

Ruby 0
[ことばの処理] カテゴリの記事
全268件 (268件中 1-50件目)
-

剽窃レポート暴きに怯えるのは学生だけかな
以前、社員教育への文書解析応用と、剽窃チェック なんていうのを書いたが、日本語対応の剽窃をチェックするソフトが発売らしい。Report × Report の レポート みたいなのがサービスである時代だからなぁ。アンク、国内初のコピペ判定支援ソフト「コピペルナー」を新発売 ~予約受付開始、発売記念特別キャンペーン実施~。金沢工大杉光教授が考案した不正コピペ判定支援ソフト発売「コピペルナー」は、1つまたは複数の文書を読み込み、インターネットのWebページや文献データベースの検索を行い、コピペ箇所を解析。コピペ割合やコピー元の文献などを表示する。コピペと思われる箇所は、完全一致またはあいまい一致によって色別表示され、直感的にコピペ状況を把握できるという。また、複数の文書を読み込み、その文書間のコピペをチェック、グループ化して相関関係を表示することも可能。コピペ問題を考える ~大学などで今起こっているレポート作成の問題と対応策~で、「正当な引用までもコピペであるとされてしまう」というご意見もありました。これについては、正当な引用についてはコピペではないと判断するような機能を付ける予定です。これはできたのかな?K.I.T虎ノ門大学院 (金沢工業大学 虎ノ門キャンパス杉光一成経営者のための知的財産入門ネット上からの不正コピペを判断する支援ソフト「コピペルナー」SBS RADIO 今日のゲスト 【情報三枚おろし】5月30日(金)放送◎ネット文献、コピペで丸写し ものぐさ学生 金沢工大の杉光教授が対策ソフト開発学生論文のコピペ見破るソフト「コピペルナー」実用化 「学生らの悪癖なくす」コピペ見破るソフト実用化 卒論提出シーズンを前に、全国の大学などから問い合わせが相次ぐコピペ論文などを見破るソフトを開発した杉光一成★コピペしたリポート、ばれちゃうぞ 検出ソフト開発WEBコンテンツの著作権侵害検出サーチエンジンに関する研究(pdf)「コピペ」は本当に悪いことなのか ― NHK『クローズアップ現代』の視点は不毛(小樽商科大学、金沢工大、茂木健一郎、野口悠紀雄、斉藤孝、みんなバカなことを言っている) 2008年09月02日講義で学生に授業を聴いてもらえない、レポート(宿題)で学生をいじめられない先生や学校が最後にやり始めるのが学生参加型の授業。先生が何もしなくても学生同士で盛り上がっている。少なくとも従来型の授業に比べて学生は寝はしない。先生も手を抜ける、学生は楽しんでいる、いいではないか、というのが、ここ数年の大学の教育改革モデルの主流。私がここ数年審査を続けた「特色GP」(http://www.tokushoku-gp.jp/)の申請のほとんどはこの種の取り組みで占められている。最近の若い人って、グループ学習好きね。企業の新人教育とかでもグループ学習すると勝手に盛り上がる。グループ学習をうまくやると、講義型よりも、ペーパーテストの結果もよくなる。なんていうのはどうでもよいとして、教授=研究者達はなぜ「コピペ」文化を嫌うのか。その理由ははっきりしている。ネット文化の方が自らの旧式の文献研究をはるかに飛び越える可能性があるからだ。場合によっては、学生達の方がはるかに有益な文献を探し出してくる可能性があるそんな馬鹿なことがあるんだろうか。新しいものを見つけてきて教えてくれるのなら、嬉しいことだろうに。先生という類の人たちは、そんなに度量が狭いのか? 問題は、新しいものを提示されたときに、その内容を正しく評価できないかもしれないという恐れのかもしれないな。最新の論文をぱくってきて、剽窃。教授はそれを知らずに、こんなのはダメだ。いや、これ有名な論文誌にも載ったものが元になっていて。。。。引用を明確にするというのは、実は、指導者側に恥をかかせないようにするための仕組みでもあるってことだな。怠惰な指導者がすぐれた剽窃論文に対して低評価して恥をかくことがなくなる(剽窃しているからダメなのではなくて、中身がダメと判断してしまう)。コピペルナーを使うと、指導者も知識が増えるとかいうメリットがもしかしたらあるかもしれない。さらに考えてみると、このソフト、先行研究を探すのに使えるかもしれない。適当なアイデアを文章化して、評価すれば、同じようなリソースを探し出してきてくれるかもしれないから。そういえば、アンチ、コピペ検出ソフトとして、言い換えエンジン KURA を使うとどうなるのだろうか。一致率が下がるようなルールを作る。それができれば怠慢学生のヒーローだw KURAは、いつか試そうと思いつつ、何年も経ってしまった。言い換え技術って、どの程度進んでいるのだろう。知識処理にはなくてはならない技術だと思うのだけど。ちなみに JST、科学文献、研究者、特許など関連付検索できるサイト開設 、J-GLOBAL(科学技術総合リンクセンター)試行版(β版の)公開について の J-GLOBAL) とかいうものも最近はできている。パテント・リザルト とか見ると、類似特許検索もかなり進んでるのね。PATENT INTEGRATION は Adobe Air を使って作られていて無料で使えるのが信じられない。おもしろい。米国特許は、Xyggy Patent みたいに Ajax を使ったシンプルな検索もある。「剽窃レポート暴きに怯えるのは学生だけかな」の答え。新聞社はかなり危ない。そもそも記事の多くの元ネタが、時事通信、共同通信やロイターの類だったりするし、論説の類でさえも山梨日日新聞社の論説委員の剽窃とかも過去あったし。「恥知らず」の言葉まで飛び出した 日経と週刊現代の「全面対決」 みたいなこともあった。海外では Elsevier社、雑誌の編集プロセスに剽窃検知サービス“CrossCheck”を導入すると発表 とかやっているところがある。テレビ番組なんかも、実は海外の番組パクって、真相究明とかやっているのあるものな。井伏さんの作品の多くが先行するものの盗用だった――井伏鱒二現象 「井伏さんは悪人です」ってね。「増補『黒い雨』と井伏鱒二の深層」(猪瀬直樹) [2009年05月21日(木)]を見ると、他の引用出典はすべて実質的な著者・編者が挙げてあるのに、シンクタンクについては、その研究を参照・引用したことが恥ででもあるかのように、その社名を挙げず、委託主にすぎない「NIRA」の名だけを挙げている。 関係者には周知のように、NIRAは当時プロパーの研究員もいて、助成先や委託先と「共同研究」の形をとることはあったが、例外的なケースを除けば、実際上は助成や委託のための打ち合わせや成果の報告会のときNIRAの研究員が参加して意見を述べる程度のことで、研究の実質的なプロセスは執筆まで含めてすべて助成先、委託先の機関の手によるものである。 NIRAの委託研究をNIRA自らがやったものとして表記することは、科学研究費を使って特定の学者たちがやった研究を、実際の研究を行った学者の名を挙げずに、すべて「文部科学省」を著者・研究主体として表記するのと同じ滑稽なことである。なんて書かれている。剽窃とは単純なコピペから始まり、ネタの剽窃レベル、名誉や成果の剽窃レベル等々、奥深いものなのだなぁ。
2009.12.29
コメント(1)
-
重要指標としての言葉の出現頻度
「グレート」は重要指標 を読む。米電機大手GE(ゼネラル・エレクトリック)の株価急落に伴い、同社幹部が連発した「グレート(素晴らしい)」という言葉も急減した。「グレート」は重要指標以前、経済参謀不在の日本の株価、底堅い指数 (August 1, 2007) とか書いたことがある。「底堅い」という言葉に注目するとおもしろいと言うことを書いた。ロイターは訂正する (May 2, 2008) でも、不思議なことに底堅いが増えると、加熱している状態でしばらくすると株価が下げるのはいつものこと。VIX指数との逆相関性が高い。と書いた。やっぱり日経平均大谷場安かぁ (February 29, 2008) のあたりでも取り上げた(他にもいくつもあるが)。言葉の出現頻度に着目すると、トレンドが分かりやすいときがある。が、この「底堅い」は FX が流行始めてから、徐々に株価との連動性が下がっていったような感じ。為替に言及するものの割合が増えたので、株価ではなく、円ドルレートの底堅さを語る文脈が増えてしまったから。ということで、言葉というのは時代によって使われる文脈が代わり、意味も微妙に変わってくるから、長期に渡って同じ意味を持つ指標として使うのはなかなか難しい。ちなみに、この関連に注目したモルガン・スタンレーのアナリスト、スコット・デービス氏はこの分析を、投資判断には利用しないとしている。「グレート」は重要指標これは、モルガン・スタンレーのアナリストのレベルでは当たり前のこと。そんなものでレーティングに影響があったらたまったものじゃないwけれども、言葉遣いに気をつけてみると、決算書に現れないトーンを感じ取ることができるというのはあるだろう。役員の言葉にやたら景気のよい言葉が増えてピークに達して、それが減り始めたら、大きな変調の時と捉えること自体は、直感的な指標として有効かもしれないが。景気動向指数的な感じで。メンタルな側面は捉えられるかもしれない。もっとも、単独の単語の場合は、指摘されることで使う側の意識が喚起されるから目安以上には使えないけど。面倒なのでやらないけれど、上場企業の決算書に現れている「サブプライムローン」という言葉の数をカウントして、これをグラフ化してみるとおもしろいと思う。「サブプライムローンの影響で」云々といった記述がどのように変動していったか。見方を変えれば、サブプライムローンという言葉が決算書の中から消えるに従って景気回復が本物になっていくということになるだろう。まあ、いつのことになるか分からないけど、来年の後半あたりになると、減少の兆しが出てくるんじゃないだろうか。2011年になるとかなり減るだろう。んー、でもサブプライムローン問題に端を発する景気後退云々でという記述は景気が良くならない限り消えないだろうから、完全に消えるのはいったい何年後になるんだろう。。。。。Googleトレンドで「増資」を調べてみる。こういうのって長期のスパンで見るとあまり正確なことは分からないなぁ。でも、ピーク時にどういうニュースがあったのかという視点で見ると、やはりおもしろい。野村證券とか、東芝の増資の話は三菱UFJの増資のときよりもインパクトはなかったのね。三井住友FGの増資の話もピークとしてはでてこないのか。もうちょっと細かく、増資の企業がピックアップされていると、時代によって、どの分野の企業が巨額の増資したかが分かって、おもしろいんだけど。とりあえず、2008年、2009年は金融業が多いっていうのは、今は見なくても分かるけど。5年も経つと忘れちゃうし。Googleトレンドで「倒産」を調べてみる。すごい右肩上がり。実態も倒産数がスゴイからなぁ。じゃあ、Googleトレンドで「自殺」を調べてみると、意外に伸びていないのね。まあ、この数年、3万人台で安定しているっていうのがあるからなんだろうか。むしろ、2004年がピーク値つけているのね。もしかすると、2010年か2011年頃に再びピークを付けるかな。それにしても、年間 3万人以上の自殺者が出るという状況が続く国というのは、どういうものなんだろうなぁ。という話は置いておき、何かを知るのに重要な指標となるような言葉をいかに抽出すべきか。単純な出現頻度(ランキング)では分からないけれども、一定期間のナニカの具体的な指標と相関するような言葉が抽出されるとおもしろいのだけど。
2009.04.11
コメント(0)
-
mecab-0.98pre1
mecab 0.98 のプレリリース・リリースキャンディデートという位置づけの mecab-0.98pre1 がリリースされた。1ヶ月ぐらいころがしておくらしいので、ビルドエラーなどがあれば報告してほしいとのこと。[mecab-users 347] mecab-0.98pre1 より。主な変更点は次の通り。Shift-JIS環境で半角カタカナの扱いに問題があったのを修正online learning のサポート (実験的)Wno-deprecatedをつけなくてもコンパイルできるようにした細かいバグの修正Python のバインディングが問題ないか、試そうかと思ったが、とりあえず、しばし忙しいので、2週間ぐらい先に試す予定。mecab (ダウンロード)
2009.03.08
コメント(0)
-
MozillaアプリケーションからJavascriptで MeCab を呼び出す
黒鉄 章さんという方が、xpcom-mecab (The Mecab library wrapped in XPCOM) が公開したようだ。Firefoxアドオンとして提供されている。Mozillaアプリケーション内の Javascript で Mecab の APIを呼び出せるらしい。XPCOM を使っているのね。C/C++ API を XPCOMインターフェイスラップして FireFox から使うときの参考になる。ただし、Firefox 3.0+ のみ対応のようだ。ちなみに開発者向けのものなので、一般ユーザが直接使うものではない。これ以前に Furigana Injector (Inserts furigana for kanji words (Mozilla Firefox extension)) も公開されていらっしゃる。ふりがな>RUBY<をつける FireFox アドオン。こちらは、エンドユーザーでも使うことができる。Furigana Injector をインストールすると、ステータスバーに「振」のボタンが表示されるようになる。実際にこれを使うためには、「XHTML ルビサポート」アドオンもインストールする 必要がある。ルビサポートがないと、文字(もじ)のように表示され、あるとルビとして漢字の上にちいさいひらがなでルビが表示される。ルビサポートをインストールしたら、ふりがな表示する漢字のレベルを設定する。この説明については、Furigana Injector をインストールすると表示される。スライダーを動かして、「最も一般的な漢字 n 語まで、ふりがなの対象外になります。」を調整する。また、参照しているページ上で右クリックすれば、ふりがなを消したり、ふりがなを振ったりする設定もできる。また、ステータスバー「振」のアイコンを右クリックしてでてくるメニューで「オプション」を選択すれば、「ふりがなインジェクターの設定」が表示され、ふりがな対象外漢字を追加したりすることもできる。「リンクを含む」をチェックしておくと、リンクの文字にもふりがなが振られる(逆に言えば、これを選択しておかないと、リンクの文字列にふりがなが振られない)。「全ページで自動処理」をチェックしておけば、自動的にすべての参照ページにふりがなが振られる。これをチェックしておかないと、毎ページ手動で「振」をクリックすることになる。漢字レベルを再設定するときは、「振」の右クリックのメニューから「ようこそのページ」を選択。これ、子供によいな。とはいえ、私に子供はいないが。。。。いや、麻生総理にもお勧めかwxpcom-mecab の方もインストールすると、下のようなテストページが表示される。あとは サンプル など参照して、自由に使ってねということ。ん、リンクを新しいウィンドウで開くと、そのたびにこのページが表示されちゃうなぁ。というか、FireFox を再起動しても、毎回、このページが表示されちゃうのはちょっと嫌かも。ふーん、FireFox + XPCOM でアプリケーションていうのも、けっこういいのかもしれないと今さらながらに思ったりする。PyXPCOM とかもあるし(ActiveState PyXPCOM)。PyXPCOM入門、PyXPCOM入門: 第2回。とか書きつつ、試す予定は今のところないが、参照したウェブページをどうこうするとかに使えそうなので、いつか試すかも。
2009.02.12
コメント(0)
-
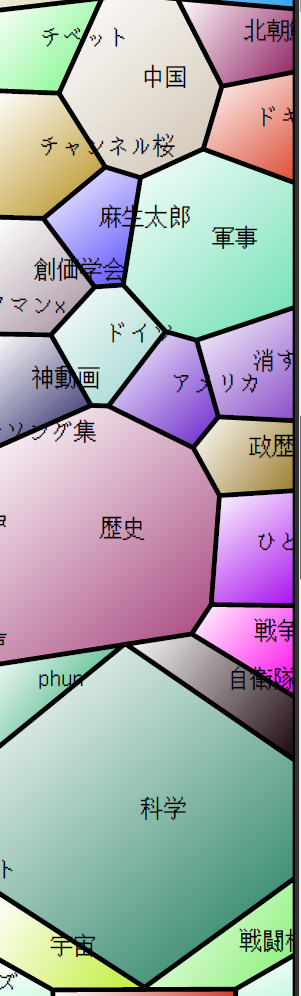
ニコニコ動画のデータ分析研究発表会の資料とか見てみる
グニャラくんの ニコニコ動画データ解析発表会でニコニコ大百科の宣伝を行いました(発表資料もあるよ!) を読む。GLOCOM で行われた ニコニコ動画データ分析研究発表会 について書かれている。「膨大なデータを分析して見えてくること」ニコニコ動画データ分析研究発表会 なども参照。発表資料一式 をダウンロードしてみてみた。むむ。はっきり言って、材料が材料だけに (ニコニコ動画のデータ分析だから)、それなりにオタク度が高い人でないと、そこに並んでいる言葉の意味が分からないものだらけだったりする。比較的理解可能だと思われる動物のあたりを見ても、「ぬこ」ってなんだよ、「ぬこ」って。Google で「ぬこ」。ぬこ に一致する日本語のページ 約 3,080,000 件。ふーん、かなり普通に使われているんだ。そもそも、「ニコニコ動画データ分析研究発表会」感想など(追記有) とか見ると、1つ目の資料からはまず「アイドルマスター」の横に「大愚熊P」がきてるのがいいですね。わからんだろ、わからんだろ、わからんだろ。「美希」「Im@sコラボPV」「真」「雪歩」という並びは『ゆきまこ』が『みきまこ』に対して優勢なのをよく表してるなあとか。まったくわからん。ニコニコ動画のデータ分析研究発表会を見た を見ると、亜美タグと真美タグがすぐ近くにあったり、その隣にロリトリオタグがあったり、東方はニコ全体でみると音楽のあたりにあるんだなぁとか、おっさんほいほいはボカロの近くなのかとかwその手のことを知らない人には、感想も意味不明になる。オヤジにはついていけねぇ。。。。でも、こういうニッチな対象というか細分化された対象ってのも、ある意味おもしろい。 ニコニコ動画データ分析研究発表会 のリンクにある資料とかも見てみる。なんか、楽しげね。マニアの切り開く境地というかなんというか。特定集団とその細分類集団のジャーゴンの分析っていうかなんというか。比較的小さい集団の方が、時系列なども捉えやすいだろうし。比較的小さい集団とはいってもデータ量はそれなりの量だし。実験用にちょうどよいのかもなぁとか。s.o.c.i.a.r.i.u.m なんかも、コミュニケーションのイベントログからソーシャルネットワークの時系列を生成し,そこから抽出されたコミュニティ構造の遍歴を可視化するソフトウェアです.というもので、これを使った発表もあったのね。時系列系は好き。ソースが公開されたら試してみたいな。とりあえず実行ファイルをダウンロードして動かそうとしたら、私の環境じゃエラー(FTGL Error: Fail to create FTGL font object)で動かなかった。まあ、何にせよ、おもしろがってやっているうちに、もっとおもしろいものが出てくるのかもしれない。肩肘張らずにおもしろがってやって、それを一緒におもしろがってくれる人がいるという環境が、そこかしこにできているのがよい流れかなと。とりあえずやってみるっていう。グニャラくんの資料に戻って、ゲーム系もアニメ系もよく分からないので、Voronoi Treemaps の中から自分の分かりそうなところだけ切り出してみる。自衛隊の位置がおもしろい。チベット、中国、チャンネル桜のあたりもおもしろい。実際にニコニコ動画とかたくさん見ていれば、一言二言言えるだろうけど、以前アカウント作ってちょこっと覗いただけなのでなぜにこういう結果になっているのか分からないが、おもしろい。ツールの話では、Cytoscape もおもしろそうだから、今度使ってみるかな。Cytoscape + R + igraphのようにも使えるのね。Cytoscape Japanese Documentation Project に日本語のドキュメントがある。
2009.01.30
コメント(0)
-
なんとなく音声合成を試す
大量の文書を読んでいると、だんだん目が疲れてくる。音声合成を使って、寝っ転がりながら聞きたいときがある。やっぱり、音声合成のソフトが欲しくなった。以前 ピグマリオン・コンプレックス とか、簡単に使える音声合成プログラム とか、書いたときにあれこれためしてみたが、改めて試してみた。フリーの音声合成ソフト Galatea Project は無償で使えるのはよいけど、うーん、やっぱり聞いて疲れる。少々、お金払ってもいいやと、比較的安く入手できるものを探す。Skyfish の JukeBox が、実用的に比較的使えそうな感じ。サンプルあり。個人向け製品の音声エンジンは富士通製(FineSpeech)だけど、デモを聞く限り、法人向け製品の日立KEシステムズの方がいい。とりあえず、体験版をダウンロードして使ってみたが、なんとか使えそう。個人向けでも 18,900円 (法人向けのは 200,000円~)。ちょっと高いかなぁ。PDF ファイルとかも、そのまま食わせることができて便利。対応ファイルフォーマット一覧。これはポイントが高い。英語のところだけ、英語用の TTS (Text-to-Speach) を使うようにできるのもいい。ちなみに青空文庫 のテキストを読み上げさせようとするとき、ルビが邪魔になるので ルビなしテキストの作り方 みたいなことをする必要がある。ルビつきの字を読みのみに変換するプログラム みたいのもある。もっと読ませる範囲が広がると、あれこれ処理を入れてやらないといけない。いろいろな形式のファイルから直接読めても、ゴミの文字が多いと聞いていて疲れるから、事前の処理が必要になる。となると、対応フォーマットの多さはあまりメリットでないとかいうことになるかもしれないが。そういう意味で、フィルタが欲しいところだな。ユーザ辞書程度じゃ、不足。もっと安いのはないかということで、あらためて、Windows だと無償で使える AquesTalk を使ってみるかな。でも、読みを渡してやらないといけないので、茶筅や MeCab あたりで解析させて読みを取り出さないと。とはいえ、IPA DIC を使った解析結果を見てみると、読みがちゃんと付かないことが多くて、UniDic を使えばいいかなと思っているうちに面倒になって諦めてしまっていた。と思っていたら、ドキュメントトーカ が AquesTalk を日本語合成エンジンとして使っていて無償で使えるのね (ダウンロード (DTALKERPV2115.EXE: 9.39MB))。 AquesTalk はそれなりによい線まで行っているので、なんとか使えるか。製品版「ドキュメントトーカ日本語音声合成エンジン for Windows」 は、無償版で付いている制限がはずれて、より実用的に使えるようだけど(無償版では、例えば、ときどき「ドキュメントトーカプラス フリー版で喋っております。」というメッセージが入ります。とかある)。サンプルは こんな感じ。SAPI に対応しているから、他の SAPI 対応のソフトからも使える。でも、ペンタックス音声合成ソフトウェア: VoiceTextデモンストレーション と比べると、やっぱりなぁ。。。。。MISAKI の声が欲しい。このレベルのものがあるんだと分かっちゃうと、使いたくなるのが人情。Misaki の声も入っている xpNavo は、税込:¥26,040 か。あれこれ探すうちに、電子かたりべ.com の電子かたりべプレーヤーをインストールして、高品質音声合成サービスを買えば、なんと VoiceText が使えるじゃんということに気づく。しかし、分かりにくいよなぁ、このサイト。。。。でも、Misaki の声には満足。とりあえず、一年で \3,150 をとりあえず購入した。ということで、Misaki にしゃべらせることができるようになった。現状で一番これがよい選択しかもしれない。しゃべるんです。 (シェアウェア) なんかも、電子かたりべプレーヤーをインストールした後なら、ちゃんと Misaki の声でしゃべるようになる。読み上げソフト開発と音声学習 の Text To Wav も使える。要するに、Microsoft の SAPI5 (Speech API) に対応しているソフトで VW Misaki が使えるようになるのね。自分でも何か SAPI 対応のソフトを作ればよいのだな。PlaggerでSAPI5を使ってフィード読み上げ 的なこともよいかな。SAPI5の音声ファイルを作るWSHスクリプト、青空文庫のテキストを音声ファイルにするWSHスクリプト2 が便利か。みたいのもできるようになるわけね。JavaScript などで英語を喋らせる方法 とか、Microsoft .NET Speech - 技術リソース とか参照。日本語の TTS がインストールされていれば、例えば、次のように sample.js とかファイルを作って、var spkr = new ActiveXObject("SAPI.SpVoice");spkr.Speak("今日は天気が良いですね。");spkr.Speak("外に出て遊びましょう。");コマンドラインからC:\work> cscript sample.jsで、しゃべっちゃうのだな。なんか嬉しい。Python だと pyTTS みたいのもある。Text to Speech in Python のような使い方。 でも、pyTTS はもう更新されてない。Speech API を使うだけだから特にバグもないからか不明。Text to Speech using COM (Python) みたいに win32com から直接 speak = win32com.client.Dispatch('Sapi.SpVoice') って、単純に使うのもいいか。A SAPI Module With Pitch and Create も参照。NVDA日本語化のためのTTSの開発 とか見たら、オープンソースのWindows用スクリーンリーダNVDAってのは、Python 使っているのだな。NVDAJp の方々が日本語化を進めているのね。MS SAPI を離れた世界では 日本語を音素に分解してくれるPythonスクリプト とかもあるのね。でも、「平成17年10月1日に調査された日本の総人口は、127,767,994人です。」のデモ(mp3) なので、研究用としてはおもしろいだろうけど、実用ですぐに使うのには辛い。でも、Microsoft 以外のプラットフォームで使えるところはいいけど。そういえば、GalateaTalk は、NHK の TVML の TVML プレーヤー で使われているのね。TV4U 日本放送協会 放送技術研究所 : DigInfo (YouTube) ということか。TV4U(TV For You)。こういうの や、こういうの みたいのもできるわけね。視覚的には iClone や CrazyTalkの方がインパクトあるなぁ。そのうち試してみるかな、とか書いているときは、そのまま放置モードになることが多いのだけど。話が逸れてしまったが、ペンタックス音声合成ソフトウェア: VoiceText は、とってもよい。実用で使ってみようという気になる。ただ、微妙に間をとって欲しいところで、間を取ってくれたりとかまではしてくれないときがあるから(変につながってしまうときがある)、癖をつかんで事前処理を入れた方が聞きやすくなりそう。あとは、やっぱり、ちゃんと読めないものは辞書を作るとか、書き換えをするとかも必要かな。とりあえず、たくさん使って癖をつかむか。
2008.12.28
コメント(1)
-
特定カテゴリーにおけるブロガーの熟知度ランキングをベースとする検索エンジン
ブログ検索結果をマニア/ファン指向度順に表示、実験サイト公開 を読む。京都産業大学、きざしカンパニー、情報通信研究機構(NICT)は1日、重要で信憑性の高いブログを探すことを目的としたブログサーチエンジンの実証実験サイトを公開したと発表した。 特定カテゴリーにおけるブロガーの熟知度ランキングをベースとする検索エンジン なのね。プレスリリースを見てみる。「重要かつ信憑性の高いブログに、より容易に、より速く到達する」ことを目的としたブログサーチエンジンを開発、実証実験サイトを公開 本実証実験サイトでは、検索キーワードに対して、キーワードに関連するマニア/ファングループを抽出し、そのグループ内のブロガーの熟知度順にブログ検索結果を表示します。趣味嗜好性・価値観に基づいたグループ、かつ、当該グループにおけるブロガーの熟知度順に結果を表示させることで、情報閲覧者が、自身にとって重要かつ信憑性の高いブログに、より容易に、より速く到達できることを目指しています。 発想的にはおもしろいところ。熟知度をどうやって判断するか、どうやってマニア/ファングループを抽出するか。書き手のグルーピングと文書のグルーピングをしているのね。 kizasi・京都産業大学 共同研究プロジェクト を見てみる。 感情表現に着目していたり、グルーピングしていたり背後にあるおもしろさは感じることができるものの、んー、精度とかインターフェイスの作りとかは改良の余地ありかなぁ。方向的にはおもしろいけど、現時点では実用的でない印象。こういうのって、2単語で検索した方が精度的におもしろいものになると思うのだが、対応してないのね。Internal Server Error になる。。。。。Google などで検索すると追加キーワードが表示されるのと同じように、単語で検索したあと、もう一つなにか選ばせた方が精度が出ておもしろいものができるんじゃなかろうか。フレッシュアイの コトバノウチュウとかは、2単語以上のキーワードの威力を認識して作った感じね。論文ありサービス、コトバノウチュウは刺激的 (2008.09.21)。
2008.10.02
コメント(0)
-
論文ありサービス、コトバノウチュウは刺激的
経済や株価について書いているとネガティブかつ後ろ向きになっていく自分を感じるので、明るい未来を少しでも描けるようなことも書こう。ということで、コトバノウチュウを再び取りあげる。すでに フレッシュアイのコトバノウチュウおもしろい を書いたが、9月1日に コトバノウチュウのβがとれた ので、再び取り上げる。これはやっぱりおもしろいと思う。コトバノウチュウは、ウチュウに瞬く話題のコトバをクリックするだけで、欲しい情報をまとめて収集できる検索サイトです。サイト内での体験を通し、あなたにぴったりの情報をお届けできる、そんなサービスを目指して、コトバノウチュウは無限にひろがり続けます。どうぞコトバノウチュウで未知なるコトバとの出会いをお楽しみください。 コトバノウチュウ にアクセスすると下のような画面が出てくる。後はとりあえず、目の前に表れたものをざっと眺めて、気になるコトバをどんどんクリックしていけばいい。それだけでもおもしろい。そのときに、漠然と何か考えるとかなり楽しめる。第一にキーワードの出し方がおもしろい。フレッシュなニュース、ブログ、テレビから抽出したキーワードが最初に表示されるので、とりあえず「今」に関心がある私にはとても気持ちがいい。そして表示されるキーワードには 適合性フィードバック (レレバンス・フィードバック) なる技術を使っているらしい。だから、これをユーザー層が変化すると表示されるものも変わるかもしれないが、今のところ時事問題とかに興味がある人がユーザー層としてそれなりに多いから私の興味ともマッチしたものが出てくる。芸能あるいはスポーツに興味がある人ばかりが使うようになってしまうと、最近なんか表示されるキーワードが...とかなる可能性もあるかなぁ。第二にキーワードの距離感が実によい感じ。平面上に等間隔でない状態で並べられると、自然に頭の中で意味を見いだす動きが始まるので刺激される。想像力をかき立てるもの、相関図ジェネレータや「勝手にブログ評論」から脱線あたりを見ると、私がこの手の表現方法に弱いのがわかるかな。刺激物が好きなんだよなぁ。たとえばリーマン・ブラザーズを中心としたキーワードだと、バンク・オブ・アメリカ、ニューヨーク証券取引所、ライブドア、金融庁、サブプライムローン、アメリカ合衆国が表示される。この感度がよい感じ。ちょっと残念なのは、時系列的には AIG も出てきていいかなぁというところ。時間とともに変化していくだろうから、そのうち出てくるか、出てこないままか不明。連邦倒産法第11章や民事再生法などは4/5に出てきている。とりあえず 1/5 ~ 3/5 まで並べて見ると下のような感じ。米AIG公的救済 の方には、「米リーマン・ブラザーズ破綻」が出ているんだけど。ニュース等での扱われ方と、ユーザーの反応の仕方で変わって来るところだろうから、いつも私が期待するものとならないのは仕方あるまい。が、基本的に、いい感じに出てくるので感心する。ちょっとここで、連想検索エンジン reflexa でリーマン・ブラザーズを検索してみよう。さあ、どっちが今の話題を中心に探索的な検索を刺激してくれるか。想 IMAGINE Book Seachではどうか。リーマン・ブラザーズだけだとおもしろい結果にならない。「リーマン・ブラザーズ 金融 破綻」ぐらいで検索するとおもしろくなってくるので、結果のページを何分間も眺めて楽しめる。でも終着点があくまで書籍になってしまう。最新のニュースに対応するようには探索しづらい。reflexa も 想 もどちらもおもしろいのだが、今旬の話題を中心として私の脳みそを刺激し、最新のニュースにたどり着く目的には向いていない。コトバノウチュウの場合、リンクをたどっていたら。米リーマン破綻:欧州部門、野村が買収交渉 モルガンからも出資要請なんて出会いがある。んー、野村も大分痛んでいるだろうから、どうなんだろう。欲しい部分をうまく切り離してもらって、欲しい値段で都合良く買えるだろうか。キーワードからニュースにたどり着くと刺激してくれるのだな。麻生太郎みたいな人間のキーワードを見てもおもしろい。麻生太郎:メディア別にみる話題度推移 みたいなものもおもしろい。ニュースの話題度だから、ブログみたいに簡単に操作効かないからね。記事数とクリック数の関係も意外に興味深いものがある。キーワードによって各キーワードのページに表示されるものが微妙にちがうが、企業の場合、R・PR情報や株価情報なども表示されれるのが便利。動画や画像、話題度、地図等、その他諸々マッシュアップされている。ちょっと残念なのは、スライダーを使った機能がなくなってしまったこと。ランキング表示があるから、それを見ながら動きはある程度頭の中で組み立てることはできるかもしれないが、トップページでグリグリっと過去にさかのぼれると嬉しいのだが。10分更新になったからなのかな。せめてトップページに6時間前、12時間前、24時間前、48時間前のボタンを付けて、過去の状態が表示されるといいのだけど。あるいは、別のタイムマシーンのページを作って、何日の何時から表示とかいうことができて指定秒ごとにスライド表示されるとか。んー、サーバーの負荷とか大変だからきついのかな。時間軸がやっぱり欲しいかなぁ。リコーのオンラインストレージサービスの quanp をちょっと応援したいなぁとか思うのも、3D のユーザーインターフェイスで冒険して頑張っているから。quanp は「quanp に保存した写真をデスクトップ上でスライドショー表示して楽しむ」quanp slideshow も公開されて、地道に発展しているのね。こうやってチャレンジしていく人たちって好きなんだわ。最後になってしまったのだが、コトバノウチュウを提供している Fresheye ラボ研究所長 酒井 哲也さんが、コトバノウチュウに関する論文第一弾が金メダル獲得 らしい。おめでとうございます。「クリックスルーに基づく探検型検索サイトの設計と開発」の論文 (pdf) と 発表スライド(pdf) を見てみる。ちなみに、本ブログエントリの表題は「論文ありサービス、コトバノウチュウは刺激的」としたのだけれど、なぜそうしたかというと、この論文のことを指しているのね。Google が話題になり始めた頃、ベースになる論文が公開されていたからこそ、日本でも Google の秘密 - PageRank 徹底解説 みたいな解説を書く人も現れて、刺激を与えて盛り上がったところがあると思う。新しいサービスの形の一つに、こうした公開論文で、私たちはこういう理論に基づいてサービス作ってますぜというのを公開しちゃう形態があると思う。なんだか凄いなぁ。なんでなんだろう。ここで論文が公開されているのといないのとでは大きな差が出る。ある程度、手の内をサラしてしまうことによって、その流れに乗るという選択肢だって生じる可能性が出てくるわけだし、もっとユニークなものを作ってやろうとかいう人も出てくるだろう。特許だって、そもそも、新しい技術を独占しないで公開し、適切な対価を払えば使わせてあげるよ、というのがベースにあるでしょ。とりあえず発表スライドを見てみると、研究の目的のところにユーザの情報要求の変化を促進し、検索開始時には必ずしも意識されていなかった有用な情報を提供する探検型検索サイト「コトバノウチュウ」とある。株式を頻繁に売買したりする人は、漠然と今起きていることから刺激を得て、だんだんとあるポジションをとるための確信に迫っていくとかいうことがあると思う。そんなときに漠然とした刺激から探索的に検索していく検索サイトというのはおもしろいと思うのね。テクニカルチャート派には不要だろうけどwユーザのクリックスルーがランク付けに取り入れられるということは、その話題に対する一般的な注目度も推し量る手掛かりになる。皆が反応する話題かどうかというのは、株式相場が大きく動くかどうか、そしてその方向の手掛かりになる。また、ユーザがランクを重視するのと同様に、株式相場は美人投票とも言われるようにランクが重視される。だから、とっても相性がよいと思うのだな。できれば、ロイター、ブルームバーグ、日経のいずれかが、このコトバノウチュウの背後にあるものを取り入れて、新しいニュースの見せ方にチャレンジしてくれると嬉しいのだが。Fresheye ラボ所長ブログ 検索メイニアックのコトバノウチュウ関連の記事コトバノウチュウに関する論文第一弾が金メダル獲得コトバノウチュウのβがとれたコトバノウチュウBetaの使い方見せちゃいますコトバノウチュウの企画書金融破綻とかに関連することを書くと気分が暗くなるが、こういうことを書いていると前向きな気分になってくるなぁw
2008.09.21
コメント(3)
-

Yahoo! の日本語係り受け解析Webサービス API 等
ちょっと今、時間がなくてできないのだが、Yahoo! が日本語係り受け解析のWebサービス APIを公開したのね。ヤフー、係り受け解析と指定形容詞係り先検索をWebサービスで提供 等参照。Yahoo! 日本語係り受け解析Webサービス を使って、ヤフーの日本語係り受け解析APIとサンプルプログラム「なんちゃって文章要約」 なんて作っている方がいらっしゃる。修飾はバッサリ省いちゃうのね。プログラムは Perl で書かれている。Python だと inforno の方が Python版Yahooテキスト解析 APIライブラリを日本語係り受け解析に対応させました ってあるので、そのうち使わせていただこう。ちなみに XREAで好きなバージョンのPythonを使う方法 があるらしいので、これも参考にさせてもらう。XREAはバイナリCGIが動くのでバイナリにしてしまえばどんなバージョンのPythonでも問題ありません。しかも、たとえばMySQLDBなどの拡張モジュールもきちんとバイナリに含まれるので、多少ファイルサイズは大きいですがアップロードするだけで動くので非常に楽です。 ということで、ローカルで作ったアプリを bbfreeze でバイナリ化して動かしてしまえばいいのね。とか書きながら、いつまでたっても XREA の方は放置したままだな。Yahoo! 指定形容詞係り先検索Webサービス がおもしろくて、「うれしい」「おもしろい」「すごい」「たのしい」「かっこいい」「かわいい」「きれい」「おいしい」の 8つの形容詞が係る単語を返してくれるのね。形容詞の数が限られているから、使い方は限定されるだろうけど、こういうのがサービスとして提供されるというのがおもしろい。ちなみに、「うれしい」の指定だと「うれしい」「嬉しい」「ウレシイ」といった異表記でもちゃんと扱ってくれるらしい。形容詞の数が限定されているから、用途も限られるがお手軽なのでよいかも。もっとも、ローカルでやるなら ctypes で CaboCha を使う みたいにすればいいのだけど、指定形容詞係り先検索Webサービスみたいに、形容詞を指定して係り先を抽出して分析してみるとかやるとおもしろいかな。日本語係り受け解析器 Cabocha 0.60 pre2 ちょっと使う あたりも参照。かな漢字変換Webサービス を使った例も見つけた。Yahoo変換 (sokoide.com/)。そう言えば、ロイターのセマンティックタグサービスAPI Calaris ってどうなったかな。10月あたりはこのあたりチャレンジしてみるかなぁ。最近、自然言語系をやっていなかったが 形態素解析辞書UniDic も 7/16 に 1.3.9 がリリースされているので、MeCab版辞書が使えるので試してみようと忘れていた。UniDic の特徴は、国立国語研究所で規定した「短単位」という揺れがない斉一な単位で設計されています。語彙素・語形・書字形・発音形の階層構造を持ち,表記の揺れや語形の変異にかかわらず同一の見出しを与えることができます。(詳しくはこちらのページをご覧ください。)アクセントや音変化の情報を付与することができ,音声処理の研究に利用することができます。詳しくは多様な目的に適した形態素解析システム用電子化辞書の開発(PDF)をご覧ください。 ということらしいので、IPA辞書使うよりよいはずで試そう試そうと思いつつ。。。。なのだ。せっかく税金を投入して公開してくれているものなんだから使わないともったいないよね。読み上げなんかさせる場合も、GalateaTalk Demo なんかは、chasen-2.4.1, unidic-1.3.0 で UniDic を使っている。玄箱galatea再挑戦 なんてやっている方がいらっしゃる。近代文語UniDic も公開されていて、これも試したいところ。普通に近代文語を形態素解析にかけると、あまり良い結果が得られないけど、これならいけそうね。ただし、「主として近代の論説文を対象としています。現在のところ,文学作品などでは必ずしも良い解析結果が得られません。」らしいけど。Python の統合開発環境に関してAptana Acquires Pydev to add Python Support to Studio で、Aptana Pydev か。そのうち試してみるかな。NetBeans の nbpython は、まだ完成度低いし(参考: NetBeans が Python/Jython に対応、nbpython M4.2 では ipython の Console が使えるようだ)。PyScripter は PyScripter で UnitTest を自動で生成 なんてできるのね。Python開発統合環境の決定版! PyScripter(for Windows)の紹介 あたりも参照。PyScripterの日本語化 も進んでいるのね。Windows 環境に限って言えば、これが一番お手軽だろうけど。Python のスレッドについての資料と Python の統合開発環境 (IDE) なども参照。でも、いろいろ試す割には、ipython とテキストエディタが多い私。たいしたもの作らないし。統合環境って、人のソースを見るときだけ使うことが多い。けど、このところ、あまりソースも見ないし、作ってない。その他、あれこれ最近、次から次へと、ニュース等のヘッドラインが流れてきて、それを見た人間が、どのような印象を持つようになるかに興味があったりする。「勝手にブログ評論」から脱線 あたりも参照。行動経済学 - 経済は「感情で動いている」と経済は感情で動く を読み始めた。ニュースのヘッドラインといえば、見出しに非常に気合いを入れて定評があるらしい カレーを食べて記憶力アップ…アルツハイマー予防に期待 とか読売新聞が記事を出しているけれど、新聞記事が信用ならないという例 なのだな。読売新聞やっちゃったね。「カレーを食べて記憶力アップ」は伝言ゲームだった (PSJ渋谷研究所X) や、カレーに使われるスパイス「ターメリック」には記憶力アップの効果アリ (slashdot) なども参照。私家版「ニセ科学用語の基礎知識」β1 (PSJ渋谷研究所X) とかもおもしろい。カレーで記憶力アップなんて、発掘!あるある大事典が生き残っていれば飛びつきそうなネタだったか。惜しかったなぁ。あるあるが生き残っていれば、効果があるって実験結果出してくれたろうにwマスコミって、刺激的なヘッドラインを求めて、間違いを犯し続けるのだなぁと改めて思う今日この頃。断片的な情報を元に頭の中に何かを適当に組み立てて投資行動に移ったとき、いわゆるノイズトレーダーとなるわけだが、ノイズトレードを盛り上げるのもマスコミの目標とするところ。株価が上がろうが下がろうが、とにかく刺激が大きくなるようなヘッドラインを考えているんじゃなかろうか。受ければ間違っていても構わないって?
2008.08.26
コメント(4)
-
OKI の音声合成すごい
OKI、口調や抑揚など肉声に近い音声を再現する音声合成ソフト 、自分の声で音声合成 OKIがソフト発売 から、自分の声ソフトウェア「Polluxstar(R)」(ポルックスター) あたりを見る。この名前の由来は、Polluxstar(ポルックスター)は、ふたご座の2つの星のうちの弟の星 Pollux(ポルックス)にちなんで名づけられました。あなたの声を大切にしたい、そして仲のよい双子のようにあなたの代わりに話しかけてくれるそんなソフトを作りたい、という思いが込められています。らしい。自分の声のサンプリングをして音声合成をするというところがおもしろい。初音ミクなんかも声優の声を使っているし、生の声をベースに声を作る方が、完全にデジタルないかにも音声合成ですって感じにならないのがいい。ただし、Polluxstar の場合は、初音ミクのようにできあがった声を使うお手軽な路線ではなく、音声収録から音声データベースの完成までは、約1ヶ月かかる 上、価格は個人使用向けPC版で100万円(税別)と高価なもの。「自分の声ソフトウェア」利用事例 にあるように病気治療で声帯を摘出された大阪芸術大学の牧泉教授が、2008年4月に自分の声ソフトウェア 「Polluxstar(R)」を利用して教壇復帰を果たされました。と、手や足を失った人が義手や義足を使うように、声を失った人が自分の声を取り戻すことができるというコンセプトか。自分の声を再現する音声合成ソフトウェア「Polluxstar (R)」の提供を開始 あの声でなければならない、そんな思いに応えます ということで 適用分野。「自分の声ソフトウェア」の音声の試聴 や 自分の声ソフト(Polluxstar)について を聞いてみる。いかにもな音声合成ではなく自然な感じがする。まだ、イントネーションや語と語の間の間の置き方等改良の余地はあるだろうけど、かなり良い線を行っている印象。病気や事故により声を失う方・発話障害が発生する方は、年間1万人にものぼるといわれています。 って、結構な数の方が声を失っているのね。もっと、こういう技術が安く使えるようになると、いいのにね。しかし、突発的な事故や病気で音声を記録する前に声を失ってしまったらダメなのか。そういえば、OKIとリクルートの「ラダリング型検索サービス」、経済産業省の「情報大航海プロジェクト」に平成20年度も引き続き採択 - 対話でユーザの希望を引き出して検索する次世代型サービス、より実用レベルを目指した開発へ らしいが、ラダリング対話エンジンを中心としたシステムを技術開発し、約800人のユーザを対象に転職者向け職業紹介ドメインにおける実証実験を行いました。その結果、平均33対話(システム発話とユーザの回答のセットで1対話)がなされ、平均32属性の情報をユーザから取得することができました。同時に実施したアンケート調査では、24%のユーザが対話によって気づきが得られたと回答し、コンピュータとの対話によってユーザ自身では気づかなかったニーズを引き出せることが実証できました。また、現時点で54%、2年後では75%のユーザが同サービスを使いたいという高い期待があることもわかりました。らしい。例えば「転職」というようにドメイン限定型だとある程度の効果が期待できるレベルにあるのかな。まあ、ドメイン知識の実装が手間暇かかるだろうから、現状では対費用効果の点から言ったらまだまだなんだろうけど、方向的にはおもしろいかな。まあ、ELIZA効果 とか考えると意外にうまく成り立ってしまうものなのかもしれない。でも、エキスパートシステム みたいなものと比べたときに本質的な違いってあるんだろうか。試しに「エキスパートシステム、ラダリング」で検索したら、個人の認知・評価構造の 確率的モデリングと応用 データ・知識の獲得と利用 が見つかった。方向的にはそういうものと類似した路線なんだろうか。旅行プラン作成支援ツール「トラベルコンパス?」を発売 - 観光地の位置・イベント開催日時情報と連携、誰でも簡単に最適な旅行プラン作成が可能に とかいうのもリリースしているのね。OKI といえば、なぜなら、給料が安いから とか ITPro - TechOn! の記事があったなぁ。「技術力には自信があるんだけど、どうもカネ儲けがヘタでねぇ」 OKI のイメージって変わっていくのかなぁ。こういう企業が良い意味で化けると、世の中おもしろくなるんだけど。売上げ的には小さくても、自然言語処理の技術力の強みを活かして一般の人にももっとアピールするとイメージを変えるのに役立つのかもしれない。村田製作所 なんかも自転車漕ぐロボットでイメージずいぶん変わったものね。
2008.07.29
コメント(0)
-
殺人予告をつぶやけば多くの人が注目してくれる時代
本当に危険な「ネット犯行予告」を検知できるか? - 総務省が技術開発へ を読む。新しく開発する技術は、情報通信研究機構などで開発されている「自然言語処理技術」を応用。単語に関わる文脈や時間的変遷を解析することで、「どの情報が本当に危険なものかを検知することができる」(総務省)という。表向きはそういうことで、ほんとうは日本版のエシュロンみたいのをつくりたいんじゃなかろうかと妄想w さて、そんなニュースが出たと思ったら、もう、犯罪予告を2ちゃんねるやブログから自動収集,投稿もできるサイト「予告.in」公開 した方がいらっしゃるのね。仕事早っ。字幕.in とかの方なのね。予告.in を見てみる。「今から部屋のゴキブリを殺します」って書いても、予告.in に表示されるのかなって試している人がいらっしゃるwこういうのがあると、確信犯は逆に注目を受けやすくなるから、びみょーなところがある。経団連会館に爆破予告 3時過ぎても異常なし とか起きているが、しばらくの間、この手のものもでてきちゃいそうな予感。殺人予告は表面上、無視して裏で対処策を打った方がよいのか、それとも、検知からして表で対処した方がよいのか。人の注目を浴びつつ、自分をその境遇に追い込んだと思いこんでいる何かに復習するという強い意志を持っている人にとっては、注目が増えれば増えるほど嬉しいことになるだろう。逆に、そうではなく、どこかで止められるようなものであれば、注目を浴びることによって、その時点で犯行を思いとどまることもあり得る。主として注目を浴びるための犯罪に対しては、それを煽る面がある。注目を浴びる可能性が高まるわけだから。でも、そこで満足して止まるのであれば、それはそれで、やるよりまし。両方のパターンがあるから、びみょーだなと思う。当面の間は、これ自体が話題になってしまうので、わざわざ殺してやると書く人も増えるだろう。しかし、それはそれで、実際に犯行に及ばない大量のサンプルを提供することになるので、よいのかもしれない。けれども、そんなところまで考えもせずに、よし俺も的な短絡思考に走った人が同じようなことを使用とした場合、そうしたサンプルに埋もれて、現実の犯行予告が見過ごされてしまうかもしれない。結局、空けてみないと分からない。国が数億円かけてやろうとしているという話、この方面に興味がある人にとっては、無駄になる可能性も高いけれど、やってみればと思ったりする。ただし、ベンダー○投げ、公開検証なしではなく、IPA の未踏プロジェクトでやっているような形で進めればいいんじゃなかろうか。あるいは、自然言語処理を学んだ新卒の学生を来年 5人とって、たとえば月給25万円で 5名雇い1年間、ネット上の殺しのサンプル集めと分類だけをやらせる。2年目に、システム化をするときに仕様検討に参加させる。25x5x12 = 1500万。管理費等合わせて倍がけで 3000万。まともな人を雇えば、さすがにツールなしで延々と見ているのはつらくなるので何か作る。だから 1日4時間はひたすら見る。それ以外は研究にあてて良いということにする。1年たったときの成果をふまえて、その後に、まともな予算を付ける。そのときに、監視をしていた人を大学に帰して研究室内で研究させるとかもありだろう。自然言語処理はいずれ人工知能が進んできたときに(いつのことだぁ)、重要な要素の一つなわけで、継続的に無駄金を投資する必要がある。 Google なんかがなんだかんだで国防省のお金が入っていたりするのと同じように、Powerset なんかも、そういうお金が流れていると思う。大規模ブログデータの研究基盤の構築―「Yahoo!ブログ」の研究利用による言語研究の新展開―、国立国語研究所、1,000万語分の日本語コーパスを試験公開 第1弾は「Yahoo!知恵袋」と政府刊行白書のデータ、最終的には1億語が目標 みたいな形にもっていくのもありかもしれない。いずれにせよ、成果を公にしながら、一般の人が対抗して、お前ら金とってその程度かよっ、と煽れるような形で進めた方がいいし、そこで得られた知見も公開性を高くすべき。そういう意味で、予告.in はその先手を取ったわけだな。これで、あれより下のものではお金を取ったら税金泥棒になる。元にもどって、殺人予告を検知した場合、それをリアルタイムに公開した方がよいか否かは、難しいところがあることも、十分認識すべき。私がテロリストであれば、わざと犯行予告をそうしたものにひっかかるように行うだろう。リアルタイムに広報するメディアがあれば、これほど都合のよいものはない。最近思うのは、ネットが普及したことによって、テロリストがテレビ局を乗っ取るというシナリオって急速にしぼんだなぁと。ネットになにかあれば、勝手に報道してくれるからね。犯行声明文を警察に送りつけて何かをする場合、その犯行声明が公にされる可能性は低いが、ネットに出しちゃえば、皆が勝手に宣伝してくれることになる。そういえば以前に 情報戦としての仕手戦とカブロボ で、メリーランド大学でテロの発生を事前に予測するポータルを開発とかの話題も書いたか。国がそれなりにお金を出してという背景には、そうしたことも念頭にあるんじゃなかろうか。だから、情報大航海プロジェクト的なものとは、また違った文脈も含まれていると思う。
2008.06.13
コメント(1)
-
社員教育への文書解析応用と、剽窃チェック
協和発酵工業の「教えない教育」が眠れる能力を目覚めさせた を読む。この記事はおもしろい。協和発酵工業では、シードウィン が開発した文章解析システム「文道」を使っているらしい。この文道を取り入れたシステム SAI は 日経産業新聞 2/7 社員の文章力 10秒で採点 の記事にもなっている。体言率と用言率に注目し、統計データの分析から書き手のプロフィールを割り出す。「体言率」は「考える材料の多さ」を表し、用言率が高いと他人への命令が多いとか、「助詞・助動詞の使い方からは他人に対する配慮の度合いが分かる」などの特徴を利用しながら、文章を通して、研修のパフォーマンスをチェックするのだな。これはおもしろい。研修は講義形式ではなく、自ら学ばせ、討論・発表というのが効果的なのは、新人研修などやっていると実感できるだろうけど、そこに留まらずに、もう一歩進んでいるところが偉いなと思った。安易なテストで効果を測定するのではなく、毎日書く活動報告を使って定量的な比較をするというのは良い視点だと思う。表面上の知識偏重にならないのがいい(まあ、そういうことも実際にはやるだろうけどバランスの問題として)。知識偏重にならないようにと表面上、心がける会社は多いだろうが、実はこれが意外に難しいところがある。数値偏重の今日この頃、研修をやればそれを定量的に示さなければいけないという風潮がある。そうすると、どうしても安易に知識テストをすることになって、これが結果として知識偏重になってしまう。知識偏重でなければ、何をして測定するのか。その一つの答えとして、こうしたやり方はありだと思う。さらに、同一の組織に所属する複数の人が書いた文章を解析すると、非常に似たパターンを示すという。人の思考傾向が、企業風土や企業文化といったものに一定の影響を受けていることを示唆する結果だ。中途入社が多い、中小企業の場合は必ずしもそうならないだろうが、退職率が比較的低い安定した職場の場合は、その傾向が強まるだろう。また、定型化された文書をたくさん扱うようなところも、その傾向が強まるだろう。ある意味での洗脳というかスタイルの定着が起きる。「お役所文書」的なイメージを考えてみれば、お堅い会社ほど、文書の傾向も同じようになる。逆に、締め付けが弱いところはバラエティーが広がるだろうが、逆にそれが、一つの特徴になるのかもしれない。天声人語風メーカー みたいなものを見ると、特徴的なものってあるのねぇ。特徴をつかむと、あたかも、そこが作り出したような文章を作ることができる。特におもしろいのは、このあたり。企業でこうしたことを継続的にやっていると、どの程度妥当性があるかも判断しやすいから、おもしろいだろうなと思う。例えば「リーダー」(低干渉・低指示型)と「マネジャー」(高干渉・高指示型)のどちらにより向いているのか、あるいは「物販営業」と「提案営業」のどちらにより適性があるか、といったことも明らかになる。何気なく書いた文章から、自分が気づいていなかった眠れる能力や適性が浮かび上がる、ということもありそうだ。でもですよ、「同一の組織に所属する複数の人が書いた文章を解析すると、非常に似たパターンを示す」ということと、個別のプロファイリングというのは、ある意味、相反するところがあるとか思えないこともない。まあ、大枠としてみると似ているけれど、細かいレベルに着目すれば個性は出るということなんだろうけど。ちなみに、文章の内容に無関係に書き手が特定されるという点は筆跡鑑定に似ているが、手で文章を書く機会が激減した昨今、文章解析はネット時代の筆跡鑑定とも言えそうだ。とかあるけれど、どうあがいても、筆跡鑑定のような高精度は出せるはずがない。まあ、この手の記事で、多々ある行き過ぎ表現ってやつだな。参考になるにしても、それで個人の特定が必ずしも成功するわけではないわけだし。だいたい、極端な成功例を持ち出してきてあたかもすごいようにサービスで書いちゃうんだよなぁ。でも、まあ、この分野、盗用の検知が進んでいるから、そちらから切り崩してもおもしろいところがある。コピペの論文を検出するとかは英国ですでにやっているようだし。たとえば、ラビン-カープ文字列検索アルゴリズム などを応用したものなどがあるのだろうか。plagiarism で検索すると、英語学科からのお知らせ: 2007 レポート等での盗作(Plagiarism)について) と Osaka Jogakuin College Writing Center: Plagiarism(無断盗用)要点の日本語説明 が見つかった。これは自動的にどうこうという話ではなくて、無断盗用を戒め、Plagiarismを避けるためにはどうしたらいいかの説明やリンクがある。上智大学のページには(リンクが切れているが)、plagiarism.org のリンクがあった。これはおもしろいリソース。そこからさらに iThenticate や turnitin など知る。そういえば、NHK chairman apologizes for reporter's plagiarism とか検索すると出てくるな。NHK記者記事盗用:長野放送局長が視聴者に謝罪 /長野 の話。まあ、今の報道って、まともに取材しないで垂れ流しが多いから、だんだんと末端の社員がおかしくなっちゃってるのかもね。こういう社員が出ないような教育っていうのは、難しいねぇ。マスメディアは、恥をかかないように剽窃チェックのシステムが必要かもしれない。その他、SAGrader や Criterion (Criterion とは)のようにレポートを採点するようなシステムもあるようだ。自然言語処理の世界って、まだまだこれからなところが多いから、応用システムもおもしろい分野が残されていると思う。ただし、地道で地味な分野だろうけど。でも、おもしろい。ちょっと違う話になってしまうが言葉の処理として、KiTT (KiTT とは)なども、おもしろいと思う。「感情」や「興味」に焦点をあてて、そこを自分らしさの基準とする。そして、似ている人と結びつけるといったコンセプトのようだ。残念ながら楽天ブログは、対応ブログ一覧に入っていないので、私は使えない。使えない。使えない。ブログには、「感情」や「興味」が知らず知らずのうちに表れます。KiTTでは、そんなブログの言葉を解析し、さまざまな「あなた」を読み取ります。新しいブログを書けば、新しい「あなた」を発見できるかもしれません。今のあなたに似た「知らない誰か」とつながることができるかもしれません。コンセプト: ブログ解析KiTTキット 自分らしいブログを書くさて、元にもどって、もし、会社の提携パターンの理想的なものと判断される文章パターンがあったとき、それにマッチする形の文章を書く人が理想的とされるかどうか。兵隊レベルではそれはそれでいいんじゃなかろうか。つまり、plagiarism のチェックにかけたときにパクリ度高しの人ほど、忠実な社員。ところが、そんな社員ばかりじゃ、やっぱり会社は沈滞するから、そうでない人、部分も必要。会社固有のモードやトーンを身につけた上で、自らのモードやトーンでも語れる人を作るとき、どういう形でチェックをかけるかというのはおもしろい課題でもあると思う。要領がよいタイプの人は、会社固有のモードやトーンを素早く身につけるが、意外に自分の言葉で語ることができずにおもしろくなかったりすることもある。逆に、おもしろいけど会社のカラーに合っているか微妙なタイプの人もいたりするだろう。そういう人をどのくらいの割合で許容するのかもおもしろ課題。
2008.06.08
コメント(0)
-
プログラム可能なニュース
New York Times,APIを公開しコンテンツをプログラマブルに を読む。New York Times API Coming も読む。日本語では、New York Times も API 公開へ とかにその記事の紹介がある。Google Earth上でNew York Timesの最新ニュースをチェック みたいな試みも進んでいるわけね。New York Times は Time Machine とかもあって頑張っているのね。1912年タイタニック号の記事 なんかも読める。ちなみに、日本の新聞社はこういう形で公開したくないだろう。特に、日本は過去を見つめるべきだなんて書く新聞に限ってwちなみに New York Times は購読部数とか苦しいからこそ、前のめりに新しい試みを試しつつ現状打破の道を進んでいるんだろうけど、朝日新聞なんかも、もっと真剣に新しい道を探った方がよさそうなものだが。ちなみに、ジョーク系では 便利な!天声人語風メーカー ver.2.2 なんておもしろい。もっともらしいものができる。古い話題が検索にひっかかってきた。検証、朝日新聞「天声人語」の盗用疑惑!。これ、自然言語処理的に類似度とったらどうなるかな。今さらだけど、ちょうど、福島中央テレビアナウンサーのブログの おい、人間としてのプライドはないのか? とか話題に上がっている時期だから。ふーむ、たしかにぱくってるな。しかし、ブログランキングに載るような人の記事をなんでぱくちゃったんだろう。不思議だ。でも不思議なことは多い。データねつ造の新日鉄子会社、JIS表示認定を取り消し とか、JFEに厳重注意 経産省、データ捏造で とか、いったい一流企業は何をやっているんだろう。耐震偽造問題、再生紙問題、あれこれあれこれ(あまりに多くて忘れちゃった)、日本中でほころびが広がっている。船場吉兆も廃業に追い込まれた。景況感の伴わない好景気は、結局、なりふり構わずで不正の連続で危うく成り立っていたのだなぁ、と改めて思う。まあ、新日鉄は 伯ヴァーレ、新日鉄傘下のウジミナスの全持ち株売却へ の話があるから、やたらと売り込まれてということはなかったようだが。。。。野村證券はけっこうあわてているだろう。しかし、新日鉄子会社の不祥事がニュースに載る直前にレーティングを上げるというタイミングがなんとも言えない。知ってか知らずか。。。。。とにかく、日本人がベーシックなところで、やっぱり倫理観を忘れてしまっているってことだな。突っ込まれれば無傷でいられる業界なんてないのだろう。景気の先行きが怪しいことより、その方が気にかかる。金には金で、どんどんと懲罰制裁型にならざるを得ないだろう。一流企業の不祥事続きにはうんざり。基本的には暗黙の了解で業界ぐるみでやっているから、一社出てくると、次々出てくるのも特徴なんだなぁ。そういえば、ロイターのセマンティックタグサービスAPI Calaris は、もうすぐ日本語の対応始まるんだろうか。ワクワク。そろそろ、英語版の方で少し見ておこうかな。とりあえず、やりたいことリストに入れておこう。
2008.06.01
コメント(0)
-
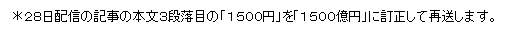
ロイターは訂正する
訂正:三井住友FG、08年3月期当期利益見通しを当初予想比‐19.3%減に引き下げ を読む。「1500億円」を「1500円」で最初に出しちゃったところは、まったくもう、という感じだけれど、ロイターは待ちえたときにはちゃんと訂正だすんだよな。どこぞの日本の新聞社とは違って。こっそり直す新聞社とは違う。最近では、粉飾決算で 1700円の支払い命令 とかがある。あぁ、でも、「与信関係費用が当初の1100億円から1500億円(訂正)に増加。」みたいのも、簡単な処理をすれば防げるものだから、報道機関は単純なミスを防げるように、チェックしすてむ作るべしだな。過去の訂正例を見れば、どのような機能を作ればよいか明確になるから、同じミスを防ぐようなレベルの実装から始めればいい。ニュース速報の本数が増えてるから、チェックする人間の負荷も高くなっているはず。そういう人の集中力に頼るだけじゃ、テンションが落ちているときに見逃しが起きるし、1分でも早く出したいという流れを安定化させるために、チェックプログラムを作るべき。海外勢の日本株買いが鮮明に、「持たざるリスク」も意識か って、そうなのかなぁ。そうなのかなぁ。「買い安心感」とか「持たざるリスク」とかいう言葉が飛び交うような状況っていうのは、とってもあれなんだなぁ。不思議なことに底堅いが増えると、加熱している状態でしばらくすると株価が下げるのはいつものこと。VIX指数との逆相関性が高い。
2008.05.02
コメント(0)
-
【初音ミク】 PROLOGUE 【ぼかりす】すごい、すごい
【初音ミク】 PROLOGUE 【ぼかりす】 を聴く。すごいねこれは。ここまでできるのか。初音ミクの“神調教”が自動で!? 「ぼかりす」に話題騒然。
2008.05.02
コメント(0)
-
日本語テキストの難易度を測る
名古屋大学の 佐藤研究室 が 日本語テキストの難易度を測る なるツールを公開しているのね。入力された文から難易度を判定して、1から13までのいずれかの値(小学(1年 - 6年)~大学)を出力してくれるというもの。帯:日本語テキストの難易度推定 解説を読む。新書の難易度推定 とか見てみると、これらのグラフの形から推定される難易度の順番は、やさしい順に、 次のようになります。(上のグラフは、この順番に並んでいます。)S2005sao - さおだけ屋はなぜ潰れないのか?S2004com - コミュニケーション力S1995net - インターネットS1999ren - 日本語練習帳S2006goo - Google 既存のビジネスを破壊するS2005kok - 国家の品格S2003bak - バカの壁S1993sei - 「超」整理法S2005kar - 下流社会S2006web - ウェブ進化論S2006tan - 他人を見下す若者たちS1981sak - 理科系の作文技術ふーむ。意外におもしろいかもしれない。本プログラムは、rubyで書かれており、標準的なunix環境で動作します。なので、あれこれ試してみるかなぁ。モデルのデータが入っているから、なんたらコーパスがないと動かないとかいう類のものじゃないのがよかったりするかも(新たにモデルを作るためのプログラムは同梱されてないから、独自の難易度モデルは作れないが)。でも、ことば不思議箱 の 基本慣用句五種対照表 や 日本語基本語彙表JC2 みたいのが、実は地味で手間がかかってすごいなぁとか思う。自然言語処理といえば 「国際電気通信基礎技術研究所(ATR)と内田洋行が語学教育の新会社を設立 ~ATR20年来の言語習得研究の成果を事業展開~ か。英語は「聞き取り」と「発音」から ATRと内田洋行、語学教育の新会社を設立 (@IT)。ATR はさんざん この手のこと やってきているからか。Robovie-X みたいなこともやっていたのね。そういえばそういえば、KH Coder に ”専門用語(キーワード)自動抽出システム” の TermExtract が組み込まれたらしい。
2008.05.01
コメント(0)
-

粉飾決算で 1700円の支払い命令
1700円の支払いをトーマツに命令 ナナボシ粉飾判決 を読む。なんのこっちゃと思ったら、1700万円のミスだな。証拠を残しておこう。すでに修正されているけど。以前、スポーツ報知が「三菱UFJの損失が5100億円規」と報じる でも指摘したが、マスメディアは、こういう数字間違えちゃダメだよなぁ。修正を明確にせずいつの間にか直しとくというのを平気でやるマスメディアというのは信用できない。だいたい、時間が経つと元記事消しちゃうところが多いし。ロイターとかも間違えることがあるが、間違えたときには訂正記事がちゃんと出ることが多いと思う。信頼あるニュースサイトから脱落リスト:スポーツ報知、Fuji Sankei Business i.それにしても、金額の転記ミスというのは、簡単なチェックプログラム作れば防げるのになぁ。
2008.04.19
コメント(0)
-
フレッシュアイのコトバノウチュウおもしろい
フレッシュアイ の コトバ ノ ウチュウBeta と テレビ・フォアキャスト を見てみる。おもしろい。質が高い。不満な点としては、経済系のはまだ弱い。試してみるのが一番なのと、あれこれ書いている時間がないので、細かいことは書かないでおく。ほんとにおもしろいし、質の点でも潜在的な可能性が感じられる。ちらっと見た瞬間にまあこの程度だろうなとか思ってしまうサービスとかもあるが、これは、そういうレベルではない。ちなみに、フレッシュアイのクリップは、私のお気に入りのサービスの一つ。Google アラート と併用しているのだが、気になる言葉を登録しておくとメールで新しい URL を見つけると送ってきてくれるのでとっても便利。Google アラートが他の人がどんな言葉をチェックしているのかが分からないのに対して(まあ、Google はこれがまたリソースのひとつなのだなぁ)、フレッシュアイはどんな言葉(クリップ)が人気があるのかが分かるだけでなく、下のようにクリップのアクセスシェアを円グラフにしてくれていたりするのがいい。基本的に、フレッシュアイはニュースを追いかけたりするときに質の点でレベルが高いのがいい。質が高いのは、検索メイニアック! とか見てみれば、まあ、こういうレベルの高い人が背後に控えていてやってるんだから当然って感じ。コトバノウチュウBetaの使い方 とか、見せちゃいますコトバノウチュウの企画書 のあたりに、コトバノウチュウの記述がある。これはとってもおもしろい。あと、レレバンス・フィードバック の視点は好きなので、これがコトバノウチュウみたいなインタラクティブなサービスがフィードバックの一つとして組み込まれて検索の質がまたさらに上がっていくと嬉しい。ちなみに、キーワードを視覚的に表してくれるサービスとして、他に Blog Keyword Visualizer とかあるが、これはこれでおもしろいとは思うのだが、コトバノウチュウのおもしろさにはかなわない。まあ、個人的な興味の問題もあるけど。
2008.04.15
コメント(2)
-
自然言語処理関連のライブラリ SlothLib をちょこっと使う
以前 自然言語処理関連のライブラリ SlothLib があるということでそのうち使ってみようと書いて、そのままになっていたので、ちょっとだけ使ってみた。使うといっても、とりあえず SlothLib Wiki: 実践解説 にあるチュートリアルをやってみただけだが。複数のチュートリアルのコードを一つにまとめてしまった。こういうものがあっという間に作れてしまうので、C# を使える人には便利かもしれない。クリックで拡大表示
2008.04.03
コメント(0)
-
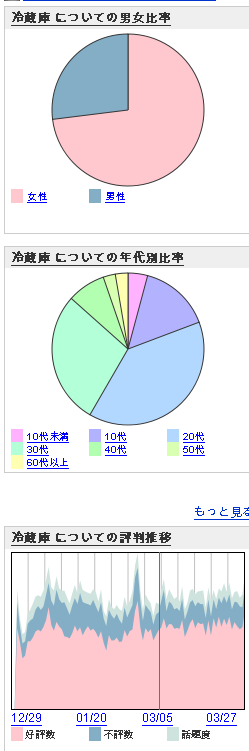
goo の評判検索、「性別」や「年代別」での口コミ情報の分析が可能に
「goo」がブログ上の口コミ情報を分析する機能を強化 ~「性別」や「年代別」での口コミ情報の分析が可能に~ ということらしい。(1)「性別」、「年代」別の絞り込み機能(2)「地域」、「血液型」、「星座」別の評判分析機能(3)評判グラフの表示期間の拡大(4) 画像を含むブログ記事のみを検索可能になかなかおもしろそう。「gooブログ検索」 を見てみる。実際に検索してみた結果を見てみる。冷蔵庫を見てみると、さすがに女性が多い。20代、30代が多いというのはおもしろい。40代以上が極端に少なくなる。今度は国をいくつか見てみる。中国、韓国、アメリカ、米国をそれぞれ見てみる。女性は韓国がお好き。そして、「アメリカ」を「米国」とは言う人は少ない。日本電気、NEC、富士通、FUJITSU も見てみる。日本電気とか富士通とか表記するのは男性の方が多いのに対し、FUJITSU が女性が多いってのは、どういうあれかな。日銀総裁、暫定税率、道路特定財源、福田首相とか見てみる。女性はそうしたことに感心を示さない傾向にある。値上げ、値下げ、値上がり、値引きを調べてみる。値上がり、値引きといった感情に根ざした言葉の方が女性の感情には訴えるかもしれないとかふと思った。値上げは問題であるというよりも、値上がりすると困ると言及した方が有利だろうとかふと思う。これけっこうおもしろくて遊べる。どの程度正確は分からんけど、ある程度の傾向はつかめそうな感じ。もっとも、10代未満で、暫定税率とか、日銀総裁とかブログを書いている子供がそんなに多いと考えるとどうなんだって感じもするが。自動的に入ってくるものを拾っているところがあるのかな。もうちょっと、細かいところもちゃんと見て、どの程度、意味がありそうか見てみるかな。「環境goo」で「CSR検索」を提供開始 ~気になる会社のCSR活動情報を簡単に検索可能に~ で 環境 goo のリリースも出ているが、これはまたあとで見る。いいところついてきたと思う。
2008.03.28
コメント(0)
-
25kバイトの分かち書きソフトウェア
きまぐれ日記: TinySegmenter: Javascriptだけで分かち書き から TinySegmenter:Javascriptだけで書かれたコンパクトな分かち書きソフトウェア を見る。TinySegmenterはJavascriptだけ書かれた極めてコンパクトな日本語分かち書きソフトウェアです。わずか25kバイトのソースコードで、日本語の新聞記事であれば文字単位で95%程度の精度で分かち書きが行えます。 Yahoo!の形態素解析のようにサーバーサイドで解析するのではなく、全てクライアントサイドで解析を行うため、セキュリティの観点から見ても安全です。分かち書きの単位はMeCab + ipadicと互換性があります。ということで、25kバイトで書けるのか、すげぇー、と試してみる。雰囲気的には、そこそこうまく分かち書きしてくれるものの、実用上の精度としては厳しいかな。品詞もつかないし。でも、TinySegmenterは機械学習のみを使って分かち書きを行います。TinySegmenterは入力文すべての文字について、文字の前が単語境界かどうかを、文字、文字N-gram、ひらがな・カタカナといった文字種情報とその組み合わせを特徴量として使いながら、学習・分類しています。学習データにRWCPコーパスを使っているので、新聞記事には強いですがチャットやブログといったくだけた文、ひらがなだけの文の解析精度は高くありません。しかし、辞書を使っていないぶん、未知語の解析精度はMeCabより良い場合があります。ということで、技術的な観点からおもしろいし、学習対象を適切なものにすれば(分かち書きしたいものに合わせれば)、精度的にも実用的なものになるのかもしれない。おもしろいけど、んー、使い道は思いつかない。個人のブログで形態素解析を使えないけれども、分かち書きしてタグクラウドを作るのに使ったり、ページ内索引を作るのに使ったりとかできないことはないのかな。twitter とかで何か使えるのか。でも、ゲーム的な使い方は何かできないのかな。普段、これがしたいのに何が使えるかと探すことはよくあるが、これを使って何かおもしろいものはできないかということを最近してないな、とかふと思った。とりあえず、こういうものをさくっと作ってしまうところが、こういう人はすごいよなと思った。こうしてさらしておけば、誰か何かおもしろいもの作る人出てくるかもしれないし。パッと見た目でおもしろい感じがするものって、誰からおもしろい使い方を必ず見つける。で、もって凡人は、それを見て、ほーぅ、そういう使い方ができたかとまた感心するのであろうと 凡人の一人としては思うのであった。
2008.03.20
コメント(0)
-
言葉の入力だけで3Dアニメを生成
NICT、言葉の入力だけで3Dアニメを生成できるCGMサイトを公開 を読む。独立行政法人情報通信研究機構(NICT)が公開した「Anime de Blog」(アニメ・デ・ブログ)では、言葉の入力から3Dアニメを生成できるらしい。NICT の報道発表を見る。世界で初めて、アニメーションCGMの開発に成功 ~Web2.0による3Dアニメーションデータの収集・利活用~。今回開発した3DアニメーションCGMでは、アニメーションを部品化することや、再構成することで、新たなアニメーション・コンテンツを容易に作成できます。さらに、一般利用者がインターネット上で言葉を入力するだけで簡単にアニメーションを生成でき、インターネット上で共有のアニメーションデータを増やしていくことができます。例えば、利用者が、「誰?(例:お父さん)」、「何をする?(例:怒る)」、「誰を?(例:私)」、「どこで?(例:森)」など、一般利用者が使い慣れた「言葉」を使いシナリオを入力するだけで、これまで素人では作れなかったアニメーション・コンテンツの作成が可能になります。入力した言葉に対応する画像やアニメーションデータがない場合にも、写真や専用エディタで作成したアニメーションをアップロードすることで、一般利用者がこの共有データベースをカスタマイズできます。アニメーションの部品化と、共有化による再利用とかいうところが肝なのかな。「空間的キーフレーム法」という、初心者でも直感的に利用できるアニメーション生成手法の一つ。ユーザが3Dキャラクタの姿勢と3次元空間中の位置を結びつけたキーフレーム(動きの基点となる姿勢や位置)を空間的に配置させ、その位置をインタラクティブに変化させることで、複雑なアニメーションを手軽に生成することができる。ということで、このあたりが CGM を成り立ちやすくするところか。Anime de Blog(アニメ・デ・ブログ) を見ようとしたら、ユーザー登録しないと見ることもできないのね。やっぱり、参照だけはユーザー登録しなくてもできるようにしておかないと、アレだと思うが。そのうち、見てみることにしよう。と、スタックリストに入ってしまった。いくらなんでも、プライバシーポリシーも何もなくていきなり新規登録しなきゃならないってのはどうなのよ。まずは、誰でもさんしょうできるようにしてほしいものだ。このあたりが、研究者的というか、なんというかというところだったりするなぁ。ちなみに自然言語からロボットを動かす的なものだと、自然言語によるアニメーションコントロールシステム : 傀儡とかある(ちなみに、この傀儡と傀儡師の館はまったく関係ない)。「傀儡」は、自然言語によって仮想空間上のソフトウエアロボットを制御するシステムである。ユーザは音声により仮想空間上のロボットやカメラに対して指示を与えることができる。システムはその指示を解析し、意図を理解し、その意図に適した動作をソフトウエアロボットに実行させる。また、本システムは照応・省略という言語現象を扱うことができる。これらを解決するために、各ロボットは照応や省略の対象となる名詞句を保持するためのデータベースを持っている。そして、ユーザの指令から発話行為を分析し、対話の主題を推測しながらこれらのデータベースを更新することによって照応や省略を解決する。この際、ロボットやカメラからの視覚情報も用いている。自然言語理解による知能ロボットの動作生成法 なども参照。古典的なところでは SHRDLU。NICT では 世界初、非言語コミュニケーションスキルを持つ多機能・高機能ヒューマノイドロボット -自然で豊かなコミュニケーションを実現する高機能ロボットを開発- みたいな研究も他にあるのね。自然言語を、理解し、知識と絡めた上で動作に結びつけたり、あるいは、動作を自然言語にしたりとか、やっぱりロボットが人間の通常生活の中に紛れ込むためには、将来的に必要になるところだな。まあ、なかなか難しい分野だろうけど、いろんな遊びをしながら、可能性を探っていくフェーズが続くかなと。本題に戻って「Anime de Blog」の場合は、作ったものをどうするかってところだなぁ。作ったものがブログパーツにできるとか、Flash アニメにするとか GIF アニメにするとか、なんでもアウトプットを利用しやすくしないと使ってくれる人も増えないかなと。まあ、使ってもらうためにあるというより、これを使って何かサービス利用ができないか考えて、サービス化できるような方向があれば相談してくださいってことなんだろうけど。いわゆる産学連携ってやつで。だったら、そういうところを強調したプレスリリースにするとか考えた方がよいんじゃなかろうか。今回、この成果をインターネット上のサイト(http://www.animedeblog.com/)に公開し試験運用を開始しました。ユーザ登録することにより誰でも利用できます。今後実用化されれば、ユビキタス社会に不可欠なデジタル・コンテンツの流通・利活用が可能になるものと期待されます。世界で初めて、アニメーションCGMの開発に成功 ~Web2.0による3Dアニメーションデータの収集・利活用~とあるけど、税金が投入されている以上は、どうしたいのというビジョンをもっと明確に出した方がいいんじゃなかろうか。民間の企業なら自分たちの資金でやる分にはおもしろいねぇで済むところだけど。関連論文のリンクつけるとかも必要だろうし。まったく表に何も出さずに淡々と研究者が研究していることに比べたら何かを表に出すのはよいとはいえるけれど。出し方をもっと工夫した方がいいんじゃなかろうか。。。。。
2008.03.05
コメント(0)
-
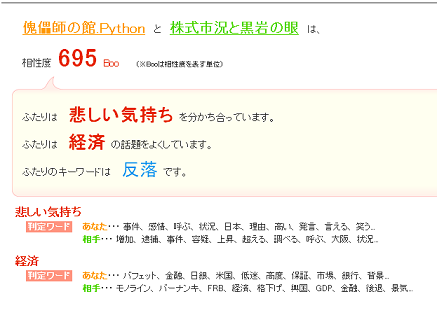
ブログの相性診断を Myピース ベータ版でやってみる
kizasi.jp で Myピース ベータ版とかいうのが始まっていたので早速試してみる。ちなみに、MyBoo ベータ版については、MyBoo ベータ版によると、傀儡師の館.Pythonは悲しい気持ちがにじみ出ているブログらしい ですでに試しているが、今日また試してみると、 「怒ってる感 がブログからにじみ出ています。話題に関しては 経済 について多く書かれているみたいです。」ということらしい。さて、Myピース ベータ版でいくつかのブログを試してみて、最近プログラミング関連より経済・株関連のエントリがけっこうあるので、その方面と相性を見てみる。ぱっと見た感じ、良くできている。株式市況と黒岩の眼と相性を見てみると、次のような感じ。サブプライム問題のまとめとだと次の結果。ということで、思った通り相性が高く出た。でもって、じゃあ しょこたん ぶろぐ はどうかと見てみると、相性が低いが、ちゃんと、マンガ、アニメとかのポイントが拾われている。ざっと見た感じ、そこそこ良くできている感じ(あらを探すと、共通キーワードが RSS になったりとか変なときあるとか、まあいろいろあるだろうけど)。こういうの見ると、だいたい、kizasi がブログのカテゴライズをやったときにどの程度の精度でできそうかというのが検討が着く。ただし、大枠で見たときのお話と、個別の記事をみたときはまた別の話がある。通常は相性がそれほど高く見えないけれども、このジャンルの話題については、相性がいい(同じようなカテゴリの単語を使っている)というブログの関係もある。つまり、ブログの過去のエントリをジャンル分け(タグを使ったりするなどもありだろう)し、特定ジャンルにおいて相性が良いかどうかを見るとかいうのもあると、貴方と共通性を持つ、お勧めのブログみたいなものをやったときに、共通性が高く、納得いくような結果が出てくるような気がする。たとえば、今は経済系の記事が多いが、Python を中心に書いているときに、相性が良いようなものも知りたいとか思ったりする。まとめて、Python の記事を書いて RSS の中がそれ系で埋まるようにしておいて、他のそれ系のブログと相性を見てみるとかすればいいだろうが、そうしなくても、あるキーワードを含むエントリだけを初期段階として抽出しておいて、そのエントリの相性を見るという感じのものがあると、おもしろい。似たブログを探すというより、似たブログのエントリをまとめるという方向性か。このページと同じような傾向のページを探して欲しいとかいう検索があるといいなとか。まあ、今の Myピース ベータ版とは、また違った方向のお話になるが。何はともあれ、インチキ系、ジョーク系の相性診断ではなくて、使われている言葉をちゃんとチェックした上での相性診断なので、API 化されるとまたおもしろい使い方が出てくると思う。力業でスクレイピングするなりして外部から使う手もあるけれど。
2008.02.17
コメント(0)
-
「駄目な言語はPHP」が流行っている
Google で "PHPは駄目な言語なのか?" を検索してみると、"PHPは駄目な言語なのか?" の検索結果 約 28,300 件 とけっこうな数になっている。"駄目な言語" の検索結果 約 41,600 件"駄目な言語" -PHP の検索結果 約 4,360 件"駄目な言語" +PHP の検索結果 約 36,700 件つまり、「PHPは駄目な言語」という言説が非常に流行っている。PHP は駄目言語に反論することを書こうとして、PHPは駄目な言語と言われるが云々と書けば、PHPは駄目な言語というページをさらに増やしてしまう皮肉な結果になる。「PHPは駄目な言語なのか?」の震源地は下のもの。ほぼ震源地は 3ページに集約されるだろう。Slashdot: PHPは駄目な言語なのか?Matzにっき: Attacking PHP404 Blog Not Found:「PHPなめんな」と「(Perl|Python|Ruby)をなめんな」の違い以下は話がかなり脱線。Google で「北畑隆生」を検索すると、論談:ノーパンしゃぶしゃぶ「楼蘭」顧客名簿がトップに出てくる。これは 北畑隆生 みたいな酷いリンクを張る人がたくさんいるということなのだろう。身から出た錆なのだが、北畑隆生は結局、Google 上は、ノーパンしゃぶしゃぶの顧客名簿なるものに名前が記載されている、デイトレバカ発言の事務次官ということで名前が残ることになってしまう。ちなみに、日本株売りが激しくなり始めたのは スティールを「乱用的買収者」とした高裁判断、海外勢に影響も (2007年 07月 10日) あたりからだと思う。ここにサブプライムローン問題の顕在化と自民党の参議院選挙惨敗が重なった。6割の売買を外国人に占められた状態で外国人の売りを誘えば株価が下がるのは当たり前な気がする。しかし、北畑隆生事務次官は、それを狙って日本人が株を買いやすくするチャンスを作ってくれたのであった。株価が下がったところで日本人が現物株を押さえてしまえば、そこから先は安泰だと。そして自社株買いについても事前に指導がされていた。さすが高級官僚は考えることが大胆だ(笑)可哀想だから 日本株式会社の救世主 というリンクも張っておいてあげよう。Wikipedia にページができているのね。話が変な方にいってしまったが、リンクテキストで知識が蓄えられるということは、反論しているつもりで、元の言説を強化することにも成り得るという皮肉を引き起こすことがあるということが書きたかった。ネガティブキャンペーンや情報攪乱を組織的に行われた場合、それにいかに対抗するか。Google 様に依頼して特定のページを Google 八分にしてもらうとかしても(可能な場合)、あちこちからリンクが張られていれば無力。では Google は Google 八分にしているページにリンクを張っているページまでも Google 八分にするべきか。否というのが普通の感覚だろう。さて、ここで Google 八分にされるようなページにリンクを張っているページをたくさん持っているユーザとはどんなユーザかを考えてみる。これらを抽出してクラスタリングしていくと、反社会勢力のクラスタができたりしてw 評判検索なんかも次世代のものを考えると、そうしてクラスタリングされレッテルを貼られた集団ごとの評判を抽出するなんていうところまでいくとおもしろいな。時代は 大人のサイトにとっても詳しい東京大学大学院講師たち まで来ているから、技術的には可能なところに来ているかな。「PHPは駄目な言語か」にしても PHP の重要サイトにリンクがたくさん張られているような人のページに書かれていることと、そうしたリンクがなく、他の言語の重要なサイトにリンクがあるサイトでは簡単に色分けができる。色分けを上で、そこに含まれている文章を解析して云々なんていう方向もあるのかなと。ファンの解析と嗜好の分析みたいな。そうすると例えば ××使いは××が多いとか出てきたりして。語彙が少ないとか、表現が貧しいとか、コピペが多いとか。
2008.02.14
コメント(0)
-
民主党参議院議員が国会議事録をデータマイニング、それはパンドラの箱
ふじすえ教授のやさしい政経塾 国会議事録をデータマイニングする を読む。大学の教え子が経営する会社と一緒に「国会の議事録をデータマイニング」するプロジェクトを動かそうとしています。らしいが、とりあえず記事では、「偽」を含む発言の分析がされている。これを見ると、政党別発言数では、自民党44%、民主党36%、公明党8%であるのに対し、「偽」という文字を含む発言では、民主党46%、自民党25%、共産党11%という順になりました。共産党は発言数割合が 6% で、偽を含むのが 11% ということ?ということは、一番、偽の追求が厳しかったのは共産党ということになるのかな。民主党ではなくて。いや、よく見たら、割合的には社民党が多いな。各党ごとに全発言中における「偽」を含む割合を見てみると(党ごとの偽を含む発言数 / 党ごとの全発言数)、自民党 0.50%、民主党 1.13%、公明党 0.997 %、共産党 1.625%、社民党 1.772% ということで、民主党は、共産党や社民党よりも「偽」についての追求が弱かったということになる。つまり、社民党がその少ない発言数の 1.772% を割り振ったので一番「偽」の追求には気持ち的に熱心だったと。党ごとの tf/df 的な見方だとそいうことになるわなぁ。罠。そこに気づいているだけに、偽を含む議員のランキングでは絶対数を使ってきましたね。これも、その議員の発言数の内の何パーセントに「偽」が出現しているかをカウントしなおしてください。いや、絶対数が重要なのですというのであれば、それでいいですよ。民主党の「偽」を含む絶対数は一番なのですから。変な割合だすことないじゃん。ちなみにリクエストとしては 2006年の「偽」もやってみて欲しい。偽メールとかw さらに、くだらない揚げ足取りなんだけど、「偽」という漢字は単独では意味を持ちません。では、国会でどんな「偽」を含む言葉が使われたかを見てみましょう。なのだけど、大臣、ことしの、〇七年を一番象徴する言葉が「偽」ということのようであります。[004/376] 168 - 衆 - 経済産業委員会 - 6号 平成19年12月21日ウソ行っちゃいけねいだ。「偽」って単独で使われてんじゃん。○内閣総理大臣(福田康夫君) 漢字。昨日テレビでやっていたやつですか。「偽」というのですね。○尾立源幸君 偽というと分からないですけれども、偽りですよね、「偽」。その点を中心に今日はお聞きをしたいと思います。 まず、「偽」、偽りに関して、若干、昨日から議論になっておりますが、年金の問題をまずお聞きをしたいと思います。[013/376] 168 - 参 - 外交防衛委員会 - 12号平成19年12月13日ゲラゲラ。いいかげんなこと書いちゃダメだよ。単独で使われてんじゃん。というか、そもそもこういう形で答弁繰り返して、偽が沢山出てくるように意図的にやってたじゃん。あ、申し訳ない、こういう意味のない答弁はカウントしないのだな。で、民主党は意味のない答弁をやっていたのだな。というか、やらせの部類になっちゃうなぁ、これは。ついでだから、改めて偽メールの問題とかもテキストマイニングしてみるとおもしろいかもしれない。という冗談はさておき、実際のところ、国会答弁はテキストマイニングしてみるとおもしろいと思う。あと、外務省とかウェブサイトにいろいろ載せているから、日本と外国との関係を国名をベースにしてやってみるとおもしろいと思う。加えて無償資金援助とか、訪問とか、いろんなキーワードを抽出して、それを元に国をクラスタリングする。誰かやってくんないかなぁ。ぜったいおもしろいと思う。まじめにやって論文書けば CIA からスカウトが来ると思う。あるいは、中国からかもしれないけど。それとも日本版エシュロンやってるところからか。あとは、go.jp サイトをクロールして、官僚や政治家の名前と財団法人名や独立行政法人名を同一文中に表れる頻度から、ネットワークグラフ化してみるとか、関係が始まったのはいつからか検索できるとか。補助金といちばん一緒に出てくる頻度が多い政治家は誰かとか。特定の企業名と一緒に出てくる頻度が多い政治家は誰かとか。そういうのがテキストマイニングでできるといいねぇ。特定の議員や官僚ごとに何に関心があるかとか調べるとか。go.jp のテキストマイニングは、パンドラの箱であろう。パンドラの箱は開かれた! 試み自体はおもしろいと思うので是非とも勧めて欲しい。ふじすえ教授、次回はもうちょっと緻密なの出してくださいませ。ということで、楽しみにしておこう。でも、やっぱり偽メールにしても 私に寄せられましたメールの中にこういう意見がありましたのでちょっと御紹介しておきたいと思うんですが、これは決して偽メールではありませんので、よろしくお願いします。[001/004] 164 - 参 - 総務委員会 - 20号平成18年05月11日みたいなものもあるわけで、あんまりラフなやり方をしていいかげんな結果を出すと、検証されたときにボロが出るので気をつけないといけないだろうな。傾向をざっくりつかむというのは手法の一つとしてあり得るにしても、そこから何かを言おうとする場合には気をつけないといけないかもしれない。やっぱり KWIC とかでざっとでも見ないといけないだろうな。最後に、正直なところ、国会議員の中には、国会活動を軽視し、地元で選挙活動を重点的にやっている議員が選挙で勝ち、国会活動をまじめに行っている議員が選挙で苦戦してしまう現状もあります。ふじすえ教授のやさしい政経塾 国会議事録をデータマイニングするまさに、小沢氏、テロ新法より大阪府知事選!衆院本会議を途中退席。地元じゃないからいいんですねw
2008.02.10
コメント(0)
-
ロイターのセマンティックタグサービスAPI Calaris
Reuters,新しいCalais Webサービス向けにAPIを公開 らしい。セマンティックウェブ時代へ向けてという感じか。まあ、炉板のようなコンテンツを持っているところがやり始めると俄然説得力が出てくる。自分だけでやっても、あんまり盛り上がらないだろうから、皆でやろうよぉという感じか。タグ付けはうちがやるからさぁ、という誘惑わくわく。Calais Webサービスは,パブリッシャ,ブロガー,Webサイトがコンテンツに自動的にメタタグを付けられるようにするサービス。検索における関連性を高め,アクセスしやすくする。さて、こういうコンテンツの有力な企業がこういうことを始めるとどうなるか見物。Calais APIを使った開発を促進するために,Calais Webサービスのコンテストを発表した。米Automatticのブログ構築ソフトウエア「WordPress Personal Publishing Platform」向けのプラグインを募集し,賞金として5000ドルを用意する。賞金がちょっと安いんじゃないかいというところが、あれだが。とりあえず、うまくいくかこっちの方向に踏み出してやってみませんかというお誘いと考えてみれば、まあ、そんなものなんじゃないかと。Jumpstarting Calais Powered Applications を見ると、「"a" buying company "b" 」のようなブログの記事に対して、"Acquisition", "Company A", "Company B" のようなタグを提示するとか、ブログの記事からセマンティックタグクラウドを生成するとか、ユニークな識別子(GUID)をつけて RSS に組み込むだとかいった機能を持つ WordPress のプラグインが最初のコンテストでは求められているようだ。こういうのを公開するということは、そのうちロイターのニュースはセマンティックウェブ化するのは確実な方向性としてあるのだろう。どれだけ直近でやるかというのをこのサービスがどれだけ受けるかというところで探ろうとしてるんじゃないだろうか。そして、ロイターのニュースとブログとを繋いでいく方向も考えられる。The Calais Web Service Roadmapを見ると、R3 July 2008 で日本語とかも対応するらしい。ということで、日本のニュースメディアも負けずにやって欲しいなぁと。一般の人は 日本語係り受け解析器 Cabocha 0.60 pre2 ちょっと使う でちらと書いた Cabocha とか 日本語構文解析システム KNP 使えば、辞書の問題はあるけどある程度実験できるんじゃなかろうか。サービスとしての真価が試されるのは、R4 あたりからか。スクレイピング的な要素が入ってきているか。セマンティックタグに対応していないサイトでもスクレイピングしてタグを付けて利用するなんていう方向になってくると、セマンティックウェブの流れも加速してくるかな。R4 September 2008Calais R4 is the next big step ? providing users with a development environment that will allow them to create new extraction capabilities unique to their needs. Want to analyze movie reviews to extract ratings? Automatically process the latest detailed weather forecasts from NOAA? This is the place where users will be able to create these capabilities and share them with the rest of the Calais community.The Calais Web Service Roadmap最終的にどうなるんだか別として、ロイターは87億ポンドで、トムソンによる買収を受諾 - 英国 でトムソン・ロイターズの金融情報・データ市場におけるシェアは、ライバルのブルームバーグ(Bloomberg)の33%を抜き業界トップの34%になる見込み。なわけで、金融情報・データ市場では優位になるとして、ロイターの野望としては、金融分野+αのところをもっと拡大したいとかあると思う。つまり、コンシューマーへの切り込みをさらに進める。これはすでにロイターのウェブサイトの存在感を考えてみれば、明白。以前は、ポータルサイトなどへのニュース配信(たとえば、Goo でも Yahoo! でもなんでも)がメインだったのに対して、この1年間で独自のサイトの存在感を上げる方向にある。ページビューはおそらんくこの1年でかなり上がっていると思う。コンシューマーに強くなることで逆にプロユースの情報も爆撃力がさらに上がる。ロイターはコンシューマー向けには経済のスポーツ新聞といった感じで刺激的なタイトルの記事を出してくる。日本経済は景気の下振れリスク高まった=大田担当相、 株式こうみる:日本株は業績というサポートを失いつつある=いちよし証券 高橋氏、インタビュー:世界経済安定に日本がとるべき政策は金融緩和など=自民元幹事長。スピード感と刺激の点で良い線を行っている。この半年、売り煽りすごすぎんだけど方向としては間違っていない感じだった。でも、徐々に刺激は刺激、中立は中立という感じになってきた。たぶん、刺激でトラフィックを集めるところから、質に変化してきているところもあると思う。例えば、asahi.com の 「基本的には利上げの方向」日銀・西村審議委員 と ロイター すべての選択肢を排除しない=金融政策で西村日銀審議委員 と比べてみる。どっちが判断を誤らせないか。利上げがないときに、基本的に利上げの方向なんていうのを書くのは大本営発表的だと思う。日本人なら「には」の意味をくみ取ってくれってところなんだろうが、水野審議委員が利上げの手を下ろしてるときに、利上げという言葉をわざわざ持ってくることもあるまいに。ロイターは市場の want に近いことを書いている。朝日新聞は日銀の want を書いている。日銀の want は市場と今隔たりがある。市場が比較的利上げに同意しているときに利上げできなかったのは痛い。ちなみに煽り好きのロイターでも「利下げの可能性」までは書くことができないので、排除しないという臭わせ方に止めたという感じがする。やっぱり、日銀発表の 西村審議委員記者会見要旨 をちゃんと見てみるか。生の読んだ方がおもしろいね、これは。誘導質問うまいというかなんというか。リセッション、もしくはリセッションライク、あるいはリセッションライト - これは1%以下の成長が続くことをいいます - になる可能性というのは否定できませんし、その可能性は以前と比べてかなり高くなっているということは確かだと思います。なんて言わせる方向に質問が持って行っている。誘導尋問。 リセッションライク、リセッションライトwの可能性は否定しないですか。普通に読むと、現状、利上げはしない。利下げもしない。現状維持。中長期では利上げ路線はまだ崩れてはいないけど、足踏み状態は否めない。ちょっと弱気虫はいる。だから、意地でも利下げしないとまでは言わない。将来的に利下げの可能性が明確にないとは言わない。長期的に見て弱いとか言えるような状態にはないって感じだけど、やっぱりこの閉塞感の打破のためには、中小企業の調子が良くならないとダメね。中小企業の悪化が進んじゃうと、経済指標よりもリセッション感が強くなる。日銀がリセッションとは言えない状況でも、実感としてはリセッションになる。日銀がリセッションライトという状況になれば、下々は完璧なリセッション状態だろう。しかし、経済の記事でロイターと朝日新聞を比較するのは残酷か。それにしても朝日新聞は日本の新聞なんだから、ついでに熊本の話とかも少しは取り上げてあげればいいのに。地方経済を気にしているんだったらさぁ。格差が問題なら、まずこういうときに、ちゃんと利上げだ、利下げだって話だけでなくて、一言でも熊本の話を出してあげればいいのに。新聞と違ってウェブサイトではスペースにそれほどこだわる必要もないわけだし。利上げの可能性が低いときにそんな記事書くならさあ。なんていうのはさておいて、ニュースメディアがセマンティックウェブの中心地となるように手を挙げたというところが、とっても興味深い動き。
2008.02.01
コメント(0)
-
日本語構文解析システム KNP
日本語係り受け解析器 Cabocha 0.60 pre2 ちょっと使う してみたが、京都大学の 日本語構文解析システム KNP も公開されている。KNPを試してみるにデモがある。ソースコードや Windows 版のバイナリも公開されている。JUMAN/KNPのチュートリアルのスライド (ppt)(京都大学学術情報メディアセンター, メディア情報処理専修コース「自然言語処理技術」, 2005/08/30) を見ると、インストールの仕方から使い方まで分かる(KNP に加えて、日本語形態素解析システム JUMAN と ActivePerl を使ったチュートリアル)。ちなみに、JUMAN も 5.1 のあとに 6.0 が控えているのね。リリース準備版のソースが公開されていた。そのうち試してみることにしよう。Cabocha と KNP の比較とか。とりあえず、くだらない比較。Google で 「Cabocha 係り受け」 の検索結果 約 5,350 件 Google で 「KNP 係り受け」 の検索結果 約 442 件Google で 「ac.jp での KNP 係り受け」 の検索結果 約 141 件中Google で 「ac.jp での cabocha 係り受け」 の検索結果 約 209 件数的には、Cabocha が勝っている。速度も Cabocha の方が速い。というか、JUMAN vs MeCab の時点で差が出てしまうので、MeCab + JUMAN 辞書とかで試すか。純粋に係り受け解析だけの速さを比べないと不公平だな。そのうちやってみよう。そもそも、正確さを見ないと意味がない。ということで、そのうち結果を比べてみる。どうもそのうちといいつつ溜まっていて、やりたいことが 10個ぐらいになってきたかもしれない。。。。。3歩で忘れる鳥頭。そういえば、「クチコミ好感度計算サイト BuzzTunes?」が2008年1月11日をもって一旦閉鎖になっているのね。なおブログ記事クロールと構文解析インデクシングについては引き続き質量とも強化しつつ、今後は外部へのAPI及び解析データの有料提供に特化する形で「BuzzTunes?データベース運営事業」を継続してまいりますので、何卒宜しくお願い申し上げます。 らしい。とりあえず、一旦閉鎖は残念。再開の日を待つことにしよう。
2008.01.28
コメント(0)
-
「勝手にブログ評論」から脱線
紹介 - 「勝手にブログ評論」評論 から 勝手にブログ評論 を知る。で、使ってみた。自分のブログを試してみると、有価証券報告書、マンダレイ、インフルエンザが抽出されて、いろいろ作られた。とりあえず、自分のブログでも使ってやってみるといいだろう。でも、アクセス数が多いから生成される文が短くなっているとかいうことあるのかな。端的には人工無能的やり方。RSS を読み込んで、そこから名詞のリストを作って、単語を選択してテンプレートに当てはめるというやり方をしているようだ。名詞の抽出は、これはストップワード検出というやり方でやっているらしい(正規表現で大胆に抽出している)。どういう正規表現かは あなたのブログ、評論します。 に書かれている。勝手にブログ評論がα版へと無意味にバージョンアップ に「勝手にブログ評論」の原理を解説をしたUstreamビデオがあったので見てみる。モンタージュ効果についてなども話している。ここで言うモンタージュ効果は、人間にはモンタージュ効果というものがあり、全く無意味な現象の組み合わせでも、その順番にストーリーを見いだしてしまう傾向があります。失敗のススメ、成功の罠あるいは、しかし人間の意識にはモンタージュ効果というものがあって、全く意味の無い数字や文字の並びであっても、意味を見出してしまうのです。つまり、3,8,1,5と続いてきたら、奇数が多いから次は偶数だ、などとなんの根拠も無いことを瞬時に思ってしまうのです。ジェフ・ホーキンスは知性とは予測だと定義しましたが、とんでもない。知性とは妄想する能力だと思います。3,8,1,5の並びにはなんの意味もありません。けど、人間は次を予「想」するのです。予「測」ではありません。予測とは根拠のあるものですが予想にはありません。ゲームと無料喫茶店とニュースサイトが毎日更新される理由のような話が出てくる。なんだか分からなくても、出てきたものを見ると解釈してしまう。そういう意味では、傀儡師を脳内メーカで見てみたら とか、想像力をかき立てるもの、相関図ジェネレータ みたいなのも同じカテゴリに自分の中では入る。あるいは、My三国志の相関図ツクールとかも。でも、視覚に訴えるものと、言語に訴えるものは、また、違うところが刺激される。クレショフ効果クローズアップの無表情な顔の映像に様々な映像を組み合わせてみると、同じ顔であるにもかかわらず、後に繋がる映像によって最初の顔の印象が変わって見えるというものだった。後の映像が食べ物なら空腹を連想させ、棺おけならば悲しみ、女性なら欲情という具合。逆に、何かの後に人の顔を繋げると、その表情によって映像の意味を変えることもできる。モンタージュ理論エイゼンシュタインのモンタージュ「パッと見ほとんどつながりがないようなもの同士をモンタージュして、ただ補完するだけではなく、新しい意味を作り出す」というモンタージュを始めるわけです。考え方としては、ショットAと、それに続く(空間的・意味的に明らかなつながりのない)ショットBが衝突することによって、新たな意味が生まれる、っつうことですね。これを衝突的モンタージュ(Conflictive Montage)と呼びます。一般的には、これがエイゼンシュタインのモンタージュ、ということになります。映画学入門 Week5 (その3)その他参考モンタージュ理論のクレショフ効果クレショフ効果: クレショフの実験を再現これに加えて、プライミング効果という言葉が頭に浮かんだ。先行する事柄が後続する事柄に、影響を与える状況を指して「プライミングの効果(または”プライミング効果”)があった」と称される。そのような状況における「先行する事柄」をプライムと称す。先行する事柄には、単語、絵、音などがありうる。例えば、「医者」という言葉を聞くと、その後「看護師」、「あかひげ」などという言葉の読みが、「富士山」や「帰郷」という言葉の読みよりも早くなるのはプライミング効果があったこととなる。記憶 (Wikipedia)そうすると、連想の技術、プライミング効果、履歴からお薦めWebページこのエントリーを含むはてなブックマーク が見つかる。ふとキーワード抽出法で検索してみると ドキュメントからのキーワード抽出法の研究 なんていうのがヒットした。従来、作成者がテキスト内容を解読し、シソーラス用語を用いキーワードを設定してきた。しかし、大量のテキストに対し、人手によるキーワード付与には限界があり、情報提供に対するタイムラグ、キーワードの質の揺れ等の問題が生じ、検索精度に影響を及ぼしている。 これらの問題回避のために、テキストの内容を自動解析し、テキスト内に出現する単語を対象にキーワードとして抽出するキーワード自動抽出システムが提案されているで、次に 行動ファイナンスが頭に浮かんだ。代表性バイアス、保守性バイアス、損失回避バイアス、トレンド追随行動、自信過剰、云々。行動ファイナンス理論と株式市場分析 (野村證券)。 野村證券【サブプライム直撃】赤字転落 からの孫引き 古賀社長は「激変する市場で絶えずマイナスを回避する状況を作り出せるかといわれたら、『神様でなければ無理』という考えもある」と釈明した。行動ファイナンスの社会心理学的基礎 なども見てみる。熱狂やパニックが起こるプロセスは、一般に6つのステップがある。構造的誘発要因ストレイン(緊張や不安)一般的な信念きっかけ要因特定の信念行動への動員そこから、東京新聞:不正取引で7600億円損失 仏大手銀、職員が越権行為:国際(TOKYO Web) に繋がる。すごい、しびれちゃう。これ自体はサブプライムローン問題とは関係無しに出した損失らしい。けど、サブプライムローン絡みの損失も何気に増えている。事件を起こしたのはジェローム・ケルビエル氏なる 31歳の人らしいが、約49億ユーロ(約7600億円)とは、すごい。脳天しびれただろう。よくバレずにそこまで損失を広げられたものだと思うと、優秀なんだか、優秀じゃないんだか。んー、でも、やはり、こういうときには、生け贄ってやつが必要なわけだな。ソシエテ・ジェネラルはまた、米サブプライム住宅ローン関連で新たに二十億五千万ユーロの評価損が出たことも公表。これら損失により二〇〇七年の利益が減少したことを認め、資本増強のため五十五億ユーロを調達すると明らかにした。巨額の損失を計上するついでに、サブプライムローンの評価損追加が二十億五千万ユーロか。それでもニュース上では、個人の不正がサブプライムローン関連の損失を覆い隠しちゃった感じ。Rogue Trader(詐欺師トレーダー)。SocGen trader cooperating with French police | Reuters にも顔写真がある。さらしもの。7600億円といえば、Microsoft が過去最高の売上でまたも好決算 で、純利益が 47億700万ドルだから、一人でマイクロソフトの純利益を吹っ飛ばしても余りある損失を出したというのがすごい。ちなみに営業利益が64億8100万ドルだから、それよりもでかい。やっぱりすごすぎる。脱線しすぎて何のことやら状態なので終わり。
2008.01.27
コメント(0)
-
企業の有価証券報告書を簡単比較できるシステム
矢野経済研究所など、企業の有価証券報告書を簡単比較できるシステムを開発 を読む。本システムでは、九州大学 廣川佐千男教授が開発した独自技術である「ConceptGraph?」および「MINDEX?」を活用、 利用者の方が入力した報告書から、特徴的なキーワードが抽出され、ツリー状のマップにより表示されます。これにより利用者は検索しようとしている 市場領域のみならず関連する製品、技術、ニーズ、周辺ビジネスなどに対する“気づき”を得ることができると同時に、そのキーワードを中心とした 市場トレンド全体を俯瞰することが可能となります。有価証券報告書を対象としたテキストマイニングサービスを開始 矢野経済研究所 も眺めて、トライアルページから デモ を見てみる。トライアル版では、分析対象企業の一部について、実際の機能をご利用いただくことができます。分析対象企業は「東芝、村田製作所、松下電工」の3社です。ということで、対象が限定されているが雰囲気は感じることができる。ここで使われている技術は Lafla(らふら):Laflaの技術Laflaの技術は大きく3つに分かれます。1つ目は、文章から単語を抽出し、その出現頻度に基づき単語間の関係を分析するテキストマイニング技術。2つ目は、単語同士の関係を視覚的にわかりやすく表現するための視覚化技術。そして、3つ目は、インターネット上から目的とするデータを効率良く収集するWebクローラー技術です。Lafla MINDEX なども見てみる。インターフェイスとしてはおもしろいとは思う。でも、それよりも トヨタ株など「51%取得」虚偽報告か、川崎市の企業・金融庁調査 ってすごいのがまたでてきたなぁ。トヨタ自動車、ソニー、NTT、三菱重工業、フジテレビジョン、アステラス製薬の6社の株式51%を取得したとEDINETを通じ発表した。その額、約20兆円。EDINETを見てみると、大量保有報告書の提出に関する調査について 本日16時12分頃、以下の発行会社に係る大量保有報告書が関東財務局に提出されました。 しかしながら、当該取引については、同報告書によれば、全体で約20兆円という異例な取引規模となっていることから、金融庁としては、現在、急ぎ事実関係を調査中であり、仮に虚偽記載と認められれば、訂正命令を含め厳正に対処します。と出ている。EDINET といえば ジャストシステム、EDINETに対応したXBRL形式データ作成ソフト の発表が 1月17日(プレスリリース [ 2008.01.17 ] 金融庁が4月より開始するEDINETへの XBRL形式での提出データの作成・活用ができる 「xfy Report Writer for XBRL(R) EDINET対応版 2008」を2月26日(火)より発売)。データ作るところまではいいとして、電子化されたものにチェックをどう入れるかというところがこれから問題と。何かを探すテキストマイニングではなくて、整合性検証のテキストマイニングとかももっと研究されてもよいのだろうな。あり得ない数字の validation なんていうのはおもしろい。固定的な数値ではなく、状況に応じて変動するけれど理屈上ほとんどあり得ない数字。先日も スポーツ報知が「三菱UFJの損失が5100億円規」と報じる とかあり得ないことが起きているし。本文とヘッダのチェックが自動的にかかるようにすれば、こうしたものは防げる。スポーツ報知って三菱UFJにちゃんと謝ったのかなぁ。元の話に戻って大量保有報告書問題。UPDATE1: ソニーなど6銘柄の大量保有報告に虚偽の疑いで調査開始=金融庁によると大量保有報告書の電子化は昨年4月から実施された。金融庁に、個人であれば住民票、法人なら定款を提出すれば、登録のためのIDとパスワードが付与される。入力されたデータは即座に公開され、事前チェックの仕組みがないことから、大量保有報告書の公開のあり方で議論を呼ぶ可能性がある。で、EDINET攻撃を確信犯が経済テロとしても使えるってことが今回ので証明された。しかし、もしウソでなく、本当に 51% も取得していたらすげぇーぉー。でも、「もし」って思う人がいないように、今回は事実関係を確認する前に「虚偽の疑い」ということで異例の報道なんだろう。一種の緊急事態対応だわね。仮に 5.1% と書くところを小数点が抜けて 51%と誤って書いてしまったとしても約 2兆円。それでもあり得ないだろう。でも念のため大口に確認してもそういう額が動いたことを裏付けるようなことはできなかったから、それもありえないでしょうとうことであえて「誤り」ではなく「虚偽の疑い」という表現にしたのだろう。とはいえ、背後関係なども明確にした上でないと続報が打てない状態か。チェックを厳しく確認が入るようにすれば、別の問題も起きる。管理を簡素化すればコストは減るが、簡素化しすぎれば問題が起きる。問題が起きたときに管理のせいにし過ぎれば、防衛的な動きにつながり過剰な規制と管理でコストが上昇する。高コストの組織や仕組みは誰かの利益になることがある。手続きを複雑化すればするほど、高コストの組織が正当化される。耐震偽装問題の追求は、結果として規制の強化を正当化し建築業界の窮状をさらに強め、景気減速の原因の一つとなった。痛し痒し。
2008.01.27
コメント(0)
-
農作業体験学習とテキストマイニング
農作業に教育効果 作文調査「苦労」「喜び」が頻出/近中四農研センター を読む。テキストマイニング系の話題なのでアンテナにひっかかってきた。この記事に「都市部で周辺に農家はなないが」にあるが「ないいが」はないでしょ。。。。。先進校の取り組みから農業体験学習の主要効果を特定しました の研究か。でも、なんだか結論ありきのあれで、テキストマイニングの結果新たな知見が得られました系ではないな。ちなみに TRUE TELLER みたいな高価なソフト使っていて、1ライセンスあたり 600万円~のソフトを買える程度の予算を持っているようだ。独立行政法人 農業・食品産業技術総合研究機構 近畿中国四国農業研究センター の 農業・農村のやすらぎ機能研究チーム なんてあるのね。独立行政法人 農業・食品産業技術総合研究機構 平成1 8 年度計画を見ると、日本版バイ・ドール条項 の記述もあった。産官学連携のモデルって 1980年代の米国がベースになっているのか。我が国においても、米国バイ・ドール法を参考とし、政府資金による委託研究開発から派生した特許権等を民間企業等に帰属させることにより、 ・政府資金による民間企業や大学での研究開発及びその実施化を活性化させる、 ・これらを用いた新しい商品の生産・販売、新しい役務の提供、新しい生産方式等の導入、新たな事業分野の開拓につながる、といった効果がもたらされ、新たな技術が活発に生まれる環境が整備され、全体として我が国産業の生産性向上が図られることとなる。 日本版バイ・ドール条項について(産業活力再生特別措置法第30条) 農業・食品産業技術総合研究機構って、年間 511億円程度の税金が投入されてるのね。さて、これは多いか少ないか。
2008.01.11
コメント(0)
-
Graphviz と日本語のフォント (2)
花園フォント (Hanazono fonts)(ハナミン) が公開されている。漢字データベース計画 で作られたものが公開されたらしい。これでまた一つフリーフォントの選択肢が増えたのが嬉しい。と思って Graphviz と日本語のフォント で試したのと同じように試してみたら、漢字以外(かな、カナ、アルファベット、数字)が文字化けしてしまうので単独では使えなかった。いろいろな字形を KAGE(影)システム でアウトラインフォントに比べて簡単に作れるらしいので、そのあたりがポイントなのかな。つまり、普通にはない字形を作って使いたい人向け。よく見たら「JIS X 0208:1997の6,355漢字+1非漢字「仝」の6,356字が収録されています。非漢字は含まれません。」と書いてあった。水面字フォント 、切り絵字、モフ字 というのを見つけたのでこれも試してみる。サイズは小さいと見づらいので大きめにしておく。水面字切り絵字モフ字あんずもじ も試してみる。あんずもじフリーフォント最前線 とか見ると、いろいろ見つかる。純粋な見やすさの点から言えば、手書き風文字ではない方が見やすいけれど、手書き風の文字って、なにか脳みそを刺激する感じがする。発想の転換をしたいときには、手書き風のフォントを使って表示してみるといいかもしれないとか思う今日この頃。
2008.01.01
コメント(0)
-
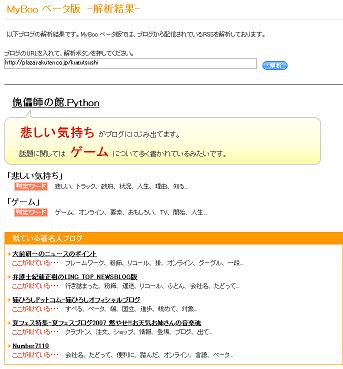
MyBoo ベータ版によると、傀儡師の館.Pythonは悲しい気持ちがにじみ出ているブログらしい
しばらく前に 新機能☆ブログ解析 『MyBoo』ベータ 公開! されていたので、使ってみる。http://myboo.kizasi.jp/ で http://www.plaza.rakuten.co.jp/kugutsushi を入れて検索してみる と、悲しい気持ちがにじみ出ているらしい。まあ、確かにそういえないこともないのだが、どの単語に反応しているんだろうか。「話題に関しては ゲーム について多く書かれているみたいです。」とあるが、確かにゲームについて書くこともあるが、そんなに多いかな。直近のものに引きずられるのか。最近の注目ワードも出してくれて、下のような感じ。ちなみに、最近使ってなかったなぁの JUSTBLOG に置いてある 傀儡師の別館 の http://kugutsushi.justblog.jp/ を入れてみると、もっと悲しい結果になった。TypePad はまだ対応してないのか、JUSTBLOG のがダメなのか。また、そのうち試してみるが、使えないブログもあるのは確認できた。ひさびさに kizasi.jp でサブプライムローン問題を見てみると、みんな忘れたがっているようだw。大分下がってきた。下がってきたのと問題が消えたのは別の話で来年、また上がることがあるだろう。株価と逆相関の関係にある指標になるな。底堅いを見てみると、頻度が低いから、株価は案外、底堅いかも知れない。まあ、とりあえず新年に入って株価が下げると底堅いの頻度が上がると思う。このところ毎年、この時期になると上昇する仕手株ダイワボウは、鳥インフルエンザの頻度が上がっていないにもかかわらず上昇している。今年は、そろそろ頭打ちになるんじゃなかろうか。年末、材料難なときに仕手化して、証券会社などもそれを盛り上げて、メディアも便乗してあげる傾向にあるが、メディアと証券会社が怪しい筋とと手を組む瞬間でもある。意図しようがしまいが同じことだ。鳥インフルエンザ関連のダイワボウ(3107)が東証1部値上がりランク3位に 商い閑散で低位材料株に物色向かうなどと煽るわけだな。普通は、ダイワボウマテリアルズ株式会社舞鶴工場の火災事故による損害額に関するお知らせ のような状態で、そんなに強く上がるはずもない。そもそも、そんなの関係ねぇって感じだけど。紡績の会社って昔は生糸の値段もあって仕手化するっていうのの伝統の延長線上なのかなぁ。こういうのはご本尊様の資金力と、どのタイミングでどうしたいかというところにかかっているから、よくわかんない。ただ、今年のはどちらかといえば、年末だから大口が空売りを買い戻しただけなのが発端で、これに、また今年もと火がついたような感じがしないでもない。これに証券会社などの自己売買部門が乗っかった。なので、しぼむのが早いかもしれない。ブログに表れる絶対数も少ないから、提灯筋が少ないような感じ。けど、やっぱり、こういうのはよくわからんなぁ。株価は下のような感じね。一回目の下げは、たぶん、仕掛けた人がわざと空売りを入れて売り崩して下げに入ったと思わせて (仕手化している場合よくあるパターン)、空売りが入り始めたら、急激に買い戻すとかやって二回目の上げになったんだろうけど。ちょうど上げても、下げても、どちらもありそうな感じのところに来た。
2007.12.27
コメント(0)
-
おもしろいを調べるとおもしろい
調べごとが行き詰まったので、何かおもしろいことをしようかと思って「おもしろい」を検索して KWIC (Key Word in Context) 形式で表示したものを眺めてみた。「おもしろいといえばおもしろいけど」「おもしろいといえないことはないけど」と言及されているものは、おもしろいか、おもしろくないか。「けど」は難癖の「けど」。Ajax を使った KWIC (KeyWord In Context)DevasKWIC FinderKWIC Concordance for WindowsText Finder (Freeware) Ruby on Rails + Tritonnによるらくらく全文検索+KWIC表示のチュートリアル全文検索システム『ひまわり』KWICコンコーダンス作成マクロ(WSH)WebLEAP ( - Webの知識を使った文書作成支援システム -)Antconcを使ってみようKWIC日本語辞書使用例検索・コロケーション抽出システム窓口 FOR 日本語コーパス言語学Tea -- KWIC ツール源氏物語の語彙検索(KWIC)日本法令英訳プロジェクト の Bilingual KWIC:対訳表現抽出支援ソフト koyori駆け出し教師のためのDual WISDOM 用例コーパス活用法Easy Pieces in Python: Keyword in ContextUsing Python, Jython, and Lucene to Search Outlook EmailPyWN("pin") Python Wordnet
2007.12.27
コメント(0)
-
国立国語研究所の言語コーパス整備計画はどうなるか
独立行政法人、少なくとも16を削減…政府計画の骨格 によると、国立国語研究所 が廃止、統合の対象となるようだ。そこで気になるのが、言語コーパス整備計画 KOTONOHA や 日本語話し言葉コーパス あるいは、形態素解析辞書 UniDic などのプロジェクト。ただでさえ、この手のことは着手が遅れていたわけで、後退してしまうのは惜しい。文部科学省配下ということだと、独立行政法人 科学技術振興機構 とかの開発センターの一つという位置づけになるのだろうか。でも、どうせなら 総務省系の 情報・システム研究機構 国立情報学研究所 に併合してしまった方が、よい面があるんじゃなかろうか。
2007.12.25
コメント(0)
-

ピグマリオン・コンプレックス
『ローゼンメイデン』の真紅が思いのままに喋る!? (アニメイトTV) ということで、NEC BIGLOBE の ローゼンメイデン「Alice Project」 を見てみる。使えないクズね とか、聞いてみるとそれなりの可能性を感じる。けど、いろいろ聞いてみると、きれいにしゃべらせるのは、それなりに大変そうな感じ。調べてみたら、“アニメ声”で自然にしゃべる音声合成技術、富士通が新開発 (2004/05/27) とか以前にあった。自然で多様な喋り方をする音声合成技術を開発 (2004年5月27日)とか聞いてみると当時の感じが分かる。初音ミクで自然に歌わせる、Alice Project で自然にしゃべらせる。音声合成もだいぶ進化してきた感じがするが、苦労せずに使えるようになるには、あともう少しって感じ。まだ、職人が頑張る領域だから。でも、それを遊びの一つにして使ってもらうことによって、データも蓄積されて、そこまで苦労しなくても使えるって領域にいずれ行くのだろう。でも、辞書とかの問題もあるだろうけど(未知語・新語の登場)、イントネーションの付け方って、その単語が置かれる場所によってずいぶん違ってくるから、大変なんだろうな。方向としては、人間がしゃべる、イントネーション等解析する、音声合成で声を作り直す、というのが使う側の手間はかからないと思うが。いつのことになるか分からないが、手軽に音声合成ができて、動画合成ができるようになると、とんでもないものが作られるようになるだろう。世界が混乱する事件も起きるかもしれない。ニュース配信メディアに真贋判定機が備えられる日がいずれ来るだろう。例えば、バーナンキFRB議長や福井日銀総裁のような地位にある人にもっともらしいことをビデオでしゃべらせてネットに流布させるとどういうことが起きるか。サブプライムローン問題で世界が一番冷静さを失っていたときにやったらどうだったか。まあ、クリティカルな事件が起きるのはまだまだ先のことだろうが、いずれそういう日が来る。100年以内かな。Galatea Toolkit ビデオデモ がもっと進化するとどうなるか。これを成功させるには、まず、オフレコトークの本物をネットに何回か流して、信頼できる筋という印象を作り、いざというときに使う。いたるところに監視カメラや盗聴器が仕掛けられ、それがリークされるという現象が先立っていることが前提条件として重要。一般の人が受け入れやすい状態になっているときに、それが起きると大変なことになる。考えてみると、もっと音声合成が進んでいたらオレオレ詐欺なんて、もっとすごいことになっていたかもしれない。技術だけが中途半端に進みすぎていないということが実は救いになることもある。もっとも、やっぱりマクドナルドの巨乳店長代理はテレビ朝日の仕込みでした♪ とかに見られるように、テレビは日常から偽造しているわけだが (テレ朝「報ステ」 マクドナルド報道で謝罪)、合成するよりも手がかからないコスプレ、顔隠し、音声変換手法を多用しているようだ。情報操作をしたい場合、その真贋あるいは信憑性の問題を超越したところで雰囲気が作られることがある。株式アナリストや経済評論家はいくらウソを意図的についても罰せられることはない。そういえば、サブプライムローン問題に起因する日本の金融機関の今年の損失は、合計1兆円ぐらいかな。サブプライムローン問題は日本の実体経済に影響を与えないと言っていた人たちは、総懺悔しなきゃいけないというか、振り返って分析してみるにつけ、わざとやっていた筋があるような感じ。久々にまた分析を始めてみるかな。あぁ、話題がそれてしまった。音声合成には期待しているところがあって、朝起きたときとかに、自動的にまとめておいた記事を読ませるとかできると嬉しいなとか思ったりする。動画なしの音声というのも、シチュエーションによってはけっこう使える。ペンタックス音声合成ソフトウェア って、けっこういい感じ。ページの右側にある、無料デモンストレーションとか聞いてみるとかなりいい感じ。VoiceTextデモンストレーション の方がいいかな。電子かたりべ.com のプレーヤーは、それなりに使える。あと 5年もしたら、かなりのレベルに粋そうな予感。あとはうまくいっていないところをいかにするかがうまくいけばいい。視覚障害者にとっては、現状でも昔に比べたらかなり嬉しいレベルになってきたんじゃなかろうか。問題は人でを加えずにどこまで自動対応していけるかというところ。無償でとりあえず試せるものとして、GalateaTalkDemo とか聞いてみる。以前に比べて品質は上がってきたのだろうか。まだまだ厳しい。AquesTalk - テキスト音声合成ミドルウェア とかも、それなりのレベルだと思うのだが、やっぱり聞いていると疲れる。でも、個人で使うとなるとこのあたり。簡単に使える音声合成プログラム でちょこっと試して忘れていたが、少し使ってみるかな。MeCab の解析結果の読みがあまり嬉しくないものを出してくれるのが気になる今日この頃、茶筅+ Unidic でいくかな。辞書の精度という点からしても、こういうことやるには 「国立国語研究所で規定した「短単位」という揺れがない斉一な単位で設計されています。」というところがメリットになるはずだし。でもって、まだ、Unidic は使おう使おうと思いつつ、ちゃんと見ていなかった。でもって最後にピグマリオン・コンプレックスってのは、日本語の Wikipedia にはあるけど英語版にはない。Doctor to speak at Yale on "Pygmalion Complex" (November 14, 2002) とか検索すると見つかるから和製英語というわけでもないようだけど、Google で Web 全体でも 1,590 件と用例としては多くないからかな。これに対して「ピグマリオン・コンプレックス」だと 4,510 件。用例としては多くないものの Wikipedia のページになっている。国ごとに付き合わせていくと、案外、その国民性とか編集ポリシーとかに違いがあるのかもしれないと思う今日この頃。ピグマリオンコンプレックス (Wikipedia)Pygmalion (mythology)Galatea (mythology)Pygmalion and GalateaMy Fair Lady
2007.12.20
コメント(0)
-
助詞に気をつけて Google で検索すると
「Pythonで」googleに、「Pythonで」で google 検索をするとおもしろいものが出てくるとある。自分がよくやるのは、「とは」で検索すること。検索語の直後の助詞に注目して分類するとおもしろい結果になるだろう。「Pythonって」とかやってもおもしろい。助詞を付けて検索すると、表示順が当然変わるので、今まで目にしなかったようなものにも出会える。これを徹底的にやるとさらにおもしろいことになるだろう。人名など固有名詞の場合は、特におもしろい結果が出るだろう。
2007.12.02
コメント(0)
-
日本語文節構造解析システムibukiC
岐阜大学、池田研究室 が 日本語文節構造解析システムibukiC を公開していた。まだ、version0.10 ということだが、おもしろそう。機能語部分は、実際はもっと踏み込んで、機能的・意味的内容から設定した6つの要素部に分割しています。たとえば、 「食べたのが悪かったようです」は、 (食べる Φ た Φ Φ Φ Φ 連体) (Yの Φ が Φ Φ Φ Φ 連用) (悪い Φ た Φ Φ ようだ Φ Φ 文末)のように解析されます。この要素分割も辞書記述で設定します辞書記述でいろいろできるということかな。このあたりに説明がある。形態素解析の ibukiK、文章構想解析の ibukiC、構文解析の ibukiS となっていて、公開されているのは ibukiC だから、係り受けの木まではできないのか。まあ、でも、こういうものが公開されるとは、良い時代になったものだ。日本語係り受け解析器 CaboCha/南瓜: Yet Another Japanese Dependency Structure Analyzer の文節の切り方と比べるとどんな具合なのだろうか。ibuki の場合、「機能的・意味的内容から設定した6つの要素部に分割」というところで、おもしろい用途が考えられるかもしれない。言語処理学会 第10回年次大会 プログラム とか見ると「長単位の機能語を辞書に持たせた文節構造解析システムibukiC」とか、言語処理学会第12回年次大会(NLP2006)本会議プログラム とか、言語処理学会第13回年次大会(NLP2007)本会議プログラム とかで発表しているようだが、ネット上の資料はあまり引っかかってこない。「言語・認識・表現」第12回年次研究会 で、「機能文節を導入した文節構造解析システム(ibukiC v0.20)」の発表が行われるらしい。「大学発ベンチャーにおける自然言語処理の研究開発‐三浦文法に基づく商用ベースの日本語統語解析システムについて -」宮崎正弘((株)ラングテック、新潟大学)] とか、以前 鳥バンク (Tori-Bank) すげっ で書いた 鳥バンク の「「CREST研究の成果と今後の課題」 池原悟 鳥取大学」とかの発表もあるようだ。検索していたら、1文字未知語を核とする未知語候補の抽出 なんてものが見つかった。ibukiC の辞書は貧弱だが、「語「川崎フ」などが未知語として、抽出できていた」らしい。その後、辞書はどうなったのかな。まあ、ダウンロードして見れば分かるか。しかし、試したいものスタックがどんどん膨れあがってくる。。。。。
2007.11.27
コメント(0)
-

自然言語処理関連のライブラリ SlothLib
なんとなくふらついていたら、情報爆発時代に向けた新しいIT基盤技術の研究 の SlothLib というライブラリが目に付いた。SlothLibは .Net Framework 上で利用可能なプログラムライブラリです。研究目的のプログラムが手軽に作成できるようになることのみを目的とし、プログラムとしての安全かどうか、高速かどうか、といったことは二の次と考えています。SlothLibの概要11月29日(木)にチュートリアルが開かれるらしい。SlothLib: Web検索研究支援プログラミングライブラリの資料 (pdf) とか見ると、形態素解析関連だけでなく、特徴ベクトル関連とかあってよいかもしれない。しかし SlothLibを利用する前に必要な前準備 Visual Studio 2005 うぉい。C# かぁ。。。。。でも、ちょっと使ってみようかな。機能的には次のようなものを備えている。これだけのものが継続的に利用されることを前提にしたライブラリとして日本で公開されたことはないはずで、そうした意味は大きい。自然言語処理関連(形態素解析と、英文切り分け、各種フィルタ)特徴ベクトル関連(文書の特徴ベクトルの作成と各種操作)データ操作(特徴ベクトルのクラスタリング)IO関連(外部文書読み込み、xdoc2txtの利用)Web関連(各種Web検索エンジンの利用やHTTPによるデータ取得)mono とかって、そろそろある程度使いものになるんだろうか。特集:全1回 .NET FrameworkをUNIXで動かす「Mono Project」 (1/9)。 Mac OS X と MONO で動かすIronPython とかやっている人がいたが、最新の状況はどうなんだろうか。Mono:Solaris とかもあるし、選択肢としてはあり得るってことか。
2007.11.09
コメント(0)
-
Google の日本語解析データ
グーグルが大規模な日本語の解析データを公開、「20%ルール」の成果グーグルでは、200億文に上る日本語データを解析したという。含まれている単語は、約2550億個。1~7gramのデータを公開しており、例えば7-gramのデータは11億種類以上にも上る。Google Japan Blog: 大規模日本語 n-gram データの公開 を読む。すごいなぁ。特定非営利活動法人 言語資源協会 の GSK2007-C Web日本語Nグラム第1版 で公開されているのね。といっても無料じゃないけど。「抽出対象となった文数は約200億文で、出現頻度20回以上の1~7グラムを収録している。」で DVD-R 6枚の 26GB(gzip で圧縮した状態で)。すごい量だな。ちなみに 個人・非会員42,000円か。んー、個人でも会員になれば 2,1000円か。ってことは、正会員(個人/団体):5,000円/年 だから、会員になっちゃった方がこの際、得だってことじゃん。ということで、これは言語資源協会のいい宣伝にもなって、二重の社会貢献だったりする。また、ブログの中に 北陸先端科学大学院大学 白井清昭先生 の名前があるので、大学と先生に対する後援にもなっていて、四重の社会貢献だったりする。こうやって、Google はアメリカでもいろんな大学と連携を深めて人材獲得の面でも、社会的な評価の点でもプラス点を付けながら大きくなってきたのだろう。Win-Win の関係を築くのが会社としてうまいのね。イメージとして、マイクロソフトが結果としてすべてを奪っていくイメージなのに対して、Google はシェアする会社のイメージがある。まあ、実際のところ、マイクロソフトはよいパートナーとなった会社には、実はそれなりに便宜を図って生き延びさせているわけだけど、一般的なイメージからすると排他的なのね。Google は検索市場で大きなシェアをとることによって、意識せずに結果として、いろんな会社をつぶしてきた面があるけど、マイクロソフトがライバルをつぶしてきたようなやり方じゃないから、イメージが悪くない。まあ、オープン性の高い会社と低い会社のイメージの差ってことだな。そのあたり、マイクロソフトもなんとか変えようとしてはいるんだろうけど。そういえば、マイクロソフトが Facebook に 出資した と思ったら、mixi、GoogleのSNS共通規格「Open Social」に賛同 か。OpenSocial ね。ミクシィと同時にOpen Socialに賛同した企業には、MySpace、Friendster、hi5、imeem、LinkedIn、Ning、Oracle、orkut、Plaxo、Salesforce.com、Six Apartなどがある。mixi、GoogleのSNS共通規格「Open Social」に賛同話を元に戻し、実際に作業したのは、工藤拓氏と賀沢秀人氏らしい。工藤氏は MeCab の作者、加賀氏は、賀沢氏は NTTコミュニケーション科学基礎研究所 知能情報研究部 知識処理研究グループだった人かな。機械学習とか知識習得、テキストマイニングのあたりを研究してきた人か。なるほど。「構造化データの機械学習」研究会 Machine Learning on Structured Data (MOST) にも二人の名前が並んでいるし、NTT の時代からいろいろやっている間柄なのかな。それにしても NTT も二人もおいしいところもってかれちゃって、もったいない。でもって、GSK2007-C Web日本語Nグラム第1版 は気分的には欲しいが、ちょっと遊ぶのに何万もかけられないので、そのうち宝くじがあたったら購入することにしよう(本当はほしくてたまらないのだが。。。。)。英語版の All Our N-gram are Belong to You も。まあ、何はともあれ企業イメージって、こういうものによっても地道に作られていくのねぇ。イメージってオープンソースでも重要で、たとえば組み込み型全文検索エンジン Senna とか、2ch 系に分類されるから、以前はちょっとねぇというイメージがあったと思うが、未来検索ブラジル、NTTデータの全文検索機能「Ludia」に「Senna」提供 (2006年10月) となればぜんぜんイメージが変わってしまう。それまで見なかった人が見るようにもなるし、NTTデータが使ってるんだからとかいって使いやすくもなっただろう。いかに、人がイメージだけでよいものであっても見る手間を省くかということ。まあ、日本の場合、権威主義というかなんというかあれだが、日本の場合、なかなか、そのもの自体を見ない人が多いだけにね。。。。こういうのを発表することによって Google が「日本語でも」重要な位置を占めるんだぞといういいアピールになっている。自然言語処理とかやっている学生の Google 脂肪率がいちだんと跳ね上がるんじゃなかろうか。そして、こういうニュースが流れると、Google っていったって、所詮は日本語は日本の会社の方が得意でしょ、というイメージを打ち砕いていったりする。そういう意味でも一般のニュースにこうしたものが載っていくのはインパクトがある。
2007.11.03
コメント(0)
-
TTM: TinyTextMining で簡単なテキストマイニング
TTM: TinyTextMining を見る。テキストファイルをドラッグアンドドロップすると、CSV 形式で結果ファイルを作ってくれる。自由記述のアンケートの分析のために作られたのかな。KH-Coder と比べると気軽に使える。形態素解析は MeCab を使っているので、あらかじめダウンロード、インストールしておく必要がある。結果として作られるファイルは、次のものでクロス集計まで出してくれるのでけっこう便利かもしれない。語のタグ別出現度数(単語頻度)語のタグ別出現度数(文書頻度)語×タグのクロス集計(単語頻度)語×タグのクロス集計(文書頻度)語×語のクロス集計(文書頻度)テキスト×語のクロス集計(単語頻度)使い方は簡単で TTM: 初心者のためのインストールガイド を見れば、誰でもすぐに使える。KH-Coder は 10月11日に新しいバージョンが出ていた。この手の解析をするときは、速度的には MeCab に劣るが、茶筅 + 形態素解析辞書UniDic とかいう選択肢がよいのかもしれないとか思わないでもない。オープンソースの人化音声対話エージェントのツールキット galatea は、この組み合わせを使っていたりするようだ。ちなみに UniDic は UniDic-chasen-1.3.5 がリリースされている。UniDicの特長 は、形態素解析辞書UniDicによると、国立国語研究所で規定した「短単位」という揺れがない斉一な単位で設計されています。語彙素・語形・書字形・発音形の階層構造を持ち,表記の揺れや語形の変異にかかわらず同一の見出しを与えることができます。アクセントや音変化の情報を付与することができ,音声処理の研究に利用することができます。ということで、自分の中では速度に惹かれて MeCab がよいと思ってきたけれど、辞書面からすると茶筅が優位って感じ。ちょっと比較してみるかな。
2007.10.24
コメント(0)
-

□という漢字を含む n 文字熟語を検索する、漢字ナンクロ支援用 Python のプログラム
子供でもできる Pythonへのトラックバックから Kawasaq通信 を見に行くと、Python ナンクロ用 というカテゴリがあったので見てみた。全漢字ナンクロ とかいうものを見てみると、ふーん、こういうのがあるのね。しかし、うぁ、うぁ、ぅあ。分からん。。。。ナンクロって、ナンバークロスワードパズルを縮めてナンクロで、ハドソンのニンテンドーDS用ソフト、ナンクロ ってのがあるのね。知らなかった。でもって、□ という漢字を含む n 文字熟語を検索する プログラムを Python で作ったわけか。なるほど、こういうのがないと辛い。こういうのを作りたくなった気持ちが分かる。それでも、全自動で全部埋めるプログラム作ってしまったら別の世界にいってしまうから、ちょうどよいヒント程度で良い感じか。ちなみに Django で作っているらしい。ナンクロをさらに調べてみると、プレイステーション版のナンクロは1999年発売だからけっこう長寿のゲームなのね。まあ、クロスワードものはマニアがつくからかな。ちなみに漢字ナンクロが出始めたのはいつだか面倒とりあえず、2004年には書籍が出版されている。オヤジはこんなのしらないのさ。数独なんかもちょっとやってみたけど疲れて途中で止めた。頭悪い。慣れれば快感なんだろうけど。クロスワードもやらないなぁ。人生自体がクロスワードパズルみたいなもんなので。。。。。人生半分終わったのに、いまだに埋まらないところばかりだ。。。。。
2007.10.17
コメント(2)
-
Amazonでの評判をランキング化
NECビッグローブ、Amazonでの評判をランキング化した「BIGLOBE みんなの評判β」を公開 らしい。どの程度の精度か見てみようと思ったが面倒なので止めた。といわずに、ちょっとだけ見て見ようか。ハリー・ポッターと謎のプリンス ハリー・ポッターシリーズ第六巻 上下巻2冊セット (6) のページを見てみると、ストーリーの評価で、ハリポタ世界は最高ですw2007年05月19日... はたしてスネイプは味方なのか、敵なのか、この先の展開が気になる終わり方であり、失われた主要人物は、本当に亡くなったのかのか、次の巻が気になる。...プラスになるべきものをマイナスにしちゃってるなぁ。「失わ」がマイナスなの??? 中立のところも、ちょっと安易にやりすぎ。プラス評価にすべきなのが中立になっている。簡単なやつはけっこううまく判断しているようなので、まあ、地道にチューニングしてくれろという感じ。印象としては、判断が難し目の単語表現については、下手に悪く倒すよりかは中立にしちゃうというポリシーっぽい。ドラゴンクエストIV 導かれし者たち とか見ると、「価格が高い」を中立にしていたりする。取り出し方は悪くない印象。この手のは、地道にやっていけば必ずよくなるはず。検証作業に人を雇って(安い人たちを何人も)、違和感があるような分類をまとめてもらって、再検討するとよいかも。まあ、開発者がちゃんと見直すのは当然だけど、サービスの初期にいっきに見直しをかけた方がいい。展開が気になる プラスのことが多い。重さが気になる マイナスのことが多い。パターンをどれくらい登録していくかによって精度が変わってきそうな印象。NECって格フレームとかの扱いは得意だろうから、お金さえかければなんとかなるだろう。下手に自社サイトのショップでの売りにつなげないで Amazon のアフィリエイトにしたところが、以前の BIGLOBE にはない路線なのかな。まあ、時代を取り入れてやるのはよいことだな。現状としては、「がんりましょう」レベル。
2007.10.16
コメント(0)
-
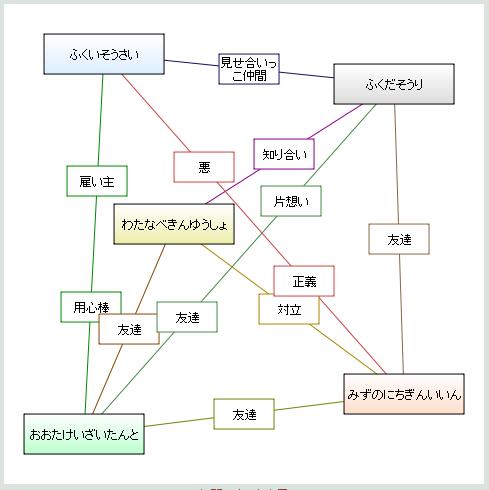
想像力をかき立てるもの、相関図ジェネレータ
kizasi.jp を見ていたら 相関図ジェネレータ が 3位に入っていたので見てみた。これはおもしろい。相関図ジェネレータ(そうかんずジェネレータ) はアクセスが集中して死にそうらしいので、相関図ジェネレータ 第二サーバ で試してみた。なんでも適当に関係を入れてみると、想像と創作を生むネタになる。出てきた結果を正当化する理屈を考えてみるとか。ネタがあれば人の頭は勝手に働く。脳内メーカーとかもそうだけど、適当に何か出てくるだけでおもしろがる遊び心というのがあるんだろう。みずのにちぎんいいん-[対立]-わたなべきんゆうしょ とかも、偶然とはいえおもしろいじゃない(ちなみに文字数の制限で「う」が切れた。10文字までみたいね)。ふくいそうさい-[悪]-[正義]-みずのにちぎんいいん、とか、本人たちが見たら笑えるだろう。偶然であってもおもしろい結果が出ている。ふくいそうさい-[雇い主]-[用心棒]-おおたけいざいたんとふくだそうり-[知り合い]-わたなべきんゆうしょふくだそうり-[友達]-みずのにちぎんいいんおおたけいざいたんと-[友達]-わたなべきんゆうしょみずのにちぎんいいん-[対立]-わたなべきんゆうしょおおたけいざいたんと-[友達]-みずのにちぎんいいんふくだそうり-[片想い]-[友達]-おおたけいざいたんとふくだそうり-[見せ合いっこ仲間]-ふくいそうさいふくいそうさい-[悪]-[正義]-みずのにちぎんいいん自民党の総裁+新四役バージョンもやってみる。こがまこと-[友達]-いぶきぶんめいたにがきさだかず-[友達]-にかいとしひろふくだやすお-[○○○仲間]-たにがきさだかずふくだやすお-[○○○仲間]-にかいとしひろふくだやすお-[○○仲間]-こがまことこがまこと-[共犯者]-たにがきさだかずこがまこと-[共犯者]-にかいとしひろふくだやすお-[尽くし攻]-[女王様受]-いぶきぶんめいたにがきさだかず-[攻]-[誘い受]-いぶきぶんめいにかいとしひろ-[攻]-[誘い受]-いぶきぶんめい理由を無理矢理にでも考えてみるとおもしろい。結局、ロールシャッハテストみたいなところがあるのかなぁ。出てきたものそれ自体より、そこから引き出されてくるものがおもしろい。
2007.09.28
コメント(0)
-

形態素解析にとって困った名前、町村大臣は困った存在
潘基文国連事務総長による町村大臣着任への祝意表明について という文字列を、MeCab で形態素解析すると、潘 名詞,固有名詞,人名,姓,*,*,潘,ハン,ハン基 名詞,固有名詞,人名,名,*,*,基,ハジメ,ハジメ文 名詞,一般,*,*,*,*,文,フミ,フミ国連 名詞,固有名詞,組織,*,*,*,国連,コクレン,コクレン事務 名詞,一般,*,*,*,*,事務,ジム,ジム総長 名詞,一般,*,*,*,*,総長,ソウチョウ,ソーチョーによる 助詞,格助詞,連語,*,*,*,による,ニヨル,ニヨル町村 名詞,一般,*,*,*,*,町村,チョウソン,チョーソン大臣 名詞,一般,*,*,*,*,大臣,ダイジン,ダイジン着任 名詞,サ変接続,*,*,*,*,着任,チャクニン,チャクニンへ 助詞,格助詞,一般,*,*,*,へ,ヘ,エの 助詞,連体化,*,*,*,*,の,ノ,ノ祝意 名詞,一般,*,*,*,*,祝意,シュクイ,シュクイ表明 名詞,サ変接続,*,*,*,*,表明,ヒョウメイ,ヒョーメイについて 助詞,格助詞,連語,*,*,*,について,ニツイテ,ニツイテとなる。潘基文 の「潘」は登録されているから、「基文」を登録するのがいいか、「潘基文」で登録するのがいいか。形態素解析ということでちゃんとするなら「基文」を登録か。「モトフミ」という日本人もいるから、登録するなら「モトフミ」という形で入れておかないと確率的にはあれかな。でも、そうすると、「ハン モトフミ」となってしまう。「バン・ギムン」という読みは絶対に出てこないから読み上げをやる場合には、「潘基文」の一単語で登録しないとダメだろうな。でも、そうすると、「潘国連事務総長」と「潘基文国連事務総長」は同じにならない。とすると、読みは犠牲にして「基文」を登録した方がいいか。一単語で登録しておいて、解析後にばらすマークを入れておいて、後処理に任せるというのも一つの手かもしれない。読みがいろいろ考えられる日本人の有名人の場合も、その手があるか。「町村」氏を「名詞、固有名詞」で登録したら、どういう副作用が出るかな。「市町村」とかすると大丈夫かなと思ったが、「市町村」が一単語登録されているから副作用はなかった。でも、「各町村の調査」とか解析させると、「町村」は固有名詞になってしまう。こういう困る名前って、実は、けっこうたくさんある。たんに分かち書きができていればいいという世界では問題にならないが、品詞を見て人名を拾うとかやろうとすると、登録しないわけにいかないし、登録すると悪影響がある。ついでに 機械読取渡航文書に関連する新技術情報の情報提供依頼(RFI) を解析すると、機械 名詞,一般,*,*,*,*,機械,キカイ,キカイ読取 動詞,自立,*,*,五段・ラ行,体言接続特殊2,読取る,ヨミト,ヨミト渡航 名詞,サ変接続,*,*,*,*,渡航,トコウ,トコー文書 名詞,一般,*,*,*,*,文書,モンショ,モンショに 助詞,格助詞,一般,*,*,*,に,ニ,ニ関連 名詞,サ変接続,*,*,*,*,関連,カンレン,カンレンする 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル新 接頭詞,名詞接続,*,*,*,*,新,シン,シン技術 名詞,一般,*,*,*,*,技術,ギジュツ,ギジュツ情報 名詞,一般,*,*,*,*,情報,ジョウホウ,ジョーホーの 助詞,連体化,*,*,*,*,の,ノ,ノ情報 名詞,一般,*,*,*,*,情報,ジョウホウ,ジョーホー提供 名詞,サ変接続,*,*,*,*,提供,テイキョウ,テイキョー依頼 名詞,サ変接続,*,*,*,*,依頼,イライ,イライ( 記号,括弧開,*,*,*,*,(,(,(RFI 名詞,固有名詞,組織,*,*,*,*) 記号,括弧閉,*,*,*,*,),),)と、解析される。そんなものがあるかは別にして「機械書込渡航文書」は、機械 名詞,一般,*,*,*,*,機械,キカイ,キカイ書 名詞,接尾,一般,*,*,*,書,ショ,ショ込 名詞,一般,*,*,*,*,込,コミ,コミ渡航 名詞,サ変接続,*,*,*,*,渡航,トコウ,トコー文書 名詞,一般,*,*,*,*,文書,モンショ,モンショとなり、「機械書き込み渡航文書」は、機械 名詞,一般,*,*,*,*,機械,キカイ,キカイ書き込み 名詞,一般,*,*,*,*,書き込み,カキコミ,カキコミ渡航 名詞,サ変接続,*,*,*,*,渡航,トコウ,トコー文書 名詞,一般,*,*,*,*,文書,モンショ,モンショとなる。「機械読み取り渡航文書」は機械 名詞,一般,*,*,*,*,機械,キカイ,キカイ読み取り 名詞,一般,*,*,*,*,読み取り,ヨミトリ,ヨミトリ渡航 名詞,サ変接続,*,*,*,*,渡航,トコウ,トコー文書 名詞,一般,*,*,*,*,文書,モンショ,モンショとなる。「読取」を動詞として解析するのはどうなのだろう。名詞を登録しちゃえ。「読取ってみる」「読取ります」を解析しても、ちゃんと動詞になる。ついでに、「書込」も名詞登録。「書込みます。書き込んだ」にも悪影響なし。こうやって登録していくときに、悪影響があるかないか、Wikipedia を検索して、その文字列を含む例文を引っ張ってきて、デグレード試験をかけるとか、そういう仕組みが必要かな。あるいは、Google で検索して例文を引っ張ってくるか。でも Google だと、検索結果が変わってしまうから、やっぱり固定したものをまずやって、プラスで Google かな。めんどくさ。
2007.08.31
コメント(0)
-

テキスト・マイニングツールの市場シェア
国内BI市場は10%増 ブログ分析でテキスト・マイニングが急成長、ITR調査で判明。2006年度のテキスト・マイニング市場は前年比約24%増の11億5000万円。表に現れる金額は、意外に小さい。金額ベースのシェアは、次のようになっているらしい。上位4社で 81%。60% が野村総研ということで、まあ、大企業向けのコンサルに強いところから高額なところでできるという優位性もあるだろうな。カタログベースで見ても、よくできている感じに見えるけど、できがいいだけじゃないだろう。製品買ってはいおしまいの世界じゃないから。野村総合研究所 60%数理システム7.8%クオリカ 7.8%エス・ピー・エス・エス 5.4%だけれど、BI市場としてみたときにそうなるということで、テキストマイニング全般で見ると、もっと市場規模は大きいだろう。検索とか、コンテンツ依存の広告とかに使われているものとか広義のテキストマイニングを考えたら、どの程度の規模になるだろう。ちなみに True Teller (野村総研のテキストマイニング製品) を Google で検索すると、ジャストシステムのスポンサードリンクが出てくる(笑)。
2007.08.22
コメント(0)
-
「Yahoo!の形態素解析をMeCabで無理やり再現してみる」を試してみて
Yahoo!の形態素解析をMeCabで無理やり再現してみる を読む。MeCabで形態素解析器を作りたい場合は以下の二つの言語リソースが必要です。1. 辞書 (単語と品詞のペアの集合)2. 入力文と、それに対応する正解出力ペア(正解データ)学習させるときには、辞書と、正解データを用意しなきゃならない。これが面倒だから、なかなか自作の辞書を作る気にならない。Wikipedia のデータをダウンロードすれば、大量のテキスト文章は得られるけれども、正解出力を手作業で作るのは大変だし、元辞書も作らなきゃならないから、不可能に近い。じゃわ、正解出力をちゃんと手作業で作るのではなくて、Yahoo! API の 日本語形態素解析Webサービス を使って得られた解析結果を擬似的に 正解と見なして、そのデータから学習することができるでしょうと。辞書も解析結果をソートしてユニークなものだけ残せばよいしと。そうして学習させたものは、結果的に、Yahoo 形態素解析と同じような結果が得られることになろうと。原理的には。試みとしてはおもしろい。けど、Yahoo! API を使って「陸奥圓明流外伝 修羅の刻」とか形態素解析させても、MeCab で解析させたものと変わらないようなものしか返ってこない。ちょっとがっかり。現状の MeCab とほぼ同じような結果しか返って来ないのだったら、あんまし意味ないもんね。と思って、「日本語、ドイツ語、スワヒリ語。」などを Yahoo で解析すると、それぞれ一語で返される。MeCab だと「日本語、ドイツ//語、スワヒリ//語」と分けられる。「スカンジナビア語」は、どちらも「スカンジナビア//語」。まだ、全部の言語が登録されているわけではない感じ。「防護服、犠牲者、生存者、名古屋空港」のような単語も Yahoo だと一単語だけれど、MeCab だと「防護//服、犠牲//者、生存//者、名古屋//空港」と分かれる。Yahoo APIの返してくる解析結果は、イメージ的には MeCab の単語登録をもっとたくさん入れてやった感じで、基本的には同じような動き。Yahoo は、一単語にした方が何かと扱いやすいものについては、積極的に登録していっているという感じなんだろうか。「歎異抄」みたいのも登録されているから一単語になる。Wikipedia の中にある『』で囲まれているものについては、基本的に書籍、作品等の名前のはずだから、まとめて登録しちゃうとかありかもしれないなとかふと思う。何はともあれ、これは辞書作りの基本を体験してもらおうというデモンストレーションの一種なわけだな。収穫として、webma.tar.gz に含まれている mkmecabdic.pl を使えば、簡単に活用がある単語の辞書登録ができるということに気がついた。MeCab は活用がない語の登録は比較的楽なのだが、活用がある単語の登録はやたらと面倒。自分で活用形をすべて登録しなければならないから。ということで、例えば、ナウい 形容詞,形容,基本形,ナウい,なうい,なういのように基本形だけ登録したファイル (katsuyo.csv)を作って、$ ./mkmecabdic.pl katsuyo.csvとしてやれば、ナウ,0,0,0,形容詞,形容,ガル接続,ナウ,ナウ,なういナウけれ,0,0,0,形容詞,形容,仮定形,ナウけれ,なうけれ,なういナウけりゃ,0,0,0,形容詞,形容,仮定縮約1,ナウけりゃ,なうけりゃ,なういナウきゃ,0,0,0,形容詞,形容,仮定縮約2,ナウきゃ,なうきゃ,なういナウき,0,0,0,形容詞,形容,体言接続,ナウき,なうき,なういナウかれ,0,0,0,形容詞,形容,命令e,ナウかれ,なうかれ,なういナウい,0,0,0,形容詞,形容,基本形,ナウい,なうい,なういナウし,0,0,0,形容詞,形容,文語基本形,ナウし,なうし,なういナウかろ,0,0,0,形容詞,形容,未然ウ接続,ナウかろ,なうかろ,なういナウから,0,0,0,形容詞,形容,未然ヌ接続,ナウから,なうから,なういナウう,0,0,0,形容詞,形容,連用ゴザイ接続,ナウう,なうう,なういナウぅ,0,0,0,形容詞,形容,連用ゴザイ接続,ナウぅ,なうぅ,なういナウかっ,0,0,0,形容詞,形容,連用タ接続,ナウかっ,なうかっ,なういナウく,0,0,0,形容詞,形容,連用テ接続,ナウく,なうく,なういナウくっ,0,0,0,形容詞,形容,連用テ接続,ナウくっ,なうくっ,なういと、活用系を展開してくれるので後はコストの調整をすればよしと。83's: MeCabの辞書作成補助 だと、別途ローマ字ひらがな変換ライブラリ suikyoと、茶筌に(多分)付属しているcforms.chaが必要です。まー基本的にはcforms.chaでなくても、同じフォーマットで、かつ活用形の中に「基本形」が入っていれば動くはずです。あとRubyも必須です。と、ちょっと環境を整えるのが面倒に感じて(めんどくさがりなので)、躊躇したが、これなら楽に活用語を登録できる。ん、でもよく見たら、通常の MeCab の辞書だと読みや発音はカタカナで入力するのに、なんでこれはひらがなでないとダメなのかな。Yahoo API がひらがなで読みを返してくるから、それに合わせてるのか、なるほどと思いつつ、んー、辞書の構造的にはどっちでも入れられないことはないのか。発音のところも、表記が入っていたりするけど、それでも大丈夫なわけか。結果の出力にしか使わないからなのか。何はともあれ、一回、体験してみると、やってみるかなという気になるわけだな。オリジナル辞書/コーパスからのパラメータ推定 を眺めていてふと思った。あっそっか。ルー語変換を MeCab だけで実現 みたいのとかできるのこういうことねと改めて思う。華々しく,51,51,4244,ブリリアントゥっぽく「外来語」言い換え提案 なんかも、同じように辞書を作ってやれば、言い換えをできちゃうわけだな。ルー語変換みたいに変換してくれるページを作って言い換えたものが分かるようにしてやれば、言い換え提案をそのまま採用したらどの程度影響があるかとか、見やすいのにね。と話がそれて終わる。
2007.08.20
コメント(0)
-

博報堂とNECが連携してブログの商品評価
博報堂、ブログ分析で商品評価 を読む。博報堂がNECの技術を使って商品化したようだ。テッキーとマーケッターが組むというのはよい方向だろう。ちなみに、買物におけるWebの影響度調査 結果速報 買物をする際にWebで情報収集する比率が高いのは、「パソコン」「デジカメ」「自動車」。買物時にWebで情報収集する率は、平均30.8%。 らしい。結局のところ 企業のM&Aプロセスにおける戦略的なブランディング実施プログラム 「博報堂M&Aブランディング・プログラム」を開発、本格的な運用開始 とか、購買を決定する瞬間の心境変化や行動の実態を把握する 「デタミナント調査」を開発、運用開始 とか、そうした文脈の中に組み込まれてブログ分析を使うのかな。ブログを考えると、トーカティブ・マイノリティーなんて言葉が浮かんできた。やっぱり、マジョリティーはサイレント。数をカウントして短絡に結果に結びつけるようなやり方は間違った方向にいく可能性がある。マーケティングのプロがうまくツールを使うとおもしろい結果も出てくるというものだろう。小さな声の中から新しい発想を得るなら、別な方向になるだろう。むしろ、何かのアクションに対するフィードバックを得るための一つの指標として使われるんじゃないかなとか思ったりする。やっぱりポイントは時系列で揺れを把握することなんじゃなかろうか。何も分かっていない会社が使うものではなく、それなりに分かっているつもりの会社が、何かするときに効果測定の一環として使う感じか。関係ないけど 6月末に調査した2007年7月の「消費意欲指数」の結果がまとまりました。2007年7月の消費意欲は、先月から1.1ポイント増加し、54.2点でした。前年同月比は0.2ポイント減少、再び前年割れに。 らしい。この指標チェック対象にしようかな。消費者物価指数との連動性はどの程度あるのかな。
2007.08.19
コメント(0)
-
形態素解析エンジン「マリモ」の記事から
先日、日本語解析製品マリモは未知語の自動登録をするらしいを書いたが、@IT にマリモの記事があった。開発元のムーターに聞く 辞書不要の形態素解析エンジン「マリモ」とは。「処理対象となるテキストの文を、1文字ごと、2文字ごと、3文字ごとと10文字単位になるまで、すべての組み合わせを解析します。漢字部分以外は、すべてローマ字に変換して行うため、母音と子音の組み合わせから新語の品詞が推定できます」(テクノロジー部門担当執行役 田中優氏)。なるほど、そういうことやってるのね。 前略プロフを見てみる に書いた例文、悩み深きみずがめ座♪くるまを売るなんかはうまく解析できるのかな。MeCab だと、こういうのはこけちゃう。マリモは、あらかじめ動詞や形容詞の活用形についての知識を持たず、頻度情報と位置情報を使った統計処理だけで、どの音のつながりが単語で、その単語が動詞であるか形容詞であるかまで判定するという。ということだから、うまくできる可能性が高いような気がする。MeCab は IPA辞書が弱いところがあるから、漢字を使っているものを、ひらがな表記も辞書登録してやれば、もっと精度が向上するけど。辞書の作り直しを、いつかやってみたいと思いつつやってない。水瓶座。水瓶座 名詞,固有名詞,一般,*,*,*,水瓶座,ミズガメザ,ミズガメザ。 記号,句点,*,*,*,*,。,。,。EOSみずがめ座み 動詞,自立,*,*,一段,未然形,みる,ミ,ミず 助動詞,*,*,*,特殊・ヌ,連用ニ接続,ぬ,ズ,ズがめ 名詞,一般,*,*,*,*,がめ,ガメ,ガメ座 名詞,接尾,一般,*,*,*,座,ザ,ザMeCab のような形態素解析を使うと、活用がある語の原型を使って、「走る」「走れば」「走った」等の活用形を「走る」にまとめることができるけど、マリモの場合はどうなんだろうか。品詞判定ができるということは、当然できるということかな。ところで「かっこいい」の否定形は、「かっこよくない」を使うと思うが(まれに「かっこいくない」と使う人もいるだろうが)、この手のものはどう扱われるのだろうか。かっこよいかっこよい 形容詞,自立,*,*,形容詞・アウオ段,基本形,かっこよい,カッコヨイ,カッコヨイEOSかっこよくないかっこよく 形容詞,自立,*,*,形容詞・アウオ段,連用テ接続,かっこよい,カッコヨク,カッコヨクない 助動詞,*,*,*,特殊・ナイ,基本形,ない,ナイ,ナイEOSかっこいいかっこいい 形容詞,自立,*,*,不変化型,基本形,かっこいい,カッコイイ,カッコイイEOSかっこいくないかっこ 名詞,サ変接続,*,*,*,*,かっこ,カッコ,カッコいく 動詞,自立,*,*,五段・カ行促音便,基本形,いく,イク,イクない 形容詞,自立,*,*,形容詞・アウオ段,基本形,ない,ナイ,ナイEOSかっこいければかっこ 名詞,サ変接続,*,*,*,*,かっこ,カッコ,カッコいけれ 動詞,自立,*,*,一段,仮定形,いける,イケレ,イケレば 助詞,接続助詞,*,*,*,*,ば,バ,バEOSマリモも 日本語形態素解析Webサービス のように API サービスを提供してくれれば、ベンチマークに使えておもしろいのになぁとか思う。それにしても、「格好良い」、「かっこうよい」、「かっこよい」、「かっこいい」は、日本語の乱れというのか、なんというのか。IPA辞書に登録されているぐらいだから、ある意味、認められた日本語とも言える。こうした日本語の変化というのを時系列で例文と頻度を見ることができるとおもしろいのだが。Oxford English Dictionary みたいに。Blog 検索なんかも、ある単語の初出を出すものがあるとおもしろいのにね。Blog は一応、公開時期が特定できるから(ウソつくことも可能だろうが、チェックし続けていればウソが分かる)、初出や年代ごとの検索ができてもいいようなものだし。なかなかそういうものが出てこない。
2007.08.16
コメント(1)
-
日本語解析製品マリモは未知語の自動登録をするらしい
画期的な日本語解析製品(開発コード)「マリモ」を提供開始 を読む。マリモはインターネット上の様々なカテゴリのテキスト文書を収集して単語候補を選別し、さらに選別された単語候補から不適切なものを排除して必要な単語だけを抽出し新造語を含む一億語以上の単語を学習しています。また、マリモ最大の特徴である、単語の前後関係から品詞を判断する品詞予測アルゴリズムは流行し始めた新語の品詞を特定することができます。これにより日々進化し続ける新しいテクノロジーやサービスに伴って生まれてくる言葉に的確に対応できる唯一の日本語解析として「マリモ」が登場しました。らしい。形態素解析を行うものを作る場合の一つのネックが未知語。ここに焦点を当てて製品化したところはよいと思う。品詞推定はどの程度の精度なんだろうか。たとえば、こんなもの拾えるようになったとか、実例があればいいのにね。Mooter テクノロジを見ると、ヒットした情報の数と検索にかかったコンマ何秒の数字を誇らしく表示してもユーザーには何のメリットもありません。これは Google への当てつけだろうか(笑)。検索結果の数は、それは一つの情報だと思うけどな。だいたい Mooter だって、何件て表示されてんじゃん。こういう表現はどうかなぁ。何秒って表示されることによって、返答が遅いときにネットワークの問題か Google の返答時間の問題かって切り分けできる分けだし意味あるじゃん。Google のファンからは誤解と反感買うだけだと思うけど。ちなみに分類の力を試すために「サブプライムローン」を検索してみると、Google が「サブプライムローン問題」しか出てこないのに対して、問題(39) 米国(29) 住宅ローン(17) 信用度(20) ローン(17) 信用力(17) 借り手(15)、Yahoo!ニュース(11) ロイター(11) サブプライム問題直撃(10) アメリカ市場(9) 市場(13) 低所得者層(8) 融資(12)等が Mooter では出てくるので、その点は使えるつくりになっているとは思う。この手のサブカテゴリが出てくるようなものをそのうち比較してみるかな。創設者メッセージ は、稲村 尚志氏だけど、Mooter 創始者であるLiesl Capper (リーゼル・ケイパー)は とあるので、一瞬面食らう。Mooter 会社情報 を見ると分かるんだけど。検索ページの概要から飛んでくるのは テクノロジーのページ だから、そこでちゃんと分かるように書いた方がよいと思うが。Mooter のブログフィルタって、ちゃんとブログがフィルタリングされてない。rss ファイルとかも引っかかって来ちゃったりしてる。なおした方がよろしと思う。http://feeds.feedburner.com/ とかの引っかかってる。ダメじゃんとかもあるし。あと、楽天と楽天市場はずしのフィルタとかあるといいな(笑)。というか、ショップ関連をはずしたフィルタがほしい。こういう自動分類の弱いところって、「抹茶」と来たら「茶筅」とかの分類も出てきて欲しいのに出てこないとこrなのだな。ウェブページの重み付けが大きすぎると、知識ベースからは当然のように導かれてくる分類が出てこない。結局、ブログだけでなくショッピングサイトのページに毒され過ぎちゃうと知識を中心とした検索サイトとしては役立たなくなっちゃう。ショッピングサイトの検索結果を排除したとき、スポンサーリンクのクリック率も上がる可能性があるわけだから、そういうのを試してほしいとか思ったりする。ちなみに Mooter で kugutsushiを検索してみたら、楽天ブログ(80) TAGSTA(73) TITLE(62) TAG(72) 検索(57) タグ検索(27) 普通(33)、RAKUTEN(18) DIARY(17) TWISTED(14) 使い方(17) DATE(9) PYTHON(11)、 Blog(5) という感じで出てきた。楽天とか TAGSTA とかその手のものは、まあ仕方ないかとか思ったが(ブログ検索で、こういう分類が出てきたら失格だと思う)、普通(33) って何だ。んー。こういうところを見ていると弱点が明確に見えてくる。。。。。というのはさておき、Liesl Capper 氏は 自分の代わりに他人とチャット--ネット上の分身を創造するソフト登場 にも登場している。インタラクションに興味がある人なのね。
2007.08.03
コメント(1)
-
cmecab -- Mecab-Python高速バインディング
cmecab -- Mecab-Python高速バインディング を公開している方がいらっしゃる。MecabのPythonバインディングの改良高速版です。SWIGを使わず、Mecabの最低限の機能だけをPython-C APIで実装しました。mecab-pythonバインディングの以下のメソッドを実装しています。 1. createTagger 2. Tagger.parseToNode 3. Nodeからのデータ取得(surface, feature, posid, char_type, statのみ)ということで、mecab-python より処理速度が速いようだ。Windows でも Linux でも手間なく使えるように私は ctypes を使ってしまっているが、少しでも速いほうがうれしいというときには、やっぱりこういうやり方がよいのだろうな。近いうちに試してみるかな。
2007.07.15
コメント(0)
全268件 (268件中 1-50件目)
-
-

- デジタル一眼レフカメラ
- OM SYSTEM OM-1 Mark IIレビュー
- (2024-05-25 00:00:18)
-
-
-

- iPad
- 【iPad Pro 2024】iPadケースのおす…
- (2024-04-24 15:57:48)
-
-
-

- 楽天市場のおすすめ商品
- ウニ・・・トロトロ
- (2024-05-27 08:48:30)
-



