前編 に引き続き、Trados 内でタイピングを減らす方法を考えてみます。今回は、プロジェクトの設定ではなく、 [ファイル] > [オプション]から行う Trados 環境全体の設定です。これらの設定の詳細については、以前の記事「 Trados の設定を変えるには − [ファイル] と [プロジェクトの設定] 」を参照してください。
[ファイル] > [オプション]の設定は、プロジェクトの設定と異なり、一度設定すればどのプロジェクトで作業をしても有効です。これは便利である反面、プロジェクトごとに設定を変えることはできないということでもあります。言語の方向 (日英か、英日か) によって設定を変えたくなることはありますが、プロジェクトを変えても設定は変わらないので、そうした場合は手動で設定を変えるしかありません。(結局、プロジェクトごとに設定を変えるんじゃん! ということです。)
今回紹介する機能は、主に AutoSuggest です。AutoSuggest は、英訳をする (英語を入力する) ときはうまく機能しますが、和訳をする (日本語を入力する) ときは、IME との関係上、あまり期待どおりの動作になりません。和訳の場合は、AutoSuggest は無効にして IME の機能を活用するのも一つの選択肢です。この記事の以下の説明は、英訳をする (英語を入力する) 場合を前提としています。では、始めていきましょう。
AutoSuggest
AutoSuggest の有効無効の切り替えや詳細の設定は、 [ファイル] > [オプション] > [AutoSuggest]から行います。
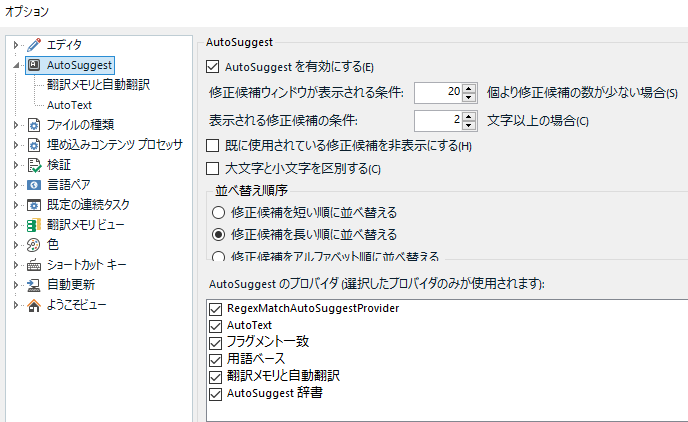
画面下部の [AutoSuggest のプロバイダ]リストで、AutoSuggest の候補をどこから持ってくるのかを指定できます。順番も変更できます。私はすべてのチェックボックスをオンにしていることが多いですが、不要なものはオフにできます。
このリストの一番上に表示されている [RegexMatchAutoSuggestProvider]は、AutoSuggest を強化する プラグイン です。これについては後で説明します。 [AutoText]と [翻訳メモリと自動翻訳]については、別の画面で詳細を設定できます。これも後述します。
[AutoSuggest 辞書]は、 特定のメモリから用語を抽出した対訳集 (.bpm ファイル) のようなものです。長らく、フリーランス版ではこの辞書を生成することができなかったのですが、なんと Trados Studio 2021 からは生成できる ようになっています。(私は、この記事を書いていて、辞書生成機能がフリーランス版に追加されていることを初めて知りました。びっくりしました。) これも後で簡単に説明します。
この画面の細かい設定は、正直に言って、個人の好みです。メモリや用語集の充実度にもよりますし、慣れの問題もあります。候補があまりに多く表示されるようなら [翻訳メモリと自動翻訳]をオフにするとか、作業しているプロジェクトに合わせて面倒がらずに設定を変えてください。(まあ、結局、プロジェクトごとに設定を変えることになるので面倒です。)
では、いくつかの機能を詳しく見ていきます。
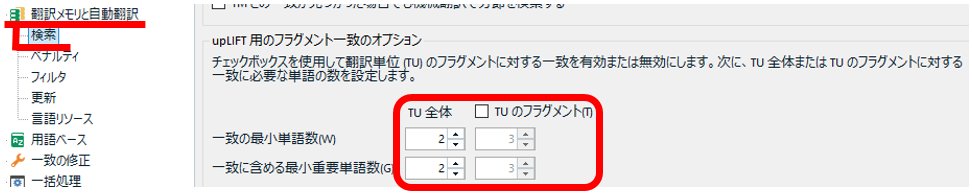
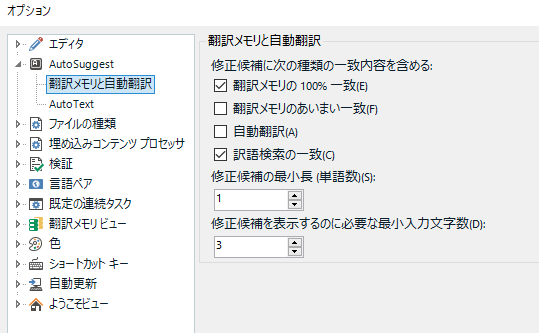
翻訳メモリと自動翻訳
この機能を有効にすると、表示される候補がかなり多くなります。私は、候補を減らすため、たいてい「あいまい一致」のチェックボックスはオフにしています。
AutoText
訳文でよく使う語句を自分で登録しておくことができます。AutoText は、原文に関係なく表示されるのが特徴です。メモリや用語集は原文に該当する語句がなければ機能しませんが、AutoText は訳文の語句を登録しているので、最初の数文字を入力すれば原文に関係なく候補が表示されてきます。「person in charge」や「company/organization」など、空白やスラッシュを含む語句も登録できます。

AutoText のリストはファイルとして保存できます。右下にある [インポート]と [エクスポート]のボタンを使います。このリストは、Trados が落ちたりすると、新しく追加した語句が消えてしまうことがあるので、こまめにエクスポートしておくことをお勧めします。
Regex Match AutoSuggest Provider
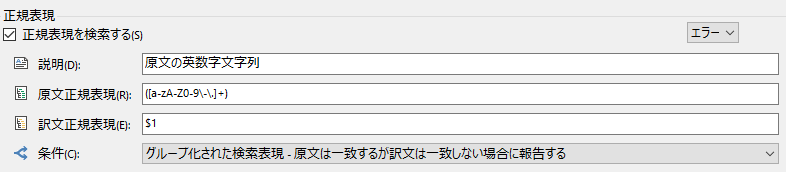
Regex Match AutoSuggest Provider は、AutoSuggest を強化してくれるプラグインです。無料で使用できます。詳細については、以前の記事「 ■プラグイン■ 原文にある英数字を訳文にコピーする (日⇒英の場合) 」を参照してください。
以前の記事では英数字をコピーする方法しか説明していませんが、もちろん、いろいろな使い方ができます。基本的には正規表現ですが、普通の語句を登録するだけなら正規表現を特に意識する必要はありません。
たとえば、日本語でよく使われる丸囲み数字を以下のように変換できます (?@ を (1) に変換する)。
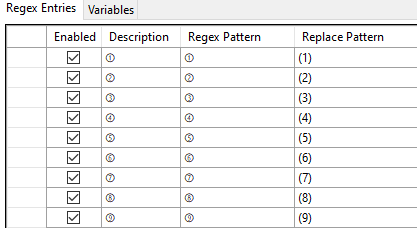
以下は、数字を月名に変換しています。全角に対応するため少しだけ正規表現を使っています (すみません、順番がばらばらなことに特に意味はありません)。

上図のように設定した場合、 11に対しては Novemberと Januaryの両方が候補として表示されます。また、単に数字を指定しているだけなので、月名とは関係のない数字の場合も月名が候補として表示されます。その辺りは、私としては許容範囲内です。
AutoSuggest 辞書
最後に AutoSuggest 辞書です。前述のとおり、この辞書はこれまでフリーランス版では作成できなかったので、私は使ったことがありません。どの程度役立つのかは未知数ですが、大きなメモリが提供されている場合は便利に機能するのではないかと思います。
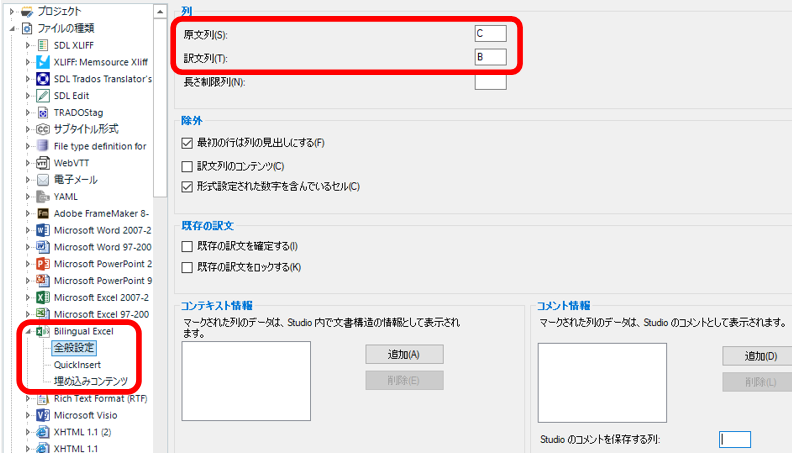
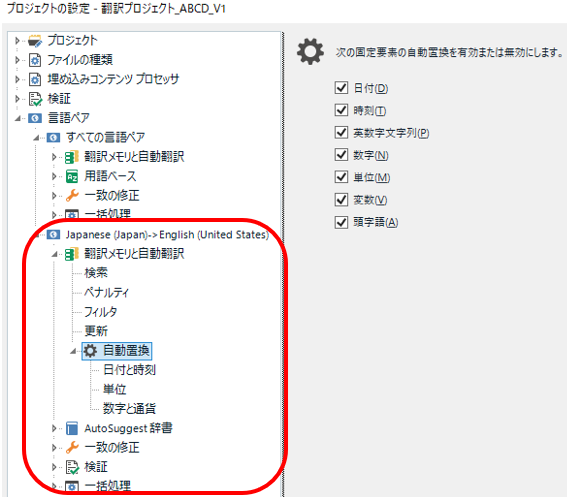
AutoSuggest 辞書の個々の設定は、 [ファイル] > [オプション]ではなく、プロジェクトの設定から行います。プロジェクトの設定で [言語ペア] > [ 特定の言語ペア ] > [AutoSuggest 辞書]をクリックすると以下の画面が表示されます (言語に依存するものなので、 [すべての言語ペア]ではなく、Japanese など特定の言語ペアから設定します)。

まず、辞書を作成します。この画面で [生成]ボタンをクリックするとウィザードが開始されます。ウィザードを進めていけば、辞書ファイル (.bpm) ができあがります。メモリが大きいとかなり時間がかかると思われるので、設定を適宜調整してみてください。また、辞書の作成は、この画面ではなく、 [翻訳メモリ]ビューから行うこともできます。
辞書ファイルが作成されたら、 [追加]ボタンをクリックしてそのファイルを登録します。これで、準備は完了です。辞書の内容が候補に表示されてくるはずです。
今回は以上です。AutoSuggest は、設定によっては、期待どおりの候補が表示されなかったり、表示される候補が多すぎたりすることがあります。ベストな設定を見つけるのはなかなか難しいですが、いろいろとお試しください。作業しているプロジェクトに応じて、こまめに設定を変えることも大切かと思います (そう思ってはいますが、実際のところは面倒です)。
Tweet