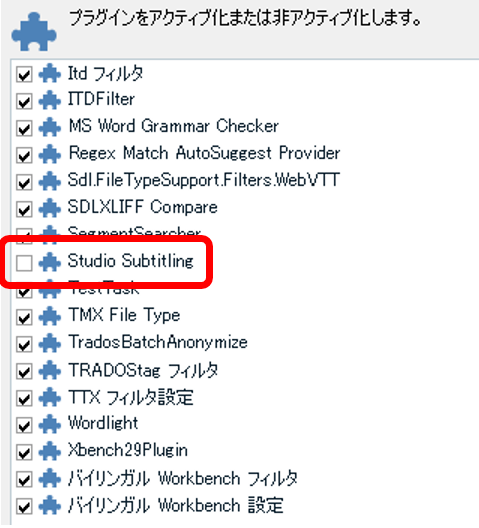
手順は、ざっとこんな感じです。
1. インストール後、アクティベーションはしない
2. 一括タスクの「連続タスク」を作成
3. ショートカット キーなどの設定を移行
4. 各種アプリをインストール
1. インストール後、アクティベーションはしない
Trados Studio 2024 をインストールすると、製品のアクティベーション画面が表示されますが、この時点ではアクティベーションは行いません。初めて 2024 をインストールした場合限定ですが、インストール後の 30 日間は試用期間として Professional 版を利用できます。Freelance 版のライセンスしか持っていなくても、Professional 版を利用できるので、試用期間中はアクティベーションをせずに、試用を続けます。Professional 版では、パッケージの作成や、完全一致の適用が可能です。そして何より、一括タスクの「連続タスク」を作成できます (これについては、後述します)。

ライセンスを持っていても、30 日間の試用期間中はアクティベーションを行わず、画面右下の [トライアルを継続する]をクリックしてください。起動のたびにこの画面が表示されてしまうので少し面倒ですが、30 日間は頑張りましょう。
2. 一括タスクの「連続タスク」を作成
試用期間中の Professional 版を使ってやっておきたいことのひとつが、一括タスクの「連続タスク」の作成です。Professional 版では、各種の一括タスクを自由に選択してカスタムの連続タスクを作成できます。Freelance 版では、自分で連続タスクを作成することはできず、既定の連続タスクをそのまま使うことしかできません。
ただ、少し裏技的ですが、試用期間中の Professional 版で連続タスクを作成しておけば、その後、Freelance 版でアクティベーションをしても、作成した連続タスクはそのまま使用し続けることができます。すみません、今回の 2024 へのアップグレードで本当に使用し続けられるかどうかはまだわからないですが、前回のアップグレードではこれができたので、今回もできるのではないかと期待しています。
さて、私が欲しい連続タスクは、単純に「翻訳形式への変換」と「訳文言語へのコピー」だけをしてくれるタスクです。私が自分でプロジェクトを作成するときは、メモリの適用などはせず、まっさらな状態から作業を始めたいことが多いので、この単純な連続タスクはどうしても欲しいと思っています。
タスクが 2 つだけなら手動でそれぞれ実行してもよいのでは? と思うかもしれませんが、実際にやってみると個別に実行するのはかなり面倒です。新しい文書の翻訳を始めるときは、設定を変えながら「翻訳形式への変換」を何回か試すこともあるので、変換とコピーを一気に実行してくれるタスクがあると便利です。
連続タスクの作成方法
1)ファイル ビューで、対象のファイルを右クリックして [一括タスク] > [カスタム]と選択し、表示された画面で [連続タスク]ボタンをクリックします。
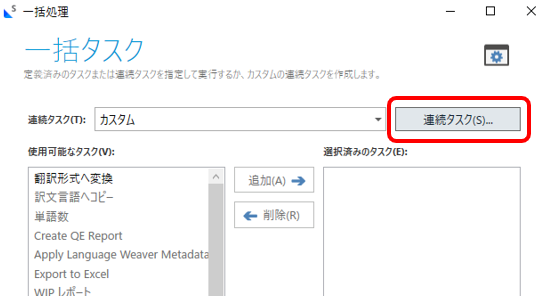
2) [連続タスク]画面で [追加]ボタンをクリックすると、下図の連続タスクの編集画面が表示されます。ここで、新しい連続タスクを作成します。

3)作成したら、ファイル ビューに戻り、 [一括タスク]を選択すると、作成した連続タスクが表示されます。(今回は、「変換とコピーと解析」という連続タスクも作成しました。)

これで、連続タスクの設定は完了です。あとは、Freelance 版でアクティベーションした後も、このタスクが表示されてくることをお祈りしておきます。 (たぶん、大丈夫だろうと思っているけど、ちょっと不安です。)
3. ショートカット キーなどの設定を移行
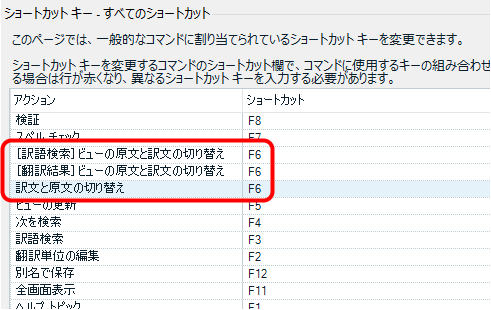
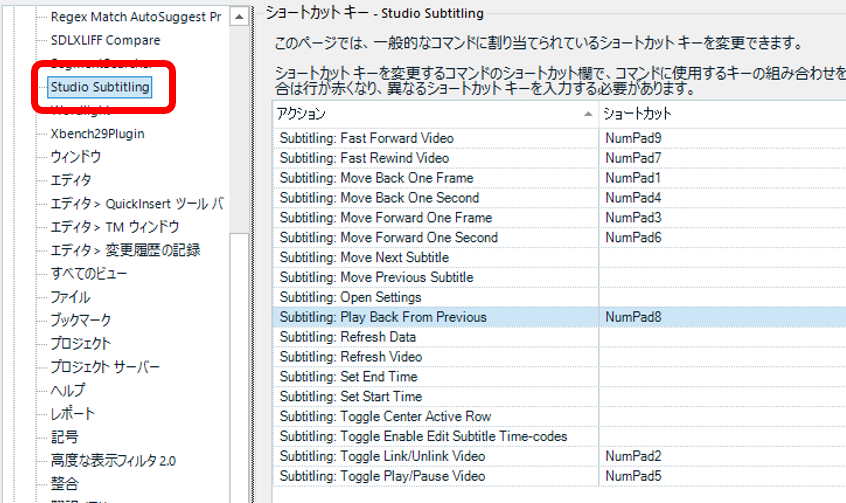
次に、ショートカット キーなどの設定を以前のバージョンから移行します。今回は、ユーザー プロファイルを使って設定全体を一気に移行しました。ユーザー プロファイルの中には、ショートカット キーだけでなく、 AutoText のエントリー や、 エディターの色 の設定も含まれています。
ユーザー プロファイルは設定全体を移行できて便利ですが、正直にいうと、この中にどのような設定が含まれているのかはよくわかりません。ショートカット キーも、私は長年使っているので、自分が設定したキーが原因で、Trados の動きがおかしくなっている可能性がないとも言い切れません。アップグレードを機会に、過去の設定をいったん忘れてクリーンな状態で始める、というのもよいかと思います。
それでも、やっぱり設定を一気に移行したい、という場合は、以下の手順でユーザー プロファイルを移行できます。
ユーザー プロファイルの移行方法
1)まず、2022 で現在のユーザー プロファイルをエクスポートします。 [ファイル] > [設定] > [ユーザー プロファイルの管理]を選択し、以下の画面が表示されたら、 [ユーザーの設定のエクスポート]を選択します。

2)次の画面で、ファイルのパスと名前を指定し、設定をファイルにエクスポートします。
3)次に、2024 でユーザー プロファイルをインポートします。エクスポート時と同じように、 [ファイル] > [設定] > [ユーザー プロファイルの管理]を選択し、以下の画面が表示されたら、今度は [ユーザープロファイルの変更]を選択します。

4)次の画面で、2022 でエクスポートしたファイルを指定します。あとは、ウィザードを進めていけば、設定が移行されます。
これで、以前に使用していたショートカット キーなどを新しいバージョンでも使用できるようになります。
4. 各種アプリをインストール
最後に、各種のアプリをインストールします。アプリは、 [ようこそ]画面の [RWS AppStore]からインストールできます。左側のメニューで [AppStore]を選択すると、インストールが可能なアプリが一覧されます。
この一覧には、2024 に対応していないアプリは表示されてきません。前回の記事で、2024 年 8 月 28 日現在の対応状況を紹介していますが、いつ対応するかはアプリによって異なります。RWS のチームが公式に提供しているものは、さすがに対応も早いですが、個人から提供されているものなどは、少し時間がかかる場合もあるようです。個人的には、 Xbench と Regex Match AutoSuggest Provider の対応を、強く、強く、強く、希望します。

一覧に表示されたアプリは、 [ダウンロード]アイコンをクリックするだけで、自動的にインストールされます。インストールが終わったら、メッセージに従って Trados を再起動して完了です。
今回は、以上です。2024 を実際に使うようになったら、その機能なども徐々に紹介していきたいと思います。
タグ: アップグレード
2024
一括タスク
連続タスク
ユーザー プロファイル
Freelance 版の制限
Regex Match AutoSuggest Provider
Xbench
アプリ
バージョン
エディション
Tweet