
今のところは、ただただ、淡々と、黙々と、自分にできることを続ける以外になさそうなので、またまた Trados さんの重箱のスミをつついていこうと思います。今回は、検証機能です。
検証機能では、正規表現を知っているとできることがとても多くなります。でも、私はこの正規表現がどうも苦手です。そこで今回は、正規表現なしでもここまでできる!というところを紹介してみたいと思います。
設定を変える前に
Trados の検証機能には、QA Checker、タグ検証機能、用語検証機能の 3 つがあります。これらの概要については、以前の記事 検証機能の設定を調整する も参照してください。
設定の変更は [プロジェクトの設定] > [検証] から
プロジェクトを作成した後、またはパッケージを開いた後で設定を変えたい場合は、[ プロジェクトの設定] > [ 検証] に移動します。[ ファイル] > [ オプション] > [ 検証] ではないので注意してください。この 2 つの設定の違いについては、以前の記事 Trados の設定を変えるには − [ファイル] と [プロジェクトの設定] を参照してください。
既存の設定をエクスポートして保存しておく
検証の設定は、翻訳会社さんがパッケージに設定してきていることがあります。納品時に検証結果のログも一緒に納品するように求められることがあるので、既存の設定に自分で手を加える前に、設定をエクスポートしてファイルとして保存しておきます。エクスポートしておけば、自分でいろいろ設定を変えても、エクスポートしておいたファイルをインポートすることで元の状態に戻せます。エクスポートとインポートは、[ QA Checker のプロファイル] から行います。
エクスポートして設定ファイルを保存したら、あとは自由にいろいろ試してみましょう。
分節の検証 — 禁止文字がないかチェックする
私は、この禁止文字のチェックが、最も簡単で、最も役立つのではないかと思っています。UI はなんだかよくわからない表示になっていますが、チェックボックスをオンにして、右側のテキストボックスに禁止したい文字をずらずらと入力すれば OK です。
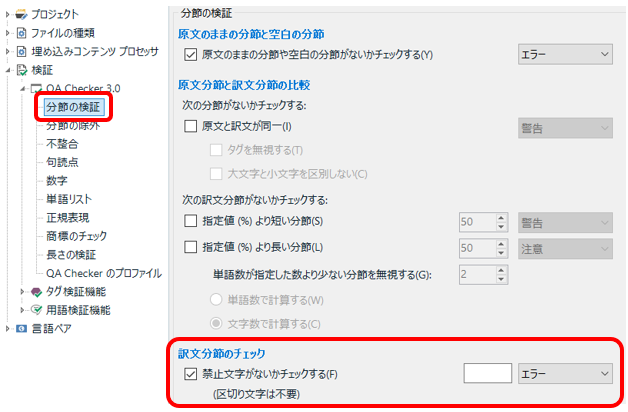
禁止する文字は、スタイルガイドに従って、全角の英数字、各種の括弧、コロン、引用符などなどです。入力が面倒だったら、以下をコピペしてください。こんなにたくさん入力してもまったく問題なく機能します。括弧やコロンなど、スタイルガイドによって変わる文字は、先頭の方に入力しておき、そのたびに書き換えて使うと便利です。
():“”ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをんアイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヲンーがぎぐげござじずぜぞたぢづでどばびぶべぼザジズゼソタヂヅデドバビブベボぱぴぷぺぽパピプペポぁぃぅぇぉっァィゥェォッ
正規表現を使っても同じチェックをできますが、禁止文字として設定した方がエラーがわかりやすく安全です。正規表現でのチェックは、いろいろな設定ができるだけにエラーが多くなり、誤検知も多くなりがちです。そうなると、エラーとして検出されても見落とす危険が出てきます。絶対に禁止とわかっている文字には、この禁止文字のチェックの方がお勧めです。
句読点 − 余分なピリオドとスペース
英訳のときは、連続するスペースのチェックが欠かせませんが、こうした一般的なチェックはある程度用意されています。

[ 句読点] には、上図のようにいろいろ便利そうな設定があります。が、便利そうなだけで、[ 余分なピリオドとスペース] 以外の設定は、日本語と英語の組み合わせのときはあまり役立ちません (あくまで、個人的感想です)。特に、[ 括弧のチェック] は、説明を見るといかにも便利そうですが、この説明のとおりには機能してくれません。このチェックは、原文と訳文に同じ種類の括弧があるかを確認しているようで、たとえば、原文は全角の括弧、訳文は半角の括弧としただけでもエラーになるので、閉じ括弧がないといったケースを見つけるのにはあまり役立ちません。
単語リスト
名前のとおり、チェックしたい単語をリストアップしてチェックします。正しくない単語と、正しい単語を入力するだけなので、とてもわかりやすくて簡単です。スタイルガイドで、「例えば」と漢字ではなく「たとえば」とひらがな書きにするという指示がある場合などに使うと便利です。

長音のチェックには限界がある
単語リストの問題点としてよく挙げられるのが長音のチェックです。単語リストは、シンプルに単語を検出するだけなので、「サーバ」が正しくなくて、「サーバー」が正しいというケースには対応できません。正しくない単語の「サーバ」が、正しい単語の「サーバー」の中に含まれているので、「サーバー」と正しくなっていてもエラーとして検出されます。
下部に [ 単語単位で検索する] というチェックボックスもありますが、これは日本語の場合にはあまり適切に機能しません。「サーバ」を検出したい場合は、正規表現を使うしかなさそうです。(具体的な正規表現については、こちらの記事 オンライン質問会から (2019年12月) を参照してください。)
すみません、エスケープ文字だけは使います
この単語リストですが、実は、入力には正規表現を使う必要があります。どこにもそんなことは書いてないですし、「正規表現」というチェックは別に独立してあるのですが、なぜか単語リストでも正規表現を使う必要があります。といっても、それほど心配する必要はありません。「サーバー」や「たとえば」など、普通の文字から成る単語を入力するときは何も意識しなくて大丈夫です。注意が必要になるのは、半角の丸括弧、ピリオド、疑問符など、正規表現に使われる記号を含む場合だけです。
たとえば、以下のように設定したとします。
正しくない語形:
(ファイル)
正しい語形:
ファイル
(ファイル)と丸括弧付きの表記は正しくなく、 ファイルと括弧なしが正しいとします。しかし、上記のように入力すると、
(ファイル)
の丸括弧は正規表現の記号として解釈されるので、実際に丸括弧付きの (ファイル)をエラーとして検出することはできません。この丸括弧を、正規表現ではなく、文字そのものとして認識させたいときに使うのが、エスケープ文字と呼ばれる円マーク \
です。\
を付ける
ルールはこれだけです。丸括弧、疑問符、アスタリスクなど、正規表現に使われそうな記号の前には円マーク
\
を付けておきます。これを付けると、その記号は、正規表現の式ではなく、文字そのものとして解釈されます。\(ファイル\)
--> (ファイル)という丸括弧付きの単語が検出される\\n
--> 改行マークではなく、 \nという文字そのものが検出される私は、正規表現なんて見たくもない!と思っている人間ですが、このエスケープ文字だけは使わざるを得ません。今回の記事は、正規表現を使わずになんとか頑張るという趣旨ではありますが、すみません、エスケープ文字だけは使ってください。
正規表現
では、いよいよ「正規表現」です。正規表現と名付けられていますが、実は、正規表現を使わないチェックも可能です。前述の単語リストのように、普通の文字から成る単語を検出するだけなら、正規表現は不要です (すみません、ここでも、エスケープ文字は必要です)。「正規表現」は、「単語リスト」よりいろいろな設定ができるので、より複雑なチェックが可能です。
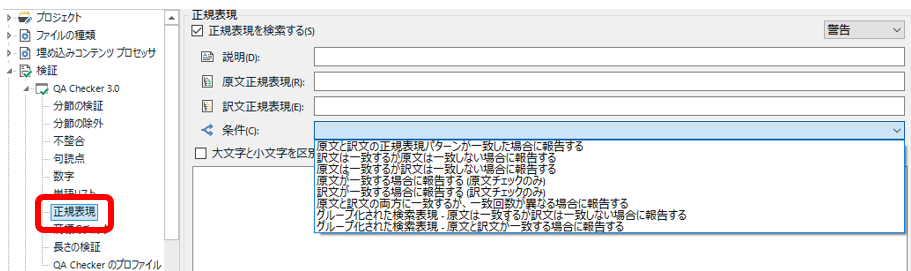
上図のように、[ 条件] ドロップダウンにいろいろな条件が最初から用意されています。[ 原文正規表現] と [ 訳文正規表現] のそれぞれに原文と訳文で検出したい語句を普通に入力して、あとは適切な条件を選べば、設定は完了です。
原文と訳文の正規表現パターンが一致した場合に報告する
この条件は、単語の見間違いの検出に使えます。たとえば、virtually と vertically は似てますよね。私は、うっかり見間違えてしまったことがあるので、以下のように設定しています。
原文正規表現:
vertically
訳文正規表現:
仮想
条件: 原文と訳文の正規表現パターンが一致した場合に報告する
これで、原文に verticallyがあるのに、訳文には 仮想が含まれている分節がエラーになります。これでも心配な場合は、条件を [ 原文が一致する場合に報告する (原文チェックのみ)] に変更します。こうすれば、原文に verticallyが含まれる分節を、訳文がなんであろうと関係なく、すべて検出できます。検出されたら、あとは 1 つ 1 つ確認していきます。vertically なんてめったに出てこない、という文書だったら、モレなく検出できるこの条件の方が安全です。
原文と訳文の両方に一致するが、一致回数が異なる場合に報告する
原文と訳文で、語句の登場回数をチェックしてくれます。たとえば、注釈のアスタリスクの個数がだんだん増えていく、というような表記が使われているときに便利です。(アスタリスクを検出したい場合は、下記のようにエスケープ文字の円マークを付けます。)
原文正規表現:
\*
訳文正規表現:
\*
条件: 原文と訳文の両方に一致するが、一致回数が異なる場合に報告する

上図のように設定すると、以下のような結果になります。

1 行目は、アスタリスクが原文に 1 個、訳文にも 1 個なので、エラーではありません。2 行目は、原文には 2 個ですが、訳文には 1 個なので、エラーになります。3 行目のようにたくさんあって数えるのが面倒なときは特に便利です。
さて、ここで条件の文言をもう一度よく読んでみます。もう既に気付いている方もいらっしゃると思いますが、「原文と訳文の両方に一致するが」となっているので、両方に一致しないケースはこの条件では検出できません。つまり、訳文にアスタリスクが 1 個もない分節はエラーになりません。

上図の 2 行目ように、アスタリスクを入力し忘れてしまってもエラーにはなりません。これを検出するには、[ 原文と訳文の両方に一致するが〜] の条件とは別に [ 原文は一致するが訳文は一致しない場合に報告する] という条件を使う必要があります。
今回は以上です。正規表現を知らなくても、結構いろいろできます。翻訳会社さんからもらうパッケージには検証の設定が含まれていることがあるので、そうした設定を参考にいろいろ試してみるのもいいかと思います。
| |
|


