

2007年11月の記事
全42件 (42件中 1-42件目)
1
-
Gnuplot.py の -noend オプション など
Gnuplot.py で日本語を表示する (2) に引き続き、Gnuplot.py の話。Gnuplot.py は Unix だと -persist オプションが使えて、スクリプトの実行後もウィンドウが残るようにできるが、Windows だとスクリプトが終了した時点でウィンドウが閉じられてしまう。けれども、Gnuplot を調べてみると、-noend というオプションが Windows 環境でも使えて、これを指定すれば Python のスクリプト終了後に Unix と同じように Gnuplot のウィンドウを残すことができることが分かった。Gnuplot.py のパッケージの中の go_win32.py の中には test_persist という関数があって、これが常に 0 をリターンするので、-persist オプションを指定しても使えないよ '-persist is not supported under Windows!' とエラーで終了してしまう仕組みになっている。そして、-noend オプションを扱うコードは入っていないので、-noend オプションは Gnuplot.py からは使うことができない。なので、test_persist と同様に test_noend を作って、GnuplotProcess をキーワード noend を受け付けるようにして、若干のコードを追加すると、-noend も使えるようになる。端的に言えば、次のように popen で nuplot_command('pgnuplot.exe) を呼び出しているところで -noend を入れたものも用意して、そこに noend が指定されたときに流れるようにすればよいということ。- self.gnuplot = popen(GnuplotOpts.gnuplot_command, 'w')+ self.gnuplot = popen('%s -noend' % GnuplotOpts.gnuplot_command, 'w')乱暴にやるなら、上の箇所を変更すれば Python を終了した後でも、常時ウィンドウが残るようになる。けど、ちゃんと noend オプションを受け取れるように変更した方がよい。gp_win32.py と _Gnuplot.py に手を入れると noend オプションが使えるようになる。それにしても、ウィンドウに表示するときには cp932 でスクリプトを書くと日本語が表示できて、png に出力するときには UTF-8 にしなきゃいけないというところが不便この上ない。Gnuplot に渡すところで文字変換を入れて、どちらで書いても大丈夫にしないと面倒でしょうがない。debug=1 でデバグモードにしているとき、コマンドの画面に表示される文字化けは、 _Gnuplot.py class Gnuplot の__call__ に手を入れて強制的に cp932 で出力するようにしてみる。気分が少しよくなった。class _GnuplotFile __call__ にも手を入れて、指定したエンコーディングで出力できるようにした。これで、wgnuplot の画面で出力するときも、png に出力するときもソースコードは utf-8 でいけるようになった。しかし、意外な問題として、画面に出すときは X軸の日本語が横向きに出力されるのに対して、png で出力するときは縦書きになること。不思議。。。。。まあ、とりあえず何とか使えるような感じになってきたので引き続き使ってみようかと思う。
2007.11.30
コメント(0)
-
pydot でカレンダーを作る (2)
pydot でカレンダーを作る (1) を作るの続き。とりあえずの枠組みができたので、今度は、ダミーだったカレンダーの中身を作る。Python には標準モジュールでカレンダーに関する関数があるのでこれを使うことにする。5.18 calendar -- 一般的なカレンダーに関する関数群 Python ライブラリリファレンス。monthcalendar(year, month) を使えば、一発でカレンダーの行列が得られる。>>>import calendar>>>calendar.monthcalendar(2007,11)[[0, 0, 0, 1, 2, 3, 4], [5, 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17, 18], [19, 20, 21, 22, 23, 24, 25], [26, 27, 28, 29, 30, 0, 0]]よく見ると、月曜日から始まっている。次のように日曜から始まっているリストが欲しい。これは calendar.setfirstweekday(calendar.SUNDAY) と実行すればよい。$ cal 11 2007 11月 2007 S M Tu W Th F S 1 2 3 4 5 6 7 8 9 1011 12 13 14 15 16 1718 19 20 21 22 23 2425 26 27 28 29 30カレンダーは、数字ではなくて、文字列にしておきたいので、まとめて文字列に変換して、曜日のリストと一緒にして、表示用のノードリストとする。month(year, month) を使えば文字列として、「 November 2007\nSu Mo Tu We Th Fr Sa\n 1 2 3\n 4 5 6 7 8 9 10\n11 12 13 14 15 16 17\n18 19 20 21 22 23 24\n25 26 27 28 29 30\n'」のような結果が得られるので、これをばらしてもいいが。import calendaryear = 2007month = 11week = [u'日',u'月',u'火',u'水',u'木', u'金', u'土']# 日曜から始めたい。これで日曜から始まるcalendar.setfirstweekday(calendar.SUNDAY)caldata = calendar.monthcalendar(year, month)# 文字列にまとめて変換node_list = [[str(x) for x in y] for y in caldata]# 曜日を先頭に追加node_list.insert(0, week)これを前のプログラムの前の方に入れると、次のようなグラフになってしまう。カレンダーの最初の方と最後の方に 0 があるから、それを律儀に繋いでくれた。まあ、当たり前といえばあたりまえのことであった。ということで、この手の、表面上同じ値であったも、別の実体としてそれぞれを扱いたいときには、ノード名をユニークにして、ラベルで値を付けるということをしないといけないので書き直す。ノードはユニークな値をつけなきゃいけない。0 が表示されるのも変なので、これは空白文字にする。ついでなので属性も付ける。ちなみに year と month は直書きしてあるが、import sys; year = sys.argv[1]; month = sys.argv[1] に変えれば、コマンドラインから指定できるようになるので、だいたい例題と同じような感じのものができたかな。#!/usr/bin/env python#-*- coding: utf-8 -*-from pydot import Dot, Cluster, Node, Edgeimport calendar# カレンダーを作ってノードリストとする。year = 2007month = 11head_name = "%d年%d月" % (year, month)week = [u'日',u'月',u'火',u'水',u'木', u'金', u'土']calendar.setfirstweekday(calendar.SUNDAY)caldata = calendar.monthcalendar(year, month)# 0 は表示したくないのでスペースに変換し、すべて文字列に変換。def to_str(s): if s == 0: return " " else: return str(s)node_list = [[to_str(x) for x in y] for y in caldata]node_list.insert(0, week)# 属性設定用の関数def set_node_attr(node, label, dayofweek, subgnum): node.set_label(label) if subgnum == 0: node.set_fontname("arialuni.ttf") node.set_fontcolor("black") node.set_color("lightgray") node.set_shape("egg") node.set_style("filled") node.set_width(1.15) node.set_height(.60) else: node.set_fontname("arialuni.ttf") node.set_color("black") node.set_shape("box") node.set_style("solid") node.set_height(.60) if dayofweek == 0: # 日曜 node.set_fontcolor("red") node.set_width(.85) elif dayofweek == 6: # 土曜 node.set_fontcolor("blue") node.set_width(.75) else: node.set_fontcolor("black") node.set_width(1.15) # グラフを用意するg = Dot()n = Node('node')n.set_fontname('arialuni.ttf')n.set_fontsize(14)n.set_style('solid')g.add_node(n)# ヘッドを追加するn = Node('head')n.set_label(head_name)n.set_shape('Msquare')g.add_node(n)# 列ごとにサブグラフを作る。cluster = {}node_id = 0for subgnum, nodes in enumerate(node_list): # サブグラフの名前を指定して、サブグラフを生成。 name = 'sub_%d' % subgnum cluster[subgnum] = Cluster(graph_name=name) c = cluster[subgnum] # [1,2,3..] を [2,3,4,...] と合わせて、 # (1,2),(2,3),(3,4) というエッジを生成 edges = zip(nodes, nodes[1:]) edge_list = [] for dayofweek, label in enumerate(edges): # ノード名を付けて、エッジを生成 e1 = "day%d" % node_id node_id += 1 e2 = "day%d" % node_id c.add_edge(Edge(e1, e2)) # 自動作成されたノードに属性を設定する n = c.get_node(e1) set_node_attr(n, label[0], dayofweek, subgnum) n = c.get_node(e2) dayofweek = dayofweek + 1 set_node_attr(n, label[1], dayofweek, subgnum) # 一つのサブグラフが終了したら、次のグラフの中の要素と # つながらないように id を増やす node_id += 1 # 先頭のノードをヘッドにつなぐ c.set_color('white') n = c.get_node_list()[0] g.add_edge(Edge('head', n.name)) # クラスタをメインのグラフに追加する g.add_subgraph(cluster[subgnum])g.write_png('calendar.png')
2007.11.29
コメント(0)
-
pydot でカレンダーを作る (1)
Python から Graphviz を使う( pydot を日本語で出力)(10) からの引き続き、An Introduction to GraphViz の Figure 4. A Month Calendar に挑戦してみる。このシリーズ長くなってきて、どこに何を書いたのか分からなくなってきたので、今後のことを考えて題名をまとまりごとに付けることにする。とりあえず、多少汎用性のあるものを作ってから、カレンダーを入れたものを作り直す。まず、頭の部分につながっている下の部分は、それぞれサブグラフとして作って、頭につなげる。そして、それができあがったら、カレンダーをリストとして使う。そして、色を付けるなどして完成させる。まずは、サブグラフを作って頭につなげるところまでやってみる。要素のリストからサブグラフを作る細かいところは考えずに大枠を考えて作ってみる。#!/usr/bin/env python#-*- coding: utf-8 -*-from pydot import Dot, Cluster, Node, Edgeimport calendarhead_name = "200?年??月" # 頭の表示# 列ごとのノードのダミーnode_list = [[u'日',u'月',u'火',u'水',u'木', u'金', u'土'], ['1', '2', '3', '4', '5', '6', '7'], ['8', '9', '10', '11', '12', '13', '14'], ['15', '16', '17', '18', '19', '20', '21'], ['23', '24', '25', '26', '27', '28', '29'], ['30', '31'],]# グラフを用意するg = Dot()n = Node('node')n.set_fontname('arialuni.ttf') # 日本語フォント指定n.set_fontsize(9)g.add_node(n)# 列ごとにサブグラフを作る。cluster = {}for i, nodes in enumerate(node_list): name = 'sub_%d' % i cluster[i] = Cluster(graph_name=name) edges = zip(nodes, nodes[1:]) g_nodes = [Edge(x[0], x[1]) for x in edges] for n in g_nodes: cluster[i].add_edge(n) g.add_subgraph(cluster[i])# リストの先頭をすべてヘッドにつなげるtop_node = [x[0] for x in node_list]for n in top_node: g.add_edge(Edge('head', n))# 頭の属性を指定するn = g.get_node('head')n.set_label(head_name)n.set_shape('Msquare')g.write_png('calenda1.png')次へ続く。365日月の満ち欠けがわかるインテリアカレンダー♪月齢ムーンカレンダーPHASES OF THE MOON
2007.11.29
コメント(0)
-

Python から Graphviz を使う( pydot を日本語で出力)(10)
プログラミング言語Erlang入門 なんて出るのね。というのはさておき、Python から Graphviz を使う( pydot を日本語で出力)(9) からの引き続き。An Introduction to GraphViz のFigure 3. A twopi Graph のようなものを作ってみる。ちなみに、Listing 3. Source Code for Figure 3 は Figure 3 と一致していないのでおかしい。が、気にしない。やはり、これもリスト渡しでざっくり作る方法をとる。以前に手を入れて追加設定なしに日本語が出せるようにした graph_from_edges2 を使って、普通にグラフを描いて、そこに shape = record と各ノードへのラベルを設定し、twopi で出力する。#-*- coding: utf-8 -*-from pydot import graph_from_edges2node_list = [[u'あ',u'い'], [u'あ', u'う'], [u'あ', u'え'], [u'あ', u'お'], [u'い', u'か'], [u'か', u'き'], [u'か', u'く'], [u'う', u'こ'], [u'え', u'さ'], [u'え', u'し']]# リストからグラフを作成g = graph_from_edges2(node_list)# ノードに追加の設定n = g.get_node('node')n.set_shape('record')n.set_height(.1)# ノードにラベルを設定for node in g.get_node_list(): label = " | %s | " % node.name node.set_label(label)# 出力するprint unicode(g.to_string(), "utf-8")g.write_png("twopi1.png", prog="twopi")g.write_png("twopi2.png")出力は twopi を使ったものと、デフォルトの dot を使ったものの両方をしてみた。twopi の出力dot の出力そういえば、最初に Graphviz に出会ったのは、ツリーにグラフに分散・集中 で July 28, 2002 だったのに、使い始めるまでに 5年以上も経っているw。もし、5年後にもまだブログを書いていたら、この一年におもしろいとか書いていたことを使って遊んでいるかもしれない。ほんとに進歩ないなぁ。
2007.11.28
コメント(0)
-

Python から Graphviz を使う( pydot を日本語で出力)(9)
Python から Graphviz を使う( pydot を日本語で出力)(8) からの引き続き。An Introduction to GraphViz の Figure 2. A Hash Table を作ってみる。やはり、これもリスト渡しでざっくり作る方法をとる。頭の部分を作る先頭の部分から順次生成してみる。まずは、リストがつながるヘッドの部分を生成する。#!/usr/bin/env python#-*- coding: utf-8 -*-from pydot import Dot, Node, Edgeimport renode_list = [ [[u'あ', u'い'],[u'う', u'え']], [[u'お', u'か'],[u'き', u'く']], [[u'け', u'こ'], ['さ', 'し']], [[u'す', u'せ'],[u'そ', u'た'],[u'ち',u'つ'], [u'て', u'と']], [[u'な', u'に'],[u'ぬ', u'ね'],[u'の', u'は']], [[u'ひ',u'ふ']] ]# グラフを作って、左から右へ(LR) で記述を指定する。g = Dot(type="digraph")g.set_rankdir("LR")# ノードの shape は record にし、width, height を設定。# また、日本語が出力できるようにする。n = Node('node')n.set_shape('record')n.set_width(.1)n.set_height(.1)n.set_fontname("arialuni.ttf")n.set_fontsize(9)g.add_node(n)# ヘッドに追加する枝の数分の接続先を作る関数def make_head_node(num): n = Node('head') n.set_height(3) label_list = [''] for i in range(num + 2): lb = "<p%d>" % i label_list.append(lb) label_list.append("|") label = " | ".join(label_list) n.set_label(label) return n# ヘッドに直接つながっている枝の先頭の接続先を作る。node_len = len(node_list)n = make_head_node(node_len)g.add_node(n)各ノードを作成してラベルを設定し、エッジを作成するノードを作りながらラベルを付ける。その次に、エッジを作る。同時にやればループが少なくて済むが、あえて別にしておく。# 接続されるリストの属性を設定するためにノードを一つ追加n = Node('node')n.set_width(2)g.add_node(n)# 接続されるリストの属性を設定するためにノードを一つ追加n = Node('node')n.set_width(2)g.add_node(n)# ノードの作成for branch in node_list: # 一つの枝を処理 for node in branch: # 一つのノードを処理 g_node = Node(node[0]) label = u"{<e> %s | %s | <p> }" % (node[0], node[1]) g_node.set_label(label) g.add_node(g_node)# エッジの作成p = 0 # ヘッドからの (p)ointer のカウントfor branch in node_list: # ヘッドに繋ぐ先頭を作る prev = branch[0][0] edge0 = "head:p%d" % p edge1 = "%s:e" % prev edge = Edge(edge0, edge1) g.add_edge(edge) p += 1 # 後続の枝の要素があれば、作成して繋ぐ if len(branch) > 1: for node in branch[1:]: edge0 = "%s:p" % prev edge1 = "%s:e" % node[0] edge = Edge(edge0, edge1) g.add_edge(edge) prev = node[0]ゴミノードを削除して出力するエッジを追加したときに "foo":p0 や "bar":e といったゴミノードができてしまうので削除してから出力する。相変わらず汚いやり方。そもそも pydot が余計なノードを作らないように改造してしまいたいところ。to_remove = re.compile(":p[0-9]*$|:e$")for n in g.get_node_list(): if re.search(to_remove, n.name): g.node_list.remove(n)elems = []for elem in g.sorted_graph_elements: if isinstance(elem, Node) and re.search(to_remove, elem.name): pass else: elems.append(elem)g.sorted_graph_elements = elems# 出力g.write_png("hash1.png")でもって、こんな図が描ける。
2007.11.28
コメント(0)
-

サイト名を 傀儡師の館.Python にした
サイトの名前を、「傀儡師の館.Python」としてみた。特に意味はない。Python 関連の記事が多いので、タイトルに Python と入ったらアクセス数に影響があるだろうかというくだらない実験を兼ねて。そのうち別の単語に代わるかもしれないが、「傀儡師の館」の部分は変更しない。そういえば、また、Python の本が新しく出ているようだ。日本人が書いた Python の本もだいぶ増えてきた。
2007.11.27
コメント(0)
-
日本語文節構造解析システムibukiC
岐阜大学、池田研究室 が 日本語文節構造解析システムibukiC を公開していた。まだ、version0.10 ということだが、おもしろそう。機能語部分は、実際はもっと踏み込んで、機能的・意味的内容から設定した6つの要素部に分割しています。たとえば、 「食べたのが悪かったようです」は、 (食べる Φ た Φ Φ Φ Φ 連体) (Yの Φ が Φ Φ Φ Φ 連用) (悪い Φ た Φ Φ ようだ Φ Φ 文末)のように解析されます。この要素分割も辞書記述で設定します辞書記述でいろいろできるということかな。このあたりに説明がある。形態素解析の ibukiK、文章構想解析の ibukiC、構文解析の ibukiS となっていて、公開されているのは ibukiC だから、係り受けの木まではできないのか。まあ、でも、こういうものが公開されるとは、良い時代になったものだ。日本語係り受け解析器 CaboCha/南瓜: Yet Another Japanese Dependency Structure Analyzer の文節の切り方と比べるとどんな具合なのだろうか。ibuki の場合、「機能的・意味的内容から設定した6つの要素部に分割」というところで、おもしろい用途が考えられるかもしれない。言語処理学会 第10回年次大会 プログラム とか見ると「長単位の機能語を辞書に持たせた文節構造解析システムibukiC」とか、言語処理学会第12回年次大会(NLP2006)本会議プログラム とか、言語処理学会第13回年次大会(NLP2007)本会議プログラム とかで発表しているようだが、ネット上の資料はあまり引っかかってこない。「言語・認識・表現」第12回年次研究会 で、「機能文節を導入した文節構造解析システム(ibukiC v0.20)」の発表が行われるらしい。「大学発ベンチャーにおける自然言語処理の研究開発‐三浦文法に基づく商用ベースの日本語統語解析システムについて -」宮崎正弘((株)ラングテック、新潟大学)] とか、以前 鳥バンク (Tori-Bank) すげっ で書いた 鳥バンク の「「CREST研究の成果と今後の課題」 池原悟 鳥取大学」とかの発表もあるようだ。検索していたら、1文字未知語を核とする未知語候補の抽出 なんてものが見つかった。ibukiC の辞書は貧弱だが、「語「川崎フ」などが未知語として、抽出できていた」らしい。その後、辞書はどうなったのかな。まあ、ダウンロードして見れば分かるか。しかし、試したいものスタックがどんどん膨れあがってくる。。。。。
2007.11.27
コメント(0)
-

Python から Graphviz を使う( pydot を日本語で出力)(8)
また、しつこく pydot を使って遊ぶ。Python から Graphviz を使う( pydot を日本語で出力)(7) からの続き。もうちょっと複雑なものにもチャレンジする。An Introduction to GraphViz にあるような図に挑戦。Listing 1. Dot Source Code for Figure 1 からやってみる。pydot には、こうしたグラフをまとめて書けるようなメソッドはない。なので作ってみる。ベースの考え方としては、graph_from_edges と同じように、エッジを中心にして考えるか( A→B, A→C, B→D, B→E, C→F, C→G...)、明らかな構造を持っていると仮定して、親と子の関係でリストを作るか( [A, [B, C]], [B, [D, E]], [C, [F, G]], ...)。なんとなく、親子の関係でノード中心に作った方がよさそうなので、そうしてみる。ネストしたリストからすべての要素を取り出す次のようにネストしたリストから、要素を取り出す関数を作っておく。なんかもっとスマートに書けそうな気もするが。。。。#-*- coding: utf-8 -*-import setsfrom types import ListTypenode_list = [[u'あ', [u'い', u'う']], [u'い', [u'え', u'お']], [u'う', [u'か', u'き']], ]def extract_nodes(node_list): """ ネストしたリストから すべての要素を取り出す """ nodes = sets.Set() if type(node_list) == ListType: for x in node_list: nodes = nodes.union(extract_nodes(x)) else: nodes.add(node_list) return nodes# すべてのノードを取り出すnodes = extract_nodes(node_list)すべてのノード要素に対して、ラベルを付ける前準備として、グラフを生成して、shape = record のノードを追加しておく。次に、ノードの各要素に対してノードオブジェクトを生成して、それぞれにラベルをつけ、グラフに追加する。from pydot import Dot, Graph, Node, Edgeg = Dot(graph_type='digraph')# node [shape = record] を作って追加n = Node('node')n.set_shape('record')n.set_fontname('arialuni.ttf')n.set_fontsize(9)g.add_node(n)for node in nodes: g_node = Node(node[0]) label = u"<f0> | <f1> %s | <f2> " % node[0] g_node.set_label(label) g.add_node(g_node) print g_node.labelエッジを生成して、ポインタを付ける渡ってくるものが [A, [B, C]] のように [親, [子1, 子2]] というのを前提として、 親:f0→子1:f1、親:f2→子2:f1 の繰り返し処理になればよいと考える(エラー処理はとりあえずなし))。ノード名に f0, f1 ,f2 を適切に繋いだ名前を作ってエッジを作っていく。一応、子供がない場合も考慮しておく。for x in node_list: parent = x[0] print x, parent try: child = x[1][0] edge0 = "%s:f0" % parent edge1 = "%s:f1" % child print edge0, edge1 g.add_edge(Edge(edge0, edge1)) except: pass try: child = x[1][1] edge0 = "%s:f2" % parent edge1 = "%s:f1" % child print edge0, edge1 g.add_edge(Edge(edge0, edge1)) except: passゴミノードを削除して出力するエッジを追加したときに、よけいなノード A:f0 等々が作られてしまうので、出力しないようにする。ちょっと泥臭い。for n in g.get_node_list(): if n.name[-3:-1] == ":f": g.node_list.remove(n)elems = []for elem in g.sorted_graph_elements: if isinstance(elem, Node) and elem.name[-3:-1] == ":f": pass else: elems.append(elem)g.sorted_graph_elements = elems# 出力g.write_png("tree.png")こんな出力結果が得られるこれで、次のように dot ファイルから、画像が作られる。digraph G {node [fontsize=9, fontname="arialuni.ttf", shape=record];"あ" [label="<f0> | <f1> あ | <f2> "];"い" [label="<f0> | <f1> い | <f2> "];"う" [label="<f0> | <f1> う | <f2> "];"え" [label="<f0> | <f1> え | <f2> "];"か" [label="<f0> | <f1> か | <f2> "];"お" [label="<f0> | <f1> お | <f2> "];"き" [label="<f0> | <f1> き | <f2> "];"あ":f0 -> "い":f1;"あ":f2 -> "う":f1;"い":f0 -> "え":f1;"い":f2 -> "お":f1;"う":f0 -> "か":f1;"う":f2 -> "き":f1;}やっぱり pydot はグラフからノードを削除したりとか、グラフの操作に関しては弱いので汚いことをしなければならなくなるけれども、いじくれば、なんとかならないこともない。
2007.11.27
コメント(0)
-
Gnuplot.py で日本語を表示する (2)
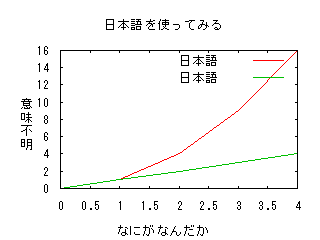
縦書き用に文字列を反転させるかGnuplot-py で日本語を表示する で、グラフの縦軸に文字列を入れるときに、「文字列」を「列字文」と入れてやると縦に読めて読みやすいので、文字列を反転させるのにはどうするか考える。首を横にしないと読みにくいの嫌なのね。元の文字列が UTF-8 を前提として、いったんユニコード文字列にしてからひっくり返して、また UTF-8 に戻すと楽? こんなんかな(端末が UTF-8 の環境の前提)。def reverse_str(str, enc='UTF-8'): ustr = unicode(str, enc)[::-1] return ustr.encode(enc)>>> original = "意味不明">>> reversed = reverse_str(original)>>> print reversed明不味意Gnuplot-py で日本語を表示する の文字化けの原因その一Gnuplot.py から Gnuplot にデータが渡されるとき、プロットすべきデータが一時ファイルとして作られて、plot "datafile" のような形で Gnuplot に渡される。つまり、Gnuplot がデータを表示するときには標準入力経由で渡されたデータではなく、一時ファイル上に保存されたデータを読んでいるようだ。このファイルが作られるのは環境変数 TEMP に指定されているディレクトリなので、デフォルトの状態だと \Documents and Settings\username\Local Settings\temp\randomfilename.gnuplot のように長くなってしまう。実際にはパス名が 8文字に短縮されるので "c:\\docume~1\\kugutsu\\locals~1\\temp\\tmp5cdjds" となるがやはり長い。このためタイトルの文字列が長くなりすぎたときに Gnuplot が、この長すぎる文字列をうまく受け取ることができなくなって文字列が壊れたりすることがあるように思える。そこで、TEMP を \TEMP など短い名前にしてやると、次のように渡されるコマンドが短くなる(\temp のところがデフォルトだとやたら長い)。これが一つの問題になっていると思われる(あくまで推測)。gnuplot> plot "c:\\temp\\tmpw2jj4y.gnuplot" title "aaaaa" withlinespoints, "c:\\temp\\tmpehyes_.gnuplot" title "bbbbb" with linesgo_win32.py を見ていると、prefer_inline_data = 0 になっていて、インラインでわざと渡さないようにしている。特に理由はないようなので、ここをあえて 1 にしてみる。そうすれば一時ファイルを作らなくなるはず。とやってみると、一時ファイルは作らなくなった。とりあえず、g = Gnuplot.Gnuplot('commands.txt')としたときに、コマンドがファイルに書き出されてデバグしやすくなるので、一時ファイルは作らないようにしておくことにした(データも commands.txt に書き出されるので)。文字化けを起こすのは Gnuplot 側の問題のように思える。とりあえずの対策として次のことをすれば、日本語を使うのに問題がなさそう。UTF-8 で Python のソースファイルを作ることタイトルやラベルの文字列の末尾に全角スペースを一つ入れることos.environment['TEMP']="\\TEMP" のように短いテンポラリファイルのディレクトリ指定にするか prefer_inline_data = 1 にすることpgnuplot.exe の置き場所Gnuplot のコマンドについては、gp_win32.py で gnuplot_command = r'pgnuplot.exe' のように設定されているので、パスの通ったところにコマンドをあえておきたくないときは、ここを直接いじって r'"C:\Program Files\gp371w32\pgnuplot.exe"' のように書き換えてしまうか、あるいは、プログラム中で Gnuplot.GnuplotOpts.gnuplot_command = r'"C:\path\to\pgnuplot.exe"' としてしまえばよいようだ。フォントの指定たとえば、次のようにフォントを指定しても指定したフォントが反映しない。g.title("日本語を使ってみるよ ", font="E:/Windows/Fonts/msgothic.ttc,16")_Gnuplot.py の中の class Gnuplo の def set_label の中で、次の行がおかしい。 if font is not None: cmd.append('"%s"' % (font,))となっているところは if font is not None: cmd.append('font "%s"' % (font,))としないとフォントが反映されない。そうすれば、下のようにフォントの指定ができるようになる。#-*- coding: utf-8 -*-import Gnuplotimport osos.environ['TEMP'] = "\\TEMP"g = Gnuplot.Gnuplot(debug=1)#g = Gnuplot.Gnuplot('commands.txt')LARGEFONT = "E:/Windows/Fonts/msgothic.ttc,18"MEDIUMFONT = "E:/Windows/Fonts/msgothic.ttc,12"SMALLFONT = "E:/Windows/Fonts/msgothic.ttc,8"TERMINAL = 'set terminal png size 420, 400 font "%s"' % SMALLFONTSAVETO = 'set output "sample.png"'g(TERMINAL)g(SAVETO)g.title("日本語を使ってみるよ ", font=LARGEFONT)g('set data style linespoints')data1 = [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16]] data2 = [[0, 0], [1, 1], [2, 2], [3, 3], [4, 4]] plot1 = Gnuplot.PlotItems.Data(data1, with="linespoints", title='日本語大丈夫 ')plot2 = Gnuplot.PlotItems.Data(data2, with="lines", title='大丈夫なんだ ')g.xlabel("なにがなんだか ", font=MEDIUMFONT)g.ylabel("明不味意 ", font=MEDIUMFONT)g('set pointsize 1')g.plot(plot1, plot2)
2007.11.26
コメント(1)
-
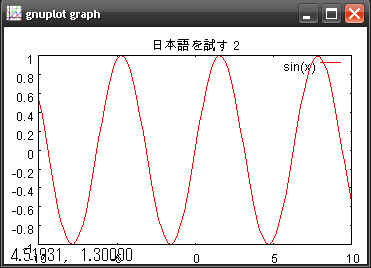
Gnuplot-py で日本語を表示する
GnuPlot を Python から使ってみることにした。Python からは、gnuplot-py を使ってみる。以前、 Solaris 10 で iozone を使ってディスクIOのパフォーマンスを「見る」 のときに、iozone の結果をプロットするのに GnuPlot を使ったのだが存在を忘れてた。でもツールが勝手にやってくれただけなので、中身は理解してなかった。とりあえず Windows で Gnuplot-py が使えるか確認。gnuplot 4.4.2 をダウンロードして使ってみる。Gnuplot.py は sourceforge からダウンロードして python setup.py install でインストール。gnuplot の動作確認。wgnuplot.exe をダブルクリックして起動すると表示が汚い。画面で右クリックして、Choose Font を選択してフォントを変更しておく。 初歩 gnuplot 入門 のあたり参照。日本語版を使った方がとまどいは少ないか。とりあえず、フォントを変更したあと右クリックで Update を選択して変更を保存しておかないと再起動したあとまた元にフォントが戻るので注意。[File]-[Demos]メニューを選択して、ファイル選択画面で上に上がってから demo を選択し、all.dem を選択すると、次々とデモが表示される。OK ボタンを押すかリターンを押していくとどんどん次のグラフが表示される。かなりたくさんのデモがある。こういうのが描けるのねぇと見ながら、基本的な表示に問題がないのを確認。wgnuplot.exe のプロンプトで、「plot sin(x)」とかやってグラフが表示されたら、そこでも右クリックしてと思ったら、いったん m キーを押してからでないの右クリックは利かない(マウスのモードを変更 unset mouse の状態へ)。あるいは、ウィンドウの左上のタイトルバーのアイコンをクリックして、Option Choose Font で変更。そして Update。グラフの描画画面でもフォントを変更しておかないとダメということ。グラフを一旦閉じて、set title "日本語試す"plot sin(x)と入力してみる。wgnuplot 上では日本語は文字化けして使えるのかーという状態になるが、これは我慢する。ちゃんとグラフの描画時には正しく表示された。同じように gnuplot-py を使って書いてみる。import Gnuplotg = Gnuplot.Gnuplot(debug=1)g('set data style linespoints')g.title("日本語を試す 2")g.plot('sin(x)')raw_input('リターンを押すと終了\n')ちゃんとタイトルに日本語も表示できた。とりあえず使えるようだ。ところが、png ファイルを書き出すことができない。import Gnuplotg = Gnuplot.Gnuplot(debug=1)g('set terminal png')g('set output "sample.png"')g('set data style linespoints')g.title("日本語を試す 2")g.plot('sin(x)')"日本語を試す 2"のところを "Sampe 03" とすれば、ちゃんと png ファイルが作成される。ということで、png ファイルへの日本語の書き出しがうまくいっていない。png ファイルに書き出すと文字化けしてしまう。悩む。こうなったら強引にやってやれ。UTF-8 にして、さらに文字列の末尾に全角スペースを2つ入れてみる。するとなんと日本語が表示できた。#-*- coding: utf-8 -*-import Gnuplotg = Gnuplot.Gnuplot(debug=1)g('set terminal png size 320, 240 font "E:/Windows/Fonts/msgothic.ttc,10"')g('set output "sample.png"')g.title("日本語を使ってみる ")g('set data style linespoints')data1 = [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16]] data2 = [[0, 0], [1, 1], [2, 2], [3, 3], [4, 4]] plot1 = Gnuplot.PlotItems.Data(data1, with="lines", title="日本語 ")plot2 = Gnuplot.PlotItems.Data(data2, with="lines", title="日本語 ")g.xlabel("なにがなんだか ")g.ylabel(" 明不味意 ")g.plot(plot1, plot2)Gnuplot-py の参考ほとんど詐欺的なやり方。いつもちゃんと表示されるわけではないので現状実用的ではないが、無理矢理日本語表示ができた。それにしても、どこが悪さをしているのだろうか。つきとめればもしかしていつでもちゃんと表示できるようになるかもしれない。どなたか解決方法を知っていたら教えてくださいませ。追記原因が分かった。どうやら環境変数のTEMP に一時ファイルの書き出しを行っている際に、これが長すぎると (例えば、\Documents and Settings\username\Local Setings\temp\bababababa) おかしくなるようだ。ということで、次のような行を入れて、一時的に TEMP を短い名前のディレクトリにしておけば、日本語でも問題なく表示できるようになったと思ったら、やっぱりダメなときもあるので、全角スペースは常に後ろに1つだけつけておくことにした。import osos.environ['TEMP'] = "\\TEMP"これとは違う話だが、痛い日記 Gnuplot-pyのインストールGnuplot.pyはNumericを想定して作ってるのでnumpyとgnuplotのみをインストールしている環境ではGnuplotのtest.pyやdemo.pyが動かない.とかいう話もあるようだ。自分の場合は Numeric がインストールされていたので問題なかった。Numeric をインストールしていない場合は、svn co https://gnuplot-py.svn.sourceforge.net/svnroot/gnuplot-py gnuplot-pydemo.py を見ると、from numpy import * となっているので、開発中のバージョンを使った方がよいかもしれない。Gnluplot-pygnuplot-pyGnuplot.py Documentgnuplot.pyの使い方その他 gnuplot 関連gnuplotgnuplot のページ (Takeno Lab)グラフは Gnuplot にお任せgnuplot tips - not so Frequently Asked Questions -Windows版 Gnuplot の使い方GNUPLOTクイックマニュアルgnuplotの使い方gnuplot 入門gnuplot (Ghostscript 8.61 + GSview 4.9 の日本語版 ◆ PostScript フォントの利用 ◆)公開プログラムのページ (ゴミ箱?おもちゃ箱?)GNUPLOTで簡易アニメーションを作るグラフを画像ファイルにするgnuplot マニュアル日本語訳
2007.11.25
コメント(0)
-

Python の文法チェックには何を使う? lint はないの?
C 言語などでは、文法チェックをしてくれる lint があるが、PyChecker がある。たとえば、こんな具合にチェックをしてくれる。Processing test1...Warnings...test1.py:25: Invalid arguments to (jjj2), got 4, expected between 1 and 3test1.py:28: Invalid arguments to (ddd), got 0, expected at least 1test1.py:35: No global (sys) foundtest1.py:39: self is not first method argumenttest1.py:40: No global (nofunc) foundtest1.py:41: No global (self) foundtest1.py:42: Function (jjj) doesn't support **kwArgstest1.py:42: Invalid arguments to (jjj), got 3, expected 1test1.py:48: No global (jjjj) foundtest1.py:54: Invalid arguments to (xxx), got 2, expected 11Python のスレッドについての資料と Python の統合開発環境 (IDE) でも書いた SPE IDE - Stani's Python Editor にも pyckecker がプラグインとして使われているので、Ctr-Alt-C キーを押すと自動的に編集中のソースファイルを pychecker にかけてくれる。下の図の左側に並んでいる文字がエラーやワーニング。そこをクリックすると、該当箇所に飛んで水色の反転表示になる。ということで、引数の数がおかしいとか動かせば落ちるという当然のレベルだけでなく、未使用の変数を指摘してくれたり等、コードを少しきれいにするのに役立ってくれる。が、Sourceforge Index of /pychecker を見ても、開発は止まっているみたい。これに代わるものとして、pylint がある。Pychcker でチェックできるものはすべてカバーしているのに加えて、行が長すぎるもののチェック、コーディングスタイルに合わせて変数名が適切につけられているかのチェック、あるいは、宣言されたインターフェイスが実際に使用されているかのチェックなどもしてくれるようだ (Card pylint features)。pylint 本体は easy_install でインストールできるものの、依存しているモジュールの logilab-astng と logiab-common が合わせてインストールされないところがちょっと難。optik にも依存しているが、これは Python 2.2 以降では不要なので問題なし(OptionParser が標準モジュールになったから)。astng は easy_install astng でインストールできないと思ったら、Reading http://cheeseshop.python.org/pypi/astng/0.16.1No local packages or download links found for astngerror: Could not find suitable distribution for Requirement.parse('astng')easy_install logilab-astng でインストールできた。が、怪しいので site-package にインストールこれはいったん削除して、python setup.py install でインストールし直す(easy_install だと 0.16.1 だが 0.17.1 がすでにある)。logilab-common も easy_install ではインストールできないので python-setup.py でインストール。現状、中途半端な状態なので、すべて ftp://ftp.logilab.fr/pub/ のlogilab の ftp サイトから手動でダウンロードして setup.py でインストールするのが妥当かもしれない。インストール環境としては中途半端でよろしくない。ウェブページのダウンロード用のリンクは、左の上の方にあるが、最初どこからダウンロードしていいのか分からなかった。。。。とりあえず動かしてみる。Windows の場合は、\Python24\Scripts\にコマンドがインストールされるのでパスを通しておくか、直でパス名を含めて起動する。pylint est.py でチェックしてくれる。Report======44 statements analysed.Duplication-----------+-------------------------+------+---------+-----------+| |now |previous |difference |+=========================+======+=========+===========+|nb duplicated lines |0 |NC |NC |+-------------------------+------+---------+-----------+|percent duplicated lines |0.000 |NC |NC |+-------------------------+------+---------+-----------+から始まって、Raw metrics, Statistics by type, Messages by Category, Messages といった具合に統計情報を出してくれる。そして、最後に、レーティングが 10点満点で出る。コピペたくさんのコードは、ちゃんと動いても点数低くなるだろうな。docstring が入ってないのとかもだめよん。Global evaluation-----------------Your code has been rated at 6.14/10(GUI 版は pylint-gui もあって起動すると Tk の小さなウィンドウが表示されるので、Module or package にファイルのパス名を入れたら、下のように表示された。出力自体はコマンドラインと同じ。動作を妨げるようなものから、短い変数名を始めとして、docstring がないとか、うるさく出してくれる。A More Complete PyLint on Windows Walkthrough や Komodo Hacks: Integrating Pylint を見ると、Komodo の外部ツールとして使うこともできるようだし、Integrate Pylint and Pychecker support あるいは、PyLint can be used with PyDev! といった具合に他の IDE から使うこともできるようだ。Python対応統合開発環境、最新版登場 - Eric4 (2007/06/04) の The Eric Python IDE は、pylint を組み込んでいるようだ。Eric Python IDE って、もしかしてすごくよいかもしれない。現状、機能的には一番豊富かもしれない。今度インストールして使ってみるかな。Django のソースを pychecker や pylint にかけた人がいる。pychecker vs pylint vs Django。pychcker だと指摘しないようなことも pylint は指摘する。Line too long (208/80) ... Too many local variables (23/15) 28 Apr 2006 22:03 時点ではこんな感じだったようだ。とりあえず、うるさいけど、こういうものを使っているとコードの質は上がるだろうなと。
2007.11.24
コメント(4)
-
Python のファイル参照や操作は面倒だというあなたに path モジュール
Python を使ってディレクトリやファイルをたどりながら何かするのは面倒。たとえば、このディレクトリの下のファイル名が「~」で終わっているファイルを削除したいとかいうのを書こうとすると、unix だったら find コマンドを使って、find . -name \*~ -print -exec rm {} \; とかあるわけで、そんな風にもっと簡単にできないかなぁと思う人も多いだろう。で、path モジュールを使えば、この手のものも簡単に書けるようになる。端的に言うと path モジュールは os.path をラップして使いやすくしたものなので、なければないでゴリゴリと書けばよいわけだけど、あったらあったでソースがシンプルになるので便利でしょうというもの。ちなみにライセンスはパブリックドメインなので自由な使い方ができる。easy_install には対応していないので、path-2.2.zipをダウンロードして、解凍後、「python setup.py install」 でインストール。$ unzip path-2.2.zip$ cd path-2.2$ sudo python setup.py installさて、その威力といえば、例えば、htdocs 配下にある ~ でファイル名が終わっているバックアップファイルをすべて削除するなんていうのは、下のように書けるようになる。#!/usr/bin/env pythonimport pathd = '/var/apache/htdocs'for f in d.walkfiles('*~'): f.removeとまあ、このぐらいだと、そんなものとか思われるかもしれないが、このとき、f.mtime とか f.ctime、f.atime とかいう具合にファイルの更新時や作成時、アクセス時を参照することもできるし、f.size でファイルサイズ、f.f.owner で所有者も参照できる。さらに便利なことに、f.text() でファイルの中身を取り出せたりとかもする。E:\WORK の下にある s*py にマッチするファイルの内、3000バイト以上で1時間以内に作成したものがあれば、ファイル名と所有者を表示し、ついでに、一行目も表示するなんていうのも、下のように数行で書けてしまう。ちょこっとファイル整理用にスクリプトを書くときなど、特に重宝すると思う。#!/usr/bin/env pythonimport pathimport timed = path.path("e:/work")for f in d.walkfiles("s*py"): if f.size > 3000 and f.ctime > time.time() - 3600: print f.name, f.owner, f.lines()[0]と、まあ、えろえろできるので便利よ。
2007.11.23
コメント(0)
-
Python のいろいろな方法でキーと値の保存と検索をやってみようかと(2)
Python のいろいろな方法でキーと値の保存と検索をやってみようかと 書いたが、cdb、gdbm、qdbm、Tokyo Cabinet をそれぞれ使ってみるとパフォーマンスはどの程度なのだろうということで、取り組み始めた。やっぱり、cdb はどういうときでも別格に速い。スタティックなデータのルックアップあるいは、データの一方的な記録(参照せずに記録するだけで、データを使うのは別フェーズ)であれば、もう断然 cdb。これは Python から使っても問題なく速い。cdb の地位は揺るがない感じ。Python からは python-cdb 0.3 で今のところ問題なし。でも、読み書き両方が交錯する場合は使えないので、何を使ったらよいか。Berkeley DB に関して何でもかんでも RDBMS に突っ込むのがいいかといえばそんなわけもなく、RDBMS を使わない方がいい場合もあるじゃないのというのは、当然なわけで、そんな折り、ちょうど Oracle も Why a Non-Relational Database? A Comparison of Berkeley DB and Relational Databases なんてまた出してきた。Oracle Berkeley DB: Performance Metrics and Benchmarks みたいなホワイトペーパーも出している。でもって、Oracle Berkeley DB なんてのも、ちゃんと市場のニーズを取りこぼしなく抑えておこうということなんだろう。この市場はどうあがいても捨てられないものね。AES encryption 版ってどの程度のパフォーマンスなんだろうか。ということで、Berkeley DB 試すの忘れてた。Python Bindings for BerkeleyDB 3.3 thru 4.5 とかいう選択肢もある。標準モジュールでも、BSDDB は使えるが後付けでインストールするなら、これを使うといいかもしれない。標準モジュールの bsddb でも、どちらもパフォーマンス的には変わらない印象。下の QDBM のところにある GDBM と比較すると、書き込みのパフォーマンスが若干よい感じ。ちなみに現状で Python バインディングが正式に対応しているのは BDB 4.5 までで最新の 4.6 には対応していないようだ。BSDDB btopen WriteWritereal 0m25.679suser 0m13.754ssys 0m6.946sReadreal 0m13.858suser 0m10.492ssys 0m3.300sQDBM に関してQDBM: Quick Database Manager に関しては、GDBM の代わりに QDBM に置き換えたら、パフォーマンスがよくなった。QDBM のバインディングは Python のコンパイル前に直接ソース(Module/gdbmmodule.c)や Module/Setup などを書き換えてコンパイルしたもので、GDBM を語って動く環境で試している。QDBMのチュートリアル を見ていて、いっそのことこれでやってしまえとやってみたら案外簡単だった。古い GDBM のデータは不要とかいうのであれば、従来の import gdbm とやっていたプログラムであっても、ソースの変更なしに使い続けられてパフォーマンスがあがりそう。ただ、書き込みは確実に速くなるのに対して、読み込みは場合によって同程度とかもデータによってはあり得る感じ。そういう強引はだめよという場合は、QDBM Python bindingでも、ほぼ同じパフォーマンスが出せる。けど微妙に前述の方法の方が試した限りでは高速な感じ。GDBM-- Write --real 0m27.888suser 0m6.793ssys 0m10.630s-- Read --real 0m12.878suser 0m7.704ssys 0m5.116sQDBM-- Write --real 0m17.520suser 0m5.988ssys 0m8.471s-- Read --real 0m12.821suser 0m6.757ssys 0m6.017sまあ、条件とかによって数値はいくらでも変わってくるところがあるが、どうあがいても QDBM と GDBM だと Python から使っても、QDBM の方に軍配があがる感じ。Tokyo Cabinet に関して感触として Tokyo Cabinet のPythonバインディングを書いている人いますか? PyTCのリポジトリ のもは、実用レベルという感じ。100万文の登録・読み込みテストをやっても問題が生じなかった。パフォーマンス的にも良い感じ。単純な使い方をする限りは問題なさそう。これはかなり使えそう。GDBM や QDBM ではパフォーマンスが劣化してしまうようなデータを使っても、pytc.BDB を使うと大丈夫だったりした。 pytc.HDB は、キーの長さが文章の一文相当で、値もその数倍というようなデータをたくさん追加していくと、劣化が激しいのに、BDB の場合はそれほど劣化しない。データの性質とか量によって、ちゃんと使い分けないといかんねという感じ。Tokyo Cabinet BTWritereal 0m9.947suser 0m6.340ssys 0m2.881sReadreal 0m9.258suser 0m6.499ssys 0m2.643sTokyo Cabinet HashWritereal 0m18.427suser 0m6.377ssys 0m7.234sReadreal 0m12.335suser 0m7.177ssys 0m5.101sCDB に関してCDB の速さは別格。用途が限られるけれど、CDB で大丈夫な用途であれば、CDB が一番。でも、データによっては Tokyo Cabinet をチューンしながら使ったら、そこそこ近いパフォーマンスが出せるのかもしれない。CDBWritereal 0m8.236suser 0m4.916ssys 0m3.154sReadreal 0m7.379suser 0m6.081ssys 0m1.269sざっと見た感じ Tokyo Cabinet とその Python バインディングは、バランス的にかなり期待できそうな印象がある。これで信頼性と安全性が高まれば、CDB を使っていたところ用途でも使い分け面倒だし、これでいこうかという感じになるかもしれない。データベースの選択にあたっては、表面上のパフォーマンスだけでなくて、壊れにくさとかそういうところもあるかもしれない。というか、それがかなり大きい選択の要因になるわけで、mixi で実用で使い始めましたとなれば、そのあたりもクリアできたんだろうという目安になるかな。まあ、長い間、使われているものは、いろいろなデータや使い方がされていているだけに隠れた地雷を踏む確率は低いわけだけど、とにかく速いの欲しいというところから使って枯れていけばかなりよいものになりそう。全般的な印象として、Tokyo Cabinet はかなり期待できそうな印象が強い。Tokyo Cabinet + PyTC は、十分実用のために本格的に試して意味があるレベルにあると思う。いいなこれ。以上、データによって、かなり変わるからあくまで参考レベルということで。なんて、この手のものを使う人にはあえて言う必要もないだろうけど。追記 2007/11/24pytc-0.1 - Tokyo Cabinet Python bindings公開 で、http://tasuku.suenaga.name/pub/pytc/pytc-0.1.tar.gz にとりあえず公開されたらしい。sourceforge には現在申請中とのこと
2007.11.22
コメント(0)
-

Python のいろいろな方法でキーと値の保存と検索をやってみようかと
少し長目の文字列をキーとして、何かもっと長い文字列を保存あるいは検索するようなことをする場合、Python から行うというのを前提条件にしたとき、何で作るのがよいのか実験してみたくなった。Benchmark Test of DBM Brothers (pdf) を見ると、CDB (日本語ドキュメント)ってやっぱり速いのね。スタティックだから用途に制限があるけど、すでに固まったデータがあってルックアップを高速にっていうのなら一番か。4ギガバイトまでとかいうのも制限だけど。そういう意味では QDBM の Depot: 基本API とか使っても 2GB の制限ありか。QDBM: Quick Database Manager とか良さそうだし、その後続にあたる Tokyo Cabinet は、Benchmark Test of DBM Brothers (pdf) を見るとさらによさそう。mixi engineer blog: 最適化しよう? とか、そのあたりのものも見てみる。ふーん。こういうものを見ていると、mixi も使ってみるかという気になってくるが、mixi ってアカウントは前に作ったのだけど使ってないのだな。いまだによく分からない世界。そういう意味では twitter とかもそうなのだな。なんていうのはさておき、Tokyo Cabinet は Python から使えないのかなぁと調べてみたら、TokyoCabinetのPython Binding が見つかった。ぐにゃらさんが「Tokyo CabinetのPython Bindingでもつくっかー」と言いつつ放置プレイ気味だったので,取り急ぎ欲しかったハッシュDBだけ気合で作った.ということだが、そのグニャラくんのグニャグニャ備忘録@はてな Tokyo CabinetのPythonバインディングを書いている人いますか? も進行中なのだな。PyTCのリポジトリ のものはハッシュDB ほとんどできたということだから、一応、試してみるか。BDB も作られているようだし、とりあえず使えるのかなぁ。QDBM は、QDBM Python binding が見つかった。とりあえず、Depot だけとか書いてあるから 2GB の制限有りだな。QDBMのチュートリアル を見ていて思ったのだが、Relic: NDBM互換API、Hovel: GDBM互換APIを使って、Python のライブラリを書き換えて、コンパイルし直せばいいじゃんね。それもやってみるかな。たいした手間はかからなそうな感じだし。CDB も試してみる。Python バインディングは python-cdb 0.32 を使うことにする。とりあえず、cdb、gdbm、qdbm が使える環境にする。むむ、Tokyo Cabinet が Solaris 10 で make 通らない。PATH_MAX が未定義だと怒られるので指定してやったが、それでも、ld: warning: option -o appears more than once, first setting takenでダメ。Makefile の中でリンカに渡すオプションを -Wl で指定しているところ引っかかる。えいやと -Wl の箇所を外す。そして、 /usr/include/stdbool.h の "Use of <stdbool.h> is valid only in a c99 compilation environment." の問題にぶち当たる。よく分からないので CFLAGS に -D_STD_C99 追加して再度 make したら通るようになった。make check も問題ない。pytc も CFLAGS を環境変数で指定しておいて、何とかコンパイル・インストールできたので使えるようになった。testDBD.py も testHDB.py も ok が返ってきた。とりあえず動いたのでめでたしとしておく。ちなみに環境は SPARC 版の Solaris 10 で試した。CentOS のマシンの方で先に試せば楽だったかなぁ。何はともあれ、cdb、gdbm、qdbm、Tokyo Cabinet が一応、Python から使える状況になったが疲れた。。。。こういうのは苦手だ。。。。。
2007.11.21
コメント(2)
-
Marici の「ブログ関心マップ」など
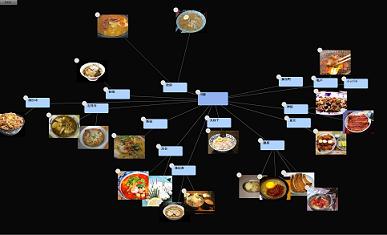
ちょっと TurboGears を使ってみようとふらついていた。Marici - TurboGarsで作られたMind Map風サービス から マインドマップ風Webサービス Marici を見て、Marici (マインドマップを作ってみよう!) を見てみる。TurboGears を使って作っているらしい。マップの表示は Flash で、こんな感じ。ちょうど pydot - Graphviz でグラフ書いていたところで、こういうものが出てくると目についちゃうのね。通常のページを見てみると、「マップを開く」というというリンクの文字が小さい。たとえば、外部の検索エンジンから こういうページに飛んできたとして、マップを開くというリンクをクリックできるだろうか。押したくなるようなものにしないと分かっている人しかマップを見ない。もったいない。マップを 縮小したような画像を入れるなり、もっと目立つボタンにでもした方がいいんじゃなかろうか。技術的にはおもしろいことろがあるけど、サービスとして見たときには改善の余地有りって感じ。やりようによっては、まだ、この分野おもしろいものが出てきそうな気はするのだが。と思っていたら、ブログの内容をマインドマップ風に表示する「ブログ関心マップ」 で ブログ関心マップ ができたことを知る。これおもしろいかもしれない。傀儡師の館のブログ関心マップ を見てみると、こんな感じ。こっちの方がさしあたっておもしろみがある。本文の切り出しもうまくやっているみたいだし、なかなか良くできているかもしれない。定期的に画面を保存して、ペラペラで眺めてみると、同じ人のブログがどういう興味の変化かって分かるかもしれない。そうすると、固定的な話題をけいぞくしているブログと、あちこち動くブログとの分類が出てきておもしろいかもしれない。スナップショットが時系列でどう変化していくか。似たような複数のブログをまとめた状態(合成して)、一つのブログとして扱って、その変化をみていくとコミュニティの興味変化とかも見れたりするのでおもしろいかもしれない。Planet を対象にすればいいのね。たとえば、「unofficial planet python」の関心マップ とか、「Planet Plone」の関心マップ とか見てみるわけですな。そうすると流行が追える。でも、英語が対象だと今いちな感じがする。にゃんとなくアルゴリズムがふふふっ。せっかくなら英語圏の人が使ってもいい感じが出せるとよいのにね。でも、なかなかおもしろいかもしれない。ちょこちょこ使ってみるかな。つながりといえば、関心空間 を思い出した。テーマに沿ってキーワード(記事)を集めたのがコレクション コレクション β とかあるな。といえば、「といえばサーバ」 なんていうのもあったな。分類といえば、i-FILTER の URL カテゴリって、API 化されて一般公開されると嬉しいのにね。トラックバックスパムをはじくために、トラックバックが来たら、その URL を渡して、どの分類に当てはまるかを返してもらって、大丈夫そうなカテゴリからだったらばトラックバックを OK にするとかいった使い方で。1日 50までは無料にして、それ以上であれば有料。サイト単位だったら幾らとか、トラックバックチェック用のサービスでも作ってくれればいいのにね。そういえば、i-FILTER SSL Adapter はおもしろい。「i-FILTER SSL Adapter」オプションを使用すると、従来は管理者の手が及ばなかったSSL通信を「丸裸」にします。i-FILTER SSL Adapterなるほどね。それはさておき、結局、こういう会社って、機械的にやる部分はあっても、結局、人手の介在があるから強いのね。発展しつづけるWebサイトにキャッチアップして、進化する独自検索エンジンと人の判断をマシンラーニングするデータ分類が実現しました。i-FILTERの次世代フィルタリングテクノロジー「ZBRAIN」人がつけるつながりや分類と、機械的な分類をミックスさせる。いわゆる CGM 的なものの場合、人手を使っているところはユーザなわけだけど、こういうサービスはそこを会社がやっている。検索では オープンディレクトリプロジェクト のように人手でがんばっているのがあるが、フィルタリングではその手のものはないんだろうか。メールのスパムとかもベイジアンでやっても、今いちなところがあるから、ブラックリスト も積極的に使いたくもなる。メールのスパムとトラックバックのスパムと、発信元にはどの程度の相関関係があるんだろうか。スパムメールをたくさん送るようなところは、トラックバックでもはじいちゃっていいんじゃなかろうかとか。MediaWiki‐ノート:Spam-blacklist とか見てみると、こういうところも大変ねと思う。
2007.11.19
コメント(0)
-
iSCSI で Windows から Solaris のディスクを使う
iscsiで接続 solaris(target)-windows(initiator) に書かれている手順で試してみる。試しに 5GB のディスク領域を割り当てる。# svcadm enable svc:/system/iscsitgt:default# zfs create -V 5gb mypool/windows# zfs set shareiscsi=on mypool/windows# iscsitadm list targetTarget: mypool/windows iSCSI Name: iqn.1986-03.com.sun:02:9999999-999c-zz99-999c-9999999999999 Connections: 0 (iqn. のところは変えてある) 確かに、あっけないほど簡単に Solaris 側の設定が終わった。Windows 側も をインストールして、デスクトップ上にできた Microsoft iSCSI Initiator でIP アドレスを指定して問題なく接続できた。後は、コンピュータの管理のディスクの管理で通常のハードディスクと同じように見えるのでパーティションを割り当ててフォーマットして使う。そして、あっさり Windows から Solaris のディスクを iSCSI で使えるようになった。マニュアルは Solaris iSCSI ターゲットおよびイニシエータの構成。ZFS すばらしい。
2007.11.19
コメント(0)
-
OpenSolaris ベースのソフトウェアストレージアプライアンス NexentaStor
OpenSolaris と NexentaOS で以前書いた Nexenta Operating System だが、ストレージ製品の NexentaStor を出してきた出てきた。Nexenta Offers Free ZFS-Based Storage Management Software PR Newswire, Nov. 12, 2007 。Nexenta は、OpenSolaris をカーネルとして、GNU/Debian/Ubuntu のよいところを使っているから、けっこう期待している。ZFS は取り扱い楽だし。ストレージのソフトウェアアプライアンスというのは、いい線ついていると思う。来年の2月には 1.0 がリリースされるようだが、VMware で動く NexentaStor Virtual Appliance が出ているので試してみるかな。そういえば Solaris の iSCSI の機能をまだ試していなかった。試してみようかな。Solaris iSCSI ターゲットおよびイニシエータの構成。Xen ベースの仮想化技術 Solaris xVM も出てきたし、来年はこれまでより広い層に普及するんじゃないかな。
2007.11.19
コメント(0)
-
Python から Graphviz を使う( pydot を日本語で出力)(7) - サブグラフの中のサブグラフ
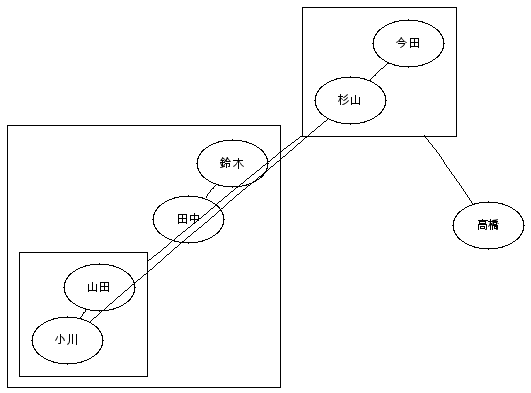
Python から Graphviz を使う( pydot を日本語で出力)(6) でサブグラフを描いてみたが、subgraph の中にサブグラフがあるときはうまく描けるだろうかと試してみる。Graphviz のサイトにある Undirected Graph Clusters のようなものを。グラフの中にサブグラフが3つ。そのうち1つは他のサブグラフの中にある。骨組みとしては次のようなものになる。graph G { subgraph clusterA { // subgraph cluster C { // } } subgraph clusterB { // } clusterC -- clusterB}なので、基本としては Python から Graphviz を使う( pydot を日本語で出力)(6) でやったようにサブグラフ A, B を作って、さらにその中に C を作ればよいかなと。まずは、プリミティブにグラフを作って、サブグラフをつないでみる。#!/usr/bin/env python# -*- coding: utf-8 -*-from pydot import *g = Dot('graph', graph_type='graph')# 日本語フォント指定用のノードを追加する。n = Node('node')n.set_fontname('arialuni.ttf')n.set_fontsize(9)g.add_node(n)# サブグラフを生成する。cluster_a = Cluster(graph_name='sub01')cluster_b = Cluster(graph_name='sub02')cluster_c = Cluster(graph_name='sub03')# サブグラフにエッジを追加する。cluster_a.add_edge(Edge('田中', '鈴木'))cluster_c.add_edge(Edge('山田', '小川'))cluster_b.add_edge(Edge('杉山', '今田'))# グラフにノードとエッジを追加する。g.add_node(Node('高橋'))g.add_edge(Edge('杉山', '小川'))g.add_edge(Edge('高橋', cluster_b.get_name()))g.add_edge(Edge(cluster_c.get_name(), cluster_b.get_name()))# グラフに cluster_A, Cluster_B を追加。g.add_subgraph(cluster_a)g.add_subgraph(cluster_b)# cluster_A に cluster_C を追加。cluster_a.add_subgraph(cluster_c)g.write_png('subgraph3.png', prog='fdp')最後の行の、書き出し用のプログラムの指定は fdp を使わないと、ノードとサブグラフ間のエッジや、サブグラフ同士のエッジを描くことができないようだ。とりあえず、こんな感じになる(クリックで拡大)。また、サブグラフを端点とするエッジ を描くやり方もあるようだ。サブグラフを端点とするエッジを描くには、グラフ全体の compound 属性が true になっていなければなりません。その上で、エッジに対して、ltail/lhead 属性を付けて、どのサブグラフを端点とするのかを示します。とかするようだ。この場合のグラフ書き出しは fdp でなく、dot でいけるようだ。ただし、サブグラフとサブグラフを端点としてつないでいるエッジも、見かけ上はサブグラフとサブグラフをつないでいるけれども、あくまでもエッジはノード間で張るやり方。つなぎ先はいったんノードにしておいて、属性でどのサブグラフかを指定している。元のプログラムに戻り、ちょっとえぐいのは、サブグラフの名前。生成時に "sub01" ~ "sub03" を指定しているが、これは内部的に勝手に "cluster_sub01" のように "cluster_" が付けられてしまう。そのため、後で名前を使うときには、get_name() で取り出し直さなければならない。これが嫌な場合は、生成時には名前を指定せずに、生成したあとに set_name() で指定するとかいうことになるかな。リストから自動生成するときには、そういうやり方をするようにしないとエッジの名前と実体の対応が取れなくなってしまう。とりあえず、下のようなものができた。サブグラフを含むようなグラフを簡単に各方法については、おいおい考える。
2007.11.17
コメント(0)
-
Python から Graphviz を使う( pydot を日本語で出力)(6)
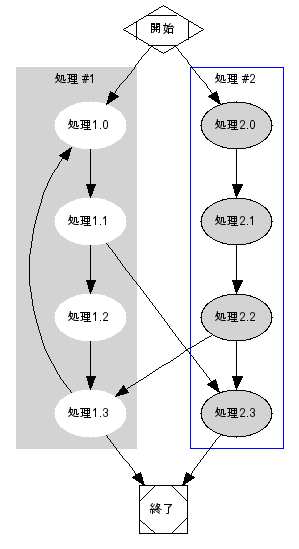
Python から Graphviz を使う( pydot を日本語で出力)(5) の続き。pydot でまだサブグラフを描いていなかったので試してみることにする。まずは、第一の目標として、下のようなグラフを生成することにする。枠でくくられた 2 つがサブグラフになっている。まずはサブグラフを使わないとどうなるか試す。日本語対応させた graph_from_edges2 を使って描いてみる(フォントを指定し直すのが面倒なので、デフォルトで日本語のフォントを指定するようにしてある)。#!/usr/bin/env python# -*- coding: utf-8 -*-import pydotegdges = [ (u"開始", u"処理1.0"), (u"処理1.0", u"処理1.1"), (u"処理1.1", u"処理1.2"), (u"処理1.2", u"処理1.3"), (u"処理1.3", u"終了"), (u"開始", u"処理2.0"), (u"処理2.0", u"処理2.1"), (u"処理2.1", u"処理2.2"), (u"処理2.2", u"処理2.3"), (u"処理2.3", u"終了"), (u"処理1.1", u"処理2.3"), (u"処理1.3", u"処理1.0"), (u"処理2.2", u"処理1.3"), ]g = pydot.graph_from_edges2(egdges, directed=True)# ノードの形の変更 (開始, 終了, その他)for node in g.get_node_list(): if node.name == u"開始": node.shape = "Mdiamond" elif node.name == u"終了": node.shape = "Msquare" g.write_png('subgraph1.png')すると、こんな感じになる。1.0 と 2.0 が左右反転してしまっているが、とりあえず気にしないでおく。でもって、枠で囲われたところはサブグラフにしたいので、処理1.0 ~ 処理1.3、処理2.0 ~処理2.3 のところをまずリストから省く。そして、独立したサブグラフを作ってやって、追加すればよいかなという方針を立てる。ところが、サブグラフをリストから作るような関数が用意されていない。そこで、graph_from_edges のようなものを作って、リストからまとめて追加できるようにすればよいかな。ということで、ほとんど graph_from_edges と同じような cluster_from_edges と cluster_from_edges2 を作った。とりあえず、動作が確認できればいいやという感じ。試行錯誤でやったのでかなり泥臭い。もっと汎用的に書き直したくなってきた。属性などはリストにしておいて、制御できるようにして、まとめて設定できるような仕組みが欲しい。加えて、サブグラフがいくつあっても動くようにすれば、それなりに有用なものになるかもしれない。一通り試し終わったら、pydot 自体を見直して、まとめて属性を設定しやすいように、あるいは何らかの基準で自動設定できるように改造するというのも、ありかもしれない。#!/usr/bin/env python# -*- coding: utf-8 -*-import pydotegdges = [ (u"開始", u"処理1.0"), (u"処理1.3", u"終了"), (u"開始", u"処理2.0"), (u"処理2.3", u"終了"), (u"処理1.1", u"処理2.3"), (u"処理2.2", u"処理1.3"), (u"処理1.3", u"処理1.0"), ]sub1 = [(u"処理1.0", u"処理1.1"), (u"処理1.1", u"処理1.2"), (u"処理1.2", u"処理1.3"),]sub2 = [(u"処理2.0", u"処理2.1"), (u"処理2.1", u"処理2.2"), (u"処理2.2", u"処理2.3"),] def cluster_from_edges(edge_list, node_prefix='', directed=False): """Creates a Cluster out of an edge list. The edge list has to be a list of tuples representing the nodes connected by the edge. The values can be anything: bool, int, float, str. If the cluster is undirected by default, it is only calculated from one of the symmetric halves of the matrix. """ if directed: cluster = pydot.Cluster(graph_type='subdigraph') else: cluster = pydot.Cluster(graph_type='subgraph') for edge in edge_list: e = pydot.Edge(node_prefix+str(edge[0]), node_prefix+str(edge[1])) cluster.add_edge(e) return clusterdef cluster_from_edges2(edge_list, directed=False, node_prefix='', node_attrs={}): """ cluster_from_edge でサブグラフを作成してから、 指定された属性またはデフォルト属性を持つノードを追加する。 """ cluster = cluster_from_edges(edge_list, node_prefix, directed) cluster.set_fontname('arialuni.ttf') cluster.set_fontsize(9) if node_attrs == {}: node_attrs = pydot.DEFAULT_NODE_ATTRS # 属性用にノードを作って、属性を反映する。 node = pydot.Node('node') for n, v in node_attrs.items(): node.__setattr__(n, v) # グラフのノードリストの先頭にに挿入する。 cluster.node_list.insert(0, node) cluster.sorted_graph_elements.insert(0, node) return cluster# メインのグラフを作るg = pydot.graph_from_edges2(egdges, directed=True)# ノードの形の変更 (開始, 終了, その他)for node in g.get_node_list(): if node.name == u"開始": node.shape = "Mdiamond" elif node.name == u"終了": node.shape = "Msquare" # クラスター(サブグラフ)を 2つ作って、属性を設定する。cluster1 = cluster_from_edges2(sub1)cluster1.set_name('cluster_sub01')cluster1.set_style('filled')cluster1.set_color('lightgrey')cluster1.set_label(u"処理 #1")for node in cluster1.get_node_list(): node.set_style('filled') node.set_color('white') print "here1"cluster2 = cluster_from_edges2(sub2)cluster2.set_name('cluster_sub02')cluster2.set_color('blue')cluster2.set_label(u"処理 #2")for node in cluster2.get_node_list(): node.set_style('filled') node.set_color('gray') print "here2"# メインのグラフにクラスターを追加する。g.add_subgraph(cluster1)g.add_subgraph(cluster2)g.write_png('subgraph2.png')
2007.11.16
コメント(0)
-

発想を変えると見えるもの - 視覚化について
郵便番号分布図を作ってみた というのを見つけた。郵便番号は、郵便を届けるために日本の地区をコード化したものである。7ケタの郵便番号のデータは12万件強ほど。郵便事業は公共サービスだから、一応、全国を網羅している(はず)。ならば、郵便番号から緯度/経度を算出した群を、白紙の座標にマッピングすれば、日本地図が現れるはずであるはず、、、ですよねぇ。で、実際にやってみた地図が出ている。そのページにあった 似たようなのUSA(The US ZIPScribble Map (Updated)) も見てみる。ふーん、おもしろい。USA の方は州の境界が見えるのだな。確かに言われてみればそう、なるほど、そういう発想もできるのか。確かにそうだけど、やってみるところが偉いなぁと。さらに実際にやってみると、気づかなかったところに気づいたりして。zipdecode なんかも、ほうっ、て感じ。こういうことってけっこうあるのかもしれない。EagerEyes.org を見ると、いろいろな視覚化の試みを見ることができるし、書かれていることも興味深く考えさせられる。お気に入りに入った。
2007.11.16
コメント(0)
-

Python から Yahoo! 日本語形態素解析Webサービスを使う + pydot (3)
Python から Yahoo! 日本語形態素解析Webサービスを使う (1) と Python から Yahoo! 日本語形態素解析Webサービスを使う (2) で Yahoo! 日本語形態素解析Webサービス API を使って指定した文から指定した品詞の単語を取り出すことができるようになった。ということで、ここから応用。せっかく pydot を使ってグラフが書けるようになったのだから、取り出した単語をグラフで表現してみましょうかと。#!/usr/bin/env python#-*- coding: utf-8 -*from webma import *import pydotmyapp = '自分のアプリケーションID'sample="""散歩と犬。私は、今日、天気が良かったので散歩をしました。散歩をしているときに、大きな犬に吠えられました。犬は立ち上がれば、子供の背丈ほどあるような感じでした。頭に来たので、犬をにらみつけました。犬は、もっと吠えました。もっとにらみつけると、犬は吠えるのを止めました。さらににらみつけると尻尾を振り始めました。犬の心はよく分かりません。でも、人の心もよく分かりません。分からないということでは、人も犬も変わりません。犬から目をそらし、ふと空を見上げました。いつの間にか、雨が降りそうな空。冷たい。突然、雨が降ってきました。それで私は慌てて家に帰りました。"""# sample = sample.replace('。', '。\n')sample = sample.splitlines()# フィルタを作るdef make_filter(filter): return "|".join([str(x) for x in filter])filter = (ADJECTIVE, ADJECTIVAL_NOUN, ADVERB, ADNOMIAL, PREFIX, SUFFIX, NOUN, VERB )filter_str = make_filter(filter)# テキスト解析するma = WebMA(app_id=myapp, filter=filter_str)all_words = []# 単語を前後のペアにして取り出すfor line in sample: print line word_list = [] pre_word = None cur_word = None for w in ma.parse(line): cur_word = "%(baseform)s" % w # [["単語1", "単語2"], ["単語3", "単語4"]] の # ようなリストを作る。 if pre_word: word_list.append([pre_word, cur_word]) pre_word = cur_word if cur_word and word_list == {}: all_words.append(["単独出現", cur_word]) else: all_words += word_listg = pydot.graph_from_edges2(all_words, directed=True)g.write_png("sample2.png")こんな感じのグラフができる。 (クリックするとオリジナル画像: 1016×1307)実際のところ、ちょっと大きい文章になると、これではまともに動かなくなる。第168回国会における福田内閣総理大臣所信表明演説 ぐらいの大きさだと1時間やそこらでは終わらず、できあがったファイルも 10MB ぐらいになって、ぎゃーこんなんじゃ見ることできないやというものができあがる。まあ、あたりまえといえば、あたりまえだが。でも、Graphviz が偉いのは、そんな無茶なものでも落ちないで描いてくれること。(政治と行政に対する信頼の回復)の段落だけでも、末尾のようになるわけで、全部をやったら、まあ、とんでもないことになるのはあたりまえだけど、あえてやってみたわけ。ということで、どういう品詞と基準で単語対を作る(ノードの関係を作っていく)か、というところがポイントになるかな。あるいは、接続がない部分は、別のグラフに書き出すなどするとかも考えられる。さらに、形容詞と名詞とかにポイントを絞るとか。名詞だけに限って、文をまたいだものもつないでいくとか。ちなみに、同じ組み合わせが出現した場合、上記のままだと複数のエッジがノード間に惹かれることになる。数が少なければ良いけれど、ユニークなものだけ残しhたほうがいいかもしれない。あるいは、色によって頻度を表すとか、ノードの枠の大きさで頻度を表すとか。あとは、nakatani @ cybozu labs: Webページの本文抽出 みたいのを使って Webページの本文抽出をして、あれこれ集めて、それをグラフ化するとかもありえる方向かな。ちなみに、上記の graph_from_edges2 は、日本語を扱うときにフォントの指定が面倒なので Python から Graphviz を使う( pydot を日本語で出力)(3) で作ったものを(下のようなもの)を pydot.py の末尾に入れてあるものを使っていて、オリジナルの pydot にはない。DEFAULT_NODE_ATTRS = {'fontname':'arialuni.ttf', 'fontsize':9}def graph_from_edges2(edge_list, directed=False, node_prefix='', node_attrs={}): """ graph_from_edge でグラフを作成してから、 指定された属性またはデフォルト属性を持つノードを追加する。 """ graph = graph_from_edges(edge_list, node_prefix, directed) if node_attrs == {}: node_attrs = DEFAULT_NODE_ATTRS # 属性用にノードを作って、属性を反映する。 node = Node('node') for n, v in node_attrs.items(): node.__setattr__(n, v) # グラフのノードリストの先頭にに挿入する。 graph.node_list.insert(0, node) graph.sorted_graph_elements.insert(0, node) # print "here %s" % (node.to_string()) return graph第168回国会における福田内閣総理大臣所信表明演説 の(政治と行政に対する信頼の回復)の段落の解析結果。画像が大きすぎてアップロードできないので縮小画像のみ。
2007.11.15
コメント(0)
-
Python から Yahoo! 日本語形態素解析Webサービスを使う (2)
Python から Yahoo! 日本語形態素解析Webサービスを使う (1) では、ヒビノキロク: Yahoo! 形態素解析 API for Python の webma.py を使わせてもらうかなということで、そこで使われているライブラリを見ていたら、前置きが長くなってしまった。lxml と formencode がインストールされていないとこれは使えないよということでインストールを済ませたら早速使ってみる。とりあえず ヒビノキロク: Yahoo! 形態素解析 API for Python コードを webma.py として保存して、lib/site-package に放り込む。コード中の、default_app_id = 'Yahoo! MAService API for Python'" の部分は、どうページのようにコマンドラインで実行するのであれば書き換える必要があるが、下のようにして使うときには引数で渡せば変更しなくても使えるようにできている。とりあえず使ってみる。#!/usr/bin/env python#-*- coding: utf-8 -*import webmamyap = '自分のアプリケーションID'ma = webma.WebMA(app_id=myapp)sample = [u'今日は天気がよいです。', u'明日の天気は晴れです。']for line in sample: for w in ma.parse(line): print "%(surface)s\t%(feature)s" % w print "EOS"これを実行すると、今日 名詞,名詞,*,今日,きょう,今日は 助詞,係助詞,*,は,は,は天気 名詞,名詞,*,天気,てんき,天気が 助詞,格助詞,*,が,が,がよかっ 形容詞,形容,連用タ接続,よかっ,よかっ,よいた 助動詞,助動詞た,基本形,た,た,たです 助動詞,助動詞です,基本形,です,です,です。 特殊,句点,*,。,。,。EOS明日 名詞,名詞,*,明日,あした,明日の 助詞,助詞連体化,*,の,の,の天気 名詞,名詞,*,天気,てんき,天気は 助詞,係助詞,*,は,は,は晴れ 名詞,名詞,*,晴れ,はれ,晴れです 助動詞,助動詞です,基本形,です,です,です。 特殊,句点,*,。,。,。EOS動くことは確認できた。今度はフィルタを指定してみる。感動詞(3)、接続詞(6)、助詞(11)、助動詞(12)、句読点など特殊(13) を省いて、それ以外の形容詞(1)、形容動詞(2)、副詞(4)、連体詞(5)、接頭辞(7)、接尾辞(8)、名詞(9)、動詞(10) だけを取り出す。ということで取り出すものだけ指定すればよいので、"1|2|4|5|7|8|9|10" をフィルタとして指定する。出力は基本形だけにする。#!/usr/bin/env python#-*- coding: utf-8 -*from webma import *myapp = '自分のアプリケーションID'sample = [u'あぁ、今日は天気がよかったな。', u'そして、明日の天気は晴れなのです。']# フィルタを作るdef make_filter(filter): return "|".join([str(x) for x in filter])filter = (ADJECTIVE, ADJECTIVAL_NOUN, ADVERB, ADNOMIAL, PREFIX, SUFFIX, NOUN, VERB )# "1|2|4|5|7|8|9|10"filter_str = make_filter(filter)ma = WebMA(app_id=myapp, filter=filter_str)for line in sample: for w in ma.parse(line): print "%(baseform)s" % w print "\n"そうすると、次のような出力が得られる。今日天気よい明日天気晴れこの品詞だけ要らないというのであれば、全部まとめてリストになっているところから、不要のものを削除するのも作っておいた方が、いいかな。これで指定した単語の基本形が取り出せたので次に続く。
2007.11.15
コメント(0)
-
Python から Yahoo! 日本語形態素解析Webサービスを使う (1)
日本語形態素解析Webサービス を使ってなんかするかな。とりあえず、だれか Python でいいもの作っていないかなぁと捜してみると、2つ見つかった。ヒビノキロク: Yahoo! 形態素解析 API for PythonInforno: Python版 Yahooテキスト解析 APIライブラリヒビノキロク の方は、pyparsing を使った 検索式を構文解析するPythonモジュール とかも公開されている。pylonshqのWikiのソースを表示するGreasemonkey マニアだなぁ。Monoで.NET Compact Framework向けのアプリケーションをコンパイルする とかもある。Inforno の方は、Python:お手軽にPluggableにする とか公開されている。Python版Lingr APIライブラリ とか PythonによるNESエミュレータ開発5 とか見ると、やっぱり、この方もマニアな方か。とりあえず、両方見てみる。Inforno の jlp の方は、他の Yahoo! API にも対応することを前提とした設計のライブラリになっている。検索 API 等他の API も組み込んでいくのであれば、これをベースにするのもよいかもしれないが、テキスト解析のみだと overkill な感じなので、とりあえず置いておく。ヒビノキロク の webma.py の方は、テキスト解析のみに対応している。解析後のデータの取り出しもシンプルなので、とりあえずは、こちらを使わせてもらう。ちょっと、ヒビノキロク: Yahoo! 形態素解析 API for Python のコードを眺めてみる。使っているライブラリは、urllib、lxml、formencode。urllib は標準ライブラリで、HTTP のアクセスをするときによく使われるもの。lxml と fromencode は easy_install でインストールできる。easy_install lxml とか、easy_install formencode とか。formencode は SQLObject や TurboGears などを使っている人は easy_install でインストールしていればまとめてインストールされているはず。使っていなくても手動でインストールしているはず。lxml だが、これは便利だな。現状、2.0系統と(まだ alpha)、lxml 1.3.x 系統が開発されている。lxml is a Pythonic, mature binding for the libxml2 and libxslt libraries. It provides safe and convenient access to these libraries using the ElementTree API.ということで、libxml2 と libxslt のバインディングで、ElementTree API を使ったライブラリ。XML を扱う Python のライブラリとしては、最近は ElementTree が標準的な地位を占めていると思うが(Python 2.5.x から標準ライブラリに入った)、これは、壊れた XML データを渡すと扱えないのに対して、lxml だと、壊れた XML や HTML データでも適当に直してくれるようだ。Twisted Mind: 誰もさわらないlxmlについて。 にその例がある。# vim: fileencoding=utf8from lxml import etreefrom StringIO import StringIObroken_html = "<head><title>ついすてっどまいんど<body><h1>Django!!</html>"parser = etree.HTMLParser()et = etree.parse(StringIO(broken_html), parser)print etree.tostring(et.getroot(), 'utf-8', pretty_print=True)Twisted Mind: 誰もさわらないlxmlについて。壊れているのに、ちゃんと、<html>、</titlel>、</head> 等々、足りない部分を勝手に補完してくれている。ふーん。いつでもそれが良いとは限らないかもしれないけど、便利かもしれない。ElementTree だと壊れているとエラーで扱えないし。Python で HTML ファイルから情報を取り出すには で以前にはまった。lxml なら、こういう問題もクリアかな。lxmlでHTMLスクレーピングをやっている人がいた。lxmlを使ってあるURLから画像のURL一覧を取得する もあった。その他、Humming Via Kitchen: lxmlを試してみたよ。。perezvonの日記: libxml2でのXPathの練習。でもって、perezvonの日記: lxmlのlibxml2バージョンを確認する には、>>> from lxml import etree>>> etree.LIBXML_VERSION(2, 6, 28)もう一つ使われているのは、 FormEncode。これも最近よく使われるてのかな。SQLObject、Subway、TurboGears、Pylons でも使われているから、このあたりを扱っている人たちが使うようになっているのか。フォームの validation とか生成のために作られたもので、ここでは validation のために使われている。下の例では Int かどうかをチェックして、そうでなければエラーにできる。>>> import formencode>>> from formencode import validators>>> validator = validators.Int()>>> validator.to_python("10")10>>> validator.to_python("ten")Traceback (most recent call last): ...Invalid: Please enter an integer valueFormEncode ValidationFormEncodeで複合validation、FormEncodeでイメージアップロード用のバリデータを作る なども参照。本題に入る前に、長くなってしまったので次へ続く。
2007.11.15
コメント(0)
-
Python から Graphviz を使う( pydot を日本語で出力)(5)
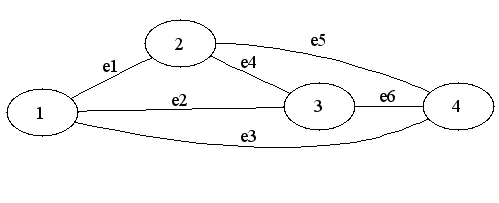
Python から Graphviz を使う( pydot を日本語で出力)(4) では、pydot を使って隣接行列からグラフを描いてみた。今日は、接続行列(incidence matrix) からグラフを描いてみる。たとえば、次のようなグラフがあったとする。これを隣接行列で表せば、次のようになる。a のノードと b のノードは隣り合っているので 1。a と b も隣り合っているので 1...。ここでは、あくまでもノードとノードの隣接状態だけを見ている。別の言葉で言えば、始点と終点を表したもの。 終点 a b c d ----------始 a 0 1 1 1点 b 1 0 1 1 c 1 1 0 1 d 1 1 1 0次に、本題の接続行列。接続行列では、このエッジにつながっているのはどのノードという見方をする。e1 につながっているのは、a と b なのでそこが 1、それ以外は 0。e2 につながっているのは a と c なのでそこを1、それ以外は 0 という形で行列を作る。つまり、あるエッジにはどのノードがつながっているかが端的に表されたものになる。e1~e6の行は必ず2 になる(エッジの両端を表すところに 1 なので)。これが接続行列ということになる。通常は、ノードとエッジが逆にすると思うが、pydot だと、この状態で渡さないと処理上グラフが描けないので注意。それじゃいやな場合は末尾参照。 ノード a b c d---------------エ e1 1, 1, 0, 0 e1 の行を足すと 2 になるッ e2 1, 0, 1, 0 e2 の行を足すと 2 になるジ e3 1, 0, 0, 1 e3 の行を足すと 2 になる e4 0, 1, 1, 0 e4 の行を足すと 2 になる e5 0, 1, 0, 1 e5 の行を足すと 2 になる e6 0, 0, 1, 1 e6 の行を足すと 2 になるということで、これを実際に pydot のコードで書いてみる。import pydot# 接続行列を用意するmatrix = [[1, 1, 0, 0], [1, 0, 1, 0], [1, 0, 0, 1], [0, 1, 1, 0], [0, 1, 0, 1], [0, 0, 1, 1]]# 接続行列からグラフを生成する。g = pydot.graph_from_incidence_matrix(matrix)# 左から右へ描くオプションをここでは使ってみる。g.set_rankdir('LR') # グラフを出力する。g.write_png('test5.png')これで、接続行列からグラフを作成することができた。だけども、エッジにラベルを付けたいなということで、もう少しやってみる。edges = g.get_edge_list()e = 1for edge in g.get_edge_list(): label = "e%s" % e # ラベルは e1 ~ e6 とする。 edge.set_label(label) e += 1# グラフを出力する。g.write_png('test6.png')結果として、下の図が描けた。生成される dot ファイルは下のようなものになる。graph G { [rankdir=LR;]"1";"2";"1" -- "2" [label=e1];"3";"1" -- "3" [label=e2];"4";"1" -- "4" [label=e3];"2" -- "3" [label=e4];"2" -- "4" [label=e5];"3" -- "4" [label=e6];}試しに、ここでも日本語を使ってみる。エッジのラベルに日本語が使えるかの確認。e = 1for edge in g.get_edge_list(): label = "エッジ: %s" % e # ラベルは e1 ~ e6 とする。 edge.set_label(label) edge.set_fontname('arialuni.ttf') edge.set_fontsize(9) e += 1# グラフにタイトルを日本語で付けるg.set_fontname('arialuni.ttf')g.set_size(12)g.set_label('接続行列からのグラフの生成例')# グラフを出力する。g.write_png('test7.png')もし、接続行列を上記のようにするのが嫌だという場合は、次のようにすればいいかな。import Numeric# このままだと pydot が扱えないので# e1 e2 e3 e4 e5 e6matrix = [[1, 1, 1, 0, 0, 0], [1, 0, 0, 1, 1, 0], [0, 1, 0, 1, 0, 1], [0, 0, 1, 0, 1, 1]])# これで pydot が扱えるように並び替えられる# ちなみに、これでリストが array になるのだが、そのままでも# 扱える。もし、リストに直すなら、# Numeric.transpose(matrix).tolist()matrix = Numeric.transpose(matrix)# あとは同じ# 接続行列からグラフを生成する。g = pydot.graph_from_incidence_matrix(matrix)# 左から右へ描くオプションをここでは使ってみる。g.set_rankdir('LR') # グラフを出力する。g.write_png('test8.png')
2007.11.13
コメント(0)
-
Python から Graphviz を使う( pydot を日本語で出力)(4)
Python から Graphviz を使う( pydot を日本語で出力)(3) からの続き。pydot は 隣接行列 (adjacency matrix) (Wikipedia) からグラフを一発で描くことができるので、それを試してみる。例は Wikipedia にあるものをまず使ってみる。まずは隣接行列を Python のリストとして用意する。matrix = [[0, 1, 0, 0, 1, 0], [1, 0, 1, 0, 1, 0], [0, 1, 0, 1, 0, 0], [0, 0, 1, 0, 1, 1], [1, 1, 0, 1, 0, 0], [0, 0, 0, 1, 0, 0]]あるノードと隣接している(リンクがある=エッジを描く)ノードに 1、隣接していなければ 0 を付けていったもので、上記の隣接行列を言葉で表し直すと、次のようになる。1番のノードと隣接しているのは、2番、5番。2番のノードと隣接しているのは、1番、3番、5番。3番のノードと隣接しているのは、2番、4番。 4番のノードと隣接しているのは、3番、5番、6番。5番のノードと隣接しているのは、1番、2番、4番。6番のノードと隣接しているのは、4番。pydot で隣接行列からグラフを描く方法pydot を使って隣接行列からグラフを生成するプログラムは下のようになる。とりあえず、dot と neato の2通りで出力してみる。import pydot# 隣接行列のデータmatrix = [[0, 1, 0, 0, 1, 0], [1, 0, 1, 0, 1, 0], [0, 1, 0, 1, 0, 0], [0, 0, 1, 0, 1, 1], [1, 1, 0, 1, 0, 0], [0, 0, 0, 1, 0, 0]]# 隣接行列からグラフを生成するg=pydot.graph_from_adjacency_matrix(matrix)# グラフを出力、2通り出力してみるg.write_png('a_matrix01.png')g.write_png('a_matrix02.png', prog='neato')a_matrix01.pnga_matrix02.png隣接行列のリストを渡してやるだけでよいのでとっても楽に描ける。1,2,3,4,5,6 というノード番号ではなく、何かの文字列に変えたいと思った。次のようにしたらできた。# 表示用のラベルを用意する。node_label = {'1':'First', '2':'Second', '3':'Third', '4':'Forth', '5':'Fifth', '6':'Sixth'}# ノードを取り出すnodes = g.get_node_list()# ノードごとにラベルを設定するfor n in nodes: n.set_label(node_label[n.name])# ファイルに出力するg.write_png('a_matrix03.png', prog='neato')ということでラベルを後から付けてやれば、文字を入れることができた。さらに日本語を入れたらどうか試してみる。ここでは、前と同じように属性を付けたノードを先頭に挿入してみる。node_label = {'1':'一番目', '2':'二番目', '3':'三番目', '4':'四番目', '5':'五番目', '6':'六番目'}# ノードを取り出すnodes = g.get_node_list()# ノードごとにラベルを設定するfor n in nodes: n.set_label(node_label[n.name])# 属性を設定するノードを作って先頭に追加するn = pydot.Node('node')n.fontname = "arialuni.ttf"g.sorted_graph_elements.insert(0, n)# ファイルに出力するg.write_png('a_matrix04.png', prog='neato')ということで、隣接行列から作成したグラフに日本語のラベルを付けて表示することもできた。
2007.11.12
コメント(1)
-
Graphviz と日本語のフォント
この数日 Python から Graphviz を使う( pydot を日本語で出力)(3) とかちょこちょこと使っていてふと思った。Graphviz で日本語表示をするときに Windows でも *nix でも、どちらでも使えるフォントで何がよいのだろうかと。ちなみに Solaris でも Graphviz + pydot は動いた。Graphviz は Blastwave.org の pkg-get を使えば簡単にインストールできた。そういえば IPAが日本語フォント「IPAフォント」を一般に配布 が先日あったなと 一般利用者向けIPAフォントのダウンロード を試してみる。アルファベットの文字間隔がちょっと広すぎるのでもう少し詰まっている方がグラフ表示したときにきれいに見えるような気がする。ちょっと厳しい。。。。。IPAモナーフォント はどうだろうと試してみる。基本的にそんなに変わらない感じ。モナーフォントの方がアルファベットの間隔が狭くなるのできれいに見える。でも、もっと他にないか調べてみる。M++IPAはどうだろうか。M+ と IPAフォントの合成フォント : フォント一覧のようなもの。これはなかなか見やすいかもしれない。sazanami-gothic.ttf も良い感じか。ただし、「-」がフォント名に含まれていると Graphviz がいやがるので名前を変えて使う。Y.OzFontペン字 も意外と見やすいかもしれない。例えば、こんな感じの文字。ちなみに、Arialuni.ttf と msgothic.ttc だと下のような感じ。Arialuni.ttfMSGOTHICみかちゃんフォント も試してみる。念のため、たれフォント も使ってみる。
2007.11.12
コメント(0)
-

Python から Graphviz を使う( pydot を日本語で出力)(3)
pydot の graph_from_edges は、エッジのリストを渡すと、グラフを一発で作ってくれる便利な関数なのだが、これをそのまま使うと日本語が表示できない。Python から Graphviz を使う( pydot を日本語で出力)(2) を毎回やるのは面倒だ。日本語を使っても、一発でリストからグラフが作れるものが欲しい。これを pydot の中はいじらないという方針でやるとするとどうなるかということで新しい関数を一つ作って終わらせることにした。graph_from_edges をそのまま使って、結果をちょっといじってやる。デフォルト値をDEFAULT_NODE_ATTRSで指定しておけば、通常の graph_from_edges と同じに使える。そして、属性の入ったディクショナリを渡してやれば、その値に応じた値を設定してくれるというもの。これで、日本語でも一発でグラフができるようになった。import pydot# -- ここから --DEFAULT_NODE_ATTRS = {'fontname':'msgothic.ttc', 'fontsize':9}def graph_from_edges2(edge_list, directed=False, node_prefix='', node_attrs={}): """ graph_from_edge でグラフを作成してから、 指定された属性またはデフォルト属性を持つノードを追加する。 """ graph = pydot.graph_from_edges(edge_list, node_prefix, directed) if node_attrs == {}: node_attrs = DEFAULT_NODE_ATTRS # 属性用にノードを作って、属性を反映する。 node = pydot.Node('node') for n, v in node_attrs.items(): node.__setattr__(n, v) # グラフのノードリストの先頭にに挿入する。 graph.node_list.insert(0, node) graph.sorted_graph_elements.insert(0, node) # print "here %s" % (node.to_string()) return graph# -- ここまで -- が、簡単に書くための関数の定義# ここからテストで使ってみる# エッジのリストを定義して、edges=[(u'私', u'食べる'), (u'私', u'遊ぶ'), (u'食べる', u'野菜'), (u'食べる', u'肉'), (u'遊ぶ', 'Python'), ('Python', 'pydot'), ('pydot', 'pyparsing'), ('pydot', 'Graphviz'), ]# 何も指定しないでデフォルト出力でグラフを生成# graph_from_edges と同じ使い方g=graph_from_edges2(edges)# 1番目のグラフを出力g.write_png('test3.png', prog='dot')# 通常は、上のところまでで OK。# 属性をいろいろ指定するattrs={'fontname':'msmincho.ttc', 'fontsize':10, 'fontcolor':'blue', 'color':'gray', 'style':'filled'}# ついでなので、有向グラフ、文字列の前にprefixを付けるのも# 試す。これは、オリジナルと同じ動き。# オリジナルとの違いは、node_attrs を追加してあること。g=graph_from_edges2(edges, directed=True, node_prefix="a_",node_attrs=attrs)# 2番目のグラフを出力g.write_png('test4.png', prog='dot')こうして描かれたのが下の図。1番目のグラフ2番目のグラフ
2007.11.11
コメント(1)
-

Python から Graphviz を使う( pydot を日本語で出力)(2)
先日、Python から Graphviz を使う( pydot を日本語で出力) を書いたが、不都合があるのでダメ。まず、先日のやり方だと、graph_from_edges でグラフをリストから作ったあとに、さらに、そこに別のノードを追加して別のフォント属性を指定するとかいったことがちゃんとできなくなってしまう。そこで、直接、Graph オブジェクトの add_node メソッドには手を入れず、リストの先頭で追加することにした。こうしたやり方をすれば、pydot にまったく手を入れずにフォントの指定等ができる。というか、graph_from_edges に手を入れればよかったわけだけど、今回は pydot は手を入れずに使うということで次のようにする。やり方は 2つ考えられる。属性を付けた 'node' を挿入する方法先日の Python から Graphviz を使う( pydot を日本語で出力) では、add_node メソッドを使うと、一番後ろに追加されて不都合なので 'node' という名前のノードなら先頭に追加しちゃえとしたのだが、浅はかであった。graph_form_edges 関数だけしか使わなければ問題ないが、手動でノードを追加したりあれこれやっているとダメなのが発覚した。ということで下のようにした。#!/usr/bin/env python#-*- coding: utf-8 -*-import pydotedges=[('root', u'日本語'), ('root', 'Latin'), ('root' , 'English'), ('Latin', 'English')]# グラフを生成してg=pydot.graph_from_edges(edges)# 属性用にノードを作って、n = pydot.Node('node')n.fontname = "arialuni.ttf"n.fontsize = 9n.fontcolor = "blue"# グラフのノードリストの先頭にに挿入する。g.node_list.insert(0, n)g.sorted_graph_elements.insert(0, n)# png ファイルを生成する。g.write_png('test1.png', prog='dot') 個々のノードで属性を指定する方法ここで発想を変えて、先頭でフォント属性等を指定するのではなく、個別のノードごとにいろいろいじってみましょうというのが次のコード。この場合、ノードごとに属性が指定されるので、生成される dot ファイルの中身が冗長になるという欠点があるけれども、あれこれ条件に応じて後から属性を変更できる。ということで、graph_from_edges から作られたグラフに、ノードごとに指定を入れてあげましょうということをすれば、次のようになる。# グラフを生成してg = pydot.graph_from_edges(edges)# エッジごとに属性を指定するfor node in g.get_node_list(): node.set_fontname="msgothic.ttc" node.set_fontsize=9これを応用して、ノードの文字がアルファベットのときと、それ以外のときで属性を変えて表示するのをやってみる。#!/usr/bin/env python#-*- coding: utf-8 -*-import pydotedges=[(u'私', u'食べる'), (u'私', u'遊ぶ'), (u'食べる', u'野菜'), (u'食べる', u'肉'), (u'遊ぶ', 'Python'), ('Python', 'pydot'), ('pydot', 'pyparsing'), ('pydot', 'Graphviz'), ]# リストからグラフを生成するg=pydot.graph_from_edges(edges)# グラフに含まれるノードごとに、フォント等の指定をするfor node in g.get_node_list(): # アルファベットのみの場合、 # フォントは Times を使い、フォントは12ポイント、 # フォント色は白、 ノード色は赤 if node.name.isalnum(): node.set_fontsize(12) node.set_fontname("times.ttf") node.set_fontcolor("white") node.set_color("red") # それ以外の場合は、 # フォントは MS Gothic を使い、フォントは 9ポイント、 # フォント色は青、 ノード色は緑 else: node.set_fontsize(9) node.set_fontname("msgothic.ttc") node.set_color("green") node.set_fontcolor("blue") node.set_shape("rectangle") node.set_style("filled")g.write_png('test2.png', prog='dot') # 確認のため標準出力に dot ファイルの中身を出力# print unicode(g.to_string())そうすると、dot ファイルはこんな風になる。ノードごとに設定があるのでゴチャゴチャ。でも、出力には問題ない。graph G {"私" [fontcolor=blue, fontsize=9, fontname="msgothic.ttc", shape=rectangle, style=filled, color=green];"食べる" [fontcolor=blue, fontsize=9, fontname="msgothic.ttc", shape=rectangle,style=filled, color=green];"私" -- "食べる";"遊ぶ" [fontcolor=blue, fontsize=9, fontname="msgothic.ttc", shape=rectangle, style=filled, color=green];"私" -- "遊ぶ";"野菜" [fontcolor=blue, fontsize=9, fontname="msgothic.ttc", shape=rectangle, style=filled, color=green];"食べる" -- "野菜";"肉" [fontcolor=blue, fontsize=9, fontname="msgothic.ttc", shape=rectangle, style=filled, color=green];"食べる" -- "肉";"Python" [fontcolor=white, fontsize=12, fontname="times.ttf", shape=rectangle, style=filled, color=red];"遊ぶ" -- "Python";"pydot" [fontcolor=white, fontsize=12, fontname="times.ttf", shape=rectangle, style=filled, color=red];"Python" -- "pydot";"pyparsing" [fontcolor=white, fontsize=12, fontname="times.ttf", shape=rectangle, style=filled, color=red];"pydot" -- "pyparsing";"Graphviz" [fontcolor=white, fontsize=12, fontname="times.ttf", shape=rectangle, style=filled, color=red];"pydot" -- "Graphviz";}ノード単位で処理しているので、"私"、"遊ぶ"、... とノードのところだけ属性が設定され、"私" -- "食べる" 等のエッジには当然のことながら何も属性は付かない。冗長にならないように、共通部分はやはりノードを作って、最初に指定しておいた方が、dot ファイルの中身はシンプルになるな。描かれるグラフはこんな風になる。でも、せっかく一発でグラフが作れる関数なんだから、そうしたいよね、ということで次へ続く。
2007.11.11
コメント(1)
-

SQLite/Mecab の日本語全文検索をちゃんとやる方法
ってみる (1)、SQLite の全文検索を Python から使ってみる (2)、SQLite の全文検索を Python から使ってみる (3) を以前書いたが、これに対して、SQLite Full Text Search with MeCab の方が、実はfts2のころから簡単にユーザーが独自のtokenizerを作って組み込めるようになっていたのですよ・・・。MeCabで分かち書きをした文字列を無駄に持つくらいなら、そのままMeCabをtokenizerとして使えばいいですやん?というわけです。はい、ごもっともです。ちなみに、この方は、Tcl 使いのようで Tcl から使っているが Python からも使えるだろう。これは結構嬉しい。近々試してみる予定。このお方、TkSQLite とか公開していらっしゃる。GUI で SQLite のデータベースを管理できるので便利かも。FireFox のアドインの SQLite Manager なんかもちょこっと使うには便利な感じそうだが、各種文字コードの対応とか、SQLite2 DB と SQLite3 DB のどちらを指定しても新規DB が作成できるとか、TkSQLite の方がきめ細かい。ユーザインターフェイスが日本語の SQLite をいじれるツールとしては、SQLite ControlCenter 日本語版 もあるが、パッと見た目、やはり TkSQLite の方がきめ細かい感じ。使わせていただこうかな。考えてみてもみなくても、Python の TkInter は Tcl/Tk を取り込んでいるわけで、Tcl/Tk なくしてはあり得なかったりする。Tkinter について書かれた日本語の本はないので、Tk の資料を見ると、TkInter の勉強になったりするかも。最近では Python の GUI ツールキットとしては wxPython、pyGTK、pyQT とか選択肢が増えたけど、Python をインストールしてすぐに使えるのは Tkinter。その他は環境を整える必要がある。wxPython なんかは、Python Enthought Edition だと wxPython もすぐに使える。ただし、Python 2.5.x はなくて、Python 2.4.x しかないけど。GIMP2で縦書き とか、すごい。Tcl 8.4.1 Manual Command ReferenceもっとTcl/TkTcl/TkでWindowsプログラミングTcl/Tk GUI ProgrammingTkinter -- Tcl/Tk への Python インタフェースCafe de Paison: TkinterプログラミングOn Python: Tkinter 入門ひよ子のきもち: Python.use(better, GUI=Tkinter)Tkinter と py2exe ~ python で Windows アプリケーションを作成 (1) ~話が本題とはずれたが、今日はいずれやりますとの予告のみ。
2007.11.10
コメント(0)
-
楽天の新しいブログ検索も不評っぽいが
楽天ブログスタッフBlog: ブログ検索仕様変更のお知らせ (October 30, 2007) で予告されていたものが、楽天ブログスタッフBlog: ブログ検索の変更を行ないました (November 7, 2007) ということなので、ちょっと使ってみる。その前に、上記お知らせのトラックバックを見てみると これ、マジで困ってます。 とか、ついに改悪されましたね のようにおおむね不評っぽいトラックバックが多いようだ。どうもタグ検索の利用度を上げるために戦略的にとった仕様のようだが、どんなもんでしょうねと。不評の原因の一つは「ブログ内の検索」ができなくなったことのようだが、もともと精度がひどかったので自分ではほとんど使うことはなかったので不満には思っていない。トラックバックの絶対数があまり多くないことからすると、使っていなかった人が実は多いので、別に変えちゃってもいいだろうとかいう判断をしたのかもしれない。でも、使う人は使っていたわけで、まあ、そうした人からすると評判悪いだろうなと。そもそも Infoeek ハイブリッド検索 って、ボソボソボソ。だから、自分はあまり気にしてなかったりする。ブログ検索で更新日付が「当日のみ」「1日前まで」「3日前まで」「1週間前まで」「1ヶ月前まで」と指定できるので、最近、このキーワードでおもしろい話題はないかなぁとか探すときには使えないことはないかもしれない。が、が、Google ブログ検索 使うべとか思ってしまったりする。ちなみに、自分が書いた過去のものを探すときには、Google で 検索 site:plaza.rakuten.co.jp/kugutsushi/diary とかするのが一番見つけやすいなぁというのが実感。楽天は、わざわざ自分のところの忠実なユーザから不評を買うようなことをしないで、もう少し考えた方がいい。タグの利用を推進したいなら、タグクラウドを個人のブログパーツとして使えるようにとかした方がいい。どうも優先度の付け方があれなんだな。それにしても、楽天ブログは何かやるたびに不評を買うのもご愁傷様でしたって感じ。まあ、確信犯でやっているだろうから何とも言えないのだけど。要するに自分の使っている機能などが削除された場合、コンビニでお気に入りの商品が消えたのと同じような感覚で捉えればよいと。お前は好きで買ってるかもしれないけど、売れ筋じゃないんだよと。でも、サービスを変更するときには、こういう状況だからと数字を挙げて、具体的な根拠を示し、あるいはアンケートを募り、事前に複数ユーザーからの聞き取りを行うなど念を入れてやらないとユーザー離れにつながるかもしれない。いえ、そこまで考慮してのことなんですということであれば、自分の欲しいものがない=ターゲットのユーザ層ではないから、ここは貴方向きではないんですということで、別のサービスを使えばいいということになる。ということで、経営上の選択をしているわけだ。その意識があるのならば、まあ、仕方あるまい。我思うに、自分のブログ内検索を使いたいと思っている層は、楽天への忠誠度が比較的高い層なので、ブログ内検索を充実させて、そこに効率的に広告を出すようにすれば、売上げアップにつながると思うのだが。利用頻度が高いユーザを使って個人に特化した広告の出し方を工夫するとか、そういう方向があってもいいんじゃなかろうか。過去半年間に「スイーツ」を買った人に対してはどんなキーワードで検索しても、「スイーツ」関連の広告が出るとか。Infoseek と楽天のユーザの統一化がその前に必要だったりするし、プライバシーポリシーの再確認とかも必要にはなるだろうけど、もっと融合させればいいのに。まあ、めんどくさいから後回し、後回しにしてるんだろうけど。まあ、お金にしやすいところから注力してやってるんだろうけど。そういえば、笑えるのは、楽天ブログスタッフBlog: スパム対策のお知らせ -第二弾- への禁止キーワード機能とは、ユーザの皆さまが設定した禁止キーワードをタイトルと本文に含む、トラックバックやコメント、掲示板への書き込みをはじくことが出来る機能になります。(こちら、もともとトラックバックに存在した機能を拡充しました)これは個人的には嬉しい対応なのだが(もう少し登録できる数を増やしてほしいところだが)、この対応をほとんどコケにするように、こんなところからはトラックバックされたくないというところから、やられまくり。お気の毒。なにはともあれ、Infoseek 検索には期待してないからどうでもいいや。なっ、なんという結論なんだ。。。。そういえば、最近タグを付けてなかったな。検索には引っかかりやすくなるのは確かだろうから、また、ちゃんと付けるようにしよう。でも、タグクラウドのブログパーツ作ってほしいものだ。
2007.11.09
コメント(0)
-

自然言語処理関連のライブラリ SlothLib
なんとなくふらついていたら、情報爆発時代に向けた新しいIT基盤技術の研究 の SlothLib というライブラリが目に付いた。SlothLibは .Net Framework 上で利用可能なプログラムライブラリです。研究目的のプログラムが手軽に作成できるようになることのみを目的とし、プログラムとしての安全かどうか、高速かどうか、といったことは二の次と考えています。SlothLibの概要11月29日(木)にチュートリアルが開かれるらしい。SlothLib: Web検索研究支援プログラミングライブラリの資料 (pdf) とか見ると、形態素解析関連だけでなく、特徴ベクトル関連とかあってよいかもしれない。しかし SlothLibを利用する前に必要な前準備 Visual Studio 2005 うぉい。C# かぁ。。。。。でも、ちょっと使ってみようかな。機能的には次のようなものを備えている。これだけのものが継続的に利用されることを前提にしたライブラリとして日本で公開されたことはないはずで、そうした意味は大きい。自然言語処理関連(形態素解析と、英文切り分け、各種フィルタ)特徴ベクトル関連(文書の特徴ベクトルの作成と各種操作)データ操作(特徴ベクトルのクラスタリング)IO関連(外部文書読み込み、xdoc2txtの利用)Web関連(各種Web検索エンジンの利用やHTTPによるデータ取得)mono とかって、そろそろある程度使いものになるんだろうか。特集:全1回 .NET FrameworkをUNIXで動かす「Mono Project」 (1/9)。 Mac OS X と MONO で動かすIronPython とかやっている人がいたが、最新の状況はどうなんだろうか。Mono:Solaris とかもあるし、選択肢としてはあり得るってことか。
2007.11.09
コメント(0)
-

ユビキタス社会を拒否してアーミッシュのように生きたりして
最近、高木浩光@自宅の日記を見ていなかったなぁと見てみる。なんだかショッキングなことが書いてある。ユビキタス社会の歩き方(5) [重要] 自宅を特定されないようノートPCの無線LAN設定を変更する を読む。普段使わない自動接続の設定は、削除しておいた方がいい。職場や集会や家庭でWi-Fi信号を傍受されると、自分が最近どこへ行ったかがバレてしまうというプライバシー問題があると言える。そして、もっと簡単に言うと、(自宅の無線LANアクセスポイントの設定によっては)ノートPCを持ち歩いていると、近くに居る人に自宅の場所を知られてしまう場合があるということ。 でもって、位置特定につながるSSIDの割合は約17% (東海道新幹線沿線2007年8月調べ) らしい。びっくり。無線 LAN を使っている女性は特に注意が必要かもしれない。たとえば、外で PC を使っているときに、変態男に目を付けられて、つけねらわれるとかあり得るわけだし。有名人や、そうでなくても金持ちそうに見える男だって、こういう時代どんな目に遭うか分からない。いつの間にか恨みをかっている場合もあり得るし、そもそもただ目の前にたまたまいただけで犯罪の被害者になってしまうことだってあり得る。やっぱり知らない人間からトラッキングされるのっていうのは、生理的に受け付けがたいものがある。ちなみにトラッキングといえば「なかのひと」をこうして使っていると、企業や大学などのアクセス状況が見やすくなるわけだが、こうしたものものを組織はどう考えているのだろうか。別にログを解析すれば分かることなので新たに気にすることはないと考えるか、これまでログ解析をしなかったユーザでも楽に使えるので気になるととらえるか。考えてみれば個人のアクセスなんかも細かくログ解析しているところだと、どのあたりに住んでいるかなんかはある程度特定できたりする。たとえば こんなサービスを使えば 県名までは特定できる。個人情報を扱っているログインしてなにかするようなことをやっているサービスがその気になって IP アドレスとユーザ情報を対にして、データベースを作っていけば、もっと正確なものもできるだろうし。でも、PlaceEngine とかだとそういうレベルじゃないのね。PlaceEngineのプライバシー懸念を考える とか ユビキタス社会の歩き方(2) ストーカーから逃れて転居したら無線LANを買い換える とか見ていると、うぁとか思ってしまう。PlaceEngine: 実世界集合知に基づくWiFi位置情報基盤 も読んでみる。PlaceEngineの次に来るもの そしてRFIDタグの普及する未来 を読むと、次のように書かれている。さらに、数年~10年後、RFIDタグが人々の持ち物に内蔵されるようになり、RFIDリーダ搭載の無線LAN機器が普及した暁にはどうなるか。周囲の RFIDタグのIDを読み取りながら、PlaceEngineで位置を測定して、それらを蓄積するというソフトウェアが普及してしまうかもしれない。2004年10月10日の日記にも書いていたが、他人のRFIDタグのIDを勝手に読み取る行為の電波法59条での扱いもどうなのか。ユビキタス社会の歩き方(1) もらったEdyはam/pmで使わない。am/pmで使ったEdyは渡さない。 みたいのもあれだなぁ。そういうのとは、また違う話で ドイツ政府、テロ対策で市販PCに監視用プログラムの導入を検討 みたいな方向もある。じゃあ、これがクラックされて悪用されたらどうなんのとか。各種の無料サービスも突き詰めていけば、何らかの利益を生み出すから無料なのであって、無邪気に使っているサービスがいつの間にか人の個人情報を暴くのに協力することになったりとかも十分あり得ることだし。まあ、死なばもろともというかなんというか。色々な物を合わせ技にしていくと、個人の生活情報っていうのはどんどん丸裸になっていくイメージがある。すべてが嫌になると アーミッシュ のように現代技術を拒否した生活をする人たちが、宗教とは別の次元でいずれ出てきてもおかしくはないとか思ったりする。アーミッシュのように現代技術を拒否することなく、しかも、安心感を感じながら生きるにはどうしたらよいのだろうか。漠然とした不安と、諦めの日々。
2007.11.08
コメント(0)
-
Python から Graphviz を使う - networkx & PyGraphviz、pydot など
AT&T が開発したグラフ描画ツール Graphviz を Python から使いたいと思って、いろいろ調べている最中。とりあえず、pydot で日本語が出せるのは確認できた(別のやり方は後に書く)、pyGraphviz というのもあるのを知る。ロスアラモス研究所 で開発されていて、グラフ操作のための networkx と、グラフ描画のための pyGraphviz という感じのようだ。つまり、AT&T (Graphviz) + ロスアラモス研究所 (networkx) = グレートって感じ。こうしてアメリカに洗脳されていく。。。。。networkx は easy_install でインストールできるが、問題は pyGraphviz。これは Windows のバイナリがないために自分でコンパイルしなければならない。まだ Windows でのバイナリはなく、動くようになったら教えてねという感じ。 がんばればできないことはないと思うが、コンパイルできる環境を整えるのが面倒なのでとりあえず諦める。理屈上は、setup の中で dotneato-config を始めとしたライブラリパスやインクルードパスを取得するスクリプトの類が Windows 環境では動かないので、この部分を手で指定してやるところからスタートしてコンパイルできない原因を一つずつつぶしていく感じになるだろう。がんばればできないことはないとは思う。けど面倒だ。とりあえずの印象として、pydot に比べると、networkx がグラフを操作するためのライブラリとしては使い勝手が良さそうで、サンプルも豊富。pydot にはそういう高度な部分が基本的にはなくて、あくまでも dot ファイルをゴリゴリと生成してグラフを描画するという低レベルのライブラリ。pyGraphviz は、networkx との連携を考えて作られていて使いやすそう。高度なグラフの操作 (networkx)と描画 (PyGrapnviz) と役割分担ができているから広がりを感じる。gallary なんか見ても、これなら PyGraphviz 使うかなぁという気になる。一番大きな違いは pydot が Pure Python のモジュールで、dot ファイルを生成したら グラフの描画は外部の Graphviz のコマンドを呼び出している点。これに対して、PyGraphviz は Graphviz のライブラリのラッパが C で書かれていて拡張モジュールになっている点。たくさん処理するのであれば、dot ファイルを毎回裏側でファイル出力しない PyGraphiz の方が処理速度の点でも有利なはずだし、Graphviz がフルに使える感じ。gallery: minard.png など、おぉーって感じ。minard.py 程度のコーディングでこれが描ける。gallery: chess_masters_graph.png は、chess_masters.py ぐらい。とってもいい感じ。ちなみに、pydot は開発が止まっているような感じだが、networkx と PyGraphviz は頻繁にアップデートされているようだ。Windows で PyGraphviz が使えるようになったら乗り換えようかな。。。。いずれは、このライブラリを使いたい。Windows と *nix の両方で簡単に使えるものが好きなので。でも、とりあえず dot ファイルを書き出すという pydot でどの程度までいけるかを試してみる。まず、Windows 環境で dot ファイルから Graphviz のコマンドを使って、ちゃんと描画できるのかなという点をチェック。これがそもそもできていないと失望するから。Graphviz Galley にあるサンプルをとりあえず dot コマンドで描画させてみる。だいたいのものが描けるが、twopi2 を描画させようとすると、次のようにエラーになってしまう。Windows 上では JPEG ライブラリが 65500 pixels を超えるものは扱えないということか。考えてみたら jpg 使わずに gif とか png 使えばいいのねと試してみると、gif や png ならちゃんと描画できた。dot -Ktwopi -Tgif sample11.dot -o sample11.gif とかすればいい。$ dot -Tjpg sample11.dot -o sample11.jpggd-jpeg: JPEG library reports unrecoverable error: Maximum supported image dimension is 65500 pixelsfdpclust と、process と softmaint などもレイアウトエンジンを dot コマンドを使うときに指定してやらないと表示が同じようにならない。-K オプションで circo, dot, fdp, neato, twopi のどれかを指定すれば同じように表示できるようだ。dot がデフォルト。dot コマンドのオプションを把握しないといけないな。とりあえず、dot(有向グラフ)、neato(無向グラフ)が基本で、circo(環状レイアウト)、towpi(放射状のレイアウト)、fdp(無向グラフ) と。Graphviz (Wikipedia 参照)Graphviz Galley にあるレベルであれば dot ファイルを書き出すタイプの pydot でも、対応できないこともない感じなので、実際に、pydot を使って、それらの dot ファイルを生成できるかを試していこうかと思う。同時に日本語がそのときに出せるかについても。ちなみに Graphviz のニュースのページ を見たら Ajax で Graphviz とか公開している日本人の方がいらっしゃる。Graphviz をちょっと試してみるのにいいかも。加えて、canviz: graphviz on a canvas を見ると、簡単にどんなグラフが描けるか確認できる。同じ dot ファイルでも、レイアウトエンジンの指定によって表示が変わるのも簡単に確認できる。ZGRViewer, a GraphViz/DOT Viewer はすごいな。大きなものでも、こういうものを使えば全体からズームをしながら細部を眺めていくことができる。これはすごい。大きいグラフでも、こうやってみればいいのだな。これは本当にすごい。すごいすごい。Graphviz ってやっぱりおもしろい。もっと早く試せばよかったなぁ。可能性はあちこちに書かれているのを見て認識してはいたのだが、簡単に日本語使えなきゃおもしろくねぇやと使わなかったのだが、やってみたら、簡単に日本語使えるじゃんということで積極的に使ってみることにするのであった。ちなみに WinGraphviz なんていうものもあって、Shift_JIS でなきゃいやとかいう人も、これを使えば日本語が扱える。Use WinGraphviz in ASP なんてこともできる。ただし、2004 04/28 WinGraphviz ver1.02.25s とかなっているから古いけど。他にも、mfGraph Library Homepage や、Yapgvb (Yet Another Python Graphviz Binding)、GvGen などが Python からグラフを扱えるライブラリとしてある。これらについても、後日チェックしたいと思う。Graphviz 関連の参考dot を使ったグラフ描画 (pdf)Drawing graphs with dotGraphviz チュートリアルGraphvizの使い方メモGraphviz 簡単な使い方グラフが簡単に描ける―Graphvizの使い方
2007.11.08
コメント(0)
-
Python から Graphviz を使う( pydot を日本語で出力)
グラフ図を書きたくなったので、pydot がどの程度使えるか調べてみる。こんな図とか、こんな図とか Python のプログラムから描けたらいいなと。この図は Graphviz - Graph Visualization Software で描かれたもので、この Python のラッパーとなるのが pydot。pydot のオリジナルの作者のサイト を見ると pydot - Python interface to Graphviz's Dot language(Google code) をメインにするよということなので、そちらを中心に見る。でもドキュメントは pydot (version 0.9.10): Graphviz's dot language Python interface でオリジナルサイトにあったりする。現状、まだ、オリジナルサイトの方が情報が多い。必要なものGraphviz - Graph Visualization Softwarepyparsing(dotファイルのロードに使う)pydot - Python interface to Graphviz's Dot language(Google code)Windows の場合、標準の Python ではなく、Python Enthought Edition とかインストールしておくと、Graphviz や pyparsing、pydot が最初からインストールされているので楽だったりする。インストールされていない環境の場合は個別にインストールする。残念ながら pydot は easy_install に対応していない。ん、pypi も pydot の URL がまだ dkbza.org(オリジナルのサイト) で Google Code に移行していない。pydot のダウンロードはここから。# easy_install pydotSearching for pydotReading http://cheeseshop.python.org/pypi/pydot/Reading http://dkbza.org/pydot.htmlReading http://cheeseshop.python.org/pypi/pydot/0.9.10No local packages or download links found for pydoterror: Could not find suitable distribution for Requirement.parse('pydot')なお、注意点としては、Graphviz のバイナリ (fdp, twopi, neato, dot, circo) があるディレクトリをパスに追加しておくこと。そうしないと使えない。Enthought の場合は、\Python24\Enthought\Graphviz\bin が PATH に追加されているはずなので特に問題なし。もし、使えない場合は PATH をチェック。実際に使ってみる。とりあえず、まずは動くかどうかを http://dkbza.org/pydot.htmlと同じようにしてテスト。import pydotedges=[(1,2), (1,3), (1,4), (3,4)]g=pydot.graph_from_edges(edges)g.write_jpeg('graph_from_edges_dot.jpg', prog='dot') 無事に表示される。では日本語を入れるとどうなるだろうかとやってみる。数字ではなく、文字列を入れるとアルファベットは表示されるが、日本語は文字化けしてしまう。#!/usr/bin/env python#-*- coding: utf-8 -*-import pydotedges=[('root', u'日本語'), ('root', 'Latin'), ('root' , 'English'), ('Latin', 'English')]g=pydot.graph_from_edges(edges)g.write_jpeg('graph_from_edges_dot.jpg', prog='dot') さて、文字化けする原因はどこにあるか。とりあえず Graphviz が日本語が通るか見てみる。Graphviz 簡単な使い方 を見ると、Windows版のdottyで日本語を表示することはできない(ようだ)が、dotから出力する画像ファイルで日本語を出力することは可能。バージョンはGraphviz2.6。以下そのやりかた。が書かれていた。一つはdotファイルをUTF-8で書いて、フォントの指定をすること。もう一つは、lefty を改造して Shift_JIS に対応したパッチを当てたものを使う方法が書かれている。UTF-8 でいいので、前者を試すことにする。pydot.py の末尾 class Dot の def create を見てみると、self.write(tmp_name)stdin, stdout, stderr = os.popen3(self.progs[prog]+' \ -T'+format+' '+tmp_name, 'b')と、テンポラリファイルに dot ファイルを書き出しておいて、popen3 で Graphviz のプログラムを呼び出してそのファイルを処理させているようなので、書き出すところでフォントの指定を入れてやればよいかな、と思ったら、各クラスをよく見たら、fontpath とか fontname の attribute を持たせられるようになっているので、そこで指定してやればよいか。で、次のようにしてみる。g=pydot.graph_from_edges(edges)g.fontname="arialuni.ttf"g.fontsize=10ところが、これでは文字化けのまま。原因を探るために、試しに、dot ファイルをまず手で書いてみる。graph "g" { node [fontname="arialuni.ttf", fontsize=10] "root"; "日本語"; "root" -- "日本語"; "ラテン語"; "root" -- "ラテン語"; "英語"; "root" -- "英語"; "ラテン語" -- "英語";}test.dot ファイルに上記を入れておいて実行してみる。dot -Kneato -Tjpg test.dot -o pydotteset01.jpgこれだと、ちゃんと日本語が表示される。pydot から出力されているファイルを見ると、次のようになっている。node の属性がベタに書き出されていて、ちゃんとリストになっていないからなのかな。graph G {fontsize=10;fontname="arialuni.ttf";"root";"日本語";"root" -- "日本語";"Latin";"root" -- "Latin";"English";"root" -- "English";"Latin" -- "English";}試しに手書きで、node [fontsize=10, fontname="arialuni.ttf"] と書き換えてやると、日本語が表示できるようになった。ということで node を作って、そこに属性を指定することにした。が、g.add_node でそのノードを追加すると一番最後に追加されてダメなので、pydot.py の class Graph の def add_node の中を書き換えてみるとちゃんと日本語が表示されるようになった。、- # self.sorted_graph_elements.append(graph_node)+ if graph_node.name == 'node':+ self.sorted_graph_elements.insert(0, graph_node)+ else:+ self.sorted_graph_elements.append(graph_node)なんだか強引なやり方だが、とりあえず pydot で日本語が出せた。適当なことをやっているので副作用があるかもしれない。というか、ドキュメントちゃんと読んだら、もっとちゃんとした使い方があるのかもしれないが、面倒なのでとりあえず。あとで Google で探してみるかな。まあ、とりあえず日本語が使えることは確認できたのでよしとする。#!/usr/bin/env python#-*- coding: utf-8 -*-import pydotedges=[(u'私', u'食べる'), (u'私', u'遊ぶ'), (u'私' , u'寝る'), (u'寝る', u'ベッド'), (u'寝る', u'道端'), (u'食べる', u'魚'), (u'食べる', u'米'), (u'食べる', u'肉'), (u'遊ぶ', 'Python'), ('Python', 'pydot'), ('pydot', 'pyparse'), ('pydot', 'Graphviz'), ]n = pydot.Node('node')n.fontname = "arialuni.ttf"n.fontsize = 9n.fontcolor = "blue"g=pydot.graph_from_edges(edges)g.add_node(n)g.write_jpeg('graph_from_edges_dot.jpg', prog='dot')
2007.11.07
コメント(5)
-

OpenSolaris の Project Indiana の成果を見てみる
使い勝手をLinuxに近づけたSolaris LiveCDでインストールできるOpenSolaris公開へ を読む。今回リリースされたのは OpenSolaris Developer Preview で、来年3月に正式版がリリースされる予定らしい。 Project Indiana milestone reached! を見ると、次のようなことが書かれている。1枚の LiveCD で、インストール前にも動作を確認できる(try before you install' capabilities)インストーラは Caiman で使い勝手が向上しているZFS がデフォルトのファイルシステム になったイメージパッケージシステム(IPS)はネットワークインストールが可能になったGNU utilities が $PATH に追加されたbash がデフォルトのシェルになったデスクトップ環境は GNOME 2.20OpenSolaris Project: Indiana の Get the OpenSolaris Developer Preview のページから ダウンロードして起動してみる。発表されたばかりだからだろうか、ダウンロードにはだいぶ時間がかかった。とりあえず、VMWare 上で動かしてみる。メモリは 512 MB、ハードディスクは 10GB が最低必要。とりあえず起動してみると、あれこれアプリケーションが使える状態で起動した。デスクトップにあるインストーラを起動してハードディスクにインストールしようと思ってもエラーでストップしてしまう。パーティションがあらかじめないとだめなのかなと root になろうとしたがなれない。Username "jack"、Password "jack" でログイン。root パスワード "opensolaris" と Release Notes for the OpenSolaris Developer Preview に書かれているが、jack ではログインできるが、root ではログインできなかった。なんでかな。これは、インストーラを起動して設定をすると、root のパスワードが動作環境にも繁栄されるために、インストーラを起動したあとは root のパスワードがその設定したものになるからだった。起動してすぐに su するときには "opensolaris" 。インストーラを動かした後は途中で失敗したとしても、そこで設定した root のパスワードに置き換わる。また、途中でインストーラがエラーで止まった場合、そこで追加したユーザ名が /etc/passwd に追加されているので 2度目にはそのユーザを削除しておかないと設定できない。結局、format コマンドでパーティションを作ってからインストールしようと思ってそうしてみたのだが、やっぱり途中でしまってしまってハードディスクへのインストールはできなかった。VMWare にインストールが成功している人もいるようなので、どこかちょっとしたことが問題になっているんだろうけど分からない。インストールできても、OpenSolaris Forums: VMWare tools installation error.... ... とか、Bug 66 ? No network interface found とか対処しないとダメなようだ。ということで、VMWare にインストールしようとしたら、それなりに分かっている人でないとちゃんと使えるようにできないかもしれない。しばらくバージョンが上がるの待って、もう少し楽に使えるにようになってからにするかな。OpenSolaris Forums: unable to install zones ... とかいろいろまだ問題はあるようで、ほんとうの Solaris の開発者用のレベルなので、一般ユーザがまだ手出しする段階にはない。まあ、リリース自体が Developer Preview なので当然といえば当然だが。でも、雰囲気として半年後はけっこう期待できそうな感じ。とはいえ、当面は新しいもの好きでも、自己解決能力がある人でない限りは Solaris 10 の Developer Edition とか使っておいた方がよいと思う。逆にいえば、あれこれ問題を解決しながらコミュニティに参加しつつ楽しみたいというのであれば、バグにしてもたくさんあるだろうから貢献できそうねという感じ。その手のことが好きな人にはけっこう楽しいフェーズじゃなかろうか。ちなみに、日本語の記事にインストーラは Slim と書かれていて、Caiman とは違うのかなと見てみると Slim Install Documentation 、LiveCD 用のコアコンポーネントのインストールは Slim インストーラとある。Caiman のサブプロジェクトという位置づけかな。FireFox や GIMP などのアプリケーションも CD から起動しただけで使える。デスクトップの左上のインストーラアイコンをダブルクリックするとインストーラが起動する。
2007.11.07
コメント(1)
-
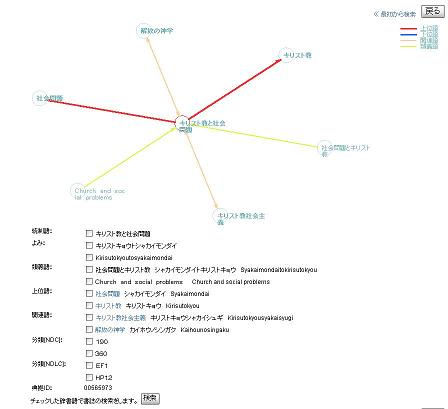
国会図書館の検索ポータル 「PORTA」 を見てみる
国会図書館、約800万件のデジタルデータを検索できるポータル「PORTA」 ということで、PORTA (国立国会図書館デジタルアーカイブ) を見に行く。何ページか見ていたら、エラーが出てまともに使えなくなった。Request Entity Too LargeA request entity is longer than the server can handle.なんとなく、Internet Explorer だと問題ないが、FireFox だと問題が出てしまうようなつくりになっているような気がする。善処を希望するってここに書いて意味あるかって話もあるが、以外に直リンク張っておくと見に来るものなので書いておくのであった。ユーザ登録すると何がいいことあるのかなと思って見てみると、次のカスタマイズができるようになるということらしい。とりあえずまだユーザ登録はしていない。ユーザグループの選択デザインの選択ポートレットの表示位置の変更、表示/非表示の切替検索オプションの初期設定ダイレクトメニューの編集ブックマーク機能キーワードランキング を見てみると夏目漱石がトップだった。とりあえず試してみようって感じで使われている感じ。ちなみに夏目漱石は私は好きではないが、それはどうでもいい。アクセスランキング なども見てみる。第1位 (51ヒット) なのでまだ、あまり使われていない感じ。第4位(12ヒット) の 「日本之下層社会 横山源之助著 土屋喬雄解説」 をクリックして見てみる。確認した後、元に戻ろうと思ってもアクセスランキングの画面に戻れない。貧困といえば、このサイトとの話とはまったく関係ないけど 日本経済 ~低所得層を苦しめる物価の二極化~ なんていうレポートが第一生命経済研レポート 2007.11に出ている。辞書検索で、「貧困」とか検索してみる。関連後がたくさん出てくる。そこから、「社会問題」の「キリスト教と社会問題」をクリックすると、こんな画面が出てきた。このインターフェイスはおもしろい。貧困から解放の神学にたどりつけるのね。視点を広げるときには、やはりこの手のものは使える。辞書検索の結果は、テキストで表示するほか、統制語、よみ等、類義語、上位語、下位語、関連語の関係を視覚的に見ることができるようグラフィカル表示を行っています。グラフィカル表示では次々にクリックした他の語を起点とした表示に移動していくことができます。相関関係をもつ語が多い統制語を表示する場合、表示に数分程度の時間を要することがあります。機能概要 辞書検索連想検索は、次のを参照と書いてあるので、そのあたりと同じ仕組みか。汎用連想計算エンジン(GETA) 公開HP Webcat Plus 連想検索についてでも、残念なことに全般的にとっても使いにくい。サイト自体には意味があるにしても、こんなに使いにくいってのはいかんなぁ。機能的にはおもしろいものもあるけど、何しろ使いにくい。もったいないなぁ。開発したところってあまり一般人向けのサイトを作ってないところじゃないかな。ふつー、一般人向けのサイトでこんなにユーザビリティの悪いもの作ったら、お客さんからダメだし食らうと思うけど。。。。。そういえば 近代デジタルライブラリー の資料が 7月に増えていたのね。国立国会図書館入門
2007.11.05
コメント(0)
-
会計監査院、えらい!
以前に よーく考えよう、お金は大事だよ (February 8, 2007) で、独立行政法人 国立印刷局 の土地について触れた。けっこうあちこちに土地を持っていたのね。こういう敷地って何に使っていたのだろう。原材料を備蓄とか、中間財の備蓄とか、職員の宿舎とかそういうものだったのだろうか。けっこうあちこちに土地を持っていたのね。こうした土地の売却に当たっては、パフォーマンスの一つとして、何に利用していた土地かをどこかに公開すべきだろうな。さて、これ売ると全部でいくらになるんだろう。国が持っている土地って、国土の何パーセントだったかな。日本国土の半分が国有地だったはず。河川や山林も含まれるものの一等地も結構あるのだね。独立行政法人国立印刷局における土地及び土地譲渡収入などによる資金について で指摘してくれている。会計検査院、ちゃんと仕事してるねぇ。土地売却で282億円、国庫返納33億円のみ・国立印刷局、 元国有地の売却、国庫返納できず=国立印刷局、資産膨張も規定なし-会計検査院 などの記事になっている。しかし、こういうことになっちゃったのは、もうどうしようもなく最初から官僚の意図していたところであって、国会議員が間抜けだからこういうことになる。間抜けであったのは仕方ないとして、不要な資産を国庫に返納させるよう適切な制度を整備する要があると認められる。ようなところはたくさんあるわけで、国会議員、ちゃんと働けよって感じ。ようするに、国立印刷局みたいなところの問題は、素人がチラっと見ただけで見て取れるわけで、こういうのはいっぱいある。
2007.11.05
コメント(0)
-
Python Magazine を読む
先月から始まった Python Magazine を PDF で見ることができるので、流し読みしてみた。全部で 46ページ。内容は、次の通り。Extending Python - Build your own Python extensions using CProcessing Web Forms Using Anonymous Functions & WSGICreating custom PyGTK widgets with CairoWorking with IMAP and iCalenerCOLUMNS:Import This - Welcome to the debut of Python MagazineAnd now for something completely different - Modern process management modules alleviate GIL woesWelcome to Python - XML Processing with ElementTreeRandom Hits - The Python Community掲載されているコードは、PyMag_2007-10.zip からダウンロードできる。Doug Hellmann 氏の AND NOW FOR SOMETHING COMPLETELY DIFFERENT では、マルチスレッドアプリケーションの話が書かれている。Python は GIL (Global Interpreter Lock) があるから、インタプリタが実行するバイトコードは、1つのプロセッサで1つのスレッドだけ。じゃあ、GIL をなくした Python の実装したらいいじゃんということだけど、かつてそういう試みもあったけど、パフォーマンスが出なかった。もし、パフォーマンスに優れた実装が表れれば GIL はなくなるだろうけど、実際にそういうものは出てきていない。ということで Python 3.0 でも GIL は存在し続けるようだ。だから現状では、Python はマルチプロセッサのメリットを十分活かせなかったりするが、まあ、それはそれで打つ手はあると。Vitalii Vanovschi 氏の Parallel Python パッケージとかは、ジョブサーバを動かして、そこから個々のプロセッシングノードにワーカージョブを振り分けるような仕組みらしい。これを使うと複数の CPU があるマシンでも CPU を有効に使えるようだ。他には Richard Oudkerk 氏の processing パッケージもある。プロセス間のデータ共有もやりやすくできている。リモートサーバで処理させるのも楽なようだ(pickle でデータをやりとりするから、セキュリティには配慮した実装にする必要がある)。なんていう話題が扱われていたりする。日本の雑誌見ても、なかなかそういうレベルの記事がないから(たぶん。最近、また雑誌読んでないので、あったらごめんね)、このレベルの雑誌が出てきたのは嬉しい感じだが、問題は継続するかなのだな。Python Magazine にも書いたけど PyZine は 8号でストップしちゃったし、なかなか、こういうのって続けるの難しいのだろうね。とりあえず他の記事もおもしろいので、Python ユーザは一読の価値ありと思う。
2007.11.03
コメント(0)
-
Google の日本語解析データ
グーグルが大規模な日本語の解析データを公開、「20%ルール」の成果グーグルでは、200億文に上る日本語データを解析したという。含まれている単語は、約2550億個。1~7gramのデータを公開しており、例えば7-gramのデータは11億種類以上にも上る。Google Japan Blog: 大規模日本語 n-gram データの公開 を読む。すごいなぁ。特定非営利活動法人 言語資源協会 の GSK2007-C Web日本語Nグラム第1版 で公開されているのね。といっても無料じゃないけど。「抽出対象となった文数は約200億文で、出現頻度20回以上の1~7グラムを収録している。」で DVD-R 6枚の 26GB(gzip で圧縮した状態で)。すごい量だな。ちなみに 個人・非会員42,000円か。んー、個人でも会員になれば 2,1000円か。ってことは、正会員(個人/団体):5,000円/年 だから、会員になっちゃった方がこの際、得だってことじゃん。ということで、これは言語資源協会のいい宣伝にもなって、二重の社会貢献だったりする。また、ブログの中に 北陸先端科学大学院大学 白井清昭先生 の名前があるので、大学と先生に対する後援にもなっていて、四重の社会貢献だったりする。こうやって、Google はアメリカでもいろんな大学と連携を深めて人材獲得の面でも、社会的な評価の点でもプラス点を付けながら大きくなってきたのだろう。Win-Win の関係を築くのが会社としてうまいのね。イメージとして、マイクロソフトが結果としてすべてを奪っていくイメージなのに対して、Google はシェアする会社のイメージがある。まあ、実際のところ、マイクロソフトはよいパートナーとなった会社には、実はそれなりに便宜を図って生き延びさせているわけだけど、一般的なイメージからすると排他的なのね。Google は検索市場で大きなシェアをとることによって、意識せずに結果として、いろんな会社をつぶしてきた面があるけど、マイクロソフトがライバルをつぶしてきたようなやり方じゃないから、イメージが悪くない。まあ、オープン性の高い会社と低い会社のイメージの差ってことだな。そのあたり、マイクロソフトもなんとか変えようとしてはいるんだろうけど。そういえば、マイクロソフトが Facebook に 出資した と思ったら、mixi、GoogleのSNS共通規格「Open Social」に賛同 か。OpenSocial ね。ミクシィと同時にOpen Socialに賛同した企業には、MySpace、Friendster、hi5、imeem、LinkedIn、Ning、Oracle、orkut、Plaxo、Salesforce.com、Six Apartなどがある。mixi、GoogleのSNS共通規格「Open Social」に賛同話を元に戻し、実際に作業したのは、工藤拓氏と賀沢秀人氏らしい。工藤氏は MeCab の作者、加賀氏は、賀沢氏は NTTコミュニケーション科学基礎研究所 知能情報研究部 知識処理研究グループだった人かな。機械学習とか知識習得、テキストマイニングのあたりを研究してきた人か。なるほど。「構造化データの機械学習」研究会 Machine Learning on Structured Data (MOST) にも二人の名前が並んでいるし、NTT の時代からいろいろやっている間柄なのかな。それにしても NTT も二人もおいしいところもってかれちゃって、もったいない。でもって、GSK2007-C Web日本語Nグラム第1版 は気分的には欲しいが、ちょっと遊ぶのに何万もかけられないので、そのうち宝くじがあたったら購入することにしよう(本当はほしくてたまらないのだが。。。。)。英語版の All Our N-gram are Belong to You も。まあ、何はともあれ企業イメージって、こういうものによっても地道に作られていくのねぇ。イメージってオープンソースでも重要で、たとえば組み込み型全文検索エンジン Senna とか、2ch 系に分類されるから、以前はちょっとねぇというイメージがあったと思うが、未来検索ブラジル、NTTデータの全文検索機能「Ludia」に「Senna」提供 (2006年10月) となればぜんぜんイメージが変わってしまう。それまで見なかった人が見るようにもなるし、NTTデータが使ってるんだからとかいって使いやすくもなっただろう。いかに、人がイメージだけでよいものであっても見る手間を省くかということ。まあ、日本の場合、権威主義というかなんというかあれだが、日本の場合、なかなか、そのもの自体を見ない人が多いだけにね。。。。こういうのを発表することによって Google が「日本語でも」重要な位置を占めるんだぞといういいアピールになっている。自然言語処理とかやっている学生の Google 脂肪率がいちだんと跳ね上がるんじゃなかろうか。そして、こういうニュースが流れると、Google っていったって、所詮は日本語は日本の会社の方が得意でしょ、というイメージを打ち砕いていったりする。そういう意味でも一般のニュースにこうしたものが載っていくのはインパクトがある。
2007.11.03
コメント(0)
-

株価操作とインサイダー取引
大物仕手筋ら3人を起訴 株価不正操作で大阪地検 で、起訴状によると、西田被告らは2002年11月下旬から12月中旬、南野建設株の買い注文を高値で繰り返すなどして株価を高騰させた。さらに活発に売買されているように装うため、売り注文と買い注文を同時に出す仮装売買をした。これで捕まるなら、ほんとうはもっとたくさん捕まってもいいのにね。最近のストップ高、ストップ安連発って、東証 自主規制法人始動 市場の監視役 独立 とか、市場監視が強まるから仕手筋が売り逃げするためにやってるのもあるのかなぁと思う今日この頃。それに協力している証券会社ってあれだなぁ。そういえば、金融審、インサイダー課徴金上げで大筋一致――対象範囲も拡大 らしいが、日経新聞をはじめとしたメディアの審査をどうするか。過去にインサイダーで逮捕者出しているからねぇ。テレビで特集組む場合もそう。こういうのって、実はインサイダーの温床になっているんじゃないかとか疑いを捨てきれない。あるいは、政府の各機関がたとえば業務改善命令を出す場合の情報漏れもインサイダー取引につながる。そういえば、またしても福井日銀総裁、利上げ決定にインサイダー疑惑 みたいな話もあった。公的機関の規制緩和や規制に関しても、インサイダー情報があれば有利な株取引ができる。ニチアスの問題にしても、前日にこれを知って全力空売りしていれば大儲けできた。何せ、ウナギや天ぷら食わせるとペンタゴンにペラペラしゃべっちゃってた法務大臣がいる国だから、何が起きているかは分からない。政府関連の人間に対して、情報漏洩に対する罰則を明確にしなきゃいかんでしょ。インサイダー取引は定義的には明確なんだろうが、実際には捕まえるのは難しい。仕手や株価操作は、何をして株価操作というのか定義が明確でないところがある。普通に証券会社がやっているような売買だって、仕手と変わらないようなことをしているわけだろうし。インチキ投資顧問会社がはめこみ顧客にこの株買えと買わせて売り抜けるのと、証券会社がマスメディアも利用しながら売り抜けたりするのと、どこが違うのだろうか。株価操作自体よりも、その主体が反社会的なものにつながるから罰しているというのが実状だろう。株価操作自体は操作的定義が行えない限りは後を絶たない。証券取引監視委員会は改めて、何を株価操作として取り締まるかのガイドラインを明確にすべきだろう。証券法令解釈事例集 とかのレベルなら日常茶飯事だが、じゃあ、たとえば大口の注文というのは操作的に何をして大口と定義されるのか。そういえば、最近ロボット売買と見られる出したり引っ込めたりの板が気になる。出した時点では売る気がない、あるいは買う気がないというわけではないにしても、自動売買で何かの連動する値に従って出したり引っ込めたり頻繁にやっているのはどうなんだろうね。日本の金融市場を世界的にそれなりの地位にしたいというのは国策なんだろうから、もっとルールの明確化が行われて、その適用も厳格に行っていかないといかんよね。現状は、やりたい放題じゃん。課徴金制度 の課徴金を重くしていくのはよい方向だと思うが、ルールが明確でないと、けっきょく捕まらなければいいやという感じになるだろう。ルールが明確でないから、捜査も立件も時間がかかってたくさんは捕まえられないわけだし。今年はとりあえず暴力団関連に注力するという方針ならそれはそれでよいかもしれないが、暴力団以外の仕手筋や証券会社やヘッジファンドに対する牽制も、もっとすべきだろうに。不正な取引をアルゴリズム的に捕まえられるのはいつの日か。。。。。
2007.11.03
コメント(0)
-

犯人捜しに Yahoo! が協力
Yahoo! なんでも交換 を見ると、Yahoo!なんでも交換 - 「犯人捜しています」特集 を見る。指名手配情報を流し始めたのね。単なる話題作りとか、権力へのすり寄りと取られようが、何といわれようが、こういうのはよいと思う。スタッフブログ: 犯人捜していますか?。これ実は、使いやすさを発展させていくとおもしろいアプリケーションのベースになりそう。捜しものは何ですか、見つけにくいものですか。通常の検索は、探す主体が何かを求めているので前向きな検索が行われるが、こうした探す主体が情報を出しているだけの場合、なかなか前向きな検索は行われない。情報の提供者がパッシブである場合には、主体的な検索とは違う方向が考えられる。それにしても、犯人捜しのページのトップに何人か顔を出した方がいいと思うが。。。。ポリスチャンネル にも 指名手配 のページがあるが、例えば 発生場所の地図などの情報もこっちはある。こういう犯罪情報って、どういう出し方すると犯人が捕まりやすくなるんだろう。上祖師谷三丁目一家4人強盗殺人事件 とか見ていると、単なる強盗殺人事件ではなくて、それを装っただけのもので、実は公園の立ち退き問題に絡んだ殺人だったんじゃないかとか思えてくるなぁ。まあ、警察の誘導なんだろうけど。ということで情報の出し方によって、結びついていなかったものが結びつくと、犯罪情報が連鎖して犯人逮捕につながるものも出てくるのかもしれない。行方不明者のページとかもあるのね。こういうのブログパーツ化してくれたら、役立つかもしれないなぁ。要するに、そこへわざわざ行ってみるということでなしに、街にある指名手配のポスターのように何気なく歩いていると見えてしまう状態になっていた方が効果がある。もしかして、指名手配の犯人なり、尋ね人なりがウェブサーフィンしていたら自分の写真が出ていて名乗り出るなんてこともあり得ないことではない。そういえば、最近、画像認識技術が向上しているから、画像検索で犯人逮捕の有力情報が得られたとか、そのうち出てくるとおもしろい。写真を撮って、ネットに公開していたら、たまたまそこに犯人の顔が写っていて、画像検索によってそれが見つかり、警察からコンタクトがあり、いつどこで等の情報を提供したら、それが犯人逮捕につながったとか。まあ、画像検索技術が高度になると、プライバシーの問題とかも出てくるし、不倫がばれちゃいましたとかもありえるし、AV 出演親バレしちゃいましたとかもあり得たりするわけだが。本当は、全国のいたるところにある監視カメラを警察に直結させれば(リアルタイムでなくても、ビデオ提供で)犯罪監視ネットワークができあがるわけだが、当然プライバシーの問題とか、公権力の不正な利用とかもあり得るわけで、現状では厳しいものはあるが。とかいいながらも、すでに Nシステム (自動車ナンバー自動読取装置) みたいのは稼働しているわけではあるが。全国にこの程度は最低あると。ここが分かりやすいか、あるいは winnyに暴かれたNシステムの一端 。ETC の導入がさらに進むとそれもトラッキング情報になるし。まあ、こういうシステムは随意契約の固まりだろうw。スーパー防犯灯 とかにしてもあれだな。(スーパー防犯灯の仕様)。さらには PASOMO とか SUICA なんかの利用状況とかチェックすれば、けっこうトラッキングって可能だったりして、さらには GPS や携帯電話も。その気になってトラッキングすれば、特定の個人の動きってけっこう把握できるのね。インターネットなんかにしたって、その気になれば行動監視は可能なわけだし。と話はそれたが、いったん特定してからのトラッキングよりも、特定するまでの方が通常の犯罪捜査ではメインになるわけだな。にも関わらず、犯人の写真が公開されている状況であっても、なかなか捕まらない人は捕まらないというのは、その程度のものでしかないということでもある。ネット犯罪しかり。犯人が特定されてからの検挙率が異常なまでに高くなったとしたら、それは監視網が機能し始めたということか。それは良いのか、悪いのかということにもいずれはなるんだろう。
2007.11.03
コメント(0)
-

カロリーを気にしないでポテトチップスを食べる
ポテトチップスが好き。でも、カロリー高いし躊躇する。そんなときによいのがこれ。ジャガイモをスライスして並べて電子レンジでチンでポテトチップスを作ることができる。油を使わないので、それほどカロリーが気にならない。これはとっても気に入った。自分がしばらく前に買ったときよりも、安い店があったので、そこのリンクを入れておく。945円(税込み)。電子レンジで何分加熱するかは多少コツがいるが、何回かやれば適切な時間が分かる。目安に従ってやってみて、10秒ずつ増やしていけば、いい感じの時間が分かる。やりすぎると焦げるので注意。
2007.11.01
コメント(0)
全42件 (42件中 1-42件目)
1
-
-

- 携帯電話のこと
- 菊陽町の楽天市場利用者が楽天モバイ…
- (2026-05-24 08:00:07)
-
-
-
- 楽天ブログいろいろ
- 5/28ぐらいに?247万アクセスになっ…
- (2026-05-31 12:00:04)
-
-
-

- 大好き!デジカメ!
- 新しいコンパクトデジカメ買いました
- (2026-03-20 07:03:08)
-



