
PR
Free Space
〖政治の貧困〗緊急銃猟って、政府、国会の無為無策の結晶か?
〖政治の貧困〗公共事業の誘致が地域政党の生きる道?万博の次は副首都?
〖政治の貧困〗物価高対策はどうなるの?理屈が破綻している?
〖OCNモバイルONE〗そろそろ終了が近いのか?格安SIMサービスの弱点を利用して解約させるのか??非論理的で驚愕の対応!
〖超便利なTailscale VPN〗ロケフリ、アニメロッカーだけでなく、RDPも便利に
【消費税減税】消費税減税に反対の構図とは?
【ソニーロケフリのDDNS終了】ソニーのロケフリのDDNS(ダイナミックDNS)サービス停止後にロケフリを利用する方法
【OCNモバイル】末期に突入なのか?SIM不良って何?
【ミニPC】もうミニパソコンでええやん(いいじゃん)という感じです
【能登半島地震】無法地帯に4G防犯カメラ
〖政治の貧困〗公共事業の誘致が地域政党の生きる道?万博の次は副首都?
〖政治の貧困〗物価高対策はどうなるの?理屈が破綻している?
〖OCNモバイルONE〗そろそろ終了が近いのか?格安SIMサービスの弱点を利用して解約させるのか??非論理的で驚愕の対応!
〖超便利なTailscale VPN〗ロケフリ、アニメロッカーだけでなく、RDPも便利に
【消費税減税】消費税減税に反対の構図とは?
【ソニーロケフリのDDNS終了】ソニーのロケフリのDDNS(ダイナミックDNS)サービス停止後にロケフリを利用する方法
【OCNモバイル】末期に突入なのか?SIM不良って何?
【ミニPC】もうミニパソコンでええやん(いいじゃん)という感じです
【能登半島地震】無法地帯に4G防犯カメラ
2019.08.27

カテゴリ: データ分析
楽天市場の商品レビューをスクレイピングするためのRのコードです。スクレイピングしたデータのテキストを分析するのが目的です。
先日作成したRのコードでは、取得したデータに対して、Excelで列の分割をしたりして項目を切り分ける必要がありましたが、コード上で処理をすることによってExcelでの切り分け作業が不要になりました。Excelで修正が必要だった「列のずれ」もなくなりました。
また、コード処理によって、「年代性」の項目から「性別」と「年代」を切り分けたりもしています。
▼今回の改訂版のRコードで取得できるデータの例です
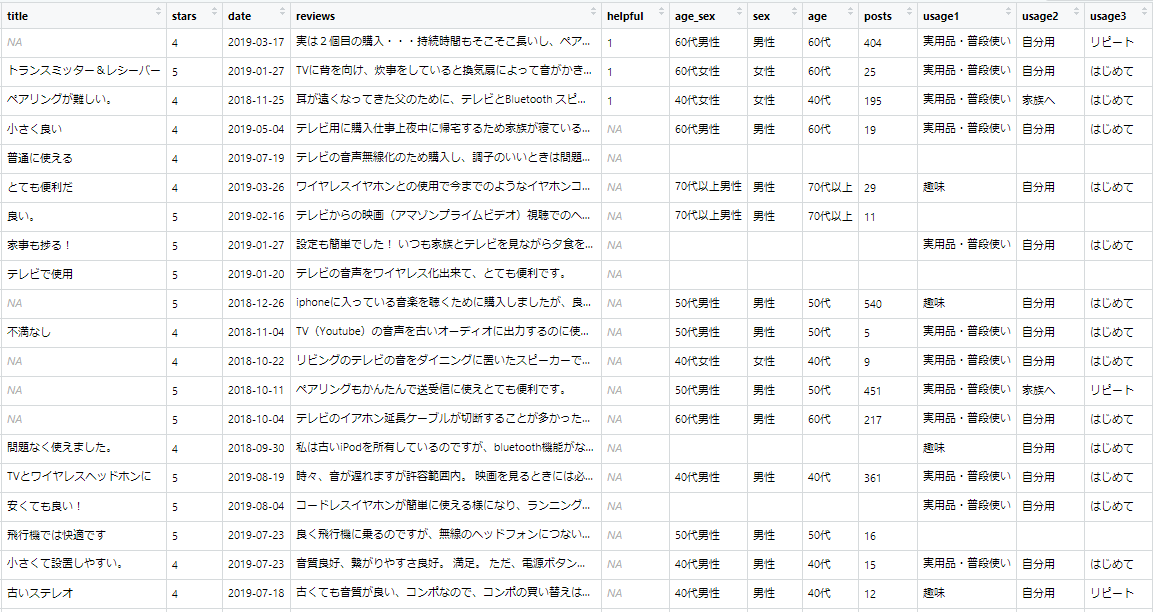
【20190827】「R」による楽天市場の商品レビューのスクレイピングコード改訂版
※このコードには再改訂版があります。
url_txt <- "https://review.rakuten.co.jp/item/1/・・・/"
pages_num <- 3
get_r_reviews <- NULL
df_reviews <- NULL
for(i in 1:pages_num){
url <- paste0(url_txt,i,'.','1/')
page <- read_html(url)
get_r_reviews <- page %>%
html_nodes ('.hreview') %>%
map_df(~list( name = html_nodes(.x, '.reviewer') %>%
html_text(.,trim = FALSE) %>%
{if(length(.) == 0) NA else .},
title = html_nodes(.x, '.summary') %>%
html_text(.,trim = FALSE) %>%
{if(length(.) == 0) NA else .},
stars = html_nodes(.x, '.value') %>%
html_text() %>%
{if(length(.) == 0) NA else .},
date = html_nodes(.x, '.dtreviewed') %>%
html_text() %>%
{if(length(.) == 0) NA else .},
reviews = html_nodes(.x, '.description') %>%
html_text(.,trim = FALSE) ,
helpful = html_nodes(.x, '.revEntryAnsNum') %>%
html_text(.,trim = FALSE) %>%
{if(length(.) == 0) NA else .} ,
age_sex = html_nodes(.x, '.revUserFaceDtlTxt') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "購入者|レビュー投稿.*|.*件","") %>%
str_replace_all(., " ","") ,
sex = html_nodes(.x, '.revUserFaceDtlTxt') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "購入者|レビュー投稿.*|.*件|.*代|以上","") %>%
str_replace_all(., " ","") ,
age = html_nodes(.x, '.revUserFaceDtlTxt') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "購入者|レビュー投稿|.*件|男性|女性","") %>%
str_replace_all(., " ","") ,
posts = html_nodes(.x, '.revUserFaceDtlTxt') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., ".*代.*|購入者|レビュー投稿|件","") %>%
str_replace_all(., " ","") ,
usage1 = html_nodes(.x, '.revRvwUserDisp') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "商品を使う人.*|購入した回数.*|商品の使いみち:","") %>%
str_replace_all(., " ","") ,
usage2 = html_nodes(.x, '.revRvwUserDisp') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "商品の使いみち.*|購入した回数.*|商品を使う人:","") %>%
str_replace_all(., " ","") ,
usage3 = html_nodes(.x, '.revRvwUserDisp') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "商品の使いみち.*|商品を使う人.*|購入した回数:","") %>%
str_replace_all(., " ","") ))
Sys.sleep(5)
df_reviews <- rbind(df_reviews, get_r_reviews)
}
view(df_reviews)
※留意事項:コードの1行目と2行目については、レビューデータを取得したい商品に対応した情報を記入する必要があります。
※1行目の「url_txt」の右の” ”のところに、楽天市場の特定の商品の「みんなのレビュー」の一覧ページのURLを記入するのですが、末尾の「1.1/」や「2.1/」よりも前の部分のURLの「・・・/」までを記入します。「.」や「/」が過不足しないように注意する必要があります。
「for i」文の「i」がURLの末尾の「i.1/」のところに入る形です。この「i」の後ろに「.」と「1」と「/」を付け足しています。URLの末尾が「1.1/」「2.1/」「3.1/」「4.1/」「5.1/」と変化することで、無理やり、ページ送りをしています。
※2行目の「pages_num <- 3」のところですが、数字の「3」のところにレビューのページの最終ページの数字を調べて記入します。10ページ目が最終ページであれば「10」を記入して「pages_num <- 10」とします。
なお、公開されているページの上限は「100」のようです。20,000件を超えるレビューがある商品でも100ページまでしか表示されません。
※必要なパッケージ
私の環境ですが、Rstudioを利用しています。上記コードに必要なパッケージは、おそらく下記のようなものではないでしょうか。いろいろと試行錯誤したので、上記コードには不要なパッケージもいくつか含まれているはずです(笑)。なお、Rstudioに未登録のパッケージは、「install.packages()」などによって、インストールしておく必要があります。
library(rvest)
library(purrr)
library(pipeR)
library(textreadr)
library(RCurl)
library(XML)
library(tidyverse)
library(lubridate)
library( stringr )
※レビュー投稿者の「年代性」「投稿数」「商品の使いみち」「商品を使う人」「購入した回数」の項目をコード上で切り分けるようにしました。この改訂版のコードを用いることによって、Excelシートで列を分割したり、ずれの補正をしたりする必要がなくなりました。
でも、「商品の使いみち」「商品を使う人」「購入した回数」などの項目は、あまり分析に使わないかもしれません。商品ジャンルによっては重要な切り口になる場合もあると思いますが。
※コード上で、個別の要素を細かく抽出しようとしてみましたが、うまくいかなかったので、多めに取り込んでいた要素を「str_replace_all()」によって削って、必要な個別の要素を残すようなコードにしたら、うまくいったようです。
「商品の使いみち」とか、必要な要素が一定ではない一方、不要な要素は一定なので、不要なものを削った方が簡単なようです。
なお、「NA」を入れるコードがはたらかず、「NA」がうまく入らなかった項目の欠損値は、「空欄」になっています。そして、上記のコードでは、ワークしなかったコードは省いています。
「押してもだめなら引いてみな」ということわざは的確なようです。
☆関連記事
▼楽天市場の 特定の商品のレビューを「R言語」でスクレイピングするコード:一部の項目の空欄・欠損値(missing values)を「NA」に置き換えてデータフレームを作成:継ぎはぎのコードですが・・・
▼JPRiDEの新モデル・完全ワイヤレスイヤホン「JPRiDE TWS-520」のアマゾン・カスタマーレビューのテキストを分析
▼「JPRiDE」ブランドのワイヤレスイヤホン「JPRiDE 708」の楽天市場のレビューのテキストを分析:ReviewMetaでアマゾンのカスタマーレビューの信頼性の高さを推定できるJPRiDEの製品
▼雑誌など第3者の高評価をアピールしている「JPRiDE(ジェイピー・ライド)」ブランドのワイヤレスイヤホン「JPA2」の楽天市場のレビューのテキスト分析です
▼JVCケンウッドの高評価イヤホン「HA-FX3X」とソニーの「MDR-EX450」のカスタマーレビューを比較
▼3000円クラスの高評価イヤホン「HA-FX3のカスタマーレビューのテキスト分析を「User Local」の「AIテキストマイニング」で行ってみました:こんな分析ツールがあったとは、驚きです
▼カスタマーレビュー分析で、Microsoft Power BIの「Word Cloud」とスライサーの組み合わせは便利です:3000円クラスで、高評価のイヤホン「HA-FX3X」のカスタマーレビューのテキスト分析
▼アマゾンのカスタマーレビューを購入の判断材料にする場合、「ReviewMeta」(レビューメータ)によるチェックが役立ちます
▼先日購入したイヤホン「HA-FX3X」のアマゾン・カスタマーレビュー分析:低音の良さ、コスパなどが高評価の理由のようです:3000円クラスで、高評価のイヤホンです


先日作成したRのコードでは、取得したデータに対して、Excelで列の分割をしたりして項目を切り分ける必要がありましたが、コード上で処理をすることによってExcelでの切り分け作業が不要になりました。Excelで修正が必要だった「列のずれ」もなくなりました。
また、コード処理によって、「年代性」の項目から「性別」と「年代」を切り分けたりもしています。
▼今回の改訂版のRコードで取得できるデータの例です
【20190827】「R」による楽天市場の商品レビューのスクレイピングコード改訂版
※このコードには再改訂版があります。
url_txt <- "https://review.rakuten.co.jp/item/1/・・・/"
pages_num <- 3
get_r_reviews <- NULL
df_reviews <- NULL
for(i in 1:pages_num){
url <- paste0(url_txt,i,'.','1/')
page <- read_html(url)
get_r_reviews <- page %>%
html_nodes ('.hreview') %>%
map_df(~list( name = html_nodes(.x, '.reviewer') %>%
html_text(.,trim = FALSE) %>%
{if(length(.) == 0) NA else .},
title = html_nodes(.x, '.summary') %>%
html_text(.,trim = FALSE) %>%
{if(length(.) == 0) NA else .},
stars = html_nodes(.x, '.value') %>%
html_text() %>%
{if(length(.) == 0) NA else .},
date = html_nodes(.x, '.dtreviewed') %>%
html_text() %>%
{if(length(.) == 0) NA else .},
reviews = html_nodes(.x, '.description') %>%
html_text(.,trim = FALSE) ,
helpful = html_nodes(.x, '.revEntryAnsNum') %>%
html_text(.,trim = FALSE) %>%
{if(length(.) == 0) NA else .} ,
age_sex = html_nodes(.x, '.revUserFaceDtlTxt') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "購入者|レビュー投稿.*|.*件","") %>%
str_replace_all(., " ","") ,
sex = html_nodes(.x, '.revUserFaceDtlTxt') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "購入者|レビュー投稿.*|.*件|.*代|以上","") %>%
str_replace_all(., " ","") ,
age = html_nodes(.x, '.revUserFaceDtlTxt') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "購入者|レビュー投稿|.*件|男性|女性","") %>%
str_replace_all(., " ","") ,
posts = html_nodes(.x, '.revUserFaceDtlTxt') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., ".*代.*|購入者|レビュー投稿|件","") %>%
str_replace_all(., " ","") ,
usage1 = html_nodes(.x, '.revRvwUserDisp') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "商品を使う人.*|購入した回数.*|商品の使いみち:","") %>%
str_replace_all(., " ","") ,
usage2 = html_nodes(.x, '.revRvwUserDisp') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "商品の使いみち.*|購入した回数.*|商品を使う人:","") %>%
str_replace_all(., " ","") ,
usage3 = html_nodes(.x, '.revRvwUserDisp') %>%
html_text(.,trim = FALSE) %>%
str_replace_all(., "商品の使いみち.*|商品を使う人.*|購入した回数:","") %>%
str_replace_all(., " ","") ))
Sys.sleep(5)
df_reviews <- rbind(df_reviews, get_r_reviews)
}
view(df_reviews)
※留意事項:コードの1行目と2行目については、レビューデータを取得したい商品に対応した情報を記入する必要があります。
※1行目の「url_txt」の右の” ”のところに、楽天市場の特定の商品の「みんなのレビュー」の一覧ページのURLを記入するのですが、末尾の「1.1/」や「2.1/」よりも前の部分のURLの「・・・/」までを記入します。「.」や「/」が過不足しないように注意する必要があります。
「for i」文の「i」がURLの末尾の「i.1/」のところに入る形です。この「i」の後ろに「.」と「1」と「/」を付け足しています。URLの末尾が「1.1/」「2.1/」「3.1/」「4.1/」「5.1/」と変化することで、無理やり、ページ送りをしています。
※2行目の「pages_num <- 3」のところですが、数字の「3」のところにレビューのページの最終ページの数字を調べて記入します。10ページ目が最終ページであれば「10」を記入して「pages_num <- 10」とします。
なお、公開されているページの上限は「100」のようです。20,000件を超えるレビューがある商品でも100ページまでしか表示されません。
※必要なパッケージ
私の環境ですが、Rstudioを利用しています。上記コードに必要なパッケージは、おそらく下記のようなものではないでしょうか。いろいろと試行錯誤したので、上記コードには不要なパッケージもいくつか含まれているはずです(笑)。なお、Rstudioに未登録のパッケージは、「install.packages()」などによって、インストールしておく必要があります。
library(rvest)
library(purrr)
library(pipeR)
library(textreadr)
library(RCurl)
library(XML)
library(tidyverse)
library(lubridate)
library( stringr )
※レビュー投稿者の「年代性」「投稿数」「商品の使いみち」「商品を使う人」「購入した回数」の項目をコード上で切り分けるようにしました。この改訂版のコードを用いることによって、Excelシートで列を分割したり、ずれの補正をしたりする必要がなくなりました。
でも、「商品の使いみち」「商品を使う人」「購入した回数」などの項目は、あまり分析に使わないかもしれません。商品ジャンルによっては重要な切り口になる場合もあると思いますが。
※コード上で、個別の要素を細かく抽出しようとしてみましたが、うまくいかなかったので、多めに取り込んでいた要素を「str_replace_all()」によって削って、必要な個別の要素を残すようなコードにしたら、うまくいったようです。
「商品の使いみち」とか、必要な要素が一定ではない一方、不要な要素は一定なので、不要なものを削った方が簡単なようです。
なお、「NA」を入れるコードがはたらかず、「NA」がうまく入らなかった項目の欠損値は、「空欄」になっています。そして、上記のコードでは、ワークしなかったコードは省いています。
「押してもだめなら引いてみな」ということわざは的確なようです。
【参考ページ】:「AmazonのレビューデータをRとExploratoryでスクレイピングしてみた」(https://qiita.com/A_KI/items/6863d158b9c938055f5a)
【参考ページ】:「stackoverflow」:Inputting NA where there are missing values when scraping with rvest】(https://stackoverflow.com/questions/45901532/inputting-na-where-there-are-missing-values-when-scraping-with-rvest)
☆関連記事
▼楽天市場の 特定の商品のレビューを「R言語」でスクレイピングするコード:一部の項目の空欄・欠損値(missing values)を「NA」に置き換えてデータフレームを作成:継ぎはぎのコードですが・・・
▼JPRiDEの新モデル・完全ワイヤレスイヤホン「JPRiDE TWS-520」のアマゾン・カスタマーレビューのテキストを分析
▼「JPRiDE」ブランドのワイヤレスイヤホン「JPRiDE 708」の楽天市場のレビューのテキストを分析:ReviewMetaでアマゾンのカスタマーレビューの信頼性の高さを推定できるJPRiDEの製品
▼雑誌など第3者の高評価をアピールしている「JPRiDE(ジェイピー・ライド)」ブランドのワイヤレスイヤホン「JPA2」の楽天市場のレビューのテキスト分析です
▼JVCケンウッドの高評価イヤホン「HA-FX3X」とソニーの「MDR-EX450」のカスタマーレビューを比較
▼3000円クラスの高評価イヤホン「HA-FX3のカスタマーレビューのテキスト分析を「User Local」の「AIテキストマイニング」で行ってみました:こんな分析ツールがあったとは、驚きです
▼カスタマーレビュー分析で、Microsoft Power BIの「Word Cloud」とスライサーの組み合わせは便利です:3000円クラスで、高評価のイヤホン「HA-FX3X」のカスタマーレビューのテキスト分析
▼アマゾンのカスタマーレビューを購入の判断材料にする場合、「ReviewMeta」(レビューメータ)によるチェックが役立ちます
▼先日購入したイヤホン「HA-FX3X」のアマゾン・カスタマーレビュー分析:低音の良さ、コスパなどが高評価の理由のようです:3000円クラスで、高評価のイヤホンです
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/18c0b2f0.c9791c8f.18c0b2f1.b0422fd2/?me_id=1213310&item_id=18827663&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8147%2F9784873118147.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8147%2F9784873118147.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
|
Rではじめるデータサイエンス [ Hadley Wickham ]
|
お気に入りの記事を「いいね!」で応援しよう
[データ分析] カテゴリの最新記事
-
CHATGPTって何しているの? 2023.11.22
-
コスタリカの話題はあまり見られない:ツ… 2022.12.03
-
【新型コロナ】Qatarでは感染確認者数が減… 2022.11.29




【毎日開催】
15記事にいいね!で1ポイント
© Rakuten Group, Inc.