
「フラグメント一致」は「upLIFT テクノロジー」によって実現される機能の 1 つです。upLIFT テクノロジーでは、フラグメント一致だけでなく「あいまい一致の自動修正」という機能も実現されています。upLIFT テクノロジーとは、簡単に言えば、分節の中の単語 (フラグメント) レベルで一致を見つけてくれるテクノロジーのようです。この記事のタイトルはわかりやくするため「フラグメント一致」としましたが、記事の内容は、フラグメント一致に限らず、upLIFT テクノロジーが関係する各種設定ということで進めたいと思います。
「2017 SR1 アップグレード セミナー」に参加してみました 」で少し紹介しました。詳細については、SDL の公式ブログ「 SDL Trados Studio 2017 SR1におけるupLIFTの日本語対応と解析結果の差異について 」が参考になります。
注記:今回の説明に使っている Trados は、バージョン 2017 SR1 (正確には、2017 SR1 14.1.10012.29730) です。最新の 2019 では一部変わっているところがあるようです。
upLIFT テクノロジーが関係する機能の設定を以下の表にまとめました (私が見つけられた限りです。ほかにもありましたら、ぜひご意見ください)。今回の前編の記事では「プロジェクトの設定」を取り上げます。そのほかの設定は、 次回の後編 で紹介したいと思います。
プロジェクトの設定:
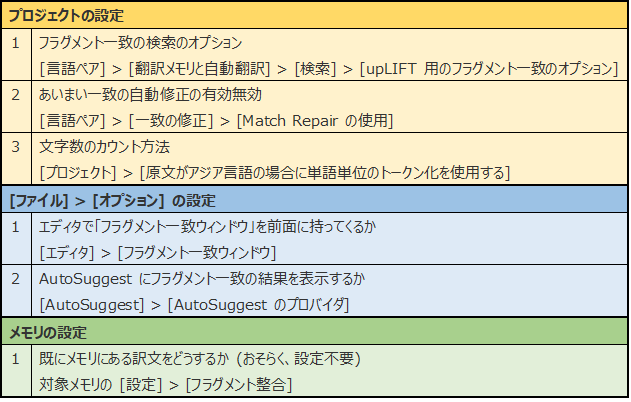
[言語ペア] > [翻訳メモリと自動翻訳] > [検索] > [upLIFT 用のフラグメント一致のオプション]
[言語ペア] > [翻訳メモリと自動翻訳] > [検索] > [upLIFT 用のフラグメント一致のオプション]
ここが、フラグメント一致の検索動作そのものに影響を与えるメインの設定です。[ TU 全体] はチェックボックスになっていないので、有効無効を切り替えることはできません。つまり、「フラグメント一致」の機能そのものを無効にする設定はないようです。(私が探した限り、ありませんでした。)
[ TU のフラグメント] は、分節全体ではなく、その中の一部だけ一致したものを表示するかどうかです。これは、デフォルトではオフですが、オンにした方がヒットが多くなります。また、単語数は、以前に SDL のセミナーで、日本語原文のときは「2」に設定するとよいと説明されました。
まず、[ TU のフラグメント] チェックボックスをオンにすると、下図の右側のように赤色のマークの付いたヒットが表示されるようになります。これが「TU のフラグメント」です。一番上に表示されている青色のマークは、「スペース」という文字列だけの分節があることを意味しており「TU 全体」として表示されています。

さらに、単語数を変えると下図のようになります (ここでは、[ 一致の最小単語数] と [ 一致に含める最小重要単語数] の両方に同じ値を設定しました)。単語数を少なくした方がヒットが多くなります。「2」にすると、少し多すぎるようにも思えますが、「設定」という 2 文字の単語の訳語が表示されてきます。日本語の場合、漢字 2 文字の単語はよくあるのでちょっと便利かもしれません。

「単語数」の設定なのに文字数になってる??という疑問が湧いてはきますが、あまり深く考えないことにします。まずは「2」に設定してみる、ヒットが多すぎるようだったら「3」にしてみる、という感じで私は使っています。
プロジェクトの設定:
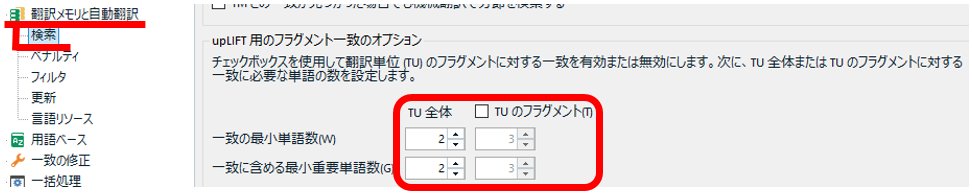
[言語ペア] > [一致の修正] > [Match Repair の使用] と [Match Repair ソース]
[言語ペア] > [一致の修正] > [Match Repair の使用] と [Match Repair ソース]
[ Match Repair の使用] では、「あいまい一致の自動修正」の有効無効を切り替えます。デフォルトで [ エディタ] のみオンになっています。つまり、エディタで普通に作業するときに、この機能が有効ということです。これが有効の場合、メモリの検索結果に、自動で修正が加えられた訳文が表示されてきます。修正が加えられているかどうかは、一致率のところに
 のようにスパナのアイコンがあることでわかります。
のようにスパナのアイコンがあることでわかります。
この「あいまい一致の自動修正」ですが、エディタで有効にしていると、エディタの動きが著しく遅くなることがあります。私の経験では、メモリがたまってきて自動修正がうまく機能するようになってきたかなぁ、とちょうど思う頃から検索結果がなかなか返ってこなくなり、耐えられなくなることが多いです。そのような場合は、以前の記事「 Trados のエディタの動きが遅い! 」でも紹介しましたが、この機能をオフにします。
同じページの下部には、[ Match Repair ソース] という設定 ※2 もあります。これは、修正の参考にするソースという意味だと思われます。翻訳メモリで機械翻訳を使用するように設定している場合に限り、有効無効を切り替えられます。私は、機械翻訳を使って仕事をすることがあまりないのですが、もし使える環境なら有効にした方がいいのかもしれないです。
※2 バージョン 2019 では、この設定のオプションが増えており、用語集についても有効無効を切り替えられるようです。
プロジェクトの設定:
[プロジェクト] > [原文がアジア言語の場合に単語単位のトークン化を使用する]
[プロジェクト] > [原文がアジア言語の場合に単語単位のトークン化を使用する]

これは、文字数のカウント方法に関する設定で、メモリとの一致率に影響がでてきます。プロジェクトの設定の一番上にある [ プロジェクト] から設定します。オフ (= 使用しない) にすると、upLIFT テクノロジーが有効であっても文字単位で一致率が計算されます。原語が日本語などのアジア言語のときにのみ考慮する必要のある設定で、原語が英語のときは無視できると思います。詳細は、SDL の公式ブログ「 SDL Trados Studio 2017 SR1におけるupLIFTの日本語対応と解析結果の差異について 」を参照してください。日英翻訳のとき、料金が文字ベースなら、ここはオフになっているべきです。
この設定は、以前に SDL のセミナーで「カウントに影響する」と説明された記憶があるので私はそのように理解していますが、UI の文言には「カウント」や「解析」といった言葉は一切入っておらず、カウントに影響するだけなのか、検索機能そのものに影響があるのか、実際にはよくわかりません。ただ、これまでの私の経験では、ここがオフでも、エディタでは普通に upLIFT テクノロジーが機能するように思います。
前編の今回は以上です。残りの設定は次の後編の記事で説明したいと思います。といっても、実は、デフォルトから変更する必要のある設定は、最初に説明した検索オプションの [ TU のフラグメント] くらいです。後は、あまり気にせず、デフォルトのままでなんとなく適当に動くような気がします。
2017 SR1
フラグメント一致
upLIFT テクノロジー
TU のフラグメント
一致の修正
Match Repair の使用
原文がアジア言語の場合に単語単位のトークン化を使用する
文字数
カウント
あいまい一致の自動修正
Tweet


