen -R 192.168.0.160ホスト名も削除する場合、$ ssh-keygen -R 2ndwatt以降、1 度だけ known_hosts を更新する旨の警告が出るだけで ssh の pipe を経由したコピーは終了した。これを踏まえると scp が stalled で停止したときに yes [enter] と入力していれば先に進んだのかもしれない。ssh でログインする度に host と IP アドレスの矛盾を指摘する警告が出て、煩いなと思ってスルーしていた。意外に後から問題を起こす警告だったとは。
2019.05.13
コメント(0)
-

WDC WD10J31X SSHD の奇妙な壊れ方 - 全 block 読み出し可能なのに書き込みできない
Windows 10 システムイメージを格納している WDC WD10J31X SSHD が壊れてしまった。奇妙な壊れ方だ。全 block 読み出しできる。書き込みができない。壊れた WD10J31X から状況を採取する。smartctl -a, smartctl -x, hdparm -I それぞれのリンク先はテキストファイルだ。SMART 情報を読んだ限りは、14065 時間使われ、それなりに使用感はある。約 1.6 年で十分に現役だろう。エラーは皆無、元々ログ機構が無いのか、何が起きたのかは読み取れない。まるで正常なのだ。格納されたデータを壊さないように partition として使われていない領域を read, write してみる。Last LBA 付近は使われていない。size は AFT サイズ 4KiByte とした。/dev/sdb は WD10J31X の block device node だ。[読み出し]# dd if=/dev/sdb skip=1953525160 count=8 | od -A x -t x1000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 008+0 records in8+0 records out*0010004096 bytes (4.1 kB) copied, 0.000371121 s, 11.0 MB/s→ エラー発生せず。[書き込み]# dd if=/dev/zero of=/dev/sdb seek=1953525160 count=88+0 records in8+0 records out4096 bytes (4.1 kB) copied, 2.58513 s, 1.6 kB/s→ 一見エラーなし。手応え的に時間が掛かりすぎている感がある。書き込みの手応えが何かおかしい。dd の出力からも分かるように転送に時間が掛かりすぎる。何回か試しても数 kB/s から 10 数 kB/s 台だ。dmesg で kernel log を見てみることにした。起動直後からの kernel logkernel log から WD10J31X 書き込みエラー部分を抜粋[ 3662.119993] ata4.00: limiting speed to UDMA/33:PIO4[ 3662.120001] ata4.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6[ 3662.126450] ata4.00: irq_stat 0x00060002, device error via D2H FIS[ 3662.132622] ata4.00: failed command: WRITE DMA EXT[ 3662.137412] ata4.00: cmd 35/00:08:a8:6d:70/00:00:74:00:00/e0 tag 22 dma 4096 out[ 3662.137412] res 61/04:08:a8:6d:70/00:00:74:00:00/e0 Emask 0x1 (device error)[ 3662.152601] ata4.00: status: { DRDY DF ERR }[ 3662.156863] ata4.00: error: { ABRT }[ 3662.160432] ata4: hard resetting link-- snip --[ 3664.792020] sd 3:0:0:0: [sdb] [ 3664.792023] Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE[ 3664.792026] sd 3:0:0:0: [sdb] [ 3664.792028] Sense Key : Hardware Error [current] [descriptor][ 3664.792032] Descriptor sense data with sense descriptors (in hex):[ 3664.792033] 72 04 44 00 00 00 00 0c 00 0a 80 00 00 00 00 00 [ 3664.792044] 74 70 6d a8 [ 3664.792049] sd 3:0:0:0: [sdb] [ 3664.792052] Add. Sense: Internal target failure[ 3664.792055] sd 3:0:0:0: [sdb] CDB: [ 3664.792057] Write(10): 2a 00 74 70 6d a8 00 00 08 00[ 3664.792073] end_request: I/O error, dev sdb, sector 1953525160[ 3664.797902] Buffer I/O error on device sdb, logical block 244190645[ 3664.804168] lost page write due to I/O error on sdb[ 3664.804175] ata4: EH completeエラーが発生していた。書き込めない。dd command がエラー終了とならずに kernel log にエラーが残ることがあるのか。気をつけないと。何かのページで SSHD は Flash Memory が損耗限界に達したら、ただの HDD になるだけだと読んだことがある。違うようだ。読み出せるのに書き込めない原因として最もらしいのは、Flash Memory が損耗してしまい、Flash Memory 書き込みエラーが Write Command を error にしているという状況だ。別の状況も考えられる。Flash Memory を代替領域として使っているとする。Flash Memory が損耗限界に達したか代替数の上限に達したところで、代替不能になり書き込みを受け付けなくなっている。考えにくい。従来通り、プラッタの一部を代替領域にするのが妥当な実装だと思う。SSHD を作るときにライフサイクル全体を通してどんな挙動をするべきなのか? 仕様検討が不十分なのか、実装、テストが不十分なのか、未成熟のまま市場に出したような...ここで区切って、ことの始まりから書く。メインで使ってる PC がフリーズしだす、ネットの動画を見ていたら止まった。どの window も閉じることができず、task manager を使った終了もできなくなった。シャットダウンも止まる。リセット・電源 off/on を何回かしても、起動途中で HDD アクセスランプが点きっぱなしで停止、10 分ほど待つと Blue screen "0x000000ED UNMOUNTABLE_BOOT_VOLUME" が出て再起動する。この時点で起動ドライブ WD10J31X か swap file を格納している SSD のどちらかが故障していると考えていた。"UNMOUNTABLE_BOOT_VOLUME" なので起動ドライブが故障していると考えるのが一番妥当だろう。セーフモード起動はできず。Windows 10 のインストールメディアを作成し、修復セットアップを試みる。mediacreationtool1809.exe は半日くらい経つと、失効するのだろうか?時間が経つとメディア作成に失敗する。1809 build の DVD メディアで起動に成功する。1 時間くらい待っただろうか。自動的な修復は「修復できませんでした」で終了する。コマンドラインを開き、dir command を試みる。I/O エラーだった。chkdsk /f を試みる。「不明なエラーが発生しました (6e74667363686b2e 116e)」、「不明なエラーが発生しました (6e74667363686b2e 1713)」で終了する。"6e74667363686b2e" は何だろうか?文字列に変換すると "ntfsck." だった。識別情報か...この状況は良くない。read できない block が多数発生し、致命傷に至る前に手を打つべきだ。クローン作成とクローンを使った修復作業をする方針に切り替える。clonezilla で全バックアップ、エラー無しで終了する。リストア作業に失敗する。clonezilla による作業は断念した。信頼できないツールを非常事態に使うのは危険だ。保守用に買っておいた TOSHIBA MQ02ABD100H に dd で全コピーすることにした。こちらも 1Tbyte で同一容量だ。512byte LBA 数も 1953525168 で完全に一致する。コマンドラインの斜字体部分は該当するドライブに割り当てた [a-z] の文字になる。# dd if=/dev/sdWD10J31X_block_device of=/dev/sdMQ02ABD100H_block_device bs=8192bs を 8KiByte にしたのは、(1953525168 * 512) のもっとも大きな 2^n を満たす約数だからだ。小さい値だ。確実に余りなくコピーできるのだから、時間は犠牲にしよう。次にディスクイメージを VirtualBox Disk Image file (VDI) ファイルとして保存する。qemu-img コマンドを使用して次の様に作成した。これで何度でも色々な方法で修復作業を試せるようになる。# qemu-img convert -O vdi /dev/sdWD10J31X_block_device backup-image-file.vdiここまで clonezilla, dd, qeum-img を使って read するだけなら WD10J31X は全くエラーを起こさない。chkdsk /f で論理的破損が多数出る状況は心配しつつ、データに致命的損傷が無い期待も有りそうだ。平行して、別の Windows 10 PC を久しぶりに電源を入れて、最新の更新状態にする。chkdsk /f 中にリブートするのは悲劇だからだ。別の Windows 10 PC に全コピーでクローンになった MQ02ABD100H を接続する。chkdsk /f を実行する(と言うより Windows 起動中に自動的に修復が始まった)。1 時間ほど掛かっただろうか?起動終了後にディレクトリ、ファイルの存在を確認してみる。普通にエクスプローラで見ることができ、2, 3 分で見られる範囲で欠損は見当たらなかった。MQ02ABD100H を メインで使ってる PC へ接続する。起動を試みる。プロダクトキー認証で何かいわれたら、「ハードディスク故障です」で交渉するつもりだった。再認証などは特に行われず、起動した。時刻がなぜか故障で動かなくなった時刻の 4, 5 時間前になっていた。4, 5 時間前に故障事象が発生していたのだろうか?イベントログが更新されなくなったのも、時計が止まった時刻近辺だ。ネットワーク時刻に同期して時刻を修正する。暫く使う、問題は起きず。溜まっていたメールも読め、サーバーに保留していたメールも受信し読める。ネット接続に大きな問題はなし。MQ02ABD100H も SSHD なんだよなぁ... 検索してみると アマゾンのレビューが見つかる 直ぐに壊れるとな...
2019.05.13
コメント(0)
-

クリスマスはフィッシングサイトの対応 - 単にブラウザを閉じるだけで良い
親からネット閲覧をしていたら、変な警告が出たということで見て欲しいと言われた。昨日から起きていることらしい。初めのうちは何が起きたか説明を聞いてもサッパリ分からず、仕方が無いので 4 時間掛けて PC を取りあえずバックアップすることにした。クリスマスはこれで何も出来ず。親が PC を操作していて、また警告表示が出たという。その現場を押さえて、色々と情報収集をしてみる。変な警告のページタイトルは Win Erx03 で URL は http://d1rnysi2im327b.cloudfront.net/prelander_secure/index.html?... だった。? 以下は CGI 変数が多数続く。多分今はアクセスできない。DNS 解決が出来なくなっている。文面をページのソースからコピーすると次の様な感じだ。システム警告Windowsセキュリティシステムが破損していますWindows: 「ここには Windows バージョン文字列が入る」ご注意: Windowsセキュリティによってシステムが壊れていることが検出されました。ファイルは: 「250 ~ 0 秒でダウンカウント」秒で削除されます必須: 下の[更新]ボタンをクリックして、最新のソフトをインストールしてスキャンし、ファイルが保護されていることを確認してください.サーバーから流れてきたページのソースコードを読む限り、Windows の状態は何一つチェックしていないように見える。厳密に言えばブラウザが送ってくる情報を表示内容のために使っている。言語情報、Windows Version だ。ファイルは 250 秒経っても削除されない(表示は「0 秒で削除されます」で止まる)。色々としようとすると、うるさい Beep 音が鳴る。次の様なスクリプトが仕込まれている。audCenter = new(window.AudioContext || window.webkitAudioContext)();function sound() { volume = 0.56; duration = 354; type = "square"; // "sine", "sawtooth", "triangle" frequency = 951; var oscillator = audCenter.createOscillator(); var gainNode = audCenter.createGain(); oscillator.connect(gainNode); gainNode.connect(audCenter.destination); gainNode.gain.value = volume; oscillator.frequency.value = frequency; oscillator.type = type; oscillator.start(); setTimeout( function() { oscillator.stop(); }, duration );};var i = 1x = setInterval(function() { sound(); i++; if (i > 2) { clearInterval(x); }}, );ちょっと変な箇所がある。まぁ、これでも鳴るのだろう。URL にエンコードされている CGI 変数 lang を弄ると、あまり出来が良くない仕掛けだとすぐに分かる。表示に undefined が並ぶ。英語圏の人たちは次の様な画面を見ているはずだ。対応方法は単にブラウザを閉じれば良い。スクリプトを見ると Close や Click を妨害する様な仕掛けがある。閉じることが出来ない可能性が高い。この場合、[Ctrl] + [Alt] + [Del] キーを押す。画面に選択肢が出てくるので「タスクマネージャー」を選択する。タスクマネージャーが開いたらブラウザのプロセス、Internet Explorer や Edge などの 所を右クリックして「終了」する。ページに埋め込まれた広告に強制 Jump のスクリプトでも仕込まれたか。
2018.12.24
コメント(1)
-
github の障害に巻き込まれていたときの色々 - うーん、アトミックなトランザクションじゃないのか...
仕事先で github を使っている。日本時間 10/22 午前 10:00 ~ 11:00 位の pull request で障害に巻き込まれたことが分かった。その時に思っていたことをつらつらと書く。pull request が web page に反映されず、push した branch すら無かったことになっていた。「え?」と思い、ページをリロードして見たら branch が見えて pull request が不成立になっていた。もう一回しつこく pull request する。なんか受け付ける。リロードを繰り返すと pull request は不成立、どうなっているんだろう?「いいや、branch を 削除だ」ゴミ箱 icon をクリックするまではなんの躊躇も無くスルッとマウスカーソルを進めて、ポチッ。そう、いやな予感はやってしまった後でジワジワと脳裏をよぎる。もし裏で pull request が成立していて、その branch を削除したらどうなるのだっけ?なんか論理的な矛盾が起きそうだ。ここまで操作していて、チラチラと server が不調の時に出てくる怒っているユニコーンが出てきた。ああ、github 壊れているんだ。branch 一覧ページをリロードすることを繰り返すと、希に pull request が成立した画面も出てくる。そうか、ロードバランサーの向こうで分散処理しているサーバー群がそれぞれに抱えているデータベースかファイル群の同期が壊れているんだ。「なんだろなぁ。色々な操作って、アトミックじゃないのか。」と思っていた。分散データベースやファイル群も含めて、全て同期が取れた、あるいは、全て同期が取れるまでにトランザクションが分散された時点で、リクエスト成立じゃないのか。何か動作がおかしいと分かった時点で、全てのリクエストを拒否するのでは無く、受け付けてしまうのも、どうかしているなぁ。マスタデータベースかマスターファイルとタイムスタンプ同期できなくなっても動き続けちゃうのか。そもそも同期出来ない状態を認識できない?色々と弄ることに耐性が無さそうなシステムだと思い始める。昼前にはページをリロードするだけにした。リロードで壊れることは無いよなぁ...
2018.11.04
コメント(0)
-
組み込み SoC もチップセットなのかな - リファレンスデザイン以外は茨の開発
組み込み SoC の仕事が続いてる。良く出回っているラズベリーパイとかそんな類いのハードウエアで動くドライバの開発だ。リファレンスデザインは SoC メーカーから、評価キットとして提供される。ハードとソフトが一体だ。開発している製品の最終形態は、評価キットの基板を四角いケースに入れた形とは違う。メモリ、周辺デバイス、基板形状、それぞれ製品として必要な仕様を満たした部品を使い、設計をする。リファレンスデザインと違うと、「動かない」という状況が発生することがある。SoC メーカーと色々とやりとりをしているうちに、「リファレンスデザインと違う部品や基板は...」と、難色を示し始める。難な所を一つ、二つ見ていく。{DRAM | Flash} メモリの様な汎用部品の組み合わせであっても、今時はソフトウエアによる細やかな制御をしないと動かない。動いたとしても詳細な挙動を調べると、未実装だったり、汎用部品として程々に使える程度でベンダー独自の仕様になっている。「別の部品を使うなら、ソフトを頑張って修正・実装してね...」と言うことだ。電源周りはどうだろうか。電源入/切、休止/再開、Reset/Reboot 動作の際の所で主プロセッサ上のドライバでは操作できない処理がある。このような処理は簡単なシーケンサーや補助プロセッサが行っている。「自分自身や今動作中のプログラムを格納しているメモリの電源を切る・入れる・必要最小限にする」といった処理は難しい。補助プロセッサに格納されるプログラムは多くの場合、バイナリーで提供され、SDK は提供されない。「別の電源制御 IC を使いたい?ならば、補助プロセッサに関する NDA を締結して、さらに社内ツール・レベルの SDK を使ってね」ということになる。他の周辺デバイスも、リファレンスデザイン通りなら始めから動くデバイス・ドライバ付きだ。オープンソースでソースコードを読めたとして、殆ど関心を持たなくて良い。開発資金や人員に余裕がある所なら、ハードもソフトも独自実装・あるいは大幅な修正も可能だろう。そんな余裕を持てるところは希少だろう。大人しくリファレンス・デザイン通り SoC メーカーがチップセットとして提供するものを使うしか無いのだ。汎用部品を組み合わせ、部品メーカーが品質・価格を競い、自由な市場から部品を調達するなんてことはできない。「安い部品を見つけた!組み合わせると動かない。ドライバ修正してね!」という繰り返しをしているのは良いことなんだろうか。
2018.08.02
コメント(0)
-

最近 SD Card Reader が使えない日記の参照が増えたと思ったら - 「ディレクトリ名が無効です」Windows 10 1803 update で再発
最近 SD Card Reader が使えない日記の参照が増えていたのが気になっていた。実家に寄ってみたら、また「ノート PC の SD Card Reader が使えなくなったので見て欲しい」との事だった。「ディレクトリ名が無効です」、また出たか。前の日記と同じように SD Card Reader のドライバを「SDA 標準準拠 SD カードホストコントローラー」に変更して修復した。Windows 10 1803 へのアップグレードをした直後から症状が出たようだ。前回も同様にアップグレードで起きていた。うーん、Microsoft は前回の問題を全く省みていないのか?
2018.06.20
コメント(0)
-
ソフトウエア工学はプロジェクト手法を評価できるようになったのか - 現場で人間モルモット感
仕事を始めた先で新しいソフトウエア開発手法を導入するという流れになった。「何だろうな、合わないな...」という何となくな言葉が思い浮かぶ。もう少し、具体的な言葉にこの感を置き換えられないだろうか。久しぶりにダラダラと日記を書くことになりそうだ。手法が要求している事項: 「チームメンバーの誰もが同じスキルを持ち、誰にでも仕事を割り振ることができて、開発工程の全てを短期間でできる。」... 何だろう、基本的な生産工学の観点無視な手法は。人間で無くても製造装置には能力差があり、できることに違いがある。使用可能な資源割り振りは、基本的な課題のはずだ。そんなの無視で「上手くいきますよ」と... 正直言えばこの時点で手法の有効性に疑問が出てくる。ソフト開発はほぼ人間の手による。お互いの相性、気持ちの持ちよう、疲労度、作業内容の伝達解像度、ほか色々、製造装置には無い特性がある。この特性も加味して仕事の割り振り、進捗管理、打ち合わせ(あるいは議論)を持たないとチームは半年もすれば暗い雰囲気になる。おおよそ最近の手法論ではコミュニケーションをすれば、人間的特性が開発進行に与える影響は軽減されるとの立場を取っている。本当だろうか? 自分も既に 40 才台後半、性格は変わらないし、人との相性も変わらない。色々と高齢者達を話す機会を持った経験からすると、一生変わらない、あるいは加齢に伴う認知能力低下でさらに難しい状態になる。正面切って「開発チーム内のお互いの相性重視でプロジェクトを進めるよ」といった手法論は無いのだろうか?手法が要求している事項: 「要求の受付・変更は 2 週間程度のインターバル単位で行う」。そうですか、外部要因(内部要因も多くある)はほぼ時間軸で無視して上手くいきますよ。ですか。理想論を押し通しだ。現実に目を向ければリリース後に行われる外部の途中評価、徐々に完成・変化する結合対象となる周辺状況は、自分たちのチームとは非同期に変化する。こういった変化を自分たちが決めたクロック・エッジで入力、出力するのか(出力はクロック・エッジには乗せないのかも)。チーム外部とのやりとりに使われる時間間隔はどんなものが有っただろうか、定時 → 翌朝一、午前終わり → {午後一, 定時前}、月→{水|金}、1週間後、最小単位くらいで 3 時間くらいか。2 週間のサンプリング周期では周囲状況に追従することはできない。なんだろう、標本化定理とか制御理論とか難しいことは言わなくても、おかしな想定だと分かりそうなものだ。応答性が悪い人・チーム・組織はどうなるのだろうか?似たような手法を導入して、一度経験したことが有る。恐ろしいことに会社の中で組織ごと浮いてしまう。組織単位で周囲は離れていく。個人は首にできない、一方、組織はリストラできる。組織全体で誰も口にせずとも恐怖感が共有されるのだ。誰かが口にしたときは相当に深刻な状況だ。手法が要求している事項: 「作業内容は 2 ~ 3 時間単位で区切る」、「2 週間単位の大まかな仕事内容は 1 つにする」「2 週間後には完了・動作可能なものになっている」。開発手法を考えた人、何作っていたんだろう? 自分が開発をしている現場では部分ビルドだけで少なくとも 30 分は掛かる。フルビルドで 3 時間だ。その間、「ただ待っている?」そんな段取りはしない。次週から 3 週間後くらい先までの作業予定内容の勉強、前終わった作業結果の再確認をする。終わったのに何故に再確認?単発的なテストは済ませている。その後は 1 日から 1 週間程度の連続稼働テストを実施する。ループ・スクリプトを組み自動実行を続ける。出力結果の確認、メモリリークやプロセッサ負荷に異常が無いかの確認、最も影響が出やすそうな結合対象の状況変化、その担当者の感触の再確認、おおよそ 2 ~ 3 の作業内容を同時に進めている。2 週間で動作可能に持ち込むのも難がある。自分はデバドラ屋だ。デバイスを Read/Write して、DMA を動かして、file operations を実装して、部分部分は動くかもしれない。それは結合相手にとっては何も動いていないのと同じだ。デバイスのデータシート読み、ハードウエア設計部門からの制御指示を熟読し、ステートマシン設計(他色々)、破綻を起こさない排他制御、OS 由来の制約条件、全てを満たすように実装していく。デバイスの Read/Write だけをして、「言われたとおりの動作をしました。ウレシイネ。」なんてストーリーは無いのだ。ここだけ動けばいいや的なインクリメンタルな開発をしていくと、考えもしなかった排他制御矛盾に陥ったり、ステートマシンの遷移不良を起こしたり、リソースの解放不良を起こす。気づいたときには後戻りする方法すら思いつかない状況だ。電池ドライバ屋だったときの思いを重ねると、インクリメンタルな開発で、充電しっぱなしで電池爆発、放電しっぱなしでセット文鎮化なんてとてもできないからな...色々と考えを巡らせてみた。まだスッキリしない。新しい手法を思いついたら人間の現場に持ち込んでメトリック(計測)して評価するなんて、古いのではないか?モデルで表現した(具体的に言えばイベントドリブンで変化するステートマシンで表現した開発者、成果物、外部、内部、を使って表現した)開発現場で有効性と適応できない状況を検証してから、人間を動かすために使って欲しい。摩滅する肉体を持ったもので実験をするなんて勘弁して欲しい。自分が大学で「ソフトウエア工学」を学んだのは 20 年以上前だ。あれから、何らかの進歩は有ったのだろうか?モデルができるなら、開発者そのものを置き換えれば良いって? FPGA の上で「開発者」という回路が動いて「成果物」ができる。ああ、それが一番の願いだ。
2018.05.18
コメント(0)
-
ハードディスク内容整理 - 今すぐ使うあてが無いのに消すのは...
ゴールデンウイーク中に短期運用に付いた Linux PC のディスク内容を整理する。この PC はもともとファイル・バックアップ兼仮想マシンサーバーとして稼働していた。OS が古くなったのと、電力消費が多いので次第に使われなくなり、半年程度に 1 回電源を入れる以外は使っていなかった。OS が古いまま放置したのは、無償だった VMWare Server を動かすことができるのが古い kernel だったのと、色々と手を入れた iSCSI target の kernel driver を新しい kernel に適応させる修正が面倒になったためだ。ディスクに入っているファイルの殆どがディスクイメージのバックアップ、仮想マシンの仮想ディスク、ISO イメージ、アナログ放送時代の録画データも有ったな...バックアップのうち、複数世代があるものは最新のみ残すことにした。最新と言っても西暦 2012 年くらいだ。ISO イメージは現在稼働中のサーバーへ移動する。Ubuntu 10.04 なんて今後使う?仮想マシンは別のサーバーで稼働を続けている。名前は同じか ~2 なんて名前に変わっている。バックアップイメージをリストアしても現在動いている仮想マシンの機能は復旧しない。むしろ周囲を巻き込み、破壊的な結果になるだろう。それでも維持するのだろうか?アナログ放送時代の録画データは... ちょっと見てみる。時間が過ぎてしまうので後回し。もう動かない仮想マシンのディスクイメージを削除する。qemu-nbd --connect, losetup -P (-P はパーティション認識オプション), mount でマウントしてみて、インストールを試しただけか調べる。500Gbyte くらいは減らしたかな。直近で 500Gbyte を使う予定は無し。今日の作業の結果、今後に変化なし。
2018.05.12
コメント(0)
-
連休明けの社内のネット遅いのはどうして - みんな回線輻輳だと思っているのかな
連休が明け出勤する。勤め先のネットワークが遅くなっていた。自分だけ監視対象になったかな?と思っていたら、周囲の人たちも遅いと言っていた。全体的に遅いのか。みんな一斉に update のせいだろうと、理由を推測する声が聞こえてきた。確かに update のせいなのは間違いないだろう。速度を律速する設備は何だろうか?ネットワーク設備の構成は知らされていない。ヨソ者に簡単に教える情報では無いだろう。単純に考えれば、回線を構成する光ファイバーだったり、メタルのツイストケーブルだったりする。やたらと情報統制が厳しい勤め先だ。本当は L3 ルーターか L2 スイッチにトランスペアレント・プロキシが入っているのでは?と思う事が有る。接続先の TCP port と直接コネクションが確立しているつもりでも、パケットを監視するフィルターを経由したり、送信元を偽装するため VPN を経由して別のプロバイダーから繋いだり、通信量を減らすためにキャッシュを経由している? 目に見えない経由が律速の原因?自営の野良サーバー相手に試せばある程度分かるかも... 自重しよう... 本当に夜に誰か訪ねてくるかもしれない。
2018.05.07
コメント(0)
-
android の build を RAM 8Gibyte の PC でしてみる - _JAVA_OPTIONS を設定、android studio との共存要注意
Android Source Code を構築するための要求事項(Requirements) を見ると 16Gibyte の RAM/SWAP が必要と有る。Android を構築しようとする環境は RAM: 8Gibyte, SWAP: 23Gibyte, CPU: AMD Phenom II X4 945 (4core 3.0GHz) だ。メモリは足りているはず?と思って Android 8.1.0 の構築を arm と x86 ターゲットでしてみる(時間的に直列に)。どちらも "GC overhead limit exceeded." ですか...FAILED: out/target/common/obj/JAVA_LIBRARIES/framework_intermediates/with-local/classes.dex/bin/bash out/target/common/obj/JAVA_LIBRARIES/framework_intermediates/with-local/classes.dex.rspOut of memory error (version 1.3-rc7 'Douarn' (445000 d7be3910514558d6715ce455ce0861ae2f56925a by android-jack-team@google.com)).GC overhead limit exceeded.Try increasing heap size with java option '-Xmx<size>'.Warning: This may have produced partial or corrupted output.[ 2% 310/13030] //art/runtime:libartd clang++ parsed_options.cc [linux]ninja: build stopped: subcommand failed.11:53:25 ninja failed with: exit status 1-Xmxオプションを試してみてと有るので、ヒントを手掛かりに色々と検索して、try and error を繰り返す。pkill java で(あるいは昔ながらの手法通り ps auxww | grep java で PID を検索して kill $PID で) make が終了した後も残存している java process を終了して、次の様に _JAVA_OPTIONS 経由で java の heap 量と Garbage Collection (GC) 方針を設定した。export _JAVA_OPTIONS=-Xmx4400m -XX:ConcGCThreads=2 -XX:+AggressiveHeap -XX:-UseGCOverheadLimit -XX:+UseParallelGClunch aosp_x86-eng; make -j 4 で 03:55:02 でコンパイルが終わる。java process は最大 RSS(実メモリ使用量) 5Gibyte 程、SWAP 最大使用量は約 5Gibyte だった。4400Mibyte と指定したのに 5Gibyte を使用するのは謎だな。#### build completed successfully (03:55:02 (hh:mm:ss)) ####非力な CPU なりのコンパイル時間だ。GC で大幅に構築時間が延びずに済んだ。SWAP を / (binary と data) を格納したハードディスクと別にしていたのが良かったかもしれない。_JAVA_OPTIONS の指定が有ると android studio が起動できなくなった。studio.sh を修正して _JAVA_OPTIONS を export -n _JAVA_OPTIONS で削除するのが簡単だろう。それにしても、5Gibyte のメモリを消費して、2 thread で GC して、java の言語設計と実行環境設計は何か間違っているような... 1995 年に発表された当時、メモリは「高級」ワークステーションで 128Mi ~ 256Mibyte だった。メモリリッチな時代になれば「java のメモリ食いは問題にならなくなるさ」という話だったな。あれから 23 年、もっと酷くなっているのだが...さて、x86 emulator ターゲットの Android ができた。emulator で実行してみる。sse3 が必要とな... Phenom II では実行できないと ... NFS export して別の PC で実行しよう。
2018.05.05
コメント(0)
-
メモリを 4Gibyte から 8Gibyte にしたら起動しなくなった - 古い PC を引っ張り出して再稼働
大規模な make を実施したくなった。こういう時は新しい PC を調達するのが普通だと思う。そこそこ処理能力が高そうな古いマシンを探す。M2A-VM HDMI, AMD Phenom II X4 945 (4core 3.0GHz), 4Gibyte の構成で暫く稼働していなかった。M2A-VM HDMI を 8Gibyte 構成にした時の dmidecode 出力 と lspci 出力 だ。今時 4 core だ。電力効率が悪い。短期運用だから不問にするか。Lubuntu 16.04 x64 をインストールして、暫く動かしてみる。Lubuntu 16.04 のネットワーク設定がおかしく、繋がらない以外の問題は特に無かった。IPv4 のアドレスが設定されない。下に修正後の /etc/network/interfaces を示す。iface 行に下線を付けた dhcp 部分が manual だった。Live boot では DHCP 構成だったのに、何でインストールは手動設定なんだろう。$ cat /etc/network/interfaces# interfaces(5) file used by ifup(8) and ifdown(8)auto loiface lo inet loopbackauto enp3s0iface enp3s0 inet dhcpauto enp4s0iface enp4s0 inet dhcp暫く動かしてみて問題が無かったので 8Gbyte にメモリを増やした。起動しなくなった。メモリを増やした直後に memtest86+ を実施して PASS している。どうも、MBR を読んだか、読んでその直後辺りで起動処理を続けられなくなった様だ。メモリを増やしただけで MBR かその直後の段階の boot loader が壊れるのか? 4Tbyte の HDD を認識しなくなった?(直前までインストール作業が出来ていたのに?) 原因と結果が結びつかない現象に悩む。色々とやってみた結果を先に言えば、起動 HDD の接続先を PCI express に繋がった Marvell 88SE9123 から 32bit PCI bus に繋がった Silicon Image SiI 3114 に変えたら起動する様になった。チップセットの AMD SB600 に接続した場合も起動せず。どれも BIOS 起動処理段階ではハードディスクを認識して型名を表示できている。容量表示も正しい。うーん、PCI express 接続の SATA コントローラーなのに 4Gibyte より大きい領域が有ると DMA 転送できない? 32bit BUS 接続の SATA コントローラだと bounce buffer 経由の I/O になるよな...遅くなる。ここは「動かない」より「動く」選択だ。「色々とやってみた」内容は、MBR を修復してみる → 同様に起動しない、あるいは grub の rescue prompt が出る。再インストールをしてみる → grub の rescue prompt が出る。再インストールをしたのだ。また設定し直しだな... ところで 8Gibyte でメモリ足りるの?
2018.04.30
コメント(0)
-
IO DATA mAgicTV 録画予約情報表示ツール - 録画開始前に色々とできないかな
ここ 3 週間ほど riset3v IO DATA mAagicTV GT 番組予約ファイル riset3.ri 表示ツール を作っていた(riset3v.zip ダウンロード一式)。mAgicTV GT の録画失敗など色々な事象を何とかしようと、録画予約情報が取得できないか試していた。riset3.ri というファイルに録画予約情報が入っていることが分かってくる。録画開始時刻が取得できれば、録画開始前に色々と仕込める。できたツールで次の様な情報が取得できるようになった。riset3v -f "%s,%e,%N,%T,%t" -t "%Y/%m/%d %H:%M:%S"2018/03/30 07:00:00,2018/03/30 07:45:00,0x7fe0,0x7fe0,"NHKニュース おはよう日本[字]"2018/03/30 10:15:00,2018/03/30 10:25:00,0x7fe1,0x7fe1,"おとなの基礎英語[終] Session96「Review Test」"riset3v -f "%s,%e,%N,%T,%t" -t "%s"1522360800,1522363500,0x7fe0,0x7fe0,"NHKニュース おはよう日本[字]"1522372500,1522373100,0x7fe1,0x7fe1,"おとなの基礎英語[終] Session96「Review Test」"riset3.ri には録画失敗分も含まれている。再放送に備えるような情報が入っている様子。フィルターして整理する必要があることも分かった。ツールには C 言語で書いたソースコードも付けた。Visual Studio Community で構築できる様にするには必要な条件だ。手元では Visual Studio, Embarcadero C++, cygwin GCC, Linux GCC で構築できている。放送局を 16 進数では無く、愛称で表示できるようにとか、色々と改良点はある。録画時刻を知るのが目的なので今のところ機能実装は見送っている。さて、「録画開始前の仕込」を色々と試してみるか。
2018.03.31
コメント(0)
-

x86 16bit DOS コンパイラを動かしてみる - Linux の上で dosbox
Shift JIS コードで文字列を保存してあるバイナリファイルを読み取るちょっとしたツールを作り始めた。うーん、C 言語で作ろうか。実行環境は Windows10 64bit だ。昔の 16bit DOS コンパイラ Turbo C を引っ張り出す。「64 ビットバージョンの Windows での非互換のため、プログラムまたは機能である ~(以下略)」、「このバージョンの D:\TURBO\TC\TCC.EXE は、実行中の Windows のバージョンと互換性がありません。コンピューターのシステム情報を確認してから、ソフトウェアの発行元に問い合わせてください。」... そうですか。16bit コードは動かないですか。Shift-JIS 関連の関数は実装することにして、実装結果をテストするために 16bit 環境は必要だ。dosbox を使うことにした。Windows, Linux どちらでも動く。Linux で動かすことを選択する。$ sudo apt-get install dosboxインストールするとデスクトップ環境メニューの Games/DOSBox Emulator にインストールされる。ゲームですか...以下の流れは色々と試行錯誤して、それなりにすぐ使える手順として整理したものだ。まず、dosbox 内でドライブとして使うディレクトリを作る。MS-DOS でいう SUBST コマンドでドライブとして認識させるディレクトリだ。ここでは ~/dosbox とする。$ mkdir ~/dosbox~/dosbox 以下に使いたいファイルをコピーする。ファイル名は 8.3 規則に従って無くても良い。従っていない場合、LFN(VFAT) - SFN(FAT) 互換の様にファイル名が短縮される。$ dosbox最低限のツールは Z ドライブに入っている。COMMAND.COM を代表とする各ツールのバイナリは特殊な命令列を emulator call にしている様子。懐かしい COMMAND.COM 似のプロンプトで、ディレクトリをマウントする。ドライブ Z は特殊な Read Only drive の様だ。Z:\>MOUNT C ~/dosbox毎回面倒であれば ~/.dosbox/dosbox-0.74.conf の中の [autoexec] セクションで AUTOEXEC.BAT の様に書けば良い。実行ファイルパスも SET PATH=Z:\;C:\TOOLS の様に書ける。Linux 環境で更新したファイルを dosbox 環境に同期するには、RESCAN を使う。Z:\>RESCANソースコード管理は Git で、コンパイルは dosbox でという作業環境も少しの手間さえ掛ければ可能だ。Mouse Capture/Release をする [Ctrl]-[F10] (Ctrl は右の方が良いかも) を覚えればほぼ困らないはず。tcc 2.01 on dosboxTurbo Debugger (Borland C++ 5.0) on dosbox
2018.03.14
コメント(0)
-

全損ハードディスク分解 - 機構部を分解する前に基板の付け直しをして復活を試みるべきだったかな
認識できずに全損したハードディスクを分解してみることにした。分解途中で付けた傷以外にプラッタに目立った傷はなかった。ヘッドとボイスコイルモーターに繋がるコネクタと接触する基板の配線露出部に腐食が見られた。下の画像は分解がおおよそ終わったところ。機構部を分解する前に、基板の付け直しをすれば、もしかしたら復活したかも。確認事項、手順、試みるべきことに反省点が残る。分解途中の画像を見て行く、プラッタには目立った傷が無い。よく見ると傷、指紋、埃も見えるこれらは分解作業で付けたものだ。よく見られるような円環の傷もないし、ヘッドをシークさせた時に付く半月状の傷もない。表から見える基板のメッキ部分がくすんだり酸化か何かで変色していることにもう少し注意深くなる必要が有った。これだけの変色が見られるのだから、内側に有るヘッドとボイスコイルモーターに繋がるコネクタ接触部とスピンドルモーターに繋がる接触部も同様な状況になっていると考えるべきだった。基板の内側、部品面を見てみる。左上のヘッドとボイスコイルモーターに接続する配線の接触部には変色が見られた。接触痕が付いているので基板の付け直しをしても、何も変わらなかった可能性もある。目視では接触痕も酸化していた様には見えなかった。基板を外して付け直す、外したついでに接触部に着いた酸化膜の除去程度なら、実施しても認識しないという状況はほぼ変わらないか、良くなるかのどちらかしかないはず。ヘックス・ドライバでできる作業なので難度も低い。SATA コネクタ、電源コネクタ付け直し、ホスト側コントローラ変更で好転しないなら、次に試すべき作業は、ドライブの制御基板付け直しだったのかも。基板材料(メッキ)を選んだり、ケーブルの接触構造を選択するとき、メーカーでは十分にテストしたんだよな。
2018.03.08
コメント(0)
-
bash script で CGI 作り - 指定時刻に Wake on LAN service
bash script で CGI を書いて指定時刻に Wake On LAN をする自宅内サービスを作っている。そういえば昔shellshockなんていう話も有った。一応サーバーの bash を確認して問題を起こさないことを確かめる。働いていた時に bash で CGI を書いていると言ったら、「どうやって?」て言われたっけ?環境変数 QUERY_STRING から CGI 変数(正確な言い方はなんだっけ?)を取り出せる仕掛けを作れば、コマンドラインから起動するスクリプトと同じような感覚で書ける。次のコード片は CGI 変数を取り出す部分だ。書いた CGI より抜粋する。(2018/4/5 追記 余計な key="$1" を削除)#!/bin/bash -f# wakeup host at specified time.# CGI vars:# hostname=HostName# wake_second=UnixTimeSecond# wake_time=HumanReadableDateTimefunction uri_unescape() { local b c i l b="" while read do i=0 l=${#REPLY} while (( ${i} < ${l} )) do c=${REPLY:${i}:1} case ${#b} in (0) case "${c}" in (+) echo -n " " ;; (%) b='\x' ;; (*) echo -n "${c}" ;; esac ;; (2) b="${b}${c}" ;; (3) b="${b}${c}" printf "%b" "${b}" b="" ;; (*) echo -n "${c}" b="" ;; esac i=$(( ${i} + 1 )) done done}function query_var() { echo ${QUERY_STRING} | \ tr '&' '\n' | \ grep "^$1=" | \ sed -n -e "s/^$1=//p" | \ uri_unescape}shell_operators='$|&;<>(){}[]`'wake_host=`query_var hostname | tr -dc '[:alnum:]._-' `wake_second=`query_var wake_second | tr -dc '+-[:digit:]'`wake_time=`query_var wake_time | tr -d "${shell_operators}"`あまり込み入ったトリックは使わず、平凡に書いた。uri_unescape が % や + で escape された文字を decode する処理、query_var が CGI 変数名を指定して、値を取り出す処理になる。perl を使えば簡単では?... まあそうなんだ。大よそ動いている指定時刻に Wake On LAN する CGI scriptはまだ改良の余地がある。マシンが稼働していなくても動くように hostname → MAC address の辞書を持たせる。form を付けるcancel 機能を付ける。DoS に耐性を持たせる。仮稼働中をさせて実用に支障が無いか見つつ改良方針を考えないと。本当は RTC の wake 機能を使えば十分なはず。Windows ならタスクスケジューラーだし、Linux なら /sys/class/rtc/rtc0/wakealarm だ。たまに不発になるときの bad knowhow 的な CGI なんだよな...
2018.03.07
コメント(0)
全882件 (882件中 1-50件目)
-
-

- 楽天市場のおすすめ商品
- ふりかけ・・・おかわりしたくなる
- (2024-05-17 05:35:43)
-
-
-

- 楽天アフィリエイト♪
- レディース かわいいショートパンツ
- (2024-05-18 23:17:50)
-
-
-

- iPhone
- iPhoneのトラッキングがオフになって…
- (2024-05-17 14:42:07)
-



