
今回は、私が翻訳会社さんと実際にどのような仕事をしているのかを少しだけ紹介したいと思います。私は、主に IT 分野の日英と英日の翻訳をしており、分野も言語の種類も決して多くありませんが、それでも翻訳会社によっていろいろなことが大きく違います。
A 社: 小規模ならではの “適当さ”
言語方向: 英 -> 日
ファイルの種類: Word と PowerPoint がほとんど
ソース クライアント: ほぼ 1 社
まず、小規模ですがなかなか頑張っている A 社を紹介します。私は A 社からほぼ決まったソース クライアント 1 社の仕事を受けています (おそらく、A 社全体でも、このソース クライアントの仕事が大きな割合を占めていると思います)。ソース クライアントが決まっているので、翻訳するファイルも似たようなものが多く、Word と PowerPoint がほとんどで、Trados のプロジェクト設定もほぼ毎回同じです。
巨大なメモリが提供される
A 社は、この決まったソース クライアントの訳文を集めた巨大なメモリを 1 つ持っていて、たいていのプロジェクトにそのメモリを設定してきます。ただ、新規翻訳の案件が多いので、巨大なメモリであってもほとんどマッチはしません。マッチするのは、著作権や免責事項の定型文くらいです。
ほとんどマッチがないので、前処理もされていません。翻訳ファイルを開くと、まっさらな状態で、100% マッチやコンテキスト マッチがあっても事前に訳文が挿入されていることはありません。A 社は、100% マッチなどにも料金を払ってくれる (割り引きはありますが) ので、前処理がされていなくても特に問題はありません。というより、新規翻訳なら、下手に訳文が挿入されているより、何もされていないほうがやりやすく感じます。
適当にいい感じ
巨大なメモリからたまに見当違いな訳文がヒットしてくるとか、発注書の発行が遅いとか、用語ベースを使わないとか、なんとなく問題はありますが、納期はきつくないし、単価も高めだし、変に面倒な指示はないので、全体としては “適当に” いい感じです。
B 社: クライアントの指定で Trados を使う
言語方向: 英 -> 日
ファイルの種類: XML ファイル
ソース クライアント: ほぼ 1 社
次に、A 社よりかなり会社の規模が大きい B 社を紹介します。 B 社からも私はほぼ決まったソース クライアント 1 社の案件しか受けませんが、A 社とは状況がだいぶ違います。B 社は、会社としては Memsource をメインの CAT ツールとして使い、特定のソース クライアントのときのみ Trados を使っているようです。
私が受ける案件のソース クライアントはいわゆる大手 IT 企業で、多言語の翻訳を行っています。Trados を導入しているのは、そのソース クライアント自体か、B 社よりさらに上流の MLV (Multiple-Language Vendor) らしく、プロジェクトやメモリの仕様は基本的にはその上流で決められているようです。
プロジェクト用翻訳メモリしか提供されない
B 社から受け取る Trados のプロジェクトには、プロジェクト用翻訳メモリのみ含まれていて、メイン メモリは含まれていません。「プロジェクト用翻訳メモリ」とは、一定のマッチ率 (おそらく、70%) 以上の分節だけを抽出したメモリです (詳しくは、公式ブログ「 プロジェクト用翻訳メモリについて 」を参照してください)。 メイン メモリが巨大でも各プロジェクトに含めるデータの量を減らせるので翻訳会社には便利なメモリです。
ただ、翻訳者としては、メイン メモリも提供して欲しいと思っています。マッチしてこなくても訳語検索はできますし、最近は「フラグメント一致」という機能で、分節全体としてはマッチしなくても、一部の用語だけがヒットしてくることもあります。B 社は、75% マッチから料金を割り引いてきますが、75% マッチで料金を割り引くほど適切で関連性のあるメモリなら 69% マッチの訳文も参照の必要があるでしょうし、69% マッチが参照不要となる程度の雑多なメモリなら 75% マッチの訳文も割り引きをするほど適切で関連性のあるものではない可能性が高いのではと思います。
以前に、メイン メモリの提供をお願いしたことがありますが、提供できないとの返事でした。おそらく、「巨大なメモリ」と紹介した A 社のメモリとは比にならない巨大さなのだと思います。そのうえ、多言語なので、ソース クライアント側にはその巨大なメモリが言語の数だけ存在しているはずであり、まあ管理が大変そうであることは想像がつきます。
多言語プロジェクトの注意点
多言語が関わる案件では、自分の担当が単一言語だとしても Trados のプロジェクト設定で少し注意が必要になります。
言語ペア
以前に Trados のワナ として紹介しましたが、プロジェクトの設定には「すべての言語ペア」と「特定の言語ペア」の両方があります。

両方で設定がされている場合、優先されるのは「特定の言語ペア」の方です。メモリの設定などを変える場合は、「すべての言語ペア」ではなく、「Japanese」と表示されている特定の言語ペアの方で変える必要があります。
用語ベース
このソース クライアントの案件では、UI の文言が Excel ファイルと Trados の用語ベースの両方で提供されます。用語ベースの提供は大変嬉しいのですが、以前に用語がうまく認識されないことがあり、確認してみたら言語の設定が間違っていました。
多言語の場合は、そもそものソース言語が English だったり、Source だったり、en-US だったり、またはまったく違う言語だったりします。このソース クライアントから提供される Excel ファイルを見ると、十数言語の列が横にずらっと並んでいて、その中に Source 列と English 列があり、English 列は空になっていることがあります。こうしたファイルから用語ベースを作成するときは、どの列を用語ベースの「英語」とするのかに注意が必要です。
全体としては、きちんと整っている
B 社もソース クライアントも大手だけあって、作業データの内容や手順はかなりきちんと整えられています。翻訳するファイルは XML ファイルですが、完成形に近いプレビューができるように設定がされています。原文や UI のデータも最初に必ず提供されますし、発注書も作業前に発行されます。メイン メモリを提供してくれない点以外は、とても効率的に作業が進められて快適です。
C 社: 細部までの配慮がされている
言語方向: 日 -> 英
ファイルの種類: Word、PowerPoint、HTML ファイル
ソース クライアント: 3、4 社
次に、会社の規模としては A 社より大きく、B 社よりは小さい中程度の C 社を紹介します。C 社は、かなり以前から Trados をメインに使っているようで、技術的な知識も豊富な感じの会社です。作業データの内容などを見ると、細部までいろいろな配慮がされていることがわかります。
参照用メモリと更新用メモリが設定されている
C 社は、Trados のプロジェクトに参照用メモリと更新用メモリを最初から設定してきてくれます。参照用メモリは更新されず、自分が訳したメモリは更新用メモリに登録されていきます。更新するメモリの設定については、以前の記事「 提供された訳文と自分の訳文を区別する ー ?@ メモリを分ける 」も参照してください。
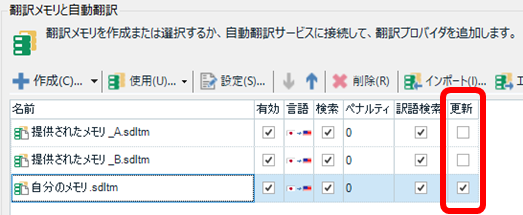
翻訳会社から提供されたメモリを自分の訳文で更新してしまうと、後から確認したくなったときに困るので、提供されたメモリは更新しない設定にしておくほうが安全です。ただ、Trados の既定設定では更新されてしまうため、私はたいてい自分で設定を変えています。C 社はこの設定までしてきてくれるので、自分で設定する必要がなく、設定を忘れて更新してしまうこともありません。とても助かります。
英数字のみの分節をロックしてくる
細部までの配慮はすばらしいことですが、翻訳者にとっては少しシビアな点もあります。C 社は、日本語から英語に訳す案件の場合、日本語内の英数字のみの分節をロックして、作業対象外としてきます。「作業対象外」ということは、当然ながら、料金 0 円です。
ロックまでしてくるので 0 円でも構わないですが、「英数字のみ」の抽出は正規表現か何かで機械的に行われています。このため、和製英語や日本語独特の略語など (たとえば、OK/NG の「NG」、Number を略したピリオドなしの「No」) はロックされてきます。また、数字と単位だけの分節もロックされてきます。スタイルガイドに「数字と単位の間には空白を入れる」と書いてあっても、原文の「10cm」はそのままロックされてきます。おそらく、レビュアーさんがロックを解除して対応しているのではないかと思います。
D 社: いろいろな手法を挑戦的に取り入れる
言語方向: 日 -> 英
ファイルの種類: Word、PowerPoint、HTML ファイル、その他いろいろ
ソース クライアント: 不特定
次に、C 社と同程度か、少し規模の大きい D 社を紹介します。D 社も Trados の使用実績は豊富と思われますが、C 社より個人の裁量が大きい社風のようで、コーディネーターさんによって作業データの内容や手順がさまざまに変わります。また、ソース クライアントや翻訳ファイルの種類が多いためか、いろいろな手法を挑戦的に取り入れている感じがします。
コンテキスト マッチが作業対象外のことがある
D 社は、私がお付き合いしている翻訳会社の中で唯一、コンテキスト マッチ (CM) を作業対象外としてくる “ことがある” 会社です。CM や 100% マッチについては公式ブログの 「100%一致」と「完全一致」の違い でも説明されていますが、簡単にいうと、CM は 100% マッチより信頼度が高いマッチです。このため、Trados の設定では「100% マッチはロックしないが、CM はロックする」ことが可能です。Trados で「ロックする」ということは、作業対象外として 0 円にするという意味です。
とはいえ、翻訳会社さんも設定で可能だからといってむやみに CM を作業対象外にするわけではありません。品質、予算、納期などいろいろと検討した上でどこを作業対象とするかを決定しているはずです。D 社の場合も、すべての案件で CM が作業対象外となるわけではないので毎回確認が必要です。
作業対象の確認は、指示書、翻訳ファイル、発注書の 3 つで間違いがないか確認します。一番多い間違いは、指示書に「CM も作業してください」とあるのに、発注書で CM が 0 円になっているケースです。
また、もう 1 つ困るケースとして、CM が対象外なのに、翻訳ファイルでロックされていない場合があります。ロックされていないと、うっかり作業してしまう可能性があり、トラブルになりかねないので、私は必ず翻訳会社さんに対象外の部分をロックしてきてくれるようにお願いしています。
更新用メモリはないこともある
CM に加えて、もう 1 つ D 社の特徴的な点は、Trados のプロジェクトに更新用メモリを設定してこないことです。これも、コーディネーターさんによってばらつきはありますが、新規翻訳の場合にメモリが 1 つも設定されていなかったり、参照用メモリが設定されている場合に「更新」のチェックがオフにされていたりすることが多々あります。
「更新」のチェックがオフにされていれば、参照用メモリを間違って更新してしまうことはないので安心です。更新用メモリをあらかじめ設定してくる C 社の場合と異なり、自分で更新用メモリを作成してプロジェクトに追加する必要はありますが、自分で自由に設定したいこともあるので、私としては「更新」のチェックがオフにされているだけで十分です。
翻訳ファイルにいろいろな加工がされている
D 社は、C 社と同様、Trados などに関する知識は豊富なようで、翻訳ファイルに手の込んだ加工がされていることがあります。英数字のみの分節はロックしてきますし、何か別の基準でロックがされていることもあります。また、改訂版の翻訳で改訂部分だけが抜き出されていることもありました。加工されたファイルが翻訳者にとって作業しやすいものかといえば必ずしもそうではないこともあるのですが、いろいろと工夫がされていることは確かです。
E 社: IT 翻訳をメインにしていない会社
言語方向: 英 -> 日
ファイルの種類: Word、その他いろいろ
ソース クライアント: 不特定
上で紹介した C 社と D 社は Trados を積極的に活用しようとする雰囲気が感じられますが、もちろん、世の中そんな会社ばかりではありません。私にたまに依頼をしてくる E 社は IT 翻訳をメインにする会社ではなく、Trados を長年使ってはいますが、積極的に活用しようとする意識はなさそうな感じです。
パッケージを使わない
Trados をあまり使わないためか、E 社はデータの受け渡しにパッケージを使用しません。プロジェクトのフォルダー (sdlproj ファイルと関連の各フォルダー) をそのまま送ってきます。作業後にこちらから納品するのは、sdlxliff ファイルです。
「パッケージを使わないから、とんでもなく不便」ということはありませんが、E 社以外はどの会社もパッケージを使います。パッケージは、Trados の長い歴史から見れば比較的新しい機能といえないこともないので、昔から Trados をほそぼそと使ってきた会社なら、パッケージを使わないという選択も自然かもしれません。
F 社: Trados を使わない会社
言語方向: 日 -> 英
ファイルの種類: Word、PowerPoint、Excel
ソース クライアント: 不特定
さて、ようやく最後です。F 社は Trados をまったく使わない会社です。ほとんどの案件は Office 文書で、原文のファイルがそのまま送られてきます。私は、送られてきたファイルを Trados に取り込み、翻訳をして、訳文生成をして、レイアウトを整えて納品します。レイアウトの料金は追加で支払われますが、これまであまり複雑なものはなく、Trados の訳文生成後にそれほど手間がかかったことはありません。
自分の裁量で Trados を使う
自分の裁量で Trados を使用するので、何か問題が発生したときは自分で対処する必要があります。ただ、どうしても問題が解決できなければ、もちろん Trados を使わないという選択肢もあるので、最初から Trados を指定されるよりいいかもしれません。
Trados で問題が発生しないかを早めに確認するため、私は、原文をもらったらすぐに Trados に取り込み、訳文を少しだけ入力して訳文生成をしてみます。そこで、レイアウトが維持されるか、フォントがうまく変換されるかなどを確認して、大丈夫そうなら Trados で作業します。
今回は以上です。いろいろな会社があるということをお伝えしたくて、いろいろなことを書いていたら、ものすごく長くなってしまいました。プロジェクト用翻訳メモリとか、CM とか、ロックとか、今回はざっとしか説明しませんでしたが、また機会があったら詳しい記事を書きたいと思います。
Tweet


