
上記のセッションでも言われていましたが、ツールは使う目的も使い方も人それぞれです。ある人が「これは便利」と言っていても、それが自分の目的には合わないこともあります。私のこのブログ全体は個人翻訳者を想定していますが、今回の Xbench の観点からもう少し細かく状況を説明するとこんな感じです。
- Trados と Xbench の組み合わせが多い (= 他の CAT ツールの使用頻度は低い)
- 言語方向は主に、日本語 -> 英語
- Xbench は無料版で済ませたい
- 翻訳会社からパッケージを受け取る (= 原文や設定を勝手には変えられない)
- メモリや用語集が支給される (= 絶対に見落とせない資料がある)
- Xbench の主目的は検索 (= QA 機能は補助的にしか使わない)
以下には、こんな状況の私が便利だと思っていることを紹介したいと思います。ぜひぜひ、ご自身でいろいろと試してみてください。
まずは大前提 — Trados で分節を確定し、Xbench でファイルを更新する
Trados と Xbench を組み合わせて使う場合、まずは、Trados 上で分節を確定する必要があります。Xbench では確定済みの分節しか検索や QA の対象になりません。Trados 上で訳文を入力していても、ステータスが未確定だと Xbench では Untranslated となり、訳文が認識されません。
Trados で分節を確定してファイルを保存したら、その後、Xbench に移動してファイルの更新をします。これで初めて、最新のファイルに対して検索や QA が行えるようになります。更新をするには、[ View] > [ Refresh] (F5 キー) か、上部に並んでいるボタンの [ Reload] ボタン (Shift+F5 キー) を使います。[ Refresh] は、Trados で翻訳中のファイル (Ongoing Translation に設定しているファイル) のみを更新する場合に使います。[ Reload] は、用語集なども含めてすべて更新したい場合に使います。特定の時間間隔で自動更新を行うオプションもありますが、私は、更新したいときに手動で更新しています。

要注意! — 結合した分節の訳文は認識されない
Trados 上で 分節を結合する ことがあると思います。これは、翻訳作業では便利ですが、Xbench を使うときは問題になります。Trados で結合した分節は、Xbench でステータスがうまく認識されないらしく、上記と同じ Untranslated になってしまい検索や QA の対象になりません。数個の結合なら無視してもいいかもしれませんが、大量にあるとその分節は QA がされないことになるので問題です。(これが、有料版の V3 だったら改善されているといったことはないですかね? もしそうなら、購入を検討してもいいかもしれないです。あくまで、検討ですが ...)
検索のための設定 — 優先度と順序
Trados で分節を確定して Xbench で更新をしたらいよいよ検索です。でも、まだ少し注意したい設定があります。Xbench では大量のデータでも検索結果がすぐに返ってきますが、その仕組みを理解しておかないと検索漏れにつながります。

Xbench のプロジェクトでは、上図のように Priority として High、Medium、Low の 3 つのレベルを指定できます。さらに、その優先度の各レベルの中で順序 (Order) を指定できます。検索結果は、この Priority と Order の順番で上から順に表示されます。
私は、たいてい、以下のような設定にしています。
- High: 翻訳会社から提供されたメモリと用語集 (= 絶対に見逃したくない資料)
- Medium: 翻訳中のファイル (= 自分の現在の訳文)
- Low: その他 (= 任意で参考にする資料。過去の訳文、類似文書のメモリなど)
Priority を分けておくと、下図のように色も変わるので見落とす心配がありません。既定で、緑色が High です。

検索結果の画面では、上図のように、右下隅に [ Click here to show all matches] というメッセージが表示されていないかに注意する必要があります。
検索のための設定 — レベルごとの表示数
実際に検索を行うと、右下隅に [ Click here to show all matches] と表示されることがあります。このメッセージは、この検索結果に表示されていないマッチがあることを意味しています。
大量のデータを検索すると、当然ながら検索結果も大量になりがちです。Xbench では、それを避けるために Priority のレベルごとに検索結果の表示数を設定できます。既定では (おそらく) 25 行です。High がもちろん優先ですが、High の結果を 25 行表示したら、それ以上マッチがあってもそれは表示せず、Medium を表示します。Medium も 25 行まで表示して、その後は Low を表示します。こうすることによって、どんなに大量のマッチがあっても、検索結果の最初の画面で High から Low まですべてのレベルのマッチを一覧できるようにしています。
レベルごとの表示数の設定は、[ Tools] > [ Settings] と選択して [ Layout & Hotkeys] タブで行います。

検索結果ですべてのマッチを表示したいときは、一覧の右下隅に表示されている [ Click here to show all matches] をクリックするか、下図のように一覧上で右クリックして [ Zoom to 〜] を選択します。

Zoom を使うと、特定の優先度レベルやファイルに絞ってすべてのマッチを表示できます。
検索のための設定 — 検索結果に表示する列数
用語集などでは、原語と訳語のほかにコメントが含まれていて、検索結果でコメントまで参照したいときがあります。たまに「使用禁止」なんてコメントが入っていることもあるので注意が必要です。そうしたコメントなどのために、検索結果の画面に [ Source] と [ Target] 以外の列を追加で表示できます。

あまり見やすい表示にはなりませんが、表示する列数を増やすことで追加情報を表示できます。設定は、[ Project] > [ Properties] と選択して [ Settings] タブで行います。[ Columns in list] に、[ Source] と [ Target] を含めて何列表示するかを設定します。私は、たいてい 4 列くらいにしています。
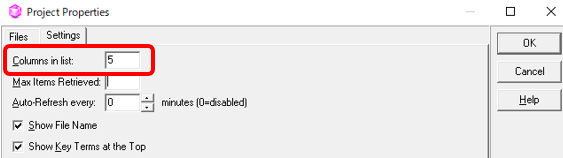
列数を増やせばいろいろ表示できますが、すべてを表示できるわけではありません。用語集の構造によっては、コメントを表示できないことや、表示できても読みにくいことがあります。必要であれば、右端に検索元のファイル名が表示されているので、それを頼りにオリジナルのファイルを参照します。
自動置換 (Automatic Substitution)
私が Xbench で便利だと思っている機能のひとつに自動置換 (Automatic Substitution) があります。これは、検索結果が 1 つしかないときに Xbench の画面を表示せず、エディター上で用語を直接置き換えてくれる機能です。たとえば、「このサービスは、以下の言語でご利用いただけます」という文の後ろに言語名がずらずらと並んでいることがあったりしませんか。そうした場合は、言語名の用語集を Xbench に登録し、Automatic Substitution を使ってひたすら置換していきます。訳語が決まっている UI も Automatic Substitution がとても便利です。UI が用語集としてちゃんと提供されているときは、もう Xbench 様々です。対象の用語を選択して、Automatic Substitution のホットキーである Ctrl+Alt+PageDown を押せば一発で入力完了です。

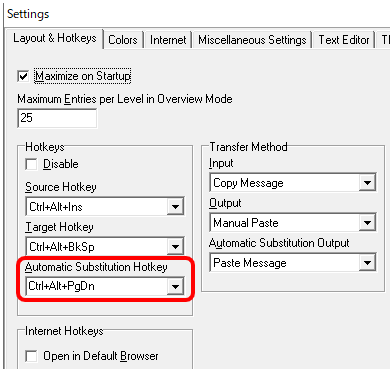
Automatic Substitution のホットキーは、レベルごとの表示数の設定と同じ、[ Tools] > [ Settings] の [ Layout & Hotkeys] タブで行います。このタブでは、Automatic Substitution 以外にも、原語検索と訳語検索のホットキーやそのアクションの詳細を設定できます。(すみません、[ Transfer Method] の詳細はよくわからないのですが、私は以下のような設定にしています。)
QA 機能 — 実行前の確認
さて、最後に QA 機能も少しだけ紹介します。 前編 にも書いていますが、私は翻訳チェックの用途には Trados の検証機能を主に使い、Xbench は補完として使っています。Trados の検証機能では不便なところを Xbench で補う形です。
QA 機能を使う前に、まずは、チェック対象のファイルを Ongoing Translation に設定していることを確認します。QA 機能は Ongoing Translation のファイルのみ対象とします。また、この記事の最初に説明しましたが、Trados 上で分節を確定済みにしていること、そして、Xbench で最新のファイルに更新していることも確認してください。
QA 機能 — 訳揺れのチェック
まず、私がよく使うチェックは [ Basic] の [ Inconsistency in Source]と [ Inconsistency in Target] です。(ちなみに、オプションの [ Exclude ICE Segments] を選択すると、Trados 上でロックされているセグメントを除外できます。)
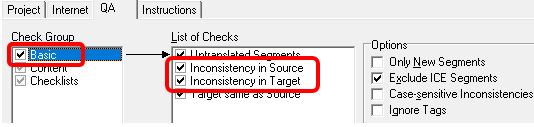
Trados でも同様のチェックはできますが、結果の表示は Xbench の方が断然わかりやすいので、私は Xbench を使っています。
QA 機能 — 数字のチェック
[ Content] の [ Numeric Mismatch] もよく使います。これも、Trados でできないわけではありませんが、Xbench では原文と訳文が上下に表示されるので数字の比較がしやすいです。

数字のチェックは、Trados や他の CAT ツールと同様、10月と October はエラーになりますし、全角の数字にも対応していません。なので誤検出も多く発生しますが、数字のミスは致命的になるので、安全のために私は Trados と Xbench の両方でチェックすることが多いです。
今回は以上です。Xbench には、ここで紹介した以外にもまだまだたくさんの機能があります。検索の Power Search は便利ですし、TMX 形式への変換もできますし、ブラウザーの代わりにもなります。自分なりに便利な使い方を見つけられると楽しいと思います。
| |
|
Tweet


