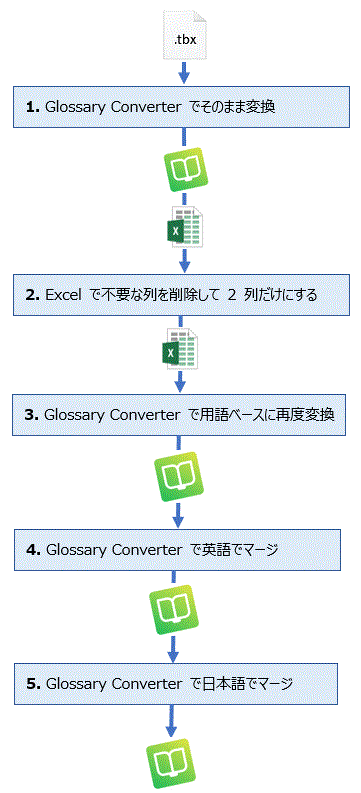
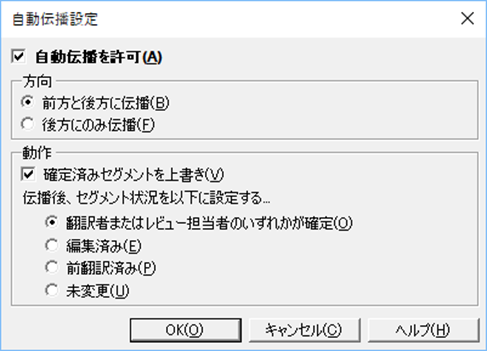
今回は、数字と単位記号と間のスペースです。上図のように、原文は「4km」だけど、訳文は「4 △ km」するというようなケースです。スタイルガイドで、スペースを入れてくださいとか、入れないでくださいとか、ノーブレークスペースにしてくださいとか、細かいことを指定されることがあると思います。このような処理は、プロジェクトの設定で自動化できます。設定してしまえば、QuickPlace (Ctrl+Alt+下矢印) や繰り返しの自動反映で入力するときに自動的にスペースが調整されます。細かいことですが、数字と単位記号は自分でタイプせずに入力することが多いので結構便利です。
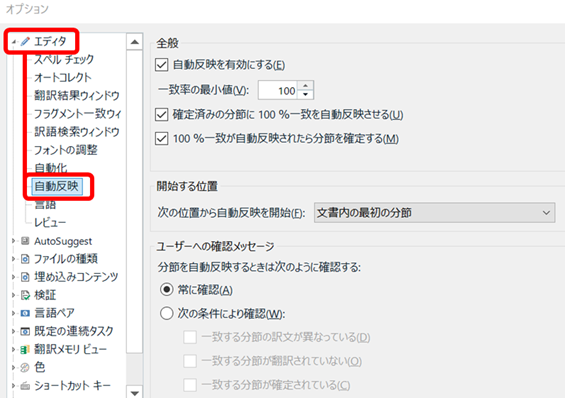
さて、ではその設定がどこにあるかですが、以下にあります。
[プロジェクトの設定] > [言語ペア] > [ 特定の言語ペア ] > [翻訳メモリと自動翻訳] > [自動置換] > [単位]

[ 言語ペア] の下で、[ すべての言語ペア] ではなく、[ Japanese (Japan) 〜] などの特定の言語ペアを選択する必要があります。私は多言語プロジェクトの経験はほとんどないのでこの2つの設定の違いがよくわからないのですが、言語固有の設定の場合は、その言語を選択して設定する必要があるようです。
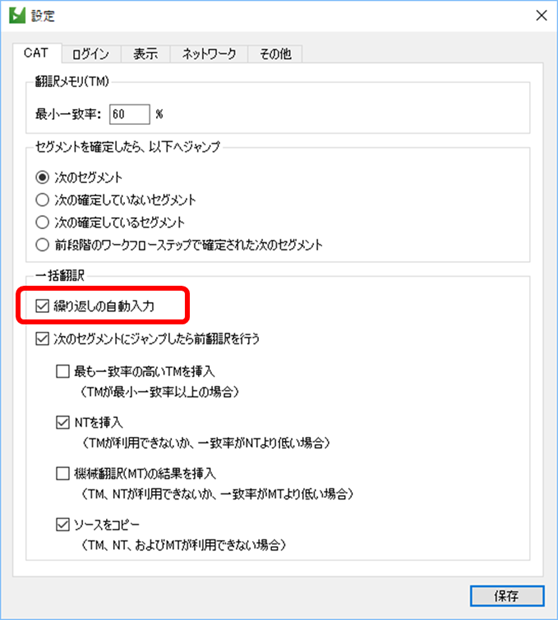
デフォルトの設定は、一番上の「 同じスペースを使用」です。このため、原文が「4km」なら、訳文も「4km」になります。訳文でスペースを入れたい場合は、真ん中あたりの「 通常のスペースを挿入」を選択します。これで、「4km」が「4 △ km」になります。
ほかにもスペースの種類を選べますが、私は、スタイルガイドで特に指定されない限り「通常のスペース」にしています。訳文が最終的にどのような形式で使われるのか翻訳者の段階ではわからないことも多いので、あまりいろいろなことはしないのが安全です。
なお、この機能が有効に働くのは Trados が単位として認識できる一般的な単位のみです。特殊な単位には効きません。たとえば、GB (ギガバイト) や TB (テラバイト) までは認識してくれますが、PB (ペタバイト) はだめでした。また、bps (bits per second) や pps (packets per socond) もだめでした。設定してもうまく機能しないときは、私はあまり考えず諦めることにしています。
最後に、この設定は「プロジェクトの設定」なので、パッケージで設定できるものです。つまり、パッケージを作る人がスタイルガイドに合わせて設定してきてくれれば、翻訳者は何もしなくていいんですよね〜。でも、翻訳会社さんはそんなことまではまずしてくれません。そこで、自分で設定するんですが、「ファイルが追加になりました」などと言われて新しいパッケージを開くと、設定が上書きされてしまい、設定のやり直しになります。「プロジェクトの設定」の中の設定は、パッケージで指定されている設定が優先なので、パッケージを開いたら、やり直しです。
今回は、以上です。ここで紹介した特定の言語ペアの下にある [ 自動置換] には、単位のスペースのほかにもいろいろ便利そうな設定があります。それについては、また次回の機会に取り上げたいと思います。
Tweet