Trados のエディタでは、空白や改行文字などを表示することができます。これを表示していないと、ただの空白なのか、改行なのか、はたまたタブなのかわからず、訳文生成してみたらレイアウトが崩れてしまったということになり兼ねません。
たとえば、こんな原文が

実は、こうだったということもあり得ます。

私の場合、空白は表示されなくてもいいんですが、改行とタブは表示して欲しいと思っています。特に改行はいくつか種類があるので、どの種類の改行かを意識する必要があります。で、「改行を表示しよう」と思って設定を探し回り、ぜんぜん見つからず、確か表示できたはずなのにと悩む、ということを私は過去に何回か繰り返していました。
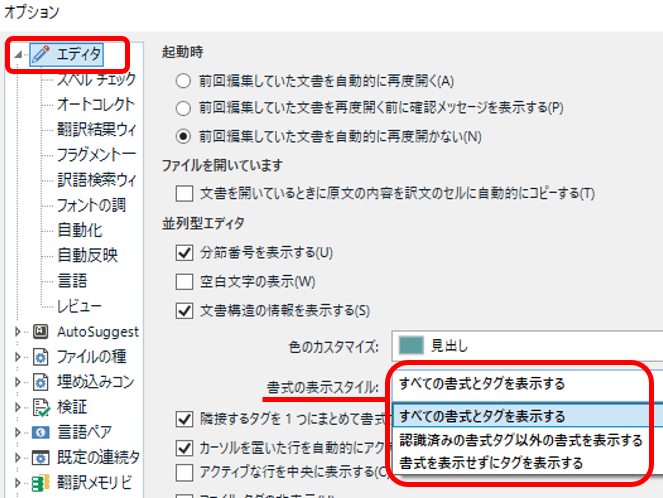
設定は「空白文字の表示」
「改行を表示しよう」と思って設定を探しているから見つからないのです。Trados の UI は、広い心をもって、しかし細心の注意を払って見なければいけません。

設定は、[ ファイル] > [ オプション] > [ エディタ] の [ 空白文字の表示] です。「空白文字」とありますが、このチェックボックスで改行もタブも表示されるようになります。Word で言えば「編集記号」ですね。チェックボックスが 1 つなので、Word のようにどの編集記号を表示するかを個別に設定することはできません。改行を表示したければ、空白も表示するしかありません。
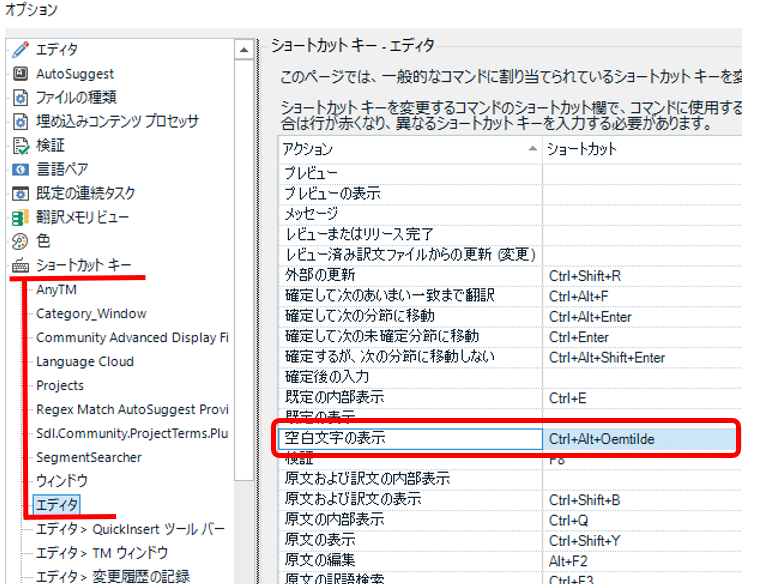
ショートカット キーを設定できる
空白の表示はうるさく感じることもあるので、私はショートカット キーを設定して、切り替えながら作業しています。ショートカット キーの設定は、[ ファイル] > [ オプション] > [ ショートカット キー] > [ エディタ] の [ 空白文字の表示] で行います。私は以下のように設定していますが、任意のキーを設定できます。
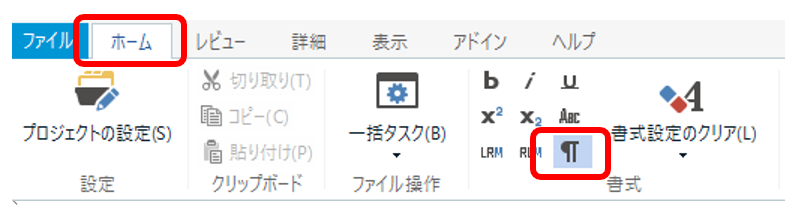
リボンからも切り替えられる
私自身はリボンを使うことはあまりありませんが、リボンのボタンからも表示を切り替えられます。[ ホーム] > [ 書式] の ¶ (段落記号) のアイコンです。ここでの表現は、空白文字ではありません。さすがに、空白文字はアイコンにしにくかったのでしょう。
改行の種類は原文と同じにする
リボンのアイコンは ¶ ですが、実は、Trados のエディタで ¶ を入力することはできません。分節内で改行を入力したいときは Shift+Enter を押しますが、これで入力できるのは、普通の ↵ (リターン) です。
私が試した限り、↓ (ライン フィード?) や ¶ (段落記号) をキーボードから入力することはできませんでした。これらの改行を使いたいときは、原文からコピーします。改行の種類は、 原文と同じにするのが大原則だと私は考えているので、原文からコピーして入力できれば、キーボードから入力できなくても特に問題はありません。
正直に言うと、それぞれの改行が Trados でどのように訳文生成されるのかはよくわかりません。また、Trados 以外の変換やコピー&ペーストでどうなるのかもよくわかりません。たとえば、自分は Trados 上で Word ファイルを訳していると思っていても、本当の元原稿は PowerPoint だったとか、最終的には HTML ファイルに変換されるものだったとか、訳文生成された後に実は Excel ファイルに訳文がコピー&ペーストされたとか、そんなことがないとは言い切れません。いろいろな可能性を考えるときりがないので、改行の種類は原文のとおりにしておくのが最も安全です。
今回は以上です。「空白文字の表示」で改行が表示されるということを理解するまでに、私は数年かかりました。まあ、改行もタブも、見た目は空白ですよね。そうなんですが、その考え方になかなか至りませんでした。
| |
|
Tweet