



この広告は30日以上更新がないブログに表示されております。
新規記事の投稿を行うことで、非表示にすることが可能です。
広告
posted by fanblog
2020年02月02日
文字列を比較する — AutoHotKey と WinMerge と Trados とレビュー
先日、東京ほんま会の『 中級AutoHotKey講座
』に参加させてもらいました。以前から AutoHotKey は使っていましたが、誰かが作ってくれたスクリプトを拝借するところから先にはなかなか進めずにいたので、思い切って参加してみました。丁寧な資料と説明のおかげで、だいぶ理解が深まりました! 今回の企画には本当に感謝です。せっかくいろいろ教えてもらったので、講座の中で紹介されたスクリプトを応用して 2 つの文字列を比較する方法を考えてみました。
ほんま会の講座では、自分で用語集を作成する方法として、原語と訳語をクリップボードにコピーして両方を一気にテキスト ファイルに書き出すスクリプトが紹介されました。この「2 つのテキストを一気にファイルに書き出す」という処理を 2 つのテキストを比較する操作に応用しました。具体的には、AutoHotKey を使って 2 つのテキストをファイルに書き出し、 WinMerge を使って実際の比較を行います。
実は、 WinMerge でのテキスト比較は以前からよく使っていたのですが、毎回毎回、比較対象の 2 つをそれぞれクリップボードにコピーして、それぞれ貼り付けてという操作が面倒でした。今回の AutoHotKey で少しだけですが手間が減ります。
さて、そもそもなぜテキストを比較したいのかというと、Trados でレビュー作業をしなければならないからです。Trados なので当然メモリを使って翻訳されたものをレビューするのですが、これがなかなか大変です。
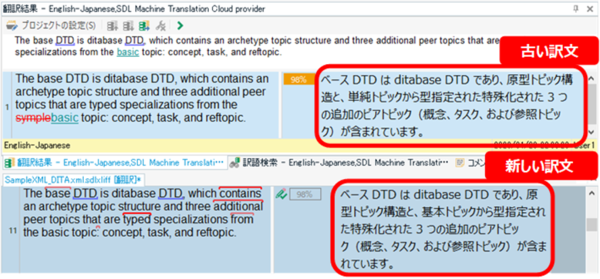
ファジー マッチの分節をレビューする場合、Trados の画面は上図のようになります。メモリの内容が [ 翻訳結果] ウィンドウに表示され、エディタ部分には、翻訳者さんが入力した新しい訳文が表示されています。中央のステータスの欄に「98%」と白枠で表示されているので、98% マッチのメモリを使ってどこかを編集したということまではわかりますが、どこを編集したのかはわかりません。原文の違いは、[ 翻訳結果] ウィンドウに変更履歴のような形式で表示されますが、訳文についてはそのような表示はありません。
こうしたときに、メモリ内の古い訳文と翻訳者さんの新しい訳文を比較できるととても便利です。下図のように 2 つのテキストを WinMerge で表示すれば、どこが変わったのかがひと目でわかります。
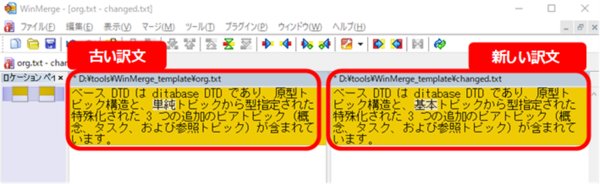
WinMerge は、2 つのテキスト ファイルを比較してくれるツールです。細かい設定はいろいろありますが、私は、単純に以下のように使っています。
<準備>
1. 古い訳文用に org.txt を作る。
2. 新しい訳文用に changed.txt を作る。
3. この 2 つのファイルの組み合わせをテンプレートとして保存しておく。
<比較する>
1. WinMerge で、保存しておいたテンプレートを開く。
2. 古い訳文を org.txt に入力する。
3. 新しい訳文を changed.txt に入力する。
4. Ctrl+F5 を押して比較する。
今回の私の AutoHotKey のスクリプトでは、既に WinMerge でテンプレートが開かれていることを前提としました (すみません、テンプレートは手動で開きます)。で、Trados 上で古い訳文と新しい訳文をクリップボードにコピーしたら (ここまで手動です)、あとは AutoHotKey で 2 つの訳文をそれぞれのファイルに入力して、WinMerge のウィンドウをアクティブにするところまでを行います。
AutoHotKey では、ウィンドウをアクティブにした後で Ctrl+F5 を入力することもできますが、私の環境では、WinMerge 自体からメッセージボックスが表示されるので、今回は Ctrl+F5 を入力する処理は行いませんでした。(今回のスクリプトは、ほんま会提供のスクリプトをほぼそのまま使っているので、詳しい説明は省略させてもらいます。)
ほんま会の皆さんの熱気に圧倒されつつ、ツールってなんて便利なんだろうと感動し、その興奮をそのままに帰宅して、早速スクリプトを書きました。実際に試して、考えていた動作を実現できたときは、これはすごいかも!!と嬉しくなりました。が、しばらくして気持ちが落ち着いてくると、AutoHotKey は便利だとしても、レビュー作業自体はそれほど変わっていないかもと思えてきました。原文を読んで、訳文を読んで、メモリの内容も確認して、と Trados でのレビュー作業はやっぱり手間がかかります。
レビューの料金もマッチ率で割り引いてくるけど
レビュー作業の手間がこんなに気になる原因は、その単価です。私は翻訳会社からレビューを依頼されることが多いのですが、たいていの翻訳会社はレビューのときも翻訳と同じようにマッチ率での割引を適用してきます。なので、マッチした部分のレビュー単価は、とても、とても、とても安くなります。小数点以下 3 桁くらいまで計算が必要な感じです。
メモリがあってもレビューの作業量はそんなに変わらない
私の感覚的には、レビューのときは、マッチするメモリがあってもそれほど作業時間は変わりません。メモリを使うこと自体にいろいろ問題はあるかもしれませんが、それでも翻訳作業では、マッチする訳文があれば新しく入力する文字は少なくて済むという事実はあると思います。でも、レビュー作業では、訳文は既に入力されているので文字の入力量は最初から多くありません。メモリがあるからといって文字が速く読めるようになるわけではないし、マッチする訳文があれば読む量は増えるし、マッチ率での割引は実作業に合っていないのではと私は感じています。
でも、翻訳会社に反論できない (;。;)
マッチ率での割引は実作業に合わないと思いつつも、翻訳会社にそう反論したことはまだありません。どのように反論すべきか、なかなか良い案が浮かびません。レビューではメモリがあっても文字の入力量は変わらない、というのは 1 つの理由になりそうですが、じゃ、99% マッチと 0% マッチで作業量が同じかと聞かれれば、同じとは言えないような気もしてきます。
レビュー料金のマッチ率での割引って、一般的なんでしょうか。もしかしたら、レビューのときは割り引かないとか、割り引くとしても翻訳のときとは率が違うとか、そんな会社もあるんでしょうか。翻訳会社への反論に使える材料みたいなものがあったら、ぜひぜひご教示ください。
Tweet
ほんま会の講座では、自分で用語集を作成する方法として、原語と訳語をクリップボードにコピーして両方を一気にテキスト ファイルに書き出すスクリプトが紹介されました。この「2 つのテキストを一気にファイルに書き出す」という処理を 2 つのテキストを比較する操作に応用しました。具体的には、AutoHotKey を使って 2 つのテキストをファイルに書き出し、 WinMerge を使って実際の比較を行います。
実は、 WinMerge でのテキスト比較は以前からよく使っていたのですが、毎回毎回、比較対象の 2 つをそれぞれクリップボードにコピーして、それぞれ貼り付けてという操作が面倒でした。今回の AutoHotKey で少しだけですが手間が減ります。
テキストを比較したくなるとき
さて、そもそもなぜテキストを比較したいのかというと、Trados でレビュー作業をしなければならないからです。Trados なので当然メモリを使って翻訳されたものをレビューするのですが、これがなかなか大変です。
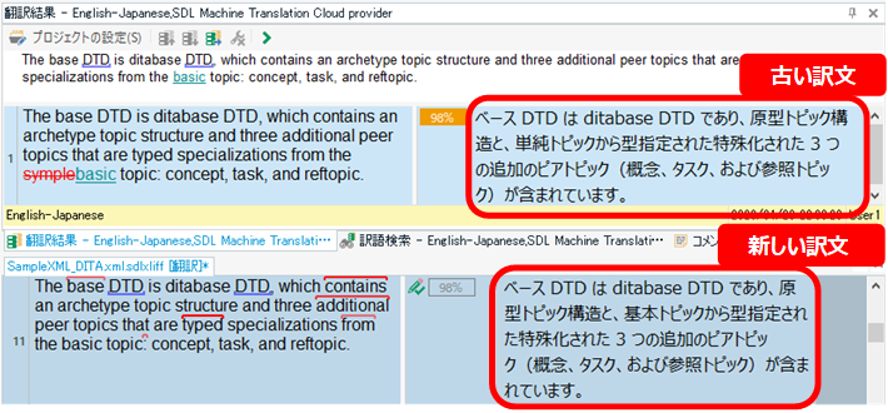
ファジー マッチの分節をレビューする場合、Trados の画面は上図のようになります。メモリの内容が [ 翻訳結果] ウィンドウに表示され、エディタ部分には、翻訳者さんが入力した新しい訳文が表示されています。中央のステータスの欄に「98%」と白枠で表示されているので、98% マッチのメモリを使ってどこかを編集したということまではわかりますが、どこを編集したのかはわかりません。原文の違いは、[ 翻訳結果] ウィンドウに変更履歴のような形式で表示されますが、訳文についてはそのような表示はありません。
こうしたときに、メモリ内の古い訳文と翻訳者さんの新しい訳文を比較できるととても便利です。下図のように 2 つのテキストを WinMerge で表示すれば、どこが変わったのかがひと目でわかります。

WinMerge を使って比較する
WinMerge は、2 つのテキスト ファイルを比較してくれるツールです。細かい設定はいろいろありますが、私は、単純に以下のように使っています。
<準備>
1. 古い訳文用に org.txt を作る。
2. 新しい訳文用に changed.txt を作る。
3. この 2 つのファイルの組み合わせをテンプレートとして保存しておく。
<比較する>
1. WinMerge で、保存しておいたテンプレートを開く。
2. 古い訳文を org.txt に入力する。
3. 新しい訳文を changed.txt に入力する。
4. Ctrl+F5 を押して比較する。
今回の私の AutoHotKey のスクリプトでは、既に WinMerge でテンプレートが開かれていることを前提としました (すみません、テンプレートは手動で開きます)。で、Trados 上で古い訳文と新しい訳文をクリップボードにコピーしたら (ここまで手動です)、あとは AutoHotKey で 2 つの訳文をそれぞれのファイルに入力して、WinMerge のウィンドウをアクティブにするところまでを行います。
AutoHotKey では、ウィンドウをアクティブにした後で Ctrl+F5 を入力することもできますが、私の環境では、WinMerge 自体からメッセージボックスが表示されるので、今回は Ctrl+F5 を入力する処理は行いませんでした。(今回のスクリプトは、ほんま会提供のスクリプトをほぼそのまま使っているので、詳しい説明は省略させてもらいます。)
それでも、レビューには手間がかかる
ほんま会の皆さんの熱気に圧倒されつつ、ツールってなんて便利なんだろうと感動し、その興奮をそのままに帰宅して、早速スクリプトを書きました。実際に試して、考えていた動作を実現できたときは、これはすごいかも!!と嬉しくなりました。が、しばらくして気持ちが落ち着いてくると、AutoHotKey は便利だとしても、レビュー作業自体はそれほど変わっていないかもと思えてきました。原文を読んで、訳文を読んで、メモリの内容も確認して、と Trados でのレビュー作業はやっぱり手間がかかります。
レビューの料金もマッチ率で割り引いてくるけど
レビュー作業の手間がこんなに気になる原因は、その単価です。私は翻訳会社からレビューを依頼されることが多いのですが、たいていの翻訳会社はレビューのときも翻訳と同じようにマッチ率での割引を適用してきます。なので、マッチした部分のレビュー単価は、とても、とても、とても安くなります。小数点以下 3 桁くらいまで計算が必要な感じです。
メモリがあってもレビューの作業量はそんなに変わらない
私の感覚的には、レビューのときは、マッチするメモリがあってもそれほど作業時間は変わりません。メモリを使うこと自体にいろいろ問題はあるかもしれませんが、それでも翻訳作業では、マッチする訳文があれば新しく入力する文字は少なくて済むという事実はあると思います。でも、レビュー作業では、訳文は既に入力されているので文字の入力量は最初から多くありません。メモリがあるからといって文字が速く読めるようになるわけではないし、マッチする訳文があれば読む量は増えるし、マッチ率での割引は実作業に合っていないのではと私は感じています。
でも、翻訳会社に反論できない (;。;)
マッチ率での割引は実作業に合わないと思いつつも、翻訳会社にそう反論したことはまだありません。どのように反論すべきか、なかなか良い案が浮かびません。レビューではメモリがあっても文字の入力量は変わらない、というのは 1 つの理由になりそうですが、じゃ、99% マッチと 0% マッチで作業量が同じかと聞かれれば、同じとは言えないような気もしてきます。
レビュー料金のマッチ率での割引って、一般的なんでしょうか。もしかしたら、レビューのときは割り引かないとか、割り引くとしても翻訳のときとは率が違うとか、そんな会社もあるんでしょうか。翻訳会社への反論に使える材料みたいなものがあったら、ぜひぜひご教示ください。
| |
|
Tweet
2020年01月26日
分節の結合は慎重に
先日、コミュニティに「 訳文生成エラー
」という書き込みがありました。SDL の方の丁寧な対応により、原因が「分節の結合」であることがわかり、問題は解決したようでした。ただ、その SDL からの最後の回答に、次のような趣旨のアドバイスがありました。
分節の結合を行ったら、その後すぐに「訳文の生成」を実行して、
エラーが出ないことを確かめる。
実行した後、エラーが出ないことをユーザーが確認しないといけない、というところがいかにも Trados っぽいですが、自己防衛のためにはこのアドバイスに素直に従っておくのが賢明かと思います。
そうはいっても、訳文生成を毎回行うのは現実的ではないので、私は、訳文の表示 (Ctrl+Shift+P) 機能を使ってプレビューしてみるようにしています (プレビューについては、以前の記事 「訳文の表示」を使ってみる も参考にしてください)。プレビューと訳文生成は厳密には異なる処理ですが、私の経験的には、プレビューができれば訳文生成もできます。
以下に、分節の結合を行う際の注意点をいくつか挙げてみたいと思います。(結構、たくさんあります!)
分節を結合した後のエラーとしては、上記のコミュニティの投稿のように訳文生成の処理が失敗するケースだけでなく、訳文生成の処理は成功したのに、結合した分節の周辺の文字が消えているといったケースもあります。私は、PowerPoint で何回かこの種のエラーに遭遇しました。特に複雑な構成のファイルではなく、なぜそうなってしまうのかは結局わかりませんでした。
どんなエラーが起こるかわからないので、やはり、訳文生成やプレビューでの確認は欠かせないかなぁと思います。訳文生成の場合は、処理がエラーなく完了することだけでなく、生成されたファイルを開いて、結合した分節の周辺も確認した方が安全です。
分節は、いったん結合すると元に戻せません。通常の Ctrl+z (元に戻す) が効く範囲では戻せますが、これが効かなくなったらもう戻せません。「分節の分割」という機能もありますが、これは「分節の結合」とは別の機能です。結合した分節を「分割」しても、元の状態に戻るわけではありません。
元に戻す手段がないので、訳文生成を試してエラーに気付いたとしても、もうその時点からはどうすることもできません。こうなると困るので、私は、分節の結合を行う前にまずバイリンガル ファイルをバックアップするようにしています。バックアップをした後で、分節の結合をして、訳文生成かプレビューをして、もしだめだったらバックアップしたファイルを戻します。かなり、面倒です。
前述のように、いったんエラーになってしまうと手間がかかるので、最初から変な結合は行わないように注意することも大切です。Trados のエディタ上では連続している分節のように見えても、実際にはそうでないこともあります。単純な改行で分割されているだけなら結合しても OK ですが、行頭文字のある箇条書きや、PowerPoint のスライド上で離れた場所にあるテキストなどは、エラーになりそうなので私は結合しないようにしています。
2 つの分節を結合した後で、実は、その下の分節も結合したかったということはたびたびあります。しかし、段落を越えた分節の場合、いったん結合した分節にさらに結合を行うことは (基本的には) できません。段落を越えない通常の分節同士は結合を繰り返すことができます。
「段落を越えた分節」であるかどうかが重要なポイントなのですが、Trados のエディタ上にはそれをはっきりと示す表示がありません。右端の「文書構造」の情報を見ればなんとなくわかりますが、分節を結合するときにそこまで確認できるくらいなら、そもそも結合したい分節を選択し忘れるなんてミスはしません。
というわけで、段落を越えた分節の結合を少しだけわかりやすく表示する方法と、結合を複数回行うちょっと裏技的な方法を次に説明します。
Trados には、段落を越えて結合した分節を表示するというオプションが用意されています。
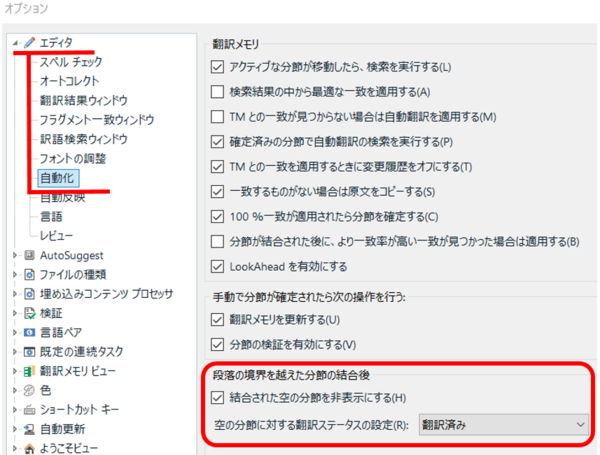
[ ファイル] > [ オプション] > [ エディタ] > [ 自動化] と選択すると、上図の設定画面が表示されます。デフォルトでは、[ 結合された空の分節を非表示にする] がオンになっているため、結合された分節は表示されません。下図の例では、分節番号が 19 から 21 に飛んでいます。
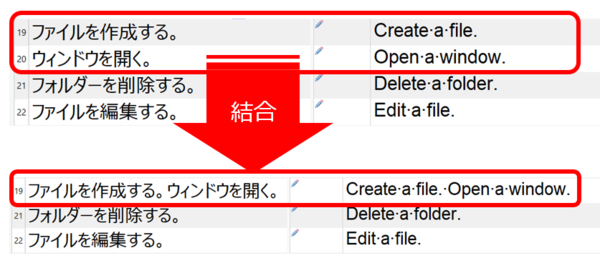
[ 結合された空の分節を非表示にする] をオフにすると、下図のように、結合された分節が表示されます。分節番号 20 が表示され、原文も訳文も空でロックされているのがわかります。

1 つ注意点として、このオプションは、UI の文言のとおり、「段落の境界を越えた分節」にしか有効に働きません。段落の境界を越えない通常の分節は、このオプションを設定しても表示されません。
段落を越えて結合した分節にさらに結合を行うことができないのは、単に分節がロックされているからのようです。前述のように、結合された分節は中身が空になったうえでロックされます。このロックを手動で解除すれば、また結合を行うことができます。下図は、分節 19 と 20 を結合した後、ロックを解除してから、分節 21 を結合した結果です。(結合した後は、再びロックされてしまいます。)

まあ、ただでさえ不安定な機能なので、すべての操作は自己責任でお願いします。バックアップと、訳文生成やプレビューでの確認はこまめにしておくのが安全です。
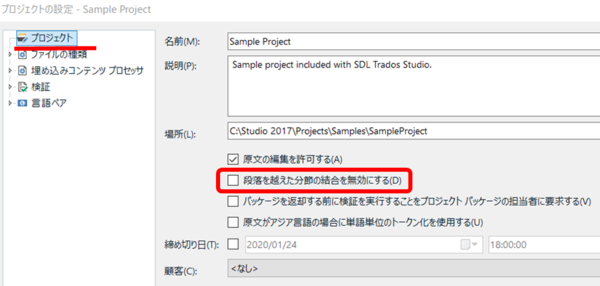
いろいろと書いてきましたが、段落を越えた分節の結合ができるかどうかはパッケージの設定で決まります。[ プロジェクトの設定] > [ プロジェクト] と選択すると、上図の設定画面が表示されます。自分で作成したプロジェクトの場合は、この辺りのチェックボックスの設定を自分で変更できますが、パッケージとして受け取った場合は、チェックボックスがグレーアウトされていて設定を変更できません。
このため、パッケージの作成者さんが「段落を越えた分節の結合」を有効にしてくれていない場合、パッケージを受け取った翻訳者側でこれを有効にすることはできません。たいていは、コーディネーターさんに有効にしてくださいとお願いすれば、設定を変えてパッケージを送り直してきてくれます。ただ、自分からお願いした場合は特に、分節の結合が原因で訳文生成ができなくなりました、なんてことは許されないので、訳文生成できるかの確認がますます重要になります。
今回は以上です。分節の結合は、便利ではありますが、かなり不安定な機能です。翻訳者としては、分節の結合を使わなくても済むように原文を整えて欲しいなぁと思います。
Tweet
分節の結合を行ったら、その後すぐに「訳文の生成」を実行して、
エラーが出ないことを確かめる。
実行した後、エラーが出ないことをユーザーが確認しないといけない、というところがいかにも Trados っぽいですが、自己防衛のためにはこのアドバイスに素直に従っておくのが賢明かと思います。
そうはいっても、訳文生成を毎回行うのは現実的ではないので、私は、訳文の表示 (Ctrl+Shift+P) 機能を使ってプレビューしてみるようにしています (プレビューについては、以前の記事 「訳文の表示」を使ってみる も参考にしてください)。プレビューと訳文生成は厳密には異なる処理ですが、私の経験的には、プレビューができれば訳文生成もできます。
以下に、分節の結合を行う際の注意点をいくつか挙げてみたいと思います。(結構、たくさんあります!)
訳文生成はできても、文字が消えていることがある
分節を結合した後のエラーとしては、上記のコミュニティの投稿のように訳文生成の処理が失敗するケースだけでなく、訳文生成の処理は成功したのに、結合した分節の周辺の文字が消えているといったケースもあります。私は、PowerPoint で何回かこの種のエラーに遭遇しました。特に複雑な構成のファイルではなく、なぜそうなってしまうのかは結局わかりませんでした。
どんなエラーが起こるかわからないので、やはり、訳文生成やプレビューでの確認は欠かせないかなぁと思います。訳文生成の場合は、処理がエラーなく完了することだけでなく、生成されたファイルを開いて、結合した分節の周辺も確認した方が安全です。
結合した分節を元に戻すことはできない
分節は、いったん結合すると元に戻せません。通常の Ctrl+z (元に戻す) が効く範囲では戻せますが、これが効かなくなったらもう戻せません。「分節の分割」という機能もありますが、これは「分節の結合」とは別の機能です。結合した分節を「分割」しても、元の状態に戻るわけではありません。
元に戻す手段がないので、訳文生成を試してエラーに気付いたとしても、もうその時点からはどうすることもできません。こうなると困るので、私は、分節の結合を行う前にまずバイリンガル ファイルをバックアップするようにしています。バックアップをした後で、分節の結合をして、訳文生成かプレビューをして、もしだめだったらバックアップしたファイルを戻します。かなり、面倒です。
変な結合は行わない
前述のように、いったんエラーになってしまうと手間がかかるので、最初から変な結合は行わないように注意することも大切です。Trados のエディタ上では連続している分節のように見えても、実際にはそうでないこともあります。単純な改行で分割されているだけなら結合しても OK ですが、行頭文字のある箇条書きや、PowerPoint のスライド上で離れた場所にあるテキストなどは、エラーになりそうなので私は結合しないようにしています。
結合した分節にさらに結合を行うことはできない (段落を越えた分節の場合)
2 つの分節を結合した後で、実は、その下の分節も結合したかったということはたびたびあります。しかし、段落を越えた分節の場合、いったん結合した分節にさらに結合を行うことは (基本的には) できません。段落を越えない通常の分節同士は結合を繰り返すことができます。
「段落を越えた分節」であるかどうかが重要なポイントなのですが、Trados のエディタ上にはそれをはっきりと示す表示がありません。右端の「文書構造」の情報を見ればなんとなくわかりますが、分節を結合するときにそこまで確認できるくらいなら、そもそも結合したい分節を選択し忘れるなんてミスはしません。
というわけで、段落を越えた分節の結合を少しだけわかりやすく表示する方法と、結合を複数回行うちょっと裏技的な方法を次に説明します。
結合された分節を表示する
Trados には、段落を越えて結合した分節を表示するというオプションが用意されています。

[ ファイル] > [ オプション] > [ エディタ] > [ 自動化] と選択すると、上図の設定画面が表示されます。デフォルトでは、[ 結合された空の分節を非表示にする] がオンになっているため、結合された分節は表示されません。下図の例では、分節番号が 19 から 21 に飛んでいます。

[ 結合された空の分節を非表示にする] をオフにすると、下図のように、結合された分節が表示されます。分節番号 20 が表示され、原文も訳文も空でロックされているのがわかります。

1 つ注意点として、このオプションは、UI の文言のとおり、「段落の境界を越えた分節」にしか有効に働きません。段落の境界を越えない通常の分節は、このオプションを設定しても表示されません。
段落を越えて結合した分節も、さらに結合を行うことができる?!
段落を越えて結合した分節にさらに結合を行うことができないのは、単に分節がロックされているからのようです。前述のように、結合された分節は中身が空になったうえでロックされます。このロックを手動で解除すれば、また結合を行うことができます。下図は、分節 19 と 20 を結合した後、ロックを解除してから、分節 21 を結合した結果です。(結合した後は、再びロックされてしまいます。)

まあ、ただでさえ不安定な機能なので、すべての操作は自己責任でお願いします。バックアップと、訳文生成やプレビューでの確認はこまめにしておくのが安全です。
「段落を越えた分節の結合」はパッケージの設定
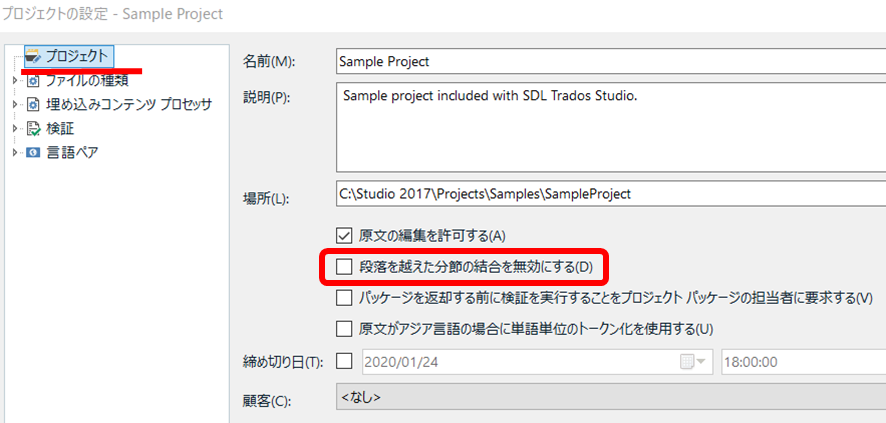
いろいろと書いてきましたが、段落を越えた分節の結合ができるかどうかはパッケージの設定で決まります。[ プロジェクトの設定] > [ プロジェクト] と選択すると、上図の設定画面が表示されます。自分で作成したプロジェクトの場合は、この辺りのチェックボックスの設定を自分で変更できますが、パッケージとして受け取った場合は、チェックボックスがグレーアウトされていて設定を変更できません。
このため、パッケージの作成者さんが「段落を越えた分節の結合」を有効にしてくれていない場合、パッケージを受け取った翻訳者側でこれを有効にすることはできません。たいていは、コーディネーターさんに有効にしてくださいとお願いすれば、設定を変えてパッケージを送り直してきてくれます。ただ、自分からお願いした場合は特に、分節の結合が原因で訳文生成ができなくなりました、なんてことは許されないので、訳文生成できるかの確認がますます重要になります。
今回は以上です。分節の結合は、便利ではありますが、かなり不安定な機能です。翻訳者としては、分節の結合を使わなくても済むように原文を整えて欲しいなぁと思います。
| |
|
Tweet
2020年01月10日
オンライン質問会から (2019年12月)
もうすっかり 2020 年ですが、去年の質問会での話題を取り上げたいと思います。
以前から たびたび書いていた パッケージが開けない問題ですが、バージョン 2017 でも解決したそうです。コミュニティでは、以下に投稿されていました。
Translation Productivity > SDL Trados Studio
Studio2017をアップデート後、返却パッケージが開けない
SDL Trados Studio 2017 SR1 CU18(Build 14.1.10018.54792) に更新すればこの問題は解決します。私は、問題が発生していたパッケージを 2 つを試してみましたが、正常に開くことができました。当初は、バージョン 2017 での修正予定はないなどと冷たい対応でしたが、ちゃんと修正されたようです。良かったです。
カタカナの長音は悩ましいスタイルの 1 つです。最近の私の仕事の範囲では長音を省略しない傾向が強くなってきているような気がしますが、面倒であることにあまり変わりはありません。今回の質問会では、便利な正規表現の例として、「サーバー」と「サーバ」が混在しているときに「サーバ」のみを検出する以下の表現が紹介されていました。
サーバ[^ー]
私も以前はこの正規表現をよく使っていましたが、実は、これでは「サーバ」をすべて検出することはできません。この正規表現は、分節の最後にある「サーバ」にマッチしないのです。
下図は、 サーバ[^ー]を QA Checker に指定した場合の例ですが、「サーバ」で終わっている分節はエラーになりません。「サーバ環境」と後ろに文字がある場合のみエラーになります。

私は、代わりに以下を使うようにしています。
サーバ(?!ー)
私の理解の範囲で、ごくごく簡単にこの 2 つの正規表現の意味を説明すると、こんな感じです。
サーバ[^ー]は、「サーバ」の後ろが「ー」以外の文字だったらマッチする
サーバ(?!ー)は、「サーバ」の後ろに「ー」がある場合のみマッチしない
[^ー]は、「長音以外の文字」という意味なので、何か文字が存在していないとマッチしません。このため「サーバ」の後ろに何もなく分節が終わってしまっているケースは検出されません。後ろに存在する文字は、通常の文字でなくても、改行でもスペースでもいいんですが、とにかく何か文字っぽいものが存在する必要があります。
通常のエディター上のテキストの場合は、行末に改行があるので サーバ[^ー]でもあまり問題になりません。 しかし Trados の場合は、分節の最後に改行がないので今回のような問題が生じてきます。私は、以下のような正規表現を使っていたこともあります。
サーバ($|[^ー])
「 $」は、一般的には文末を意味しますが、Trados の分節の終わりにもマッチします。なので、この正規表現を使えば分節の最後にある「サーバ」も検出されます。「 $」が分節の終わりにマッチするというのは覚えておくとけっこう便利です。たとえば、「ピリオドで終わっている分節」などを検索できます。
今回の質問会で説明されていた機能の中には、パッケージを受け取る翻訳者は使えず、パッケージの作成者だけが使える機能がいくつかありました。SDL Trados Studio は、クライアントから、翻訳会社のコーディネーター、個人の翻訳者まで、さまざまな役割の人が使うツールです。全員がすべての機能を使うわけではなく、役割によって、よく使う機能、使う権限がない機能、使う権限はあるけれども使わない機能、などが変わってきます。SDL からの説明はとにかく全体を対象としていることが多いので、個人翻訳者、特にパッケージを受け取って作業するという人は、説明されている機能が自分に使える機能なのか、使えるとしても個人として使うべき機能なのか、といった点に注意する必要があります。
たとえば、今回の質問会では、以下のような説明がありました。
・略語の設定や分節規則で分節の区切りを調整する方法
・ファイルタイプを作成する方法
・Excel を翻訳ファイルに変換するときにセルの順序を変える方法
(質問会の中では順序は変えられないと説明されていましたが、ある程度は設定で変えられると思います。)
これらの機能は、パッケージを受け取って作業する翻訳者は使えません。もし、分節の区切りを変えて欲しい場合は、パッケージの作成者にお願いして作り直してもらう必要があります。
実際の仕事で翻訳会社さんに「パッケージを作り直してください」とお願いするのはちょっと勇気がいりますが、意外と簡単に対応してくれることもあります。単にコーディネーターさんが設定を忘れているだけ、という場合もあるので、「もし可能だったらでいいんですが〜」という感じで確認してみるといいかと思います。
ただ、複数の翻訳者さんがかかわっているプロジェクトの場合は難しいかもしれません。また、パッケージの再作成に応じてくれたとしても納期まで延ばしてくれることはまずないので、翻訳作業自体は進めておく必要があります。作業できるところの作業を進め、訳文をメモリにためておき、新しいパッケージがきたら自分のメモリから訳文あてる、といった対応は必要になります。
今回は、以上です。思っていたより長文になってしまいました。この記事では取り上げませんでしたが、今回の質問会では、最新バージョンである 2019 だけの機能がいくつか登場していました。もう 2020 年だし、アップグレードした方が良さそうな雰囲気ではあるのですが、私はもう少し 2017 で頑張ってみようと思っています。
Tweet
パッケージが開けない問題が解決されました
以前から たびたび書いていた パッケージが開けない問題ですが、バージョン 2017 でも解決したそうです。コミュニティでは、以下に投稿されていました。
Translation Productivity > SDL Trados Studio
Studio2017をアップデート後、返却パッケージが開けない
SDL Trados Studio 2017 SR1 CU18(Build 14.1.10018.54792) に更新すればこの問題は解決します。私は、問題が発生していたパッケージを 2 つを試してみましたが、正常に開くことができました。当初は、バージョン 2017 での修正予定はないなどと冷たい対応でしたが、ちゃんと修正されたようです。良かったです。
カタカナの長音に関する正規表現
カタカナの長音は悩ましいスタイルの 1 つです。最近の私の仕事の範囲では長音を省略しない傾向が強くなってきているような気がしますが、面倒であることにあまり変わりはありません。今回の質問会では、便利な正規表現の例として、「サーバー」と「サーバ」が混在しているときに「サーバ」のみを検出する以下の表現が紹介されていました。
サーバ[^ー]
私も以前はこの正規表現をよく使っていましたが、実は、これでは「サーバ」をすべて検出することはできません。この正規表現は、分節の最後にある「サーバ」にマッチしないのです。
下図は、 サーバ[^ー]を QA Checker に指定した場合の例ですが、「サーバ」で終わっている分節はエラーになりません。「サーバ環境」と後ろに文字がある場合のみエラーになります。
私は、代わりに以下を使うようにしています。
サーバ(?!ー)
私の理解の範囲で、ごくごく簡単にこの 2 つの正規表現の意味を説明すると、こんな感じです。
サーバ[^ー]は、「サーバ」の後ろが「ー」以外の文字だったらマッチする
サーバ(?!ー)は、「サーバ」の後ろに「ー」がある場合のみマッチしない
[^ー]は、「長音以外の文字」という意味なので、何か文字が存在していないとマッチしません。このため「サーバ」の後ろに何もなく分節が終わってしまっているケースは検出されません。後ろに存在する文字は、通常の文字でなくても、改行でもスペースでもいいんですが、とにかく何か文字っぽいものが存在する必要があります。
通常のエディター上のテキストの場合は、行末に改行があるので サーバ[^ー]でもあまり問題になりません。 しかし Trados の場合は、分節の最後に改行がないので今回のような問題が生じてきます。私は、以下のような正規表現を使っていたこともあります。
サーバ($|[^ー])
「 $」は、一般的には文末を意味しますが、Trados の分節の終わりにもマッチします。なので、この正規表現を使えば分節の最後にある「サーバ」も検出されます。「 $」が分節の終わりにマッチするというのは覚えておくとけっこう便利です。たとえば、「ピリオドで終わっている分節」などを検索できます。
パッケージを作り直してもらおう
今回の質問会で説明されていた機能の中には、パッケージを受け取る翻訳者は使えず、パッケージの作成者だけが使える機能がいくつかありました。SDL Trados Studio は、クライアントから、翻訳会社のコーディネーター、個人の翻訳者まで、さまざまな役割の人が使うツールです。全員がすべての機能を使うわけではなく、役割によって、よく使う機能、使う権限がない機能、使う権限はあるけれども使わない機能、などが変わってきます。SDL からの説明はとにかく全体を対象としていることが多いので、個人翻訳者、特にパッケージを受け取って作業するという人は、説明されている機能が自分に使える機能なのか、使えるとしても個人として使うべき機能なのか、といった点に注意する必要があります。
たとえば、今回の質問会では、以下のような説明がありました。
・略語の設定や分節規則で分節の区切りを調整する方法
・ファイルタイプを作成する方法
・Excel を翻訳ファイルに変換するときにセルの順序を変える方法
(質問会の中では順序は変えられないと説明されていましたが、ある程度は設定で変えられると思います。)
これらの機能は、パッケージを受け取って作業する翻訳者は使えません。もし、分節の区切りを変えて欲しい場合は、パッケージの作成者にお願いして作り直してもらう必要があります。
実際の仕事で翻訳会社さんに「パッケージを作り直してください」とお願いするのはちょっと勇気がいりますが、意外と簡単に対応してくれることもあります。単にコーディネーターさんが設定を忘れているだけ、という場合もあるので、「もし可能だったらでいいんですが〜」という感じで確認してみるといいかと思います。
ただ、複数の翻訳者さんがかかわっているプロジェクトの場合は難しいかもしれません。また、パッケージの再作成に応じてくれたとしても納期まで延ばしてくれることはまずないので、翻訳作業自体は進めておく必要があります。作業できるところの作業を進め、訳文をメモリにためておき、新しいパッケージがきたら自分のメモリから訳文あてる、といった対応は必要になります。
今回は、以上です。思っていたより長文になってしまいました。この記事では取り上げませんでしたが、今回の質問会では、最新バージョンである 2019 だけの機能がいくつか登場していました。もう 2020 年だし、アップグレードした方が良さそうな雰囲気ではあるのですが、私はもう少し 2017 で頑張ってみようと思っています。
| |
Tweet
2019年12月11日
用語ベースが巨大すぎる!
先日のお仕事で Trados のプロジェクトに設定されていた用語ベースが、なんと 34 万語もありました。普通の「用語集」としてはあり得ない語数です。なぜこんなことになっていたかというと、UI のデータがそのまま用語ベースに入っていたからでした。こうした用語ベースは、翻訳者としては扱いにちょっと困ります。
UI のデータは、たいてい、画面上の要素 1 個につきレコードが 1 行存在する形になっています。たとえば「表示」というボタンが 10 画面に存在していて合計で 10 個あるとすると、データ上では「表示」というレコードが 10 行存在することになります。こうした形式のデータをそのまま用語ベースにしてしまうと、Trados の用語認識ウィンドウがこんな感じになります。
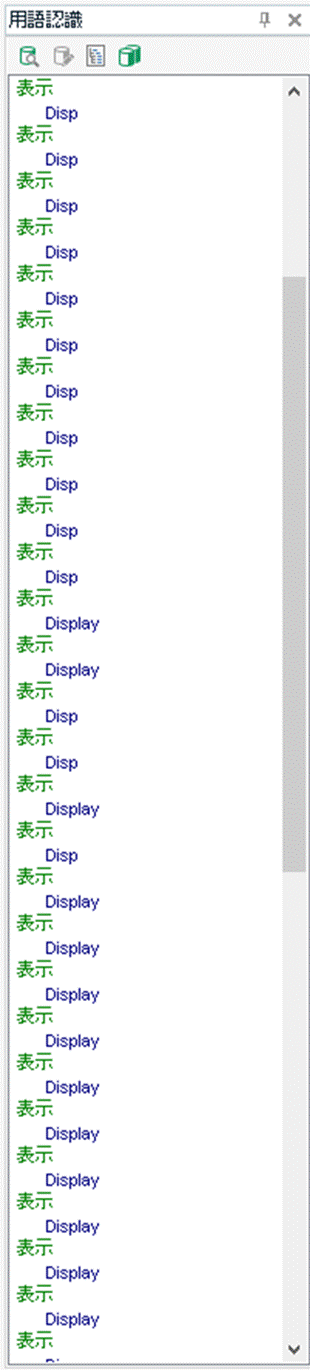
もうこうなると用語認識の意味がありません。しかも、Trados の用語認識機能は、用語ベースが大きい場合、すべての用語を検索してくれません。今回の記事では、こんな風になってしまう 34 万語の用語ベースをどう扱ったかをグチりたい、じゃなくて説明したいと思います。今回、私が行ったのは、以下の 3 つです。
1. 重複する用語を削除する
2. 用語ベースの検索設定を調整する
3. Xbench を使って手動で検索する
最初から言っておきますが、最後は「手動で検索」しました。Xbench を使えばワンアクションですが、それでも多くの用語でそのワンアクションが必要でした。
UI のデータをそのまま用語ベースにしてくる翻訳会社さんは多いので、重複を削除する処理はよく必要になります。ただ、今回はあまりにも量が多く、この削除が大変でした。私が重複を削除する方法として思い付くのは、以下の 3 つくらいです。
(1) Glossary Converter でマージする
(2) Excel で数式を使う
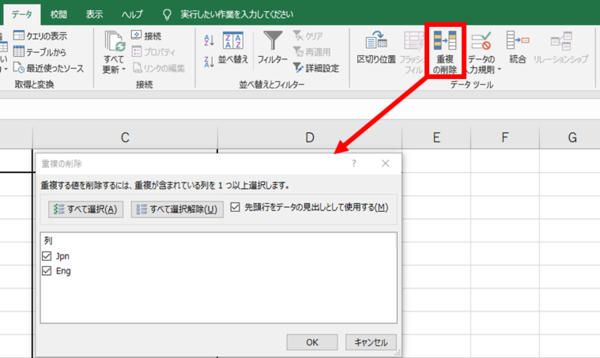
(3) Excel で [ 重複の削除] を使う (大文字小文字を区別できない)
(1) Glossary Converter でマージする
用語ベース ファイル (.sdltb) を直接 Glossary Converter で処理します。これが最も簡単で便利だと思います。大文字小文字も区別できます。Glossary Converter は、SDL AppStore から無料でダウンロードできるアプリです。操作方法については、以前の記事「 【後編】マイクロソフトの用語集を使いたい 」も参照してください。
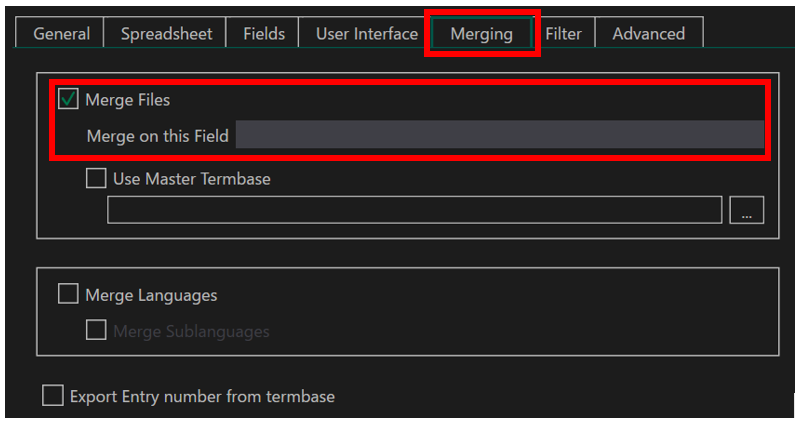
Glossary Converter を起動して [ settings] をクリックすると設定画面が表示されます。[ Merging] タブで [ Merge Files] チェックボックスをオンにすると、重複する用語をマージできます。今回は日本語原文だったので、用語集の日本語のフィールドを設定してマージしてみました。
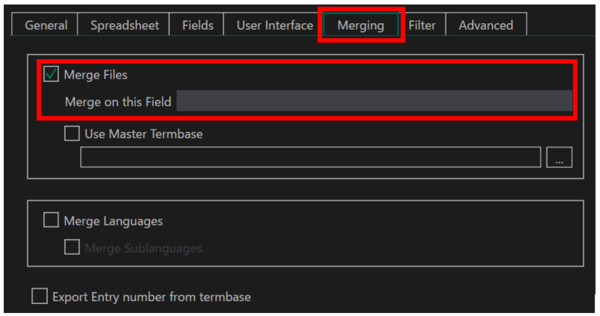
で、結果はというと、だめでした。原因は、メモリ不足。何回か試したのですが、毎回途中でエラーになってしまいました。ということで、Glossary Converter は諦めて Excel で処理することにしました。
(2) Excel で数式を使う
Excel で処理するには、当然ながら Excel ファイルが必要です。今回は、翻訳会社さんから用語ベース ファイル (.sdltb) だけでなく、Excel ファイルも提供されていたのでそれを使いました。もし、Excel ファイルが提供されていない場合は、Glossary Converter を使って用語ベースを Excel ファイルに変換します。
Excel には [ 重複の削除] という機能があり、実はこれを使えば重複しているデータを簡単に削除できます (後述します)。ただし、この機能は大文字小文字を区別しません。今回の用語ベースは UI であり、訳出では大文字小文字を区別する必要があったので、[ 重複の削除] ではなく、大文字小文字を区別できる方法を先に試しました。
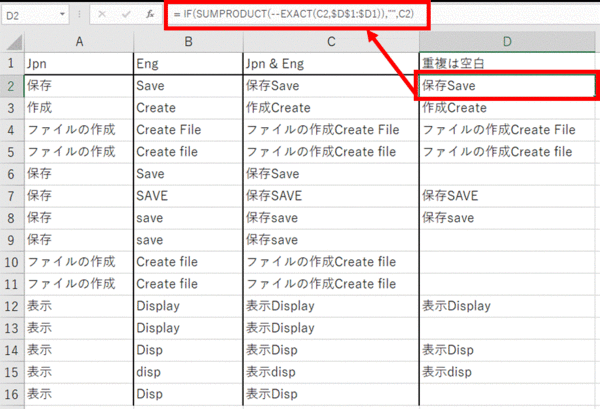
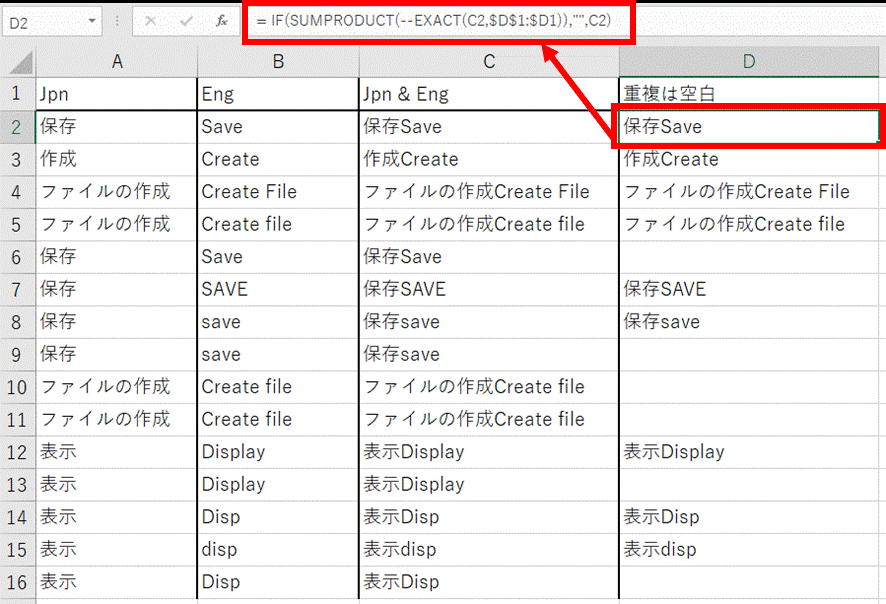
A 列: 日本語
B 列: 英語
C 列: 日本語と英語を結合する
数式 = A2&B2
D 列: 日本語と英語の両方とも同じ用語が既にある場合は空白にする
数式 = IF(SUMPRODUCT(--EXACT(C2,$D$1:$D1)),"",C2)
D 列の数式を簡単に説明すると、EXACT で大文字小文字も含めて一致しているかをチェックし、SUMPRODUCT を使った計算で D 列に既に存在していないかをチェックしています。
たいていの用語集はこれで処理できるのですが、今回はこの方法もだめでした。SUMPRODUCT は D 列全体をチェックすることになるので、34 万行は多すぎたようです。数式を入力した後、一向に結果が戻らず、カーソルがグルグルと回ったままでした。しばらく待っていましたが無理そうだったので、これも諦めました。(気長に待っていればもしかしたら成功したのかもしれないですが、待ちきれませんでした。)
(3) Excel で [重複の削除] を使う
仕方がないので、大文字小文字の区別は諦めて、[ 重複の削除] を使いました。さすがにこれは成功しました。で、重複を削除した後の語数はというと、約 15 万語でした。かなり減りました!
Excel で重複を削除した後、その Excel ファイルを用語ベース ファイルに変換し、プロジェクトに設定したら、こんな感じでした。だいぶすっきりしました。

でも、これで安心はできません。重複を削除しても、まだ 15 万語ですから。実は、作業をしているうちに、用語ベースに存在するのに用語認識されてこないものがあることに気付きました。そこで、用語ベースの検索設定を少し調整しました。

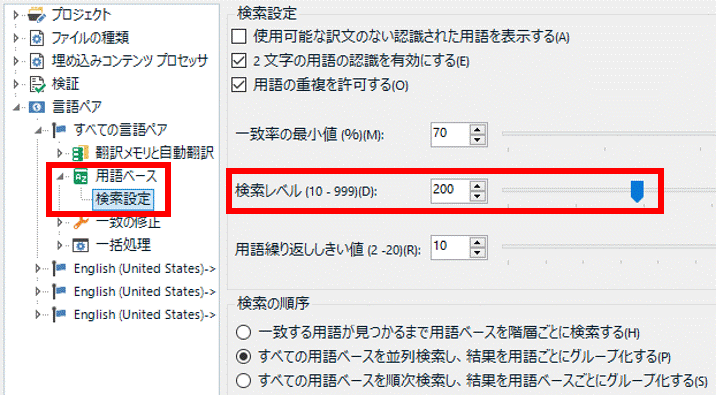
[ プロジェクトの設定] > [ 言語ペア] > [ すべての言語ペア] > [ 用語ベース] > [ 検索設定] と選択すると上図の画面が表示されます。この画面で用語ベースの検索方法をいろいろと設定できます。この画面の設定については、以前の記事「 用語ベースの設定 」も参考にしてください。
用語が認識されてこない原因は、おそらく [ 検索レベル] です。「レベル」というのが実際に何を意味しているのかは不明ですが、数字を大きくした方が認識される用語は多くなります。ただ、すべての用語が認識されてくるとはいえないようです。
一応、ヘルプは以下のようになっていますが、「中規模」や「大規模」が具体的にどれくらいの語数を指すのかはわかりません。今回は、既定値の 200 を 500 に変更して作業しました (処理速度は、特に気になりませんでした)。ただ、あまりに用語が多いので [ 用語の重複を許可する] はオフにしました。

いろいろ苦労したのですが、結局、用語認識で必ずすべての用語を認識するのは無理なのかなぁ、と思っています。[ 検索レベル] を 500 にしても、認識されてこない用語はありました。最大値は 999 ですが、ヘルプの文面からすると、最大値に設定したからといってすべて検索されるということではなさそうな気がします。
最後の手段は、Xbench での検索です。普段から、用語認識だけに頼らず、Xbench での検索を併用するようにはしていますが、それはあくまで念のためです。今回は、用語認識ウィンドウはいっぱいだし、大文字小文字を区別せずに重複を削除してしまっているし、[ 検索レベル] の影響で認識されていない用語もありそうだし、ということで Xbench での検索が多くなりました。
Xbench で検索をするためには、MultiTerm を使って用語ベースから xml ファイルをエクスポートして、それを Xbench に設定するという方法がベストかと思っています。この辺りの詳細は、またいずれ、ということにしたいと思います。
今回は、以上です。34 万語はとても困りました。ここで説明した方法は、あくまで「用語集に存在することを認識する」までの方法です。実際には、用語集に存在するなら元の Excel ファイルを参照してみたり、複数の選択肢があるなら前後も参照してみたり、とまだまだ作業は続きます。用語集もメモリも、適量以上にたくさんあっても翻訳者としては手間がかかるだけ、ということを強調したくて長い記事にしてみました。最後までお読みくださり、ありがとうございました。
Tweet
UI のデータは、たいてい、画面上の要素 1 個につきレコードが 1 行存在する形になっています。たとえば「表示」というボタンが 10 画面に存在していて合計で 10 個あるとすると、データ上では「表示」というレコードが 10 行存在することになります。こうした形式のデータをそのまま用語ベースにしてしまうと、Trados の用語認識ウィンドウがこんな感じになります。
もうこうなると用語認識の意味がありません。しかも、Trados の用語認識機能は、用語ベースが大きい場合、すべての用語を検索してくれません。今回の記事では、こんな風になってしまう 34 万語の用語ベースをどう扱ったかをグチりたい、じゃなくて説明したいと思います。今回、私が行ったのは、以下の 3 つです。
1. 重複する用語を削除する
2. 用語ベースの検索設定を調整する
3. Xbench を使って手動で検索する
最初から言っておきますが、最後は「手動で検索」しました。Xbench を使えばワンアクションですが、それでも多くの用語でそのワンアクションが必要でした。
1. 重複する用語を削除する
UI のデータをそのまま用語ベースにしてくる翻訳会社さんは多いので、重複を削除する処理はよく必要になります。ただ、今回はあまりにも量が多く、この削除が大変でした。私が重複を削除する方法として思い付くのは、以下の 3 つくらいです。
(1) Glossary Converter でマージする
(2) Excel で数式を使う
(3) Excel で [ 重複の削除] を使う (大文字小文字を区別できない)
(1) Glossary Converter でマージする
用語ベース ファイル (.sdltb) を直接 Glossary Converter で処理します。これが最も簡単で便利だと思います。大文字小文字も区別できます。Glossary Converter は、SDL AppStore から無料でダウンロードできるアプリです。操作方法については、以前の記事「 【後編】マイクロソフトの用語集を使いたい 」も参照してください。
Glossary Converter を起動して [ settings] をクリックすると設定画面が表示されます。[ Merging] タブで [ Merge Files] チェックボックスをオンにすると、重複する用語をマージできます。今回は日本語原文だったので、用語集の日本語のフィールドを設定してマージしてみました。
で、結果はというと、だめでした。原因は、メモリ不足。何回か試したのですが、毎回途中でエラーになってしまいました。ということで、Glossary Converter は諦めて Excel で処理することにしました。
(2) Excel で数式を使う
Excel で処理するには、当然ながら Excel ファイルが必要です。今回は、翻訳会社さんから用語ベース ファイル (.sdltb) だけでなく、Excel ファイルも提供されていたのでそれを使いました。もし、Excel ファイルが提供されていない場合は、Glossary Converter を使って用語ベースを Excel ファイルに変換します。
Excel には [ 重複の削除] という機能があり、実はこれを使えば重複しているデータを簡単に削除できます (後述します)。ただし、この機能は大文字小文字を区別しません。今回の用語ベースは UI であり、訳出では大文字小文字を区別する必要があったので、[ 重複の削除] ではなく、大文字小文字を区別できる方法を先に試しました。
A 列: 日本語
B 列: 英語
C 列: 日本語と英語を結合する
数式 = A2&B2
D 列: 日本語と英語の両方とも同じ用語が既にある場合は空白にする
数式 = IF(SUMPRODUCT(--EXACT(C2,$D$1:$D1)),"",C2)
D 列の数式を簡単に説明すると、EXACT で大文字小文字も含めて一致しているかをチェックし、SUMPRODUCT を使った計算で D 列に既に存在していないかをチェックしています。
たいていの用語集はこれで処理できるのですが、今回はこの方法もだめでした。SUMPRODUCT は D 列全体をチェックすることになるので、34 万行は多すぎたようです。数式を入力した後、一向に結果が戻らず、カーソルがグルグルと回ったままでした。しばらく待っていましたが無理そうだったので、これも諦めました。(気長に待っていればもしかしたら成功したのかもしれないですが、待ちきれませんでした。)
(3) Excel で [重複の削除] を使う
仕方がないので、大文字小文字の区別は諦めて、[ 重複の削除] を使いました。さすがにこれは成功しました。で、重複を削除した後の語数はというと、約 15 万語でした。かなり減りました!

Excel で重複を削除した後、その Excel ファイルを用語ベース ファイルに変換し、プロジェクトに設定したら、こんな感じでした。だいぶすっきりしました。

2. 用語ベースの検索設定を調整する
でも、これで安心はできません。重複を削除しても、まだ 15 万語ですから。実は、作業をしているうちに、用語ベースに存在するのに用語認識されてこないものがあることに気付きました。そこで、用語ベースの検索設定を少し調整しました。
[ プロジェクトの設定] > [ 言語ペア] > [ すべての言語ペア] > [ 用語ベース] > [ 検索設定] と選択すると上図の画面が表示されます。この画面で用語ベースの検索方法をいろいろと設定できます。この画面の設定については、以前の記事「 用語ベースの設定 」も参考にしてください。
用語が認識されてこない原因は、おそらく [ 検索レベル] です。「レベル」というのが実際に何を意味しているのかは不明ですが、数字を大きくした方が認識される用語は多くなります。ただ、すべての用語が認識されてくるとはいえないようです。
一応、ヘルプは以下のようになっていますが、「中規模」や「大規模」が具体的にどれくらいの語数を指すのかはわかりません。今回は、既定値の 200 を 500 に変更して作業しました (処理速度は、特に気になりませんでした)。ただ、あまりに用語が多いので [ 用語の重複を許可する] はオフにしました。
いろいろ苦労したのですが、結局、用語認識で必ずすべての用語を認識するのは無理なのかなぁ、と思っています。[ 検索レベル] を 500 にしても、認識されてこない用語はありました。最大値は 999 ですが、ヘルプの文面からすると、最大値に設定したからといってすべて検索されるということではなさそうな気がします。
3. Xbench を使って手動で検索する
最後の手段は、Xbench での検索です。普段から、用語認識だけに頼らず、Xbench での検索を併用するようにはしていますが、それはあくまで念のためです。今回は、用語認識ウィンドウはいっぱいだし、大文字小文字を区別せずに重複を削除してしまっているし、[ 検索レベル] の影響で認識されていない用語もありそうだし、ということで Xbench での検索が多くなりました。
Xbench で検索をするためには、MultiTerm を使って用語ベースから xml ファイルをエクスポートして、それを Xbench に設定するという方法がベストかと思っています。この辺りの詳細は、またいずれ、ということにしたいと思います。
今回は、以上です。34 万語はとても困りました。ここで説明した方法は、あくまで「用語集に存在することを認識する」までの方法です。実際には、用語集に存在するなら元の Excel ファイルを参照してみたり、複数の選択肢があるなら前後も参照してみたり、とまだまだ作業は続きます。用語集もメモリも、適量以上にたくさんあっても翻訳者としては手間がかかるだけ、ということを強調したくて長い記事にしてみました。最後までお読みくださり、ありがとうございました。
| |
|
2019年11月02日
新しいパソコンへの移行
もう 11 月になってしまいましたが、実は、消費税が上がる前に新しいパソコンを買っていました。我が家では同じ時期に洗濯機も購入していて、まさに「駆け込み」でした。それから、高機能な洗濯機に悪戦苦闘したり、台風が来たり、翻訳祭があったり、ということであっという間に 1 か月以上が過ぎ、ようやく今頃になって新しいパソコンへの移行が終わりに近づいてきました。
今回は、新しいパソコンを一式購入し、一から環境を構築しました。前の環境をコピーせず新規に作るのは面倒でしたが、心機一転、変なものが残っていないきれいな環境にするのもいいかなぁと思い頑張りました (というか、まだまだいろいろやり残しがあり、頑張っている最中です)。今回の環境は、Windows 10、Office 2016 (64 ビット版)、SDL Trados Studio 2017 で、手順はざっとこんな感じです。
1. Windows のユーザー名を設定
2. Office の 64 ビット版をインストール
3. SDL Trados Studio 2017 をインストール
4. Trados の設定を移行
5. プラグインを移行、アプリは再インストール
まずは、Windows の設定です。Trados を使う予定なら気を付けておきたいのが Windows のユーザー名です。 Trados では、コメントや変更履歴などに、問答無用で Windows のユーザー名が記録されてしまいます。これを Trados 側の設定で変更することはできません。詳しくは、以前の記事「 Trados で使われるユーザー名 」を参照してください。
私は個人の自宅で作業をしているのですが、前のパソコンではあまり考えず変な名前を付けてしまい、かなり後悔しました。コメントや変更履歴に記録されるユーザー名は、翻訳会社さん側で、誰のコメントなのか、誰の変更なのかを区別するために確認している可能性があり、変な名前にするとちょっと恥ずかしい思いをします。
ユーザー名に使う名前は、正直に本名でもいいですが、私は私本人が特定されないように「Translator A」のような汎用的な名前を使っています。コメントや変更履歴は、レビューアーなど外部の人にそのまま送られることが多いですし、sdlxliff ファイルに登録されたユーザー名は、処理方法によってはクライアントまで行ってしまう可能性があります。
実際には、知らない人の名前をメモリなどで目にしてもそれほど気にはならないですが、とは言っても自分の名前をあまり広くお知らせしたくはないので、なるべく名前が残らないように気を付けています。
これまで Office は 32 ビット版を使っていましたが、思い切って 64 ビット版にしました。Trados が 64 ビット版をサポートしているのかどうかは調べてもはっきりとわからなかったのですが、まあ大丈夫だろうと思って入れてみました。
結果は、今のところ問題なく動いています。さすがに、Word のバイリンガル ファイルを使うことはもうないと思うので、大丈夫でしょう。
Office の 64 ビット版のインストールは少し手間取りました。「64 ビット版をインストールしよう」と決めて注意しながらインストール手順を進めたつもりでしたが、画面上の指示に従っていたらいつの間にか 32 ビット版がインストールされてしまいました。仕方ないので、32 ビット版をいったんアンインストールして、再挑戦しました。実は、下図の「その他のオプション」から選ぶことができました。わかりにくいよ〜 (T-T)

いよいよ Trados のインストールです。私は、まだ 2017 のライセンスしかないので、SDL のサイトからダウンロードできる以下をインストールしました。
SDLTradosStudio2017_SR1_44945.exe (SDL Trados Studio 2017 SR1 CU15)
これをインストールして、その後はアップデートしてはいけません!
※※※※※ 追記 2019/12/26 ※※※※※※※※※※※※※※※※※
ここで取り上げた問題は、2017 でも解決されました。
SDL Trados Studio 2017 SR1 CU18 (Build 14.1.10018.54792) に更新すれば、問題が発生しなくなると思います。私は、問題が発生していたパッケージを 2 つ試してみましたが、2 つとも無事に開くことができました。
かなり困っていたので、解決してホントに良かったです。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
アップデートすると、パッケージが開けなくなるという問題が発生します。詳しくは、こちらの記事「 パッケージが「正常に」開かない 」を参照してください。この問題は、全角文字がファイル名などに含まれる場合に発生しますが、かなり致命的です。(2017 で修正して欲しいので、しつこく書いてすみません。) コミュニティ での投票にご協力頂けると大変助かります (_ _)
試用版を有効に使いましょう!
さて、Trados をダウンロードしてインストールしてみたら、なんと試用版として使うことができました。試用版の存在はすっかり忘れていたので、これは嬉しい誤算でした。試用版が使えれば、同時に 2 つのパソコンで Trados を起動できるので、ライセンスのアクティベートと非アクティベートを繰り返す手間がなくなり、とても便利です。
試用版は 30 日間使えます。しかも、Professional 版の機能を使えます。試用版はライセンスをいったんアクティベートすると使えなくなるので、試用期間が終了するまでアクティベートはしないでおきます。ボタンが表示されてくると、ついつい癖でアクティベートしたくなりますが、そこは細心の注意を払って回避します。試用期間の途中でアクティベートしたらもったいないです。
で、2017 の試用期間が終わったら、今度は、2019 の試用版が使えるのではないかと思っています。そうすれば、約 2 か月は時間があることになるので、移行の面倒な作業をするのには便利そうです。
Trados をインストールできたら、ショートカット キーなどの設定を前の環境から移行します。方法は簡単です。以下のファイルを前の環境からコピーするだけです。
C:\Users\[ ユーザー名 ]\AppData\Roaming\SDL\SDL Trados Studio\14.0.0.0\UserSettings.xml
この方法は、少し古い情報ですが「 Ctrl/Shift shortcuts for cut, copy and paste 」を参考にしています。今回の私の場合は特に問題ありませんでしたが、正式な方法とは言えないようなので、試す方は自己責任でお願いします (^_^;)
このファイルには、ショートカット キーだけでなく、AutoText の内容も含まれています。AutoText は、単体でインポート/エクスポートすることもできますが、このファイルをコピーしてしまえばその手間も省けます。
ただ、Trados のショートカット キーの設定は、かなり複雑で、面倒で、動きもなんだか不可解です。私は、長年使っているうちに、正直、何をどう設定したのかわからなくなってしまっています。今回は前の環境からコピーしましたが、新しい環境にしたらいっそのこと前の設定は捨ててまっさらな状態から始める、というのも一案かと思います。
ここまでで Trados は使えるようになりましたが、まだプラグインとアプリが残っています。Trados に組み込んで使うプラグインは、フォルダーをコピーするだけでまとめて移行できます。1 つ 1 つインストールし直さなくても大丈夫です。Trados の外で動くアプリは、1 つ 1 つインストールし直すしか方法がなさそうです。
プラグインを移行するためにコピーするのは、以下の 2 つのフォルダーです。
C:\Users\[ ユーザー名 ]\AppData\Roaming\SDL\SDL Trados Studio\14\Plugins\
Packages
Unpacked
基本的には、Packages をコピーするだけで大丈夫です。Unpacked は Trados が自動的に作成するらしいので、コピーしなくても問題ありません。
では、Unpacked は何かというと、各プラグインで行った設定などが格納されているようです。私は、 Regex Match AutoSuggest Provider を使っていますが、このプラグインで設定していた正規表現は、Packages をコピーしただけでは復元されず、Unpacked をコピーしたら復元されました。
私の場合、設定が消えて困ったプラグインはこの 1 つくらいです。新しい環境での動作が不安な場合は、Packages だけをコピーして、Unpacked は Trados に作らせる、という方が安全かもしれないです。
さて、プラグインはこれで移行できたのですが、Trados の外で動くアプリは 1 つ 1 つインストールし直しました。 PackageReader 、 SDLTMExport 、 Glossary Converter などです。何をインストールしていたかなんてすっかり忘れているもので、実際に使おうとして、あぁこれもない、あれもない、となって徐々にインストールしていきました。
今回は、以上です。Trados 以外にも、辞書ツールとか、AutoHotkey とか、Trados 以外の CAT ツールとか、まだまだ格闘の日々は続きそうです。新しい環境を作るときはいつも、きれいに使っていこう、と思うのですが、そのうちぐちゃぐちゃになりよくわからなくなってしまうんですよね。で、もうよくわからないから、一気に新しい環境にしちゃおうとなって、結局、今回のような状態に陥っています。はぁ、進歩がないです。
今回は、新しいパソコンを一式購入し、一から環境を構築しました。前の環境をコピーせず新規に作るのは面倒でしたが、心機一転、変なものが残っていないきれいな環境にするのもいいかなぁと思い頑張りました (というか、まだまだいろいろやり残しがあり、頑張っている最中です)。今回の環境は、Windows 10、Office 2016 (64 ビット版)、SDL Trados Studio 2017 で、手順はざっとこんな感じです。
1. Windows のユーザー名を設定
2. Office の 64 ビット版をインストール
3. SDL Trados Studio 2017 をインストール
4. Trados の設定を移行
5. プラグインを移行、アプリは再インストール
1. Windows のユーザー名を設定
まずは、Windows の設定です。Trados を使う予定なら気を付けておきたいのが Windows のユーザー名です。 Trados では、コメントや変更履歴などに、問答無用で Windows のユーザー名が記録されてしまいます。これを Trados 側の設定で変更することはできません。詳しくは、以前の記事「 Trados で使われるユーザー名 」を参照してください。
私は個人の自宅で作業をしているのですが、前のパソコンではあまり考えず変な名前を付けてしまい、かなり後悔しました。コメントや変更履歴に記録されるユーザー名は、翻訳会社さん側で、誰のコメントなのか、誰の変更なのかを区別するために確認している可能性があり、変な名前にするとちょっと恥ずかしい思いをします。
ユーザー名に使う名前は、正直に本名でもいいですが、私は私本人が特定されないように「Translator A」のような汎用的な名前を使っています。コメントや変更履歴は、レビューアーなど外部の人にそのまま送られることが多いですし、sdlxliff ファイルに登録されたユーザー名は、処理方法によってはクライアントまで行ってしまう可能性があります。
実際には、知らない人の名前をメモリなどで目にしてもそれほど気にはならないですが、とは言っても自分の名前をあまり広くお知らせしたくはないので、なるべく名前が残らないように気を付けています。
2. Office の 64 ビット版をインストール
これまで Office は 32 ビット版を使っていましたが、思い切って 64 ビット版にしました。Trados が 64 ビット版をサポートしているのかどうかは調べてもはっきりとわからなかったのですが、まあ大丈夫だろうと思って入れてみました。
結果は、今のところ問題なく動いています。さすがに、Word のバイリンガル ファイルを使うことはもうないと思うので、大丈夫でしょう。
Office の 64 ビット版のインストールは少し手間取りました。「64 ビット版をインストールしよう」と決めて注意しながらインストール手順を進めたつもりでしたが、画面上の指示に従っていたらいつの間にか 32 ビット版がインストールされてしまいました。仕方ないので、32 ビット版をいったんアンインストールして、再挑戦しました。実は、下図の「その他のオプション」から選ぶことができました。わかりにくいよ〜 (T-T)
3. SDL Trados Studio 2017 をインストール
いよいよ Trados のインストールです。私は、まだ 2017 のライセンスしかないので、SDL のサイトからダウンロードできる以下をインストールしました。
SDLTradosStudio2017_SR1_44945.exe (SDL Trados Studio 2017 SR1 CU15)
これをインストールして、その後はアップデートしてはいけません!
※※※※※ 追記 2019/12/26 ※※※※※※※※※※※※※※※※※
ここで取り上げた問題は、2017 でも解決されました。
SDL Trados Studio 2017 SR1 CU18 (Build 14.1.10018.54792) に更新すれば、問題が発生しなくなると思います。私は、問題が発生していたパッケージを 2 つ試してみましたが、2 つとも無事に開くことができました。
かなり困っていたので、解決してホントに良かったです。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
アップデートすると、パッケージが開けなくなるという問題が発生します。詳しくは、こちらの記事「 パッケージが「正常に」開かない 」を参照してください。この問題は、全角文字がファイル名などに含まれる場合に発生しますが、かなり致命的です。(2017 で修正して欲しいので、しつこく書いてすみません。) コミュニティ での投票にご協力頂けると大変助かります (_ _)
試用版を有効に使いましょう!
さて、Trados をダウンロードしてインストールしてみたら、なんと試用版として使うことができました。試用版の存在はすっかり忘れていたので、これは嬉しい誤算でした。試用版が使えれば、同時に 2 つのパソコンで Trados を起動できるので、ライセンスのアクティベートと非アクティベートを繰り返す手間がなくなり、とても便利です。
試用版は 30 日間使えます。しかも、Professional 版の機能を使えます。試用版はライセンスをいったんアクティベートすると使えなくなるので、試用期間が終了するまでアクティベートはしないでおきます。ボタンが表示されてくると、ついつい癖でアクティベートしたくなりますが、そこは細心の注意を払って回避します。試用期間の途中でアクティベートしたらもったいないです。
で、2017 の試用期間が終わったら、今度は、2019 の試用版が使えるのではないかと思っています。そうすれば、約 2 か月は時間があることになるので、移行の面倒な作業をするのには便利そうです。
4. Trados の設定を移行
Trados をインストールできたら、ショートカット キーなどの設定を前の環境から移行します。方法は簡単です。以下のファイルを前の環境からコピーするだけです。
C:\Users\[ ユーザー名 ]\AppData\Roaming\SDL\SDL Trados Studio\14.0.0.0\UserSettings.xml
この方法は、少し古い情報ですが「 Ctrl/Shift shortcuts for cut, copy and paste 」を参考にしています。今回の私の場合は特に問題ありませんでしたが、正式な方法とは言えないようなので、試す方は自己責任でお願いします (^_^;)
このファイルには、ショートカット キーだけでなく、AutoText の内容も含まれています。AutoText は、単体でインポート/エクスポートすることもできますが、このファイルをコピーしてしまえばその手間も省けます。
ただ、Trados のショートカット キーの設定は、かなり複雑で、面倒で、動きもなんだか不可解です。私は、長年使っているうちに、正直、何をどう設定したのかわからなくなってしまっています。今回は前の環境からコピーしましたが、新しい環境にしたらいっそのこと前の設定は捨ててまっさらな状態から始める、というのも一案かと思います。
5. Trados のプラグインを移行、アプリは再インストール
ここまでで Trados は使えるようになりましたが、まだプラグインとアプリが残っています。Trados に組み込んで使うプラグインは、フォルダーをコピーするだけでまとめて移行できます。1 つ 1 つインストールし直さなくても大丈夫です。Trados の外で動くアプリは、1 つ 1 つインストールし直すしか方法がなさそうです。
プラグインを移行するためにコピーするのは、以下の 2 つのフォルダーです。
C:\Users\[ ユーザー名 ]\AppData\Roaming\SDL\SDL Trados Studio\14\Plugins\
Packages
Unpacked
基本的には、Packages をコピーするだけで大丈夫です。Unpacked は Trados が自動的に作成するらしいので、コピーしなくても問題ありません。
では、Unpacked は何かというと、各プラグインで行った設定などが格納されているようです。私は、 Regex Match AutoSuggest Provider を使っていますが、このプラグインで設定していた正規表現は、Packages をコピーしただけでは復元されず、Unpacked をコピーしたら復元されました。
私の場合、設定が消えて困ったプラグインはこの 1 つくらいです。新しい環境での動作が不安な場合は、Packages だけをコピーして、Unpacked は Trados に作らせる、という方が安全かもしれないです。
さて、プラグインはこれで移行できたのですが、Trados の外で動くアプリは 1 つ 1 つインストールし直しました。 PackageReader 、 SDLTMExport 、 Glossary Converter などです。何をインストールしていたかなんてすっかり忘れているもので、実際に使おうとして、あぁこれもない、あれもない、となって徐々にインストールしていきました。
今回は、以上です。Trados 以外にも、辞書ツールとか、AutoHotkey とか、Trados 以外の CAT ツールとか、まだまだ格闘の日々は続きそうです。新しい環境を作るときはいつも、きれいに使っていこう、と思うのですが、そのうちぐちゃぐちゃになりよくわからなくなってしまうんですよね。で、もうよくわからないから、一気に新しい環境にしちゃおうとなって、結局、今回のような状態に陥っています。はぁ、進歩がないです。
| |
|
タグ: CU15
パッケージが開かない
2017
トラブルシューティング
プラグイン
アプリ
AppStore
PackageReader
Regex Match AutoSuggest Provider
SDLTMExport
試用版
ユーザー名
Tweet
2019年09月25日
upLIFT テクノロジー:最近のまとめ (まだ 2017 だけど)
最近、SDL さんからの日本語での情報発信が多くなってきたような気がします。日本語を扱う翻訳者としては嬉しい限りです。もちろん、英語でも別にいいんです。翻訳者ですし。でも、日本語特有の問題もあるし、ね。やっぱり。
upLIFT テクノロジーについては以前に何回かとりあげました ( 前編 、 後編 ) が、そのときはまだよくわかっていないことがあったので、アップデートされた機能なども含めて改めてまとめてみたいと思います。ただし、バージョンは 2017 を前提とします (すみません、私がまだ 2017 を使っているので)。
upLIFT テクノロジーについての SDL さんからの情報としては、以下のブログに最近の状況がまとめられています。参考にしてください。
SDL Trados Blog: ハウツーガイド
Trados Studio 2019 – 進歩した日本語原文の解析
まずは、バージョンです。英語 (などのヨーロッパ言語) が原文の場合は 2017 の初期バージョンから upLIFT が使えたようですが、日本語 (などのアジア言語) が原文の場合は SR1が必要です。さらに、当初の SR1 には文字数のカウントに不具合 (?) があり、あいまい一致のカウントが大きく違った結果になるようなので、 CU15が必要です。
日本語原文の場合は、料金の単位が「単語」ではなく「文字」であることが多いので、文字数のカウント方法はかなり重要です。CU15 より前のときは、あいまい一致のカウントが翻訳者にとってかなり不利な感じになっていました。上記のブログによると、CU15 でこの不一致は解消されたようです。(が、すみません、本当に解消されたのかを私は検証していません。一応、信じるけど、どうなのかなぁ。)
※※※※※ 追記 2019/12/26 ※※※※※※※※※※※※※※※※※
以下の問題は、2017 でも解決されました。
SDL Trados Studio 2017 SR1 CU18 (Build 14.1.10018.54792) に更新すれば、問題が発生しなくなると思います。私は、問題が発生していたパッケージを 2 つ試してみましたが、2 つとも無事に開くことができました。
かなり困っていたので、解決してホントに良かったです。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
CU15 は必要なのですが、最新の CU を適用すると、前回の記事に書いた パッケージが開けない という問題が発生します。この問題はファイル名などに全角文字が含まれている場合に発生しますが、日本語原文のときはファイル名も日本語であることが多いので要注意です。
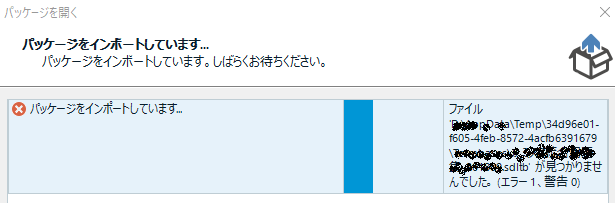
上記のブログで必要とされているビルド: 14.1.10015.44945
コミュニティ で問題が発生するとされているビルド: 14.1.10016.54660
微妙に違います。SDL のサイトからダウンロードできる最新のファイルは、SDL Trados Studio 2017 SR1 CU15 (SDLTradosStudio2017_SR1_44945.exe) です。なので、これをインストールして、後は更新しない、というのがベストかと思います。(すみません、これも実際にやってみたわけではありません。)
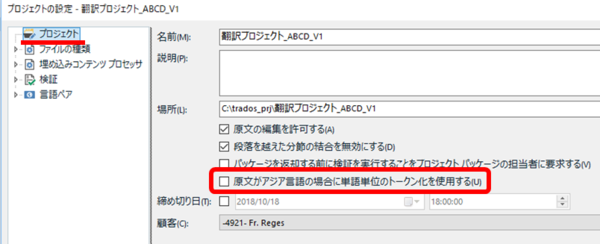
プロジェクトの設定にあるオプションです。これは、上にも書いたように、文字数のカウントを単語ベースではなく文字ベースで行うために「単語単位のトークン化を使用しない」にしておく必要があります。この設定について私が不安に思っていたのは、「使用しない」にすると翻訳作業時の upLIFT の動作に影響するのではないか?という点でした。これは影響しないそうです。この設定は、文字数のカウントに影響するだけで、実際に翻訳作業をしているときの動作には影響しません。つまり、この設定で「単語単位のトークン化を使用しない」ことにしていても、作業時は upLIFT をちゃんと使えます。
デフォルトで「使用しない」設定になっていると思いますが、文字カウントをする方は、どうぞ安心してそのまま「使用しない」にしておいてください。お願いします。
※※※※※ 追記 2020/03/31 ※※※※※※※※※※※※※※※※※
いろいろ混乱しておりましたが、こちらの新しい記事 「単語単位のトークン化」は単語数を数えるだけ をご覧ください。
だいたい、上記の記述のとおりですが、
・文字数ではなく、単語数のカウントのための設定であり
・翻訳作業時に使う必要はないので、デフォルトのままオフにしておけばよい
ということになります。この設定のオン・オフにより翻訳作業時の動作や解析結果が変わりますが、この設定はあくまで単語数を数えるためのものなので、普段はオンにする必要はありません。オフにしたままでも upLIFT は有効ですし、単語やフレーズ単位でのマッチもちゃんと見つかってきます。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
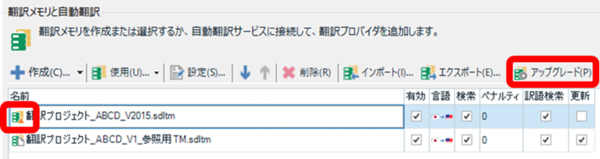
upLIFT テクノロジーが導入されてから、下位のバージョンで作ったメモリはアップグレードして使うことになっています。最初にプロジェクトを開いたときに、設定画面やエディタなど、いろいろなところに警告が出てきます。このアップグレードですが、1 回実行したらそれで終わりではありません。ある程度メモリが増えたら、再度アップグレードをする必要があります。また、2017 SR1 CU15 以降で新規作成したメモリでも、ある程度まで量が増えるとアップグレードが必要になります。
私は、何回も警告が表示されてきてかなり焦りましたが、それが正常な動作のようです。警告が表示されたら素直にアップグレードしましょう (かなり面倒ですが)。
プロジェクトの設定にある [ TU のフラグメント] チェックボックスをオンにします。これはデフォルトではオフですが、オンにした方が一致が多く見つかるので、私は、毎回、オンに変更しています。
プロジェクトの設定: [言語ペア] > [翻訳メモリと自動翻訳] > [検索] > [upLIFT 用のフラグメント一致のオプション]
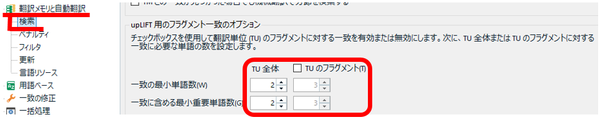
単語数は、以前のセミナーで SDL さんが「2」を推奨していたので、そのように設定しています。ただ、メモリの内容によっては一致が多くなりすぎることもあります。その場合は「3」にすると一致が少なくなります。
詳しくは、 以前の記事 も参照してください。
upLIFT が導入されてから、メモリの検索などの動作がかなり遅くなって耐えられないということがたびたびあります。そんなときは、エディタ上での [ Match Repair の使用] を無効にすると改善することが多いと思います。エディタと一括タスクそれぞれについて設定できますが、デフォルトでエディタのみ有効になっています。
プロジェクトの設定: [言語ペア] > [一致の修正] > [Match Repair の使用]
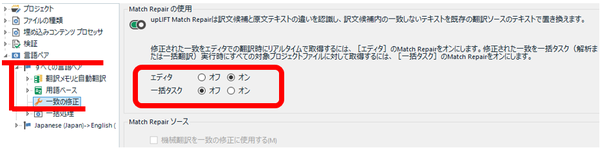
この機能は SDL さんの説明では必ず紹介されますが、私個人の感想としては、それほど役立ちません。無効にして動作が速くなるなら、その方がいいと思っています。
これについても、詳しくは、 以前の記事 を参照してください。
今回は、以上です。特に新しい情報はないのですが、前回の パッケージが開けない という問題が 2017 で対応されない件がどうしても諦めきれず、、、 しつこく書いてみました。
upLIFT テクノロジーについては以前に何回かとりあげました ( 前編 、 後編 ) が、そのときはまだよくわかっていないことがあったので、アップデートされた機能なども含めて改めてまとめてみたいと思います。ただし、バージョンは 2017 を前提とします (すみません、私がまだ 2017 を使っているので)。
upLIFT テクノロジーについての SDL さんからの情報としては、以下のブログに最近の状況がまとめられています。参考にしてください。
SDL Trados Blog: ハウツーガイド
Trados Studio 2019 – 進歩した日本語原文の解析
日本語原文の場合は SDL Trados Studio 2017 SR1 CU15が必要
まずは、バージョンです。英語 (などのヨーロッパ言語) が原文の場合は 2017 の初期バージョンから upLIFT が使えたようですが、日本語 (などのアジア言語) が原文の場合は SR1が必要です。さらに、当初の SR1 には文字数のカウントに不具合 (?) があり、あいまい一致のカウントが大きく違った結果になるようなので、 CU15が必要です。
日本語原文の場合は、料金の単位が「単語」ではなく「文字」であることが多いので、文字数のカウント方法はかなり重要です。CU15 より前のときは、あいまい一致のカウントが翻訳者にとってかなり不利な感じになっていました。上記のブログによると、CU15 でこの不一致は解消されたようです。(が、すみません、本当に解消されたのかを私は検証していません。一応、信じるけど、どうなのかなぁ。)
しかし、最新の CU を適用してはいけない
※※※※※ 追記 2019/12/26 ※※※※※※※※※※※※※※※※※
以下の問題は、2017 でも解決されました。
SDL Trados Studio 2017 SR1 CU18 (Build 14.1.10018.54792) に更新すれば、問題が発生しなくなると思います。私は、問題が発生していたパッケージを 2 つ試してみましたが、2 つとも無事に開くことができました。
かなり困っていたので、解決してホントに良かったです。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
CU15 は必要なのですが、最新の CU を適用すると、前回の記事に書いた パッケージが開けない という問題が発生します。この問題はファイル名などに全角文字が含まれている場合に発生しますが、日本語原文のときはファイル名も日本語であることが多いので要注意です。
上記のブログで必要とされているビルド: 14.1.10015.44945
コミュニティ で問題が発生するとされているビルド: 14.1.10016.54660
微妙に違います。SDL のサイトからダウンロードできる最新のファイルは、SDL Trados Studio 2017 SR1 CU15 (SDLTradosStudio2017_SR1_44945.exe) です。なので、これをインストールして、後は更新しない、というのがベストかと思います。(すみません、これも実際にやってみたわけではありません。)
[ アジア言語の原文テキストの場合に単語単位のトークン化を使用する] は作業時の動作に影響しない
プロジェクトの設定にあるオプションです。これは、上にも書いたように、文字数のカウントを単語ベースではなく文字ベースで行うために「単語単位のトークン化を使用しない」にしておく必要があります。この設定について私が不安に思っていたのは、「使用しない」にすると翻訳作業時の upLIFT の動作に影響するのではないか?という点でした。これは影響しないそうです。この設定は、文字数のカウントに影響するだけで、実際に翻訳作業をしているときの動作には影響しません。つまり、この設定で「単語単位のトークン化を使用しない」ことにしていても、作業時は upLIFT をちゃんと使えます。
デフォルトで「使用しない」設定になっていると思いますが、文字カウントをする方は、どうぞ安心してそのまま「使用しない」にしておいてください。お願いします。
※※※※※ 追記 2020/03/31 ※※※※※※※※※※※※※※※※※
いろいろ混乱しておりましたが、こちらの新しい記事 「単語単位のトークン化」は単語数を数えるだけ をご覧ください。
だいたい、上記の記述のとおりですが、
・文字数ではなく、単語数のカウントのための設定であり
・翻訳作業時に使う必要はないので、デフォルトのままオフにしておけばよい
ということになります。この設定のオン・オフにより翻訳作業時の動作や解析結果が変わりますが、この設定はあくまで単語数を数えるためのものなので、普段はオンにする必要はありません。オフにしたままでも upLIFT は有効ですし、単語やフレーズ単位でのマッチもちゃんと見つかってきます。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
メモリのアップグレードは 1 回だけではない
upLIFT テクノロジーが導入されてから、下位のバージョンで作ったメモリはアップグレードして使うことになっています。最初にプロジェクトを開いたときに、設定画面やエディタなど、いろいろなところに警告が出てきます。このアップグレードですが、1 回実行したらそれで終わりではありません。ある程度メモリが増えたら、再度アップグレードをする必要があります。また、2017 SR1 CU15 以降で新規作成したメモリでも、ある程度まで量が増えるとアップグレードが必要になります。
私は、何回も警告が表示されてきてかなり焦りましたが、それが正常な動作のようです。警告が表示されたら素直にアップグレードしましょう (かなり面倒ですが)。
[ TU のフラグメント] を有効にする
プロジェクトの設定にある [ TU のフラグメント] チェックボックスをオンにします。これはデフォルトではオフですが、オンにした方が一致が多く見つかるので、私は、毎回、オンに変更しています。
プロジェクトの設定: [言語ペア] > [翻訳メモリと自動翻訳] > [検索] > [upLIFT 用のフラグメント一致のオプション]
単語数は、以前のセミナーで SDL さんが「2」を推奨していたので、そのように設定しています。ただ、メモリの内容によっては一致が多くなりすぎることもあります。その場合は「3」にすると一致が少なくなります。
詳しくは、 以前の記事 も参照してください。
動作が遅いときは [ 一致の修正] を無効にする
upLIFT が導入されてから、メモリの検索などの動作がかなり遅くなって耐えられないということがたびたびあります。そんなときは、エディタ上での [ Match Repair の使用] を無効にすると改善することが多いと思います。エディタと一括タスクそれぞれについて設定できますが、デフォルトでエディタのみ有効になっています。
プロジェクトの設定: [言語ペア] > [一致の修正] > [Match Repair の使用]
この機能は SDL さんの説明では必ず紹介されますが、私個人の感想としては、それほど役立ちません。無効にして動作が速くなるなら、その方がいいと思っています。
これについても、詳しくは、 以前の記事 を参照してください。
今回は、以上です。特に新しい情報はないのですが、前回の パッケージが開けない という問題が 2017 で対応されない件がどうしても諦めきれず、、、 しつこく書いてみました。
| |
|
タグ: 文字数
カウント
2017 SR1
CU15
フラグメント一致
Match Repair の使用
upLIFT テクノロジー
TU のフラグメント
一致の修正
原文がアジア言語の場合に単語単位のトークン化を使用する
あいまい一致の自動修正
メモリ
アップグレード
パッケージが開かない
単語単位のトークン化
Tweet
2019年09月08日
パッケージが「正常に」開かない
※※※※※ 追記 2019/12/26 ※※※※※※※※※※※※※※※※※
ここで取り上げた問題は、2017 でも解決されました。
SDL Trados Studio 2017 SR1 CU18 (Build 14.1.10018.54792) に更新すれば、問題が発生しなくなると思います。私は、問題が発生していたパッケージを 2 つ試してみましたが、2 つとも無事に開くことができました。
かなり困っていたので、解決してホントに良かったです。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
前回の記事では、久々に Trados の便利さを実感したお話をしましたが、今回は、久々にかなり苦戦したお話です。やはり、Trados を甘くみてはいけません (^_^;)
問題は、以下です。コミュニティにちゃんと載っていました。
Translation Productivity > SDL Trados Studio
Studio2017をアップデート後、返却パッケージが開けない
2017 に最新の CU (Cumulative Updates) を適用すると、以下のようなエラーが発生してパッケージをうまく開けなくなるという問題です。でも、私の場合、自分の問題がこれに該当するとはなかなか気付けませんでした。CU を適用したのは少し前でしたし、発生する現象もいろいろで、ここにたどり着くまでにずいぶん時間がかかりました。
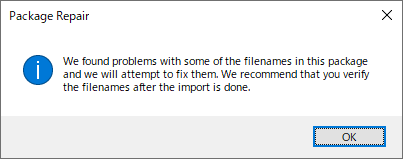
普通のパッケージも開けない
上記のコミュニティの書き込みでは「返却パッケージ」となっていましたが、私が開けなかったのは、翻訳会社さんからもらったパッケージです。つまりこの問題は、返却パッケージだけでなく、翻訳開始時にもらう普通のパッケージでも発生するらしいです。
パッケージ自体は開くこともある
さらに、まったく「開けない」というわけでもありません。現象はいろいろです。パッケージを開く処理が途中で終わってしまってプロジェクトが作られないときもあれば、プロジェクトは作られるけれどメモリなど一部のファイルがなくなっているときもあります。
私の最初のケースは、プロジェクトは作られたけれどメモリのファイルがなくなっている、という状態でした。メモリの設定ミスはたまにあるので、翻訳会社さんに「メモリがないんですけど〜」というメールを、そっちのミスじゃないの?という雰囲気で送ってしまいました (すみません)。その後、翻訳会社さんから「こちらでは正常に開けますが〜」という強気な返信が来てしまい、あれ、ちょっといつもと違う?と少しだけ感じました。でも、上記の問題との関係はまったく思い付きませんでした。
その後もいくつかのパッケージが失敗したので、今度は、別の翻訳会社さんのコーディネーターさんに相談してみました。そして返ってきた答えが「おそらく、CU のアップデートが原因だろう」というものでした。そう言われてみて、初めて上記のコミュニティに掲載されていた問題と同じかも、と思いました。
バージョン 2015 で開けた!
上記のコミュニティで確認したところ、2017 の場合の解決方法としては、CU を下げてアップデート前の状態に戻すしかなさそうでした。相談した翻訳会社さんからのアドバイスも同じでした。でも、CU を下げるにはアンインストールして再インストールする必要があり、それはとても面倒だし、そこまでしてもし解決しなかったら嫌だなあなどと考えてしまい、なかなか決断がつきませんでした。
で、CU を下げてアップデート前の状態に戻せばいいんだったら、2015 でもいいんじゃないかと思ってやってみたら、これが正解でした! パッケージを開いてプロジェクトが作成されるところまでを 2015 でやって、その後は、2017 に戻って、作成されたプロジェクトを開いて作業ができます。
いやぁ、2015 を残しておいて良かったです。でも、これも何かあったら使えなくなってしまいます。というのも、2015 はライセンスの問題で、いったんアクティブでなくなったら、再アクティブ化することはできないはずなので。やはり、2017 の CU を下げておく必要はありそうです。そして、最終的な解決方法は 2019 へのアップグレードなんですが、これこそなかなか決断がつきそうにありません。
上記のコミュティティの書き込みでは、2017 でこの問題を修正してもらえるよう、ユーザーの賛同を求めています。まだ、2017 を使っているという方、ぜひぜひ投稿をお願いします。

Tweet
ここで取り上げた問題は、2017 でも解決されました。
SDL Trados Studio 2017 SR1 CU18 (Build 14.1.10018.54792) に更新すれば、問題が発生しなくなると思います。私は、問題が発生していたパッケージを 2 つ試してみましたが、2 つとも無事に開くことができました。
かなり困っていたので、解決してホントに良かったです。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
前回の記事では、久々に Trados の便利さを実感したお話をしましたが、今回は、久々にかなり苦戦したお話です。やはり、Trados を甘くみてはいけません (^_^;)
問題は、以下です。コミュニティにちゃんと載っていました。
Translation Productivity > SDL Trados Studio
Studio2017をアップデート後、返却パッケージが開けない
2017 に最新の CU (Cumulative Updates) を適用すると、以下のようなエラーが発生してパッケージをうまく開けなくなるという問題です。でも、私の場合、自分の問題がこれに該当するとはなかなか気付けませんでした。CU を適用したのは少し前でしたし、発生する現象もいろいろで、ここにたどり着くまでにずいぶん時間がかかりました。
普通のパッケージも開けない
上記のコミュニティの書き込みでは「返却パッケージ」となっていましたが、私が開けなかったのは、翻訳会社さんからもらったパッケージです。つまりこの問題は、返却パッケージだけでなく、翻訳開始時にもらう普通のパッケージでも発生するらしいです。
パッケージ自体は開くこともある
さらに、まったく「開けない」というわけでもありません。現象はいろいろです。パッケージを開く処理が途中で終わってしまってプロジェクトが作られないときもあれば、プロジェクトは作られるけれどメモリなど一部のファイルがなくなっているときもあります。
私の最初のケースは、プロジェクトは作られたけれどメモリのファイルがなくなっている、という状態でした。メモリの設定ミスはたまにあるので、翻訳会社さんに「メモリがないんですけど〜」というメールを、そっちのミスじゃないの?という雰囲気で送ってしまいました (すみません)。その後、翻訳会社さんから「こちらでは正常に開けますが〜」という強気な返信が来てしまい、あれ、ちょっといつもと違う?と少しだけ感じました。でも、上記の問題との関係はまったく思い付きませんでした。
その後もいくつかのパッケージが失敗したので、今度は、別の翻訳会社さんのコーディネーターさんに相談してみました。そして返ってきた答えが「おそらく、CU のアップデートが原因だろう」というものでした。そう言われてみて、初めて上記のコミュニティに掲載されていた問題と同じかも、と思いました。
バージョン 2015 で開けた!
上記のコミュニティで確認したところ、2017 の場合の解決方法としては、CU を下げてアップデート前の状態に戻すしかなさそうでした。相談した翻訳会社さんからのアドバイスも同じでした。でも、CU を下げるにはアンインストールして再インストールする必要があり、それはとても面倒だし、そこまでしてもし解決しなかったら嫌だなあなどと考えてしまい、なかなか決断がつきませんでした。
で、CU を下げてアップデート前の状態に戻せばいいんだったら、2015 でもいいんじゃないかと思ってやってみたら、これが正解でした! パッケージを開いてプロジェクトが作成されるところまでを 2015 でやって、その後は、2017 に戻って、作成されたプロジェクトを開いて作業ができます。
いやぁ、2015 を残しておいて良かったです。でも、これも何かあったら使えなくなってしまいます。というのも、2015 はライセンスの問題で、いったんアクティブでなくなったら、再アクティブ化することはできないはずなので。やはり、2017 の CU を下げておく必要はありそうです。そして、最終的な解決方法は 2019 へのアップグレードなんですが、これこそなかなか決断がつきそうにありません。
上記のコミュティティの書き込みでは、2017 でこの問題を修正してもらえるよう、ユーザーの賛同を求めています。まだ、2017 を使っているという方、ぜひぜひ投稿をお願いします。
Tweet
2019年08月26日
英日と日英で同じメモリを使う — AnyTM
少し前に、日本語スピーカーと英語スピーカーの間で行われる Q&A のやり取りを翻訳する仕事がありました。日本語のものは英語に、英語のものは日本語に、と双方向で訳す必要があるものです。少し長期的な作業が予定されていたので、メモリを貯めようと思い AnyTM を使ってみました。いやぁ、久々に Trados って便利だなぁと思いました。
手順は、以下のとおり、いたってシンプルです。
?@ 日英のプロジェクトを作り、言語方向が同じ日英メモリを AnyTM として追加する。
?A 英日のプロジェクトを作り、 ?@で使った日英メモリを AnyTM として追加する。
ポイントは、?@のステップでも AnyTM を使うことです。言語方向の同じメモリを追加するので通常のメモリとしても追加できてしまいますが、AnyTM として追加します。日英と英日の両方のプロジェクトでメモリが AnyTM として設定されている状態を作ります。こうすることによって、両方のプロジェクトで同一のメモリを更新し、参照できるようになります。
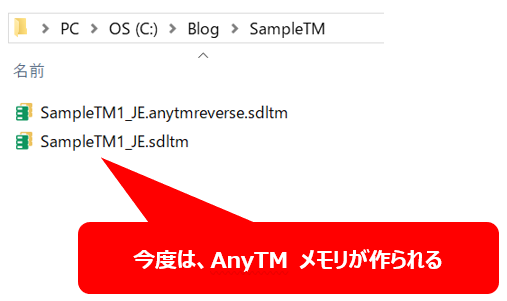
メモリを AnyTM として追加すると、以下のように 「anytmreverse」と付いたメモリが自動的に作成されます。Trados がやってくれる処理は単純で、この AnyTM メモリと元のメモリを常に同期するというものです。つまり、元のメモリに訳文を入力すると、自動的に AnyTM メモリにも訳文が追加され、同様に AnyTM メモリに訳文を追加しても、元のメモリにも訳文が追加されます。

まず、日英プロジェクトに、言語方向が同じ日英メモリを AnyTM として追加します。追加する方法は簡単です。[ 使用] メニューから「 AnyTM」と表示があるものを選ぶだけです。

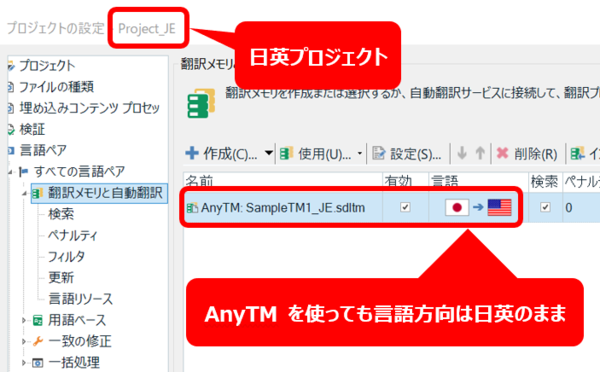
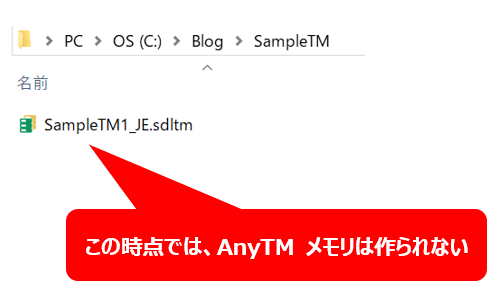
ここで、1 つ注意する点があります。言語方向が同じメモリは AnyTM として追加はできますが、追加しても「anytmreverse」メモリは作成されません。言語方向が同じなので確かに不要なのですが、この状態で翻訳作業をしても普通に日英メモリに訳文が貯まっていくだけで、AnyTM メモリは作られません。
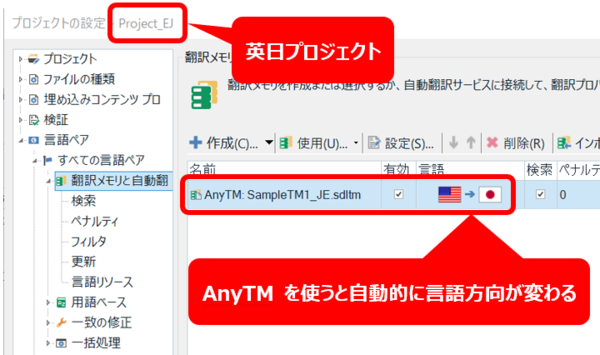
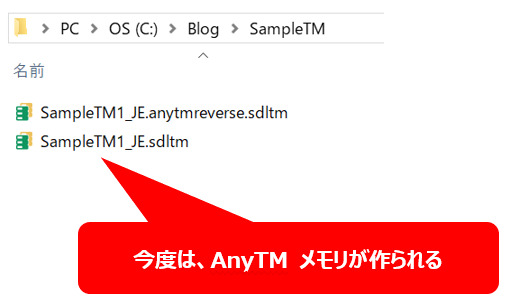
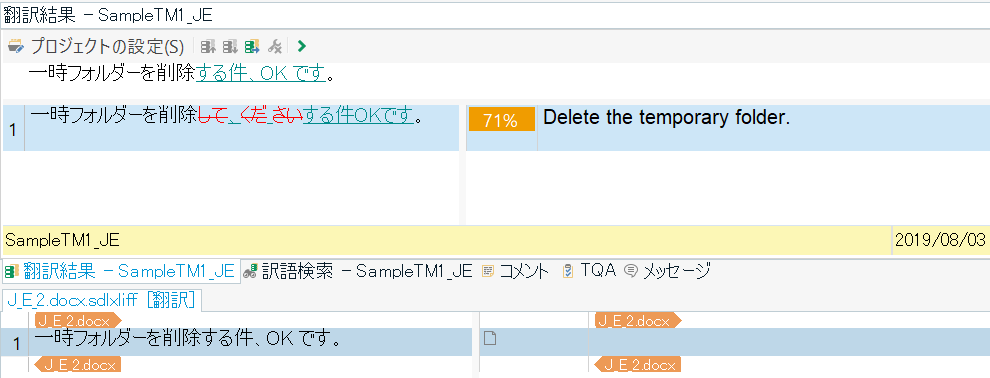
英日プロジェクトに、?@で追加した同じ日英メモリを AnyTM として追加します。今度は、プロジェクトの言語方向とメモリの言語方向が違うので、追加した時点で AnyTM メモリが自動的に作成されます。AnyTM メモリが作成されれば、準備は完了です。
では、少しだけ試してみましょう。
日英プロジェクトで以下の文を訳して、メモリに登録したとします。
原文: 日本語 設定ファイルを作成してください。
訳文: 英語 Create the setting file.
その後、英日プロジェクトで「I heard the request "Create the setting file".」という文を訳そうとしてメモリを検索すると、「Create the setting file」の対訳がメモリに見つかります。便利です!!
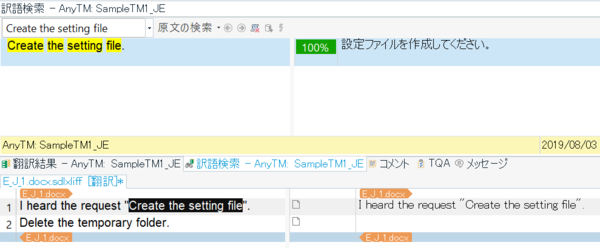
反対の方向も同様に機能します。英日プロジェクトで以下の文を訳して、メモリに登録したとします。
原文: 英語 Delete the temporary folder.
訳文: 日本語 一時フォルダーを削除してください。
日英プロジェクトに移動して、「一時フォルダーを削除する件、OK です。」という文を訳そうとすると、「一時フォルダーを削除してください」の対訳が表示されてきます。
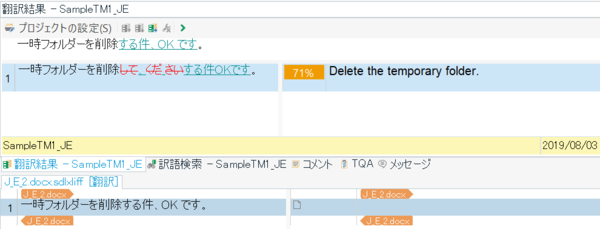
今回は以上です。英日と日英の双方向で訳したい場合は、実はもう 1 つ「多言語構成の原文の翻訳」という機能もあります。上で説明した方法は、英日と日英でファイルが分かれていることが前提ですが、同一のファイルに英日と日英が混在する場合は、こちらの方が便利です。詳しくは、また次回!
Tweet
手順は、以下のとおり、いたってシンプルです。
?@ 日英のプロジェクトを作り、言語方向が同じ日英メモリを AnyTM として追加する。
?A 英日のプロジェクトを作り、 ?@で使った日英メモリを AnyTM として追加する。
ポイントは、?@のステップでも AnyTM を使うことです。言語方向の同じメモリを追加するので通常のメモリとしても追加できてしまいますが、AnyTM として追加します。日英と英日の両方のプロジェクトでメモリが AnyTM として設定されている状態を作ります。こうすることによって、両方のプロジェクトで同一のメモリを更新し、参照できるようになります。
AnyTM の仕組み
メモリを AnyTM として追加すると、以下のように 「anytmreverse」と付いたメモリが自動的に作成されます。Trados がやってくれる処理は単純で、この AnyTM メモリと元のメモリを常に同期するというものです。つまり、元のメモリに訳文を入力すると、自動的に AnyTM メモリにも訳文が追加され、同様に AnyTM メモリに訳文を追加しても、元のメモリにも訳文が追加されます。
?@ 日英プロジェクトに、日英メモリを AnyTM として追加する
まず、日英プロジェクトに、言語方向が同じ日英メモリを AnyTM として追加します。追加する方法は簡単です。[ 使用] メニューから「 AnyTM」と表示があるものを選ぶだけです。

ここで、1 つ注意する点があります。言語方向が同じメモリは AnyTM として追加はできますが、追加しても「anytmreverse」メモリは作成されません。言語方向が同じなので確かに不要なのですが、この状態で翻訳作業をしても普通に日英メモリに訳文が貯まっていくだけで、AnyTM メモリは作られません。

?A 英日プロジェクトに、日英メモリを AnyTM として追加する
英日プロジェクトに、?@で追加した同じ日英メモリを AnyTM として追加します。今度は、プロジェクトの言語方向とメモリの言語方向が違うので、追加した時点で AnyTM メモリが自動的に作成されます。AnyTM メモリが作成されれば、準備は完了です。

試してみます
では、少しだけ試してみましょう。
日英プロジェクトで以下の文を訳して、メモリに登録したとします。
原文: 日本語 設定ファイルを作成してください。
訳文: 英語 Create the setting file.
その後、英日プロジェクトで「I heard the request "Create the setting file".」という文を訳そうとしてメモリを検索すると、「Create the setting file」の対訳がメモリに見つかります。便利です!!

反対の方向も同様に機能します。英日プロジェクトで以下の文を訳して、メモリに登録したとします。
原文: 英語 Delete the temporary folder.
訳文: 日本語 一時フォルダーを削除してください。
日英プロジェクトに移動して、「一時フォルダーを削除する件、OK です。」という文を訳そうとすると、「一時フォルダーを削除してください」の対訳が表示されてきます。
今回は以上です。英日と日英の双方向で訳したい場合は、実はもう 1 つ「多言語構成の原文の翻訳」という機能もあります。上で説明した方法は、英日と日英でファイルが分かれていることが前提ですが、同一のファイルに英日と日英が混在する場合は、こちらの方が便利です。詳しくは、また次回!
| |
Tweet
2019年07月28日
オンライン質問会から
先日、Trados のオンライン質問会に参加しました。今回は、その中から、私が気になった点をいくつか紹介したいと思います。詳しく調べてからきちんとした記事にしようかとも思ったのですが、すみません、記事をあげないと広告が表示されてしまうので、とりあえず、簡単な記事にさせてもらいます。
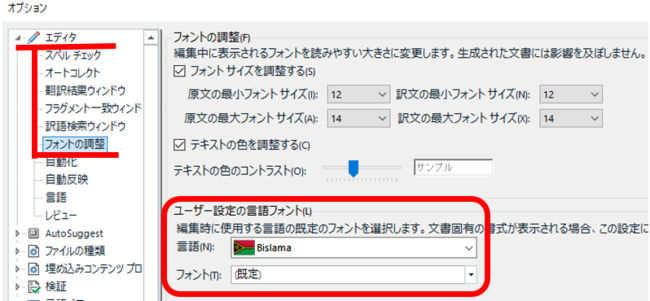
なりますよね!日本語のフォントを設定しても、設定画面を開くといつも Bislama が表示されてきます。私もこれには随分悩まされました。結論を言うと、表示が Bislama でも問題ありません。日本語に設定したフォントは、ちゃんと設定されています。ドロップダウンから改めて日本語を選んで、自分が設定したフォントが表示されてくれば大丈夫です。
詳しくは、こちらの記事「 エディタ上のフォントを変える 」もご覧ください。
XML の翻訳は、いろいろな設定がきちんとされていないととてもやりにくいです。「文書構造」を使うという案は私は思い付きませんでしたが、名案かもしれないです。SDL の方で改善要望をあげるということでしたので、早めに実装されることを期待します。
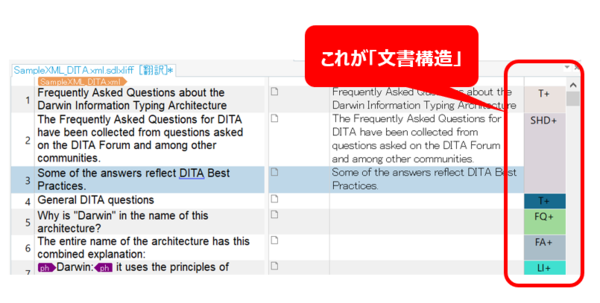
ただ、XML はファイルによっては文書構造がまったく表示されてこないこともあります。そうなると、もう何を訳しているのかわからなくて本当に困ります。そんなときに、私は次の 2 つを試してみます。
・プレビューを表示する
プレビューを表示すると、完成形の文書が見られることがあります。完成形が見られない場合でも、通常は、XML のタグがそのまま表示されます。タグが表示されれば、今何を訳しているかはわかります。Trados のプレビュー機能は、Office 文書などでは重すぎてあまり使えないですが、XML なら軽いので大丈夫です。プレビューを表示していても、エディタが変な動作になることはありません。
・表示フィルタを「すべてのコンテンツ」にする
プレビューを表示しても、エラーになってしまい XML そのものすら表示されてこないことがたまにあります。そんなときは、[ レビュー] タブ > [ 表示フィルタ] で「 すべてのコンテンツ」を選んでみると、翻訳対象文字以外のタグなどの要素が表示されてくることがあります。通常、表示フィルタは「 すべての分節」に設定されていて、翻訳対象文字のある分節のみが表示されてくるようになっています。
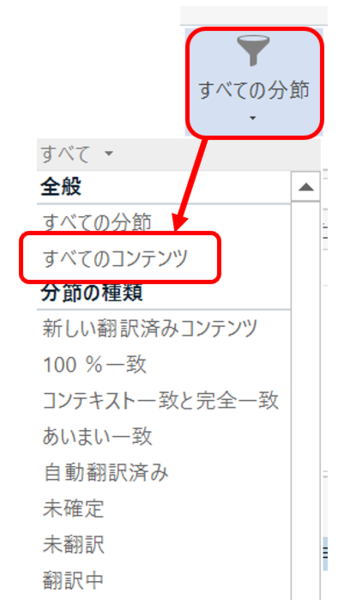
表示フィルタを切り替えてタグが表示されてくるかどうかは、XML からバイリンガル ファイルへの変換方法によると思います。残念ながら、成功する可能性はあまり高くないですが、私はとりあえず試してみます。
SDL の回答としては、上記でも登場した表示フィルタを使用してロックを掛け、ロック部分を非表示にするというものでした。ただ、翻訳者としては非表示にすることにはあまり賛成できません。前後関係がわからなくなるので、とても訳しにくくなります。(非表示にするならまだしも、翻訳会社さんによっては、100% をそもそもバイリンガル ファイルに含めてこないことがあります。そうなると、いちいち Trados から離れて文脈を確認しないといけないので非常に効率が悪いです。)
また、ロックはとても便利ですが、翻訳者の立場からすると少し使いにくいです。というのも、翻訳会社さんからのファイルはたいてい既に一部の分節がロックされています。この状態で、翻訳者が勝手に分節をロックすると、そもそもロックされていた分節なのか、自分でロックした分節なのかがわからなくなり、元の状態に戻すことができなくなってしまいます。
ロック箇所は作業対象外として 0 円のことが多く、料金に直接関係してきます。私は、自分でロックしたいなぁと思うときは、まずコーディネーターさんに相談するか、元の状態に確実に戻せることを確認してから行うようにしています。
・それでも表示フィルタを使う
というわけで、表示フィルタとロックは、翻訳者にとってはあまり良い方法ではないのですが、それでも使いたいときはあります。Trados で使える表示フィルタは、実は 3 つあります。
?@ [レビュー] タブの「表示フィルタ」
?A [表示] タブから表示する「高度な表示フィルタ」
?B プラグインの Community Advanced Display Filter
?@「表示フィルタ」は最もシンプルで簡単に使えますが、1 つの条件しか設定できません。?A「高度な表示フィルタ」は、条件も若干増え、複数の条件を設定できます。たとえば、「ロック解除されている 100%」や「100% とコンテキスト マッチ」 などの指定が可能です。?B「 Community Advanced Display Filter 」はプラグインなのでインストールする手間がかかりますが、かなりいろいろな操作ができます。たとえば、100% 以外といった否定での条件設定も可能です。このプラグインについては、こちらの記事「 ■プラグイン■ フィルタで繰り返しを除外する 」もご覧ください。
・ジャンプ機能を使う
分節をどうしても非表示にしたくない場合、私は表示フィルタは使わず、すべての分節を表示したままの状態でジャンプ機能を使うことがあります。
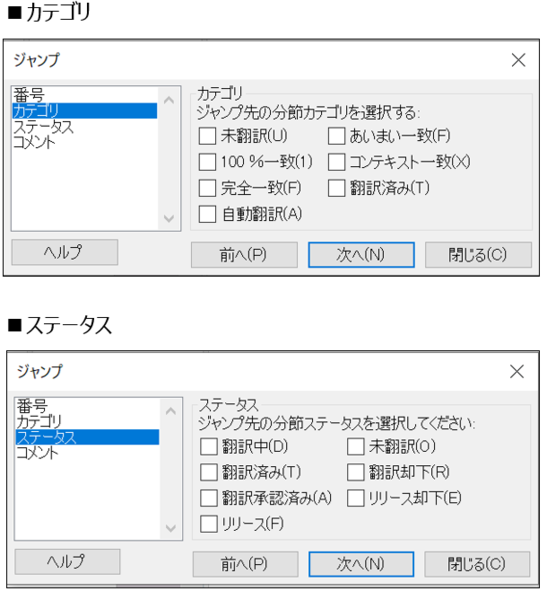
Ctrl+G で設定画面を表示して設定をしたら、Ctrl+J で次へ次へと進むことができます。「カテゴリ」と「ステータス」で表示フィルタと同じような条件を設定できます。ただ、「カテゴリ」と「ステータス」の両方の条件を同時に設定することはできません。またロックの条件はないので、ロック箇所を飛ばすことはできません。まあ、つまりはあまり使いやすくないのですが、役立つケースがないわけではないと思います。
今回は以上です。なんともまとまりのない感じになってしまいました。もし、何か良いアイデアや情報などありましたら、ぜひお知らせください。


Tweet
日本語のフォントを設定しても Bislama になってしまう
なりますよね!日本語のフォントを設定しても、設定画面を開くといつも Bislama が表示されてきます。私もこれには随分悩まされました。結論を言うと、表示が Bislama でも問題ありません。日本語に設定したフォントは、ちゃんと設定されています。ドロップダウンから改めて日本語を選んで、自分が設定したフォントが表示されてくれば大丈夫です。

詳しくは、こちらの記事「 エディタ上のフォントを変える 」もご覧ください。
XML で属性値を訳すときにタグを文書構造に表示して欲しい
XML の翻訳は、いろいろな設定がきちんとされていないととてもやりにくいです。「文書構造」を使うという案は私は思い付きませんでしたが、名案かもしれないです。SDL の方で改善要望をあげるということでしたので、早めに実装されることを期待します。

ただ、XML はファイルによっては文書構造がまったく表示されてこないこともあります。そうなると、もう何を訳しているのかわからなくて本当に困ります。そんなときに、私は次の 2 つを試してみます。
・プレビューを表示する
プレビューを表示すると、完成形の文書が見られることがあります。完成形が見られない場合でも、通常は、XML のタグがそのまま表示されます。タグが表示されれば、今何を訳しているかはわかります。Trados のプレビュー機能は、Office 文書などでは重すぎてあまり使えないですが、XML なら軽いので大丈夫です。プレビューを表示していても、エディタが変な動作になることはありません。
・表示フィルタを「すべてのコンテンツ」にする
プレビューを表示しても、エラーになってしまい XML そのものすら表示されてこないことがたまにあります。そんなときは、[ レビュー] タブ > [ 表示フィルタ] で「 すべてのコンテンツ」を選んでみると、翻訳対象文字以外のタグなどの要素が表示されてくることがあります。通常、表示フィルタは「 すべての分節」に設定されていて、翻訳対象文字のある分節のみが表示されてくるようになっています。
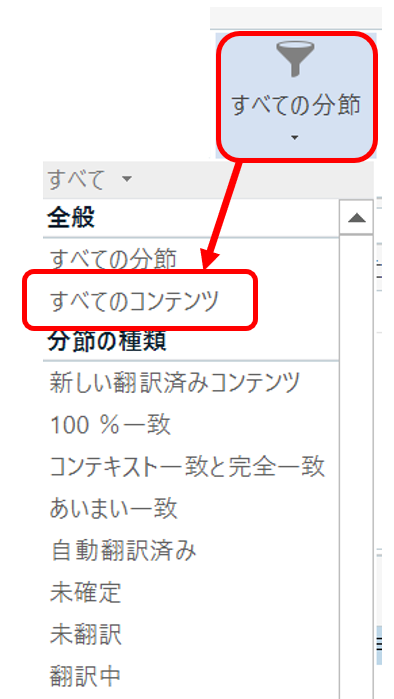
表示フィルタを切り替えてタグが表示されてくるかどうかは、XML からバイリンガル ファイルへの変換方法によると思います。残念ながら、成功する可能性はあまり高くないですが、私はとりあえず試してみます。
パーフェクト マッチや 100% を除いて翻訳したい
SDL の回答としては、上記でも登場した表示フィルタを使用してロックを掛け、ロック部分を非表示にするというものでした。ただ、翻訳者としては非表示にすることにはあまり賛成できません。前後関係がわからなくなるので、とても訳しにくくなります。(非表示にするならまだしも、翻訳会社さんによっては、100% をそもそもバイリンガル ファイルに含めてこないことがあります。そうなると、いちいち Trados から離れて文脈を確認しないといけないので非常に効率が悪いです。)
また、ロックはとても便利ですが、翻訳者の立場からすると少し使いにくいです。というのも、翻訳会社さんからのファイルはたいてい既に一部の分節がロックされています。この状態で、翻訳者が勝手に分節をロックすると、そもそもロックされていた分節なのか、自分でロックした分節なのかがわからなくなり、元の状態に戻すことができなくなってしまいます。
ロック箇所は作業対象外として 0 円のことが多く、料金に直接関係してきます。私は、自分でロックしたいなぁと思うときは、まずコーディネーターさんに相談するか、元の状態に確実に戻せることを確認してから行うようにしています。
・それでも表示フィルタを使う
というわけで、表示フィルタとロックは、翻訳者にとってはあまり良い方法ではないのですが、それでも使いたいときはあります。Trados で使える表示フィルタは、実は 3 つあります。
?@ [レビュー] タブの「表示フィルタ」
?A [表示] タブから表示する「高度な表示フィルタ」
?B プラグインの Community Advanced Display Filter
?@「表示フィルタ」は最もシンプルで簡単に使えますが、1 つの条件しか設定できません。?A「高度な表示フィルタ」は、条件も若干増え、複数の条件を設定できます。たとえば、「ロック解除されている 100%」や「100% とコンテキスト マッチ」 などの指定が可能です。?B「 Community Advanced Display Filter 」はプラグインなのでインストールする手間がかかりますが、かなりいろいろな操作ができます。たとえば、100% 以外といった否定での条件設定も可能です。このプラグインについては、こちらの記事「 ■プラグイン■ フィルタで繰り返しを除外する 」もご覧ください。
・ジャンプ機能を使う
分節をどうしても非表示にしたくない場合、私は表示フィルタは使わず、すべての分節を表示したままの状態でジャンプ機能を使うことがあります。

Ctrl+G で設定画面を表示して設定をしたら、Ctrl+J で次へ次へと進むことができます。「カテゴリ」と「ステータス」で表示フィルタと同じような条件を設定できます。ただ、「カテゴリ」と「ステータス」の両方の条件を同時に設定することはできません。またロックの条件はないので、ロック箇所を飛ばすことはできません。まあ、つまりはあまり使いやすくないのですが、役立つケースがないわけではないと思います。
今回は以上です。なんともまとまりのない感じになってしまいました。もし、何か良いアイデアや情報などありましたら、ぜひお知らせください。
2019年06月25日
用語ベースの設定
以前の記事 ( 前編
、 後編
) でマイクロソフト提供の用語集を Trados の用語ベースに変換する方法を説明しました。そのときに、用語ベースを実際に使用するときに気を付ける設定を紹介すると予告していたのですが、遅くなりました (_ _) ようやくまとめました。
Trados の用語ベースや用語認識の機能はとても便利ですが、設定や動作を理解しないまま使っていると、せっかくの情報をうまく生かせず用語の見落としなどにつながることがあります。私個人的には、用語認識機能はあくまで補助的なものと考え、面倒でも自分で検索するのが安全かなと思っています。
今回は、マイクロソフトの用語集を使うときに特に注意したい設定も含め、用語ベース全般の設定をいくつか紹介します。
まず、[ プロジェクトの設定] > [ 言語ペア] > [ 用語ベース] > [ 検索設定] の設定です。ここにある [ 用語の重複を許可する] をオンにします。この設定は、以前の記事「 パッケージを受け取ったら、ココの設定を変えます 」でも紹介しましたが、私はパッケージを受け取ったら必ず変更しています。
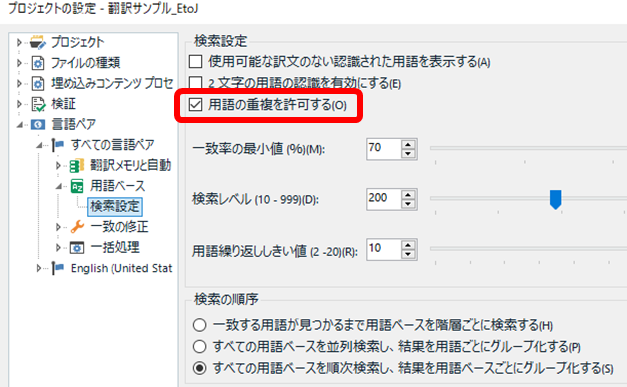
原文に「system administrator」という用語があったとします。[ 用語の重複を許可する] がオフの場合は、下図の左側のように「system administrator」という 2 語の一致しか表示されてきません。用語集に「system」や「administrator」という 1 語だけで登録があっても、それは用語認識ウィンドウに表示されてきません。つまり、長い用語が一致するとその長い用語だけが表示され、短い用語は表示されてこないのです。[ 用語の重複を許可する] をオンにしておくと、右側のように、長い用語に加えて短い用語も表示されてきます。
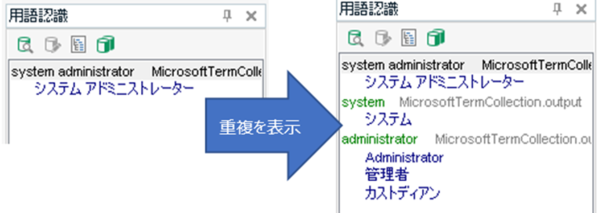
長い用語だけ表示されれば十分かと思いがちですが、翻訳会社さんから提供された用語集とマイクロソフトの用語集の両方を使う場合はこのオプションが欠かせません。たとえば、以下のように administrator が両方の用語集に登録されているとします。
・マイクロソフトの用語集: system administrator -> システム アドミニストレーター
・翻訳会社提供の用語集: administrator -> 管理者
[ 用語の重複を許可する] がオフの場合、「system administrator」という原文に対して用語認識ウィンドウに表示されてくるのは「システム アドミニストレーター」だけです。提供された用語集にある「管理者」は表示されてきません。これは非常に困ります。提供された用語集の用語を見落とす原因となってしまいます。
[ プロジェクトの設定] > [ 言語ペア] > [ 用語ベース] > [ 検索設定] の設定をもう 1 つ紹介します。
マイクロソフトの用語集は大量なのでヒットする用語がかなり多くなります。また、上記の [ 用語の重複を許可する] をオンにすることもヒットが多くなる要因になります。一覧に用語が大量に表示されていると、用語を見落とす危険性が高まるので注意が必要です。
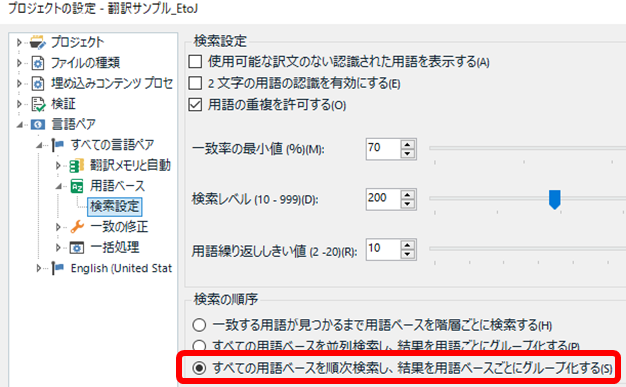
翻訳会社さんから提供された用語集とマイクロソフトの用語集の両方を使う場合は、用語ベースごとに表示を分けると安全です。そのための設定が [ 用語ベースごとにグループ化する] です。
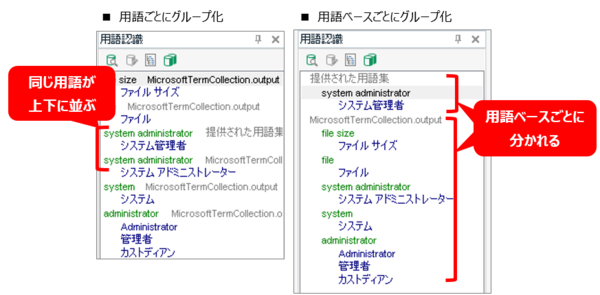
同じ用語が上下に並ぶ表示の方がわかりやすいときもありますが、マイクロソフトの用語集はかなり大量にヒットしてくるので、「用語ごとにグループ化」にしていると、マイクロソフトの用語がずらっと並ぶ中に別の用語がポツポツと挟まるという表示になりがちです。そうなると、どうしても見落とす危険性があるので、私は「用語ベースごとにグループ化」を使っています。
しかし、この設定には 1 つ問題があります。それは、この設定が入力補助用のリスト ([ 翻訳の表示] コマンドまたは Ctrl+Shif+L で表示される) には適用されないことです。入力補助用のリストと用語認識ウィンドウで表示順序が違うことになるので、選択して入力するときに注意が必要です。ヒットが大量にあるとスクロールの量がかなり増え、返って手間になることもあります。
次は、マイクロソフトの用語集ではなく、主に翻訳会社さんから提供される用語集に役立つ設定です。用語認識ウィンドウには用語ベースに設定されている「フィールド」を表示できます。下図の「UI文言」や「一般用語」と表示されている部分がフィールドです。各用語についてのコメントなどが設定されていることが多いです。
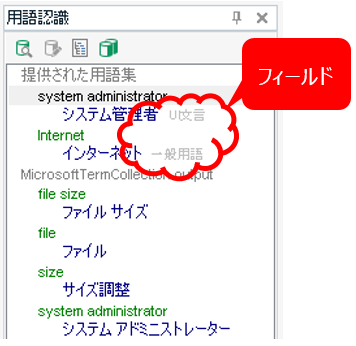
参照する必要のあるフィールドがある場合は、たいてい、翻訳会社さんからそのように指示されます。おそらく、パッケージで事前に設定されていることが多いと思いますが、自分で設定する場合は、以下のようにします。
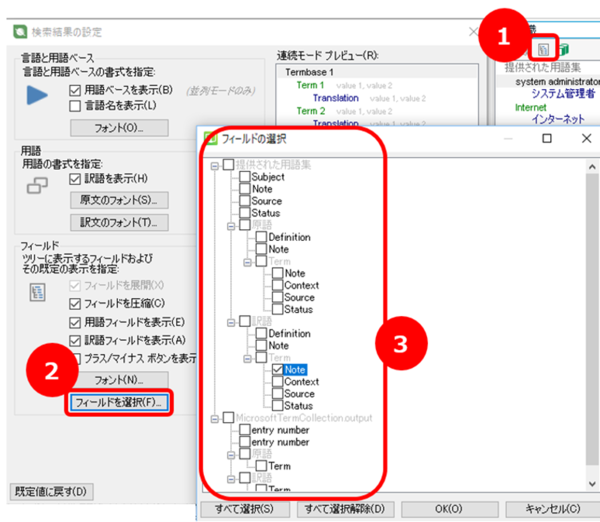
これで、設定されているフィールドの内容が表示されるようになります。ただ、用語認識ウィンドウは小さいので表示できてもあまり読みやすいとは言えません。用語ベースの元データが Excel などで提供されているなら元データを直接参照する方が便利な場合もあります。
さて、用語認識ウィンドウの設定をいろいろ説明してきましたが、一番重要なポイントは「用語認識を信用しすぎないこと」です。この機能は便利ですが、すべての用語が必ず認識されてくるわけではありません。
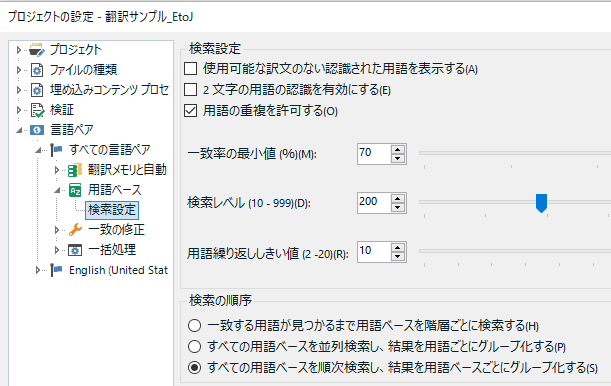
用語ベースの [ 検索設定] を見るとわかりますが、いろいろ設定があり、この設定によって用語認識の動作は変わります。用語認識は単純なテキストの一致で用語を見つけてくるわけではありません。
[ 2 文字の用語の認識を有効にする] はデフォルトでオフです。これがオフの場合、「in」や「my」など 2 文字の用語は用語集に登録されていても用語認識ウィンドウには表示されてきません。
また [ 一致率の最小値] という設定からわかるとおり、用語認識はメモリと同じようにあいまい一致の用語も表示してきます。単数形と複数形や動詞の活用などを考えるとあいまい一致は便利ですが、あいまい一致と気付かずそのまま使っていると危険です。
その他の設定についてもヘルプにはいろいろと説明がありますが、とにかく通常のテキスト検索とは動きが違うということを意識しておく必要があります。私は、用語認識はあくまで補助的なものと考え、単純なテキスト検索が行える Xbench などのツールを併用しています。
最後に、翻訳作業中に用語ベースに用語を追加するときの注意点です。原文と訳文でそれぞれの用語を選択して Ctrl+Shift+F2 または Ctrl+F2 を押すと、選択した用語を用語ベースに追加できます。この機能はワンアクションで用語を登録できるのでとても便利ですが、[ プロジェクトの設定] で設定している用語ベースの順序に注意しておく必要があります。Ctrl+Shift+F2 と Ctrl+F2 はどちらも、プロジェクトの設定の一覧で一番上にある用語ベースに追加を行います。どの用語ベースに追加するかを選ぶことはできません。
このため、翻訳作業中に用語を追加したい場合は、あらかじめ追加用の用語ベースを一番上に置いておく必要があります。翻訳会社から提供された用語ベースは自分では変更を加えず参照だけする方が安全なので、追加用の用語ベースを自分で作成し、プロジェクトの設定で一覧の一番上に設定しておきます。
ただ、追加用の用語ベースを一番上に置くことには少し問題があります。それは、プロジェクトの設定の順序は用語認識ウィンドウに表示される順序に影響するからです。プロジェクトの設定で一番上に置いた用語ベースは、用語認識ウィンドウの一番最初に表示されてきます。なので、本来なら、翻訳会社さんから提供された用語ベースを一番上に置きたいところです。ですが、そうするとワンアクションで用語を登録することができません。まあ、そういう動きになるのはなんとなく理解はできるのですが、実際に作業していると、これがどうも気になって気になってイラッとしてきます。
以上です。ちょっと長くなりました。用語ベースの機能はとても便利ですが、それだけでは不安なこともあります。翻訳会社さんによっては、用語ベースをプロジェクトに設定してくるだけで、用語ベースの元データを提供してくれない場合があります。用語ベースの設定はもちろん必須ですが、それと合わせて元データも参照できる方がより安全です。
Tweet
Trados の用語ベースや用語認識の機能はとても便利ですが、設定や動作を理解しないまま使っていると、せっかくの情報をうまく生かせず用語の見落としなどにつながることがあります。私個人的には、用語認識機能はあくまで補助的なものと考え、面倒でも自分で検索するのが安全かなと思っています。
今回は、マイクロソフトの用語集を使うときに特に注意したい設定も含め、用語ベース全般の設定をいくつか紹介します。
用語の重複を許可する
まず、[ プロジェクトの設定] > [ 言語ペア] > [ 用語ベース] > [ 検索設定] の設定です。ここにある [ 用語の重複を許可する] をオンにします。この設定は、以前の記事「 パッケージを受け取ったら、ココの設定を変えます 」でも紹介しましたが、私はパッケージを受け取ったら必ず変更しています。
原文に「system administrator」という用語があったとします。[ 用語の重複を許可する] がオフの場合は、下図の左側のように「system administrator」という 2 語の一致しか表示されてきません。用語集に「system」や「administrator」という 1 語だけで登録があっても、それは用語認識ウィンドウに表示されてきません。つまり、長い用語が一致するとその長い用語だけが表示され、短い用語は表示されてこないのです。[ 用語の重複を許可する] をオンにしておくと、右側のように、長い用語に加えて短い用語も表示されてきます。
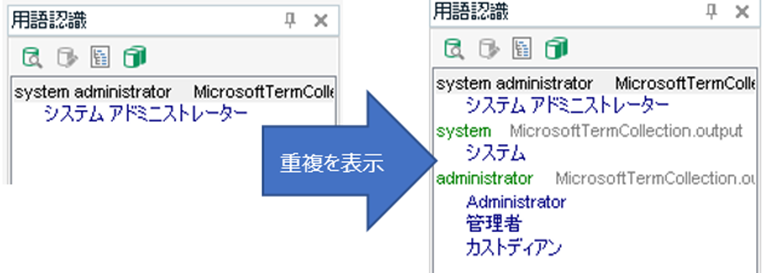
長い用語だけ表示されれば十分かと思いがちですが、翻訳会社さんから提供された用語集とマイクロソフトの用語集の両方を使う場合はこのオプションが欠かせません。たとえば、以下のように administrator が両方の用語集に登録されているとします。
・マイクロソフトの用語集: system administrator -> システム アドミニストレーター
・翻訳会社提供の用語集: administrator -> 管理者
[ 用語の重複を許可する] がオフの場合、「system administrator」という原文に対して用語認識ウィンドウに表示されてくるのは「システム アドミニストレーター」だけです。提供された用語集にある「管理者」は表示されてきません。これは非常に困ります。提供された用語集の用語を見落とす原因となってしまいます。
用語ベースごとにグループ化する
[ プロジェクトの設定] > [ 言語ペア] > [ 用語ベース] > [ 検索設定] の設定をもう 1 つ紹介します。
マイクロソフトの用語集は大量なのでヒットする用語がかなり多くなります。また、上記の [ 用語の重複を許可する] をオンにすることもヒットが多くなる要因になります。一覧に用語が大量に表示されていると、用語を見落とす危険性が高まるので注意が必要です。
翻訳会社さんから提供された用語集とマイクロソフトの用語集の両方を使う場合は、用語ベースごとに表示を分けると安全です。そのための設定が [ 用語ベースごとにグループ化する] です。

同じ用語が上下に並ぶ表示の方がわかりやすいときもありますが、マイクロソフトの用語集はかなり大量にヒットしてくるので、「用語ごとにグループ化」にしていると、マイクロソフトの用語がずらっと並ぶ中に別の用語がポツポツと挟まるという表示になりがちです。そうなると、どうしても見落とす危険性があるので、私は「用語ベースごとにグループ化」を使っています。
しかし、この設定には 1 つ問題があります。それは、この設定が入力補助用のリスト ([ 翻訳の表示] コマンドまたは Ctrl+Shif+L で表示される) には適用されないことです。入力補助用のリストと用語認識ウィンドウで表示順序が違うことになるので、選択して入力するときに注意が必要です。ヒットが大量にあるとスクロールの量がかなり増え、返って手間になることもあります。
フィールドを表示する
次は、マイクロソフトの用語集ではなく、主に翻訳会社さんから提供される用語集に役立つ設定です。用語認識ウィンドウには用語ベースに設定されている「フィールド」を表示できます。下図の「UI文言」や「一般用語」と表示されている部分がフィールドです。各用語についてのコメントなどが設定されていることが多いです。
参照する必要のあるフィールドがある場合は、たいてい、翻訳会社さんからそのように指示されます。おそらく、パッケージで事前に設定されていることが多いと思いますが、自分で設定する場合は、以下のようにします。
- 用語認識ウィンドウの上部にある [ 検索結果の設定] アイコンをクリックする。
- [ 検索結果の設定] ウィンドウが開くので、[ フィールド] ボタンをクリックする。
- [ フィールドの選択] ウィンドウが表示されたら、必要なフィールドのチェックボックスをオンにする。

これで、設定されているフィールドの内容が表示されるようになります。ただ、用語認識ウィンドウは小さいので表示できてもあまり読みやすいとは言えません。用語ベースの元データが Excel などで提供されているなら元データを直接参照する方が便利な場合もあります。
用語認識を信用しすぎない
さて、用語認識ウィンドウの設定をいろいろ説明してきましたが、一番重要なポイントは「用語認識を信用しすぎないこと」です。この機能は便利ですが、すべての用語が必ず認識されてくるわけではありません。
用語ベースの [ 検索設定] を見るとわかりますが、いろいろ設定があり、この設定によって用語認識の動作は変わります。用語認識は単純なテキストの一致で用語を見つけてくるわけではありません。
[ 2 文字の用語の認識を有効にする] はデフォルトでオフです。これがオフの場合、「in」や「my」など 2 文字の用語は用語集に登録されていても用語認識ウィンドウには表示されてきません。
また [ 一致率の最小値] という設定からわかるとおり、用語認識はメモリと同じようにあいまい一致の用語も表示してきます。単数形と複数形や動詞の活用などを考えるとあいまい一致は便利ですが、あいまい一致と気付かずそのまま使っていると危険です。
その他の設定についてもヘルプにはいろいろと説明がありますが、とにかく通常のテキスト検索とは動きが違うということを意識しておく必要があります。私は、用語認識はあくまで補助的なものと考え、単純なテキスト検索が行える Xbench などのツールを併用しています。
追加したい場合は、用語ベースの順序に注意
最後に、翻訳作業中に用語ベースに用語を追加するときの注意点です。原文と訳文でそれぞれの用語を選択して Ctrl+Shift+F2 または Ctrl+F2 を押すと、選択した用語を用語ベースに追加できます。この機能はワンアクションで用語を登録できるのでとても便利ですが、[ プロジェクトの設定] で設定している用語ベースの順序に注意しておく必要があります。Ctrl+Shift+F2 と Ctrl+F2 はどちらも、プロジェクトの設定の一覧で一番上にある用語ベースに追加を行います。どの用語ベースに追加するかを選ぶことはできません。
このため、翻訳作業中に用語を追加したい場合は、あらかじめ追加用の用語ベースを一番上に置いておく必要があります。翻訳会社から提供された用語ベースは自分では変更を加えず参照だけする方が安全なので、追加用の用語ベースを自分で作成し、プロジェクトの設定で一覧の一番上に設定しておきます。
ただ、追加用の用語ベースを一番上に置くことには少し問題があります。それは、プロジェクトの設定の順序は用語認識ウィンドウに表示される順序に影響するからです。プロジェクトの設定で一番上に置いた用語ベースは、用語認識ウィンドウの一番最初に表示されてきます。なので、本来なら、翻訳会社さんから提供された用語ベースを一番上に置きたいところです。ですが、そうするとワンアクションで用語を登録することができません。まあ、そういう動きになるのはなんとなく理解はできるのですが、実際に作業していると、これがどうも気になって気になってイラッとしてきます。
以上です。ちょっと長くなりました。用語ベースの機能はとても便利ですが、それだけでは不安なこともあります。翻訳会社さんによっては、用語ベースをプロジェクトに設定してくるだけで、用語ベースの元データを提供してくれない場合があります。用語ベースの設定はもちろん必須ですが、それと合わせて元データも参照できる方がより安全です。
| |
|