

2008年05月の記事
全15件 (15件中 1-15件目)
1
-
おいしくない米らしい秋田63号ってどんな味なんだろうから PyPedal へ
<秋田63号>幻の「おいしくない米」復活、作付け開始 飼料価格高騰受け、家畜用に を読む。秋田63号は旧県農業試験場(現・県農林水産技術センター農業試験場)が88年から実験を重ね、02年に品種登録された。10アール当たりの収量は最大982キロ、平均でも900キロ近くと600キロ前後の「あきたこまち」のほぼ1・5倍。粒が大きく肥料も少なくて済む。穀物価格高騰のため、食用には向かないけど飼料用に試験的作付けが始められたということなのだが、どれくらい「おいしくない」のか食べてみたいものだ。それにしても 穀物価格高騰:消費超せぬ生産量 背景に途上国の人口増 というのはどうしようもないなぁ。登録品種データベース 秋田63号【アキタ63ゴウ】(食用作物)を見てみると玄米の見かけの品質は中の下、光沢はやや不良、香りは無、腹白の多少は多、食味は中の中である。「食味は中の中」ってことは「うまい」とはいえないけれど「まずい」ともいえないというレベルか。この品種を使って、また新しいものが作られているのね。越南182号/秋田63号 とか、秋田63号/上育440号//初雫 とか。大量に採れて、味もよいもの目指していろいろやっているということなのね。地道だよなぁ、こういうのって。XX号っていうのは、けっきょく商品化されない品種改良の途中で、売れるものになってはじめて名前が付けられるということか。そりゃそうだよなぁ。米じゃなくて、小麦の話だが、16億人以上の命を支える小麦農林10号の発明 稲塚権次郎って知らなかった。現在、「農林10号」の遺伝子を受け継ぐ品種は、世界50ヶ国で500品種(世界の小麦の約2/3)以上が栽培されている。秋田63号の子孫がダークホースでそんな存在になることは将来ないのかな。そういえば、この手の系統図のようなものを扱う Python のプロジェクトがあったよなと、以前に、pydot を調べているときにの記憶をたよりに探してみる。見つけた。PyPedal というのがある。PyPedal screenshot みたいなものができる。血統書とか、系統図とかが必要になる、その手のことをやっている人なら役立つんじゃなかろうか。過去の私の pydot 関連の記事を参考にすれば、たぶん、日本語化もできるだろう(pydot 回り以外にも、あれこれ手を入れる必要があるだろうけど)。Installing PyPedal under Debian を見ると、Debian の場合のインストール方法がまとまっている。
2008.05.26
コメント(0)
-
Python でエンコーディングを判定する
Python でエンコーディングの自動判定をするにはいくつかの方法がある。文字列のコードを直接調べてその情報だけで判定するタイプと、HTML や XML ファイルに含まれるメタ情報なども利用し、そうした情報で判定できないものは文字コードの情報から判定するタイプがある。前者のタイプでは、pykf や、nkfpython、kanjilib などがある。pykf は、ShiftJIS, EUC-JP, JISコードを相互に変換するためのPython拡張モジュールで、Universal Encoding Detector や encutils のようには、メタ情報を使わない直接文字コードをチェックするタイプ。日本語のみを前提とするのであれば、比較的短い文字列であっても、正しい判定をしてくれる。一時、入手が難しかったが、sourceforge で再公開されたので、今は入手できる。Windows 環境用には Python 2.4 と 2.5 のバイナリも公開されている (pykf download)。nkfバージョン2用 python インターフェース という、日本語漢字フィルタ nkf バージョン2用の python インターフェースを公開されていらっしゃる方もあるが、バイナリは Python 2.4 用のみで、2007年2月1日が最終公開日。自分でコンパイルするには、nkf2 のソースコードも用意する必要がある。Pure Python のものでは kanjilib などが is_sjis や is_euc といった関数を持っているので、これもあり(ちょっと古いソースなので、そのままだと warning が出る。ソースに EUC-JP が含まれているので、今時の環境で使うなら # -*- encoding: euc-jp -*- を先頭に入れる)。後者のものとしては、Mark Pilgrim さんの Universal Encoding Detector があるが、他にも、Christof Hoeke さんの encutils があるのでちょっと使ってみた。Universal Encoding Detector も、encutils も、直接短い文字列を渡して判定すると、判定をしくじる場合があるが、HTML ファイルや XML ファイルのようにエンコーディングの指定がちゃんと含まれているようなものであれば問題はない。けれど、どちらもデフォルトが windows-1252 に落ちるようで、短めの文字列のみを判定させると、そこが不幸の原因になる場合がある。Universal Encoding DetectorUniversal Feed Parser の Universal Encoding Detector (Character Encoding Detection) を使う方法を見てみる。auto-detection code in Mozilla のアルゴリズムが使われていて、そこそこよい判定をしてくれる。easy_install chardet でインストールして、>>> import urllib>>> urlread = lambda url: urllib.urlopen(url).read()>>> import chardet>>> chardet.detect(urlread("http://google.cn/")){'encoding': 'GB2312', 'confidence': 0.99}ただし、エンコーディングが指定されている HTML ファイルや XML ファイル等であれば、メタ情報を利用しているので正しく判定されるので問題ないが、文字コード判定ライブラリ Universal Encoding Detector にあるように、短い個別の文字列を渡してやると判定をしくじる場合がある。>>> import chardet>>> chardet.detect("これはなに"){'confidence': 0.5, 'encoding': 'windows-1252'}>>> chardet.detect("蛇のとぐろを見る"){'confidence': 0.21941992101760521, 'encoding': 'IBM866'}>>> chardet.detect("東京のこれは何"){'confidence': 0.5, 'encoding': 'windows-1252'}>>> chardet.detect("文字列の判定をするのだ"){'confidence': 0.5, 'encoding': 'windows-1252'}句読点が含まれない短い文字列を判定させると、こける可能性があります。句読点を含む文字列なら大丈夫だと思いますが。chardet.detect("。")chardet.detect("、")メタ情報がないときには文字の出現頻度を使っているからのようだ。import pykfpykf.guess("これはなに")だとこけないので、短い文字列で日本語の文字列と分かっているなら pykf 等使った方が安全かもしれません。ということで、そういう場合には pykf の方が安全と。encutils - encoding detection collection for Pythonencutils は、新しくエンコーディングの判定のために作られたライブラリで、HTML, XHTML, XML, CSS 等のテキストファイルのエンコーディングの判定ができる。Universal Encoding Detector を使うときには urllib を別途インポートしなければいけないのに対して、encutils は、内部で urllib をインポートしているので、少しだけ、コードの量が少なくて済む。また、media type の情報も取り出して利用できるようにしているところが特徴か。BOM 付きのファイルに対してもちゃんと見ているので安心。ただし、chardet と違って、判定の確信度はない。easy_install encutils でインストールして試す。>>> import encutils>>> info = encutils.getEncodingInfo(url='http://cthedot.de/encutils/')>>> info<encutils.EncodingInfo object encoding='utf-8' mismatch=False at 0x12e3270>>>> print infoutf-8>>> print info.logtextHTTP media_type: text/htmlHTTP encoding: utf-8HTML META media_type: text/htmlHTML META encoding: utf-8Encoding (probably): utf-8 (Mismatch: False)Universal Encoding Detector にやったのと同じように意地悪してみる。>>> encutils.tryEncodings('これはなに')'windows-1252'>>> encutils.tryEncodings('蛇のとぐろを見る')'IBM866'>>> encutils.tryEncodings('東京のこれは何')'windows-1252'>>> encutils.tryEncodings('文字列の判定をするのだ')'windows-1252'>>> encutils.tryEncodings('。')'SHIFT_JIS'>>> encutils.tryEncodings('、')'SHIFT_JIS'やはり、判定に失敗する。同じようなロジックなのだろうかと見てみると、encutils は tryEncodings の中で文字列を直接判定するときに、Universal Encoding Detector (chardet) がインストールされていると、それを使って判定していた。インストールされていなければ、独自のやり方で判定する。 try: import chardet encoding = chardet.detect(text)["encoding"]独自の判定方法は、'ascii','iso-8859-1', 'windows-1252', 'utf-8' の順に、 text.encode(e) を try して、例外が発生したら次のエンコーディングを試し、変換できたら、それに決まりという流れ。従って、SHIFT_JIS や EUC-JP、ISO-2022-JP などに落ちることはない。ここに、'shift_jis', 'euc_jp', 'iso-2022-jp' を追加してやれば、chardet がなくても日本語が判定できるようになるだろう。けど、ちょっと強引だから精度は落ちるだろう。なので、ここに pykf を使った判定を入れるようにすれば、高い精度の文字列判定ができるようになるはず。つまり、外側の情報を使って判定できるものはそうして、文字列を見なきゃ判定できないものは、pykf を使うという流れになる。pykf + encutilspykf は、ShiftJIS, EUC-JP, JISコードを相互に変換するためのPython拡張モジュールで、日本人の atsuo ishimoto さんが公開しているもの。エンコーディングの判定機能も持っている。オリジナルは kf -- 漢字コード変換ソフト で、これを Python 対応にしたものだが、pykf は UTF-8 の判定もできる。import pykfpykf.setdefault(pykf.SJIS) # デフォルトは SJIS にしてみるpykf.setstrict(TRUE) # 厳しく判定enc = {pykf.UNKNOWN:None, pykf.ASCII:'ASCII', pykf.SJIS:'SHIFT-JIS', pykf.EUC:'EUC-JP', pykf.JIS:'ISO-2022-JP', pykf.UTF8:'UTF-8', pykf.UTF16:'utf-16', pykf.UTF16_BE:'utf-16_be', pykf.ERROR:None}def detect_encode(text): g = pykf.guess(text) return enc[g] print detect_encode('これはなに')print detect_encode('蛇のとぐろを見る')print detect_encode('東京のこれは何')print detect_encode('文字列の判定をするのだ')とすれば、Windows の SJIS の環境からだと SHIFT-JIS が返る。なので、とりあえずちょっと試しに 上記コードを encutils の __init__.py の中に適当に入れて(475行目から)、 try: import pykf pykf.setdefault(pykf.SJIS) enc = {pykf.UNKNOWN:None, pykf.ASCII:'ASCII', pykf.SJIS:'SHIFT-JIS', pykf.EUC:'EUC-JP', pykf.JIS:'ISO-2022-JP', pykf.UTF8:'UTF-8', pykf.UTF16:'utf-16', pykf.UTF16_BE:'utf-16_be', pykf.ERROR:None} encoding = enc[pykf.guess(text)]とかしてみる。これで、短い文字列を判定させても、判定を間違えることはなくなった。けど、これはこれで ISO-8859-1 の文字列を SJIS に判定したりとかなっちゃうので困るときもある。文字列が長くても、短くても、日本語でも西欧の文字でも、もう少し判断がこけない方法はないかなぁ。chardet のモデルを少し調整して、もう少し日本語に倒れるようにできればよいのだけど。あちらをたてれば、こちらがたたずの部分はあるだろうけど。。。。
2008.05.25
コメント(1)
-
商品先物市場暴落説
ホットケーキミックスの値段が上がっていた。まったく、炭水化物食いの自分には小麦粉の値上がりはボディーブローになる。しかし、痩せない。。。。頭に来たので近々、商品先物市場大暴が起きると予言することにした。根拠はないw けれども、たぶん、原油価格なんかもいったん落ちると思うことにする。、これだけ原油価格が上がる背景にはヘッジファンドが動いているから大もうけしているんだろうと思いきや 資源価格高騰の中、ヘッジファンドがエネルギー市場で苦戦 らしい。ペトロブラス、BM-S-8鉱区での油田発見を確認 は試掘が進むに従ってジワジワと下げ圧力となるだろうし、1バーレル 90ドル以上を維持していれば北極海の油田開発だって進むだろうから下げ圧力になる。そのために温暖化なんかどうでもいいや、北極圏の氷よもっと溶けろもっと溶けろとやっている国があるわけだし。。。。。この点については、米国とロシアの利害が完全一致している。あとは中東の安定化だ。やっぱり安定化させたくない奴らが多すぎるのが難点だが。まあ、そんなこたぁどうでもいいが、小麦の価格が下がるより、原油価格が下がる方が食料価格は下がる。原油、暴落せよ。理由はどうでもいい。商品先物市場は暴落する。これは私の怒りに満ちた予言である。
2008.05.24
コメント(0)
-
フィードデータのキャッシング (feedparser + feedcache)
Doug Hellmann さんの Caching RSS Feeds With feedcache を読む。この文書は feedcache がどうやって作られたか書かれていて、とてもおもしろい。コンセプトから始まって UnitTest の話、テスト用の HTTP サーバを作る話、等々、順を追って書かれているので Python でちょっとしたツールを作るときのとってもよい教材になっている。ちなみに Doug Hellmann さんの、PyMOTW Python Module of the Week は要チェック。とってもよい学習リソースになる。feedcache Wrapper for the Universal Feed Parser which caches the results は、CastSampler 用に作られたらしい(CastSampler Custom Podcast Feed Aggregato)。CastSampler は、podcast の feed の全部が欲しいわけでなく、実際に購読したいのはその一部のエピソードだけのとき、それを取り出すようなツール。このツールの一部が feedcache として独立したパッケージになっている。Mark Pilgrimさんの Universal Feed Parser は RSS や Atom の feed をダウンロード、解析して、どちらの feed であっても単一の API からデータを利用できるようにしてくれるライブラリ。けっこう頻繁にあちこちで使われている。ここで問題なのは、feedparser は feed をキャッシュしていないこと。実行の度にダウンロードが行われる。あまり頻繁にアクセスすると制限がかけられてしまうようなサイトもある。また、購読していないデータを保存すると保存されたデータの大部分が不要なデータになる。よい具合にフィードデータをキャッシュすれば、あちらにとっても、こちらにとっても効率がよいではないかと。作りとして Cache はメモリを使いたい場合もあるし、ディスク上に格納する何かを使いたい場合もあるだろうし、どちらにでも対応できるように作る必要がある。その点考慮しましょと。当然、キャッシュは生存時間も指定できなきゃダメね。最新のフィードかどうかを確認するのは、ETag と If-Modified-Since を使っている。永続的なストレージの例では shelve モジュールを使っている。複数のスレッドからのアクセスがあったときにどうなるか明確ではないので、ロックをかけて同時にアクセスできるのは一つのスレッドだけにして壊れないようにする。このあたりのコードは Python 2.6 から正式採用になる With 文を使っているので、__future__ を使って Python 2.5 で動くようにしている。shelve は標準モジュールだからいつでも使えるけど、複数のプロセスがキャッシュを更新するような用途まで考えると、いろいろなバックエンドのストレージを使える L. C. Rees さんの shove を使うとよいのね。ちなみに、shove を easy_install shove でインストールすると、boto もインストールされた。Amazon S3 等の Amazon Web Servicesを使えるようにするためね。うーん、shove は要チェックだなぁ。ディクショナリ形式のアクセス用のフロントエンドで、バックエンドはいろいろ選べる。キャッシングも対応している。これ試してみるかなぁ。ちなみに、こういうアプリケーションはシングルスレッドで書くと、ネットワーク経由でフィードをダウンロードするときに、とっても反応が遅いとかあるし、マルチスレッドで複数のサイトにアクセスするように書かないと効率が悪いので、そういう対応もしましょねと。ということで、Python でマルチスレッドのプログラムを書くときの教材にもなっている。この記事とってもよい記事なので、原文とサンプルを通して見てみるとよいと思う。で、もって、そういう理屈抜きに feedcache を使うなら、easy_install feedcache でインストールして、import shelveimport feedcacheurl = 'http://api.plaza.rakuten.ne.jp/kugutsushi/rss/'storage = shelve.open('.feedcache')try: fc = cache.Cache(storage) data = fc.fetch(url) print data.feed.title for entry in data.entries: print '\t', entry.titlefinally: storage.close()ちなみに feedcache を使わなければ、import feedparserurl = 'http://api.plaza.rakuten.ne.jp/kugutsushi/rss/'data = feedparser.parse(url)print data.feed.titlefor entry in data.entries: print '\t', entry.titleちょっとだけコードを付け足せば、キャッシュ対応にできるのだから、なかなかいいかもね。時間を計ってみると、上記の例であれば shelve をオープンクローズする時間で新たなデータを取って来られるぐらいなのでキャッシュしていない方が速い。でも、キャッシュファイルを開いた状態から時間を計れば、キャッシュしている方が速くなる。まあ、それでなければ困るが。沢山のフィードをチェックする場合も同じことになるので有効に使えそう。ちなみに、キャッシュの時間は (timeToLiveSeconds=300) なので、cache.Cache(storage, timeToLiveSeconds=600) とかすると キャッシュの生存時間を10分間に指定できる(デフォルト 5分)。
2008.05.24
コメント(0)
-
リコー、オンラインストレージサービス quanp を使ってみる
リコー、オンラインストレージサービス本格展開--月300円で10Gバイト利用可能 を見る。「quanp(クオンプ)」は、quanpは、デジタルカメラで撮影した画像やビデオ映像、PCで作成した文書、音楽ファイルなどを専用のクライアントソフト「quanp.on」で直感的にウェブ上にアップロードしたり、共有できるというサービス。指定したフォルダを定期的に監視し、更新されたファイルを自動的にquanpにアップロードする機能を搭載することで、手間をかけずにアップロード忘れを防止できるとしている。時間軸を取り入れた立体感のあるユーザーインターフェイスとか、いい感じ。だが、不具合に関する重要なお知らせ で早速不具合でファイル消失を起こしている。作業ミスでリカバリできないなんて、運用体制はまだまだだね。消失ファイルしたファイルにつきましては、お手数をおかけいたしますが、お客様サイドでの復旧をお願い申し上げます。という意識では、まともなオンラインストレージとしてとらえられないので、あくまで共有用途で、ローカルに元ファイルを保存しておかないとダメだってことになる。無料で使える 1GB あれば、使い勝手がよければ一時的に共有する用途で使ってもいいかなという感じもするが、それ以上には使う気にはなれないな。。。。でも、ユーザーインターフェイスとしてはおもしろいので捨てがたい部分はある。でも、想定内の使い方から一歩出た瞬間に、この作りがいかにダメダメなところがあるかというのも分かる。たとえば、500ページ程度の PDF を放り込んでみるとよい。そういう使い方は想定外なのでお話にならない状態になる。ドキュメントの場合、想定内なのはせいぜい数十ページ前後かなあ。画像とかも、200枚弱ほど一気にアップロードしようとしたら、途中でエラーになった。弱い。....もっと、動作が高速になって、PPT や PDF ファイルの文字列の検索がちゃんとできるようになったら、お金を払って使ってもいいかなという感じ。要するに DocuWorks のオンライン版みたいな感じで、使えるようなものになればなぁと。現状のターゲットとは違うだろうけど、画像が中心の使い方だけでなく、おもしろそうな論文とかレポートとか、ホワイトペーパーとか放り込んでおいて、使うようなユーザーを想定すると、情報ツールとしても発展性があると思うんだけど。
2008.05.18
コメント(0)
-
ミャンマー サイクロン被害
ミャンマーのサイクロン被害すごいのね。ユニセフ ミャンマー・サイクロン緊急募金赤十字 ミャンマー・サイクロン救援金受付についてから募金しよう。ユニセフはクレジットカードでも募金できるから楽。ちなみに Wikipedia を見たら、市内を走る路線バスの多くが日本の中古車で、神奈川中央交通・相模鉄道・東武バスなどが、車体の色をそのままに走っている事がある。その中でも多くを占める神奈中バスの場合は「運賃前払い」「出入口」「神奈中運転士募集」などの表示が、そのままになっている事が多い。ヤンゴンとかあるけど、まさにそんな感じ。何とか建設とか書かれた中古車とか、そのまんま日本車が走っている。昔の日本かこれはって感じ。現地に行くと、日本車の数にびっくりする。私が乗ったタクシーなんかも、20年ぐらい前の車じゃないかなぁとかいう感じの日本車だった。そのときに、日本車はやっぱり良くできているのねぇと思った。ミャンマーは日本車を日本人以上に大切に乗ってくれている国の一つ。政治的にはまだまだ難しい状況が続きそうだなぁ。潜在的にはとてもいい国になれる要素がたくさんあるのに残念。とかいうのはさておき、目先の問題として政治的な問題はいったん横においておき、人道支援は必要。自力でなんとかなるような国ではないと思う。
2008.05.11
コメント(0)
-
Wing IDE 3.1がリリースされた
Python の統合開発環境 Wing IDE 3.1 がリリースされた。Support for zip archivesSupport for pkg_resources name spaces and eggsSupport for doctest and nose style unit tests (*)Scan for sys.path changes such as those used in buildoutHow-To and support for Google App EngineInline context appropriate templates/snippets integrated with autocompleter (*)Word list driven auto-completion in non-Python files (**)Quick navigation to files and symbols by typing a fragment (**)Improved support for Stackless PythonPreference to strip trailing white space on saveDisplay gi_running and gi_frame for generatorsImproved code analysis for Python 2.5Other minor features and bug fixes not found in Wing 3.0.x 頑張っている感じね。無償でいいものがあるので、有償の Wing IDE は (無償のものもあるが)、そうしたものと差別化するところで頑張らざるを得ないところもあるだろうし。マルチスレッドプログラムのデバグも、少し前からできるようになっているし。地道によくなっている感じ。Support for doctest and nose style unit tests なんていうのは企業ユーザーからのリクエストではいったのかな。How-To and support for Google App Engine なんかも、目を引くところだろうし、Improved support for Stackless Python みたいなところは、実際に使っている人からの要望なのかな。その他、着実に機能的には押さえるべきところは押さえてきている。が、もっと軽ければよいのだけど。ん、でも、なんか心なしか少し軽くなったように思えるのは気のせいかな。日本語を print したときに Debug I/O で文字化けするとかあったのも直っている。
2008.05.11
コメント(0)
-
Amazon EC2 が OpenSolaris に対応
OpenSolaris on Amazon EC2 が始まったのね。Sun is offering two Amazon Machine Images (AMIs) in the beta program:OpenSolaris OS 2008.05 - Sun's first supported offering of OpenSolaris (formerly known as "Project Indiana") Solaris Express Community Edition - Sun's binary release for OpenSolaris developers based on the latest OpenSolaris source base (code named "Nevada")そういえば、OpenSolaris OS2008.05 (いわゆる Project Indiana もの) が、リリースされたということで、そろそろ、手持ちのマシンに入れたいなぁとか思っているのだが、なにせ非力なマシン、Virtual Machine 上で動かしても遅い。実機で動いているものを入れ替えるのもとりあえず面倒。新しいマシンを買わずに、こいつでいくかなぁとか密かに思っていたりする。他人にサービスを提供するためじゃなく、使いたいときだけ動かしてというのであれば、一ヶ月あたりの維持費も抑えられるかなと。とかいいながら動かしっぱなしにして月に1万円ぐらいかかっちゃいましたとか、気がしないでもないが、まあ、年間にならしたときに、あまり高く付かなければいいかなと。ということで、毎日ちょっとずつ調べて、動かす方向で考える。とりあえず、Amazon Machine Image (AMI) として、OpenSolaris OS 2008.05 を使うのか、Solaris Express Community Edition を使うのか検討するか。そのためにはローカルで両方が動く環境を用意して、動かして、あぁ、やっぱり新しいマシンが欲しい(爆)あぁ、でも、Solaris Express Community Edition (SXDE) のページを見たら、Note: This marks the end of the SXDE program. To provide a smooth transition, the SXDE 1/08 site will remain available through July of 2008. At that time, the site will be taken down and links redirected to the OpenSolaris site. Existing SXDE documentation will remain available on docs.sun.com and at the Solaris Developer Center. Thank you for your support and participation. We look forward to seeing you at opensolaris.com.このプロジェクト SXDE の橋渡しの役割は終わったから、OpenSolaris の方が本筋で Go! Go! になるのね。ということで、OpenSolaris OS の方を使ったほうがいいのかもね。EC2 もちょっとあれこれまじめに調べてみるかな。
2008.05.06
コメント(0)
-
Enthought Python が新しくなった
Enthought Python Distribution (EPD) の新しいバージョンが出ている (Python 2.5 ベースになった)。Enthought Python は一言でいうと科学技術計算系のライブラリてんこ盛りのヘビーパイソン。以前は無償だったのだが、新しく無償のオープンソースライセンスに加えて、Enthought Python Distribution - Enterprise Edition が加わっている。商用利用や政府の利用の場合は、$99 となった。ActiveSate の ActivePython のようにビジネスで利用する場合のサポートを受けられるようになる。有償のライセンスができたのは、The real intent of the license is to provide a service for those firms who plan on using our bundle of software (EPD) in their commercial operation. Academic and hobbyist use is, and will remain, free.ということで、お金払うからサポートしてよという企業の声に応えたもので、個人利用や学術利用で、サポートがいらなければ、フリーのままだよと。Enthought Python は、以前は Windows 版だけだったのだが、新しく Red Hat Linux 用のバイナリがすでに公開されていて、次のものに対応するようになったようだ。Windows (32-bit)RedHat Linux (64-bit x86)SUSE Linux (64-bit x86, Itanium)Ubuntu Linux (64-bit x86)対応プラットフォームは、ActivePython の方が MacOS、Linux、Solaris、AIX、HP-UX と幅広いが、Enthought のよいところは、標準の Python に加えて、NumPy、SciPy、Enthought Tool Suite (ETS)、Traits、Mayavi、Chaco、Kiva、Enable、Matplotlib、wxPython、Visualization Toolkit (VTK) といった数値演算、2D、3D のモジュールが最初から入っていること。こんなものがはいっている(普通に使う ipython、や PIL、Graphviz, matlib, Reportlab, MySQL-python のようなものも入っている)。なので、Enthought Python をインストールすれば、その手のものがまとめてインストールされるのでとても便利。個別にこれらをインストールしていくのは、けっこう大変。easy_install とかでインストールできるようなものも増えてきたが、数多くのモジュールがちゃんと整合性をもって動くようにテスト済みなので、特に企業などでまともに使おうとしている場合にはメリットになるだろう。ただし、あれこれ入っているのでとっても大きい。インストーラーが 179MB と、標準の Python の 10.8 MB の 17倍近くの大きさ。まあ、いかにあれこれ入っているかということが大きさを見ただけでも明白。インストール後は、780MB 程度とかなりの巨漢。ちょっと Django を使ってみたいだとか、TurbGears だ Pylons だとか、そういうウェブ系のものをやりたい人にはメタボリック状態なのでオススメできない。で、これだけあるものを自分で管理しようとすると、大変なことになるって想像つくでしょw 自力で Windows 版と Linux 版のバージョンをそろえて同じように動く環境を維持しようとしたら、もう大変なこと。ZODB3 みたいなものも入っているし、使わない人はまったく使わないとかいうものもたくさん入っている一方で、必要なものはたいてい入っているので、まとめて入れちゃえ管理はまかせたという感じになる。何はともあれインストールしちゃったので、これから Windows では Python 2.5 をメインに使うことになるかな。しかし、まあ、大きく育っちゃったなぁ。でも、これまで使っていた、Python 2.4 の大きさを見てみたら、674MB とかになっていたw 使ってないものもかなり多いのだけど、まとめてインストールしておくと、ちょっと試すときにインストールの手間なく試すことができるところが好きなのだけど、冷静に見てみるとやっぱりでかいなぁw挑戦しようと思って挑戦していないのが、Mayavi (3D)とか、Chaco(2D)で、これを使わないと、ほんとうは、そこまでディスクを食うようなものいれとくのは何なのじゃないのということもあるのだが。高度なビジュアルモデリングとかやっているのでなければ、ここまですごいのは、ほんとは必要じゃないのだけど、せっかくなので、これまで使っていなかったものも含めて Enthought Python 探索やるかな。とりあえず、まとめとして、Enthought Python は科学技術計算やビジュアルモデリング等をやる人に最適。でも、BioPythonは入っていないのでバイオ系の人にはまだ不足のはず (バイオ系はまったく分からないので BioPython は中身もぜんぜん知らない私)。Web 系などで軽量な Python の使い方を考えている場合は問題外。標準の Python に必要なものだけインストールした方がいい。けれども、デスクトップならあまり気にしないでまとめてインストールできるので楽ちんなので、ちまちまあれこれインストールするのが面倒な不精者にはお勧め。ちょっと中を見る。swig とかどこいっちゃたんだと思ったら、\Python25\Lib\site-packages\swig-1.3.31.0001_s-py2.5-win32.egg にインストールされるようになっている。mingw とかどこいったと思ったら、mingw-3.4.5.0001_s-py2.5-win32.egg にインストールされている。\Python24\Entought に以前はあったのだが、深いところにはいってしまった。不便になったはずはないので、どうにか使うとこれが便利になるような構成になっているんだろうな。んー、以前はよく分かっていなくても独立したところにあったから分かりやすかったのだけど。まあ、個別のアップグレードのときには easy_install 一発でアップグレードとかいうところがメリットになるのか。でも、まあ、C コンパイラも同梱されているのは変わらないわけで、拡張モジュールをコンパイルするときにはよかったりするわけだな。まあ、こういうものまであるからでかくなるwそういえば、Python Magazine の 4月号が出ている。Driving into the Gene Pool with BioPythonA Database in the CloudPortable Data with PyTablesscripting Xcode with Pythonということで、そっち方面の人はかなりおもしろいんじゃなかろうか。ちなみに、A Database in the Cloud は Google Data API の話。PyTables は Enthought にも入っている。
2008.05.04
コメント(0)
-

日銀を退職して民間に再就職した人について
平成19年度中の役員及び局室長級職員の主な再就職状況 を見る。小山高史前日銀名古屋支店長が、サブプライムローンに関連する巨額の損失を出した農林中金系の(株)農林中金総合研究所 顧問になったのね。うーん、巨額の損失を表に出した背景には、この方が行ったからとかいう背景があったりして。単なる憶測だけど。リスク管理高度化(Basel II)の下での民間金融機関と中銀の関係なんて出しているし。この手のことに詳しい方なんでしょ。大手金融機関の共同監視の会合を設置、バーゼルII強化も提言=FSF (2008年 04月 12日, ロイター)な今日この頃、実にタイムリーな再就職だったりして。バーゼルIIに関するQ&A〔農協系統金融機関関係〕の文脈から考えると、ぴったり来る再就職だったりして。現在の趣味は野鳥。野の鳥です。決して夜の蝶ではありません。念のため(笑)。 今回もこの近郊の野鳥観察には何回か出かけております。野鳥を観て歩くことで、運動にもなっています。歩いております。名古屋で驚いたのは冷やし中華にマヨネーズが載っていることです。ちなみに名古屋支店長だったということは、かなり優秀な人?というか、日銀のどこでも支店長クラスは優秀なんだろうけど、トヨタのある名古屋だから、かなり格が上なのだろうか。日銀名古屋支店長 早川英男さん とかもそうだし。ということで、日本銀行名古屋支店のページを見てみる。支店のホームページは手作り感あふれるお金のかかっていないページなのがほほえましい。最近の管内金融経済事情 日本銀行名古屋支店 2008年4月14日 を見ると、管内景気は、緩やかな拡大基調にあるが、その速度は足もと鈍化している。で、個人消費・・・底堅く推移している設備投資・・・高水準にあるが増勢は鈍化している住宅投資・・・持ち直している公共投資・・・低水準で推移している輸 出・・・足もとの増勢は一服しているらしい。ちなみに、その他の地域は 地域経済報告 ─さくらレポート─ (2008年4月)で、各地域の取りまとめ店の報告によると、足もとの景気は、地域差はあるものの、エネルギー・原材料価格高の影響などから、全体として減速している。で、小山前支店長の講演の資料を見てみる。東海経済の八つの試練 (2007/3/26)今年の日本経済と地域経済を考える (2007/3/9) (図表)実務肌でまともっぽい感じ。早川支店長の方が外向的というかメッセージ性というか主張が強い。小山前支店長の方が、観察者的な感じ。まあ、あくまで素人から見た目だけど、野鳥観察が趣味のようだしなぁ。今後、製造業を中心としたものの見方に加えて、農林中金総合研究所顧問になることによって農林水産業に関する関心が強まると、どういう発言をするようになっていくのかな。元々、長野県上田市の出身の方のようだから、農村の実体とかも肌身で知っている感じだし、自由度の増した発言がナニカの機会に出てくるとおもしろいかも。上田市って、けっこう貧富の差も何気に大きかったりする田舎とか言ったらその地方の方には叱られそうだが、そういうところの出身者って、都会しか知らない人とはまた違うだろう。まあ、気位は高い地方だな。ということで、顧問だから表にそれほど出ることはないだろうけど、農林中金総合研究所 のレポートに注目することにした。経済金融ハンドブック『金利の動きを読む』 が出ている。内容については一般の経済解説書とは異なり、系統職員が資金証券業務などに携わる際に一番関心の高い金利に焦点を当てて、金利動向を読み解くために必要な知識・事柄を整理し盛り込んでいます。 で、こういった人たちがどういう視点から経済を読み解いているかを知る上でおもしろい資料かもしれない。ついでに、小麦加工食品を巡る最近の動向 についても見てみる。その後、水田転作作物として小麦の生産が奨励されため、06年の生産量は84万トン、自給率は13%になっている。「生産が奨励されため」、ちゃんと校正しましょう。小麦の 12.1% は菓子に使われているんだな、とどうでもよいところに感心する。95年から05年の変化で、パン用 36.4% から 41.1%、麺用 36.6% から 32.5%と、ラーメンブームとかあった割には全体の麺類の消費量は減っているのね。ただし、即席麺に関しては伸びているらしい。農林漁業・環境問題 / レポート(分野別) は、けっこう読み物としてもおもしろいな。ウナギをめぐる情勢変化とわが国への影響 を見ると、ウナギもマグロに続いて値上がりしそうということか。でも鰻はそんなに好きでもないので構わない。こういうの新聞読むよりおもしろいね。新聞の方が目立つ、おもしろさをどうしても追求してしまうことがあるから、それより、淡々とこうですよって方がおもしろい。まあ、新聞もこの手の機関の人に取材とかしていろいろ記事を作ったりするんだろうけど、表面上のおもしろさとか、アイキャッチーに走ってしまう面がある。ゆえに、株価の底値圏で売り煽り、高値圏で買い煽るという愚行を犯しがち。下がっているときに下がっていることを無理に説明しようとし、上がっているときに上がっていることを無理に説明しようとする。そうしたものよりも、定期的に特定分野を観察している人たちの情報を見た方が判断を誤らないんじゃないかと思う今日この頃。まあ、それでも、時流に流される面はあるだろうけど。もっとも新聞というのは、そもそも、情報源にはなるけれども、どちらかといえば、社会的な合意形成の場の一つの意味が大きいとも言えるだろうけど。つまり、たとえば日経新聞を読むということは、日本経済の一般的な合意形成の過程を見るいう感じ。だから、マクロ指標が遅れて出てくるのと同じで、そこから先読みしないと過去で現在を語ることになり、現実とのギャップが大きくなる。洗脳と啓蒙、啓発、指導、矯正、強制、服従というのも微妙だよなぁ。mild yoke of something というかなんというか。全然関係ないんだけど、なんとなく、John Milton のソネットを思い出した。When I consider how my light is spent,Ere half my days in this dark world and wide,And that one talent which is death to hideLodged with me useless, though my soul more bentTo serve therewith my Maker, and presentMy true account, lest He returning chide,'Doth God exact day-labour, light denied?'I fondly ask. But patience, to preventThat murmur, soon replies, 'God doth not needEither man's work or his own gifts. Who bestBear his mild yoke, they serve him best. His stateIs kingly: thousands at his bidding speed,And post o'er land and ocean without rest;They also serve who only stand and wait.'今年は、ジョン・ミルトンの生誕 400年の年だ。失楽園でも読むかなぁ。
2008.05.04
コメント(0)
-

IronPython 2.0 Beta 2
2.0 Beta 2">IronPython 2.0 Beta 2 リリースされたのね。We’ve also made a minor change to our packaging by adding a Microsoft.Scripting.Core.dll in addition to the Microsoft.Scripting.dll that’s been around since the start of 2.0. とか、変わっている。アーキテクチャの見直しが入っているのね。ぶひAs a consequence of the new DLL, the deprecated file IronPython2005.sln is broken. IronPython 2.0 を使う場合、Visual Studio 2005 でなくて Visual Studio 2008 を使うべしの方向になっているのかな。Windows 上で CPython を使っているときでも、C の拡張モジュールとか自分でコンパイルしようとすると、VC のバージョンを合わせなきゃならないのと同じで、IronPython でもそういう感じか。私の PC だと Visual Studio 2008 Express が不安定で、ポコポコ落ちる。何がいけないんだろうか。インストールしなおしてみるかな。Expression とか、試用版でちょっと動かしてみたけど、WPF の世界は、やっぱり、こういうの使った方が楽。でも、お金かかるねぇ。こういうものを使うと、ちょっと重いから PC も新しくしなきゃとかなりそうだし。最初のSilverlight 2でExpression Blendの使用 みたいのを見ると、いいなぁとは思うけど。Kaxaml は無償で使えていいかも。コンプリーションが効く上、書いたコードがすぐに WYSIWYG で表示されるので、テキストエディタだけで作るより、はるかに楽。xamlpad よりいいか。 Visual Studio Book ExpressVisual Studio Express Edition に関連する書籍の一部を公開します。学習や書籍購入の検討の際にお役立てください。なんてページあったのね。しかし、最近、ちょっと MS に洗脳され過ぎかなぁw
2008.05.03
コメント(0)
-
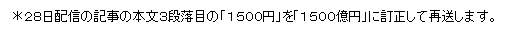
ロイターは訂正する
訂正:三井住友FG、08年3月期当期利益見通しを当初予想比‐19.3%減に引き下げ を読む。「1500億円」を「1500円」で最初に出しちゃったところは、まったくもう、という感じだけれど、ロイターは待ちえたときにはちゃんと訂正だすんだよな。どこぞの日本の新聞社とは違って。こっそり直す新聞社とは違う。最近では、粉飾決算で 1700円の支払い命令 とかがある。あぁ、でも、「与信関係費用が当初の1100億円から1500億円(訂正)に増加。」みたいのも、簡単な処理をすれば防げるものだから、報道機関は単純なミスを防げるように、チェックしすてむ作るべしだな。過去の訂正例を見れば、どのような機能を作ればよいか明確になるから、同じミスを防ぐようなレベルの実装から始めればいい。ニュース速報の本数が増えてるから、チェックする人間の負荷も高くなっているはず。そういう人の集中力に頼るだけじゃ、テンションが落ちているときに見逃しが起きるし、1分でも早く出したいという流れを安定化させるために、チェックプログラムを作るべき。海外勢の日本株買いが鮮明に、「持たざるリスク」も意識か って、そうなのかなぁ。そうなのかなぁ。「買い安心感」とか「持たざるリスク」とかいう言葉が飛び交うような状況っていうのは、とってもあれなんだなぁ。不思議なことに底堅いが増えると、加熱している状態でしばらくすると株価が下げるのはいつものこと。VIX指数との逆相関性が高い。
2008.05.02
コメント(0)
-
【初音ミク】 PROLOGUE 【ぼかりす】すごい、すごい
【初音ミク】 PROLOGUE 【ぼかりす】 を聴く。すごいねこれは。ここまでできるのか。初音ミクの“神調教”が自動で!? 「ぼかりす」に話題騒然。
2008.05.02
コメント(0)
-
日本語テキストの難易度を測る
名古屋大学の 佐藤研究室 が 日本語テキストの難易度を測る なるツールを公開しているのね。入力された文から難易度を判定して、1から13までのいずれかの値(小学(1年 - 6年)~大学)を出力してくれるというもの。帯:日本語テキストの難易度推定 解説を読む。新書の難易度推定 とか見てみると、これらのグラフの形から推定される難易度の順番は、やさしい順に、 次のようになります。(上のグラフは、この順番に並んでいます。)S2005sao - さおだけ屋はなぜ潰れないのか?S2004com - コミュニケーション力S1995net - インターネットS1999ren - 日本語練習帳S2006goo - Google 既存のビジネスを破壊するS2005kok - 国家の品格S2003bak - バカの壁S1993sei - 「超」整理法S2005kar - 下流社会S2006web - ウェブ進化論S2006tan - 他人を見下す若者たちS1981sak - 理科系の作文技術ふーむ。意外におもしろいかもしれない。本プログラムは、rubyで書かれており、標準的なunix環境で動作します。なので、あれこれ試してみるかなぁ。モデルのデータが入っているから、なんたらコーパスがないと動かないとかいう類のものじゃないのがよかったりするかも(新たにモデルを作るためのプログラムは同梱されてないから、独自の難易度モデルは作れないが)。でも、ことば不思議箱 の 基本慣用句五種対照表 や 日本語基本語彙表JC2 みたいのが、実は地味で手間がかかってすごいなぁとか思う。自然言語処理といえば 「国際電気通信基礎技術研究所(ATR)と内田洋行が語学教育の新会社を設立 ~ATR20年来の言語習得研究の成果を事業展開~ か。英語は「聞き取り」と「発音」から ATRと内田洋行、語学教育の新会社を設立 (@IT)。ATR はさんざん この手のこと やってきているからか。Robovie-X みたいなこともやっていたのね。そういえばそういえば、KH Coder に ”専門用語(キーワード)自動抽出システム” の TermExtract が組み込まれたらしい。
2008.05.01
コメント(0)
-
Python で planet (1)
このところ RSS リーダーを使ってあちこちのブログを見始めたのだが(前にもちょっと使って止めたが)、planet サーバを動かしてみようと思い立つ。とりあえず、Python で書かれたものは 3つみつける。planetFeedjackcogplanetplanet は Planet GNOME や Planet Debian をはじめとしてあちこちで使われているもので一番メジャー。Feedjack は Django を使って作られていて planet より新しい。cogplanet は、TurboGears を使って作られている。1年以上、手が入っていないしマイナーな存在か。なぜに planet サーバの類を使おうかと思ったかといえば、やっぱり、どんどんフィードを登録していくと、読まなくなっちゃう傾向があるから(たくさんありすぎるから、おもしろそうな記事を探して読むのも面倒になってしまうので)、独自のフィルターをかけて好みの記事だけ自動抽出して読めるようにしたいなと。クライアントで動かすとフィードの数が多くなると重くなって不快なので( RSS リーダーとか使ってみて、こりゃいやだと)、サーバで動かしたいなということで planet ベースに何かするかなと。とりあえず、全部、使ってみることにする。まずは、メジャーな planet から。自分の好みのカスタムPlanetの構築 のあたりを参照すると概要が分かる。デザインテンプレートは、独自のhtmltmpl を使っている。既存のデザインには basic と、fancy が用意されているが、basic は時代遅れの感があるから、fancy をベースにした方がいいかもと。購読するサイトは、config.ini に次のように登録するようだ。[http://www.gnome.org/~jdub/blog/?flav=rss]name = Jeff Waughface = jdub.pngfacewidth = 70faceheight = 74フィードは [] で囲む。name = の後ろにフィード名。face = で hackergotchi があればそれを指定。facewidth と faceheight でそのアイコンの縦横幅を指定等々。準備ができたら、次のコマンドで実行。planet.py path/to/config.iniとりあえずは、./planet.py examples/fancy/config.iniで動かしてみる(解凍したディレクトリで)。examples/output にファイルが書き出されるので、それを Apache 等から参照できるようにしてブラウザから見ると下のようなものができている。とってもシンプルですぐに使えるものなので、役には立つけれど自分が今欲しいものではない。もうちょっとあれこれしたいので使わないけど、ソースコードは参考にする。
2008.05.01
コメント(0)
全15件 (15件中 1-15件目)
1
-
-

- Amazonマケプレ
- PR 招待購入 ポケモンカードゲーム…
- (2026-06-02 20:04:50)
-
-
-

- 楽天市場のおすすめ商品
- 【身支度の完全自動化】2026年最新!…
- (2026-06-04 21:00:06)
-
-
-

- 携帯電話のこと
- リアルな声から浮かび上がる楽天モバ…
- (2026-06-01 08:00:06)
-



