

2007年12月の記事
全29件 (29件中 1-29件目)
1
-
探しものが見つかった - 業務改善
調べたいと思っていた会社が見つかった。そもそも勘違いをしていて、他の会社とごっちゃになっていた。調べるものが、そもそも存在しないものになってしまっていたので見つからないはずだ。。。。見つけたかった会社は見つかったけれども、微妙に中身が違ってたので、キーワードがちょっと違ってた。これだと思うキーワードで見つからないときには、ちょっと視点をそらせて周辺のキーワードに切り替えて探して力業で探していくと、勘違いではまってしまった場合もリカバリーが効く。部屋の中で何かなくしてしまって探している場合もそうだなぁなんて思った。力業でひたすらいろんなものを見ている過程でおもしろいものを見つけたりする。まあ、見つからなくても楽しみながら探していれば、視野も広がるというものだ。時には効率が悪いのもよいと自分を慰める。転んだときにはタダで起きない。そんな中でたまたま見つけたもの。DELMIA ASSEMBLY WORK INSTRUCTIONS のデモ動画を見るとおもしろい。組立て工程における作業指示書を作成するツール。へぇ、こういうものもあるんだなぁ。工場見える化システム なんていうのもおもしろい。さすがに、松下電器なんていうのは、こういうレベルなのだな。これと連携する OTRS で分析して、結果を改善活動・教育訓練、作業指示書等に活用するとかある。製造ドキュメントも作ることができる。こういうのは、やっぱり製造業だよねというと、エイアンドティー のように医療分野の検査に焦点をあてて成功している会社がある。病院の検査室を中心としたリエンジニアリングで実績を上げている。テクニカルプレゼンテーション・ライブラリ にある「東海大学病院の経営戦略 ~年間30億円の赤字脱出は検査室から始まった」なんておもしろい。人材依存型のビジネスも、まだ努力できる余地があるなぁと、こういうものを見ると思える。このビデオは、ほんとうにおもしろい。「みんなで蛸壺を出よう - 病院は蛸壺倉庫」。これは病院だけじゃないなぁと思う。人材依存型のビジネスに共通したことかもしれない。Patient Flow Management のあたりなども他の分野も応用できる。ボトルネックになる箇所を時間的にずらしてしまって解消している。というのはさておき、本来探していたのは 大手小売りの棚卸しを“独占”ITで作業精度と人員を最適化 (2007/08/09) の棚卸しサービスの エイジス。国内の年間売上高上位100社の小売りチェーンのうち、実に約70社がエイジスに棚卸し業務を委託している。セブン-イレブン・ジャパン、ローソン、イオン、マツモトキヨシ、ライトオンなど小売業界のそうそうたる面々が、取引先リストに名を連ねる。エイジス (ジャスダック : 4659) の株価を見ると、着実な推移になっている。急激に伸びるものでもないし、出来高もすくないから、あまり投機の対象にならずに高くなりすぎれば売られて、下げれば買われるという感じで地道な動きって感じ伸びてきた感じ。長期投資のお金持ち銘柄。まあ、ここからはちょっと分からない感じもするが。数字で見るエイジスの強み を見ると、30期連続して増収とはえらい。売上げの規模がそれほど大きくないからシェアが高くても目立たないのね。ちなみに、ここについて、以前、書いてアップロードしたと思っていたらしてなかったようだ。記事を見たときにチェックして、おもしろいなと思って、ローカルのファイルにメモを残して終わっていた。エイアンドティーの株価を見てみると、ふーん、ここは、これからの時期、下げたところで買って持っているとスイングでいける銘柄っぽい。400円切ったところで買ってしばらく持っているといいかも。小金持ちの投資銘柄かな。現状では変に仕手的な動きが出て跳ね上がったときにはいったん売り抜けって感じかもしれない。行大敵には地道な伸びしかないはずなので、跳ね上がったときにはそのあと売り込まれる。基本的にボックス圏で推移してきた感じ。配当利回り 1.98% だから、貯金するつもりで買って、上がっちゃったらラッキーで売り抜けるし、上がらなくとも配当もらえて OK という感じだったらよい感じの銘柄かもしれない。エイジスとかと同じで、ほとんど出来高がないから、遊び道具にされていないのかもしれないな。エイアンドティーに戻って、ここは会社としてみたときには、おもしろい方向性だと思う。弱みとしては、厚生労働省の方針に左右されやすい部分があるってことかな。厚生労働省ははしごはずしがうまいから(ひどい)、どんなことがこの先、医療分野で起きるか分からないところがリスク要因か。臨床検査試薬・分析装置・コンピューターシステム・検体搬送システムの4分野全てについて、開発・製造・販売・保守サービスを行っているから、臨床検査試薬が減ってもシステムが伸びれば、今期のように利益が伸びる。医療全般が落ち込むようになれば、そのときは全部落ちるだろうけど、基本的には伸びるかなと。電子カルテとレセプト関連のシステム化のあたりでのびしろがまだあるような感じ。お金持ちなら下げているところで買ってほっぽらかしてとかいうのにいいかもね。調べごとは、作業分析をベースにした業務システム設計法 みたいな方向性。基本的には、作業の繰り返しが生じるようなものを効率化したりとかいうことの前に調査測定を行って、作業コストとかも割り出しましょうということで、その手のものを調べていたわけ。エイジスの場合、調査もやるけど、調査よりもアウトソーシングの方がメインでそこを間違って調査をメインに調べたからなかなか見つからなかった。まあ、見つかったので気持ちいい。ついでなので、個人ベースで作業時間の測定や管理をやるツールなどあれこれ調べてみる(末尾のリスト参照)。ちなみに、業務用のだと シスコムの「仕事測る君」とか「動作測る君」 とか、スペースコムの PERSIMMON(事務量調査、特に銀行・証券・保険等)、DLS の事務量分析システム みたいなのもある。あるいは、NTTデータフォースの OPpyi、日本能率協会 自治体経営革新センターの事業別定員管理、NJFS の事務量分析ソリューション などがある。こういうものはドメイン依存性が強いから、コンサルティングを含めた形になるな。業務改善なんて結局のところ働いている人たちを蛸壺から出すためのプロセスが常に伴うわけで、現場の協力なくしてできないわけでと。業務効率やコスト算出のために時間を計ったら、それで短絡的に労働組合が怒るようなところではできないぞっと。さらには、お役所で 総合窓口実現のためのABC - 今、なぜ「総合窓口」なのか?、 総合窓口実現のためのABC - 役所の窓口業務をどうやって見直すのか みたいなレベルになると、さぞかし大変だろう。誰からも文句の出ない自分の時間も計ってみよう。作業を変えずに訓練すると速くなることと、限界があること。効率化が可能なことと不可能なこと。作業そのものをなくしてしまえるもの。Task Coachこれは Python で書かれている。タスク管理と時間管理ができるので便利。たたし CPU を常に食ってしまうところが気に入らないところ。原因を追及しようと思いつつやっていない。LapTime自分を追い込むときに使っている。集中力が切れるごとにラップを取ったりしている。タバコを吸うごとにラップとか。グラフ化されるのがいい。作業時間測定ツール jikan 複数の作業の時間をテキストファイルで測定 シンプルなツール。作業時間計測ツール 作業記録を取るのによさそう。Task Coach にこういうのが付くといいのだが。作業時間を管理しよう「jWorkSheet」長時間のPC作業による疲労症状を予防する VDTタイマーTimeTracker (ブラウザの表示時間を自動カウント) (Firefox Add-ons: TimeTracker)時間測定機能付きタスク管理「Kimai」ブラウザベースの高性能プロジェクト管理「Epiware Document Management」高性能!Java製プロジェクト管理「OpenProj」プロジェクト管理のソフトあれこれ (MOONGIFT)MOONGIFTって、地道にいい紹介を続けている。前から気になっているのだけど、どういう人たちがやっているんだろうか。
2007.12.30
コメント(2)
-
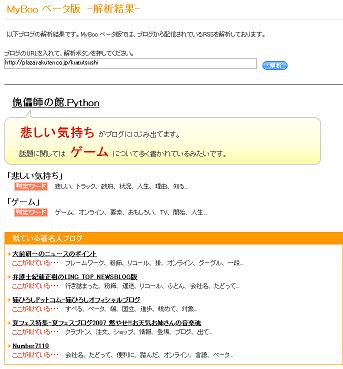
MyBoo ベータ版によると、傀儡師の館.Pythonは悲しい気持ちがにじみ出ているブログらしい
しばらく前に 新機能☆ブログ解析 『MyBoo』ベータ 公開! されていたので、使ってみる。http://myboo.kizasi.jp/ で http://www.plaza.rakuten.co.jp/kugutsushi を入れて検索してみる と、悲しい気持ちがにじみ出ているらしい。まあ、確かにそういえないこともないのだが、どの単語に反応しているんだろうか。「話題に関しては ゲーム について多く書かれているみたいです。」とあるが、確かにゲームについて書くこともあるが、そんなに多いかな。直近のものに引きずられるのか。最近の注目ワードも出してくれて、下のような感じ。ちなみに、最近使ってなかったなぁの JUSTBLOG に置いてある 傀儡師の別館 の http://kugutsushi.justblog.jp/ を入れてみると、もっと悲しい結果になった。TypePad はまだ対応してないのか、JUSTBLOG のがダメなのか。また、そのうち試してみるが、使えないブログもあるのは確認できた。ひさびさに kizasi.jp でサブプライムローン問題を見てみると、みんな忘れたがっているようだw。大分下がってきた。下がってきたのと問題が消えたのは別の話で来年、また上がることがあるだろう。株価と逆相関の関係にある指標になるな。底堅いを見てみると、頻度が低いから、株価は案外、底堅いかも知れない。まあ、とりあえず新年に入って株価が下げると底堅いの頻度が上がると思う。このところ毎年、この時期になると上昇する仕手株ダイワボウは、鳥インフルエンザの頻度が上がっていないにもかかわらず上昇している。今年は、そろそろ頭打ちになるんじゃなかろうか。年末、材料難なときに仕手化して、証券会社などもそれを盛り上げて、メディアも便乗してあげる傾向にあるが、メディアと証券会社が怪しい筋とと手を組む瞬間でもある。意図しようがしまいが同じことだ。鳥インフルエンザ関連のダイワボウ(3107)が東証1部値上がりランク3位に 商い閑散で低位材料株に物色向かうなどと煽るわけだな。普通は、ダイワボウマテリアルズ株式会社舞鶴工場の火災事故による損害額に関するお知らせ のような状態で、そんなに強く上がるはずもない。そもそも、そんなの関係ねぇって感じだけど。紡績の会社って昔は生糸の値段もあって仕手化するっていうのの伝統の延長線上なのかなぁ。こういうのはご本尊様の資金力と、どのタイミングでどうしたいかというところにかかっているから、よくわかんない。ただ、今年のはどちらかといえば、年末だから大口が空売りを買い戻しただけなのが発端で、これに、また今年もと火がついたような感じがしないでもない。これに証券会社などの自己売買部門が乗っかった。なので、しぼむのが早いかもしれない。ブログに表れる絶対数も少ないから、提灯筋が少ないような感じ。けど、やっぱり、こういうのはよくわからんなぁ。株価は下のような感じね。一回目の下げは、たぶん、仕掛けた人がわざと空売りを入れて売り崩して下げに入ったと思わせて (仕手化している場合よくあるパターン)、空売りが入り始めたら、急激に買い戻すとかやって二回目の上げになったんだろうけど。ちょうど上げても、下げても、どちらもありそうな感じのところに来た。
2007.12.27
コメント(0)
-
おもしろいを調べるとおもしろい
調べごとが行き詰まったので、何かおもしろいことをしようかと思って「おもしろい」を検索して KWIC (Key Word in Context) 形式で表示したものを眺めてみた。「おもしろいといえばおもしろいけど」「おもしろいといえないことはないけど」と言及されているものは、おもしろいか、おもしろくないか。「けど」は難癖の「けど」。Ajax を使った KWIC (KeyWord In Context)DevasKWIC FinderKWIC Concordance for WindowsText Finder (Freeware) Ruby on Rails + Tritonnによるらくらく全文検索+KWIC表示のチュートリアル全文検索システム『ひまわり』KWICコンコーダンス作成マクロ(WSH)WebLEAP ( - Webの知識を使った文書作成支援システム -)Antconcを使ってみようKWIC日本語辞書使用例検索・コロケーション抽出システム窓口 FOR 日本語コーパス言語学Tea -- KWIC ツール源氏物語の語彙検索(KWIC)日本法令英訳プロジェクト の Bilingual KWIC:対訳表現抽出支援ソフト koyori駆け出し教師のためのDual WISDOM 用例コーパス活用法Easy Pieces in Python: Keyword in ContextUsing Python, Jython, and Lucene to Search Outlook EmailPyWN("pin") Python Wordnet
2007.12.27
コメント(0)
-

トラック運送事業経営をやってみたくなってきた
「トラック運送事業経営をやってみたくなってきた」とはいっても、実際のお話ではなく、ゲームの話。トラック運送事業経営のシミュレーションゲームが人気 「フレイトタイクーン日本語版」 を見ていたら、やってみたくなったわけ。ロシアで作られたものでヨーロッパではすでに人気になっているらしい。フレイトタイクーン 日本語公式サイト も見てみる。アクションゲーム系は単純にストレス発散できるけれど、たまにこういう地味~なゲームとかやってみると気分転換になるかなとか思ったりした。(株)ラッセル フレイトタイクーン 日本語版 RW45281010定価 8,190円 (税込)eBEST価格 6,727円 (税込 7,063 円) 送料別全ト協 「運転者調査」まとめる ドライバーの高齢化進行が顕著。しかし、目先の危機は 軽油価格高騰下における下請・荷主適正取引推進のための緊急協力要請について するような状況。年ベースではトラック業界全体で6千億円を超えるコスト増となっておりますが、長年にわたり運賃低落が続き、今や年間の全体の利益規模が5百億円弱のトラック業界としては、到底自助努力で吸収できるものではなく、今後軽油価格が急速に下がる見通しもない中、トラック運送事業の経営は今まさに存亡の危機に立たされております。荷主 の 皆様へ原油高の煽りはどこの業界も受けていて涙目の業界も多いだろう。しかし、商品先物取引でヘッジしていれば、見た目ほど打撃を受けていないところもあるんじゃなかろうか。とはいえ、予想以上の原油高が続いてやっぱり辛いところが多いだろう。というか、投機的な原油高でインフレになっちゃうってのは、現実の悲しいあれだなぁ。金価格も来年は史上最高値をつけることになるかな。もっとも、原油高のおかげで新規の油田開発も進んで、原油がなくなるとかいうシナリオがどんどん先に伸びるのね。高く売れるから高いコストでの開発も可能になる。これが安いままだと新規開発コストがまかなえない。それにしても原油が 100ドルの大台に乗っても、スーパーインフレ状態にならないなんてことは、30年前には思ってもみなかった。ゲームに戻ってフレイトタイクーンって、軽油価格の変動まではないのかな。原油価格をにらみながら事業計画も考えなきゃならないとかなったら、難し過ぎ、リアル過ぎ。想像するに、ドライバーの給料を下げすぎるとストを起こしたりとか、配送をスピーディーにしようとし過ぎると事故を起こしたりとか、そういうレベルの要素はありそうな感じはする(まだ、買ってないのでどの程度のものか分からないが)。こういうゲームって、どの程度リアルにするか難しいところなんだろうな。リアル度を高めれば高めるほど難しくて複雑になりすぎるから、難しくし過ぎず、リアルな感じを味わえる程度の説得力を持たせる(この範囲のリアルさを狙っているのですという)。
2007.12.27
コメント(0)
-
粉飾の一年と、見つからない会社名
今年はたくさん粉飾決算とか出てくるだろうなと思っていたら、まあ、出るわ出るわで、決算から、食品の賞味期限から何から何まで粉飾がはがれた一年だった。振り返ってみると、まあ、よくここまで出たわなぁという感じ。三洋電機も粉飾決算か と2007.02.23に書いたが、10ヶ月たっても収まらず、とうとう過去に赤字だったのに違法配当してたということで 監理ポスト入り・三洋電機株はどうなる となった。関係会社の株式評価損を前倒しで計上した結果、01年3月期の最終損益が176億円の黒字から908億円の赤字に訂正されるなど、決算は軒並み赤字に転落。また、03年3月期から04年9月中間期まで配当原資が不足していたにもかかわらず、違法に計280億円を配当していた。新興企業であったなら 100% 上場廃止だろう。日興コーディアルも、なんだかんだで市場へのインパクトを考慮して(やっぱり新興企業だったら、上場廃止ものだっただろう)、上場廃止にならなかったけど、三洋電機はどうなんだろう。結局、日興コーディアルの場合、日興コーディアルグループ、臨時株主総会で米シティ子会社を決議 ということで、株式市場から消えていくのと同じように、三洋電機も似たような結末をたどることになるのかな。なんてことは、どうでもよくて、ある会社の名前を思い出したいのだが、どうしても思い出せずに困っている。いろいろ検索しても、見つからない。数ヶ月前にちょっと調べた会社なのだが、思い出せない。キーワードが違っているのだろうか、何もひっかからない。たとえば、日銀が企業物価指数を出すときにパソコン関連についても調査しているが、このとき使っている手法の名前はなんでしょう。「日銀 パソコン 調査」で Google で検索したら、ヘドニック法ってすぐに見つかる。適切なキーワードさえ見つかればいいのに、それが見つからない。ブログにそうやってメモを残しておくと、あとで自分のブログに教えてもらうことができるわけで、今回も、何か書いていたはずだと探してみたのだが何もヒットしない。なんとなく、投稿しようと思ったら、消えちゃったブログに書いたもののような気もしてきた。。。。。あることについて、シェアが 70%だか80%以上だったかある企業で、特別な端末を使って調査を行う企業で云々。いろいろ検索してみるが出てこない。どうでもいいものは目に付く。むぅ。確か、こういう会社があったとか、こういう製品があったとか記憶は残っているのに、いざそれを見つけられないとストレスになる。
2007.12.27
コメント(0)
-
国立国語研究所の言語コーパス整備計画はどうなるか
独立行政法人、少なくとも16を削減…政府計画の骨格 によると、国立国語研究所 が廃止、統合の対象となるようだ。そこで気になるのが、言語コーパス整備計画 KOTONOHA や 日本語話し言葉コーパス あるいは、形態素解析辞書 UniDic などのプロジェクト。ただでさえ、この手のことは着手が遅れていたわけで、後退してしまうのは惜しい。文部科学省配下ということだと、独立行政法人 科学技術振興機構 とかの開発センターの一つという位置づけになるのだろうか。でも、どうせなら 総務省系の 情報・システム研究機構 国立情報学研究所 に併合してしまった方が、よい面があるんじゃなかろうか。
2007.12.25
コメント(0)
-
ひさびさに甘い物注文
久々に禁断のスイーツを注文した。このショップの難点は人気がありすぎて注文してから届くまでに時間がかかること。2週間以上またなければならない。でも、これだけ入って特価 3,129円 (税込) 送料込だから、まあ仕方あるまい。さて、冷静に 1Kg 以上の甘い物を食べるとなると、それまでに減量せねばなるまい。。。。(1)生チーズケーキ×1本(サイズ:長さ約17.5cm、横幅約6cm、高さ約4cm、重量約260g)(2)生チョコケーキ×1本(サイズ:長さ約17.5cm、横幅約6cm、高さ約4cm、重量約240g)(3)パイシュー×3個(1個約45g)※3個で一袋になっております(4)生ロールハーフサイズ×1本(幅約8cm×長さ約9cm)(5)禁断のキャラメル生チーズケーキ×1本(長さ約17.5cm、横幅約6cm、高さ約4cm)(6)プチ禁断の生チーズケーキ(ミルク瓶入り)×1個(容器サイズ:高さ7.2cm×直径5cm、1個約230g)(7)プチ禁断の生チョコケーキ(ミルク瓶入り)×1個(容器サイズ:高さ7.2cm×直径5cm、1個約230g)【30万セット突破★年間ランキング食品部門1位】送料無料!禁断のスイーツ福袋♪新春スペシャル版
2007.12.23
コメント(0)
-

天才は何度でも這い上がり深みを増す
Gyao: SELECTED CLAPTON を観るというか聴くというか。クラプトンは自分にとって永遠のヒーローだな。しかし、クラプトンの人生をたどってみると、まあ、よく潰れずに何度も這い上がってきたもんだと思う。ヤク中だった時代もあるし、アル中だった時代もある。子供の死さえも味わっている。でも、したたかな天才は、どん底の苦しみを名曲に変えて蘇る。というか、ある意味、どうしようもない人間ともいえるわけだが、とっても人間的なわけで、人間身を感じる天才なのだな。ジェフベックとかとは違った天才。こういう人って好き。ちなみに、下のアルバム クロスロード・ギター・フェスティヴァルにはジェフベックも登場していてお買い得らしい。公式ページ見てみる。んー、これは欲しいな。ちなみに、私はリアルタイムでヤードバーズの時代を聴いていたほどの歳ではない。けど、最初にアルバムを買ってから、すでに四半世紀以上経っている。飽きっぽい自分がこれだけ長期間に渡って好きなのだから、普通と違う何かがある。それにしても、天才は何度でもはい上がれるが、凡人はなかなかそうはいかない。
2007.12.22
コメント(0)
-
Google の knol って Wikipedia + AllAbout ?
グーグル版ウィキペディア「knol」がテスト運用を開始 を読む。この記事からだけ思ったのは、Google 版 Wikipedia というか、All About の要素を取り入れたって感じで、Wikipedia + All About が knol なのかなと。人が全面に出てるから。印象でそう思った。Wikipedia って、ページ上には表れない編集者たちがいるわけで、Deletion of article web.py みたいに、これはページとして作るべきではないみたいな編集も行われている。Aaron Swartz のページはあるけれど、web.py は不要という判断がされている。これだけでなく編集を巡って紛争も起きるわけで、ページの執筆者が明確で議論はその執筆者とすればよく、最終的な判断は明確にそのページの執筆者が権限を持ち、同じ単語のページに対して、複数のページが成り立ち得て、その人気によってランクが変わるという方向は、十分にあり得るし、ある意味分かりやすい。集団体制を取るところの場所が違うわけだな。作り手は、一人(フィードバックを反映させるというのはあるにしても)なのか、複数なのか。そして、評価のランキング手法に検索のランキング手法を応用するということで、既存の Google の路線から出ないで妥当な線なのだろう。Google はコンテンツの作り手ではなく、あくまでコンテンツの収容するだけであり、使いやすく検索機能を提供するという路線からのブレがない。それとともに、言葉の検索から、人という単位での検索にも力を入れ始めているということなのかもしれない。Google Finance にしても、企業名を軸とした検索として考えると、やっぱり同じ路線。属性(株価等)を持った主体の検索。ちなみに Google で MSFT とかティッカーシンボルを使ったイメージ検索をするとおもしろい。Googleイメージ: MSFT みたいに。Google イメージ: graph とかしても、いろんなグラフが出てくるので眺めてみると楽しい。加えて適当な単語を付けるともっと楽しい。グラフ でも同様。グラフにすると分かった気になれる。が、判断を誤らせるグラフもたくさんある。
2007.12.22
コメント(0)
-
Amazon SimpleDB
Amazon,オンラインDBサービス「Amazon SimpleDB」の限定ベータ提供を開始 ということで、Amazon SimpleDB?- Limited Beta 眺めてみる。Amazon SimpleDB requires no schema, automatically indexes your data and provides a simple API for storage and access. ということで、スキーマが不要で、自動的にデータのインデックスを作ってくれると。例えば "123" というアイテムに対して、 "description" とか、"color" とか "material" とかいった属性(256まで)とその値を持たせると、それぞれインデックスが自動作成される。Excel のワークシート1枚のような表データが扱えるということのようだ。ある domain に対して GET/PUT/DELETE でデータの操作、加えて QUERY で「=, !=, <, > <=, >=, STARTS-WITH, AND, OR, NOT, INTERSECTION, UNION」が使える。1つの domain で 10GB までのデータを扱えて、ユーザあたり 100 domain まで使える。10GB まで使えるとはいえ、大きいデータには適していないので、データが大きい場合は、S3 サービスにデータは置いた方がよいようだ(SimpleDB でポインタだけ扱って、実体は S3 に置くとか)。料金は、Machine Utilization - $0.14 per Amazon SimpleDB Machine Hour consumedData Transfe$0.10 per GB - all data transfer in$0.18 per GB - first 10 TB / month data transfer out$0.16 per GB - next 40 TB / month data transfer out$0.13 per GB - data transfer out / month over 50 TBStructured Data Storage - $1.50 per GB-monthだが、Amazon Web Service との転送に関しては無料。そのうち使ってみるかもしれない。ちなみに、A First Look at Amazon SimpleDB とか見ると、SimpleDB は Erlang が使われているらしい。ruby の人は、gem install amazon_sdb で幸せになれるようだ。Python の場合は、boto が対応しているようだ。このあたり おもしろいものがあるかもしれない。
2007.12.22
コメント(0)
-

もう少し速読頑張る
先日、特打式 速読を買った が、ちょっと空けてしまったが再び訓練。昨日は 2082文字/分だった。ちょっとやれば、思ったよりも回復してくるものなのね。でも、まだ若い頃みたいに読めないし、読んだことを覚えていられない。そもそも、速読のイメージって、やっぱりペラペラペラとページをめくって頭に入ってしまうという感じだから、1分間に数万文字って感じなのね。2日目にして、そういう世界は一生無理だと、もう諦めた(諦めが早い)。とはいえ、とりあえず 5000文字/分程度までは老化防止で頑張らんと。最近、ほんとに絶望してしまいそうなほどやばい。それにしてもレベル低い。読みたい物はたくさんあっても、気力と読む速度と記憶力が追いつかない。ぐすん。 ソースネクスト(株) 特打式 速読 説明扉付きスリムパッケージ版 60890 <お取り寄せ> \1,727
2007.12.22
コメント(0)
-

Pylons の資料とか、なぜか PHPCake にちょっと浮気とか
Python Unconference Tokyo 1 の Pylons とその仲間たち から、Pylons とその仲間たち ~フレームワークのためのメタフレームワーク~ (pdf) を見る。この資料 Python Unconference Tokyo 1 での講演の資料らしい。Pylons に関連する文書の日本語訳 で、ドキュメントの日本語訳もだいぶ進んでるのね。それはそうと、ちょっと PHP をまた使う用事があるので XAMPP を Windows でインストールした。Apache Web ServerとMySQL、PHP、Perl 等々、まとめてインストールできるのがお手軽でいい。でも、mod_python とか使えないじゃんと、mod_python の Windows 用のバイナリ もついでなのでダウンロードしてインストールしておく。が、インストール簡単といえば、All-In-One Trac って、All-In-One Trac v0.1.1 以降リリースされてないな。Trac月 が 1.5.0 がリリースされている。今回から小数点下一桁が奇数は不安定バージョン。偶数は安定バージョン。Trac月独自のパッチを廃止し、Shibuya.tracの成果を利用するように変更。今後、Trac月への機能拡張は、全てShibuya.tracで機能を作りこんでからTrac月へ反映するので、LinuxユーザもTrac月の拡張機能の恩恵を受けることができるようになる。Trac以外の各ソフトウェアもバージョンアップ。Trac月1.5リリースでも、Trac月は使ったことがないので開発版ではなくて安定版の 1.4.6 を使うことにする。Trac月は mod_python がインストールされる。ではなくて、とりあえず PHP を使わなきゃいけないので、そっちが本質であった。CakePHP とかで、ちょっと遊んでみる。Ruby on Rails の影響で作られた PHP のフレームワーク。『 CakePHPガイドブック』が出ている。そういえば、『みんなの Python』 の著者が新しく『みんなのPython(Webアプリ編)』出したのね。そのうち買うと思う。
2007.12.22
コメント(0)
-

ピグマリオン・コンプレックス
『ローゼンメイデン』の真紅が思いのままに喋る!? (アニメイトTV) ということで、NEC BIGLOBE の ローゼンメイデン「Alice Project」 を見てみる。使えないクズね とか、聞いてみるとそれなりの可能性を感じる。けど、いろいろ聞いてみると、きれいにしゃべらせるのは、それなりに大変そうな感じ。調べてみたら、“アニメ声”で自然にしゃべる音声合成技術、富士通が新開発 (2004/05/27) とか以前にあった。自然で多様な喋り方をする音声合成技術を開発 (2004年5月27日)とか聞いてみると当時の感じが分かる。初音ミクで自然に歌わせる、Alice Project で自然にしゃべらせる。音声合成もだいぶ進化してきた感じがするが、苦労せずに使えるようになるには、あともう少しって感じ。まだ、職人が頑張る領域だから。でも、それを遊びの一つにして使ってもらうことによって、データも蓄積されて、そこまで苦労しなくても使えるって領域にいずれ行くのだろう。でも、辞書とかの問題もあるだろうけど(未知語・新語の登場)、イントネーションの付け方って、その単語が置かれる場所によってずいぶん違ってくるから、大変なんだろうな。方向としては、人間がしゃべる、イントネーション等解析する、音声合成で声を作り直す、というのが使う側の手間はかからないと思うが。いつのことになるか分からないが、手軽に音声合成ができて、動画合成ができるようになると、とんでもないものが作られるようになるだろう。世界が混乱する事件も起きるかもしれない。ニュース配信メディアに真贋判定機が備えられる日がいずれ来るだろう。例えば、バーナンキFRB議長や福井日銀総裁のような地位にある人にもっともらしいことをビデオでしゃべらせてネットに流布させるとどういうことが起きるか。サブプライムローン問題で世界が一番冷静さを失っていたときにやったらどうだったか。まあ、クリティカルな事件が起きるのはまだまだ先のことだろうが、いずれそういう日が来る。100年以内かな。Galatea Toolkit ビデオデモ がもっと進化するとどうなるか。これを成功させるには、まず、オフレコトークの本物をネットに何回か流して、信頼できる筋という印象を作り、いざというときに使う。いたるところに監視カメラや盗聴器が仕掛けられ、それがリークされるという現象が先立っていることが前提条件として重要。一般の人が受け入れやすい状態になっているときに、それが起きると大変なことになる。考えてみると、もっと音声合成が進んでいたらオレオレ詐欺なんて、もっとすごいことになっていたかもしれない。技術だけが中途半端に進みすぎていないということが実は救いになることもある。もっとも、やっぱりマクドナルドの巨乳店長代理はテレビ朝日の仕込みでした♪ とかに見られるように、テレビは日常から偽造しているわけだが (テレ朝「報ステ」 マクドナルド報道で謝罪)、合成するよりも手がかからないコスプレ、顔隠し、音声変換手法を多用しているようだ。情報操作をしたい場合、その真贋あるいは信憑性の問題を超越したところで雰囲気が作られることがある。株式アナリストや経済評論家はいくらウソを意図的についても罰せられることはない。そういえば、サブプライムローン問題に起因する日本の金融機関の今年の損失は、合計1兆円ぐらいかな。サブプライムローン問題は日本の実体経済に影響を与えないと言っていた人たちは、総懺悔しなきゃいけないというか、振り返って分析してみるにつけ、わざとやっていた筋があるような感じ。久々にまた分析を始めてみるかな。あぁ、話題がそれてしまった。音声合成には期待しているところがあって、朝起きたときとかに、自動的にまとめておいた記事を読ませるとかできると嬉しいなとか思ったりする。動画なしの音声というのも、シチュエーションによってはけっこう使える。ペンタックス音声合成ソフトウェア って、けっこういい感じ。ページの右側にある、無料デモンストレーションとか聞いてみるとかなりいい感じ。VoiceTextデモンストレーション の方がいいかな。電子かたりべ.com のプレーヤーは、それなりに使える。あと 5年もしたら、かなりのレベルに粋そうな予感。あとはうまくいっていないところをいかにするかがうまくいけばいい。視覚障害者にとっては、現状でも昔に比べたらかなり嬉しいレベルになってきたんじゃなかろうか。問題は人でを加えずにどこまで自動対応していけるかというところ。無償でとりあえず試せるものとして、GalateaTalkDemo とか聞いてみる。以前に比べて品質は上がってきたのだろうか。まだまだ厳しい。AquesTalk - テキスト音声合成ミドルウェア とかも、それなりのレベルだと思うのだが、やっぱり聞いていると疲れる。でも、個人で使うとなるとこのあたり。簡単に使える音声合成プログラム でちょこっと試して忘れていたが、少し使ってみるかな。MeCab の解析結果の読みがあまり嬉しくないものを出してくれるのが気になる今日この頃、茶筅+ Unidic でいくかな。辞書の精度という点からしても、こういうことやるには 「国立国語研究所で規定した「短単位」という揺れがない斉一な単位で設計されています。」というところがメリットになるはずだし。でもって、まだ、Unidic は使おう使おうと思いつつ、ちゃんと見ていなかった。でもって最後にピグマリオン・コンプレックスってのは、日本語の Wikipedia にはあるけど英語版にはない。Doctor to speak at Yale on "Pygmalion Complex" (November 14, 2002) とか検索すると見つかるから和製英語というわけでもないようだけど、Google で Web 全体でも 1,590 件と用例としては多くないからかな。これに対して「ピグマリオン・コンプレックス」だと 4,510 件。用例としては多くないものの Wikipedia のページになっている。国ごとに付き合わせていくと、案外、その国民性とか編集ポリシーとかに違いがあるのかもしれないと思う今日この頃。ピグマリオンコンプレックス (Wikipedia)Pygmalion (mythology)Galatea (mythology)Pygmalion and GalateaMy Fair Lady
2007.12.20
コメント(0)
-
シーネットネットワークスジャパン編集部は Python が分からずに記事にする
Pythonで簡単なウェブスクレイパーを書く を読む。この編集部は、まったく Python が分かっていない。def printText(tags):for tag in tags:if tag.__class__ == NavigableString:print tag,else:printText(tag)print ""のような必要なインデントを削除したソースコードが意味をなさないというのを認識していない。def printText(tags): for tag in tags: if tag.__class__ == NavigableString: print tag, else: printText(tag) print ""原文見たら ちゃんとなっているから、編集部がダメなのね。これはシステムのせいというより、最終確認を怠った編集部の怠惰によるものだろう。とか書きつつも、過去にちょっと違うけど、同じようなことをやっていた。 日経平均を表示する で、コードの中に &amp; というのがあって HTML で表示されたときに、& になっちゃってた。コードをコピペした場合、ちゃんと意図したとおりに表示されているか確認しないとダメね。まあ、自戒の意味も込めて、つるし上げておいてあげる。Python の記事とか扱うメディアが増えてきている昨今、気をつけて欲しいものだという意味も込めて。特に、書籍なんかでインデントが崩れているものは、チェックがきちんと行われていないということだから、やっぱりつるし上げてもいいだろうなぁ。
2007.12.20
コメント(0)
-
すべるコタツ掛ふとんはリコール対象になり得る
イオン株式会社 トップバリュ「こたつ掛ふとん」のリコール情報を見る。リコール実施の理由ふとんの端部分を踏んだ際に、足を滑らせたの情報が寄せられたため。厳しいなぁとか思った。トップバリュ「こたつ掛ふとん」商品回収のお願いお客さまより、ふとんの端部分を踏んだ際に、足を滑らせたとのお申出をいただきました。つきましては、念のために該当商品を回収させていただきますということで、イオンがトップバリュのブランドを大切にするために、「念のため」あえてリコールに踏み切ったというところなんだろうか。まあ、こたつの周辺で足を滑らせれば、危険といえば危険だけど、そういうところまで気をつけて作らないとダメなのね。まあ、考えてみると、「良い」商品でなければ、トップバリュのブランドをつける商品としてはよろしくないということでもあるし、主力商品というわけでもないだろうから、ブランドイメージを大切にしてというところか。まあ、こういう商品開発も大変だよなぁと思った。トップバリュ厳選24品値下げ とは、値上げが相次いでいるこの時期、イオンも頑張ってるな。
2007.12.18
コメント(0)
-
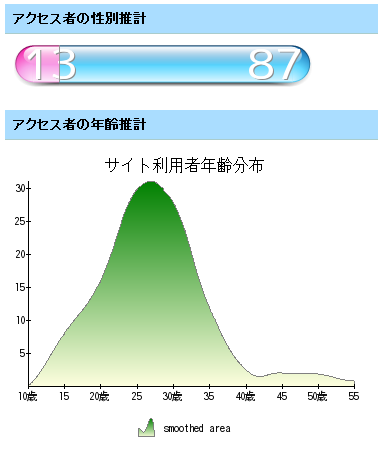
明日でブログ開設2000日、なかのひとで見るとこんな感じのアクセス状況
ブログ開設以来、今日で 1999日になった。5年以上経っているのに自分が進歩していないなぁというのが悲しい。というより老化と退化が激しい。ということで、先日から 速読の訓練を始める ことにした。まあ、2,3日に一回のペースで続けていれば老化も少し防げるかなと。速読の速度は 3回目にして 2082文字/分まで上がった。一応ソフトの効果はあるみたい。老化したとはいっても、継続的に鍛えれば何とかなるのかな。5000文字/分まで上がれば少しはボケ防止になるだろう。しかし、努力しても、数万/分とか、本当に速い人のレベルから比べると 1/10 以下なんだよねぇ まあ、それが現実だから仕方あるまい。3ヶ月ほど前ぐらいから なかのひと を入れて、組織からのアクセス状況を簡単に調べることができるようになったが、状況は下のような感じ。徐々に組織数も増えてきた。これまで眺めてみた感じでは、やっぱり人口が多いところからアクセスが出てくる感じだった。地方が弱い。これは単に人口が少ない分、確率的にアクセスが低くなるとかいうことではなくて、アンテナの張り方が都心部の方が強いって感じがする。絶対数だけの問題ではないような感じ。属性を見てみると、男女比では圧倒的に男性優位で、年齢構成も20~35歳のところでかなりの部分を占めている。実際のところ、アクセス元の組織の男女構成比から出てくる値なので、ほんとうにアクセスしている人がその性別であるかは分からないが、男性が多い組織からのアクセスが圧倒的に多いということだけは言えるようだ。たぶん、ソフトウェア・テクニカル系のことを書いていると大学からのアクセスが来てしまうので年齢層を引き下げる効果があるかもしれない。週に一回ぐらいは年齢構成を幅広くするようなものや、女性が比較的多い企業からのアクセスが増えるようなものを書いてみようかな。
2007.12.18
コメント(0)
-
IPython 0.8.2 で一段と便利になってる
IPython 0.8.2 が 11月30日にリリースされていた。New features in 0.8.2 を見ると、一段と便利になったようなのでアップグレードした。履歴(%hist) に -g オプションが付いて、「%hist -g foo」とすると、履歴から grep で foo した結果を返してくれる、履歴の検索機能が付いた。「%rep ls」としておけば、履歴表示(%hist)したときに、ls が含まれる履歴は表示されないようにできる、履歴表示の抑止機能が付いた。macro で引数を取れるようになった。とかいうのからもっと便利なものまでたくさん機能アップされている。IPython Cookbook を見ると、へぇとか思う。String list processing とか AWK like に使えて便利。たとえば、line.field(1) みたいなことができる。別に split して云々してもいいのだけど、タイプ量が減る。UsingIPipe なんかも、便利。例えばfrom ipipe import *iwalk | ifilter("_.endswith('.pyc')") | idump# あるいはlines = !lslines.grep("\.pyc$")とかすると、.pyc で終わっているファイルを一覧表示してくれたりとか、あれこれできる。これは使いこなすと、かなり強力。時間がかかる処理とかだったらバックグラウンドで動かせばいい。Running a file in the background%bg _ip.magic('run -i foo.py')alias なんかも、設定ファイルに書き込まないで StoringAliasesのように、%store を使って覚えさせちゃえばコマンドラインから設定したものが再起動してもちゃんと残る。IPython を使っている人は、IPython Cookbook を見ると幸せになれる。IBM developerWorks に新しい記事が出ていた。Using Net-SNMP and IPython。ちなみに、IPython をインタラクティブに使っているとき doctest がこけちゃって困るのは、%doctest_mode で OK なのね。IPython FAQ を見ると、In [6]: iphook = sys.displayhookIn [7]: sys.displayhook = sys.__displayhook__In [8]: doctest.testmod(dtest)とやって、戻すときには、In [9]: sys.displayhook = iphookとあるけれど、%doctest_mode がトグルスイッチになっているから(実行するごとにモードが変わる)、これを使った方が楽ね。
2007.12.17
コメント(0)
-

IronPython Studio
IronPython Studio 登場 経由で、IronPython Studio がリリースされているのを知る。ちなみにこの方の 実践Python errata のページは Google 八分されているらしい。「# None ふぁ返される」は私も読んでいるときに笑ってしまった。実践Python
2007.12.13
コメント(0)
-
Pytohn 3.0 a2 が使えるようになった
Python 3000 a2 がリリースされたので試そうと思ったが、エラーで動かんと書いたら、親切な方がコメントを入れてくれて vcredist_x86.exe をインストールすればよいことが分かったのでインストールしたら使えるようになった。 morchinさん、ありがとうございました。この方 なんでしょうか。Programmer's Gate とか書かれている。Microsoft Visual C++ 2008 Redistributable Package (x64) か Microsoft Visual C++ 2008 Redistributable Package (x86) のどちらかインストールしていないとダメなのね。ということで x86 版なのでそれをインストールしたら使えるようになった(ちゃんと書かれていたのに読んでなかった)。とりあえず、print 文が変わったのって痛い。これまでも下のような書き方ができたが、python 3.0 だと下の書き方しかできなくなる。print "Hello, World!" がダメになった。print("Hello, World!")後々のことを考えると、これから書くプログラムは全部上記のような書き方にしようかな。Python 2.4 でも大丈夫なわけだし。とってもくだらないレベルの話ではあるが影響、特大レベル。まあ、そういうものは後で機械的に書き換えても問題ないだろうけど。とりあえずベンチマークを動かそうにも print 文を書き換えないとエラーになっちゃうし。pystone を試そうと思って print 文を書き換えたが、まだ捕まる。 File "E:\work\pystone.py", line 102, in Proc0 Array2Glob[8][7] = 10TypeError: 'itertools.imap' object is unsubscriptable見てみると、Array2Glob = map(lambda x: x[:], [Array1Glob]*51)で、map も変わってる。map の返り値が itertools.imap になっているのでとりあえず下のように書き換えて動かしてみる。Array2Glob = [x for x in map(lambda x: x[:], [Array1Glob]*51)]Python 2.5 vs Python 3.0 a2 では、現状ほとんど同程度の速さのようだ。正式リリース時点では Python 3.0 が速くなるのか、それとも同程度のままか。もっともベースの部分で変わらなくても、上記のように map がイテレータを返すことによってメモリの消費量が減ってとか、そういうメリットが出てくるだろから、書き方によってパフォーマンスに差が出てくるかもしれない。Visual Studio 2008 の PGO (Profile-Guided Optimizations) を使っているということで、速くなっているのかと思ったら、特にそういうこともないみたい。ということで、以下、pystones でベンチマークを流してみた結果。Python 2.5Pystone(1.1) time for 50000 passes = 1.01513This machine benchmarks at 49254.6 pystones/secondPystone(1.1) time for 50000 passes = 1.06821This machine benchmarks at 46807.2 pystones/secondPystone(1.1) time for 50000 passes = 1.04287This machine benchmarks at 47944.6 pystones/secondPystone(1.1) time for 50000 passes = 1.06861This machine benchmarks at 46789.7 pystones/secondPystone(1.1) time for 50000 passes = 1.02245This machine benchmarks at 48902.3 pystones/secondPystone(1.1) time for 50000 passes = 1.02659This machine benchmarks at 48704.9 pystones/secondPystone(1.1) time for 50000 passes = 1.02322This machine benchmarks at 48865.5 pystones/secondPystone(1.1) time for 50000 passes = 1.03129This machine benchmarks at 48482.9 pystones/secondPystone(1.1) time for 50000 passes = 1.0235This machine benchmarks at 48851.9 pystones/secondPystone(1.1) time for 50000 passes = 1.02254This machine benchmarks at 48897.7 pystones/secondPython 3.0 a2Pystone(1.1) time for 50000 passes = 1.0867This machine benchmarks at 46011 pystones/secondPystone(1.1) time for 50000 passes = 1.0595This machine benchmarks at 47192.2 pystones/secondPystone(1.1) time for 50000 passes = 1.06709This machine benchmarks at 46856.4 pystones/secondPystone(1.1) time for 50000 passes = 1.03201This machine benchmarks at 48449.3 pystones/secondPystone(1.1) time for 50000 passes = 1.03057This machine benchmarks at 48516.6 pystones/secondPystone(1.1) time for 50000 passes = 1.02954This machine benchmarks at 48565.3 pystones/secondPystone(1.1) time for 50000 passes = 1.0359This machine benchmarks at 48267.3 pystones/secondPystone(1.1) time for 50000 passes = 1.03264This machine benchmarks at 48419.5 pystones/secondPystone(1.1) time for 50000 passes = 1.03045This machine benchmarks at 48522.3 pystones/secondPystone(1.1) time for 50000 passes = 1.03759This machine benchmarks at 48188.7 pystones/second
2007.12.13
コメント(0)
-
速読の訓練を始める
最近、老化現象が一段とひどくなって、記憶力も落ちてきた。本を読む速度も集中力が落ちてきたせいかとても遅くなって理解度も落ちてきた。流し読みしても昔のようにすんなりと頭に残らない。ということで、思い切って速読の訓練を始めることにした。ソースネクストの特打式 速読を買って始めてみた。開始時点での速度は 1149文字/分で遅くはないレベルのようだが、当面の目標に定められた 1750文字/分はかなり辛い感じ。しばらく辛抱してとりあえず読書速度を上げたら頭の老化も少し止まるかなぁなんてことで頑張ってみる。値段も2000円弱なので、パフォーマンス的にかなりよいと思う。ちなみに自分はソースネクストのサイトでダウンロード版を買った。パッケージ媒体不要だし、送料不要だし。 ソースネクスト(株) 特打式 速読 説明扉付きスリムパッケージ版 60890 <お取り寄せ> \1,727
2007.12.13
コメント(0)
-
pysqlite2 の 2.4.0 Changelog を見る
2007-11-25 に pysqlite 2.4.0 がリリースされていて、pysqlite 2.4.0 Changelog を見たら、おもしろことができるようになっているのね。Python 2.5 対応が入って with が使えるようになって、ここを抜けたときに con.commit() してくれる。insert に失敗したら、con.rollback() してくれる。with con: con.execute("insert into person(firstname) values (?)", ("Joe",))ただし、エラーはちゃんと自分でキャッチして対処する必要はある。try: with con: con.execute("insert into person(firstname) values (?)", ("Joe",)) except sqlite.IntegrityError: print "couldn't add Joe twice"もう一つおもしろいのは、APSW でコネクションをはって createscalarfunction で関数を定義しておいて、そのコネクションを pysqlite が引き継いで使うとかおもしろいことができるようになっている。ある関数を使いたいのに sqlite にはないというのであれば、この仕組みで作ってしまえば使えるようになる。 from pysqlite2 import dbapi2 as sqliteimport apswapsw_con = apsw.Connection(":memory:")apsw_con.createscalarfunction("times_two", lambda x: 2*x, 1)# Create pysqlite connection from APSW connectioncon = sqlite.connect(apsw_con)result = con.execute("select times_two(15)").fetchone()[0]assert result == 30con.close()その他、set_progress_handler とか実装されたので、長時間かかるようなクエリを発行したときに進行状況を Python 側から把握できるようになったとかあるらしいなどなど、地道に改良されていたのね。
2007.12.12
コメント(0)
-

メーリングリスト・アーカイバ Lurker
Lurker なるメーリングリストのアーカイバがあるのをたまたま知った (Lurker っていう名前は、投稿はしないけれど潜んで見ている人たち)。なかなか高速で使いやすそうな感じ。大量のメールでも速度が落ちないそうだ。MailMan のアーカイブより見やすい感じがする。Luker 自体にはメーリングリスト自体の機能はなく、あくまでアーカイバのみなので、MailMan + Lurker とかもありだろう。見た目は W4PY Archives な感じ。大量でも大丈夫っていうのは、Mailing List Archives by the Free Network Group あたり見ると感じられる。ここを見ると 以前、池田さんという方が日本語化をされていたようだが、そのページにアクセスしてみると動いていなかった。残念。
2007.12.11
コメント(0)
-
最近書いた、pydot/Graphviz、Gnuplot.py 関連の記事
あとで記事が見つけやすいように、最近書いた pydot / Graphviz について書いたものをまとめておく。最近書いた pydot/Graphviz 関連の記事Python から Graphviz を使う( pydot を日本語で出力)Python から Graphviz を使う( pydot を日本語で出力)(2) Python から Graphviz を使う( pydot を日本語で出力)(3)Python から Graphviz を使う( pydot を日本語で出力)(4) Python から Graphviz を使う( pydot を日本語で出力)(5) Python から Graphviz を使う( pydot を日本語で出力)(6) Python から Graphviz を使う( pydot を日本語で出力)(7)Python から Yahoo! 日本語形態素解析Webサービスを使う (1) Python から Yahoo! 日本語形態素解析Webサービスを使う (2)Python から Yahoo! 日本語形態素解析Webサービスを使う + pydot (3)Graphviz と日本語のフォントpydot でカレンダーを作る (1)pydot でカレンダーを作る (2)最近書いた Gnuplot 関連の記事Gnuplot-py で日本語を表示するGnuplot.py で日本語を表示する (2)
2007.12.10
コメント(0)
-
Python 3000 a2 がリリースされたので試そうと思ったが
Python 3000 a2 がリリースされたようだ。実用で使えるようになるのは、まだまだ先。3.0 のリリース予定は 2008年8月。Python 3000 の Windows 版は、Visual Studio 2008 の PGO (Profile-Guided Optimizations) を使ってコンパイルされているらしい。そうすると必然的に Python の拡張モジュールをコンパイルするのにも Visual Studio 2008 を使うということになる。とりあえず Python 3000, Release 3.0a2 をダウンロードしてちょっとだけ試してみようと思ったが、まともにインストールして実行することができなかった。まだベーシックな部分でも環境に依存する部分もあるみたい。おそらく自分がメインで使い始める可能性があるのは 2011年以降。いまだに Python 2.4 をメインに使っている状態だし。世の中 Python 2.5 に対応しきれていないものもあるわけで、3.0 のリリースが出た後も、それなりに時間がかかるだろうから、気長に見ておけばいいかなって感じ。興味本位で、どの程度、高速になったかは見ておきたかったのだけど。後方互換性を捨ててすっきりした部分で速度向上があるんだろうしと。とりあえず楽しみはお預け。主要なサードパーティーのライブラリが Python 3000 に対応するのは、3.0 リリース後、何年もかかるだろうろし、Python 2.x 系もまだ続いていくのは問題ないので、新しいもの好きでなければ、どちらかといえば Python 2.6 をウォッチして将来、自分が書いたものや使っているものが、どの程度影響を受けるかを見ていく方がよいかもね。実際の問題として、ちょうど、Zope が 2.x 系から 3.x への移行で、3.x 系がコードベース 2.x 系をジワジワ侵食していっているのと同じように、2.x 系を使っているけれど、実は、3.x 系のメリットが受けられまっせという世界と同じように、2.x 系を使っている間にゆったりと 3.x 系に移行していくような感じか。まあ、ブログのネタとしては10年程度使えるネタだなぁ、なんて思ったりもする。
2007.12.09
コメント(2)
-
楽天ブログの下書き機能
【リリースのお知らせ】日記に下書き機能を搭載しました!ということだが、これはうれしい。素直に評価できるような機能が公開されると、使っている側もうれしいし、実装している人も評価されてうれしいだろう。せっかく作っても、ボロクソに書かれたらモチベーション下がるだろうし。下書きを保存するとメールを送信するところも気が利いている。これで書きかけの記事が消えて悲しい思いをすることも減る。このブログも開設日数:1989日で、もうすぐ 2000日になるが、いったいこれまで何回書きかけで飛ばしてしまったことか。望むらくは、下書きのボタンはページの下ではなく、エディタの選択の横あるいは、プレビューを開くのすぐ上、または、横にでも入ってくれた方が押しやすい。記事を書いているところになるべく近いところにあった方が便利。サーバーに負荷はかかるかもしれないが、5分に一回とか10分に一回とか、自動保存する機能があったっていい。あるいは、100文字以上打ち込んでいたら自動保存とか。その場合はメールの送信はしない。それとは関係ないが、テキストを書き込んでいる画面の横というのは、広告スペースの価値としてとても高いのに空白。飲料や化粧品や嗜好品などインプレッション自体に非常に意味があるような広告をここに置くとよいかもしれない。うるさいって言われたら、もっとブログを使いやすくするために予算が必要なんだい!と言えばいい。表に現れない管理画面というのは、見る人の属性も明確なだけにターゲティング広告にも適している。利用者が大きな不快感を感じずない道筋でやるならば、とてもよい広告媒体になると思うのだが。あるいは、過去にものを買ったショップの広告が表示されても不快感はない。これが最も妥当な線かな。管理画面の広告はアクセス数を稼ぐために不正に行われる機械的なアクセスがないわけだし、効果測定もやりやすい。
2007.12.08
コメント(0)
-
Python のテンプレートエンジン Cheetah について調べてみる
Pythonのテンプレートエンジンの一つ、Cheetahについてちょっと調べたみた。まずは速度の点。Mako が速いのか試してみた を見ると、ClearSilver 圧倒的に速く、ClearSilver 圧倒的に速い、Mako がそれに次ぐ。そして、Cheetah ということで、速い部類に入るようだ。Mako Templates for Python を見ると Mako とCheetah が方を並べて~いる。Mako: 1.10 ms Myghty: 4.52 msCheetah:1.10 ms Genshi: 11.46 msDjango: 2.74 ms Kid: 14.54 msPythonのテンプレートエンジン には、Cheetah, Mako, Jinja, Django, Kid, Genshi などについて書かれている。Genshi Performance のあたりにもパフォーマンスの差が書かれている。ClearSilverのExampleを見たら、Yahoo! Groups だけでなく Google Groups とかでも Cearsilver が使われてるのね。レスポンスを求められるようなところで好まれているのかな。Cheetah: The Python-Powered Template Engineを流し読みしながら思ったのは、Cheetah みたいなテンプレートエンジンって、何もウェブサイトを作るのだけじゃなくて、他にも使えるのねと。Graphviz の dot ファイルのテンプレートを作って、そこに流し込むのに使ったっていいわけだ。TeX のファイルを作ったっていいし。そういう意味で、XML 系のテンプレートエンジンとはちょっと違った使い方ができるというメリットもあるなんて思った。Python-Powered Templates with Cheetahも古い記事だがおもしろい。PyUnit のテストケースを自動生成するのにまず使っている。メール送信のテンプレートにだって使える。このあたりが、HTML/XML 用のテンプレートエンジンとは違うところだろうか。まあ、使って使えないことはないだろうけど。Clearsilver のドキュメントを見ていたら、これはこれでおもしろいなと思った。HDF (Hierarchial Data Format) という独自のフォーマットを中間言語的なものとして使っていて、XML/XSLT 的なことをしているようだ。テンプレートからコールバックしてという形式ではなくて、データは HDF に落として、それをテンプレートに適応させる感じのようだ。Comparison with XML/XSLT。そういえば、Python にもテンプレートがあるのだな。PEP:292 Simpler String Substitutions のやつ。from string import Templates = Template('${name} was born in ${country}')print s.substitute(name='Guido', country='the Netherlands')Guido was born in the Netherlands が得られる。まあ、制御構造を持てないから、単純な埋め込み以外には使えないけど。Cheetah の話に戻って、Cheetar って、いったんテンプレートを Python のクラスにして、それから処理してるのね。ほかのもそうなのかな。テンプレートエンジンのソースは追ったことがないのでよくわからないが。cheetah-compile コマンドを使うとこれが明示的に確認できる。たとえば、テンプレートファイルが Example.tmpl だとしたら次のようにすれば、どんな Python のコードが生成されているのかを確認できる。-p をつけると標準出力にコードが出てくる。-p をつけなければ、Example.py が自動的に生成される。テンプレートにバグがあればコンパイルした時点で誤りを発見できるのがメリット。テンプレートのバグなのか、プログラムのバグなのか切り分けが楽になる。cheetah-compile -p Example.tmpl生成されたコードは実行可能で、python Example.py とかするとテストできる。末尾に下のようなコードが入っている。## if run from command line:if __name__ == '__main__': from Cheetah.TemplateCmdLineIface import CmdLineIface CmdLineIface(templateObj=Example()).run()ただし、値を呼び込まないと表示できないようなものの場合は、そのまま実行してもエラーになる。何か渡したいとき~は、--env を指定して値を渡してやればいい。環境変数の値を参照してくれる。$ name=hogehoge python Example.py --envあるいは、簡単なプログラムを別に作って、下のようにしても確認できる (searchList には、変数名と値のディクショナリのリストを入れる)。import Exampletemplate = Example.Exampeprint template(seachList=[{'FirstName':'foo'}, {'LastName':'bar'}])つまり、本体のプログラムを動かさずにテンプレートだけのテストが可能である点が大きなメリットだと思う。なかなかおもしろい。
2007.12.08
コメント(0)
-
Python で人が読み書きできる形式で保存した設定情報を読み込む方法
アプリケーションの設定情報をプログラム中に含めずに、外部のファイルに保存しておけば、設定が変更されるたびにプログラムを修正する必要がなくなる。だから使用状況に応じて変更する可能性のある値は、プログラムから追い出したい。人が直接参照したり変更したりしないのであれば、pickle が一番効率がよいかもしれな~い。でも、人間が直接読み書きできるような形式ではない(やってできないことはないに~しても) 。その次に効率がよいとすれば、miniconf。テキスト形式で変数名と値をペアにして保存できる。ディクショナリ形式をそのままテキストファイルにダンプしたり、読み込んだりできるので、とっても楽に使える。たとえば、次のような設定値を辞書として持っているとする。config = {}config['name'] = 'kugutsushi'config['mailserver'] = 'mail.example.com'config['email'] = ['kugutsushi2 atm infoseek dot jp', 'nanika atmark example dot com', 'dokoka atmark example dot com']この値を保存する前に、miniconf を使って文字列に変換する。import miniconfdata = miniconf.dump(config)fo = open('config.cfg', 'w')fo.write(data)fo.close()そうすると、data には次のような文字列が代入される。これをファイルに書き込んでお~けばいい。逆に読み込みのときは、読み込んだ文字列を miniconf.load してやれば、ま~た辞書形式に戻る。値にはディクショナリ、リスト、タプル、整数、小数、文字列、ユニコード文字列、ブール、None が使えるので、読み書き可能な形で値を保存するなら一番~お手軽。import miniconffi = open('config.cfg', 'r')data = fi.read()config = miniconf.load(data)でも、これだとたくさんの値があるときに、複数の領域に分けて保存したり、設定ファイルにコメントを残しておいたりとか、そういうことには困る。一般ユーザー向けにはちょっとなところがある。そういう場合は、ConfigParser -- 設定ファイルの構文解析器を使えば、Windows の INI ファイルのような形式で値を保存しておくことができる。[server1]server = mail.example.comuser = foopassword = bar[server2]server = mail2.example.comuser = hogepassword = hogehogeConfigParser に関しては The ConfigParser module や Configuration Files Made Easy や Doug Hellmann - PyMOTW: ConfigParser あたり参照。例があってわかりやすい。ConfigParser は標準モジュールとして Python に含まれる形で配布されていることから、簡単に扱うことができるというメリットもある。それなりに便利だとは思うのだが、いろいろ問題や足りない点はある~。もっと詳細な設定がしたいということで、XML 形式(ZCML) の zconfig が Zope3 の開発を通じて考案され使わ~れてきたたが、ちょっと複雑になりすぎでちょこっと使うという感じではなくなってしまっている。その間隙を埋めるようなものとしては、ConfigParser の延長線上にある ConfigObject やiniparse あるいは Configuring Python applications with the config module などがある。iniparse とかだと、元のファイルに書かれた順番を保持してくれているので、場合によってはメリットが大きい(値を変更して、元と同じ順番で書き戻したりとか)。ConfigParserShootout あたりをみると、たくさんの提案がある。ちなみに、Windows だったらレジストリに保存したいとかいう場合は Title: Extending ConfigParser for reading and writing options from Windows Registry 感じの方法もある。
2007.12.05
コメント(0)
-
助詞に気をつけて Google で検索すると
「Pythonで」googleに、「Pythonで」で google 検索をするとおもしろいものが出てくるとある。自分がよくやるのは、「とは」で検索すること。検索語の直後の助詞に注目して分類するとおもしろい結果になるだろう。「Pythonって」とかやってもおもしろい。助詞を付けて検索すると、表示順が当然変わるので、今まで目にしなかったようなものにも出会える。これを徹底的にやるとさらにおもしろいことになるだろう。人名など固有名詞の場合は、特におもしろい結果が出るだろう。
2007.12.02
コメント(0)
-
python 用 lint、Pyflakes vs. pyChecker vs. pylint
Python の文法チェックには何を使う? lint はないの? で Python だと lint 相当のものは何があるということで pyChecker と pylint を取り上げたが、pyflakes もシンプルなので、うるさすぎる警告で肝心な警告を見逃すことがないからよいということで教えていただいた。Re:pyflakes(11/24) yasusiiさんpyflakes を普通にインストールすると c:\Python25\Scripts などに pyflakes というファイルがあるはずです。これを pflks.py など pyflakes.py 以外の名前にリネームします(中で import pyflakes を実行してるので、pyflakes.py にすると自分自身をインポートしてしまう)。環境変数 PATH に上記パスを追加、PATHEXT に .py を追加すれば pflks というコマンドとして実行可能になります。(November 27, 2007 02:29:46)実を言うと、一回試して、ちゃんと動かない止めと思って書かなかったのだった。「pflks.py など pyflakes.py 以外の名前にリネームします(中で import pyflakes を実行してるので、pyflakes.py にすると自分自身をインポートしてしまう)。」、というところで、ろくすっぽ見ずに、これをやって投げてしまっていた。あほな。。。あらためて、yasusiiさんありがとうございます。ということで、改めて pyflakes についても触れてみる。pyflakes のコマンドを眺めてみると、最初に標準モジュールの compiler を使って (compiler.parse)、ソースコードをコンパイルしてしまい、構文木を得る。コンパイルエラーが出るようなコードであれば、エラーを表示する。コンパイルに成功した場合には、得られた構文木を pyflakes の checker.Checker にかけるという流れになっているようだ。エラー処理や複数ファイルの処理をなくして、単純化して、途中の結果を見てみる。#!/usr/bin/env python#-*- coding: utf-8 -*-import compiler, sysimport os#from pyflakes import checkerimport pyflakes.checkerfilename = sys.argv[1]print u"ファイル名: %s" % filenameprint "*" * 20# ファイルからソースを読み込んでcodeString = file(filename, 'U').read()# コンパイルするtree = compiler.parse(codeString)# 出力して、どんな風にコンパイルされているか見てみようprint treeprint "*" * 20w = pyflakes.checker.Checker(tree, filename)w.messages.sort(lambda a, b: cmp(a.lineno, b.lineno))for warning in w.messages: print warningprint u"メッセージ数: %d" % len(w.messages)そうすると次のような出力が得られる(長いのやるとすごい量になる)。ファイル名: a.py********************Module(None, Stmt([Import([('sys', None)]), Import([('sonnanonaiyo', None)]), Assign([AssName('naiyo', 'OP_ASSIGN')], CallFunc(Getattr(Name('sonnanonaiyo'), 'usoclass'), [], None, None)), Class('class_a', [], None, Stmt([Function(None, '__init__', ['self'], [], 0, None, Stmt([Pass()])), Function(None, 'test', ['self'], [], 0, None, Stmt([Pass()]))])), Function(None, 'test_func', ['x'], [], 0, None, Stmt([Pass()])), Assign([AssName('x', 'OP_ASSIGN')], Const('OK')), Assign([AssName('y', 'OP_ASSIGN')], Const('NG')), Printnl([Name('x')], None)]))********************a.py:1: 'sys' imported but unusedメッセージ数: 1実際に pyflakes を実行したときに出力されるのは、最後の「a.py:1: 'sys' imported but unused」だけのシンプルなもの。pyflakes は、***** の部分のように構文解析されたものに対して、チェックしている。ということで、import 文があっても読み込むことはしないし、命令も実行されないので安全。上のチェックは下の意味のないコードにしたものだが、import sonnanonaiyo に対してはチェックがかからない。naiyo = sonnanonaiyo.usoclass() に対しても。要するに構文的に OK で、それが不使用でなければチェックはされない。import sys は、使われていないのでチェック対象になっている。parser -- Python解析木にアクセスする、 19.3 Python 抽象構文。import sysimport sonnanonaiyonaiyo = sonnanonaiyo.usoclass()class class_a: def __init__(self): pass def test(self): pass def test_func(x): passx = "OK"y = "NG"print xこれを pyChecker で試してみると、Processing a... ImportError: No module named sonnanonaiyoWarnings...a:1: NOT PROCESSED UNABLE TO IMPORTと、import sonnanonaiyo の時点でエラーを出す。が、それ以上のチェックは行えない。要するに、pyChecker はインポート文を実行しながら動く。つまり、ファイルを読み込むときに実際にインポートしてしまうので (print "OK" は実行されてしまう)、自分で動きを把握してないものに対して使うと、インポートしたときに何があるか分からないのでセキュリティ上はよろしくない。これに対して、pyflakes は実際にはインポートしないので、その点は安全だし、インポートしないだけ軽く動く。逆に言えば、sonnanonaiyo というモジュールがあり、sonnanonaiyo.usoclass() を呼び出すコードがあったとき、usoclass() がないというのを pyChecker は sonnanonaiyo をインポートしているので、正しくあるなしを判定してくれるのに対して、pychecker は読み込まないので、構文的に正しければ、エラーにはならない。このソースの場合、その点を除けば、pyChecker と pyflakes はほぼ同じような結果が得られる。要するに import sys だけがチェック対象。そして、途中にエラーがあるソースに対しては、エラーが出たところまでしかチェックすることができない。エラーのチェックという点では十分といえば十分。では pylint を使うとどうなるか。pylint だけは、import できない行があっても気にせずに処理してくれる。そして、下のようなメッセージを出す。デフォルトの状態だと、まああれこれうるさい。チェック時に実際にインポートを実行してないという点では pyflakes と同様のメリットがある。E から始まっている行だけを grep などで絞り込んでしまえば、たくさんありすぎて重要なものを見失うということもなさそう(大量のソースをやると、まあ、それもあれだが)。おもしろいのは、W: 12:test_func: Unused argument 'x' で、 x は print 文で使っているけれども、こういうのもチェック対象になるところかな。やはり、設定ファイルを自分でちゃんと作って、制御しないと辛いところがあるかもしれないのは事実。ちなみに、もし、sonnanonaiyo が存在して、test がないのに sonnanonaiyo.test() を呼び出せば、pylint は、「E: 13: Module 'sonnanonaiyo' has no 'usoclass' member」のようにチェックしてくれる。print の結果は表示されないので、命令を実行はしないけれど、ちゃんとインポートしているファイルは追跡している。************* Module aC: 1: Missing docstringC: 4: Invalid name "naiyo" (should match (([A-Z_][A-Z1-9_]*)|(__.*__))$)C: 6:class_a: Invalid name "class_a" (should match [A-Z_][a-zA-Z0-9]+$)C: 6:class_a: Missing docstringC: 9:class_a.test: Missing docstringR: 6:class_a: Too few public methods (1/2)C: 12:test_func: Missing docstringC: 12:test_func: Invalid name "x" (should match [a-z_][a-z0-9_]{2,30}$)W: 12:test_func: Redefining name 'x' from outer scope (line 15)W: 12:test_func: Unused argument 'x'C: 15: Invalid name "x" (should match (([A-Z_][A-Z1-9_]*)|(__.*__))$)C: 16: Invalid name "y" (should match (([A-Z_][A-Z1-9_]*)|(__.*__))$)W: 1: Unused import sys(以下、統計情報は長いので省略)さらにおもしろいのは、エラー時のメッセージ量。pyCheckerProcessing a... SyntaxError: invalid syntax (a.py, line 10) pass ^pyflakesa.py:10: could not compile pass ^pylintE: 10: invalid syntaxpyChecker と pyflakes はエラー箇所の文字列まで表示するのに対して、pylint は行と原因までしか分からない。ざっくりとした印象としてpyChecker は本当にモジュールをインポートしてしまうので危険な場合がある。pyflakes はモジュールをまたがる問題に対しては無力。pylint はうるさすぎ。きちんと設定して制御すべし。pylint をちゃんと設定して使うのがよいのだろうけど、それもプロジェクトで本格的に使うのでなければ面倒ねと。バランス的に、一定のレベルにある人がさくさくと使えて、最低限の要をなしてくれるプロが生産性のために pyflakes を好むのも分かる感じがする。けれども、ドキュメントストリングや変数名の規約を含めて複数の人間が一定の量のソースコードの品質を上げようとするならば pylint が好ましいとも思える。問題を分かった上で使うのであれば、pyChecker が個人で使うには、便利な面もある、けれど、やっぱり使うときに注意はすべきだし、本来デバグしているファイル以外の影響でインポート時に落ちてしまえば、そのファイルのチェックができないという弱点もある。
2007.12.01
コメント(1)
全29件 (29件中 1-29件目)
1
-
-

- ジャンクパーツ
- 秋原他でのお買い物250111ハーフその…
- (2025-02-15 18:03:22)
-
-
-

- 私のPC生活
- PCの設定がほぼ終わりました
- (2026-05-29 00:07:22)
-
-
-

- 新製品発売情報・予約情報
- 5/16発売!6枚2980円で予約できると…
- (2026-05-08 12:04:39)
-



