
PR
Free Space
〖政治の貧困〗緊急銃猟って、政府、国会の無為無策の結晶か?
〖政治の貧困〗公共事業の誘致が地域政党の生きる道?万博の次は副首都?
〖政治の貧困〗物価高対策はどうなるの?理屈が破綻している?
〖OCNモバイルONE〗そろそろ終了が近いのか?格安SIMサービスの弱点を利用して解約させるのか??非論理的で驚愕の対応!
〖超便利なTailscale VPN〗ロケフリ、アニメロッカーだけでなく、RDPも便利に
【消費税減税】消費税減税に反対の構図とは?
【ソニーロケフリのDDNS終了】ソニーのロケフリのDDNS(ダイナミックDNS)サービス停止後にロケフリを利用する方法
【OCNモバイル】末期に突入なのか?SIM不良って何?
【ミニPC】もうミニパソコンでええやん(いいじゃん)という感じです
【能登半島地震】無法地帯に4G防犯カメラ
〖政治の貧困〗公共事業の誘致が地域政党の生きる道?万博の次は副首都?
〖政治の貧困〗物価高対策はどうなるの?理屈が破綻している?
〖OCNモバイルONE〗そろそろ終了が近いのか?格安SIMサービスの弱点を利用して解約させるのか??非論理的で驚愕の対応!
〖超便利なTailscale VPN〗ロケフリ、アニメロッカーだけでなく、RDPも便利に
【消費税減税】消費税減税に反対の構図とは?
【ソニーロケフリのDDNS終了】ソニーのロケフリのDDNS(ダイナミックDNS)サービス停止後にロケフリを利用する方法
【OCNモバイル】末期に突入なのか?SIM不良って何?
【ミニPC】もうミニパソコンでええやん(いいじゃん)という感じです
【能登半島地震】無法地帯に4G防犯カメラ
2019.09.05

カテゴリ: データ分析
NASAのサイト
(https://cneos.jpl.nasa.gov/ca/)
から、「2019 OK」のようなNEO(Near Earth Object:地球に接近する小惑星)のデータをダウンロードすることができます。
そのデータの前処理をして、グラフを作成したりする作業をできるだけ自動化してみたいと思います。
最終的には、API接続でデータを取り込んで、ということがいいのかもしれませんが、一見したところ、APIのデータにはNEOの大きさの推定値が含まれていないような気がします。
API接続は、今後の課題としながら、ダウンロードしたデータの前処理をいかに自動化できるのかを考えてみました。
ExcelやPower BIのPower Query(パワークエリ)を利用して前処理をするという方法もありますが、今回はRpubsでNASAのNEOデータの前処理をする「R」のコードを見つけたので、そのコードに継ぎ足しをしたコードでの処理方法を検証しています。
なお、最初の一部分だけ、Power Query(パワークエリ)を利用しています。
▼「R」のコードによるNASAのNEOデータの前処理
1)NASAのサイトから、データをExcel形式でダウンロードして、Excelのパワークエリで年月日の文字列を分割処理
データの2列目の「年月日時刻」の「±」の右側の数字を削除して、日付時刻データにしたいのですが、「R」での処理では、ゴミが残ってしまうので、Excelのパワークエリを用います。
まず、NASAから、過去に5LD以下の距離まで地球に接近したNEOのデータをExcel形式でダウンロードして 保存します。
次に、クエリ処理用のExcelファイルを新規作成します。ダウンロードしたExcelファイルを「データ取得」の対象にします。
パワークエリエディターでデータの2列目の「年月日時刻」の列を「±」の記号で列分割します。分割してできた「±」記号の右側の数字の列を削除します。
右端の列に列名を設定します。
クエリを適用してできたデータの表をCSV形式で保存します。
以上で、Excelの処理は終了です。まとめると下記のような流れになります。
◆Excelでのパワークエリの処理の流れ
ダウンロードした「データファイル1」 → クエリの対象にする → クエリの編集 → クエリを適用して作成した「データファイル2」 → 「データファイル2」をCSV形式で保存
Excelでのパワークエリの処理は、このような流れになっているので、「データファイル1」は元のままです。「データファイル1」を開いて、何か変更するということはありません。
「データファイル1」のデータをクエリの処理対象にします。クエリを編集し、クエリで処理したデータが「データファイル2」で、この「データファイル2」を使います。
「クエリ」の処理手順は保存されているので、データが更新されたら、クエリでデータを読み込み、「クエリ」を適用して、「データ2」を更新します。
「クエリ」は一度作成しておけば、繰り返して使えるので、「R」の「コード」で処理するのと同じようなものです。「クエリ」自体が「コード」なので、当然ですが。
ということで、「前処理」の手順が「クエリ」として保存されていることになります。クエリのExcelファイルは、「NASA_NEO_Query」とか、適当な名前を付けて保存しておきます。
2)CSV形式で保存した「データファイル2」を「R」(「R Markdown」)に読み込みます
CSVファイルを読み込んで、「R Markdown」で前処理とレポート作成を行います。
data <- read.csv('cneos_closeapproach_data.csv',fileEncoding = "utf8",stringsAsFactors = FALSE)
3)「R」でデータのクレンジング、前処理を行います: こちらのサイトのコード が元になっています。
元のコードが対象としているデータは、今回NASAからダウンロードしたデータと同じ形ではないので、元のコードに継ぎ足しをしたり、変更したりする必要があります。
☆列名(変数名)が長いので、短い名称に変更します。
names(data) <- c('Object', 'Date', 'D_n', 'D_m', 'V_r', 'V_i', 'H', 'Diameter','obj')
☆年月日の文字列を日付データの型に変換します。
Excelのクエリで、すでに年月日の文字列になっているので、「R」ではデータ型を変換するだけです。
☆グラフ作成や分析用に年と月などの数字を抽出しておきます。日付の列を分割する形で抽出するので、日付の列を「Datetime1」として複製し、その複製した列を分割して「year」「month」などを抽出します。
data$Datetime <- as.Date(data$Date)
☆「Object」の名前にある「()や[]」を削除します。これは、元のコード通りです。
☆1つのセルに2つのデータが入っている、地球への接近距離のデータ「LD | au」を切り分けます。
切り分け記号の「 | 」の前後の半角の空白の有無で、結果が変わるので、注意が必要です。これは、Excelのパワークエリで行ってもいいかもしれません。
☆1つのセルに2つのデータが入っている、NEOの大きさの推定値のデータ「下限値-上限値」を切り分けて、kmの単位をmに変換します。
以前は、Excelシートで関数を用いて処理していましたが、「R」のコード例があったので、それを利用してみました。
最初、元のコードでは、処理がうまくいきませんでした。
ダウンロードしたデータの「下限値-上限値」の「下限値-」と「上限値」間のスペースが一定していないのが原因のようです。そこで、事前にスペースを削除してから処理するとうまくいきました。
なお、コードにあるスペースも正規表現の一部になっているので、削除して詰めます。
それから、欠損値の行を削除しておかないと「if文」が動かなかったので、欠損値の行を削除しました。
「na.omit」のコードでは、「Diameter」の列を指定して、「Diameter」で、欠損値のある行を削除するようにしているつもりですが、「cols="data$Diameter"」が機能せず、他の列に欠損値がある行も削除されてしまいます。
元データの行数(データ数)は、n=2838でしたが、欠損値のある行の削除処理の結果、n= 2822となりました。「Diameter」の列の欠損値のある行の削除だけであれば、このデータでは、1行の削除で済むはずなので、処理方法は今後の課題です。Excelのパワークエリで処理しておいてもいいかもしれません。
元のコードは、「str_match」と正規表現を活用し、「60m - 130m」といった推定値を、「数字」「単位」「 - 」「数字」「単位」という5つの部分に分け、「if文」を使って距離の単位を変換するコードで、勉強になりました。
4)基本的なグラフを作成するコード:今後充実予定
「R Markdown」を利用する理由は、レポート更新の自動化です。基本的なグラフがデータ読み込みと同時に作成されるようにしたいと思います。
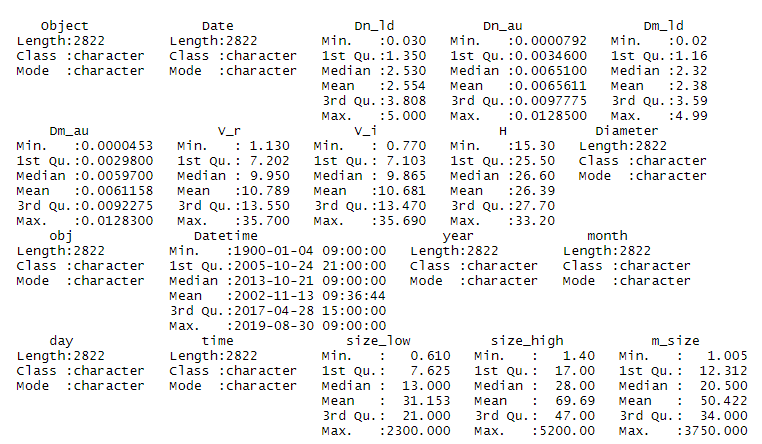
summary(data)
☆関連記事
▼8月21日放送のフジテレビ「とくダネ!」で「直径160mの小惑星が今月末に最接近」という話題がありましたが、地球にはあまり接近しないようです
▼地球に接近したNEOの日別の個数をMicrosoft Power BIで表示してみました
▼【平均値の差の検定をしてみました】地球に接近する小惑星の数の10月と8月の平均値には、統計的に有意な差が見られます
▼地球に接近する小惑星の数が多いのは10月頃?。少ないのは8月?:月別にかなり違いが見られます:Microsoft Power BI Desktopは、無料で利用できる、インタラクティブなインフォグラフィック作成ツールです
▼データ前処理の例(その2):Microsoft Power BI用データを準備するための処理の例:NASAのNEOデータをダウンロードし、英語の月名を含む日付の文字列を日付データに変換して、Power BIに読み込む
▼Microsoft Power BI用データを準備するための前処理の例です:NASAのNEOデータをダウンロードし、小惑星の大きさの推定値をExcelで取り出し、単位変換して、Power BIに読み込む
▼地球をかすめた小惑星「2019 OK」は、0.2LD以下の距離に接近したNEOの中で過去最大だったようです:NASAの1万3千件以上のNEOデータから
▼小惑星「2019 OK」は、過去3年間に0.2LD以下まで地球に接近したNEOの中でも最大でした:NASAのNEOデータをPower BIで分析してみました
▼【グラフを追加しました】:小惑星「2019 OK」はOKでしたが・・・:7月25日に地球とニアミスした、今年最大の小惑星の名前です。

そのデータの前処理をして、グラフを作成したりする作業をできるだけ自動化してみたいと思います。
最終的には、API接続でデータを取り込んで、ということがいいのかもしれませんが、一見したところ、APIのデータにはNEOの大きさの推定値が含まれていないような気がします。
API接続は、今後の課題としながら、ダウンロードしたデータの前処理をいかに自動化できるのかを考えてみました。
ExcelやPower BIのPower Query(パワークエリ)を利用して前処理をするという方法もありますが、今回はRpubsでNASAのNEOデータの前処理をする「R」のコードを見つけたので、そのコードに継ぎ足しをしたコードでの処理方法を検証しています。
なお、最初の一部分だけ、Power Query(パワークエリ)を利用しています。
▼「R」のコードによるNASAのNEOデータの前処理
1)NASAのサイトから、データをExcel形式でダウンロードして、Excelのパワークエリで年月日の文字列を分割処理
データの2列目の「年月日時刻」の「±」の右側の数字を削除して、日付時刻データにしたいのですが、「R」での処理では、ゴミが残ってしまうので、Excelのパワークエリを用います。
まず、NASAから、過去に5LD以下の距離まで地球に接近したNEOのデータをExcel形式でダウンロードして 保存します。
次に、クエリ処理用のExcelファイルを新規作成します。ダウンロードしたExcelファイルを「データ取得」の対象にします。
パワークエリエディターでデータの2列目の「年月日時刻」の列を「±」の記号で列分割します。分割してできた「±」記号の右側の数字の列を削除します。
右端の列に列名を設定します。
クエリを適用してできたデータの表をCSV形式で保存します。
以上で、Excelの処理は終了です。まとめると下記のような流れになります。
◆Excelでのパワークエリの処理の流れ
ダウンロードした「データファイル1」 → クエリの対象にする → クエリの編集 → クエリを適用して作成した「データファイル2」 → 「データファイル2」をCSV形式で保存
Excelでのパワークエリの処理は、このような流れになっているので、「データファイル1」は元のままです。「データファイル1」を開いて、何か変更するということはありません。
「データファイル1」のデータをクエリの処理対象にします。クエリを編集し、クエリで処理したデータが「データファイル2」で、この「データファイル2」を使います。
「クエリ」の処理手順は保存されているので、データが更新されたら、クエリでデータを読み込み、「クエリ」を適用して、「データ2」を更新します。
「クエリ」は一度作成しておけば、繰り返して使えるので、「R」の「コード」で処理するのと同じようなものです。「クエリ」自体が「コード」なので、当然ですが。
ということで、「前処理」の手順が「クエリ」として保存されていることになります。クエリのExcelファイルは、「NASA_NEO_Query」とか、適当な名前を付けて保存しておきます。
2)CSV形式で保存した「データファイル2」を「R」(「R Markdown」)に読み込みます
CSVファイルを読み込んで、「R Markdown」で前処理とレポート作成を行います。
data <- read.csv('cneos_closeapproach_data.csv',fileEncoding = "utf8",stringsAsFactors = FALSE)
3)「R」でデータのクレンジング、前処理を行います: こちらのサイトのコード が元になっています。
元のコードが対象としているデータは、今回NASAからダウンロードしたデータと同じ形ではないので、元のコードに継ぎ足しをしたり、変更したりする必要があります。
☆列名(変数名)が長いので、短い名称に変更します。
names(data) <- c('Object', 'Date', 'D_n', 'D_m', 'V_r', 'V_i', 'H', 'Diameter','obj')
☆年月日の文字列を日付データの型に変換します。
Excelのクエリで、すでに年月日の文字列になっているので、「R」ではデータ型を変換するだけです。
☆グラフ作成や分析用に年と月などの数字を抽出しておきます。日付の列を分割する形で抽出するので、日付の列を「Datetime1」として複製し、その複製した列を分割して「year」「month」などを抽出します。
data$Datetime <- as.Date(data$Date)
data$Datetime <- as.POSIXct(data$Datetime)
data$Datetime1 <- as.POSIXct(data$Datetime)
data <- tidyr::separate(data,col = Datetime1,into = c("year","month","day","time"))
☆1つのセルに2つのデータが入っている、地球への接近距離のデータ「LD | au」を切り分けます。
切り分け記号の「 | 」の前後の半角の空白の有無で、結果が変わるので、注意が必要です。これは、Excelのパワークエリで行ってもいいかもしれません。
data <- tidyr::separate(data,col = D_n, into = c("Dn_ld","Dn_sep","Dn_au"), sep = " | ")
data <- tidyr::separate(data,col = D_m, into = c("Dm_ld","Dm_sep","Dm_au"), sep = " | ")
data <- data[, !(colnames(data) %in% c("Dn_sep", "Dm_sep"))]
data$Dn_ld <- as.numeric(data$Dn_ld)
data$Dn_au <- as.numeric(data$Dn_au)
data$Dm_ld <- as.numeric(data$Dm_ld)
data$Dm_au <- as.numeric(data$Dm_au)
☆1つのセルに2つのデータが入っている、NEOの大きさの推定値のデータ「下限値-上限値」を切り分けて、kmの単位をmに変換します。
以前は、Excelシートで関数を用いて処理していましたが、「R」のコード例があったので、それを利用してみました。
最初、元のコードでは、処理がうまくいきませんでした。
ダウンロードしたデータの「下限値-上限値」の「下限値-」と「上限値」間のスペースが一定していないのが原因のようです。そこで、事前にスペースを削除してから処理するとうまくいきました。
なお、コードにあるスペースも正規表現の一部になっているので、削除して詰めます。
それから、欠損値の行を削除しておかないと「if文」が動かなかったので、欠損値の行を削除しました。
「na.omit」のコードでは、「Diameter」の列を指定して、「Diameter」で、欠損値のある行を削除するようにしているつもりですが、「cols="data$Diameter"」が機能せず、他の列に欠損値がある行も削除されてしまいます。
元データの行数(データ数)は、n=2838でしたが、欠損値のある行の削除処理の結果、n= 2822となりました。「Diameter」の列の欠損値のある行の削除だけであれば、このデータでは、1行の削除で済むはずなので、処理方法は今後の課題です。Excelのパワークエリで処理しておいてもいいかもしれません。
data$Diameter <- gsub(' ', '', data$Diameter)
data <- na.omit(data, cols="data$Diameter")
元のコードは、「str_match」と正規表現を活用し、「60m - 130m」といった推定値を、「数字」「単位」「 - 」「数字」「単位」という5つの部分に分け、「if文」を使って距離の単位を変換するコードで、勉強になりました。
4)基本的なグラフを作成するコード:今後充実予定
「R Markdown」を利用する理由は、レポート更新の自動化です。基本的なグラフがデータ読み込みと同時に作成されるようにしたいと思います。
summary(data)
▼データ数が多いので、グラフ作成対象データを絞り込みます。
(http://www.rpubs.com/primaryobjects/asteroids)▼データ数が多いので、グラフ作成対象データを絞り込みます。
☆2010年以降のデータに絞ります。
data <- data[data$year >= "2010",]
data <- data[data$year >= "2010",]
☆地球に1LD以下の距離まで接近したNEOに絞ります。
<グラフ例>
▼横軸:接近日、縦軸:接近距離(LD)
特に、傾向はないようです。ランダムに分布しているようです。
ggplot(data, aes(y = Dn_ld, x = Datetime)) + 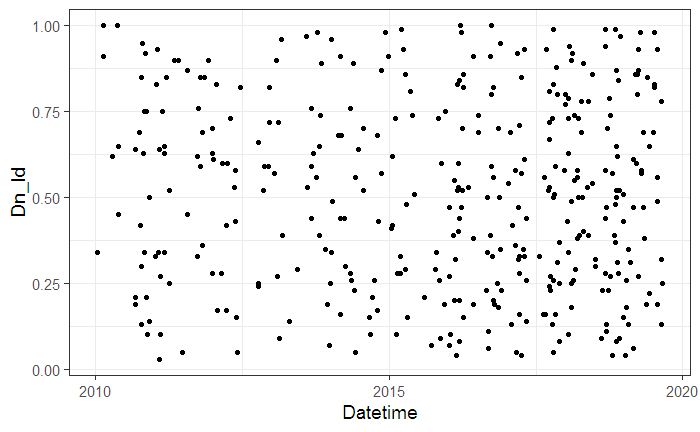
▼年別のNEOの接近距離(LD)の分布
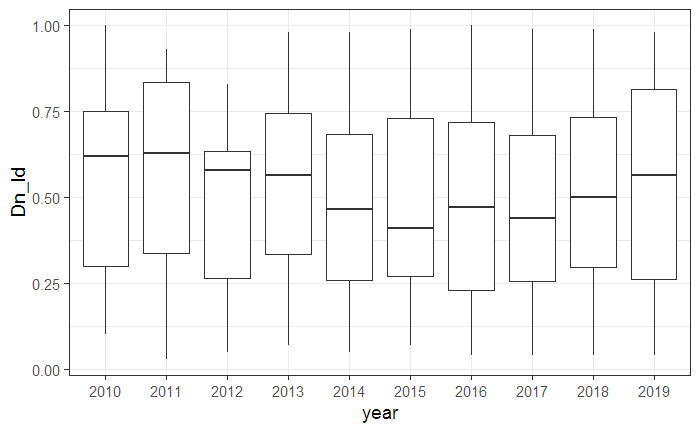
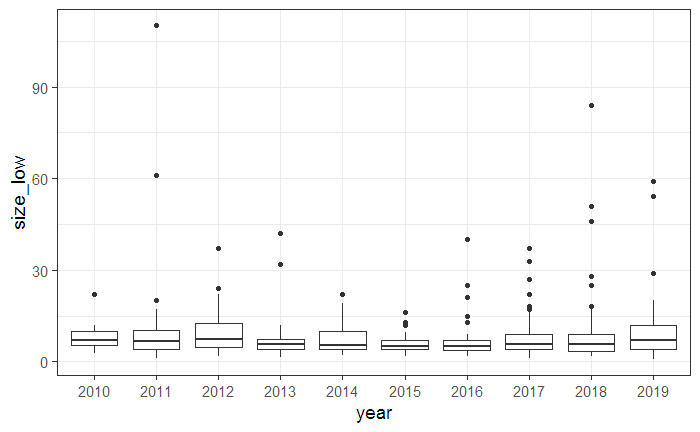
▼年別のNEOのサイズ(推定の下限値)の分布
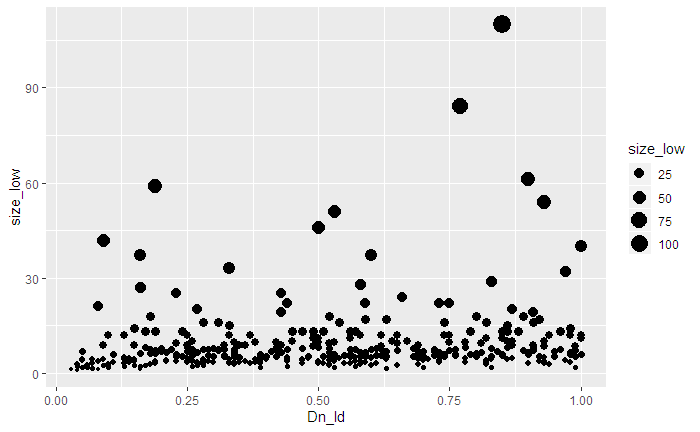
▼横軸:距離(LD)、縦軸:推定サイズの下限値、点の大きさ:推定サイズの下限値
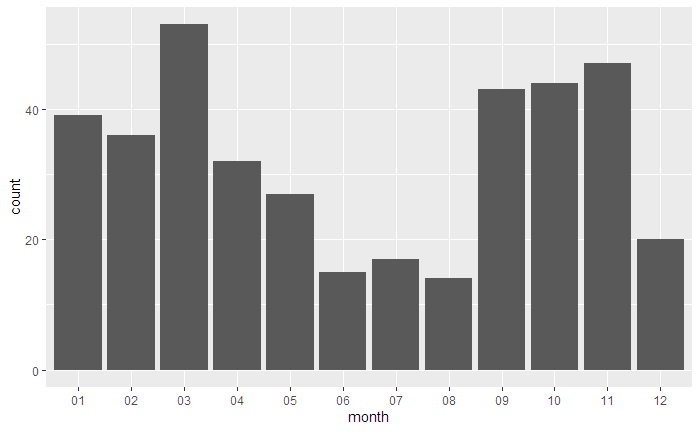
▼月別のNEOの観測数
6月~8月は、観測数が少ない時期のようです。
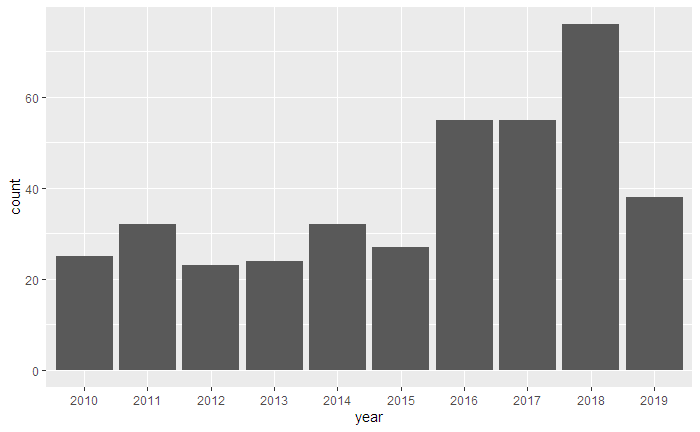
▼年別のNEOの観測数
☆地球に1LD以下の距離まで接近したNEOに絞ります。
data <- data[data$Dn_ld <= 1,]
<グラフ例>
▼横軸:接近日、縦軸:接近距離(LD)
特に、傾向はないようです。ランダムに分布しているようです。
ggplot(data, aes(y = Dn_ld, x = Datetime)) +
geom_point() +
theme_bw(base_size = 14)
▼年別のNEOの接近距離(LD)の分布
ggplot(data, aes(y = Dn_ld, x = year)) +
geom_boxplot() +
theme_bw(base_size = 14)
▼年別のNEOのサイズ(推定の下限値)の分布
ggplot(data, aes(y = size_low, x = year)) +
geom_boxplot() +
theme_bw(base_size = 14)
▼横軸:距離(LD)、縦軸:推定サイズの下限値、点の大きさ:推定サイズの下限値
ggplot(data, aes(x = Dn_ld , y = size_low , size = size_low)) +
geom_point()
▼月別のNEOの観測数
6月~8月は、観測数が少ない時期のようです。
ggplot(data, aes(x = month)) +
geom_bar(stat = 'count')
▼年別のNEOの観測数
ggplot(data, aes(x = year)) +
geom_bar(stat = 'count')
☆参考にしたページ:
Analysis of the Near Earth Object Asteroid Dataset:
Kory Becker - October 21, 2015
☆関連記事
▼8月21日放送のフジテレビ「とくダネ!」で「直径160mの小惑星が今月末に最接近」という話題がありましたが、地球にはあまり接近しないようです
▼地球に接近したNEOの日別の個数をMicrosoft Power BIで表示してみました
▼【平均値の差の検定をしてみました】地球に接近する小惑星の数の10月と8月の平均値には、統計的に有意な差が見られます
▼地球に接近する小惑星の数が多いのは10月頃?。少ないのは8月?:月別にかなり違いが見られます:Microsoft Power BI Desktopは、無料で利用できる、インタラクティブなインフォグラフィック作成ツールです
▼データ前処理の例(その2):Microsoft Power BI用データを準備するための処理の例:NASAのNEOデータをダウンロードし、英語の月名を含む日付の文字列を日付データに変換して、Power BIに読み込む
▼Microsoft Power BI用データを準備するための前処理の例です:NASAのNEOデータをダウンロードし、小惑星の大きさの推定値をExcelで取り出し、単位変換して、Power BIに読み込む
▼地球をかすめた小惑星「2019 OK」は、0.2LD以下の距離に接近したNEOの中で過去最大だったようです:NASAの1万3千件以上のNEOデータから
▼小惑星「2019 OK」は、過去3年間に0.2LD以下まで地球に接近したNEOの中でも最大でした:NASAのNEOデータをPower BIで分析してみました
▼【グラフを追加しました】:小惑星「2019 OK」はOKでしたが・・・:7月25日に地球とニアミスした、今年最大の小惑星の名前です。
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/18c0b2f0.c9791c8f.18c0b2f1.b0422fd2/?me_id=1213310&item_id=18827663&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8147%2F9784873118147.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8147%2F9784873118147.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
|
Rではじめるデータサイエンス [ Hadley Wickham ]
|
お気に入りの記事を「いいね!」で応援しよう
[データ分析] カテゴリの最新記事
-
CHATGPTって何しているの? 2023.11.22
-
コスタリカの話題はあまり見られない:ツ… 2022.12.03
-
【新型コロナ】Qatarでは感染確認者数が減… 2022.11.29




【毎日開催】
15記事にいいね!で1ポイント
© Rakuten Group, Inc.